Abstract
Partial least squares (PLS) and linear regression methods are widely utilized for quality-related fault detection in industrial processes. Standard PLS decomposes the process variables into principal and residual parts. However, as the principal part still contains many components unrelated to quality, if these components were not removed it could cause many false alarms. Besides, although these components do not affect product quality, they have a great impact on process safety and information about other faults. Removing and discarding these components will lead to a reduction in the detection rate of faults, unrelated to quality. To overcome the drawbacks of Standard PLS, a novel method, MI-PLS (mutual information PLS), is proposed in this paper. The proposed MI-PLS algorithm utilizes mutual information to divide the process variables into selected and residual components, and then uses singular value decomposition (SVD) to further decompose the selected part into quality-related and quality-unrelated components, subsequently constructing quality-related monitoring statistics. To ensure that there is no information loss and that the proposed MI-PLS can be used in quality-related and quality-unrelated fault detection, a principal component analysis (PCA) model is performed on the residual component to obtain its score matrix, which is combined with the quality-unrelated part to obtain the total quality-unrelated monitoring statistics. Finally, the proposed method is applied on a numerical example and Tennessee Eastman process. The proposed MI-PLS has a lower computational load and more robust performance compared with T-PLS and PCR.
1. Introduction
Process quality monitoring methods can be divided into two types: Direct monitoring and processed monitoring. Direct monitoring, the traditionally used quality monitoring method, is based on the different characteristics of quality variables, chooses a suitable method to model the quality variables directly, and monitors the changes in the quality variables. Processed monitoring methods use quality variables to supervise and model process variables, use orthogonal decomposition to extract quality-related features in the process variables and project the process variable space into quality-related and quality-unrelated feature spaces. If the number of quality variables is not large, univariate statistical graph methods can be directly applied for monitoring, such as Shewhart plots, cumulative sum (CUSUM) plots, and exponentially weighted moving average (EWMA) plots. [1]. This has good detection performance for short-term and severe fault conditions. When the number of quality variables is large, multivariate statistical analysis methods can be applied. Among these methods, principal component analysis (PCA) is a relatively basic process monitoring method and has been extensively used in research [2,3,4,5].
In actual production operations, most quality variables are difficult to obtain by direct online measurement. For example, in the petrochemical production process, the product concentration or purity requires further offline analysis and inspection with the help of analytical testing instruments. If the energy consumption of the process operation is considered, a variety of performance indicators need to be integrated before the calculation can be performed. The online measurement and application of these quality variables are often time-consuming and involve certain delays. Therefore, when implementing a direct quality monitoring method, the steps of quality prediction need to be completed before modeling and monitoring are performed.
The key to direct quality monitoring methods is quality prediction and obtaining accurate prediction results is the core of subsequent quality monitoring steps. Extensive research has focused on improving modeling accuracy, reducing prediction errors, and ensuring prediction accuracy for online applications. Based on previous research, Chen et al. [6] divided the prediction process into three main aspects: feature (variable) selection, predictive modeling, and parameter optimization. Therefore, we can start from these three aspects and study how to improve the prediction accuracy.
First, feature (variable) selection attempts to use only the most relevant quality variables of the process variable, eliminating weakly related and unrelated variables. Such dimension reduction helps to reduce the computational complexity of the process, while improving the prediction accuracy and modeling efficiency. Second, with regard to predictive modeling, the appropriate forecasting model is mainly selected based on different forecasting requirements or different data characteristics, depending on the production conditions [6]. For example, short- and long-term prediction models can be used according to the prediction duration, single- and multiple-output models can be used according to the number of quality variables, data-driven models and data-mechanism hybrids model can be used depending on whether or not mechanism knowledge is combined, and single and integrated models can be used according to the distribution of data [7,8] Finally, in terms of parameter optimization, the basic idea is to use a regression model built based on different objective functions to analyze the critical parameters that should be optimized (regularization parameters, the number of hidden neurons in the neural network and the corresponding weight values; Kernel function parameters in the kernel method, etc.), which are mainly divided into offline and online optimization. Offline optimization aims to minimize prediction error and variance or optimize the probability density function of the prediction error, and uses gradient descent, conjugate gradient, and intelligent optimization methods, among others [9], to obtain the optimal solution. Online optimization methods are based on a comparison between the predicted value at each step and the real value, and simulation models in the Simulink environment [10,11,12]. The extraction method is used to predict the error compensation to make online corrections to the next predicted value and continuously updates the model parameters to achieve a rolling optimization.
After obtaining accurate quality prediction results, modeling and direct monitoring can be carried out. The direct quality monitoring method intuitively reflects the change in the quality variable and has a good performance for the quality variable. The traditional PCA method only models and monitors variables. It belongs to an unsupervised learning method and cannot reflect the relationship between process variables and quality variables [13,14]. By contrast, the partial least squares (PLS) method supervises quality variables, linearly decomposing the process variable to obtain a regression model that can extract the correlation between the process variable and the quality variable [15]. It is often used for quality prediction and quality monitoring. Based on the improved PLS algorithm, Yin et al. [16] assumed that the industrial process can be described by a general linear time-invariant system, and established a soft measurement strategy in the framework of a diagnostic observer, and used generated residual signals for monitoring. Ding et al. [17] extended the method in [16] to a dynamic form, using the left coprime factorization method, combined with the above-mentioned soft measurement and residual monitoring framework, to achieve the quality prediction of dynamic processes. Both methods in [16] and [17] have been successfully applied in the process of the hot strip rolling industry, which has improved quality prediction accuracy and quality monitoring performance. However, both are based on linear conditions, and therefore are only applicable to linear processes.
Focusing on the problem of quality monitoring of non-linear processes, Ju et al. [18] combined wavelet variation and the kernel PLS (KPLS) method to propose a multi-scale KPLS algorithm. They established a wastewater treatment process key performance indicator—the COD concentration in the effluent—and monitored its change in real time. The method introduced in [18] is suitable for steady-state processes. When the actual process has time-varying conditions, its monitoring performance decreases. In order to solve the problem of quality prediction and monitoring of nonlinear multi-period intermittent processes, Yu et al. [19] proposed a multi-directional Gaussian mixed model for period division and identification. In each period, multiple local KPLS regression models are built to perform quality prediction. The Bayesian inference strategy was used to adaptively select a suitable local model for online prediction based on the maximum posterior probability. This method combines the variable selection and the predictive modeling optimization methods described above. The PLS method uses data for modeling and can effectively solve the problem of variable collinearity, and is suitable for multi-output predictions and quality monitoring of multi-variable processes [20,21]. PLS has been studied and applied in quality monitoring and many other fields [22,23].
