5.1. Simulation Study
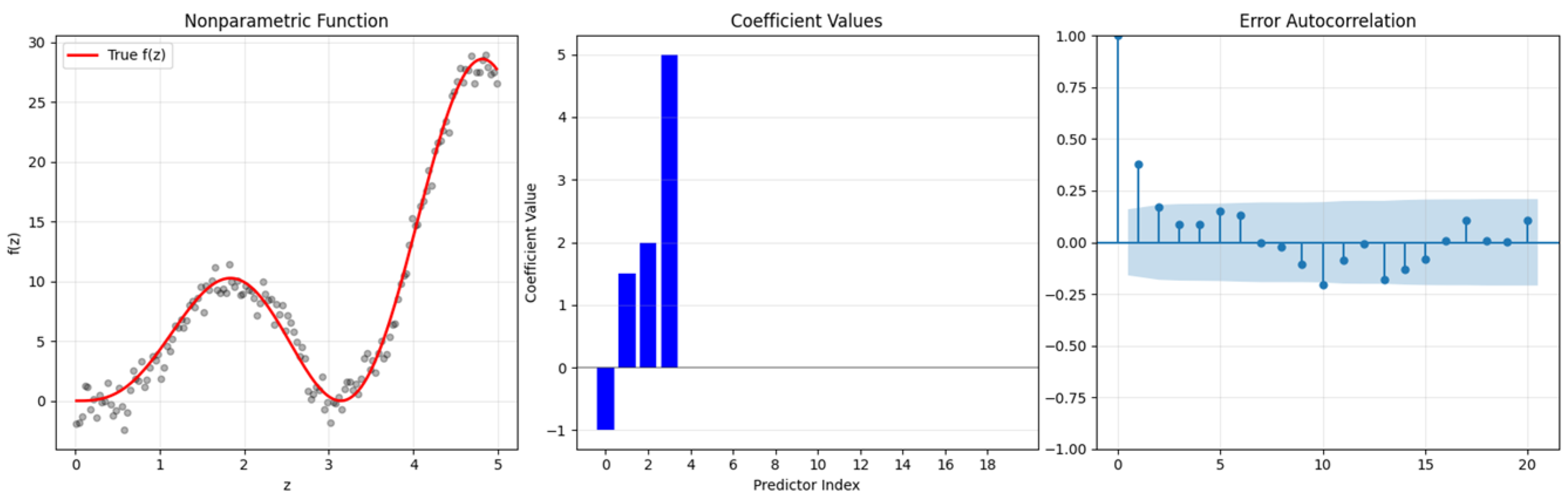
This section presents a Monte Carlo simulation study designed to compare the estimation performances of the introduced kernel-type ridge estimator (GRTK) and shrinkage estimators for model (1) in the presence of correlated errors. To generate parametric predictors, we use a sparse model with
. To introduce multicollinearity, covariates are generated with a specific level of collinearity, denoted as
, the following equation is used:
where
p is the number of the predictors,
’s generated as
, and
denotes the two correlation levels between the predictors of parametric component. In this context, the simulated data sets are generated from the following model,
as defined in (1). In given model (32),
,
is constructed by Equation (31); the regression function
and
; the error terms
are generated using a first order autoregressive process (that is,
) with
and
. Using data generation procedure given by Equations (31) and (32), we consider the three different sample sizes that are
and
to investigate the performance of the introduced estimators for low, medium and large samples, and each we use 1000 repetition for each simulation combination. The simulation results are provided in the following figures and tables. In addition,
Figure 1 shows the generated data to clarify the data generation procedure better.
From a computational perspective, the GRTK estimation procedure involves several steps: (1) initial parameter estimation to obtain residuals, (2) estimation of the autocorrelation parameter , (3) data transformation, (4) parameter selection for (), and (5) final estimation. The most computationally intensive step is typically the selection of () pairs, requiring a two-dimensional grid search. In our implementation, the GCV-based estimator was the most computationally efficient, followed by BIC, AICc, and RECP where RECP involves a pilot variance estimation, and it is more costly than others.
