Abstract
In the context of global demographic aging, falls among the elderly remain a major public health concern, often leading to injury, hospitalization, and loss of autonomy. This study proposes a real-time fall detection system that combines a modern computer vision model, YOLOv11 with integrated pose estimation, and an Artificial Intelligence (AI)-based voice assistant designed to reduce false alarms and improve intervention efficiency and reliability. The system continuously monitors human posture via video input, detects fall events based on body dynamics and keypoint analysis, and initiates a voice-based interaction to assess the user’s condition. Depending on the user’s verbal response or the absence thereof, the system determines whether to trigger an emergency alert to caregivers or family members. All processing, including speech recognition and response generation, is performed locally to preserve user privacy and ensure low-latency performance. The approach is designed to support independent living for older adults. Evaluation of 200 simulated video sequences acquired by the development team demonstrated high precision and recall, along with a decrease in false positives when incorporating voice-based confirmation. In addition, the system was also evaluated on an external dataset to assess its robustness. Our results highlight the system’s reliability and scalability for real-world in-home elderly monitoring applications.
1. Introduction
The rapid demographic shift toward an aging global population has introduced new challenges for healthcare systems, particularly in ensuring the safety and independence of seniors living alone. The World Health Organization (WHO) expects the number of people aged 60 and older to double by 2050, reaching over 2 billion globally [1]. This demographic transition increases the demand for long-term care solutions that ensure safety, independence, and dignity for elderly individuals in both institutional and home-based settings.
One of the most pressing risks for older adults is falling. Falls represent the second leading cause of unintentional injury deaths worldwide [2], with adults over the age of 65 being particularly vulnerable. Beyond the physical injuries, such as fractures or head trauma, falls often lead to a loss of confidence, increased fear of falling again, and a decline in physical activity, which further accelerates health deterioration and social isolation [2].
Traditional fall detection systems, such as wearable sensors or floor-based sensors, have proven effective. Still, they often require active user compliance or complex installation, which limits their practicality and scalability [3]. In response to these limitations, computer vision and Artificial Intelligence (AI) have emerged as powerful tools for unobtrusive and intelligent monitoring of human activity, enabling real-time fall detection with increased accuracy. However, most current solutions use automated detection and static alert methods, which frequently result in false alarms because of environmental awareness constraints or the inability to determine the user’s condition after an incident occurs [4].
The YOLO (You Only Look Once) object detection framework has gained considerable attention due to its real-time performance and high accuracy in detecting complex movements and body postures [5]. The YOLO family of object detection models has undergone continuous development, resulting in notable improvements in both speed and accuracy.
This study extends previous research that demonstrated the feasibility of pose-based fall detection using YOLOv7-W6-Pose [6]. We present an AI-based system that combines real-time computer vision with contextual voice interaction to enhance fall detection in elderly monitoring. Our approach adopts the latest YOLOv11 architecture, offering improved object detection accuracy, faster inference, and better performance in challenging environments [7].
The system also integrates a smart voice assistant capable of engaging in real-time dialogue with the user after a fall is detected. This dual-modality design, merging visual analysis with verbal interaction, aims to reduce false positives, ensure user safety, and improve system responsiveness. This approach, integrated into the NeuroPredict platform developed by our team, advances fall detection technology, supporting better care for older adults.
The main objectives of the study are as follows:
- Improve detection accuracy with an upgraded object identification and position estimation model;
- Decrease false positives by including a voice interaction module that confirms the user’s condition prior to sending out notifications;
- Create and assess comprehensive system architecture that guarantees responsiveness, scalability, and privacy in diverse home environments.
By enabling proactive and context-aware assistance, this approach advances the development of intelligent monitoring solutions that support safe aging in place.
The main contributions of this study are as follows:
- Proposing a real-time fall detection system based on YOLOv11, enhanced with integrated pose estimation and a Convolutional Neural Network (CNN) architecture, achieving higher accuracy and robustness compared to YOLOv7-based approaches;
- Implementing a dual-camera setup that minimizes occlusions and blind spots in realistic, cluttered indoor environments, increasing reliability in challenging scenarios;
- Introducing a rule-based voice assistant module that interacts with the user after a detected fall, confirming his/her condition and reducing false positive alarms by approximately 75%;
- Evaluating the impact of the voice assistant module by comparing system performance with and without voice interaction on a dataset of 200 annotated sequences collected by our development team.
To highlight the advantages of YOLOv11 over its predecessor, YOLOv7-W6-Pose, we present a comparative analysis in Table 1 [8].

Table 1.
Comparison between YOLOv7-W6-Pose and YOLOv11.
These improvements make YOLOv11 a strong candidate for deployment in real-time applications, where both speed and reliability are paramount. The switch to this new version enables the system to detect falls with greater contextual understanding, which also benefits the voice-assistance response mechanism.
As seen in Table 1, YOLOv11 outperforms YOLOv7-W6-Pose by offering higher accuracy, faster inference, and better robustness in challenging conditions. With its hybrid CNN-Transformer architecture and native pose estimation, YOLOv11 simplifies deployment while reducing computational load. Its end-to-end design and improved feature modeling make it a more efficient and reliable choice for real-time detection and pose tasks.
At the same time, advancements in voice-assisted technologies offer new possibilities for interaction between monitoring systems and users. Voice-based communication, rule-based keyword matching and AI can be particularly beneficial for elderly individuals who may have limited mobility or cognitive challenges. Integrating fall detection with an intelligent voice response system creates an opportunity for immediate, context-aware interventions, reducing response time and improving overall outcomes. It is important to note that we do not train or test the audio system ourselves; instead, we rely on existing, validated functions already integrated in Python, ensuring both reliability and ease of implementation.
This paper is structured as follows: Section 1 defines the main goals and rationale of the study, focusing on how combining human detection with pose estimation can enhance fall detection systems. Section 2 reviews the current landscape in the field by classifying existing fall detection technologies based on AI paradigms, analyzing AI-based monitoring systems, and identifying key limitations of current solutions. Section 3 outlines the technical setup, including data acquisition, preprocessing steps, the proposed fall detection algorithm, and the integrated alert mechanism. Section 5 presents performance metrics and experimental insights, emphasizing the practical relevance of the system in monitoring elderly individuals. The paper concludes with the Section 6, where key outcomes are interpreted, existing limitations are discussed, and potential future improvements are proposed.
2. Related Work
2.1. Fall Detection Technologies: A Classification Based on AI Paradigms
Traditionally, fall detection systems have been classified according to the types of sensors they employ—wearables, ambient, or vision-based devices [9]. While this classification highlights the hardware involved, it does not adequately reflect the rapid evolution of computational techniques driving these systems. A more insightful fall detection technology is achieved by the data processing paradigms they utilize, ranging from simple rule-based methods to advanced multimodal AI models.
2.1.1. System Classification by Computational Paradigms
This development can be generally categorized into four computational paradigms. Each has distinct technological foundations, advantages, and limitations [10]:
- (a)
- Rule-Based Systems
Rule-based systems represent the earliest generation of fall detection solutions. These systems typically operate using predefined threshold conditions applied to sensor data, most commonly from wearable inertial measurement units (IMUs) such as accelerometers and gyroscopes [11]. A typical detection rule might identify a fall if a sudden spike in acceleration is followed by a period of inactivity [12]. These approaches are straightforward to implement and can operate on low-power, embedded platforms.
These systems depend heavily on user adherence, as the wearable device needs to be continuously worn and properly placed to operate effectively. Incorrect placement (e.g., rotated on the wrist or worn loosely) can significantly degrade performance. Furthermore, studies [13] have shown that threshold-based fall detectors often misinterpret normal daily activities, such as sitting abruptly, bending, or lying down voluntarily, as potential falls, especially in elderly users with unsteady gait or frailty [14].
Although ambient rule-based systems are advantageous for being non-intrusive and not needing any wearable devices or user engagement, they heavily rely on location and are limited to the specific zones where sensors are placed. Their rigid decision rules can also result in false negatives, particularly if a fall occurs outside the monitored area or if noise or lighting conditions interfere with sensor performance. Moreover, calibration is often required for each physical space, making them difficult to scale in dynamic or large environments [15].