In this paper, we propose a novel mutual information partial least squares (MI-PLS) approach for quality-related and quality-unrelated monitoring. The proposed method considers quality-related and quality-unrelated faults to ensure there are no false alarms and no missed alarms. We then apply it to a numerical example and Tennessee Eastman (TE) process to verify its effectiveness.
2. Related Work
The principal component analysis (PCA) algorithm models process variables and can be regarded as an unsupervised learning algorithm, ignoring quality variables and their relationship with process variables. PLS utilizes quality variables to guide the modeling of process variables, and the latent variables obtained by decomposing the process variables can reflect the quality-related parts. Therefore, PLS is also called projection to latent structure (PLS) [16]. Here, we assume that the normalized process variable can be expressed as , the quality variable as y, and that is the number of samples, and and are the number of process variables and quality variables, respectively. PLS linearly decomposes and to obtain the following regression model
where and denotes the score matrices of the input and the output , and represents the loading matrices of the input, , and the output , and denotes the residual parts; and are the th latent variables extracted, and is the number of latent variables retained. In the process of applying PLS, the most commonly used method is nonlinear iterative partial least squares (NIPALS) [16], which follows the steps in Algorithm 1. During an iteration, the goal of PLS is to maximize the covariance of and .
| Algorithm 1. The Description of NIPALS Algorithm, Nonlinear Iterative Partial Least Squares (NIPALS) Algorithm Description |
| Let , start. (1) Take any column in and record as . (2) Calculate the regression of each column in on , and get the regression matrix as . (3) Normalize and calculate the score vector for as . (4) Calculate the regression of each column in on , and get the load matrix of as . (5) Compute the new score vector for as . (6) If converges, go to step (7), otherwise return to step (2). (7) Calculate the load matrix of as . (8) Calculate the residual matrices for and as and , respectively. (9) Replace and with and , respectively, and let return to step (1); repeat the calculation until latent variables are extracted, that is, stop iteration at . |
In order to achieve process monitoring, similar to PCA, a monitoring statistic can be built in the score matrix , as shown in the following equation
where is the projection matrix, which can be calculated by
The matrices in Equation (3) satisfy the following relationship: , where represents the identity matrix with dimension . Similarly, the KDE method can be used to estimate its control limit. During the online application, the value of the statistic corresponding with the new sample is calculated and compared with the control limit to determine whether the process is normal or not, and can reflect the changes related to in . By comparing the monitoring statistic and the control limit, it is possible to determine whether the fault condition occurring in affects the quality variable .
However, for standard PLS, the process variable is decomposed into a quality-related part and a quality-unrelated part , but the quality-related part still contains some components unrelated to the output , so these components should be removed to avoid false alarms. Besides, in standard PLS, the variance in is extracted by maximizing the covariance between process variables (input) and quality variables (output), without necessarily being in descending order [24]. As a result, the residual component may consist of some variables responsible for predicting the output . Due to these drawbacks of standard PLS, a novel method is proposed in this paper, namely, MI-PLS, which takes these problems into consideration and further decomposes but does not “discard” the residual of , to ensure that no information is lost from either the quality-related or quality-unrelated parts.
3. Quality-Related and Quality-Unrelated Fault Detection Based on MI-PLS
In this section, our novel PLS based on the mutual information quality variable selection method is presented. The proposed method is easy and effective for quality-related and quality-unrelated faults. MI-PLS is applied to a numerical example and compared with PCR and TPLS.
3.1. A Novel Quality Variables Selection Based on Mutual Information
Mutual information (MI) is an effective measure of information in probability theory and information theory, and is a quantitative representation of the statistical dependence between two sets of variables. It can be used to measure the amount of process variable information contained in quality variables, that is, the correlation between the two. It is, therefore, also a type of correlation coefficient. Over recent years, mutual information has been used widely in the field of process monitoring for variable selection and process decomposition. Mutual information can be defined as the degree of correlation between the product of the joint distribution and the marginal distribution. Correspondingly, the mathematical expression is
where and . In addition, represents the joint probability density function of the process variable, , and quality variable, , and and represent the marginal probability density function of and , respectively. When calculating mutual information, information entropy is mainly used and Equation (4) can be rewritten as
where and represent the marginal entropy of and , respectively, which can be calculated as follows
where represents the joint entropy, which can be calculated as
According to the given process variable and quality variable, the mutual information can be calculated and the correlation between the two can be quantitatively described. The mutual information matrix is constructed as follows
Sum up each row to obtain the total mutual information value of each process variable for all quality variables to form a total mutual information vector
Finally, the variable selection strategy based on mutual information will be
The total mutual information value is greater than the mean value. Its corresponding process variable is selected.
3.2. The Proposed MI-PLS
After all the process variables are assigned, the input matrix is divided into two parts: the quality-related part, , and quality-unrelated part,
According to the preliminary part of PLS above, the regression coefficient between the latent variable and the quality variable is
where is the regression coefficient, is the score matrix, and is the output. Then, we perform singular value decomposition (SVD) on
where , , . The orthogonal projection matrices of quality-related and quality-unrelated parts and subsequently should then be constructed as follows
where denotes the projection matrix of quality-related part, and is the projection matrix of the quality-unrelated part.
By projecting the input variable onto and , two orthogonal subspaces, and , are obtained by
where represents the quality-related subspace and represents the quality-unrelated subspace.
In the online monitoring, a new sample, , can be divided into and . We then take into consideration the quadratic forms of the new and
where and are appropriate applicant for the monitoring statistic ; is directly used for statistics to monitor the quality-related part, is combined with the score matrix of the residual part, and used for statistics to monitor the quality-unrelated part.
The monitoring statistic of quality-related part is built as follows
where is the monitoring statistics of the quality-related component.
Then, PCA is performed on the residual, , to obtain the latent variable matrix, .
Therefore, the total latent variable of unrelated part is constructed by
The quality-unrelated monitoring statistic is built as follows
where is the monitoring statistics of quality-unrelated part.
