Abstract
The Barzilai-Borwein (BB) method usually uses BB stepsize for iteration so as to eliminate the line search step in the steepest descent method. In this paper, we modify the BB stepsize and extend it to solve the optimization problems of three-dimensional quadratic functions. The discussion is divided into two cases. Firstly, we study the case where the coefficient matrix of the quadratic term of quadratic function is a special third-order diagonal matrix and prove that using the new modified stepsize, this case is R-superlinearly convergent. In addition to that, we extend it to n-dimensional case and prove the rate of convergence is R-linear. Secondly, we analyze that the coefficient matrix of the quadratic term of quadratic function is a third-order asymmetric matrix, that is, when the matrix has a double characteristic root and prove the global convergence of this case. The results of numerical experiments show that the modified method is effective for the above two cases.
Keywords:
unconstrained optimization; quadratic functions; Barzilai-Borwein stepsize; R-superlinear convergence; global convergence MSC:
49K35; 65K10
1. Introduction
In this paper, we consider the unconstrained optimization problem of minimizing the quadratic function,
where is the coefficient matrix of the quadratic term, . In order to solve (1), common optimization methods usually take the following iterative approach:
where , is called stepsize. Different method has different definition of the stepsize, so the studies on stepsize are diverse. The most common method is the classical steepest descent method [1], whose stepsize is called Cauchy stepsize,
this method to find the stepsize is also called accurate one-dimensional line search, and Forsythe proved the rate of convergence of the classical steepest descent is linear in [2]. Although the stepsize is effective, the classical steepest descent method will not work well when the condition number of A is large, see [3] for details.
In order to ensure the convergence speed and reduce the amount of computation, Borwein and Barzilai [4] proposed a new stepsize, they turned the iterative formula into
where , I is identity matrix. It is similar to the quasi-Newton method [5], can be regarded as an approximate Hessian matrix of f at . And then, in order for to have quasi-Newton property, they chose so that meets the following condition:
and they have
where , and denotes the Euclidean norm. Additionally, in another way to choose the stepsize , they let satisfy
and then they have another stepsize
As we can see, if , then , so is a long stepsize and is a short stepsize. So will perform better than in solving some optimization problems, see [6,7] for details. And the methods that use or as stepsize are collectively referred to as BB methods.
In recent years, there has been a lot of research on the convergence and stepsize modification of the BB methods [8,9,10]. From previous studies, it can be found that the convergence rate of BB methods are usually R-superlinear and R-linear. For example, in [4], Barzilai and Borwein proved R-superlinear convergence of their method with the stepsize for solving two-dimensional strictly convex quadratics. And Dai and Liao [11] proved R-linear convergence of the BB method for n-dimensional strictly convex quadratics. Now we give the definition of these two rates of convergence as follows.
Definition 1.
Set
According to the above formula, the R-convergence rate can be divided into two cases:
(i) When , the sequence of iterated points is said to have R-superlinear convergence rate;
(ii) When , the sequence of iterated points is said to have R-linear convergence rate.
In addition to solving quadratics, the BB method can also solve nonlinear optimization problems. Raydan [12] proposed a global Barzilai-Borwein method for unconstrained optimization problems by combining with the nonmonotone line search proposed by Grippo et al. [13]. Dai and Fletcher [14] developed projected BB methods for solving large-scale box-constrained quadratic programming. Additionally, Huang and Liu [15] extended the projected BB methods by using smoothing techniques, and they modified it to solve non-Lipschitz optimization problems. In [16], Dai considered alternating the Cauchy stepsize and the BB stepsize, and proposed an alternate step gradient method. And in [17], Zhou et al. proposed an Adaptive Barzilai-Borwein (ABB) method which alternated and .
In addition, the relationship between BB stepsizes and the spectrum of the Hessian matrices of the objective function has also attracted wide attention. Based on the ABB method in [17], Frassoldati et al. [18] tried to use close to the reciprocal of the minimum eigenvalue of the Hessian matrix. Their first implementation of this idea was denoted by ABBmin1 and in order to better the iteration effect, they proposed another method, denoted by ABBmin2. De Asmundis et al. [19] used the spectral property of the stepsize in [20] to propose an SDC method, the SDC indicated that the Cauchy stepsize was alternated with the Constant one. In [21], the Broyden class of quasi-Newton method approximates the inverse of the Hessian matrix by
where , and are the BFGS and DFP matrices satisfying the formula , respectively. In the quasi-Newton method, these are the two most common corrections for . Among them, the DFP correction was first proposed by Daviden [22] and later explained and developed by Fletcher and Powell [23], while the BFGS correction was summarized from the quasi-Newton method proposed by Broyden, Fletcher, Goldfarb and Shanno independently in 1970 [24,25,26,27]. Similarly, applying this idea to the BB method, Dai et al. [28] solved the following equation
to obtain the convex combination of and
where , and they further proved that the family of spectral gradient methods of (12) have R-superlinear convergence for two-dimensional strictly convex quadratics.
In addition to the several stepsize definitions mentioned above, there are also some BB-like stepsize. In [29], Dai et al. set and , where , they obtained a positive BB-like stepsize by averaging and geometrically as follows
whose simplification is equivalent to
and they proved the R-superlinear convergence of the method. In addition, (14) can also be seen as a delay extension of the stepsize proposed by Dai and Yang in [30],
Interestingly, it has been shown in [30] that (15) will eventually approach the minimum value of , precisely
where and are the minimum and maximum eigenvalues of A, and their corresponding eigenvectors are and , respectively. The minimum stepsize of (16) is the optimal stepsize in [31], i.e.,
In this paper, we mainly research on the three-dimensional cases. That is to say, the coefficient matrix A of the quadratic term is a third-order matrix. In [29], their BB-like method applied only to , . Based on it, we modify the stepsize in (14) as follows:
and make it applicable to both cases and , . For the case , , we generalize it to a more general form which is , where . For these two cases, we have carried out the proof of convergence and numerical experiments.