- (b)
- Classical Machine Learning Systems
Classical machine learning (ML) systems marked a major advancement over rule-based methods by enabling data-driven learning and greater flexibility in modeling. These systems apply algorithms such as Support Vector Machines (SVMs), k-Nearest Neighbors (k-NNs), Decision Trees, and Random Forests to features manually extracted from raw sensor data or video streams [16]. Common features include jerk, postural angles, velocity changes, energy consumption, and temporal sequences of motion states [17].
In wearable-based systems, ML is typically applied to inertial sensor data, such as acceleration and angular velocity, collected from IMUs attached to the body (e.g., wrist, waist, ankle). Feature engineering in this context may include both time-domain (e.g., signal variance, mean crossing rate) and frequency-domain metrics (e.g., dominant frequency, Fast Fourier Transform components) for capturing meaningful aspects of human motion indicative of a fall.
However, one of the major drawbacks in wearable ML systems is the user dependence and variability of sensor data. The same movement can produce very different signals across individuals due to differences in gait, body composition, or sensor positioning. The systems remain susceptible to false positives, especially when routine activities like quickly sitting, stepping down, or reaching are interpreted as falls [3,18].
In vision-based systems, classical ML methods rely on descriptors derived from handcrafted visual features, such as bounding box trajectories, silhouette shapes, or skeletal keypoint dynamics. Classifiers such as SVMs or k-NN often receive these descriptors. For example, a rapid transition from a vertical to a horizontal bounding box, followed by inactivity, could be interpreted as a fall [19].
Yet, as with wearable applications, vision-based ML suffers from sensitivity to environmental variations, including lighting conditions, camera angles, and occlusions. Feature extraction pipelines must often be recalibrated for each deployment scenario to maintain acceptable accuracy [20]. Overall, classical machine learning systems offered significant improvements in adaptability and accuracy over rule-based methods, especially when trained with well-curated data.
- (c)
- Deep Learning Systems
Deep learning (DL) methods have revolutionized fall detection by enabling systems to automatically learn complex spatiotemporal representations from raw data, eliminating the need for manual feature engineering. These systems commonly use models such as CNNs for spatial feature extraction, Long Short-Term Memory (LSTM) networks for capturing temporal dependencies, and increasingly, Transformer-based models that can process long sequences with attention mechanisms [21]. These models are applied across multiple data modalities, including inertial sensor streams (IMU data), video feeds, and audio recordings.
In wearable sensor systems, deep learning models, especially 1D-CNNs and LSTM networks, are commonly applied to raw accelerometer and gyroscope data [22]. These architectures can detect subtle fall-related motion patterns and distinguish them from normal activities like walking, sitting, or transitioning [23]. Models like Bidirectional LSTM (BiLSTM), Gated Recurrent Unit (GRU), or hybrid CNN-LSTM setups allow for capturing both local motion features and temporal dynamics across multiple time steps [24,25]. Furthermore, Transformers, though more computationally intensive, have been explored for their ability to model long-range dependencies in sensor streams, offering a promising direction for continuous fall risk monitoring [26].
However, the performance of these systems is heavily dependent on the availability of annotated sensor datasets, which are limited in both size and diversity [27]. Most existing datasets feature scripted falls under controlled conditions, which may not reflect real-world behavior, particularly among elderly users with frailty or mobility impairments [21].
Despite their impressive capabilities, deep learning models are often viewed as “black boxes,” lacking transparent decision processes [28]. This poses challenges for clinical acceptance and user trust, particularly in eldercare settings. Moreover, deploying such models on real-time or edge systems requires model optimization (e.g., pruning, quantization) to ensure responsiveness without compromising accuracy [29].
- (d)
- Multimodal AI Systems
Multimodal fall detection systems represent an advanced direction in monitoring technologies by simultaneously integrating multiple data streams from various sensor types, such as inertial sensors (IMUs), RGB and depth cameras, and microphones for detecting impact sounds, as well as contextual data like location, time, or user activity patterns [30]. This approach enables complex and comprehensive analysis, enhancing both detection accuracy and context awareness of the event.
To process these heterogeneous data inputs, multimodal systems use sensor fusion architectures such as hybrid Convolutional Neural Network–Recurrent Neural Network (CNN–RNN) models or multimodal transformers, which effectively combine temporal and spatial signals from different sources. These models allow not only the identification of a fall from a single data source but also cross-validation across multiple streams, significantly reducing false alarms, a common issue in single-channel systems [31].
However, several limitations hinder the widespread adoption of such systems:
- Increased complexity: Integrating and synchronizing data from multiple sensor modalities presents significant hardware and software challenges.
- Calibration and maintenance requirements: Each sensor may necessitate individual calibration, and the entire system must maintain synchronized and stable performance over time, factors that increase costs and technical support demands.
- High resource consumption: Real-time processing of multimodal data streams requires substantial computational power and energy, potentially limiting deployment on resource-constrained edge devices.
A relevant example is the study by Liu et al. (2025), who developed a hybrid model combining YOLOv8s, a high-performance object detection network, with AlphaPose, a human skeleton tracking system that estimates joint positions [32]. This integration enhanced detection accuracy by simultaneously analyzing visual input and body posture, illustrating the considerable potential of multimodal systems for improving monitoring reliability.
Furthermore, such systems can incorporate voice interaction components or conversational AI, enabling real-time confirmation or dismissal of detected events. This additional validation mechanism not only improves accuracy but also enhances user trust and facilitates acceptance of the technology in care environments.
2.1.2. Computer Vision-Based Systems in Fall Detection
Computer vision has become a central pillar in fall detection research due to its ability to non-invasively monitor human posture and behavior. Over time, researchers have developed various methods, ranging from traditional image processing techniques to state-of-the-art deep learning architectures.
- (a)
- Traditional Vision Systems
Early computer vision systems used handcrafted image processing techniques, including background subtraction, silhouette tracking, and optical flow analysis. These systems attempted to detect abnormal posture or sudden motion patterns using RGB or depth video. While innovative for their time, these methods struggled in cluttered environments and were prone to false positives from non-fall activities (e.g., sitting abruptly, bending, or crouching) [33].
- (b)
- Pose Estimation with Rule-Based Logic Systems
The introduction of depth sensors, such as Microsoft Kinect [34], and pose estimation algorithms, like OpenPose, HRNet, and MediaPipe, has enabled fall detection systems to use skeletal keypoints (e.g., head, hips, knees) to infer postural instability or horizontal collapse [35]. These systems typically apply rule-based logic or threshold-based conditions to skeletal angles [36] or keypoint velocities to identify potential falls [37].
These approaches offer several advantages, including increased interpretability, improved performance in multi-person environments, and enhanced privacy due to depth-based imaging.
However, rule-based logic can be susceptible to errors in dynamic or cluttered environments. Moreover, real-time inference is often constrained by the computational limitations of edge devices. Additionally, such systems generally require extensive camera coverage to achieve consistent detection accuracy across different areas.
- (c)
- Convolutional Neural Network (CNN)-Based Systems
CNN-based models have enhanced visual recognition tasks in fall detection by automatically learning spatial features from image sequences. Architectures such as VGG, ResNet, and 3D-CNNs have been used to classify activity types or detect fall events within video segments [38,39,40]. Compared to classical methods, these models demonstrate greater robustness; however, they often rely on frame accumulation or sliding window techniques, which can introduce latency, an important limitation in time-critical applications such as fall detection [41].
- (d)
- YOLO-Based Fall Detection Systems
YOLO stands out as a real-time, highly efficient framework for object detection and pose-aware activity recognition. YOLO networks are designed to process entire images in a single forward pass, identifying objects, humans, and actions in real time [42]. For fall detection, pose estimation integrated with YOLO (e.g., YOLO + AlphaPose, YOLO-Pose, or YOLOv8-seg) amplifies its benefits, allowing systems to detect human bodies and analyze posture changes frame by frame [43].
These systems offer high processing speed, established accuracy in recent versions, and the ability to integrate on the edge device. However, they can be sensitive to occlusions, rely primarily on frame-by-frame analysis, and require specialized datasets for training [44].
To contextualize the strengths and limitations of different fall detection paradigms, Table 2 presents a comparative summary of their core characteristics and capabilities.
Table 2.
Comparative Overview: proposed vs. existing systems.
As summarized in Table 2, YOLO-based systems clearly outperform traditional and CNN-based approaches in terms of real-time performance, posture sensitivity, and suitability for edge deployment. Furthermore, the integration of pose estimation into the YOLO framework enhances its ability to differentiate between intentional and accidental movements while maintaining efficiency and scalability. Based on these advantages, the proposed system adopts a YOLOv11-based architecture that integrates with a voice-based AI dialogue module. This hybrid solution not only improves detection accuracy and responsiveness but also introduces a novel layer of interactivity and validation by reducing false positives and enhancing trust in safety environments.