Thresholds of the monitoring statistics can be determined by kernel density estimation (KDE) and the control limit is presented as and for the quality-related part and quality-unrelated parts, respectively. The monitoring logic is as follows:
- quality-related fault.
- no quality-related fault.
- quality-related or unrelated fault.
- no quality-unrelated fault.
Finally, the main steps of the proposed MI-PLS can be summarized as follows:
- Construct the offline process variable and quality variable matrices and ;
- Apply the proposed MI-based filtering method on the process variable matrix, , and quality variable matrix, , as summarized in Section 3.2. The filtered process variable matrix is denoted as . The loading and weight matrices are represented as and , respectively;
- Calculate the regression coefficient by performing standard PLS onto the filtered process data, , and quality data, , using the NIPALS in Algorithm 1;
- Perform SVD on to obtain and by (13);
- For each online test sample , correct it by ;
- Perform PCA on and combine with ;
- Calculate statistics and by (22) and (24), where is and is ;
- Calculate thresholds and by kernel density estimation (KDE);
- Diagnosis logic:
- quality-related fault has occurred;
- no quality-related fault has occurred;
- quality-related or unrelated fault has occurred;
- no fault unrelated to quality has occurred.
The superiorities of the proposed MI-PLS algorithm can be summarized as follows:
- MI-PLS requires few model latent variables; therefore, MI-PLS has a low computational load;
- MI-PLS utilizes the MI-based filtering method to remove variables that are irrelevant to quality before applying PLS. After this, it decomposes the selected part into quality-related and quality-unrelated subspaces in the postprocessing process; therefore, MI-PLS is more robust than other traditional methods;
- MI-PLS does not discard the residual, ; it participates in modeling and combines with unrelated parts from to ensure no information is lost.
The schematic diagram of the proposed fault detection method is shown in Figure 1.
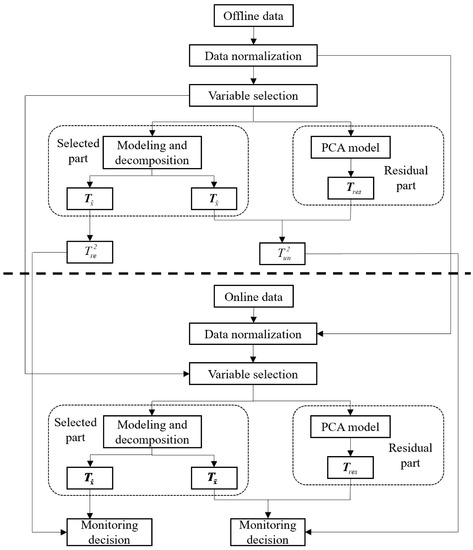
Figure 1.
Schematic diagram of the proposed mutual information partial least squares (MI-PLS) approach.
4. Case Study
We used two case studies to test the proposed MI-PLS. The first is a numerical example and the second uses the TE process. In these experiments, PCR and T-PLS—two of the most commonly used methods in quality relevant and irrelevant fault detection—are used to provide a comparison among methods.
4.1. Numerical Example
We used this numerical example to test the effectiveness of the MI-PLS algorithm. Performance evaluation uses two indicators, namely, false alarm rate (FAR) and fault detection rate (FDR). FAR is the detection of faulty samples that are not related to quality, , whereas FDR indicates the detection of faulty samples relevant to quality . The FDR and FAR can be calculated as follows
where represents the number of faulty samples, is the number of false alarms, and is the number of alarms.
From an industrial process perspective, a quality monitoring algorithm should be able to achieve the following
- (1)
- With regard to quality-irrelevant faults, a low false-alarm rate in quality relevant monitoring statistics, and high fault-detection rate in quality-irrelevant monitoring statistics;
- (2)
- For quality-relevant faults, a high fault-detection rate in quality relevant monitoring statistics, but no specific requirement in relation to quality-irrelevant monitoring statistics.
To determine whether the fault affects the quality variable , a novel statistic is proposed to directly monitor the output residual, which can be obtained as follows
It is worth noting that is only used for quality-related and quality-unrelated fault classification and not for process monitoring.
The numerical example is constructed as follows
where and . When the fault occurs in , the product quality, , will be directly influenced. While the fault is added in , it will not exert an effect on the product quality.
- Fault No.1: , quality-irrelevant;
- Fault No.2: , quality-irrelevant;
- Fault No.3: , quality-relevant;
- Fault No.4: , quality-relevant.
The selection of numbers can be based on the monitoring problem targeted by article. Here, the training sample is set as . The test sample number is set as 200, in which the first 100 samples are normal data, and the other 100 samples are fault data. The models of MI-PLS and PCR were constructed from the training samples. In this work, we first select the key process variables. Figure 2 shows the mutual information between input variables and the output (quality) variable. Therefore, the first, third, and fourth process variables were chosen as the key process variables, as shown in Figure 2. Fault 1 was selected as quality-unrelated and Fault 3 as quality-related; they were chosen to demonstrate the performance of MI-PLS, T-PLS, and PCR.
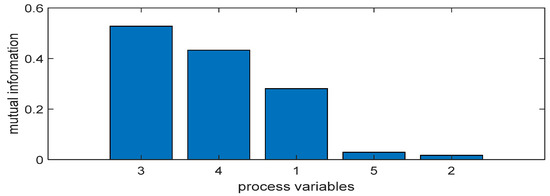
Figure 2.
Mutual information between the quality variable and process variables.
- Case study on Fault 1: The fault is added to
As shown in Figure 3, when Fault 1 occurred, the output was not affected; the changing trend of the quality variable in this state was unchanged, meaning Fault 1 was not related to quality.
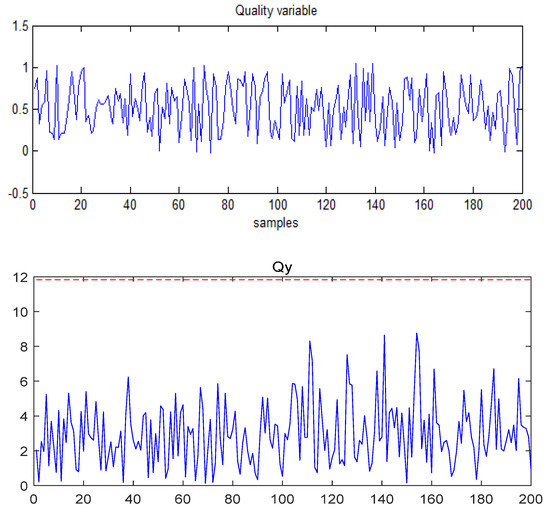
Figure 3.
