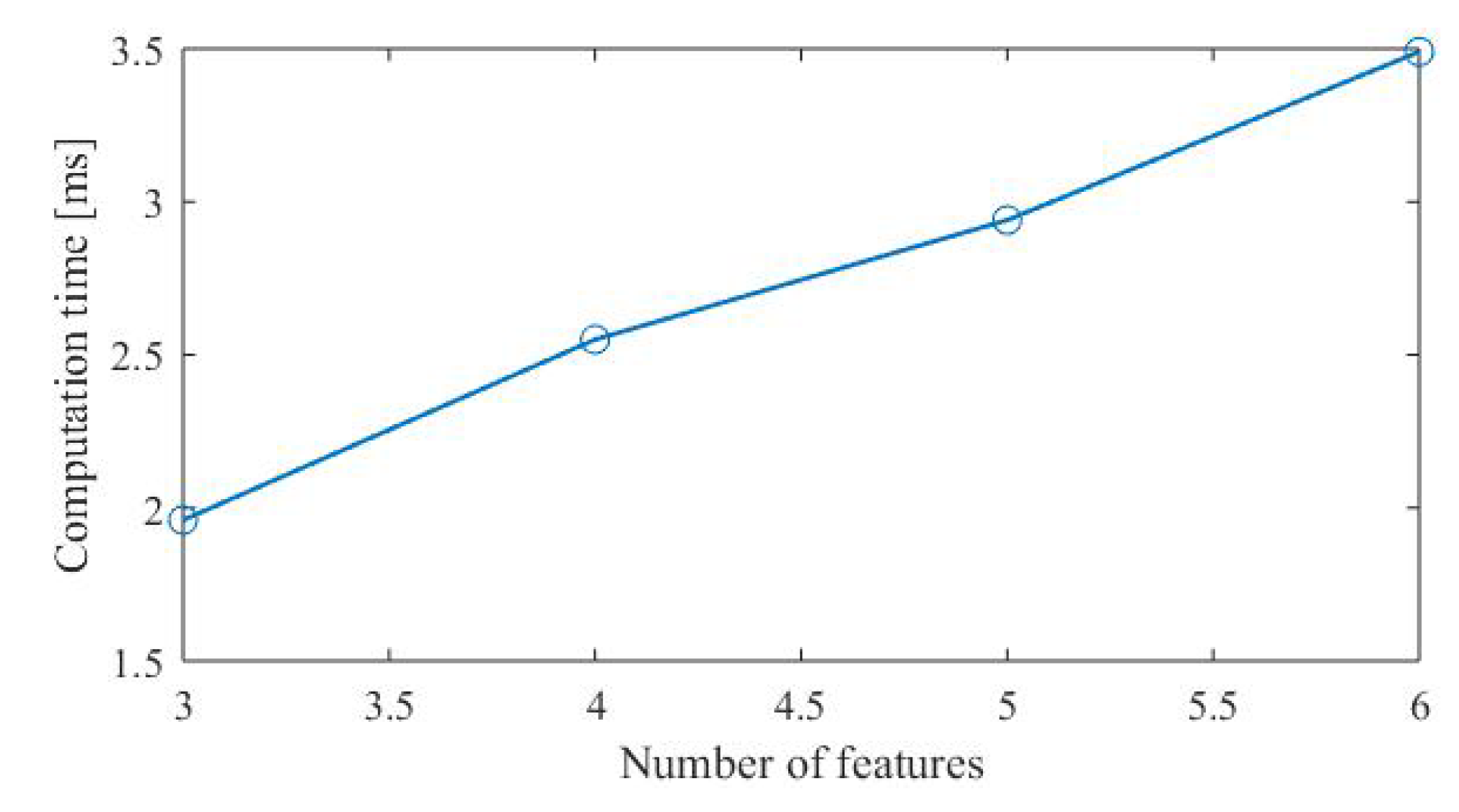
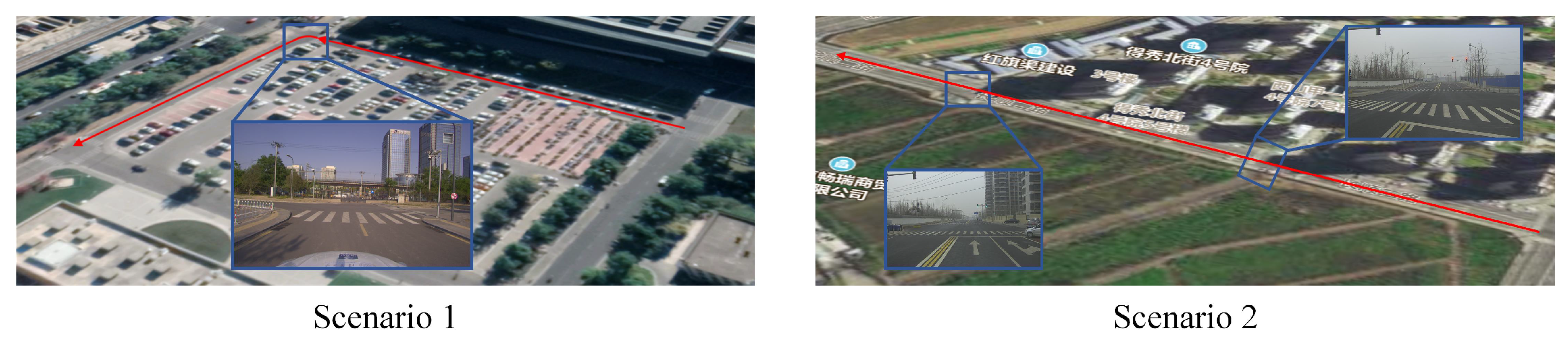
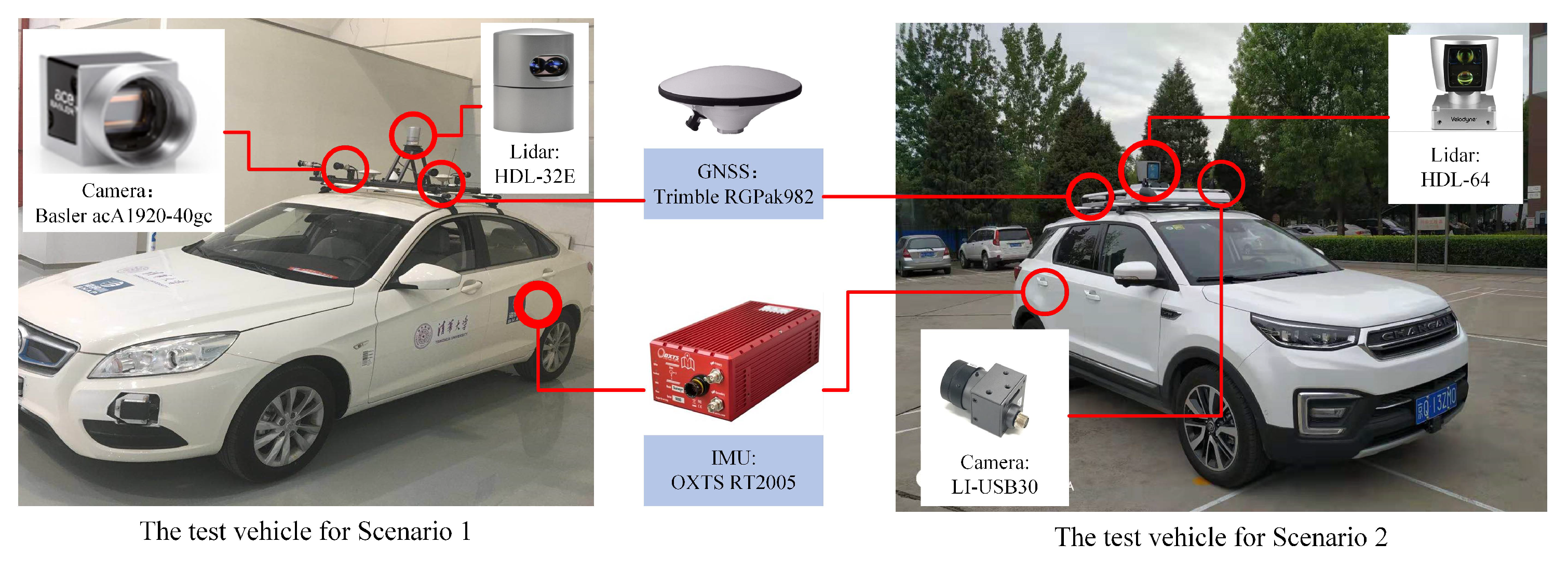
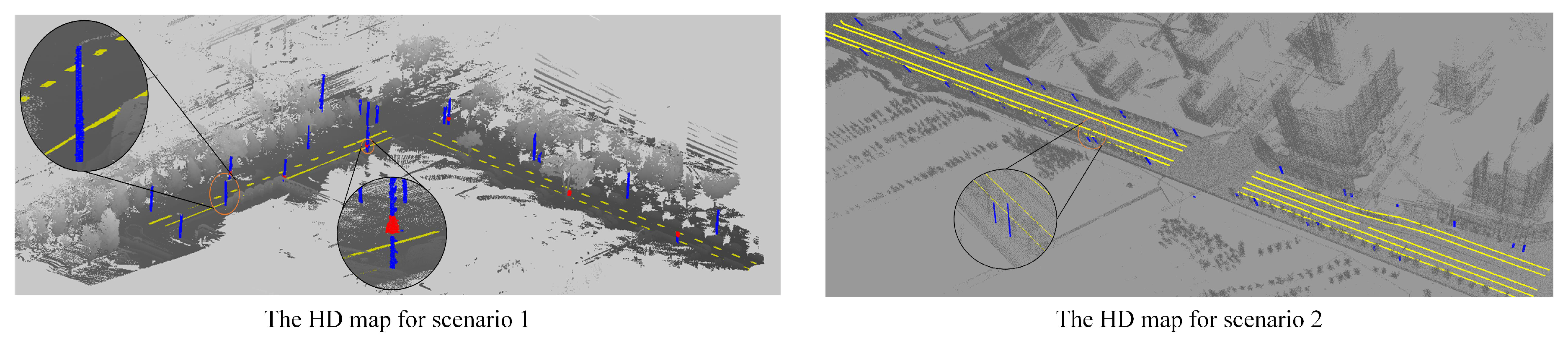
1. Introduction
Precise knowledge of the localization and orientation of a vehicle is critical in realizing many map-based IV applications [
1,
2], such as decision-making, cooperative driving, map updating, etc. The state-of-the-art integrated inertial navigation system based on the global navigation satellite system (GNSS) real-time kinematic (RTK) module, high-quality IMU, and LiDAR-based positioning technology is well-known to deliver high-precision localization [
3]; however, due to its high cost, it remains mostly in the research stage and is seldom seen in mass-produced vehicles.
As an effective augmentation tool among on-board sensors, the HD compact map has gained tremendous popularity as a consumer vehicle add-on feature. With pre-collected environmental information, the HD map can act as a virtual sensor to improve vehicle safety without incurring additional hardware system complexity [
4]. As a result, high-precision HD maps are considered the cornerstone of IV technology, especially for more advanced automated vehicles [
2]. Although HD maps are often deployed in costly equipment such as LiDAR and the corresponding high-performance integrated inertial navigation system, the HD map itself is not considered as a costly technology, and thus are widely available as an optional feature for most of the vehicles in the market. Some map-based applications [
5,
6,
7] implement the point cloud maps as shown in
Figure 1a. This kind of map retains raw geometric information and may be segmented with semantic labels; however, it is not a market-favorable choice due to its huge data size. On the other hand,
Figure 1b shows an example of a vector HD map, of which the refined data are extracted from the raw point cloud map for a smaller data size. It contains the precise geometric descriptions of road elements and retains higher-level semantic information such as road topology, lane type, speed limit, etc. In recent years, with the release of various high-precision map standards such as OpenDrive and NDS, vector HD maps from mainstream cartographers (e.g., TomTom and HERE) have thrived in commercial vehicles.
High-precision absolute vehicle localization is particularly important for HD map-based applications in IVs. For example, the vehicle must be able to localize itself before the information in the map becomes relevant for IV route planning; in some applications such as the Road Experience Management of Mobileye [
8], vehicle localization is a prerequisite for pending map updates. GNSS is one of the most commonplace localization technology deployed on vehicles. The RTK technology can even achieve centimeter-level localization by modifying the mobile station with reference station data [
9]. Nevertheless, its high accuracy can only be maintained in open areas. On typical urban roads, the accuracy of GNSS RTK struggles to remain stable due to satellite signals suffering from multipath fading and shadow effects by the nearby buildings and vegetation [
10,
11]. Such GNSS signal degradation issues are dealt with by dead reckoning (DR). With the information from inertial sensors such as gyroscope, accelerometers, or LiDAR odometry, the current position of the vehicle can be effectively inferred [
12]. However, the cumulative positional errors can quickly spiral out of control due to the long-term absence of global localization information, especially when compromised by inertial sensors with sub-par performance [
13]. This shortcoming of DR is addressed by the map-matching positioning process [