The paper is organized as follows. In Section 2, we analyze the new BB-like method which uses the stepsize for the case of , and , , we prove the rate of convergence of the new method is R-superlinear. Additionally, we extend this case to n-dimension, which means that , where . And we prove the rate of convergence in the n-dimensional case is R-linear. Section 3 provides the research of the case , , and we prove the global convergence of this case under some assumption. In Section 4, we give some numerical experiment results to show the effectiveness of the new method. Finally, the conclusions are given in Section 5.
2. The Case Where A Is a Diagonal Matrix and Its Convergence Analysis
2.1. Three-Dimensional Case
In this section, we start with the basic case that
where . According to the iteration formula , we assume that are given initial iteration points and they satisfy
As we know,
so we have
we set
then can be written as
Notice that so the iteration formula for is
Let
then
We define , by (28) we have
In order to prove the R-superlinear convergence of this case, we give three Lemma firstly.
Lemma 1.
Assume that , the function is monotonically increasing and when .
Proof.
The proof of Lemma 1 can fully refer to the proof of Lemma 1.2.1 in [29].
By direct calculation, we can obtain
Since , we have . So is monotonically increasing and when , we have
In addition to that, we have
So in summary, we obtain that when , . □
In the next Lemma we will give the definition of and its lower bound.
Lemma 2.
We define , where γ satisfies , if
then there exists , such that
Proof.
According to the definition of and (29),
Notice that , and from Lemma 1 we have , so
where . By (32), we can obtain
so we finish the proof. □
Lemma 3.
Under the conditions of Lemma 2, we have
Proof.
By (34), if
or
holds, thus (35) holds. Now, we consider other cases. We assume that the above two inequalities are not true, so we have
or
and by (29) we know that
Next, we prove (35) in two cases.
In the following theorem, we will prove the rate of convergence of this case is R-superlinear.
Theorem 1.
Proof.
Notice that and , so we can obtain
where and .
Firstly, we consider the third component of the gradient. From (24) we know
Since , so by using (36) we have
Similarly, as for the first component of the gradient, we calculate directly,
By (38) and , we can obtain
And from (24) we know that the condition of the second component of the gradient is the same as the first component, so
can be obtained.
On the basis of the above conclusion we generalize this case to a more general form, we set , . According to the assumptions and conditions mentioned above, we have
Substituting of (21) into the above equation, then
According to (23), we have
Let
then
So we obtain something similar to (28), and by using the same proof method as Lemmas 1–3 and Theorem 1, we can also prove that when , , the BB-like method using the new stepsize is convergent and the rate of convergence is R-superlinear.
2.2. n-Dimensional Case
In this case, we consider that
where . Then, we will prove R-linear convergence of the new method for n-dimensional case.
In [16], Dai has proved that if , where , and the stepsize has the following Property 1, then either for some finite k or the sequence of gradient norms converges to zero R-linearly.
Firstly, we give the Property 1 and the Theorem in [16]. In the Property 1, they define is the ith component of and
Property 1
([16]). Suppose that there exist an integer m and positive constants and such that
(i) ;
(ii) for any integer and , if and hold for , then .
Theorem 2
([16]). Consider the linear system
where , and . Consider the gradient method where the stepsize has Property 1. Then either for some finite k, or the sequence converges to zero R-linearly.
Proof.
The proof can fully refer to the proof of Theorem 4.1 in [16].
By (23), we have
The rest of the proof will be divided into three parts as follows:
(I). We prove that, for any integer and , if there exist some and integer such that
then we must have
where
In fact, suppose that
So (50) must hold.
(II). Denoting and , we prove that if (49) holds, we can further have
In fact, by (I), we know that there are infinitely many integers and with such that
and
Due to the arbitrariness of and , (57) and (59), we know that the following inequality holds for any :
(III). Denoting for any ,
and setting , for and , we prove by induction that for all ,
According to the Property and the Theorem given above, we will prove that the stepsize satisfies Property 1 and the n-dimensional case has R-linear convergence rate in the following Theorem.
Theorem 3.
If , where , then either for some finite k or the sequence of gradient norms converges to zero R-linearly.
Proof.
And from (18), we have
So, the following formula holds
Then,
Similarly,
So, (i) of Property 1 holds.
If and hold for any integer , and , we have
For the second inequality, we define and . Obviously, the function is monotonically increasing when . According to the assumption, we have which means that . So we can obtain
the third inequality holds.
Thus, (ii) of Property 1 also holds.
Above all, the conclusion of the Theorem holds, we finish the proof. □
3. The Case Where A Is an Asymmetric Matrix and Its Convergence Analysis
In this case, we consider that
where . Clearly, in this case, A has a double characteristic root and it is not a symmetric matrix, so the analysis of this case will be different from that in Section 2.
Firstly, we give two initial iteration points , which satisfy
In this case,
so the stepsize will be
And by , we have
That is to say
we set
so we can obtain
From (66), we have
As we know and , but we cannot be sure whether M is positive or negative. So in order to prove the global convergence, we consider two cases and .
Theorem 4.
When , the sequence of gradient norms converges to zero.
Proof.
At first, we assume that for all . Since , so and . Next, as for the product term in (67) we discuss it in two cases and .
Case (i). When , we have . By (67),
If i.e., ,
where , so converges to zero.