The quality variable and the statistic for Fault 1.
Figure 4, Figure 5 and Figure 6 show the detection results of T-PLS, PCR, and the proposed MI-PLS, respectively. As shown in Figure 4, the part exceeded the control limit, which means that the quality-unrelated fault was successfully detected. However, exceeded the control limit as well, while in this case the fluctuations and changes in process variables should be regarded as normal disturbances or normal adjustments and responses of the process itself to external disturbances. The expectation for false alarms should be reduced, and there is no need to issue an alarm for such a fault.
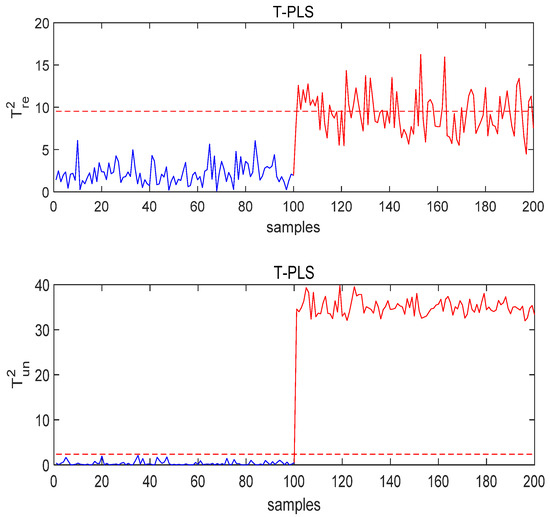
Figure 4.
The monitoring results of T-PLS under Fault 1 conditions.
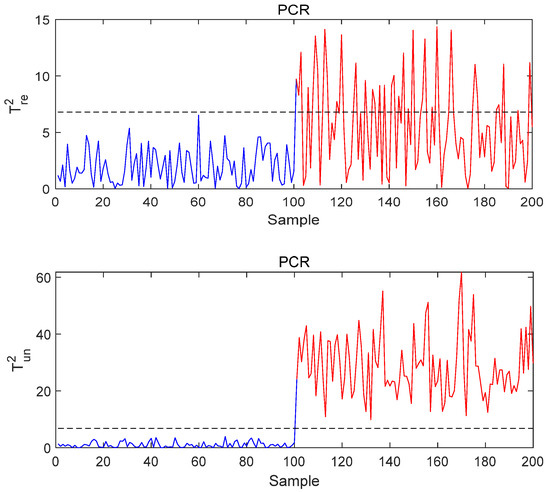
Figure 5.
The monitoring results of PCR under Fault 1 conditions.
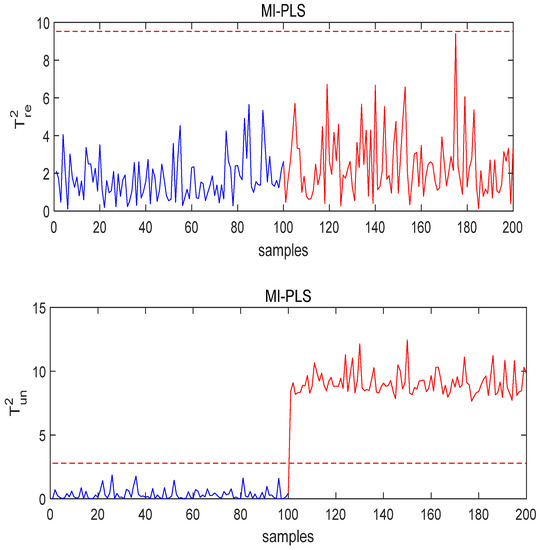
Figure 6.
The monitoring results of MI-PLS under Fault 1 conditions.
The same situation can be observed in Figure 5. When the quality-unrelated fault occurs, the quality-related monitoring statistic gives an alarm because the FAR in T-PLS and PCR is so high, meaning that these methods cannot distinguish whether is affected or not under this fault. Therefore, T-PLS and PCR do not provide correct results, forcing the process into unnecessary stops and reconditioning.
In Figure 6, exceeds the control limit, but the quality-related part does not; this is the best result, as unnecessary alarms are avoided. Compared with the PCR and T-PLS methods, the proposed method has better performance.
Figure 4 and Figure 5 show that a large number of quality-related statistics in the PCR and T-PLS methods exceed the control limit, which means they can effectively monitor the fluctuations in the process data but cannot identify whether these “abnormalities” will affect the quality. Thus, it can be concluded that the MI-PLS method gives satisfactory detection results with regard to faults not related to quality.
- 2.
- Case study on Fault 3: The fault is added to
Figure 7 shows that the output, , changes when Fault 3 occurs. The quality variable was affected to a certain extent, producing abnormal fluctuations, and has deviated from the original operating state, which means that Fault 3 is quality-related. Figure 8, Figure 9 and Figure 10 demonstrate the monitoring results for this quality-related fault using the T-PLS, PCR, and MI-PLS methods, respectively.
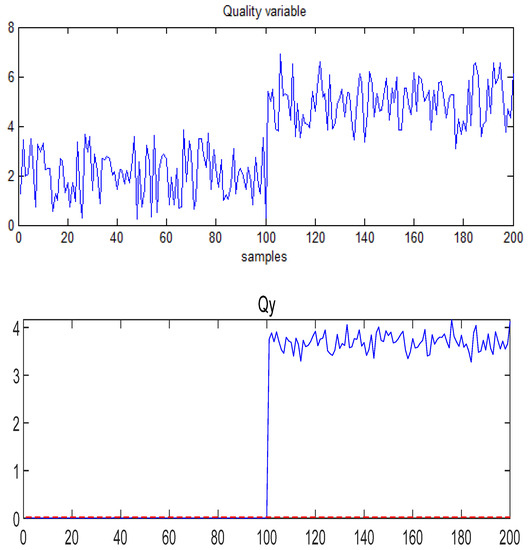
Figure 7.
The quality variable and statistic of under Fault 3 conditions.