14], in which LiDAR is primarily used to collect maps beforehand to generate the raw point cloud maps (as is shown in
Figure 1a) with dense features [
14,
15]; then the point cloud of the vehicular LiDAR is registered by the ICP [
16] or NDT [
17] method to calculate the accurate vehicle position and rotation with centimeter-level precision. While both families of localization methods—RTK GNSS and DR with LiDAR—offer accurate vehicle localization, both require high-cost in-vehicle sensors. Consequently, their intimidating price point prevents them from becoming truly viable solutions for the IV market. In order to break the price barrier and deliver a market-friendly vehicle localization solution, a completely different design philosophy must be taken. Rather than relying on the high-end hardware, this article proposes to develop a new vehicle localization method based on low-cost visual sensors and vector HD maps, both of which are commonly equipped solutions on Tesla, MobilEye, BOSCH, and Baidu Apollo Lite as cost-down strategies.
The association between the pre-collected map and visual sensors is a key issue in localizing the visual sensor in the map coordinates [
18]. There have been many research papers on visual feature points in the SLAM domain. Among them, there are many works based on local features, and many of them have made great basic contributions to robot positioning and mapping, such as Scale-Invariant Feature Transform (SIFT) [
19,
20], Speeded Up Robust Features (SURF) [
21] and ORB [
22,
23]. These methods can provide stable features under changes of illumination, viewing angle, and scale. In some articles, visual feature points are extracted and matched against point cloud maps [
5,
24]. However, problems starting to rise due to limited storage and computational power [
25]. On the other hand, some scholars have put forward easy-computation global appearance descriptors, which are mainly used for robot positioning and topology map construction [
26,
27]. Principal Components Analysis (PCA) [
28] and Discrete Fourier Transform (DFT) [
29] are used for generating global appearance descriptor to concentrate the information of an image in a lower number of components. This kind of description method describes the whole image as a single descriptor, which has advantages in some unstructured or dynamic environments where road landmarks are not easy to be extracted.
In recent years, with the development of deep learning and the improvement of on-board computing ability, the information contained in an image can be interpreted down to pixel-level resolution [
30], thereby enabling more complex image feature recognition such as semantic information extraction [
31,
32]. Compared with traditional visual descriptors, semantic information is more robust against seasonal changes, ambient illumination fluctuations, and occlusions due to dynamic obstacles. In addition, semantic features are more easy to be matched maps storing semantic features. Consequently, it gained some popularity as cues in map matching process [
6]. However, all the published semantic matching methods are centered around a stereo vision system composed of either a high-cost specialized camera [
33], LiDAR [
34], or based on the less-favored point cloud map instead of the vector map. In addition, since deep learning inherently consumes lots of computing resources, the extraction of semantic features in these algorithms takes a lot of time, resulting in limited real-time performance [
33,
35]. In this paper, one consideration of the integration of visual odometry is that the frame rate is higher, which can compensate the time lag from semantic segmentation in the map localization module, and finally output the localization results in real-time.