And if i.e., ,
where
so , converges to zero.
Case (ii). When , we have , and , then hold. By (67),
Since (69) is the same as (68), so the proof of Case (ii) is similar to Case (i), and converges to zero, too.
According to the above analysis, we finish the proof. □
Before we prove the case of , we set and then we will give the following theorem.
Theorem 5.
When , if , we assume , the sequence of gradient norms converges to zero; if , the sequence also converges to zero.
Proof.
Firstly, for any we assume that . By (67), whether is positive or negative, we have
If , we can see that , so . As we know,
Let , then we have
From the assumption , we can obtain and , so the sequence converges to zero.
And if , it follows that and then . Since so it is obvious that converges to zero.
Above all, we finish the proof. □
From the above two theorems, we can see that when , , the new method is globally convergent. In order to prove the convergence of the new method, we add the assumption condition , but the value of Q does not need to be considered in the actual calculation, and it does not affect the computational efficiency of the new method.
4. Numerical Results
In this section, we present the results of some numerical experiments on how the new BB-like method using the new stepsize compares with other BB methods in solving optimization problems. The main difference between the different methods we compare here is the choice of the stepsize. We finally choose the following stepsizes for comparison: [4], [4], [30], [32] and the stepsize in [28]. From (12) we can see the stepsize in [28] is a convex combination, so in our experiments we set and use it to represent this method. In addition to this, for the case when A is an n-dimensional symmetric matrix, we compare our BB-like method with the ABBmin1 and ABBmin2 methods in [18], and ABB method in [17]. The calculation results of all methods were completed by Python (v3.9.13). All the runs were carried out on a PC with an Intel Core i5, 2.3 GHz processor and 8 GB of RAM. For the examples we wanted to solve in the numerical experiments, we chose the following termination condition:
for some given , so that we can obtain the expected results.
In our numerical experiments, we mainly considered five types of optimization problems. And now we give the five examples in specific forms as follows.
Example 1.
Consider the following optimization problem,
where , initial point , .
For Example 1, we compared the number of iterations and the minimum points of the new method with the other five methods in solving optimization problems when changes. The specific results are shown in Table 1. Moreover, we give a comparison of the CPU time of different methods when solving Example 1 in Figure 1.

Table 1.
Number of iterations and minimum points of compared methods for Example 1.
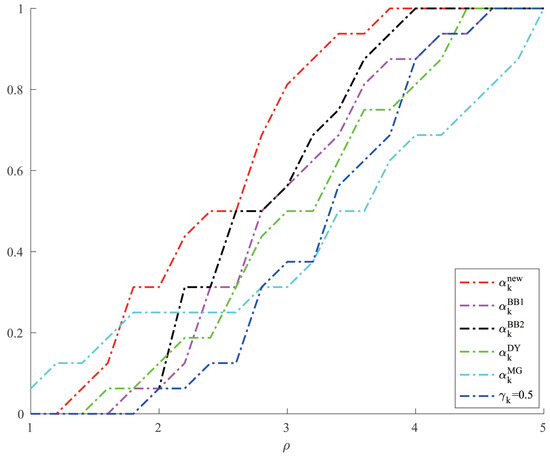
Figure 1.
Comparison of six methods on CPU time for Example 1.
Example 2.
Consider the following optimization problem,
where , initial point , .
For Example 2, we give the comparison results of the number of iterations and the minimum points of each method when solving the optimization problems with different values of a and b in Table 2. And we give a comparison of the CPU time of different methods when solving Example 2 in Figure 2.
Table 2.
Number of iterations and minimum points of compared methods for Example 2.
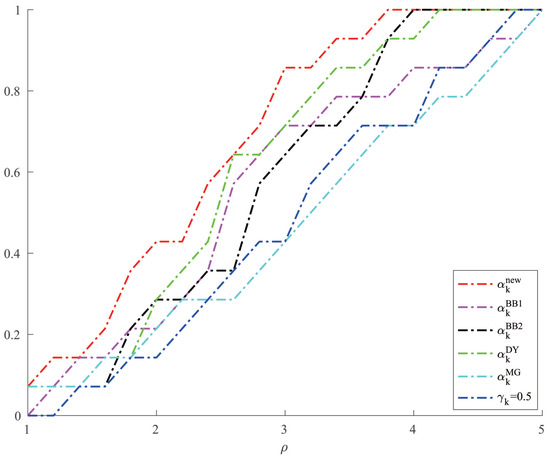
Figure 2.
Comparison of six methods on CPU time for Example 2.
Example 3.
Consider the following optimization problem,
where , and the initial point can be chosen at random.
For Example 3, due to the particularity of its form, A is not a symmetric matrix but other forms of BB methods require A to be a symmetric positive definite matrix. Therefore, we only give the results of the number of iterations and the minimum points of this kind of optimization problems by using the new method when the initial points change in Table 3.
Table 3.
Number of iterations and minimum points of our method for Example 3.
Example 4.
Consider the following optimization problem,
where , , and the initial point can be chosen at random.
