1. Introduction
The China International Water and Electric Corporation is an enterprise focused on water conservancy, hydropower engineering, and infrastructure construction. As the world’s largest hydropower engineering contractor, the corporation engages in the construction of large-scale hydropower stations, reservoirs, irrigation systems, and other projects internationally, with operations spanning Asia, Africa, South America, and beyond. The company manages numerous hydropower station management systems and holds extensive operational data from these facilities. Given that hydropower facilities represent critical infrastructure for host countries, ensuring the cybersecurity of critical information infrastructure sector has become essential for safeguarding national cyberspace security, particularly in the context of today’s complex and volatile international landscape [
1,
2,
3,
4,
5,
6]. The types, scale, and complexity of cyber threats targeting critical infrastructure significantly differ from traditional IT-based systems [
7]: (1) Attacks on critical infrastructure are more intricate than conventional cyber threats [
8,
9,
10,
11,
12,
13]. (2) Overseas power stations present a specific vulnerability to exploitation [
14,
15,
16]. (3) Cross-border data transfers require exceptionally high security standards [
17,
18,
19]. Therefore, the establishment of robust cybersecurity defense mechanisms for critical infrastructure is an urgent imperative.
Malicious traffic detection is a vital method for identifying network attacks. Developing effective malicious traffic detection methods has become a critical task in maintaining the normal operations of critical infrastructure’s network. Malicious network traffic detection methods can be classified into three categories. Firstly, rule-based detection methods identify malicious traffic according to pre-defined traffic signatures (e.g., patterns and keywords in the data packets from the payload). These methods achieve high detection accuracy for the known attacks but fail to detect the unknown attacks and attack variants. Secondly, traditional machine learning-based detection methods extract statistical features and employ classical machine learning algorithms to detect malicious traffic. These approaches can effectively identify variant and unknown malicious traffic, but they highly rely on expert experience for feature selection. Thirdly, deep learning-based detection methods automatically learn complex behavioral features using deep neural networks. However, most of these methods require a vast amount of labelled training data, while large-scale and high-quality labeled datasets are scarce.
Recently, pre-training-based methods have shown promise in addressing the problem of limited labeled data. These methods learn general data representations from large, unlabeled datasets. Such data representations can be transferred to the specific downstream tasks by fine-tuning on limited labeled data. Pre-training-based methods have demonstrated outstanding performance in natural language processing (NLP) and Computer Vision (CV) tasks. However, their application in malicious network traffic detection by applying pre-training techniques remains limited. In addition, most existing pre-training models are trained and fine-tuned in centralized learning techniques. The fine-tuning datasets consist of labeled samples, but collecting high-quality labeled malicious network traffic datasets centrally raises privacy concerns.
Federated learning (FL) is an emerging deep learning framework. It facilitates data sharing of multiple organizations to collaborate without uploading data to a central server, thereby addressing data silos and enhancing data privacy. Whereas, training complex models within the FL framework incurs high communication and computational costs, as client devices applied in one organization often possess limited hardware resources and network bandwidth, especially when dealing with pre-trained language models.
In this paper, we focus on the pre-training-based method for malicious traffic detection in an FL framework by addressing the following questions: (1) Can we pre-train the BERT and fine-tune it for malicious network traffic detection across multiple organizations using an FL framework? (2) Can we achieve an excellent malicious traffic detection performance while using cost-effective model training in resource-constrained clients in an FL framework?
In order to address these questions, we propose a malicious traffic detection model based on an efficient federated learning framework of BERT, called MT-FBERT. MT-FBERT firstly pretrains BERT using self-supervised learning on large-scale, unlabeled network traffic data to learn generic traffic representations. Specifically, it employs two pre-training tasks separately, and the overall pre-training task loss. Then, MT-FBERT finetunes the pre-trained model using FL by creating small local models for each client. In order to consume fewer computational resources and transmit fewer weights, only a subset of crucial neurons in the global model is selected and updated.
The main contributions of this paper are as follows:
We propose a novel pre-training model for malicious network traffic detection, called MT-FBERT. It leverages BERT to take advantage of the unlabeled traffic data to learn generic traffic patterns without relying on expert experience. And then the fine-tuning for malicious traffic detection in the FL framework can assure both the data privacy and the detection accuracy for multiple organizations.
