Abstract
In this paper, a nonlinear system is interpreted as an operator transforming random vectors. It is assumed that the operator is unknown and the random vectors are available. It is required to find a model of the system represented by a best constructive operator approximation. While the theory of operator approximation with any given accuracy has been well elaborated, the theory of best constrained constructive operator approximation is not so well developed. Despite increasing demands from various applications, this subject is minimally tractable because of intrinsic difficulties with associated approximation techniques. This paper concerns the best constrained approximation of a nonlinear operator in probability spaces. The main conceptual novelty of the proposed approach is that, unlike the known techniques, it targets a constructive optimal determination of all ingredients of the approximating operator where p is a nonnegative integer. The solution to the associated problem is represented by a combination of new best approximation techniques with a special iterative procedure. The proposed approximating model of the system has several degrees of freedom to minimize the associated error. In particular, one of the specific features of the developed approximating technique is special random vectors called injections. It is shown that the desired injection is determined from the solution of a special Fredholm integral equation of the second kind. Its solution is called the optimal injection. The determination of optimal injections in this way allows us to further minimize the associated error.
1. Introduction
1.1. Motivation
Over the last few decades, the problem of constructive approximation of nonlinear operators has been a topic of profound research. A number of fundamental papers have appeared, which have established significant advances in this research area. Some relevant references can be found, in particular, in [1,2,3,4,5,6,7,8,9,10,11,12,13,14].
The known related results mainly concern proving the existence and uniqueness of operators approximating a given map, and justifying the bounds of errors arising from the approximation methods. The assumptions are that preimages and images are deterministic and can be represented in an analytical form, that is, by equations. At the same time, in many applications, the sets of preimages and images are stochastic and cannot be described by equations. Nevertheless, it is possible to represent these sets in terms of their numerical characteristics, such as the expectation and covariance matrices. Typical examples include stochastic signal processing [15,16,17,18,19], statistics [20,21,22,23,24], engineering [25,26,27,28], and image processing [29,30]; in the latter case, a digitized image, presented by a matrix, is often interpreted as the sample of a stochastic signal.
While the theory of operator approximation with any given accuracy is well elaborated (see, e.g., [1,2,3,4,5,6,7,8,9,10,11,12,13,14]), the theory of best constrained constructive operator approximation is not particularly well developed, although this is an area of intensive recent research (see, e.g., [31,32,33,34,35,36]). Despite increasing demands from applications [17,18,19,21,22,23,25,26,27,28,30,31,32,33,34,36,37,38,39,40,41,42,43,44,45,46], this subject is minimally tractable because of intrinsic difficulties in best approximation techniques, especially when the approximating operator should have a specific structure implied by the underlying problem. Recent studies related to this topic can be found in [47,48,49,50,51,52,53,54,55]. In particular, in [47], an approach to modeling of nonlinear systems was proposed based on observed input-output data. The proposed method constructs an approximate model by decomposing the unknown function into multiple components, aiming to minimize the associated error. Special random vectors, called injections, are used to refine the approximation while specific transformations simplify the optimization process. The approach provides flexibility in adjusting parameters to improve accuracy.
We wish to extend the known results in this area to the case when the sets of preimages and images of map are stochastic, and the approximating operator we search is constructive in the sense it can numerically be realized and, therefore, is applicable to problems in applications.
1.2. Short Description of the Method
Let be a set of outcomes in the probability space for which is a –field of measurable subsets of and is an associated probability measure. Let and be random vectors, be a nonlinear map, and .
A nonlinear system is interpreted as the map where and are random output and input signals, respectively. It is assumed that is unknown, and and are available. We propose and justify a new method for the constructive approximation such that first, an associated error is minimized and second, a structure of the approximating operator satisfies the special constraint related to the dimensionality reduction of vector . More specifically, we develop a new approach to the best constructive approximation of the map in probability spaces subject to a specialized criterion associated with the dimensionality reduction of random preimages. The latter constraint follows from the requirements in applications such as those considered in [20,21,22,23,24,26,41,42]. In particular, in signal processing and system theory, a dimensionality reduction of random signals is used to optimize the cost of signal transmission. It is assumed that the only available information on is given by certain covariance matrices formed from the preimages and images. This is a typical assumption used in applications such as those considered, e.g., in [15,16,17,18,19,20,21,22,23,37,38,44,45,46]. Here, we adopt that assumption. As mentioned, in particular, in [56,57,58,59,60,61], a priori knowledge of the covariances can come either from specific data models, or after sample estimation during a training phase.
The problem we consider (see (7) below) concerns finding the best approximating operator that depends on unknown matrices and , for and p more unknown random vectors . We call the injections. Here, p is a non-negative integer p. The injections are aimed to further diminish the associated error. The difficulty is that unknowns should be determined from a minimization of the single cost function given in (7).
The main difference between the approach in [47] and the method proposed in this paper is in their approach to modeling of nonlinear systems. The method in [47] constructs the model as a sum of specific components, and the original optimization problem is decomposed into simpler sub-problems. The method empirically determines the special random vectors, called injections, to reduce the associated error. In contrast, the method proposed here solves the problem of a best constrained approximation of a nonlinear operator in probability spaces. It introduces the concept of an optimal injection, which is determined by solving a Fredholm integral equation of the second kind. While the method in [47] focuses on a structured numerical implementation, the proposed method provides a more general theoretical framework that optimally determines all parameters through a combination of best approximation techniques and an iterative procedure.
The solution is represented in Section 3 and Section 4, and is based on the following observation. Methods for best approximation are aimed at obtaining the best solution within a certain class; the accuracy of the solution is limited by the extent to which the class is satisfactory. By contrast, iterative methods are normally convergent, but the convergence can be quite slow. Moreover, in practice, only a finite number of iteration loops can be carried out, and therefore, the final approximate solution is often unsatisfactorily inaccurate. A natural idea is to combine the methods for best approximation and iterative techniques to exploit their advantageous features.
