Abstract
Multi-plane computer-generated holography is a key technology for enabling volumetric and near-eye displays. However, its widespread adoption remains constrained by the high computational cost of phase optimization and the persistent issue of axial crosstalk between depth planes. In this work, we propose a physics-informed deep learning framework that directly generates holograms for 3D multi-plane displays. Our approach implements a learnable mapping from spatial distributions to depth-dependent reconstructions and incorporates a trainable Fourier transform layer, enabling end-to-end optimization entirely in the physical domain (i.e., from the hologram plane to the multi-plane reconstruction). As a result, hologram generation time is decreased significantly, while effectively suppressing crosstalk across axial planes. Experimental validation demonstrates that the obtained phase hologram successfully reconstructs sparse multi-plane structured patterns with low visible crosstalk. These results highlight the potential of deep learning to advance practical applications in dynamic 3D display and holographic optical tweezer technologies.
1. Introduction
Holographic displays are widely regarded as a powerful tool for the ultimate three-dimensional (3D) display technology since they can, in principle, reproduce all information of geometric and physical depth for 3D scenes [1,2,3,4]. Enabling this technology is computer-generated holography, which replaces physical optical recording with numerical wavefront engineering. Computationally generated hologram (CGH) has been extensively developed for applications ranging from free-space volumetric displays [5,6,7,8] to, more recently, near-eye displays for virtual and augmented reality [7,9,10,11]. For a realistic sense of volume, many systems depend on multi-plane CGH, typically implemented by using a single phase-only spatial light modulator (SLM) to reconstruct a stack of two-dimensional intensity patterns at multiple axial depths [12,13,14,15,16].
Traditional algorithmic approaches for multi-plane CGH generally fall into two categories. The first encompasses iterative phase-retrieval methods, such as the Gerchberg–Saxton (GS) algorithm and its variants. These methods propagate wavefields between different planes under amplitude constraints [6,7,17]. While conceptually straightforward, they are computationally demanding and their convergence deteriorates with an increasing number of planes. The second category consists of optimization-based approaches that explicitly minimize an image-domain loss via gradient descent [18,19]. Although these can achieve high reconstruction quality, they require many propagation steps for every hologram and are often sensitive to initialization.
To overcome these limitations, deep learning has emerged as a powerful tool for accelerating and regularizing CGH. Networks have been successfully deployed to generate phase-only holograms for single or multiple depths, and to compensate for optical aberrations [18,20,21,22,23,24,25,26,27]. A prevalent strategy embeds a differentiable wave propagation model as a fixed network layer, amortizing the optimization cost into training and enabling real-time inference. However, a critical and outstanding issue persists: the explicit axial crosstalk in multi-plane systems that rely on a single phase-only SLM. Unsuppressed crosstalk significantly degrades image contrast and depth fidelity, limiting the perceptual quality of the reconstructed 3D scene.
In this paper, we propose a physics-informed deep learning framework designed specifically for fast, high-fidelity multi-plane hologram generation with suppressed axial crosstalk. Firstly, we formulate multi-plane hologram generation as a volumetric inverse problem. Secondly, we introduce a U-Net-based architecture by employing space-to-depth operations to capture global diffraction dependencies without the information loss typical of pooling layers. Thirdly, we integrate a Fourier transform module and train the model end-to-end with a volumetric structure-sensitive loss (cosine similarity) defined across the entire 3D focal stack. This cohesive design enables the network to learn an optimal mapping that inherently minimizes interference between planes. A comprehensive evaluation combining numerical simulations and optical experiments quantitatively confirms the advancement of our multi-plane CGH approach, achieving high-fidelity 3D reconstruction with significant crosstalk suppression over existing approaches. We anticipate that the principles of our method will be applicable to a broader range of wave-based computational imaging and display tasks, paving the way for more efficient and perceptually faithful holographic displays and optical manipulation.
2. A Deep Learning Method for Multi-Plane CGH
Figure 1 illustrates the optical configuration for a multi-plane display. A phase-only SLM (FSLM-2K39-P, CAS Microstar, Xi’an, China) is used to display the hologram and generates a 3D image composed of patterns (e.g., an array of focal spots) at discrete axial planes (, where is located at the focal plane). The SLM is followed by a 4f relay system (lenses L1 and L2), which images the hologram onto the back aperture of an objective lens. In the theoretical or simplified model, this 4f relay can be conceptually omitted, which is equivalent to placing the hologram directly at the rear focal plane of the objective lens.
