Abstract
This paper aims to find optimal feedback policies for the tracking control of Markovian jump Boolean control networks (MJBCNs) over a finite horizon. The tracking objective is a predetermined time-varying trajectory with a finite length. To minimize the expected total tracking error between the output trajectory of MJBCN and the reference trajectory, an algorithm is proposed to determine the optimal policy for the system. Furthermore, considering the penalty for control input changes, a new objective function is obtained by weighted summing the total tracking error with the total variation of control input. Certain optimal policies sre designed using an algorithm to minimize the expectation of the new objective function. Finally, the methodology is applied to two simplified biological models to demonstrate its effectiveness.
Keywords:
Boolean control networks; Markov switching; optimal output tracking control; dynamic programming; semi-tensor product (STP) MSC:
93C29; 93E99; 94C11
1. Introduction
Boolean networks (BNs) were first put forward by Kauffman as a kind of model for genetic regulatory networks (GRNs) [1]. When simulating a GRN with a BN, each node of the BN represents a gene, whose state is quantified as 1 or 0, and the genes’ mutual regulatory interactions are characterized by logical functions. Moreover, sometimes, there are external drug interventions in GRNs, which can be interpreted as control inputs in BNs. BNs with control input nodes are termed Boolean control networks (BCNs). There was no unified tool for studying BNs until semi-tensor product (STP) was proposed [2], which has greatly facilitated research on many related problems regarding BNs, including stability and stabilization [3,4,5], controllability and observability [6,7,8], state estimation [9,10,11,12], state compression [13], and the output tracking control (OTC) problem [14,15,16,17]. In addition, STP has also been widely adopted in other areas like nonlinear shift registers [18] and fuzzy relational inequalities [19].
As we know, there is usually randomness in gene expression. Consequently, Shmulevich et al. proposed probabilistic Boolean networks (PBNs) to characterize the uncertainty in GRNs [20,21]. A PBN has several realizations, and each realization is selected according to a probability distribution for each time. Similarly, probabilistic Boolean control networks (PBCNs) are derived from PBNs by incorporating control inputs into networks. In addition, a Markov chain was shown to emulate the dynamic of a small GRN well [22]. Furthermore, Markovian jump Boolean control networks (MJBCNs) form another category of stochastic extensions to BNs. As stated in [23], PBCNs can be regarded as a special kind of MJBCNs. In an MJBCN, mode transitions are governed by a Markov chain. Recently, some results on MJBCNs have been obtained, such as controllability [23] and stabilization [24,25].
The significance of OTC lies in its ability to design the control so that the system output closely follows a desired reference trajectory. This is valuable in various practical applications such as robotic manipulator control [26] and flight control [27]. By solving the OTC problem, systems can operate stably in dynamic environments, reduce errors, improve performance, and lower costs and energy consumption. In fields like disease treatment, it can also help precisely control drug concentrations and treatment processes, enhancing effectiveness and safety. The finite-time OTC of BCNs was first investigated by Li et al. [14,15]. Moreover, the finite-time OTC of PBCNs has been studied in [28]. In addition, the asymptotic OTC of PBCNs has been addressed by Chen et al. [29]. In these studies, the tracking objective is a constant state or a reference system.
As stated in [30], a useful method to improve the efficiency of bioreactors is forcing the states of microalgas to follow a predetermined reference trajectory. Motivated by this, Zhang et al. [16] investigated the optimal (i.e., minimum error) OTC of BCNs over a finite time horizon, where the tracking objective is a predefined finite-length trajectory. Moreover, in practice, it is difficult to make substantial changes to the control inputs in a short period, or it may require increased costs. For example, in disease treatment, the concentration of a drug in the body typically decreases gradually rather than instantaneously. Thus, the penalty for the control input changes was taken into account in [16]. After that, the OTC problems of PBCNs and MJBCNs with respect to a predefined reference trajectory were studied in [31,32,33], respectively. However, there was no feedback policy provided for all of the initial states in [33]; moreover, a penalty for control input changes was not considered in [31,32,33].
In this article, we study the finite horizon OTC of MJBCNs with respect to a predefined reference trajectory with a finite length.
- The OTC problem is reformulated as an optimal control problem, and then an optimal policy is obtained to minimize the expected total tracking error.
- A new objective function is constructed by performing a weighted sum of the total tracking error and the total variation of the control input. An optimal policy is given to minimize the expected objective function value.
- The optimal feedback policies obtained in this paper apply to all initial states. As shown in the examples, the design of policies is based on the specific weightings given to the two objectives (i.e., reducing tracking errors and decreasing input variations).
2. Preliminaries
The basic symbols are given in Table 1. Due to STP being a generalization of ordinary matrix multiplication [2], in the sequel, we omit symbol ⋉ as long as there is no ambiguity.

Table 1.
Notations.
MJBCN is presented as follows:
where is the state vector, is the control input vector, is the output vector, and is a Markov switching signal with a transition probability matrix (TPM) , that is, . In addition, all and are logical mappings.
Assumption 1
([35]). and are conditionally independent of for all .
Let , , and . Introduce instrumental variables and . Define a matrix
where is called the swap matrix [2]. Split matrix into M blocks of the same size: .
Proposition 1.
For any and ,
Proof.
Suppose and . Note that , so
Moreover, note that , so
Therefore, under Assumption 1,
That is, . □
3. Main Results
3.1. Finite Horizon OTC of MJBCNs
A reference trajectory of length is given as follows:
where , .
A policy is a sequence of mappings in the form of , where . There is a for each such that . If policy is determined, we stipulate
Conversely, if the feedback control (5) is given, policy is also determined. represents the set of all policies.
