
QoS-Effective and Resilient Service Deployment and Traffic Management in MEC-Based Crowd Sensing

Abstract
1. Introduction
- 1.
- We conducted a detailed analysis on the MEC-based crowd sensing service system’s performance. Our investigation aimed to quantify the influence of service deployment and network strategies on system costs.
- 2.
- We thoroughly investigated the tradeoff between performance and cost in the system across various service placement and traffic management strategies by creating a mathematical model of the QoS-effective joint service deployment and traffic management problem (QST).
- 3.
- To address the target problem in a manageable way for a given system configuration, we propose an algorithm named GA4QST, which is based on the classical genetic algorithm framework. A comprehensive analysis of the proposed algorithm is also provided.
- 4.
- To thoroughly evaluate the efficacy of the proposed algorithm, we conducted a detailed comparative analysis with baseline algorithms. The experimental results demonstrate that GA4QST performs excellently in generating optimal solutions. In addition, our experiments explored the impact of different system settings on the performance of the proposed algorithm.
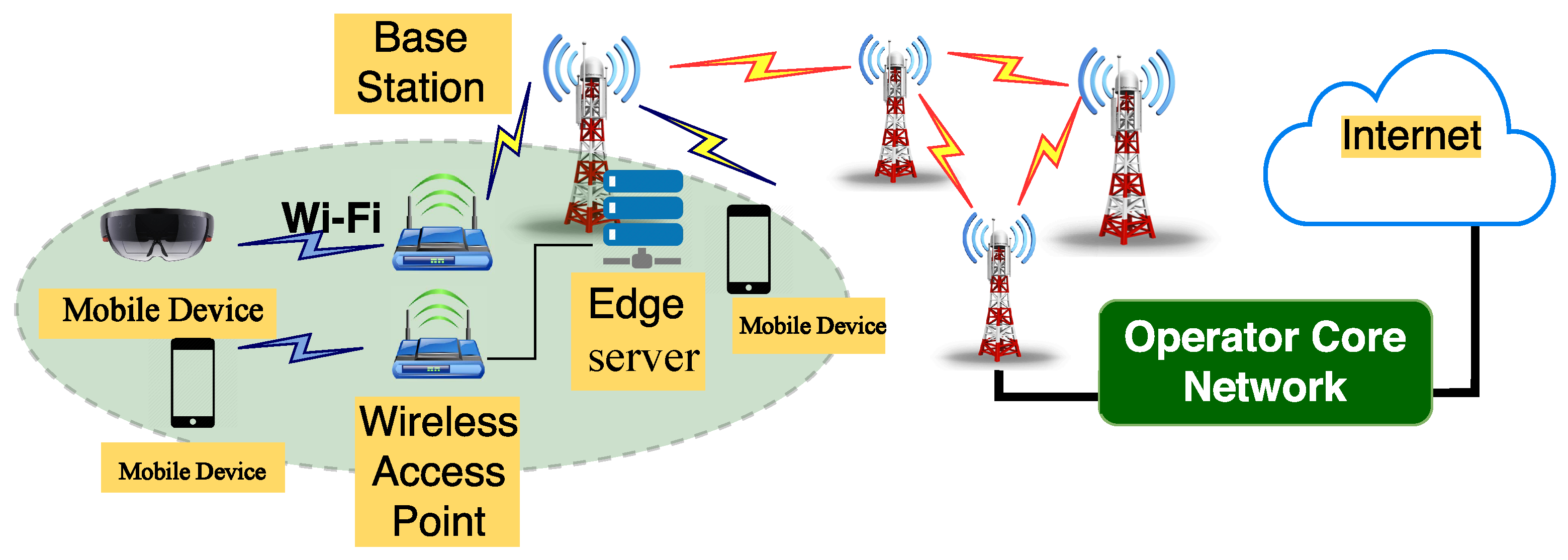
2. Motivation and Scenarios
3. Literature Review
3.1. Service Deployment in Edge Environments
3.2. Network Management in Edge Environment
4. System Model and Problem Description
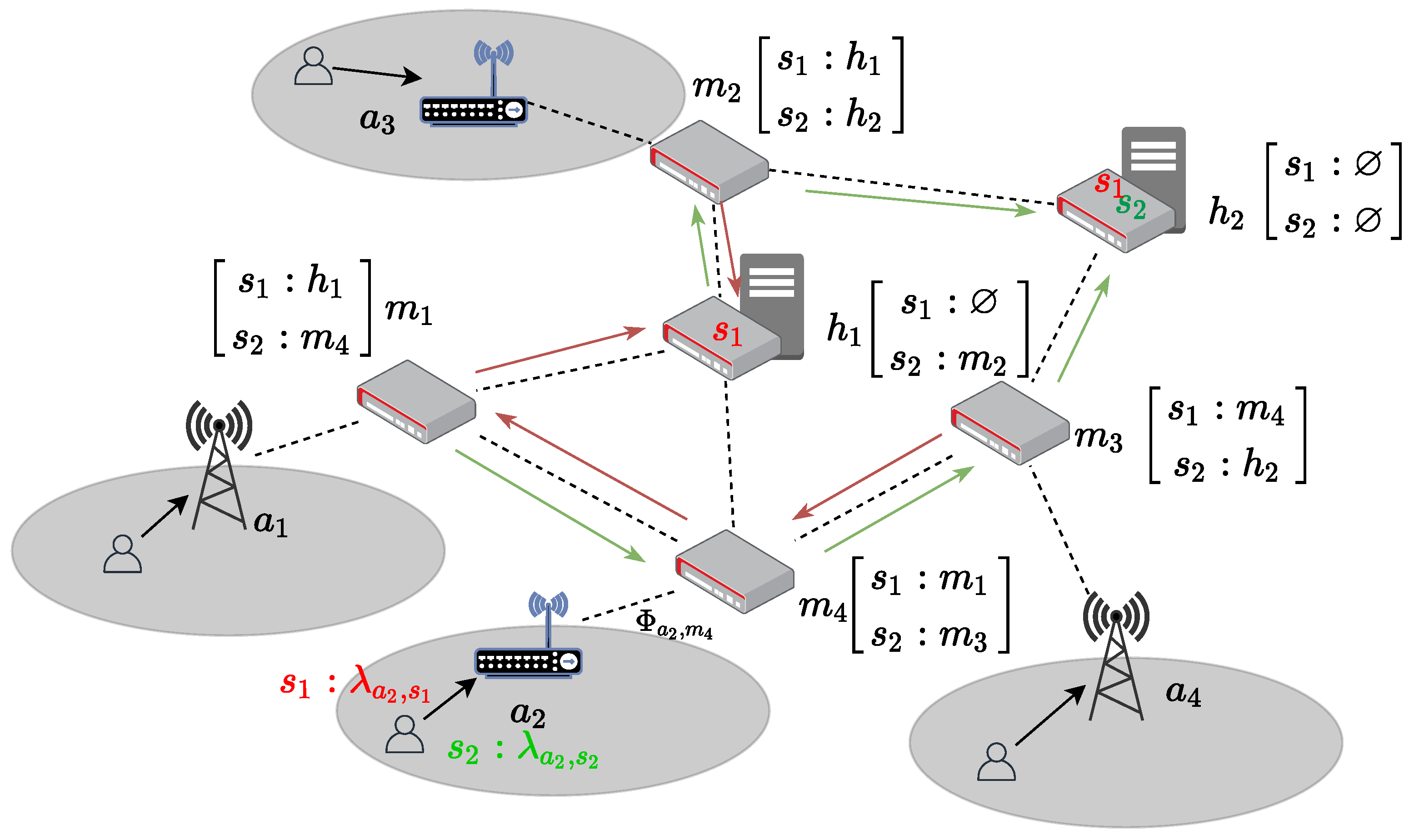
4.1. Introduction to System Entities
4.2. System QoS Analysis
4.2.1. Wireless Transmission
4.2.2. Request Routing
4.2.3. Service Execution
4.3. System Cost Evaluation
4.4. Problem Formulation
5. Metaheuristic Algorithm for QST
| Algorithm 1: GA for QST, GA4QST |
 |
- (1)
- Encoding and Initialization. In this phase, our objective is to represent our solution as a series of binary digits, commonly referred to as chromosomes, which is a term borrowed from biology where chromosomes carry genetic information and represent individuals. In this study, because and are 0–1 (binary) variables, it is unnecessary to make an additional effort to encode chromosomes or solutions. After the encoding is established, we proceed to initialize the population, as shown in Algorithm 2. Typically, a