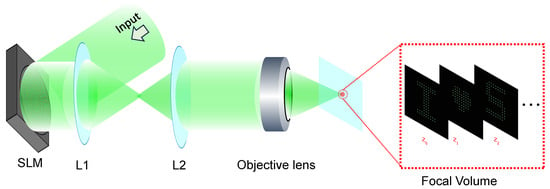
Figure 1.
The optical configuration for a multi-plane display. A hologram displayed on the SLM is first relayed through lenses L1 and L2 to the back aperture of the objective, and the objective subsequently focuses the modulated beam, creating sparse arrays of focal spots at multiple axial planes.
The optical configuration is based on the standard Fourier holography; denotes the phase distribution displayed on the SLM. Assuming a uniform input beam (i.e., unit amplitude) for this configuration, the complex optical field immediately after the SLM can be written as:
This field is relayed by a 4f system and imaged onto the back aperture of an objective lens. And at the image space (i.e., after the objective lens), the resulting complex field, denoted as , can be described by the Fresnel diffraction integral:
Moreover, in the far-field regime, the field at a given depth Z can be expressed by [28]:
where denotes the two-dimensional Fourier transform, and the amplitude factor .
Conversely, if the field is known, the corresponding SLM field can be recovered using the inverse Fourier transform
The intensity at each depth is obtained as . Given a target of intensity distribution defined over the 3D volume, the core optimization problem is to find a single phase profile displayed on the SLM such that the reconstructed intensity I matches at all designated planes, while simultaneously suppressing crosstalk and background noise in non-target regions.
2.1. Network Framework
As illustrated in Figure 2, our goal is to generate a 3D intensity stack comprising a set of distinct patterns [here exemplified by the text “I♡STU” shown in Figure 2a] distributed across multiple axial planes on both sides of the focal plane (). To achieve this target 3D intensity distribution, we employ a deep neural network built upon a U-Net-style encoder–decoder architecture. The network is designed to process a discretized representation of the 3D target volume, formatted as an input with size . Here, m denotes the lateral dimension of each 2D intensity pattern and p corresponds to the number of depth channels, each representing a specific axial plane within the defined 3D volume.
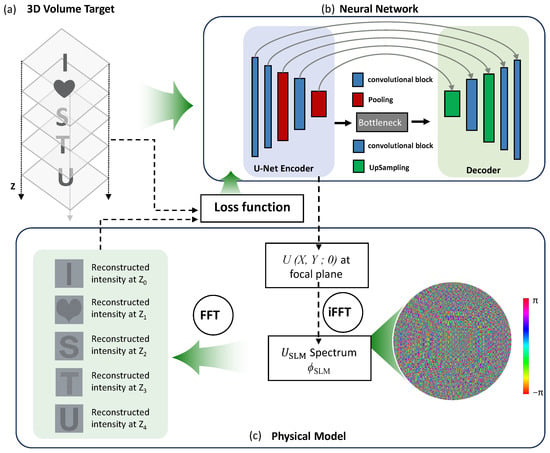
Figure 2.
The proposed network framework for multi-plane CGH. (a) 3D volumetric target. (b) U-Net-based encoder utilizing space-to-depth and depth-to-space operations to process a 3D intensity stack. (c) Physical model for prediction of hologram.
The network architecture, depicted in Figure 2b, comprises six convolutional blocks for multi-scale feature extraction, integrated with two pooling and two up-sampling stages. The incorporation of a bottleneck structure significantly reduces the number of feature map channels, thereby enhancing the performance of the network and computational efficiency. A key innovation in the encoder is the replacement of conventional max-pooling with a space-to-depth (interleave) operation. This operation reshuffles local spatial regions into separate channel groups, thereby preserving high-frequency fringe details—essential for accurate diffraction modeling—while effectively expanding the receptive field. This design avoids the information loss typically incurred by standard down-sampling. Correspondingly, the decoder reconstructs the spatial layout via depth-to-space (deinterleave) operations, restoring the original resolution.
