Abstract
As the field of big data continues to evolve, there is an increasing necessity to evaluate the equality of multiple high-dimensional covariance matrices. Many existing methods rely on approximations to the null distribution of the test statistic or its extreme-value distributions under stringent conditions, leading to outcomes that are either overly permissive or excessively cautious. Consequently, these methods often lack robustness when applied to real-world data, as verifying the required assumptions can be arduous. In response to these challenges, we introduce a novel test statistic utilizing the normal-reference approach. We demonstrate that the null distribution of this test statistic shares the same limiting distribution as a chi-square-type mixture under certain regularity conditions, with the latter reliably estimable from data using the three-cumulant matched chi-square-approximation. Additionally, we establish the asymptotic power of our proposed test. Through comprehensive simulation studies and real data analysis, our proposed test demonstrates superior performance in terms of size control compared to several competing methods.
Keywords:
k-sample equal-covariance matrix testing; chi-square-type mixtures; high-dimensional data; three-cumulant matched chi-square-approximation MSC:
62H15; 62F03
1. Introduction
With the rapid advancement in data collection and storage, it has become increasingly common to encounter datasets characterized by a large number of features but a limited number of individuals. For instance, in financial studies, particularly those involving long-term data, each index often comprises hundreds or thousands of time points. However, due to constraints such as market capacity, policy restrictions, and other factors, resources are typically scarce, resulting in only a few subjects available for comparison across indexes. In such scenarios, the data dimension p approaches or even surpasses the total sample size n, a characteristic known as the “large p, small n” phenomenon. This feature renders many conventional methods inapplicable, necessitating specialized approaches. We refer to datasets exhibiting this characteristic as high-dimensional data, and the associated challenge as a “large p, small n” problem. A key focus of multivariate statistical analysis is to compare covariance matrices across several high-dimensional populations. The motivation for this paper partially stems from a financial dataset provided by the Credit Research Initiative of the National University of Singapore (NUS-CRI). In finance, contagion refers to a phenomenon observed through concurrent movements in exchange rates, stock prices, sovereign spreads, and capital flows [1]. Identifying the presence of financial contagion is crucial, as it signifies potential risks for countries aiming to integrate their financial systems with international markets and institutions. Additionally, it aids in understanding economic crises that spread to neighboring countries or regions. A common approach to detecting contagion involves examining the variance–covariance relationships of financial indices across different regions or time periods, as demonstrated by [2,3,4]. The Probability of Default (PD) serves as a metric for quantifying the likelihood of an obligor being unable to meet its financial obligations and forms the core of the credit product within the NUS-CRI corporate default prediction system, built on the forward intensity model of [5]. A notable example is the financial contagion observed during the 1997 Asian Financial Crisis, described in Section 4. Consequently, there is interest in investigating whether the covariance matrices of daily PD for neighboring countries during periods of stability and crisis are equal. This inquiry stimulates a k-sample equal-covariance matrix testing problem tailored for high-dimensional data.
Mathematically, a k-sample equal-covariance matrix testing problem for high-dimensional data is described as follows. Let us consider the following k independent high-dimensional samples:
where the dimension p is significantly large, potentially exceeding the total sample size . The objective is to test whether the k covariance matrices are equal:
When , the k-sample equal-covariance matrix testing problem in (2) simplifies to a two-sample equal-covariance matrix testing problem, which has been the subject of several previous studies. Ref. [6] devised a test based on an unbiased estimator using U-statistics of the usual squared Frobenius norm of the covariance matrix difference . Under certain stringent conditions, ref. [6] demonstrated that the null distribution of their test statistic is asymptotically normal, without relying on the normality assumption for the samples. However, this test may lack power when the entries of the covariance matrix difference are sparse, due to its reliance on an -norm-based approach. To address this limitation, ref. [7] proposed an -type test. They showed that under certain regularity conditions, their test statistic asymptotically follows an extreme-value distribution of Type I. Unfortunately, simulation results presented in [8] reveal that [7]’s test is excessively conservative, exhibiting notably small empirical sizes.
For a general , the problem of testing for equality of covariance matrices across all groups has attracted significant attention from researchers. Extending the test to multiple groups necessitates careful consideration of the problem’s complexity and the potential trade-offs between power and Type I error control. Ref. [9] addressed (2) by constructing an unbiased estimator for the sum of the usual squared Frobenius norm of the covariance matrix difference , where . However, to derive the asymptotic normal distribution of his test statistic, Schott imposed strong assumptions, including the assumption of Gaussian populations. Nevertheless, this assumption may not hold in real datasets, leading to inaccurate results. Specifically, empirical results in Section 3.1 demonstrate that [9]’s test is overly permissive, particularly when the k samples (1) are non-Gaussian. With a nominal size of 5%, the empirical sizes of [9]’s test can exceed 9.61% and 10.08% for and 4, respectively, when the samples are normally distributed. Conversely, when the samples are not normally distributed, the empirical sizes can soar to 32.14% and 41.86% for and 4, respectively. To mitigate the reliance on normality assumptions, ref. [10] proposed a test statistic to extend [6]’s test for the k-sample high-dimensional equal-covariance matrix testing problem. However, they also followed strong assumptions imposed by [6], such as the existence of the samples’ eighth moments. According to the results from Section 3.1, [10]’s test may also be overly permissive, with empirical sizes reaching as high as 13.46% when the assumptions are not satisfied. This aligns with the simulation results presented in [8], which suggested that [6]’s test is overly permissive. Furthermore, both [9]’s and [10]’s tests are -norm-based, which may yield poor performance when the entries of the covariance matrix difference are sparse. In an effort to address both sparse and dense alternatives, ref. [11] combined two types of norms to characterize the distance among the covariance matrices: the Frobenius norm, as adopted by [6], and the maximum norm, introduced by [7]. However, empirical results displayed in Section 3.1 indicate that [11]’s test remains overly permissive in many cases. A common issue with these existing tests is their reliance on achieving normality of their null limiting distributions under certain strong conditions. However, in numerous scenarios, satisfying these conditions is challenging, rendering testing based on normal distribution inadequate.
