Abstract
Mulch-film covering technology has been widely adopted in cotton production in arid regions; however, the associated problem of residual-film pollution has become increasingly prominent, creating an urgent demand for efficient and accurate monitoring approaches. Owing to the small target scale, irregular morphology, blurred boundaries, and complex soil backgrounds of residual-film fragments, residual-film detection based on close-range UAV imagery remains a challenging task. To address these issues, this study proposes an improved algorithm, termed YOLO-EGASF, for residual-film detection in arid-region cotton fields, built upon the lightweight YOLOv11n framework. To enhance the detection of small targets with weak boundary characteristics, the baseline model is improved from three aspects. First, a boundary-enhanced multi-branch small-target extraction module (EMSE) is designed to reinforce shallow-layer details and gradient information through multi-scale convolution and explicit edge enhancement. Second, a GLoCA attention module that integrates global coordinate information with local geometric features is constructed to improve the discriminative capability of the model for residual-film targets under complex background conditions. Third, an ASF-layer multi-scale feature fusion structure is introduced, together with an additional small-target detection layer, to strengthen the participation of high-resolution features in cross-scale fusion and prediction. Experimental results on a self-constructed UAV-based residual-film dataset from cotton fields demonstrate that YOLO-EGASF outperforms several mainstream detection models in terms of Precision, Recall, mAP@0.5, and mAP@0.5:0.95, achieving mAP@0.5 and mAP@0.5:0.95 values of 71.9% and 26.8%, respectively. These results indicate a significant improvement in detection accuracy and robustness, confirming that the proposed method can effectively meet the practical requirements of fine-grained residual-film monitoring in arid-region cotton fields.
1. Introduction
Plastic mulch–based cotton cultivation has been widely adopted in arid and semi-arid regions due to its significant benefits in improving soil temperature, conserving moisture, and enhancing crop yield [1,2,3]. However, the extensive use of polyethylene mulch films has resulted in the long-term accumulation of residual plastic fragments in farmland soils, posing a growing threat to soil health and agricultural sustainability [4]. In Xinjiang and other major cotton-producing regions, harsh climatic conditions such as strong radiation and high temperature accelerate mulch-film fragmentation, leading to widespread surface accumulation of residual plastic debris [5]. Efficient monitoring of residual-film distribution is therefore essential for environmental risk assessment and for guiding mitigation strategies such as degradable mulch replacement and pollution control.
At present, residual-film investigation still relies heavily on manual field sampling and quadrat-based surveys, which are labor-intensive and difficult to scale for large-area monitoring. With the rapid advancement of unmanned aerial vehicle (UAV) platforms, high-resolution aerial imagery has emerged as an efficient tool for large-scale farmland observation [6]. UAV-based sensing provides flexible data acquisition and fine spatial resolution, enabling automated monitoring of surface contaminants in agricultural environments [7,8]. Meanwhile, deep learning–based computer vision methods have demonstrated strong feature-learning capability under complex backgrounds and have been increasingly applied in agricultural remote sensing and environmental monitoring tasks [9].
In recent years, object detection and segmentation techniques have been explored for agricultural plastic monitoring. Segmentation-based approaches such as CBAM-DBNet and related hybrid frameworks have shown promising performance in extracting plastic-covered regions [10,11,12]. Detection-based approaches, particularly those derived from the YOLO family, have gained increasing attention due to their balance between accuracy and computational efficiency [13,14]. Several studies have enhanced YOLO architectures by introducing attention mechanisms, multi-scale feature-fusion strategies, or small-object detection refinements to improve performance in UAV imagery [15,16,17,18]. More recent research has focused on small-object detection refinements and task-specific optimizations in agricultural scenarios [19,20,21,22]. Despite these advances, detecting residual mulch films remains challenging due to the small size, irregular morphology, and fragmented distribution of targets, as well as strong background interference caused by soil texture, crop residues, and illumination variation [23].
Recent studies have further explored task-specific improvements of YOLO-based frameworks for residual plastic detection. For example, attention-enhanced YOLO variants have demonstrated improved residual-film recognition performance through refined feature modeling and detection-head optimization [24]. Frequency-aware detection frameworks have also been proposed to enhance boundary and texture discrimination via multi-scale frequency-domain feature fusion. In addition, other YOLOv11-based improvements have incorporated lightweight multi-scale fusion and attention-assisted feature aggregation for cotton-field mulch monitoring. Beyond detection-based pipelines, alternative strategies such as spectral phenotyping and segmentation architectures (e.g., U-Net variants) have also been investigated to exploit material-level discrimination or pixel-level delineation of plastic residues. However, these methods often require multi-sensor inputs, higher computational cost, or more complex deployment pipelines, which may limit their applicability in routine UAV-based field inspection scenarios.
Although notable progress has been achieved, several limitations remain in existing studies. Many models exhibit insufficient sensitivity to weak boundaries and fine-scale structures, resulting in missed detections of fragmented residual films. Most existing approaches focus on generic agricultural targets and lack task-oriented optimization for residual-film detection in arid cotton-field environments [24,25]. These challenges highlight the necessity of developing task-specific detection frameworks capable of enhancing boundary awareness and multi-scale feature representation in UAV imagery.
To address these challenges, this study proposes an improved detection framework, termed YOLO-EGASF, for fine-grained residual mulch-film detection in UAV imagery of arid cotton fields. Built upon the YOLOv11n baseline, the proposed model incorporates multiple task-oriented architectural enhancements. Specifically, an edge-enhanced multi-branch small-target extraction module is designed to strengthen boundary-gradient perception, a geometric-enhanced local–global coordinate attention mechanism is introduced to improve discriminative capability under complex backgrounds, and an adaptive multi-scale feature fusion strategy with an additional small-target detection layer is employed to enhance localization performance in dense and fragmented scenarios.
The main contributions of this study can be summarized as follows:
- (1)
- An improved detection framework is developed for small-target residual-film detection in UAV imagery of arid-region cotton fields.
