2.1.1. System Classification by Computational Paradigms
This development can be generally categorized into four computational paradigms. Each has distinct technological foundations, advantages, and limitations [
10]:
- (a)
Rule-Based Systems
Rule-based systems represent the earliest generation of fall detection solutions. These systems typically operate using predefined threshold conditions applied to sensor data, most commonly from wearable inertial measurement units (IMUs) such as accelerometers and gyroscopes [
11]. A typical detection rule might identify a fall if a sudden spike in acceleration is followed by a period of inactivity [
12]. These approaches are straightforward to implement and can operate on low-power, embedded platforms.
These systems depend heavily on user adherence, as the wearable device needs to be continuously worn and properly placed to operate effectively. Incorrect placement (e.g., rotated on the wrist or worn loosely) can significantly degrade performance. Furthermore, studies [
13] have shown that threshold-based fall detectors often misinterpret normal daily activities, such as sitting abruptly, bending, or lying down voluntarily, as potential falls, especially in elderly users with unsteady gait or frailty [
14].
Although ambient rule-based systems are advantageous for being non-intrusive and not needing any wearable devices or user engagement, they heavily rely on location and are limited to the specific zones where sensors are placed. Their rigid decision rules can also result in false negatives, particularly if a fall occurs outside the monitored area or if noise or lighting conditions interfere with sensor performance. Moreover, calibration is often required for each physical space, making them difficult to scale in dynamic or large environments [
15].
- (b)
Classical Machine Learning Systems
Classical machine learning (ML) systems marked a major advancement over rule-based methods by enabling data-driven learning and greater flexibility in modeling. These systems apply algorithms such as Support Vector Machines (SVMs), k-Nearest Neighbors (k-NNs), Decision Trees, and Random Forests to features manually extracted from raw sensor data or video streams [
16]. Common features include jerk, postural angles, velocity changes, energy consumption, and temporal sequences of motion states [
17].
In wearable-based systems, ML is typically applied to inertial sensor data, such as acceleration and angular velocity, collected from IMUs attached to the body (e.g., wrist, waist, ankle). Feature engineering in this context may include both time-domain (e.g., signal variance, mean crossing rate) and frequency-domain metrics (e.g., dominant frequency, Fast Fourier Transform components) for capturing meaningful aspects of human motion indicative of a fall.
However, one of the major drawbacks in wearable ML systems is the user dependence and variability of sensor data. The same movement can produce very different signals across individuals due to differences in gait, body composition, or sensor positioning. The systems remain susceptible to false positives, especially when routine activities like quickly sitting, stepping down, or reaching are interpreted as falls [
3,
18].
In vision-based systems, classical ML methods rely on descriptors derived from handcrafted visual features, such as bounding box trajectories, silhouette shapes, or skeletal keypoint dynamics. Classifiers such as SVMs or k-NN often receive these descriptors. For example, a rapid transition from a vertical to a horizontal bounding box, followed by inactivity, could be interpreted as a fall [
19].
Yet, as with wearable applications, vision-based ML suffers from sensitivity to environmental variations, including lighting conditions, camera angles, and occlusions. Feature extraction pipelines must often be recalibrated for each deployment scenario to maintain acceptable accuracy [
20]. Overall, classical machine learning systems offered significant improvements in adaptability and accuracy over rule-based methods, especially when trained with well-curated data.
- (c)
Deep Learning Systems
Deep learning (DL) methods have revolutionized fall detection by enabling systems to automatically learn complex spatiotemporal representations from raw data, eliminating the need for manual feature engineering. These systems commonly use models such as CNNs for spatial feature extraction, Long Short-Term Memory (LSTM) networks for capturing temporal dependencies, and increasingly, Transformer-based models that can process long sequences with attention mechanisms [
21]. These models are applied across multiple data modalities, including inertial sensor streams (IMU data), video feeds, and audio recordings.
In wearable sensor systems, deep learning models, especially 1D-CNNs and LSTM networks, are commonly applied to raw accelerometer and gyroscope data [
22]. These architectures can detect subtle fall-related motion patterns and distinguish them from normal activities like walking, sitting, or transitioning [
23]. Models like Bidirectional LSTM (BiLSTM), Gated Recurrent Unit (GRU), or hybrid CNN-LSTM setups allow for capturing both local motion features and temporal dynamics across multiple time steps [
24,
25]. Furthermore, Transformers, though more computationally intensive, have been explored for their ability to model long-range dependencies in sensor streams, offering a promising direction for continuous fall risk monitoring [
26].