Definition 1.
If the reference output trajectory (4) can not be exactly tracked, we attempt to find a policy that can minimize the expected total tracking error between the output trajectory of MJBCN (2) and the reference trajectory (4) from to .
Given two output state vectors and , let and . The distance between and (or between and ) is given as follows [16]:
For example, suppose and . We can calculate and . By (6), . Although and (likewise and ) uniquely determine each other, cannot be intuitively observed from and . In fact, the Euclidean distance of and is either 0 or , which cannot reflect the degree of difference between and . The distance formula (6) represents the number of different components of and . In comparison, the distance formula (6) is more in line with our requirements than the Euclidean distance.
The total tracking error between the output trajectory of MJBCN (2) and the reference trajectory (4) is expressed as
As the output state vectors of system (2) are finite in number, means that MJBCN (2) exactly tracks the reference trajectory (4). We intend to find a policy to minimize for all .
Define weight factor vectors:
Then , and . Consequently,
When the dimensions of the matrices do not match, we default to using STP.
Update the weight factor vectors:
Then we have
Minimizing by a policy can be formulated as addressing an optimization problem as follows:
is called an optimal policy if (11) holds for all .
The sub-policies of are denoted by , . The set of all possible is represented by . Next, define the optimal values of the optimization problem (11) and its sub-problems as follows:
The expectation in (12) is actually the conditional expectation given and . The following lemma, based on dynamic programming, is given to calculate through an iterative process for all . We omit the detailed proof for brevity, which is similar to the Lemma 2 of [36] and the Theorem 4.1 of [37].
Lemma 1.
Specifically, given in (13), by Proposition 1,
Furthermore, define the optimal value vectors:
Then, Equation (14) is equivalent to
where represents the -th entry of .
Theorem 1.
Proof.
Remark 1.
Algorithm 1 calculates , recursively and elementwise. The calculation of takes a time complexity of , while lines require time complexity, which is negligible compared with . Therefore, Algorithm 1 takes, at most, time complexity.
| Algorithm 1: Find an optimal solution for (11). |
 |
3.2. Finite Horizon OTC of MJBCNs with a Penalty for Control Input Changes
Given two control input vectors , let and . Similar to the distance formula (6), the distance between and (or between and ) is given by
Then, the total variation of the control input of MJBCN (2) within the time period of is expressed as
Define a penalty factor vector:
which satisfies . Then
By performing a weighted sum of (10) and (17), a new objective function denoted by is obtained as follows:
where . We aim to minimize for all . When we are more concerned with the tracking error, we can set to a larger value. Conversely, if we want to reduce the variation of the control input, we can set to a smaller value.
Based on the Kronecker product and STP, we can derive
Introduce another instrumental variable as follows:
Define weight factor vectors:
Then we have
Define two matrices as follows:
Split R and L into M blocks of the same size: and .
Proposition 2.
For any and ,
for any and ,
Proof.
The proof is similar to Proposition 1. □
Next, a policy is in the form of , where and . There is a such that , and for each with , there is a such that . Once a policy is given, a feedback control is determined as follows:
The set of all possible is represented by .
Minimizing the expected value of (20) by a policy is equivalent to solving an optimization problem as follows:
is called an optimal policy if (23) holds for all .
The sub-policies of are denoted by , . Denote by the set of all possible . Define the optimal values of the optimization problem (23) and its sub-problems as follows:
Similar to Lemma 1, the following lemma is given to determine through an iterative process for all .
Lemma 2.
Theorem 2.
The policy obtained by Algorithm 2 can minimize the expectation of the objective function (20) for all initial states.
Proof.
Based on Lemma 2, the proof is similar to Theorem 1. □
Remark 2.
Algorithm 2 calculates , recursively and elementwise. The calculation of takes a time complexity of , while lines operate in time. Thus, lines require . The time complexity of the rest is obviously less than . Therefore, Algorithm 2 takes at most time complexity. Comparing Algorithm 1 with Algorithm 2, we observe that Algorithm 1 has a lower time complexity. Therefore, if the penalty for control input changes is not considered in the OTC problem, we prioritize using Algorithm 1 to design an optimal strategy for MJBCN (2). However, when such a penalty is incorporated, it becomes necessary to employ Algorithm 2 to develop an optimal strategy .
| Algorithm 2: Calculate an optimal solution for (23). |
 |
Remark 3.
Generally, is given from . In [16], the virtual variable needs to be used. Although time-invariant BCNs were considered, the optimal finite horizon OTC problem with a penalty for control input changes has not been completely addressed. In this paper, we define in segmented form, which can effectively solve this problem.
4. Illustrative Examples
Example 1.
Consider an MJBCN model of the form (1) with 3 internal nodes, 1 input node, 2 output nodes and 2 realizations [38], where , , , , , , , . The TPM of is assumed to be .
Let , , , and . Then, this system can be converted into the form (2) with , and . The calculation results of , R, and L are omitted.
A reference trajectory is given in Table 2. By (8), we can obtain
Next, by (9), we can calculate
By Algorithm 1, we can successively obtain
and an optimal policy with feedback matrices
Table 2.
Reference trajectory 1.
Next, take the penalty for the control input changes into account. Let . By (16) and (19), we can obtain and
By Algorithm 2, we can successively get
and an optimal policy with feedback matrices
For each given parameter α, we can always obtain the optimal value of and an optimal policy by Algorithm 2. However, these optimal values are not directly comparable across different α settings. Therefore, to evaluate the relative merits of different α values, we compare the performance of and under their respective optimal policies generated by varying α. This approach allows us to select a preferable α value.
