1. Introduction
The standard Vasicek models, including the diffusion models based on Brownian motion and the jump-diffusion models driven by Lévy processes, provide good service in cases where the data demonstrate the Markovian property and a lack of memory. However, over the past few decades, numerous empirical studies have found that the phenomenon of long-range dependence may be observed in the data of hydrology, geophysics, climatology, telecommunication, economics, and finance. Consequently, several time series models or stochastic processes have been proposed to capture long-range dependence, both in discrete time and in continuous time. In the continuous time case, the best-known and widely used stochastic process that exhibits long-range dependence or short-range dependence is of course the fractional Brownian motion (fBm), which describes the degree of dependence by the Hurst parameter. This naturally explains the appearance of fBm in the modeling of some properties of “real-world” data. As well as in the diffusion model with the fBm, the mean-reverting property is very attractive to understand volatility modeling in finance. Hence, the fractional Vasicek model (fVm) becomes the usual candidate to capture some phenomena of the volatility of financial assets (see, for example, [
1,
2,
3]). More precisely, the fVm can be described by the following Langevin equation:
where
,
, the initial condition is set at
, and
, an fBm with Hurst parameter
, is a zero mean Gaussian process with the covariance:
The process
is self-similar in the sense that
,
. It becomes the standard Brownian motion
when
and can be represented as a stochastic integral with respect to the standard Brownian motion. When
, it has long-range dependence in the sense that
. In this case, the positive (negative) increments are likely to be followed by positive (negative) increments. The parameter
H, which is also called the self-similarity parameter, measures the intensity of the long-range dependence. Recently, borrowing the idea of [
4], these papers [
5,
6] used the mixed fractional Vasicek model (mfVm) to describe some phenomena of the volatility of financial assets, which can be expressed as:
where
,
, and the initial condition is set at
. Here, the process of the so-called mixed fractional Brownian motion
is defined by
where
W and
are independent standard and fractional Brownian motions.
When the long-term mean
in (
3) is known (without loss of generality, it is assumed to be zero), (
3) becomes the mixed fractional Ornstein–Uhlenbeck process (mfOUp). Using the canonical representation and spectral structure of the mfBm, the authors of [
7] originally proposed the maximum likelihood estimator (MLE) of
in (
3) and considered the asymptotical theory for this estimator with the Laplace transform and the limit presence of the eigenvalues of the covariance operator for the fBm (see [
8]). Using an asymptotic approximation for the eigenvalues of its covariance operator, the paper of [
9] explained the mfBm from the viewpoint of spectral theory. Some surveys and a complete literature related to the parametric and other inference procedures for stochastic models driven by the mfBm were summarized in a recent monograph of [
10,
11].
However, in some situations, the long-term mean
in (
3) is always unknown. Thus, it is important to estimate all the drift parameters,
and
, in the mfVm. To the best of our knowledge, the asymptotic theory of the MLE of
and
has not developed yet; even some methods for the fractional diffusion cases can be applied in this situation (e.g., see [
12]). This paper fills in the gaps in this area. Using the Girsanov formula for the mfBm, we introduce the MLE for both
and
. When a continuous record of observations of
is available, both the strong consistency and the asymptotic laws of the MLE are established in the stationary case for the Hurst parameter
.
