Abstract
Multi-Object Tracking (MOT) is an integral part of any autonomous driving pipelines because it produces trajectories of other moving objects in the scene and predicts their future motion. Thanks to the recent advances in 3D object detection enabled by deep learning, track-by-detection has become the dominant paradigm in 3D MOT. In this paradigm, a MOT system is essentially made of an object detector and a data association algorithm which establishes track-to-detection correspondence. While 3D object detection has been actively researched, association algorithms for 3D MOT has settled at bipartite matching formulated as a Linear Assignment Problem (LAP) and solved by the Hungarian algorithm. In this paper, we adapt a two-stage data association method which was successfully applied to image-based tracking to the 3D setting, thus providing an alternative for data association for 3D MOT. Our method outperforms the baseline using one-stage bipartite matching for data association by achieving 0.587 Average Multi-Object Tracking Accuracy (AMOTA) in NuScenes validation set and 0.365 AMOTA (at level 2) in Waymo test set.
1. Introduction
Multi-object tracking have been a long standing problem in computer vision and robotics community since it is a crucial part of any autonomous systems. From the early work of tracking with hand-craft features, the revolution of deep learning which results in highly accurate object detection models [1,2,3] has shifted the focus of the field to the track-by-detection paradigm [4,5]. In the framework of this paradigm, tracking algorithms receive a set of object detection, usually in the form of bounding boxes, at each time step and they aim to link detection of the same object across time to form trajectories.
While image-based methods of this paradigm have reached a certain maturity, 3D tracking is still in its early phase where most of the published approaches are originated from successful 2D exemplars. One popular method is [6] which extends [4] into 3D space. In these works, detections are linked to tracks by solving a bipartite matching with the Hungarian algorithm [7], then states of tracks are updated by a Kalman filter. Taking a similar approach to establishing detection-to-track correspondence, [8] trains a network for calculating the matching cost instead of using the 3D Intersection over Union (IoU). In [9,10], objects’ poses in the current and several future frames are predicted by deep neural networks. Thus, tracks can be formed by greedy closest-point matching.
Even though 3D tracking has been progressed rapidly thanks to the availability of standardized large scale benchmarks such as KITTI [11], NuScenes [12], Waymo Open Dataset [13], the focus of the field is placed on developing better object detection models rather than developing better tracking algorithm as shown in Table 1 which presents the performance measured by the AMOTA metric of tracking algorithms following the track-by-detection paradigm and the performance of their object detector measured by mean Average Precision (mAP). AMOTA is a scalar value representing how well the algorithm does in limiting:

Table 1.
Summary of tracking methods which details are published in the leader board of NuScenes and Waymo Open Dataset.
- ID switches (IDS): the number of times tracks are associated with wrong detections;
- False Positives (FP): the number of times real objects are missed detected;
- False Negatives (FN): the number of times the tracking algorithm reports tracks in places where there are no real objects present.
There are two trends that can be observed in this table. First, tracking performance experiences a boost when a better object detection model is introduced. Second, the method of AB3DMOT [6], which uses the Hungarian algorithm on some metrics (e.g., 3D IoU, Mahalanobis distance) to perform data association, Kalman Filters to update tracks’ states once they have associated detections, and set of heuristic rules to manage birth and death of tracks, is favored by most recent 3D tracking systems.
The reason for AB3DMOT’s popularity is that despite its simplicity, it achieves competitive result in challenging datasets at significantly high frame rate (more than 200 FPS). However, such simplicity comes at the cost of the MOT system being vulnerable to false associations due to occlusion or imperfect detections which is case for objects in a clutter or far away from the ego vehicle.
Aware of the shortage of a generic 3D tracking algorithm which can better handle the occlusion and imperfect detections, yet remains relatively simple, we adapt the image-based tracking method proposed by [22] to the 3D setting. Specifically, this method is a two-stage data association scheme. In this scheme, each tracked trajectory is called a tracklet and is assigned a confidence score computed based on how well associated detection matches with tracklet. The first association stage aims to establish the correspondence between high-confident tracklets and detection. The second stage matches the left over detection with the low confident tracklets as well as link low-confident tracklets to high-confident ones if they meet a certain criterion.