- (2)
- Task-oriented architectural refinements are introduced to enhance boundary representation and multi-scale feature fusion.
- (3)
- Comprehensive experiments, including ablation studies and multi-model comparisons, are conducted to validate the effectiveness of the proposed approach in realistic agricultural scenarios.
2. Materials and Methods
2.1. Study Area and UAV Image Acquisition
In this study, surface residual-film images were independently collected from cotton fields located in a typical arid region (Alar City, First Division of the Xinjiang Production and Construction Corps). The image acquisition was conducted using a Mavic Air 2 series UAV (DJI Innovation Technology Co., Ltd., Shenzhen, China). The UAV image acquisition campaigns were conducted from 5 November 2024 to 10 December 2024. This UAV platform integrates multiple intelligent and safety-control functions and is capable of meeting image-acquisition requirements under diverse operational scenarios. Under low-illumination conditions, the system enhances image quality through multi-frame noise-reduction algorithms, increasing overall brightness and finely adjusting color parameters, thereby effectively improving imaging performance in complex farmland environments. During image acquisition, operations were carried out under clear weather conditions with no wind or light wind to minimize environmental interference with image quality. Insufficient illumination under cloudy conditions can degrade image quality, whereas high wind speeds may adversely affect vertical shooting stability and hovering accuracy of the UAV. The flight altitude was set to 5 m, and the camera viewing angle was fixed at −60°. Under these settings, images were captured at each sampling site, and surface residual-film images were acquired at different times of the day and under varying illumination conditions (10:00–18:00). A total of 1286 raw images were collected. After data transfer to a computer for subsequent processing, abnormal or low-quality images were removed through quality screening, and 907 valid images were ultimately retained for analysis. Representative examples of surface residual film in cotton fields acquired by UAV are shown in Figure 1.

Figure 1.
Representative UAV images of surface residual mulch film in cotton fields. (a–c) Typical examples under varying illumination and background conditions. (d) Example with manual annotation highlighting residual mulch-film fragments.
2.2. Dataset Construction, Preprocessing, and Annotation
After image acquisition, the original images exhibited excessively high pixel resolution, which would increase training time and memory consumption during model training. Therefore, the OpenCV library (OpenCV v4.10.0) [26] was used to resize all images to a resolution of 640 × 640 pixels for subsequent model training. To achieve multiple objectives, including expanding the dataset size, enhancing model robustness, regularizing the training process, and improving performance under real-world conditions, various data-augmentation operations were applied to the dataset. These augmentations introduced diverse transformations and variations, enabling the model to learn from heterogeneous samples and better adapt to different scenarios. To increase dataset diversity, four augmentation methods were employed: brightness enhancement, contrast enhancement [27], rotation, and flipping. Specifically, images were rotated 90° clockwise, brightness was increased by 10%, and contrast was increased by 10%, as illustrated in Figure 2. A selective augmentation strategy was adopted, in which the test set consisted of original, non-augmented UAV images, while augmentation was primarily applied to enrich the training data. After augmentation, approximately 2100 images were retained rather than being exhaustively expanded. The dataset was then divided into training, validation, and test sets using an 8:1:1 ratio [28], with 1680 images used for training (80%), 210 for validation (10%), and 210 for testing (10%). Residual-film images were precisely annotated using the LabelImg tool (LabelImg v1.8.6, developed by Tzutalin, open-source project, https://github.com/tzutalin/labelImg, accessed in 1 March 2025). During annotation, rectangular bounding boxes were applied to mark residual-film regions, and the category label was set to “mo (plastic mulch residue).” Only fully visible and clearly identifiable residual-film fragments were annotated to reduce interference from farmland backgrounds and other irrelevant objects.

Figure 2.
Image preprocessing. (a) Brightness enhancement, (b) Contrast enhancement, (c) Rotation augmentation, (d) Flip augmentation.
2.3. Baseline Model and Proposed YOLO-EGASF Framework
To meet the detection requirements of surface residual film in UAV imagery of arid-region cotton fields—characterized by small target scale, dense distribution, weak boundaries, and strong background interference—this study proposes an improved algorithm, termed YOLO-EGASF, built upon the YOLOv11n baseline framework [29]. The proposed method enhances the network architecture along three main lines: small-target detail preservation, local geometric discrimination, and multi-scale information fusion. Specifically, an edge-enhanced multi-branch module (EMSE) is introduced in the feature-extraction stage to strengthen film–soil boundaries and fine-grained texture information; a local–global geometric coordinate attention module (GLoCA) is incorporated in the feature-modeling stage to improve discriminability under complex backgrounds; and an ASF-layer multi-scale fusion structure is constructed in the feature-fusion and prediction stage, together with an additional small-target detection layer, to alleviate small-target information loss caused by downsampling and to improve recall for densely distributed small targets. The overall network architecture is illustrated in Figure 3, where the integration of EMSE, GLoCA, and ASF modules is highlighted.
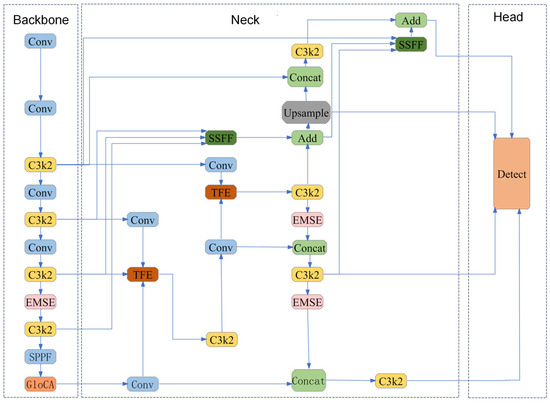
Figure 3.
