
ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models


Abstract
1. Introduction
- We identify and analyze critical mismatches between commonly used standard Text-to-SQL evaluation metrics (Execution Accuracy and Exact Set Matching).
- We introduce and implement Enhanced Tree Matching (ETM), a novel metric that integrates syntactic normalization and rule-based semantic equivalence to better evaluate structural correctness in SQL generation.
- We conduct comprehensive empirical studies across nine models on the Spider and BIRD benchmarks, showing that ETM reduces variance in evaluation and resolves failure cases missed by EXE and ESM.
- We present detailed error analyses and rule-level ablations, providing insight into the kinds of reasoning and structure that ETM captures more effectively than existing metrics.
2. Related Work
2.1. Text-to-SQL Models
2.2. Evaluation of SQL Equivalence
3. Materials and Methods
3.1. False Positives in ESM
3.2. False Negatives in ESM
3.3. New Evaluation Metric
- Keywords: The keywords LEFT JOIN, RIGHT JOIN, OUTER JOIN, INNER JOIN, CAST, CASE, and others, previously disregarded by ESM, are now properly considered.
- Foreign Key Preservation: ESM rebuilds queries such that all foreign keys become their primary key counterparts, causing false positives. In ETM, all foreign keys are preserved.
- Join Conditions: ESM never compares JOIN conditions between queries. Conditions for any JOIN are correctly assessed by ETM.
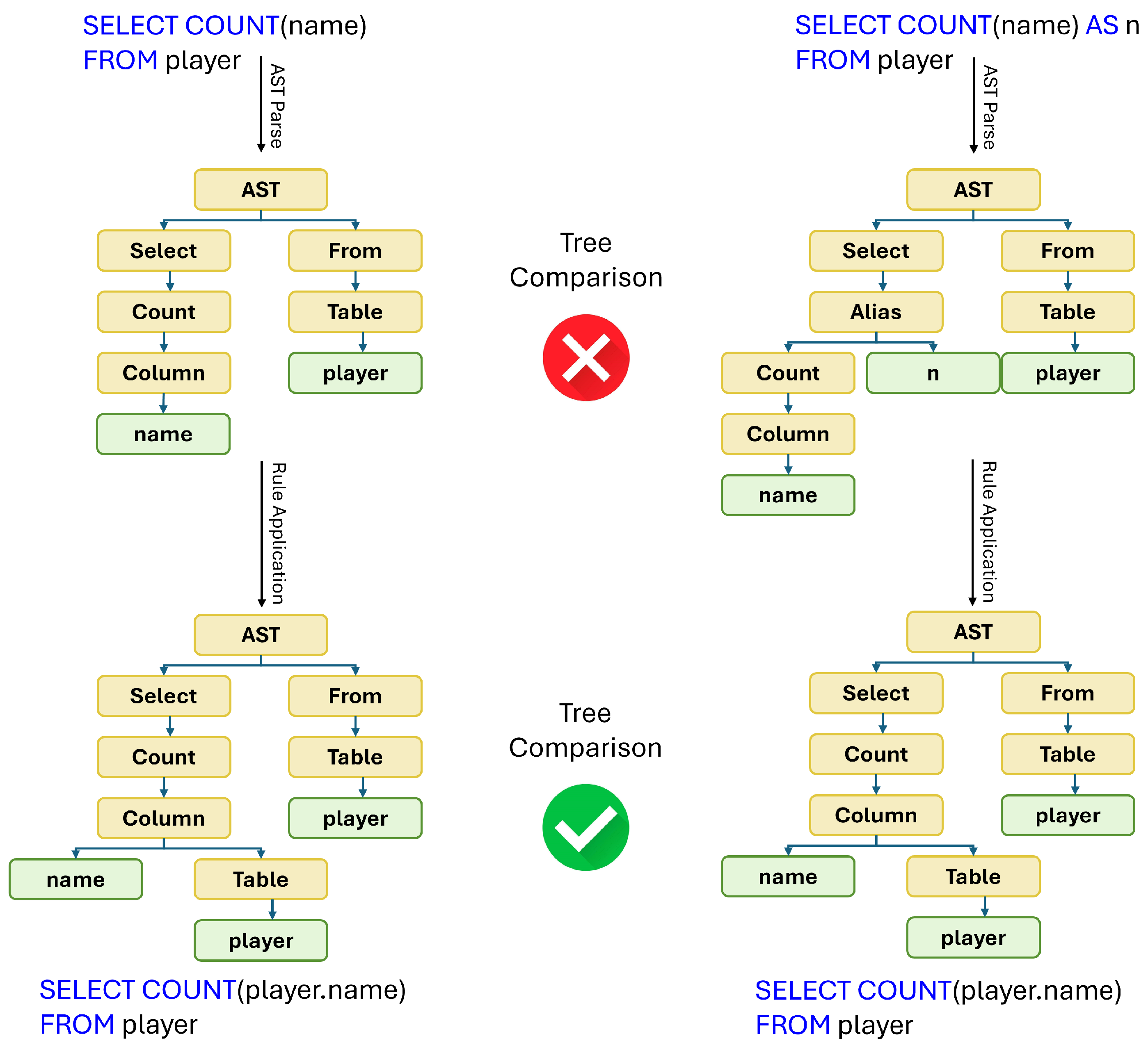
- Local Aliases: ESM extends aliases to the entire query, causing issues in subqueries where aliases are local. ETM properly scopes aliases to their corresponding subqueries (Listing 1).
| Listing 1. ESM evaluates this incorrectly as it does not recognize that t is not only an alias for t3 in the subquery but also for t1 in the outer query. |
| SELECT c1 FROM t1 AS t JOIN t2 ON t.c1=t2.c2 WHERE c1 IN (SELECT c3 FROM t3 AS t); |
- 5.
