Abstract
Predicting dental development in individuals, especially children, is important in evaluating dental maturity and determining the factors that influence the development of teeth and growth of jaws. Dental development can be accelerated in patients with an accelerated skeletal growth rate and can be related to the skeletal growth pattern as a child. The dental age (DA) of an individual is essential to the dentist for planning treatment in relation to maxillofacial growth. A deep-learning-based regression model was developed in this study using panoramic radiograph images to predict DA. The dataset included 529 samples of panoramic radiographs collected from the dental hospital at Imam Abdulrahman Bin Faisal university in Saudi Arabia. Different deep learning methods were applied to implement the model, including Xception, VGG16, DenseNet121, and ResNet50. The results indicated that the Xception model had the best performance, with an error rate of 1.417 for the 6–11 age group. The proposed model can assist the dentist in determining the appropriate treatment for patients based on their DA rather than their chronological age.
1. Introduction
Dental age (DA) can be estimated based on an individual’s dental development. Chronological age (CA) is based on birth date [1]. DA can be helpful in determining age when a birth certificate is not available or when it is evident that the age of the patient does not match their dental development. In such cases, the dentist can estimate DA before undertaking treatment. Several methods have been developed for estimating DA. The accurate estimation of DA is useful to dentists; however, inaccurate estimation is a risk with serious and potentially permanent consequences. Artificial intelligence (AI) techniques are generally considered to be helpful in decision making. In addition, AI reduces the time required to perform a task compared to human decision making; moreover, AI can perform multiple tasks simultaneously [2]. AI is considered autonomous in that it can learn by analyzing and extracting patterns within the data. It can also replace human decision making when risk is involved and perform tasks continuously without breaks [3]. AI can be used in many fields, including medicine. For example, the authors in [4] developed a deep-learning-based model to detect impacted canines based on the Yamamoto classification. The DenseNet-121, VGG-16, Inception V3, and ResNet-50 are four deep learning models that were created to classify the type of canine impaction from panoramic dental radiography pictures. With an accuracy of 0.9259, the data demonstrate that Inception V3 performs better than the other classifiers. By automating the canine impaction prediction process, the suggested model may be able to assist dentists by saving them time and effort while also making the procedure simpler and more accurate. In addition, the authors in [5] applied a systematic review to identify the frequency of the use of artificial intelligence (AI) in the dental literature from 2011 to 2021. Then, they determined the publications’ specific dentistry specialties and themes of interest from January 2021 to the present. A total of 1497 papers were included in that review which were divided into six categories: therapeutic dentistry, oral and maxillofacial surgery, orthodontics, periodontology, endodontics, prosthodontics and smile design, and airway management. According to this review, artificial intelligence is now used primarily in dentistry to evaluate digital diagnostic techniques, particularly radiography; however, it is slowly making its way into all facets of the field.
AI has the potential to aid dentists in accurately estimating the DA of a patient. The main objective of this study is to develop a deep learning model that automates DA prediction to aid dentists in determining the appropriate treatment. In this paper, we seek to develop a model that helps dentists in estimating dental age accurately. Our motive is purely to help dentists by enabling them to know the correct dental age of a patient before undergoing any procedure.
This paper presents the development and results of a deep learning model that predicts DA. The main contribution in this paper are as follows:
- Developing a methodology to predict dental age using deep learning techniques to provide an automated method that helps dentists, who are end-users of the system, to apply the appropriate procedures.
- Using real data from Imam Abdulrahman Bin Faisal (IAU) university dental hospital to validate the model and assess its performance and effectiveness.
- Applying pre-processing techniques for the real data in order to achieve a low mean absolute error when applying the models.
- Reducing the dentist’s time and hospital resources’ consumption by using an automated method for predicting dental age.
2. Related Studies
In this section, previous studies have been reviewed related to DA estimation methods using AI.
