Abstract
The node representation learning capability of Graph Convolutional Networks (GCNs) is fundamentally constrained by dynamic instability during feature propagation, yet existing research lacks systematic theoretical analysis of stability control mechanisms. This paper proposes a Stability-Optimized Graph Convolutional Network (SO-GCN) that enhances training stability and feature expressiveness in shallow architectures through continuous–discrete dual-domain stability constraints. By constructing continuous dynamical equations for GCNs and rigorously proving conditional stability under arbitrary parameter dimensions using nonlinear operator theory, we establish theoretical foundations. A Precision Weight Parameter Mechanism is introduced to determine critical Frobenius norm thresholds through feature contraction rates, optimized via differentiable penalty terms. Simultaneously, a Dynamic Step-size Adjustment Mechanism regulates propagation steps based on spectral properties of instantaneous Jacobian matrices and forward Euler discretization. Experimental results demonstrate SO-GCN’s superiority: 1.1–10.7% accuracy improvement on homophilic graphs (Cora/CiteSeer) and 11.22–12.09% enhancement on heterophilic graphs (Texas/Chameleon) compared to conventional GCN. Hilbert–Schmidt Independence Criterion (HSIC) analysis reveals SO-GCN’s superior inter-layer feature independence maintenance across 2–7 layers. This study establishes a novel theoretical paradigm for graph network stability analysis, with practical implications for optimizing shallow architectures in real-world applications.
Keywords:
stable propagation rule; graph convolutional network; precision weight parameter mechanism; dynamic step-size adjustment mechanism MSC:
68T07
1. Introduction
Graph Convolutional Networks (GCNs) have emerged as a fundamental framework for graph data modeling by extending convolutional operations from Euclidean to non-Euclidean domains [1,2,3]. Since the seminal work of Kipf and Welling [4], GCNs have demonstrated remarkable success in social network analysis [5], recommendation systems [6], and biomolecular interaction prediction [7]. The core mechanism of GCNs—spectral-domain filtering for neighborhood information propagation—effectively captures topological features while maintaining computational efficiency. However, recent studies reveal that GCNs’ dynamic stability limitations in heterophilic graph structures constrain both theoretical interpretability and practical applicability [8,9].
1.1. Related Work
Despite significant advances in GCN performance [10,11,12,13], three fundamental theoretical gaps persist. First, a comprehensive framework for quantifying dynamic stability is lacking; while methods such as residual connections [14] and geometry-driven propagation [15] mitigate oversmoothing, rigorous mathematical characterization of Lyapunov stability remains absent. Although Chen et al. [16] demonstrated that an uncontrollable spectral radius causes deep GCN failure, stability mapping from parameter to feature space has not been established.
Second, discretization error control remains inadequate. Traditional forward Euler discretization often leads to numerical divergence in dynamic graph convolutions, and while Rusch et al. [17] introduced a gradient gating mechanism, fixed-step-size strategies still cause superlinear growth of node feature variance in heterophilic graphs, exacerbating training instability.
Third, existing studies predominantly address oversmoothing in deep networks, largely neglecting stability optimization in shallow architectures [18], resulting in suboptimal performance on complex graph structures.
1.2. Our Approach
To address these challenges, we propose the Stability-Optimized Graph Convolutional Network (SO-GCN), a dynamically stabilized framework that enhances intrinsic stability and feature representation in shallow architectures (2–7 layers). The innovations include the following:
- We developed a time-varying differential equation model for graph convolution propagation, establishing mathematical criteria for the Precision Weight Parameter Mechanism through stability mapping analysis.
- We formulated stability domain constraints for the weight matrix through Jacobian spectral analysis and proposed a Dynamic Step-size Adjustment Mechanism based on forward Euler discretization, applying stability mapping during gradient descent.
- We designed stable propagation rules integrating dual protection mechanisms with self-loop factors, optimizing feature stability and independence through quantitative metrics.
Recent theoretical advances, including adaptive frequency response filters [19,20,21] and potential connect of Lipschitz stability in graph neural diffusion provide foundational support for our stability quantification framework [22,23,24,25]. These developments not only validate our approach but also advance robust applications of GCNs in complex systems and depth optimization in shallow and stable networks.