In current implementation, the trainable Fourier transform layer is designed based on the far-field diffraction approximation described by Equation (3). This approximation is valid when the propagation distance Z is much greater than the beam radius. In our framework, the Fourier transform layer is used to map the optical field from the hologram plane to the target reconstruction planes, and all target planes in our model are located beyond the focal plane and satisfy the far-field condition (, f is focal length of focusing lens).
Once trained, the network establishes an end-to-end mapping from the target intensity distribution to a physically realizable approximation of the complex optical field at the focal plane, denoted as . This estimated field is subsequently back-propagated to the SLM plane via an inverse 2D Fourier transform, as described by Equation (4). The final output of this computational framework is the phase-only mask , which represents the solution to the optimization problem of hologram and is directly deployable on the SLM, as illustrated in Figure 2c.
The network is trained using a cosine similarity loss applied to the 3D intensity volumes:
where and represent the inner product and the modulus, respectively. The inner product is computed across all pixels and all depth planes. Owing to its scale invariance, the cosine similarity loss promotes accurate spatial structure reconstruction. This property is particularly beneficial for penalizing low-intensity crosstalk in regions that are intended to remain dark. In practice, a regularization term is applied to the reconstructed background lying outside a narrow mask defined around the target points.
2.2. Generation of Training Data
To train the network for multi-plane CGH, we first synthesize random sparse 3D point clouds and arrange them into binary intensity volumes distributed across five depth planes. Each point is randomly assigned to a specific plane and can be viewed as a diffraction-limited spot. An example of such a training sample is shown in Figure 3.
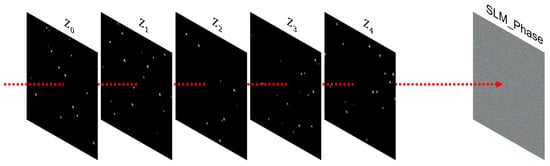
Figure 3.
Illustration of a training sample. The network takes a 3D intensity volume (defined by a five-plane sparse point cloud) as input and outputs an SLM phase pattern capable of reconstructing all planes.
For each 3D volume, a reference phase pattern is computed using an angular spectrum-based CGH algorithm [19,29], which approximates the reconstruction of the target scene. During the initial training epochs, these reference holograms serve as supervisory targets. Subsequently, they are gradually phased out and replaced by a self-supervised loss evaluated directly in the focal volume. This training strategy follows the methodology adopted in prior deep-learning-based holography studies [18,21,24].
The network weights were initialized using He initialization. The model was implemented in PyTorch (version 2.8.0, Meta AI, https://pytorch.org) and optimized using the Adam optimizer with a learning rate of 1 × and a batch size of 8.
The training process was conducted over 200 epochs using a dataset of 20,000 synthetically generated volumes. The corresponding training and validation loss curves are presented in Figure 4. The monotonic decrease in both curves, coupled with the consistently small gap between them, indicates a stable optimization process with minimal overfitting. This suggests that the model generalizes well to unseen data from the same synthetic distribution, providing a reliable foundation for the subsequent experimental evaluations.
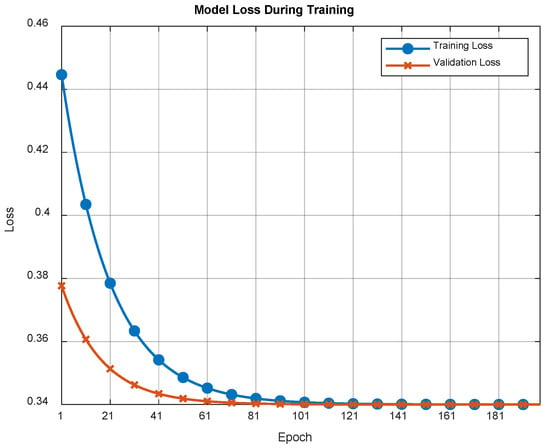
Figure 4.
Training and validation loss curves for the multi-plane CGH network. Both losses decrease monotonically and exhibit a narrow gap, indicating stable and consistent convergence of the physics-informed model.