From the preceding discussion, it is apparent that existing methods often struggle to control the size of the test effectively. In this paper, we address this issue by proposing and examining a normal-reference test for the k-sample equal-covariance matrix testing problem for high-dimensional data as described in (2). Our primary contributions are outlined below. Firstly, leveraging the well-known Kronecker product, we transform the k-sample equal-covariance matrix testing problem (2) on original high-dimensional samples (1) into a k-sample equal-mean vector testing problem on induced high-dimensional samples. This novel approach offers a fresh and innovative method tailored specifically for testing the equality of covariance matrices in high-dimensional data settings. Secondly, to address the k-sample equal-mean vector problem, we adopt the methodology introduced by [12] to construct a U-statistic-based test statistic on the induced high-dimensional samples. Under certain regularity conditions and the null hypothesis, it is demonstrated that the proposed test statistic and a chi-square-type mixture share the same normal or non-normal limiting distribution. Therefore, approximating the null distribution of the test statistic using the normal distribution, as carried out in the works of [9,10], may not always be appropriate. Our approach, termed the normal-reference approach, utilizes the chi-square-type mixture, obtained when the k induced samples are normally distributed, to accurately approximate the null distribution of the test statistic. A key advantage of this approach is its elimination of the need to verify whether the limiting distribution is normal or non-normal. Thirdly, instead of estimating the unknown coefficients of the chi-square-type mixture, we employ the three-cumulant matched chi-square-approximation method proposed by [13] to approximate the distribution of the chi-square-type mixture. The approximation parameters are consistently estimated from the data. Fourthly, we establish the asymptotic power under a local alternative. Fifthly, alongside the theoretical foundation, we conduct two simulation studies and a real data application to empirically demonstrate the superiority of our method over several competitors, such as the tests proposed by [9,10,11]. It is worth highlighting that our adaptation of the normal-reference test to the k-sample equal-covariance matrix testing problem is not a direct application of the results from [8]. The asymptotic properties presented in Theorems 1–3 are not directly derived from the theoretical results of [8,14], as these were proposed for the two-sample testing problem. The proofs of Theorems 1–3 are significantly more complex than those in [8].
The structure of this paper is organized as follows: Section 2 presents the main results. Simulation studies are detailed in Section 3. An application to a financial dataset is provided in Section 4. Concluding remarks are offered in Section 5. The technical proofs of the main results are outlined in Appendix A.
2. Main Results
2.1. Test Statistic
Without loss of generality and for simplicity, throughout this section, we assume , since in this paper, we focus solely on the equal-covariance matrix testing problem. This zero-mean assumption is commonly adopted for equal-covariance matrix testing in high-dimensional data, following a convention observed in various studies including [15,16,17], among others. In practice, it is often sufficient to replace with , where are the usual group sample mean vectors of the samples (1) when are not actually equal to . Under this assumption, we can express the equal-covariance matrix testing problem (2) based on the k samples (1) as an equal-mean vector testing problem using the following simple transformation.
Let denote a column vector obtained by stacking the column vectors of a matrix one by one. We have , where ⊗ denotes the well-known Kronecker operator, and is a column vector. Then, the equal-covariance matrix testing problem (2) can be equivalently expressed as the following equal-mean vector testing problem:
based on the following k induced samples:
with and for . To test (3), it is natural to construct an unbiased estimator of , where denotes the usual -norm of a vector . It is also apparent that , representing the usual squared Frobenius norm of the covariance matrix difference for . Let
represent the usual group sample mean vectors and sample covariance matrices of the k induced samples (4). Following [12], for , the U-statistics for estimating and are given by
2.2. Asymptotic Null Distribution
To further investigate the null distribution of (6), we set , and let be the usual sample mean vector of , so that . We can then further write
where
with . It is clear that under the null hypothesis, and have the same distribution. For further study, we can express in (8) as , where , and with . It is easy to check that is an idempotent matrix. Following the proof of Theorem 3 in [12], we have , and
When the k induced samples (4) are treated as normally distributed, we denote the k Gaussian induced samples as and set . Then, we have , where , , , and . In other words, is obtained from when the k induced samples (4) are treated as normally distributed. We then call the distribution of the normal-reference distribution of and the resulting test a normal-reference test. In what follows, we shall show that the distribution of can be asymptotically approximated by the distribution of .
Throughout this paper, let denote equality in distribution and denote a central chi-square distribution with v degrees of freedom. For any given n and p, it is easy to show that has the same distribution as that of a chi-square-type mixture as follows:
where are the eigenvalues of
while are the eigenvalues of for , and , and are mutually independent. Obviously, we have and .
Remark 1.
In practice, the k induced samples (4) are rarely normally distributed. Nevertheless, as a normal-reference test, we treat them as normally distributed to simplify to a chi-square-type mixture (10). The crux of the proposed normal-reference test is thus to demonstrate that and share the same asymptotic limit and that approximating the distribution of is straightforward.
For further theoretical discussion, following [14], we introduce a norm which measures the difference between two probability measures. For two probability measures and on , let denote the signed measure such that for any Borel set A, . Let denote the class of bounded functions with continuous derivatives up to order 3. It is known that a sequence of random variables converges weakly to a random variable x if and only if for every , we have ; see [14] for some details. We use this property to give a definition of the weak convergence in . For a function , let denote the r-th derivative of . For a finite signed measure on , we define the norm as where the supremum is taken over all such that . It is straightforward to verify that is indeed a norm. Also, a sequence of probability measures converges weakly to a probability measure if and only if . For simplicity, we often denote and as and , respectively. Let . These values represent the eigenvalues of , arranged in descending order, as are the eigenvalues of as defined in (11). We further impose the following conditions.
- C1.
- As , we have .
- C2.
- There is a universal constant such that for all real matrix , we have , for all .
- C3.
- As , we have for all uniformly.
- C4.
- As , we have .