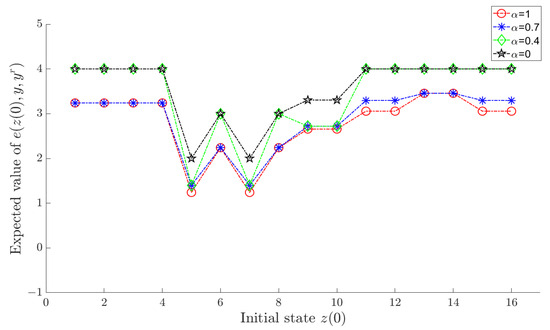
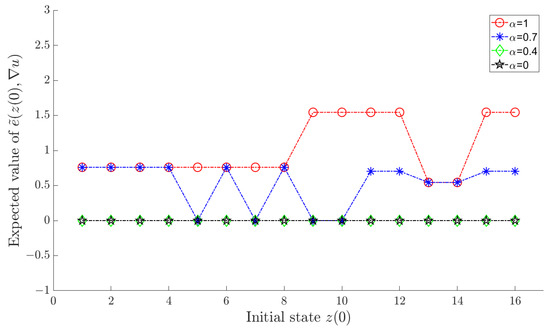
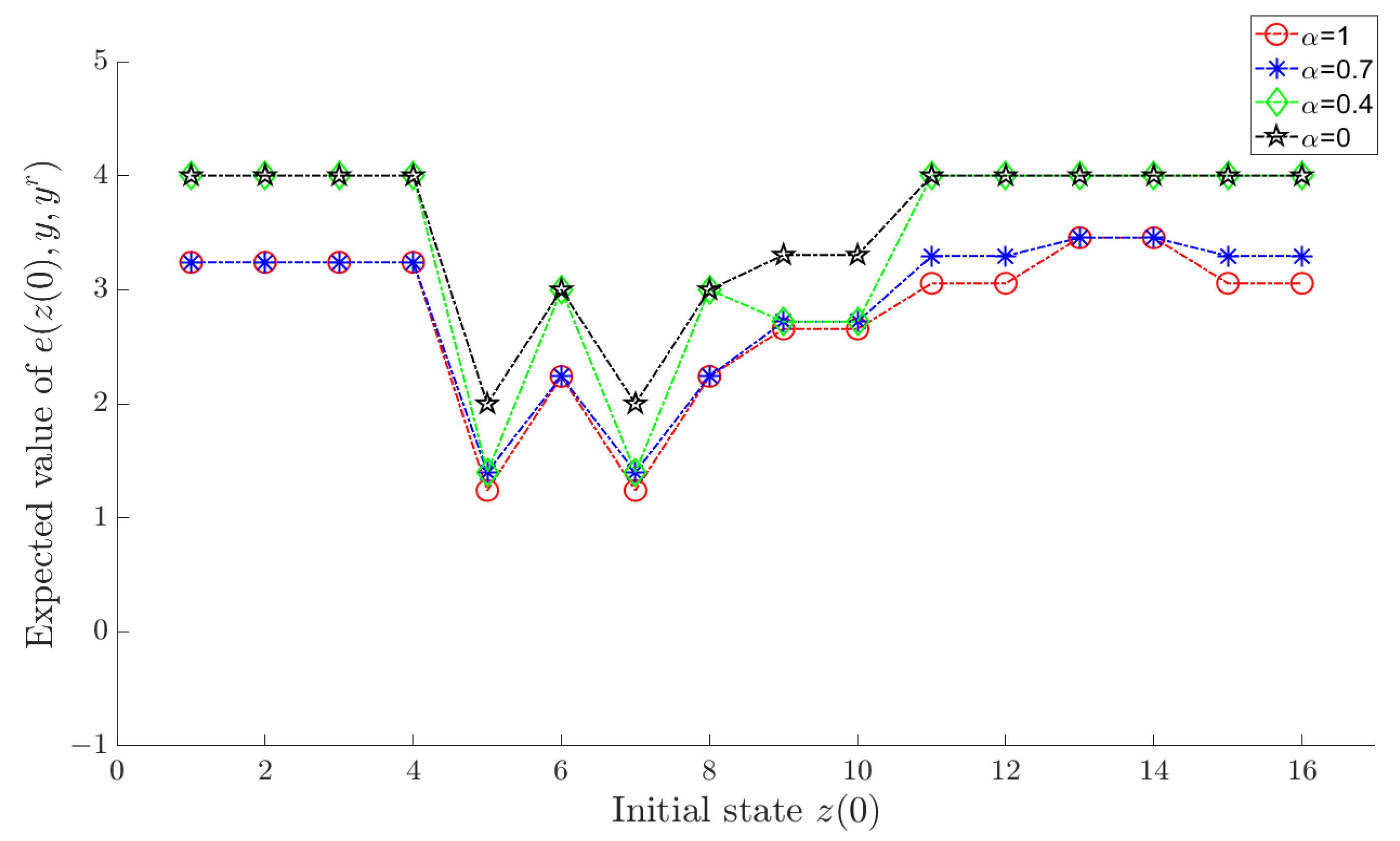
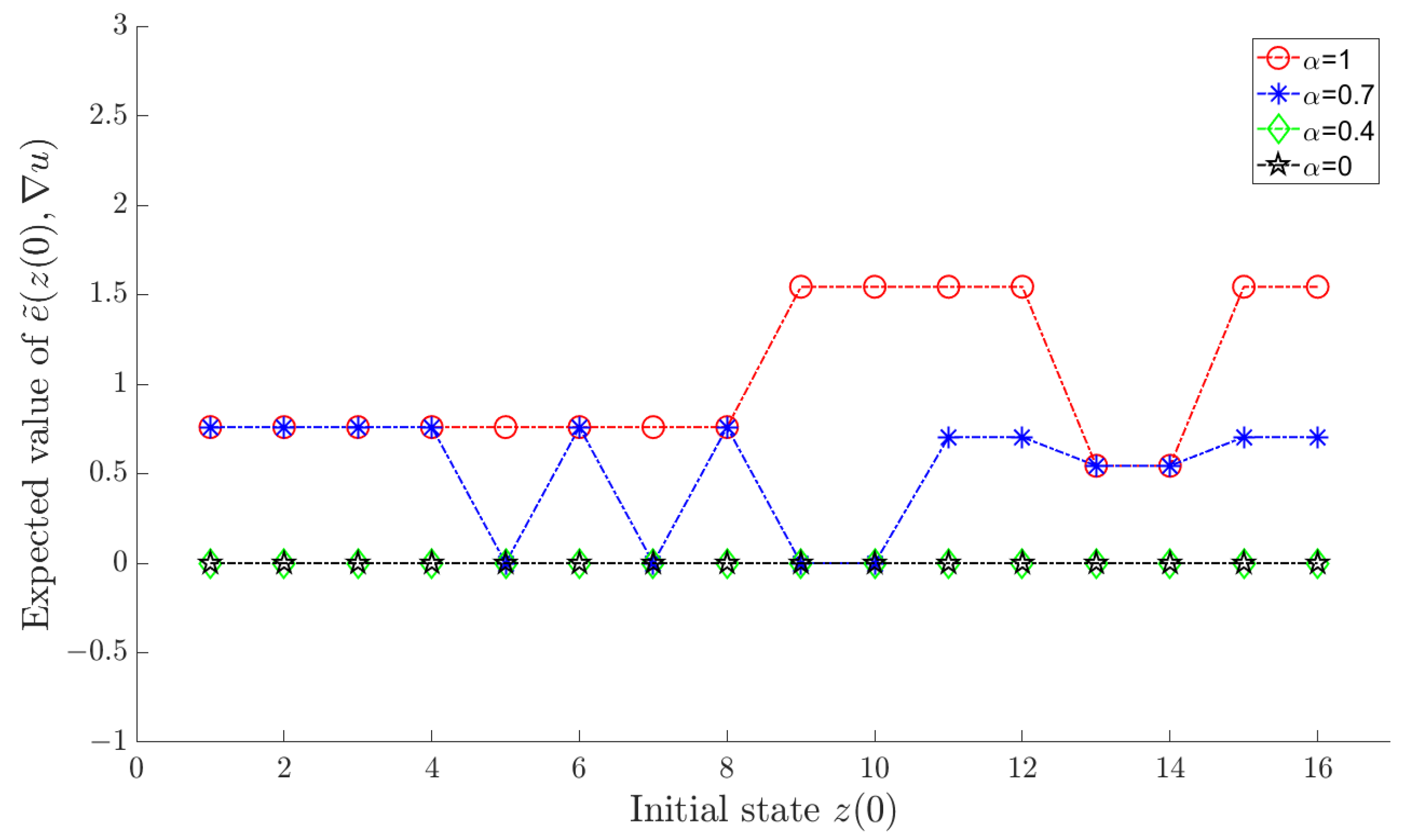
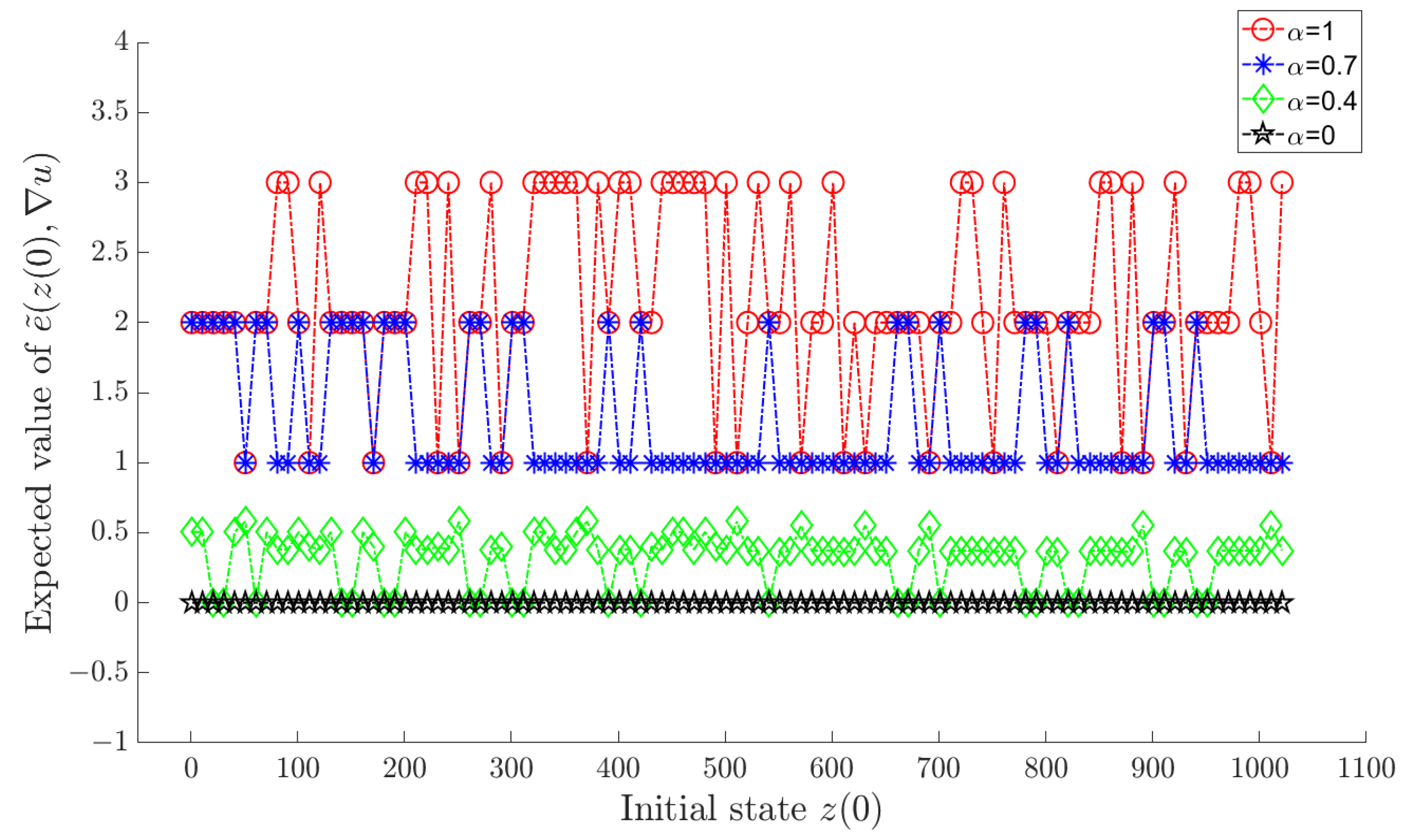
Let α in the objective function (18) take sequentially, and an optimal policy can be determined by Algorithm 2 for each value of α. Under each corresponding optimal policy, and for each are shown in Figure 1 and Figure 2, respectively, where a horizontal axis value of i actually means , .
Figure 1.
for each under the optimal policy.
Figure 2.
for each under the optimal policy.