- DISTINCT: While ESM checks for DISTINCT only within aggregate functions, ETM consistently considers it across the entire query (Section 3.1).
- 6.
- IN with lists: ESM allows the keyword IN followed by a subquery, but doesn’t allow a list of values. ETM properly parses and evaluates lists within the IN keyword (Listing 2).
| Listing 2. ESM disregards this query as it cannot parse a list of values. |
| SELECT c1 FROM t1 WHERE c1 IN (1, 2, 3); |
- 7.
- Complex Queries: ESM only allows for a single subquery, intersection, or union operator. ETM correctly allows any query to be parsed.
- 8.
- Retrieval from Subquery: Queries retrieving columns from the subquery are not properly parsed by ESM. An example of this is SELECT c1 FROM (SELECT * FROM t1). ETM properly allows retrieving columns from subqueries.
- 9.
- Parentheses: Queries using parentheses to order conditional statements are not handled correctly by ESM (Listing 3). ETM correctly handles parentheses.
| Listing 3. ESM incorrectly parses this the same way with and without parentheses. |
| SELECT c1 FROM t1 WHERE c1 = x AND (c2 = y OR c1 = z); |
- 10.
- Alias Definition: In ESM, only table names can have aliases, and they must be defined with the optional AS keyword. ETM properly evaluates all aliases, including for columns and expressions, and correctly allows aliases to be defined without AS.
- 11.
- Quote Types: In SQL, single quotes are treated as a literal, while double quotes can be used for column names or literals. ESM incorrectly treats all quotes the same way, while ETM correctly handles different quote types.
4. Results
4.1. Spider Models
- DAIL (PLM): DAIL-SQL + GPT4 [10]https://github.com/BeachWang/DAIL-SQL accessed on 17 January 2025.
- DIN (PLM): DIN-SQL+GPT4 [9]https://github.com/MohammadrezaPourreza/Few-shot-NL2SQL-with-prompting accessed on 17 January 2025.
- C3 (PLM): C3 + ChatGPT + Zero-Shot [8]https://github.com/bigbigwatermalon/C3SQL accessed on 17 January 2025.
- R+N (FLM): RESDSQL-3B + NatSQL [15]https://github.com/RUCKBReasoning/RESDSQL accessed on 17 January 2025.