Condition C1 is regular for any k-sample testing problem. It requires that the k sample sizes tend to infinity proportionally. Under Condition C1, by (9) and (11), as , we have
Condition C2 is a key condition in this study. It is largely equivalent to the assumption that the original k samples (1) have the finite 8-th moment as imposed in [18]. Remark 1 of [8] has shown that Condition C2 automatically holds under Assumption 1 of [18]. To give more insight about Condition C2, we list the following remarks.
Remark 2.
When is a row vector, e.g., , Condition C2 implies that the kurtosis of is bounded by γ for all : . In simpler terms, it means that the kurtosis of is uniformly bounded in any projection direction for all . According to [19], the kurtosis value reflects the tails of the distribution. Thus, Condition C2 essentially ensures that the distribution of does not exhibit heavy tails in any projection direction. This condition may seem quite weak.
Remark 3.
We have . This expression, along with Condition C2, implies that the variances of ’s are uniformly bounded by and that the noise-to-signal ratios are also uniformly bounded.
Remark 4.
When are normally distributed, Condition C2 is automatically satisfied with . A proof is outlined in Appendix A.
Condition C3 ensures the existence of the limits of which are the eigenvalues of . It is used to obtain the limiting distributions of the standardized versions of and , namely, , and , where and have zero mean and unit variance. Condition C4 is imposed for studying the ratio consistency of the estimators used in the proposed normal-reference test. This is analogous to the condition imposed in [20] for testing the high-dimensional p-dimensional mean vectors, while in our equal-covariance matrix testing, the associated dimension is . Throughout this paper, let denote the distribution of a random variable y and denote convergence in distribution. We have the following useful theorem whose proof is presented in Appendix A.
Theorem 1.
Under Condition C2, we have
where γ is defined in Condition C2.
Theorem 1 states that the distance between the distributions of and is , where . This theorem demonstrates that the distributions of and become asymptotically equivalent. Hence, Theorem 1 furnishes a systematic theoretical justification for employing the distribution to approximate the distribution of . Consequently, we study the asymptotic distribution of in Theorem 2, which is proved in Appendix A.
Theorem 2.
Under Conditions C1–C3, as , we have with
where are i.i.d. , and are defined in Condition C3.
Theorem 2 offers a unified expression for the possible asymptotic distributions of , denoted as the distribution of a weighted sum of a standard normal random variable and a sequence of centered chi-square random variables. From Fatou’s Lemma and Condition C3, we have , indicating that lies within the interval . Below, we provide some remarks to elucidate certain special cases of the possible distribution of (13).
Remark 5.
We have when , equivalently, , which holds when the following condition holds: as ,
The above condition was proposed and used in [12] which is a multi-sample analogy of [21]’s condition (3.6).
Remark 6.
We have , a weighted sum of centered chi-square random variables when , which holds under Condition C3 and when holds.
Remark 7.
The preceding two remarks suggest that the null limiting distribution of can either be normal or non-normal. Nevertheless, in practical scenarios, verifying whether or can be quite challenging. Consequently, it may not always be suitable to rely on the normal approximation for the null distribution of . This theoretical insight elucidates why test statistics grounded on normal approximation, such as those proposed by [9,10], are not universally applicable.
2.3. Implementation
To implement the proposed normal-reference test, we approximate the null distribution of with the distribution of , which is akin to a chi-square-type mixture as outlined in (10). However, accurately estimating the coefficients of this mixture poses a challenge. To surmount this hurdle, we adopt the three-cumulant (3-c) matched chi-square-approximation [13] to approximate the distribution of . The core concept of the 3-c matched -approximation involves approximating the distribution of using that of a random variable defined as , where , and d are the approximation parameters with d representing the approximate degrees of freedom of the 3-c matched -approximation. These parameters are determined via matching the first three cumulants (mean, variance, and third central moment) of and R. For simplicity, let denote the first three cumulants of a random variable X. It is evident that the first three cumulants of R are given by , , and while the first three cumulants of are given by ,
By some simple algebra, we have
It is evident that and since we should always have and being non-negative for all . Matching the first three cumulants of and R then leads to
This leads to , and . The negative value of is expected since is a chi-square-type mixture with both positive and negative coefficients. Note that the skewness of can be expressed as
To apply the 3-c matched -approximation, we need to estimate and consistently. Recall that the usual unbiased estimators of are given by as in (5). We first find an unbiased and ratio-consistent estimator of . According to (15), to obtain an unbiased and ratio-consistent estimator of , we need the unbiased and ratio-consistent estimators of , and , respectively. By Lemma S.3 of [22], the unbiased and ratio-consistent estimators of are given by
By the proof of Theorem 2 of [23], when the k induced samples (4) are normally distributed, the unbiased and ratio-consistent estimator of is given by . Therefore, based on (15), the unbiased and ratio-consistent estimator of is given by
We now find an unbiased and ratio-consistent estimator of . According to (15), to obtain an unbiased and ratio-consistent estimator of , we need the unbiased and ratio-consistent estimators of , , and , respectively. By Lemma 1 of [24], under Condition C4 and when the k induced samples (4) are normally distributed, the unbiased and ratio-consistent estimators of are given by
By Lemma 1 of [12], when the k induced samples (4) are normally distributed, the unbiased estimators of are given by
Under some regularity conditions and when the k induced samples (4) are normally distributed, ref. [25] showed that the above estimators are also ratio-consistent for . By Lemma 2 of [12], when the k induced samples (4) are normally distributed, the unbiased estimators of are given by . Then, the unbiased and ratio-consistent estimator of is given by
It follows that the ratio-consistent estimators of , and d are given by
Remark 9.
Recognizing that the k induced samples (4) typically deviate from a normal distribution, it follows that the estimators , , and are, at best, of a normal-reference nature. Nevertheless, the simulation results presented in Section 3 demonstrate the robust size control of the proposed normal-reference test, indicating that, as anticipated, the normal-reference estimators , , and can still effectively perform even when the k induced samples (4) are not normally distributed.
For any nominal significance level , let denote the upper -percentile of . Then, using (17), the normal-reference test for the k-sample equal-covariance matrix testing problem (2) is conducted via using the approximate critical value or the approximate p-value .
