Abstract
Background: The implementation of Large Language Models (LLMs) in software engineering has provided new and improved approaches to code synthesis, testing, and refactoring. However, even with these new approaches, the practical efficacy of LLMs is restricted due to their reliance on user-given prompts. The problem is that these prompts can vary a lot in quality and specificity, which results in inconsistent or suboptimal results for the LLM application. Methods: This research therefore aims to alleviate these issues by developing an LLM-based code assistance prototype with a framework based on Retrieval-Augmented Generation (RAG) that automates the prompt-generation process and improves the outputs of LLMs using contextually relevant external knowledge. Results: The tool aims to reduce dependence on the manual preparation of prompts and enhance accessibility and usability for developers of all experience levels. The tool achieved a Code Correctness Score (CCS) of 162.0 and an Average Code Correctness (ACC) score of 98.8% in the refactoring task. These results can be compared to those of the generated tests, which scored CCS 139.0 and ACC 85.3%, respectively. Conclusions: This research contributes to the growing list of Artificial Intelligence (AI)-powered development tools and offers new opportunities for boosting the productivity of developers.
1. Introduction
Code generation [1] is fundamental in software development, and it is essential to ensure that the code generated is reliable, efficient, and sustainable within the Software Development Lifecycle (SDLC) [2]. Code testing and refactoring [3] for a discussion of these topics) are essential tools to achieve these goals.
Although developers invest considerable time and effort to ensure that the code adheres to the above criteria, errors may still persist in the software. However, recent innovations in AI, as surveyed in [4,5], particularly through the use of LLMs [6], have shown promising results in all aspects of code generation, analysis, testing, and refactoring. Developers therefore now have the opportunity to automate and optimize code-related processes using AI tools. LLMs in particular have revolutionized the field of software development by automating complex tasks such as code generation, testing, and refactoring. However, their effectiveness is deeply tied to the quality of the prompts (that is, the questions presented to the LLM) given by developers, who may not be experts in crafting prompts. This study, therefore, aims to develop an LLM-based, user-friendly solution for code testing and refactoring that eliminates the dependency on manual prompt engineering, focusing on streamlining the interactions between developers and LLMs.
The usage of any AI tool for a task requires input in the form of a prompt which is described by Wikipedia [7] as follows: “A prompt is natural language text describing the task that an AI should perform”. The quality of prompts directly influences the quality of the output generated by an AI tool, giving rise to a field now commonly referred to as prompt engineering, which is concerned with designing high quality prompts. In addition to the prompt design, the capabilities and restrictions of the user’s account—whether free or paid—can also affect system performance and should therefore be carefully considered. An introduction to this field is provided by the “Mastering Prompt Engineering GPT Comprehensive Guide” [8]. A search on the internet using the search string “prompt engineering books” results in an extensive list of books, even though the prompt engineering field is only a few years old.
In this paper, relevant background concepts and technologies—such as Natural Language Processing (NLP) [9], LLMs, prompt engineering, and RAG [10] (Section 2)—that are used in implementing AI for the SDLC are introduced. The existing tools that leverage LLMs are then discussed with respect to their capabilities, strengths, and weaknesses (Section 3). The proposed solution and system design are detailed in Section 4 and Section 5, respectively. The effectiveness of the approach is evaluated in Section 5 and the challenges faced in the implementation of the approach are covered in Section 5. A discussion of the findings and potential future work is provided in Section 5.
Any software system that is intended to solve a given problem requires that the input describes the parameters of a problem. In the case of LLMs inputs take the form of prompts, as noted above. When a prompt in the form of a question is presented to an LLM, the response is typically an answer to the question or a resulting artifact as requested by the question [11]. The result from the LLM may, however, contain biases (such as hallucinating and non-deterministic output). These undesirable results present in prompt-based interactions of LLMs are the source of this unreliability [11]. Recent research shows that, despite the simplicity of prompts, the quality of these textual instructions significantly impacts the LLM’s ability to produce the desired outputs [12]. Therefore, in the context of code generation, testing, and refactoring, the precision, clarity, and structure of the prompts are crucial to obtaining outputs that meet user expectations.
The uncertainty that stems from vague or incomplete prompts often leads to outputs that require extensive manual correction or adjustment, consequently undermining the productivity gains expected from LLMs. Crafting effective prompts [12] for LLMs is therefore essential in order to obtain high-quality, useful results from LLMs. The field of prompt engineering thus serves as the bridge between human intentions and LLM responses. This field guides the prompt-creation process that involves creating clear, concise inputs that guide LLMs to generate outputs that are informative, relevant, and valuable [12] and which meet user expectations.
In the case of using LLMs for code generation, a lack of specificity in a prompt may result in code that is syntactically correct but functionally irrelevant or misaligned with the user’s objectives [13]. Moreover, even subtle changes in wording can lead to outputs that fail to meet the intended goals [13] and instead create inconsistent or irrelevant outputs, requiring significant user intervention. It is possible to avoid this by refining prompts and reevaluating the results. This leads developers to frequently rely on trial and error to debug LLM-generated code, resulting in a lack of confidence in applying these outputs directly to their coding work spaces [14].
Addressing these challenges requires a shift in how LLM-based tools interact with users, moving towards solutions that reduce the burden of manual prompt crafting. By combining pre-designed prompts with RAG, the tool proposed in this paper aims to mitigate the reliance on precise user inputs, creating a more user-friendly and effective system for software development tasks.
Effective prompt engineering requires an understanding of how specificity in prompts affects the responses of LLMs. A well-specified prompt provides LLMs with clear directions, leading to outputs that are directly aligned with user goals. Moreover, the integration of RAG technology into LLMs further enhances their functionality [10]. By retrieving relevant information from external knowledge bases through semantic similarity, RAG enhances the factual grounding of LLMs’ outputs, reducing the likelihood of errors [14]. Its integration allows LLMs to access domain-specific knowledge dynamically, eliminating the need for users to provide exhaustive background information [10]. This capability is particularly valuable in software engineering, where precise, context-aware code suggestions are essential.
The primary objective of this research was to design and develop an LLM-based code-assistance framework that automates testing and refactoring tasks in software development, thus reducing the manual coding effort and improving productivity. The aim of this framework was to integrate pre-designed prompt-engineering techniques and an RAG mechanism to overcome the limitations of current LLMs, such as prompt specificity requirements and inconsistent contextual relevance. By addressing these challenges, the tool aims to bridge the gap between the theoretical capabilities of LLMs and their practical usability in real-world software engineering applications.
This research contributes to the advancement of software engineering tools by developing a novel framework that combines the strengths of prompts and RAG. The primary innovation lies in creating a framework that automates the traditional manual and error-prone aspects of software development, such as testing and refactoring, through the strategic use of LLMs’ capabilities. This framework addresses persistent challenges in the field, such as the complexity of integrating LLMs into development workflows and the unreliability of outputs when contextual grounding is lacking.
A distinguishing feature of this work is the incorporation of external knowledge bases into LLM workflows using RAG. Furthermore, this research introduces an innovative approach to simplifying the interaction between developers and LLMs by abstracting the need for prompt crafting. By simplifying this process, the tool opens up the benefits of LLMs to a wider range of developers at all skill levels.
