
Predicting the Window Opening State in an Office to Improve Indoor Air Quality †

Abstract
:1. Introduction
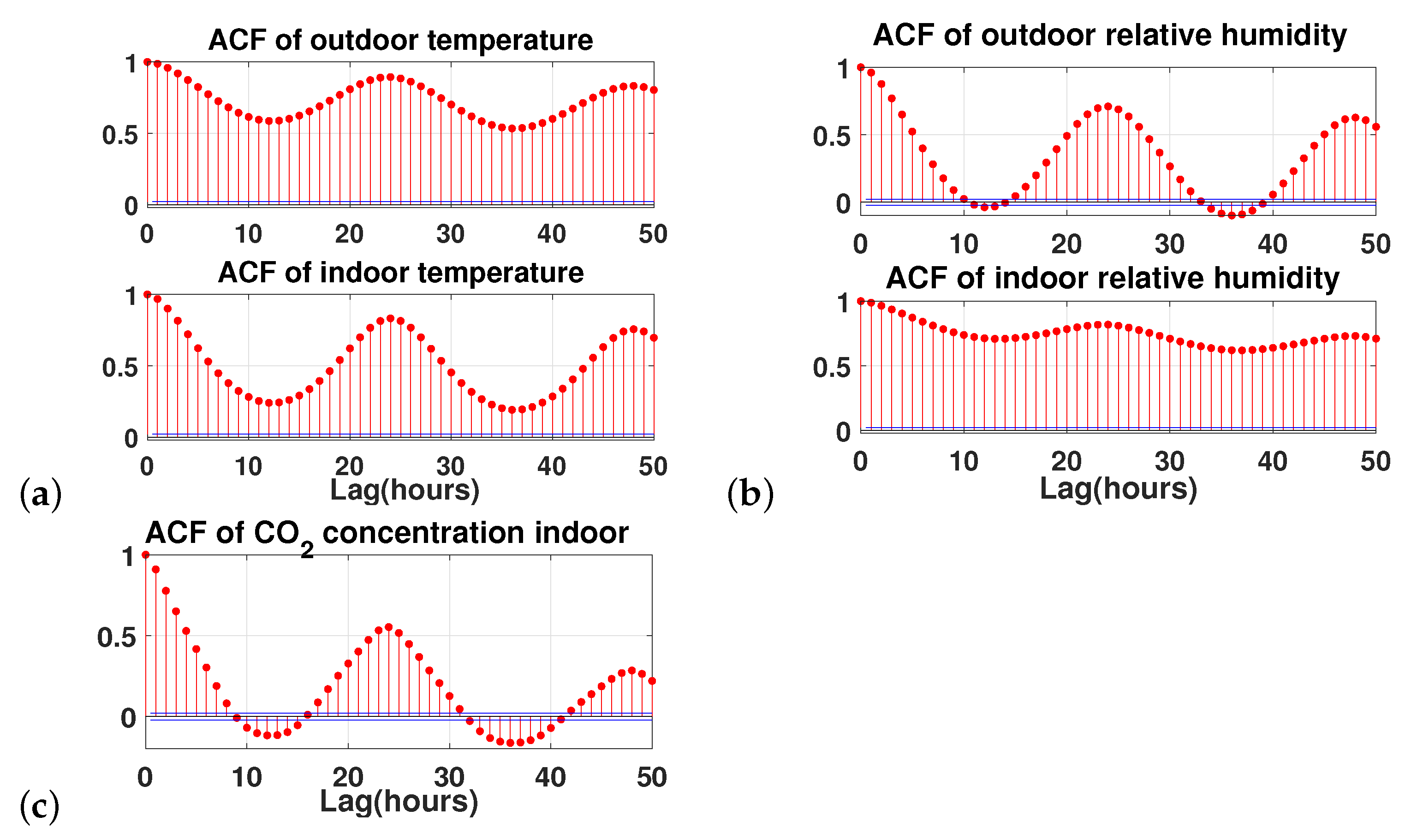
2. Methodology
2.1. Study Case and Parameters Selection
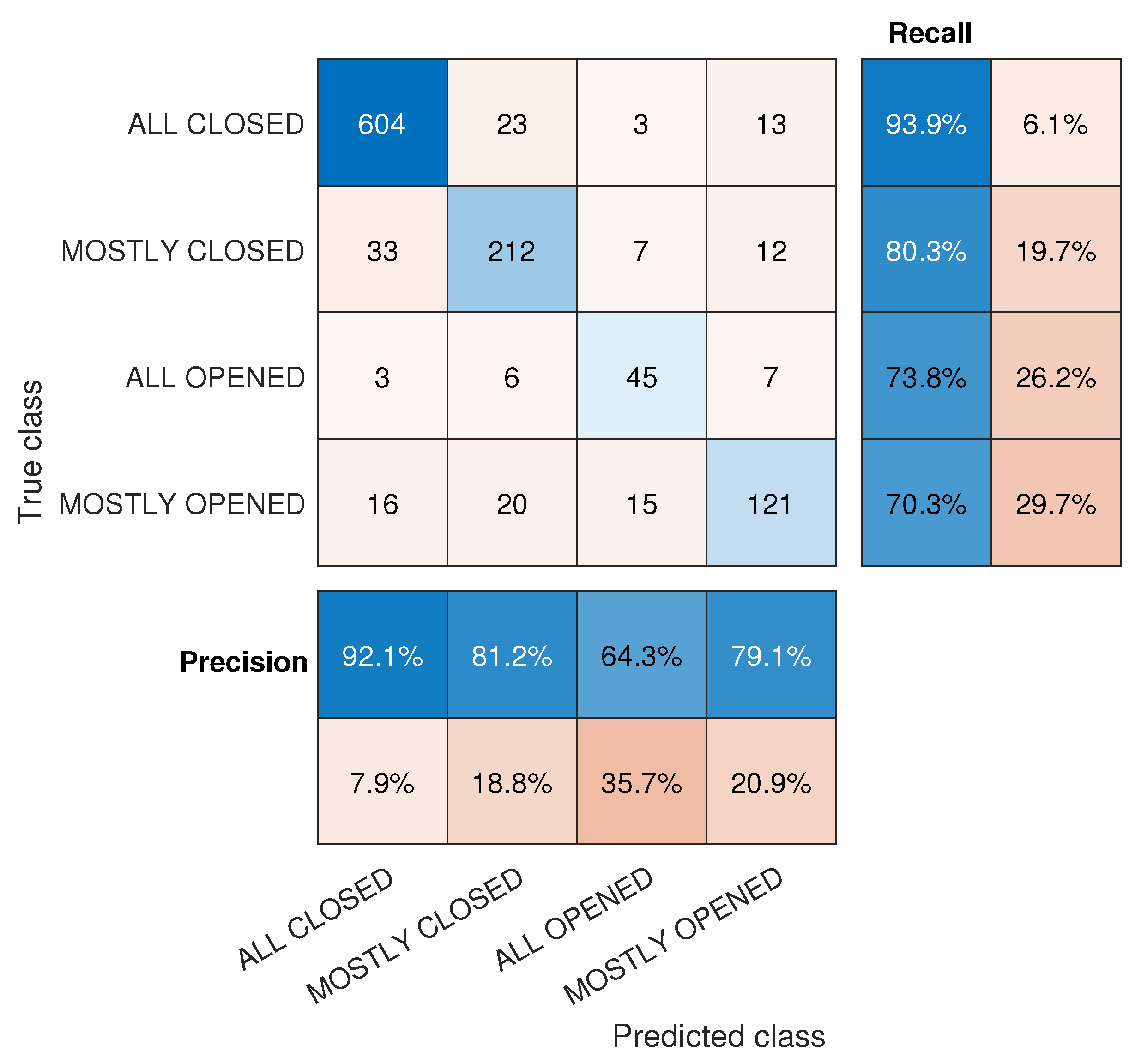
2.2. Classification Model Implementation