In practice, one may often use the normalized version of : . Then, to approximate the null distribution of , using the distribution of is equivalent to approximate the null distribution of using the distribution of . In this case, the normal-reference test using is then conducted via using the approximate critical value or the approximate p-value .
2.4. Asymptotic Power
We now consider the asymptotic power of under the following local alternative:
where is defined in (8) and . This is the case when is ignorable compared with so that we have
Under Condition C1, as , we have , where so that
The asymptotic power of is established in Theorem 3, and its proof is provided in Appendix A.
Theorem 3.
Assume that as , , and are ratio-consistent for , and d. Under Conditions C1–C4, and the local alternative (18), as , we have
where ζ is defined in Theorem 2. In addition, when , the above expression can be further expressed as
where denotes the upper -percentile of .
3. Simulation Studies
In this section, we conduct two simulation studies to assess the finite-sample performance of the proposed normal-reference test, denoted as , via comparing it against three competitors, [9]’s test (), [10]’s test (), and [11]’s test (), in terms of size control and power. We compare their performance for the k-sample equal-covariance matrix testing problem (2) in cases where and . To generate “large p, small n” samples, we consider three cases with . For , we specify three cases of as , and for , we specify three cases of as . We compute the empirical size or power of a test as the proportion of the number of rejections out of N simulation runs. Throughout this section, we set the nominal size as and the number of simulation runs as . We adopt the average relative error (ARE) to measure the overall performance of a test in maintaining the nominal size. The ARE value of a test is calculated as , where denote the empirical sizes under M simulation settings. A smaller ARE value of a test indicates a better performance of that test in terms of size control.
3.1. Simulation 1
In this simulation study, under Condition C2, we generate the k samples (1) using where are i.i.d. random variables with and . The p entries of are generated using the following three models:
- Model 1:
- .
- Model 2:
- , with .
- Model 3:
- , with .
The above three generative models correspond to three types of distributions: the normal distribution, a symmetric but non-normal distribution, and an asymmetric distribution, respectively. Without loss of generality, we set . The covariance matrices are specified as , where is the matrix of ones, and with . It is apparent that the covariance matrix difference is determined by two tuning parameters, and . In particular, controls the variances of the generated k samples (1) while controls their corresponding correlations. The null hypothesis (2) holds when and . For simplicity, we set where represents the p-dimensional vector of ones, and consider three cases of , and 0.9 so that the simulated data are less correlated, moderately correlated, and highly correlated, respectively. For power consideration, we keep , but for , we set , with randomly generated from the uniform distribution . Additionally, we set and consider three cases of with . The empirical powers of the tests are expected to increase when the value of increases.
Table 1 displays the empirical sizes of , , and when with the last row showing their ARE values associated with the three values of . From Table 1, we can draw the following conclusions regarding size control. Firstly, generally performs well regardless of the correlation in the generated data, as its empirical sizes under various settings range from 4.11% to 6.67%, with ARE values of 8.06, 14.86, and 20.55 for , and , respectively. Secondly, appears to be rather liberal, with empirical sizes ranging from 8.58% to 32.14%, and ARE values of 185.76, 120.06, and 108.41. When comparing the empirical sizes under different models but keeping the other settings the same, it appears that is more liberal for Model 2, which represents a non-normal but symmetric distribution, and is the most liberal for Model 3, which represents an asymmetric distribution. This suggests that in the case of non-normal data, would be inadequate due to its assumption of normality in the population. Thirdly, is generally less liberal than because it does not require the assumption of normality for the k samples. Nevertheless, it is still quite liberal with empirical sizes ranging from 8.29% to 13.47% and ARE values of 116.80, 113.60 and 111.76. This is not surprising since extends [6]’s test to the k-sample case and hence exhibits similar performance to [6]’s test in Tables 1 and 4 of [8]. Fourthly, similar to , exhibits superior performance compared to since the former does not require the normality of the k samples. Although incorporates approaches from both [6]’s and [7]’s tests, it still exhibits a general trend of being liberal in terms of empirical sizes, which range from 4.74% to 12.63%. Additionally, its associated ARE values are 72.93, 37.65, and 29.06, respectively, when and 0.9. To sum up, generally outperforms its competitors , , and in terms of size control.

Table 1.
Empirical sizes (in %) of , , , and in Simulation 1 when .
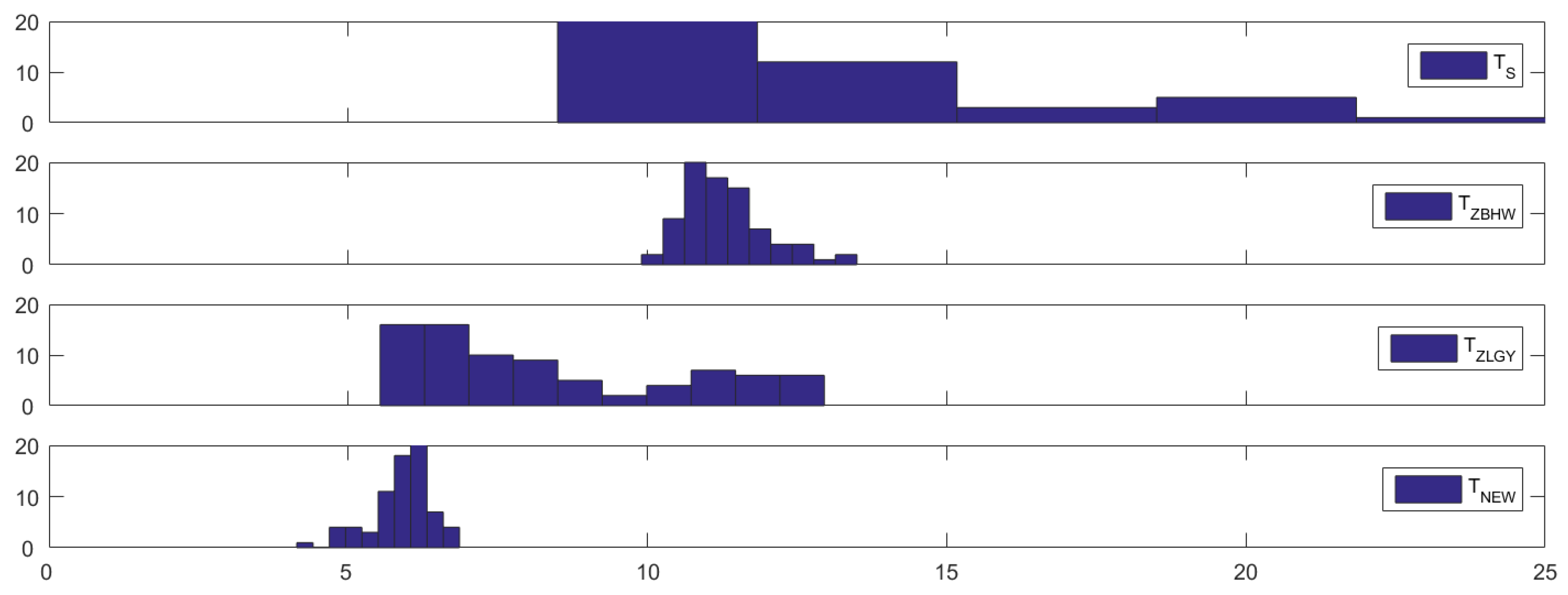
For a more direct visualization, Figure 1 illustrates the histograms of the empirical sizes of , and (from top to bottom), from which some of the above conclusions may be further verified visually. For example, all three competitors exhibit liberal behavior as shown by their histograms being shifted to the right from the nominal size (5%), while is more liberal compared to and as evidenced by its greater degree of deviation. On the other hand, demonstrates better size control performance, as indicated by its histogram being more concentrated around the nominal size.