We introduce an efficient malicious traffic fine-tuning mechanism with FL for MT-FBERT on labeled malicious traffic data. It selects and updates the important neurons of the global model in each client to save computational resources and transmission bandwidth.
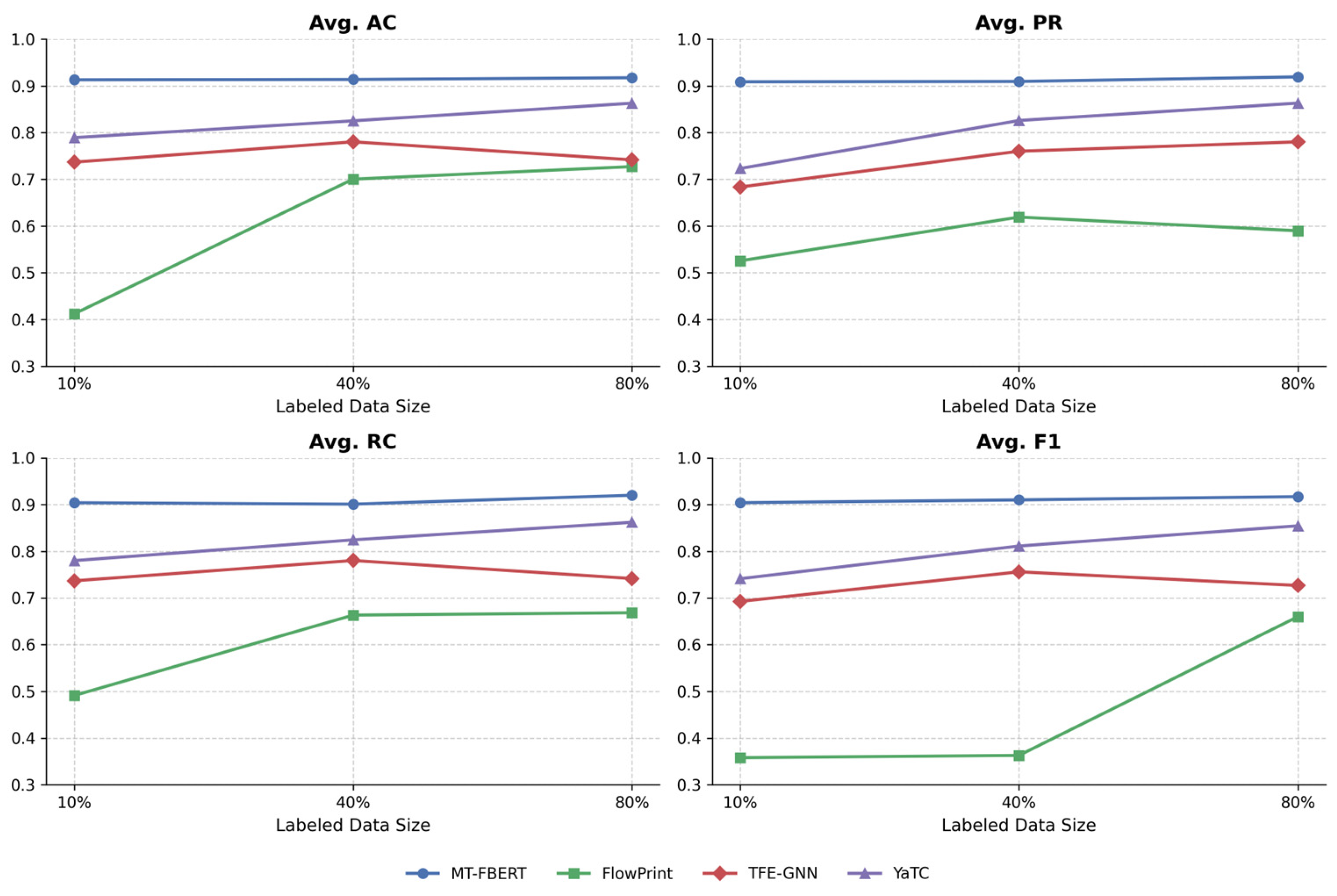
We conduct experiments on several public datasets, which demonstrate the excellent malicious traffic detection performance of MT-FBERT by comparing it to the state-of-the-art baselines with multiple evaluation metrics. Under the conditions of limited labeled samples, distribution shifts, or constrained computational resources, MT-FBERT consistently performs with stability and efficiency.