In Section 3 and Section 4, we present an approach which realizes this. First, a special iterative procedure is proposed which aims to improve the accuracy of approximation with each consequent iteration loop. Secondly, the best approximation problem is solved providing the smallest associated error within the chosen class of approximants for each iteration loop. In Section 4, we show that the combination of these techniques allows us to build a computationally efficient and flexible method. In particular, we prove that the error in approximating by the proposed method decreases with an increase in the number of iterations. An application is made to the optimal filtering of stochastic signals.
1.3. Novelty and Advantages
The novelty of the proposed method is in its approach to the best constructive approximation of nonlinear operators in probability spaces. Unlike methods that primarily focus on the existence and uniqueness of approximating operators, the proposed method aims to achieve an optimal constructive approximation by targeting a specific structure for the approximating operator, which is constrained by dimensionality reduction of random preimages. The focus on dimensionality reduction and the optimization of random vectors, known as injections, distinguishes the proposed method from existing approaches.
The advantages of the proposed method are twofold. First, it allows us to determine optimal injections which are derived from solving a Fredholm integral equation of the second kind, thereby providing a more robust and theoretically sound approach to approximating nonlinear systems. Second, the method combines best approximation techniques with a special iterative procedure, ensuring that the accuracy of the approximation improves with each iteration. This combination not only enhances the computational efficiency of the model but also provides a flexible framework that can be adapted to various applications, particularly those associated with signal processing and system theory, where dimensionality reduction plays a crucial role in optimizing signal transmission costs. By approximating using the best constrained constructive operator approximation, one can design efficient algorithms for signal reconstruction or denoising. In system identification, this approach can be used to model and estimate dynamic systems with stochastic inputs, enabling more accurate predictions and adaptive control strategies.
2. The Proposed Approach
2.1. Some Special Notation
Let us write and where , for and , and and for all . Each matrix defines a bounded linear transformation . It is customary to write A rather then since , for each . Let us also write
The covariance matrix formed from and is denoted by such that
The Moore–Penrose pseudo-inverse [62] of matrix M is denoted by .
2.2. Generic Structure of Approximating Operator
Let be random vectors such that , for . We write and . As mentioned before, we call the injections. This is because contribute to the decrease of the associated error, as shown in Section 4.4 below. The choice of is considered in Section 4.2, where each , for is defined by a nonlinear transformation of , i.e., . To facilitate the numerical implementation of the approximating technique introduced below, each vector , for , is transformed to vector by transformation so that
where . The choice of is considered in Section 3.1.
Further, for , let where is given, , and
Here, r is a positive integer such that .
It is convenient to set and . To approximate for a given reduction ratio
we consider operator represented by
where and , for , are linear operators (i.e., and are represented by and matrices, respectively. Recall that we use the same symbol to define a matrix and the associated linear operator).
Importantly, operators imply the dimensionality reduction of vector . This is because where , for .
We call p the degree of . It is shown below that approximates an operator of interest , with the accuracy represented by theorems in Section 3.3, Section 3.4, and Section 4.4.
2.3. Statement of the Problem
Let be a continuous operator. We consider the problem as follows: Given and , find matrices and vectors that solve
subject to
and
where and denotes the zero matrix (and the zero vector).
2.4. Related Work
2.4.1. Low-Rank Approximations
2.4.2. Tensor Methods
In [70,71,72], the problem in (10) is generalized and studied in terms of tensors. Together with methods formulated in terms of matrices and mentioned in Section 1 and Section 2.4.1, the tensor methods represent an important research subject both in the theoretical and applied sense. In this paper, the problems in (10) and (11) are generalized in a different way, which was described in Section 2.2 and Section 2.3, and will be justified in Section 3 and Section 4.4 below.
2.4.3. System Identification and Modeling
The problem we consider can also be represented as a black-box problem [73,74] where and are an available random input and output, respectively, and is an unknown system. Then, the approximating operator identifies a model of the system. Its particular features are detailed in Section 4.
2.5. Contribution
2.5.1. Challenges of High-Dimensionality
The proposed approach achieves the dimensionality reduction of preimages in the following way. In (6), let us write as
where , , . Here, H is the block-diagonal matrix with on the main diagonal and the dimensionality of vector is r, which is defined by (4). Therefore, H realizes the dimensionality reduction in vector with the reduction ratio defined by (5). Unlike the known techniques [20,21,22,23,24,26,41,42] for dimensionality reduction, the proposed approach achieves this by using terms, . This allows us to increase the accuracy associated with optimal determination of approximating operator . More details can be found in Section 2.5.3 and Section 4.
2.5.2. Challenges of Accuracy
It is shown in Theorems 3, 4, and 5 below that, for the same reduction ratio, accuracy associated with the approximating operator improves if the degree p or dimensions of injections increase. For the case of the optimal determination of injections , the associated error is further improved. This is established in Theorems 10 and 11 in Section 4.4.
2.5.3. Novelties and Relation to Existing Concepts
Commonly, an approximating operator is represented by where are known basis functions and are scalars or matrices which should be determined from (desirably) an error minimization.
The main conceptual novelty of the proposed approach is that, unlike the known techniques, it targets a constructive optimal determination of all ingredients of the approximating operator in (6). They are . The solution of the associated problem (7)–(9) is provided in Section 3.1, Section 3.2, Section 4.1, and Section 4.2, and is represented by a combination of a new best approximation technique with a special iterative procedure.
A basic idea of the solution is to reduce the original problem (7)–(9) with unknowns to simpler problems in (25) and (63) so that each of them, for , contains only three unknowns, , and . For , there are only two unknowns, and . This is achieved due to exploiting operators determined in Theorem 1.
