Given a set of uncropped videos, the TAL model first extracts the temporal features
of each video using a visual backbone network, where
D and
T are the number of channels and frames. Then, it predicts a series of possible action instances
, where
M presents the number of predicted results for this video, and
,
and
denote the boundary and action category of the
m-th predicted result, respectively. It is summarized as
3.1. Framework Overview
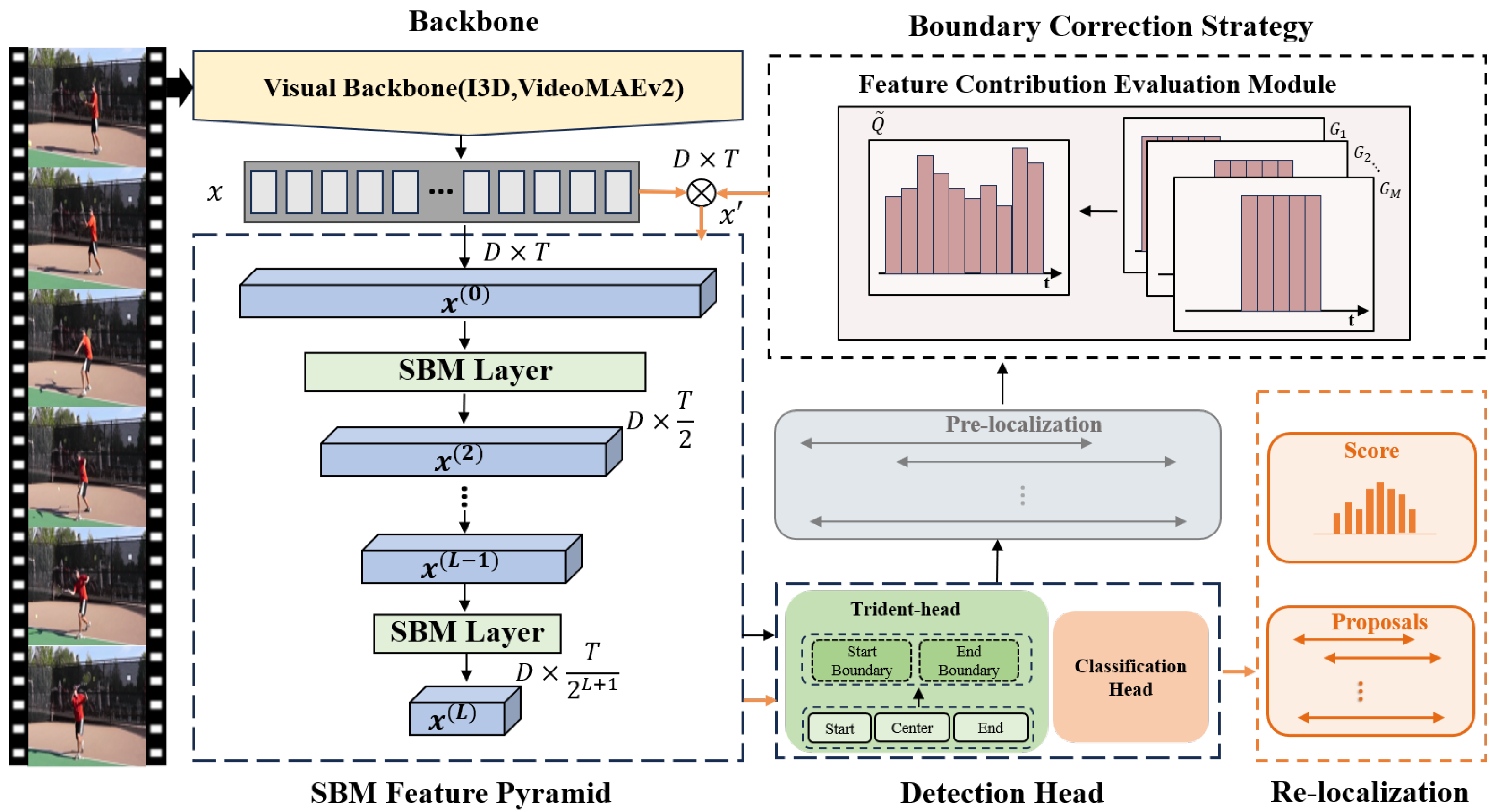
The overall framework is shown in
Figure 1, which includes four components: visual backbone network, SBM feature pyramid, detection head, and BCS.
First, the model extracts temporal features using a visual backbone network, and the SBM feature pyramid encodes them into multi-scale temporal features containing global context information. Next, the detection head performs frame-level localization and classification to generate pre-localized results.