2.1.3. Ambient and Hybrid Systems in AI Context
These systems offer passive monitoring without needing user interaction, are commonly installed in care homes or multi-occupant settings, and have the benefit of being non-intrusive. They have a number of important advantages, including the ability to monitor continuously and passively without the need for active user interaction, scalability for tracking numerous individuals at once, and suitability for long-term background operation in controlled environments [45].
Technical installation and accurate sensor calibration are required for their deployment; their functionality is limited to certain physical locations; and their integration of audio/video modalities may present privacy and regulatory compliance issues, among other significant limitations [45,46].
Despite these issues, ambient sensors can be embedded into multimodal systems to validate events detected by other means. For instance, an abrupt drop in pressure from a chair mat may support an accelerometer-based fall alert.
Hybrid systems, which integrate wearable, ambient, and vision-based components, represent the cutting edge of fall detection. These systems capitalize on redundant sensing and cross-modal validation to significantly improve accuracy and reduce false positives.
They provide more flexibility and resilience, but they also come with higher hardware costs and more complicated software.
The field of fall detection is shifting from hardware-centric classifications to AI-driven taxonomies based on data processing capabilities. The transition from rule-based to deep and multimodal learning has led to increasingly sophisticated systems capable of handling the complexity of real-world scenarios.
The most promising advances come from multimodal architectures, where complementary data sources enable context-aware, personalized monitoring. The present research aligns with this trajectory by proposing a hybrid fall detection system based on YOLOv11 with pose estimation and a voice assistant, aiming to improve accuracy, reduce false positives, and enhance user interaction.
2.2. AI-Based Monitoring Systems for Elderly Care
AI-based monitoring systems for elderly care have advanced significantly, integrating multimodal technologies like computer vision, voice interaction, ML, and predictive analyses to balance safety with autonomy. These systems prioritize real-time anomaly detection, adaptive responses, and user-centric design, with recent innovations focusing on hybrid approaches that combine sensing modalities and conversational AI for proactive care [47].
Recent studies have focused on:
- Activity recognition that uses video feeds to detect anomalies or dangerous patterns. Systems analyze skeletal poses and movement patterns to detect falls or unsafe behaviors, achieving real-time processing with minimal latency [48];
- Voice interaction that allows elderly users to interact naturally with assistive systems. However, setup complexity remains a barrier, but studies show that touchscreens and simplified instructions improve adoption among older adults [49]. These findings are relevant to the design of our system, as they show that ease of setup and interaction directly influence the acceptance of voice technologies among older adults;
- ML for Predictive Analytics, where models analyze gait patterns, historical health data, and environmental factors to predict fall risks. Logistic regression and neural networks generate personalized risk scores, enabling preemptive interventions like balance exercises [50].
The combination of real-time monitoring with intelligent responses, especially using conversational AI, is considered the next step in proactive and user-centric elderly care. By enabling not only the detection of incidents but also dynamic interaction with the user, these systems bridge the gap between passive surveillance and responsive assistance.
2.3. Limitations of Existing Approaches
Despite recent progress, current systems continue to face key challenges. High false alarm rates, especially in vision-only setups that misinterpret rapid but non-dangerous movements, limit trust and usability [10]. Furthermore, the lack of contextual awareness often leads to inappropriate or delayed responses, as most systems do not verify the user’s condition after a detected event [51].
Privacy concerns also persist, particularly in camera-based monitoring systems, which are frequently perceived as intrusive. This perception significantly reduces user acceptance, especially in private home settings [14].
Limited Real-World Testing remains a major barrier. Many fall detection models are trained and evaluated using simulated datasets or controlled laboratory conditions, typically involving young, healthy participants. This limits their generalizability to real-world scenarios, where elderly users exhibit more diverse and unpredictable movement patterns. The absence of benchmark datasets containing real falls from elderly individuals further complicates performance validation [10].
Hardware limitations and usability issues present challenges in adoption, particularly for frail users or low-resource environments [52].
To mitigate these issues, our system introduces several practical features that prioritize reliability, privacy, and real-world feasibility:
- It uses two cameras, which improves spatial coverage and reduces blind spots, leading to more reliable fall detection. Unlike many existing solutions that rely on a single camera, this dual-camera approach enhances spatial robustness and reduces the risk of occlusion-related misdetections;
- Local processing avoids dependence on cloud services and enhances data security;
- Importantly, the system does not store any recorded images or videos, directly addressing one of the main privacy concerns associated with vision-based monitoring.
The design of our system highlights privacy, practicality, and user acceptability, establishing a solid foundation for future real-world deployment, despite its current evaluation being conducted in laboratory using a simulated dataset.
3. Materials and Methods
3.1. Materials
The system proposed in this study is designed to function as a non-intrusive, real-time fall detection and response solution for elderly care. Its architecture combines computer vision techniques with a lightweight voice assistant, all running locally to ensure privacy, responsiveness, and independence from cloud services.
To provide reliable video-based monitoring, two INSTA360 GO3 cameras (64 GB, Wi-Fi) were selected for their portability, high resolution (up to 2.7 K), and ability to capture stable footage in dynamic indoor environments. The dual-camera setup ensures increased spatial coverage and reduces blind spots, allowing the system to maintain visibility of the monitored subject from multiple angles. The system processes each video stream independently to enhance robustness against occlusions [6]. To mitigate privacy concerns, the system was designed to operate in real time, processing each video frame on the fly without storing any data locally or in the cloud. Frames are analyzed as they are captured and immediately discarded after processing. Additionally, all data used during development originated from simulated scenarios involving internal participants recruited from within the organization.
The system uses the YOLOv11 object detection framework, which integrates pose estimation capabilities within a single architecture. This enables simultaneous detection of the human body and tracking of critical skeletal keypoints, such as the head, shoulders, hips, knees, and feet, directly from the video feed. YOLOv11 was chosen for its superior inference speed and accuracy in complex visual scenes, particularly those involving movement transitions or unusual body orientations. The model was initialized using pre-trained weights from the official repository on GitHub and further fine-tuned using publicly available datasets relevant to fall detection.
We used a subset of the publicly available Le2i dataset [53], from which we extracted 130 sequences for evaluation purposes. These included both fall events and daily living activities (e.g., walking, sitting, bending). We manually annotated each Le2i sequence using a custom labeling interface. Labels included binary classification (“fall”/“no fall”) as well as activity tags such as “bent over,” “sitting down,” “standing,” or “lying down.” The Le2i subset was particularly useful for evaluating the generalization ability of our model in scenes with different camera angles and environmental conditions.
Complementing the vision-based detection, the system integrates a voice assistant based on rule-based keyword matching, designed to assess the user’s condition immediately after a fall is detected. It uses the speech_recognition library for speech-to-text conversion and pyttsx3 for text-to-speech output. This voice interface was chosen for its lightweight implementation, full on-device local capability (no cloud API dependency), and compatibility with resource-constrained devices. When the system detects a fall, it automatically sends an alert via the Telegram API to a caregiver or family member.
A GPU-enabled development environment (NVIDIA GeForce RTX 4070, Python 3.10, PyTorch 2.6.0 backend) executes all audio and video processing locally, eliminating the need for internet access and protecting sensitive user data. The system utilizes a local pipeline for both speech-to-text (STT) and text-to-speech (TTS) processing. The device processes all audio directly, using the integrated camera microphone to capture voice input. This approach ensures low latency and preserves user privacy by keeping all data local.
3.2. Study Design
To simulate real-world usage, all tests were conducted in an office room partially adapted to approximate a typical indoor environment. The testing space included common furniture items such as chairs and tables, as well as objects placed on the floor to create cluttered conditions. Although not a fully equipped domestic space, the setup was designed to evaluate the system’s ability to operate effectively in constrained and dynamic layouts that resemble home environments where falls are likely to occur.
After the YOLOv11n-Pose posture classification model detected a potential fall, the system initiated a local voice-based verification process. A speech synthesis module (pyttsx3) vocalized a prompt such as “Did you fall? Do you need help?” to assess the user’s condition. The system then entered a listening phase using the speech_recognition library, capturing the user’s response through the camera’s built-in microphone.