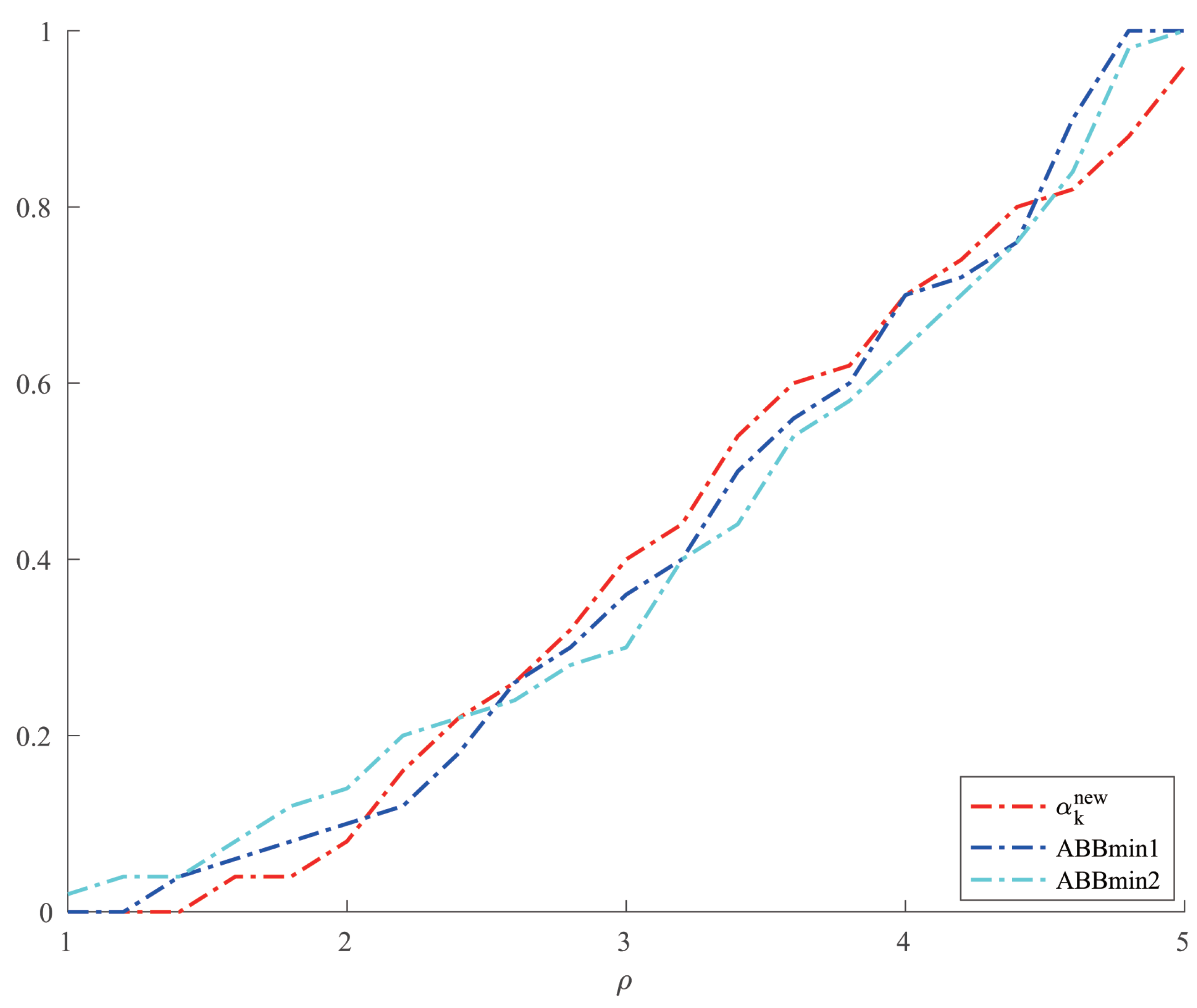
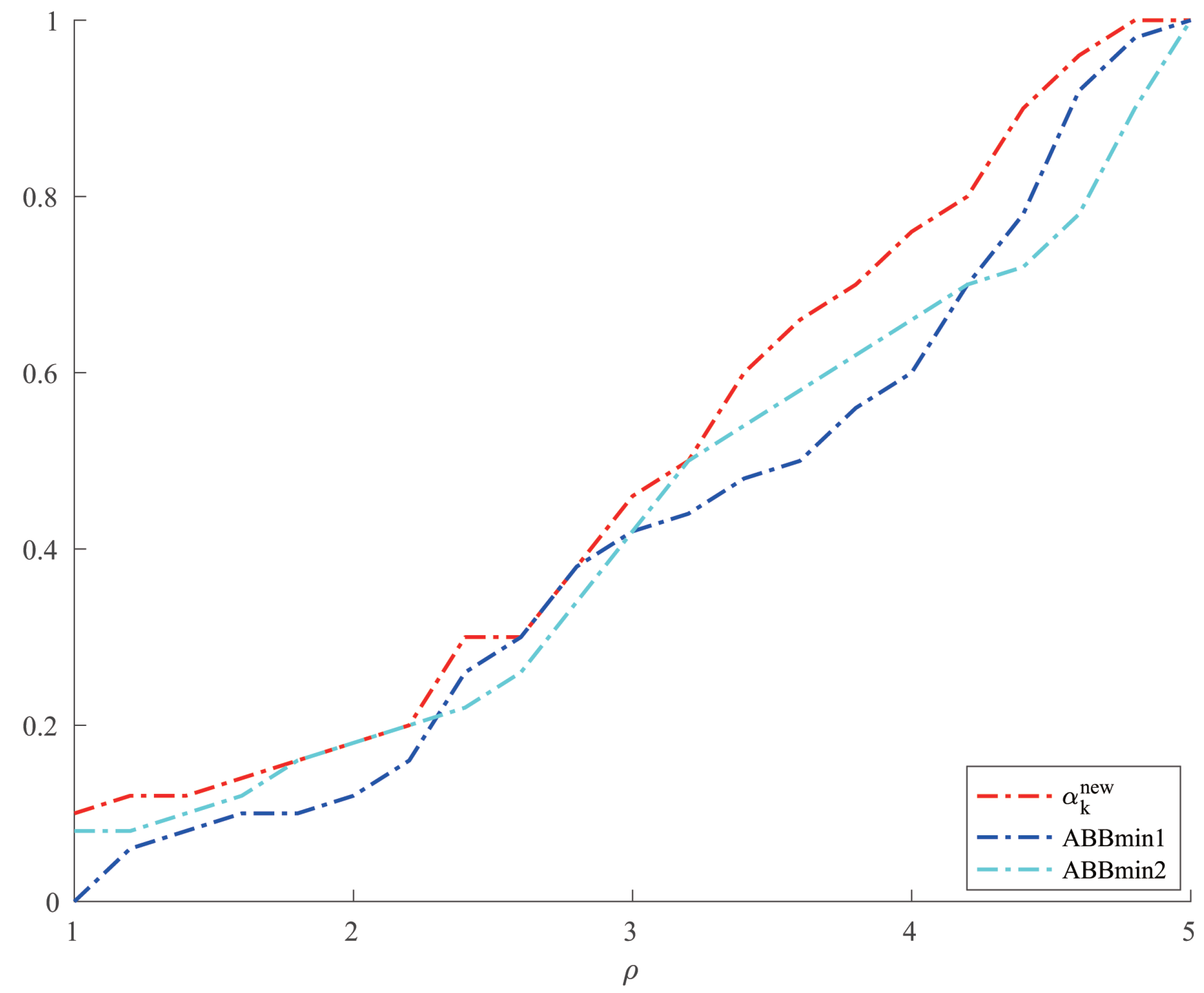
For Example 4, we chose two other methods, ABBmin1 and ABBmin2 methods, to compare with our method. The parameters of ABBmin1 and ABBmin2 methods were selected as in [18], which were , and , respectively. The initial points we chose were , and . For each initial point, we randomly chose ten different sets of values of , , which satisfied , 10,000, and was evenly distributed between 1 and 10,000 for . Figure 3 and Figure 4, respectively, show the results of