Architecture of the proposed YOLO-EGASF framework. The network follows the Backbone–Neck–Head paradigm, where EMSE modules enhance boundary-aware feature extraction, GLoCA improves geometric discrimination, and ASF-based fusion strengthens multi-scale aggregation. Legend: Blue indicates convolutional operations; yellow indicates C3 modules; pink indicates EMSE modules; orange indicates GLoCA modules; green indicates feature fusion operations.
YOLO-EGASF adopts the Backbone–Neck–Head architecture of YOLOv11n as the main framework, retaining the efficient end-to-end one-stage detection characteristics while inserting task-oriented modules at key positions to enhance small-target residual-film detection capability. Specifically, the Backbone is responsible for extracting multi-level semantic features from input UAV images; the Neck facilitates information interaction between high- and low-level features through cross-layer connections and multi-scale fusion; and the Head outputs classification and regression results at different scales to accomplish residual-film target localization and recognition.
To address missed detections caused by fragmentation and boundary weakening of residual-film targets, the EMSE module is introduced at the shallow and intermediate feature-extraction stages to enhance boundary-gradient responses and multi-scale detail representation, thereby improving small-target separability at the source. To mitigate false detections induced by textured backgrounds such as soil cracks and straw residues, the GLoCA module is embedded in the main feature-transmission path, where adaptive fusion of local geometric structures and global coordinate cues enhances discriminative robustness. In addition, an ASF-layer multi-scale fusion structure is constructed at the Neck stage, and an additional small-target detection layer is incorporated, enabling shallow fine-grained features to participate more effectively in fusion and prediction, thus improving recall and localization accuracy for densely distributed small targets.
2.4. Edge-Enhanced Multi-Branch Small-Target Feature Extraction Module (EMSE)
Residual film in close-range UAV imagery often appears as narrow strips, sheet-like fragments, or irregular debris, exhibiting low grayscale and texture contrast between its boundaries and the surrounding soil background. During the successive downsampling processes of conventional convolutional networks, boundary-gradient information is prone to being smoothed or attenuated, which can lead to missed detections of small targets. To strengthen boundary representation and multi-scale detail characterization of small targets while maintaining controllable computational complexity, this study proposes an edge-enhanced multi-branch small-target feature extraction module, termed EMSE (Edge-Enhanced Multi-branch Small-target Extractor), which reinforces multi-scale detail features and boundary-gradient information under a constrained computational budget. The architecture of the EMSE module is illustrated in Figure 4.

Figure 4.
Architecture of the proposed EMSE module. The module adopts a multi-branch design consisting of depthwise convolution, dilated convolution, and Sobel edge-enhancement branches to capture multi-scale texture and boundary information. The extracted features are fused through concatenation and channel attention, followed by residual aggregation to preserve original spatial details while enhancing edge-aware feature representation.
Let the input feature map be denoted as
The EMSE module first applies a 1 × 1 convolution to compress and reorganize the feature channels, yielding an intermediate feature map Xc. Subsequently, a multi-branch parallel structure is constructed to extract information at different scales and enhance boundary representations, and the outputs of each branch can be expressed as
where denotes a depthwise separable convolution branch (DWConv 3 × 3) for local texture extraction, represents a dilated convolution branch (dilation = 3) designed to enlarge the receptive field, and corresponds to a Sobel edge-enhancement branch used to explicitly extract gradient discontinuities at the film–soil interface. After concatenation of the outputs from all branches along the channel dimension, a channel-attention mechanism is introduced to adaptively recalibrate the multi-scale features, and the process can be expressed as
where denotes the channel-attention mapping function, which is employed to suppress soil-texture noise and ineffective background responses.
Finally, the EMSE module employs a residual connection to add the enhanced features to the original input features, yielding the output feature representation
This design ensures stable gradient propagation while effectively preserving shallow fine-grained information and boundary-gradient features, thereby providing a high-quality feature foundation for subsequent multi-scale fusion and small-target detection.
2.5. GLoCA Local–Global Geometric Coordinate Attention Module
In arid-region cotton-field backgrounds, high-frequency textures and linear structures such as soil cracks, straw residues, and shadows cast by drip-irrigation belts are commonly present. Their local morphological patterns exhibit a certain degree of visual similarity to residual-film fragments, which can easily lead to false detections. Conventional channel- or spatial-attention mechanisms primarily focus on saliency reweighting, but they are insufficient in characterizing the strip-like or sheet-like local geometric structures of residual film and provide limited representation of target spatial positional information. To address these limitations, this study proposes a GLoCA (Geometric-enhanced Local–global Coordinate Attention) module to improve discriminability and localization stability under complex background conditions. The network architecture of GLoCA is illustrated in Figure 5.
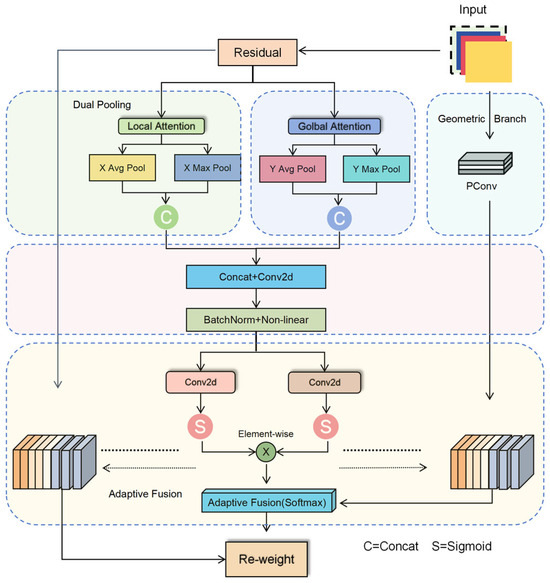
Figure 5.
Architecture of the proposed GLoCA module. The module consists of three key components: a dual-pooling attention mechanism for global feature aggregation, a geometric strip-convolution branch for modeling directional structures, and an adaptive fusion module for integrating global and local attention responses.