To determine the appropriate response, the system analyzed the transcribed input using two predefined sets of keywords:
- Help-related expressions (indicating distress or need for assistance): “I’m not okay,” “I need help,” “Help,” “It hurts,” “I fell,” “I can’t move,” “Pain,” “Not feeling well” and “Need assistance.”
- Reassuring expressions (indicating safety): “I’m okay,” “I’m fine,” “No help needed,” “All good,” “I’m alright,” “No worries” and “No problem.”
If the system detected any help-related phrases in the speech, it classified the situation as critical and immediately sent an alert via the Telegram Bot API. Conversely, if a reassurance phrase was detected, the event was logged as non-critical and no alert was sent.
In cases where no valid response was received within a defined timeout (e.g., 15 s), or if the recognized speech confidence was low or unintelligible, the system defaulted to sending an automated alert, assuming that the user might be incapacitated or unable to respond.
This protocol ensured both prompt verification and minimal intrusion, balancing user independence with effective monitoring. The time delay before triggering the alert, the recognition threshold, and the phrasing of voice prompts were iteratively tested and adjusted during development to optimize user experience and system reliability.
The study involved multiple test scenarios that aimed to reproduce both fall-related events and normal activities of daily living (ADLs). These included the following:
- Simulated falls: Participants under controlled supervision performed forward, backward, and lateral falls to assess the system’s ability to distinguish between different types of genuine falls.
- Rapid or unstable movements: Sudden sitting, stumbling, or leaning over (e.g., to pick up objects) were included to evaluate the system’s precision in avoiding false positives.
- Normal behaviors: Walking, turning, sitting down, standing up, or reaching for objects were performed to ensure the system does not misclassify routine movements as dangerous.
A total of 200 sequences were recorded using the INSTA360 GO3 cameras, capturing both RGB video and synchronized voice input via the built-in microphone.
Each fall event was manually annotated to establish ground truth data, and the system’s performance was measured in terms of detection accuracy, sensitivity (true positive rate), and specificity (true negative rate). This allowed for quantitative evaluation of the model’s ability to differentiate between actual falls and non-fall actions.
3.3. Data Collection and Preprocessing
To fine-tune and evaluate the proposed real-time fall detection and response system, a comprehensive dataset was created using custom-recorded video sequences and voice interaction scenarios.
- (a)
- Video Data Collection
Video recordings were conducted using two cameras placed at different angles, positioned to capture the full body of participants in various household settings. The dual-camera setup allowed for multi-view analysis, reducing occlusions and improving pose estimation accuracy. Volunteers of diverse ages, genders, and physical characteristics were recruited to perform a series of predefined actions that simulate typical daily activities and potential fall scenarios, including the following:
- Intentional fall scenarios: forward falls, backward falls, and side falls;
- Fall-like actions: sitting abruptly, stumbling, or bending to pick up objects;
- Normal activities: walking, standing, sitting, and lying down.
Each video frame was annotated with the following:
- Pose keypoints, including head, shoulders, elbows, hips, knees, and feet;
- Fall event labels, categorized as “Fall detected,” “Sitting,” “Bent over,” or “Standing”;
- Additional annotations, such as movement types.
- (b)
- Voice Interaction Data
Since the system also includes a voice-based assistant, interaction testing was integrated into the data collection workflow. This assistant is triggered after a detected fall event, prompting the user with a spoken message (e.g., “Do you need help?”) and awaiting a verbal response.
The system matches the transcribed text against these lists to determine the appropriate response:
- If any help-related phrase is detected, an immediate alert is sent via the Telegram Bot API to notify caregivers;
- If a reassuring phrase is detected, the fall is logged as a non-critical event and no alert is sent;
- If no response is detected within a timeout (typically 15 s), or the confidence in recognition is low, the system assumes the user is incapacitated and sends an automated alert.
The voice assistant uses a local speech-to-text (STT) and text-to-speech (TTS) pipeline, leveraging the following:
- speech_recognition for converting speech to text;
- pyttsx3 for converting system prompts to speech.
This entirely on-device local processing approach was chosen to preserve user privacy and reduce latency, ensuring a responsive system.
3.4. Pose Estimation and Fall Detection Algorithm
This section presents the complete methodology for real-time human pose estimation and fall detection using the YOLOv11-Pose model and a set of rule-based computations. The system processes video feeds from two cameras to improve detection accuracy and spatial coverage, making it suitable for indoor elderly monitoring scenarios. The system achieves fall detection by analyzing spatial relationships between anatomical keypoints in each frame.
3.4.1. Keypoint Detection
The YOLOv11-pose model provided by the Ultralytics framework detects 17 anatomical keypoints per person, including the nose, shoulders, hips, knees, and ankles. Each keypoint is defined by 2D spatial coordinates (xi, yi) and an associated confidence score ci ∈ [0, 1]. Only keypoints with confidence ci > 0.5 are considered reliable and used in further computations. Table 3 summarizes the selected keypoints and their corresponding indices used in the fall detection algorithm.
Table 3.
Keypoint index mapping for human pose estimation.
Threshold values were empirically selected based on preliminary tests. These thresholds rely on specific anatomical keypoints extracted by the YOLOv11-Pose model. These thresholds can be adapted to different environments or user profiles through calibration modules, which will be explored in future versions of the system.
3.4.2. Center of Gravity (CoG) Estimation
To assess potential falls, the system computes an approximate Center of Gravity (CoG) for each person, based on a subset of keypoints associated with major body mass regions:
where K = {0,5,6,11,12,13,14} includes keypoints for the head, shoulders, hips, and knees, and N is the number of valid keypoints with ci > 0.5.
A rapid downward shift in the vertical coordinate of the CoG across consecutive frames is considered a strong indicator of a fall.
3.4.3. Posture Evaluation Metrics
To determine the subject’s posture, several geometric metrics are computed based on keypoint coordinates:
- Shoulder and Hip Centers
- Trunk Orientation (Body Angle)
The orientation of the upper body is evaluated using the ratio of vertical to horizontal displacement between shoulders and hips:
where ϵ = 10−5 is a small constant to avoid division by zero.
- Relative Hip Position to Feet
A person is considered to be above ground level if
3.4.4. Posture Classification Criteria
Based on these metrics, the system categorizes posture into predefined classes. Table 4 summarizes the heuristic conditions used to determine each posture category. If the number of detected keypoints is insufficient or the metrics are inconclusive, the posture is labeled as Unknown.
Table 4.
Rule-based criteria for posture classification.
To evaluate the effectiveness of the proposed posture detection system, multiple experiments were conducted using a dual-camera configuration. This setup allows for simultaneous observation of the user from different angles, which enhances robustness in cases of occlusion or limited visibility. The following figures present the results obtained from processing the image streams captured by both cameras.
Figure 1 illustrates pose detection results obtained from both Camera 1 and Camera 2, enabling simultaneous monitoring from different angles, and correct identification of the user’s posture as “Standing” and “Fall detected!” based on skeletal keypoints extracted in real time. The red dots correspond to detected body keypoints, while green lines connect adjacent keypoints to form a skeletal representation of the posture.

Figure 1.
Pose detection results using dual-camera input: (a–d) examples showing accurate identification of the “Standing” and “Fall detected!” postures from different viewpoints.
Figure 2 shows examples of real-time detected postures such as “Sitting” and “Bent over,” demonstrating the system’s capability to operate correctly even when one of the cameras is not functional.
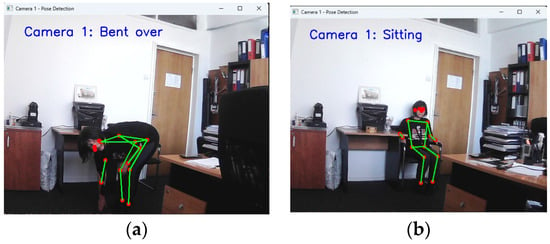
Figure 2.
Real-time detected postures with operation maintained despite one camera failure: (a) Bent over, (b) Sitting.
3.5. AI-Based Voice Assistant Module
To increase the robustness of fall detection and provide user-centered interaction, the system integrates a voice assistant module that is triggered immediately after a fall is detected. This module serves a dual role: verifying the user’s state post-incident and initiating appropriate emergency procedures based on the response.
- (a)
- Activation Trigger
The voice assistant is activated only when the fall detection logic confirms a potential fall event. Once a fall is flagged, the assistant issues an audible prompt using the pyttsx3 text-to-speech engine.