In this paper, we make two contributions
- Our main contribution is the adaptation of an image-based tracking method to the 3D setting. In details, we exploit a kinematically feasible motion model, which is unavailable in 2D, to facilitate the prediction of objects’ poses. This motion model defines the minimal state vector needed to be tracked.
- Extensive experiment carried out in various datasets proves the effectiveness of our approach. In fact, our better performance, compared to AB3DMOT-style models, show that adding a certain degree of re-identification can improve the tracking performance while keeping the added complexity to the minimum.
- Our implementation is available at https://github.com/quan-dao/track_with_confidence accessed on 21 April 2021.
2. Related Work
A multi-object tracking system in the track-by-detection paradigm consists of an object detection model, a data association algorithm and a filtering method. While the last two components are domain agnostic, object detection models, especially learning-based methods, are tailored to their operation domain (e.g images or point clouds). This paper targets autonomous driving where objects’ poses are required thus being interested in 3D object detection models. However, developing such a model is not in the scope of this paper, instead we use the detection result provided by baseline models of benchmarks (e.g., PointPillars of NuScenes) to focus on the data association algorithm and to have a fair comparison. Interested readers are referred to [23] for a review of 3D object detection.
Data association via the Hungarian algorithm was early explored in [24] where a 2-stage tracking scheme was proposed for offline 2D tracking. Firstly, detections are linked frame-by-frame to form tracklets by associate detections to tracklets via solving a LAP with the Hungarian algorithm. The cost matrix of this LAP is computed based on geometric and appearance cue. While the geometric cue is the 2D IoU, the appearance cue is the correlation between two bounding boxes. Secondly, tracklets are associated with each other to compensate trajectory fragments and ID switches due to occlusion. Similar to the previous step, this association is also formulated as a LAP and solved by the Hungarian algorithm.
Due to its batch-processing nature, the method of [24] cannot be applied to online tracking. The authors of [4] overcomes this by eliminating the second stage, which effectively sacrifices the ability of re-identifies objects after a period of occlusion. Despite its simplicity, SORT — the method proposed by [4] – achieves competitive result in MOT15 [25] with lightning-fast inference speed (260 Hz). The success of SORT inspired [6] to adapt it to 3D setting by using 3D IoU as the affinity function. The performance of SORT in 3D setting is later improved in [15] showing the superiority over 3D IoU of the Mahalanobis distance which is the magnitude of difference between the expected detection given the ego vehicle pose and the real detection while taking into account their uncertainty. In [26], the authors integrate the 3D version of SORT into a complete perception pipeline for autonomous vehicles.
The two-stage association scheme is adapted to online tracking in [22] which proposes a confidence score to quantify tracklets quality. Based on this score, tracklets are associated with detections or another tracklets, or terminated. The appearance model learned by ILDA in [22] is improved by deep learning in the follow-up work [27]. Recently, this association scheme is revisited in the context of image-based pedestrian tracking by [28] which proposed to use the rank of the Hankel matrix as tracklets motion affinity. To be specific, this technique estimates a tracklet ’s dynamic by a linear regressor taking its previous states as input. In noise-free scenarios, the order of such a regressor (i.e., the number of past states needed to estimate the current state) is equal to the rank of the Hankel matrix which formula can be found in [28]. The intuition behind this technique is that if two tracklets belong the same trajectory, explaining their merged trajectory would require a low order regressor. This technique is popular in image-based tracking despite being prone to deterioration due to noise because of the absence of an accurate motion model in this space. However, objects’ motion in 3D can be well explained by their kinematic models. Therefore, our approach employs two different kinematic models for two different categories of objects to have more computationally efficient and accurate motion affinity.