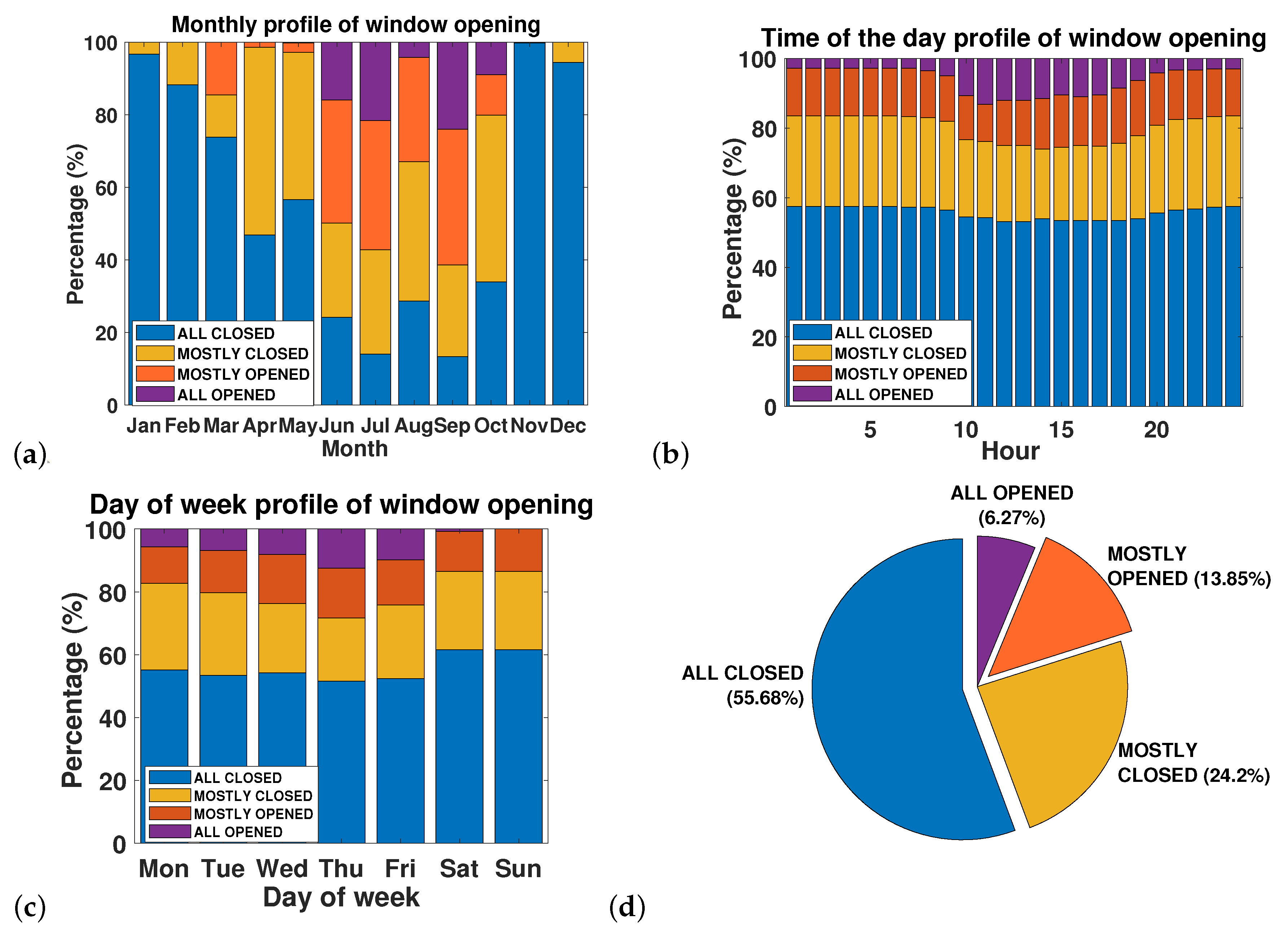
- ALL CLOSED: less than 1 window is opened ()
- MOSTLY CLOSED: from 1 to less than 2 windows are opened ()
- MOSTLY OPENED: from 2 to less than 4 windows are opened ()
- ALL OPENED: 4 windows or more are opened ()
3. Results and Discussion
4. Conclusions
References
- Indoor Air Division, Office of Atmostpheric and Indoor Air Programs. Congress on Indoor Air Quality: Assessment and Control of Indoor Air Pollution; Technical Report; U.S. Environmental Protection Agency: Washington, DC, USA, 1989.