2. Preliminaries
Based on Kipf’s seminal work [4], the standard Graph Convolutional Network (GCN) propagates node features by spectral filtering. The propagation rule is defined as follows:
Consider an undirected graph , where denotes the node set and represents the edge set. The augmented adjacency matrix is , with A as the original adjacency matrix and as the identity matrix. Here, is the feature matrix at layer l, denotes the learnable weight matrix, and is the activation function. The initial input is , the node feature matrix.
Despite its effectiveness in graph modeling, this framework suffers from training instability and limited noise robustness on heterophilic graphs [8,9]. To address these limitations, we reformulate the graph convolution mechanism from a continuous dynamics perspective and establish a rigorous stability guarantee framework.
2.1. Continuous Dynamics Model
To establish the theoretical connection between graph convolutional networks and dynamical systems, we extend the discrete layer index l to a continuous time variable , deriving the continuous propagation equation for graph convolution as follows:
where represents the node feature matrix at time t, denotes the symmetric normalized graph Laplacian operator, is the time-dependent parameter matrix, and indicates the element-wise activation function.
2.1.1. Stability Analysis of Equilibrium State
The existence of an equilibrium state is essential for stable propagation, as it enables the system to resist noise from minor disturbances or initial condition variations. Using fixed-point theory [26,27], we establish the following key result:
Theorem 1
(Existence of Equilibrium). The continuous propagation equation guarantees an equilibrium state when ; the activation function σ is globally Lipschitz continuous. Then, there exists an equilibrium state satisfying
This differential equation characterizes the evolution dynamics of node features in continuous time. We analyze the system’s dynamic behavior near the equilibrium point , where input and output feature dimensions are identical and Equation (3) holds. To quantify the system’s convergence rate, we define the feature contraction rate:
Definition 1
(Feature Contraction Rate). The instantaneous contraction rate of the propagation operator is
when and the system is asymptotically stable.