As shown in the figures, increasing α results in a smaller tracking error, whereas reducing α leads to diminished variation in the control input. This aligns with the design intent of the objective function (18). In comparison, we observe that when , both the tracking error and variation of control input are effectively maintained at satisfactory levels.
Example 2.
Consider an MJBCN model of the form (1) with 9 internal nodes, 2 input nodes, 3 output nodes, and 2 realizations [39], where
The TPM of is assumed to be . Let , , , and . The transition matrices of this MJBCN are not presented here due to the large dimensionality.
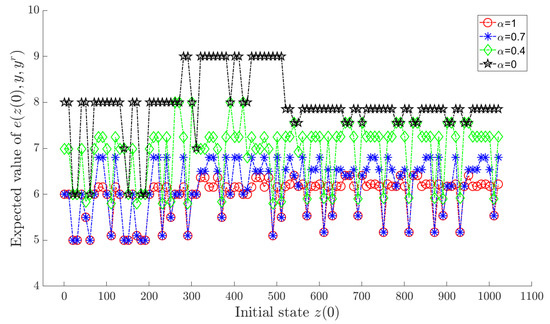
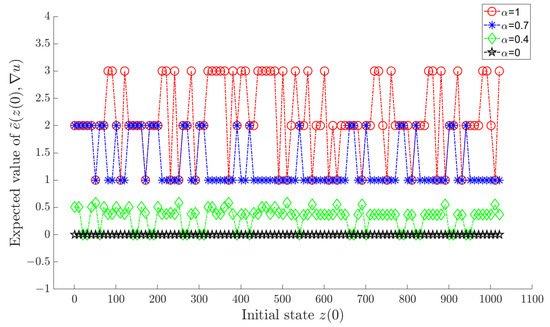
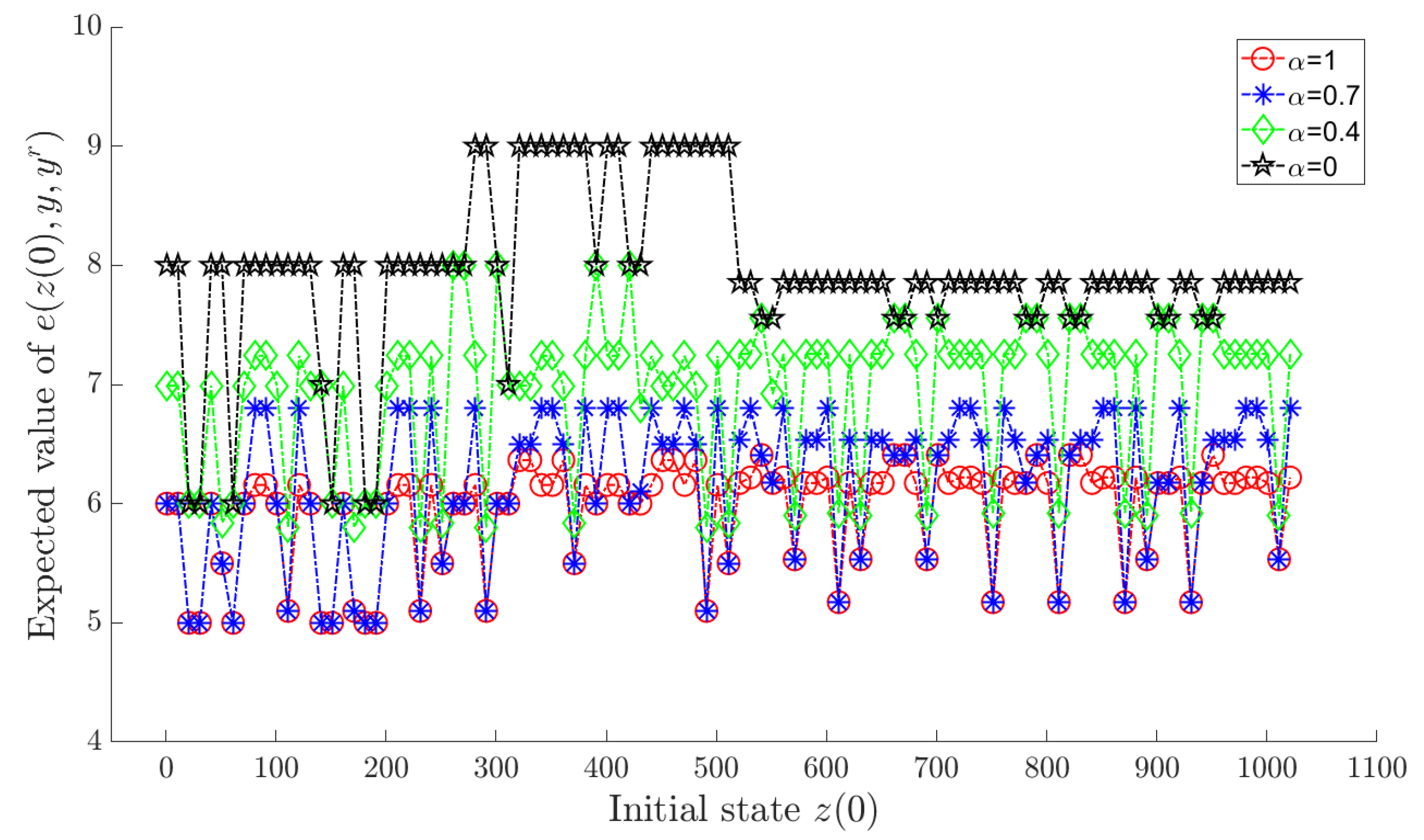
