1. Introduction
Stochastic claims reserving in non-life insurance, also known as general insurance in the UK or property and casualty insurance in the US, is an important and challenging discipline for actuaries. Since the claims settlement in non-life insurance may last several years, insurers have to set aside money that enables them to handle the liabilities related to current insurance contracts. These outstanding claims reserves are often the largest position on the liability side of the balance sheet of a non-life insurance company.
A well-known and widely used technique to forecast future claims is the chain ladder method, a deterministic algorithm which estimates the future claims recursively using a set of development factors. To include a stochastic component, this simple technique can be embedded into the statistical framework of generalized linear models (GLM), introduced by
Nelder and Wedderburn (
1972). The relationship between the deterministic chain ladder method and various stochastic models based on GLMs is discussed in
England and Verrall (
2002) and
Wüthrich and Merz (
2008) for instance.
A non-life insurance company typically divides portfolios into correlated subportfolios, so that certain homogeneity properties on each subportfolio are satisfied. The chain ladder method is then typically applied to the different subpfortfolios, presented in the form of a single run-off triangle. By doing so, the contemporaneous correlations between these various subportfolios are however ignored. It is well known that the chain ladder predictions for the aggregate portfolio, which consists of the sum of the different subportfolios, is in general different from the sum of the chain ladder predictions for each of the separate subportfolios (
Ajne 1994). To address this issue the claims reserving problem is also studied in a multivariate context to cope with the problem of dependence between different subportfolios.
Braun (
2004) studied the bivariate model which takes into account the correlation between two subportfolios of an aggregate portfolio.
Merz and Wüthrich (
2007) consider claims reserving for a portfolio consisting of
N correlated run-off triangles.
Pröhl and Schmidt (
2005) and
Schmidt (
2006) proposed a multivariate chain ladder (MCL) model where they deduced multivariate chain ladder predictors that take into account the dependency between the different subportfolios. These predictors are shown to satisfy a classical optimality criterion. Moreover, it is explained how multivariate methods solve the lack of additivity of the chain ladder predictions. Multivariate methods also have the advantage that we can learn something about the behavior of several subportfolios by observing another subportfolio.
Merz and Wüthrich (
2008) further discussed the conditional mean squared error of prediction (MSEP) for the MCL model.
Recently,
Zhang (
2010) proposed a general multivariate chain ladder (GMCL) model that further extends the MCL model by including intercepts to improve model adequacy. The parameters of this flexible model are estimated using the seemingly unrelated regression (SUR) framework. The SUR model (
Zellner 1962) is a generalization of a linear regression model which consists of more than one equation and where the error terms of these equations are contemporaneously correlated. The SUR model is very popular and has found many applications in finance and insurance. Taking into account the contemporaneous correlations among different portfolios may lead to more accurate uncertainty assessments. Another advantage is that also structural relationships between triangles where the development of one triangle depends on past losses from other triangles can be included in the GMCL model. The GMCL model also allows joint development of the paid and incurred losses from multiple business lines. The similarity and difference between the GMCL model on bivariate data and the Munich chain ladder model (
Quarg and Mack 2004) are discussed by
Zhang (
2010), who also shows that several existing multivariate claims reserving estimators can find their equivalent in the SUR estimator family.
To estimate the parameters in a SUR model, one typically uses the feasible generalized least squares (FGLS) estimator (
Zellner 1962), which takes into account the covariance structure of the errors. Since FGLS is based on the classical covariance matrix and ordinary least squares estimation, using FGLS makes the SUR estimates and thus in particular the GMCL estimates very sensitive to outliers, which are data points that deviate from the pattern suggested by the majority of the data. Such atypical observations may have a large impact on traditional statistical techniques. On the other hand, robust statistics aim to obtain estimates for the claim provisions that is close to the classical estimates applied on the data without the outliers (without modeling the outlier generating process). As a consequence of fitting the majority of the data well, the outliers can be reliably detected by their large deviations from this fit. The flagged outliers may then be inspected by experts. In
Koenker and Portnoy (
1990) a robust SUR estimator is proposed based on M-estimators. Since this procedure is not affine equivariant and does not take full account of the multivariate nature of the problem, a method based on S-estimators was introduced in
Bilodeau and Duchesne (
2000). This robust SUR estimator is regression and affine equivariant, but is computationally expensive. Therefore,
Hubert et al. (
2017) proposed the FastSUR algorithm, which implements the ideas of the FastS algorithm (
Salibian-Barrera and Yohai 2006) for the SUR S-estimator. Recently,
Peremans and Van Aelst (
2018) developed robust inference for the SUR model based on MM-estimators.
This paper is structured as follows. A review of the GMCL model of
Zhang (
2010) is given in
Section 2. In
Section 3 the GMCL model is formulated in the SUR framework and the FGLS estimator is introduced.
Section 4 describes robust MM-estimators for estimating the parameters in GMCL models and its numerical algorithm for computation. We then show the good performance of these estimators in an extensive simulation study in
Section 5. In
Section 6 the robust procedure is illustrated on a real dataset from a non-life business line. Some concluding remarks and potential directions for further research are given in
Section 7. The Appendix contains the parameter estimates obtained from the GMCL models for the real dataset.
2. General Multivariate Chain Ladder Model
We assume that the non-life insurance company needs to handle subportfolios. Let I and K denote the final accident and development period respectively. For , and denote the random variable as the cumulative claims amount of accident period i and development period k of subportfolio m. Depending on the size of K, one refers to long or short tail business and for simplicity we take .
At time
I the claims
with
are observed, while the claims
with
are not observed. Typically, the observed claims of subportfolio
m are then presented in the structure of a run-off triangle as illustrated in
Table 1.
This triangle structure shows the development of claims for each accident period. Usually yearly, quarterly or monthly periods are used. The columns represent the development periods whereas the diagonals present payments in the same calendar period. The overall outstanding reserve
R that will need to be paid in future, is defined as
and depends on the ultimate claim values
. The aim of claims reserving is then to complete the run-off triangles into squares, i.e., forecasting the future claims in the bottom right corner of the run-off triangles in order to estimate the overall outstanding reserves.
Let
denote the vector of cumulative claims of accident period
i and development period
k. Consider the following model structure from development period
k to
:
where
is the
M vector containing intercepts
,
is the
matrix that contains the development parameters
for run-off triangle
m in row
m, and
are independent (over
i) and symmetrically distributed random vectors representing the error terms. For a non-diagonal development matrix
, the model allows the development of one run-off triangle in development period
k to depend linearly on the claims in the other run-off triangles at development period
k. Moreover, it is assumed that the errors
satisfy
where
is the set of cumulative claims for accident period
i up to and including development period
k,
is a symmetric positive definite
matrix, and
is the operator that turns its argument(s) into a diagonal matrix. Consequently, for a non-diagonal matrix
the components of the error terms
are allowed to be correlated. Equations (
1)–(
3) for development periods
constitute the general multivariate chain ladder (GMCL) model as proposed in
Zhang (
2010). Hence, the GMCL model is a collection of
linear models. A separate chain ladder (SCL) model can be obtained as a special case by taking
the zero vector, and by imposing that
and
are diagonal matrices. The advantages of the GMCL model over already existing models like SCL are evident (
Zhang 2010). The parameters
,
and
are unknown model parameters and need to be estimated from historic claims in order to predict future losses.
