Abstract
Recently, a derivative-free optimization algorithm was proposed that utilizes a minimum Frobenius norm (MFN) Hessian update for estimating the second derivative information, which in turn is used for accelerating the search. The proposed update formula relies only on computed function values and is a closed-form expression for a special case of a more general approach first published by Powell. This paper analyzes the convergence of the proposed update formula under the assumption that the points from where the function value is known are random. The analysis assumes that the points used by the update formula are obtained by adding vectors to a central point. The vectors are obtained by transforming a prototype set of vectors with a random orthogonal matrix from the Haar measure. The prototype set must positively span a dimensional subspace. Because the update is random by nature we can estimate a lower bound on the expected improvement of the approximate Hessian. This lower bound was derived for a special case of the proposed update by Leventhal and Lewis. We generalize their result and show that the amount of improvement greatly depends on N as well as the choice of the vectors in the prototype set. The obtained result is then used for analyzing the performance of the update based on various commonly used prototype sets. One of the results obtained by this analysis states that a regular n-simplex is a bad choice for a prototype set because it does not guarantee any improvement of the approximate Hessian.
MSC:
90C56; 90C53; 65K05; 15A52
1. Introduction
Derivative-free optimization algorithms have attracted much attention due to the fact that in many optimization problems, the evaluation of the gradients of the function subject to optimization and constraints is expensive. Such optimization problems can be often formulated as constrained black-box optimization (BBO) [1] problems of the form
Functions f and are maps from to . The objective is to minimize f subject to nonlinear constraints defined by functions . The method for computing f and is treated as a black-box, and the gradients are usually not available. Such problems often arise in engineering optimization when simulation is used for obtaining the function values. BBO often relies on models of the function and of the constraints. Various approaches to building black-box models were developed in the past, such as linear [2] and quadratic models [3], radial-basis functions [4], support vector machines [5], neural networks [6], etc.
In this paper, we focus on the quadratic models of f and . The most challenging task in building these models is the computation of the Hessian matrix. Instead of using the exact Hessian, the model can utilize an approximate Hessian. The approximation can be improved gradually by applying an update formula based on the function and the gradient values at points visited in the algorithm’s past. As the algorithm converges towards a solution, the approximate Hessian converges to the true Hessian.
For derivative-based optimization, several approaches for updating the approximate Hessian are well studied and tested in practice (e.g., BFGS update, SR1 update [7]). Unfortunately, these approaches rely on the gradient of the function (constraints), which, by assumption, is not available in derivative-free optimization.
Let n denote the dimension of the search space. For derivative-free optimization, a Hessian update formula based on the function values computed at points visited in the algorithm’s past was proposed by Powell in [8]. The update formula was obtained by minimizing the Frobenius norm of the update applied to the approximate Hessian subject to linear constraints imposed by the function values at m points in the search space. The paper proposed an efficient way for computing the update and explored some of its properties. The convergence rate of the update formula was not studied.
In a later paper, a simple update formula that uses three collinear points for computing the updated approximate Hessian [9] was examined. The normalized direction along which the three points lie was assumed to be uniformly distributed on the unit sphere. With this assumption, the convergence rate of the update was analyzed and shown to be linear. This update formula was successfully used in a derivative-free algorithm from the family of mesh adaptive direct search algorithms (MADS) [10]. A similar Hessian updating approach was used for speeding up global optimization in [11].
The assumption that the points taking part in an update must be collinear is a significant limitation for the underlying derivative-free algorithm. With this in mind, a new simplicial update formula was proposed in [12]. The formula relies on points. The reason for choosing the term simplicial Hessian update is the fact that the points form a simplex centered around the first point. For , the formula is a special case of the update formula proposed in [8]. By imposing some restrictions on the positions of the m points, the update formula can be used for any m that satisfies . The case corresponds to the update formula proposed in [9].
To illustrate the approach for obtaining the update formula, let us assume that the current quadratic model of function f is given by
is the current approximate Hessian. Let the points where the function is known be denoted by . For the sake of simplicity, let denote . Based on these points, we are looking for an updated model:
The model must satisfy m constraints
that are linear in and the components of and . Based on these constraints, we are looking for an updated approximate Hessian . Because we have fewer constraints than there are unknowns, we also require that is minimal ( denotes the Frobenius norm). The update formula we obtain in this way is a minimum Frobenius norm update formula.