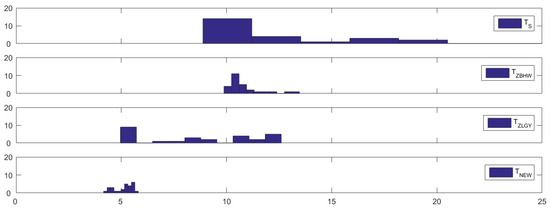
Figure 1.
Histograms of the empirical sizes (in %) of , , and (from top to bottom) in Simulation 1 when .
Table 2 and Figure 2 display the empirical sizes and the corresponding histograms of , , and when . We can draw similar conclusions as those drawn from Table 1 and Figure 1. Essentially, continues to perform well as evidenced by its histogram of empirical sizes being concentrated at the nominal size, ranging from 4.14% to 6.86%, and its ARE values are 13.33, 21.27, and 23.22 for 0.3, 0.5, and 0.9, respectively. In addition, continues to perform much better than , , and when , since their empirical sizes range from 8.50% to 41.86%, 9.9% to 13.50%, and 5.53% to 12.96%, respectively. In terms of ARE values, it is worth noting that all of the competitors for the 4-sample case are more liberal than those for the 3-sample case, indicating that , , and perform less effectively when dealing with more samples.
Table 2.
Empirical sizes (in %) of , , and in Simulation 1 when .
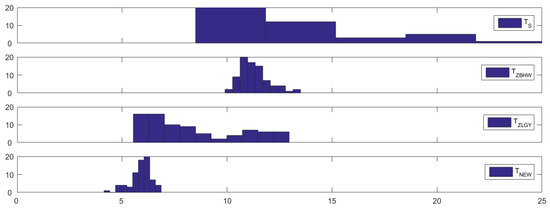
Figure 2.
Histograms of the empirical sizes (in %) of , , and (from top to bottom) in Simulation 1 when .
Table 3 displays the estimated approximate degrees of freedom (17) of under various settings in Simulation 1 when and , which explains why and perform worse than in terms of size control in Table 1 and Table 2. It is seen that the values of are generally quite small under each setting, showing that the underlying null distribution of is unlikely to be normal. Therefore, the null distributions of and are inadequate to be approximated to normal distributions. This partially explains why in terms of size control, and are inaccurate no matter how the data are correlated. It is also seen that the value of decreases with the value of increasing. This means that the more highly correlated the data are, the less adequate the normal approximations to the null distributions of and would be.
Table 3.
Estimated approximate degrees of freedom of under various settings in Simulation 1.
We now proceed by comparing the empirical powers of the four considered tests: , , , and . Table 4 and Table 5 present the empirical powers of these tests when and under various configurations, respectively. As anticipated, with an increase in the value of , the empirical powers of the tests rise due to the escalating differences between the covariance matrices. It is noteworthy that a strong correlation exists between the empirical powers and the corresponding empirical sizes. In essence, a test with a larger empirical size tends to exhibit a greater empirical power compared to another test under the same conditions, and vice versa. Hence, from Table 4 and Table 5, it is evident that the empirical powers of , , and generally surpass those of . This aligns with the conclusions drawn from Table 1 and Figure 1 for the 3-sample case, and the conclusions from Table 2 and Figure 2 for the 4-sample case, namely that , , and tend to be liberal. These similarities underscore the challenge and the unnecessary nature of comparing empirical powers when their empirical sizes vary significantly, emphasizing that relying solely on empirical powers can be misleading if the test fails to control the size properly. A test with robust size control is often preferred over a test with high empirical powers but poor size control.
Table 4.
Empirical powers (in %) in Simulation 1 for with .
Table 5.
Empirical powers (in %) in Simulation 1 for with .
3.2. Simulation 2
In this simulation study, we continue to compare against , , and in terms of size control but with the k samples (1) generated from the following moving average model:
where denotes the h-th component of , and are i.i.d. random variables generated in the same ways as described in Simulation 1. The covariance matrix difference is then determined by and . When and , the generated k samples (1) share the same covariance matrix so that the null hypothesis (2) holds. To evaluate their level accuracy, we set , and let be generated from the uniform distribution . For power comparison, we set and let be generated from the uniform distribution . Since the data in this simulation are generated from a moving average model, the correlations between samples are expected to decrease as the order of moving items increases. As a result, the samples in this study are only moderately correlated or even close to uncorrelated.