3. Results and Discussion
Figure 5 presents the simulated and experimental multi-plane reconstructions of a representative “I♡STU” 3D volume using the proposed method. The top row illustrates the ground-truth target intensity patterns at five distinct axial planes. The middle row displays the corresponding simulated reconstructions from the generated phase-only hologram. In simulation, the network successfully reconstructs bright, well-localized focal spots at each intended plane, with minimal inter-plane leakage (i.e., unwanted intensity diffraction from adjacent planes) of letter patterns. This observation confirms that the learned model effectively suppresses axial crosstalk—a longstanding challenge in multi-plane CGH. For instance, the letter “S” appears sharply in focus at its designated plane (), while the “♡” () and “T” () patterns remain correctly defocused, manifesting as low-intensity background noise in non-target planes. These results collectively demonstrate the capability of the model to confine optical energy to the specified depths, thereby achieving effective axial crosstalk suppression.

Figure 5.
Multi-plane reconstruction of the “I♡STU” volume. Top: target intensity patterns at five planes. Middle: simulated reconstructions from a multi-plane CGH. Bottom: experimental camera captures.
To validate the method under practical conditions, the network-predicted phase patterns were experimentally tested using the optical setup shown in Figure 1. The corresponding holograms were displayed on a phase-only SLM (with pixels and each pixel size is ) without any system-specific fine-tuning. A laser source with a wavelength of nm (MSL-R-532-2W, Changchun New Industries, Changchun, China) was used, and the focusing objective had an effective numerical aperture of . The five target planes were uniformly spaced with an axial interval of 10 mm, and the imaging field covered an area of . The measured intensity distributions (as shown in the bottom row of Figure 5) at each depth were captured using a camera mounted on a translation stage, confirming the experimental viability of the method.
Furthermore, we conducted a comparative analysis against two mainstream methods: the traditional iterative GS algorithm [30] and an iterative stochastic gradient descent (SGD)-based optimization method [31]. As summarized in Table 1, the Iterative SGD method yields high-quality reconstruction but requires a significant computation time (≈14.42 s). The GS algorithm is faster (≈1.38 s) but still falls short of real-time requirements. In contrast, our proposed method achieves a generation time of approximately 0.13 s, which is two orders of magnitude faster than SGD. Furthermore, in terms of image quality, our network maintains high peak signal-to-noise ratio (PSNR) and structure similarity index measure (SSIM) scores comparable to the iterative baselines, demonstrating its unique advantage in high-speed, high-precision control for sparse 3D point displays.

Table 1.
Quantitative comparison of reconstruction quality and computation time across methods for five-plane holograms.
To further evaluate reconstruction performance on structured sparse patterns, we compare the proposed network with classical hologram generation approaches using multi-plane sparse targets, as shown in Figure 6. The targets consist of spatially separated binary point distributions located at different axial depths, which impose strict requirements on both depth selectivity and lateral localization accuracy. The proposed method reconstructs well-defined sparse patterns at the designated planes while maintaining minimal background leakage in non-target planes. In contrast, the GS method exhibits strong speckle-like background and depth defocus, causing partial activation of points at incorrect planes. The Iterative-SGD optimization improves energy concentration but still introduces intensity fluctuation and structural distortion due to local minima during optimization.

Figure 6.
The comparison of multi-plane sparse-pattern reconstruction using the GS algorithm, Iterative-SGD optimization, and the proposed method.
Our work builds upon the rapidly evolving field of neural CGH, which leverages deep learning to generate phase-only or complex amplitude holograms from 2D images or multi-plane targets [18,20,21,24,25,26,27]. Notably, prior deep-learning-based approaches have demonstrated the ability to match or surpass the reconstruction quality of classical iterative algorithms (e.g., GS algorithm) for multi-depth CGH, while achieving orders-of-magnitude acceleration in computation [18,21]. While sharing this overarching objective of high-speed, high-fidelity hologram generation, our approach introduces two key architectural and optimization distinctions: first, an explicit learning objective designed to suppress axial crosstalk; second, the incorporation of a space-to-depth receptive-field expansion module that more effectively captures global diffraction across disparate planes, thereby improving reconstruction accuracy.