large number of possible chromosomes are randomly generated (CI in line 3 of Algorithm 2) to form an initial population. The random generation is aimed at covering a wider solution space. However, because our problem imposes constraints on the solutions, the initialization cannot be random. On the contrary, we employ Algorithm 3 to initialize a valid solution. Initially, it randomly chooses an available that is able to accommodate more than one service instance for each involved service , ensuring the existence of all services (Algorithm 3, lines 3–5). Subsequently, it considers different service deployment strategies, where certain services may have multiple instances (Algorithm 3, lines 6–9). During this phase, a hyperparameter proby is used to control the number of instances in the final service deployment strategy. The function randAvailableMECServer() selects the MEC server with the following probability:
| Algorithm 2: Population Initialization, PI |
 |
| Algorithm 3: Chromosome Initialization, CI |
 |
| Algorithm 4: Routing Path Generation, RPG |
 |
- (2)
- Selection. The genetic algorithm operates through the process of generation updating, with each iteration representing a attempt to find new solutions. In each update, some of the existing solutions are chosen to reproduce and create a new solutions based on their fitness or qualities. In our research, where the goal is to minimize the cost–performance ratio , the fitness function f in our approach can be defined as . Let represent the i-th chromosome in the population POP. The probability of selecting as a parent can be denoted as
- (3)
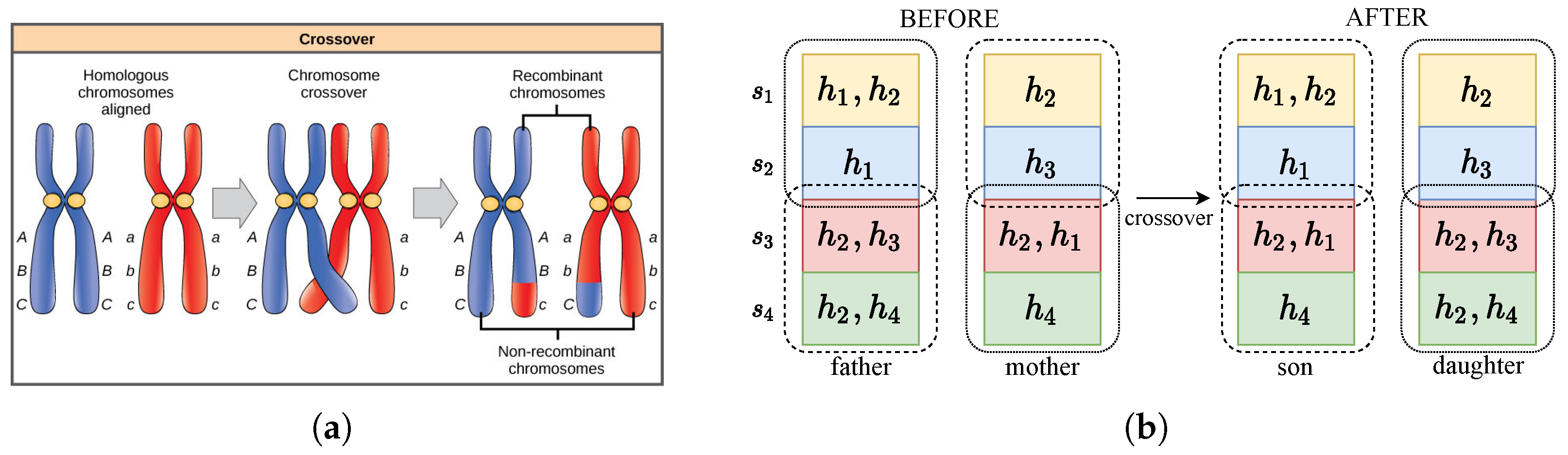
- Crossover. After selecting the mother chromosome and father chromosome with probabilities , as shown in Equation (24), the partial values carried by the father solution are exchanged into the mother solution to generate new child solutions. This process is similar to the chromosome crossover shown in Figure 4a (https://open.lib.umn.edu/horticulture/chapter/14-3-linkage-and-inheritance-of-small-differences/, accessed on 1 January 2024). In the method proposed in this paper, the crossover of two solutions in Algorithm 5 stands for the exchanging of selected service instances and their network status.