The purpose of the study in [6] was to develop an accurate diagnostic system based on AI for age-group estimation using a convolutional neural network (CNN). A total of 2025 panoramic radiograph images were collected. The patients were divided into three age groups: children and youth (0–19 years), young adults (20–49 years), and older adults (>50 years). However, the number of patients in the young adult group was too large, so an extra division was performed (20–29, 30–39, and 40–49), which created five age groups in total. Thus, the model compared the results between dividing the patients into three age groups and dividing them into five age groups. As a result, combining the prediction results of the three groups and the five groups showed 90.37 ± 0.93% accuracy. The performance accuracy was assessed using a majority voting system and an “area under curve” score (AUC), which resulted in a range from 0.94 to 0.98 for all age groups. The limitations of this study were that it only used the four first molars, so the performance could have been improved by using additional teeth.
Mualla et al. [7] created a model that aimed to automate DA estimation using X-ray images. The dataset consisted of 1429 dental X-ray images from both sexes and different age groups. The first step in the approach was image preprocessing, whereby the X-ray images were converted into the RGB color model and then resized to fit the requirements of each deep neural network. The study used four classifiers, as follows: decision tree (DT), K-nearest neighbor (K-NN), linear discriminant (LD), and support vector machine (SVM). Following this, each classifier was used with CNN models: AlexNet and ResNet. The results showed that K-NN and DT had the highest accuracy with both AlexNet and ResNet, whereas SVM had the lowest accuracy. The limitation of this study was that the dataset was region-specific.
Another study in [8] aimed to use the pulp-to-tooth ratio of canines in estimating age using neural networks and to compare the neural network performance with the regression model. The study used 300 cone-beam computed tomographic (CBCT) scans of patients 14–60 years of age. CBCTs with root infiltration, decay, significant repair, congenital abnormalities, and low resolution were excluded. The selected scans were divided into two sets: a training set containing 270 images and a test set with 30 images. They measured the pulp-to-tooth-area ratio, pulp-to-tooth-length ratio, and pulp-to-tooth-width ratio. The artificial neural network model used the pulp-to-tooth ratio as an input to produce the age as an output. Both the neural network and regression models were applied to the same training and testing sets. The set that was used for testing contained the actual age to determine if the estimation was accurate. The MAE and RMSE were calculated to compare the performance of the two models. The results indicated that the neural network was more effective than the regression model. The RMSE was 4.40 years for the neural network method; the MAE was 4.12 years. For the regression model, the RMSE was 10.26 years, and the MAE was 8.17 years. A limitation of this study was that it was conducted on a specific population. As a result, the findings cannot be generalized to other populations.
Another study was undertaken in 2020 [9] to compare the results of 10 machine learning approaches with the conventional D-method approach. The aim was to calculate DA without using conversion tables, as these tables are usually specific to a certain population. A total of 3605 panoramic radiographs were included in the dataset, with 1734 females and 1871 males from 2 to 24 years of age. The dataset went through several pre-processing steps. Abnormal radiographs were excluded (individuals with systemic disease), producing an even range of radiographs from both sexes. Two subgroups were identified. The first group (U16 Group) included individuals less than 16 years old with a maturity score for their seven mandibular teeth. The second group (U24 Group) included those with seven permanent teeth and all three molars at a maturity stage. To train the machine learning approaches, two pieces of background information were considered in all cases: the age and maturity stage of all third molars, and the seven lower left permanent teeth as assigned by the observer. In the study, no information was given on how machine-learning approaches were developed or used; only the 10 machine learning approaches and the results were reported. They used five indicators to calculate the results and determine the error rate of each machine learning approach: coefficient of determination (R2), mean error (ME), RMSE, MSE, and MAE. In the end, all machine learning approaches outperformed the D-method and W-method, with an MAE less than 0.811. The MAE values for the D-method and W-method were 1.107 and 0.927, respectively. A limitation of this study was that the findings were compared to other studies using a classification reference method. Individual variability, individual origin, and social and nutritional factors were considered.
The study in [10] aimed to improve the accuracy of DA estimations using several machine learning algorithms. The experiment in this study was divided into two parts. First, for comparative experiments, the same data and features as the Demirjian method (D-Method) and Willem method (W-Method) were used. The data in this study consisted of 1636 cases, with 849 females and 787 males, ranging in age from 11 to 19. The results of these methods show that the values of RMSE, MSE, and MAE in males was 1.332, 1.775, and 0.990, respectively. However, in females, changes in RMSE, MSE and MAE were 1.671, 2.616, and 1.261, respectively.