A reference trajectory is given in Table 3. Letting α take in (18) sequentially, we can obtain an optimal policy by Algorithm 2 for each value of α. Under each corresponding optimal policy, and for each are shown in the Figure 3 and Figure 4, respectively, where a horizontal axis value of i actually means , . To avoid visual clutter, the figures selectively display sparsely sampled data points on the horizontal axis.
Table 3.
Reference trajectory 2.
Figure 3.
for each under the optimal policy.
Figure 4.
for each under the optimal policy.
5. Conclusions
This paper studied the minimum error OTC of an MJBCN with respect to a predefined trajectory with a finite length, which was transformed into a dynamic optimization problem in terms of the instrumental variable . An optimal policy was designed using an algorithm to minimize the expected total tracking error.
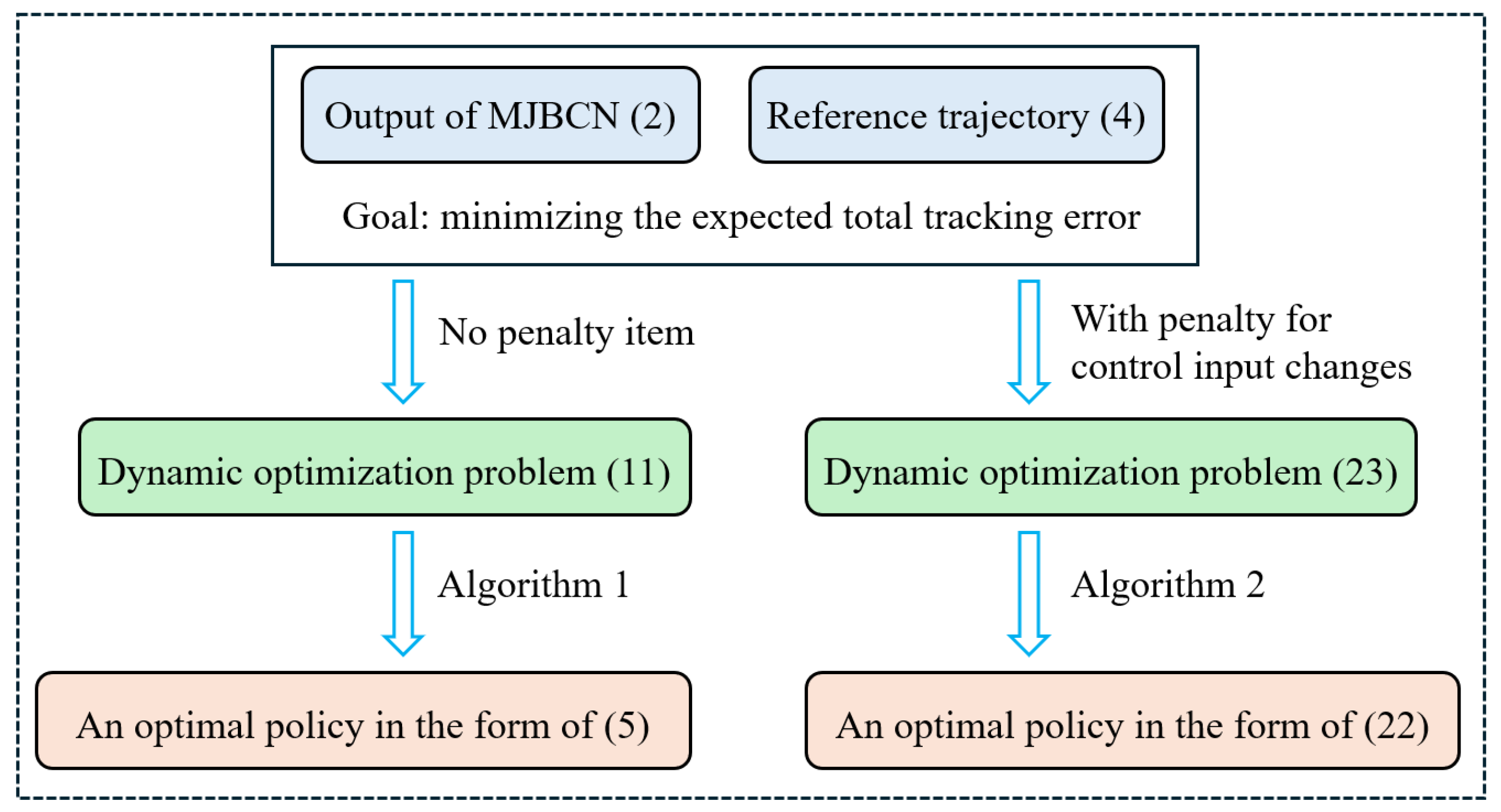
Next, the penalty for control input changes was taken into account. Through the weighted summation of the total tracking error and the total variation of the control input, a new objective function was constructed. The optimal expected value of the objective function and the optimal policy were determined through the dynamic programming of the instrumental variable . A methodology framework diagram of this paper is provided in Figure 5.
