

Digital Twin-Empowered Robotic Arm Control: An Integrated PPO and Fuzzy PID Approach



 and
and 
Abstract
1. Introduction
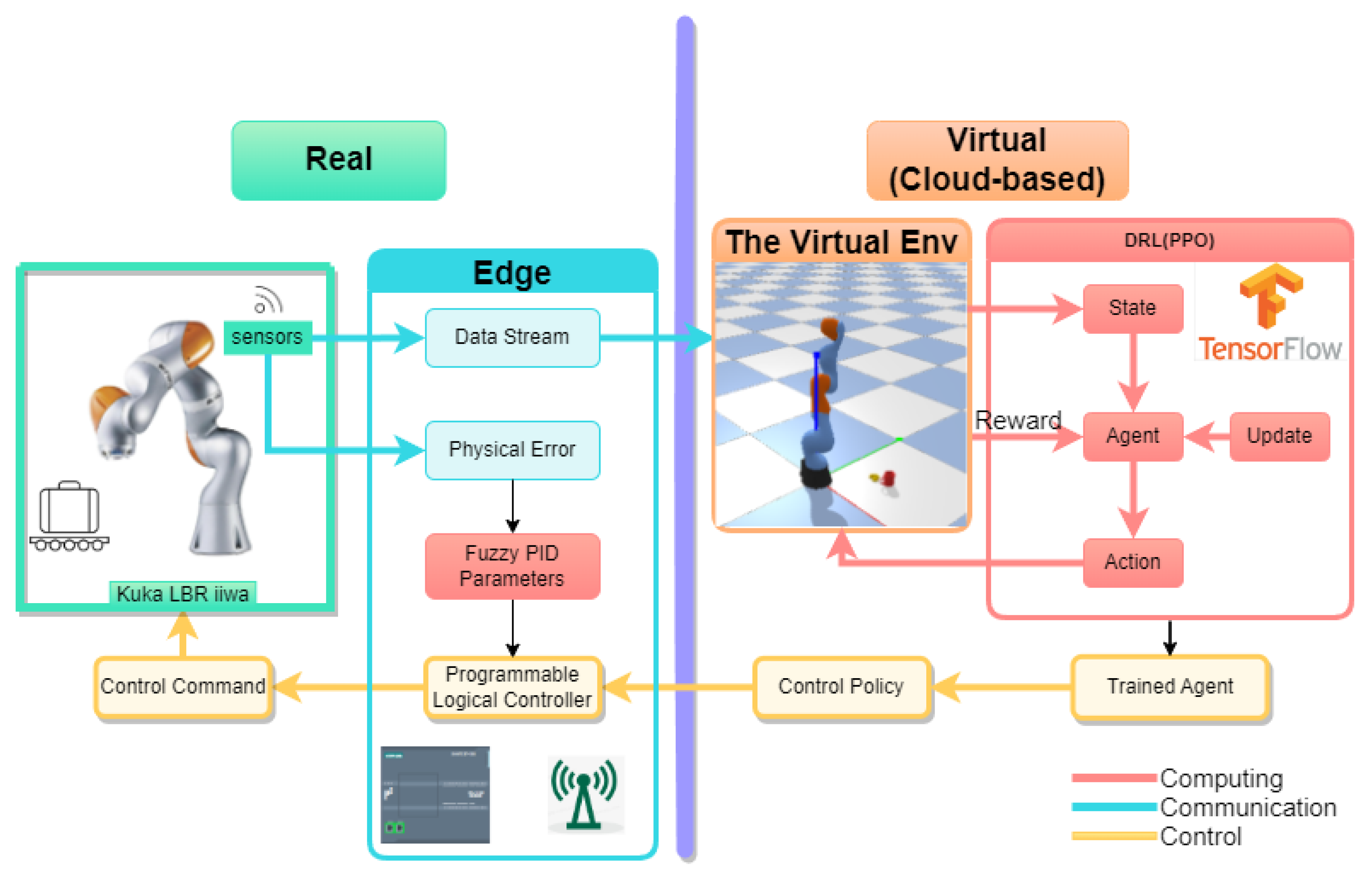
- Based on the IIoT environment, we propose a DT-empowered robotic arm control system. This system systematically elaborates the connections between the physical system and the control, communication, and computing subsystems. We also propose deploying computing tasks in the cloud to achieve decision-making and real-time control of the robotic arm, ensuring both safety and efficiency.
- We performed the kinematic analysis of the 6-degree-of-freedom robotic arm. We propose an integrated approach to achieve low-error control for the robotic arm. Specifically, for collision avoidance and trajectory planning, we developed a PPO-based adaptive control strategy. The PPO algorithm, deployed on the cloud computing center, serves as the primary decision-making mechanism. To further reduce errors following the algorithm’s decisions, we introduced a fuzzy PID controller at the device level. This controller was meticulously designed as an error compensation mechanism, forming a two-stage control framework that enhances the overall system’s precision and reliability.
- In the simulation environment, we conducted experimental simulations to validate the effectiveness of the robotic arm control algorithms employed in the proposed DT system. The advantages of PPO as a decision algorithm are verified by comparing different schemes and baselines. At the same time, the advantages of fuzzy PID controllers are verified by comparing the performance with general PID controllers. The results show the performance and robustness of the integrated approach and also show its performance in mapping and execution error elimination.