the comparison of the number of iterations and the CPU time when the three methods solve Example 4.
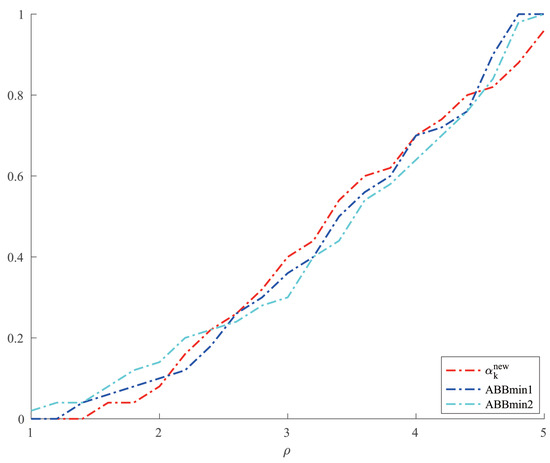
Figure 3.
Comparison of three methods on number of iterations for Example 4.
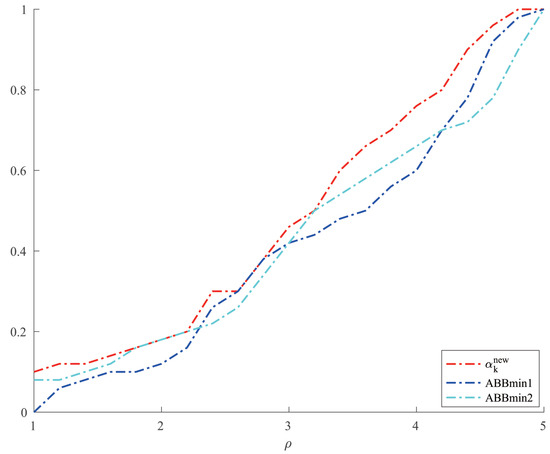
Figure 4.
Comparison of three methods on CPU time for Example 4.
Example 5
(Random problems in [33]). Consider , where
and , , are unitary random vectors, is a diagonal matrix where , , and is randomly generated between 1 and condition number for . We set , , and the initial point .