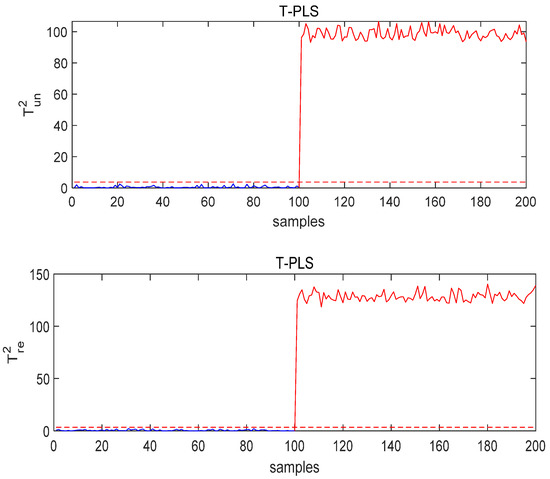
Figure 8.
The monitoring results of T-PLS under Fault 3 conditions.
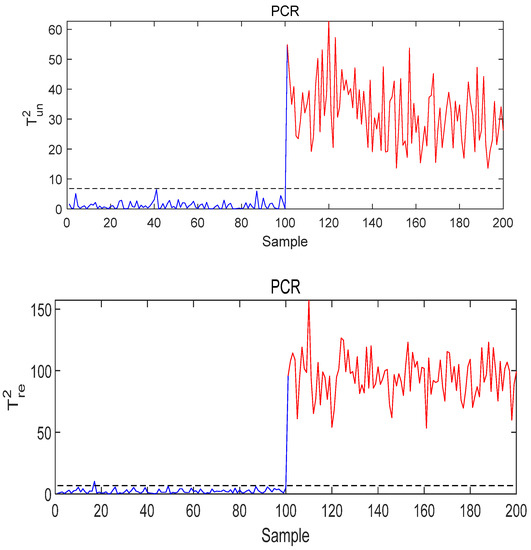
Figure 9.
The monitoring results of PCR under Fault 3 conditions.
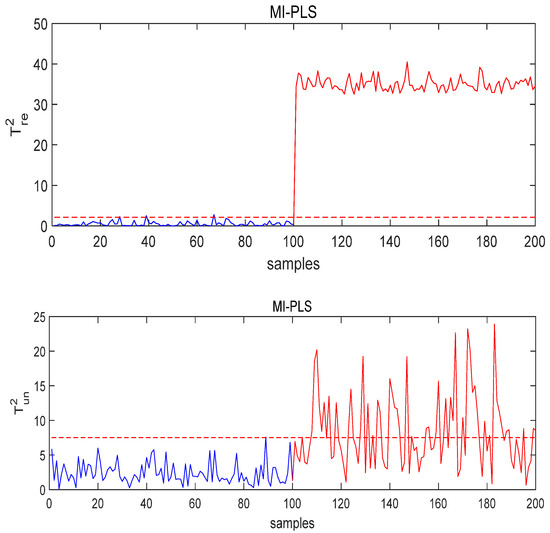
Figure 10.
The monitoring results of MI-PLS under Fault 3 conditions.
Figure 8 and Figure 9 show the monitoring results under quality-related fault using the T-PLS algorithm and PCR, respectively. It can be seen from the results that although the fault is detected, both quality-related and quality-unrelated monitoring indices exceeded the threshold. By contrast, the MI-PLS algorithm proposed in this paper successfully detected the quality-related fault and the quality-unrelated indicator did not seriously exceed the threshold, as can be seen in Figure 10.
The false alarm rate (FAR) and fault detection rate (FDR) for TPLS, PCR, and MI-PLS are shown in Table 1, Table 2 and Table 3. For faults related to quality, the false alarm rate (FAR) should be as low as possible. The statistical indicators should not exceed the threshold in the case of a fault not related to quality.

Table 1.
False alarm rate (FAR) for faults not related to quality using quality-related statistical indicators.
Table 2.
Fault detection rate (FDR) for faults not related to quality using quality-unrelated statistical indicators (%).
Table 3.
Fault detection rate (FDR) for quality-related faults using quality-related statistical indicators.
For both quality-related faults and faults unrelated to quality, the proposed MI-PLS approach achieved the best overall result. However, in order to closely follow the monitoring performance of this method and verify that it can monitor the fault conditions of quality variables in real time, we carried out the two simulations using the same high configuration computer and recorded running times of 4.13 and 3.26 s for T-PLS and MI-PLS, respectively. MI-PLS has a lower computational load requirement than T-PLS.
4.2. Tennessee Eastman Process Simulation
The Tennessee Eastman process (TEP) was originally a real chemical process built by Eastman Chemical Company. Later, Downs et al. [25] developed the chemical test experimental platform based on the actual reaction process, which has been successfully used to test and evaluate the performance of process control strategies and various monitoring algorithms. After years of research and application, it has become a standard test platform in the field of quality monitoring. The flowchart for the process is shown in Figure 11 [25].
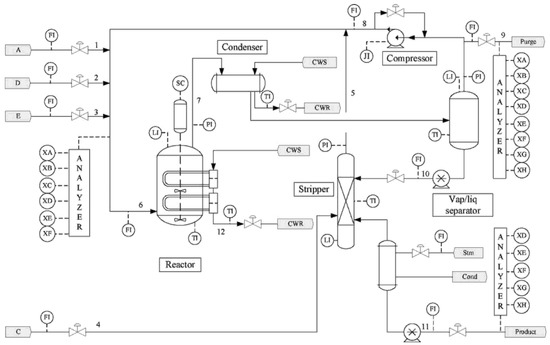
Figure 11.
Schematic of the Tennessee Eastman (TE) process.
The TE process simulator contains five main units: the compressor, reactor, stripper, condenser, and separator. The input reactants include five components—A, B, C, D, E—and the quality variables G and H. In this industrial process, all 53 process variables are divided into two parts: 41 measured variables and 12 manipulated variables. In this experiment, the output variables are XMEAS 35 and 36, which are the measurement values of product components H and G. The process variable matrix contains two sections: 22 measured variables (XMEAS 1–22) and 11 manipulated variables (XMV 1–11). These input variables are listed in Table 4.
Table 4.
The description of process variables in the matrix.
The sampling interval for measurement was set at 3 min. Then, Simulink codes were used to produce fifteen datasets. One dataset was produced under normal operation, and the other datasets corresponded to fourteen different faults. These faults are listed in Table 5.