This interaction simulates a real-world caregiver inquiry and ensures the system seeks user input before triggering emergency protocols.
- (b)
- Response Handling Logic
The system enters a listening mode for a predefined time window (15 s) using the speech_recognition library. During this period, it processes the user’s vocal response and classifies the input into predefined categories, as shown in Table 5. This rule-based classification provides a lightweight yet effective intent recognition mechanism, suitable for embedded systems or low-resource environments.
Table 5.
Classification of user vocal responses and corresponding system actions.
- (c)
- Emergency Protocol and Alerting
If the response is absent, delayed, or clearly indicates distress, the system initiates the emergency response protocol:
- Audible Feedback: “No response detected.”
- Alert Transmission:
- -
- The system sends an automated alert via secure API.
- -
- The API then handles notification delivery via push notification to a mobile app or caregiver dashboard.
To demonstrate the actual operation of the system, a fragment of the execution terminal is presented in Figure 3. This output highlights the complete sequence of events, including posture detection, initiation of voice interaction, and alert transmission in the absence of a user response.
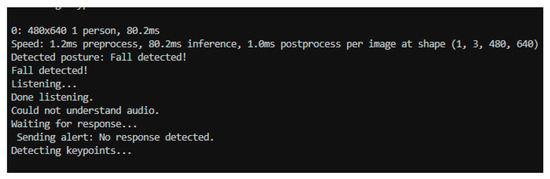
Figure 3.
Terminal output showing the system’s runtime behavior.
This sequence of operations, as illustrated in the terminal output in Figure 3, is supported by a set of integrated software components. Table 6 provides an overview of the technical stack used to implement the voice assistant and its related functionalities.
Table 6.
Technical stack used for voice-based interaction and notification.
The voice assistant module significantly enhances the human-in-the-loop approach of the fall detection system. By allowing the user to confirm or deny a fall via speech, the system achieves the following:
- Reduces false positives from misclassified motions;
- Adds an empathetic interaction layer;
- Ensures fast emergency response when needed.
3.6. Experimental Setup and Test Scenarios
3.6.1. Test Environment
To evaluate the practical feasibility of the proposed system, all tests were conducted in an indoor environment designed to simulate typical residential conditions. The test area included common household furniture to create natural obstacles and simulate re-al-world spatial constraints.
Video data were captured using two INSTA360 GO3 cameras, positioned to provide complementary angles and reduce blind spots. The lighting was kept at standard indoor levels, with no special adjustments to enhance visibility, to assess the system’s performance in typical usage conditions.
Five volunteers (aged 25–58, with varied height and body build) participated in the experiments. Each participant was instructed to perform predefined sequences of movements simulating both fall events and activities of daily living (ADLs).
3.6.2. Test Scenarios
To assess the robustness of the system under different conditions, several test scenarios were designed and executed. Table 7 summarizes each scenario, its description, and the specific detection goal.
Table 7.
Description of experimental scenarios and corresponding detection objectives.
All scenarios were included in the evaluation dataset of 200 video sequences, as detailed in Section 3.3.
4. System Implementation
4.1. System Architecture
The proposed fall detection system is built on a modular architecture that integrates real-time video analysis, pose estimation, voice interaction, and automated alert functionalities. The components are organized into a pipeline that ensures efficient and low-latency response. The main modules include the following:
- Video Acquisition Module: Utilizes two cameras strategically positioned to maximize spatial coverage and reduce blind spots.
- Pose Estimation and Fall Detection Engine: Powered by YOLOv11 with integrated pose estimation to extract 17 anatomical keypoints per person.
- Voice Assistant Interface: Activates when a fall is detected. It uses Text-to-Speech (TTS) and Speech-to-Text (STT) components to communicate with the user and process verbal responses.
- Intent Recognition Unit: Analyzes user responses and categorizes them into actionable intents (e.g., “I’m fine,” “Help,” or no response).
- Alert and Notification System: Sends real-time alerts to caregivers or family members via the Telegram API when assistance is needed.
Fall detection is triggered by the first video stream that confirms an incident, without waiting for cross-validation from the second camera. This allows for quicker interventions in time-critical scenarios when an emergency alert is automatically sent via the Telegram API to the designated caregivers.
This design guarantees robustness and fault tolerance. If one camera fails to detect a fall due to occlusion or other factors, the second camera can still independently trigger the appropriate response.
Figure 4 illustrates the end-to-end workflow of the proposed fall detection system, from video acquisition to emergency alerting. The flowchart highlights the key processing stages, including YOLOv11-based pose estimation, voice-based condition verification, and automated Telegram notifications.
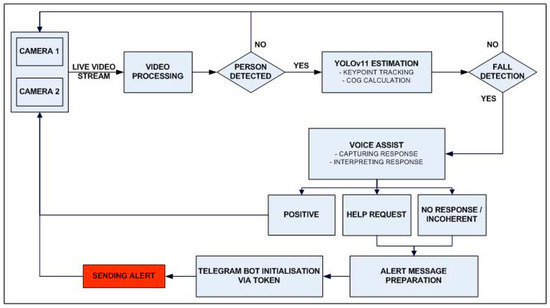
Figure 4.
Real-time fall detection and alert workflow.
4.2. Technologies and Libraries Used
The development of this fall detection system relies on a combination of Python libraries, each contributing to specific functionalities such as posture detection, fall recognition, user interaction, and emergency alerting. The system’s architecture brings together both computer vision and voice processing tools to create a robust, real-time monitoring solution.
At the core of the visual processing component lies OpenCV, an open-source computer vision library used to access the webcam feed, capture video frames in real time, and render visual feedback such as body keypoints, skeletal overlays, and posture labels directly on the video stream. To complement this, NumPy is employed for efficient numerical computations, especially when handling vectors and matrices associated with body pose data. It facilitates keypoint processing, angle calculations, and classification of postures by analyzing spatial relationships among detected body parts.
The backbone of the fall detection model is the YOLOv11-pose architecture, accessed through the Ultralytics API. This model enables fast and accurate pose estimation, serving as the foundation for recognizing abnormal movements and potential fall events.
For voice interaction, the system utilizes pyttsx3, a text-to-speech synthesis library that operates on-device locally, enabling the platform to deliver vocal alerts when a fall is detected. It also engages the user by asking for verbal feedback regarding their condition. In parallel, the speech_recognition library captures audio input via the microphone and processes it using Google’s speech recognition API. This allows the system to interpret spoken responses such as “I’m okay” or “I need help,” determining the appropriate course of action based on the user’s reply. These functions have already been validated and tested under suitable conditions, and for this development phase, we decided to use them in their predefined form without further modifications or enhancements.
To manage asynchronous operations, the system employs asyncio, which ensures that tasks like sending messages do not interfere with ongoing video processing. Similarly, the threading module allows various components, such as real-time image analysis and background communications, to run in parallel, maintaining smooth and responsive performance.
Finally, the system integrates with the Telegram messaging platform through the python-telegram-bot library. This enables the system to send immediate alerts to caregivers when a fall is confirmed and assistance is requested, supporting remote supervision and timely intervention.
Together, these libraries form a cohesive and efficient software stack that supports the system’s multimodal functionality, real-time responsiveness, and user-focused interaction.
Figure 5 illustrates the automatic alert message sent via the Telegram API when a fall is detected and the user fails to respond. The message provides concise, actionable information to caregivers in real time.
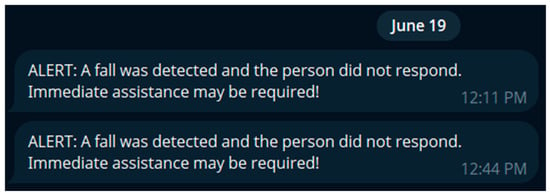
Figure 5.
Emergency alert message sent via Telegram when no user response is detected after a fall.
5. Results
This section presents the evaluation of the developed system, with a particular focus on fall detection performance. While the system may have the capacity to recognize various human activities, the primary objective of this project was to accurately detect fall events. To assess this, we analyzed the system’s behavior using standard classification metrics derived from the confusion matrix, which specifically reflect the system’s ability to distinguish between fall and non-fall scenarios.