The iteration procedure represented in Section 4.1 is based on the idea of the maximum block improvement method [75] which is an efficient technique for solving the spherically constrained homogeneous polynomial optimization problems. The associated novelties are in the techniques for the determination of matrices given in Section 3.2, injections represented in Section 4.2, and for the error analysis given in Section 3.3 and Section 4.4. In particular, it is shown in Theorem 8 in Section 4.2 that the desired vector is determined from the solution of a special Fredholm integral equation of the second kind (71). Its solution is called the optimal injection.
Further, unlike the known techniques, the proposed approximating operator has several degrees of freedom to minimize the associated error. They are:
- ‘degree’ p of ,
- matrices ,
- optimal injections ,
- values of in (4), and
- dimensions of injections .
It is shown in Section 3.3 and Section 4.4 below that both the optimal choice of and injections , and the increase in and lead to the decrease in the error associated with approximating operator . Injections represent a new special feature of the proposed technique.
In terms of multilayer networks, the novelties are as follows. First, the associated network consists of four hidden layers, i.e., more than in the known networks. Second, it exploits the interaction between the hidden layers (see Figure 1 where a particular case of for is illustrated). These particular features imply the improvement in the associated accuracy (see Section 3.3 and Section 4.4). In Figure 1, denotes the approximation of determined by the proposed technique, i.e., . Details are provided in Section 4.
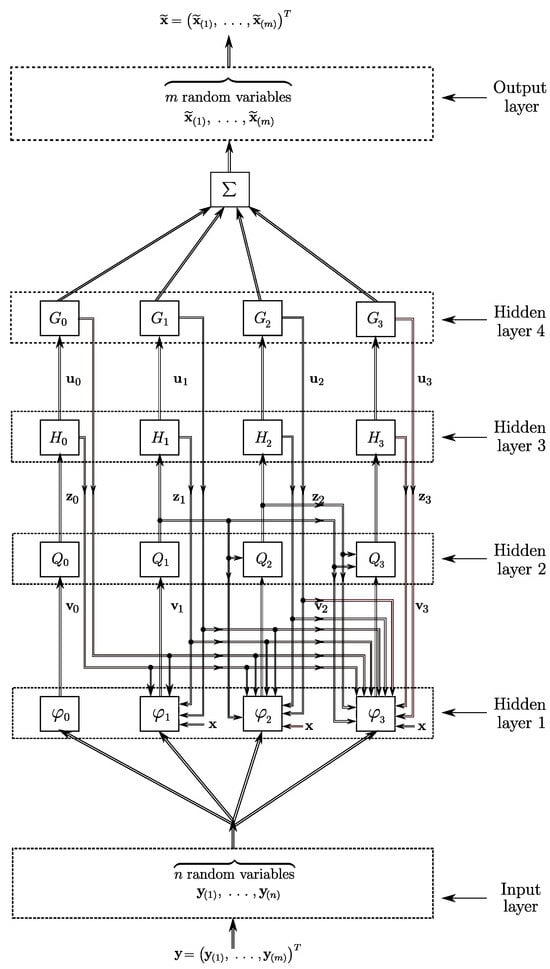
Figure 1.
Diagrammatical representation of the proposed technique.
In terms of system identification, side by side with the black-box problem as in [73,74], the problem in (7)–(9) can be interpreted as a quite wide generalization of the blind system identification problem considered, in particular, in [17,76,77,78]. This is because vectors are assumed to be unknown. Unlike the existing work on blind system identification, the problem in (7)–(9) is stated in terms of random vectors. Other novelties associated with system identification are similar to those considered above, i.e., the proposed model of the system contains unknowns, the method of their determination is different from the existing techniques, and the associated accuracy is improved by a variation in more degrees of freedom.
3. Preliminary Results
Here, we consider the determination of vectors (in Definition 1 that follows, they are called pairwise uncorrelated vectors) and the solution of a particular case of the problem in (7), (8), (9) where the minimization with respect to is not included. These preliminary results will be used in Section 4, where the solution to the original problem represented by (7), (8), (9) is provided.
Definition 1.
Random vectors are called pairwise uncorrelated if the condition in (9) holds for any pair of vectors and , for , where . Two vectors and belonging to the set of the pairwise uncorrelated vectors are called uncorrelated.
For , let be a null space of matrix .
Definition 2.
Random vectors are called linearly independent in the generalized sense if, for every collection of matrices ,
for almost all , implies that , for each , and almost all .
Definition 3.
Random vector , for is called the well-defined injection if
where is defined by (3). Otherwise, injection is called ill-defined.
An explanation for introducing Definition 3 is provided by Remark 1 at the end of Section 3.2 below.
3.1. Determination of Pairwise Uncorrelated Vectors
Theorem 1.
Let random vectors be linearly independent in the generalized sense. Then they are transformed to the pairwise uncorrelated vectors by transformations as follows:
Proof.
In terms of a multi layer network, this procedure is illustrated diagrammatically in Figure 1.
The solution device of the problem in (7)–(9) is based, in particular, on the solution of the problem
subject to (8) and (9). In the following Section 3.2, matrices that solve this problem are given.
3.2. Determination of Matrices That Solve the Problem in (16), (8) and (9)
First, recall the definition of a truncated singular value decomposition (SVD). Let the SVD of matrix be given by where are unitary matrices, and is a generalized diagonal matrix, with the singular values on the main diagonal. For , and , we denote
and write
For ,
is the truncated SVD of A. For , we write .
Proposition 1.
For any random vector ,
Proof.
We have
Thus, (18) is true. □
Theorem 2.
Let be well-defined injections and vectors be pairwise uncorrelated. Then the minimal Frobenius norm solution to the problem in (16) is given, for , by
Proof.
Let , and . Then, for ,
where and by Theorem 1, matrix is block-diagonal, Thus,
and then
At the same time,
Therefore, (20) and (21) imply
The RHS in (22) is nonnegative. Indeed, for , we have , i.e., . Here, . Further, the case is not possible since matrix is singular. Further,
because and
(see [80]).
Remark 1.