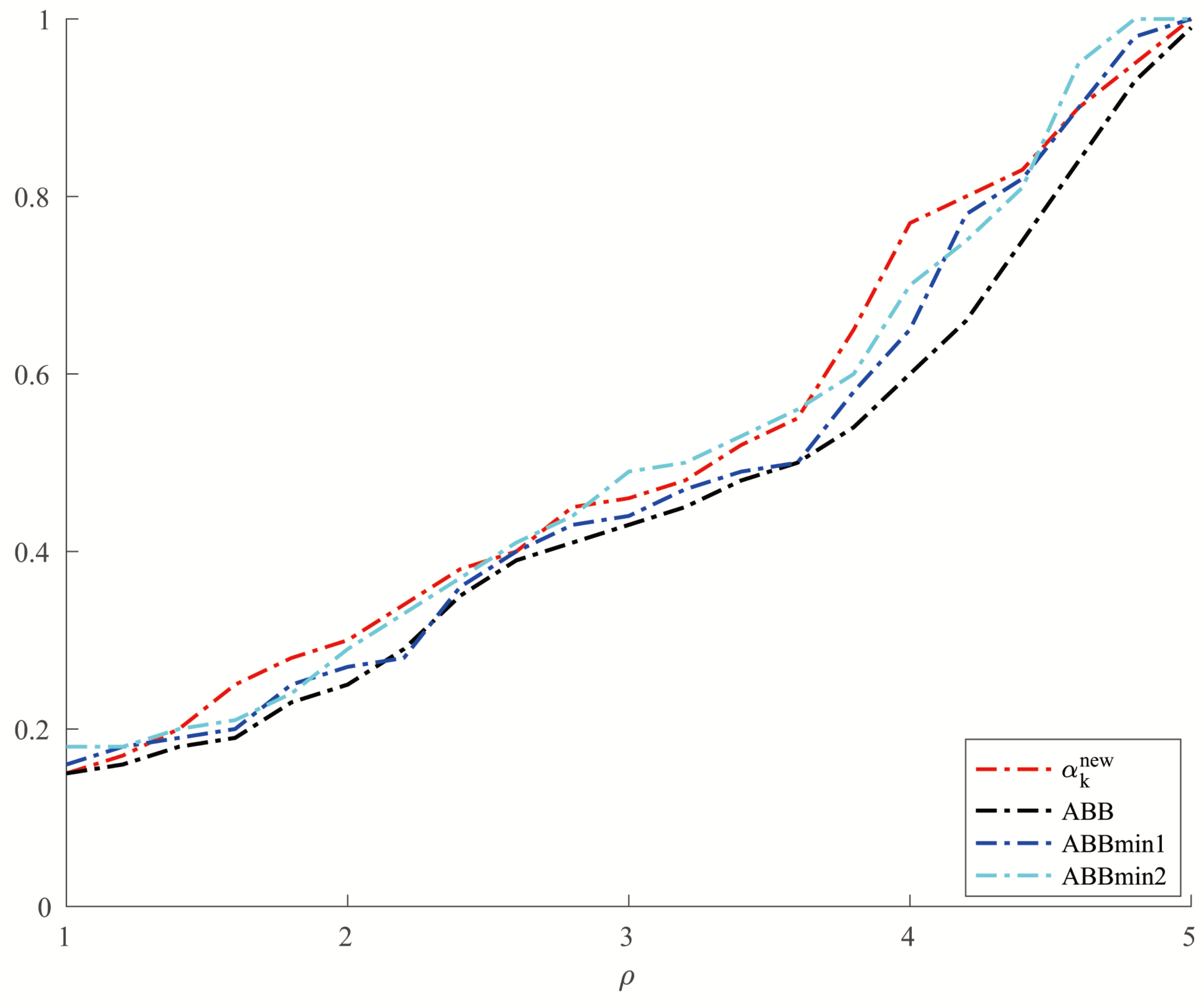
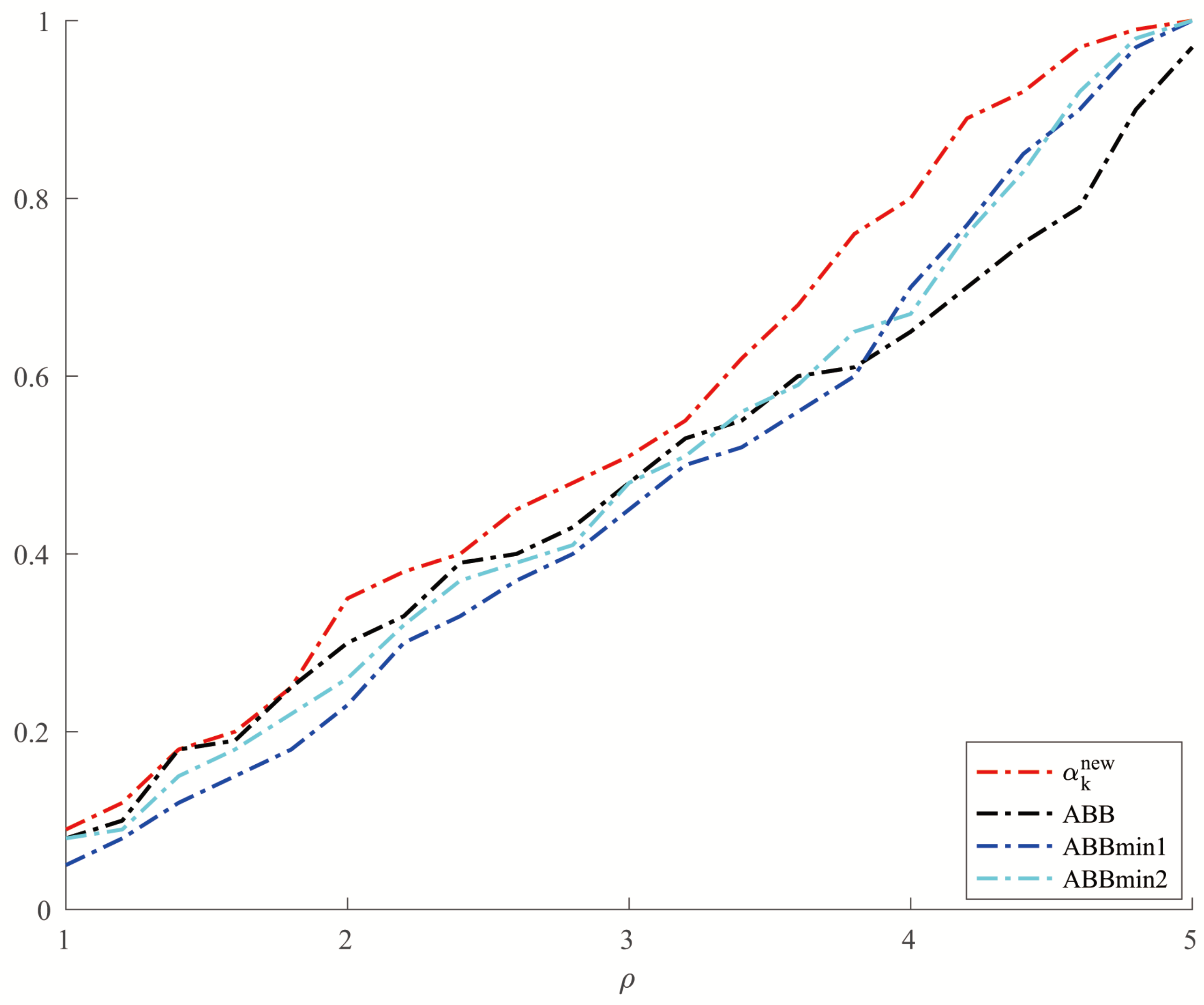
For Example 5, we set and allowed a maximum of 10,000 iterations. In order to make a better comparison, we chose three other methods, which were ABBmin1 and ABBmin2 methods, and ABB method. The parameters used by the ABBmin1 and ABBmin2 methods were the same as Example 4. And for the ABB method, we set , which was different from that in [17]. In the experiments, three values of the condition number cond: were chosen. For each value of , ten instances with evenly distributed in were generated, . The comparison of the number of iterations and the CPU time of several methods in solving Example 5 are shown in Figure 5 and Figure 6.