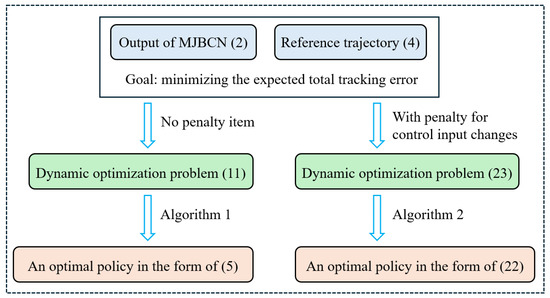
Figure 5.
Methodology framework diagram.
Finally, the main results were applied to two simplified biological models. As shown in the examples, the parameter can be adjusted according to different requirements, and different values of lead to optimal policies with varying emphasis on the tracking error and the variation of the control input.
Author Contributions
Writing—original draft preparation, B.C.; validation, writing—review and editing, Y.X. and A.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (Grant Nos. 62403253 and 12401642), in part by the Natural Science Foundation of Jiangsu Province (Grant Nos. BK20240604 and BK20240606), and in part by the Natural Science Research Start-up Foundation of Recruiting Talents of Nanjing University of Posts and Telecommunications (Grant Nos. NY223195 and NY223198).
Data Availability Statement
All data are included in this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kauffman, S.A. Metabolic stability and epigenesis in randomly constructed genetic nets. J. Theor. Biol. 1969, 22, 437–467. [Google Scholar] [CrossRef] [PubMed]
- Cheng, D.; Qi, H.; Li, Z. Analysis and Control of Boolean Networks: A Semi-Tensor Product Approach; Springer: London, UK, 2011. [Google Scholar]
- Liu, W.; Fu, S.; Zhao, J. Set stability and set stabilization of Boolean control networks avoiding undesirable set. Mathematics 2021, 9, 2864. [Google Scholar] [CrossRef]
- Sun, Q.; Li, H. Robust stabilization of impulsive Boolean control networks with function perturbation. Mathematics 2022, 10, 4029. [Google Scholar] [CrossRef]
- Deng, L.; Cao, X.; Zhao, J. One-bit function perturbation impact on robust set stability of Boolean networks with disturbances. Mathematics 2024, 12, 2258. [Google Scholar] [CrossRef]
- Tang, T.; Ding, X.; Lu, J.; Liu, Y. Improved criteria for controllability of Markovian jump Boolean control networks with time-varying state delays. IEEE Trans. Autom. Control 2024, 69, 7028–7035. [Google Scholar] [CrossRef]
- Li, Y.; Feng, J.-E.; Wang, B. Observability of singular Boolean control networks with state delays. J. Franklin Inst. 2022, 359, 331–351. [Google Scholar] [CrossRef]
- Li, Y.; Li, H. Relation coarsest partition method to observability of probabilistic Boolean networks. Inf. Sci. 2024, 681, 121221. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Z.; Liang, J.; Li, M. State estimation for stochastic time-varying Boolean networks. IEEE Trans. Autom. Control 2020, 65, 5480–5487. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Z.; Shen, B.; Liang, J. Model evaluation of the stochastic Boolean control networks. IEEE Trans. Autom. Control 2022, 67, 4146–4153. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Xiao, G. Luenberger-like observer design and optimal state estimation of logical control networks with stochastic disturbances. IEEE Trans. Autom. Control 2023, 68, 8193–8200. [Google Scholar] [CrossRef]
- Li, B.; Pan, Q.; Zhong, J.; Xu, W. Long-run behavior estimation of temporal Boolean networks with multiple data losses. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 15004–15011. [Google Scholar] [CrossRef]
- Li, B.; Lu, J.; Xu, W.; Zhong, J. Lossless state compression of Boolean control networks. IEEE Trans. Autom. Control 2024, 69, 4166–4173. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Xie, L. Output tracking control of Boolean control networks via state feedback: Constant reference signal case. Automatica 2015, 59, 54–59. [Google Scholar] [CrossRef]
- Li, H.; Xie, L.; Wang, Y. Output regulation of Boolean control networks. IEEE Trans. Autom. Control 2017, 62, 2993–2998. [Google Scholar] [CrossRef]
- Zhang, Z.; Leifeld, T.; Zhang, P. Finite horizon tracking control of Boolean control networks. IEEE Trans. Autom. Control 2018, 63, 1798–1805. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, X.; Fu, S.; Xia, J. Robust output tracking of Boolean control networks over finite time. Mathematics 2022, 10, 4078. [Google Scholar] [CrossRef]
- Gao, Z.; Feng, J.-E. Research status of nonlinear feedback shift register based on semi-tensor product. Mathematics 2022, 10, 3538. [Google Scholar] [CrossRef]