However, the performance of these systems is heavily dependent on the availability of annotated sensor datasets, which are limited in both size and diversity [
27]. Most existing datasets feature scripted falls under controlled conditions, which may not reflect real-world behavior, particularly among elderly users with frailty or mobility impairments [
21].
Despite their impressive capabilities, deep learning models are often viewed as “black boxes,” lacking transparent decision processes [
28]. This poses challenges for clinical acceptance and user trust, particularly in eldercare settings. Moreover, deploying such models on real-time or edge systems requires model optimization (e.g., pruning, quantization) to ensure responsiveness without compromising accuracy [
29].
- (d)
Multimodal AI Systems
Multimodal fall detection systems represent an advanced direction in monitoring technologies by simultaneously integrating multiple data streams from various sensor types, such as inertial sensors (IMUs), RGB and depth cameras, and microphones for detecting impact sounds, as well as contextual data like location, time, or user activity patterns [
30]. This approach enables complex and comprehensive analysis, enhancing both detection accuracy and context awareness of the event.
To process these heterogeneous data inputs, multimodal systems use sensor fusion architectures such as hybrid Convolutional Neural Network–Recurrent Neural Network (CNN–RNN) models or multimodal transformers, which effectively combine temporal and spatial signals from different sources. These models allow not only the identification of a fall from a single data source but also cross-validation across multiple streams, significantly reducing false alarms, a common issue in single-channel systems [
31].
However, several limitations hinder the widespread adoption of such systems:
Increased complexity: Integrating and synchronizing data from multiple sensor modalities presents significant hardware and software challenges.
Calibration and maintenance requirements: Each sensor may necessitate individual calibration, and the entire system must maintain synchronized and stable performance over time, factors that increase costs and technical support demands.
High resource consumption: Real-time processing of multimodal data streams requires substantial computational power and energy, potentially limiting deployment on resource-constrained edge devices.
A relevant example is the study by Liu et al. (2025), who developed a hybrid model combining YOLOv8s, a high-performance object detection network, with AlphaPose, a human skeleton tracking system that estimates joint positions [
32]. This integration enhanced detection accuracy by simultaneously analyzing visual input and body posture, illustrating the considerable potential of multimodal systems for improving monitoring reliability.
Furthermore, such systems can incorporate voice interaction components or conversational AI, enabling real-time confirmation or dismissal of detected events. This additional validation mechanism not only improves accuracy but also enhances user trust and facilitates acceptance of the technology in care environments.
2.1.2. Computer Vision-Based Systems in Fall Detection
Computer vision has become a central pillar in fall detection research due to its ability to non-invasively monitor human posture and behavior. Over time, researchers have developed various methods, ranging from traditional image processing techniques to state-of-the-art deep learning architectures.
- (a)
Traditional Vision Systems
Early computer vision systems used handcrafted image processing techniques, including background subtraction, silhouette tracking, and optical flow analysis. These systems attempted to detect abnormal posture or sudden motion patterns using RGB or depth video. While innovative for their time, these methods struggled in cluttered environments and were prone to false positives from non-fall activities (e.g., sitting abruptly, bending, or crouching) [
33].
- (b)
Pose Estimation with Rule-Based Logic Systems
The introduction of depth sensors, such as Microsoft Kinect [
34], and pose estimation algorithms, like OpenPose, HRNet, and MediaPipe, has enabled fall detection systems to use skeletal keypoints (e.g., head, hips, knees) to infer postural instability or horizontal collapse [
35]. These systems typically apply rule-based logic or threshold-based conditions to skeletal angles [
36] or keypoint velocities to identify potential falls [
37].
These approaches offer several advantages, including increased interpretability, improved performance in multi-person environments, and enhanced privacy due to depth-based imaging.
However, rule-based logic can be susceptible to errors in dynamic or cluttered environments. Moreover, real-time inference is often constrained by the computational limitations of edge devices. Additionally, such systems generally require extensive camera coverage to achieve consistent detection accuracy across different areas.