Table 5.
Description of fourteen fault types used in this study.
According to the prior knowledge of these faults, there were ten quality-related faults (IDV 1, 2, 5–8, 12, 13, 18, and 21) and eleven faults unrelated to quality (IDV 3, 4, 9–11, 14, 15, 16, 17, 19 and 20). The prediction result is a suitable way to illustrate the model’s accuracy. In this experiment, to verify the predictive ability of MI-PLS, the quality variable XMEAS (35) was selected as the true value. For fair comparison, 16 latent variables for the two methods were selected. The confidence level was 99% when computing the limit of each monitoring index.
Figure 12 shows the predicted and true values using the MI-PLS algorithm under normal (fault free) conditions. The prediction accuracy of MI-PLS is very high, for example, comparing the mean and STD between the predicted series and the actual output series, the means are 17.301 and 16.912, respectively, and STD are 5.91 and 5.72, respectively. Afterwards, the MI-PLS algorithm was tested with quality-related Fault 8, and Fault 14, which was not related to quality.
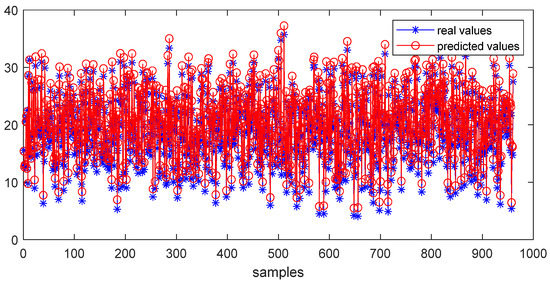
Figure 12.
The prediction result of MI-PLS under fault-free conditions.
- 3.
- Case study of Fault 14
Fault 14 consists of a sticking fault on the reactor cooling water valve. Figure 13 shows that the output variable has not changed. It shows almost no change before and after the fault occurs, and always remains within the normal range. Thus, Fault 14 is not related to quality.
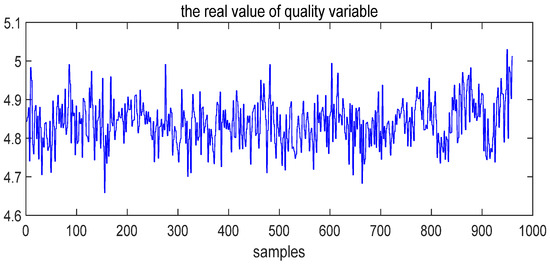
Figure 13.
The real value of the quality variable under Fault 14 conditions.
Figure 14, Figure 15 and Figure 16 show the monitoring results for Fault 14 using T-PLS, PCR, and MI-PLS, respectively. As shown in Figure 14 and Figure 15, although T-PLS and PCR can detect this fault successfully, the quality-related monitoring statistics exceed the control limit, which is not in line with the actual situation. By contrast, the quality-related monitoring statistic of MI-PLS does not exceed the threshold, as seen in Figure 16, which reflects the true situation. The quality variable maintains a normal status, so no alarm should occur here. Thus, for this fault condition, it is logical that the statistic relevant to quality is below the threshold.
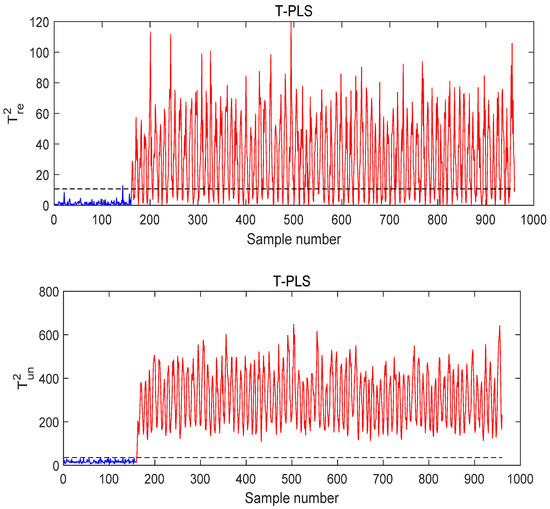
Figure 14.
The monitoring result of MI-PLS under Fault 14 conditions.
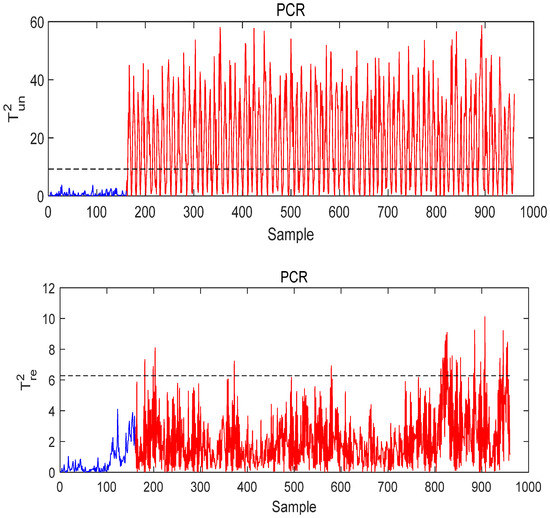
Figure 15.
The monitoring result of PCR under Fault 14 conditions.
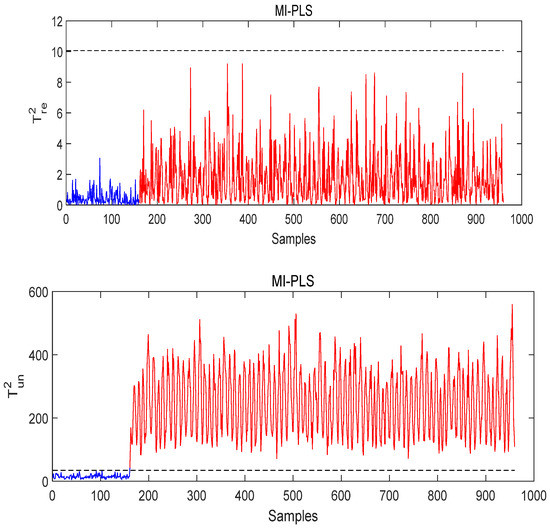
Figure 16.
The monitoring result of MI-PLS under Fault 14 conditions.
