3. Related Work
Several 6TiSCH SFs have been proposed in the literature, employing centralized, distributed, and autonomous management approaches. While centralized schedulers are consistent, they introduce higher signal overhead due to the need for network information exchange and connectivity maintenance [
14,
15]. Consequently, they limit network scalability and are more suitable for static environments. On the other hand, distributed schedulers [
16,
17] are well-suited for dynamic networks, offering lower signal overhead, improved scalability, and enhanced reliability. A Distributed Broadcast-based Scheduling (DeBraS) algorithm [
18] has been introduced for dense deployments. DeBraS reduces network traffic during control information exchange, minimizing collisions and improving throughput. Lowering collision rates reduces retransmissions, thereby decreasing latency and enhancing scalability in highly dense networks.
In LDSF [
19] distributed scheduler, two neighbors negotiate dedicated cells for communication. It divides a slotframe into smaller blocks that repeat over time. It allocates one primary cell in a specified block and several ghost cells for retransmissions in consecutive blocks. The transmitter uses ghost cells when it needs retransmission. This technique maintains the lower end-to-end delay by utilizing smaller block sizes. Distributed schedulers are appropriate for a dynamic network to some extent, as they involve cell negotiation signal overhead between pairs of nodes. DeBraS and LDSF suffer from higher energy consumption since cells are active more often to negotiate with neighbor nodes.
The Stripe is a distributed algorithm [
20] that minimizes packet delay by placing cells chronologically. It considers node location in the RPL tree and sub-tree weight. The algorithm has two phases: relocation and reinforcement. Relocation moves cells to Stripe along the route, while downward traffic is combined into broadcast cells. The reinforcement phase allocates supplementary cells based on node traffic. Through optimized cell allocation, Stripe achieves faster convergence, minimal delay, and improved PDR. Wave [
21] is a distributed scheduler that aims to minimize delays by limiting the cell count in the schedule. The algorithm schedules cells in consecutive waves, allocating them to nodes with packets for transmission. Subsequent waves are optimized versions of the initial wave. Cells are replicated in the next wave for nodes with multiple transmissions. Wave maintains a minimum number of cells, allowing packets to be forwarded from source to root in the same slotframe and ensuring all nodes have enough cells for their own and descendant packets.
The third approach, autonomous SF, is more suitable for highly dense networks. Several autonomous scheduling algorithms have been developed that do not comprise central management, information negotiation, signaling, or path resource reservation [
22,
23]. Nodes build and manage their schedule locally and autonomously by using their own and/or neighbor MAC addresses. Orchestra [
24] is a node-based state-of-the-art autonomous scheduling scheme. It uses different slotframes for the TSCH beacon, RPL control messages, and application data. It uses one common shared slot at a fixed coordinate, [0, 1] of a slotframe for all nodes in the network to transmit and receive control messages. It defines different scheduling mechanisms: Receiver-Based Shared Orchestra (RBSO) and Sender-Based Shared Orchestra (SBSO). In RBSO, any node builds a single Rx slot by using its own MAC address, and Tx cells correspond to each neighbor by using the MAC addresses of neighbors. RBSO may result in a contention problem and packet drop as the node schedules a single Rx cell to receive packets from all the neighbors. In SBSO, a node uses its own MAC address to build a single Tx cell, and the sender’s MAC address is used to build one Rx cell per neighbor. This approach offers fewer contentions compared to RBSO, as it employs an Rx cell per neighbor. However, it does result in higher energy consumption, as each Rx cell needs to wake up to sense the channel.