For computing the expected improvement of the approximate Hessian, we first assume f itself is quadratic. We also assume the aforementioned m points are obtained by applying a random orthogonal transformation to vectors that form a prototype set and adding the resulting vectors to a central point. As in [9], the convergence rate of the update is linear. The speed with which the approximate Hessian converges to the true Hessian depends on the choice of the prototype set. Our result is a generalization of the result published in [9].
This paper is divided as follows. In Section 2, some basic properties of minimum Frobenius norm updates are explored. The Frobenius product is revisited with the purpose of simplifying the notation, and the update formula is derived. In the next section, uniformly distributed orthogonal matrices are introduced. Some auxiliary results are derived that are later used for computing the expected improvement of the approximate Hessian. Section 4 analyzes the convergence of the proposed update and derives the expected value of the improvement in the sense of the Frobenius norm of the difference between the approximate Hessian and the true Hessian. The expected improvement is computed for several prototype sets. The section is followed by an example demonstrating the convergence of the proposed update and concluding remarks.
Notation. Components of vectors () and matrices () are denoted by subscripts (i.e., and , respectively). The i-th column of matrix is denoted by . The unit vectors forming an orthogonal basis for are denoted by . Vectors are assumed to be column vectors, and the inner product of two vectors is written in matrix notation as . The Frobenius norm and the trace of a matrix are denoted by and , respectively. The expected value of a random variable is denoted by .
2. Obtaining the Update Formula
Let denote the Hessian of a function. Minimum Frobenius norm (MFN) update formulas replace the current Hessian approximation with a new (better) approximation in such manner that the Frobenius norm of the change (i.e., ) is minimal, subject to constraints imposed on .
The Frobenius norm is a norm induced by the Frobenius (inner) product on the space of n-by-n matrices. The Frobenius product of two matrices is given by
Using the Frobenius product, one can express the Frobenius norm of matrix as
Quadratic terms can be expressed with the Frobenius product as
The Frobenius product introduces the notion of perpendicularity into the set of matrices (not to be confused with the orthogonality of matrices, which is equivalent to ).
Definition 1.
Two nonzero matrices and are perpendicular (denoted by ) if .
The Frobenius product can also be used for expressing linear constraints. A linear equality constraint on matrix can be formulated as
The following Lemma provides motivation for the use of minimum Frobenius norm updating.
Lemma 1.
Let , , and denote the exact, the current approximate, and the updated approximate Hessian, respectively. Suppose we have m linear equality constraints of the form
imposed on . Let denote the subspace spanned by matrices . Then, the corresponding MFN update satisfies
- , and
- .
Proof.
Finding the MFN update is equivalent to minimizing the Frobenius norm of subject to linear equality constraints (10). These constraints define an affine subspace in the dimensional space of Hessian matrices, and is a member of this affine subspace. Because the true Hessian also satisfies constraints (10), it is also a member of the aforementioned affine subspace.
To simplify the problem, we can translate it in such manner that becomes . When we do this, the linear constraints become homogeneous, and instead of an affine subspace, they now define an ordinary subspace . Its orthogonal complement is spanned by matrices . Due to translation, and are replaced by and , of which the latter is a member of . Points with constant lie on a sphere centered at . Matrix that corresponds to the smallest lies on a sphere centered at that is tangential to subspace . Therefore, must be perpendicular to , i.e., . This proves the first claim.
Due to , we can see that and are perpendicular. From , we have
The second claim immediately follows from this result. □
Consider a quadratic function
where is its Hessian and its gradient at . Let the current and the updated approximation to be given by
and
respectively. In MFN, updating is obtained by minimizing . The following lemma introduces one such update based on the case when the value of q is known at points.
Lemma 2.
Let , where denote the values of corresponding to distinct points , respectively. Let and assume with at least one . Then the simplicial MFN update satisfying the interpolation conditions for can be computed as
where
Proof.
By assumption we have
Due to the interpolation conditions, we have constraints
By subtraction, we eliminate and obtain constraints
Multiplying (20) with and adding the resulting equations yields
By assumption, the second term on the left-hand side of (21) vanishes (thus, is eliminated). We are left with a single linear constraint on :
which can be rewritten by recalling (8) as
where
Equation (23) is a linear constraint on the updated Hessian approximation . This is the only constraint on . From Lemma 1, we can see that is spanned by . Therefore, we can write
Now we can compute :
□
The simplicial update formula introduced by Lemma 2 is the closed-form solution of the equations arising from the MFN update in [8] for . One can see this by comparing the interpolation conditions to those in [8]. Due to the assumption , we can also apply it when . The assumption implies the points are positioned in a specific manner with respect to (i.e., there exists a nontrivial linear combination ).
