Abstract
Double-censored data are frequently encountered in pharmacological and epidemiological studies, where the failure time can only be observed within a certain range and is otherwise either left- or right-censored. In this paper, we present a Bayesian approach for analyzing double-censored survival data with crossed survival curves. We introduce a novel pseudo-quantile I-splines prior to model monotone transformations under both random and fixed censoring schemes. Additionally, we incorporate categorical heteroscedasticity using the dependent Dirichlet process (DDP), enabling the estimation of crossed survival curves. Comprehensive simulations further validate the robustness and accuracy of the method, particularly under the fixed censoring scheme, where traditional approaches may NOT be applicable. In the randomized AIDS clinical trial, by incorporating the categorical heteroscedasticity, we obtain a new finding that the effect of baseline log RNA levels is significant. The proposed framework provides a flexible and reliable tool for survival analysis, offering an alternative to parametric and semiparametric models.
MSC:
62F15; 62N02; 62G08
1. Introduction
A large body of statistical research in biomedicine has focused on right-censored data due to its prevalence, while less emphasis has been placed on other less common types of censored data, such as left- or interval-censored data. Left censoring occurs when the event time precedes the recruitment time, whereas (Case 2) interval censoring occurs when the event time of interest is only known to fall within a certain interval. Left and right censoring can be viewed as special cases of interval censoring. A more complicated censoring mechanism may involve more than one type of censoring in the sample or a mixture of uncensored and censored subjects. For instance, “partly interval-censored data” [1,2] arise when some failure times are interval-censored while others are uncensored. This paper studies another special type of survival data called “double-censored data” [3], in which the subjects are uncensored within a specific time interval and the subjects are either left- or right-censored when their actual event times fall outside the time interval. Due to the complex data structure and limited information, contemporary statistical methods for double-censored data are still underdeveloped and often inefficient, posing significant challenges to statistical inference, including accurate estimation and prediction. Double-censored data commonly arise in biomedical, pharmacological, and epidemiological studies [4,5]. A specific example is the randomized AIDS clinical trial [6] which aimed to compare the responses of HIV-infected children to three different treatments. The outcome variable of interest is the plasma HIV-1 RNA level (instead of a conventional “time” variable) as a measure of the viral load. The plasma HIV-1 RNA level, given by the NucliSens assay, is considered double-censored because its measurement can be highly unreliable below 400/mL or above 75,000/mL of plasma. In other words, this variable is observable only within the range of 400/mL to 75,000/mL and is left- or right-censored otherwise. To avoid ambiguity, it is remarked that “double censoring” has also been used in literature to describe another type of censoring mechanism in survival analysis, where both the time origin and event time are potentially interval-censored [7]. We adopt the first definition of “double censoring” above.
The term “double censoring” was first pinpointed by [3]. Following his research work [8] proposed a self-consistent nonparametric maximum likelihood estimator (NPMLE) of the survival function based on double-censored data. Refs. [9,10] later studied the weak convergence and asymptotic properties of the NPMLE, respectively. Refs. [11,12] developed algorithms tailored to the computation of the NPMLE. In the presence of covariates, a natural way to incorporate them into the analysis is to assume the Cox proportional hazards (PH) model [13]. For instance, Ref. [14] studied the nonparametric maximum likelihood estimation for the Cox PH model and the asymptotic properties of the estimator based on double-censored data. Ref. [15] later proposed to obtain the MLE based on the EM algorithm and approximated likelihood, which was shown to be more numerically stable and computationally efficient.
However, the proportional hazards model may be restrictive in practical applications. Therefore, it is worth considering the semiparametric transformation model [16,17,18,19] as an alternative because of its higher flexibility to cover Cox’s PH and PO models. With double-censored data, Ref. [20] (further in text Li2018) studied the nonparametric maximum likelihood estimation (NPMLE) of the semiparametric transformation model that allowed for possibly time-dependent covariates, and they proposed to use an EM algorithm to obtain the NPMLE. This route of semiparametric transformation models requires full model identifiability by assuming the model error distribution to be known or parametric, similar to the main stream of transformation model literature [19,21,22,23,24]. Despite its convenience, this strategy may encounter model misspecification (refer to the numerical studies in [25] for examples).
Compared with semiparametric transformation models, the nonparametric transformation models [26,27,28,29,30] are robust since they allow both the transformation and model error distribution to be unspecified and nonparametric. Nonetheless, to address the identifiability issue, most of the existing literature imposed complicated identification constraints on the two nonparametric components, leading to infeasible computation. To balance the model robustness and computational feasibility, ref. [25] studied the reliable Bayesian predictive inference under nonparametric transformation models with both transformation and model error unidentified. Nonetheless, they only focus on right-censored data. To the best of our knowledge, there have not yet been studies on nonparametric transformation models with double-censored data.