Building upon coordinate attention, GLoCA introduces a “dual pooling + geometric branch + adaptive fusion” mechanism, as illustrated in Figure 5. The module first adopts a dual-pooling fusion strategy using AvgPool and MaxPool [30] to jointly capture global statistical information and salient response features, thereby improving the stability of attention generation and sensitivity to fine residual-film fragments. Subsequently, a PConv pinwheel-shaped strip-convolution branch is introduced to model directional and band-like structures, enabling effective capture of common residual-film characteristics such as slender edges, folded textures, and local geometric contours, and thus improving separability between residual film and background linear textures. Finally, the module employs learnable Softmax weights [31] to adaptively fuse global coordinate attention and local geometric attention, allowing the network to dynamically adjust its focus according to variations in background conditions and residual-film morphology. This design facilitates more robust attention allocation and suppression of false detections. Let the input feature map be denoted as
First, global statistical features are extracted through average pooling and max pooling:
and the two are fused to enhance responsiveness to salient edges and fine residual-film regions. The resulting global coordinate attention can be expressed as
where denotes the linear transformation weights, and represents the Sigmoid activation function.
Meanwhile, a local geometric branch is introduced, which employs PConv pinwheel-shaped strip convolution to model directional and band-like structures of the input features, and its output is defined as
To achieve adaptive fusion between global coordinate attention and local geometric attention, learnable weights are introduced and normalized through a Softmax function:
where and represent the contribution weights of the global and local attention components, respectively.
Finally, the output feature representation of the GLoCA module is given by
where denotes element-wise multiplication. This module achieves joint modeling of global positional cues and local geometric structures while maintaining a lightweight architecture, thereby effectively enhancing discriminative robustness and localization stability for residual-film targets under complex background conditions.
2.6. Improvements to the Neck Module
Residual-film targets are small in size and densely distributed. When the network downsampling factor is excessively large, shallow detail features tend to be diluted during deep semantic aggregation, leading to localization deviations and reduced recall for small targets. To alleviate this issue, an ASF-layer multi-scale fusion structure is introduced in the Neck module, and an additional small-target detection layer is incorporated, enabling shallow fine-grained features to participate more fully in cross-scale fusion and final prediction. The overall structure is illustrated in Figure 6.
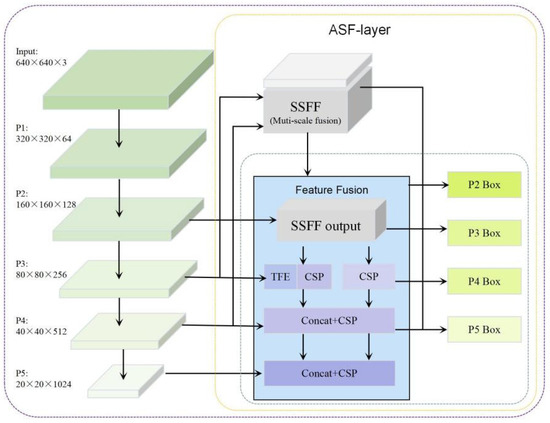
Figure 6.
Architecture of the proposed ASF-layer in the Neck module. The ASF-layer performs adaptive multi-scale feature fusion using SSFF and TFE mechanisms, enabling efficient cross-scale information aggregation. The fused features are subsequently propagated to multi-level detection heads (P2–P5), allowing shallow high-resolution features to participate in prediction and improving detection performance for small and densely distributed targets.
The ASF-layer is constructed based on multi-scale adaptive fusion principles, establishing feature-fusion pathways that enhance information transfer efficiency across different scales through strategies such as SSFF and TFE. On the one hand, high-level semantic features are strengthened to guide low-level details, improving target separability under complex background conditions; on the other hand, redundant and conflicting information arising during multi-scale fusion is suppressed, enhancing the compactness and consistency of the fused representation. Let the feature maps from different scales be denoted as
The ASF-layer performs adaptive weighted fusion of multi-scale features, and its output can be expressed as
where denotes the learnable scale weights, which are used to balance the contributions of features with different resolutions during the fusion process.
In constructing the ASF-layer, the CPAM attention module is not introduced to avoid functional redundancy with the proposed attention mechanism (GLoCA), thereby maintaining architectural simplicity and controlling computational overhead. On the detection-head side, an additional small-target detection layer is incorporated to introduce shallower high-resolution features into the prediction process, enabling the model to regress residual-film boundaries and center positions at finer spatial granularity. This design improves recall and localization accuracy for densely distributed small targets. The collaborative design of the ASF-layer and the additional detection layer enhances scale adaptability and improves detection stability for small and fragmented residual-film targets without significantly increasing computational cost.
2.7. Evaluation Metrics
To comprehensively evaluate the detection performance and generalization ability of the proposed model for residual-film detection in cotton fields, this study adopts precision (P), recall (R), and mean average precision (mAP) as the primary evaluation metrics. Specifically, mAP is calculated at an IoU threshold of 0.50 (mAP50) and over the IoU range of 0.50–0.95 (mAP50–95) to comprehensively reflect the model’s detection capability under different localization accuracy requirements. These metrics characterize model performance from multiple perspectives, including classification accuracy, localization accuracy, and overall detection effectiveness. Precision (P) represents the proportion of true positive samples among all samples predicted as positive, reflecting the model’s ability to distinguish negative samples. Recall (R) represents the proportion of actual positive samples that are correctly predicted as positive by the model. The corresponding calculation formulas are given in Equations (13) and (14).
where TP denotes true positives, referring to samples for which both the prediction and the ground truth are correct; FP represents false positives, referring to samples that are incorrectly predicted as positive; and FN denotes false negatives, referring to instances that are actually positive but are incorrectly classified as negative.