- G+P (FLM): Graphix-3B + PICARD [14]https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/graphix accessed on 17 January 2025.
- R+P (FLM): RASAT + PICARD [12]https://github.com/LUMIA-Group/rasat accessed on 17 January 2025.
- CodeS (FLM): CodeS-7b [16]https://github.com/RUCKBReasoning/codes accessed on 17 January 2025.
- Super (FLM): SuperSQL [17]https://github.com/BugMaker-Boyan/NL2SQL360 accessed on 17 January 2025.
4.2. BIRD Models
- DAIL: the same model as described in Section 4.1
- C3: the same model as described in Section 4.1
- RESD: R+N without NatSQL [15]
- CodeS-15: 15b version of CodeS
- Super: the same model as described in Section 4.1.
4.3. Results
5. Discussion
5.1. Model Evaluation
5.2. PLM Variance
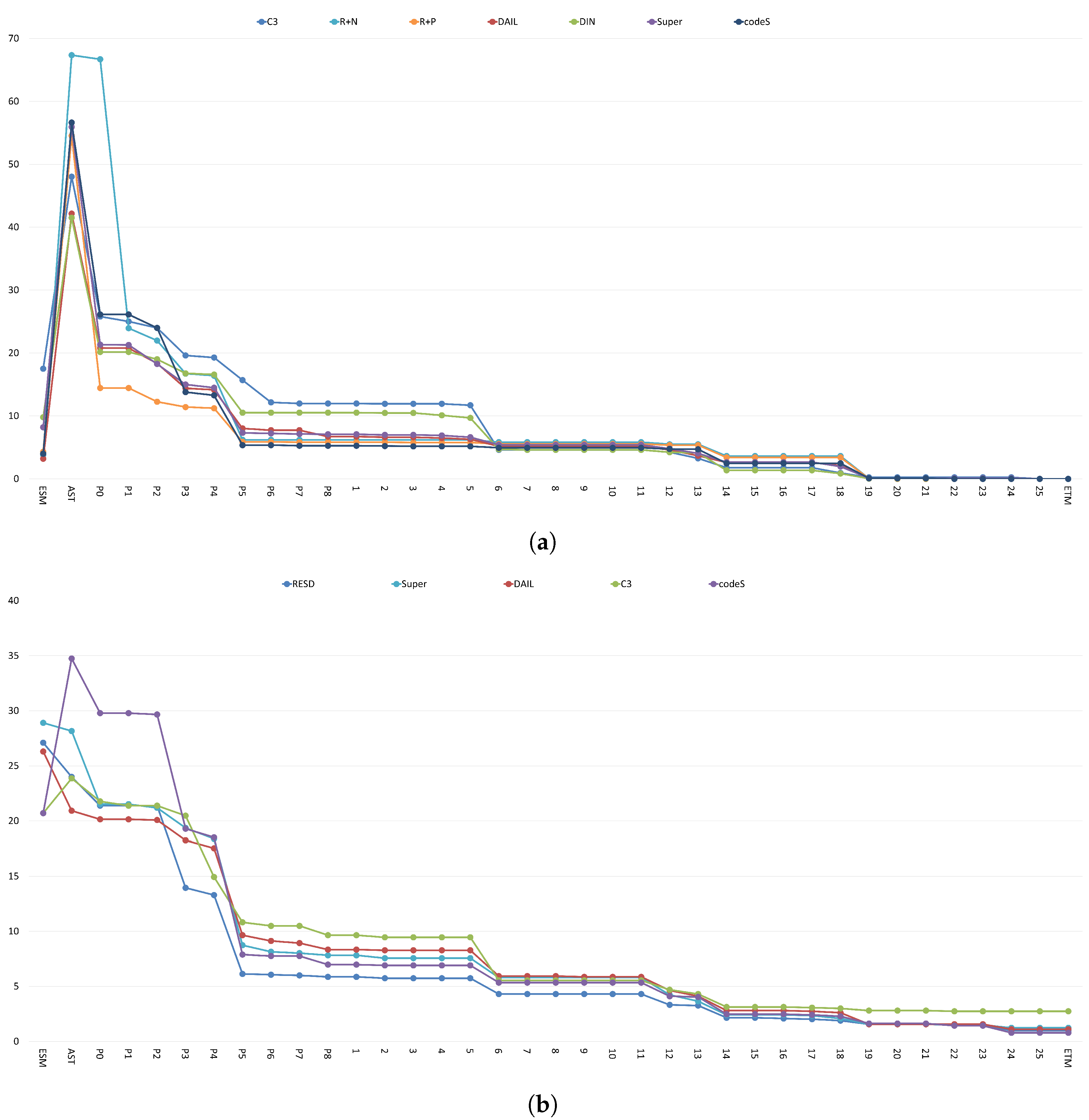
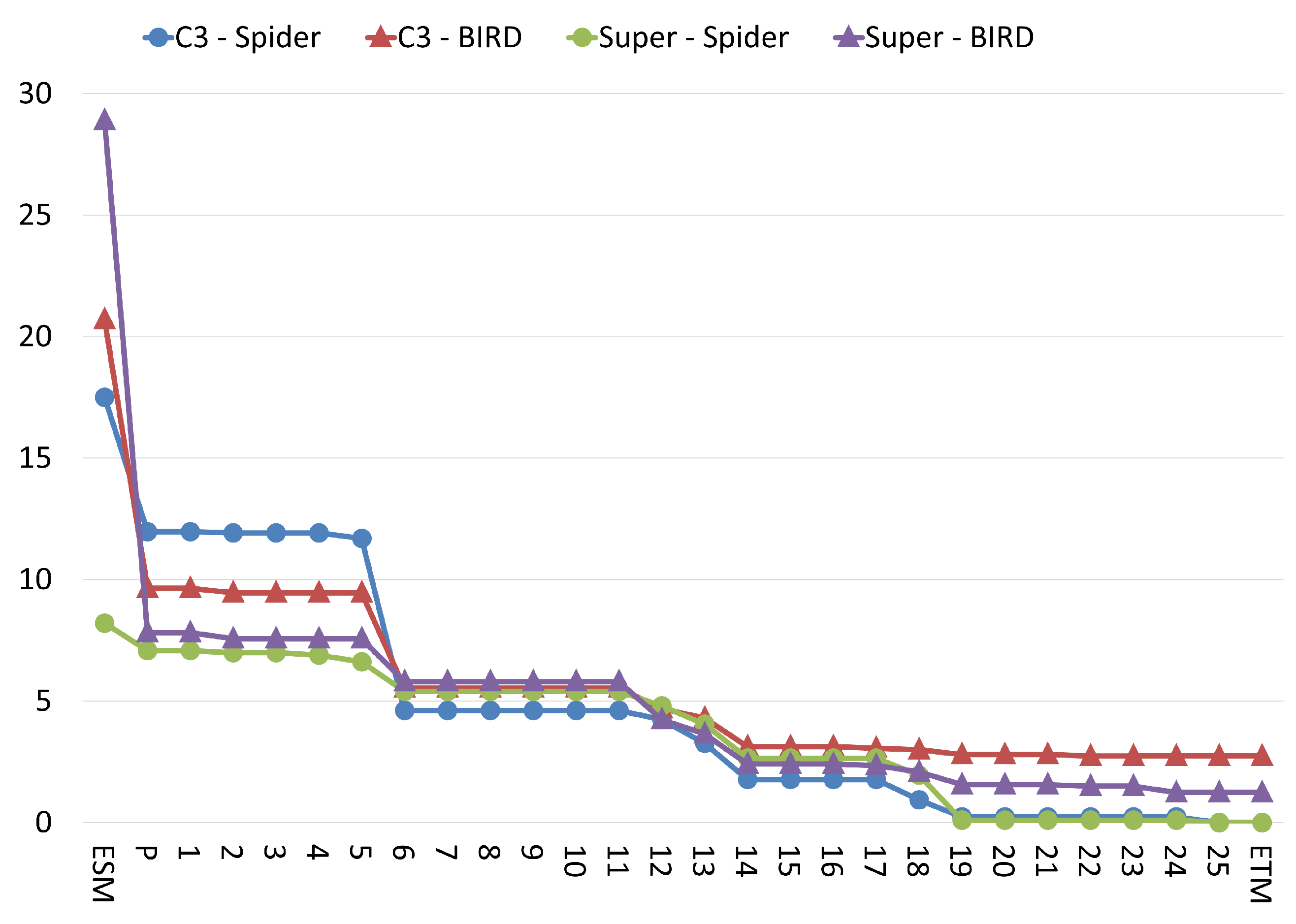
5.3. Error Analysis
5.4. Equivalence Rule Analysis
5.5. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
False Negatives with Equivalent Rules
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Yu, T.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Ma, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018. [Google Scholar]
- Li, J.; Hui, B.; QU, G.; Yang, J.; Li, B.; Li, B.; Wang, B.; Qin, B.; Geng, R.; Huo, N.; et al. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Abiteboul, S.; Hull, R.; Vianu, V. Foundations of Databases; Addison-Wesley: Boston, MA, USA, 1995. [Google Scholar]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Dong, X.; Zhang, C.; Ge, Y.; Mao, Y.; Gao, Y.; Chen, L.; Lin, J.; Lou, D. C3: Zero-shot Text-to-SQL with ChatGPT. arXiv 2023, arXiv:2307.07306. [Google Scholar]
- Pourreza, M.; Rafiei, D. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. arXiv 2023, arXiv:2304.11015. [Google Scholar]