Furthermore, most of the existing literature studied the random censoring scheme only, and excluded the fixed censoring scheme. The fixed censoring scheme, where the observations are censored with two fixed points, usually does not provide much useful information because the dataset can have many duplicate values. This scheme is a common practice in clinical trials, for example, the randomized AIDS clinical trial studied in this paper.
Besides the lack of research on the fixed censoring scheme, most of the existing literature on transformation models [20,25,26,28,31,32] assumes that the model error is independent of covariates, indicating that they can NOT model crossed survival curves. Ref. [33] introduces a semiparametric random-effects linear transformation model to estimate the crossed survival curves, while they still need to assume the density of model error to be known.
Based on the above literature review, we are driven to extend the Bayesian method by [25] to the double censoring scheme, especially the fixed censoring scheme, and introduce a special model for categorical heteroscedasticity in the sense that the model error distributions depend on the categorical covariates. Our method addresses two key challenges: (i) modeling the monotone transformation under the double censoring scheme, especially with fixed censored data; (ii) incorporating the categorical heteroscedasticity nonparametrically so as to estimate crossed survival curves.
To address the first challenge, we inherit and modify the quantile-knot I-splines [25,34] prior. For the random censoring scheme, we straightforwardly interpolate the interior knots of I-splines from the quantiles of left- and right-censoring endpoints. However, this interpolation strategy is not applicable to the fixed censoring scheme since the quantiles of censored endpoints do NOT exist anymore. We propose a novel pseudo-quantile I-splines prior for the transformation under fixed censoring by synthesizing the exact survival times and interpolating the knots of I-splines at the average of the pseudo quantiles of the synthesized data. Numerical studies demonstrate that the proposed pseudo-quantile modeling effectively captures the true distribution of the variable of interest and extracts potentially hidden information that is lost due to fixed censoring. To address the second challenge, we borrow the strength from the Dependent Dirichlet process (DDP) proposed by [35]. Specifically, we employ the ANOVA DPP [36] to model the dependency of the model error and the categorical covariates. Introducing the categorical heteroscedasticity through DDP does not change the quantile-knot i-spline modeling, making the computation by Markov Chain Monte Carlo (MCMC) still feasible and reliable. We have summarized all the symbols used in this paper in Table 1.

Table 1.
List of symbols.
The major contributions of this paper are summarized as follows.
- Contribute a novel method for survival prediction under nonparametric transformation models with double-censored data, especially for the fixed censoring scheme.
- Incorporate categorical heteroscedasticity in nonparametric transformation models so as to model crossed survival curves.
- With categorical heteroscedasticity, evidence the significance of the effect of baseline log (RNA) levels in the randomized AIDs clinical trial.
The remainder of this paper is organized as follows. We introduce our data structure and model in Section 2. Our proposed innovative priors will be explained in detail in Section 3. A special case where the model error distributions depend on the categorical covariates is discussed in Section 4. Posterior inference and estimation will be explored in Section 5. Simulation results will be presented in Section 6. We also apply our method to real data in Section 7. A discussion will be given in Section 8.
2. Data, Model, and Assumptions
2.1. Data Structure
Here, we describe the typical data structure of doubly censored data in survival analysis. Consider a study that involves n independent subjects. For subject i, let denote the time-to-event and be the p-dimensional vector of time-invariant covariates. The time-to-event can only be observed between and , and if not observed, it is either left-censored at or right-censored at . Define , , , where is the indicator function. Then, it follows . The observed data are of the form , where is the observed time-to-event for subject i. Here, we assume that if and if , since such information is generally not available, for better data organization. Furthermore, and are assumed to be conditionally independent given (noninformative censoring) as common practice.
2.2. Nonparametric Transformation Models
We consider a class of linear transformation models, which relate the time-to-event to the relative risk in a multiplicative way as follows:
where is a strictly increasing transformation function that is positive on , is the p-dimensional vector of regression coefficients coupling Z, and is the model error with distribution function . The above transformation model is considered a nonparametric transformation model when the functional forms of both and are unknown. As mentioned earlier, model nonidentifiability would mean that different sets of () can generate an identical likelihood function. For the rest of this paper, Model (1) will be treated as a nonparametric transformation model, henceforth NTM.
The NTM is obtained by applying an exponential transformation to a class of linear transformation models with additive relative risk.
where and . This transformation is necessary since the transformation function in Model (2) is sign-varying on , which leads to insoluble problems regarding prior elicitation and posterior sampling. After the transformation, is strictly positive on , thus allowing the NTM to avoid the above problems.