A study [11] created a machine learning model to predict the DA. The dataset consisted of 1697 panoramic radiographs (820 boys and 877 girls), with ages ranging from 10 to 19. The authors excluded any images taken of those above 19. Moreover, they excluded subjects without seven permanent teeth, congenital anomalies, aplasia of at least two corresponding teeth in the mandible on both sides, and unclear images. The study calculated the DA using the Demirjian and Willems methods and using their model. With Demirjian and Willems, they considered the tooth development stages (TDS) of the seven permanent teeth and then used them as features. To compare the methods, root-mean-square error (RMSE) was implemented. The Demirjian method produced an RMSE of 1.998 for males and 2.384 for females. The Willems method produced an RMSE of 2.302 and 2.485 for males and females, respectively. Their model, in contrast, produced an RMSE of 1.794 for males and 2.008 for females. They concluded that their model had the highest accuracy and lowest error estimation.
Another study [12] sought to select the most acceptable machine learning method for dental age prediction based on buccal bone level using ML and DL. The database included 150 CBCT pictures from patients aged 20 to 69 who were part of the Faculty of Dental Medicine with Clinics at the University of Sarajevo (73 men and 77 women). Age-related increases in Left and Right Buccal Alveolar Bone Levels were the most significant characteristics, notably the latter. The Random Forest algorithm produced the best results, with a mean absolute error of 6.022 and a correlation coefficient of 0.803.
3. Materials and Methods
This section includes a description of the dataset used in this study, data pre-processing, and the deep learning model used to estimate DA.
3.1. Dataset Description
Dental radiograph images are required to develop a model that predicts DA. Panoramic radiograph images were collected with dentists’ assistance from the dental hospital at Imam Abdulrahman Bin Faisal University, Dammam, Saudi Arabia [IRB: #2021-09-354]. The dataset consisted of 529 samples of panoramic radiographs from children, young adults, and adults. Figure 1 shows the number of images by gender and age. In addition, the dataset included clinical features such as age, gender, and the stages of the seven left lower mandibular teeth. The images were annotated by three dentists to determine the DA for each image. Table 1 shows the dataset attributes with type and description.
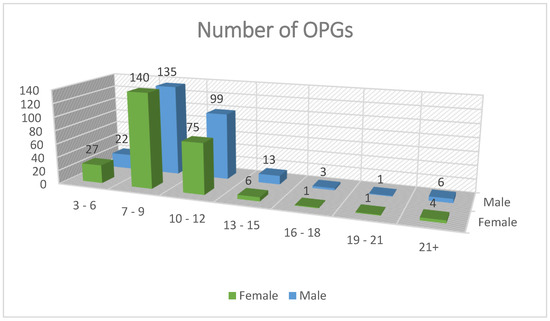
Figure 1.
Number of images by gender and age.

Table 1.
Dataset attributes with type and description.
3.2. Image Pre-Processing
Pre-processing refers to the steps taken to transform raw data into useful data for the model to interpret [13]. As panoramic radiographs can have noise and poor quality, their overall quality must be enhanced to improve the learning phase and produce more accurate results. A single pre-processing step was performed on the dataset: image cropping. Image cropping facilitates the ability of a model to learn. It identifies the important areas in an image so the model can focus on them and ignore unnecessary areas that may confuse the model. Here, the model learned to use the seven left lower mandibular teeth; thus, the images were cropped to only include the required teeth for the learning process. Figure 2 and Figure 3 show images before and after cropping.
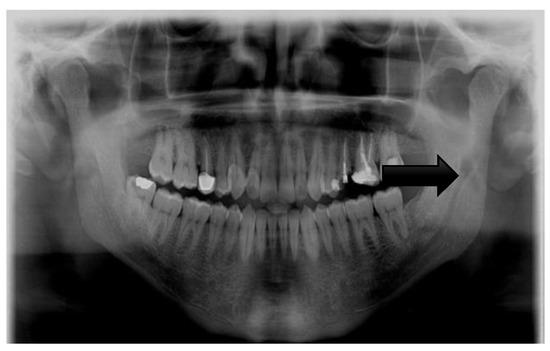
Figure 2.