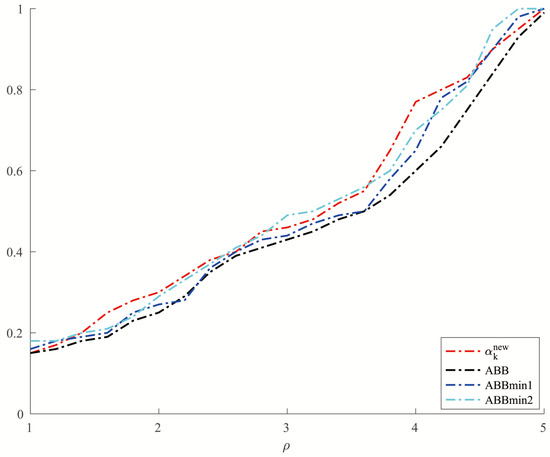
Figure 5.
Comparison of four methods on number of iterations for Example 5.
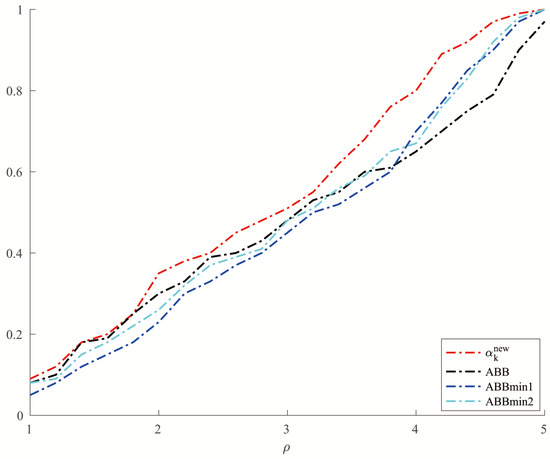
Figure 6.
Comparison of four methods on CPU time for Example 5.
In all tables, ‘iter’ represents the number of iterations and ‘’ represents the optimal solution. And the vertical axis of each figure shows the percentage of problems solved by different methods within the minimum value of the metric factor .
From Table 1 and Table 2, we can see that the new method has no obvious advantage in the number of iterations when solving the optimization problems like Examples 1 and 2 and the solution accuracy can reach the level of other methods. However, in terms of CPU time, we can see from Figure 1 and Figure 2 that the new method has a clear advantage over other compared methods. When solving optimization problems like Example 3, it is not difficult to see from Table 3 that the new method can complete well in terms of the number of iterations and the accuracy of the minimum points. And from Figure 3 and Figure 4, we can see that there is no significant difference in the number of iterations between the three methods when solving the problems such as Example 4, but the new method has a slight advantage in terms of the CPU time. For the random problems like Example 5, we can see from Figure 5 that the new method and ABBmin2 method perform better in terms of the number of iterations, while in terms of the CPU time, we can see from Figure 6 that the new method still has obvious advantages.
5. Conclusions
In this paper, we proposed a modified BB-like method which used the stepsize and analyzed two cases when the the coefficient matrix A of the quadratic term of quadratic function is a three-order matrix. For the case, , we have proved the R-superlinear convergence of this case and generalized this case to , . In addition to that, we have further generalized this case to the n-dimensional form, that is, , where . And we have proved the R-linear convergence of the n-dimensional case. The numerical experimental results have shown that this method has significant advantage in running time when comparing with some other methods. For another case , , we also proved the global convergence of this case under some assumption and by the numerical results we can see that this modified method is fast and effective in dealing with problems. To sum up, using the modified stepsize to solve three-dimensional optimization problems is well-behaved.
Author Contributions
Methodology, Q.H.; software, T.W.; supervision, Q.H.; writing—original draft, T.W.; writing—review and editing, T.W. and Q.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by National Natural Science Foundation of China grant 12171196.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
There is no conflicts of interests.