3. Likelihood and Priors
3.1. Likelihood Function
Given observed data , we can construct the likelihood function as
where is the density function of and is the survival function of .
3.2. Dirichlet Process Mixture Model
To characterize model error in the NTM, we choose the common Dirichlet process mixture (DPM) models [37] as the priors for and . In this paper, we adopt the truncated stick-breaking construction [38] of the DPM.
where and are the density and distribution functions of a Weibull distribution, respectively. The Weibull distribution is selected as the DPM kernel for two reasons: (i) it is flexible to various hazard shapes [39]; (ii) the Weibull kernel guarantees the properness of the posterior under the unidentified transformation models (refer to [25] for details).
In explicit form, the stick-breaking weights and the parameters are generated as follows
Throughout this paper, we specify in the DPM prior, which is a commonly used default choice [40]. The choice of L is relatively flexible. Since the theoretical total-variation error between the truncated DP and the true DP is bounded by [41], we suggest the readers adopt a suitable truncation level based on the data size.
3.3. Pseudo-Quantile I-Splines Prior
Regarding the transformation function of the NTM and its derivative, we rely on a type of I-spline priors to capture the relevant information. To construct such priors, we first take to be the largest observed time-to-event in the sample, then is the interval that contains all observed time-to-events. Note that is differentiable on D, thus we can model and by
where are positive coefficients, are I-spline basis functions [34] on D, and are the corresponding derivatives.
The number of I-spline basis functions , where N is the total number of interior knots and r is the order of smoothness, with th order derivative existing. We adopt the default value of in R package splines2.
Then, it becomes our primary task to specify the exact number of interior knots and pinpoint their locations. One logical way to approach this task is to base the selection of interior knots on empirical quantiles of the collected data. In doing so, we can effectively utilize useful knowledge inherent to the distribution of the observed time-to-events.
Let be the empirical distribution function of some variable X and be the corresponding empirical quantile function, where X can be equivalently replaced by T, , or other random variables. Note that since the exact (actual) time-to-events T cannot always be observed, and can only be constructed based on the subset of the observed data with (i.e., where the exact time-to-events are observed). We first consider knot selection via empirical functions under the random censoring setting, which is very often the assumed setting in related literature.
3.3.1. Random Censoring Knot Selection
Define and . Let be the initial number of knots. The interior knot selection procedure can be described as follows.
- Step 1: Choose empirical quantiles of exact time-to-events as interior knots, where each knot and , such that .
- Step 2: For , if , interpolate a new knot .
- Step 3: For , if , then interpolate another new knot .
- Step 4: Sort all the chosen and interpolated knots in ascending order resulting in the final selected interior knots.
It is worth noting that only exact time-to-events can provide information about , therefore the initial interval knots are chosen by equally spaced empirical quantiles of T, i.e., for . To mitigate the lack of information when the percentage of left or right-censored observations is high, extra interior knots are generated as needed.
The problem of interior knot selection becomes much more complex and difficult under fixed censoring. In such circumstances, the empirical distributions of observed time-to-events would heavily gravitate toward the fixed censoring points, making interpolation of additional interior knots infeasible. Therefore, in cases of high censoring, attempts have to be made to extract some information from the unobserved time-to-events. Thus, we propose a novel method for effective interior knot selection that synthesizes pseudo data to mimic the distribution of unobserved time-to-events. This innovative method then leads to a new type of prior for the transformation function, which we name the “pseudo-quantile I-splines prior” (PQI prior).
3.3.2. Fixed Censoring Knot Selection
Fixed censoring occurs when for and for , where and are the numbers of left-censored and right-censored observations, respectively, and L and R are some finite constants. Define . The specification procedure can be described as follows.
For (Steps 1–3),
- Step 1 (pseudo-left-censored data generation):Generate pseudo observations from some distribution (e.g., Weibull, gamma) such that all .
- Step 2 (pseudo-right-censored data generation):Generate pseudo observations from the same distribution such that all .
- Step 3 (pseudo-quantile computation):Let . Compute and .
- Step 4 (quantile averaging):Compute . Choose N averaged empirical quantiles of the combined time-to-events as interior knots, where each knot and . Output this series as the finally selected interior knots.
In Step 4, one can show that with sufficiently large N, the inserted pseudo quantiles become stable, and thus, the induced I-spline basis is also stable. These pseudo-quantile knots are also combined with the exact time-to-events that are observed for completeness. The averaged empirical quantiles should closely imitate the true quantiles of the exact time-to-events (observed and unobserved), and thus, the selected interior knots should provide reliable and sufficient information. Any pre-existing knowledge about the potential distribution of the exact time-to-events could help facilitate the selection process and refine the results.