ALICE [
25], a link-based autonomous scheduling scheme, has been developed, where authors claim that node-based schedulers are inefficient. Unlike Orchestra, this method does not suffer from the contention problem as it allocates a unique cell for every link. It uses a minimum slotframe size equal to (2N − 2)/3 for a network with N nodes and 2N-2 directional links. It determines the cell location by hashing the MAC addresses of the sender and receiver. The hash function can schedule the identical cell for multiple links. To address this problem, ALICE uses ASN to vary the cell location in every slotframe. Autonomous and traffic-aware scheduling [
26], an enhanced Orchestra-based scheduler for TSCH networks, has been proposed that schedules cells dynamically based on traffic handled by the nodes. This technique significantly reduces delay while maintaining higher PDR. Monitoring the packets in a queue evaluates the cell count to be allocated for a node. Without any information negotiation, it computes the number of Tx cells towards its parent. The time offset of the cell is calculated using the Orchestra method, which allocates consecutive cells equal to pending packets at the node. Accordingly, the number of Rx cells for the parent node is adjusted. By allocating multiple cells as per traffic conditions, this technique improves performance in terms of latency. However, this scheme becomes less scalable in dense networks, as consecutively allocated cells may collide.
The A
3 Adaptive Autonomous Allocation scheme [
27], integrated with existing autonomous scheduling protocols such as Orchestra and ALICE, suggests a solution to address this problem. A
3 dynamically selects the slots in a slotframe to accommodate changing traffic needs. Its main advantage is the ability to estimate receiver traffic without requiring explicit control messages. It enhances throughput and PDR while reducing latency compared to previous methods. It allocates one primary cell and several secondary cells. The slotframe is divided into different zones, and one is used for a primary cell allocation while the other zones are for secondary cells, a maximum of up to eight cells. When the cell utilization exceeds the specified higher threshold, the number of secondary cells is doubled. Conversely, they are reduced by half when the utilization is below the specified lower threshold. Also, it uses an ASN number to change the cell location in every slotframe, which avoids collision on any particular slot. TESLA [
28] is designed to optimize energy consumption and ensure reliable packet delivery in wireless networks. Nodes monitor the traffic load and adjust their Rx slot scheduling accordingly. When a node detects idle Rx slots, it expands its slotframe size to conserve energy by minimizing idle listening. Conversely, when facing a high packet flood, the node reduces its slotframe size to minimize contention and packet drop among neighboring nodes. TESLA enables dynamic adjustment of the slotframe size based on incoming traffic load without incurring additional control overhead.
While scheduling schemes like Orchestra, ALICE, and A3 support autonomous and adaptive operations, they present significant limitations. Orchestra uses node-based periodic scheduling but fails to address traffic heterogeneity. Its fixed slotframes lead to over-provisioning of cells for sparse node distributions and under-provisioning in dense regions. This results in high contention near the root due to shared Rx slots when multiple child nodes attempt to send packets to the same parent. Moreover, Orchestra does not account for topology changes or traffic bursts, affecting both latency and PDR. ALICE improves latency by employing link-based scheduling and leveraging parent–child relationship knowledge through RPL topology. However, it still relies on static slot assignments, making it inefficient under dynamic traffic conditions. It also suffers from cell overlap and slot contention in dense deployments, particularly when multiple links compete for limited slotframe space. A3 introduces traffic adaptivity using EWMA-based load estimation but lacks topology-aware slot segmentation. Its adaptation strategy ignores node depth and subtree size, leading to inefficiencies in multi-hop networks. These shortcomings highlight the need for a solution that integrates hop-based slot allocation, traffic prediction, and link quality awareness to enhance latency, delivery ratio, and energy efficiency in dynamic network environments.
Existing autonomous and adaptive scheduling approaches, in worst-case scenarios, may require multiple slotframes to achieve end-to-end packet delivery. Nodes with heavy traffic load result in queue overflow, higher latency, and contention [
29,
30,
31]. A 6TiSCH low-latency autonomous scheduler [
32] has been developed to schedule cells for all nodes at a given RPL level in a particular segment. A traffic-aware autonomous scheduler [
33] assigns supplementary cells for the heavily loaded nodes. Though they improve performance compared to the existing Orchestra and ALICE schedulers, they lack adaptability to changing topology and traffic. Like Orchestra and ALICE, they also allocate single cells per link in every slotframe, leading to contention probability and packet drop. Ultimately, there is further scope for improvement in the scheduling techniques for reliable data transmission in time-constrained heavy-load networks. The algorithm proposed in this work addresses these challenges by adaptively allocating cells and segmenting slotframes based on traffic demands while also incorporating link performance metrics. It creates a schedule based on the network topology and node density at a specified RPL level.