In summary, to the best of our knowledge, the alignment between monocular vision and the standardized vector HD map using semantic cues is a promising map-matching vehicle localization solution with lingering commercialization challenges such as weather-dependent reliability, unfavorable cost, and large map data size. Therefore, in order to address these shortcomings, we propose in this paper the concept of Monocular Localization with Vector HD Map (MLVHM), a novel map-based localization algorithm, as well as its data association method implemented on low-cost visual sensors and compact HD vector maps to deliver high-precision, drift-free vehicle localization. The preliminary version of this work was presented in [
35]. Compared with the preliminary version, we improved the method of data association between the camera and HD map data. Furthermore, we simulated and verified the accuracy of localization based on single-frame, and analyzed the failure scenarios of the preliminary version as well. We also included frame-to-frame constraints to further improve scene adaptability, positioning accuracy, and real-time performance.
The main contribution of this paper can be elaborated by the following three points:
1. We propose a low-cost and high-precision localization method based on the extraction of semantic vector features and robust map matching algorithm.
2. We propose and demonstrated a sliding-window based frame-to-frame motion fusion to effectively improve the stability of localization in scenes with sparse localization features and enable the real-time performance as well.
3. Finally, we simulate and conduct real-world experiments to fully analyse the accuracy and reliability of the proposed localization algorithm.
The remainder of the paper is organized as follows. The related works are introduced in
Section 2. In
Section 3, we give an overview of the proposed localization method, and detailed introduction of the basic theoretical methods and application details in this paper are given in
Section 4 and
Section 5, respectively. In
Section 6, we analyze the factors that affect the accuracy of the map-based localization. In
Section 7, evaluation and discussion based on real-vehicle test are given. Finally, we conclude the paper with future research efforts in
Section 8.
3. System Overview
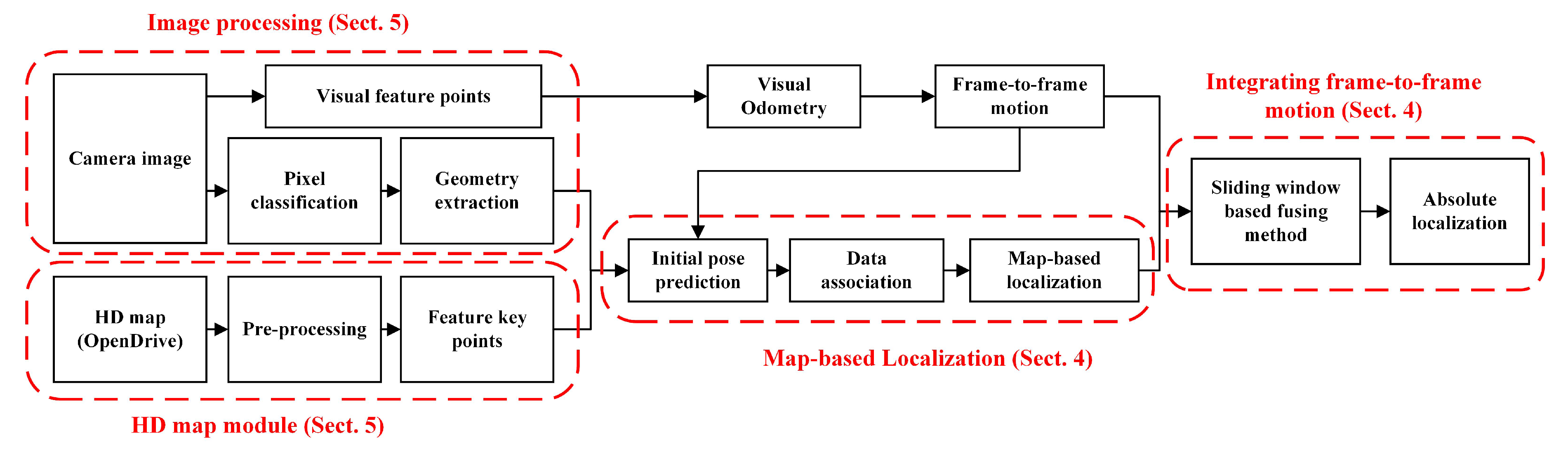