By choosing , we obtain a special case of the simplicial MFN update, where all three distinct points must be collinear to satisfy . Suppose and . Then,
where is the second directional derivative of q along direction . The convergence properties of this MFN update formula were analyzed in [9]. The formula was used in the derivative-free optimization algorithm proposed in [10].
3. Uniformly Distributed Orthogonal Matrices
The notion of a uniform distribution over the group of orthogonal matrices () can be introduced via the Haar measure [13]. Let denote a matrix with independent normally distributed elements with zero mean and variance 1. A random orthogonal matrix from the Haar measure () can then be obtained with Algorithm 1.
| Algorithm 1 Constructing a random orthogonal matrix from the Haar measure. |
|
Multiplying with any unit vector results in a random unit vector that is uniformly distributed on the unit sphere () [14]. It can be shown that is also a uniformly distributed orthogonal matrix. Consequently, every column and every row of are a random unit vector with uniform distribution on .
The results of this section are obtained with the help of the following lemma.
Lemma 3.
Let and let denote the surface element of . Then,
Proof.
See [15], Appendix B. □
From Lemma 3, we can obtain the surface area of by choosing .
Let and denote two random vectors that correspond to the i-th and the j-th column of . If , then . We denote the k-th component of as .
Lemma 4.
Let be a uniformly distributed random orthogonal matrix. Then,
Proof.
For proving (31), we can assume without loss of generality . Because is uniformly distributed on , the expected value of can be obtained by computing the mean value of over . We use Lemma 3 for expressing the integral over the surface of .
For , we assume without loss of generality , . From Lemma 3, we have
For (33) with , we can show that it is identical to (32) with . We have
where is the k-th column of . This implies
To confirm (33) for , we take into account that is also a random orthogonal matrix from the Haar measure, replace with in (32), and rename i, k, and l to k, i, and j, respectively.
Finally, to prove (33) for , we can assume without loss of generality and . The cosine of the angle between and can be expressed as . Random vector is orthogonal to . Its realizations cover a unit sphere in an -dimensional subspace orthogonal to . Unit vectors form an orthogonal basis for this subspace. Note that . The conditional probability density distribution of is uniform on the aforementioned unit sphere in . Vector can be expressed as
where vector is uniformly distributed on . Without loss of generality we can choose vectors in such manner that , where is the angle between and . Now we have
and
Next, we can express
where the first expected value refers to and the second one to . Using Lemma 3 and previously proven (32), we arrive at
□
4. Convergence of the Proposed Update
Multiplying vectors in a prototype set with a uniformly distributed random orthogonal matrix results in a set of random vectors such that every is uniformly distributed on . The angles between the vectors in a realization of such a set are identical to the angles between the corresponding vectors from the prototype set.
Suppose one is interested in the expected amount of improvement resulting from one application of the update formula from Lemma 2. We assume that the points where the function value is computed comprise and additional points generated using a random orthogonal matrix and a prototype set of vectors in the following manner.
First, we prove an auxiliary lemma.
Lemma 5.
Let , , and denote two unit vectors with and a uniformly distributed orthogonal matrix, respectively. Let and . Then,
Proof.
Without loss of generality, the coordinate system can be rotated in such manner that and . Then, we have
For , we have
The last term vanishes because the integral of odd powers of over is zero. By invoking Lemma 4, we arrive at
For ,
The last term vanishes due to odd powers of . Together with Lemma 4, we have
□
Lemma 6.
Let be a prototype set of vectors satisfying , where all and at least one . Let be a uniformly distributed random orthogonal matrix, and let with . Then, the MFN update formula from Lemma 2 involving points ( and the additional points constructed according to (47)) satisfies
where
Proof.
By repeating the reasoning in the proof of Lemma 2 on (18), we obtain
which yields together with the expression for from Lemma 2
Now we can express
Because vectors are uniformly distributed on the unit sphere, we can rotate the coordinate system without affecting so that is diagonalized.