3. MT-FBERT
3.1. Framework
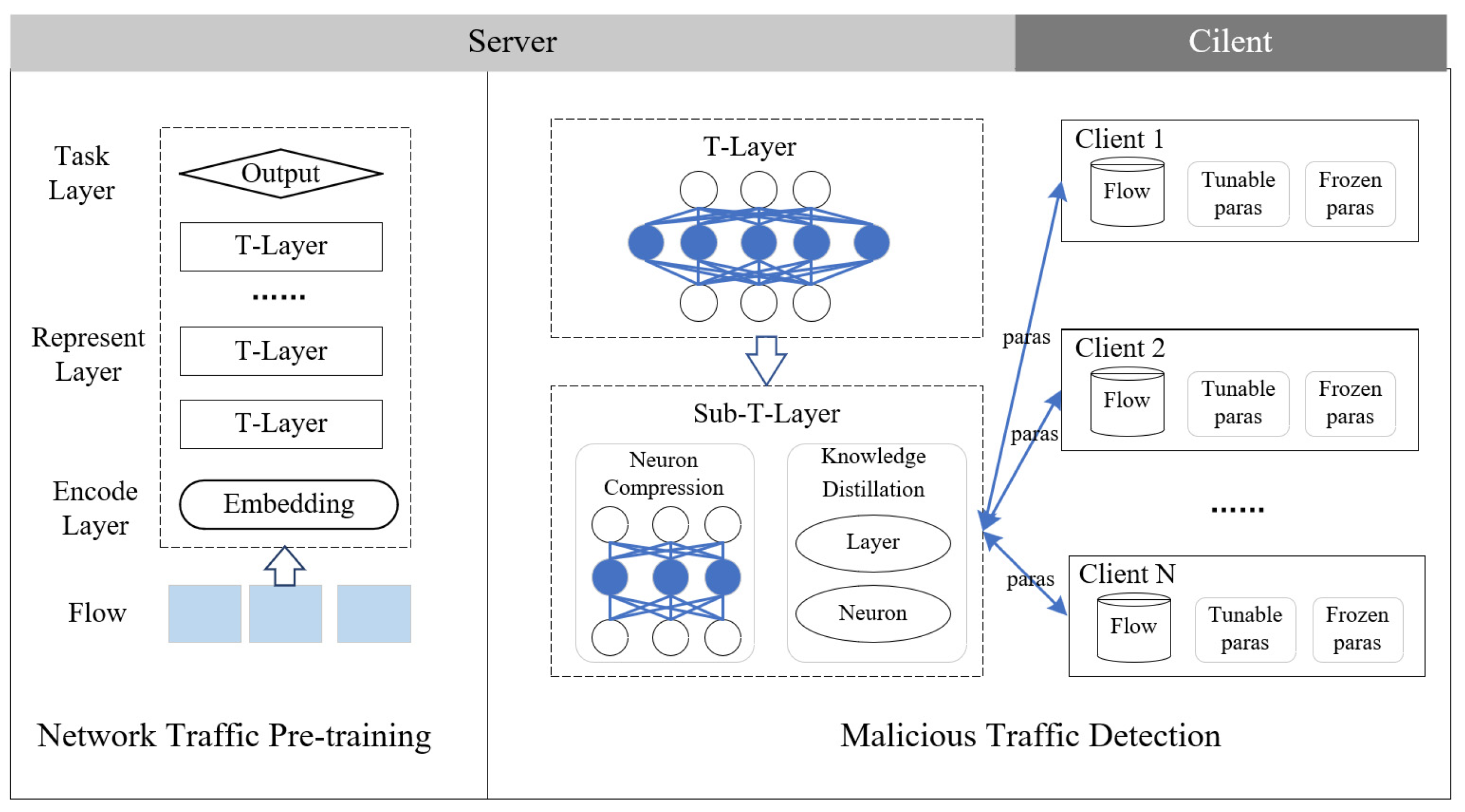
The proposed MT-FBERT contains two stages: pre-training for learning generic traffic representations with large-scale unlabeled data, and privacy-preserving fine-tuning for adjusting the pre-trained model for malicious traffic detection. The overall framework of MT-EFBERT is illustrated in
Figure 1.