2. Literature Review
3. Digital Twin-Empowered Robotic Arm Control System
3.1. System Architecture
3.2. Robotic Arm Control Problem Formalization
3.2.1. Forward Kinematics Analysis of the Robotic Arm
3.2.2. Inverse Kinematics Analysis of Robotic Arm
4. An Integrated PPO and Fuzzy PID Approach
4.1. PPO Algorithm Design
4.1.1. PPO Algorithm Principle
4.1.2. State and Action Spaces Definitions
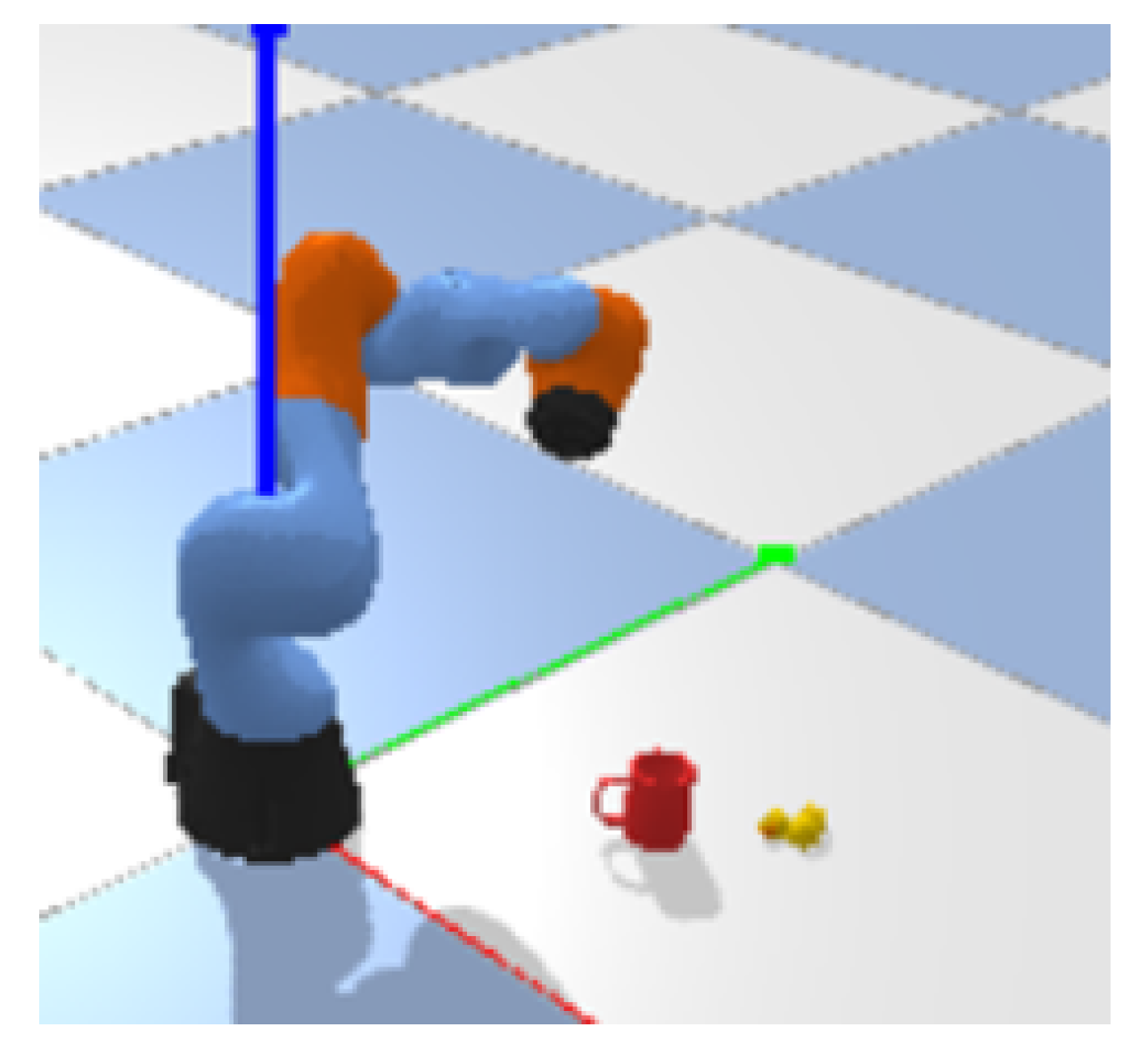
4.1.3. Collision Detection and Reward Function
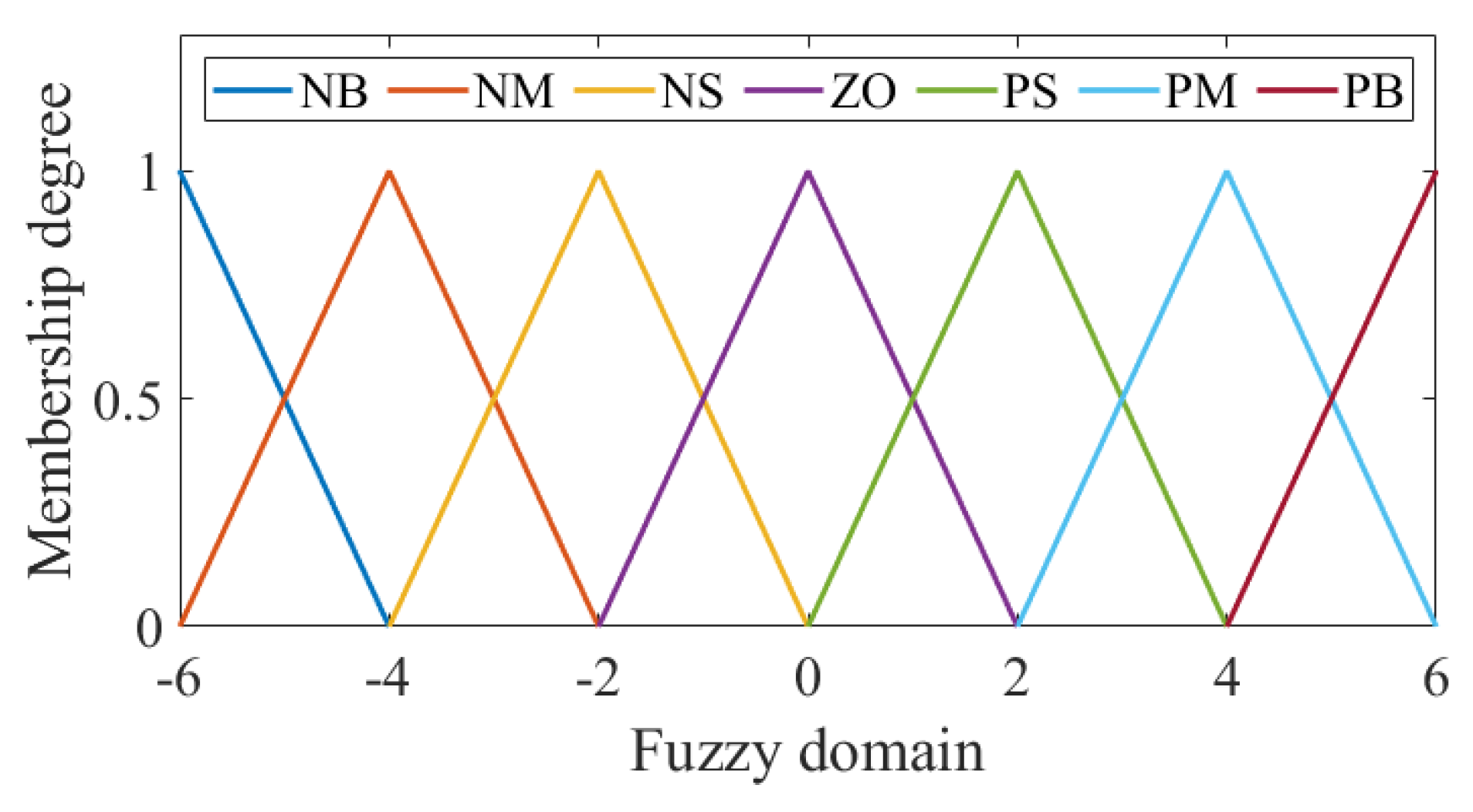
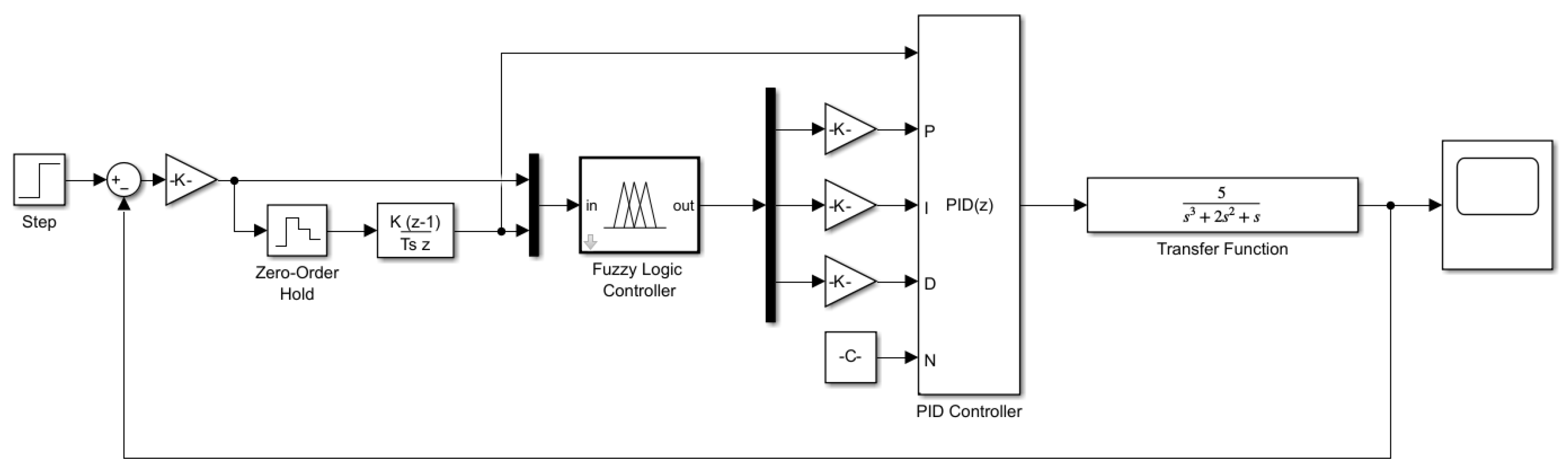
4.2. Fuzzy PID Control Design
4.3. The Integrated Approach Design
| Algorithm 1 An integrated PPO and fuzzy PID approach. |
Require: Epoch , max time steps , discount factor , actor network parameters , critic network parameters , actor learning rate , critic learning rate ; for do for do Get DT system state ; Input to actor and get output , ; Get the Gaussian distribution from and as the policy ; Select action from the policy ; Store in the buffer; if j % m == 0 then Select 10 random samples; Compute and update by (21)–(23); Compute loss function based on the critic output and discounted reward; Update based on the loss function; end if end for end for Ensure: The trained agent parameter ; Send control commands based on the trained agent to the Real; Execute control commands on the robotic arm; Measure the physical error of the robotic arm by the sensor; Require: Error , error variation ; for do Fuzzing e and ; Compute , , based on (32)–(37); Send parameters to the controller; Perform fuzzy PID control at the i joint motor; end for Ensure: The robotic arm reaches the target. |
4.4. Algorithm Complexity Analysis
5. Simulation and Performance Evaluation
5.1. Experiments Setting
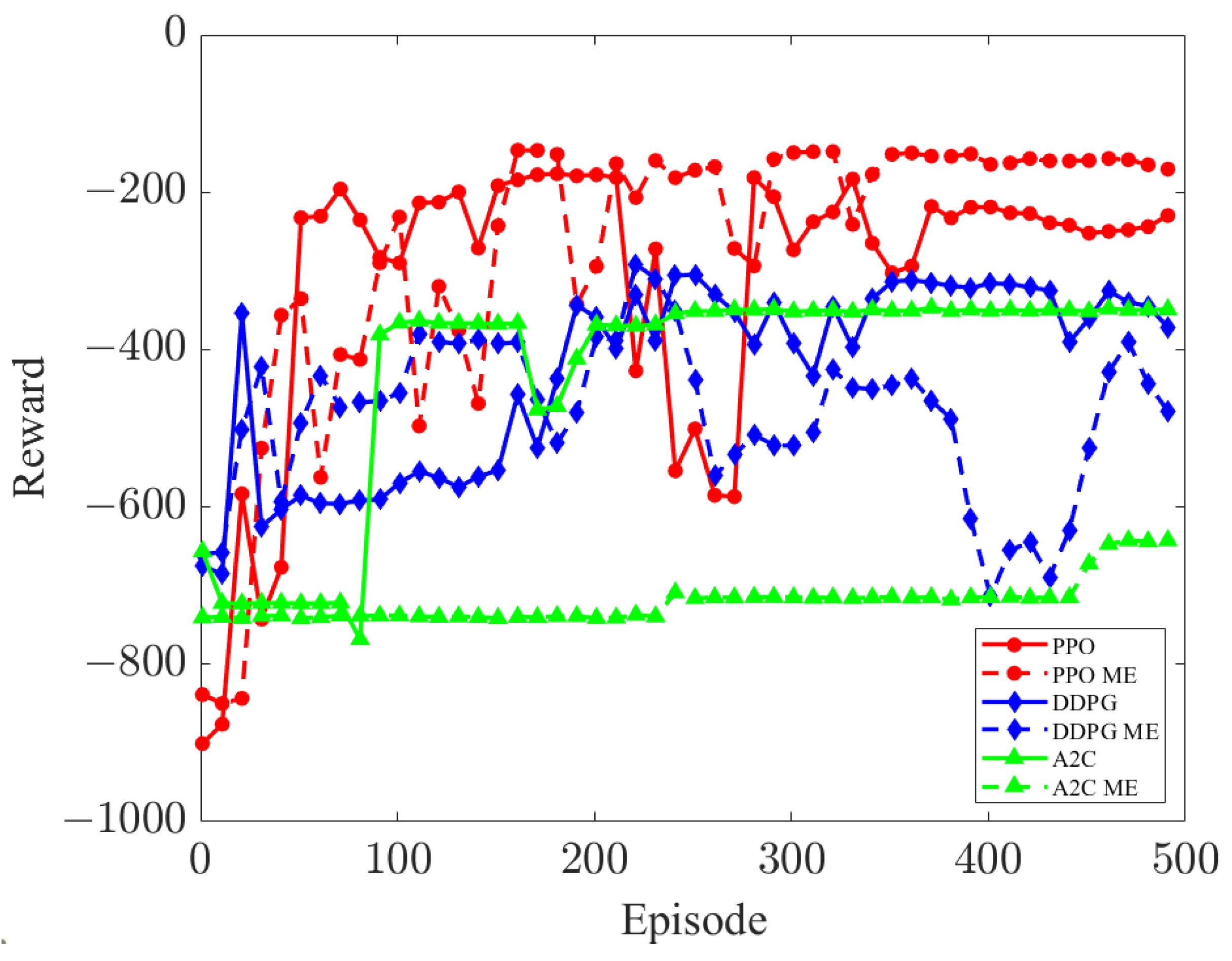
5.2. Performance Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alshamaa, D.; Cherubini, A.; Passama, R.; Pla, S.; Damm, L.; Ramdani, S. RobCap: A Mobile Motion Capture System Mounted on a Robotic Arm. IEEE Sens. J. 2022, 22, 917–925. [Google Scholar] [CrossRef]