Next, BCS determines the action sensitivity of frames based on the pre-localized results and then generates the contribution of each frame to the action instance. The contribution is adopted for the weighted aggregation of temporal features, to boost the response values of frames near boundaries and suppress others, which makes the predicted boundaries more accurate.
Lastly, the updated features are fed sequentially into the SBM feature pyramid to obtain the re-localized results.
3.2. The SBM Feature Pyramid
Current TAL methods replace the Transformer encoder with CNNs to tackle the problems of feature redundancy and rank loss caused by self-attention. However, these methods still have shortcomings. For example, it has difficulty in dealing with long-term temporal sequences, due to the limitation in capturing global time information.
Recently, SSMs have been introduced into deep learning for sequence modeling. Their main idea is applying hidden states to connect input and output sequences, essentially a sequence transformation. Unlike the local modeling of CNNs, SSMs provide a more comprehensive data description through explicit hidden states and transformation equations.
Therefore, this paper designs an SBM feature pyramid. It applies hidden states to provide forward and backward information for frames, which helps the model understand the changes between frames. Specifically, the SBM feature pyramid consists of multiple sequentially connected SBM layers, which pass the temporal features obtained from one layer to the next for encoding, thus obtaining multi-scale temporal features.
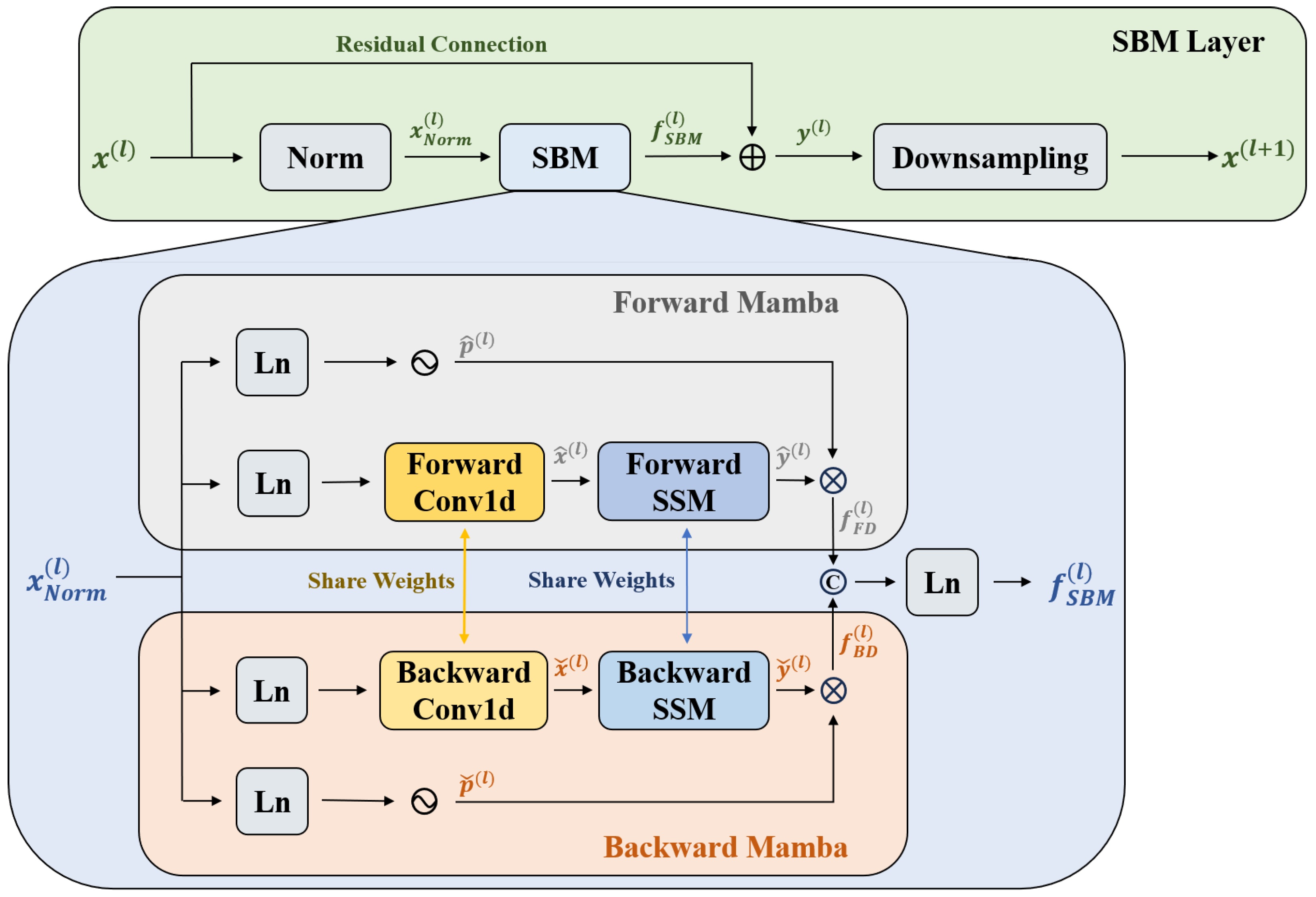
Figure 2 depicts the SBM layer, which is separated into main and branch paths. The main path contains a normalization module and an SBM module for aggregating global context information and a down-sampling layer for constructing the feature pyramid. The branch path is a residual connection, which connects the input directly to the main output to minimize original information loss. The normalization process is represented by
where
denotes the layer normalization operation,
is the input temporal feature of the
l-th SBM layer, and
is the initial temporal feature
x.