In the pre-training stage, the unlabeled traffic flows are transformed into vectors by an encoding layer, which contains token semantic encoding, word position encoding, and word segment encoding. Subsequently, these encoded vectors are then passed through a representation layer, which consists of a sequence of transformer layers. Each transformer layer (T-Layer) comprises a multi-head attention mechanism and a feedforward neural network. The attention mechanism establishes connections between each token to enable its representation by combining each token with other tokens. Finally, the token vectors are input into the task layer. The tasks in the pre-training stage include Masked Burst Modeling (MBM) and the Next Burst Prediction (NBP) tasks. The model computes gradients to optimize its parameters based on the losses received from these two tasks.
In the malicious traffic detection stage, the model is initialized with the parameters obtained from the pre-trained stage, and then the federated learning method is adopted to collaboratively train the detection model among multiple organizations on labeled malicious traffic data. In order to save the communication cost of federated learning, there are two key modules: neuron compression and knowledge distillation, which are designed to compress the parameters of the model. The neuron compression performs layer compression in each transformer layer. The knowledge distillation conducts layer-level and neuron-level distillation before and during fine-tuning, respectively.
3.2. The Pre-Training Stage
3.2.1. Traffic Data Pre-Processing
Network traffic differs greatly from natural language and images in that it does not contain human-understandable content and explicit semantic units. In order to effectively leverage the pretraining technique for traffic representation, traffic is transformed into a pattern-preserved token unit for pre-training.
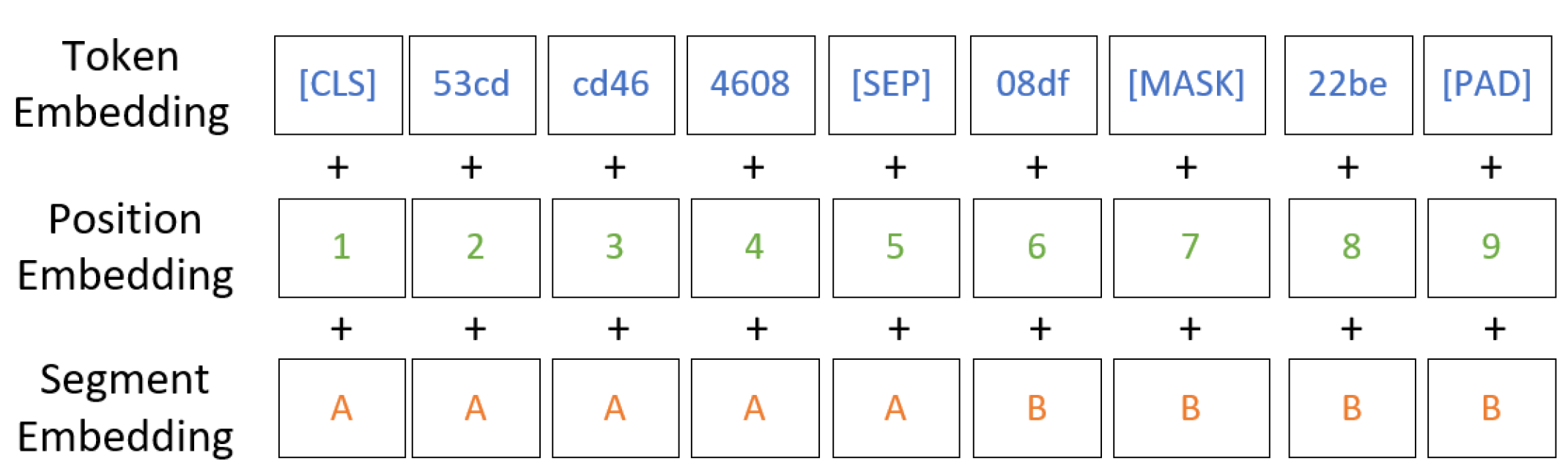
Figure 2 illustrates an example of the traffic data pre-processing.