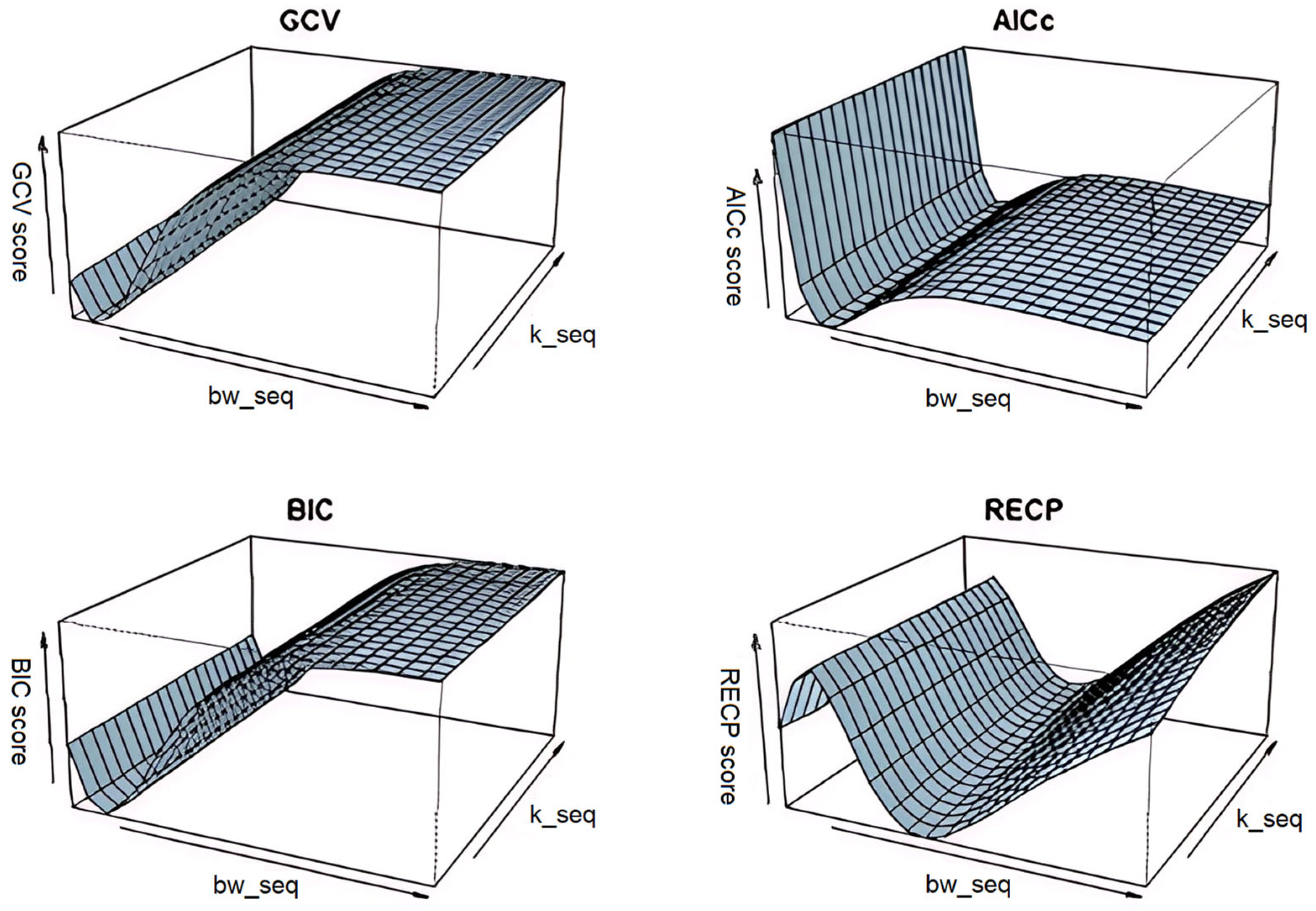
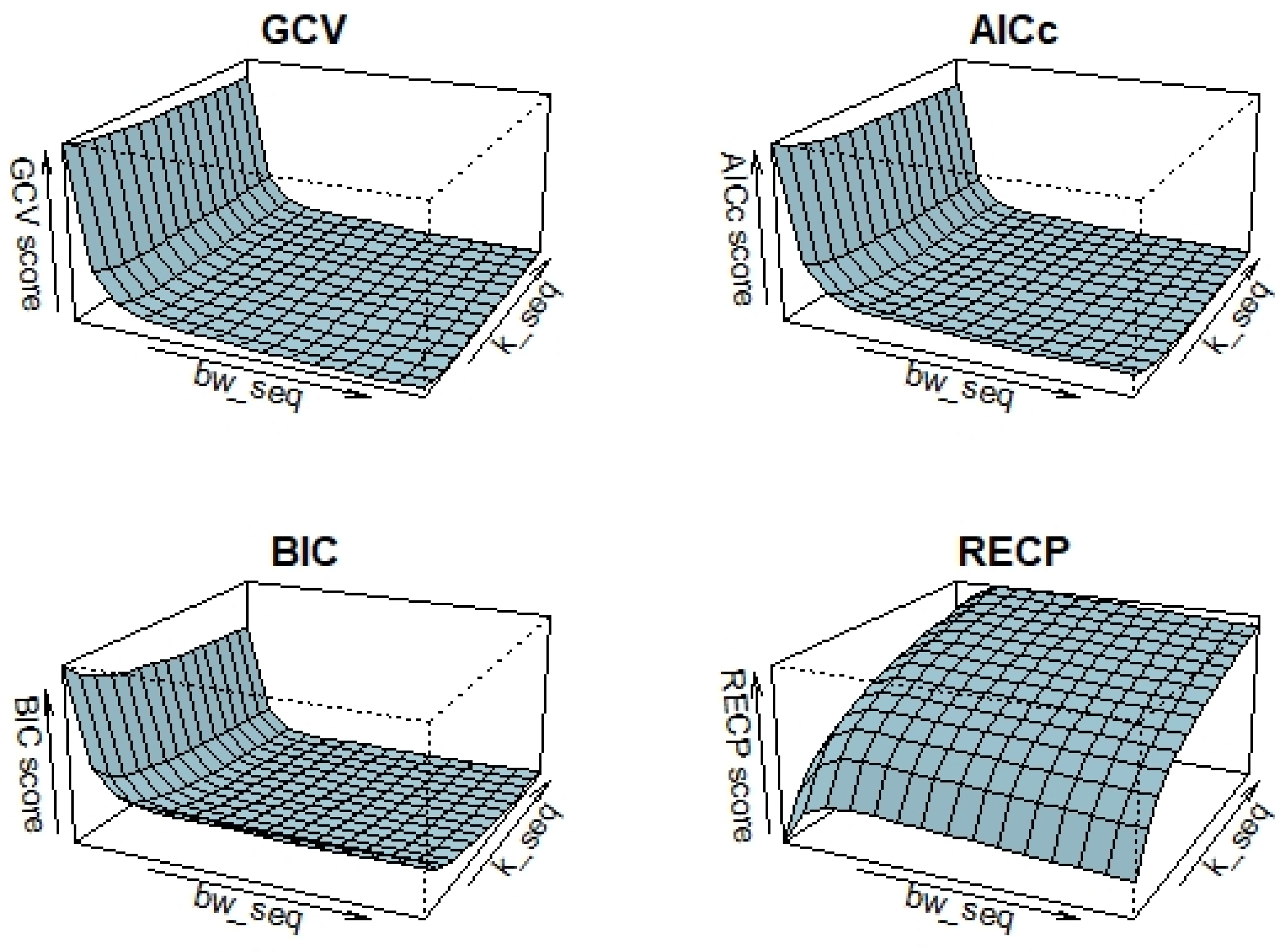
Before presenting the results, as mentioned in the sections above, selection of bandwidth of kernel smoother (
) and the shrinkage (or ridge) parameter
has a critical importance due to its effect on the estimation accuracy. Therefore, for different simulation configurations, chosen pairs of
are presented in
Table 1 and
Figure 2. Hence, it is possible to see how these parameters are affected by the multicollinearity level between predictors
and sample size
. When examining
Table 1, the chosen bandwidth and shrinkage parameters, along with the specified four criteria, are evident for all possible simulation configurations. From the values, it can be observed that the values of the pair
increase as the correlation level rises, potentially negatively impacting estimation quality in terms of smoothing. On the other hand, the increase in
, particularly when multicollinearity is high, is an expected behavior aimed at avoiding indefinability in the variance-covariance matrix. For large sample sizes, the criteria tend to select lower
but higher “
” values as a general tendency. Similar selection behavior is observed when
. We take the behavior of
obtained in
Table 1 and follow similar roadmap for the shrinkage estimators that are obtained rely on the GRTK estimator.