Differently from [22] and its related works, this paper applies the two-stage association scheme to online 3D tracking. In addition, we can provide competitive result despite relying solely on geometric cue to compute tracklet affinity by exploiting the Constant Turning Rate and Velocity (CTRV) motion model which can accurately predict objects position in 3D space by exploiting their kinematic.
3. Method
3.1. Problem Formulation
Online MOT in the sense of track-by-detection aims to gradually grow the set of tracklets by establishing correspondences with the set of detections received at every time step and updating tracklets state accordingly. A detection at time step t encapsulates information of an object as a 3D bounding box
here, is the position of the box’s center, is its heading direction, and is its size. It is worth noticing that in the context of autonomous driving, objects are assumed to remain in contact with the ground; therefore, their detections are up-right bounding boxes which orientation is described by a single number — the heading angle. A tracklet is a collection of state vectors corresponding to the same object , here are respectively the starting- and ending-time of the tracklet.
The correspondence between and can be formally defined as finding the set that maximizes its likelihood given .
Due the exponential growth of possible associations between and , Equation (2) is computationally intractable after a few time steps. In this paper, such a correspondence is approximated by the two-stage data association proposed by [22] as shown in the following.
3.2. Two-Stage Data Association
3.2.1. Tracklet Confidence Score
The reliability of a tracklet is quantified by a confidence score which is calculated based on how well associated detections match with its states across its life span and how long its corresponding object was undetected.
where is a binary indicator which takes 1 if the tracklet has a detection associated with it at time step k, and 0 otherwise. is the number of time step that the traklet gets associated with a detection. is the affinity function which evaluates the similarity between a track and a detection. Its detail will be presented in the following subsection. is a tuning parameter which takes high value if the object detection model is accurate. is the number of time step that tracklet was undetected (i.e., did not have associated detection) calculated from its birth to the current time step t.
Applying a threshold this confidence score divides the set into a subset of high-confident tracklets and a subset of low-confident tracklets . These two subsets are the fundamental elements of the two-stage association pipeline showed in Figure 1
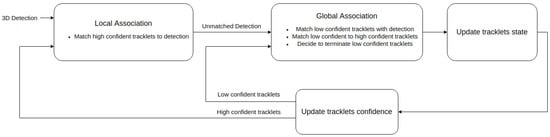
Figure 1.
The pipeline of two-stage data association. The first stage—local association establish the correspondences between detections at this time step and high-confident tracklets . Then, global association stage matches each low-confident tracklets with either a high-confident tracklet or a left-over detection, or terminates it.
3.2.2. Affinity Function
Affinity function is to compute how similar a detection to a tracklet or a tracklet to another. As mentioned earlier, due to the lack of colorful texture in point cloud, the affinity function used in this work is just comprised of geometric cue. Specifically, it is the sum of position affinity and size affinity.
The scheme for computing position affinity between a tracklet and a detection or between two tracklets are shown in Figure 2
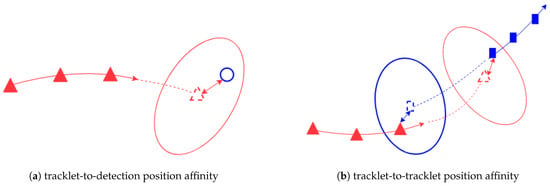
Figure 2.
The computational scheme of position affinity. The filled triangles (or rectangles) are subsequent states of a tracklet. The colored arrow represents the time order: the closer to the tip, the more recent the state. The triangle (or rectangle) in dash line is the state propagated forward (or backward) in time. The covariance of these propagated states are denoted by ellipses with the same color. The two-headed arrows indicate the Mahalanobis distance. In the subfigure (a), the blue circle denotes a detection.