3. Seemingly Unrelated Regression
In
Zhang (
2010) the model structure from development period
k to
, given in Equation (
1), has been rewritten as a seemingly unrelated regression (SUR) model. Considering the equations in (
1) for historic claims only, i.e., for
with
, the following system of equations is obtained:
where for
it holds that
is the vector of all observed losses at development period from triangle m;
is the matrix of the first observations at development period k from each triangle, including the constant 1 for the intercept. Hence, ;
is the vector of development parameters of triangle m, including the intercept;
is the vector of error terms of triangle m.
From (
2) and (
3) it follows that
where
,
is the set of the first
claims up to and including development period
k, and
with
for
. Moreover,
is the identity matrix of size
and ⊗ represents the Kronecker product. Pre-multiplying both sides of Equation (4) by
leads to the following linear regression model
with
,
, and
. Please note that now the
matrices
are different for each equation, i.e.,
for
. Moreover, denote
, then for the representation of the GMCL model given in (5) the error covariance matrix
satisfies the SUR assumption of contemporaneous correlation (
Zellner 1962):
Hence, it is straightforward to estimate the development parameters by using estimators for SUR models on the transformed data.
Consider the estimation of the unknown development parameters
under the SUR model given in (5). The equations in this model can be considered as
M separate linear regression models of the form
for
. Then, each linear regression model can be estimated separately by least squares (LS). However, this method may yield inefficient estimates since it ignores the correlation structure in the error terms. Generalized least squares (GLS) is an adaptation of least squares that can handle any type of correlation. In this context, the GLS estimator for the model in (5) becomes
where
is a block diagonal matrix of size
, and
. GLS produces efficient estimators (
Zellner 1962). However, since
is unknown a feasible GLS (FGLS) estimator is usually introduced. FGLS replaces the unknown matrix
in (7) with
, where
are the residuals obtained from estimating (6) by least squares. The efficiency of FGLS is in general smaller than for GLS, although the asymptotic efficiencies of both methods are indistinguishable. Please note that this two-step procedure can be iterated until convergence of the development parameter estimates. After estimating the development parameters
or equivalently the development matrix
using the LS or the FGLS estimation procedure consecutively for all development periods
, the bottom right corner of the run-off triangles can be predicted and the overall reserve estimate
can be obtained (for all
M triangles simultaneously).
4. Robust GMCL Method
In the univariate setting (
)
Verdonck and Debruyne (
2011) have demonstrated that outliers can affect the chain ladder method so strongly that there is huge over- or underestimation of the overall reserve estimate. Several robust alternatives have already been developed in the univariate claims reserving framework (see e.g.,
Brazauskas et al. (
2009);
Brazauskas (
2009);
Verdonck et al. (
2009);
Verdonck and Van Wouwe (
2011);
Pitselis et al. (
2015);
Peremans et al. (
2017)).
Hubert et al. (
2017) have shown that FGLS estimators in the GMCL model are also very sensitive to outliers. Please note that the multivariate aspect makes the task of outlier detection more challenging because outliers can be univariate or multivariate. Multivariate outliers are observations that deviate from the multivariate pattern indicated by the majority of the observations, i.e., inconsistent with the covariance structure of the dataset, but in contrast to univariate outliers are not necessarily extreme along a single coordinate (a single run-off triangle). Therefore, univariate outlier detection methods may fail to find these outliers and it is important to rely on robust multivariate alternatives. We propose a robust methodology for reserve estimates and outlier detection by combining robust SUR estimators with the GMCL model.
We now introduce MM-estimators for the SUR model in (5) as studied by
Peremans and Van Aelst (
2018). The system of equations in (5) can be rewritten as another linear regression model by reordering the equations. Let
,
and
be the subvector or submatrix of
,
and
respectively by extracting rows
. Then the system of equations in (5) is equivalent to
In this case we easily obtain that
. Decompose the covariance matrix
into a shape component
and a scale parameter
such that
with
. Here
denotes the determinant of the matrix
. Since we assume that
is positive definite, such a decomposition always exists. Let
be equal to
for any
vector
according to the SUR representation in (8). Then, given an initial estimator of the scale
, the MM-estimators
minimize
over all
vectors
and positive definite symmetric
matrices
with
. The MM-estimator for covariance is defined as
. Evidently, taking
yields the iterated FGLS estimator. To be robust against outliers, it is necessary to consider bounded
functions. More specifically, we assume that the function
satisfies the following conditions:
is symmetric, twice continuously differentiable and satisfies ;
is strictly increasing on and constant on for some .
The most favored family of functions for MM-estimators is the class of Tukey bisquare functions given by . The tuning parameter is usually chosen to obtain a certain level of asymptotic efficiency under the SUR model with normally distributed errors. From now on, we will always consider Tukey bisquare function with tuning parameter (to obtain MM-estimators with efficiency under the normal model).
MM-estimators require an initial estimator of scale
. In order for MM-estimators to be robust, also this scale estimator should be robust. Therefore, highly robust S-estimators are computed to obtain a highly robust scale estimator. S-estimators have been introduced for SUR models in
Bilodeau and Duchesne (
2000), and a computational efficient algorithm has been proposed in
Hubert et al. (
2017). Robustness can be measured by the breakdown point of an estimator, which is roughly equal to the maximal fraction of contaminated observations that an estimator can tolerate before its bias becomes unbounded. For MM-estimators the breakdown point can be up to
. In this paper we have tuned the MM-estimators to have a 25% breakdown point and 95% normal efficiency, which is commonly considered to be a good compromise between robustness and precision of the estimator.
MM-estimators do not have explicit solutions, although they satisfy a similar set of equations as the FGLS estimators given in (7). Indeed, the MM-estimators
satisfy the following set of equations
with
where
,
, and
are the residuals derived from the representation in (8). Starting from the initial S-estimates, MM-estimates are computed simply by iterating these estimating equations until convergence. If
w is bounded and non-increasing, the convergence of this iterative procedure to a local minimum is guaranteed (
Maronna et al. 2006). The function
w can be interpreted as a weight function that can be used to identify outliers. Indeed, a small value of
corresponds with a large residual distance
and indicates that the observation corresponding to accident period
i is an outlier. For more details on the properties of S and MM-estimators, we refer to
Peremans and Van Aelst (
2018). We now explore the use of these robust estimators in the GMCL model to obtain robust reserve estimates and identify outliers in the run-off triangles.