Image before cropping.
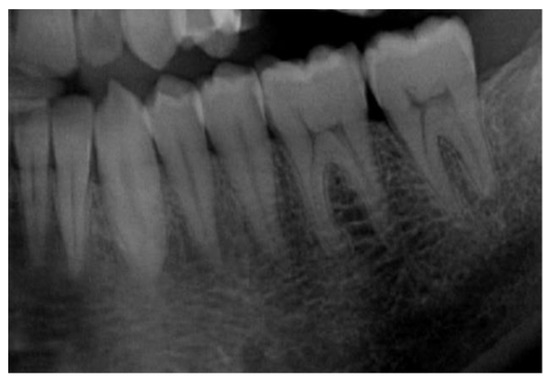
Figure 3.
Image after cropping.
3.3. Convolutional Neural Network Model
A convolutional neural network (CNN or ConvNet) is a complex feed-forward neural network. CNNs are used for image recognition due to their excellent performance. The purpose of a CNN is to reduce images into a structure that is easier to process while preserving essential features for reliable prediction [14]. A CNN can be used to classify images based on feature extraction and classification. Feature extraction redefines redundant data into a smaller number of features and transforms input data into a set of features [15]. The network performs a sequence of convolutions and pooling operations during feature extraction; the network learns specific patterns in the images and detects them everywhere. In the classification section, the model uses the image to input and output a collection of features. Building a CNN involves five steps [16]: convolution, rectified linear unit (ReLU) activation, pooling, flattening, and full connection. (1) Convolution extracts features such as edges from the input. With repetition, the network begins to recognize more complicated properties such as forms. Convolution produces a dot product between two filters or kernels. (2) The ReLU function has an advantage over other activation functions in that it does not stimulate all neurons simultaneously and can be used to enhance non-linearity. (3) Pooling primarily reduces the computing power required to process the data. It is accomplished by further reducing the size of the feature matrix. Moreover, it performs distinct operations on each feature map. There are many types of pooling [17]; the most commonly used is max-pooling, which chooses the most significant value from all values inside the pooling region, aiming to extract the most critical features from a small set of nearby data. (4) Flattening is used to create a long vector that can be used to input a CNN into a pooling feature map. (5) Full connection converts the input image into an appropriate format. The purpose of creating a CNN is to use the input and merge the features into a better range of qualities, allowing the CNN to better identify images. Model training, testing, and evaluation are conducted after the CNN building blocks have been constructed. The training set and classes are used to train the model. After the model has been trained, it is tested using a testing set that the model has never seen before, and the performance is assessed. The model may be used to classify additional images [9]. Pretrained models such as Xception, VGG16, DenseNet121, and ResNet50 were used. The models were imported from TensorFlow [18] and trained using the dataset. Figure 4 shows the model development methodology.
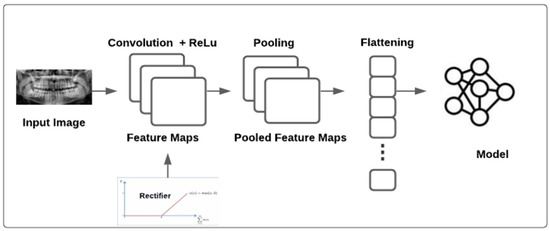
Figure 4.
The proposed model architecture.
The pretrained models used in this study are described as follows:
3.3.1. Xception
Extreme Inception (Xception) [19] is a CNN architecture. It is an extreme version of Inception which was created by Google. The Xception architecture consists of three parts (entry, middle, and exit flows) [10]. In each part, there are different layers and a different number of layers. The first part is the entry flow, which contains several convolutional layers, two of which are followed by ReLu activation. It also contains other layers, such as separable convolutional layers and max-pooling layers. The next part is the middle flow, which is repeated eight times. The last part is the exit flow, which has additional layers, such as a global average pooling layer and a fully connected layer, which are optional [20].