- Gao, D.; Wang, H.; Li, Y.; Sun, X.; Qian, Y.; Ding, B.; Zhou, J. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation. arXiv 2023, arXiv:2308.15363. [Google Scholar] [CrossRef]
- Yu, T.; Zhang, R.; Er, H.Y.; Li, S.; Xue, E.; Pang, B.; Lin, X.V.; Tan, Y.C.; Shi, T.; Li, Z.; et al. CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases. arXiv 2019, arXiv:1909.05378. [Google Scholar]
- Qi, J.; Tang, J.; He, Z.; Wan, X.; Cheng, Y.; Zhou, C.; Wang, X.; Zhang, Q.; Lin, Z. RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for Text-to-SQL. arXiv 2022, arXiv:2205.06983. [Google Scholar]
- Scholak, T.; Schucher, N.; Bahdanau, D. PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models. arXiv 2021, arXiv:2109.05093. [Google Scholar] [CrossRef]
- Li, J.; Hui, B.; Cheng, R.; Qin, B.; Ma, C.; Huo, N.; Huang, F.; Du, W.; Si, L.; Li, Y. Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing. arXiv 2023, arXiv:2301.07507. [Google Scholar] [CrossRef]
- Li, H.; Zhang, J.; Li, C.; Chen, H. RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL. arXiv 2023, arXiv:2302.05965. [Google Scholar] [CrossRef]
- Li, H.; Zhang, J.; Liu, H.; Fan, J.; Zhang, X.; Zhu, J.; Wei, R.; Pan, H.; Li, C.; Chen, H. CodeS: Towards Building Open-source Language Models for Text-to-SQL. arXiv 2024, arXiv:2402.16347. [Google Scholar] [CrossRef]
- Li, B.; Luo, Y.; Chai, C.; Li, G.; Tang, N. The Dawn of Natural Language to SQL: Are We Fully Ready? Proc. VLDB Endow. 2024, 17, 3318–3331. [Google Scholar] [CrossRef]
- Chu, S.; Wang, C.; Weitz, K.; Cheung, A. Cosette: An Automated Prover for SQL. In Proceedings of the 8th Biennial Conference on Innovative Data Systems Research, CIDR 2017, Chaminade, CA, USA, 8–11 January 2017. [Google Scholar]
- Zhou, Q.; Arulraj, J.; Navathe, S.B.; Harris, W.; Xu, D. Automated Verification of Query Equivalence Using Satisfiability Modulo Theories. Proc. VLDB Endow. 2019, 12, 1276–1288. [Google Scholar] [CrossRef]