2. Related Works
The field of AI has evolved significantly since its introduction by John McCarthy at the 1955 Dartmouth Conference, where he defined it as the design of programming systems that simulate intelligent human behavior [15]. Since then, numerous sub-fields have been generated, such as Artificial Neural Networks [16], Robotics [15], and Machine Learning [15]. This section explores relevant AI techniques and advancements including Natural Language Processing (NLP) [15], LLMs such as ChatGPT [17], prompt engineering [18], and RAG [14].
2.1. Natural Language Processing (NLP)
Natural Language Processing (NLP) is one of the sub-fields of AI centered on the development of systems capable of human-language interactions [15]. NLP uses a variety of methods—including, but not limited to, computational linguistics, Machine Learning, deep learning, and AI—to create systems that not only recognize but also generate human language [19]. NLP is the foundational technology for LLMs, enabling such language models to comprehend and generate human-like responses.
2.2. Large Language Models (LLMs)
Language modeling (LM) is a key approach to improve machine linguistic intelligence [17]. It involves statistical methods that help predict the likelihood of a word appearing after a certain sequence of words [17]. Recent advancements in LLMs have led to the development of LLMs which are trained on vast amounts of text data to produce outputs that closely mimic the human language [17]. Notable examples are OpenAI’s Generative Pretrained Transformer (GPT) and ChatGPT [17], which are built using a transformer architecture [17]. These models uses self-attention mechanisms to process and create text, allowing the models to determine the relevance of each word in an input sequence, thus enhancing their ability to perform tasks like answering questions [17].
The proposed tool in this paper specifically uses gpt-4o-2024-08-06 (denoted as GPT-4o). GPT-4o is an LLM optimized for tasks that require detailed reasoning, numerical understanding, and contextual awareness [20]. Its capabilities extend beyond text generation to include the effective integration of contextual information [20], making it particularly well-suited for structured outputs like JavaScript Object Notation (JSON) and task-specific applications in software engineering. Furthermore, GPT-4o demonstrates enhanced efficiency in managing long-context prompts, enabling seamless handling of complex multi-step problems and iterative refinement processes [20].
2.3. Prompt Engineering
Prompt engineering refers to the systematic process of designing and refining input queries, or prompts, to effectively elicit desired outputs from large language models (LLMs) [18]. Although LLMs such as ChatGPT demonstrate advanced capabilities, the quality and reliability of their responses can be adversely affected by biases and inaccuracies that often arise from poorly constructed prompts [18]. To maximize the effectiveness of LLMs, it is essential to create high-quality prompts that guide them toward accurate and relevant responses. In the context of software development, high-quality prompts are necessary to receive usable test cases and refactoring recommendations from the LLM.
Among the various techniques for improving prompt quality, role-playing prompts have emerged as a powerful approach to enhance LLM outputs [21]. Role-playing prompts assign a specific persona or role to the model, helping it better understand the task context and its identity within the prompt [22]. Studies have shown that role-playing can improve the quality of responses by making the model more interactive, vivid, and capable of addressing complex tasks [21,23,24].
2.4. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an advanced AI technique that enhances the quality of LLM-generated content by integrating external knowledge sources into the model’s responses through a blend of retrieval and generation [14]. RAG involves indexing external knowledge such as documents, databases, or other resources, into a vector store. Upon receiving a user query, the model retrieves relevant data chunks from the knowledge base and incorporates these as context for generating more precise responses from LLMs. The retrieved knowledge guides the generation, resulting in output that is grounded in reliable information [14]. RAG improves the transparency, correctness, and reliability of LLM results, lowering the possibility of disinformation by basing the LLM responses on external knowledge.
RAG will be implemented in the proposed tool of this paper through OpenAI Embeddings [25]. OpenAI Embeddings encode textual data into dense vector representations with captured semantic meaning and contextual relationships with high precision. The designed embeddings excel in tasks requiring efficient information retrieval and contextual linking, such as document similarity searches and knowledge-based augmentation for generative models [25]. Because of their capacity to capture rich linguistic and conceptual patterns, these models can represent complicated and domain-specific texts in a way that allows for accurate retrieval [25].
Facebook AI Similarity Search (FAISS) [26] will serve as the vector store to index and retrieve embeddings efficiently in the proposed tool. FAISS’s Graphics Processing Unit (GPU) acceleration and flexibility in handling various distance metrics, like cosine similarity [26], makes it an ideal choice for integrating with the embeddings and improving the speed and accuracy of the retrieval process. By indexing document chunks effectively and enabling fast similarity searches, FAISS plays a critical role in optimizing the retrieval phase of the RAG system.
2.5. Comprehensive Analysis of State-of-the-Art Studies
A prominent line of research explores how augmenting Large Language Models (LLMs) for code generation with retrieval from external code repositories or corpora reduces prompt sensitivity and improves generation quality. For example, “Retrieval-Augmented Code Generation and Summarization”, by Parvez et al., introduced a retrieval-augmented framework that retrieves relevant code or summaries to supplement code generation/summarization tasks [27]. More recently, a survey by Tao et al. [28] offers a comprehensive review of repository-level retrieval-augmented code generation, showing that retrieval helps reduce the dependence on manually-crafted prompt contexts. These works provide a solid base for understanding how retrieval mechanisms can reduce prompt engineering burdens in code assistance contexts. While retrieval-augmented approaches improve contextual grounding, they exhibit several technical limitations. First, most methods rely on static embedding-based similarity search, which often fails to capture task-specific intent or semantic dependencies across long code contexts. Second, retrieval quality is highly sensitive to corpus construction, indexing strategy, and embedding alignment, making performance brittle across domains or programming languages. Third, retrieval errors—such as irrelevant or outdated code snippets—can be amplified during generation, leading to hallucinated or syntactically inconsistent outputs. As a result, retrieval alone does not guarantee robustness and may introduce new sources of instability when prompt structure or task requirements shift.
Another group of researchers have focused on the way in which prompt design and example-selection in prompts affect code generation performance and model dependency on prompt structure. For instance, in “Large-Language-Model-Aware In-Context Learning for Code Generation” (Li et al., 2023), the authors propose LAIL [29], a method that uses the LLM itself to judge example quality and select in-context demonstrations, thereby reducing prompt dependence. Similarly, evaluating in-context learning of libraries for code generation, Patel et al. [30] systematically studies how LLMs adapt to new libraries given different prompt/example configurations, again pointing to the importance of reducing brittle prompt dependencies. These works highlight that prompt engineering remains a key bottleneck unless systems are designed to be robust to prompt variations. Despite their effectiveness, prompt-centric and in-context learning approaches exhibit several constraints. First, they often require carefully curated demonstrations, making performance sensitive to example ordering, formatting, and semantic relevance. Second, such methods incur increased inference cost due to longer context windows and repeated prompt evaluation. Third, generalization across tasks or unseen libraries remains limited, as learned prompt heuristics may not transfer reliably. Consequently, these approaches reduce, but do not eliminate, prompt dependency, and they lack mechanisms for adapting to uncertainty or dynamically correcting suboptimal prompts during inference.