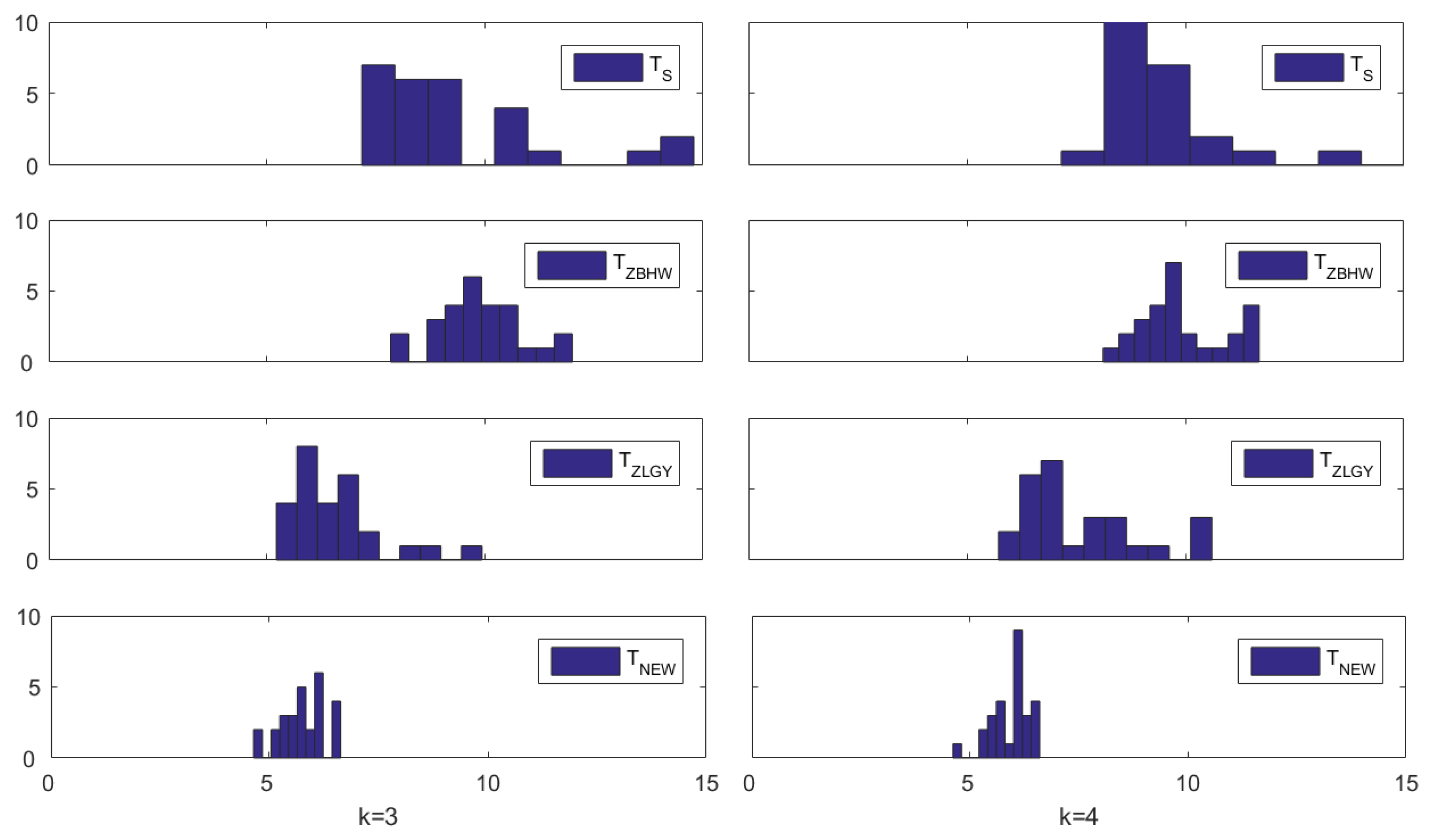
Figure 3 displays the histograms of the empirical sizes (in %) of the four considered tests when (left column) and (right column), respectively. It can be seen visually that still performs well generally regardless of whether or , since its histograms are concentrated at the nominal size (5%). All the histograms of its competitors are on the right of the nominal size.
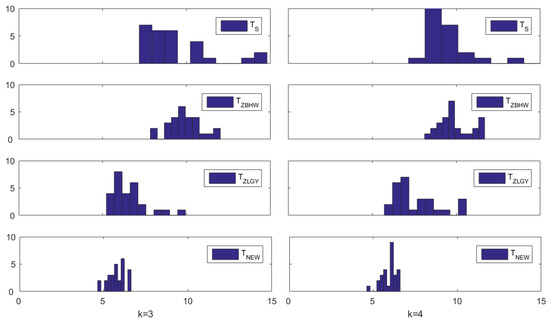
Figure 3.
Histograms of the empirical sizes (in %) in Simulation 2 when (left column) and (right column).
To save space, we do not present the empirical powers of the four tests in this simulation study since the conclusions drawn from them are similar to those drawn from Table 4 and Table 5. That is, the empirical powers of of , and are generally “larger” than those of since they are generally more liberal than .
4. Application to the Financial Data
In this section, we apply , , , and to the financial dataset briefly described in Section 1. The dataset investigates financial contagion during the period of the well-known “1997 Asian financial crisis” and is accessible at https://nuscri.org/en/datadownload/, accessed on 1 December 2024. This crisis originated in Thailand in 1997 and subsequently spread to neighboring countries such as Indonesia, Malaysia, and the Philippines, causing a ripple effect and raising concerns about a global economic downturn due to financial contagion. However, the recovery in 1998 was swift, and concerns about a meltdown quickly diminished.
The dataset provides daily aggregated Probability of Default (PD) data for four sectors, energy, financials, real estate, and industrials, across the aforementioned four countries in 1997. Our interest lies in examining whether there were any structural breaks in the correlations (variance–covariance matrices) of the PDs for these countries and sectors during the crisis period. For this purpose, we divide the dataset into four groups labeled as , , , and . These groups represent the daily aggregated PD for each quarter of 1997, with each quarter spanning a three-month period and representing the 65 trading days in a quarter. Additionally, since we analyze the daily aggregated PD of the four sectors across the four countries, each group comprises 16 observations, i.e., .