As shown in Figure 2a, the position affinity between a tracklet and a detection is defined as the Mahalanobis distance between tracklet’s last state propagated to the current time step t and the measurement vector extracted from
where is last state of tracklet propagated to the current time step using the motion model which will be presented below. is the measurement model computing the expected measurement using the inputted state and the measurement vector extracted from
The matrix is the covariance matrix of the innovation (i.e., the difference between expected measurement and its true value )
here, is the Jacobian of the measurement model. are covariance matrix of and , respectively. These covariance matrices are calculated based on training data using the approach proposed by [15].
In the case of two tracklets and , assuming starts after ended, their motion affinity is, according to Figure 2b, is the sum of
- Mahalanobis distance between the last state of propagated forward in time and the first state of ;
- Mahalanobis distance between the first state of propagated backward in time and the last state of .
The subscript in Equation (10) respectively denote the ending and starting state of a tracklet.
To reduce the risk of false association, a threshold is applied to the affinity
3.2.3. Local Association
In this association stage, high-confident tracklets () are extended by their correspondence in the set of detections . This tracklet-to-detection is found by solving the linear assignment problem characterized by the cost matrix as follows:
where are respectively the number of high-confident tracklets and the number of detections. The intuition of this association stage is that because tracklets with high-confident have been tracked accurately for several time steps, the affinity function can identify if a detection is belong to the same object as the tracklet with high accuracy, thus limiting the possibility of false correspondences. In addition, low-confident tracklets are usually resulted from fragment trajectories or noisy detections, excluding them from this association stage help reduces the ambiguity.
3.2.4. Global Association
As shown in Figure 1, the global association stage carries out the following tasks
- Matching low-confident tracklets with high-confident ones;
- Matching low-confident tracklets with detections left over by the local association stage;
- Deciding to terminate low-confident tracklets.
These tasks are simultaneously solved as a LAP formulated by the following cost matrix
here, are respectively the number low-confident tracklets and detections left over by the local association stage. is the matrix of size with every element is set to ∞. Recall h is the number of high-confident tracklets. Submatrix is the cost matrix of the event where low-confident tracklets are matched with high-confident ones
Submatrix represents the event where low-confident tracklets are terminated.
Finally, submatrix is the cost of the associating low-confident tracklets with detections left over by local association stage.
The solution to the LAP in this stage and in the Local Association stage is the association that minimize the cost and can be either found by the Hungarian algorithm for the optimal solution or by a greedy algorithm which iteratively picks and removes correspondence pair with the smallest cost until there is no pair has cost less than a threshold. The detail of this greedy algorithm can be found in [15] or in Section 3.4.
Once a detection is associated with a tracklet, its position and heading is used to update the tracklet’s state according to the equation of the Kalman Filter, while its sizes is averaged with tracklet’s sizes in the past few time steps to result in updated sizes. Detections do not get associated in the global association stage are used to initialize new tracklets.
3.3. Motion Model and State Vector
Exploiting the fact that objects are tracked in 3D space of a common static reference frame which can be referred to as the world frame, motion of objects can be described by more kinematically accurate models, compared to the commonly used Constant Velocity (CV) model. In this work, we use the Constant Turning Rate and Velocity (CTRV) model to predict motion of car-like vehicles (e.g., cars, buses, trucks), while keeping the CV model for pedestrians.
For car-like vehicles, its state can be described by
here, is the location in the world frame of the center of the bounding box represented by the state vector, is the heading angle, is longitudal velocity (i.e., velocity along the heading direction), are respectively velocity of and z.
The motion on x-y plane of car-like vehicles can be predicted using CTRV as follows:
where is the sampling time. Please note that in Equation (18), z is assumed to evolve with constant velocity. In the case of zero turning rate (i.e., ),
The state vector of a pedestrian is
The motion of pedestrians is predicted according to CV model
3.4. Complexity Analysis
As shown in Figure 1, our data association pipeline is made of four components: Local Association, Global Association, Update Tracklets’ States, Update Tracklets’ Confidence. This section gives an analysis of the time complexity referred to as complexity of these four components.