5. Simulation Study
First, we introduce a simulation design according to the GMCL model to generate multivariate run-off triangles. Then, we investigate the prediction performance of the classical and robust estimators for GMCL models by simulation.
We consider the case where two run-off triangles are available (
), but the results can easily be generalized to more triangles (
). To generate two run-off triangles under the GMCL model in (
1), we first generate
for
and
independently from a uniform distribution on the interval
. These numbers represent the losses observed in the first development period. Then, let
for
with
. The entries of the first (second) rows determine the increase of the cumulative claims of the first (second) triangle. Please note that the structural connections among triangles, i.e., the non-diagonal entries of
, decrease towards zero for
to ensure that the cumulative claims stabilize at a certain point in time. Furthermore, assume that the error terms
from the representation in (8) are independently and normally distributed with mean zero and covariance
. The covariance matrices
are defined by multiplying the equicorrelation matrix with correlation 0.5 by the scalar
for
. This choice of
leads to error terms that become smaller for
. If no shrinkage would be applied on the covariance matrices, then the error terms would grow on average because they are linearly related to the cumulative claims of the previous period which increase over time. Finally, the cumulative claims
for
,
and
can be computed according to the GMCL model in (
1) by generating independent error terms from the aforementioned error distribution. We have chosen the parameters
,
and
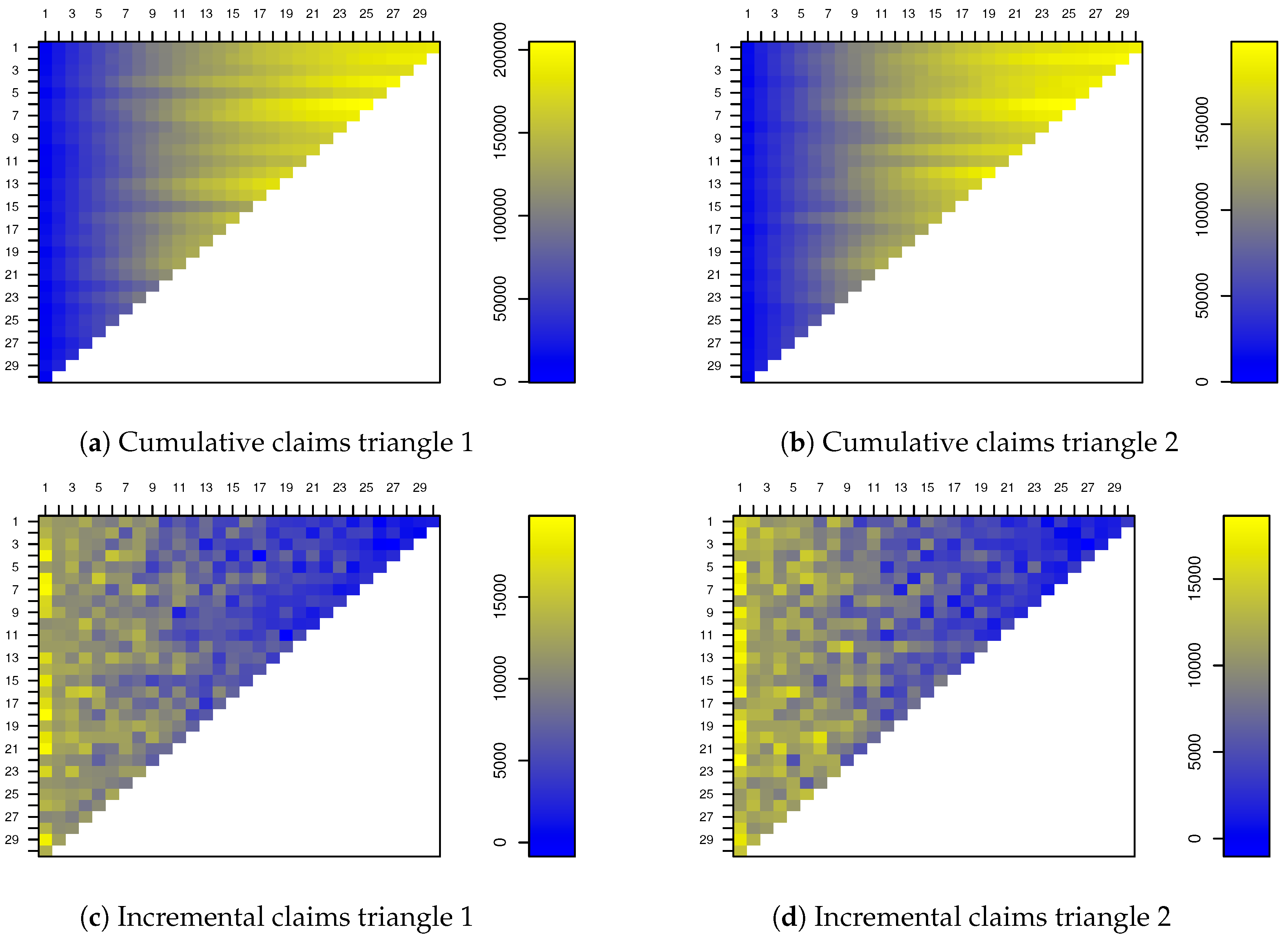
such that the resulting run-off triangles resemble real data. The cumulative and incremental claims of two run-off triangles simulated according to this data generating process are shown in
Figure 1.
Please note that the patterns in these run-off triangles behave similar for every accident period.
Consider the prediction of a single cell
of subportfolio
m for
, i.e., the prediction of a future loss. Given historic claims of
M subportfolios, the development parameters
and
of the GMCL model can be estimated for
. Following the GMCL model these parameter estimators yield a corresponding prediction estimator
for
. To measure the prediction accuracy of the estimator
, we consider its mean squared error of prediction (MSEP), given by
Since in general it is not possible to derive a simple expression for the MSEP, we adopt a Monte-Carlo simulation strategy to estimate this quantity. By repeatedly generating
M run-off triangles as described before, fitting the GMCL model and predicting
through the computation of the estimator
, we obtain
J prediction estimators denoted by
. Then, an estimator of the MSEP of
is given by
Smaller values of MSEP indicate a better prediction performance. In our simulation results we will report the square root of the MSEP denoted by RMSEP.