| Algorithm 5: Crossover |
Input: , : the father solution , : the mother solution : the capacity vector Output: , : the son solution , : the daughter solution 1 ; 2 ;
/*
instances to be exchanged */ 3 sample(, Random(W)); 4 ;
/*
separate solutions */ 5 ; 6 ; 7 ; 8 ;
/*
generate new children */ 9 ;
/*
child solution standardization */ 10 makeMatrix(), makeMatrix();
/*
heal the solutions */ 11 , ←SH(, , ); 12 , ←SH(, , ); |
| Algorithm 6: Solution Healing, SH |
 |
| Algorithm 7: Placement Violation Healing, PVH. |
 |
 |
| Algorithm 8: Service Deployment Rearranging, SPR |
 |
| Algorithm 9: Network Rearranging, NetR |
 |
- (4)
- Mutate. Following crossover, the mutate operation is adopted to prevent premature convergence. In this phase, some segments of the solutions change with probability , which is referred to as the mutation probability. In our study, mutation can occur in two directions: positive and negative. The process is illustrated in Algorithm 10. In positive mutation, a random service instance is deployed on an available MEC server , then the relationship (: ) is added to the flow tables for . Conversely, in negative mutation, a duplicate service instance is removed from a randomly selected MEC server , then the corresponding flow tables are reset.
| Algorithm 10: Mutation |
 |
 |
6. Experiments and Analysis
6.1. Preliminary
| Algorithm 11: Generate experimental data |
 |
6.2. Baselines
- 1.
- Original Genetic Algorithm (GA). As described above, the original GA draws inspiration from the process of natural selection, simulating evolution to solve optimization problems. It assesses a population of solutions using a fitness function that describes how an individual within the population adapts to the environment. The GA iteratively selects and retains those components that currently perform better, thereby facilitating adaptation.
- 2.