- Wang, S.; Li, H. Resolution of fuzzy relational inequalities with Boolean semi-tensor product composition. Mathematics 2021, 9, 937. [Google Scholar] [CrossRef]
- Shmulevich, I.; Dougherty, E.R.; Zhang, W. From Boolean to probabilistic Boolean networks as models of genetic regulatory networks. Proc. IEEE 2002, 90, 1778–1792. [Google Scholar] [CrossRef]
- Shmulevich, I.; Dougherty, E.R.; Kim, S.; Zhang, W. Probabilistic Boolean networks: A rule-based uncertainty model for gene regulatory networks. Bioinformatics 2002, 18, 261–274. [Google Scholar] [CrossRef]
- Kim, S.; Li, H.; Dougherty, E.R.; Cao, N.; Chen, Y.; Bittner, M.; Suh, E.B. Can Markov chain models mimic biological regulation? J. Biol. Syst. 2002, 10, 337–357. [Google Scholar] [CrossRef]
- Meng, M.; Xiao, G.; Zhai, C.; Li, G. Controllability of Markovian jump Boolean control networks. Automatica 2019, 106, 70–76. [Google Scholar] [CrossRef]
- Chen, B.; Cao, J.; Lu, G.; Rutkowski, L. Stabilization of Markovian jump Boolean control networks via sampled-data control. IEEE Trans. Cybern. 2022, 52, 10290–10301. [Google Scholar] [CrossRef]
- Chen, B.; Cao, J.; Lu, G.; Rutkowski, L. Stabilization of Markovian jump Boolean control networks via event-triggered control. IEEE Trans. Autom. Control 2023, 68, 1215–1222. [Google Scholar] [CrossRef]
- Melhem, K.; Wang, W. Global output tracking control of flexible joint robots via factorization of the manipulator mass matrix. IEEE Trans. Robot. 2009, 25, 428–437. [Google Scholar] [CrossRef]
- Al-Hiddabi, S.A.; McClamroch, N.H. Tracking and maneuver regulation control for nonlinear nonminimum phase systems: Application to flight control. IEEE Trans. Control Syst. Technol. 2002, 10, 780–792. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Guo, P. State feedback based output tracking control of probabilistic Boolean networks. Inf. Sci. 2016, 349–350, 1–11. [Google Scholar] [CrossRef]
- Chen, B.; Cao, J.; Luo, Y.; Rutkowski, L. Asymptotic output tracking of probabilistic Boolean control networks. IEEE Trans. Circuits Syst. I. Reg. Papers 2020, 67, 2780–2790. [Google Scholar] [CrossRef]
- Abdollahi, J.; Dubljevic, S. Lipid production optimization and optimal control of heterotrophic microalgae fed-batch bioreactor. Chem. Eng. Sci. 2012, 84, 619–627. [Google Scholar] [CrossRef]
- Zhang, Q.; Feng, J.-E.; Jiao, T. Finite horizon tracking control of probabilistic Boolean control networks. J. Franklin Inst. 2021, 358, 9909–9928. [Google Scholar] [CrossRef]
- Zhang, A.; Li, L.; Li, Y.; Lu, J. Finite-time output tracking of probabilistic Boolean control networks. Appl. Math. Comput. 2021, 411, 126413. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Xiao, G. Optimal control for reachability of Markov jump switching Boolean control networks subject to output trackability. Int. J. Control 2025, 98, 200–207. [Google Scholar] [CrossRef]
- Khatri, C.G.; Rao, C.R. Solutions to some functional equations and their applications to characterization of probability distributions. Sankhyā Indian J. Stat. A 1968, 30, 167–180. [Google Scholar]
- Li, C.; Zhang, X.; Feng, J.-E.; Cheng, D. Transition analysis of stochastic logical control networks. IEEE Trans. Autom. Control 2024, 69, 1226–1233. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Li, H. Two kinds of optimal controls for probabilistic mix-valued logical dynamic networks. Sci. China Inf. Sci. 2014, 57, 1–10. [Google Scholar] [CrossRef]
- Wu, Y.; Shen, T. An algebraic expression of finite horizon optimal control algorithm for stochastic logical dynamical systems. Syst. Control Lett. 2015, 82, 108–114. [Google Scholar] [CrossRef]
- Meng, M.; Liu, L.; Feng, G. Stability and l1 gain analysis of Boolean networks with Markovian jump parameters. IEEE Trans. Autom. Control 2017, 62, 4222–4228. [Google Scholar] [CrossRef]
- Acernese, A.; Yerudkar, A.; Glielmo, L.; Del Vecchio, C. Reinforcement learning approach to feedback stabilization problem of probabilistic Boolean control networks. IEEE Control Syst. Lett. 2021, 5, 337–342. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).