Figure 2 illustrates the system overview of the MLVHM. The HD map module is responsible for map data pre-processing and feature control point extraction for the MLVHM localization model from an HD map in OpenDrive format. In order to achieve high accuracy during map data acquisition, LiDAR is deployed in the real vehicle experiments solely for map acquisition; nowhere throughout the experiment was LiDAR used for vehicle localization. Moreover, the only limitation imposed on the experiment setup is the map data format. As long as the acquired maps conform to the requirement, the maps collected by other sensors are also compatible with our localization method.
The image processing module takes care of the geometric feature extraction with the semantic class for image-to-map alignment. First, the pixels are classified semantically through deep learning, followed by clustering the key pixels critical to the map matching process. Then, these key pixel clusters are point- or line-fitted to help extract the geometric features with semantics. At the same time, based on the SLAM algorithm, the ORB features are extracted for estimating the relative motion of the camera. It is noteworthy that the ORB features extracted here do not participate in map matching, but are only used for motion tracking.
In the map-based localization module, the camera pose is estimated based on map-visual semantic feature matching. The data association sub-module contains the algorithm for determining the optimal matching based on the consistency of random sampling, while making adaptive improvements according to the driving scenes. After the landmarks have been associated with the image features, an objective function is defined to describe the constraints of map-visual semantic features, and the camera pose is solved iteratively through the optimization algorithm.
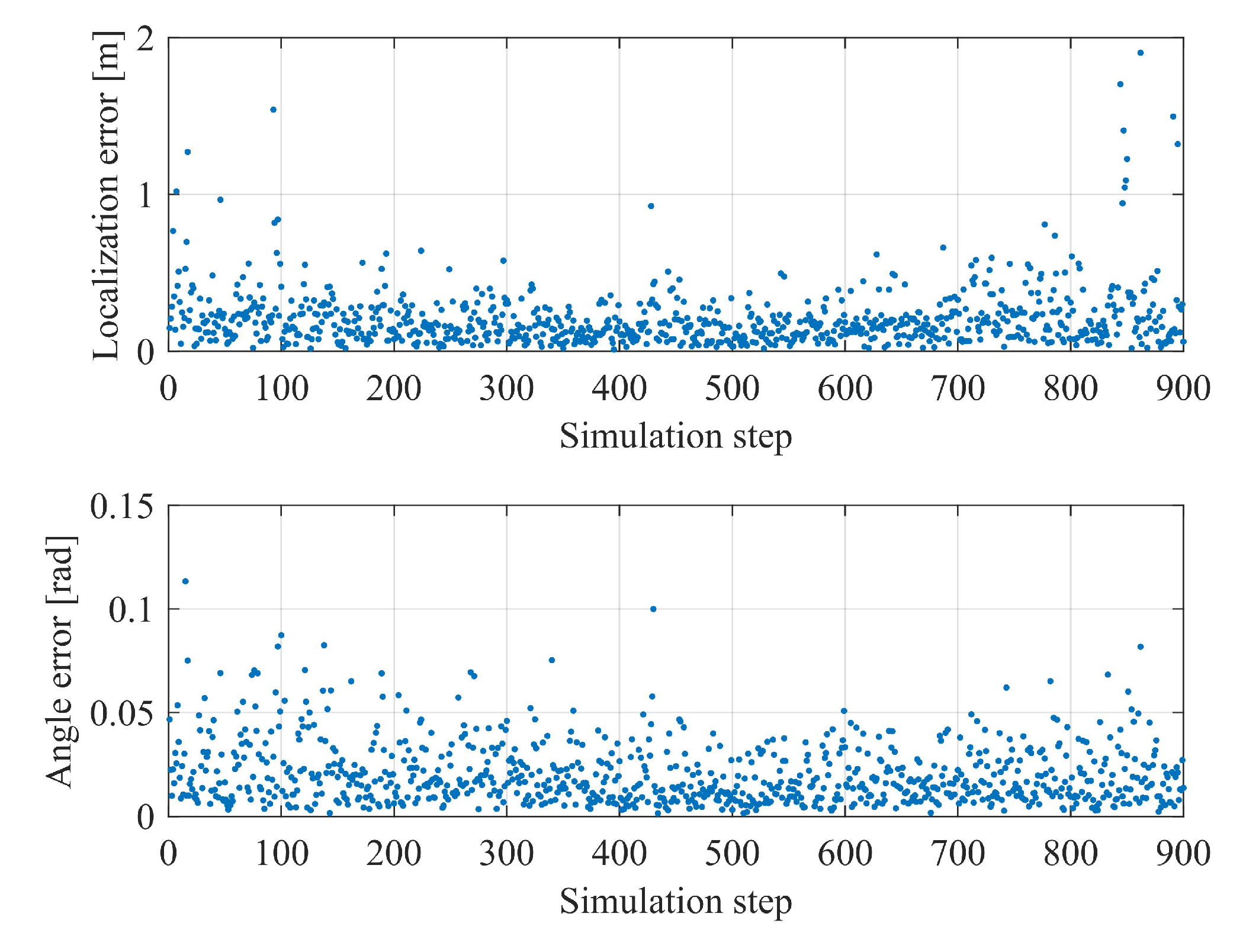
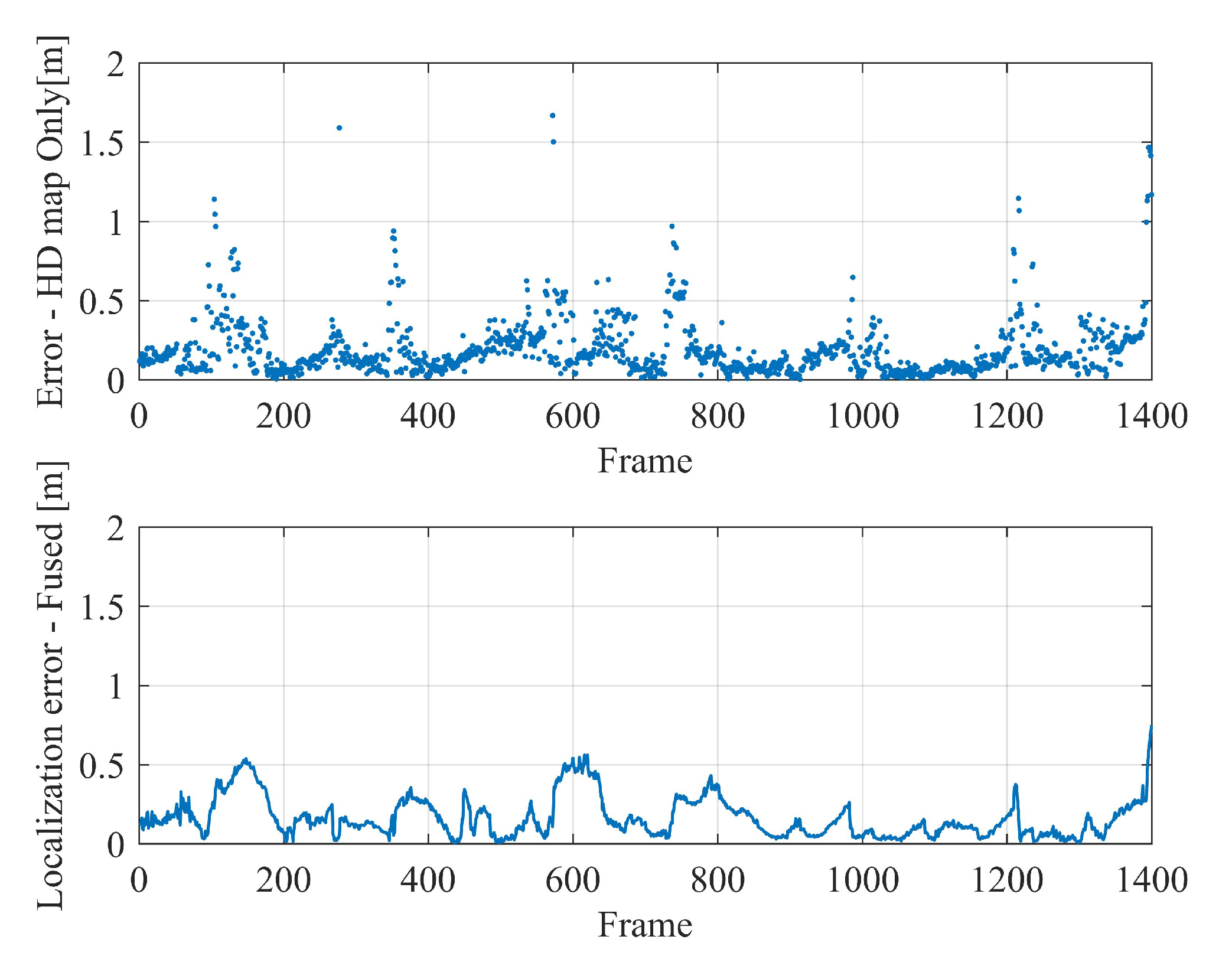
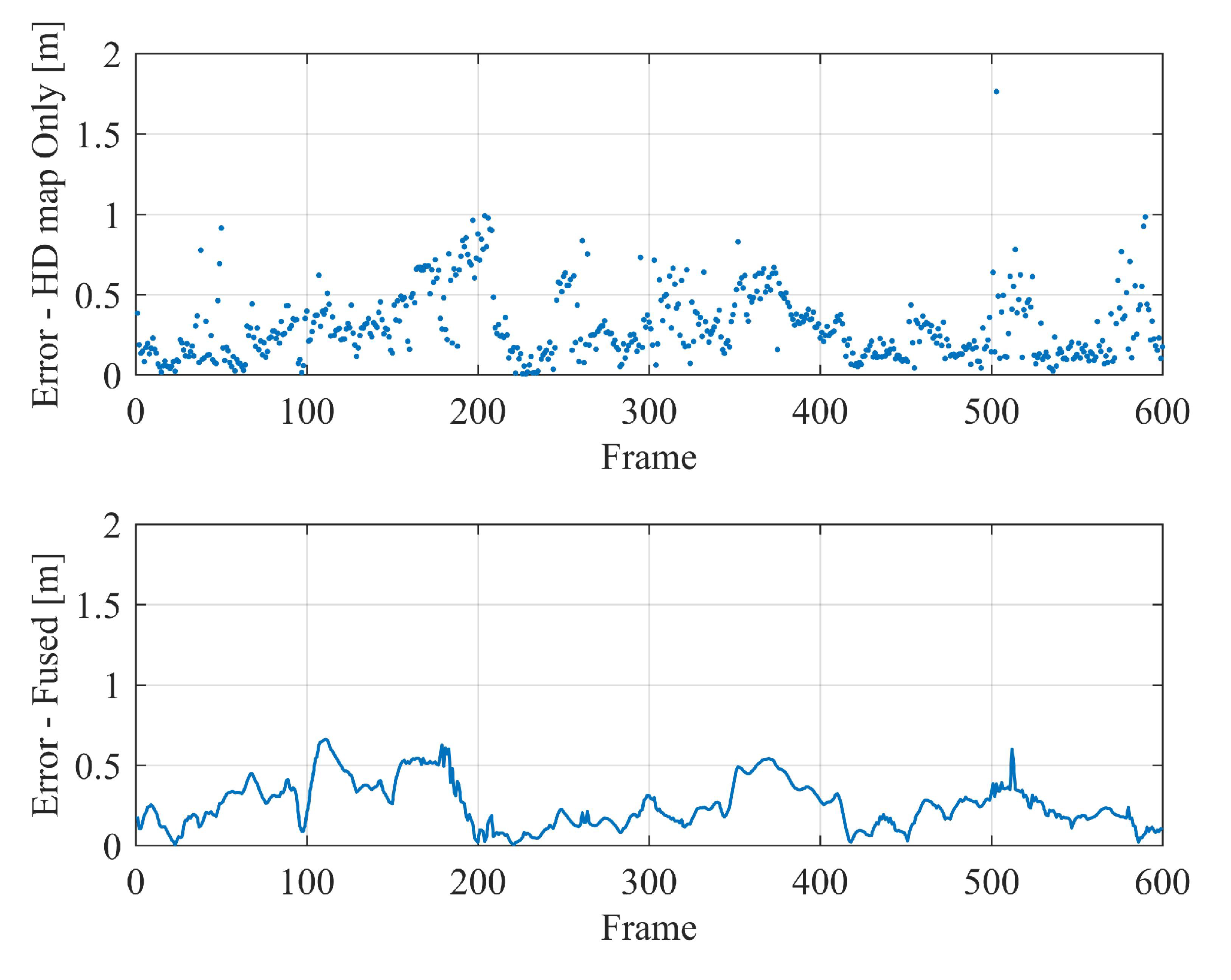
In the analysis, it is found that the localization is unstable in some sparse scenes, and the map localization module can not guarantee the real-time localization output since the calculation for semantic segmentation takes too much time. In order to further improve the stability and accuracy as well as to guarantee the real-time output of localization results, a sliding window-based method is deployed to fuse the original global pose with the frame-to-frame motion before outputting the final result—an absolute vehicle pose of 6-DOF in the map coordinates.