- Artificial Fish Swarm Algorithm (AFSA). Swarm algorithms are a family of gradient-free population-based algorithms designed to solve complex nonlinear problems. The key concept of the AFSA is to comparison the aquatic environment of a fish to the solution space of the target problem and use the analogy of a fish finding food in water to the search for an optimum solution. Typically, a fish finds food by individually observing the environment or following others. The AFSA obtains optima in a similar way [39].
- 3.
- Particle Swarm Optimization (PSO). The PSO algorithm is a population-based technique comprising numerous particles or agents. By shifting these particles or agents within the search space based on their current positions and velocities, they eventually reach the optimal position and identify the best solution [40,41].
- 4.
- Differential Evolution (DE). DE is a population-based metaheuristic iterative search algorithm used for non-convex optimization problems. Unlike traditional real-coded genetic algorithms and evolution strategies, DE employs a mandatory self-referential mutation for its population members. Each member is perturbed with the scaled difference of individuals from the current generation [42].
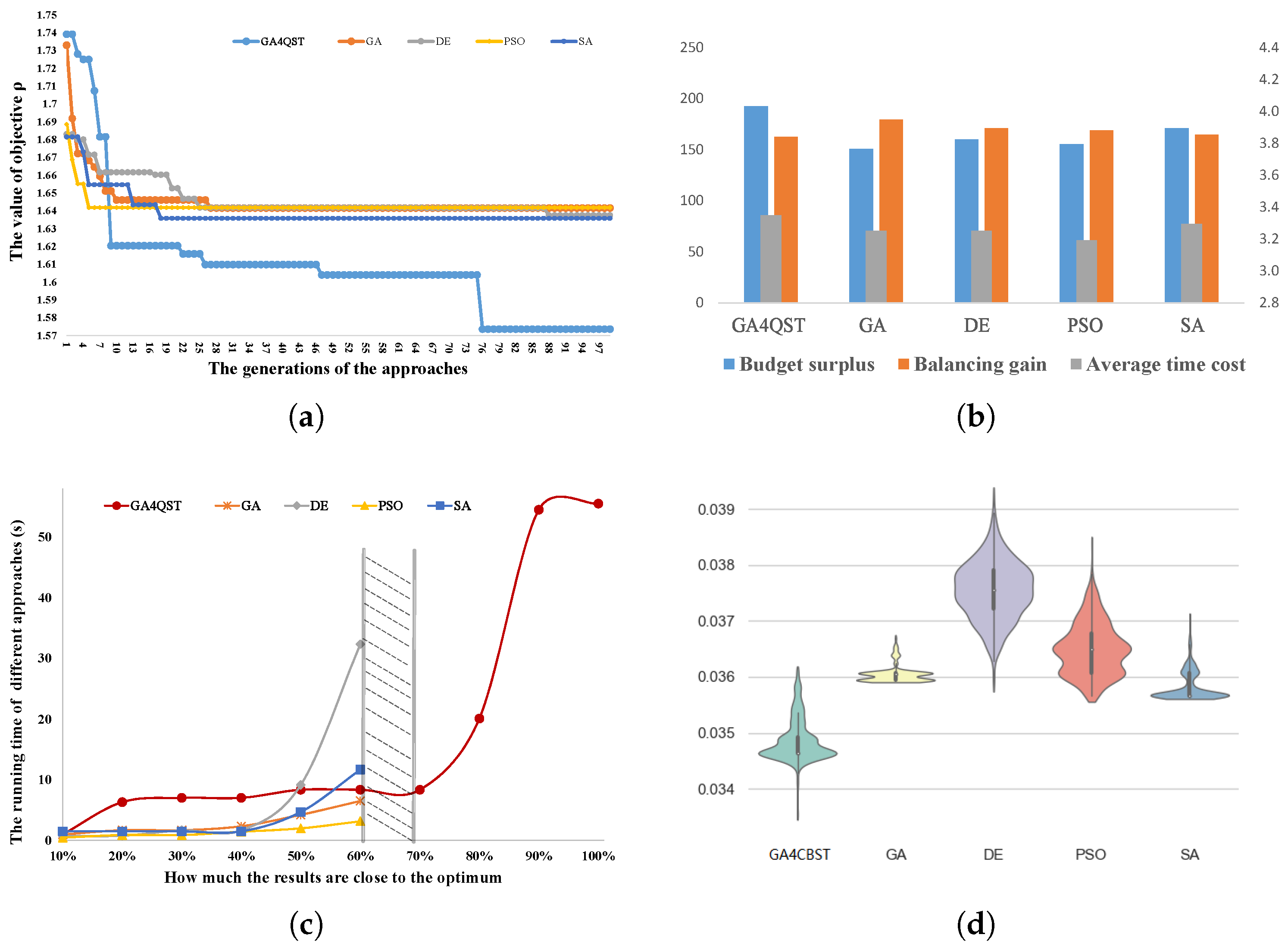
6.3. Comparison with Baselines
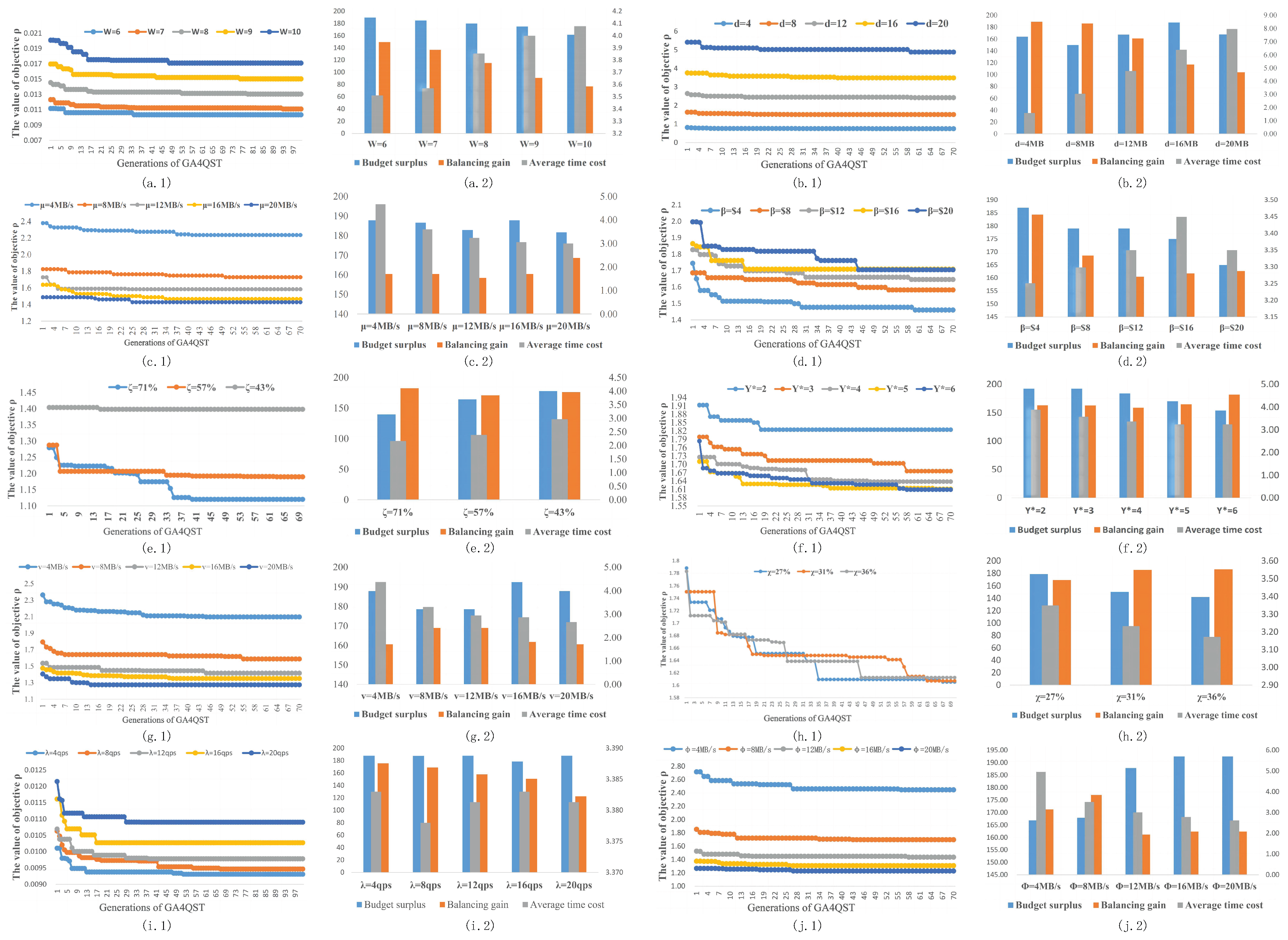
6.4. Impact of System Properties
6.5. Impacts of Service
- (1)
- Service Diversity. The service diversity (W) quantifies the complexity of the tasks handled by the system. To explore the impact of W on the results of GA4QST, we kept the same system settings as in Table 2 and varied the value of W. Figure 6(a.1) shows that the objective function value increases as W grows. Conversely, in Figure 6(a.2) we can observe a close relationship between the budget surplus, balancing gain, and average time cost regardless of the value of W. This can be attributed to the limited availability of resources. When the system must handle a larger number of services, it becomes more challenging to achieve a good balance of performance and cost.