Based on this, we derive the theoretical foundation for the Precision Weight Parameter Mechanism (PW Mechanism):
Theorem 2
(Weight Frobenius Norm Constraint). When the weight matrix satisfies
it ensures , where is the expected value of the activation function’s derivative.
2.1.2. Stability Guarantee of the Forward Euler Discretization Scheme
Discretizing Equation (2) by the forward Euler method yields the following:
where denotes the adaptive step size.
The stability of the discrete system depends on the spectral properties of the instantaneous Jacobian , providing the theoretical foundation for the Dynamic Step-size Adjustment Mechanism (DS Mechanism):
Theorem 3
(Step Size Upper Bound Constraint). The discrete system achieves numerical stability when the step size upper bound satisfies
where represents the instantaneous Jacobian matrix, denotes the smallest eigenvalue modulus, and signifies the largest singular value.
When the forward Euler discretization of the GCN continuous propagation Equation (Equation (6)) meets the stability condition (Equation (7)), we introduce a self-loop influence factor to enhance stability, yielding the discrete propagation equation:
We define as the discrete adjustment term, which balances node self-information preservation with neighborhood information aggregation. This formulation establishes a rigorous theoretical basis for SO-GCN’s stable propagation rule.
3. Stability-Optimized Graph Convolutional Network
3.1. Network Overview
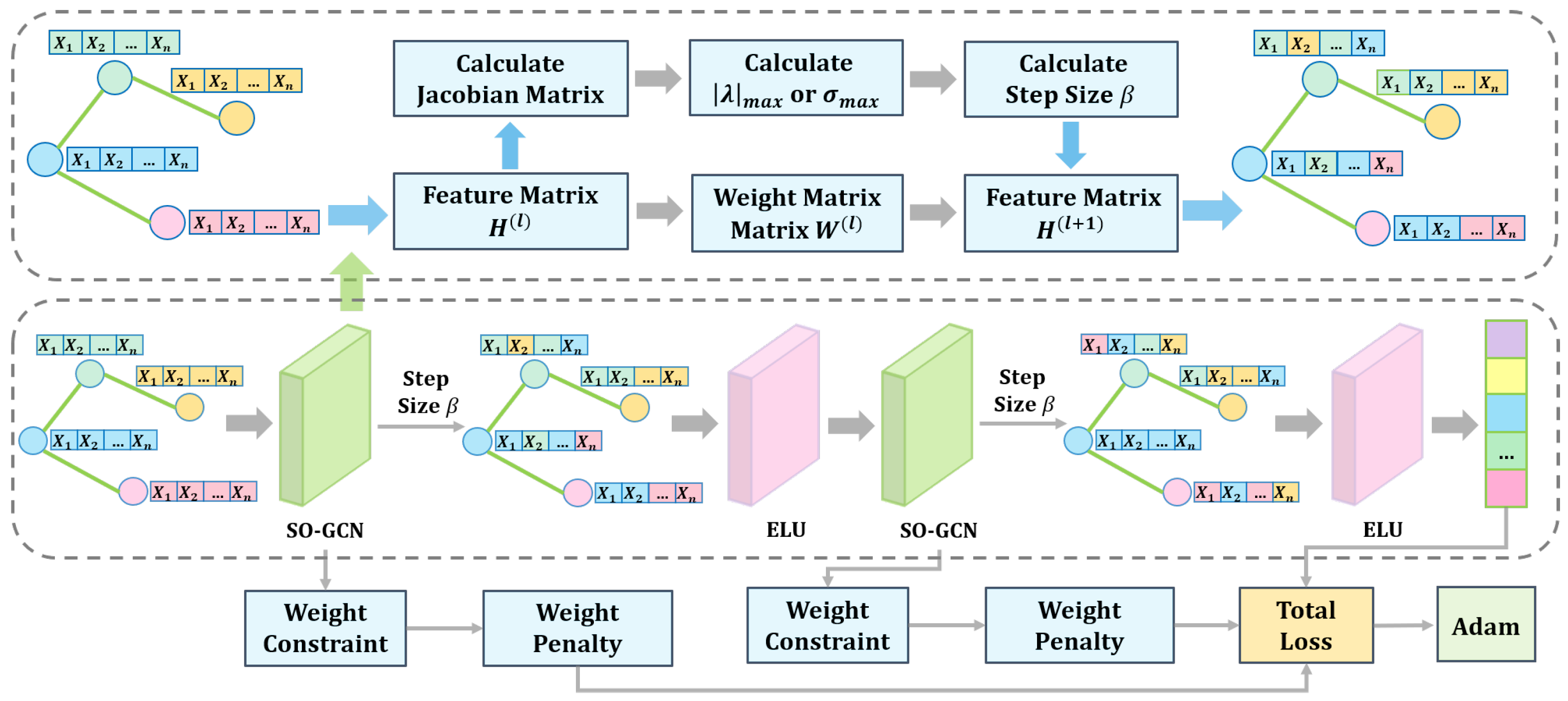
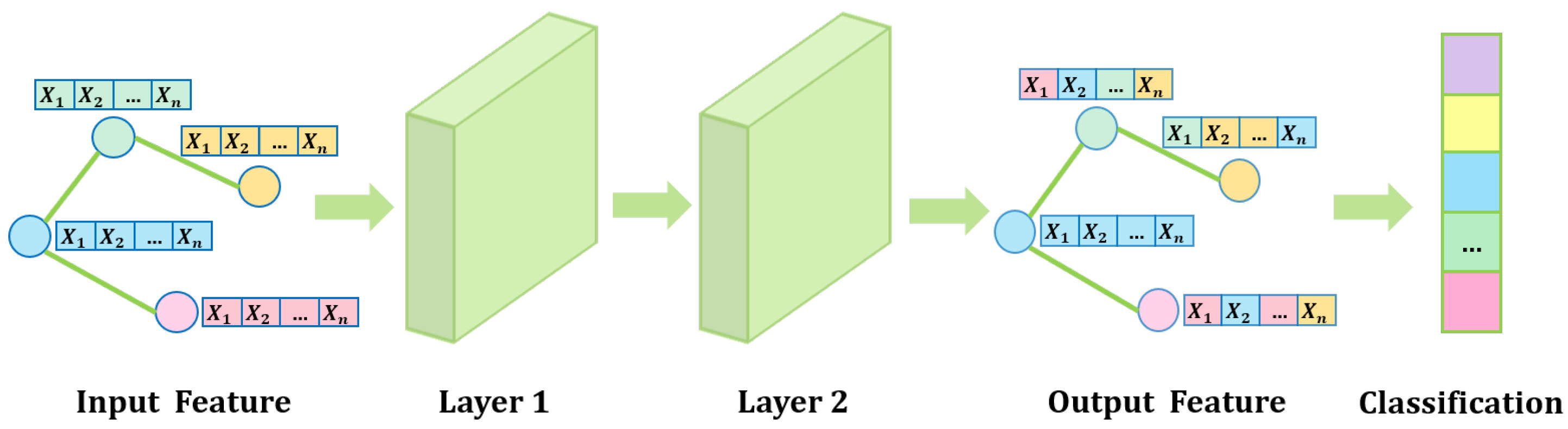
Based on the preceding theoretical results, we propose a stability propagation rule that integrates dynamic step-size adjustment, weight matrix norm constraints, and an upper-bound penalty term. By discretizing the propagation equation, we develop a Stability-Optimized Graph Convolutional Network (SO-GCN) with enhanced training stability, improved prediction accuracy, and superior loss convergence.The of SO-GCN with two layers is shown as Figure 1. During training, the network dynamically determines the weight matrix norm threshold to constrain parameter updates and optimizes parameter space distribution through a differentiable penalty term. Simultaneously, based on the spectral properties of the Jacobian matrix, we employ the forward Euler discretization method to dynamically adjust the step size and introduce a self-loop influence factor to enhance propagation stability.