Let d and h be the number of detections and the number of high confident tracklets, respectively. The time complexity of the Local Association step is the sum of the complexity of computing the cost matrix in Equation (12) and solving the LAP represented by . Since has the size of , the complexity of computing is .
The LAP represented by can be solved by either the Hungarian algorithm or a greedy algorithm [15]. The complexity of the Hungarian algorithm is . On the other hand, the greedy algorithm is made of two steps presented in Algorithm 1.
| Algorithm 1: Greedy algorithm for solving LAP |
 |
The first step of sorting the flattened cost matrix has the complexity of assuming . The complexity of the second step in the best case scenario where the for loop is stopped at , meaning there is no valid association, is . The worst case scenario happens when the For Loop proceeds till the last value of k, which means every possible association has its affinity less than the threshold . In this case, the complexity is . As the result, the complexity of the greedy algorithm is
Using Equation (22), the complexity of the Local and Global Association step solved by the greedy algorithm are and , respectively. Recall l and are the number of low-confident tracklets and the number of detections left over by the Local Association step.
The other steps, Update Tracklets’ States and Update Tracklets’ Confidence, have the linear complexity because they are made of one loop through all tracklets.
4. Experiments
The effectiveness of our method is demonstrated by benchmarking against SORT-style baseline models on three large scale datasets: KITTI, NuScenes, and Waymo. In addition, we perform an ablation study using NuScenes dataset to better understand the impact of each component on our system’s general performance.
4.1. Tuning the Hyper Parameters
There are three hyper parameters in our data association pipeline: the confidence threshold , the detection model accuracy in Equation (3), and the affinity threshold .
The confidence threshold is set to 0.5 according to [22]. It is worth noticing that [22] suggests that this parameter does not have any significant effect on the tracking performance. The value of is chosen empirically such that a high-confident tracklet becomes low-confident after being undetected for three frames.
As observed from experiments, the position affinity is the dominant component in the tracklet-to-detection and tracklet-to-tracklet affinity. Since the position affinity, which is the Mahalanobis distance between expected detection and real detection, is distributed, the affinity threshold in Equation (11) is chosen according to the percentile of distribution where the position affinity resulted from a correct association is expected to fall into. Notice that the degree of freedom of the distribution of our interest is 4 due to the dimension of the measurement vector in Equation (6).
Intuitively, the affinity threshold determines how conservative our tracking algorithm is. Small makes our algorithm be more skeptical by rejecting detections that are close, but not close enough to the prediction of tracks’ states. This works well in the scenario where a large number of false-positive detections presents (e.g., Waymo dataset). However, too small can reject correct detections thus deteriorating the tracking performance. The method used for searching for a good value of is
- Performs a coarse grid search with the expected percentile of distribution in the set which means the value of is in the set , while keeping the rest of hyper parameters unchanged. Please note that here the value of the threshold is just half of the corresponding value in Distribution Table. This is because the motion affinity is scaled by half in our implementation to reduce its dominance over the size affinity.
- Once a performance peak is identified at , a fine grid search is performed on the set
The resulted value of on KITTI, NuScenes, and Waymo are respectively , , and .
4.2. Tracking Results
Evaluation Metrics: Classically, MOT systems are evaluated by the CLEAR MOT metrics [29] which compute tracking performance based on three cores quantities which are the number of False Positives, False Negatives, and ID Switches (the definition of these quantities can be found in Section 1). Intuitively, this set of metrics aims at evaluating a tracker’s precision in estimating tracks’ states as well as its consistency (i.e., keeping a unique ID for each even in the presence of occlusion). As pointed out by [30] and later by [6], there is a linear relation between MOTA and object detectors’ recall rate, as a result, MOTA does not provide a well-rounded evaluation performance of trackers. To remedy this, [6] proposes to average MOTA and MOTP over a range of recall rate, resulting in two integral metrics AMOTA and AMOTP which become the norm in recent benchmarks.