- Hirzinger, G.; Bals, J.; Otter, M.; Stelter, J. The DLR-KUKA Success Story: Robotics Research Improves Industrial Robots. IEEE Robot. Autom. Mag. 2005, 12, 16–23. [Google Scholar] [CrossRef]
- Liu, S.; Liu, P. A Review of Motion Planning Algorithms for Robotic Arm Systems. In Proceedings of the 8th International Conference on Robot Intelligence Technology and Applications (RiTA); Springer: Singapore, 2021; pp. 56–66. [Google Scholar]
- Zheng, K.; Luo, R.; Liu, X.; Qiu, J.; Liu, J. Distributed DDPG-Based Resource Allocation for Age of Information Minimization in Mobile Wireless-Powered Internet of Things. IEEE Internet Things J. 2024, 11, 29102–29115. [Google Scholar] [CrossRef]
- Yang, L.-Y.; Chen, S.-Y.; Wang, X.; Zhang, J.; Wang, C.-H. Digital Twins and Parallel Systems: State of the Art, Comparisons, and Prospect. Acta Autom. Sin. 2019, 45, 2001–2031. [Google Scholar]
- Haag, S.; Anderl, R. Digital Twin-Proof of Concept. Manuf. Lett. 2018, 15, 64–66. [Google Scholar] [CrossRef]
- Minerva, R.; Lee, G.M.; Crespi, N. Digital Twin in the IoT Context: A Survey on Technical Features, Scenarios, and Architectural Models. Proc. IEEE 2020, 108, 1785–1824. [Google Scholar] [CrossRef]
- Bratchikov, S.; Abdullin, A.; Demidova, G.L.; Lukichev, D.V. Development of digital twin for robotic arm. In Proceedings of the IEEE 19th International Power Electronics and Motion Control Conference (PEMC), Gliwice, Poland, 25–29 April 2021; pp. 717–723. [Google Scholar]
- Zeb, S.; Mahmood, A.; Hassan, S.A.; Piran, J.; Gidlund, M.; Guizani, M. Industrial digital twins at the nexus of nextG wireless networks and computational intelligence: A survey. J. Netw. Comput. Appl. 2022, 200, 103309. [Google Scholar] [CrossRef]
- Cronrath, C.; Aderiani, A.R.; Lennartson, B. Enhancing digital twins through reinforcement learning. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 293–298. [Google Scholar]
- Xia, K.; Sacco, C.; Kirkpatrick, M.; Saidy, C.; Nguyen, L.; Kircaliali, A.; Harik, R. A digital twin to train deep reinforcement learning agent for smart manufacturing plants: Environment, interfaces and intelligence. J. Manuf. Syst. 2021, 58, 210–230. [Google Scholar] [CrossRef]