4. Map-Based Localization
This section covers the design and analysis of the proposed camera pose estimation method based on the matched geometric features with semantics. This analysis is fully generalized and not biased towards certain objects or features in a given traffic scene; however, a concrete implementation example will be provided in
Section 5. This section further covers the novel data association method between the camera image and the map features, as well as the integration of inter-frame constraints to further improve the localization stability.
4.1. Line- and Point-Based Camera Localization
Throughout the analysis, a feature refers to an object captured by an on-board camera, and a landmark is an object extracted from a pre-collected map. The features adopted by the MLVHM are geometric features with semantics, as shown in
Figure 3. In traffic scenes, the extracted geometric features include but not limited to line features, light poles, lane lines, edge of walls, edges of selected road signs, etc. Selected point features are also extracted, including, but are not limited to the center of traffic signs, corner points of buildings, markers on the ground, etc. In image processing, these point and line features are identified with semantic information (e.g., light poles identified as light pole lines, lane as lane lines, etc.). Correspondingly, the landmarks stored in the map are also geometric descriptions of the key elements of the environment.
The problem of solving for the camera localization can be described as a state estimation problem: Given the observation of features , landmarks and the correspondences , the camera pose at time t is estimated.
The six-DOF model is deployed to describe the position and orientation of the camera in the map coordinate system, that is, the world coordinate system:
where
and
are the localization and orientation parameters,
,
, and
are the three coordinates of the optical center of the camera, and
,
, and
are respectively the pitch, yaw, and roll angle of the camera in the map coordinates.
Given a set of line and point features extracted from the on-board camera as the observation at time
t:
where
and
are the number of point and line features,
is the coordinate of point feature in the pixel coordinate system, and
is composed of the coordinates of the two endpoints of a given line feature.
The landmarks from the HD map is defined as,
where
and
are the number of point and line landmarks, respectively, and
is the 3D coordinate of the point landmark. The two end-point
and
are used to describe the line landmark. Therefore,
and
.
Lastly, the correspondence is defined as , where , indicating that the ith point feature extracted from the image is associated with the jth point landmark in the HD map. Similarly, can be subsequently defined.
The measurements model of line features is:
where
.
is the measurement of the
nth line landmark at camera pose
. The measured noise is assumed to obey the Gaussian distribution, i.e.,
, which describes the uncertainty of extracting the line features.
Similarly, the point measurements model is:
where
.
is the measurement of the
jth point landmark at camera pose
.
, which altogether describes the uncertainty of point feature extractions in the image processing.
The pin-hole camera model
is applied to project the control points
to the image coordinate
based on the camera pose:
.
where
is the intrinsic matrix of the camera,
is the rotation matrix from the world coordinate system to the camera based on the camera orientation. Subsequently, in the Line measurement
, the measurement model is expressed as:
and the point measurement
is expressed as:
Therefore, the task of localizing the camera in the map is ultimately estimating from the measurements , which are assumed to be probabilistically independent conditioned on .
The camera state thereby can be estimated by applying the maximum likelihood method:
As the observation noise is assumed to conform to the normal distribution, based on the measurement models (
5) and (
6),
where
and
are the covariance matrices of the feature recognition noise. Considering (
11) and (
12), the maximum likelihood estimation problem (
10) can be transformed into the following non-linear optimization of Mahalanobis norm of all measurement residuals:
where
and
are residuals of point and line measurements respectively.
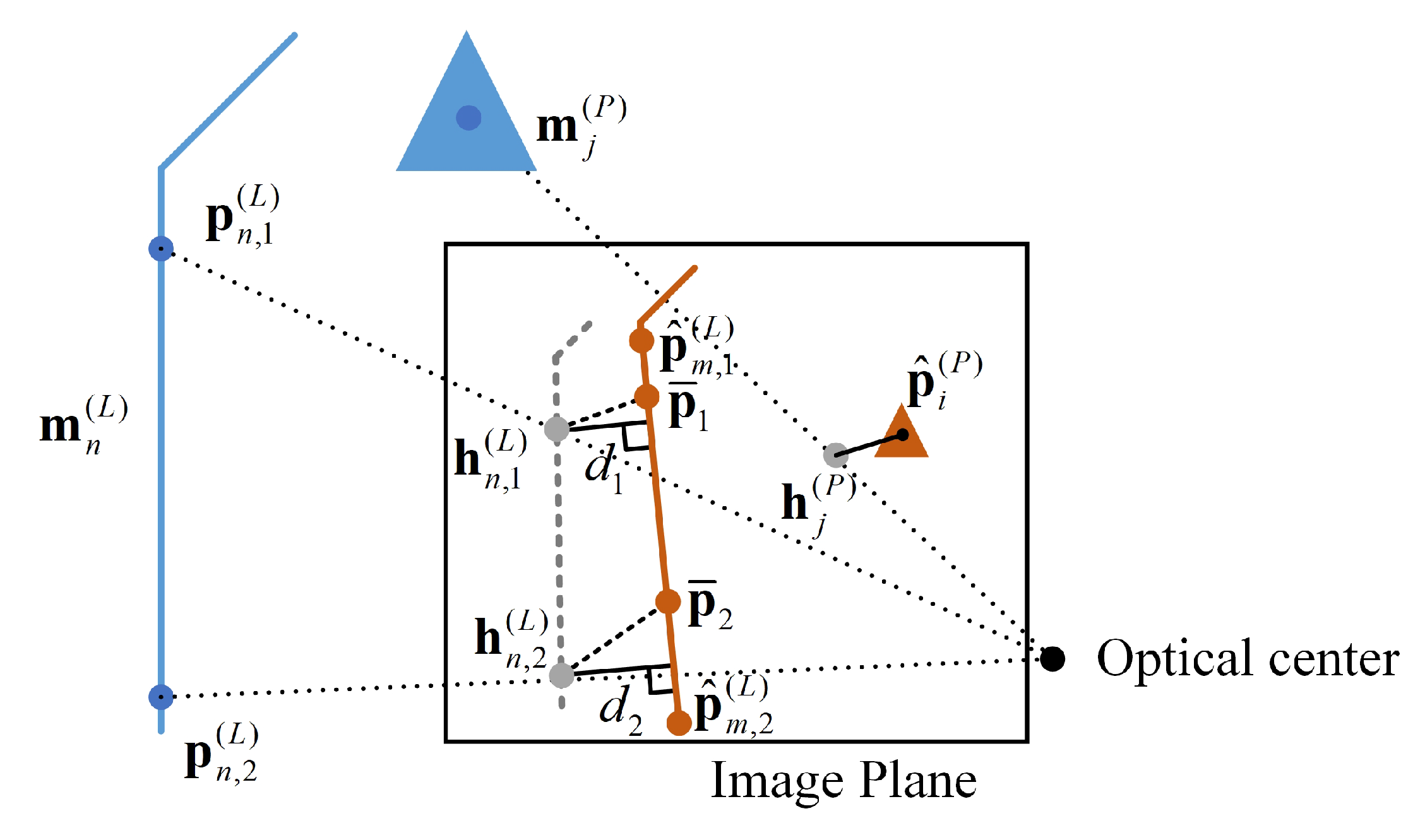
As is shown in
Figure 4, suppose the re-projected point of point landmark
is
, and the corresponding control point extracted from the image is point
(
), the residual of point features can then be expressed as
The line feature residuals are approximated due to the ambiguity in identifying the points in the image that corresponds to the two control points in the map. As is shown in
Figure 4, given a line landmark
, and its two control points in the map as
and
, their corresponding re-projected points on the image plane of camera pose
are
and
as a result. If the line feature is to be extracted and associated with this landmark (
) during image processing, the two resultant control points of the extracted feature would then be
and
. However, the true points on the extracted line is
and
. The residuals of points
and
are approximated by
, the distance from two re-projected map control points to the recognized line, where,
where
are the parameters of the line segment
, and the residual of line features is,
4.2. Data Association Method
The data association module solves the problem of correspondence between map landmarks and detected features in the observation model. Although the semantic information of the features recognized in vision is a very helpful association clue, repetitive visual semantic features, such as recurring road signs, still present tremendous difficulties in the existing semantic-based matching processes.