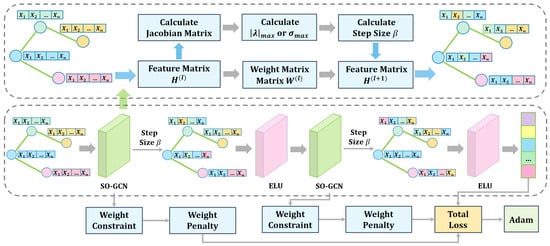
Figure 1.
Workflow of stability-Optimized Graph Convolutional Network with Two layers.
This framework incorporates three modules into the GCN feature propagation process:
- Precision Weight Parameter Mechanism (PW Mechanism): constrains the Frobenius norm of the weight matrix through stability analysis of differential equations;
- Dynamic Step-size Adjustment Mechanism (DS Mechanism): adaptively controls the propagation step size based on the instantaneous Jacobian matrix;
- Stable propagation rule: combines the PW Mechanism and DS Mechanism to optimize both numerical stability and model expressiveness.
The basic framework of SO-GCN with two layers is as Figure 2.
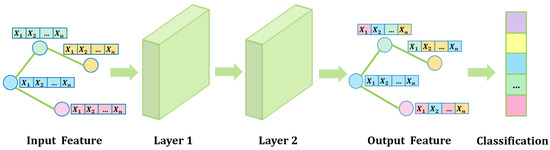
Figure 2.
Basic framework of Stability-Optimized Graph Convolutional Network with Two Layers.
3.2. Stability-Optimized Propagation Rule
To enhance graph filtering performance, we develop a stable propagation rule based on discrete dynamical system theory:
where denotes the Leaky ReLU activation function, represents the self-loop influence factor, satisfies the norm constraint in the Precision Weight Parameter Mechanism, and is dynamically determined by the Dynamic Step-size Adjustment Mechanism. This rule maintains node self-information through the term while enabling adaptive neighborhood information aggregation via .
3.2.1. Precision Weight Parameter Mechanism
To accelerate optimization, we propose the Precision Weight Parameter Mechanism (PW Mechanism). The Frobenius norm threshold for the weight matrix at layer l is
where is the expected value of the activation function derivative, is the intermediate feature matrix, and is the symmetric normalized graph Laplacian.
First, the mechanism inputs node features into SO-GCN for standard graph convolution, computes the norm threshold for layer l, and performs two-stage optimization based on Theorem 2 to obtain network response distribution characteristics. When , it applies Frobenius norm projection,
to constrain parameters within the stability domain. Simultaneously, it constructs a quadratic gradient penalty term:
This penalty term guides parameter convergence through backpropagation, preventing it from exceeding the predefined range. The pseudocode for the Precision Weight Parameter Mechanism is as Algorithm 1:
| Algorithm 1: Precision Weight Parameter Mechanism |
|
This strategy combines hard constraints with soft penalties to maintain numerical stability while preserving end-to-end differentiability, preventing extreme weight variations during iterations and ensuring smooth feature updates. After integrating the Precision Weight Parameter Mechanism into the baseline GCN, we refer to the resulting model as the Precision Weight Graph Convolutional Network (PW-GCN).