Datasets: To verify the effectiveness of our method, we benchmark it on three popular autonomous driving datasets which offer 3D MOT benchmark: KITTI, NuScenes, and Waymo. These datasets are collections of driving sequences collected in various environment using a multi-modal sensor suite including LiDAR. KITTI tracking benchmark interests in two classes of object which are cars and pedestrians. Initially, KITTI tracking was designed for MOT in 2D images and recently [6] adapts it to 3D MOT. NuScenes concerns a larger set of objects which comprises of cars, bicycles, buses, trucks, pedestrians, motorcycles, trailers. Waymo shares the same interest as NuScenes but groups car-like vehicles into a meta class.
Public Detection: As can be seen in Table 1, AMOTA highly depends on the precision of object detectors. Therefore, to have a fair comparison, the baseline detection results made publicly available by the benchmarks are used as the input to our tracking system. Specifically, we use Point-RCNN detection for KITTI dataset, MEGVII detection for NuScenes, and PointPillars with PPBA detection for Waymo.
The performance of our model compared to the SORT-style baseline model in three popular benchmarks are shown in Table 2.
Table 2.
Quantitative performance of our model on KITTI validation set, NuScenes validation set, and Waymo test set. AMOTA is the primary metric of these benchmarks. FP, FN IDS and FRAG are absolute numbers in the case of KITTI and NuScenes, while they are divided by the total number of objects in Waymo. The performance on Waymo is calculated at the difficulty of LEVEL 2.
As can be seen, our model consistently outperforms the baseline model in term of the primary metric AMOTA, thus proving the effectiveness of the 2-stage data association. Specifically, the improvements are , and for KITTI, NuScenes and Waymo, respectively. It is worth noticing that our approach has more track fragmentations (FRAG), 259 compared to 93 of the base line, in KITTI. The reason for this is that at each time step tracklets have no matched detections are not reported by our approach, while the baseline predicts their pose using the constant velocity model (CV) and reports this prediction.
The comparison runtime on KITTI dataset of our tracking algorithm against AB3DMOT [6] is shown in Table 3. Despite the additional complexity added by the second stage of the data association (i.e., the Global Association step), our approach can achieve a runtime that is close to AB3DMOT on KITTI and exceeds the real-time speed by a large margin. On more challenging datasets, the object detector generates a significantly larger number of detections per frame on average, on NuScenes and on Waymo, compared to of KITTI. This large number of detections enlarges the cost matrix of the Local and Global Association step, thus making the LAPs represented by them more costly to solve. Therefore, the runtime of our approach is reduced to frames-per-second (fps) on NuScenes and fps on Waymo. This runtime can be greatly improved if our approach is re-implemented in a compiling language such as C++.
Table 3.
Comparison of our approach’s runtime on KITTI dataset against AB3DMOT’s.
The qualitative performance on NuScenes is illustrated by drawing the bird-eye view of a scene with tracking result, ground truth objects and detection result accumulated through time as in Figure 3 and Figure 4.
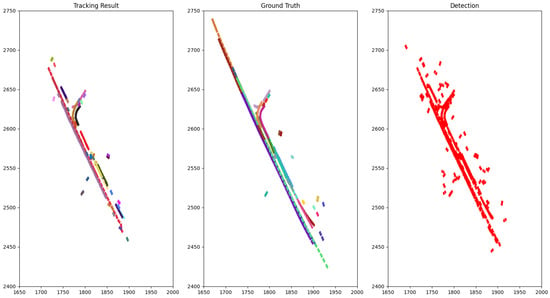
Figure 3.
The bird-eye view of the tracking result for class car compared to the ground truth of scene 0796 (NuScenes) accumulated through time. Each rectangle represents a car and each color is associated with a track ID.