Definition 3 of the well-defined injections is motivated by the following observation. It follows from (19) that if, for all vector is such that , then and . In other words, then approximating operator .
Therefore, in Theorem 2 above and in the theorems below, vectors are assumed well-defined.
3.3. Error Analysis Associated with the Solution of Problem in (16), (8) and (9)
In Theorem 3 of this section, we obtain the constructive representation of the error associated with the solution of problem in (16), (8), and (9). In Theorem 4, we show that the error can be improved by the increase in the dimensions of injections . Further, Theorems 3, 4, and 5 establish that the error is also diminished by the increase in the degree of approximating operator .
The error associated with is denoted by
Let us denote the Frobenius norm by .
Theorem 3.
For , let , and . For , let be a singular value of . Let be determined by (19). Then
In particular, the error decreases as p increases.
Proof.
Let us write
where and are entries of matrices and , respectively. Let us also denote
In the following theorem we show that injections are useful in the sense that their dimensions increase, so the error associated with the solution to the problem in (16), (8), and (9) is diminished.
Theorem 4.
Let be well-defined injections and let matrices be defined by Theorem 2. Then the associated error decreases as the sum q of dimensions of injections increases. In particular, there is such that, given , then
if
Proof.
Remark 2.
An empirical explanation of Theorem 4 is that the increase in q implies the increase in the dimensions of matrices in (6) and (19). Hence, it implies the increase in the number of parameters to optimize. As a result, for a fixed parameter r given by (4), the accuracy associated with approximating operator improves. Further, it follows from (31) that, as q increases, tends to , which is the error associated with the full rank approximating operator (see (40) and (46) below).
Remark 3.
By Theorem 3, the error associated with solution of problem (16) decreases as the degree p of the approximating operator increases. At the same time, the increase in degree p of the approximating operator may involve an increase in parameter r (see (4)). However, by a condition of some applied problem in hand, r must be fixed. In the following Theorem 5, under the condition of fixed r, the case of decreasing the error as the degree p of the approximating operator increases is detailed.
Theorem 5.
Let r and , for , be given. Let g be a nonnegative integer such that and let . If
where , then
i.e., for the same r, the error associated with the approximating operator of higher degree p is less than the error associated with the approximating operator of lower degree g.
Remark 4.
Example 1.

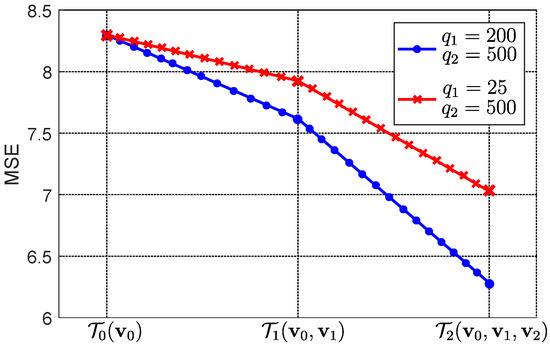
Here, we wish to numerically illustrate Theorems 3, 4, and 5. To this end, we assume that and are uniformly and normally distributed random vectors, respectively. Injections and are here chosen as uniformly distributed random vectors. Covariance matrices , , for , are represented by where and are sample matrices of and , respectively, for .
We choose and . It follows from Theorems 3, 4, and 5 that the error associated with approximating operator varies if values of p, and vary. We wish to illustrate the decrease in error when, for the same r, values of p and q increase. To this end, we provide Table 1 and Table 2, where values of the errors are given for different values of , , for and . In Table 1 and Table 2, the abbreviation MSE (mean square error) is used to unite notations and used in Theorems 3, 4, and 5. In the tables, Cases 1 and 2 for specific values of , are considered.
Table 1.
Numerical characterizations of approximating operators , , and in Case 1.
Table 2.
Numerical characterizations of operators , , and in Case 2.
In Figure 2 the MSE values are illustrated diagrammatically.
Figure 2.
Example 1: Diagrams of the errors associated with , , and .
It follows from Table 1 and Table 2 and Figure 2 that, for the same r, the error associated with the proposed system model decreases if degree p or the sum q of the injection dimensions increases. This is because the increase in the number of parameters to optimize in the operator results in a decrease in the error, as stated in Theorem 5.
3.4. Particular Case: No Reduction of Vector Dimensionality
An important particular case of the problem in (16) and (9) is when matrix is replaced with a full rank matrix , for . Operator given by
is called the full rank approximating operator. The problem then is to find matrices that solve
subject to condition (9).
In particular, searched matrices can be found, for , from equations
and
respectively. Those equations may have an infinite number of solutions or have no solutions. Therefore, instead, the following theorem provides the solution to the problem in (41) where cases (42) and (43) are excluded.
Theorem 6.
Let be well-defined injections and vectors be pairwise uncorrelated. Let , for and . Then, the minimal Frobenius norm solution to the problem (41) is given, for , by
Proof.
Theorem 7.
Let . The error associated with the minimal Frobenius norm solution to the problem in (41) is represented by
4. Solution of Problem Given by (7), (8), (9)
4.1. Device of Solution
In comparison with the problem in (16), (8), (9), a specific difficulty of the original problem in (7), (8), (9) is a determination of p additional unknowns, injections .
The device of the proposed solution is as follows. First, in (13) and (14), arbitrary linearly independent in the generalized sense vectors are denoted by and pairwise uncorrelated random vectors are denoted by . In (19), matrices and , for , are denoted by and , respectively. The associated error is still represented by (27). We also write
Then, for , searched injections and matrices , are determined by the iterative procedure represented bellow. It will be shown in Theorem 10 below that and , further minimize the associated error. The i-th iterative loop of the iterative procedure consists of the steps as follows.
The i-th iterative loop, for
Step 1. Given , , find that solve
where
The solution is denoted by . We call the optimal injections.