For data simulated as described before we consider three procedures: the SCL model in combination with LS (in short SCL-LS) and the GMCL model in combination with FGLS and robust MM-estimators (in short GMCL-FGLS and GMCL-MM respectively). As noted by
Zhang (
2010, pp. 595–96) it is difficult to fit the SUR models for the upper right part of the triangles because the data is scarce. To avoid numerical instabilities, it is recommended to use SCL for the development in the tail. Naturally, we advice to combine the robust procedure based on MM-estimators with a robust SCL method such as proposed in
Verdonck and Debruyne (
2011) for the tail development. Since the focus of this paper is on the multivariate model, we present all results without the tail development part, i.e., the final 10 development periods using traditional or robust SCL.
Consider the prediction of the expected claim size
for
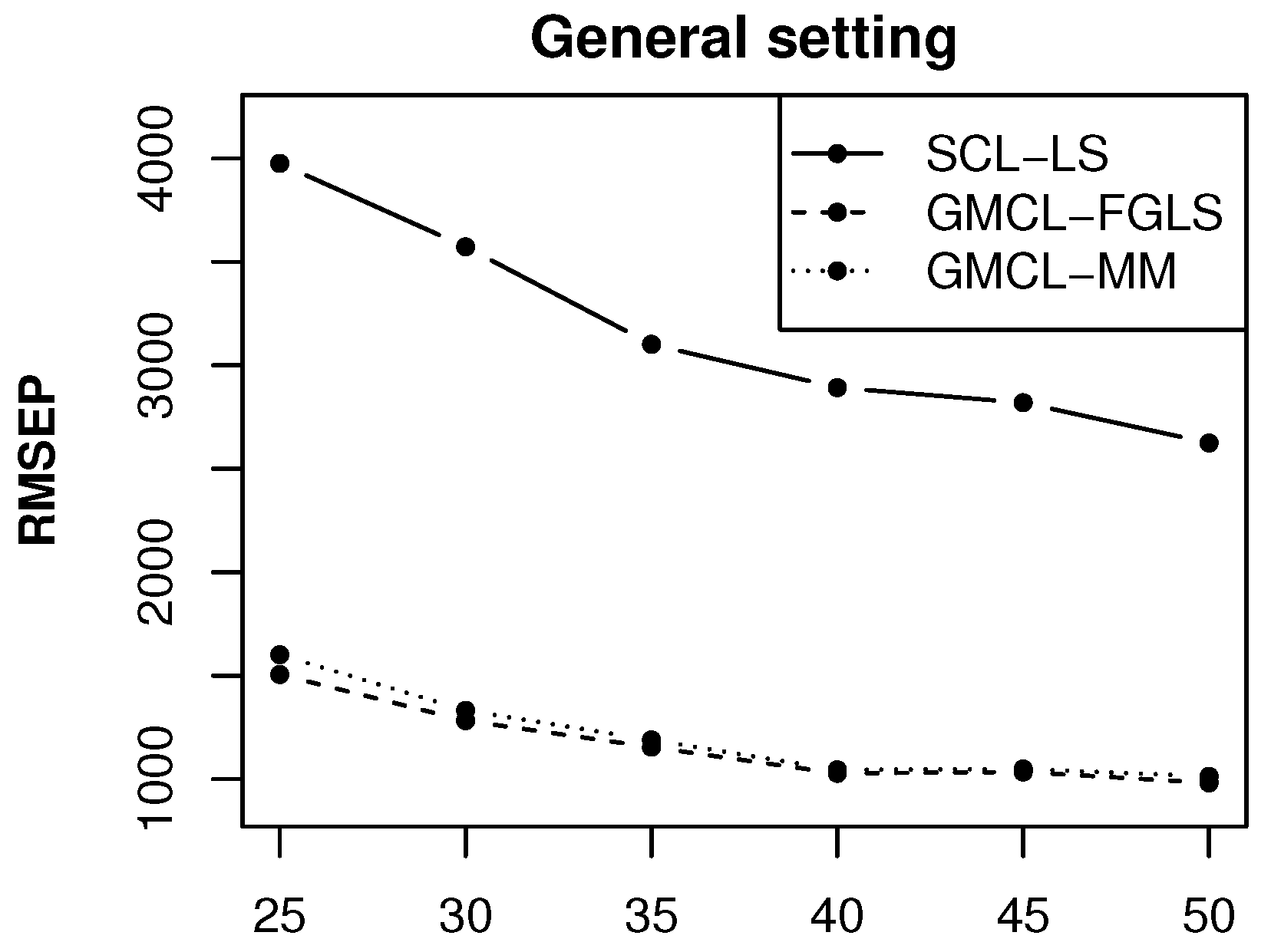
. The top right panel of
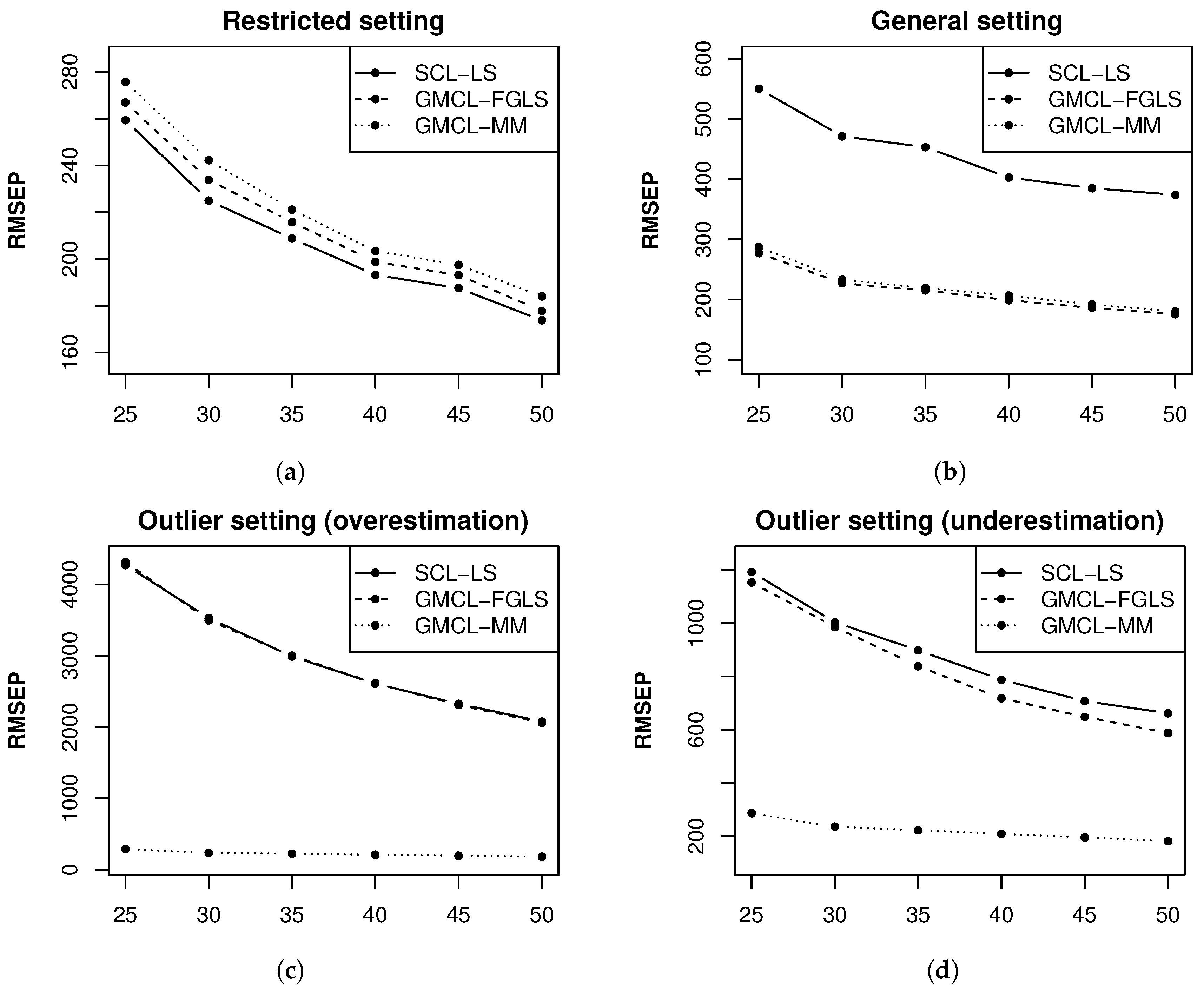
Figure 2 shows the estimated RMSEP of
for SCL-LS, GMCL-FGLS and GMCL-MM as a function of the total number of accident periods
I ranging from 25 to 50 for
simulations.