The novel data association method in this paper is an improved version of the RANSAC method. The basic idea is to randomly extract a subset of possible matching sets with the same semantics, and evaluate the quality of this subset. In basic RANSAC, the quality of subsets is measured by the number of inliers that match the model; that is, the number of matches within a certain threshold that can be obtained by projecting the position and attitude of the map to the pixel coordinate system. In the improved RANSAC method presented in this paper, the drift of the optimized position and pose away from the initial position which helps improve the robustness of the matching algorithms is deployed in conjunction with the basic RANSAC. To illustrate the association method, the algorithm pseudocode is provided in Algorithm 1.
In order to validate the algorithm, a possible correspondence set is randomly generated, and the line features with the same semantics are randomly matched within the set. Three line correspondences (which is the minimal set of correspondences to calculate the camera pose) are randomly sampled and plugged into the Equation (
14) for determining the camera position and pose, from which the landmarks in the map can be projected into the camera. If the distance between the landmark and the feature identified in the camera is less than the set threshold, it is considered as an inlier. In addition, the drift from the estimated pose to the initial guess is calculated. If the respective drift satisfies the conditions outlined in step 6 in Algorithm 1, the hypothesized correlation is added to the association hypothesis
.
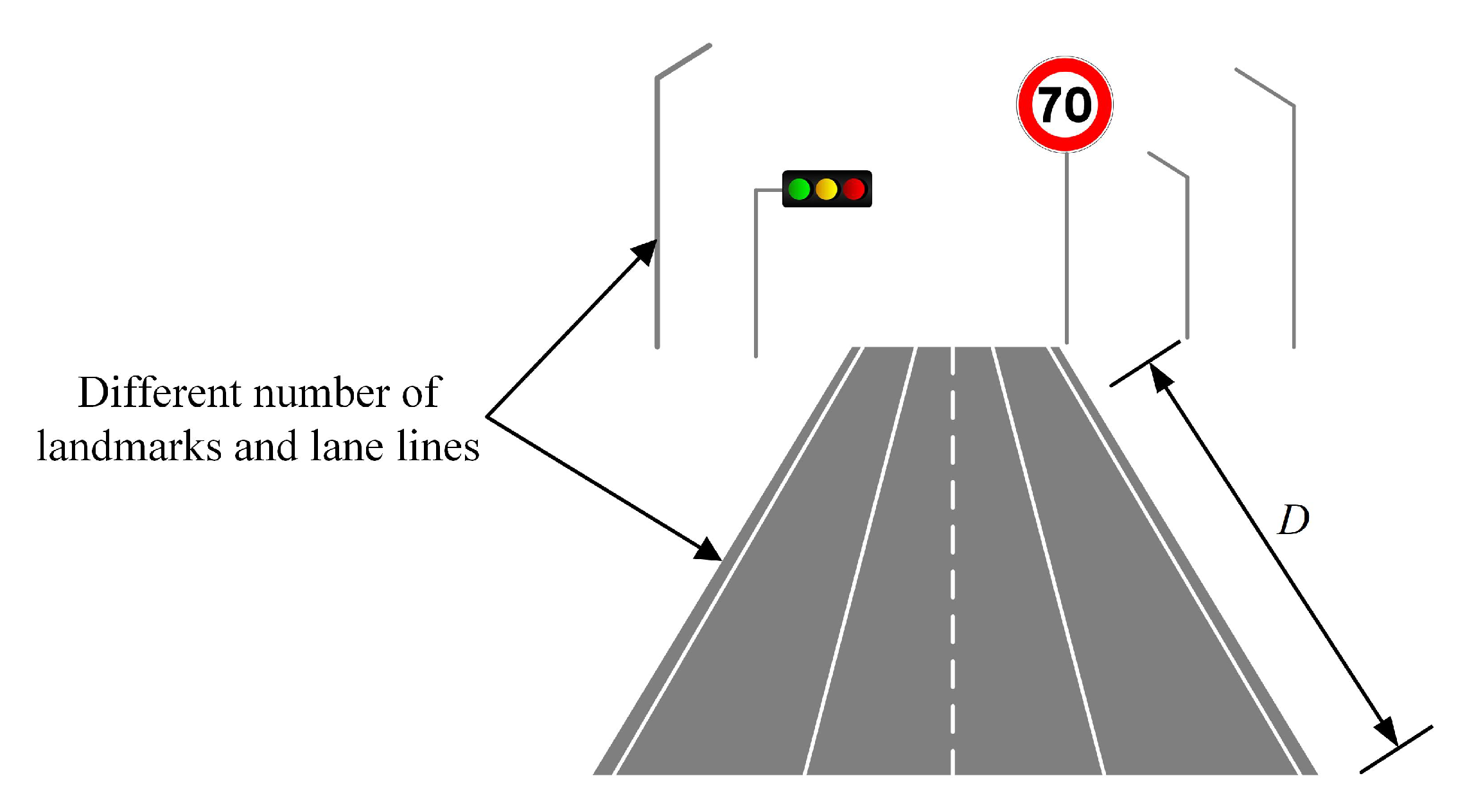
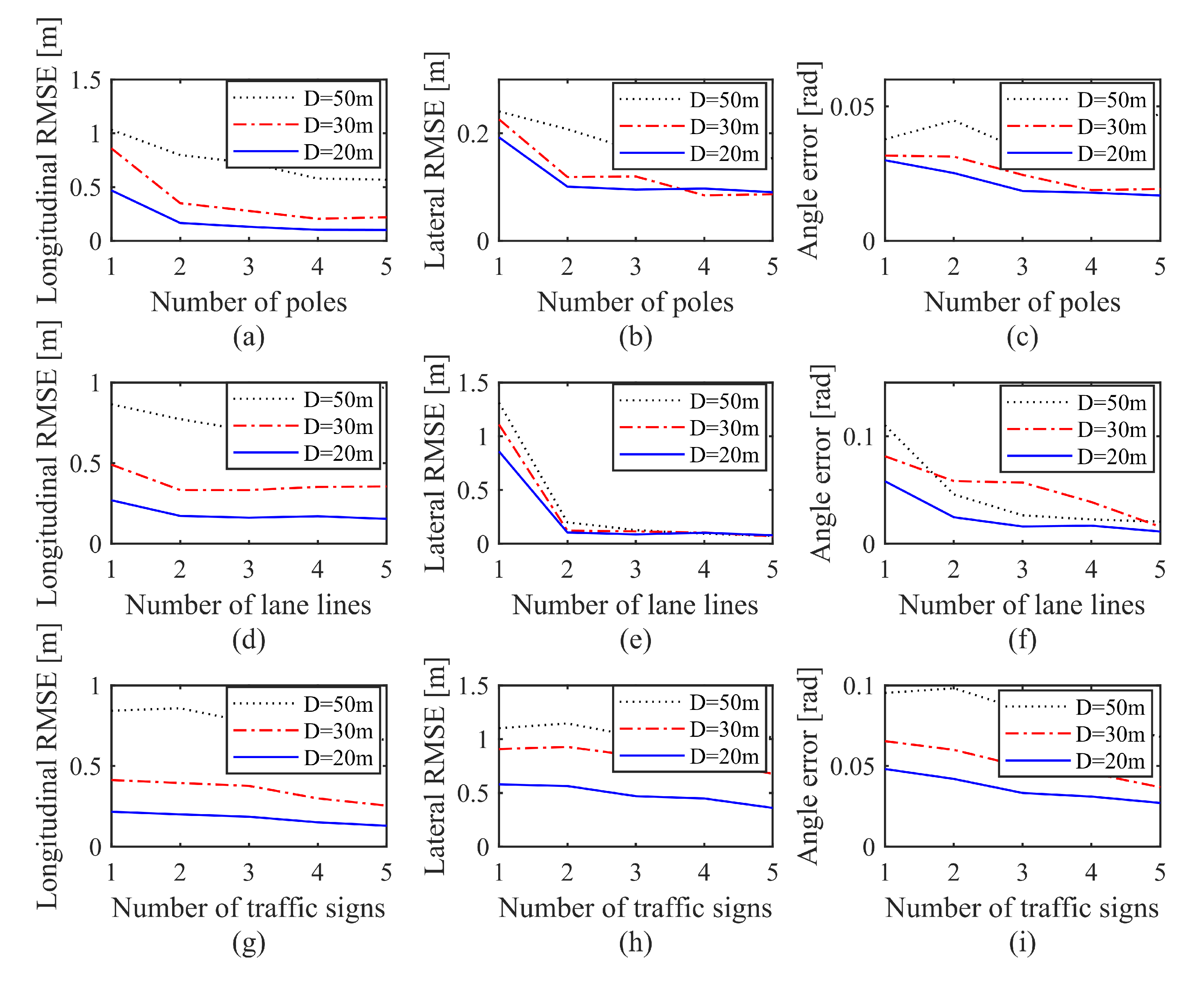
D is the distance threshold of the localization drift between the localization result and initial pose prediction, which is set according to the confidence of the initial guess of the camera pose. The initial pose the first frame is from the low-cost GNSS, and the subsequent ones are predicted based on the positioning result of the previous frame and the Visual Odometry. In our test,
D for the first frame is set to 6 m, while those for the subsequent frames are set to 1 m. The line 10 in Algorithm 1 shows how to find the best association from a bunch of association groups. Our approach is to calculate the number of association pairs in each group, that is, the size of the inliers, and find the one with the largest number of inliers as the final association.
| Algorithm 1 Data association |
| Input: |
| Initial camera position ; |
| HD Map ; |
| Extracted features ; |