Step 2. Given , find pairwise uncorrelated random vectors and denote
where, for , we set and , for all and we write
Step 3. Given , find that solve
The solution of problem (55) is denoted by . Further, denote
where, as before, for , we set and , for all .
Step 4. Denote
Step 5. If, for a given tolerance ,
the iterations are stopped. If not, then Steps 1–4 are repeated to form the next iterative loop.
The above steps of the solution device are consummated as follows.
4.2. Determination of in Step 1
Let us denote
Here, , and .
Theorem 8.
Let
where , and . Then the optimal injection , for , that solves the problem in (51) is determined by
where matrices are defined by
Here, , for .
Proof.
For let us denote . For any , let us write For , the vector of the smallest Euclidean norm of all minimizers that solves
is given by (see [85], p. 257)
Let be such that
Since then
i.e.,
Then (66) implies that, for all ,
Since it is true for all , then
i.e.,
Therefore,
Taking into account (14), Equation (69) is written as
where we denote
Thus,
Let us now write Equation (70) as follows:
where
Recall that in (72), matrix depends on , not on . Therefore, Equation (71) is a vector version of the Fredholm integral equation of the second kind [86] with respect to . Its solution is provided as follows. Write Equation (71) as
where
Let us now multiply both sides of (73) by , for , and integrate. It implies
and
where, for ,
and
Let . Then the set of matrix equations in (74) can be written as a single equation
If matrix is invertible, then (75) implies
If matrix is singular, then instead of Equation (75), we consider the problem
Its minimal Frobenius norm solution is given by [62]:
Thus, injection follows from (73), (76), and (78). □
4.3. Determination of Matrices in Step 3
In Step 3, the matrices solve problem (55). At the same time, the problems in (16) and (55) differ in notation only. Therefore, in Step 3, matrices are determined, in fact, by Theorem 2, where only the notation should be changed.
Nevertheless, to avoid any confusion, we below provide Theorem 9, where matrices are represented. To this end, we denote . To simplify the notation, we set
Theorem 9.
Let be well-defined injections and let vectors be pairwise uncorrelated. Then, the minimal Frobenius norm solution to the problem in (55) is given, for , by
Proof.
The proof follows from the proof of Theorem 2. □
4.4. Error Analysis of the Solution of Problem in (7), (8), (9)
Theorem 10.
Proof.
Let us consider the initial case of the proposed technique when .
- Here, for and . Therefore,i.e., for any , in particular, for ,andTaking into account (81), we denoteThen, by (82),For let us prove inequality (80) by induction. To this end, we first consider the basis step of the induction, which consists of cases and .
- The basis step: Case . If then the i-th iteration loop (see Section 4.1) impliesi.e., for all and with ,In particular, for and with ,Further, because for and , thenTherefore, for ,But since , and , for , thenTaking into account (88), we denote
- That is, for anyAt the same time,Denote . By (91), Thus,
- The inductive step. For let us suppose that if , and and thenBelow, we show that then and , i.e., that (80) is true.To this end, for the i-th iterative loop, let us consider case where . We haveThat is, for anyAt the same time,Denote . By the assumption , thenFurther, for let us now consider the case . ThenTherefore, for any and ,We also need the following. By (55), and solveSince by the assumption, , then (105) is equivalent toThus,Thus, (80) is true.
□
Further, we wish to show that the proposed procedure for the solution of problem in (7), (8), (9) converges to a so-called coordinate-wise minimum, which is defined in Theorem 11 below. To this end, let us denote
where, for as in (20), , , and .
For , we also write , and . As before, .
Let us now define compact sets and such that
and
Theorem 11.
Let and Let and be determined by Theorems 2, 8, and 9, respectively, and let . Then, any cluster point of sequence , say is a coordinate-wise minimum point of , i.e.,
Proof.
Since each , for , is compact, then there is a subsequence such that when . Let and be defined by
Similar to [75], and are called the best responses to P associated with and , respectively. Consider entry of . Then, on the basis of the proof of Theorem 3.1 in [75], we have
By continuity, as ,
This implies that (114) should hold as an equality, since the inequality is false by the definition of the best response . Thus, is the best response for , or equivalently, is the solution of the problem
The proof is similar if we consider entry of . □
Example 2.
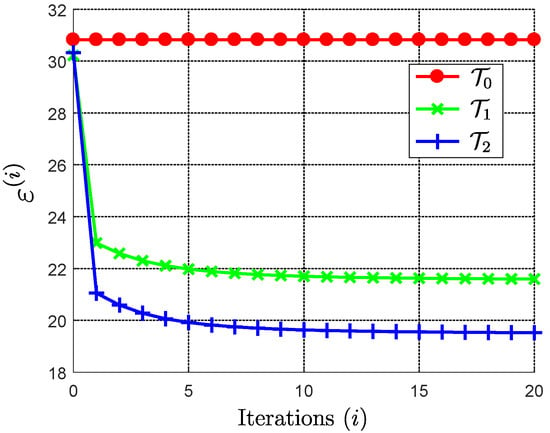
In the above Example 1, we illustrated the decrease in the error associated with approximating operator when parameters p and q increase. In Example 1, injections were not optimal.
Here, for the case of optimal injections, we wish to numerically illustrate Theorem 10, i.e., that the error decreases if the number of iterations i increases.
For we denote
and
According to the procedure described in Section 4, for each i-th iteration where , the proposed method is represented by either
or
To simplify the notation, both and are denoted by .
We assume that and are uniformly and normally distributed random vectors, respectively. Initial injections are here chosen as uniformly distributed random vectors. It is assumed that covariance matrices , , for , are given by where and are samples of and , respectively, for .
We choose and . In Table 3, values of error associated with operators , and , for are represented.
Table 3.
Numerical characterizations of approximating operators , and .
In Figure 3, diagrams of the errors are represented. It follows from Table 3 and Figure 3 that the error decreases if the number of iterations i increases. In particular, the error remains the same after .
Figure 3.