- Zhong, R.; Yu, T.; Klein, D. Semantic Evaluation for Text-to-SQL with Distilled Test Suites. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 396–411. [Google Scholar] [CrossRef]
- Nooralahzadeh, F.; Zhang, Y.; Smith, E.; Maennel, S.; Matthey-Doret, C.; De Fondeville, R.; Stockinger, K. StatBot.Swiss: Bilingual Open Data Exploration in Natural Language. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 5486–5507. [Google Scholar] [CrossRef]
- Song, Y.; Ezzini, S.; Tang, X.; Lothritz, C.; Klein, J.; Bissyande, T.; Boytsov, A.; Ble, U.; Goujon, A. Enhancing Text-to-SQL Translation for Financial System Design. In Proceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP); IEEE Computer Society: Los Alamitos, CA, USA, 2024; pp. 252–262. [Google Scholar] [CrossRef]
- Zhan, Y.; Cui, L.; Weng, H.; Wang, G.; Tian, Y.; Liu, B.; Yang, Y.; Yin, X.; Xie, J.; Sun, Y. Towards Database-Free Text-to-SQL Evaluation: A Graph-Based Metric for Functional Correctness. In Proceedings of the 31st International Conference on Computational Linguistics; Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2025; pp. 4586–4610. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Equivalent Queries | Verifiable Assumptions |
|---|---|---|
| P0 | SELECT c1 FROM t1; SELECT C1 FROM T1; | None |
| P1 | SELECT c1 FROM t1; SELECT t1.c1 FROM t1; | None |
| P2 | SELECT c1, c2 FROM t1; SELECT c2, c1 FROM t1; | None |
| P3 | SELECT t1.c1 FROM t1; SELECT t.c1 FROM t1 AS t; | None |
| P4 | SELECT _ FROM t1 JOIN t2; SELECT _ FROM t2 JOIN t1; | None |
| P5 | SELECT _ FROM _ WHERE x =/AND/OR y; SELECT _ FROM _ WHERE y =/AND/OR x; | None |
| P6 | SELECT col AS c FROM t1; SELECT col FROM t1; | None |
| P7 | SELECT _ FROM _ WHERE d1; SELECT _ FROM _ WHERE (d1); | None |
| P8 | SELECT "t1"."c1" FROM "t1"; SELECT t1.c1 FROM t1; | None |