We can see that the RMSEP estimates are larger for SCL-LS. This is expected because SCL does not take structural connections among run-off triangles into account and contemporaneous correlations between the error terms of the run-off triangles are ignored. Please note that GMCL-FGLS and GMCL-MM perform similarly in this setting where the triangles contain only regular measurements. Moreover, similar performance was obtained for and hence, these results are omitted.
We now change the parameters
,
and
in the simulation design in such a way that it matches the SCL structure. For
take
and let
be the identity matrix multiplied with the scalar
. In this setting SCL is optimal, whereas the GMCL model uses too many parameters. Intercepts, slopes measuring the effects of the other triangles and correlation parameters are unnecessary in this case. When we compare the results of both estimation procedures, presented in the top left window of
Figure 2, we observe that the RMSEP is only slightly larger for GMCL models.
To illustrate the sensitivity of the classical procedures and the robustness of MM-estimators, we now consider the following outlier setting: for each pair of run-off triangles we replace the simulated error term
to generate
with
. Based on
generated pairs of triangles of this kind, we obtained the results in the bottom left panel of
Figure 2. Clearly, both classical estimates break down because they largely overestimate
, while the robust estimates are not influenced by the outliers. The robust results are similar to the classical results that were obtained when no outliers were present in the data. We also show the effect of small losses in run-off triangles. Therefore, we consider a second outlier setting: for each pair of run-off triangles we replace
with
. The bottom right plot of
Figure 2 shows the RMSEP estimates for this outlier setting. Now, both classical estimators underestimate
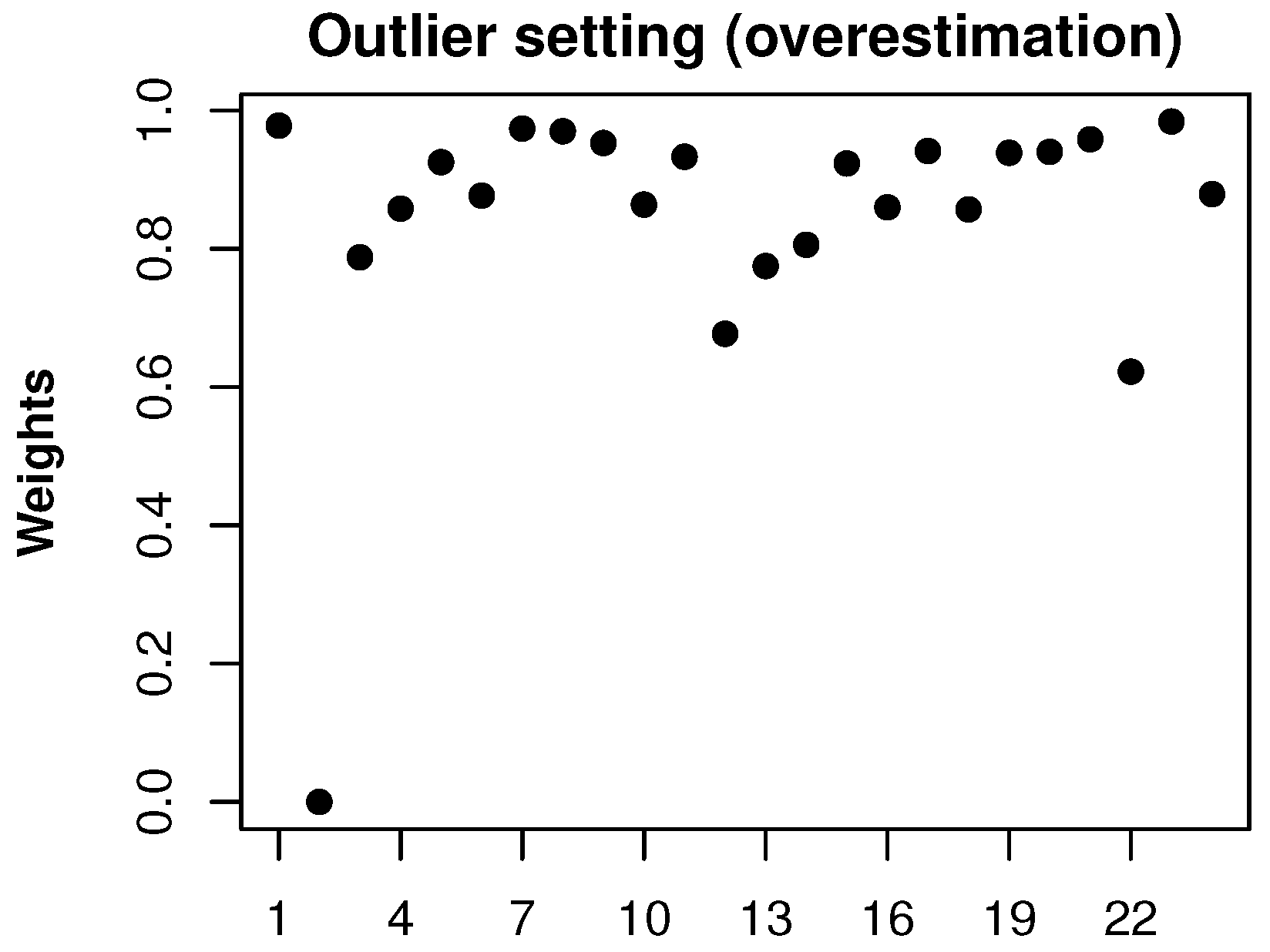
due to a small loss observed in accident period two, leading to large RMSEP values. On the other hand, the robust method resists the effect of the outlier and still performs well. In both outlier settings the robust method can also detect the outlier because the weight of the corresponding accident period is zero as can be seen in
Figure 3 for the first outlier setting.