Mean average precision (mAP) measures the overall detection performance across different recall levels and is widely used for object detection evaluation. In object detection tasks, it is commonly used to evaluate the detection performance of an algorithm for different types of targets. The calculation formula is given in Equation (15).
where C denotes the number of categories (in this study, a single residual-film class is considered, thus C = 1), and P(R) represents the variation in precision P with respect to recall R. In addition to accuracy metrics, model complexity indicators (e.g., parameter count and computational cost) are further reported in the experimental analysis to provide a more comprehensive evaluation.
3. Results
3.1. Experimental Environment
The experimental models in this study were implemented using the Anaconda deep learning environment and the PyTorch framework. The operating system was Windows 11. The hardware configuration consisted of a Ryzen 9 7945HX CPU, an NVIDIA GeForce RTX 4060 GPU (8 GB), 16 GB of memory, and a 1 TB hard disk. The development environment included PyTorch 2.2.2, CUDA 11.8, and Python 3.10.
For training parameters, the number of training epochs was set to 150, the batch size was set to 16, and the number of data-loading workers was set to 8. The SGD optimizer was adopted with a weight decay coefficient of 0.0005 to effectively suppress model overfitting. The random seed was set to 0 to ensure reproducibility across different training experiments.
To ensure fair comparisons, all models were trained and evaluated under a unified experimental protocol. The input resolution, batch size, and training schedule were kept identical across all experiments. All models were initialized using the same type of pretrained initialization strategy to ensure a fair starting point. Specifically, stochastic gradient descent (SGD) was adopted with an initial learning rate of 0.01, and a consistent learning rate scheduling strategy was applied throughout training.
During inference, a standardized evaluation pipeline was employed for all models. The non-maximum suppression (NMS) IoU threshold was fixed at 0.7, and the default confidence threshold of the Ultralytics framework (0.25) was used for all comparisons. Unless otherwise specified, preprocessing, data augmentation, and post-processing settings were kept consistent across models. This unified configuration ensures the fairness, transparency, and reproducibility of the comparative experiments.
3.2. Ablation Experiments
To verify the effectiveness and relative contributions of the proposed modules in the task of small-target residual-film detection in arid-region cotton fields, a series of systematic ablation experiments were conducted on the self-constructed UAV-based residual-film dataset. Using YOLOv11n as the baseline model, EMSE, GLoCA, and the ASF-layer multi-scale fusion structure were introduced step by step while keeping the training strategy and parameter settings consistent. The detection performance under different module combinations was then compared. The experimental results are presented in Table 1, and the corresponding ablation comparison curves are shown in Figure 7. Model complexity indicators, including parameter count and computational cost (GFLOPs), are reported to provide a more comprehensive comparison between detection accuracy and model efficiency.

Table 1.
Ablation Study Results.
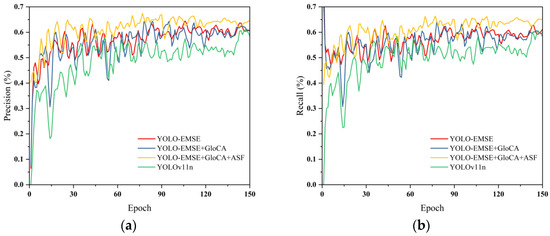
Figure 7.
Ablation comparison curves of different module combinations. (a) Precision curves; (b) Recall curves.
Results from the baseline model indicate that YOLOv11n achieves P, R, mAP50, and mAP50–95 values of 64.7%, 65.2%, 66.2%, and 23.1%, respectively, on this dataset. These results suggest that under complex soil backgrounds and densely distributed small-scale residual-film conditions, the original model still suffers from a certain degree of missed detections and insufficient localization accuracy. After introducing the EMSE module into the baseline model, precision increases to 66.7%, mAP50 rises to 68.9%, and mAP50–95 improves to 25.7%. This indicates that the edge-enhanced multi-branch feature extraction structure effectively strengthens gradient responses at the film–soil boundary and enhances representation capability for residual-film fragments of different sizes through multi-scale parallel branches, thereby improving overall detection accuracy. With the further introduction of the GLoCA module, model performance is enhanced again, with P and R increasing to 69.0% and 66.8%, respectively, and mAP50 and mAP50–95 reaching 70.7% and 26.2%. The performance gains are mainly reflected in recall and overall detection accuracy, demonstrating that the geometrically enhanced local–global coordinate attention mechanism effectively suppresses interference from soil cracks and straw residues under complex textured backgrounds, while strengthening discriminative capability for strip-like and irregular geometric shapes of residual film, resulting in more stable recognition of densely distributed small targets. When EMSE, GLoCA, and the ASF-layer multi-scale fusion structure are all incorporated, the model achieves its optimal overall performance. Precision, recall, mAP50, and mAP50–95 increase to 70.3%, 68.2%, 71.9%, and 26.8%, respectively. Compared with the baseline model, mAP50 and mAP50–95 improve by 5.7 and 3.7 percentage points, respectively. These performance gains indicate that the ASF-layer effectively alleviates small-target information loss caused by deep feature downsampling and promotes synergistic fusion between shallow detail features and deep semantic information.
In addition, a moderate increase in model complexity is observed after integrating all modules, as reflected by higher parameter counts and GFLOPs. However, the accuracy gains outweigh the additional computational cost, indicating a favorable trade-off between detection performance and model efficiency. Specifically, the inference speed gradually decreases from 152.5 FPS for the baseline model to 77.9 FPS for the final integrated model due to the introduction of additional feature extraction and attention modules. Despite this reduction, the proposed model still maintains a high inference speed exceeding real-time requirements, demonstrating that the performance improvements are achieved with an acceptable efficiency trade-off.
Overall, the ablation results demonstrate that each proposed module contributes positively to small-target residual-film detection performance. The EMSE module primarily enhances boundary representation and fine-grained feature expression, the GLoCA module effectively improves discriminative robustness under complex background conditions, and the ASF-layer multi-scale fusion structure further strengthens overall recall and localization accuracy for small targets. Through the synergistic integration of multiple modules, the model achieves consistent and stable performance improvements, validating the effectiveness of the proposed structural enhancements for UAV-based residual-film detection in arid agricultural environments.