Example 2: Diagrams of the errors associated with , and .
Similar to what is explained in Example 1, the proposed method is more effective because the increase in the number of parameters to optimize in the operator leads to the reduction in the error, as stated in Theorem 10.
Author Contributions
Conceptualization, P.S.-Q. and A.T.; methodology, A.T.; software, P.S.-Q.; validation, A.T.; writing—original draft, A.T.; visualization, P.S.-Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
This work was financially supported by Vicerrectoría de Investigación y Extensión from Instituto Tecnológico de Costa Rica (Research #1440054).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Amat, S.; Busquier, S.; Negra, M. Adaptive Approximation of Nonlinear Operators. Numer. Funct. Anal. Optim. 2004, 25, 397–405. [Google Scholar] [CrossRef]
- Bruno, V.I. An approximate Weierstrass theorem in topological vector space. J. Approx. Theory 1984, 42, 1–3. [Google Scholar] [CrossRef]
- Chen, T.; Chen, H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Trans. Neural Netw. 1995, 6, 911–917. [Google Scholar] [CrossRef]
- Dingle, K.; Camargo, C.Q.; Louis, A.A. Input–output maps are strongly biased towards simple outputs. Nat. Commun. 2018, 9, 761. [Google Scholar] [CrossRef]
- Gallman, P.G.; Narendra, K. Representations of nonlinear systems via the Stone-Weierstrass theorem. Automatica 1976, 12, 619–622. [Google Scholar] [CrossRef]
- Howlett, P.G.; Torokhti, A.P.; Pearce, C.E.M. A Philosophy for the Modelling of Realistic Non-linear Systems. Proc. Am. Math. Soc. 2003, 131, 353–363. [Google Scholar] [CrossRef]
- Istrăţescu, V.I. A Weierstrass theorem for real Banach spaces. J. Approx. Theory 1977, 19, 118–122. [Google Scholar] [CrossRef]
- Prenter, P.M. A Weierstrass Theorem for Real, Separable Hilbert Spaces. J. Approx. Theory 1970, 4, 341–357. [Google Scholar] [CrossRef]
- Prolla, J.B.; Machado, S. Weierstrass-Stone theorems for set-valued mappings. J. Approx. Theory 1982, 36, 1–15. [Google Scholar] [CrossRef]
- Rao, N.V. Stone-Weierstrass theorem revisited. Am. Math. Mon. 2005, 112, 726–729. [Google Scholar] [CrossRef]
- Sandberg, I.W. Notes on uniform approximation of time–varying systems on finite time intervals. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1998, 45, 863–864. [Google Scholar] [CrossRef]
- Sandberg, I.W. Time delay polynomial networks and quality of approximation. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 2000, 47, 40–49. [Google Scholar] [CrossRef]
- Sandberg, I.W. R+ Fading Memory and Extensions of Input-Output Maps. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 2002, 49, 1586–1591. [Google Scholar] [CrossRef]
- Timofte, V. Stone-Weierstrass theorem revisited. J. Approx. Theory 2005, 536, 45–59. [Google Scholar] [CrossRef][Green Version]
- Piotrowski, T.; Cavalcante, R.; Yamada, I. Stochastic MV-PURE Estimator-Robust Reduced-Rank Estimator for Stochastic Linear Model. IEEE Trans. Signal Process. 2009, 57, 1293–1303. [Google Scholar] [CrossRef]
- Hua, Y.; Nikpour, M.; Stoica, P. Optimal reduced-rank estimation and filtering. IEEE Trans. Signal Process. 2001, 49, 457–469. [Google Scholar]
- Zhu, X.L.; Zhang, X.D.; Ding, Z.Z.; Jia, Y. Adaptive nonlinear PCA algorithms for blind source separation without prewhitening. IEEE Trans. Circuits Syst. I Regul. Pap. 2006, 53, 745–753. [Google Scholar]
- Wang, Q.; Jing, Y. New rank detection methods for retuced-rank MIMO systems. EURASIP J. Wirel. Comm. Netw. 2015, 2015, 1–16. [Google Scholar] [CrossRef]
- Bai, L.; Dou, S.; Xiao, Z.; Choi, J. Doubly iterative multiple-input-multiple-output-bit-interleaved coded modulation receiver with joint channel estimation and randomised sampling detection. IET Signal Process. 2016, 10, 335–341. [Google Scholar] [CrossRef]
- Brillinger, D.R. Time Series: Data Analysis and Theory; SIAM: San Francisco, CA, USA, 2001. [Google Scholar]
- Jolliffe, I. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Bühlmann, P.; van de Geer, S. Statistics for High-Dimensional Data; Springer: New York, NY, USA, 2011. [Google Scholar]
- She, Y.; Li, S.; Wu, D. Robust Orthogonal Complement Principal Component Analysis. J. Am. Stat. Assoc. 2016, 111, 763–771. [Google Scholar] [CrossRef]
- Torokhti, A.; Friedland, S. Towards theory of generic Principal Component Analysis. J. Multivar. Anal. 2009, 100, 661–669. [Google Scholar] [CrossRef]
- Saghri, J.A.; Schroeder, S.; Tescher, A.G. Adaptive two-stage Karhunen-Loeve-transform scheme for spectral decorrelation in hyperspectral bandwidth compression. Opt. Eng. 2010, 49, 057001. [Google Scholar] [CrossRef]
- Kmuntchav, R.; Kountcheva, R. Hierarchical Adaptive KL-Based Transform: Algorithms and Applications. In Computer Vision in Control Systems-1; Favorskaya, M.N., Jain, L.C., Eds.; Springer: Cham, Switzerland, 2015; Volume 73, pp. 91–136. [Google Scholar]