Beyond multi-plane phase retrieval, recent advances have significantly expanded the scope of neural holography. Current research explores more complex settings including advanced network architectures, multi-wavelength and full-color hologram generation, as well as applications in metasurface optics and near-eye displays [24,26,32,33,34]. A common and powerful paradigm across many of these studies (including our own) is the integration of a differentiable physics model within the training loop. This physics-informed learning framework ensures that the solutions of the network are constrained by the underlying wave optics, enhancing their physical plausibility and robustness for inverse problem-solving in optics.
It is worth noting that the proposed framework is currently optimized for 3D structures of sparse patterns. It excels at suppressing crosstalk and delivering high-precision control in these applications. However, the reconstruction of dense, continuous grayscale images (e.g., natural scenes) may require further adaptation of the loss function to handle surface continuity and texture. Consequently, while the current iteration is ideally suited for applications centered on discrete focal points, extending its capabilities to photorealistic continuous 3D scenes also represents a key avenue for our future research.
In addition, the cosine similarity loss used during training is inherently scale-invariant and emphasizes structural similarity over absolute intensity matching. This characteristic encourages the network to prioritize accurate spatial localization of focal spots rather than precise intensity values, thereby reducing sensitivity to moderate intensity fluctuations caused by speckle or other optical imperfections. While this implicit robustness is beneficial, we recognize that explicitly incorporating noise models into the training process (e.g., through domain randomization with simulated speckle patterns) could further enhance experimental performance. We identify this as a promising direction for future work.
4. Conclusions
In summary, this work presents a neural network-based framework for high-quality, multi-plane CGH that explicitly addresses axial crosstalk. By combining a physics-informed training strategy with a specialized network architecture, we demonstrate efficient generation of phase patterns that yield sharp, well-confined reconstructions across multiple planes both in simulation and experiment. The method aligns with the broader trend of embedding physical models into deep learning for computational optics, offering a promising direction for real-time, high-fidelity holographic displays.
Looking forward, the principles demonstrated here are broadly applicable to other wave-based computational imaging and display tasks. Future work will focus on extending the framework to handle natural scenes, incorporating advanced perceptual loss metrics, adapting to higher-resolution SLMs displays [35,36], and integrating advanced functionalities such as zoom capabilities [37,38]. We believe this work represents a substantive step toward practical, real-time holographic displays for augmented/virtual reality and precise optical manipulation.
Author Contributions
Conceptualization, J.Z. and Q.W.; methodology, J.Z. and Y.C.; software, J.Z., E.K. and X.L.; validation, J.Z., X.X. and Q.W.; formal analysis, J.Z. and Y.C.; investigation, J.Z.; resources, X.X. and Q.W.; data curation, J.Z., E.K. and X.L.; writing—original draft preparation, J.Z. and Q.W.; writing—review and editing, J.Z. and Q.W.; visualization, J.Z. and Q.W.; supervision, X.X. and Q.W.; project administration, Q.W.; funding acquisition, Q.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China (12504353); Natural Science Foundation of Guangdong Province (2025A1515010738); Joint Laboratory of Guangdong, HongKong, and Macao Universities, Guangdong Province (2022LSYS006); STU Scientific Research Initiation Grant (NTF24020T); Open Subject of Hebei Key Laboratory of Advanced Laser Technology and Equipment (HBKL-ALTE2025005).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gabor, D. A new microscopic principle. Nature 1948, 161, 777–778. [Google Scholar] [CrossRef]