4. Proposed Adaptive Scheduling Technique
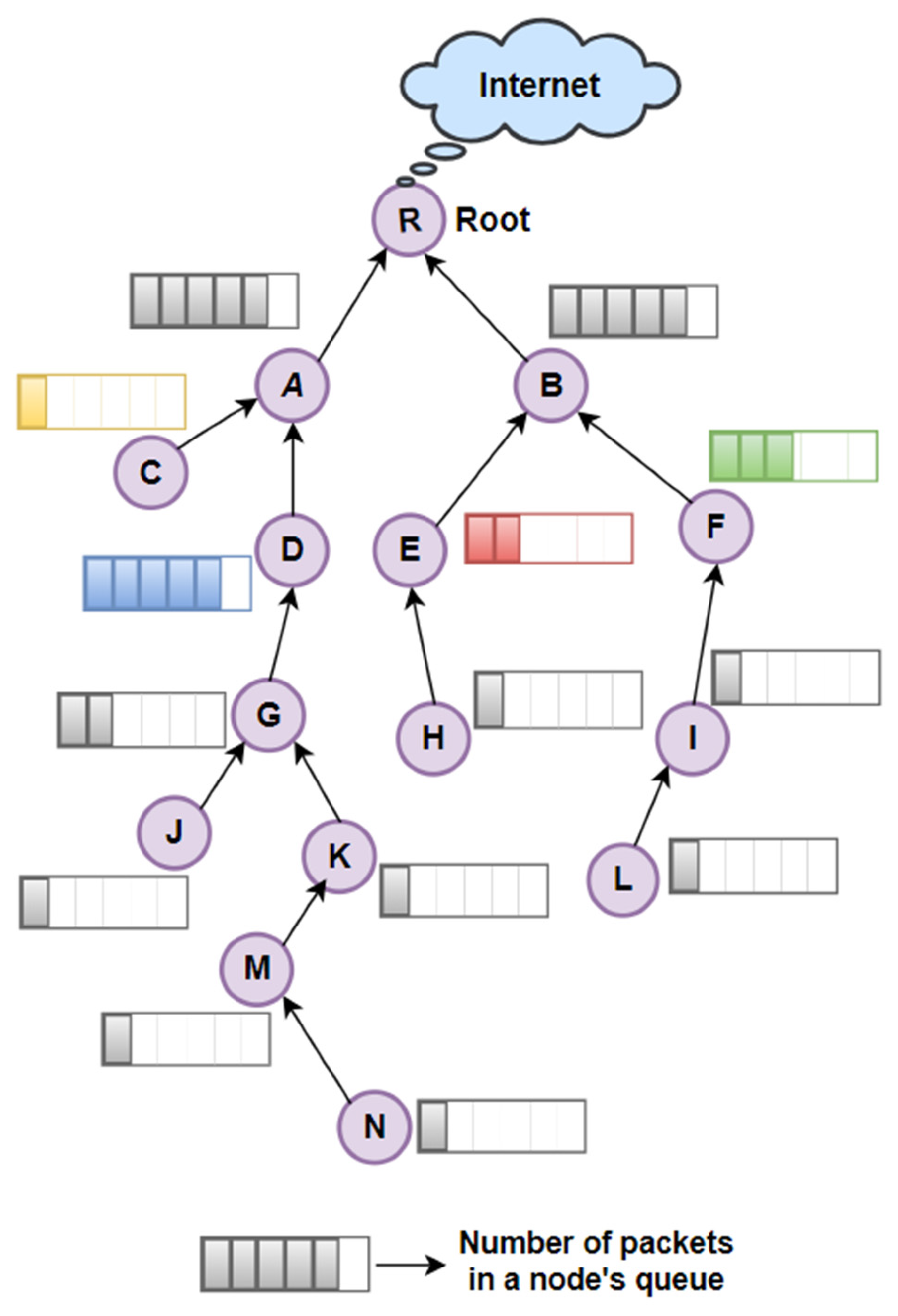
We propose a novel adaptive and autonomous scheduling technique for the network with non-periodic traffic patterns. Like ALICE, the proposed scheme utilizes node addresses to generate the schedule autonomously. The novelty of the proposed scheme lies in its dynamic allocation of Tx cells based on key network metrics such as queue backlog, link PDR, and hop count. Furthermore, the algorithm employs slotframe segmentation to ensure successive segment allocation for each link along the end-to-end communication path, thereby enhancing transmission efficiency and reliability. Moreover, by estimating the total number of transmissions required for nodes at a given hop distance, the scheme dynamically adjusts the slotframe segment size in accordance with the number of nodes and their respective hop distances. A data collection mesh network containing 60 nodes is considered for analysis, representing a typical scenario in IIoT applications. For simplicity,
Figure 3 shows a partial network structure of
nodes. RPL converts the mesh topology into a tree structure, where the root node acts as the sink for data packets transmitted by its descendant nodes. In such a configuration, nodes situated closer to the root experience significantly higher traffic loads, as they are responsible for forwarding packets generated by their respective subtrees. The end-to-end latency in packet transmission is mainly affected by the number of slotframes required to forward a packet to its destination. The proposed technique utilizes the node’s hop count to schedule cells within the slotframe, allocating a dedicated segment for all links at a specific hop distance in the RPL tree. This slotframe segmentation approach significantly reduces end-to-end latency by ensuring packet delivery within a single slotframe. Additionally, by minimizing contention probability, the technique enhances both the PDR and overall transmission reliability.
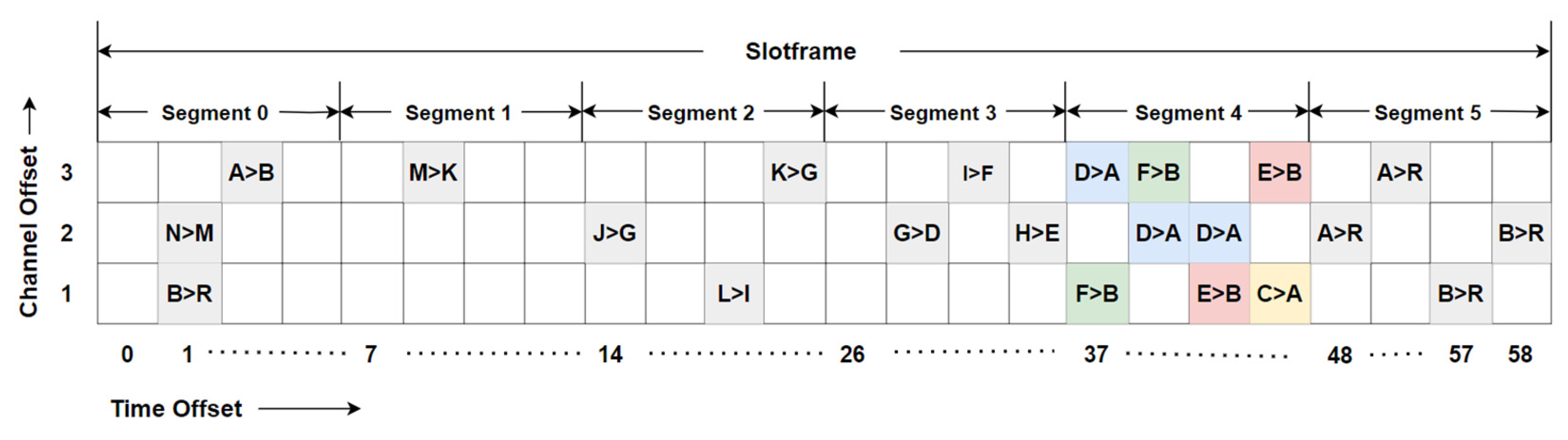
Given a maximum hop distance,
, in the network, the slotframe is partitioned into
segments of variable lengths, as illustrated in
Figure 4. Cells for each link between nodes at a specific hop distance are allocated within the designated segment of the slotframe. The number of cells scheduled for a particular link is determined by the packet count in the sender’s queue. Let
denote the set of child nodes of node
, and
represent the number of packets received from a child node
. If the number of packets generated at sender node
is denoted as
, then the total number of packets
at node
is given by