3.3.2. VGG16
The Visual Geometry Group (VGG) [21] is a CNN architecture with two types: VGG-16 and VGG-19. These types differ in the number of layers. The VGG-19 contains three more convolutional layers than the VGG-16. This architecture uses an input with a 224 × 224 image size. The architecture includes convolutional layers including a small 3 × 3 receptive field, 1 × 1 convolution filters, and a ReLu unit to decrease the training time. After the conventional layer, the max-pooling layer is used to reduce the amount of data that are sent to the next layer. Three fully connected layers are included in this architecture [22].
3.3.3. DenseNet121
A densely connected convolutional network (DenseNet) [23] is a convolutional neural network architecture. In DenseNet, the outputs of the previous layers are concatenated and act as an input for the next layer, resulting in high memory and computation efficiency. Additionally, it avoids the vanishing gradient problem, caused when information vanishes in the long path between the input layer and the output layer. The architecture begins with a single convolutional layer followed by a max-pooling layer and ends with a global pooling layer and a fully connected layer to generate the output [24].
3.3.4. ResNet50
A residual neural network (ResNet) is a CNN architecture that allows shortcuts to solve the problem of degradation, which occurs when a network increases in depth, causing the accuracy to quickly degrade. The shortcuts work by jumping one or several layers; these jumps are made when the output of the layer is the same as its input. Skipping layers allows easier optimization [25].
3.4. Evaluation Methodology
In regression, there are three primary metrics for model evaluation: MSE, RMSE, and MAE [26]. MSE is an absolute measure of the quality of fit. MAE is related to MSE. MAE is the total absolute value of error rather than the sum of the squares of the error (MSE). Table 2 shows the equation for each metric.
Table 2.
Performance metrics.
4. Results and Discussion
Five experiments were conducted using the dataset. The main focus was to reduce the error in the model for more precise DA estimation. As the dataset did not contain an equal number of panoramic radiographs for each age, the model may not have easily learned using limited data. All experiments were conducted using the pretrained Xception, VGG16, DenseNet121, and ResNet50 models.
Experiment 1 used the entire dataset containing 529 images, 423 for training and 106 for testing (80% for training and 20% for testing). In this experiment, ResNet50 produced the lowest error rate (1.5633). Figure 5 shows the error rate of ResNet50 through the epochs.
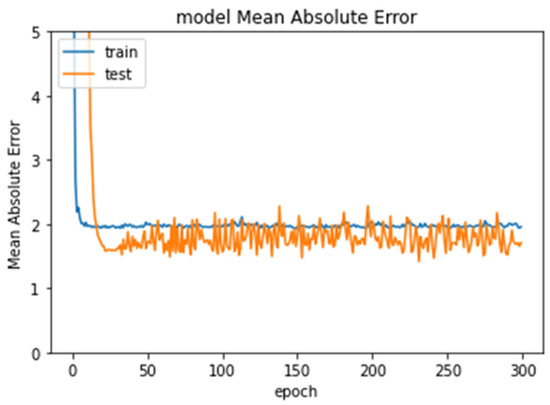
Figure 5.
Error rate in Experiment 1 through epochs.
In Experiment 2, a subset of the original dataset was used, testing ages 6–12 using 487 images, 390 images for training and 97 images for testing. ResNet50 again produced the lowest error rate (1.4429). Figure 6 shows the error rate of ResNet50 through the epochs.
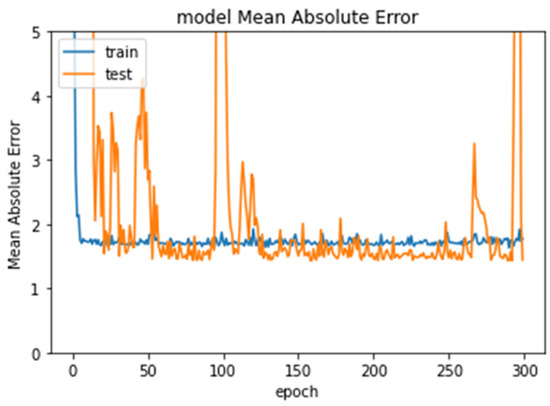
Figure 6.