| ID | Equivalent Queries | Verifiable Assumptions |
|---|---|---|
| 1 | SELECT _ FROM t1 WHERE c1 = (SELECT MIN/MAX(c1) FROM t1); SELECT _ FROM t1 ORDER BY c1 ASC/DESC LIMIT 1; | c1 is UNIQUE |
| 2 | SELECT DISTINCT c1 FROM t1;
SELECT c1 FROM t1; | c1 is UNIQUE |
| 3 | SELECT c1 FROM t1 WHERE d1 INTERSECT/UNION SELECT c1 FROM t1 WHERE d2;
SELECT c1 FROM t1 WHERE d1 AND/OR d2; | c1 is UNIQUE |
| 4 | SELECT _ FROM t1 WHERE GROUP BY c1,c2,…; SELECT _ FROM t1 WHERE GROUP BY c1; | c1 is UNIQUE |
| 5 | SELECT c1 FROM t1 EXCEPT (q1); SELECT c1 FROM t1 WHERE c1 NOT IN (q1); | c1 is UNIQUE and NON_NULL |
| 6 | SELECT COUNT(*) FROM t1; SELECT COUNT(c1) FROM t1; | c1 is NON_NULL |
| 7 | SELECT _ FROM t1 WHERE c1 is NOT NULL; SELECT _ FROM t1; | c1 is NON_NULL |
| 8 | SELECT CAST(SUM(c1) AS FLOAT) / COUNT(*) FROM t1; SELECT AVG(c1) FROM t1; | c1 is NON_NULL |
| 9 | SELECT COUNT(CASE WHEN d1 THEN 1/c1 ELSE NULL END) FROM t1; SELECT SUM(CASE WHEN d1 THEN 1 ELSE 0 END) FROM t1; | c1 is NON_NULL |
| 10 | SELECT MIN/MAX(c1), _ FROM t1; SELECT c1, _ FROM t1 ORDER BY c1 ASC/DESC LIMIT 1; | t1 is not empty |
| 11 | SELECT * FROM t1; SELECT c1, c2, … FROM t1; | t1 consists of only c1, c2, … |
| 12 | SELECT _ FROM _ WHERE c1 = 'x'; SELECT _ FROM _ WHERE c1 = x; | x is a number not starting with zero |
| 13 | SELECT _ FROM t2 WHERE c2 IN (SELECT c1 FROM t1 WHERE d1); SELECT _ FROM t1 JOIN t2 ON t1.c1 = t2.c2 WHERE d1; | Case 1 (refer to the caption) |
| 14 | SELECT X FROM t1 JOIN t2 on t1.c1 = t2.c2; SELECT X from t2; | Case 2 (refer to the caption) |
| 15 | SELECT _ FROM _ WHERE SUBSTR(c1, 1, a) = x AND SUBSTR(c1, b, c) >/</>=/<= y; SELECT _ FROM _ WHERE c1 >/</>=/<= xy; | a + 1 = b |
| 16 | SELECT _ FROM _ WHERE c1 LIKE 'x%';
SELECT _ FROM _ WHERE SUBSTR(c1, 1, n) = 'x' | len(x) = n |
| ID | Equivalent Queries |
|---|---|