Under ideal conditions with 100% link-layer PDR, a single transmission is sufficient for successful delivery. However, when the PDR is lower, retransmissions are required. If
denotes the average number of transmissions required per packet over the link
, which is the reciprocal of the average link-layer PDR, represented by
. Accordingly, the total number of transmissions
over the link can be expressed as
Each node is assigned a specific segment for cell allocation. The total number of available cells within any segment is constrained by the segment length and the number of channel offsets. Although a segment in a longer slotframe offers more available cells, it can adversely impact end-to-end transmission latency. The pending packet count in the sender’s queue determines the number of cells scheduled for a given link. However, in dense networks with high traffic, overprovisioning cells equal to the queue size may lead to cell collisions and increased energy consumption. Hence, to ensure the minimum collision and packet drop with optimal slotframe length, the number of Tx cells
allocated to node
is computed as the floor of the logarithm of the transmission traffic
.
Node allocates Tx cells using its own MAC address along with address of the receiver node , and allocates Rx cells based on its own MAC address and those of its child nodes. The sender node communicates the number of scheduled Tx cells to the receiver node via a reserved field in the packet header. To minimize end-to-end latency, each node allocates Rx cells within one segment and Tx cells in the immediately following segment. If the hop count of the sender node is , the Tx cells are allocated in the segment of the slotframe.
Let
denote the node density at hop distance,
. The total number of cells,
, allocated for all links between the sender nodes,
, and their respective parent nodes,
, within the corresponding segment is given by
This approach adapts the number of scheduled cells based on the pending packets in a node’s queue and the corresponding link-layer PDR. However, the number of allocated cells increases logarithmically rather than linearly, thereby preventing overprovisioning and reducing contention.
Furthermore, to minimize end-to-end latency and improve slotframe utilization, we propose the use of variable-length slotframe segments for links at different hop levels. By utilizing available channel offsets,
, the minimum size of a slotframe segment is determined by ensuring sufficient allocation of Tx/Rx cells for nodes at hop distance,
, as given by