3.3. Comparison of Detection Performance Across Different Models
To verify the effectiveness and advantages of the proposed method in the task of close-range UAV-based residual-film detection in complex cotton-field environments, YOLO-EGASF was compared with multiple mainstream object-detection algorithms, including RT-DETR, YOLOv5n, YOLOv6n, YOLOv8n, YOLOv9t, YOLOv10n, and YOLOv11n. All models were evaluated under identical datasets and training strategies. Precision (P), Recall (R), mAP@0.5, and mAP@0.5:0.95 were adopted as evaluation metrics. The comparative results are summarized in Table 2, the performance comparison curves of different algorithms are shown in Figure 8, and qualitative detection results before and after improvement are illustrated in Figure 9.
Table 2.
Algorithm Performance Comparison.
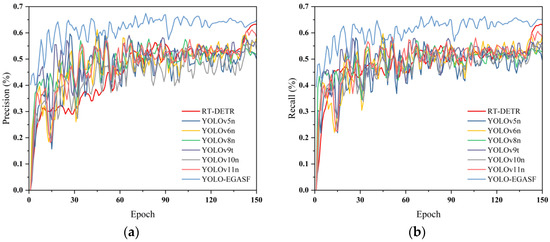
Figure 8.
Performance comparison curves of different detection models. (a) Precision comparison; (b) Recall comparison.

Figure 9.
Qualitative comparison of detection results before and after improvement. The left column shows results of YOLOv11n, and the right column shows results of the proposed YOLO-EGASF model.
From the overall results, notable differences are observed among the detection models across all evaluation metrics, reflecting their distinct emphases in feature modeling capability, scale adaptability, and localization accuracy. As a Transformer-based detection model, RT-DETR exhibits strong global modeling capability; however, for residual-film detection, which is characterized by small-scale and irregular targets, its Precision, Recall, and mAP values do not show clear advantages. This suggests that relying solely on global attention mechanisms is insufficient for effectively capturing the fine-grained boundaries and local structural characteristics of residual-film targets. This observation further indicates that fine-grained boundary modeling and multi-scale feature enhancement are essential for detecting fragmented residual-film objects in complex agricultural environments.
Models such as YOLOv5n, YOLOv6n, and YOLOv8n demonstrate certain advantages in detection efficiency, but under complex background conditions and densely distributed small-target scenarios, their ability to represent residual-film edges and fine details remains limited, resulting in a pronounced decline in performance at the mAP@0.5:0.95 metric. With the continuous evolution of the YOLO architecture, YOLOv9t, YOLOv10n, and YOLOv11n exhibit improved overall detection accuracy compared with earlier versions; nevertheless, in the residual-film detection task, they still face challenges related to shallow feature attenuation and insufficient multi-scale information fusion. This phenomenon is particularly evident under higher IoU thresholds, indicating that there remains room for improvement in fine-grained localization accuracy and scale robustness.
In contrast, the proposed YOLO-EGASF achieves the best performance across all evaluation metrics. Precision and recall reach 70.3% and 68.2%, respectively, indicating that the model significantly improves residual-film detection capability while effectively reducing false detections. In terms of overall detection accuracy, YOLO-EGASF attains an mAP@0.5 of 71.9%, representing an improvement of 5.7 percentage points over YOLOv11n. Under the more stringent mAP@0.5:0.95 metric, the proposed method achieves the highest value of 26.8%, which is 3.7 percentage points higher than that of YOLOv11n. Notably, the improvements are more pronounced under stricter IoU thresholds, highlighting enhanced boundary localization accuracy and multi-scale feature representation. These improvements can be attributed to the collaborative effects of the EMSE module for boundary enhancement, the GLoCA module for geometric-aware attention modeling, and the ASF-layer for multi-scale feature aggregation, which jointly strengthen feature discrimination and localization stability.
Despite the overall improvements, some limitations can still be observed from the qualitative results shown in Figure 9. Although YOLO-EGASF detects more residual-film fragments than the baseline model, a small number of missed detections remain under challenging illumination conditions. For example, in low-light scenes, reduced contrast between residual film and soil weakens boundary cues, making extremely small fragments difficult to distinguish. Conversely, under overly bright or high-reflectance conditions, strong background reflections may obscure fine structural details, occasionally leading to missed detections. These findings suggest that while the proposed method improves robustness across diverse field conditions, further enhancements are still required to handle extreme lighting variations and highly ambiguous visual patterns.
4. Discussion
The experimental results demonstrate that the proposed YOLO-EGASF model provides consistent improvements over the baseline and several mainstream lightweight detectors for UAV-based residual-film detection. Both quantitative metrics and qualitative comparisons indicate that the model more effectively identifies fragmented and densely distributed residual-film targets under complex cotton-field backgrounds. The performance gains are not limited to higher mAP values but are also reflected in more complete detection coverage and improved robustness in challenging scenes.
The improvements can be primarily attributed to the complementary design of the proposed modules. The EMSE component enhances boundary-related representations through multi-branch feature extraction, which is particularly beneficial for weak-edge residual-film fragments embedded in soil textures. The GLoCA module further strengthens discrimination by integrating global spatial context with local geometric patterns, thereby suppressing interference from soil cracks and straw residues. Meanwhile, the ASF-based multi-scale fusion strategy preserves shallow fine-grained features during deep feature aggregation. Together, these mechanisms improve boundary awareness, geometric discrimination, and scale adaptability, which are critical for detecting small and irregular agricultural targets.
Compared with existing YOLO-based improvements, the proposed framework follows a task-oriented design philosophy that explicitly emphasizes boundary enhancement and geometric-aware feature modeling for fragmented residual-film detection. While previous studies have explored attention-based optimization or frequency-domain feature enhancement, YOLO-EGASF focuses on strengthening boundary-gradient perception and increasing the contribution of shallow features in multi-scale fusion. This distinction makes the proposed method particularly suitable for close-range UAV scenarios, where residual films typically exhibit weak edges and dense spatial distribution.