From these results, it can be concluded that the advantage of the method proposed in this paper is in achieving the lowest false alarm rates in the case of faults unrelated to quality. Due to the effective quality variable selection method we used in this algorithm, the false alarm rate (FAR) of MI-PLS is close to 0%. Using the PCR and T-PLS methods, the false alarm rate (FAR) is higher, e.g., in T-PLS, it reached 62.5%, which leads to needless stops and reconditioning.
- 4.
- Case Study of Fault 8
Fault 8 consists of a random variation in the feed composition. From Figure 17, it can be seen that the quality variable was affected after the fault occurred; this means the fault is quality-related. The monitoring results of T-PLS, PCR, and M-PLS under Fault 8 are shown in Figure 18, Figure 19 and Figure 20.
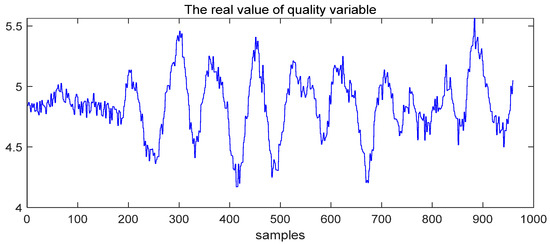
Figure 17.
The real value of the quality variable under fault 8.
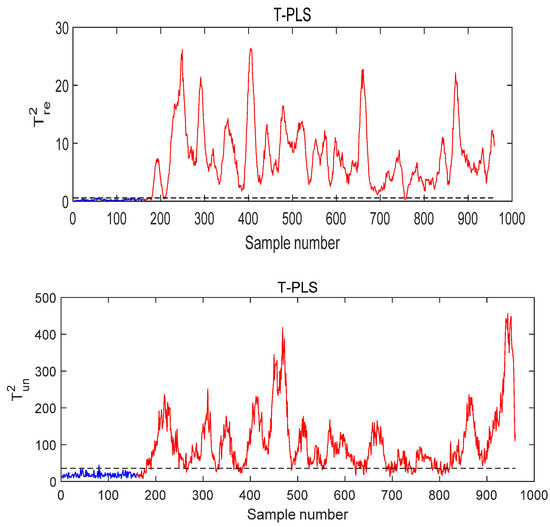
Figure 18.
The monitoring result of T-PLS under Fault 8 conditions.
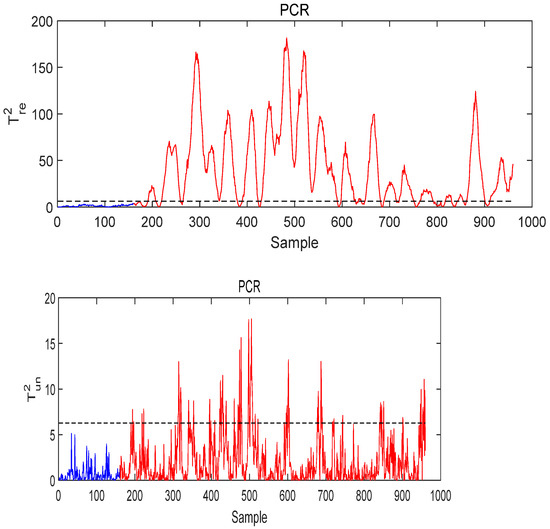
Figure 19.
The monitoring result of PCR under Fault 8 conditions.
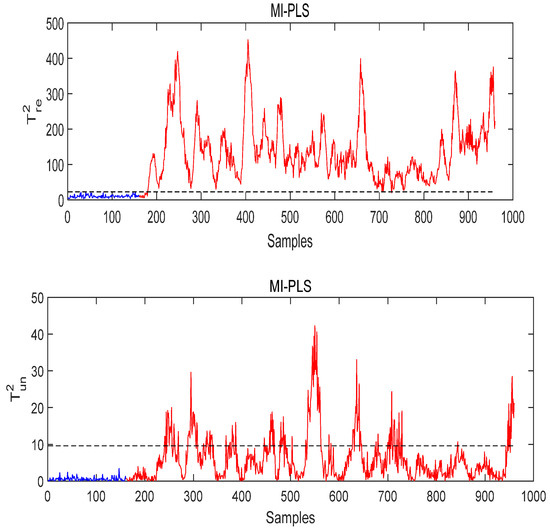
Figure 20.
The monitoring result of MI-PLS under Fault 8 conditions.
Figure 18 and Figure 19 are the monitoring results using T-PLS and PCR, respectively. As can be seen, both the T-PLS and PCR algorithms lead to a low fault detection rate (FDR). Using MI-PLS, the monitoring statistics exceed the control limit after the fault occurs and stays above the control limit, as shown in Figure 20. Besides, the quality-unrelated monitoring statistics in both the T-PLS and PCR exceed the threshold, while in MI-PLS, it does not seriously exceed it. The fault detection rate (FDR) in MI-PLS reaches 99%, while for PCR and T-PLS the FDR is 82.75% and 97.5, respectively. Therefore, MI-PLS achieved the best results in detecting Fault 8.
From these results, it can be concluded that the proposed MI-PLS outperforms the other two methods in quality-related fault detection. The variable selection method we used in the proposed MI-PLS has a better variable filtering and variable selection ability, which means that if we use better variable selection methods with traditional methods, such as PCR, PLS or ICR, we may obtain better monitoring results.
Finally, the fault detection rates (FDRs) of quality-related faults of the proposed method and DPCA are listed in Table 6; the proposed approach keeps a high FDR in most of the quality-related faults.
Table 6.
Fault detection rate (FDR) of MI-PLS, PCR and T-PLS for faults related to quality in the Tennessee Eastman (TE) process.
Table 7 shows the false alarm rate (FAR) for faults unrelated to quality using the proposed MI-PLS, PCR and T-PLS methods. Our results show that the proposed MI-PLS algorithm has a lower FAR for most of the faults that were not related to quality.
Table 7.
False alarm rate (FAR) for MI-PLS, PCR, and T-PLS with faults unrelated to quality in the TE process.