- (2)
- Data Size. The data size, denoted as d in this paper, represents the throughput of the system. To investigate the impact of d, the system settings were kept the same as in Table 2 during the experiment while varying the value of d. As shown in Figure 6(b.1), the objective function value increases as d increases. This indicates that the optimization target deteriorates as the system becomes progressively overloaded. The details are illustrated in Figure 6(b.2). Specifically, it can be observed that the average time cost exhibits a nearly linear increase due to the proportional relationship between and . Moreover, the balancing gain decreases as the system faces additional challenges in efficiently processing heavy traffic. It is worth noting that the budget surplus exhibits fluctuations in this figure, indicating that cost is no longer the primary factor contributing to the final objective when the traffic becomes heavier.
- (3)
- Processing Capacity. The processing capacity is indicative of the construction cost of the underlying infrastructure, as higher processing capacity often requires higher-quality hardware. To examine the impact of on the results, we maintained the system settings specified in Table 2 while varying the value of . In Figure 6(c.1), it is evident that the objective function value decreases as increases. However, a diminishing marginal effect becomes apparent when reaches a certain threshold. Because improving processing capacity entails significant expenses, it is not advisable to overspend on this aspect. Figure 6(c.2) reveals that the optimization of is primarily driven by the improvement in average time cost when 16 MB/s. Conversely, when 20 MB/s, the balancing gain assumes a more prominent role. This is because increasing beyond a certain level does not substantially reduce the average time cost, instead enabling the system to manage traffic scheduling more flexibly.
- (4)
- Deployment Cost. The deployment cost represents the rental cost for developers, and is sometimes related to the value of in the same system. In Figure 6(d.1), it can be observed that the increase in deployment cost leads to a larger value of , indicating a worse optimization outcome. The changes in , , and depicted in Figure 6(d.2) shed light on the relationship between the decrease in and the tradeoff between average time cost and balancing gain. Both factors vie for the available resources, with the average time cost typically exerting a greater influence due to its higher weight in the calculation of .
6.6. Impacts of Server
- (1)
- Server Density. The server density, denoted as , represents the percentage of edge servers in the device pool, and primarily reflects the parallelism of the system. In Figure 6(e.1), we can observe that an increase in server density leads to a better value of , indicating an improved optimization outcome. However, the main contribution to this improvement can be attributed to the average time cost, as demonstrated in Figure 6(e.2). A higher server density facilitates better optimization results when the balancing gains are similar, such as at = 71%, 57%, and 43%. Additionally, the budget surpluses show an upward trend in these cases.
- (2)
- Available Resources. The available resource metric represents the storage capacity of an edge server, which may have a partial effect on the value of . In Figure 6(f.1), it can be observed that an increase in available resources leads to a decrease in the value of , indicating an improvement in the optimization outcome. Similarly, in Figure 6(f.2) we can see that the contribution to this improvement primarily stems from the average time cost. This can be attributed to the fact that the edge servers can accommodate a greater number of service instances when there are more available resources, leading to better optimization results.
6.7. Impacts of Network
- (1)
- Wireless Transmission Rate. The wireless transmission rate v reflects the quality of communication between mobile IoT devices and the system. Figure 6(g.1) illustrates that an increase in the wireless transmission rate leads to a better value of . This improvement can be attributed to the fact that a higher wireless transmission rate reduces the value of . However, it is interesting to see that is not linear with v, resulting in a nonlinear improvement in the optimization outcome. Similarly, in Figure 6(g.2) it can be observed that an increase in v also leads to a reduction in budget cost. This is because in most cases the time cost of a request is dominated by the transmission time. Therefore, improving the wireless transmission rate reduces the overall cost associated with the transmission process.
- (2)
- Connection Density. The connection density, denoted as , reflects the level of connectivity, and describes the system’s ability to efficiently handle traffic. In Figure 6(h.1), we can observe that an increase in the connection density does not necessarily lead to a better value of . The relationship between the two is not straightforward. We can further examine the reasons behind this observation in Figure 6(h.2). Here, both the average time cost and balancing gain show improvements, suggesting that an increase in connections provides more opportunities for the system to optimize communication and accelerate response times. However, it is important to note that these improvements come at a cost. The decrease in the budget surplus is almost linear with the increase in due to the deployment of more service instances.
- (3)
- Request Rate. The request rate reflects the popularity or total load of the services. Figure 6(i.1) reveals that a heightened rate of requests results in an elevation of the optimization goal’s value. This is reasonable, as an increase in external requirements can strain the system’s capabilities. In Figure 6(i.2), it can be seen that the GA4QST algorithm maintains similar budget usage while adjusting the average time cost and balancing gain as the request rate changes. Furthermore, by observing the trends of the balancing gains in Figure 6(i.2), we can deduce that the GA4QST algorithm prioritizes the balancing gain as a lower optimization target when dealing with increasing values of . Therefore, if we want emphasize the importance of the balancing gain, this would require assigning it a higher weight during the optimization process.