4. Transformation Models with Crossed Survival Curves
In this section, we extend the model (1) to a special case where the model error distributions depend on the categorical covariates. Assume one or q-dimensional categorical covariates X with a total of G categories. For example, if there is only one covariate, K equals the number of categories of that covariate; if there are multiple variables, one-hot encoding can be used, and G equals the product of the categories of each covariate. The model error distributions depend on the categorical covariates, indicating that the survival curves of different categories will be crossed. And we introduce the following models
where is the model error under group k with distribution function . That is, we assume that within different categories, the distribution of the model error exhibits heterogeneity. Similarly, we denote that and . And (7) can be written as . Given observed data , we can construct the likelihood function as
where are the density function, the cumulative distribution function, and the survival function of , respectively. Compared with the likelihood function (3), (8) includes the product of the likelihood functions for each category.
ANOVA Dependent Dirichlet Process Prior
The DPM prior will no longer be applicable where the model error distributions depend on the categorical covariates. Ref. [35] defined the dependent Dirichlet process (DDP) to allow a regression on a covariate X. Since the K categories, We here specify appropriate nonparametric ANOVA DDP priors [36] for , and . Since they can be easily derived from one to the other, we here only introduce the priors for Following [42], we write the stick-breaking form of for . And We impose additional structure on the locations :
where denotes the ANOVA effect shared by all the observations, and the terms of are the ANOVA effects of different categories. For example, the locations are if . For each category, they have a similar term shared by all the observations, and different and depict the heterogeneity under different categories.
5. Posterior Inference
5.1. Posterior Prediction and Nonparametric Estimation
Given the prior settings, the nonparametric parts of (1), specifically, the functionals H and can be represented by elements in , where , , , and . Let be the collection of all unknown parameters. The estimators of can then be obtained through the posterior distribution of .
First, we set the priors for parameters in as (recall (5))
where is a prior density and is the base measure for the DPM prior. The posterior density of can then be represented as
In the above prior setting, the hyperparameter can be dependent on other hyperparameters or fixed to some constant based on existing knowledge. It is, however, recommended that the mass parameter of the Beta distribution be fixed as and the base measure also be fixed as above.
It should be noted that the prior choice for is the improper uniform prior. Such a choice simplifies the posterior form and accelerates MCMC sampling. Under mild conditions, the posterior in (10) is still guaranteed to be proper. The NUTS (No-U-Turn Sampler) from Stan [43] is implemented to achieve posterior sampling. After sufficient sampling procedures, the posterior predictive survival probability of any future time-to-event can be obtained given some vector of covariates .
For such a prediction of a future time-to-event, denote the corresponding conditional posterior predictive survival probability as . Mathematically, can be calculated through
where is the conditional posterior predictive survival probability given , and can uniquely determine if the posterior distribution is proper.
Note that the integral in (11) can be approximated by averaging over the drawn posterior samples. Denote the drawn samples of , H, and by , , and , , respectively. Then, the estimations of the conditional survival probability and conditional cumulative hazard can be given as
5.2. Posterior Projection and Parametric Estimation
Recall that the joint posterior in (10) can be obtained from the prior settings in (5) and (9), thus making the set of parameters jointly estimable. However, it is still important to marginally estimate each parameter, especially the parametric component and the relative risk . As the marginal posterior of lacks interpretability, it is more meaningful to obtain the marginal posterior of an identified equivalence of . Through the process of normalization, we denote by the identified unit vector with , and we now focus on obtaining a Bayes estimator of .
Note that the parameter space of is the same as the Stiefel manifold in , thus we utilize a posterior projection technique to estimate . Hypothetically, consider some set , the metric projection operator of such set is
Thus, the metric projection of the vector into is uniquely determined by [44], and the estimation of is given by the mean or median of the projected posterior.
5.3. Assumptions
We will now state some general assumptions for doubly censored data and the NTM.
(A1) The transformation function is differentiable.
(A2) The model error is continuous.
(A3) The continuous covariate Z is conditionally independent of model error given categorical covariate X.
(A4) The censoring variables L and R are independent of survival time T given the covariates Z and X.
(A1) is required due to the presence of the first-order derivative of , namely , in the likelihood function. (A2) is mild. (A3) is general for transformation models [26,28]. Following [25], we have under (A3). (A4) is the commonly used noninformative censoring scheme.
6. Simulations
In this section, we present the results of our simulation studies. These studies were conducted to assess the performance of our proposed methods under both random and fixed censoring schemes. We compare the proposed method with competitors (1) the R package spBayesSurv [23], a Bayesian approach that can be applied to double-censored data, and (2) the algorithm developed by [20], a frequentist method specifically works on double-censored data.