- Jian, Y.; Guo, Y.; Liu, J.; Bai, Z.; Li, Q. Case study o fwindow opening behavior using field measurement results. Build. Simul. 2011, 4, 107–116. [Google Scholar] [CrossRef]
- Andersen, R.; Fabi, V.; Toftum, J.; Corgnati, S.P.; Olesen, B.W. Window opening behaviour modelled from measurements in Danish dwellings. Build. Environ. 2013, 69, 101–113. [Google Scholar] [CrossRef]
- Yao, M.; Zhao, B. Window opening behavior of occupants in residential buildings in Beijing. Build. Environ. 2017, 124, 441–449. [Google Scholar] [CrossRef]
- D’Oca, S.; Hong, T. A data-mining approach to discover patterns of window opening and closing behavior in offices. Build. Environ. 2014, 82, 726–739. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Dai, X.; Liu, J.; Zhang, X. A review of studies applying machine learning models to predict occupancy and window-opening behaviours in smart buildings. Energy Build. 2020, 223, 110–159. [Google Scholar] [CrossRef]
- Ramalho, O.; Ouaret, R.; Ionescu, A.; Le Ponner, E.; Candau, Y. TRIBU–Suivi dynamique en Temps Réel de la qualité de l’air Intérieur dans un environnement de BUreaux. Contributions des sources et Modèle prévisionnel rapport, PRIMEQUAL APR EIAI/projet TRIBU; Technical Report; Scientific and Technical Center for Building (CSTB): Marne-la-Vallée, France, 2016. [Google Scholar]
- Fabi, V.; Andersen, R.; Corgnati, S.; Olesen, B. Occupants’ window opening behaviour: A literature review of factors influencing occupant behaviour and models. Build. Environ. 2012, 58, 188–198. [Google Scholar] [CrossRef]
- Pan, S.; Xiong, Y.; Han, Y.; Zhang, X.; Xia, L.; Wei, S.; Wu, J.; Han, M. A study on influential factors of occupant window-opening behavior in an office building in China. Build. Environ. 2018, 133, 41–50. [Google Scholar] [CrossRef]
- Box, G.; Jenkins, G.M.; Reinsel, G. Time Series Analysis: Forecasting and Control, 3rd ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 1994. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Features | Indoor CO2 (ppm) | Indoor T (C) | Outdoor T (C) | Indoor RH (%) | Outdoor RH (%) |
|---|---|---|---|---|---|
| Max value | 1144 | 31.3 | 35.6 | 74.6 | 100.0 |
| Min value | 416.8 | 15 | −4.3 | 18.3 | 26.9 |
| Mean value | 501.1 | 23 | 13.5 | 44.2 | 82.2 |
| Median value | 480.5 | 22.4 | 13.5 | 42.9 | 86.7 |
| Std value | 64.3 | 2.3 | 6 | 9.3 | 16.2 |
| Month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. of samples | 96 | 87 | 96 | 96 | 96 | 93 | 99 | 96 | 93 | 99 | 93 | 96 |
| Accuracy | 0.99 | 0.91 | 0.85 | 0.77 | 0.92 | 0.83 | 0.77 | 0.76 | 0.71 | 0.89 | 0.97 | 0.98 |
| Hour | 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | 11th | 12th |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. of samples | 44 | 44 | 46 | 48 | 49 | 49 | 48 | 48 | 48 | 48 | 48 | 48 |
| Accuracy | 0.91 | 0.91 | 0.96 | 0.96 | 0.96 | 0.98 | 0.98 | 0.96 | 0.90 | 0.67 | 0.73 | 0.81 |
| Hour | 13th | 14th | 15th | 16th | 17th | 18th | 19th | 20th | 21st | 22nd | 23rd | 24th |
| No. of samples | 48 | 48 | 48 | 48 | 48 | 48 | 48 | 48 | 48 | 48 | 47 | 45 |
| Accuracy | 0.85 | 0.81 | 0.85 | 0.90 | 0.79 | 0.88 | 0.81 | 0.73 | 0.81 | 0.85 | 0.89 | 0.78 |
| Day | Mon | Tue | Wed | Thu | Fri | Sat | Sun |
|---|---|---|---|---|---|---|---|
| No. of samples | 162 | 161 | 166 | 162 | 164 | 161 | 164 |
| Accuracy | 0.86 | 0.84 | 0.83 | 0.84 | 0.76 | 0.96 | 0.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.H.; Ionescu, A.; Ramalho, O.; Géhin, E. Predicting the Window Opening State in an Office to Improve Indoor Air Quality. Eng. Proc. 2021, 5, 24. https://doi.org/10.3390/engproc2021005024
Nguyen TH, Ionescu A, Ramalho O, Géhin E. Predicting the Window Opening State in an Office to Improve Indoor Air Quality. Engineering Proceedings. 2021; 5(1):24. https://doi.org/10.3390/engproc2021005024
Chicago/Turabian StyleNguyen, Thi Hao, Anda Ionescu, Olivier Ramalho, and Evelyne Géhin. 2021. "Predicting the Window Opening State in an Office to Improve Indoor Air Quality" Engineering Proceedings 5, no. 1: 24. https://doi.org/10.3390/engproc2021005024
APA StyleNguyen, T. H., Ionescu, A., Ramalho, O., & Géhin, E. (2021). Predicting the Window Opening State in an Office to Improve Indoor Air Quality. Engineering Proceedings, 5(1), 24. https://doi.org/10.3390/engproc2021005024