- (4)
- Wired Transmission Rate. The wired transmission rate, denoted as in this paper, reflects the quality of communication between edge devices. In Figure 6(j.1), we can observe that the value of decreases as the wired transmission rate increases. This is because a higher wired transmission rate reduces the value of , resulting in improved optimization outcomes. However, it is important to note that the relationship between and is inversely proportional, leading to a nonlinear improvement in the optimization outcome. Similarly, in Figure 6(j.2) we can observe that increasing can potentially reduce the budget cost. This is because in most cases the time cost of a service request is dominated by the transmission time. Therefore, improving the wired transmission rate can lead to a reduction in the overall cost associated with the transmission process.
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MEC | Multi-access Edge Computing |
| mMTC | Massive Machine-Type Communication |
| PaaS | Platform as a Service |
| QoS | Quality of Service |
| QST | QoS-effective Joint Service Deployment and Traffic Management Problem |
| ESTI | European Telecommunications Standards Institute |
| SDN | Software-Defined Network |
| IoT | Internet of Things |
| IoV | Internet of Vehicles |
| BPSO | Binary Particle Swarm Optimization |
| GA | Genetic Algorithm |
| GA4QST | Genetic Algorithm for QoS-effective Service Deployment and Traffic Management |
| PI | Population Initialization |
| CI | Chromosome Initialization |
| RPG | Routing Path Generation |
| SH | Solution Healing |
| PVH | Placement Violation Healing |
| SPR | Service Deployment Rearranging |
| NetR | Network Rearranging |
| AFSA | Artificial Fish Swarm Algorithm |
| PSO | Particle Swarm Optimization |
| DE | Differential Evolution |
| SaaS | Software as a Service |
References
- Badidi, E.; Moumane, K.; El Ghazi, F. Opportunities, applications, and challenges of edge-AI enabled video analytics in smart cities: A systematic review. IEEE Access 2023, 11, 80543–80572. [Google Scholar] [CrossRef]
- Lu, S.; Lu, J.; An, K.; Wang, X.; He, Q. Edge computing on IoT for machine signal processing and fault diagnosis: A review. IEEE Internet Things J. 2023, 10, 11093–11116. [Google Scholar] [CrossRef]
- Walia, G.K.; Kumar, M.; Gill, S.S. AI-empowered fog/edge resource management for IoT applications: A comprehensive review, research challenges, and future perspectives. IEEE Commun. Surv. Tutor. 2023, 26, 619–669. [Google Scholar] [CrossRef]
- Hua, H.; Li, Y.; Wang, T.; Dong, N.; Li, W.; Cao, J. Edge computing with artificial intelligence: A machine learning perspective. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Duan, K.; Fong, S.; Siu, S.W.; Song, W.; Guan, S.S.U. Adaptive incremental genetic algorithm for task scheduling in cloud environments. Symmetry 2018, 10, 168. [Google Scholar] [CrossRef]
- Cheng, X.; Lu, X.; Deng, Y.; Lu, Q.; Kang, Y.; Tang, J.; Shi, Y.; Zhao, J. Offloading Strategy for Forest Monitoring Network Based on Improved Beetle Optimization Algorithm. Symmetry 2024, 16, 1569. [Google Scholar] [CrossRef]
- Ye, J.; Jiang, Y. Data Integrity Verification for Edge Computing Environments. Symmetry 2024, 16, 1648. [Google Scholar] [CrossRef]
- Xiang, Z.; Deng, S.; Zheng, Y.; Wang, D.; Zhang, C.; Chen, Y.; Zheng, Z. Activate Cost-Effective Mobile Crowd Sensing with Multi-access Edge Computing. In Proceedings of the Communications and Networking: 15th EAI International Conference, ChinaCom 2020, Shanghai, China, 20–21 November 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 78–97. [Google Scholar]
- Xiang, Z.; Deng, S.; Jiang, F.; Gao, H.; Tehari, J.; Yin, J. Computing power allocation and traffic scheduling for edge service provisioning. In Proceedings of the 2020 IEEE International Conference on Web Services (ICWS), Beijing, China, 19–23 October 2020; pp. 394–403. [Google Scholar]
- Siriwardhana, Y.; Porambage, P.; Liyanage, M.; Ylianttila, M. A survey on mobile augmented reality with 5G mobile edge computing: Architectures, applications, and technical aspects. IEEE Commun. Surv. Tutor. 2021, 23, 1160–1192. [Google Scholar] [CrossRef]
- Van Anh, D.; Chehri, A.; Quy, N.M.; Hue, C.T.M.; Nguyen, D.C.; Quy, V.K. An Software Defined Networking (SDN) Enhanced Edge Computing Framework for Internet of Healthcare Things (IoHT). In Proceedings of the GLOBECOM 2024—2024 IEEE Global Communications Conference, Cape Town, South Africa, 8–12 December 2024; pp. 415–419. [Google Scholar]
- Al-Hammadi, I.; Li, M.; Islam, S.M.; Al-Mosharea, E. Collaborative computation offloading for scheduling emergency tasks in SDN-based mobile edge computing networks. Comput. Netw. 2024, 238, 110101. [Google Scholar] [CrossRef]
- Al-Shareeda, M.A.; Alsadhan, A.A.; Qasim, H.H.; Manickam, S. Software defined networking for internet of things: Review, techniques, challenges, and future directions. Bull. Electr. Eng. Inform. 2024, 13, 638–647. [Google Scholar] [CrossRef]