Let denote the k-th component of vector and the k-th eigenvalue of (k-th diagonal element of ).
We can rewrite (65) as
The expected value of depends on . From Lemma 5, we have
Because the eigenvalues of are the same as the eigenvalues of , we have
and
The Frobenius norm of can be expressed as
We also have
Theorem 1.
Let , , and μ be defined as in Lemma 6. Then,
Proof.
We start with the following identity.
Computing the Frobenius norm on both sides and considering results in
Taking into account (15) results in
After Lemma 6 is applied, we have
By definition, and . For , we must have . By considering , we arrive at
For , we must have . Invoking Lemma A1 yields
□
From Theorem 1, several results can be derived. First, we will assume the prototype set is a regular N-simplex (i.e., comprises vectors positively spanning an N-dimensional subspace). This case is interesting because the update formula in [9] is obtained for . We are going to show that our estimate of the expected Hessian improvement is identical to the one published in [9]. This update formula (with ) was used in an optimization algorithm published in [10].
Next, we are going to show that using a regular n-simplex as the prototype set is a bad choice. According to Theorem 1, no improvement of the Hessian is guaranteed. Even worse, we show that improvement occurs only at the first application of the update formula.
Finally, we will analyze the case where the prototype set is what we refer to as an augmented set of N orthonormal vectors. Such a prototype set with was used in the optimization algorithm published in [14].
Corollary 1.
Let be a regular N-simplex (). Then,
Proof.
For all , we have and . Because the sum of all vectors in a regular N-simplex is , we conclude and
Because for all , we have , and the result follows from Theorem 1. □
Corollary 1 implies that the most efficient approach to MFN updating with a regular simplex in the role of the prototype set of unit vectors is to use a regular 1-simplex (three collinear points).
Corollary 2.
For and , set is a regular 1-simplex and
This result was proven in [9] with a less general approach. Here, we obtain it as a special case of Corollary 1 for .
According to Corollary 1, there is no guaranteed improvement of if a regular n-simplex () is used in the update process. In fact, the situation is even worse as we show in the following Lemma.
Lemma 7.
If is a regular n-simplex (), then the MFN update from Lemma 2 improves the Hessian approximation only in its first application.
Proof.
For a regular simplex, and . The Frobenius norm of is
From definition of , we obtain
From , we can express
Let denote the approximate Hessian after the second application of the update formula.
Because , we have , and the proof is complete. □
Intuition can mislead one into considering the regular n-simplex as the best choice for positioning points around an origin when computing an MFN update based on Lemma 2. Lemma 7 shows the exact opposite—a regular n-simplex is the worst choice because the update formula does not improve the Hessian approximation in its second and all subsequent applications.
Definition 2.
An augmented set of orthonormal vectors is a set comprising N mutually orthogonal unit vectors and their normalized negative sum .
Note that an augmented set of orthonormal vectors is equivalent to a regular 1-simplex. Now, we have and . For , we have except for or when . Because is the normalized negative sum of the first N vectors, and .
Corollary 3.
If the prototype set of unit vectors is an augmented set of N orthonormal vectors, then
Proof.
Because for all , we conclude , and the result follows from Theorem 1. □
A special case of Corollary 1 is the following result.
Corollary 4.
If the prototype set of unit vectors is an augmented set of orthonormal vectors, then
Corollaries 2 and 4 indicate that for an augmented set of orthonormal vectors (used in [12]), the expected improvement of the approximate Hessian approaches half of the improvement obtained using a regular 1-simplex (introduced in [9]) when n approaches infinity.
Corollaries 1–4 indicate that the update formula yields a greater improvement of the approximate Hessian when the prototype set of vectors exhibits more directionality, in the sense that the vectors are confined to an dimensional subspace of the search space. Lower values of N result in faster convergence.
5. Example
We illustrate the proposed update with a simple example. The sequence of uniformly distributed orthogonal matrices is generated as in [14]. Three prototype sets are examined—regular 1-dimensional and -dimensional simplex and the augmented set of n orthonormal vectors. The true Hessian is chosen randomly and the initial Hessian approximation is set to . The progress of the update is measured by the normalized Frobenius distance between and .