Additionally,
Figure 1 illustrates the selection procedure of each criterion for different possible values of bandwidth and shrinkage parameters simultaneously. It can be concluded from this that
,
, and
exhibit closer patterns than
. This difference is evidently sourced from its risk estimation procedure with the pilot variance shown in (30). Accordingly,
-based estimator mostly present different performances under different conditions.
After determination of the data-adaptively chosen tuning parameters
, time series models are estimated and performance of the estimated regression coefficients of parametric component
,
) based on the selection criteria are obtained. In this sense, bias, variance and
values of
,
) are presented in
Table 2. In addition, 3D figure is given to observe the effect of both sample size and correlation level on the quality of the estimates in terms of parametric component.
Table 2 reports the numerical performance of the baseline Generalized Ridge-Type Kernel (
) estimator under various sample sizes (
) and collinearity levels (
). Looking at the bias, variance, and aggregated measures such as SMSD, one sees that high correlation (
) generally inflates estimation error compared to moderate correlation (
= 0.95). Conversely, larger sample sizes (
and
) mitigate these issues, resulting in smaller bias, variance, and SMSD. These findings confirm the paper’s theoretical claims that ridge-type kernel smoothing can handle partially linear models with correlated errors more robustly as
grows. Nevertheless, because the paper works with
(
) predictors, the variance inflation is still non-trivial, suggesting that
additional shrinkage mechanisms beyond baseline GRTK might yield further improvements.
Table 3 summarizes the performance of the shrinkage estimator (notated as
), which further regularizes the GRTK approach by incorporating Stein-type shrinkage toward a submodel. Also given
represent the average number of chosen coefficients during the simulations using penalty functions for both nonzero and sparse ones. Relative to
Table 2’s baseline GRTK results, the shrinkage estimator consistently displays smaller bias–variance trade-offs across most combinations of
and
. In particular, when the predictors are highly collinear, the
estimator’s additional penalization proves beneficial by reducing the inflated variance typically caused by near-linear dependencies among regressors. Hence, these results validate one of the paper’s key arguments: that combining kernel smoothing with shrinkage can outperform a pure ridge-type kernel approach in high-dimensional or strongly correlated settings, especially for moderate sample sizes.
Table 4 presents the outcomes for the positive-part Stein (
) shrinkage version, which modifies the ordinary Stein estimator by truncating the shrinkage factor at zero. According to the paper’s premise, PS is designed to avoid “overshrinking” when the shrinkage factor becomes negative and is thus expected to give the strongest performance among the three estimators, particularly in the given scenario with high collinearity. Indeed,
Table 4’s bias, variance, and SMSD values are generally on par with—or superior to—those reported in
Table 2 and
Table 3. When
is especially large, the PS estimator still manages to keep both the bias and variance relatively contained, highlighting that positive-part shrinkage delivers robust protection against severe collinearity. As a result, these findings support the paper’s claim that the PS shrinkage mechanism provides an appealing balance of bias and variance under challenging data conditions, outperforming both baseline GRTK and standard Stein shrinkage (S) in many of the tested simulation settings.
Overall, the results across
Table 2,
Table 3 and
Table 4 demonstrate that each proposed estimator—baseline GRTK (
), shrinkage (
), and positive-part Stein shrinkage (
)—responds predictably to varying sample sizes and degrees of multicollinearity. Larger samples result in smaller bias, variance, and SMSD values, confirming the benefits of increased information for parameter estimation. Simultaneously, strong correlation among predictors inflates these metrics, illustrating the challenge posed by multicollinearity. Transitioning from GRTK to the two shrinkage-based estimators generally yields progressively better performance, particularly in higher-dimensional settings (where
) with
. In particular, the positive-part Stein approach (
) often delivers the most stable results, indicating that its careful control of shrinkage is advantageous for mitigating both variance inflation and overshrinking.