- Recht, B. A tour of reinforcement learning: The view from continuous control. Annu. Rev. Control Robot. Auton. Syst. 2019, 2, 253–279. [Google Scholar] [CrossRef]
- Buşoniu, L.; de Bruin, T.; Tolić, D.; Kober, J.; Palunko, I. Reinforcement learning for control: Performance, stability, and deep approximators. Annu. Rev. Control 2018, 46, 8–28. [Google Scholar] [CrossRef]
- Saravanan, M.; Kumar, P.S.; Sharma, A. IoT enabled indoor autonomous mobile robot using CNN and Q-learning. In Proceedings of the 2019 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bali, Indonesia, 1–3 July 2019; pp. 7–13. [Google Scholar]
- Saroj, A.; Trant, T.V.; Guin, A.; Hunter, M.; Sartipi, M. Optimizing Traffic Controllers along the MLK Smart Corridor Using Reinforcement Learning and Digital Twin. In Proceedings of the 2022 IEEE 2nd International Conference on Digital Twins and Parallel Intelligence (DTPI), Boston, MA, USA, 24–28 October 2022; pp. 1–2. [Google Scholar]
- Zhang, X.; Lyu, X.; Wang, T.; Huang, B. Research on decision control system of tunneling robot driven by digital twin. Coal Sci. Technol. 2022, 50, 36–49. [Google Scholar]
- Wu, Z.; Yao, Y.; Liang, J.; Jiang, F.; Chen, S.; Zhang, S.; Yan, X. Digital twin-driven 3D position information mutuality and positioning error compensation for robotic arm. IEEE Sens. J. 2023, 99, 1. [Google Scholar] [CrossRef]
- Jiang, F.; Ding, K.; He, G.; Sun, Y.; Wang, L. Vibration fault features of planetary gear train with cracks under time-varying flexible transfer functions. Mech. Mach. Theory 2021, 158, 104237. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Miao, J.; Zheng, H.; Xie, Z.; Lai, J.; Jiang, L. Offloading Optimization in Digital Twin-Aided UAV Networks. J. Beijing Univ. Posts Commun. 2022, 45, 133–139. [Google Scholar]
- Borase, R.P.; Maghade, D.K.; Sondkar, S.Y.; Pawar, S.N. A review of PID control, tuning methods and applications. Int. J. Dyn. Control 2021, 9, 818–827. [Google Scholar] [CrossRef]
- Shah, P.; Agashe, S. Review of fractional PID controller. Mechatronics 2016, 38, 29–41. [Google Scholar] [CrossRef]