- Goodman, J.W. Introduction to Fourier Optics, 3rd ed.; Roberts & Company: Atlanta, GA, USA, 2005. [Google Scholar]
- Slinger, C.; Cameron, C.; Stanley, M. Computer-generated holography as a generic display technology. Computer 2005, 38, 46–53. [Google Scholar] [CrossRef]
- Peng, Y.; Choi, S.; Kim, J.; Wetzstein, G. Speckle-free holography with partially coherent light sources and camera-in-the-loop calibration. Sci. Adv. 2021, 7, eabg5040. [Google Scholar] [CrossRef]
- Dallas, W.J. Computer-generated holograms. In The Computer in Optical Research; Springer: Berlin/Heidelberg, Germany, 1980; pp. 291–366. [Google Scholar]
- Pi, D.; Liu, J.; Wang, Y. Review of computer-generated hologram algorithms for color dynamic holographic three-dimensional display. Light Sci. Appl. 2022, 11, 231. [Google Scholar] [CrossRef]
- Blinder, D.; Birnbaum, T.; Ito, T.; Shimobaba, T. The state-of-the-art in computer generated holography for 3D display. Light Adv. Manuf. 2022, 3, 572–600. [Google Scholar] [CrossRef]
- Pan, Y.; Liu, J.; Li, X.; Wang, Y. A review of dynamic holographic three-dimensional display: Algorithms, devices, and systems. IEEE Trans. Ind. Informat. 2015, 12, 1599–1610. [Google Scholar] [CrossRef]
- Yi, C.; Wang, Z.; Shi, Y.; Wan, S.; Tang, J.; Hu, W.; Li, Z.; Zeng, Y.; Song, Q.; Li, Z. Creating topological exceptional point by on-chip all-dielectric metasurface. Light Sci. Appl. 2025, 14, 262. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Xu, Y.; Wang, C.; Liu, J. Curved Holographic Augmented Reality Near-Eye Display System Based on Freeform Holographic Optical Element with Extended Field of View. Photonics 2024, 11, 1194. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, T.; Lyu, X.; Cheng, D.; Wang, Y. Large Depth-of-Field, Large Eyebox, and Wide Field-of-View Freeform-Holographic Augmented Reality Near-Eye Display. Adv. Sci. 2025, 12, e08773. [Google Scholar] [CrossRef]
- Zhang, J.; Pégard, N.; Zhong, J.; Adesnik, H.; Waller, L. 3D computer-generated holography by non-convex optimization. Optica 2017, 4, 1306–1313. [Google Scholar] [CrossRef]
- Yu, P.; Liu, Y.; Wang, Z.; Liang, J.; Liu, X.; Li, Y.; Qiu, C.; Gong, L. Ultrahigh-density 3D holographic projection by scattering-assisted dynamic holography. Optica 2023, 10, 481–490. [Google Scholar] [CrossRef]
- Horisaki, R.; Nishizaki, Y.; Kitaguchi, K.; Saito, M.; Tanida, J. Three-dimensional deeply generated holography. Appl. Opt. 2021, 60, A323–A328. [Google Scholar] [CrossRef]
- Yu, P.; Chen, X.; Zhuang, J.; Wu, Y.; Wang, Z.; Li, Y.; Zhong, M.; Gong, L. Shaping 3D diffraction patterns with a binary aperture. Appl. Phys. Lett. 2024, 125, 121112. [Google Scholar] [CrossRef]
- Dorrah, A.H.; Bordoloi, P.; de Angelis, V.S.; de Sarro, J.O.; Ambrosio, L.A.; Zamboni-Rached, M.; Capasso, F. Light sheets for continuous-depth holography and three-dimensional volumetric displays. Nat. Photon. 2023, 17, 427–434. [Google Scholar] [CrossRef]
- Gerchberg, R.W. A practical algorithm for the determination of phase from image and diffraction plane pictures. Optik 1972, 35, 237–246. [Google Scholar]
- Hossein Eybposh, M.; Caira, N.W.; Atisa, M.; Chakravarthula, P.; Pégard, N.C. DeepCGH: 3D computer-generated holography using deep learning. Opt. Express 2020, 28, 26636–26650. [Google Scholar] [CrossRef] [PubMed]
- Zhai, Z.; Li, Q.; Xiong, Z.; Feng, W.; Lv, Q. Three-dimensional computer-generated holography based on the hybrid iterative angular spectrum algorithm. Opt. Express 2023, 31, 39169–39181. [Google Scholar] [CrossRef]