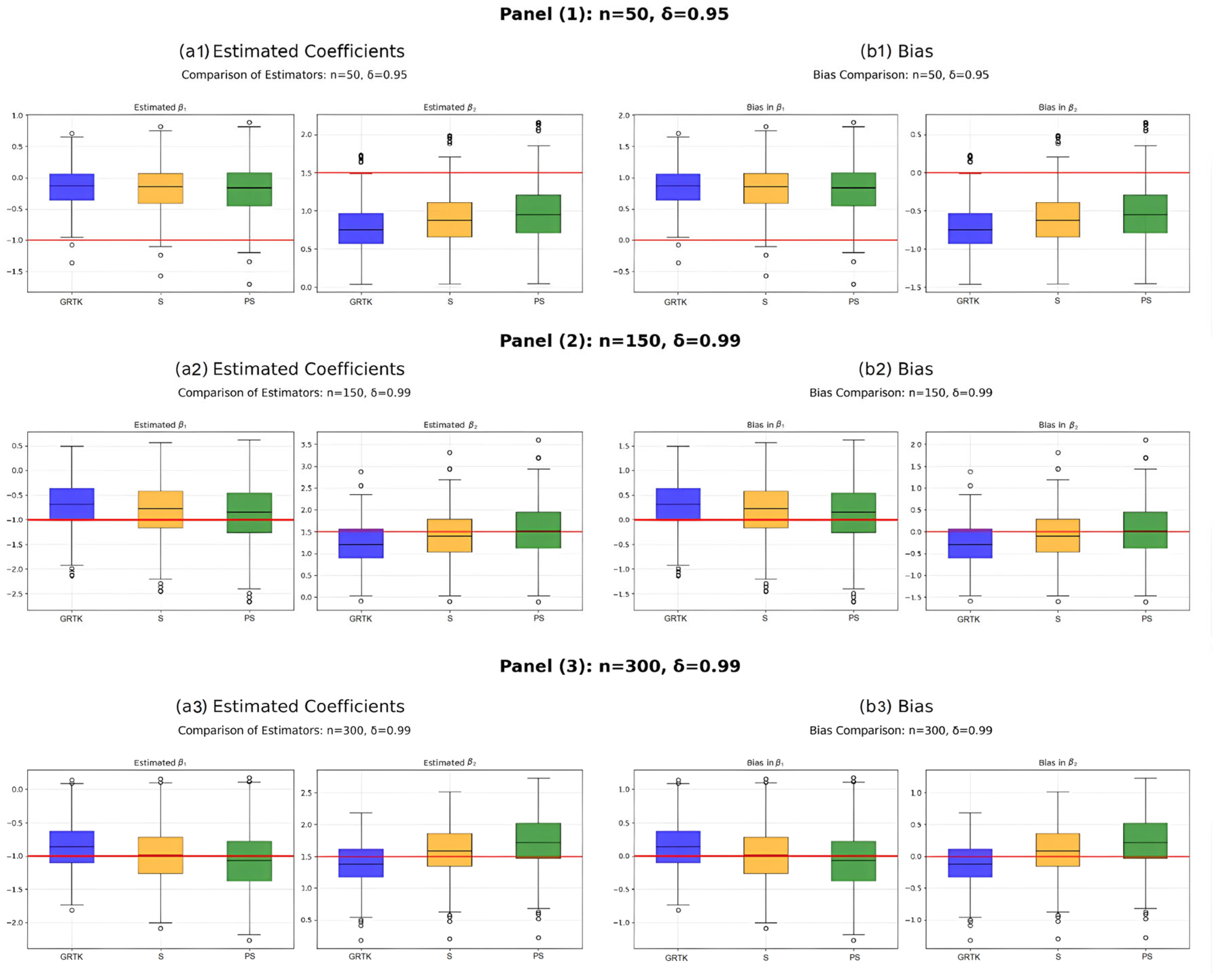
Figure 3 visually compares the distributions of the estimated coefficients for
,
, and
via boxplots under different sample sizes and correlation levels, complementing the numerical findings in
Table 2,
Table 3 and
Table 4. In each panel, the baseline
estimator often deviates from the true coefficient value and zero for the bias, but it remains competitive with shrinkage estimators in terms of variance, especially when the data exhibit high collinearity, reflecting the variance inflation reported in
Table 2. By contrast, the two shrinkage methods—
(
Table 3) and
(
Table 4)—show boxplots that are close to real values of the coefficients, indicating smaller biases and more stable estimates. Particularly under higher correlation (
) and moderate sample sizes,
tends to yield less spread than the other estimators, consistent with the idea that positive-part Stein shrinkage further controls overshrinking while tackling multicollinearity. Overall, these graphical patterns support the tables’ numeric trends, emphasizing how adding shrinkage to a kernel-based estimator improves both bias reduction and variance stabilization in partially linear models.