- Yu, J.; Alhilal, A.; Zhou, T.; Hui, P.; Tsang, D.H. Attention-based QoE-aware digital twin empowered edge computing for immersive virtual reality. IEEE Trans. Wirel. Commun. 2024, 23, 11276–11290. [Google Scholar] [CrossRef]
- Elgarhy, O.; Reggiani, L.; Alam, M.M.; Zoha, A.; Ahmad, R.; Kuusik, A. Energy efficiency and latency optimization for IoT URLLC and mMTC use cases. IEEE Access 2024, 12, 23132–23148. [Google Scholar] [CrossRef]
- Zaman, M.; Puryear, N.; Abdelwahed, S.; Zohrabi, N. A review of IoT-based smart city development and management. Smart Cities 2024, 7, 1462–1501. [Google Scholar] [CrossRef]
- Xiang, Z.; Wang, D.; He, M.; Chen, Y. Dynamic System Reconfiguration in Stable and Green Edge Service Provisioning. Mob. Netw. Appl. 2023, 29, 1663–1679. [Google Scholar] [CrossRef]
- Mehta, A.; Verma, R.K. QoS-aware edge server placement for collaborative predictive maintenance in industrial internet of things. J. Supercomput. 2024, 80, 19324–19350. [Google Scholar] [CrossRef]
- Li, X.; Teng, M.; Bu, Y.; Qiu, J.; Qin, X.; Wu, J. Cooperation-based server deployment strategy in mobile edge computing system. Comput. Netw. 2025, 257, 110932. [Google Scholar] [CrossRef]
- Xue, H.; Xia, Y. Profit-aware Edge Server Placement based on All-pay Auction for Edge Offloading. In Proceedings of the 2024 IEEE/ACM 32nd International Symposium on Quality of Service (IWQoS), Guangzhou, China, 19–21 June 2024; pp. 1–2. [Google Scholar]
- Kuźniar, M.; Perešíni, P.; Kostić, D. What you need to know about SDN flow tables. In Proceedings of the International Conference on Passive and Active Network Measurement. PAM 2015; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2015; Volume 8995, pp. 347–359. [Google Scholar]
- Borsatti, D.; Davoli, G.; Cerroni, W.; Raffaelli, C. Enabling industrial IoT as a service with multi-access edge computing. IEEE Commun. Mag. 2021, 59, 21–27. [Google Scholar] [CrossRef]
- Lv, W.; Wang, Q.; Yang, P.; Ding, Y.; Yi, B.; Wang, Z.; Lin, C. Microservice Deployment in Edge Computing Based on Deep Q Learning. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 2968–2978. [Google Scholar] [CrossRef]
- Sriraghavendra, M.; Chawla, P.; Wu, H.; Gill, S.S.; Buyya, R. DoSP: A deadline-aware dynamic service placement algorithm for workflow-oriented IoT applications in fog-cloud computing environments. In Energy Conservation Solutions for Fog-Edge Computing Paradigms; Lecture Notes on Data Engineering and Communications Technologies; Springer: Singapore, 2022; Volume 74, pp. 21–47. [Google Scholar]
- Wang, L.; Deng, X.; Gui, J.; Chen, X.; Wan, S. Microservice-oriented service placement for mobile edge computing in sustainable internet of vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10012–10026. [Google Scholar] [CrossRef]
- Tang, Q.; Xie, R.; Fang, Z.; Huang, T.; Chen, T.; Zhang, R.; Yu, F.R. Joint Service Deployment and Task Scheduling for Satellite Edge Computing: A Two-Timescale Hierarchical Approach. IEEE J. Sel. Areas Commun. 2024, 42, 1063–1079. [Google Scholar] [CrossRef]
- Zhang, X.; Cui, L.; Tso, F.P.; Li, Z.; Jia, W. Dapper: Deploying Service Function Chains in the Programmable Data Plane Via Deep Reinforcement Learning. IEEE Trans. Serv. Comput. 2023, 16, 2532–2544. [Google Scholar] [CrossRef]
- Huang, Y.; Yao, T.; Lin, Z.; Shang, X.; Yuan, Y.; Cui, L.; Yang, Y. Efficient Service Function Chain Placement Over Heterogeneous Devices in Deviceless Edge Computing Environments. IEEE Trans. Comput. 2024, 74, 222–236. [Google Scholar] [CrossRef]
- Mavromatis, A.; Colman-Meixner, C.; Silva, A.P.; Vasilakos, X.; Nejabati, R.; Simeonidou, D. A software-defined IoT device management framework for edge and cloud computing. IEEE Internet Things J. 2019, 7, 1718–1735. [Google Scholar] [CrossRef]
- Bellavista, P.; Fogli, M.; Giannelli, C.; Stefanelli, C. Application-aware network traffic management in mec-integrated industrial environments. Future Internet 2023, 15, 42. [Google Scholar] [CrossRef]
- Jaber, M.M.; Ali, M.H.; Abd, S.K.; Alkhayyat, A.; Malik, R. Application of edge computing-based information-centric networking in smart cities. Comput. Commun. 2023, 211, 46–58. [Google Scholar]
- Kim, M.; Jaseemuddin, M.; Anpalagan, A. Deep reinforcement learning based active queue management for iot networks. J. Netw. Syst. Manag. 2021, 29, 1–28. [Google Scholar] [CrossRef]
- Song, T.; Kyung, Y. Deep-Reinforcement-Learning-Based Age-of-Information-Aware Low-Power Active Queue Management for IoT Sensor Networks. IEEE Internet Things J. 2024, 11, 16700–16709. [Google Scholar] [CrossRef]
- Absardi, Z.N.; Javidan, R. IoT traffic management using deep learning based on osmotic cloud to edge computing. Telecommun. Syst. 2024, 87, 419–435. [Google Scholar] [CrossRef]
- Lai, P.; He, Q.; Cui, G.; Chen, F.; Grundy, J.; Abdelrazek, M.; Hosking, J.G.; Yang, Y. Cost-effective user allocation in 5g noma-based mobile edge computing systems. IEEE Trans. Mob. Comput. 2021, 21, 4263–4278. [Google Scholar] [CrossRef]
- Stavrinides, G.L.; Karatza, H.D. An energy-efficient, QoS-aware and cost-effective scheduling approach for real-time workflow applications in cloud computing systems utilizing DVFS and approximate computations. Future Gener. Comput. Syst. 2019, 96, 216–226. [Google Scholar] [CrossRef]