Figure 1 depicts the progress of the proposed update with various prototype sets for and . It is clearly visible that the convergence of the update is linear and depends on the choice of the prototype set. The convergence rate of the update using an augmented set of n orthonormal vectors is approximately half of the convergence rate exhibited by the update using a regular 1-simplex. It can also be seen that the bound on the amount of progress obtained from one update (Theorem 1) is fairly conservative. The actual progress of the update is much better in practice.
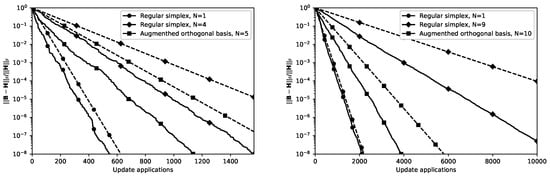
Figure 1.
Progress of three simplicial updates for (left) and (right). Dashed lines represent the progress of the update assuming every update application improves the approximate Hessian by the amount predicted in Theorem 1.
6. Discussion
The convergence of a Hessian update formula that requires only function values for computing the update was analyzed. The update formula is based on the formula published in [8] that generally requires the function values at points. The proposed update is based on the case where . An additional requirement is introduced, namely that the vectors from the central point to the remaining points must positively span a dimensional subspace of . This requirement extends the usability of the proposed update to sets of points with members. The set of m points used by the update is generated by adding vectors to a central point in the set. The vectors are obtained by applying a random orthogonal transformation to a prototype set of vectors that spans a dimensional subspace of .
A lower bound on the expected improvement of the Hessian approximation was derived (Theorem 1). Up to now, no such result was published for the update from [8] and . The obtained result was applied to several different prototype sets. The general result obtained for the case when the prototype set is a regular -dimensional simplex (Corollary 1) shows that the expected improvement of the Hessian approximation is greatest for (i.e., 1-dimensional regular simplex) and decreases as the dimensionality of the simplex increases. The special case when (1-dimensional regular simplex) corresponds to the update from [9]. The lower bound on the expected improvement obtained with our general result (Corollary 2) matches the one that was published in [9]. For the n-dimensional regular simplex, our result indicates that the lower bound on expected improvement of the Hessian approximation is 0. Furthermore, it was shown that the Hessian approximation is possibly improved only by the first application of the proposed update formula (Lemma 7). Therefore, the use of the n-dimensional regular simplex in the role of the prototype set is a bad choice.
Next, the expected improvement of the approximate Hessian for a prototype set comprising orthogonal vectors and their normalized negative sum was derived. Such a prototype set with was used in the optimization algorithm published in [12]. It was shown that using this kind of prototype set does guarantee a positive lower bound on the expected improvement of the Hessian approximation (Corollary 4). The general result (Corollary 3), however, again indicates that using a prototype set of lower dimensionality results in faster convergence. The result for (two collinear vectors in the role of the prototype set) is the same as the one obtained for the update from [9].
Finally, the results were illustrated by running the proposed update on a quadratic function with a randomly chosen Hessian for several choices of the prototype set. The observed progress was compared to the lower bound predicted by Theorem 1. The results indicate that the lower bound is quite pessimistic, and that the actual progress is faster. The observed performance was closest to the predicted lower bound for the update formula from [9].
Author Contributions
Conceptualization, Á.B. and T.T.; methodology, Á.B. and J.O.; software, J.O.; validation, J.O.; formal analysis, Á.B.; investigation, Á.B.; resources, T.T.; data curation, Á.B.; writing—original draft preparation, Á.B.; writing—review and editing, Á.B. and J.O.; visualization, J.O.; supervision, T.T.; project administration, T.T.; funding acquisition, T.T. All authors have read and agreed to the published version of the manuscript.
Funding
The research was co-funded by the Ministry of Education, Science, and Sport (Ministrstvo za Šolstvo, Znanost in Šport) of the Republic of Slovenia through the program P2-0246 ICT4QoL—Information and Communications Technologies for Quality of Life.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank the anonymous referees for their useful comments that helped to improve the paper. Most notably, the authors would like to thank the second referee whose suggestion lead to the simplification of the proof of Lemma 4.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MFN | Minimum Frobenius norm |
| BFGS | Broyden-Fletcher-Goldfarb-Shanno |
| SR1 | Symmetric rank-one |
Appendix A
The following lemma is used in the proof of the main result.
Lemma A1.
Let be a matrix. Then,
Proof.