3.2.2. Dynamic Step-Size Adjustment Mechanism
To enhance inter-layer propagation stability, we propose the Dynamic Step-size Adjustment Mechanism (DS Mechanism). The instantaneous Jacobian matrix is defined as
Based on Theorem 3’s analysis of ’s spectral properties, the upper bound of the step size is
where denotes the smallest eigenvalue modulus and represents the largest singular value.
Using the power iteration method to estimate the principal eigenvector, we set the step size as , where the safety factor of 0.85 compensates for spectral estimation errors and ensures numerical stability. This strategy maximizes information propagation efficiency while maintaining discrete system stability. The pseudocode for the Dynamic Step-size Adjustment Mechanism is as follows Algorithm 2.
Integrating the Dynamic Step-size Adjustment Mechanism into the baseline GCN yields the Dynamic Step Graph Convolutional Network (DS-GCN). The Precision Weight Parameter Mechanism ensures weight matrix stability through Frobenius norm projection and gradient penalties, while the Dynamic Step-size Adjustment Mechanism further optimizes discrete error accumulation via safety-factor-adjusted step sizes. The stable propagation rule, combining both mechanisms, provides theoretical support for enhancing feature output stability.
| Algorithm 2: Dynamic Step-size Adjustment Mechanism |
|
4. Experiments
This study conducts systematic validation on three homophilic graph datasets (Cora, CiteSeer, and PubMed) [20] and three heterophilic graph datasets (Chameleon, Texas, and Squirrel) [5]. We perform comprehensive ablation studies with four architectures: GCN, PW-GCN, DS-GCN, and SO-GCN. Model performance is evaluated through semi-supervised node classification tasks and compared to the performance of mainstream methods including GIN, GraphSAGE, GAT, and GCN. Our experimental setup adopts a learning rate of 0.01, 64-dimensional embeddings, a dropout rate of 0.5, and an parameter of 0.5. Table 1 summarizes the topological statistics of the datasets, where homophily metrics quantitatively verify structural heterogeneity.

Table 1.
Dataset statistics.
4.1. Experiment Results and Analysis
Table 2 presents a classification accuracy comparison for GCN, PW-GCN, DS-GCN, and SO-GCN across six benchmark datasets. The results demonstrate significant synergistic optimization effects between the Precision Weight Parameter Mechanism and the Dynamic Step-size Adjustment Mechanism in SO-GCN.
Table 2.
Mean accuracy (%) of SO-GCN in two-layer ablation experiment.
On homophilic datasets such as Cora and PubMed, PW-GCN improves accuracy by 0.9–1.8% through the Precision Weight Parameter Mechanism’s optimization of information propagation efficiency. However, its accuracy decreases by 0.35% on heterophilic graphs such as Chameleon, suggesting that using this mechanism alone can amplify noise. In contrast, DS-GCN achieves performance gains of 6.56% and 5.7% on Texas and Chameleon, respectively, through the Dynamic Step-size Adjustment Mechanism, effectively suppressing noise propagation in heterophilic graphs. The combined model SO-GCN achieves an average 11.65% improvement in accuracy on heterophilic datasets, demonstrating the complementary nature of the dual stabilization mechanisms.