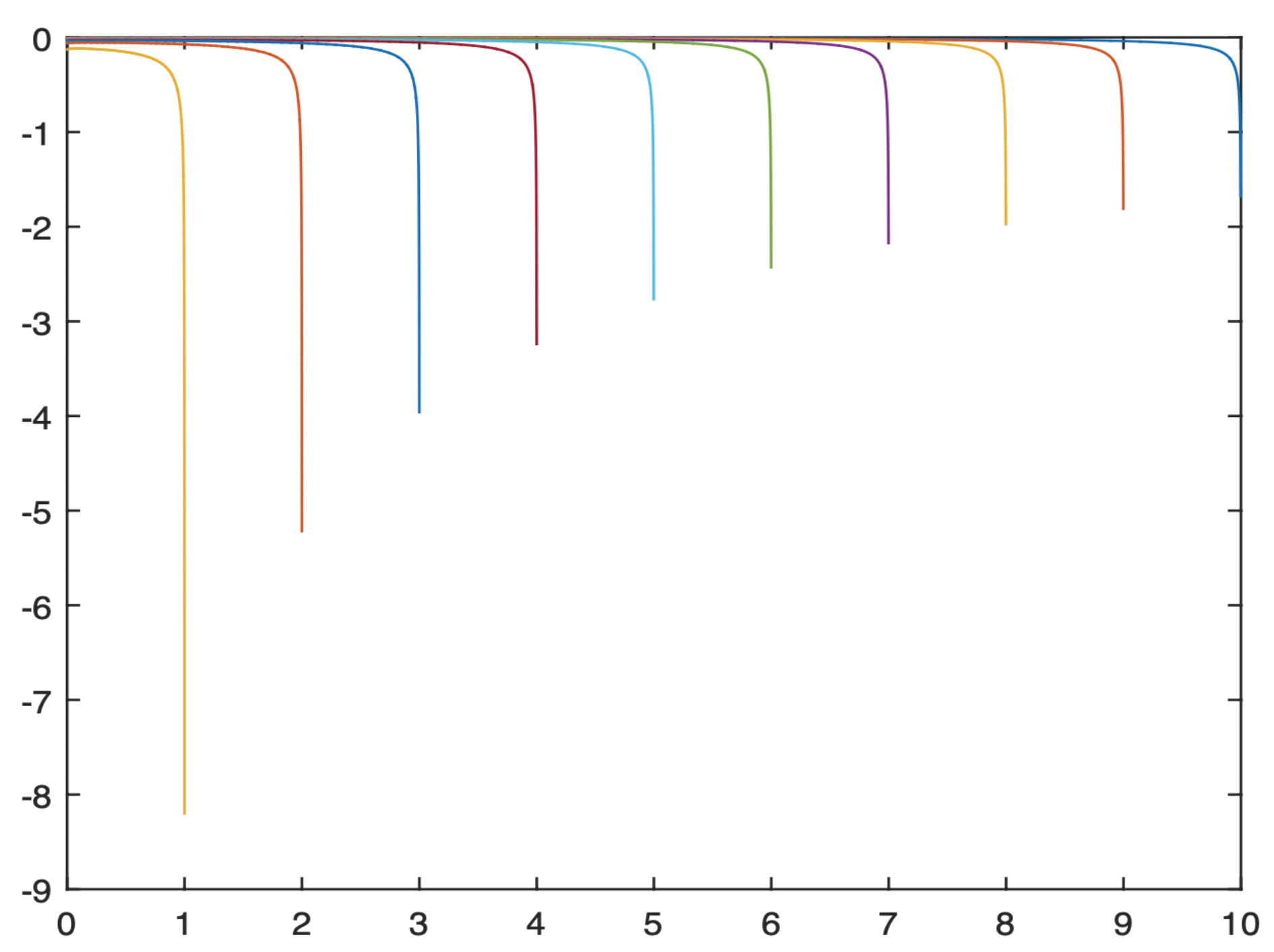
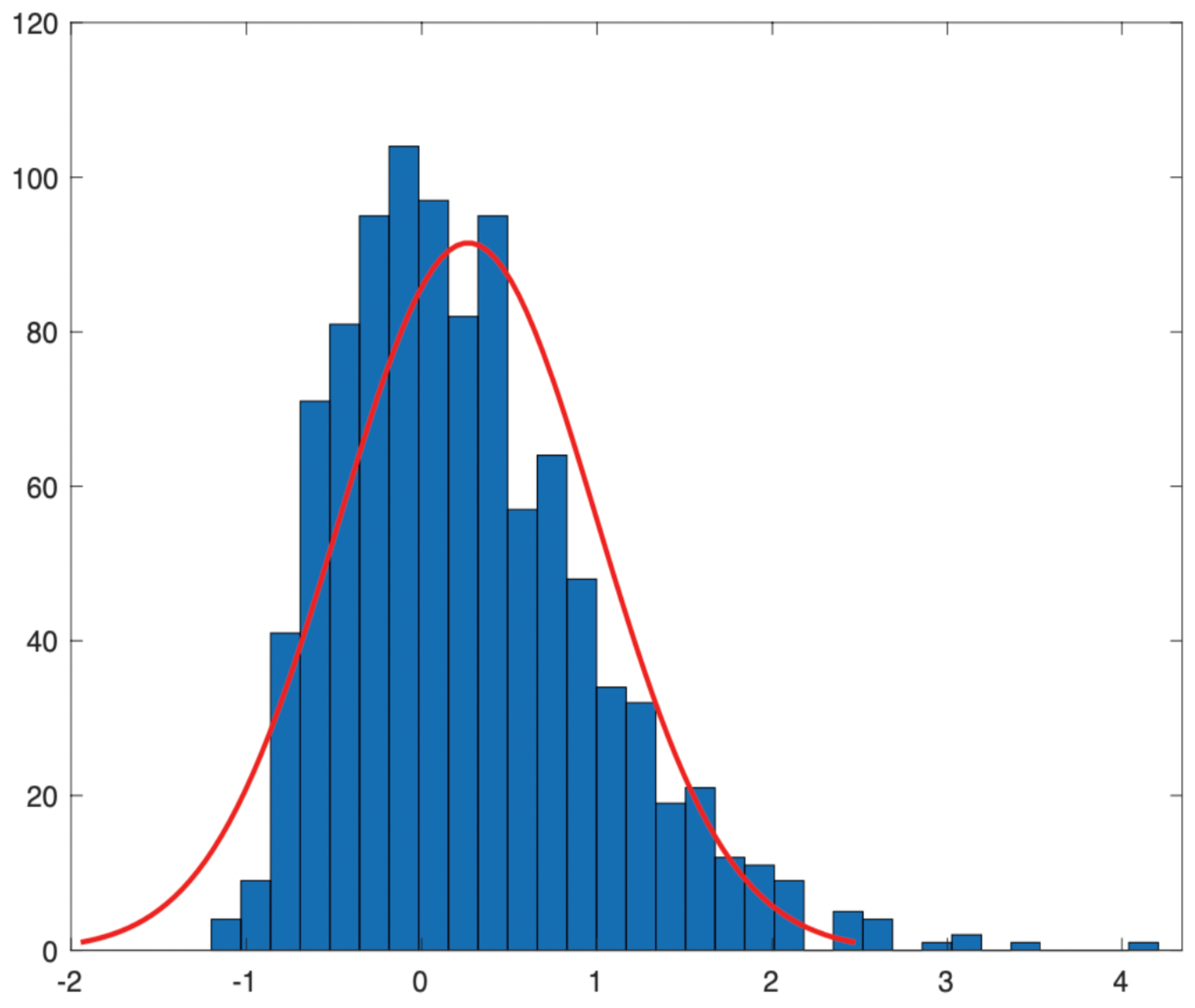
In the aspect of simulation, as far as we know, until now, there are few works referring to the exact experiment for the MLE even in the fractional O-U process. The difficulties come from the process
defined in (
9): it is not easy to simulate and also will cost much time. Here, we try to illustrate that the MLE of the drift parameter in the mixed fractional O-U process (the same for the Vasicek process) can be achieved when
, even if it is not practical.
The rest of the paper is organized as follows.
Section 2 introduces some preliminaries of the mfBm.
Section 3 proposes the MLE for the drift parameters in the mfVm and studies the asymptotic properties of the MLE for the Hurst parameter range
in the stationary case.