| Output: |
| Correspondence |
| 1: |
| 2: for each do |
| 3: |
| 4: Calculate based on according to Equation (14). |
| 5: |
| 6: ifthen |
| 7: |
| 8: end if |
| 9: end for |
| 10: |
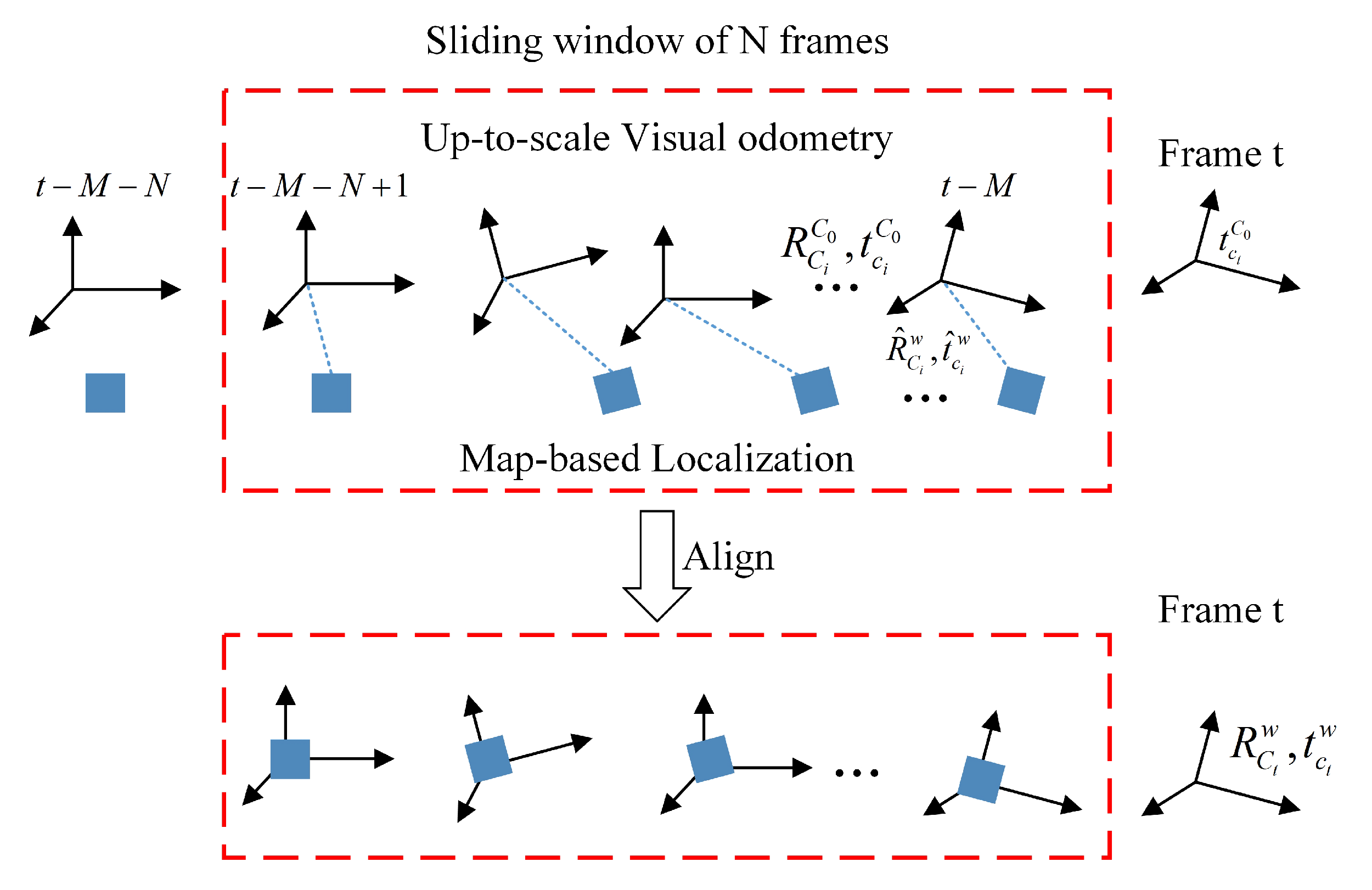
4.3. Integrating Frame-to-Frame Motion
The other branch in the MLVHM system diagram is designed to estimate the odometer readings of the camera using the ORB-SLAM algorithm [
23]. This estimation is integrated with the map-based localization results in order to improve the localization accuracy. As shown in
Figure 5, the translation vector and rotation matrix of each frame
is estimated relative to the first frame
as
and
. Note that due to the uncertainty of the monocular depth, the translation matrix is up-to-scale - that is to say, the scale of
differs from the true translation by a factor
s of one position. As the frame-to-frame motion coordinate system is different from that of the map-based localization result, the two coordinate systems must first be aligned via ORB-SLAM before the processed results can be projected on to the earth coordinate system. With a given rotation and translation matrix
and
, the translation vector of a frame
relative to its subsequent frame
can be transformed to the earth frame:
The rotation of frame
relative to its subsequent one
is:
The frame-to-frame alignment can be achieved by determining
and
. Considering the time-consuming nature of image semantic segmentation, the results of map localization generally differ from the current frame time, thus we assume that there is a delay of
M frames. Firstly, a sliding window of
N frames is built from
to
, where
is the latest frame from map-based localization. For the localization framework formed by our semantic segmentation algorithm, M is usually 6–8. Then, the constraints of each frame in the frame-to-frame motion and map-based localization is calculated within the sliding window, from which the optimization problem can be solved:
where the first term is the translation constraint (
18), and the second is the rotation (
19).
and
are respectively the translation vector and rotation matrix calculated based on the position and attitude angle estimation
derived from the map-based localization. Consequently, the rotation and translation matrix of frame t are
In practice, the size of the sliding window increases gradually from the beginning, but is capped at a selected length in order to reduce the computational complexity. This process realizes the fusion of local localization and absolute localization, and can also restore the scale of monocular SLAM.