A larger slotframe segment is assigned to RPL levels with higher node density. Moreover, nodes located closer to the root typically handle greater traffic than other nodes, often resulting in buffer overflows. To mitigate this, segment sizes are increased for nodes nearer to the root. Taking into account the higher traffic at lower hop distances, the segment size is computed as the ceiling value derived from node density, the number of available channel offsets, and the logarithm of the hop distance. On the contrary, links at higher hop distances are assigned smaller segment lengths. The minimum slotframe length,
, is determined as the sum of the lengths of all segments.
The time offset for each cell is determined using a hash function applied to the addresses of the sender and receiver. According to
,
cells are scheduled for the link
, where the time offset of the
cell within a segment of size
given by
where
for
,
and
are MAC addresses of node
and
, respectively.
The hash function used to determine the time offset ensures that cell allocation is uniformly distributed across the segment by combining sender and receiver MAC addresses along with segment length. This uniform distribution minimizes the collision among multiple nodes within the same segment. Additionally, since the hash function depends on unique MAC pairs, it avoids overlap across dissimilar links. The use of a modulo operator with the segment length ensures that cell allocation remains within the same segment.
As derived in , the proposed AAS strategy schedules unique cells within the segment for all links connecting sender nodes at hop distance to their respective parent nodes. To accommodate the high traffic generated by nodes one hop away from the root, segment can be utilized additionally alongside the last segment. This strategy provides an extra opportunity for such nodes to forward packets without causing interference with pre-allocated transmissions. By using this segmentation approach, cells are scheduled in consecutive segments according to the node’s hop distance from the root. The minimal-length slotframe segment is determined based on the number of pending packets in the transmission queues and the number of active links at a given level of the RPL DODAG tree. In this work, the traffic load is predicted by using the current queue backlog at each node along with the hop distance traffic generation in the RPL topology. Since nodes closer to the root experience higher traffic due to forwarding packets of their descendants, our algorithm assumes traffic increases proportionally as the hop distance to the root decreases. The collective traffic arriving at a node, from its children and itself, is an effective predictor of upcoming load. This estimated load impacts the number of cells allocated, using the logarithmic mapping in Equation (4) to scale scheduling based on queue occupancy and links PDR.