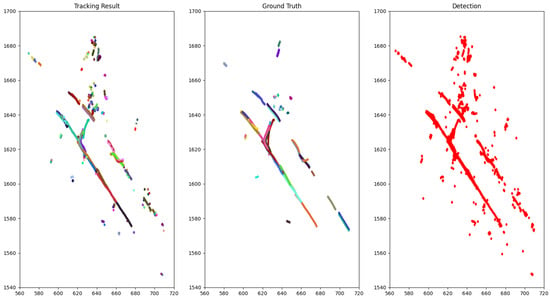
Figure 4.
The bird-eye view of tracking result for class pedestrian compared to the ground truth of scene 0103 (NuScenes) accumulated through time. Each dot represents a pedestrian and each color is associated with a track ID.
4.3. Ablation Study
In this ablation study, the default method is the method presented in Section 3 which has
- Two stages of data association (local and global). Each stage is formulated as a LAP and solved by a greedy matching algorithm [15].
- The affinity function the sum of position affinity and size affinity (as in Equation (4)).
- The motion model is Constant Turning Rate and Velocity (CTRV) for car-like objects (cars, buses, trucks, trailers, bicycles) and Constant Veloctiy (CV) for pedestrians.
- As mentioned in Section 4.1, the value of hyperparameters are set as follows: (in Equation (3)), tracklet confidence threshold , and the affinity threshold (in Equation (11))
To understand the effect of each component on the system’s general performance, we modify or remove each of them and carry out experiment with the rest of the system being kept the same as the default method and the same hyperparameters. The changes and the resulted performance are shown in Table 4.
Table 4.
Ablation study using NuScenes dataset.
It can be seen that solving the matching problem (formulated as a LAP) with the Hungarian algorithm instead of the greedy matching algorithm of [15] results in a marginal increase of AMOTA; however, this increased performance comes at the cost of increased execution time since the Hugarian algorithm has higher time complexity (cubic time compared to quadratic time.). In addition, using Constant Velocity model only reduces the AMOTA by compared to the Default setting which shows the effectiveness of the Constant Turning Rate and Velocity model in predicting motion of car-like vehicle. Finally, performing global association only deteriorates the tracking performance confirms the importance of the local association step which significantly reduce the association ambiguity for the second stage.
5. Conclusions and Perspectives
In conclusion, this paper successfully adapted an image-based tracking method to the 3D space. Particularly, extensive experiments carried out in various datasets shows that our two-stage data association pipeline can result in significant improvement in the tracking accuracy by adding a certain degree of re-identification while keeping the added complexity to the minimum. Nevertheless, medium and long-term occlusion remains challenging for our approach due to the fact that the affinity function relies mostly on tracklets position whose prediction’s reliability reduces with the length of the prediction horizon. In the domain of image-based MOT, this problem is offend solved by exploiting tracklets’ appearance with Siamese networks [31,32]. However, the extension of this method to 3D space is not straightforward due to the lack of color and texture in point cloud. A possibility to resolve this issue is to associate 3D tracklets to 2D object detections, then carry out re-identification in images. Taking a different approach, a recent work in graph neural networks [33] proposes to jointly learn affinity function from point clouds and images.