Survival times are generated according to Model (1). In each case within both censoring schemes, we generate 100 Monte Carlo replicas, each with a number of subjects . The vector of regression coefficients is set as such that . For covariates , set , , and .
Under the random censoring scheme, the performance of our method is assessed under one of the four different cases: the PH model, the PO model, the accelerated failure time (AFT) model, and none of these three models. Let be the density of . The four cases are:
- Case R-1: Non-PH/PO/AFT:
- Case R-2: PH model:
- Case R-3: PO model:
- Case R-4: AFT model:
Similarly, under the fixed censoring scheme, the performance of our method is assessed under four different cases that shared the same distribution and with Case R-1 to Case R-4, but with different and . The differences between the two censoring schemes are marked by the simulated left and right censoring times.
- Case F-1: Non-PH/PO/AFT:
- Case F-2: PH model:
- Case F-3: PO model:
- Case F-4: AFT model:
The comparison results to spBayesSurv and Li2018 under the different censoring schemes and cases are shown in Table 2, Table 3 and Table 4. To assess the estimation of , we focus on six metrics, namely, the mean, the bias, the average of posterior standard deviation (PSD), the square root of the mean squared error (RMSE), the standard error of estimators (SDE), and the coverage probability of the credible interval (CP). Table 2 and Table 3 both demonstrate that our method is comparable to the competitors in bias, and the CP is close to the nominal level. Furthermore, to evaluate the predictive capability, we report the root of the integrated mean squared error (RIMSE) between the estimated distribution and the true predictive distributions on three given covariates: . The RIMSE is an approximation of the distance between the two distributions on the observed time interval. The smaller the RIMSE, the better the prediction. Table 4 reveals that our method outperforms in predictions in Cases R-1 and F-1, with the other competitors encountering model misspecification.
Table 2.
Simulation results of parametric estimation under random censoring scenarios.
Table 3.
Simulation results of parametric estimation under fixed censoring scenarios.
Table 4.
The RIMSE between the true conditional survival functions and the predictive survival functions given by different methods under different cases in simulations.
Under the random censoring scheme, the r values in the Li2018 method are 3.5, 0, 1, 0 for Cases R-1 to R-4. It is shown that our method generally outperforms in case R-1 with the lowest RIMSE. This can be expected since spBayesSurv is specifically designed to handle estimation under Cases R-2 through R-4, yet our results in these cases are still comparable to spBayesSurv, indicating that the proposed method can be applied in a broader spectrum of situations while maintaining sufficient power. Under the fixed censoring scheme, the r values for the Li2018 method are 1.5, 0, 1.5, 5 for Cases F-1 to F-4. The simulation results of spBayesSurv and Li2018 under the fixed censoring scheme are not supposed to carry too much weight, as these methods did not take such a censoring scheme into consideration, but our results are quite promising regardless, which lends credence to the claim that our method can be applied to analyze fixed double-censored time-to-events. It is also worth noting that the proposed method is more flexible than the semiparametric approach of [20] that pre-specifies the form of the hazard function, making their results sensitive to the selection of the r value.
Table 5 reports the situation where there is heterogeneity in the categorical covariates. The results show that the proposed method achieves good estimation accuracy under both random and fixed censoring mechanisms. And the CP is close to the nominal level. Figure 1 depicts the predicted survival curves. It demonstrates that the proposed method accurately captures intersecting survival curves under both random and fixed censoring mechanisms.
Table 5.
Simulation results of crossed survival curves.
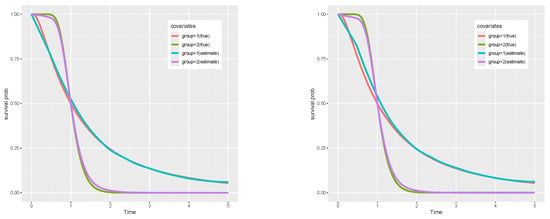
Figure 1.
Predicted survival functions for the transformation models with crossed survival curves under random censoring (left) and fixed censoring (right).
7. Real Data Analysis
In this section, we apply our proposed method to the randomized AIDs clinical trial conducted in 1997 (recall from the introduction section). As stated previously, one major objective of this study was to examine treatment effects across different treatment groups through the plasma HIV-1 RNA level as the outcome variable, which is subject to double censoring. In the analysis, we create a variable which takes up the value 0 if a subject receives either Zidovudine(ZDV)+lamivudine(3TC) or stavudine(d4T)+ritonavir(RTV), and if a subject receives ZDV plus 3TC plus RTV. A remark should be made that this dataset was actually conducted under a fixed censoring scenario due to limitations of measuring techniques, resulting in the fact that all baseline log(RNA) levels could only be exactly observed between /mL and /mL of plasma.