References
- Cauchy, A. Méthode générale pour la résolution des systemes d’équations simultanées. Comp. Rend. Sci. Paris 1847, 25, 536–538. [Google Scholar]
- Forsythe, G.E. On the asymptotic directions of the s-dimensional optimum gradient method. Numer. Math. 1968, 11, 57–76. [Google Scholar] [CrossRef]
- Nocedal, J.; Sartenaer, A.; Zhu, C. On the behavior of the gradient norm in the steepest descent method. Comput. Optim. Appl. 2002, 22, 5–35. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Dennis, J.E., Jr.; Moré, J.J. Quasi-Newton methods, motivation and theory. SIAM Rev. 1977, 19, 46–89. [Google Scholar] [CrossRef]
- Birgin, E.G.; Martínez, J.M.; Raydan, M. Spectral projected gradient methods: Review and perspectives. J. Stat. Softw. 2014, 60, 1–21. [Google Scholar] [CrossRef]
- Fletcher, R. On the Barzilai-Borwein method. In Optimization and Control with Applications; Qi, L.Q., Teo, K., Yang, X.Q., Eds.; Springer: New York, NY, USA, 2005; pp. 235–256. [Google Scholar]
- Crisci, S.; Porta, F.; Ruggiero, V.; Zanni, L. Spectral properties of Barzilai-Borwein rules in solving singly linearly constrained optimization problems subject to lower and upper bounds. SIAM J. Optim. 2020, 30, 1300–1326. [Google Scholar] [CrossRef]
- Huang, Y.K.; Dai, Y.H.; Liu, X.W. Equipping the Barzilai-Borwein method with the two dimensional quadratic termination property. SIAM J. Optim. 2021, 31, 3068–3096. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, H. On the rate of convergence of projected Barzilai-Borwein methods. Optim. Methods Softw. 2015, 30, 880–892. [Google Scholar] [CrossRef]
- Dai, Y.H.; Liao, L.Z. R-linear convergence of the Barzilai-Borwein gradient method. IMA J. Numer. Anal. 2002, 22, 1–10. [Google Scholar] [CrossRef]
- Raydan, M. The Barzilai and Borwein gradient method for the large scale unconstrained minimization problem. SIAM J. Optim. 1997, 7, 26–33. [Google Scholar] [CrossRef]
- Grippo, L.; Lampariello, F.; Lucidi, S. A nonmonotone line search technique for Newton’s method. SIAM J. Numer. Anal. 1986, 23, 707–716. [Google Scholar] [CrossRef]
- Dai, Y.H.; Fletcher, R. Projected Barzilai-Borwein methods for large-scale box-constrained quadratic programming. Numer. Math. 2005, 100, 21–47. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, H. Smoothing projected Barzilai-Borwein method for constrained non-Lipschitz optimization. Comput. Optim. Appl. 2016, 65, 671–698. [Google Scholar] [CrossRef]
- Dai, Y.H. Alternate step gradient method. Optimization 2003, 52, 395–415. [Google Scholar] [CrossRef]
- Zhou, B.; Gao, L.; Dai, Y.H. Gradient methods with adaptive step-sizes. Comput. Optim. Appl. 2006, 35, 69–86. [Google Scholar] [CrossRef]
- Frassoldati, G.; Zanni, L.; Zanghirati, G. New adaptive stepsize selections in gradient methods. J. Ind. Manag. Optim. 2008, 4, 299–312. [Google Scholar] [CrossRef]
- De Asmundis, R.; Di Serafino, D.; Hager, W.W.; Toraldo, G.; Zhang, H. An efficient gradient method using the Yuan steplength. Comput. Optim. Appl. 2014, 59, 541–563. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y.X. Analysis of monotone gradient methods. J. Ind. Manag. Optim. 2005, 1, 181–192. [Google Scholar] [CrossRef]
- Broyden, C.G. A class of methods for solving nonlinear simultaneous equations. Math. Comput. 1965, 19, 577–593. [Google Scholar] [CrossRef]
- Davidon, W.C. Variable metric method for minimization. SIAM J. Optim. 1991, 1, 1–17. [Google Scholar] [CrossRef]
- Fletcher, R.; Powell, M.J.D. A rapidly convergent descent method for minimization. Comput. J. 1963, 6, 163–168. [Google Scholar] [CrossRef]
- Broyden, C.G. The convergence of single-rank quasi-Newton methods. Math. Comput. 1970, 24, 365–382. [Google Scholar] [CrossRef]
- Fletcher, R. A new approach to variable metric algorithms. Comput. J. 1970, 13, 317–322. [Google Scholar] [CrossRef]
- Goldfrab, D. A family of variable-metric methods derived by variational means. Math. Comput. 1970, 24, 23–26. [Google Scholar] [CrossRef]
- Shanno, D.F. Conditioning if quasi-Newton methods for function minimization. Math. Comput. 1970, 24, 647–656. [Google Scholar] [CrossRef]
- Dai, Y.H.; Huang, Y.; Liu, X.W. A family of spectral gradient methods for optimization. Comput. Optim. Appl. 2019, 74, 43–65. [Google Scholar] [CrossRef]
- Dai, Y.H.; Al-Baali, M.; Yang, X. A positive Barzilai-Borwein-like stepsize and an extension for symmetric linear systems. In Numerical Analysis and Optimization; Al-Baali, M., Grandientti, L., Purnama, A., Eds.; Springer: Cham, Switzerland, 2015; pp. 59–75. [Google Scholar]
- Dai, Y.H.; Yang, X.Q. A new gradient method with an optimal stepsize property. Comput. Optim. Appl. 2006, 33, 73–88. [Google Scholar] [CrossRef]
- Elman, H.C.; Golub, G.H. Inexact and preconditioned Uzawa algorithm for saddle point problems. SIAM J. Numer. Anal. 1994, 31, 1645–1661. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y.X. Alternate minimization gradient methods. IMA J. Numer. Anal. 2003, 23, 377–393. [Google Scholar] [CrossRef]
- Friedlander, A.; Martínez, J.M.; Molina, B.; Raydan, M. Gradient method with retards and generalizations. SIAM J. Numer. Anal. 1999, 36, 275–289. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).