For the second outlier setting the plot of weights is nearly identical.
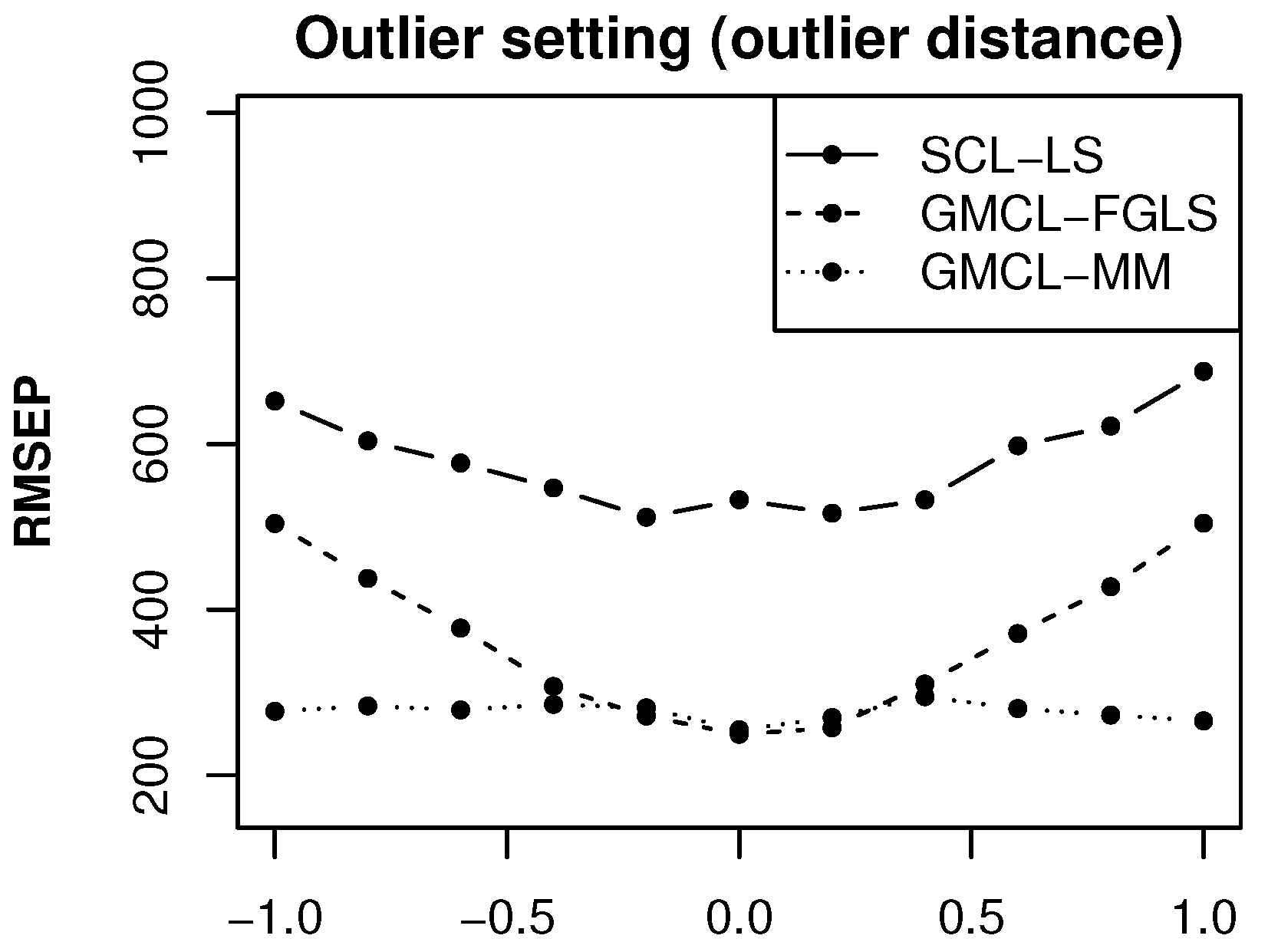
To illustrate the impact of the outlier’s distance to the regular data, we also consider a third outlier setting: for each pair of run-off triangles we replace the simulated error term
to generate
with
where
d ranges from −1 to 1. Non-contaminated error terms take values between −3000 and 3000 for the first development period. Therefore, the situations when
are cases with outliers. Again
bivariate run-off triangles are generated and the prediction accuracy of the expected claim
is measured by MSEP. As opposed to the previous simulations we now fix the number of accident periods
I to 25.
Figure 4 contains the RMSEP results for different outlier distances
d.
When no outliers are generated and the prediction performance of the procedures GMCL-FGLS and GMCL-MM are identical, as we have seen before. For situations with outliers the classical methods yield large RMSEP values because their predictions under- or overestimate the target claim due to the presence of the outliers. The larger the outlier distance d, the worse the prediction accuracy is for non-robust methods. On the other hand, the prediction estimates obtained from the robust method remain stable for all situations.
A more general case is to consider the prediction of
for
with
. In particular, we consider
. We repeat the same procedure of squaring
pairs of dependent triangles and measure the prediction accuracy of
by means of RMSEP. The results for the general setting are shown in
Figure 5. The performance of the different methods is comparable to their performance in the previous setting when predicting
. However, since
the prediction of
depends on 14 model fits, and consequently, the MSEP estimates of
become much larger. The prediction performance in the restricted setting and outlier settings (not shown) are also similar as before.
We have also investigated how the position of the outlier influences the prediction performance. Here the outlier’s position refers to the development period in which it has occurred because the effect is similar for all accident years. If the outlier occurs after the target claim, then both the classical and robust methods yield reliable prediction results for the target claim. However, when the outlier occurs before the target claim, then the classical methods yield prediction estimates that are affected by the outlier, while the robust method remains reliable. Only when the outlier appears in the upper right tail of a run-off triangle, it will affect any method, whether it is robust or not, because there is not enough data available in this tail to be able to identify an outlier. Since the position of outliers is unknown in practice, this illustrates the importance of robust procedures which offer protection against outliers in almost any position of the run-off triangles.