| 17 |
SELECT _ FROM _ ORDER BY c1; SELECT _ FROM _ ORDER BY JULIANDAY(c1); |
| 18 |
SELECT _ FROM _ WHERE c1 IN/NOT IN (x, y,…); SELECT _ FROM _ WHERE c1 =/!= x OR/AND c1 =/!= y OR/AND …; |
| 19 |
SELECT t1.c1 FROM t1 JOIN t2 on t1.c1 = t2.c2;
SELECT t2.c2 FROM t1 JOIN t2 on t1.c1 = t2.c2; |
| 20 |
SELECT _ FROM t1 WHERE c1 IN (SELECT c1 FROM t1 WHERE d1); SELECT _ FROM t1 WHERE d1; |
| 21 |
q1; q1 UNION/INTERSECT q1; |
| 22 |
SELECT _ FROM t1 WHERE c1 BETWEEN x AND y; SELECT _ FROM t1 WHERE c1 >= x/y and c1 <= x/y; |
| 23 |
SELECT _ FROM t1 WHERE c1 !=/>/</>=/<=/= x; SELECT _ FROM t1 WHERE NOT c1 =/<=/>=/</>/!= x; |
| 24 |
SELECT CASE WHEN d1 THEN x ELSE y END; SELECT IIF(d1, x, y); |
| 25 |
SELECT _ FROM t1 LEFT JOIN t2 on t1.c1 = t2.c2 WHERE t2._ IS NULL; SELECT _ FROM t1 WHERE t1.c1 NOT IN (SELECT c2 FROM t2); |
| 26 |
WITH q AS (q1) SELECT _ FROM q; SELECT _ FROM (q1); |
| Model | Development Set | Evaluation Set | Reported | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EXE | ESM | ETM | EXE | ESM | ETM | EXE | ESM | ||
| DAIL | PLM | 82.9 (3) | 70.0 (6) | 71.5 (5) | 82.2 (3) | 66.1 (4) | 68.1 (5) | 86.2 (2) | 66.5 (4) |
| DIN | PLM | 81.7 (5) | 60.1 (7) | 64.7 (7) | 81.6 (4) | 60.7 (6) | 64.8 (6) | 85.3 (3) | 60.0 (5) |
| C3 | PLM | 79.8 (7) | 46.9 (8) | 59.8 (8) | 79.5 (5) | 43.9 (7) | 58.5 (7) | 82.3 (4) | - |
| Super | PLM | 86.1 (1) | 72.1 (5) | 75.1 (2) | 85.3 (1) | 65.5 (5) | 70.4 (2) | 87.0 (1) | - |
| R+N | FLM | 82.8 (4) | 80.5 (1) | 74.9 (3) | 78.4 (6) | 70.9 (2) | 70.4 (2) | 79.9 (5) | 72.0 (2) |
| G+P | FLM | 80.1 (6) | 77.1 (3) | 72.3 (4) | - | - | - | 77.6 (6) | 74.0 (1) |
| R+P | FLM | 76.7 (8) | 75.2 (4) | 69.3 (6) | 77.9 (7) | 69.3 (3) | 69.6 (4) | 75.5 (7) | 70.9 (3) |
| CodeS | FLM | 83.5 (2) | 79.4 (2) | 76.6 (1) | 83.0 (2) | 73.7 (1) | 73.2 (1) | - | - |
| Model | Development Set | |||