Table 5 reports the mean squared errors (MSE) for estimating the nonparametric component
under various combinations of sample size (
) and correlation level
. Reflecting patterns observed in the parametric estimates, a larger
typically increases MSE values, while growing the sample size reduces them. Notably, the table shows that the proposed
and its shrinkage versions (
and
) all perform better as
becomes larger; this aligns with the theoretical expectation that more data stabilize both kernel smoothing and shrinkage procedures in a partially linear context.
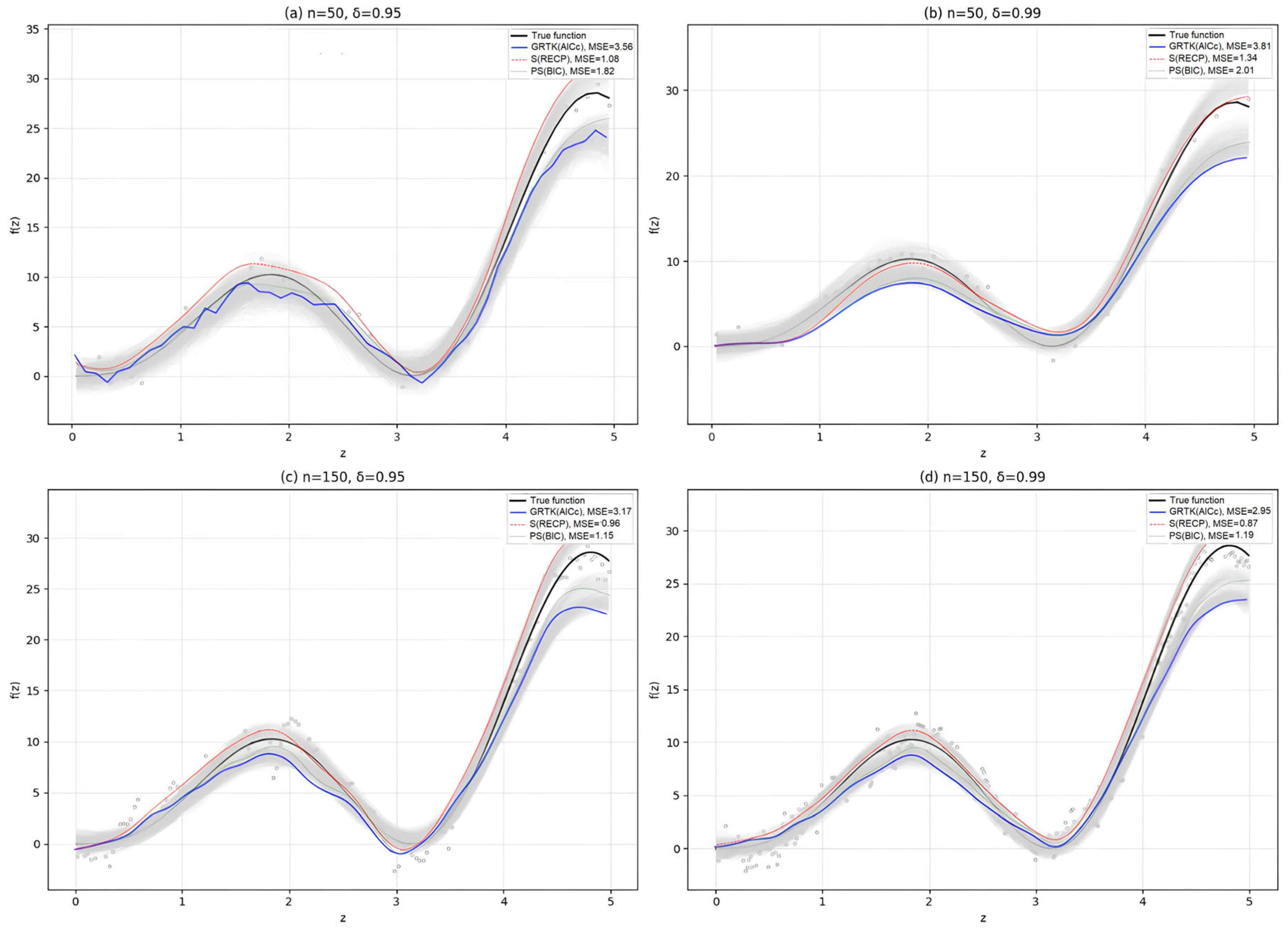
Figure 4 further illustrates these differences in estimating
by depicting the fitted nonparametric curves for selected simulation settings. Panels (a)–(b) highlight how increasing
can distort the estimated function, leading to higher MSE—an effect that is more pronounced for smaller samples. Meanwhile, panels (c)–(d) show that when nnn grows, each estimator recovers the true nonlinear pattern more closely, supporting the numerical results in
Table 5. Taken together,
Table 5 and
Figure 4 confirm that although multicollinearity and smaller sample sizes can hamper nonparametric estimation, the combination of kernel smoothing with shrinkage remains robust and delivers reasonable reconstructions of
in challenging time-series settings.