- Kumar, V.; Nakra, B.C.; Mittal, A.P. A review on classical and fuzzy PID controllers. Int. J. Intell. Control Syst. 2011, 16, 170–181. [Google Scholar]
- Ye, W.; Liu, X.; Zhao, X.; Fu, H.; Cai, Y.; Li, H. A Data-Driven Digital Twin Architecture for Failure Prediction of Customized Automatic Transverse Robot. IEEE Access 2024, 12, 59222–59235. [Google Scholar] [CrossRef]
- Yang, H.; Cheng, F.; Li, H.; Zuo, Z. Design and Control of Digital Twin Systems Based on a Unit Level Wheeled Mobile Robot. IEEE Trans. Veh. Technol. 2024, 73, 323–332. [Google Scholar] [CrossRef]
- Park, S.-Y.; Lee, C.; Kim, H.; Ahn, S.-H. Enhancement of Control Performance for Degraded Robot Manipulators Using Digital Twin and Proximal Policy Optimization. IEEE Access 2024, 12, 19569–19583. [Google Scholar] [CrossRef]
- Joshi, S.; Kumra, S.; Sahin, F. Robotic Grasping using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1461–1466. [Google Scholar]
- Cutler, M.; Walsh, T.J.; How, J.P. Real-World Reinforcement Learning via Multifidelity Simulators. IEEE Trans. Robot. 2015, 31, 655–671. [Google Scholar] [CrossRef]
- Li, J.; Shi, H.; Hwang, K.-S. Using Goal-Conditioned Reinforcement Learning with Deep Imitation to Control Robot Arm in Flexible Flat Cable Assembly Task. IEEE Trans. Autom. Sci. Eng. 2024, 21, 6217–6228. [Google Scholar] [CrossRef]
- Bing, Z.; Álvarez, E.; Cheng, L.; Morin, F.O.; Li, R.; Su, X. Robotic Manipulation in Dynamic Scenarios via Bounding-Box-Based Hindsight Goal Generation. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 5037–5050. [Google Scholar] [CrossRef] [PubMed]
- Matulis, M.; Harvey, C. A robot arm digital twin utilising reinforcement learning. Comput. Graph. 2021, 95, 106–114. [Google Scholar] [CrossRef]
- Tian, X.; Pan, B.; Bai, L.; Wang, G.; Mo, D. Fruit Picking Robot Arm Training Solution Based on Reinforcement Learning in Digital Twin. J. ICT Stand. 2023, 11, 261–282. [Google Scholar] [CrossRef]