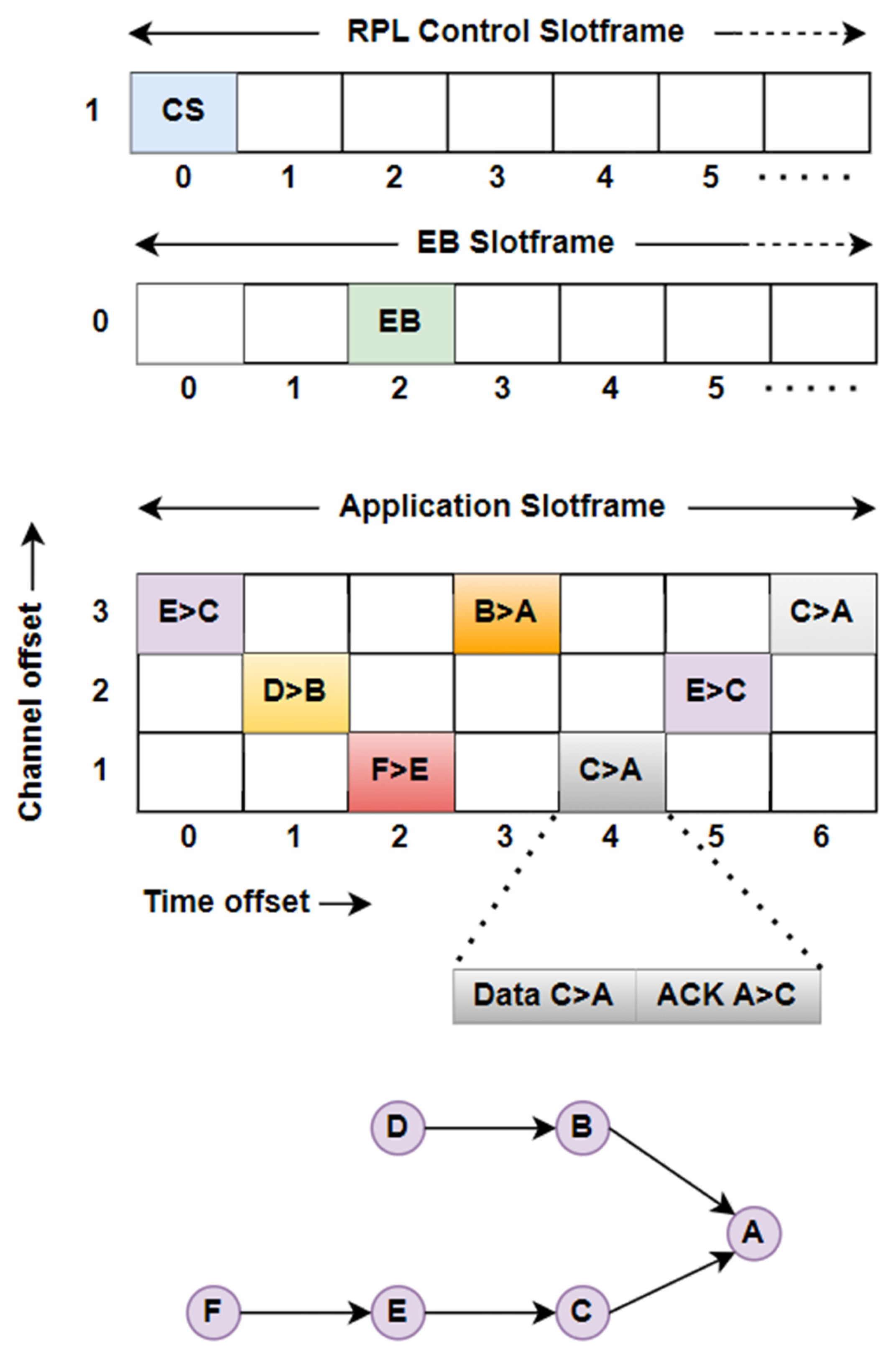
The channel offset for the application data packet is determined by using the sender’s MAC address and the total number of available channel offsets, as expressed by
The technique utilizes channel offsets and for application data. The channel offset for the EB frame is fixed at , while for RPL it is set to . The time offset for the EB frame is determined based on the sender’s MAC address, whereas the time offset for RPL remains constant at .