5. Implementation
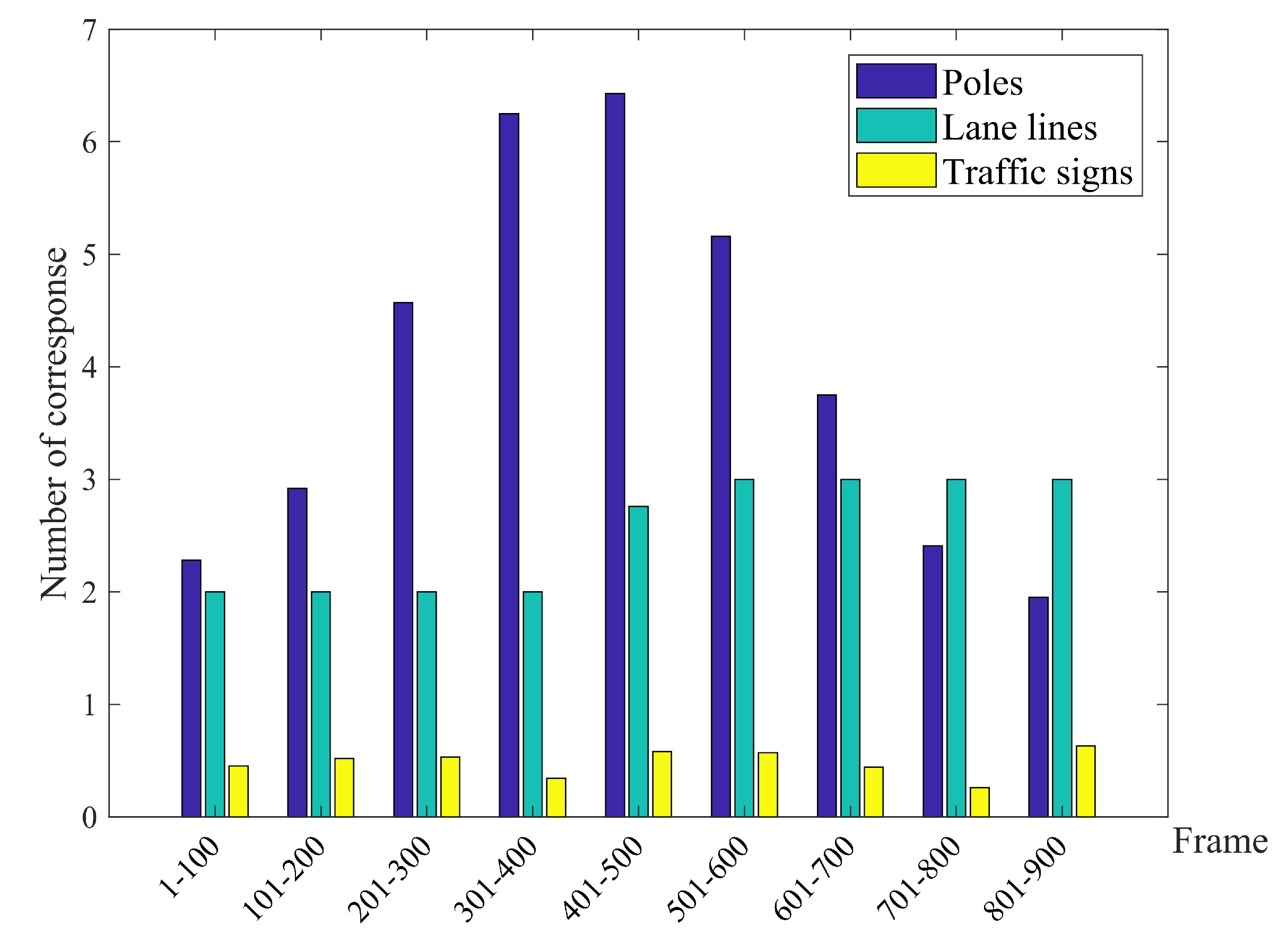
All traffic scenarios offer an abundance of point and line features that can serve for MLVHM as well as other similar algorithms developed in recent years. In this section, an example implementation of the MLVHM localization method is demonstrated using light poles and lane line as the line feature, and the center of traffic signs as the point feature. More specifically, this example deploys the method of extracting the semantic geometric features from the image, the method of extracting control points from the map, as well as the details of other algorithm applications. While MLVHM is designed to recognize a greater number of features than presented in this example, this paper will not focus on the feature recognition performance of MLVHM.
5.1. Semantic Geometry Feature Extraction
For line features, the lamp poles and lane lines are extracted such that the observation of line features can be rewritten as,
and for point features, the center of traffic signs are extracted accordingly,
In the process of feature recognition, PSPnet [
30] is deployed to semantically segment the image, thereby effectively dividing the pixels of pole-like objects and traffic signs. In order to identify lane lines, a more compact segmentation network is implemented based on the common encoder-decoder architecture, which down-samples the target image 16 times by four convolution layers and decodes with two up-sampling modules; the feature map is up-sample four times within the same process. The entropy loss is applied as the loss function [
35]. Because the training samples of segmentation network cover the data of road signs in various lighting, seasonal, and occluded conditions, compared with visual feature points, semantic vector features are more insensitive to seasonal changes and occlusion.
After getting the prediction map of each kind of semantics, we use a certain threshold of possibility to extract the pixels that are likely to belong to a certain kind, and then divide them into several blocks by region growing. After the prediction map of all the relevant semantics is acquired, a selected possibility threshold is applied to extract the pixels with high probabilities as the constituents of one of the key semantic features. These feature-critical pixels are then divided into several blocks by region growing. The line features are extracted by first filtering out blocks with an aspect ratio less than a defined threshold (i.e., not appearing line-like), followed by extracting the remaining lines from blocks by least-square fitting. For light poles, the bent portion at the top is neglected for computation simplicity. Sign-like features are fitted into point elements with its geometric center as the control point.
5.2. Utilizing the Compact Map
As mentioned previously, all the map data is organized and saved in OpenDrive format. The landmark geometric control points are extracted from the OpenDrive data and applied to the localization process. Roadside objects are represented by their respective bounding boxes.
Sign-like landmarks have their assigned control points at its geometric center, and are described as . A pole-like landmark (e.g., a light pole) often consists of a pole, a lamp holder, and some custom connection parts with irregular geometries. Only the straight pole portion of the pole-like landmarks are modeled with the two control points at the centers of the upper and lower bounding box surfaces, respectively denoted as and . Subsequently, the pole-like landmarks can be expressed as .
OpenDrive supports lane line representation with polylines. To take advantage of this, polylines with control points placed every 0.2m are used to model the lane lines as , where is the number of control points on the lane. These sampled control points are first filtered based on the selected areas in front of the vehicle, followed by line-fitting into a straight line. This way, the lane lines can be imported into the map model as solid line segments rather than a series of broken lines.
5.3. Optimization Method and Initial Values
The Levenberg-Marquardt method is deployed in MLVHM for solving the optimization problem (
14) and (
20). The residuals are minimized towards zero by iterations:
where
is determined by the Levenberg-Marquardt method;
is the cost function of each minimization problem;
is the Jacobian matrix of
with respect to the variable to be optimized.
For the initial localization, the current frame localization result is taken as the initial value based on the combination of the absolute localization and SLAM of the previous frames. If no historical frames are available upon algorithm startup, the initial pose is obtained from the low-cost GNSS.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}