Below we present the analysis results of the proposed method along with the results from spBayesSurv and Li2018 methods, mainly for demonstration purposes. A visual aid is also provided for better distinction of treatment effects between the two treatment groups.
Based on the analysis of the AIDS clinical trial data, as shown in Table 6, the results consistently show that the triple therapy treatment group (ZDV + 3TC + RTV, trt = 1) had a significantly better outcome compared to the dual therapy groups (trt = 0), indicating lower HIV-1 RNA levels or higher survival probability. This finding is supported by all the methods tested (Proposed, spBayes PH/PO, Li2018 PH/PO), as their 95% credible/confidence intervals for the treatment effect (trt) were entirely positive and excluded zero. For example, the proposed method estimated a treatment effect of 1.057 (95% credible interval: 0.504 to 1.770).
Table 6.
Results of AIDS study analysis.
In contrast, without considering the heterogeneity of the categorical covariate, the effect of baseline RNA level (baseRNA) was not statistically significant in any analysis, indicating no strong evidence that the starting RNA level influenced the outcome. However, when we took into account the heterogeneity of the categorical variables, we found that the RNA level significantly influenced the outcome. Furthermore, the length of the credible interval provided by our two methods is much shorter than the others, indicating that the effect estimated by our method is more precise. Figure 2 visually confirms the main treatment effect that the lower survival probabilities for the dual therapy group compared to the triple therapy group over time.
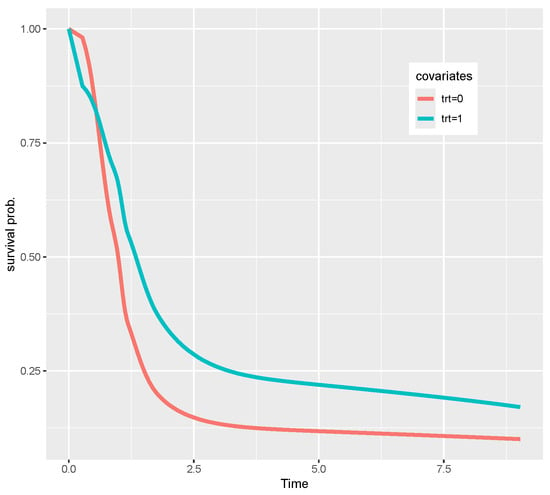
Figure 2.
Predicted survival functions for the two treatment groups under Model (7).
8. Discussion
In this paper, we have proposed an innovative approach to analyze double-censored data and demonstrated its superior accuracy and flexibility over alternative methods. Namely, we bring up a new type of weakly informative prior, the pseudo-quantile I-splines priors, that allows for nonparametric estimation and prediction of double-censored time-to-event data under both random and fixed censoring schemes. We illustrate the effectiveness of this innovative prior by performing simulation results under several scenarios and comparing the proposed methods with two leading alternative methods. Our methodology can be treated as a robust survival analysis approach, as an alternative to the widely used Cox PH model.
For fixed censoring specifically, in addition to outperforming these methods considerably in some cases and displaying comparable results otherwise, our results are quite close to the assigned true values. This lends credibility to the statement that our method is not just the first to target estimation and prediction of double-censored time-to-events under fixed censoring, but also a valid method that deserves practical considerations. Subsequently, more attention should be paid to fixed censoring as a whole, since professionals who encounter such data can now be enabled with our proposed method or any future modification of it. We understand the complexity of fixed censoring and the intricacy around when only minimal information can be drawn from a substantial portion of observations. Despite these challenges, we believe that our approach of pseudo-data substitution has its merit, as the generated data may eventually mimic the true distribution of observations with minimally available information.
Our method enjoys robustness in predictions but sacrifices interpretability compared with semiparametric or parametric approaches. Here, we quote [33] (p. 559), “we should not confine ourselves to a hazard interpretation, especially when the hazards are not proportional and alternative formulations lead to more parsimonious models”. In this sense, our method supplies an alternative to those interpretable models in predictive inference. In our application example, on the one hand, when using the same homogeneous model, the significance of the treatment effect given by our method is consistent with other methods. On the other hand, when we incorporate the categorical heteroscedasticity, we reveal that the baseRNA is also significant. This finding demonstrates the utility of our method in the interpretation of the effect.
Our method employs MCMC under unidentified models, which demand heavier computational burden compared with those computed under identified models. It will be interesting to explore the approximate Bayesian computation (ABC) under the nonparametric transformation models. We leave this as our future work. Another interesting future work will be to relax the noninformative censoring assumption on the censoring scheme.