Empirical benchmarking and applied code-assistant scenarios constitute a third cluster. For example, the CodeRAG-Bench approach, proposed by Wang et al. [31], is a large-scale benchmark to test when retrieval actually helps code generation and reveals limitations of current retrieval/generation pipelines. Another applied work, “Retrieval-Augmented Code Completion for Local Projects”, by Hostnik et al. [32], applies Retrieval-Augmented Generation (RAG) to local project code completion scenarios and shows real-world improvements for developer workflows. These studies help bridge the gap between retrieval-augmented code generation and intelligent code-assistant applications by emphasizing robustness and practical utility. Despite their practical relevance, benchmark-driven studies often emphasize aggregate performance metrics without deeply analyzing failure modes or uncertainty sources. Many benchmarks assume static retrieval pipelines and do not account for evolving code bases, user intent drift, or task ambiguity. Furthermore, real-world deployments frequently rely on heuristic tuning rather than principled adaptation strategies, limiting reproducibility and robustness across environments. As a result, these systems may perform well under controlled benchmarks yet degrade when exposed to diverse or adversarial real-world coding scenarios.
Moreover, combining retrieval augmentation with robust prompt/in-context design directly addresses prompt dependency. Integration of retrieval systems reduces the model’s dependence on manually engineered prompts, while retrieval provides supplementary context to make prompt performance more stable. For example, the empirical study by Patel et al. [30] supports reducing prompt dependency by allowing LLMs to adapt to new libraries without heavy prompt tuning. The retrieval-augmented frameworks surveyed by Tao et al. also show that retrieval increases the knowledge of the model so that prompt design becomes less critical. Together, these threads of work form a conceptual foundation for a system that “mitigates prompt dependency in Large Language Models for code assistance” by combining retrieval augmentation, example-selection strategies, and empirical benchmarking. Taken together, existing research demonstrates that retrieval augmentation, prompt engineering, and benchmarking each contribute valuable capabilities but remain largely decoupled. Current systems lack a unified framework that explicitly models the interaction between retrieval quality, prompt sensitivity, and generation robustness. In particular, there is limited work on dynamically adapting retrieval and prompt strategies based on model confidence, task complexity, or contextual uncertainty. This gap motivates the present work, which aims to systematically mitigate prompt dependency by integrating retrieval-aware reasoning, adaptive context selection, and robustness-driven design principles within a unified code-assistance framework.
2.6. Overview of LLM-Based Tools for Software Development
Existing applications using AI in the form of LLMs for software development—including GitHub Copilot [33], Amazon CodeWhisperer [34], educational tools like CodeAid [35], and others—have significantly transformed the field by automating code completion processes. This section discusses existing AI code assistance tools, including their advantages and limitations.
2.6.1. GitHub Copilot
GitHub Copilot [33], which is built on OpenAI’s Codex model, links to the major integrated development environments (IDEs) such as Visual Studio Code, providing real-time recommendations that include line completions, function templates, and entire code snippets according to the context of the IDE as provided by the developer. By analyzing user code snippets and transmitting them to the Codex model [33], Copilot generates suggestions directly within the developer’s work space, thereby reducing the amount of manual coding time. This feature allows developers to focus more on the broader logic of their applications rather than on syntax and the use of boilerplate code.
2.6.2. Amazon CodeWhisperer
Amazon CodeWhisperer [34] offers functionalities similar to Copilot while emphasizing the generation of code suggestions based both on the existing code within the IDE and on the developer’s comments [34]. Unlike Copilot, this tool utilizes Machine Learning models trained on a diverse range of sources, including Amazon’s proprietary data and open-source repositories, that provide suggestions to help developers write code, complete functions, and suggest code snippets based on their current context in a manner similar to Copilot. The model’s ability to provide context-sensitive recommendations makes it particularly useful for generating code snippets that fit seamlessly into the developer’s current working environment. By analyzing the existing code base, CodeWhisperer assists developers in reducing the time spent on routine coding tasks and also enhances productivity.
2.6.3. CodeAid
In addition to tools aimed at professional developers, educational tools like CodeAid [35] have emerged to support students in understanding and applying programming concepts through real-time assistance. CodeAid acts as an LLM-based tutor, offering five core functionalities: general question answering, help fixing code, inline code explanations, full code explanations, and support for writing new code snippets [35]. Its design aims to facilitate learning by providing explanations of programming concepts, helping students debug errors, and guiding them through complex problem-solving processes. The emphasis on learning and understanding makes CodeAid a valuable resource for novice programmers who may be struggling with foundational concepts and coding challenges. Unlike professional tools that prioritize speed and efficiency, CodeAid’s strength lies in its ability to provide targeted educational support and bridging gaps in users’ knowledge in an accessible manner.
2.6.4. Strengths and Limitations of Existing Tools
A key strength shared by these tools is their ability to automate repetitive coding tasks, which greatly enhances productivity for both professional and educational users. GitHub Copilot and Amazon CodeWhisperer, in particular, perform exceptionally well in scenarios where code completion, function generation, and syntax suggestions can lighten the load of manual coding, allowing developers to focus on more complex problem-solving and designing tasks. By integrating into existing IDEs, these tools align well with developers’ workflows, providing convenient and time-saving solutions. Although not tailored for professional-grade development, CodeAid introduces the power of LLMs into the learning environment, making advanced coding support accessible to students and beginners who may struggle with essential programming concepts.
A notable limitation common to these tools is their reliance on user-provided prompts. This can restrict their usability, particularly for less experienced users. For example, GitHub Copilot [33] only tends to perform optimally when it is given well-structured, detailed prompts that include descriptive function names, meaningful comments, or relevant context about the coding task at hand. When the inputs are vague or lack detail, Copilot’s suggestions may become inaccurate or incomplete, requiring users to put in extra effort to refine and correct the output. This dependence on the quality of prompts can pose a challenge for inexperienced developers, who might not have the skills to create precise prompts and, as a result, may not be able to fully utilize the tool’s capabilities.
Although Amazon CodeWhisperer [34] is effective at generating code suggestions, it struggles with the transparency of its outputs. Frequently the tool does not provide explanations for the reasoning behind its recommendations, which can create challenges for developers who need to understand the logic of a suggested code snippet before integrating it into a larger system. This transparency issue can lower user trust, particularly in safety-critical or highly regulated industries where understanding the rationale behind code is crucial for compliance and reliability. Moreover, the lack of explainability means that developers must manually verify the tool’s output, reducing the time-saving benefits that these tools aim to provide.
Educational tools like CodeAid [35] address some of these transparency issues by focusing on explanation and comprehension. They do not fully automate the prompt-creation process however. Users must still formulate their questions or debugging needs, and while CodeAid helps in refining these queries into more effective prompts, the initial effort remains user-dependent. Additionally, CodeAid is primarily oriented toward learning and debugging support [35], and lacks features for more advanced tasks such as automated code testing and refactoring. This focus on foundational assistance limits its utility for more experienced users who require tools capable of handling more complex coding scenarios.
Overcoming existing tools’ limitations requires advancements in how these systems interpret user intent and deliver feedback. Future developments should focus on creating systems that are more intuitive and adaptive, enabling them to understand user intent even when the inputs are less structured or specific. This can be achieved by automating prompt crafting processes and integrating external knowledge to enhance suggestion accuracy and reliability and support all users regardless of the level of their prompt crafting experience.