The traffic data is initially segmented into multiple flows, with each flow subsequently divided into multiple bursts. A flow is defined by a 5-tuple, comprising the source and destination IP addresses, source and destination ports, and the protocol. A burst is defined as a sequence of consecutive packets originating from either the request or the response within a single flow. Each packet is represented as a string of hexadecimal numbers. These hexadecimal strings are encoded in bi-grams, where each unit consists of two adjacent bytes, and each byte is represented as a 4-digit hexadecimal string. The Byte Pair Encoding (BPE) algorithm is subsequently applied for token representation, where each token unit is a 4-digit hexadecimal string with a value ranging from 0 to 65,535. The vocabulary size is specified as a maximum of 65,536. In addition, special tokens such as [CLS], [SEP], [PAD], and [MASK] are added for training tasks. [CLS] is added to the beginning of every sequence as the first token. [SEP] is used to separate sequences. [PAD] pads sequences to the maximum length to satisfy the requirement. [MASK] is used for masked language modeling tasks during pre-training to learn the context of the traffic.
Each token is represented by three types of embeddings: token embedding, position embedding, and segment embedding. Token embedding refers to the representation of tokens learned from a sequence of 4-digit hexadecimal string token units, as illustrated in
Figure 2. The final embedding dimension of the token is set to 768. Position embedding enables the model to learn temporal relationships between tokens via relative positioning. We assign a 768-dimensional vector to each token to encode its sequential position information. As shown in
Figure 2, a burst is equally divided into two segments, which are distinguished by the [SEP] token. The segment embedding is to indicate whether a token belongs to the first segment or the second segment. And the segment embedding dimension is set to 768. The final token representation is constructed by summing these three embeddings as shown in
Figure 3. Initially, the embeddings are randomly initialized, where the embedding dimension is 768, and subsequently fine-tuned through multiple iterations of transformer encoding.
3.2.2. The Pre-Training Tasks
Two pre-training tasks are employed: Masked Burst Modeling (MBM) and Next Burst Prediction (NBP). These tasks are designed to capture the contextual relationships between traffic tokens.
The MBM task is similar to the masked language modeling and Masked Image Modeling utilized by BERT [
31]. In the MBM task, the traffic token sequence of the input is masked, and the model is required to recover the masked tokens based on the contextual tokens. As shown in
Figure 4, each original burst token sequence is first randomly masked to obtain the masked input. During the masking, each token in the original sequence is randomly chosen with 15% probability. As the chosen token from each sequence, we replace it with [MASK] at 80% chance, or choose a random token to replace it at 10% chance, or leave it unchanged at 10% chance, respectively. The model then encodes the masked token sequence with the encoding layer, which consists of three embedding layers, and the vector representation of tokens is obtained by summing up these embeddings. The vectors of tokens are further input into the representation layer, which includes several encoder layers of a transformer to learn the intermediate representations of tokens by using the contextual information. The intermediate representations are processed through a mapping network to predict the masked tokens based on the contextual information; meanwhile, the prediction probabilities of the tokens can be generated. Assume the sequence as
, we mask
tokens and
represents the masked token at the
position in the sequence
. The contextual information of the
position in the sequence
is set as
. The loss function of the MBM task can be defined as
The NBP task is similar to the Next Sentence Prediction utilized by BERT. A burst is a sequence of consecutive packets originating from the same direction. We learn the correlation between packets in a burst based on the NBP task. In the NBP task, a burst is equally divided into two segments, which can be denoted as
and
. For instance, as shown in
Figure 2, “Burst 1” is represented by six traffic tokens, with the first three tokens comprising
and the remaining three tokens forming
. The NBP task is designed to predict whether two given segments belong to the same burst while simultaneously learning traffic representations by modeling packet-level dependencies within bursts. Specifically, we select
and
as input, and concatenate the two segments end to end, with [SEP] connecting them in the middle. During 50% of the time, the chosen
is the true next segment of
. During the remaining 50% of the time,
is randomly selected as long as it is not the next segment of
. Formally, the NBP task constitutes a binary classification problem, where the goal is to determine whether two segments belong to the same burst. Assume there are
bursts, denoting as
. The loss function of the NBP task can be defined as
where
equals 0 if
is the next segment of
, and 1 otherwise.