Despite these improvements, some limitations remain. Failure cases are still observed in extremely challenging conditions. Missed detections mainly occur when residual-film fragments are extremely small, partially occluded, or exhibit very low contrast with the surrounding soil. In addition, strong illumination variations, such as dim lighting or overexposed surfaces, may weaken fine-grained feature responses and occasionally lead to detection omissions. These results suggest that further improvement in ultra-small target perception and illumination robustness is still needed.
Another important consideration relates to the dataset construction. The current dataset was collected from a single geographic region, and although efforts were made to improve diversity through selective augmentation, variations in soil type, illumination, and cultivation conditions remain limited. In particular, the dataset may not fully represent the variability encountered in different cotton-growing regions. As a result, the generalization capability of the model under cross-regional scenarios still requires further validation. Future work will focus on collecting multi-regional datasets and exploring domain adaptation strategies to enhance robustness under broader agricultural conditions.
From an application perspective, translating detection outputs into quantitative pollution indicators remains an important future direction. Although the present study focuses on accurate detection, practical agricultural management often requires interpretable metrics such as residual-film coverage area or residue mass within the arable layer. Future research may integrate detection outputs with geometric calibration (e.g., ground sampling distance estimation) to derive area-based indicators, and further establish empirical mappings between image-derived statistics and residue mass through field sampling. Such extensions would bridge the gap between visual detection and environmental assessment, thereby enhancing the agronomic relevance of UAV-based residual-film monitoring.
In addition to detection accuracy, deployment efficiency is also a critical factor for practical agricultural applications. Profiling results indicate that the proposed model maintains low hardware overhead, with peak GPU memory usage remaining below 250 MB and average GPU utilization staying at a relatively low level. These findings suggest that the proposed architecture achieves strong performance improvements without introducing significant computational burden.
Finally, the proposed model maintains a relatively compact architecture despite the introduction of additional modules. This balance between detection performance and computational complexity makes it suitable for practical deployment scenarios, such as onboard UAV inspection or rapid field surveys. With further validation and optimization, the framework shows potential for supporting large-scale residual-film monitoring and intelligent agricultural management.
5. Conclusions
This study proposes a residual-film detection framework, termed YOLO-EGASF, for close-range UAV imagery in arid cotton-field environments. The proposed model integrates targeted architectural enhancements to improve detection performance for small, densely distributed residual-film targets under complex field conditions.
Experimental results on a self-constructed UAV-based residual-film dataset demonstrate that YOLO-EGASF consistently outperforms the baseline YOLOv11n model, achieving improvements of 5.7 and 3.7 percentage points in mAP@0.5 and mAP@0.5:0.95, respectively. These results indicate that the proposed framework effectively enhances detection accuracy and localization reliability for fragmented agricultural targets in real-world scenarios.
In addition to performance improvements, the proposed model maintains a compact architecture, making it suitable for practical UAV-based monitoring tasks. The framework shows potential for supporting rapid field inspection and residual-film pollution assessment, and may also be extended to related surface-object detection problems in agricultural environments.
Future work will focus on expanding validation across more diverse field conditions and broader datasets, including cross-regional and multi-season UAV imagery, to further evaluate and improve the generalization capability of the proposed approach.
Author Contributions
X.Y.: Writing—original draft, Writing—review and editing, Methodology, Software, Validation, Data curation, Formal analysis, Visualization. J.S.: Writing—review and editing, Validation, Data curation. K.Y.: Conceptualization, Supervision, Project administration, Funding acquisition, Writing—review and editing. X.L.: Methodology, Formal analysis, Writing—review and editing, Project administration. S.Z.: Resources, Validation, Writing—review and editing, Project administration, Funding acquisition. H.W.: Conceptualization, Methodology, Supervision, Project administration, Funding acquisition, Writing—review and editing. Z.L.: Conceptualization, Methodology, Supervision, Project administration. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Program of the First Division, Alar City (2022XX06), and the Graduate Scientific Research and Innovation Program of Tarim University (TDGRI2024075).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original UAV image data, annotation files, and experimental results presented in this study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gao, H.; Yan, C.; Liu, Q.; Ding, W.; Chen, B.; Li, Z. Effects of plastic mulching and plastic residue on agricultural production: A meta-analysis. Sci. Total Environ. 2019, 651, 484–492. [Google Scholar] [CrossRef]
- He, G.; Wang, Z.; Cao, H.; Dai, J.; Li, Q.; Xue, C. Year-round plastic film mulch to increase wheat yield and economic returns while reducing environmental risk in dryland of the Loess Plateau. Field Crops Res. 2018, 225, 1–8. [Google Scholar] [CrossRef]