Author Contributions
Conceptualization, P.X. and C.Z.; methodology, P.X., Z.M., S.C., and C.Z.; software, P.X. and Z.M.; validation, P.X., R.N., and Z.M.; writing—original draft preparation, S.C.; writing—review and editing, P.X., Z.M., R.N., and C.Z.; supervision, C.Z.; funding acquisition, R.N. All authors have read and agreed to the published version of the manuscript.
Funding
Z.M. is partially supported by Guangdong Basic and Applied Basic Research Foundation (2021A1515110220).
Data Availability Statement
The original data presented in the study are openly available in https://archive.ics.uci.edu/, accessed on 26 May 2025.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Huang, J. Asymptotic properties of nonparametric estimation based on partly interval-censored data. Stat. Sin. 1999, 9, 501–519. [Google Scholar]
- Gao, F.; Zeng, D.; Lin, D.Y. Semiparametric estimation of the accelerated failure time model with partly interval-censored data. Biometrics 2017, 73, 1161–1168. [Google Scholar] [CrossRef] [PubMed]
- Gehan, E.A. A Generalized Two-Sample Wilcoxon Test for Doubly Censored Data. Biometrika 1965, 52, 650–653. [Google Scholar] [CrossRef] [PubMed]
- Ren, J.J.; Peer, P.G. A study on effectiveness of screening mammograms. Int. J. Epidemiol. 2000, 29, 803–806. [Google Scholar] [CrossRef] [PubMed]
- Jones, G.; Rocke, D.M. Multivariate survival analysis with doubly-censored data: Application to the assessment of Accutane treatment for fibrodysplasia ossificans progressiva. Stat. Med. 2002, 21, 2547–2562. [Google Scholar] [CrossRef]
- Cai, T.; Cheng, S. Semiparametric Regression Analysis for Doubly Censored Data. Biometrika 2004, 91, 277–290. [Google Scholar] [CrossRef]
- Sun, J. The Statistical Analysis of Interval-Censored Failure Time Data; Springer: New York, NY, USA, 2006. [Google Scholar]
- Turnbull, B.W. Nonparametric Estimation of a Survivorship Function with Doubly Censored Data. J. Am. Stat. Assoc. 1974, 69, 169–173. [Google Scholar] [CrossRef]
- Chang, M.N. Weak Convergence of a Self-Consistent Estimator of the Survival Function with Doubly Censored Data. Ann. Stat. 1990, 18, 391–404. [Google Scholar] [CrossRef]
- Gu, M.G.; Zhang, C.H. Asymptotic Properties of Self-Consistent Estimators Based on Doubly Censored Data. Ann. Stat. 1993, 21, 611–624. [Google Scholar] [CrossRef]
- Mykland, P.A.; Ren, J. Algorithms for Computing Self-Consistent and Maximum Likelihood Estimators with Doubly Censored Data. Ann. Stat. 1996, 24, 1740–1764. [Google Scholar] [CrossRef]
- Zhang, Y.; Jamshidian, M. On algorithms for the nonparametric maximum likelihood estimator of the failure function with censored data. J. Comput. Graph. Stat. 2004, 13, 123–140. [Google Scholar] [CrossRef]
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B 1972, 34, 187–202. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, B.; Jang, W. Asymptotic properties of the maximum likelihood estimator for the proportional hazards model with doubly censored data. J. Multivar. Anal. 2010, 101, 1339–1351. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Jang, W. An EM algorithm for the proportional hazards model with doubly censored data. Comput. Stat. Data Anal. 2013, 57, 41–51. [Google Scholar] [CrossRef]
- Cheng, S.; Wei, L.; Ying, Z. Analysis of transformation models with censored data. Biometrika 1995, 82, 835–845. [Google Scholar] [CrossRef]
- Chen, K.; Jin, Z.; Ying, Z. Semiparametric analysis of transformation models with censored data. Biometrika 2002, 89, 659–668. [Google Scholar] [CrossRef]
- Zeng, D.; Lin, D. Efficient estimation of semiparametric transformation models for counting processes. Biometrika 2006, 93, 627–640. [Google Scholar] [CrossRef]
- de Castro, M.; Chen, M.H.; Ibrahim, J.G.; Klein, J.P. Bayesian transformation models for multivariate survival data. Scand. J. Stat. 2014, 41, 187–199. [Google Scholar] [CrossRef]
- Li, S.; Hu, T.; Wang, P.; Sun, J. A Class of Semiparametric Transformation Models for Doubly Censored Failure Time Data. Scand. J. Stat. 2018, 45, 682–698. [Google Scholar] [CrossRef]