5.1. Evaluation Metrics
To evaluate the performance of the fall detection system, extensive tests were carried out. The confusion matrix provides an overview of the algorithm’s ability to correctly distinguish between fall events and normal activities. The confusion matrix for this scenario, based on our collected data from simulated scenarios, is presented in Figure 6.

Figure 6.
Confusion matrix based on data collected from simulated scenarios conducted by the development team.
The components of the confusion matrix are explained below:
- True Positives (TPs): A real fall occurred and was correctly detected by the system (103 instances);
- False Positives (FPs): The system falsely detected a fall when none occurred (3 instances);
- True Negatives (TNs): No fall occurred, and the system correctly ignored it (92 instances);
- False Negatives (FNs): A fall occurred but was not detected by the system (2 instances).
Based on these counters, the following metrics were computed for each processed frame:
- Accuracy: The overall correctness of the model’s predictions across all classes;
- Precision: The proportion of detected falls that were actual falls;
- Recall (Sensitivity): The ability of the system to detect actual falls;
- F1-Score: Harmonic mean of precision and recall, useful when the dataset is imbalanced;
- Specificity: The proportion of actual negatives that are correctly identified by the model.
These metrics, obtained from the confusion matrix and summarized in Table 8, offer a comprehensive insight into the algorithm’s effectiveness in identifying fall events and differentiating them from non-fall activities.
Table 8.
Key metrics used for system evaluation on data collected from simulated scenarios conducted by the development team.
The fall detection model demonstrates strong and well-balanced performance across key evaluation metrics, making it suitable for practical deployment. It achieves a high recall of 98.1%, indicating that the system successfully identifies the vast majority of actual fall events, which is essential for these types of applications. The overall accuracy of 97.5% reflects the model’s ability to correctly classify both fall and non-fall instances across the dataset. A precision of 97.17% further confirms that most fall predictions made by the system are accurate, minimizing false alarms. Complementing these metrics, the F1 score of 97.65% highlights the model’s effective balance between precision and recall, ensuring both reliable detection and alert efficiency. Additionally, the model achieves a specificity of 96.84%, meaning it correctly identifies non-fall events in the majority of cases, reducing the likelihood of unnecessary interventions. Together, these results underscore the system’s robustness and its potential for real-world use in intelligent fall detection scenarios.
In addition to the evaluation on our internally collected dataset of 200 simulated sequences (Table 8), we also tested the algorithm on another external dataset, the Le2i dataset, to further assess its robustness and to enable comparison with prior studies (Table 9). The observed differences in performance metrics between the two tables reflect the variability of scenarios, participant behaviors, and environmental conditions in the two datasets.
Table 9.
A comparison of our new proposed method with other studies, with all results obtained on the same Le2i dataset.
5.2. Evaluation Outcomes
- The YOLOv11 pose estimation was highly stable under normal lighting and frontal view;
- Borderline motions (like abrupt sitting or crawling) were often correctly classified, likely due to pose stability and consistent spatial features;
- The voice assistant successfully reduced false alarms;
- Pose estimation inference time averaged 34 ms/frame on an RTX 4070 and 0.5 ms postprocess per image. Total time for detection, response generation, and alerting was ~1.1 s.
5.3. Impact of Voice Interaction on System Performance
To evaluate the contribution of the voice assistant module, we conducted study using the same dataset of 200 annotated video sequences described in Section 3.2. Two configurations were tested:
- YOLOv11 without voice interaction: The system automatically sent alerts upon detecting a fall based on pose estimation alone.
- YOLOv11 with voice assistant: After a detected fall, the system engaged in voice interaction to confirm the user’s condition before triggering an alert.
Table 10 summarizes the results.
Table 10.
Performance comparison between system configurations with and without voice confirmation.
Its human-in-the-loop design explains the significant reduction in false positives observed with the addition of the voice interaction module (Table 10). While the vision-based detector sometimes misclassifies abrupt but harmless activities (e.g., sitting down abruptly or bending) as falls, the voice assistant prompts the user to confirm their condition. If the user responds that they are fine, the alert is suppressed, effectively filtering out ambiguous cases that would otherwise trigger false alarms.
The contribution of the voice assistant was quantified by comparing system configurations with and without voice interaction, as shown in Table 10. Integrating the voice assistant reduced the number of false positives from 12 to 3, corresponding to approximately a 75% reduction, while maintaining the same detection accuracy and recall. These results demonstrate that even a simple, rule-based voice confirmation mechanism can substantially improve reliability in fall detection scenarios.
We further analyzed the misclassifications observed during testing. False positives were primarily associated with non-fall activities involving abrupt postures, such as quickly sitting down, bending to pick up objects, or crawling. These movements sometimes mimic a lying position or rapid transition, triggering false alarms. Infrequent false negatives typically resulted when furniture partially obscured falls or when the fall resulted in a posture that was not fully horizontal (e.g., curled), thus making it harder to distinguish from normal activities.
6. Discussion and Conclusions
The experimental results validate the effectiveness of the proposed fall detection system in real-world scenarios, combining YOLOv11-based pose estimation with interactive voice assistance to deliver accurate and responsive monitoring. Beyond performance metrics, the system introduces a context-aware approach by integrating user intent verification, which helps reduce false alarms and ensures meaningful alerts. This section discusses the system’s current limitations and proposes future directions for enhancing its robustness, usability, and applicability in diverse environments.
6.1. Limitations
Table 1 highlights the improvements of YOLOv11 over YOLOv7-W6-Pose in terms of architecture, inference speed, and detection accuracy. However, we acknowledge that this work lacked a formal ablation study isolating the impact of YOLOv11 on fall detection performance. We plan to include such a systematic analysis in future research to further substantiate the benefits of the YOLOv11 upgrade.
The experimental room was furnished and cluttered to approximate a home environment, but it does not fully replicate the diversity of real homes, which may vary in layout, lighting conditions, and furniture density. The room lacked natural lighting variations and more complex occlusion scenarios found in actual residences. These challenges can affect detection reliability, as visual accuracy remains sensitive to environmental factors such as low lighting, motion blur, and partial occlusions, particularly when falls occur behind obstacles or outside the cameras’ field of view.
Another key limitation is the composition of the testing dataset, which predominantly includes healthy adult participants. As a result, the model may not accurately represent or respond to the movement characteristics of elderly individuals or users with assistive devices, such as canes or walkers. This restricts its generalizability to its intended target group.
Furthermore, the effectiveness of the voice assistant component is limited in noisy or multi-speaker environments, where background noise and overlapping speech can impair accurate intent recognition. Additionally, the current system does not support multilingual input or dialectal variations, which may reduce usability in culturally and linguistically diverse settings. The voice interaction relies on rule-based keyword matching, which, although lightweight and efficient, can restrict the system’s ability to interpret spontaneous or non-standard expressions that may occur during real-life emergencies. Moreover, this study does not include a direct performance comparison between the YOLOv11-Pose model with and without the integrated voice assistant. Although preliminary observations suggest verbal confirmation reduces false positives, future work should formally assess the voice module’s precise impact using ablation studies because it remains unquantified.
While the voice assistant proved effective in reducing false positives, it was not benchmarked against other speech recognition solutions or evaluated under varying noise levels, multilingual conditions, or with users having speech impairments. Furthermore, its current implementation relies on standard Python libraries without specialized optimization. These aspects will be explored in future work to enhance robustness and generalizability.
These limitations can affect both detection reliability and the user experience.
6.2. Future Directions
We propose several enhancements to address the system’s limitations and improve its practical deployment. Expanding the dataset to include elderly users and individuals with mobility impairments, along with recordings from varied home environments, would significantly improve the model’s generalization and adaptability. Incorporating multimodal sensing, such as IMUs from wearable devices, can enhance detection accuracy in situations involving occlusion or poor visibility. We are also planning enhancements to the speech recognition and natural language processing components. Future work will focus on improving noise reduction capabilities, handling multiple speakers, supporting users with speech impairments, and expanding multilingual interaction to create a more intuitive and accessible user interface. Furthermore, we aim to advance the voice assistant module to enable dynamically generated responses, moving beyond predefined outputs to support more context-aware and user-specific interactions. Additionally, implementing adaptive sensitivity thresholds and a tiered alert hierarchy could personalize system responses based on user behavior and health status.