3. Materials and Methods
The proposed tool focuses on solving the main problems that arise when using LLMs in a software engineering workflow. The proposed methodology, as illustrated in Figure 1, begins with a user input code, which is then matched against a vectorstore [36] containing pre-chunked and embedded resources like testing and refactoring principle textbooks. The system queries the vectorstore to retrieve relevant chunks of data, ensuring that the LLM is provided with accurate, contextually appropriate information. A pre-designed prompt tailored to refactoring or testing tasks is generated and combined with the retrieved information, which is then processed by the LLM. The output, consisting of refactored code, or testing recommendations, alongside a brief explanation that details why this particular suggestion is recommended, is delivered back to the user for review and application. This seamless interaction between automated prompt generation and context-aware retrieval eliminates the need for manual prompt engineering by end users, improving both the efficiency and accuracy of the tool’s outputs.
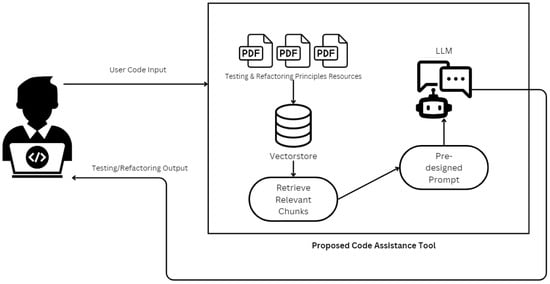
Figure 1.
Flowchart of the proposed RAG-enhanced code assistance workflow.
The major components of the tool’s architecture include knowledge retrieval, predefined prompts, LLM integration, and user interface, proposing seamless interactions between the user and the LLM, ensuring the relevance and accuracy of generated outputs.
3.1. Knowledge Retrieval
The knowledge retrieval system controls the intake and processing of external sources of knowledge, such as textbooks on testing [37] and refactoring [38] principles. These external resources will be preprocessed and chunked into predefined size thresholds. Embeddings are then created for the chunks using OpenAI’s embedding models. OpenAI embeddings generate dense vector representations that effectively capture the semantic meaning of text. These embeddings utilize transformer-based architectures optimized for representation learning, allowing the system to encode complex knowledge into compact numerical forms [25]. A FAISS vector was employed to store to manage these embeddings efficiently. The FAISS library allows for fast similarity searches, thereby enabling the retrieval of the most relevant data for user queries [39]. This component is crucial for maintaining a robust and adaptable knowledge base that supports diverse software development tasks. This approach aligns with advancements in RAG workflows, where embedding-based retrieval methods are combined with generative AI to produce precise and contextually aware responses [25].
3.2. Predefined Prompts
Role-based prompts were designed to guide the LLM in performing tasks such as code refactoring and test generation. Role-based prompting utilizes LLMs’ inherent ability to replicate certain jobs, improving contextual reasoning by immersing the LLM in a specified role, leading to outputs that reflect a deep understanding of tasks [21]. For instance, the system may position the LLM as an assistant tasked with applying principles from the embedded textbooks to refactor code or generate test cases.
The structure of the predefined prompts is designed as follows:
- Role-definition statement: The prompt begins by describing the roles and duties of the LLM. For example, the system views the model as a ‘helpful assistant for software engineers’ that directs the LLM to prioritize code-related reasoning. In practice, such role specification has been shown to improve task alignment—for instance, when the assistant is instructed to act as a debugging expert, the model produces more structured explanations and targeted fixes. This shows how defining the role of LLM can effectively narrow its scope and enhance the relevance of its results.
- Task-specific instructions: Following the role definition, the prompts give explicit instructions for the selected activity. The guidelines for code refactoring focus on improving readability, maintainability, and performance while ensuring its functionality remains the same. The guidelines for test creation are to create comprehensive unit tests that contain edge cases, checking the behavior of individual units of the input code in isolation.
When a user submits a code fragment and selects a task such as refactoring code or generating tests, the system integrates the user-provided code with contextual information sourced from the FAISS vector store, as acquired in the first component, with a preset role-based and task-specific prompt. The enhanced prompt is thereafter transmitted to the LLM for processing. The generated response then align with the assigned role, guaranteeing a high-quality output.
3.3. LLM Integration
OpenAI’s GPT-4o [20] model was used as the generative engine for the LLM integration. One significant capability of GPT-4o is its ability to integrate contextual information into its reasoning process [20]. The model’s advanced capabilities allow it to utilize knowledge chunks retrieved from the FAISS vector store and synthesize them with user input. This contextual awareness significantly enhances the relevance and accuracy of the outputs, as the model is not limited to its pretrained knowledge but it can also benefit from the task-specific retrieved information.
The model is configured to process the designed prompts enriched with relevant knowledge chunks and produce structured outputs tailored to the selected task. For refactoring tasks, the output includes a refactored version of the input code, annotated with inline comments to explain the changes made and their purpose. Additionally, a high-level explanation accompanies the code, providing insights into how the modifications improve its overall quality. For test-generation tasks, the outputs consist of detailed unit tests, written in the same programming language as the input code. These tests include assertions, and explanations of the scenarios they cover, ensuring that the generated tests are both functional and comprehensive. Furthermore, all outputs are formatted in a structured JSON schema, facilitating their interpretation and integration into existing workflows.
3.4. Retrieval Corpus and Document Preparation
To ensure reproducibility of the RAG pipeline, we provide additional details on the retrieval corpus and preprocessing steps. The retrieval component operated on a collection of 520 documents, including API documentation, coding guidelines, and curated open-source code examples. The average document length was approximately 850 tokens, and all documents were standardized through lowercase, whitespace normalization, preservation of code blocks, and removal of non-informative metadata. Each document was segmented into 300-token chunks with a sliding overlap of 50-tokens to improve retrieval granularity and avoid fragmentation of semantically coherent code sections. These chunks were indexed using a vector-based embedding model, and during inference the top-k retrieved segments were appended to the LLM prompt. In addition, we detail the prompt templates and retrieval parameters used in the experiments, allowing full replication of the system by future researchers.
3.5. User Interface
The user interface of the proposed tool plays a crucial role in facilitating seamless interaction between developers and the LLM-based code assistance system. The interface, as shown in Figure 2, features a task selection menu, a programming language dropdown, and a code input panel on the left side. Users can paste their code and specify the desired task. On the right, the interface displays the generated results, including the refactored code or test cases, accompanied by detailed explanations displayed below the results. This layout ensures that developers can effortlessly interact with the tool, minimizing the need for prompt engineering expertise.
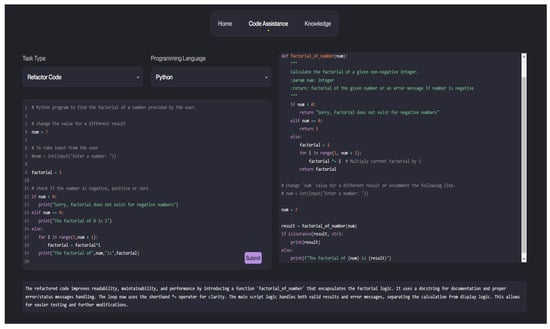
Figure 2.