Error rate for Experiment 2 through epochs.
Experiment 3 tested ages 7–11. The dataset consisted of 465 images, 372 images for training and 93 images for testing. The Xception model produced the lowest error rate (1.4173). Figure 7 shows the error rate of Xception through the epochs.
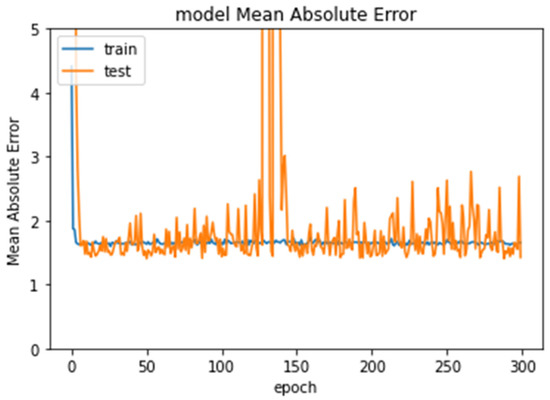
Figure 7.
Error rate for Experiment 3 through epochs.
Experiment 4 only tested the images for age seven. The dataset consisted of 85 images, 68 images for training and 17 images for testing. The VGG16 model produced the lowest error rate (0.6915). Figure 8 shows the error rate of VGG16 through the epochs.
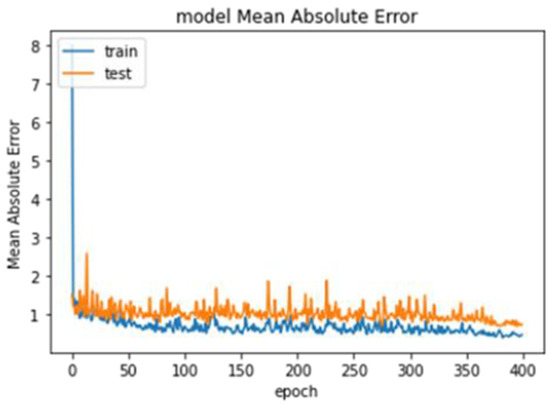
Figure 8.
Error rate of VGG16 through the epochs.
Experiment 5 tested images for age nine. The dataset consisted of 90 images, 72 images for training and 18 images for testing. The VGG16 model produced the lowest error rate (0.6915). Figure 8 shows the error rate of VGG16 through the epochs.
Model performance was dependent on the age range as the data were imbalanced. Table 3 presents a summary of the best results for the experiments.
Table 3.
Summary of best results for each experiment.
5. Conclusions
DA can be estimated from the observed phase of dental development. CA is based on birth date. However, CA does not always match DA. Usually, DA is less than CA. Dentists should determine the DA for a patient to perform the correct procedure for that age. The incorrect estimation of DA can result in a dentist using an inappropriate treatment, with serious and potentially permanent consequences. The accurate identification of DA before undergoing any procedure is highly desirable. DA aids dentists by providing a fast response and conforming to their estimates.
In this study, a deep-learning-based model was developed using panoramic radiograph images from the dental hospital at Imam Abdulrahman Bin Faisal University in Saudi Arabia. The model aims to accurately identify DA. Four CNN algorithms were used to build the model: ResNet50, VGG16, Xception, and DenseNet121. Five experiments were conducted to test the models. In the first experiment, we tested the entire dataset with cropping and renaming. The lowest MAE we observed was 1.5633 for ResNet50, which is an unacceptable error rate. For the second and third experiments, we reduced the age range as most patients were 6–13 years of age. The age range for the second experiment was 6–12 years; ResNet50 produced an MAE of 1.4429, which was lower than that in the first experiment. For the third experiment, the age range was further reduced to 6–11 years, resulting in an MAE of 1.4173 using the Xception model, which was an improvement from the previous experiment. We observed that the further we narrowed the age range, the better the models learned and performed. For the last two experiments, we evaluated the results for specific ages which had the most images. The fourth experiment used a dataset only containing images from patients seven years of age. VGG16 produced an MAE of 0.6915. For the fifth experiment, we used a dataset only containing images from patients nine years of age, which produced an MAE of 0.9499. In the future, this study could be expanded by applying the models to larger datasets with balanced age ranges.