To ensure that we have four independent samples, we conduct six pairwise independence tests by utilizing distance correlation-based tests proposed by [26], implemented in the R package energy. As all the p-values exceed 0.05, we can conclude that there is insufficient evidence to reject the null hypothesis that any two groups are independent. Subsequently, we employ , , , and to test the equality of covariance matrices for this financial dataset.
Table 6 presents the p-values of the four considered tests for testing the equality of covariance matrices, along with the corresponding estimated approximate degrees of freedom of under the column labeled “d.f.”. We initially apply the four considered tests to assess the equality of covariance matrices among the four groups. Given the small p-values observed, there is compelling evidence to reject the null hypothesis of no difference between the covariance matrices of the four groups. This suggests significant divergence among the covariance matrices, potentially indicating the presence of financial contagion during the crisis period.
Table 6.
Testing results for the financial dataset.
Subsequently, we aim to ascertain whether the inequality of the four covariance matrices is attributable to financial contagion. We commence by conducting the contrast test “”, with the test results displayed in Table 6. Notably, all considered tests yield consistent conclusions, as all p-values exceed 0.05, implying that the covariance matrices for the first three quarters are equivalent. This finding is plausible, suggesting a gradual dissipation of financial contagion towards the end of the year. The equivalence of covariance matrices for the initial three quarters indicates a relatively stable level of financial contagion during that period. It is pertinent to mention that the estimated approximate degrees of freedom (d.f.) are relatively small, indicating that the normal approximation to the null distributions of and may not be adequate. Consequently, their p-values may not be reliable.
To further illustrate the finite-sample performance of in terms of size control, we utilize this dataset to calculate the empirical sizes of these test procedures. The empirical size is computed from 10,000 runs. Building upon the testing results provided in Table 6, where we have established that the first three quarters share the same covariance matrix, we proceed to calculate their empirical sizes based on the first two quarters () and the first three quarters (). The procedures are outlined as follows: in each run, we randomly partition the samples from the first k quarters into k sub-groups of equal size and then compute the p-values to assess the equality of covariance structures among the k sub-groups. The empirical size is determined as the proportion of times the p-value is smaller than the nominal level across the 10,000 independent runs.
Table 7 presents the empirical sizes of the four tests: , , , and . It is evident from this table that exhibits significantly improved level accuracy compared to the other three tests, which tend to be quite liberal. This finding aligns with the conclusions drawn from the simulation studies presented in Section 3.
Table 7.
Empirical sizes (%) of the financial dataset with the nominal level .
5. Concluding Remarks
In this paper, we introduce and investigate a normal-reference test for the k-sample equal-covariance matrix testing problem, particularly tailored for high-dimensional data. Several existing tests necessitate strong assumptions or conditions, rendering them excessively liberal. Addressing this concern, under certain regularity conditions and null hypothesis, we establish that our proposed test statistic and a chi-square-type mixture share the same limiting distribution. This equivalence permits us to approximate the null distribution of our test statistic without solely relying on the normal approximation. Instead, we leverage the distribution of the chi-square-type mixture for this purpose, ensuring more reliable results and mitigating potential issues associated with the normal approximation, such as unreliable p-values or incorrect rejection rates. Furthermore, we utilize the three-cumulant matched chi-square-approximation proposed by [13] to approximate the distribution of the chi-square-type mixture, with parameters consistently estimated from the data. We apply our methodology to a financial dataset encompassing various sectors across multiple countries during a financial crisis, showcasing the efficacy of our approach in detecting potential financial contagion.
Author Contributions
Conceptualization, J.-T.Z.; methodology, J.W., T.Z. and J.-T.Z.; software, J.W.; validation, J.W., T.Z. and J.-T.Z.; formal analysis, J.W., T.Z. and J.-T.Z.; investigation, T.Z. and J.-T.Z.; resources, J.W.; data curation, J.W.; writing—original draft preparation, J.W.; writing—review and editing, J.W., T.Z. and J.-T.Z.; visualization, J.W.; supervision, T.Z. and J.-T.Z.; project administration, T.Z.; funding acquisition, T.Z. and J.-T.Z. All authors have read and agreed to the published version of the manuscript.
Funding
Wang and Zhang’s studies were partially supported by the National University of Singapore academic research grants (22-5699-A0001 and 23-1046-A0001), and Zhu’s research was supported by the National Institute of Education (NIE), Singapore, under its Academic Research Fund (RI 4/22 ZTM).
Data Availability Statement
The original contributions presented in this study are included in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Technical Proofs
Proof of Remark 4.
When are normally distributed, we have and hence , where are the eigenvalues of and . It follows that and Thus,
as desired. □
Proof of Theorem 1.
We firstly set and . It is seen that . Since we can write in (8) as
then can be written as the following generalized quadratic form as defined in ([14], Section S.2 of the Appendix): , where , and
Similarly, can also be written as the generalized quadratic form , where .
We will employ Theorem S.1 of [14] in the following proofs. To employ Theorem S.1 of [14], we need to check Assumptions S.1 and S.2 of [14] first. Note that we have where when . Under Condition C2, we have
where is defined in Condition C2. Then, Assumption S.1(a) of [14] is satisfied. Similarly, we can show that , , and , indicating that Assumption S.2(a) of [14] is also satisfied.
In addition, Assumptions S.1(b), S.2(b), and S.2(c) of [14] are also satisfied by and which are independent from each other. Applying Theorem S.1 of [14], we have
For , when , by ([14] p. 23 of the Appendix), we have
It is easy to see from (9) that and . Therefore, we have , and . By the Cauchy–Schwarz inequality, we have
It follows that
Thus, we have
The proof is complete. □
Proof of Theorem 2.