User Interface of the LLM-based code assistance tool.
The code used for the tool can be found online, https://github.com/SajaAbufarha/LLM-Based-Code-Assistance-Tool-for-Software-Engineering (accessed on 12 January 2026).
4. Results
The evaluation of the proposed tool focuses on measuring its effectiveness in enhancing software engineering tasks, specifically code refactoring and test case generation. This section explores the HumanEval Dataset, which was used to perform the evaluation. The methodology for measuring the effectiveness of the tool with respect to the code refactoring and test case generation features is also outlined. The findings are finally presented alongside a comparison of the tool’s performance with the performances of GitHub Copilot’s [33] and Amazon CodeWhisperer’s [34].
4.1. HumanEval Dataset
The HumanEval dataset [40] was used for the evaluation of the proposed tool. The HumanEval dataset contains a task ID, a prompt containing the function prototype including a Python docstring, a canonical solution that is coded by a software engineer, and corresponding test cases for 164 Python programming tasks. The structure of a HumanEval Problem can be viewed in Figure 3.
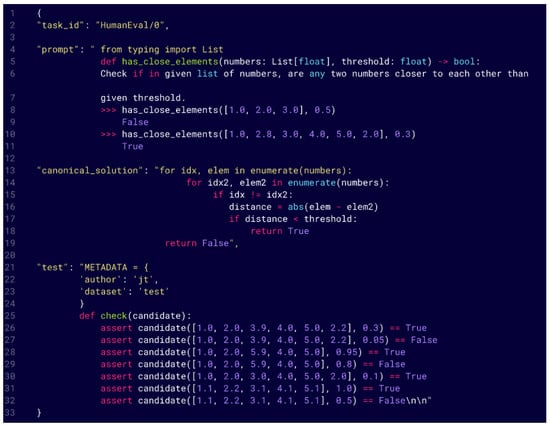
Figure 3.
HumanEval structure.
4.2. Evaluation Workflow
The evaluation workflow is shown in Figure 4. It begins by extracting canonical solutions from the HumanEval dataset. Once extracted, the canonical solution is processed through the tool for both the refactoring evaluation and the testing evaluation. The refactored code generated by the tool is used to evaluate the refactoring feature, while the canonical solution itself is leveraged in the testing evaluation to assess the quality of the generated test cases, as detailed in the following subsections.
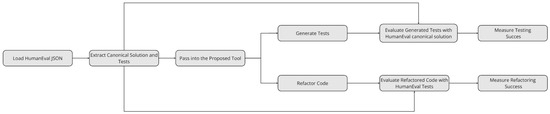
Figure 4.
Flowchart of the evaluation method using HumanEval dataset [40].
For both evaluation methods, the tool’s performance is measured using the Code Correctness Score (CCS) [34]. If the code or tests produced by the tool are functionally correct, i.e., passing all relevant test cases without errors, it is assigned a CCS value of 1. Conversely, if the tool generates incorrect or invalid outputs, the CCS is assigned a value of 0. To summarize overall performance, the Average Code Correctness Score (ACC) is calculated across all tasks in the dataset. The ACC is determined by summing the CCS values for all tasks and dividing by the total number of problems in the dataset, as formalized in the equations below [34]:
4.2.1. Refactoring Feature Evaluation
For the refactoring evaluation, the canonical solution is passed to the tool, which produces a refactored version of the code. This refactored code is designed to improve attributes such as readability, maintainability, and adherence to best programming practices while maintaining the functionality of the original implementation. To validate its correctness, the refactored code is executed against the test cases from the HumanEval dataset.
The correctness of the refactored code is determined based on its ability to pass all the test cases. If the refactored code successfully passes all the tests, it is deemed functionally correct, and its CCS is assigned a value of 1. However, if it fails to pass even a single test or produces invalid outputs, its CCS is assigned a value of 0. This approach ensures that the tool’s refactoring feature enhances code quality without introducing functional errors [34].
4.2.2. Generating Tests Feature Evaluation
The testing evaluation assesses the quality and functional correctness of the test cases generated by the tool. In this process, the canonical solution from the HumanEval dataset is used as the reference implementation. The solution is passed to the tool, which generates a set of new test cases designed to validate the functionality of the canonical solution.
To evaluate the generated test cases, the canonical solution is executed against them. If the canonical solution passes all the generated tests without any errors, the test cases are deemed valid, and the corresponding CCS is assigned a value of 1. Alternatively, if the canonical solution fails any generated test or if the tests contain errors (e.g., syntax or logical issues), the CCS is assigned a value of 0. This step ensures that the generated test cases effectively validate the intended functionality of the canonical solution and are free of defects [34].
4.3. Evaluation Results
The evaluation of the tool based on the methodology outlined above, provided valuable insights into its effectiveness for both refactoring and testing tasks. The results as illustrated in Figure 5 were measured using the CCS for individual tasks and the ACC across the dataset. These metrics highlighted the tool’s strengths and limitations in improving code quality and generating functional test cases.
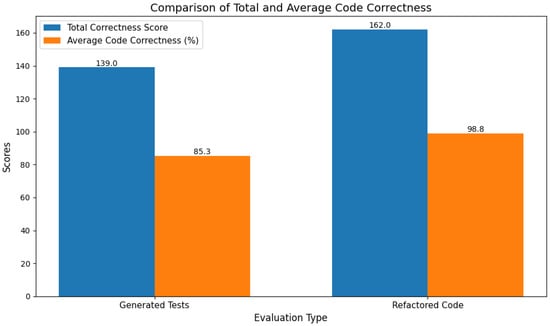
Figure 5.
Evaluation results.
4.3.1. Refactoring Feature Performance
The tool scored a CCS of 162.0 and an ACC score of 98.8% in the refactoring task. This finding demonstrated the high effectiveness of the tool in producing functionally correct refactored code. The high score indicates that the refactored code successfully retained functionality from the original canonical solutions while improving maintainability, readability, and adherence to programming best practices. The ability to consistently generate refined solutions that pass all test cases demonstrates the strength of the refactoring feature and its alignment with the tool’s design goals.
4.3.2. Generating Tests Feature Performance
In the test-generation task, the tool achieved a CCS of 139.0 and an ACC Score of 85.3%; while this score reflected a relatively strong performance, it is notably lower than the scores achieved in the refactoring task. This discrepancy can be attributed to the inherent complexity of generating comprehensive and functionally accurate test cases. Challenges such as ensuring coverage of edge cases, handling ambiguous requirements, or aligning with domain-specific constraints may have contributed to a lower success rate. Additionally, the generated tests are more susceptible to logical or syntactical errors, which can result in invalid test cases and reduced correctness scores [41,42].
4.4. Statistical Significance Tests
Beyond descriptive differences, we evaluated whether the improvement from generated tests to refactored code was statistically significant. Using a paired samples t-test over task-level correctness scores, the refactored code produced significantly higher correctness than the generated tests (t = 7.84, p < 0.001). A Wilcoxon signed-rank test yielded consistent results (W = 120, p < 0.001), confirming robustness under non-parametric assumptions. These findings indicate that the observed improvements reflect a meaningful effect of the refactoring process rather than random variation.