Overall, the loss function of the pre-training task combines the above two loss terms, which is defined as
3.3. The Malicious Traffic Detection Stage
In the malicious traffic detection stage, the model is initialized with the parameters of the pre-trained model, and then the FL method is adopted to collaboratively train the detection model among multiple organizations on labeled malicious traffic data, which can effectively protect the data privacy of the organizations. Moreover, given the computational and communication overhead of pre-training models in federated learning, we introduce an optimized framework featuring neuron compression and knowledge distillation.
The neuron compression module utilizes magnitude-based pruning [
49] to selectively retain a subset of neurons within the transformer layers. Each transformer layer comprises two primary sub-layers: a multi-head attention (MHA) mechanism and a feed-forward network (FFN). The FFN contains more parameters than the MHA [
50]. We implement the neuron compression by removing neurons with low weights in the FFN. The FFN comprises three sequential components: (1) an input fully-connected layer, (2) a ReLU activation layer, and (3) an output fully-connected layer. The output of the FFN can be denoted as
where
is the input of FFN and its dimensionality is
. Assume the fully connected layer in FFN has dimensionality
.
and
are the weight matrices of the two fully connected layers.
and
are the biases. We measure
th neuron in the fully connected layer based on the weights. We retain the neurons with large weights. Detailed descriptions can be found in
Appendix A. The compressed transformer encoder layer is denoted as Sub-T-Layer, as shown in
Figure 1.
Moreover, neuron compression introduces bias in gradient estimation, with the update direction diverging from the uncompressed model’s trajectory. To mitigate accumulated gradient errors during federated learning of the compressed detection model, we employ knowledge distillation to minimize the divergence between the compressed and uncompressed models. The distillation approach operates at two granularities: (1) layer-level distillation that matches intermediate representations, and (2) neuron-level distillation that preserves critical activation patterns. Layer-level distillation ensures consistency between the compressed and uncompressed models by aligning both forward pass outputs and backward pass gradients at each transformer layer. Each layer’s distillation loss can be denoted as
where
is the size of the distillation dataset,
and
represent the outputs from the uncompressed and the compressed models, respectively,
and
are the weight matrices in the uncompressed model,
and
are the weight matrices in the compressed models, and
is the regularization coefficient.
The frozen FFN parameters in the compressed model introduce catastrophic forgetting risks during federated learning, as they cannot adapt to client-specific malicious traffic patterns. To address this, we employ neuron-level distillation to preserve activation knowledge across server-client updates. Neuron-level distillation identifies low-impact neurons for the malicious traffic detection task by computing their Average Percentage of Zero activations (
APoZ) [
51]. Set the labelled malicious traffic data on the client
,
is a token sequence input into the transformer layer. the
APoZ for each neuron can be defined as
where
is the output of the
th token of the input
at the
th neuron in the
th layer, and
is the indicator function. We calculate the
APoZ for each neuron on the client using the local network traffic dataset. Subsequently, only selected neurons in the FFN are updated based on their
APoZ values.
6. Conclusions
In this paper, we introduce a novel malicious traffic detection method based on an efficient FL framework of BERT, called MT-FBERT. MT-FBERT pre-trains the network traffic model to take advantage of the unlabeled traffic data to learn generic traffic patterns without relying on expert experience. Furthermore, we employ an FL framework optimized for efficient malicious traffic detection, which operates across distributed clients possessing labeled malicious traffic datasets. This framework employs an adaptive neuron selection mechanism that dynamically identifies and updates only the most significant neurons in the global model during client-side fine-tuning. MT-FBERT successfully addresses the dual challenges of privacy preservation and detection efficacy in multi-organization cybersecurity environments.
Through extensive experimentation across multiple benchmark malicious traffic datasets, MT-FBERT demonstrates its powerful ability to generalize from limited data and various distribution shifts. The efficient FL framework of MT-FBERT maintains strong performance while demanding minimal computational resources. This makes it particularly advantageous in resource-constrained environments. In the future, we will deploy MT-FBERT in the real-world network environment to validate its practical efficacy.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}