- (c)
Convolutional Neural Network (CNN)-Based Systems
CNN-based models have enhanced visual recognition tasks in fall detection by automatically learning spatial features from image sequences. Architectures such as VGG, ResNet, and 3D-CNNs have been used to classify activity types or detect fall events within video segments [
38,
39,
40]. Compared to classical methods, these models demonstrate greater robustness; however, they often rely on frame accumulation or sliding window techniques, which can introduce latency, an important limitation in time-critical applications such as fall detection [
41].
- (d)
YOLO-Based Fall Detection Systems
YOLO stands out as a real-time, highly efficient framework for object detection and pose-aware activity recognition. YOLO networks are designed to process entire images in a single forward pass, identifying objects, humans, and actions in real time [
42]. For fall detection, pose estimation integrated with YOLO (e.g., YOLO + AlphaPose, YOLO-Pose, or YOLOv8-seg) amplifies its benefits, allowing systems to detect human bodies and analyze posture changes frame by frame [
43].
These systems offer high processing speed, established accuracy in recent versions, and the ability to integrate on the edge device. However, they can be sensitive to occlusions, rely primarily on frame-by-frame analysis, and require specialized datasets for training [
44].
To contextualize the strengths and limitations of different fall detection paradigms,
Table 2 presents a comparative summary of their core characteristics and capabilities.