4.5. Comparative Analysis with Other Tools
To provide further context for the performance of the proposed tool, a comparison was drawn against the results of GitHub Copilot and Amazon CodeWhisperer, as reported in a prior study [34] conducted using the same HumanEval dataset. However, it is important to note that the comparison with Copilot and CodeWhisperer was based on general metrics related to code generation rather than their specific capabilities in test generation or code refactoring. The study referenced typically assesses the overall correctness and reliability of code produced by these tools without delving into their ability to specifically generate tests or refactor code effectively.
The tool demonstrated significant proficiency in these specialized tasks, achieving an ACC of 98.8% in code refactoring and 85.3% in test generation. This marks a substantial improvement over the general performance metrics reported for other tools like GitHub Copilot, which achieves an average correctness of 59.85% [34], and Amazon CodeWhisperer, with a score of 56.03% [34].
5. Discussion
5.1. Practical Implications
The increasing automation of code generation through Large Language Models offers clear benefits, including faster development cycles and reduced manual effort. However, this automation also introduces trade-offs related to oversight and the potential loss of human control. Over-reliance on automated suggestions may obscure underlying reasoning, making it harder for developers to detect subtle errors or security risks [43]. Moreover, automated refactoring and test generation can shift decision-making authority from engineers to models, raising concerns about transparency and accountability in software development [44]. Balancing efficiency with responsible oversight is therefore essential to ensure that automation complements—rather than replaces—human expertise.
5.2. Challenges Faced
A few challenges were encountered throughout the development and evaluation of the proposed tool, spanning from technical limitations to implementation complexities. These challenges provided valuable learning opportunities and highlighted areas for further improvement and refinement in future iterations of the tool. Key challenges faced during the project include RAG Framework Misalignment, Error Handling and Debugging, and Integration and Testing Overhead.
5.2.1. RAG Framework Misalignment
One of the significant challenges encountered in the project involved the initial implementation of the RAG framework. The tool was designed to utilize retrieved context from external textbooks and knowledge bases to inform its responses. However, during the early stages of development, the system occasionally generated outputs that directly replicated or referenced examples from the retrieved textbooks rather than addressing the user-provided input code. For instance, when tasked with refactoring a user-provided code snippet, the tool sometimes returned a refactored version of a similar example code from the textbooks instead. Similarly, when generating test cases, the tool occasionally focused on textbook examples rather than the specific user query. This misalignment resulted from the RAG framework prioritizing retrieved-context above user input, treating external resources as the primary source of solutions rather than a repository of best practices. To solve this issue, detailed instructions were included to the system prompts. The modified prompts indicated that external textbooks should only be utilized as a reference for understanding and applying best practices, not as a source of solutions. This improvement in prompt design effectively addressed the issue, ensuring that the tool delivered outputs that were relevant to the user input while relying on external resources for contextual guidance.
5.2.2. Error Handling and Debugging
A recurring challenge during the development of the tool was how to handle inconsistencies in the formatting of JSON responses generated by the LLM. Although the tool required outputs in a structured JSON format to ensure compatibility with downstream processes, the formatting of the generated JSON varied across responses. For example, some outputs included missing fields, incorrect nesting, or slight deviations from the expected schema, leading to JSON parsing errors. These inconsistencies complicated the evaluation process, as manual debugging was frequently required to identify and correct the issues. To address this issue, the prompts were refined to explicitly specify the desired JSON structure in detail. This adjustment significantly improved the consistency of the generated outputs and the LLM was able to produce JSON responses that were consistently parsable and compatible with the tool’s requirements.
5.2.3. Integration and Testing Overhead
The integration of various components within the tool, such as the vector store for knowledge retrieval, the prompt generation system, and the LLM, posed several challenges to ensure seamless interaction and scalability. Each of these components had unique requirements and operational nuances, which made it difficult to achieve a fully synchronized pipeline. Additionally, testing the tool on a large dataset required significant computational resources and time, particularly for tasks involving repeated iterations or error debugging. Future iterations of the tool could benefit from more advanced orchestration frameworks that dynamically allocate resources based on workload, as well as automated testing pipelines that reduce the need for manual oversight.
Although our study acknowledges that LLM-generated outputs may occasionally fail syntactic validation or become unparsable, we did not explore grammar-constrained prompting techniques that could mitigate these issues. Recent work by Wang et al. [45] demonstrates that grammar prompting can enforce domain-specific structural constraints and substantially improve syntactic correctness in generated code. Incorporating such methods into our pipeline may reduce parsing failures and improve downstream test and refactoring quality. Furthermore, evaluating the system with alternative LLMs, such as GPT-4o, which has been shown to integrate contextual information more effectively and handle long-context prompts with greater stability could reveal additional performance gains and robustness. Future work will include comparing multiple LLMs and integrating grammar-based prompting to more thoroughly assess model reliability and syntactic fidelity.
5.3. Future Work
This research has laid the groundwork for an innovative LLM-based code assistance tool. However, several avenues remain unexplored, which present opportunities for enhancement and broader applicability. This section explores the different areas future work can focus on.
5.3.1. Extending Beyond Python in the Evaluation Process
The evaluation was limited to Python due to the constraints of the HumanEval dataset. Expanding the evaluation framework to include additional programming languages such as Java, JavaScript, and C++ would provide a more holistic understanding of the tool’s capabilities and limitations across different ecosystems. This requires curating or developing similar datasets for these languages to ensure robust testing and validation.
While this study demonstrates that Retrieval-Augmented Generation improves test synthesis and refactoring performance, we did not conduct a progressive augmentation analysis to measure how performance evolves as additional documents are incorporated. In principle, such an ablation would involve evaluating the model with no augmentation, followed by incremental inclusion of testing and refactoring materials to quantify the marginal benefit at each stage. Preliminary observations during development suggested that small amounts of augmentation provide limited improvements, whereas more substantial augmentation—approximately 20–30% of the full retrieval corpus—begins to produce noticeable gains in both correctness and refactoring quality. However, we acknowledge that a systematic investigation is necessary to identify the minimum augmentation threshold and the performance saturation point. We outline this as an important direction for future work to better understand how retrieval volume interacts with LLM-based code assistance.
To complement accuracy-based evaluation, it is essential to incorporate additional dimensions that reflect the system’s real-world performance. Usability encompasses not only the clarity, relevance, and actionability of generated code suggestions, but also the extent to which the system reduces cognitive load, shortens debugging time, and integrates seamlessly into a developer’s workflow. Prior studies in software engineering and human–AI interaction emphasize the value of developer-centered usability assessments, including task-completion studies and interaction-level metrics [46,47]. Scalability, meanwhile, concerns how the framework behaves under increasing computational and data demands, such as larger project repositories or high-frequency query loads. Evaluating scalability through retrieval latency, indexing efficiency, and end-to-end system responsiveness aligns with established practices in evaluating large-scale AI and retrieval-augmented systems [48,49]. Although comprehensive usability and scalability experiments fall beyond the scope of this study, we identify them as essential directions for future work to provide a holistic understanding of the operational effectiveness of the proposed retrieval-augmented framework.