To further increase trust and usability, future work will explore integrating explainable AI components that provide visual or verbal justifications for alerts. Long-term, in-home testing with elderly participants will evaluate the system’s stability under real-life conditions, including nighttime monitoring and variable lighting. We aim to collect data from elderly and mobility-impaired participants to better capture these variations and adapt the model accordingly, thereby improving its robustness and applicability in the target population. Future research will also focus on investigating the system’s performance when utilizing lower-resolution or thermal imaging cameras. We will explore data augmentation techniques, such as image flipping, brightness adjustment, or motion blur simulation, to enhance model robustness. We will conduct user-centered evaluations to assess social acceptability and ethical impact, ensuring alignment with the values and preferences of elderly individuals. These developments aim to transform the current system into a fully intelligent, context-sensitive assistant for fall prevention and response.
6.3. Conclusions
This study proposed and validated a real-time fall detection system that combines YOLOv11-based pose estimation with an on-device voice interaction module to improve detection accuracy and reduce false alarms. The system demonstrated high precision and recall across 200 simulated sequences, and its modular architecture enables local processing, privacy preservation, and quick emergency response. Despite promising results, we limited testing to non-elderly participants in controlled environments. Future work will focus on expanding real-world validations with elderly users, enhancing voice interaction with adaptive NLP models, and integrating wearable or ambient sensors to further increase robustness. These developments aim to support the deployment of intelligent, context-aware monitoring systems that empower aging-in-place with safety and dignity.
Author Contributions
Conceptualization, methodology, software, investigation, resources, formal analysis, and validation, E.T. (Eugenia Tîrziu), A.-M.V., A.A. and E.T. (Eleonora Tudora); data curation, E.T. (Eugenia Tîrziu) and A.-M.V.; writing—original draft preparation, E.T. (Eugenia Tîrziu), A.-M.V., A.A. and E.T. (Eleonora Tudora); writing—review and editing, A.A., A.-M.V. and E.T. (Eleonora Tudora); supervision, project administration, and funding acquisition, A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Romanian Ministry of Research, Innovation, and Digitalization, grant number 13N/2023 (PN 23 38 05 01). The APC was funded by MDPI.
Data Availability Statement
The data presented in this study are openly available on Le2i dataset at https://www.kaggle.com/datasets/tuyenldvn/falldataset-imvia (accessed on 25 April 2025).
Acknowledgments
The authors gratefully acknowledge the contribution of the Romanian Ministry of Research, Innovation, and Digitalization for the development of the NeuroPredict Platform inside the project “Advanced Artificial Intelligence Techniques in Science and Applications” (contract No. 13N/2023 (PN 23 38 05 01)) for the period 2023–2026.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ADL | Activities of daily living |
| AI | Artificial Intelligence |
| BiLSTM | Bidirectional LSTM |
| CNNs | Convolutional neural networks |
| CoG | Center of Gravity |
| DL | Deep learning |
| FNs | False negatives |
| FPs | False positives |
| GRU | Gated Recurrent Unit |
| IMUs | Inertial measurement units |
| k-NNs | k-Nearest Neighbors |
| LSTM | Long Short-Term Memory |
| ML | Machine learning |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| STT | Speech-to-text |
| SVM | Support Vector Machine |
| TTS | Text-to-speech |
| TNs | True negatives |
| TPs | True positives |
| WHO | World Health Organization |
| YOLO | You Only Look Once |
References
- UN Department of Economic and Social Affairs. Improving the Visibility of Older People in Global Statistics. Available online: https://blog.ons.gov.uk/2024/10/01/improving-the-visibility-of-older-people-in-global-statistics/#:~:text=The%20UN%20Department%20of%20Economic (accessed on 25 April 2025).
- World Health Organization. Falls. Available online: https://www.who.int/news-room/fact-sheets/detail/falls (accessed on 25 April 2025).
- Amir, N.I.; Dziyauddin, R.A.; Mohamed, N.; Ismail, N.S.; Kaidi, H.M.; Ahmad, N.; Izhar, M.A. Fall Detection System Using Wearable Sensor Devices and Machine Learning: A Review. TechRxiv, 2024; submitted. [Google Scholar] [CrossRef]
- Tohidypour, H.R.; Shojaei-Hashemi, A.; Nasiopoulos, P.; Pourazad, M.T. A Deep Learning Based Human Fall Detection Solution. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA ’22), Corfu, Greece, 29 June–1 July 2022; pp. 89–92. [Google Scholar] [CrossRef]
- Kang, S.; Hu, Z.; Liu, L.; Zhang, K.; Cao, Z. Object Detection YOLO Algorithms and Their Industrial Applications: Overview and Comparative Analysis. Electronics 2025, 14, 1104. [Google Scholar] [CrossRef]
- Tîrziu, E.; Vasilevschi, A.-M.; Alexandru, A.; Tudora, E. Enhanced Fall Detection Using YOLOv7-W6-Pose for Real-Time Elderly Monitoring. Future Internet 2024, 16, 472. [Google Scholar] [CrossRef]
- Ma, M.; Hu, X. A Deep Learning and Edge Computing Integrated Approach for Fall Behavior Detection in Buildings. J. Saf. Sci. Resil. 2025, 100218. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv11 vs YOLOv7. Available online: https://docs.ultralytics.com/compare/yolo11-vs-yolov7/ (accessed on 25 April 2025).
- Karar, M.E.; Shehata, H.I.; Reyad, O. A Survey of IoT-Based Fall Detection for Aiding Elderly Care: Sensors, Methods, Challenges and Future Trends. Appl. Sci. 2022, 12, 3276. [Google Scholar] [CrossRef]
- Wang, X.; Ellul, J.; Azzopardi, G. Elderly Fall Detection Systems: A Literature Survey. Front. Robot. AI 2020, 7, 71. [Google Scholar] [CrossRef]
- Nooruddin, S.; Islam, M.; Sharna, F.A.; Alhetari, H.; Kabir, M.N. Sensor-Based Fall Detection Systems: A Review. J. Ambient Intell. Hum. Comput. 2022, 13, 2735–2751. [Google Scholar] [CrossRef]
- Šeketa, G.; Vugrin, J.; Lacković, I. Optimal Threshold Selection for Acceleration-Based Fall Detection. In Precision Medicine Powered by pHealth and Connected Health, Proceedings of IFMBE, Thessaloniki, Greece, 18–21 November 2017; Maglaveras, N., Chouvarda, I., de Carvalho, P., Eds.; Springer: Singapore, 2018; Volume 66, pp. 125–129. [Google Scholar] [CrossRef]
- Wang, F.T.; Chan, H.L.; Hsu, M.H.; Lin, C.K.; Chao, P.K.; Chang, Y.J. Threshold-Based Fall Detection Using a Hybrid of Tri-Axial Accelerometer and Gyroscope. Physiol. Meas. 2018, 39, 105002. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Nguyen, V.T. Development of a Smart Wearable Device for Fall and Slip Detection and Warning for the Elderly People. JST Smart Syst. Devices 2024, 34, 35–43. [Google Scholar] [CrossRef]
- Singh, A.; Rehman, S.U.; Yongchareon, S.; Chong, P.H.J. Sensor Technologies for Fall Detection Systems: A Review. IEEE Sens. J. 2020, 20, 6889–6919. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Ho, Y.S.; Egwuche, O.S.; Ekundayo, O.S.; Van Der Merwe, A.; Saha, A.K.; Pal, J. Classical Machine Learning: Seventy Years of Algorithmic Learning Evolution. arXiv 2024. [Google Scholar] [CrossRef]
- Yotov, O.; Aleksieva-Petrova, A. Data-Driven Prediction Model for Analysis of Sensor Data. Electronics 2024, 13, 1799. [Google Scholar] [CrossRef]
- Saleh, M.; Abbas, M.; Le Jeannès, R.B. FallAllD: An Open Dataset of Human Falls and Activities of Daily Living for Classical and Deep Learning Applications. IEEE Sens. J. 2021, 21, 1849–1858. [Google Scholar] [CrossRef]