|---|---|---|---|---|
| EXE | ESM | ETM | ||
| DAIL | PLM | 50.1 (3) | 8.0 (3) | 31.9 (3) |
| C3 | PLM | 42.8 (4) | 5.7 (5) | 22.6 (5) |
| Super | PLM | 52.1 (1) | 8.3 (2) | 33.1 (2) |
| RESD | FLM | 37.4 (5) | 7.2 (4) | 25.4 (4) |
| CodeS-15 | FLM | 51.6 (2) | 9.1 (1) | 36.2 (1) |
| Model | EXE | ESM | ETM | |||||
|---|---|---|---|---|---|---|---|---|
| FP | FN | FP | FN | FP | FN | |||
| Spider | DAIL | P | 16.3 | 0.0 | 5.0 | 3.2 | 0.1 | 0.0 |
| DIN | P | 19.5 | 0.0 | 6.1 | 9.8 | 0.0 | 0.0 | |
| C3 | P | 23.0 | 0.0 | 2.8 | 17.5 | 0.1 | 0.0 | |
| Super | P | 15.0 | 0.0 | 3.2 | 8.2 | 0.0 | 0.0 | |
| R+N | F | 10.0 | 0.0 | 4.6 | 3.8 | 0.1 | 0.0 | |
| R+P | F | 10.0 | 0.0 | 4.1 | 4.3 | 0.1 | 0.0 | |
| CodeS | F | 12.1 | 0.0 | 4.7 | 4.0 | 0.0 | 0.0 | |
| BIRD | DAIL | P | 17.4 | 0.0 | 1.6 | 26.3 | 0.3 | 1.1 |
| C3 | P | 17.5 | 0.0 | 1.1 | 20.7 | 0.0 | 2.7 | |
| Super | P | 17.9 | 0.0 | 1.2 | 27.1 | 0.2 | 1.2 | |
| RESD | F | 11.1 | 0.0 | 1.7 | 20.7 | 0.1 | 1.0 | |
| CodeS | F | 14.8 | 0.0 | 1.2 | 28.9 | 0.1 | 0.8 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ascoli, B.G.; Kandikonda, Y.S.R.; Choi, J.D. ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models. Future Internet 2025, 17, 325. https://doi.org/10.3390/fi17080325
Ascoli BG, Kandikonda YSR, Choi JD. ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models. Future Internet. 2025; 17(8):325. https://doi.org/10.3390/fi17080325
Chicago/Turabian StyleAscoli, Benjamin G., Yasoda Sai Ram Kandikonda, and Jinho D. Choi. 2025. "ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models" Future Internet 17, no. 8: 325. https://doi.org/10.3390/fi17080325
APA StyleAscoli, B. G., Kandikonda, Y. S. R., & Choi, J. D. (2025). ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models. Future Internet, 17(8), 325. https://doi.org/10.3390/fi17080325