5.2. Simulation Study with Large Samples
In this section, we provide the results for large sample sizes to present practical proofs for the asymptotic properties. To achieve that we decided
and
with less configurations give in
Section 5.1. The results are presented in the following
Table 6,
Table 7,
Table 8 and
Table 9 and
Figure 5.
In
Table 6, the GRTK estimator represents the baseline semiparametric estimator with variance
, where
. In terms of sample size effects, one can see that bias reduces around ~27% and variance reduces around ~42% from
. Regarding the correlation impact,
increases performance get worse around three times than
case, confirming multicollinearity effects. Moreover, RECP is consistently the best (lowest SMSD), and
varies the most due to its correction term
which is sensitive to changes in both sample size and degrees of freedom.
In
Table 7, the Stein shrinkage estimator
creates a bias-variance trade-off through intentional shrinkage. The shrinkage benefits are evident with SMSD reduction compared to GRTK, demonstrating stein-type shrinkage superiority for
. Sample size effects follow similar patterns to GRTK, with bias and variance reductions maintaining the theoretical
scaling. Correlation impact shows that shrinkage provides larger relative improvements under
conditions, helping to mitigate multicollinearity effects. The selection criteria ranking
is preserved across shrinkage, indicating robust performance across different regularization approaches. Additionally, submodel selection shows sparser models (3.4, 16.6) for n = 1000 versus (3.2, 16.8) for n = 500, suggesting improved signal-noise discrimination with larger samples.
In
Table 8, the positive-part Stein estimator
prevents over-shrinking by eliminating negative shrinkage factors. This estimator shows superior performance with the lowest SMSD in the majority of scenarios, achieving improvement over
and
. The theoretical dominance property
is empirically confirmed across all scenarios. Sample size effects maintain the same asymptotic scaling patterns, while correlation impacts are similar to other estimators but with enhanced robustness. The selection criteria performance continues to favor RECP, with AICc showing the highest variability due to its correction term sensitivity. Importantly, the advantages of positive-part shrinkage persist even at
, confirming that the theoretical benefits extend to large sample scenarios and validating the methodology’s long-term effectiveness.
In
Table 9, the nonparametric component
uses Nadaraya-Watson weights as defined in Equation (7). From Theorem 2, the nonparametric estimator achieves
convergence. Sample size effects show MSE reduction from
as expected, consistent with the theoretical convergence established in Theorem 2. Another finding is shrinkage methods achieving very good MSE reduction versus GRTK, occurring because better
improves residuals in Equation (13), where parametric improvements progress to nonparametric recovery.
Correlation impact shows that
increases MSE by approximately 15–30% compared to
, which is much smaller than the increase observed for parametric components in
Table 6,
Table 7 and
Table 8, suggesting that the nonparametric component is more robust to multicollinearity in the parametric part. Regarding selection criteria performance, unlike the parametric case where RECP consistently dominated (see
Section 4), the nonparametric component shows more varied optimal criteria, with GCV performing best for S estimator and BIC excelling for PS estimator, indicating that optimal bandwidth selection from Equations (27)–(30) may require different approaches depending on the underlying parametric estimation method.
The superior performance of shrinkage estimators validates the interconnected nature of parametric and nonparametric components in semiparametric models, consistent with the bias-variance decomposition in Equation (26), where improvements in one component gradually provide benefits to the other component.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}