- Dong, H.; Li, W.; Tang, W.; Zhang, D. Early plastic mulching increases stand establishment and lint yield of cotton in saline fields. Field Crops Res. 2009, 111, 269–275. [Google Scholar] [CrossRef]
- Cui, J.; Bai, R.; Ding, W.; Liu, Q.; Liu, Q.; He, W.; Yan, C.; Li, Z. Potential agricultural contamination and environmental risk of phthalate acid esters arrived from plastic film mulching. J. Environ. Chem. Eng. 2023, 12, 111785. [Google Scholar] [CrossRef]
- Bai, R.; Li, Z.; Liu, Q.; Liu, Q.; Cui, J.; He, W. The reciprocity principle in mulch film deterioration and microplastic generation. Environ. Sci. Process. Impacts 2024, 26, 8–15. [Google Scholar] [CrossRef] [PubMed]
- Mugnai, F.; Tucci, G. A comparative analysis of unmanned aircraft systems in low altitude photogrammetric surveys. Remote Sens. 2022, 14, 726. [Google Scholar] [CrossRef]
- Agrawal, J.; Arafat, M.Y. Transforming Farming: A review of AI-Powered UAV technologies in precision agriculture. Drones 2024, 8, 664. [Google Scholar] [CrossRef]
- Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Attri, I.; Awasthi, L.K.; Sharma, T.P.; Rathee, P. A review of deep learning techniques used in agriculture. Ecol. Inform. 2023, 77, 102217. [Google Scholar] [CrossRef]
- Xiong, L.; Hu, C.; Wang, X.; Wang, H.; Tang, X.; Wang, X. Detection and threshold-adaptive segmentation of farmland residual plastic film images based on cbam-dbnet. Int. J. Agric. Biol. Eng. 2024, 17, 231–238. [Google Scholar] [CrossRef]
- Huang, D.; Zhang, Y. Combining yolov7-spd and deeplabv3+ for detection of residual film remaining on farmland. IEEE Access 2024, 12, 1051–1063. [Google Scholar] [CrossRef]
- Fang, H.; Xu, Q.; Chen, X.; Wang, X.; Yan, L.; Zhang, Q. An instance segmentation method for agricultural plastic residual film on cotton fields based on rse-yolo-seg. Agriculture 2025, 15, 2025. [Google Scholar] [CrossRef]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with you only look once (yolo) algorithm: A bibliometric and systematic literature review. Comput. Electron. Agric. 2024, 223, 109090. [Google Scholar] [CrossRef]
- Fan, X.; Sun, T.; Chai, X.; Zhou, J. Yolo-wdnet: A lightweight and accurate model for weeds detection in cotton field. Comput. Electron. Agric. 2024, 225, 109317. [Google Scholar] [CrossRef]
- Nan, Y.; Zhang, H.; Zeng, Y.; Zheng, J.; Ge, Y. Intelligent detection of multi-class pitaya fruits in target picking row based on wgb-yolo network. Comput. Electron. Agric. 2023, 208, 107780. [Google Scholar] [CrossRef]
- Li, K.; Cong, S.; Dai, T.; Zhang, J.; Liu, J. Microscopy image recognition method of stomatal open and closed states in living leaves based on improved YOLO-X. Theor. Exp. Plant Physiol. 2023, 35, 395–406. [Google Scholar] [CrossRef]
- Matsuhashi, S.; Sugiura, R.; Asai, M.; Asami, H.; Kowata, Y.; Akamatsu, Y.; Sasaki, K.; Yoshino, N.; Ihara, N.; Koarai, A. Field evaluation of an agricultural weed detector using YOLO image recognition: Background conditions affect detection performance. Pest Manag. Sci. 2025, 81, 6560–6566. [Google Scholar] [CrossRef]
- Quiñonez, Y.; Lizarraga, C.; Peraza, J.; Zatarain, O. Image recognition in UAV videos using convolutional neural networks. IET Softw. 2019, 14, 176–181. [Google Scholar] [CrossRef]
- Qu, J.; Li, Q.; Pan, J.; Sun, M.; Lu, X.; Zhou, Y.; Zhu, H. SS-YOLOv8: Small-size object detection algorithm based on improved YOLOv8 for UAV imagery. Multimed. Syst. 2025, 31, 42. [Google Scholar] [CrossRef]
- Fu, L.; He, B.; Tian, L.; Chen, D.; Chen, T. YOLOv5-based citrus detection and counting in orchards using UAV images. Comput. Electron. Agric. 2023, 207, 107734. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, H.; Chen, Q.; Luo, X. YOLOv7-based real-time grape leaf disease detection using field images. Comput. Electron. Agric. 2024, 218, 109478. [Google Scholar] [CrossRef]
- Bolikulov, F.; Abdusalomov, A.; Nasimov, R.; Akhmedov, F.; Cho, Y.-I. Early Poplar (Populus) Leaf-Based Disease Detection through Computer Vision, YOLOv8, and Contrast Stretching Technique. Sensors 2024, 24, 5200. [Google Scholar] [CrossRef]
- Zhou, H.; Cao, X.; Sun, K.; Wu, T.; Deng, B. Dense small object detection via multi-scale fusion and context information enhancement. J. Supercomput. 2025, 81, 955. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, J.; Jiang, Z.; Tang, Y. YOLOv5-Atn: An Algorithm for Residual Film Detection in Farmland Combined with an Attention Mechanism. Sensors 2023, 23, 7035. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Zhang, J.; Peng, Y.; Wang, Y. FreqDyn-YOLO: A High-Performance Multi-Scale Feature Fusion Algorithm for Detecting Plastic Film Residues in Farmland. Sensors 2025, 25, 4888. [Google Scholar] [CrossRef] [PubMed]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. Available online: https://opencv.org (accessed on 5 October 2025).
- Huang, Y.; Liu, Z.; Lu, H.; Wang, W.; Lan, R. Brighten up images via dual-branch structure-texture awareness feature interaction. IEEE Signal Process. Lett. 2024, 31, 46–50. [Google Scholar] [CrossRef]
- Ling, Z.; Fan, G.; Liang, Y.; Zuo, J. Joint optimization and perceptual boosting of global and local contrast for efficient contrast enhancement. Multimed. Tools Appl. 2017, 77, 2467–2484. [Google Scholar] [CrossRef]
- Ultralytics. Ultralytics YOLOv11. GitHub Repository. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 September 2025).
- Shadoul, I.; Al-Hmouz, R.; Hossen, A.; Mesbah, M.; Deveci, M. The effect of pooling parameters on the performance of convolution neural network. Artif. Intell. Rev. 2025, 58, 271. [Google Scholar] [CrossRef]
- Zhai, Z.; Zhang, J.; Wang, H.; Wu, M.; Yang, K.; Qiao, X.; Sun, Q. Rethinking softmax in incremental learning. Neural Netw. 2026, 193, 108017. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.