6. Performance Evaluation
The proposed AAS is implemented in the Contiki-NG operating system and evaluated using the Cooja simulator, which is a widely used tool for IIoT simulations [
34,
35]. A network of
nodes arranged in an
grid is modeled, with one node designated as the root and the remaining as sources. A typical IIoT data collection scenario is considered, wherein the root node serves as the sink for all packets transmitted by the sources, with a maximum hop distance of
. The packet transmission and interference ranges are both set to
. The simulation is carried out with varying packet intervals from 2 s to 15 s and slotframe size from 31 slots to 101 slots, representing realistic IIoT data collection patterns. To evaluate the proposed technique, key performance parameters such as average end-to-end latency, contention probability, PDR, and network lifetime were analyzed by varying the slotframe size and packet generation intervals.
As end-to-end latency tends to increase with slotframe size, smaller slotframes are preferable for time-critical applications. However, smaller slotframes lead to higher energy consumption, as nodes remain active more frequently within a shorter time span. Consequently, for energy-constrained applications, larger slotframes are more suitable, though at the cost of increased latency. Additionally, larger slotframes may lead to a reduction in PDR due to an increased contention probability. With fewer transmission opportunities available in such slotframes, packet queues tend to grow longer, thereby increasing the risk of packet drops.
The proposed scheduler minimizes end-to-end latency by ensuring the delivery of packets from source to destination within a single slotframe. An additional slotframe is required only in cases of retransmission. Cells are allocated in successive segments along the route from source to destination, with segment lengths dynamically adapted based on the number of nodes at each level and the traffic they handle. The effectiveness of the proposed AAS has been evaluated and compared with state-of-the-art scheduling approaches, including the node-based autonomous technique Orchestra, the link-based ALICE scheduler, and A
3 integrated with ALICE, as illustrated in
Figure 5.
Unlike these schedulers, AAS models latency as a function of segment length rather than slotframe length. The number of nodes determines the segment length at a given rank and the corresponding link PDR. Orchestra allocates a unique cell to each node within a slotframe, using the sender’s or receiver’s address. Similarly, ALICE assigns a unique cell to each link in the network. These schemes incur higher latency, as multiple slotframes are required for end-to-end packet delivery. In the worst-case scenario, a cell with time offset may be allocated for the link , while is allocated for the link . This hop-to-hop scheduling leads to a maximum delay of per hop. Consequently, the worst-case end-to-end latency over a path with hops, , can approach slotframes.
A
3 partitions the slotframe into multiple zones based on the traffic load at each node. Initially, it assigns primary cells to every link using the ALICE allocation strategy. When the utilization of primary cells exceeds a predefined threshold, secondary cells are allocated to accommodate the increased traffic. However, the limitation of A
3 is that it allocates primary cells anywhere within a slotframe. When the schedule relies solely on primary cells, the resulting latency is comparable to that of Orchestra. The inclusion of secondary cells in A
3 helps reduce latency by providing nodes with additional opportunities to forward packets. As shown in
Figure 5, the proposed AAS technique outperforms existing approaches across all slotframe sizes. At a slotframe size of
, the end-to-end latency achieved by AAS is
lower than A
3,
lower than ALICE, and
lower than Orchestra. For a slotframe with
timeslots, AAS exhibits
lower latency than A
3 and
lower than ALICE. Overall, AAS consistently achieves the lowest end-to-end latency among the compared techniques.