- Geng, P.; Xie, H.; Shi, H.; Chen, R.; Tong, Y. Pedestrian Fall Event Detection in Complex Scenes Based on Attention-Guided Neural Network. Math. Probl. Eng. 2022, 2022, 4110246. [Google Scholar] [CrossRef]
- Khalili, S.; Mohammadzade, H.; Ahmadi, M.M. Elderly Fall Detection Using CCTV Cameras Under Partial Occlusion of the Subjects Body. arXiv 2022. [Google Scholar] [CrossRef]
- Gaya-Morey, F.X.; Manresa-Yee, C.; Buades-Rubio, J.M. Deep learning for computer vision based activity recognition and fall detection of the elderly: A systematic review. Appl. Intell. 2024, 54, 8982–9007. [Google Scholar] [CrossRef]
- Shukla, P.K.; Vijayvargiya, A.; Kumar, R. Human activity recognition using accelerometer and gyroscope data from smartphones. In Proceedings of the 2020 International Conference on Emerging Trends in Communication, Control and Computing (ICONC3), Lakshmangarh, India, 21–22 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, X.; Yu, S.; Zheng, J.; Fang, Z.; Zhao, Z.; Qu, X. A hybrid CNN-LSTM model for involuntary fall detection using wrist-worn sensors. Adv. Eng. Inform. 2025, 65, 103178. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Phaphan, W.; Hnoohom, N.; Jitpattanakul, A. Recognition of sports and daily activities through deep learning and convolutional block attention. PeerJ Comput. Sci. 2024, 10, e2100. [Google Scholar] [CrossRef]
- Xia, M.; Que, S.; Liu, N.; Wang, Q.; Li, T. Motion Pattern Recognition via CNN-LSTM-Attention Model Using Array-Based Wi-Fi CSI Sensors in GNSS-Denied Areas. Electronics 2025, 14, 1594. [Google Scholar] [CrossRef]
- Núñez-Marcos, A.; Arganda-Carreras, I. Transformer-based fall detection in videos. Eng. Appl. Artif. Intell. 2024, 132, 107937. [Google Scholar] [CrossRef]
- Tunca, C.; Salur, G.; Ersoy, C. Deep learning for fall risk assessment with inertial sensors: Utilizing domain knowledge in spatio-temporal gait parameters. IEEE J. Biomed. Health Inform. 2019, 24, 1994–2005. [Google Scholar] [CrossRef]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey. Mach. Learn. Knowl. Extr. 2021, 3, 966–989. [Google Scholar] [CrossRef]
- Dantas, P.V.; da Silva, W.S.; Cordeiro, L.C.; Carvalho, C.B. A comprehensive review of model compression techniques in machine learning. Appl. Intell. 2024, 54, 11804–11844. [Google Scholar] [CrossRef]
- Islam, M.M.; Nooruddin, S.; Karray, F. Multimodal Human Activity Recognition for Smart Healthcare Applications. In Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Prague, Czech Republic, 9–12 October 2022; pp. 196–203. [Google Scholar] [CrossRef]
- Shin, J.; Miah, A.S.M.; Egawa, R.; Hassan, N.; Hirooka, K.; Tomioka, Y. Multimodal Fall Detection Using Spatial–Temporal Attention and Bi-LSTM-Based Feature Fusion. Future Internet 2025, 17, 173. [Google Scholar] [CrossRef]
- Liu, L.; Sun, Y.; Li, Y.; Liu, Y. A hybrid human fall detection method based on modified YOLOv8s and AlphaPose. Sci. Rep. 2025, 15, 2636. [Google Scholar] [CrossRef] [PubMed]
- Nagaj, A.; Li, Z.; Papadopoulos, D.P.; Nasrollahi, K. Visual Context-Aware Person Fall Detection. In Intelligent Decision Technologies, Proceedings of the KESIDT 2024, Rome, Italy, 17–19 June 2024; Czarnowski, I., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2025; Volume 411, pp. 215–226. [Google Scholar] [CrossRef]
- Azure Kinect DK. Available online: https://azure.microsoft.com/en-us/products/kinect-dk (accessed on 29 June 2025).
- De Coster, M.; Rushe, E.; Holmes, R.; Ventresque, A.; Dambre, J. Towards the extraction of robust sign embeddings for low resource sign language recognition. arXiv 2023. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Oussalah, M.; Nini, B. Fall detection using body geometry and human pose estimation in video sequences. J. Vis. Commun. Image Represent. 2022, 82, 103407. [Google Scholar] [CrossRef]
- Mali, V.; Jaiswal, S. Pose-Based Fall Detection System: Efficient Monitoring on Standard CPUs. arXiv 2025. [Google Scholar] [CrossRef]
- Sultana, A.; Deb, K.; Dhar, P.K.; Koshiba, T. Classification of Indoor Human Fall Events Using Deep Learning. Entropy 2021, 23, 328. [Google Scholar] [CrossRef]
- ResNet—Residual Neural Network. Available online: https://viso.ai/deep-learning/resnet-residual-neural-network/ (accessed on 29 June 2025).
- Lu, N.; Wu, Y.; Feng, L.; Song, J. Deep Learning for Fall Detection: Three-Dimensional CNN Combined with LSTM on Video Kinematic Data. IEEE J. Biomed. Health Inform. 2019, 23, 314–323. [Google Scholar] [CrossRef]
- Yang, J.; He, Y.; Zhu, J.; Lv, Z.; Jin, W. Fall Detection Method for Infrared Videos Based on Spatial-Temporal Graph Convolutional Network. Sensors 2024, 24, 4647. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process Syst. 2024, 37, 107984–108011. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–24 June 2022; pp. 2637–2646. [Google Scholar]
- Prakash, I.V.; Palanivelan, M. A Study of YOLO (You Only Look Once) to YOLOv8. In Algorithms in Advanced Artificial Intelligence; Jagan Mohan, R.N.V., Sekhar, V.C., Gupta, V.M.N.S.S.V.K.R., Eds.; CRC Press: London, UK, 2024; pp. 257–266. [Google Scholar] [CrossRef]
- Jovanovic, M.; Mitrov, G.; Zdravevski, E.; Lameski, P.; Colantonio, S.; Kampel, M.; Tellioglu, H.; Florez-Revuelta, F. Ambient Assisted Living: Scoping Review of Artificial Intelligence Models, Domains, Technology, and Concerns. J. Med. Internet Res. 2022, 24, e36553. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Martin, N.; Luo, Z.; Kaushal, A.; Adeli, E.; Haque, A.; Kelly, S.S.; Wieten, S.; Cho, M.K.; Magnus, D.; Fei-Fei, L.; et al. Ethical Issues in Using Ambient Intelligence in Health-Care Settings. Lancet Digit. Health 2021, 3, e115–e123. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Sawhney, S.; Ahmed, S. CareTaker.ai—A Smart Health-Monitoring and Caretaker-Assistant System for Elder Healthcare. Eng. Proc. 2024, 78, 7. [Google Scholar] [CrossRef]
- Ullah, R.; Asghar, I.; Akbar, S.; Evans, G.; Vermaak, J.; Alblwi, A.; Bamaqa, A. Vision-Based Activity Recognition for Unobtrusive Monitoring of the Elderly in Care Settings. Technologies 2025, 13, 184. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, H.; Zhou, B.; Wang, D.; Cui, C.; Bai, X. Factors Influencing Older Adults’ Acceptance of Voice Assistants. Front. Psychol. 2024, 15, 1376207. [Google Scholar] [CrossRef]
- Capodici, A.; Fanconi, C.; Curtin, C.; Shapiro, A.; Noci, F.; Giannoni, A.; Hernandez-Boussard, T. A Scoping Review of Machine Learning Models to Predict Risk of Falls in Elders, Without Using Sensor Data. Diagn. Progn. Res. 2025, 9, 11. [Google Scholar] [CrossRef]
- Fall Detection and Prevention for the Elderly: A Review of Trends and Challenges. Available online: https://www.academia.edu/51232799 (accessed on 29 June 2025).
- Wang, Y.; Deng, T. Enhancing Elderly Care: Efficient and Reliable Real-Time Fall Detection Algorithm. Digit. Health 2024, 10. [Google Scholar] [CrossRef]
- Le2i Fall Dataset. Available online: https://www.kaggle.com/datasets/tuyenldvn/falldataset-imvia (accessed on 25 April 2025).
- Chamle, M.; Gunale, K.G.; Warhade, K.K. Automated unusual event detection in video surveillance. In Proceedings of the International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016. [Google Scholar]
- Alaoui, A.Y.; El Hassouny, A.; Thami, R.O.H.; Tairi, H. Human Fall Detection Using Von Mises Distribution and Motion Vectors of Interest Points. Assoc. Comput. Mach. 2017, 82, 5. [Google Scholar] [CrossRef]
- Poonsri, A.; Chiracharit, W. Improvement of fall detection using consecutive-frame voting. In Proceedings of the International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).