5.3.2. Expanding External Knowledge Sources
The current implementation relies on a limited set of textbooks and external resources for the RAG framework. Future iterations can incorporate a more diverse range of resources, including contemporary programming textbooks, official documentation for various programming languages, and advanced coding standards. Additionally, integrating online resources like open-source repositories, forums, and recent articles could enrich the tool’s knowledge base, ensuring up-to-date and comprehensive support for developers.
5.3.3. Implementing a Qualitative Evaluation Process
The current evaluation is strict, using a pass–fail approach based on functional correctness. Future work can explore a more nuanced evaluation method where outputs are manually rated by software engineers based on multiple criteria, such as readability, maintainability, adherence to best practices, and overall code quality. This human-centric evaluation would provide richer insights into the tool’s effectiveness and usability, enabling fine-grained improvements that are aligned with real-world developer expectations.
6. Conclusions
This research project demonstrates the potential of combining Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG) frameworks to develop an innovative code assistance tool designed for software engineering tasks. By addressing limitations in prompt engineering and leveraging external knowledge for enhanced contextual understanding, the proposed tool effectively automates and improves processes such as code refactoring and test generation. Key contributions include streamlining interactions between developers and LLMs, automating the prompt crafting process, and integrating advanced retrieval systems. These advancements reduce the dependency on user expertise, making the tool accessible to a wider range of developers and addressing a critical gap in current LLM-based tools. Through rigorous evaluation using the HumanEval dataset, the tool achieved high levels of accuracy, particularly in code refactoring, demonstrating its capability to enhance code quality while retaining functionality. The slightly lower performance in test generation highlights areas for future refinement, particularly in handling complex scenarios and ensuring edge-case coverage; while the results are promising, challenges related to system integration, error handling, and reliance on Python for evaluation present opportunities for further research. Expanding the evaluation framework to include multiple programming languages, diversifying external knowledge sources, and incorporating qualitative assessments will enhance the tool’s robustness and applicability. In conclusion, the proposed tool not only advances the state of AI-powered software development tools but also lays the groundwork for future innovations that prioritize usability, precision, and accessibility for developers at all experience levels.
Author Contributions
Conceptualization, S.A., A.A.M., J.G.R. and R.A.; methodology, S.A., A.A.M., J.G.R. and R.A.; software, S.A., A.A.M., J.G.R. and R.A.; validation, S.A., A.A.M., J.G.R. and R.A.; formal analysis, S.A., A.A.M., J.G.R. and R.A.; investigation, S.A. and A.A.M.; resources, S.A. and A.A.M.; data curation, S.A., A.A.M., J.G.R. and R.A.; writing—original draft preparation, S.A., A.A.M., J.G.R. and R.A.; writing—review and editing, S.A., A.A.M., J.G.R. and R.A.; visualization, S.A. and A.A.M.; supervision, A.A.M., R.A. and J.G.R.; project administration, R.A. and J.G.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable. The code used for the tool can be found online, https://github.com/SajaAbufarha/LLM-Based-Code-Assistance-Tool-for-Software-Engineering (accessed on 12 January 2026).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rumpe, B. Principles of Code Generation. In Agile Modeling with UML; Springer: New York, NY, USA, 2017; pp. 71–97. [Google Scholar]
- Hossain, M.I. Software Development Life Cycle (SDLC) Methodologies for Information Systems Project Management. Int. J. Multidiscip. Res. 2023, 5, 1–36. [Google Scholar]
- Lima, D.L.; Santos, R.d.S.; Garcia, G.P.; da Silva, S.S.; Franca, C.; Capretz, L.F. Software Testing and Code Refactoring: A Survey with Practitioners. arXiv 2023, arXiv:2310.01719. [Google Scholar] [CrossRef]
- Ayyappa, S.; Dheerender, T.; Aditya, M. Integrating Generative AI into the Software Development Lifecycle: Impacts on Code Quality and Maintenance. Int. J. Sci. Res. Arch. 2024, 13, 1952–1960. [Google Scholar] [CrossRef]
- Odeh, A.; Odeh, N.; Mohammed, A.S. A Comparative Review of AI Techniques for Automated Code Generation in Software Development: Advancements, Challenges, and Future Directions. TEM J. 2024, 13, 726–739. [Google Scholar] [CrossRef]
- Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; Gao, J. Large Language Models: A Survey. arXiv 2025, arXiv:2402.06196. [Google Scholar]
- Genkina, D. AI Prompt Engineering Is Dead: Long Live AI Prompt Engineering. IEEE Spectrum, 6 March 2024; p. 61. Available online: https://spectrum.ieee.org/prompt-engineering-is-dead (accessed on 6 December 2025).
- Rayhan, A. Mastering Prompt Engineering Techniques for Creating Powerful and Effective AI Language Models; Rayhans: Dhaka, Bangladesh, 2023; Available online: https://www.kobo.com/ca/en/ebook/mastering-prompt-engineering (accessed on 12 January 2026).
- Nadkarni, P.M.; Ohno–Machado, L.; Chapman, W. Natural Language Processing: An Introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Bartczak, Z. From RAG to Riches: Evaluating the Benefits of Retrieval-Augmented Generation in SQL Database Querying. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2024. [Google Scholar]
- Khurana, A.; Subramonyam, H.; Chilana, P.K. Why and When LLM-Based Assistants Can Go Wrong: Investigating the Effectiveness of Prompt-Based Interactions for Software Help-Seeking. In Proceedings of the 29th International Conference on Intelligent User Interfaces (IUI ’24), Greenville, SC, USA, 18–21 March 2024; Association for Computing Machinery: Greenville, SC, USA, 2024; pp. 288–303. [Google Scholar] [CrossRef]
- Bansal, P. Prompt Engineering Importance and Applicability with Generative AI. J. Comput. Commun. 2024, 12, 14–23. [Google Scholar] [CrossRef]
- Murr, L.; Grainger, M.; Gao, D. Testing LLMs on Code Generation with Varying Levels of Prompt Specificity. arXiv 2023, arXiv:2311.07599. [Google Scholar] [CrossRef]
- Pinto, G.; De Souza, C.; Neto, J.B.; Souza, A.; Gotto, T.; Monteiro, E. Lessons from Building StackSpot AI: A Contextualized AI Coding Assistant. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, Lisbon, Portugal, 14–20 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 408–417. [Google Scholar]