Contention probability is evaluated across varying slotframe sizes and packet intervals. The traffic load on each timeslot was estimated based on the traffic generated by the node and the slot duration, as described in
. In larger slotframes with sparser cell distributions, high network traffic leads to increased contention due to the limited availability of cells per unit time.
Figure 6 presents the contention probability for different scheduling techniques across multiple slotframe sizes, with a packet interval of
. It is observed to be lower in AAS compared to other schedulers due to its adaptive cell allocation strategy, which enables more efficient resource utilization. At a slotframe size of
, the contention probability in AAS is
lower than A
3,
lower than ALICE, and
lower than Orchestra. In A
3, contention is comparatively more due to the dispersion of primary and secondary cells across the slotframe. In Orchestra and ALICE, contention remains high as they schedule a single Tx cell in a slotframe for every node.
Figure 7 shows the reduction in contention in AAS with increasing packet intervals. At a slotframe length of
timeslots, the contention is
lower when the packet interval is
compared to an interval of
.
The average end-to-end PDR of the network is the ratio of the total number of packets received by the sink to the total number of packets transmitted by the sender. PDR in a network is affected with the increasing slotframe size, as a lesser number of cells are available for transmission. The results in
Figure 8 show the end-to-end PDR of AAS for a slotframe size of
timeslots, and packet intervals are varied from
to
. The PDR of the AAS is
higher than A
3 when the packet interval is set to
; however, it is
higher than Orchestra and
higher than ALICE when an interval is set to
. PDR in Orchestra and ALICE is reduced due to the limited transmission opportunities within a slotframe. In the case of A
3, transmission opportunity is increased by using multiple zones; however, for higher traffic conditions, PDR is dropped below AAS due to higher congestion probability. AAS assigns the cells within a specified segment as per traffic requirement and links PDR, resulting in a lower congestion problem.
The life of the network is decided by the node with the highest energy consumption. Nodes consume energy during active slots, used for data transmission, reception, and acknowledgment. The entire network may go down if any node, specifically closer to the root, runs out of energy. Nodes in Orchestra consume energy in idle listening at most of the time, as every node has a single Tx cell and Rx cells per neighbor. However, in A3, the allocated cells are doubled when its utilization is above a threshold value, which leads to more energy consumption. The proposed AAS algorithm improves energy efficiency by adapting to traffic conditions, hop count, and link reliability. It avoids over-provisioning by allocating a logarithmic number of cells based on the estimated queue backlog, which significantly reduces idle listening and channel contention. Similarly, the slotframe segmentation based on hop distance ensures that nodes closer to the root, typically experiencing higher traffic accumulation, are allocated more communication resources, while other nodes save energy by operating with fewer active slots. Moreover, by incorporating link quality into the slot allocation strategy, AAS minimizes retransmissions due to poor links, further reducing unnecessary energy consumption. These mechanisms reduce radio-on time and improve duty-cycle performance, thereby extending the overall network lifetime. Experimental results demonstrate that AAS achieves lower energy consumption compared to other schemes like ALICE and A3.
Figure 9 illustrates the network lifetime for different slotframe lengths. The result shows that when a packet interval is set to
and the slotframe of
timeslots, the network lifetime in AAS is
higher than A
3,
higher than ALICE, and
higher than Orchestra. Node’s energy consumption is higher for a shorter slotframe, as nodes wake up more frequently. It can be minimized by increasing the slot frame size. However, it is at the cost of higher end-to-end latency. For a smaller slotframe with higher traffic conditions, AAS consumes more energy, as it has more active cells for a short period than in the Orchestra. For simulation, we considered 60 nodes that represent a mid-scale industrial scenario, balancing complexity and real-world density. To evaluate the scalability of the proposed AAS mechanism, we conducted simulations using 40 node count, arranged in grid topologies of
. The performance in terms of latency, PDR, and contention remains comparable, with AAS demonstrating its advantage over existing schedulers.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}