Formally, the SBM contains two components: the forward and backward Mamba, which are applied to incorporate forward and backward contextual information for temporal features.
Forward Mamba: The gate-modeling branch produces the temporal feature
that incorporates the forward information. The above process is summarized as
where
presents the gate function, and the SiLU function is adopted in this paper.
is the linear layer.
refers to the forward 1D convolution.
is the forward SSM.
is presented to convert the input
to the output
. Specifically, it converts the last hidden state
and the present input
into the present hidden state
, then transfers
to the present output
. This conversion is formulated as
where matrices
,
, and
are trainable parameters of
.
B represents batch size,
N is the state size, and
T and
D are the number of frames and channels. Both
and
are discretized.
and
define the evolution of hidden states, and
C projects hidden states to outputs. The initial hidden state
is defined as a zero vector.
Finally,
and
are multiplied to obtain the forward Mamba result
to emphasize the key information and reduce the influence of secondary information, which is formulated as
Backward Mamba: To fuse the bidirectional features, this method further defines the backward Mamba. It incorporates backward information in temporal features, thus complementing details and patterns that tend to be missed by forward information. Similarly to forward Mamba, the computational process for backward Mamba is represented by
where
denotes the backward 1D convolution, sharing weights with
, and
is the backward SSM, sharing weights with
.
Finally,
and
are multiplied to obtain the backward Mamba output
as shown in
SBM concatenates
with
and then obtains the final result through the linear layer. This operation is defined as
Through the above steps, the SBM layer realizes the encoding of temporal features at each scale and obtains the temporal feature
that incorporates the global context information. The overall process is summarized in
Finally,
enters the down-sampling layer to obtain the input of the next SBM layer, as shown in
where
denotes the maximum pooling layer.
3.3. Boundary Correction Strategy (BCS)
In TAL, not every frame contributes equally. In terms of the boundary regression task, frames distant from the ground-truth boundaries often lead to boundary offset errors, making predicted boundaries large biases, which reduces the localization accuracy.
Therefore, BCS calculates the frame contribution based on the pre-localized result, and then uses it for feature updating, which corrects boundaries for refined-local results. Formally, it divides the TAL into the pre-localized and the boundary refinement stage.
Pre-localized Stage: In the pre-localized stage, this paper follows the Trident-head [
7] for boundary regression. Trident-head includes start header, end header and center offset header, which determine boundaries, and action centers, respectively.
For an arbitrary scale temporal feature
, it is first encoded into three features:
,
, and
, where
and
denote each frame response value as a start and end boundary, respectively, and
denotes its relative center offsets. The coding process is expressed as
where
denotes the process of encoding.
Then, this paper estimates the distance probability distribution from the start boundary to the action center, with the start response value and the relative center offsets. For example, when frame
i is the action center, the distance probability distribution
of the distance
between the start boundary and the action center is shown in Equation (
17). Moreover,
,
B denotes the predefined maximum distance between the start boundary and the action center.
where
represents the response value (the
b-th frame to the left of frame
i is the start boundary), and
denotes its relative center offsets.
Based on the above probability distribution, this paper approximates the start boundary
by calculating the expectation
, as shown in
where
is the down-sampling rate.
Similarly, when the
i-th frame is the action center, the end boundary
is received by
where
denotes the distance from the end boundary to the action center.
represents the response value (the
b-th frame to the action center right is the end boundary), and
is its relative center offsets.
Then, the action instance
is given after merging the action boundary with the action category. The action category is obtained from
where
is the classification head.