Author Contributions
Conceptualization, M.-Q.D. and V.F.; methodology, M.-Q.D.; validation, M.-Q.D. and V.F.; formal analysis, M.-Q.D.; investigation, M.-Q.D. and V.F.; resources, V.F.; writing—original draft preparation, M.-Q.D. and V.F.; writing—review and editing, M.-Q.D. and V.F.; visualization, M.-Q.D.; supervision, V.F.; funding acquisition, V.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
This research has been conducted as part of the AIby4 project (AI by/for Human, Health and Industry), funded by the French Ministry of Education and Research and the French National Research Agency (ANR-20-THIA-0011).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MOT | Multi-Object Tracking |
| IoU | Intersection over Union |
| LAP | Linear Assignment Problem |
| CTRV | Constant Turning Rate and Velocity |
| CV | Constant Velocity |
| AMOTA | Average Multi-Object Tracking Accuracy |
| AMOTP | Average Multi-Object Tracking Precision |
| MT | Mostly Track |
| ML | Mostly Lost |
| FP | False Positive |
| FN | False Negative |
| IDS | ID Switches |
| FRAG | Fragment |
| FPS | Frames Per Second |
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Scheidegger, S.; Benjaminsson, J.; Rosenberg, E.; Krishnan, A.; Granström, K. Mono-camera 3d multi-object tracking using deep learning detections and pmbm filtering. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 433–440. [Google Scholar]
- Weng, X.; Wang, J.; Held, D.; Kitani, K. AB3DMOT: A Baseline for 3D Multi-Object Tracking and New Evaluation Metrics. arXiv 2020, arXiv:2008.08063. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Liang, M.; Yang, B.; Zeng, W.; Chen, Y.; Hu, R.; Casas, S.; Urtasun, R. PnPNet: End-to-End Perception and Prediction with Tracking in the Loop. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 11553–11562. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-based 3d object detection and tracking. arXiv 2020, arXiv:2006.11275. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3569–3577. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Garcia-Fernandez, A.F.; Williams, J.L.; Granstrom, K.; Svensson, L. Poisson Multi-Bernoulli Mixture Filter: Direct Derivation and Implementation. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1883–1901. [Google Scholar] [CrossRef]
- kuang Chiu, H.; Prioletti, A.; Li, J.; Bohg, J. Probabilistic 3D Multi-Object Tracking for Autonomous Driving. arXiv 2020, arXiv:2001.05673. [Google Scholar]
- Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; Yu, G. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv 2019, arXiv:1908.09492. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ding, Z.; Hu, Y.; Ge, R.; Huang, L.; Chen, S.; Wang, Y.; Liao, J. 1st Place Solution for Waymo Open Dataset Challenge—3D Detection and Domain Adaptation. arXiv 2020, arXiv:2006.15505. [Google Scholar]
- Ge, R.; Ding, Z.; Hu, Y.; Wang, Y.; Chen, S.; Huang, L.; Li, Y. AFDet: Anchor Free One Stage 3D Object Detection. arXiv 2020, arXiv:2006.12671. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 10529–10538. [Google Scholar]
- Cheng, S.; Leng, Z.; Cubuk, E.D.; Zoph, B.; Bai, C.; Ngiam, J.; Song, Y.; Caine, B.; Vasudevan, V.; Li, C.; et al. Improving 3D Object Detection through Progressive Population Based Augmentation. arXiv 2020, arXiv:2004.00831. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3d traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1012–1025. [Google Scholar] [CrossRef]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. Motchallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Mauri, A.; Khemmar, R.; Decoux, B.; Ragot, N.; Rossi, R.; Trabelsi, R.; Boutteau, R.; Ertaud, J.Y.; Savatier, X. Deep Learning for Real-Time 3D Multi-Object Detection, Localisation, and Tracking: Application to Smart Mobility. Sensors 2020, 20, 532. [Google Scholar] [CrossRef] [PubMed]
- Bae, S.H.; Yoon, K.J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 595–610. [Google Scholar] [CrossRef]
- Yang, H.; Wen, J.; Wu, X.; He, L.; Mumtaz, S. An efficient edge artificial intelligence multipedestrian tracking method with rank constraint. IEEE Trans. Ind. Inform. 2019, 15, 4178–4188. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]
- Leal-Taixé, L.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S. Tracking the trackers: An analysis of the state of the art in multiple object tracking. arXiv 2017, arXiv:1704.02781. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Paris, France, 12 September 2016; pp. 33–40. [Google Scholar]
- Chang, S.; Li, W.; Zhang, Y.; Feng, Z. Online siamese network for visual object tracking. Sensors 2019, 19, 1858. [Google Scholar] [CrossRef] [PubMed]
- Weng, X.; Wang, Y.; Man, Y.; Kitani, K.M. Gnn3dmot: Graph neural network for 3d multi-object tracking with 2d-3d multi-feature learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6499–6508. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).