- Ren, L.; Dong, J.; Huang, D.; Lü, J. Digital Twin Robotic System with Continuous Learning for Grasp Detection in Variable Scenes. IEEE Trans. Ind. Electron. 2024, 71, 7650–7660. [Google Scholar] [CrossRef]
- Huang, Y.; Yasunobu, S. A general practical design method for fuzzy PID control from conventional PID control. In Proceedings of the Ninth IEEE International Conference on Fuzzy Systems. FUZZ-IEEE 2000 (Cat. No. 00CH37063), San Antonio, TX, USA, 7–10 May 2000; Volume 2, pp. 969–972. [Google Scholar]
- Zhang, Y.; Sun, L.; Zhang, Y. Research on Algorithm of Humanoid Robot Arm Control System Based on Fuzzy PID Control. In Proceedings of the 2022 International Conference on Artificial Intelligence and Autonomous Robot Systems (AIARS), Bristol, UK, 29–31 July 2022; pp. 337–341. [Google Scholar]
- El-Khatib, M.F.; Maged, S.A. Low level position control for 4-DOF arm robot using fuzzy logic controller and 2-DOF PID controller. In Proceedings of the 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 26–27 May 2021; pp. 258–262. [Google Scholar]
- Chen, S. Research on the Technology of Zero Moment Control and Collision Detection of Collaborative Robot. Ph.D. Dissertation, University of Science and Technology of China, Hefei, China, 2018. [Google Scholar]
- Zhao, T.-J.; Yuan, J.; Zhao, M.-Y.; Tan, D.-L. Research on the Kinematics and Dynamics of a 7-DOF Arm of Humanoid Robot. In Proceedings of the 2006 IEEE International Conference on Robotics and Biomimetics, Kunming, China, 17–20 December 2006; pp. 1553–1558. [Google Scholar]
- Nugroho, G.; Riyadi, A.F. Design and Repeatability Test of a 6 Degree of Freedom Robotic Arm. In Proceedings of the 2021 International Conference on Advanced Mechatronics, Intelligent Manufacture and Industrial Automation (ICAMIMIA), Surabaya, Indonesia, 8–9 December 2021; pp. 218–222. [Google Scholar]
- Kofinas, N.; Orfanoudakis, E.; Lagoudakis, M.G. Complete analytical forward and inverse kinematics for the NAO humanoid robot. J. Intell. Robot. Syst. 2015, 77, 251–264. [Google Scholar] [CrossRef]
- Singh, T.P.; Suresh, P.; Chandan, S. Forward and inverse kinematic analysis of robotic manipulators. Int. Res. J. Eng. Technol. (IRJET) 2017, 4, 1459–1468. [Google Scholar]