- Hothorn, T.; Kneib, T.; Bühlmann, P. Conditional transformation models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2014, 76, 3–27. [Google Scholar] [CrossRef]
- Hothorn, T.; Möst, L.; Bühlmann, P. Most likely transformations. Scand. J. Stat. 2018, 45, 110–134. [Google Scholar] [CrossRef]
- Zhou, H.; Hanson, T. A unified framework for fitting Bayesian semiparametric models to arbitrarily censored survival data, including spatially referenced data. J. Am. Stat. Assoc. 2018, 113, 571–581. [Google Scholar] [CrossRef]
- Kowal, D.R.; Wu, B. Monte Carlo inference for semiparametric Bayesian regression. J. Am. Stat. Assoc. 2024, 120, 1063–1076. [Google Scholar] [CrossRef] [PubMed]
- Zhong, C.; Yang, J.; Shen, J.; Liu, C.; Li, Z. On MCMC mixing under unidentified nonparametric models with an application to survival predictions under transformation models. arXiv 2024, arXiv:2411.01382. [Google Scholar] [CrossRef]
- Horowitz, J.L. Semiparametric estimation of a regression model with an unknown transformation of the dependent variable. Econometrica 1996, 64, 103–137. [Google Scholar] [CrossRef]
- Ye, J.; Duan, N. Nonparametric n−1/2-consistent estimation for the general transformation models. Ann. Stat. 1997, 25, 2682–2717. [Google Scholar] [CrossRef]
- Chen, S. Rank Estimation of Transformation Models. Econometrica 2002, 70, 1683–1697. [Google Scholar] [CrossRef]
- Mallick, B.K.; Walker, S. A Bayesian semiparametric transformation model incorporating frailties. J. Stat. Plan. Inference 2003, 112, 159–174. [Google Scholar] [CrossRef]
- Song, X.; Ma, S.; Huang, J.; Zhou, X.H. A semiparametric approach for the nonparametric transformation survival model with multiple covariates. Biostatistics 2007, 8, 197–211. [Google Scholar] [CrossRef]
- Cuzick, J. Rank regression. Ann. Stat. 1988, 16, 1369–1389. [Google Scholar] [CrossRef]
- Gørgens, T.; Horowitz, J.L. Semiparametric estimation of a censored regression model with an unknown transformation of the dependent variable. J. Econom. 1999, 90, 155–191. [Google Scholar] [CrossRef]
- Zeng, D.; Lin, D. Efficient estimation for the accelerated failure time model. J. Am. Stat. Assoc. 2007, 102, 1387–1396. [Google Scholar] [CrossRef]
- Ramsay, J.O. Monotone regression splines in action. Stat. Sci. 1988, 3, 425–441. [Google Scholar] [CrossRef]
- MacEachern, S.N. Dependent Nonparametric Processes. In Proceedings of the Section on Bayesian Statistical Science; American Statistical Association: Alexandria, VA, USA, 1999. [Google Scholar]
- De Iorio, M.; Müller, P.; Rosner, G.L.; MacEachern, S.N. An ANOVA model for dependent random measures. J. Am. Stat. Assoc. 2004, 99, 205–215. [Google Scholar] [CrossRef]
- Lo, A.Y. On a class of Bayesian nonparametric estimates: I. Density estimates. Ann. Stat. 1984, 12, 351–357. [Google Scholar] [CrossRef]
- Sethuraman, J. A constructive definition of Dirichlet priors. Stat. Sin. 1994, 4, 639–650. [Google Scholar]
- Kottas, A. Nonparametric Bayesian survival analysis using mixtures of Weibull distributions. J. Stat. Plan. Inference 2006, 136, 578–596. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Ishwaran, H.; James, L.F. Approximate Dirichlet process computing in finite normal mixtures: Smoothing and prior information. J. Comput. Graph. Stat. 2002, 11, 508–532. [Google Scholar] [CrossRef]
- Zhong, C.; Ma, Z.; Shen, J.; Liu, C. Dependent Dirichlet Processes for Analysis of a Generalized Shared Frailty Model. In Computational Statistics and Applications; Løpez-Ruiz, R., Ed.; Chapter 5; IntechOpen: Rijeka, Croatia, 2021. [Google Scholar]
- Carpenter, B.; Gelman, A.; Hoffman, M.D.; Lee, D.; Goodrich, B.; Betancourt, M.; Brubaker, M.A.; Guo, J.; Li, P.; Riddell, A. Stan: A probabilistic programming language. J. Stat. Softw. 2017, 76, 1–32. [Google Scholar] [CrossRef]
- Absil, P.A.; Malick, J. Projection-like retractions on matrix manifolds. SIAM J. Optim. 2012, 22, 135–158. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).