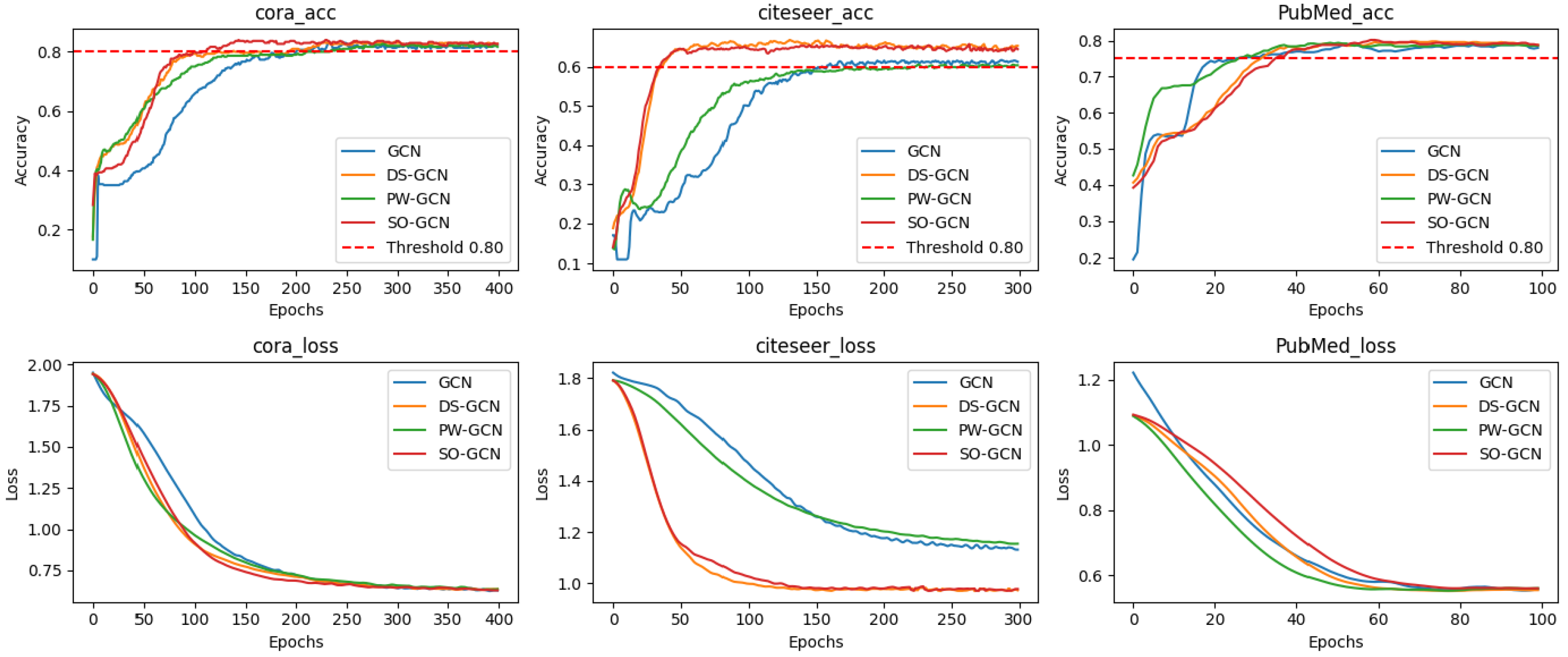
Figure 3 further reveals the dynamic properties of the four models’ training: SO-GCN’s loss curve fluctuates significantly less than GCN’s, confirming the improvement in training stability due to the Dynamic Step-size Adjustment Mechanism. On PubMed’s sparse graph, PW-GCN converges the fastest, but its overall performance is best, with faster convergence, lower training loss (on average), and smoother accuracy curves.
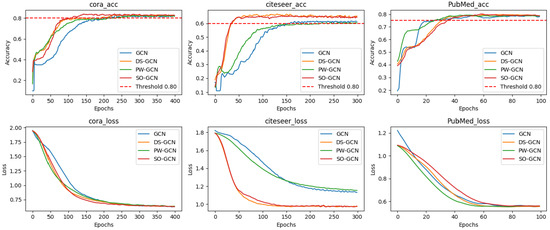
Figure 3.
Training process of four networks with two layers on homophilic graph datasets.
This paper validates the effectiveness of SO-GCN through semi-supervised node classification tasks across six benchmark datasets. As shown in Table 3, SO-GCN achieves an average classification accuracy of 68.01%, a 10.8% improvement over baseline GCN. Notably, on heterophilic graphs, the model achieves 56.83% and 71.07% accuracy on the Texas and Squirrel datasets, respectively, significantly outperforming models such as GAT.
Table 3.
Mean accuracy (%) comparison across six benchmark networks with two layers.
This indicates that the stability propagation rule based on stability theory effectively optimizes information flow and enhances the network’s ability to capture graph signals.
4.2. Depth Analysis and Feature Preservation
To explore performance variations in shallow networks, we compare SO-GCN and GCN on classification accuracy across two- to seven-layer configurations on six benchmark datasets, as shown in Table 4:
Table 4.
Performance comparison across models with different layer configurations.
SO-GCN consistently outperforms GCN across all six benchmark datasets and layer configurations, particularly showing a 15.2% improvement in accuracy on the five-layer configuration of PubMed. This validates the framework’s ability to alleviate vanishing gradients by optimizing gradient stability and feature smoothness.