- de Moura, E.P.; de Abreu Melo Junior, F.; Damasceno, F.; Figueiredo, L.; de Andrade, C.; de Almeida, M. Classification of imbalance levels in a scaled wind turbine through detrended fluctuation analysis of vibration signals. Renew. Energy 2016, 96 Pt A, 993–1002. [Google Scholar] [CrossRef]
- Azimia, R.; Ghayekhlooa, M.; Ghofranib, M.; Sajedic, H. A novel clustering algorithm based on data transformation approaches. Expert Syst. Appl. 2017, 76, 59–70. [Google Scholar] [CrossRef]
- Burge, M.J.; Burger, W. Digital Image Processing—An Algorithmic Introduction Using Java; Springer: London, UK, 2006. [Google Scholar]
- Phophalia, A.; Rajwade, A.; Mitra, S.K. Rough set based image denoising for brain MR images. Signal Process. 2014, 103, 24–35. [Google Scholar] [CrossRef]
- Chenn, S.; Billings, S.A.; Grant, P. Non-linear system identification using neural networks. Int. J. Control 1990, 51, 1191–1214. [Google Scholar] [CrossRef]
- Chenn, S.; Billings, S.A. Neural networks for nonlinear dynamic system modelling and identification. Int. J. Control 1992, 56, 319–346. [Google Scholar] [CrossRef]
- Fomin, V.N.; Ruzhansky, M.V. Abstract Optimal Linear Filtering. SIAM J. Control Optim. 2000, 38, 1334–1352. [Google Scholar] [CrossRef]
- Temlyakov, V.N. Nonlinear Methods of Approximation. Found. Comput. Math. 2003, 3, 33–107. [Google Scholar] [CrossRef]
- Torokhti, A.; Howlett, P. Best approximation of identity mapping: The case of variable memory. J. Approx. Theory 2006, 143, 111–123. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, H.; Yu, K.; Tan, X. Optimal linear filtering for networked systems with communication constraints, fading measurements, and multiplicative noises. Int. J. Adapt. Control Signal Process. 2016. [Google Scholar] [CrossRef]
- Aminzare, Z.; Sontag, E.D. Synchronization of Diffusively-Connected Nonlinear Systems: Results Based on Contractions with Respect to General Norms. IEEE Trans. Netw. Sci. Eng. 2014, 1, 91–106. [Google Scholar] [CrossRef]
- Schneider, M.K.; Willsky, A.S. A Krylov Subspace Method for Covariance Approximation and Simulation of Random Processes and Fields. Multidimens. Syst. Signal Process. 2003, 14, 295–318. [Google Scholar] [CrossRef]
- Chenn, S.; Billings, S.A. Representations of non-linear systems: The NARMAX model. Int. J. Control 1989, 49, 1013–1032. [Google Scholar] [CrossRef]
- Piroddi, L.; Spinelli, W. An identification algorithm for polynomial NARX models based on simulation error minimization. Int. J. Control 2003, 76, 1767–1781. [Google Scholar] [CrossRef]
- Alter, O.; Golub, G.H. Singular value decomposition of genome-scale mRNA lengths distribution reveals asymmetry in RNA gel electrophoresis band broadening. Process. Natl. Acad. Sci. USA 2006, 103, 11828–11833. [Google Scholar] [CrossRef]
- Gianfelici, F.; Turchetti, C.; Crippa, P. A non-probabilistic recognizer of stochastic signals based on KLT. Signal Process. 2009, 89, 422–437. [Google Scholar] [CrossRef]
- Formaggia, L.; Quarteroni, A.; Veneziani, A. (Eds.) Cardiovascular Mathematics—Modeling and Simulation of the Circulatory System; Springer: Milano, Italy, 2009; Volume 1. [Google Scholar]
- Ambrosi, D.; Quarteroni, A.; Rozza, G. (Eds.) Modelling of Physiological Flows; Springer: Milano, Italy, 2011; Volume V. [Google Scholar]
- Piotrowski, T.; Yamada, I. Performance of the stochastic MV-PURE estimator in highly noisy settings. J. Frankl. Insitute 2014, 351, 3339–3350. [Google Scholar] [CrossRef]
- Poor, H.V. An Introduction to Signal Processing and Estimation, 2nd ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Torokhti, A.; Soto-Quiros, P. Optimal modeling of nonlinear systems: Method of variable injections. Proyecciones 2024, 43, 189–224. [Google Scholar] [CrossRef]
- Yang, S.; Xing, T.; Ke, C.; Liang, J.; Ke, X. Effect of wavefront distortion on the performance of coherent detection systems: Theoretical analysis and experimental research. Photonics 2023, 10, 493. [Google Scholar] [CrossRef]
- Stanković, L.; Brajović, M.; Stanković, I.; Lerga, J.; Daković, M. RANSAC-based signal denoising using compressive sensing. Circuits Syst. Signal Process. 2021, 40, 3907–3928. [Google Scholar] [CrossRef]
- Wang, Y.; Cheng, K.; Zhao, S.; Xu, E. Human ear image recognition method using PCA and Fisherface complementary double feature extraction. J. Artif. Intell. Technol. 2023, 3, 18–24. [Google Scholar] [CrossRef]
- Al-Saffar, N.F.H.; Al-Saiq, I.R. Symmetric text encryption scheme based Karhunen Loeve transform. J. Discret. Math. Sci. Cryptogr. 2022, 25, 2773–2781. [Google Scholar] [CrossRef]
- Soto-Quiros, P.; Torokhti, A. Fast random vector transforms in terms of pseudo-inverse within the Wiener filtering paradigm. J. Comput. Appl. Math. 2024, 448, 115927. [Google Scholar] [CrossRef]
- Howlett, P.; Torokhti, A. Optimal approximation of a large matrix by a sum of projected linear mappings on prescribed subspaces. Electron. J. Linear Algebra 2024, 40, 585–605. [Google Scholar] [CrossRef]
- Torokhti, A.; Howlett, P. Optimal estimation of distributed highly noisy signals within KLT-Wiener archetype. Digit. Signal Process. 2023, 143, 104225. [Google Scholar] [CrossRef]