Let denote the n eigenvalues of . We have
The maximum of can be obtained by finding subject to . The solution of this problem is
Let be a matrix whose columns are the vectors comprising a regular simplex in n dimensions. By definition, the following must hold
Clearly, there are infinitely many possible solutions to (A5). We will assume that is upper triangular. A solution to (A5) with this property is unique and can be obtained via Cholesky decomposition of the submatrix of comprising the first n rows and columns which yields the first n columns of . The last column is then obtained as the negative sum of the first n columns. Matrix is in row echelon form and represents what we will refer to as the standard regular simplex. Its components can be expressed as
Lemma A2.
Let columns of represent a regular simplex. Then,
Proof.
Let columns of comprise a standard regular simplex. Diagonal elements of can be obtained as
Because is symmetric, we assume for computing the extradiagonal elements
This proves . Any regular simplex can be expressed with the standard regular simplex as , where is an orthogonal matrix. Therefore, we have
□
Lemma A3.
Let columns of represent a regular simplex, and let be a symmetric matrix. Then,
Proof.
□
References
- Audet, C.; Kokkolaras, M. Blackbox and derivative-free optimization: Theory, algorithms and applications. Optim. Eng. 2016, 17, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Powell, M.J.D. A Direct Search Optimization Method That Models the Objective and Constraint Functions by Linear Interpolation. In Advances in Optimization and Numerical Analysis. Mathematics and Its Applications; Gomez, S., Hennart, J.P., Eds.; Springer: Dordrecht, The Netherlands, 1994; Volume 275, pp. 51–67. [Google Scholar]
- Powell, M.J.D. UOBYQA: Unconstrained optimization by quadratic approximation. Math. Program. 2002, 92, 555–582. [Google Scholar] [CrossRef]
- Buhmann, M.D. Radial Basis Functions: Theory and Implementations, Volume 12 of Cambridge Monographs on Applied and Computational Mathematics; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Suykens, J.A.K. Nonlinear modelling and support vector machines. In Proceedings of the IMTC 2001 18th IEEE Instrumentation and Measurement Technology Conference. Rediscovering Measurement in the Age of Informatics, Budapest, Hungary, 21–23 May 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 287–294. [Google Scholar]
- Fang, Z.Y.; Roy, K.; Chen, B.; Sham, C.-W.; Hajirasouliha, I.; Lim, J.B.P. Deep learning-based procedure for structural design of cold-formed steel channel sections with edge-stiffened and un-stiffened holes under axial compression. Thin-Walled Struct. 2021, 166, 108076. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Powell, M.J.D. Least Frobenius norm updating of quadratic models that satisfy interpolation conditions. Math. Program. 2004, 100, 183–215. [Google Scholar] [CrossRef]
- Leventhal, D.; Lewis, A.S. Randomized Hessian estimation and directional search. Optimization 2011, 60, 329–345. [Google Scholar] [CrossRef]
- Bűrmen, Á.; Olenšek, J.; Tuma, T. Mesh adaptive direct search with second directional derivative-based Hessian update. Comput. Optim. Appl. 2015, 62, 693–715. [Google Scholar] [CrossRef]
- Stich, S.U.; Müller, C.L. On Spectral Invariance of Randomized Hessian and Covariance Matrix Adaptation Schemes. In Proceedings of the Parallel Problem Solving from Nature—PPSN XII: 12th International Conference, Taormina, Italy, 1–5 September 2012; Coello Coello, C.A., Cutello, V., Deb, K., Forrest, S., Nicosia, G., Pavone, M., Eds.; Springer: New York, NY, USA, 2012; pp. 448–457. [Google Scholar]
- Bűrmen, Á.; Fajfar, I. Mesh adaptive direct search with simplicial Hessian update. Comput. Optim. Appl. 2019, 74, 645–667. [Google Scholar] [CrossRef]
- Stewart, G.W. The efficient generation of random orthogonal matrices with an application to condition estimators. SIAM J. Numer. Anal. 1980, 17, 403–409. [Google Scholar] [CrossRef]
- Bűrmen, Á.; Tuma, T. Generating Poll Directions for Mesh Adaptive Direct Search with Realizations of a Uniformly Distributed Random Orthogonal Matrix. Pac. J. Optim. 2016, 12, 813–832. [Google Scholar]
- Sykora, S. Quantum Theory and the Bayesian Inference Problems. J. Stat. Phys. 1974, 11, 17–27. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).