Finally, a non-maximal suppression operation is applied to filter the redundant action instances to obtain pre-localized result
, which is expressed by
where
is a non-maximal suppression operation.
denotes the confidence of the action instance
.
is the confidence threshold.
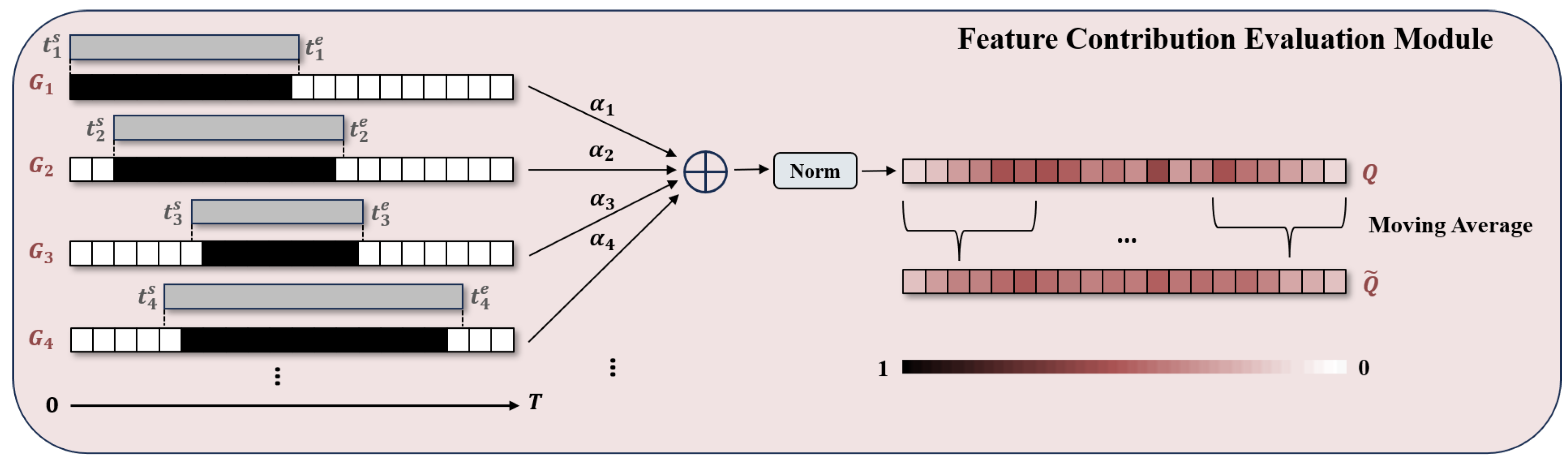
Boundary Refinement Stage: The boundary refinement stage uses the Feature Contribution Evaluation Module (FCEM) to quantify the action sensitivity of each frame and then gives it a contribution score. The FCEM is shown in
Figure 3.
First, FCEM calculates the action sensitivity for each frame based on the action instance
. Specifically, FCEM stacks each action instance with the timeline chronologically, assigning nonzero action sensitivity to the overlapping portion of frames. The frame sensitivity
is calculated using
where
is a nonzero number.
Frame sensitivity reflects the degree sensitive of the frame to each action instance. In fact, a frame often exists in multiple pre-localized action instances, and the more a frame is located near the action boundary, the higher possibility of it appearing in an action instance. Therefore, to fully utilize the information of all action instances for frames, FCEM gets the frame contribution
Q by fusing frame sensitivities
as each frame importance in TAL. The process is summarized in
where
presents the weight of
in the fusion process, and
is the normalization process.
In addition, to improve the smoothness of the contribution matrix, FCEM also performs Moving Average (MA) on
Q, which fuses the information of neighboring frames to reduce the sharp variations in data caused by noise. The frame contribution
is obtained using
Based on the frame contribution
, BCS generates the updated temporal feature
, and the calculation process is shown in
where
is the balance factor.