Author Contributions
Conceptualization, S.S.A. and M.A.; methodology, S.S.A., L.A.(Lujain Althumairy), B.A., G.A., L.A. (Lama Albluwiare) and R.A.; software, L.A. (Lujain Althumairy), B.A., G.A., L.A. (Lama Albluwiare) and R.A.; validation, S.S.A., L.A. (Lujain Althumairy), B.A., G.A., L.A. (Lama Albluwiare) and R.A.; formal analysis, S.S.A., L.A. (Lujain Althumairy), B.A., G.A., L.A. (Lama Albluwiare) and R.A.; investigation, S.S.A., L.A. (Lujain Althumairy), B.A.,G.A., L.A. (Lama Albluwiare) and R.A.; resources, M.A., A.A., A.A. and S.Y.S.; data curation, M.A., A.A. (Abdulaziz Alamri), A.A. (Afnan Alabdan). and S.Y.S.; writing—original draft preparation, S.S.A., L.A. (Lujain Althumairy), B.A., G.A., L.A. (Lama Albluwiare) and R.A.; writing—review and editing, S.S.A.; visualization, S.S.A.; supervision, S.S.A.; project administration, S.S.A., M.A., A.A. (Abdulaziz Alamri), A.A. (Afnan Alabdan). and S.Y.S.; funding acquisition, M.A., A.A. (Abdulaziz Alamri), A.A. (Afnan Alabdan)., S.Y.S., L.A. (Lujain Althumairy), B.A., G.A., L.A. (Lama Albluwiare) and R.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board of Imam Abdulrahman bin faisal University, Dammam, Saudi Arabia [IRB: #2021-09-354].
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this study is available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Maia, M.C.G.; Martins, M.d.G.A.; Germano, F.A.; Neto, J.B.; Silva, C.A.B. da Demirjian’s System for Estimating the Dental Age of Northeastern Brazilian Children. Forensic. Sci. Int. 2010, 200, 177.e1. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and Explainability of Artificial Intelligence in Medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed]
- Trocin, C.; Mikalef, P.; Papamitsiou, Z.; Conboy, K. Responsible AI for Digital Health: A Synthesis and a Research Agenda. Inf. Syst. Front. 2021, 1–19. [Google Scholar] [CrossRef]
- Aljabri, M.; Aljameel, S.S.; Min-Allah, N.; Alhuthayfi, J.; Alghamdi, L.; Alduhailan, N.; Alfehaid, R.; Alqarawi, R.; Alhareky, M.; Shahin, S.Y.; et al. Canine Impaction Classification from Panoramic Dental Radiographic Images Using Deep Learning Models. Inform. Med. Unlocked 2022, 30, 100918. [Google Scholar] [CrossRef]
- Thurzo, A.; Urbanová, W.; Novák, B.; Czako, L.; Siebert, T.; Stano, P.; Mareková, S.; Fountoulaki, G.; Kosnáčová, H.; Varga, I. Where Is the Artificial Intelligence Applied in Dentistry? Systematic Review and Literature Analysis. Healthcare 2022, 10, 1269. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Lee, Y.H.; Noh, Y.K.; Park, F.C.; Auh, Q.S. Age-Group Determination of Living Individuals Using First Molar Images Based on Artificial Intelligence. Sci. Rep. 2021, 11, 1073. [Google Scholar] [CrossRef] [PubMed]
- Mualla, N.; Houssein, E.H.; Hassan, M.R. Dental Age Estimation Based on X-Ray Images. Comput. Mater. Contin. 2020, 62, 591–605. [Google Scholar] [CrossRef]
- Farhadian, M.; Salemi, F.; Saati, S.; Nafisi, N. Dental Age Estimation Using the Pulp-to-Tooth Ratio in Canines by Neural Networks. Imaging Sci. Dent. 2019, 49, 19–26. [Google Scholar] [CrossRef]
- Galibourg, A.; Cussat-Blanc, S.; Dumoncel, J.; Telmon, N.; Monsarrat, P.; Maret, D. Comparison of Different Machine Learning Approaches to Predict Dental Age Using Demirjian’s Staging Approach. Int. J. Leg. Med. 2021, 135, 665–675. [Google Scholar] [CrossRef]