Section 4 provides the proofs of the main results of this paper. We complete with the simulation of the drift parameter in
Section 5. Some technical lemmas are gathered in
Section 6. We use the following notations throughout the paper:
,
,
, and ∼ denote convergence almost surely, convergence in probability, convergence in distribution, and asymptotic equivalence, respectively, as
.
2. Preliminaries
This section is dedicated to some notions that are used in our paper, related mainly to the integro-differential equation and the Radon–Nikodym derivative of the mfBm. In fact, mixtures of stochastic processes can have properties quite different from the individual components. The mfBm drew considerable attention since some of its properties were discovered in [
4,
11,
13]. Moreover, the mfBm has been proven useful in mathematical finance (see, for example, [
14]). We start by recalling the definition of the main process of our work, which is the mfBm. For more details about this process and its properties, the interested reader can refer to [
4,
11,
13].
Definition 1. An mfBm of the Hurst parameter is a process defined on a probability space by:where is the standard Brownian motion and is the independent fBm with the Hurst exponent and the covariance function: Let us observe that the increments of the mfBm are stationary and
is a centered Gaussian process with the covariance function:
In particular, for
, the increments of the mfBm exhibit long-range dependence, which makes it important in modeling volatility in finance. Let
. We use the canonical representation suggested in [
13], based on the martingale:
To this end, let us consider the integro-differential equation:
By Theorem 5.1 in [
13], this equation has a unique solution for any
. It is continuous on
, and the
-martingale defined in (
4) and its quadratic variation
satisfy:
where the stochastic integral is defined for
deterministic integrands in the usual way. By Corollary 2.9 in [
13], the process
admits canonical representation:
with:
Remark 1. For , the equation is a Wiener–Höpfner equation:and the quadratic variation is: Let us mention that the canonical representation (
6) and (
7) can be also used to derive an analogue of Girsanov’s theorem, which will be the key tool for constructing the MLE.
Corollary 1. Consider a process defined by:where is a process with a continuous path and , adapted to a filtration with respect to a martingale M. Then, Y admits the following representation:with defined in (8), and the process can be written as: Let us mention that is a -martingale with the Doob–Meyer decomposition:where: In particular, for all . Moreover, if:then the measures and are equivalent and the corresponding Radon–Nikodym derivative is given by:where . 3. Estimators and Asymptotic Behaviors
Now, we return to the model (
3); similar to the previous corollary, we define:
From the following Lemma 10 and Equation (
44), we know:
where
is
when
. By Theorem 2.4 of [
13] and Lemma 2.1 of [
7], we know the derivative of the martingale bracket
exists and is continuous, as well as the process
admits the representation as the stochastic integral with respect to auxiliary observation process
. That is to say, the process
is well defined.
Then, using the quadratic variation of
Z on [0,
T], we can estimate
almost surely from any small interval as long as we have a continuous observation of the process. Moreover, the estimation of
H in the mfBm was performed in [
15]. As a consequence, for further statistical analysis, we assumed that
H and
are known, and without loss of generality, from now on, we suppose that
is equal to one. For
, our observation will be
, where
satisfies the following equation:
Applying the analog of the Girsanov formula for an mfBm, we can obtain the following likelihood ratio and the explicit expression of the likelihood function:
3.1. Only One Parameter Is Unknown
Denote the log-likelihood equation by
. First of all, if we suppose
is known and
is the unknown parameter, then the MLE
is defined by:
then using (
10) for all
, the estimator error can be presented by:
We have the following results:
Theorem 2. For ,and for , Now, we suppose
is known and
is the parameter to be estimated. Then, the MLE
is:
Still with (
10), the estimator error will be:
The asymptotical property is the same, as well as the linear case, which was demonstrated in [
7]. That is, for
,
where
is a constant defined in Theorem 3 and for
,
.
3.2. Two Parameters Unknown
Then, taking the derivatives of the log-likelihood function,
, with respect to
and
and setting them to zero, we can obtain the following results:
The MLE
and
is a solution of the equation of (
16), and the maximization can be confirmed when we check the second partial derivative of
by the Cauchy–Schwarz inequality. Now, the solution of (
16) gives us:
and:
From the expression of
, we obtain that the error term of the MLE can be written as:
and:
We can now describe the asymptotic laws of and for , but .