- Mohammed, A.A.; Sunar, M. Kinematics modeling of a 4-DOF robotic arm. In Proceedings of the 2015 International Conference on Control, Automation and Robotics, Singapore, 20–22 May 2015; pp. 87–91. [Google Scholar]
- Denavit, J.; Hartenberg, R.S. A Kinematic Notation for Lower-Pair Mechanisms Based on Matrices. J. Appl. Mech. 1955, 22, 215–221. [Google Scholar] [CrossRef]
- Yang, Y.; Cui, D.; Zhou, A. Fuzzy adaptive PID controller and Simulink simulation. Ship Electron. Eng. 2010, 4, 127–130. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Descriptions |
|---|---|
| The position of each joint | |
| The distance between the target and each joint in the X-axis direction | |
| The distance between the target and each joint in the Y-axis direction | |
| The distance between the target and each joint in the Z-axis direction | |
| The velocity of each joint | |
| The distance between the end and the target | |
| The distance between the end and the obstacle | |
| Boolean algebra, indicating whether the target has been reached | |
| The position of the obstacle | |
| The position of the target | |
| The distances between the obstacle and the end in the X,Y and Z-axis direction |
| e | NB | NM | NS | ZO | PS | PM | PB | |
|---|---|---|---|---|---|---|---|---|
| NB | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | |
| NM | PB PS PS | PB PS PS | PM ZO PM | PM ZO PM | PM ZO PM | PM PS PS | PM PS PS | |
| NS | PM PB PM | PM PB PM | PM ZO PM | PM ZO PM | PM ZO PM | PM PB PM | PM PB PM | |
| ZO | PS PB PB | PS PB PB | ZO PB PB | ZO PB PB | ZO PB PB | PS PB PB | PS PB PB | |
| PS | PM PB PM | PM PB PM | PS PM PB | PS PM PB | PS PM PB | PM PB PM | PM PB PM | |
| PM | PB PS PS | PB PS PS | PM ZO PM | PM ZO PM | PM ZO PM | PB PS PS | PB PS PS | |
| PB | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | PB ZO PS | |
| Schemes | Descriptions |
|---|---|
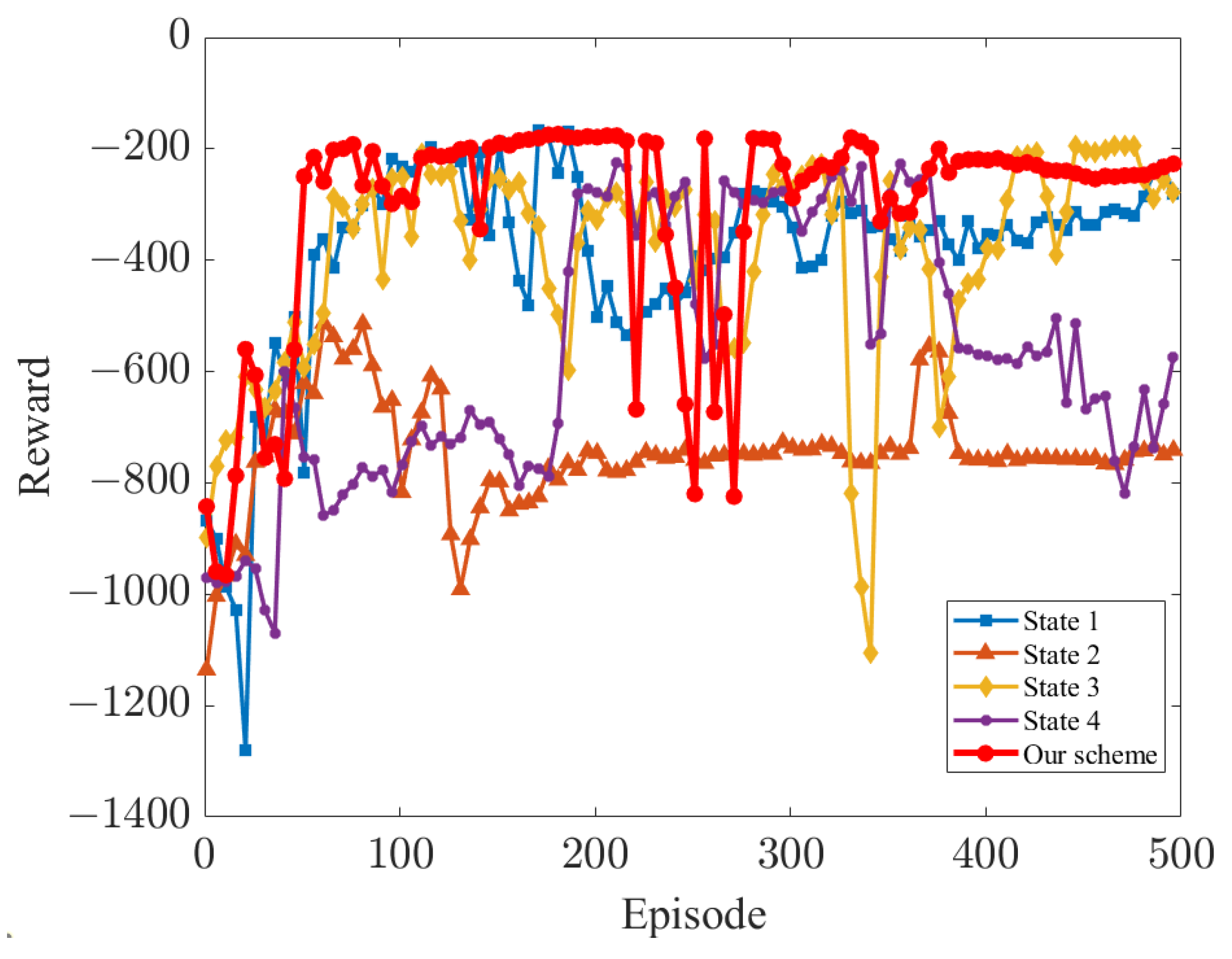
| “state 1” | Without the positions of joints 3–5 |
| “state 2” | Without all distance calculation information |