- Howlett, P.; Torokhti, A. An optimal linear filter for estimation of random functions in Hilbert space. ANZIAM J. 2020, 62, 274–301. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann. Stat. 2012, 40, 1024–1060. [Google Scholar] [CrossRef]
- Adamczak, R.; Litvak, A.E.; Pajor, A.; Tomczak-Jaegermann, N. Quantitative estimates of the convergence of the empirical covariance matrix in log-concave ensembles. J. Am. Math. Soc. 2009, 2, 535–561. [Google Scholar] [CrossRef]
- Vershynin, R. How Close is the Sample Covariance Matrix to the Actual Covariance Matrix? J. Theor. Probab. 2012, 25, 655–686. [Google Scholar] [CrossRef]
- Won, J.-H.; Lim, J.; Kim, S.-J.; Rajaratnam, B. Condition-number-regularized covariance estimation. J. R. Stat. Soc. Ser. B 2013, 75, 427–450. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Berger, J.O. Estimation of a covariance matrix using the reference prior. Ann. Statist. 1994, 22, 1195–1211. [Google Scholar] [CrossRef]
- Ben-Israel, A.; Greville, T.N.E. Generalized Inverses: Theory and Applications, 2nd ed.; Springer: New York, NY, USA, 2003. [Google Scholar]
- Hotelling, H. Analysis of a Complex of Statistical Variables into Principal Components. J. Educ. Psychol. 1933, 6, 417–441 and 498–520. [Google Scholar] [CrossRef]
- Karhunen, K. Über Lineare Methoden in der Wahrscheinlichkeitsrechnung. Ann. Acad. Sci. Fenn. Ser. A. I. Math.-Phys. 1947, 1, 1–79. [Google Scholar]
- Loève, M. Fonctions aléatoires de second ordre. In Processus Stochastiques et Mouvement Brownien; Lévy, P., Ed.; Hermann: Paris, France, 1948. [Google Scholar]
- Scharf, L. The SVD and reduced rank signal processing. Signal Process. 1991, 25, 113–133. [Google Scholar] [CrossRef]
- Hua, Y.; Liu, W. Generalized Karhunen-Loeve transform. IEEE Signal Process. Lett. 1998, 5, 141–142. [Google Scholar]
- Torokhti, A.; Soto-Quiros, P. Generalized Brillinger-Like Transforms. IEEE Signal Process. Lett. 2016, 23, 843–847. [Google Scholar] [CrossRef]
- Torokhti, A.; Miklavcic, S. Data compression under constraints of causality and variable finite memory. Signal Process. 2010, 90, 2822–2834. [Google Scholar] [CrossRef]
- Lathauwer, L.D.; Moor, B.D.; Vandewalle, J. On the Best Rank-1 and Rank-(R1,R2, …, RN) Approximation of Higher-Order Tensors. SIAM J. Matrix Anal. Appl. 2006, 21, 1324–1342. [Google Scholar] [CrossRef]
- Grasedyck, L.; Kressner, D.; Tobler, C. A literature survey of low-rank tensor approximation techniques. GAMM-Mitteilungen 2013, 36, 53–78. [Google Scholar] [CrossRef]
- Friedland, S.; Tammali, V. Low-Rank Approximation of Tensors. In Numerical Algebra, Matrix Theory, Differential-Algebraic Equations and Control Theory; Benner, P., Bollhöfer, M., Kressner, D., Mehl, C., Stykel, T., Eds.; Springer: Cham, Switzerland, 2015; pp. 377–411. [Google Scholar]
- Billings, S.A. Nonlinear System Identification-Narmax Methods in the Time, Frequency, and Spatio-Temporal Domains; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2013. [Google Scholar]
- Schoukens, M.; Tiels, K. Identification of Block-oriented Nonlinear Systems Starting from Linear Approximations: A Survey. Automatica 2017, 85, 272–292. [Google Scholar] [CrossRef]
- Chen, B.; He, S.; Li, Z.; Zhang, S. Maximum Block Improvement and Polynomial Optimization. SIAM J. Optim. 2012, 22, 87–107. [Google Scholar] [CrossRef]
- Abed-Meraim, K.; Qui, W.; Hua, Y. Blind system identification. Proc. IEEE 1997, 85, 1310–1322. [Google Scholar] [CrossRef]
- Hua, Y. Blind methods of system identification. Circuits Syst. Signal Process. 2002, 21, 91–108. [Google Scholar] [CrossRef]
- Shi, X. Mathematical Description of Blind Signal Processing. In Blind Signal Processing: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2011; pp. 27–59. [Google Scholar]
- Torokhti, A.; Howlett, P. Optimal Fixed Rank Transform of the Second Degree. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process. 2001, 48, 309–315. [Google Scholar] [CrossRef]
- Torokhti, A.; Howlett, P. Computational Methods for Modelling of Nonlinear Systems; Elsevier: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Friedland, S.; Torokhti, A. Generalized Rank-Constrained Matrix Approximations. SIAM J. Matrix Anal. Appl. 2007, 29, 656–659. [Google Scholar] [CrossRef][Green Version]
- Liu, X.; Li, W.; Wang, H. Rank constrained matrix best approximation problem with respect to (skew) Hermitian matrices. J. Comput. Appl. Math. 2017, 319, 77–86. [Google Scholar] [CrossRef]
- Boutsidis, C.; Woodruff, D.P. Optimal CUR Matrix Decompositions. SIAM J. Comput. 2017, 46, 543–589. [Google Scholar] [CrossRef]
- Wang, H. Rank constrained matrix best approximation problem. Appl. Math. Lett. 2015, 50, 98–104. [Google Scholar] [CrossRef]
- Golub, G.; Loan, C.F.V. Matrix Computations; Jons Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Kanwal, R. Linear Integral Equations; Birkhäuser Boston: Boston, MA, USA, 1996. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).