- Tao, J.; Wang, J.; Wang, A.; Xie, Z.; Wang, Z.; Wu, S.; Hassanien, A.E.; Xiao, K. Dental Age Estimation: A Machine Learning Perspective. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Cham, Switzerland, 2020; pp. 722–733. [Google Scholar]
- Tao, J.; Chen, M.; Wang, J.; Liu, L.; Hassanien, A.E.; Xiao, K. Dental Age Estimation in East Asian Population with Least Squares Regression. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Cham, Switzerland, 2018; pp. 653–660. [Google Scholar]
- Saric, R.; Kevric, J.; Hadziabdic, N.; Osmanovic, A.; Kadic, M.; Saracevic, M.; Jokic, D.; Rajs, V. Dental Age Assessment Based on CBCT Images Using Machine Learning Algorithms. Forensic. Sci. Int. 2022, 334, 111245. [Google Scholar] [CrossRef]
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big Data Preprocessing: Methods and Prospects. Big Data Anal. 2016, 1, 9. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Li, Z.; Xu, Y.; Gardoni, P.; Li, W. Evaluation of Different Bearing Fault Classifiers in Utilizing CNN Feature Extraction Ability. Sensors 2022, 22, 3314. [Google Scholar] [CrossRef]
- Daradkeh, M.; Abualigah, L.; Atalla, S.; Mansoor, W. Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics. Electronics 2022, 11, 2066. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. A Spatial Feature-Enhanced Attention Neural Network with High-Order Pooling Representation for Application in Pest and Disease Recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Novac, O.-C.; Chirodea, M.C.; Novac, C.M.; Bizon, N.; Oproescu, M.; Stan, O.P.; Gordan, C.E. Analysis of the Application Efficiency of TensorFlow and PyTorch in Convolutional Neural Network. Sensors 2022, 22, 8872. [Google Scholar] [CrossRef] [PubMed]
- Piekarski, M.; Jaworek-Korjakowska, J.; Wawrzyniak, A.I.; Gorgon, M. Convolutional Neural Network Architecture for Beam Instabilities Identification in Synchrotron Radiation Systems as an Anomaly Detection Problem. Measurement 2020, 165, 108116. [Google Scholar] [CrossRef]
- Kaur, M.; Singh, D. Multi-Modality Medical Image Fusion Technique Using Multi-Objective Differential Evolution Based Deep Neural Networks. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 2483–2493. [Google Scholar] [CrossRef] [PubMed]
- Rao, B.S. Accurate Leukocoria Predictor Based on Deep VGG-Net CNN Technique. IET Image Process. 2020, 14, 2241–2248. [Google Scholar] [CrossRef]
- Ewe, E.L.R.; Lee, C.P.; Kwek, L.C.; Lim, K.M. Hand Gesture Recognition via Lightweight VGG16 and Ensemble Classifier. Appl. Sci. 2022, 12, 7643. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, J.; Xu, X.; Yao, Y. RDense: A Protein-RNA Binding Prediction Model Based on Bidirectional Recurrent Neural Network and Densely Connected Convolutional Networks. IEEE Access 2020, 8, 14588–14605. [Google Scholar] [CrossRef]
- Ogundokun, R.O.; Maskeliūnas, R.; Misra, S.; Damasevicius, R. A Novel Deep Transfer Learning Approach Based on Depth-Wise Separable CNN for Human Posture Detection. Information 2022, 13, 520. [Google Scholar] [CrossRef]
- Liu, T.; Chen, T.; Niu, R.; Plaza, A. Landslide Detection Mapping Employing CNN, ResNet, and DenseNet in the Three Gorges Reservoir, China. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11417–11428. [Google Scholar] [CrossRef]
- Roumpakias, E.; Stamatelos, T. Prediction of a Grid-Connected Photovoltaic Park’s Output with Artificial Neural Networks Trained by Actual Performance Data. Appl. Sci. 2022, 12, 6458. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).