Since for , we have and they are independent from each other. Let denote a Wishart distribution with v degrees of freedom and a covariance matrix . Then, we have . Therefore, we have and . It follows that under Condition C1, as , we have
uniformly for all p. Thus, in probability uniformly for all p. By (12), we have . In addition, we have . Thus, we can express where . It follows that we have
Under Condition C3, the expression (13) follows from Corollary 1 of [14] immediately. The proof is complete. □
Proof of Theorem 3.
By (7) and under the local alternative (18), we have
By (9) and (19), we have . In addition, under the given conditions, we have and as . We first prove (20). Under Conditions C1–C3, Theorems 1 and 2 indicate that as , we have where is defined in Theorem 2. It follows that as , we have
where is defined in Condition C1.
References
- Dornbusch, R.; Park, Y.C.; Claessens, S. Contagion: Understanding How It Spreads. World Bank Res. Obs. 2000, 15, 177–197. [Google Scholar] [CrossRef]
- King, M.A.; Wadhwani, S. Transmission of Volatility between Stock Markets. Rev. Financ. Stud. 1990, 3, 5–33. [Google Scholar] [CrossRef]
- Bekaert, G.; Harvey, C.; Ng, A. Market Integration and Contagion. J. Bus. 2005, 78, 39–69. [Google Scholar] [CrossRef]
- Corsetti, G.; Pericoli, M.; Sbracia, M. Some contagion, some interdependence: More pitfalls in tests of financial contagion. J. Int. Money Financ. 2005, 24, 1177–1199. [Google Scholar] [CrossRef]
- Duan, J.C.; Sun, J.; Wang, T. Multiperiod corporate default prediction A forward intensity approach. J. Econom. 2012, 170, 191–209. [Google Scholar] [CrossRef]
- Li, J.; Chen, S.X. Two sample tests for high-dimensional covariance matrices. Ann. Stat. 2012, 40, 908–940. [Google Scholar] [CrossRef]
- Cai, T.; Liu, W.; Xia, Y. Two-Sample Covariance Matrix Testing and Support Recovery in High-Dimensional and Sparse Settings. J. Am. Stat. Assoc. 2013, 108, 265–277. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, T.; Zhang, J.T. Two-sample test for high-dimensional covariance matrices: A normal-reference approach. J. Multivar. Anal. 2024, 204, 105354. [Google Scholar] [CrossRef]
- Schott, J.R. A test for the equality of covariance matrices when the dimension is large relative to the sample sizes. Comput. Stat. Data Anal. 2007, 51, 6535–6542. [Google Scholar] [CrossRef]
- Zhang, C.; Bai, Z.; Hu, J.; Wang, C. Multi-sample test for high-dimensional covariance matrices. Commun. Stat.—Theory Methods 2018, 47, 3161–3177. [Google Scholar] [CrossRef]
- Zheng, S.; Lin, R.; Guo, J.; Yin, G. Testing homogeneity of high-dimensional covariance matrices. Stat. Sin. 2020, 30, 35–53. [Google Scholar] [CrossRef]
- Zhang, J.T.; Zhu, T. A new normal reference test for linear hypothesis testing in high-dimensional heteroscedastic one-way MANOVA. Comput. Stat. Data Anal. 2022, 168, 107385. [Google Scholar] [CrossRef]
- Zhang, J.T. Approximate and Asymptotic Distributions of Chi-Squared-Type Mixtures With Applications. J. Am. Stat. Assoc. 2005, 100, 273–285. [Google Scholar] [CrossRef]
- Wang, R.; Xu, W. An approximate randomization test for the high-dimensional two-sample Behrens–Fisher problem under arbitrary covariances. Biometrika 2022, 109, 1117–1132. [Google Scholar] [CrossRef]
- Li, W.; Qin, Y. Hypothesis testing for high-dimensional covariance matrices. J. Multivar. Anal. 2014, 128, 108–119. [Google Scholar] [CrossRef]
- Hu, J.; Li, W.; Liu, Z.; Zhou, W. High-dimensional covariance matrices in elliptical distributions with application to spherical test. Ann. Stat. 2019, 47, 527–555. [Google Scholar] [CrossRef]
- Yu, X.; Li, D.; Xue, L. Fisher’s Combined Probability Test for High-Dimensional Covariance Matrices. J. Am. Stat. Assoc. 2024, 119, 511–524. [Google Scholar] [CrossRef]
- Chen, S.X.; Zhang, L.X.; Zhong, P.S. Tests for high-dimensional covariance matrices. J. Am. Stat. Assoc. 2010, 105, 810–819. [Google Scholar] [CrossRef]
- Westfall, P.H. Kurtosis as peakedness, 1905–2014. RIP. Am. Stat. 2014, 68, 191–195. [Google Scholar] [CrossRef] [PubMed]
- Bai, Z.D.; Saranadasa, H. Effect of high dimension: By an example of a two sample problem. Stat. Sin. 1996, 6, 311–329. [Google Scholar]
- Chen, S.X.; Qin, Y.L. A two-sample test for high-dimensional data with applications to gene-set testing. Ann. Stat. 2010, 38, 808–835. [Google Scholar] [CrossRef]
- Zhang, J.T.; Guo, J.; Zhou, B.; Cheng, M.Y. A simple two-sample test in high dimensions based on L2-norm. J. Am. Stat. Assoc. 2020, 115, 1011–1027. [Google Scholar] [CrossRef]
- Zhang, J.T.; Zhou, B.; Guo, J.; Zhu, T. Two-sample Behrens–Fisher Problems for High-Dimensional Data: A Normal Reference Approach. J. Stat. Plan. Inference 2021, 213, 142–161. [Google Scholar] [CrossRef]
- Zhang, J.T.; Zhou, B.; Guo, J. Testing high-dimensional mean vector with applications: A normal reference approach. Stat. Pap. 2022, 63, 1105–1137. [Google Scholar] [CrossRef]
- Hyodo, M.; Nishiyama, T.; Pavlenko, T. On error bounds for high-dimensional asymptotic distribution of L2-type test statistic for equality of means. Stat. Probab. Lett. 2020, 157, 108637. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).