6. Real Data
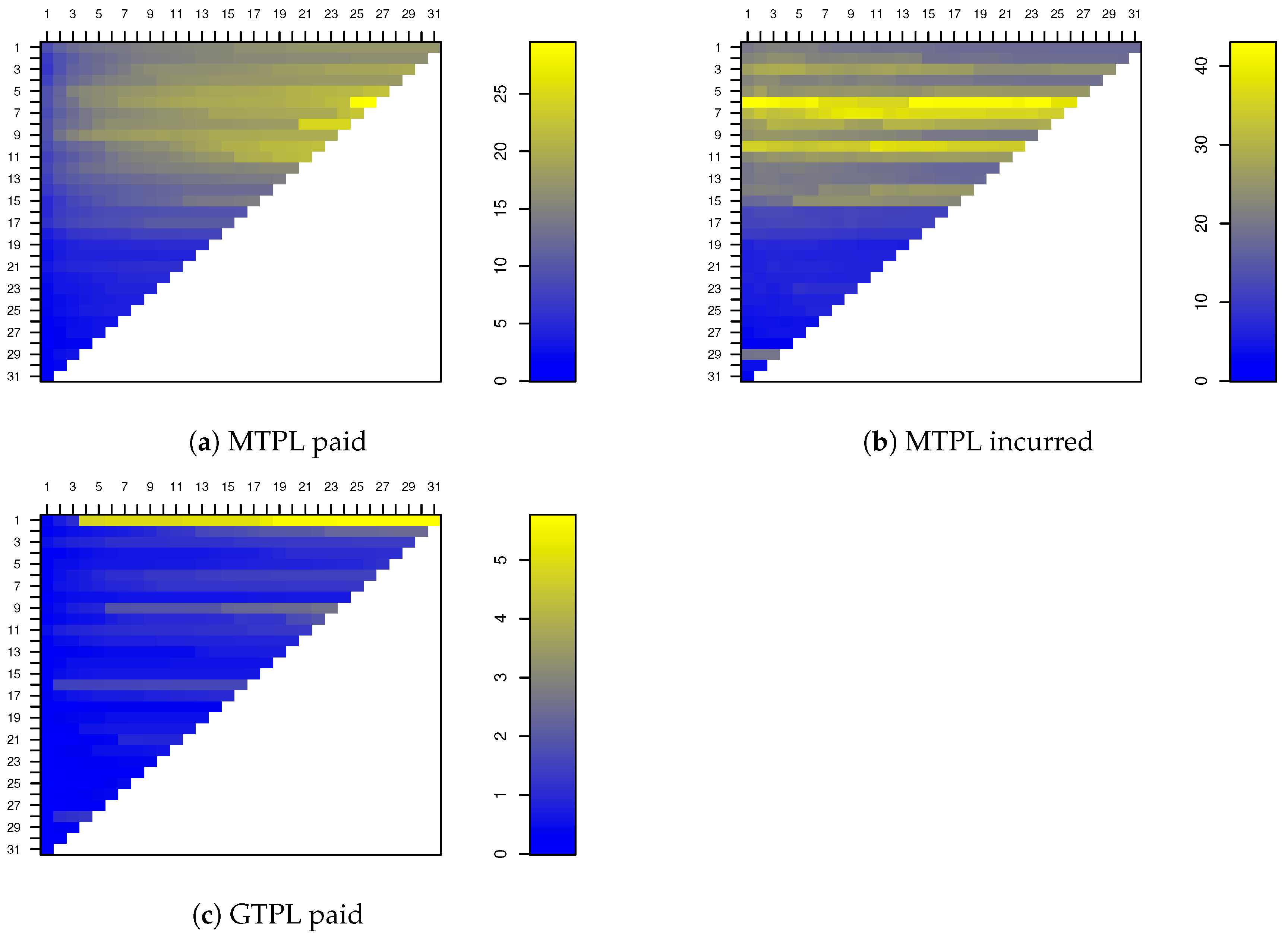
To illustrate the new methodology, we consider an example with paid and incurred data from a motor third party liability (MTPL) and a general third party liability (GTPL) insurance portfolio from a non-life insurance company operating in Belgium. The data have been recorded between March 2008 and December 2015. Quarterly data are available leading to run-off triangles of dimension
shown in
Figure 6.
Observe that from accident trimester 15 onwards the cumulative claim amounts for MTPL become much smaller. This effect is due to a decrease in total premium volume, and hence, also in total number of claims. For the GTPL data, accident trimester 1 seems suspicious. The claim amounts are much larger in comparison to any other period. Finally, notice that for the first 15 accident trimesters the losses in the subportfolios are almost fully developed, i.e., the changes in consecutive cumulative claims are minuscule in the last development years.
We model these run-off triangles separately with SCL and jointly with GMCL. The joint model is given by Equation (
1) with
. The separate model simplifies the joint model by excluding intercepts, structural connections and contemporaneous correlations. We have applied SCL-LS, GMCL-FGLS and GMCL-MM to square the run-off triangles up until period 21. As explained before, we exclude the tail development part in order to focus on the multivariate models.
Table A1 in
Appendix A contains the estimates of the development parameters and the sample correlations between the resulting residuals obtained by SCL-LS for all development periods. While the run-off triangles have been modeled separately, for some development periods there are substantial correlations between the residuals which indicates that the independence assumption might be violated for these data.
The parameter estimates obtained from GMCL-FGLS are summarized in
Table A2 in
Appendix A. The slope estimates
and
measure the contribution of the other two triangles when predicting future losses in a triangle. From
Table A2 it can be seen that for some development periods these estimates are substantially different from zero. They improve the model fit and the prediction performance. The last three columns of
Table A2 contain the sample correlations between the residuals of the three run-off triangles, which have been obtained as
for
, where
are the entries of the covariance matrix
. Several moderate to large correlations have been obtained which again supports the joint GMCL model for these data.