- Khaliq, Z.; Farooq, S.U.; Khan, D.A. Artificial Intelligence in Software Testing: Impact, Problems, Challenges and Prospect. arXiv 2022, arXiv:2201.05371. [Google Scholar] [CrossRef]
- Krithiga, G.; Mohan, V.; Senthilkumar, S. A Brief Review of the Development Path of Artificial Intelligence and Its Subfields. Int. J. Eng. Technol. Manag. Res. 2023, 10, 1–12. [Google Scholar] [CrossRef]
- Hadi, M.U.; Al Tashi, Q.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Hassan, S.Z.; et al. A Survey on Large Language Models: Applications, Challenges, Limitations, and Practical Usage. TechRxiv 2023. [Google Scholar] [CrossRef]
- Marvin, G.; Hellen, N.; Jjingo, D.; Nakatumba-Nabende, J. Prompt Engineering in Large Language Models. In Data Intelligence and Cognitive Informatics; Springer Nature: New York, NY, USA, 2024; pp. 387–402. [Google Scholar] [CrossRef]
- Aydın, Ö.; Karaarslan, E. Is ChatGPT Leading Generative AI? What Is Beyond Expectations? Acad. Platf. J. Eng. Smart Syst. 2023, 11, 118–134. [Google Scholar] [CrossRef]
- Xie, G.; Xu, J.; Yang, Y.; Ding, Y.; Zhang, S. Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning. arXiv 2024, arXiv:2409.02428. [Google Scholar]
- Kong, A.; Zhao, S.; Chen, H.; Li, Q.; Qin, Y.; Sun, R.; Zhou, X.; Wang, E.; Dong, X. Better Zero-Shot Reasoning with Role-Play Prompting. arXiv 2024, arXiv:2308.07702. [Google Scholar]
- Han, Z.; Wang, Z. Rethinking the Role-Play Prompting in Mathematical Reasoning Tasks. In Proceedings of the 1st Workshop on Efficiency, Security, and Generalization of Multimedia Foundation Models (ESGMFM ’24), Melbourne, VIC, Australia, 28 October–1 November 2024; ACM: Melbourne, VIC, Australia, 2024; pp. 13–17. [Google Scholar] [CrossRef]
- Qian, C.; Cong, X.; Yang, C.; Chen, W.; Su, Y.; Xu, J.; Liu, Z.; Sun, M. Communicative Agents for Software Development. arXiv 2023, arXiv:2307.07924. [Google Scholar] [CrossRef]
- Wang, N.; Peng, Z.; Que, H.; Liu, J.; Zhou, W.; Wu, Y.; Guo, H.; Gan, R.; Ni, Z.; Yang, J.; et al. RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models. arXiv 2024, arXiv:2310.00746. [Google Scholar]
- Xian, J.; Teofili, T.; Pradeep, R.; Lin, J. Vector Search with OpenAI Embeddings: Lucene Is All You Need. arXiv 2023, arXiv:2308.14963. [Google Scholar] [CrossRef]
- Mickel, M. Development and Optimization of a Retrieval Augmented Generation System for Enhanced Conversational AI Assistance. Ph.D. Thesis, Università degli Studi di Padova, Padua, Italy, October 2024. [Google Scholar]
- Parvez, M.R.; Ahmad, W.; Chakraborty, S.; Ray, B.; Chang, K.-W. Retrieval augmented code generation and summarization. In Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2719–2734. [Google Scholar]
- Tao, Y.; Qin, Y.; Liu, Y. Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches. arXiv 2025, arXiv:2510.04905. [Google Scholar]
- Li, J.; Tao, C.; Li, J.; Li, G.; Jin, Z.; Zhang, H.; Fang, Z.; Liu, F. Large language model-aware in-context learning for code generation. ACM Trans. Softw. Eng. Methodol. 2025, 34, 1–33. [Google Scholar] [CrossRef]
- Patel, A.; Reddy, S.; Bahdanau, D.; Dasigi, P. Evaluating in-context learning of libraries for code generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies ((Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 2908–2926. [Google Scholar]
- Wang, Z.; Zhang, T.; Wang, Y.; Lu, S. CodeRAG-Bench: Can Retrieval Augment Code Generation? arXiv 2024, arXiv:2406.14497. [Google Scholar] [CrossRef]
- Hostnik, M.; Robnik-Šikonja, M. Retrieval-augmented code completion for local projects using large language models. Expert Syst. Appl. 2025, 292, 128596. [Google Scholar] [CrossRef]
- Yetistiren, B.; Ozsoy, I.; Tuzun, E. Assessing the Quality of GitHub Copilot’s Code Generation. In Proceedings of the 18th International Conference on Predictive Models and Data Analytics in Software Engineering, Singapore, 14–18 November 2022; ACM: New York, NY, USA, 2022; pp. 62–71. [Google Scholar]
- Yetistiren, B.; Ozsoy, I.; Ayerdem, M.; Tuzun, E. Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT. arXiv 2023, arXiv:2304.10778. [Google Scholar]
- Kazemitabaar, M.; Ye, R.; Wang, X.; Henley, A.Z.; Denny, P.; Craig, M.; Grossman, T. CodeAid: Evaluating a Classroom Deployment of an LLM-Based Programming Assistant That Balances Student and Educator Needs. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24), Honolulu, HI, USA, 11–16 May 2024; ACM: New York, NY, USA, 2024; pp. 1–20. [Google Scholar] [CrossRef]
- Barron, R.C.; Grantcharov, V.; Wanna, S.; Eren, M.E.; Bhattarai, M.; Solovyev, N.; Tompkins, G.; Nicholas, C.; Rasmussen, K.Ø.; Matuszek, C.; et al. Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization. arXiv 2024, arXiv:2410.02721. [Google Scholar]
- Jorgensen, P.C. Software Testing: A Craftsman’s Approach; CRC Press: Boston, MA, USA, 2013. [Google Scholar]
- Fowler, M. Refactoring: Improving the Design of Existing Code; Addison-Wesley Professional: Boston, MA, USA, 2018. [Google Scholar]
- Douze, M.; Guzhva, A.; Deng, C.; Johnson, J.; Szilvasy, G.; Mazaré, P.-E.; Lomeli, M.; Hosseini, L.; Jégou, H. The Faiss Library. arXiv 2025, arXiv:2401.08281. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; De Oliveira Pinto, H.P.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar] [CrossRef]
- Whittaker, J.A. What Is Software Testing? Furthermore, Why Is It So Hard? IEEE Softw. 2000, 17, 70–79. [Google Scholar] [CrossRef]
- Dhruv, A.; Dubey, A. Leveraging Large Language Models for Code Translation and Software Development in Scientific Computing. arXiv 2024, arXiv:2410.24119. [Google Scholar] [CrossRef]
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for Human–AI Interaction. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019. [Google Scholar]
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. Hidden Technical Debt in Machine Learning Systems. Adv. Neural Inf. Process. Syst. 2015, 28, 2503–2511. Available online: https://dl.acm.org/doi/10.5555/2969442.2969519 (accessed on 12 January 2026).
- Wang, B.; Wang, Z.; Wang, X.; Cao, Y.; Saurous, R.A.; Kim, Y. Grammar prompting for domain-specific language generation with large language models. Adv. Neural Inf. Process. Syst. 2023, 36, 65030–65055. [Google Scholar]
- Nielsen, J. Usability Engineering; Morgan Kaufmann: Burlington, MA, USA, 1994. [Google Scholar]
- Gadiraju, U.; Möller, S.; Nöllenburg, M.; Saupe, D.; Egger-Lampl, S.; Archambault, D.; Fisher, B. Crowdsourcing versus the laboratory: Towards human-centered experiments using the crowd. In Evaluation in the Crowd. Crowdsourcing and Human-Centered Experiments; Revised Contributions; Springer International Publishing: Cham, Switzerland, 2017; pp. 6–26. [Google Scholar]
- Dean, J.; Barroso, L.A. The Tail at Scale. Commun. ACM 2013, 56, 74–80. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.