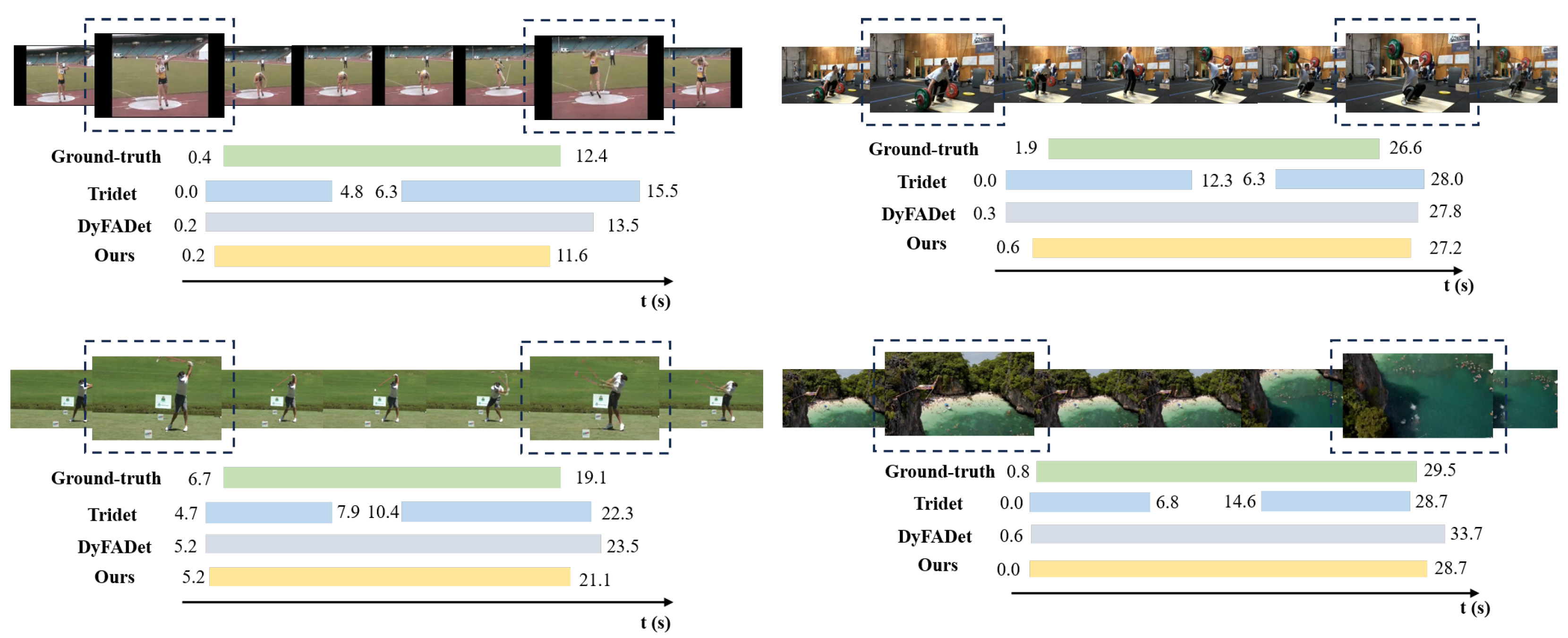
Finally, performs action localization based on Equations (2)–(24), to obtain the corrected action instances .
3.4. Time Complexity Analysis
First, the detailed processing of the SBM feature pyramid is represented by Algorithm 1.
| Algorithm 1. The process of the SBM feature pyramid |
- Input:
Temporal feature x. - Output:
Encoded features . - 1:
- 2:
/* Construct SBM feature pyramid */ - 3:
for l in {0,1,…,L-1} do - 4:
- 5:
/* SBM */ - 6:
- 7:
- 8:
- 9:
- 10:
- 11:
end for - 12:
return
|
Here, the time complexity is calculated as follows:
Since each SBM block incurs a time cost that is linear in its input sequence length [
28], the pyramid halves that length at every layer. The 0-th layer processes the original
T frames in
time, the 1-st layer processes
frames in
time, and this pattern continues until the
-th layer takes
time. Summing the costs of all
L layers yields
. Because the bracketed factor is a bounded constant, the overall complexity remains
, which is markedly better than the
complexity of Transformer.
Then, the detailed processing of BCS is represented by Algorithm 2.
| Algorithm 2. BCS process |
- Input:
Temporal feature x. - Output:
Corrected action instances . - 1:
/* Pre-localized stage */ - 2:
- 3:
- 4:
/* Boundary refinement stage */ - >5:
/* FCEM */ - 6:
for m in {1,2,…,M} do - 7:
for t in {1,2,…,T} do - 8:
if and then - 9:
- 10:
else - 11:
- 12:
end if - 13:
end for - 14:
- 15:
end for - 16:
- 17:
- 18:
- 19:
- 20:
return
|
The time consumption of BCS comes mainly from FCEM, which has to traverse each instance and each timestamp sequentially. Thus, its time complexity is . Since M is generally less than T, it could be considered as linear time complexity.
Overall, with the time complexity of the detection head , the total time complexity of the proposed method is approximately , which could be considered as linear time complexity . Therefore, compared to the Transformer-based method, the proposed method downgrades the time complexity from quadratic time complexity to linear complexity, achieving a similar time complexity as the CNNs-based method.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}