Theorem 3. For and as , we have:and:where Theorem 4. In the case of , the maximum likelihood estimator of has the same property of the asymptotical normality presented in (19), and for , we have: Remark 2. From the previous theorem, we can see that when , whether one parameter is unknown or two parameters are unknown together, the asymptotical normality of the estimator error has the same result, and they are also the same, as well as the linear case and Ornstein–Uhlenbeck process with the pure fBm with Hurst parameter . However, for , the situation changes, and these differences come from the limit representation of the quadratic variation of the martingale .
Now, we consider the joint distribution of the estimator error. For , if we consider as the two-dimensional unknown parameter, then the following theorem gives us the joint distribution of the estimator error of :
Theorem 5. The maximum likelihood estimator is asymptotically normal:where and is the matrix of the Fisher information. Remark 3. From Theorem 4, we can see that the convergence rates of and are the same, and we can use the central limit theorem of the martingale in the proof. On the contrary, for , when the function defined in (5) has no explicit formula, we cannot use the method in [16] to obtain the joint distribution of . In fact, the convergence rates of and are different, which causes many difficulties, and we leave it for further study. In the above discussions, we were concerned with the asymptotical laws of the estimators; however, even in [
7] with
, the authors did not consider the strong consistency of
. In what follows, we conclude that
converges to
almost surely.
Theorem 6. For , the estimators of have strong consistency, that is, as , Remark 4. For the estimator , the strong consistency is clear when and the same proof for β is unknown, and that is why we do not write this conclusion.
6. Auxiliary Results
This section contains some technical results needed in the proofs of the main theorems of the paper. First, we introduce two important results from [
7]:
This is Lemma 2.5 from [
7].
This is Lemma 2.6 from [
7].
The following lemma shows the relationship between the mfOUp and mfVm.
Lemma 10. Let be an mfOUp with the drift parameter β: Moreover, we have the development of with:where: Proof. In fact, the mixed fractional Vasicek process has a unique solution with the initial value
:
On the other hand, the mixed O-U process
with
is defined by:
The equality (
44) is immediate. For the equation (
44), we only need to take the integral and the derivative on the two sides of (
44). □
Next, we present some limit results.
Lemma 11. For and , as , we have:where is defined in (45). Proof. From the definition of
, we have:
The condition achieves the proof. □
Lemma 12. For , as , we have: Proof. A standard calculation yields:
Now, with the Chebyshev inequality,
:
which implies the desired result. □
Lemma 13. Let ; as , we have: Moreover, from the martingale convergence theorem, we have: Proof. From the definition of
, we can write
as:
Using (
48), we can write our target quantity as:
We consider the above six integrals separately. First, as
, from Lemma 8,
Now, we deal with the second term in (
49). From Lemmas 8 and 11, we know
. Now, we have:
and:
From [
7], as
, we have
Next, from the proof of Lemma 12 and the Borel–Cantelli theorem, as
, we obtain:
With the Cauchy–Schwarz inequality, (
51) and (
53), we obtain:
Finally, the convergence in the probability of (
46) can be obtained by (
50)–(
55).
For the convergence of (
47), since the process
is a martingale and its quadratic variance is
, we can obtain (
47) by the martingale convergence theorem. □
The following are the results for . When Lemma 11 is also available for all , then:
Proof.
The result is clear with Lemma 9. □
Now, we deal with the difficulty of the integral of :
Lemma 15. For we have:and: Proof. We still consider the integral:
as presented in Lemma 12. When
,
The first part of this expectation, which comes from the Brownian motion of course, admits the result. We develop the second part:
With this development and the same calculation in [
22], we have:
and the second converges with the inequality of Cauchy–Schwarz. □





{kind=link}
{kind=link}