We quantify feature preservation through Hilbert–Schmidt Independence Criterion (HSIC) analysis between network layers. As shown in Table 5, SO-GCN reduces inter-layer HSIC values by 16.7% in seven-layer PubMed configurations compared to GCN, demonstrating effective prevention of feature homogenization while preserving original graph structural information.
Table 5.
HSIC values across different datasets and models.
4.3. Computational Complexity Analysis
The above experimental results from multiple dimensions confirm that the SO-GCN framework, through the synergistic Precision Weight Parameter Mechanism and Dynamic Step-size Adjustment Mechanism, enhances model performance. However, its computational complexity inevitably increases in the following two aspects: (1) dynamic learning rate calculation and spectral analysis of density matrix squared neighborhoods introduce extra overhead; (2) the Precision Weight Parameter Mechanism requires calculating the Frobenius norm, resulting in an additional cost, where and are the input and output feature dimensions. For large-scale graph data, Nyström low-rank approximation can be applied to reduce matrix computation complexity to , achieving a balance between efficiency and performance.
5. Conclusions
This study systematically validates the effectiveness of the SO-GCN model in semi-supervised node classification tasks. Experimental results demonstrate that the stability propagation rule, combining the Precision Weight Parameter Mechanism and the Dynamic Step-size Adjustment Mechanism, significantly enhances model performance: on homophilic graphs such as Cora and CiteSeer, SO-GCN improves classification accuracy by 1.1–10.7% compared to traditional GCN; on heterophilic graphs such as Texas and Chameleon, accuracy increases by 11.22–12.09% over the baseline model through dynamic adjustment of neighborhood information aggregation intensity. HSIC analysis further reveals that SO-GCN reduces inter-layer feature homogenization by 16.7% compared to GCN, effectively mitigating the gradient vanishing problem in shallow networks through optimized gradient propagation stability.
From an application perspective, SO-GCN’s architectural characteristics provide significant advantages in the following scenarios:
- In heterophilic graph settings such as social network anomaly detection, the Dynamic Step-size Adjustment Mechanism dynamically suppresses noise propagation through spectral characteristic perception;
- On knowledge graphs with sparse features but complex structures, such as biomedical networks, the Precision Weight Parameter Mechanism optimizes information propagation efficiency through Frobenius norm constraints;
- In industrial-grade graph computing systems (e.g., multi-hop inference in recommendation systems), the synergistic effect of dual stabilization mechanisms ensures numerical stability during higher-order propagation.
Author Contributions
Conceptualization, L.C.; Methodology, L.C.; Validation, H.Z.; Formal analysis, L.C. and H.Z.; Investigation, H.Z.; Resources, S.H.; Data curation, L.C. and H.Z.; Writing—original draft, L.C.; Writing—review & editing, L.C., H.Z. and S.H.; Visualization, L.C.; Funding acquisition, S.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China [12471304].
Data Availability Statement
The data used in this study, including the Cora, Citeseer, PubMed, Chameleon, Texas, and Squirrel datasets, are publicly available. These datasets can be accessed through relevant libraries in PyTorch or other machine learning frameworks. Detailed instructions on how to load the datasets can be found in the official documentation of these libraries (https://pytorch.org/docs/stable/). No new data were created for this study, and the data used in the experiments are openly archived for public use.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Proof of Theorem 1
Appendix A.1. Existence of Theorem 1
Proof.
Define the nonlinear mapping as
where is an activation function satisfying the global Lipschitz condition with constant .
For any convergent sequence , consider the continuity of the linear operator :
From the finiteness of the Frobenius norms of and W, we conclude that is continuous. When we compose it with the Lipschitz continuous function , remains continuous in the Frobenius norm topology.
Define the closed ball:
Choosing , we can show by induction that . By the Heine–Borel theorem, is a compact convex set in finite-dimensional space.
Applying Brouwer’s Fixed Point Theorem, the continuous mapping has at least one fixed point satisfying
□
Appendix A.2. Uniqueness of Theorem 1
Proof.
We prove the contractive property of mapping in the Banach space .
For any :
Let the contraction coefficient be . When , is a strict contraction mapping.
To achieve a globally unique equilibrium state, we impose the following weight constraint:
By the Banach Fixed Point Theorem, there exists a unique satisfying . □
Appendix B. Proof of Theorem 2
Proof.