| “state 3” | Without the distances between joints 3 and 6 and the target |
| “state 4” | Without Z-score normalization |
| Schemes | Enable Moving Joints |
|---|---|
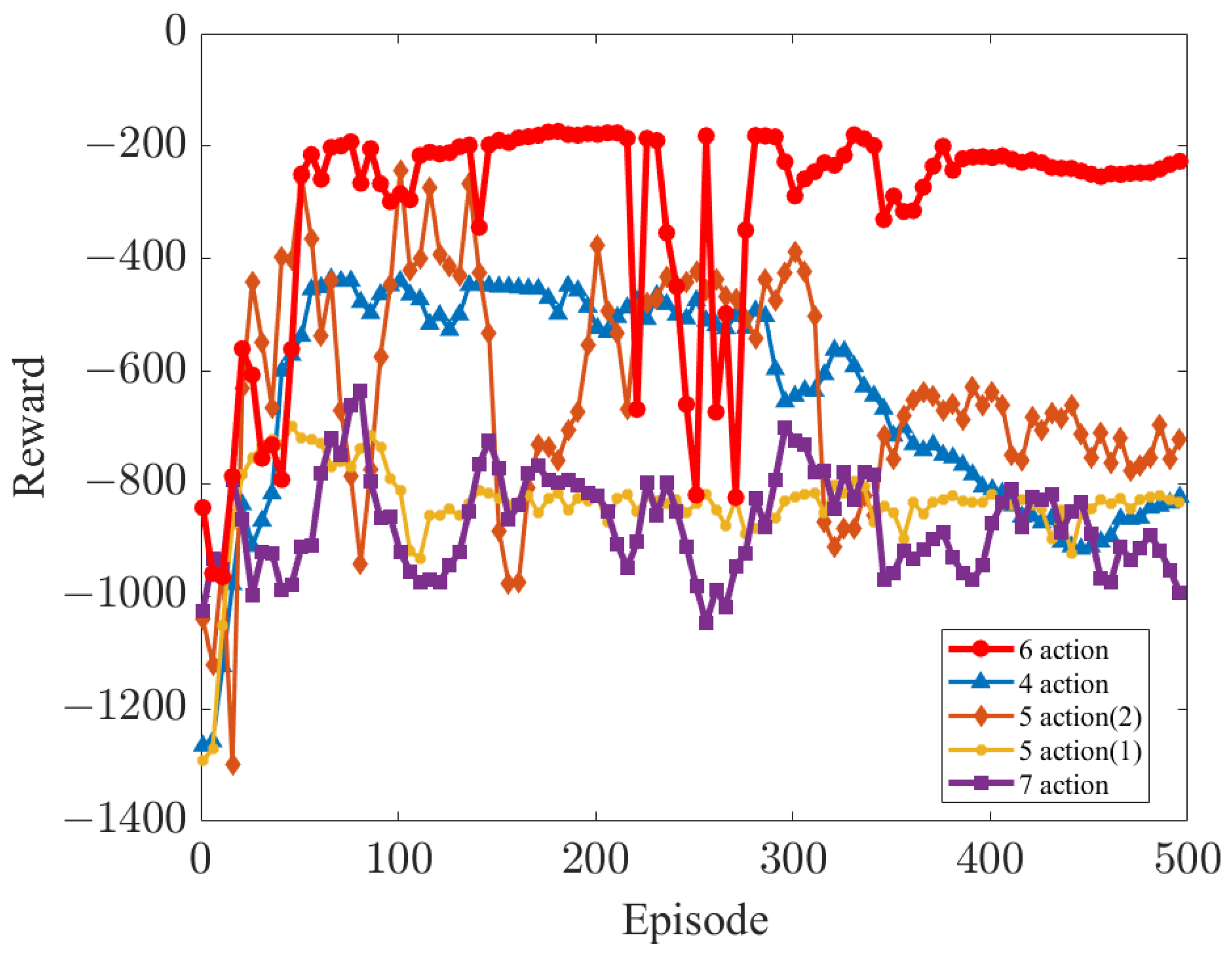
| “6 action” | Joints 1–6 |
| “5 action (1)” | Joints 1–4, Joint 6 |
| “5 action (2)” | Joint 1, Joint 2, Joints 4–6 |
| “4 action” | Joint 1, Joint 2, Joint 4, Joint 6 |
| “7 action” | All joints |
| Parameter | Value |
|---|---|
| Actor network structure | [512, 512, 256] |
| Critic network structure | [512, 512, 256] |
| Actor learning rate | |
| Critic learning rate | |
| PPO clip value | 0.2 |
| Batch size | 32 |
| Time steps t | 1000 |
| Epoch | 500 |
| Target reaching detection a | 0.2 |
| Collision detection b | 0.1 |
| Discount factor | 0.93 |
| Parameter | Value | Descriptions |
|---|---|---|
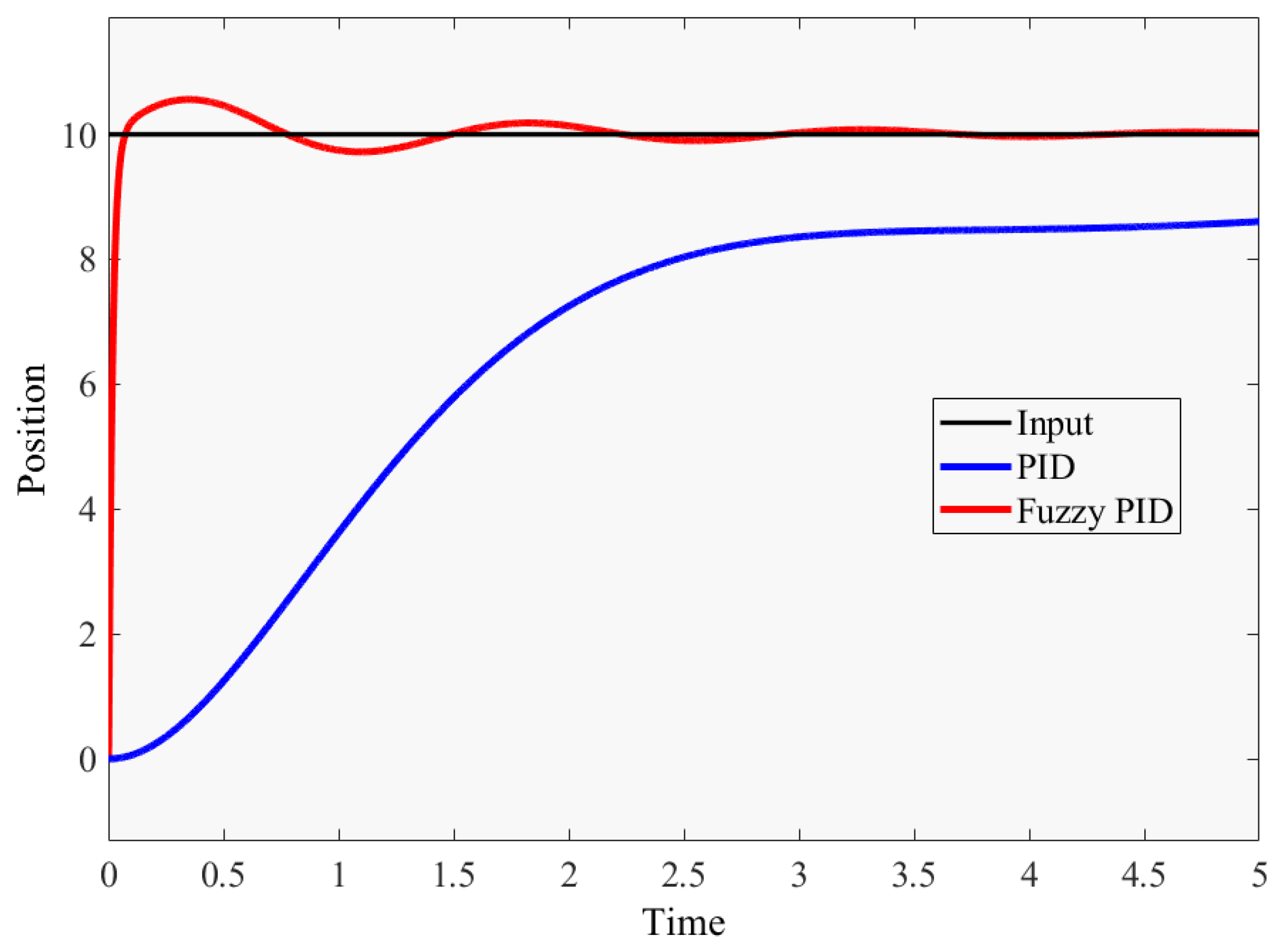
| , , | 3.629, 3.533, 0.893 | Given PID parameters in the second-order system |
| , , | 0.169, 0.003, 2.090 | Given PID parameters in the third-order system |
| 1 | System input in the second-order system | |
| 10 | System input in the third-order system |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cen, Y.; Deng, J.; Chen, Y.; Liu, H.; Zhong, Z.; Fan, B.; Chang, L.; Jiang, L. Digital Twin-Empowered Robotic Arm Control: An Integrated PPO and Fuzzy PID Approach. Mathematics 2025, 13, 216. https://doi.org/10.3390/math13020216
Cen Y, Deng J, Chen Y, Liu H, Zhong Z, Fan B, Chang L, Jiang L. Digital Twin-Empowered Robotic Arm Control: An Integrated PPO and Fuzzy PID Approach. Mathematics. 2025; 13(2):216. https://doi.org/10.3390/math13020216
Chicago/Turabian StyleCen, Yuhao, Jianjue Deng, Ye Chen, Haoxian Liu, Zetao Zhong, Bo Fan, Le Chang, and Li Jiang. 2025. "Digital Twin-Empowered Robotic Arm Control: An Integrated PPO and Fuzzy PID Approach" Mathematics 13, no. 2: 216. https://doi.org/10.3390/math13020216
APA StyleCen, Y., Deng, J., Chen, Y., Liu, H., Zhong, Z., Fan, B., Chang, L., & Jiang, L. (2025). Digital Twin-Empowered Robotic Arm Control: An Integrated PPO and Fuzzy PID Approach. Mathematics, 13(2), 216. https://doi.org/10.3390/math13020216