We now apply the robust method GMCL-MM which yields the development parameter estimates shown in
Table A3 in
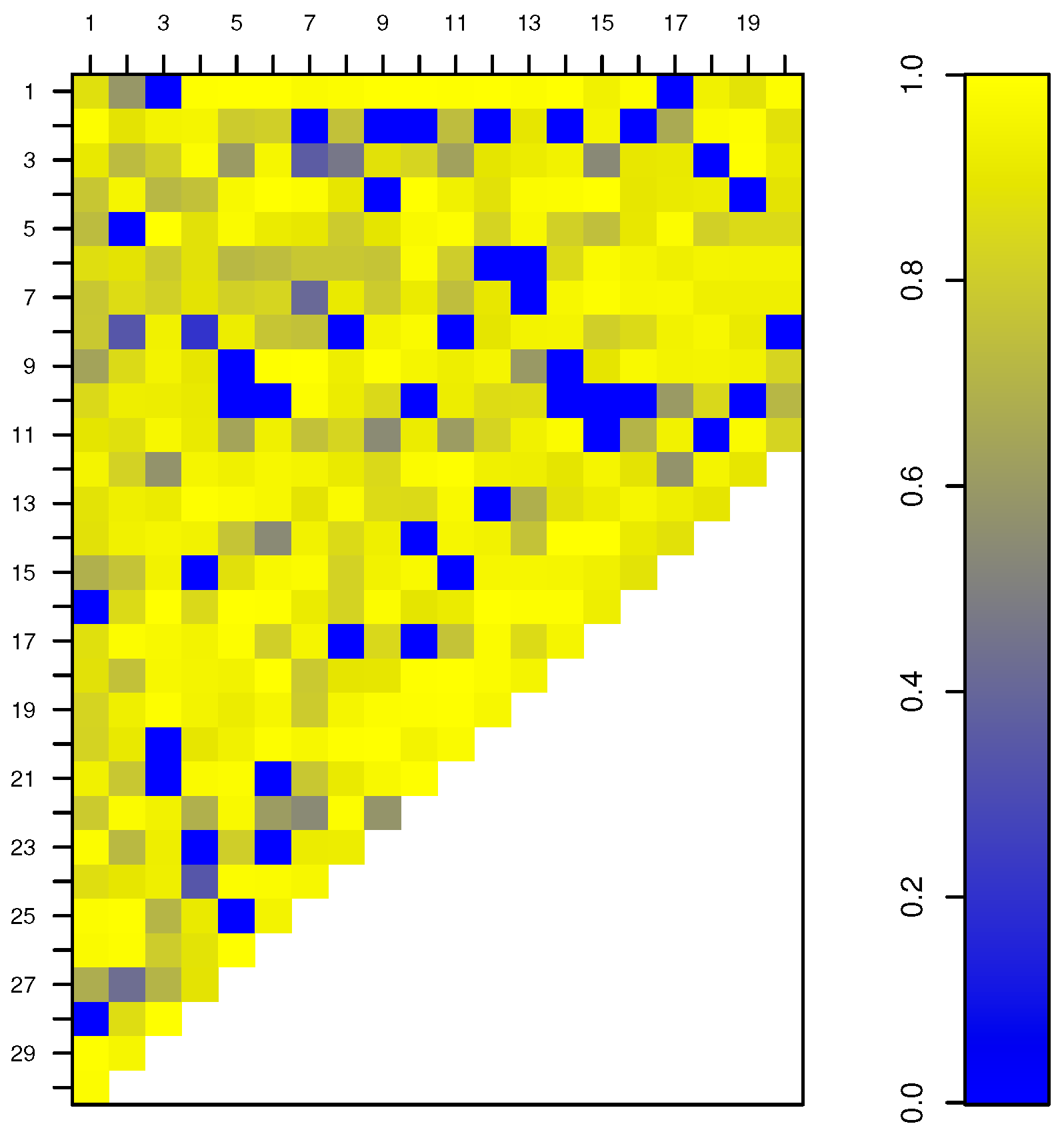
Appendix A. Based on this robust procedure we can now detect possible outliers. The weights assigned to each observation in the SUR models are shown in
Figure 7.
The smaller the weight, the more outlying is an observation with respect to the bulk of the data. For example, from
Figure 7 we can observe that in the first development period there are two major outliers corresponding to accident trimesters 16 and 28 respectively.
The outliers identified by the GMCL-MM method may have affected the classical estimators, and hence, also the prediction of future losses. Hence, in
Table 2 we compare the total reserve estimates for all methods.
Let us first focus on the paid losses of the MTPL portfolio. The non-robust SCL-LS and GMCL-FGLS methods both yield a total reserve estimate that is larger than for the robust GMCL-MM. A close inspection of the predicted run-off triangles revealed that the transition from development trimester 20 to 21 is highly responsible for these large differences. For development trimester 21 one can observe in
Figure 6 a large incremental increase of the losses that occurred in accident trimester 8. The SCL-LS and GMCL-FGLS fits for this transition period are both largely influenced by this particular observation. Consequently, the predicted future losses from this development trimester onward are much larger. On the other hand, the robust GMCL-MM method is much less influenced by this observation and is able to flag this observation as an outlier.
Let us now consider the reserve estimates of the incurred losses. The two non-robust approaches agree quite well. The difference is mainly caused by accident trimester 29 for which unexpectedly small paid losses have been observed but at the same time large incurred losses were recorded. In the joint GMCL model the development factor for the model from development period 7 to 8 differs from zero and thus influences the incurred losses obtained by GMCL-FGLS which is not the case for SCL-LS. Moreover, remark that these reserve estimates are negative. Negative reserve estimates are often observed for incurred run-off triangles due to overestimation of the losses. The robust total reserve estimate obtained by GMCL-MM is much larger than for the non-robust methods. This indicates that the presence of outliers has again affected the classical results. More specifically, in this case the classical procedures yield smaller prediction estimates as compared to the robust procedure. For example, one can verify that for the transition from development trimester 18 to 19 the prediction estimates obtained by GMCL-MM are much larger than those obtained by GMCL-FGLS.
Finally, we also consider the estimated reserve for the GTPL portfolio. The unusual data in the first accident trimester affect the total reserve estimates of both non-robust methods. On the other hand, the robust GMCL-MM detected the deviating pattern in the first accident trimester as well as other moderate outliers and yields a robust total reserve estimate that is not driven by atypical behavior in the available data. Please note that the GMCL-based methods yield negative reserve estimates for these data. While negative reserve estimates are not uncommon for incurred losses, they are rather unusual for run-off triangles with paid losses. However, the real data have been obtained from a small company and the company informed us that for some claims there has been substantial recovery of initially paid losses. These recoveries have an impact on the cumulative claims data which may explain the negative reserve estimates in this case.
To further investigate the performance of the estimation methods, we now focus on the prediction of the values on the last diagonal of all run-off triangles. To measure the accuracy of the predictions, we consider their MSEP. More specifically, we leave out the last diagonal of all three run-off triangles, apply the different methods on the remaining data and calculate the mean squared relative prediction error for each method. The results are given in
Table 3 for each subportfolio separately as well as all portfolios jointly.
While the three methods perform quite similar on the first two run-off triangles, this is not the case for the GTPL paid data as can be seen from
Table 3. The MSEP of GMCL-FGLS is large for this run-off triangle. SCL-LS performs better, but not as good as GMCL-MM which is the only method that yields reasonable performance for these data. As a result, GMCL-MM also shows the best overall performance which illustrates that the outliers in these run-off triangles affect the predictions of the non-robust methods.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