Let the perturbation of the equilibrium state be ; its dynamic equation is given by:
Perform Frechet differentiation at :
where denotes the derivative of the activation function and ⊙ represents the Hadamard product.
Let be the spatial mean of the derivative, where . By Jensen’s inequality,
When is satisfied, we have , and the system exhibits asymptotic stability. □
Appendix C. Proof of Theorem 3
Proof.
Consider the forward Euler discretization scheme , where the local truncation error is controlled by the Jacobian matrix .
Spectral Constraint Condition
To ensure numerical stability, the following condition must be satisfied:
where denotes the spectral radius. Using the Gershgorin circle theorem, we obtain
By choosing the step size upper bound , we ensure that the eigenvalue distribution remains within the unit circle, and the discrete system remains Lyapunov stable. □
References
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with localized spectral filtering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Fout, A.; Byrd, J.; Shariat, B.; Ben-Hur, A. Protein interface prediction using graph convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6533–6542. [Google Scholar]
- Li, X.; Chen, S.; Hu, X.; Yang, J. Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift. arXiv 2018, arXiv:1801.05134. [Google Scholar]
- Oono, K.; Suzuki, T. Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. arXiv 2019, arXiv:1905.10947. Available online: https://api.semanticscholar.org/CorpusID:209994765 (accessed on 27 May 2019).
- Wang, X.; Zhang, M. How Powerful are Spectral Graph Neural Networks. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 23341–23362. [Google Scholar]
- Chien, E.; Peng, J.; Li, P.; Milenkovic, O. Adaptive Universal Generalized PageRank Graph Neural Network. arXiv 2020, arXiv:2001.06922. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Xu, B.; Shen, H.; Cao, Q.; Cen, K.; Cheng, X. Graph convolutional networks using heat kernel for semi-supervised learning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1928–1934. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.-M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3538–3545. [Google Scholar]
- Pei, H.; Wei, B.; Chang, K.C.-C.; Lei, Y.; Yang, B. Geom-GCN: Geometric Graph Convolutional Networks. arXiv 2020, arXiv:2002.05287. [Google Scholar]
- Chen, D.; Liao, R. Stability and Generalization of Graph Neural Networks via Spectral Dynamics. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11289–11302. [Google Scholar]
- Rusch, T.K.; Bronstein, M.; Mishra, S. Gradient Gating for Deep Multi-Rate Learning on Graphs. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2022; pp. 22136–22149. [Google Scholar]
- Topping, J.; Giovanni, F.D.; Chamberlain, B.P.; Dong, X.; Bronstein, M.M. Understanding Over-Squashing and Bottlenecks on Graphs via Curvature. In Proceedings of the 10th International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Dong, Y.; Ding, K.; Jalaeian, B.; Ji, S.; Li, J. AdaGNN: Graph Neural Networks with Adaptive Frequency Response Filter. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, Australia, 1–5 November 2021. [Google Scholar]
- Yang, Z.; Cohen, W.; Salakhutdinov, R. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Lim, D.; Robinson, J.; Zhao, L.; Smidt, T.; Sra, S.; Maron, H.; Jegelka, S. Sign and basis invariant networks for spectral graph representation learning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 1 May 2023. [Google Scholar]
- Metz, L.; Maheswaranathan, N.; Freeman, C.D.; Poole, B.; Sohl-Dickstein, J.N. Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves. arXiv 2009, arXiv:2009.11243. [Google Scholar]
- Haber, E.; Lensink, K.; Treister, E.; Ruthotto, L. IMEXnet: A Forward Stable Deep Neural Network. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2525–2534. [Google Scholar]
- Haber, E.; Ruthotto, L. Stable architectures for deep neural networks. Inverse Probl. 2018, 34, 014004. [Google Scholar] [CrossRef]
- Haber, E.; Ruthotto, L.; Holtham, E. Learning across scales—A multiscale method for convolution neural networks. arXiv 2017, arXiv:1703.02009. [Google Scholar] [CrossRef]
- Brouwer, L.E.J. Über Abbildung von Mannigfaltigkeiten. Math. Ann. 1911, 71, 97–115. [Google Scholar] [CrossRef]
- Banach, S. Sur les opérations dans les ensembles abstraits et leur application aux équations intégrales. Fundam. Math. 1922, 3, 133–181. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).