5. Conclusions
In this article, a novel PLS based on the mutual information variable selection method was proposed. This method first utilizes mutual information (MI) to divide process variables into selected and residual parts, and then uses PLS to model the selected part and further decomposes this into quality-related and quality-unrelated parts, subsequently constructing monitoring statistics. With regard to the quality residual part, the proposed method does not ignore the residual, but performs PCA to obtain its score matrix and combines it with the quality-unrelated component of the selected part. It finally builds the total quality-unrelated statistical indicator. In this paper, a numerical example and the TE process were presented to test the proposed method and compare it with T-PLS and PCR. Numerical simulation experiments verify that the proposed MI-PLS model has a high degree of fit and can obtain more accurate prediction results. Through the experimental comparison of the numerical simulation and TE benchmark platform, it is concluded that the proposed MI-PLS method has an improved detection of fault conditions and can effectively distinguish whether a fault affects product quality in real time, reducing the rate of missed alarms and false alarms. The detection results obtained here are more in line with the actual situation, verifying the effectiveness of MI-PLS in quality-related and quality-unrelated fault detection.
Author Contributions
Conceptualization, M.A.; methodology, M.A.; software, M.A.; validation, M.A., Y.T.; formal analysis, M.A.; investigation, M.A.; resources, H.S.; data curation, M.A.; writing—original draft preparation, M.A.; writing—review and editing, M.A.; visualization, H.S.; supervision, H.S.; project administration, H.S.; funding acquisition, H.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China under grants 61703161 and 61673173, and the Fundamental Research Funds for the central universities under grant 222201714031.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: [https://depts.washington.edu/control/LARRY/TE/download.html].
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Joe Qin, S. Statistical process monitoring: Basics and beyond. J. Chemom. J. Chemom. Soc. 2003, 17, 480–502. [Google Scholar] [CrossRef]
- Tao, Y.; Shi, H.; Song, B.; Tan, S. Parallel quality-related dynamic principal component regression method for chemical process monitoring. J. Process Control 2019, 73, 33–45. [Google Scholar] [CrossRef]
- Wang, G.; Jiao, J. Quality-related fault detection and diagnosis based on total principal component regression model. IEEE Access 2018, 6, 10341–10347. [Google Scholar] [CrossRef]
- Tao, Y.; Shi, H.; Song, B.; Tan, S. A novel dynamic weight principal component analysis method and hierarchical monitoring strategy for process fault detection and diagnosis. IEEE Trans. Ind. Electron. 2019, 67, 7994–8004. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Q.; Wang, L.; Zhao, J.; Wang, W. Data-driven prediction on performance indicators in process industry: A survey. Acta Autom. Sin. 2017, 43, 944–954. [Google Scholar]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Ding, S.X. Data-driven design of monitoring and diagnosis systems for dynamic processes: A review of subspace technique based schemes and some recent results. J. Process Control 2014, 24, 431–449. [Google Scholar] [CrossRef]
- Asorey-Cacheda, R.; Garcia-Sanchez, A.-J.; García-Sánchez, F.; García-Haro, J. A survey on non-linear optimization problems in wireless sensor networks. J. Netw. Comput. Appl. 2017, 82, 1–20. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X. Quality-driven kernel projection to latent structure model for nonlinear process monitoring. IEEE Access 2019, 7, 74450–74458. [Google Scholar] [CrossRef]
- Yan, S.; Yan, X. Quality-driven autoencoder for nonlinear quality-and process-related fault detection based on least square regularization and enhanced statistic. Ind. Eng. Chem. Res. 2020, 59, 12136–12143. [Google Scholar] [CrossRef]
- Song, B.; Shi, H.; Tan, S.; Tao, Y. Multi-Subspace orthogonal canonical correlation analysis for quality-related plant wide process monitoring. IEEE Trans. Ind. Inform. 2020. [Google Scholar] [CrossRef]
- Sun, C.; Hou, J. An Improved Principal Component Regression for Quality-Related Process Monitoring of Industrial Control Systems. IEEE Access 2017, 5, 21723–21730. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.X.; Xie, X.; Luo, H. A Review on Basic Data-Driven Approaches for Industrial Process Monitoring. IEEE Trans. Ind. Electron. 2014, 61, 6418–6428. [Google Scholar] [CrossRef]
- Gang, L.; Qin, S.J.; Zhou, D. Geometric properties of partial least squares for process monitoring. Automatica 2010, 46, 204–210. [Google Scholar]
- Yin, S.; Wang, G.; Gao, H. Data-Driven Process Monitoring Based on Modified Orthogonal Projections to Latent Structures. IEEE Trans. Control Syst. Technol. 2016, 24, 1480–1487. [Google Scholar] [CrossRef]
- Ding, S.; Yin, S.; Peng, K.; Hao, H. A Novel Scheme for Key Performance Indicator Prediction and Diagnosis With Application to an Industrial Hot Strip Mill. IEEE Trans. Ind. Inform. 2013, 9, 2239–2247. [Google Scholar] [CrossRef]
- Ju, H.; Yin, S.; Gao, H.; Kaynak, O. A data-based KPI prediction approach for wastewater treatment processes. In Proceedings of the International Conference on Man & Machine Interfacing, Bhubaneswar, India, 17–19 December 2015. [Google Scholar]
- Yu, J. Multiway Gaussian Mixture Model Based Adaptive Kernel Partial Least Squares Regression Method for Soft Sensor Estimation and Reliable Quality Prediction of Nonlinear Multiphase Batch Processes. Ind. Eng. Chem. Res. 2012, 51, 13227–13237. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X.; Yi, H.; Gao, F. Data-driven batch-end quality modeling and monitoring based on optimized sparse partial least squares. IEEE Trans. Ind. Electron. 2019, 67, 4098–4107. [Google Scholar] [CrossRef]
- Si, Y.; Wang, Y.; Zhou, D. Key-performance-indicator-related process monitoring based on improved kernel partial least squares. IEEE Trans. Ind. Electron. 2020, 68, 2626–2636. [Google Scholar] [CrossRef]
- Fan, S.-K.S.; Chang, Y.-J. Multiple-input multiple-output double exponentially weighted moving average controller using partial least squares. J. Process Control 2010, 20, 734–742. [Google Scholar] [CrossRef]
- Fan, S.-K.S.; Chang, Y.-J. An integrated advanced process control framework using run-to-run control, virtual metrology and fault detection. J. Process Control 2013, 23, 933–942. [Google Scholar] [CrossRef]
- Zhou, D.; Li, G.; Qin, S.J. Total projection to latent structures for process monitoring. AIChE J. 2010, 56, 168–178. [Google Scholar] [CrossRef]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).