As summarized in
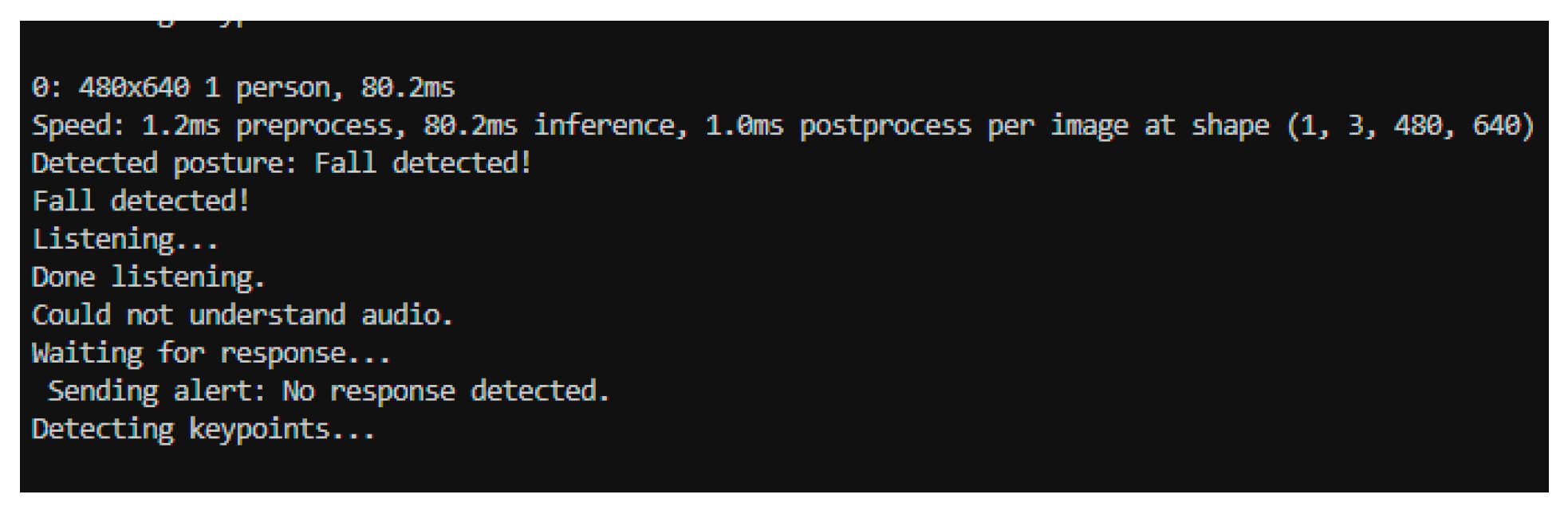
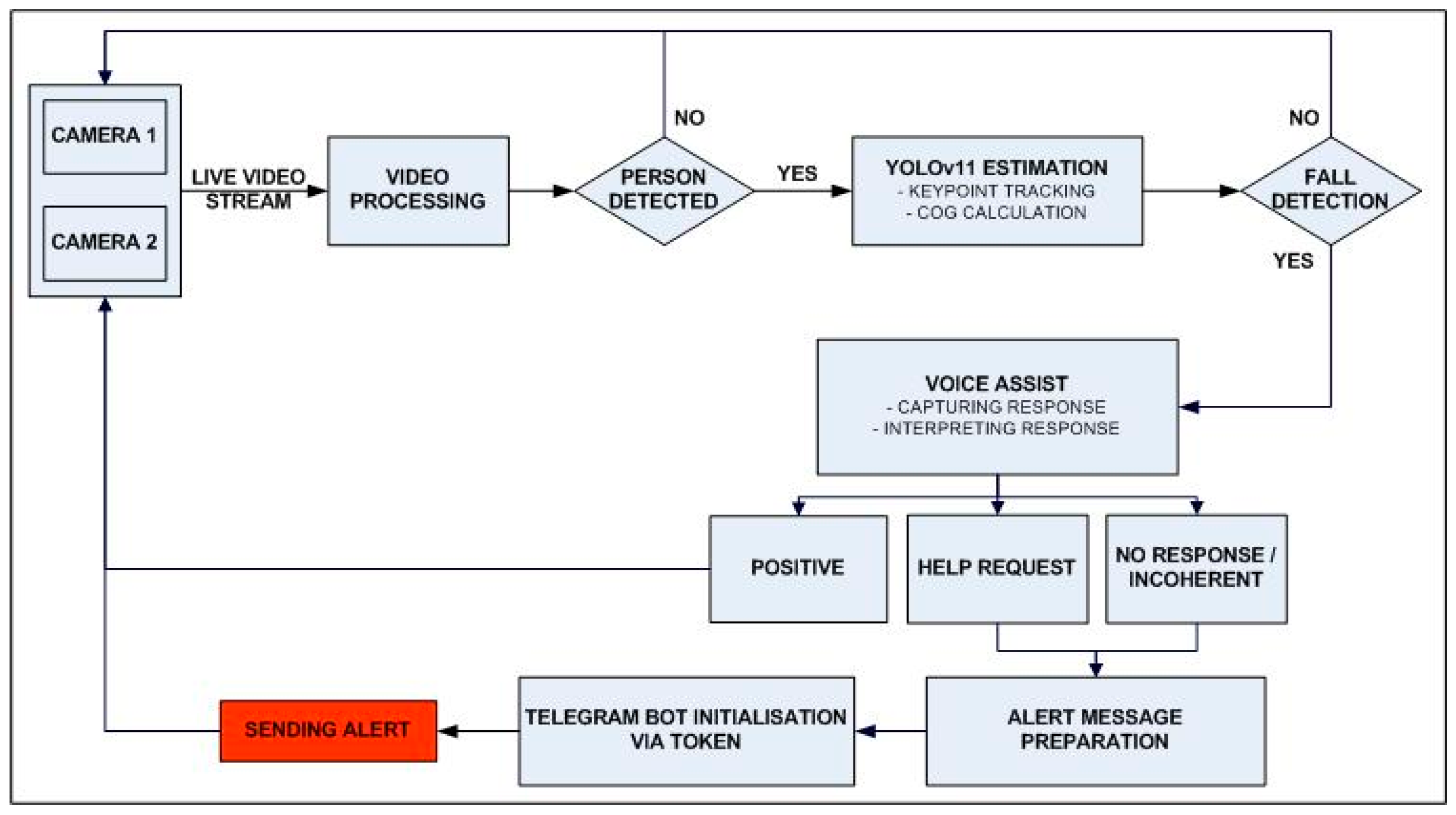
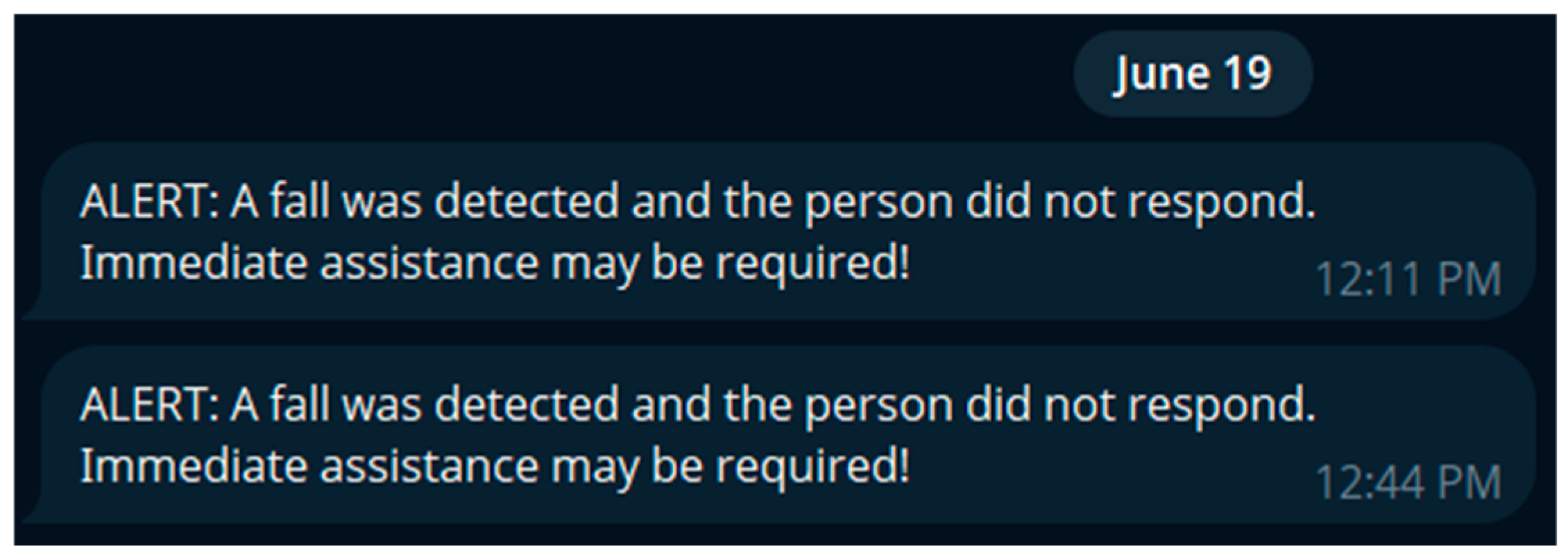
Table 2, YOLO-based systems clearly outperform traditional and CNN-based approaches in terms of real-time performance, posture sensitivity, and suitability for edge deployment. Furthermore, the integration of pose estimation into the YOLO framework enhances its ability to differentiate between intentional and accidental movements while maintaining efficiency and scalability. Based on these advantages, the proposed system adopts a YOLOv11-based architecture that integrates with a voice-based AI dialogue module. This hybrid solution not only improves detection accuracy and responsiveness but also introduces a novel layer of interactivity and validation by reducing false positives and enhancing trust in safety environments.
2.1.3. Ambient and Hybrid Systems in AI Context
These systems offer passive monitoring without needing user interaction, are commonly installed in care homes or multi-occupant settings, and have the benefit of being non-intrusive. They have a number of important advantages, including the ability to monitor continuously and passively without the need for active user interaction, scalability for tracking numerous individuals at once, and suitability for long-term background operation in controlled environments [
45].
Technical installation and accurate sensor calibration are required for their deployment; their functionality is limited to certain physical locations; and their integration of audio/video modalities may present privacy and regulatory compliance issues, among other significant limitations [
45,
46].
Despite these issues, ambient sensors can be embedded into multimodal systems to validate events detected by other means. For instance, an abrupt drop in pressure from a chair mat may support an accelerometer-based fall alert.
Hybrid systems, which integrate wearable, ambient, and vision-based components, represent the cutting edge of fall detection. These systems capitalize on redundant sensing and cross-modal validation to significantly improve accuracy and reduce false positives.
They provide more flexibility and resilience, but they also come with higher hardware costs and more complicated software.
The field of fall detection is shifting from hardware-centric classifications to AI-driven taxonomies based on data processing capabilities. The transition from rule-based to deep and multimodal learning has led to increasingly sophisticated systems capable of handling the complexity of real-world scenarios.
The most promising advances come from multimodal architectures, where complementary data sources enable context-aware, personalized monitoring. The present research aligns with this trajectory by proposing a hybrid fall detection system based on YOLOv11 with pose estimation and a voice assistant, aiming to improve accuracy, reduce false positives, and enhance user interaction.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}