- Xiang, Z.; Zheng, Y.; He, M.; Shi, L.; Wang, D.; Deng, S.; Zheng, Z. Energy-effective artificial internet-of-things application deployment in edge-cloud systems. Peer-to-Peer Netw. Appl. 2022, 15, 1029–1044. [Google Scholar] [CrossRef]
- Bhandari, D.; Murthy, C.; Pal, S.K. Genetic algorithm with elitist model and its convergence. Int. J. Pattern Recognit. Artif. Intell. 1996, 10, 731–747. [Google Scholar] [CrossRef]
- Tirkolaee, E.B.; Goli, A.; Weber, G.W. Fuzzy mathematical programming and self-adaptive artificial fish swarm algorithm for just-in-time energy-aware flow shop scheduling problem with outsourcing option. IEEE Trans. Fuzzy Syst. 2020, 28, 2772–2783. [Google Scholar] [CrossRef]
- Al Hilli, A.; Al-Ibadi, M.; Alfadhel, A.M.; Abdulshaheed, S.H.; Hadi, A.H. Optimal path finding in stochastic quasi-dynamic environments using particle swarm optimization. Expert Syst. Appl. 2021, 186, 115706. [Google Scholar] [CrossRef]
- Han, H.; Bai, X.; Han, H.; Hou, Y.; Qiao, J. Self-Adjusting Multi-Task Particle Swarm Optimization. IEEE Trans. Evol. Comput. 2021, 26, 145–158. [Google Scholar] [CrossRef]
- Ghosh, A.; Das, S.; Das, A.K.; Gao, L. Reusing the past difference vectors in differential evolution—A simple but significant improvement. IEEE Trans. Cybern. 2019, 50, 4821–4834. [Google Scholar] [CrossRef]
- Kamal, R.; Amin, E.; AbdElminaam, D.S.; Ismail, R. A Comprehensive Survey on Meta-Heuristic Algorithms for Feature Selection in High-Dimensional Data: Challenges, Applications, and Future Directions. In Proceedings of the 2024 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 13–14 November 2024; pp. 84–90. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | The Physical Meaning of the Notations |
|---|---|
| N | The number of edge nodes or devices |
| K | The number of SDN switches |
| Q | The number of access points |
| W | The number of services |
| The set of edge devices or edge nodes | |
| The set of SDN switches | |
| The set of access points | |
| The set of services | |
| The set of all devices capable of dispatching requests | |
| The topology representation between device u and device v | |
| The j-th connected subgraph | |
| The access points | |
| The services | |
| The rate at which mobile devices in the vicinity of generate service requests related to | |
| The mean rate of wireless data transmission | |
| The size of wireless data transmission | |
| The service is sent from v to u | |
| The service instance is deployed on v | |
| The maximum number of service instances that MEC server v can accommodate | |
| The maximum number of service instances that an MEC server can accommodate. | |
| The target device to which the service is directed after being sent from the MEC server v can be determined through the flow table tensor P | |
| The sequence of nodes when requesting access to service from the access point | |
| The average data transmission rate between edge devices u and v | |
| The time required for wireless data transmission between the mobile device and the access point | |
| The total time cost of routing for service | |
| The time it takes for service to process data | |
| The average rate at which service processes data | |
| The expected request lifecycle when service requests are received at the rate of queries per second near access point | |
| Function of budget surplus | |
| The unit price of instance | |
| The total throughput | |
| Function of the degree of network imbalance | |
| Function of cumulative imbalance of computing resources | |
| Function of the balancing gain | |
| The ratio of system performance to system cost | |
| The server density | |
| v | The wireless transmission rate |
| The edge devices connection density | |
| Services request rate |
| Item | Value | Item | Value |
|---|---|---|---|
| m | 5 | n | 10 |
| (2, ) MB/s | (80, MB/s | ||
| (3, ) MB | (3, ) MB | ||
| (10, ) $/MIPS | (2, ) × MIPS | ||
| (10, ) QPS | (2, ) × MI |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Z.; Ying, F.; Yan, H.; Zheng, Z.; Zhang, Y.; Xu, Y. QoS-Effective and Resilient Service Deployment and Traffic Management in MEC-Based Crowd Sensing. Symmetry 2025, 17, 718. https://doi.org/10.3390/sym17050718
Xiang Z, Ying F, Yan H, Zheng Z, Zhang Y, Xu Y. QoS-Effective and Resilient Service Deployment and Traffic Management in MEC-Based Crowd Sensing. Symmetry. 2025; 17(5):718. https://doi.org/10.3390/sym17050718
Chicago/Turabian StyleXiang, Zhengzhe, Fuli Ying, Hao Yan, Zengwei Zheng, Yufei Zhang, and Yueshen Xu. 2025. "QoS-Effective and Resilient Service Deployment and Traffic Management in MEC-Based Crowd Sensing" Symmetry 17, no. 5: 718. https://doi.org/10.3390/sym17050718
APA StyleXiang, Z., Ying, F., Yan, H., Zheng, Z., Zhang, Y., & Xu, Y. (2025). QoS-Effective and Resilient Service Deployment and Traffic Management in MEC-Based Crowd Sensing. Symmetry, 17(5), 718. https://doi.org/10.3390/sym17050718