- Horisaki, R.; Takagi, R.; Tanida, J. Deep-learning-generated holography. Appl. Opt. 2018, 57, 3859–3863. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Jeong, J.; Cho, J.; Yoo, D.; Lee, B.; Lee, B. Deep neural network for multi-depth hologram generation and its training strategy. Opt. Express 2020, 28, 27137–27154. [Google Scholar] [CrossRef]
- Peng, Y.; Choi, S.; Padmanaban, N.; Wetzstein, G. Neural holography with camera-in-the-loop training. ACM Trans. Graph. 2020, 39, 185. [Google Scholar] [CrossRef]
- Shi, L.; Li, B.; Kim, C.; Kellnhofer, P.; Matusik, W. Towards real-time photorealistic 3D holography with deep neural networks. Nature 2021, 591, 234–239. [Google Scholar] [CrossRef]
- Liu, S.C.; Chu, D. Deep learning for hologram generation. Opt. Express 2021, 29, 27373–27395. [Google Scholar] [CrossRef]
- Wu, J.; Liu, K.; Sui, X.; Cao, L. High-speed computer-generated holography using an autoencoder-based deep neural network. Opt. Lett. 2021, 46, 2908–2911. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, M.; Liu, K.; He, Z.; Cao, L. Progress of the Computer-Generated Holography Based on Deep Learning. Appl. Sci. 2022, 12, 8568. [Google Scholar] [CrossRef]
- Shimobaba, T.; Blinder, D.; Birnbaum, T.; Hoshi, I.; Shiomi, H.; Schelkens, P.; Ito, T. Deep-learning computational holography: A review. Front. Phys. 2022, 3, 854391. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, Z.; Wang, X.; Ji, S.; Zhang, C.; Li, J.; Zhu, W.; Wu, D.; Chu, J. Efficient full-path optical calculation of scalar and vector diffraction using the Bluestein method. Light Sci. Appl. 2020, 9, 119. [Google Scholar] [CrossRef] [PubMed]
- Matsushima, K.; Shimobaba, T. Band-limited angular spectrum method for numerical simulation of free-space propagation in far and near fields. Opt. Express 2009, 17, 19662–19673. [Google Scholar] [CrossRef]
- Piestun, R.; Spektor, B.; Shamir, J. Wave fields in three dimensions: Analysis and synthesis. J. Opt. Soc. Am. A 1996, 13, 1837–1848. [Google Scholar] [CrossRef]
- Velez-Zea, A.; Barrera-Ramírez, J.F. Non-Iterative Phase-Only Hologram Generation via Stochastic Gradient Descent Optimization. Photonics 2025, 12, 500. [Google Scholar] [CrossRef]
- Yu, X.; Teng, Z.; Fan, X.; Liu, T.; Chen, W.; Wang, X.; Zhao, Z.; Xiong, W.; Gao, H. IncepHoloRGB: Multi-wavelength network model for full-color 3D computer-generated holography. Opto-Electron. Adv. 2025, 8, 250130. [Google Scholar] [CrossRef]
- Fan, Z.; Qian, C.; Jia, Y.; Feng, Y.; Qian, H.; Li, E.P.; Fleury, R.; Chen, H. Holographic multiplexing metasurface with twisted diffractive neural network. Nat. Commun. 2024, 15, 9416. [Google Scholar] [CrossRef]
- Velez-Zea, A.; Barrera-Ramírez, J.F. Color multilayer holographic near-eye augmented reality display. Sci. Rep. 2023, 13, 10651. [Google Scholar] [CrossRef]
- Shi, L.; Li, B.; Matusik, W. End-to-end learning of 3D phase-only holograms for holographic display. Light Sci. Appl. 2022, 11, 247. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Liu, K.; Yang, Y.; Peng, Y.; Cao, L. Propagation-adaptive 4K computer-generated holography using physics-constrained spatial and Fourier neural operator. Nat. Commun. 2025, 16, 7761. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Huang, Q.; Liu, C.; Zheng, Y.; Lin, Y.-C.; Lin, F.-C.; Li, Y.-L.; Zheng, X.-R.; Zheng, Y.-W.; Xie, X.; et al. A 0.18 cubic centimeter 3D meta-holographic zoom micro-projector. Nat. Commun. 2025, 16, 10735. [Google Scholar] [CrossRef]
- Liu, C.; Zheng, Y.; Wang, D.; Huang, Q.; Li, X.-W.; Lin, F.-C.; Zhao, Y.-R.; Zheng, Y.-W.; Lu, X.-K.; Li, X.-R.; et al. Multi-wavelength achromatic 3D meta-holography with zoom function. Adv. Sci. 2025, 12, 2501881. [Google Scholar] [CrossRef] [PubMed]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.