1. Introduction
Gaussian noise is one of the most common types of noise observed in digital images, often introduced during image acquisition due to various factors. These factors include adverse lighting conditions, thermal instabilities in camera sensors, and failures in the electronic structure of the camera [
1]. Adverse lighting conditions have been shown to degrade the visual quality of digital images and exacerbate the noise inherent to camera sensors, thereby increasing the presence of Gaussian noise in the captured image.
The term “adverse lighting conditions” refers to two specific scenarios: low illumination and high illumination. In the case of low illumination, the resulting digital image exhibits reduced brightness and low contrast [
2]. Additionally, within the electronic structure of the camera, sensors exhibit increased sensitivity to weak signals, amplifying any signal variations and resulting in the generation of Gaussian noise. Conversely, under high illumination conditions, the camera sensors become saturated, leading to a nonlinear response in the captured data [
3] and contributing to the presence of Gaussian noise. Moreover, the heat generated, along with other types of noise, such as thermal noise, further affects the image quality.
Several techniques have been developed to mitigate the impact of Gaussian noise in images captured under poor lighting conditions. These include both classical image processing methods and advanced deep learning-based approaches [
4]. Some of these techniques focus on separately addressing noise reduction and illumination enhancement [
5]. However, it is important to distinguish between illumination enhancement and contrast enhancement as they are two distinct techniques in image processing that address different aspects of a visual quality of the image. While illumination enhancement adjusts the overall brightness to improve visibility and make the image clearer and easier to interpret [
6], contrast enhancement increases the difference between light and dark areas to make details more perceptible [
7]. This research highlights the importance of simultaneously enhancing image details through contrast adjustment and reducing noise using an autoencoder neural network. This is achieved by analyzing the image and applying trained models based on the features present in the input data.
Section 2 presents and analyzes the relevant theoretical background. The proposed model is described in
Section 3, while the experimental setup and results are discussed in
Section 4. Finally, the conclusions of this research work are provided in
Section 5.
3. Proposed Model
The aforementioned algorithms have been shown to prioritize a single objective, either noise reduction or contrast enhancement. However, a new algorithm is proposed that performs both tasks simultaneously, yielding superior results compared to existing methods. The proposed algorithm, Denoising Vanilla Autoencoder with Contrast Enhancement
(DVACE), was designed to simultaneously address the noise reduction and contrast enhancement in images represented mathematically as multidimensional arrays. First, consider an original image X, defined as a two-dimensional matrix (Gray Scale (GS) image) or a three-dimensional tensor (Red, Green, Blue (RGB) image), where each matrix entry corresponds to the pixel intensity at position .
Then, let the original multidimensional image be the following:
where
is the spatial resolution of the image,
C is the number of channels (
for
GS, and
for
RGB).
Considering a multidimensional Gaussian noise model [
20], the observed noisy image is expressed as follows:
where
is the observed noisy image,
is the original noise-free image,
is additive Gaussian noise,
is the multidimensional mean matrix (local or global) of pixels, and
is the covariance matrix representing the multidimensional noise dispersion (typically
for stationary, uncorrelated noise between pixels and channels, where
I is the multidimensional identity matrix).
For each pixel at a specific position
with observed value
(vector for
RGB and scalar for
GS), the Gaussian noise probability distribution is as follows:
where
is the column vector (for
RGB and
), the scalar (
GS,
) is observed at spatial position
,
is the original local mean at position
, and
is the noise covariance matrix (simplified often to
, with
as the
identity matrix).
If noise is stationary and isotropic (equal in all directions), the equation simplifies to the following:
The joint probability for the entire observed image, assuming independence among pixels and channels, is as follows:
This provides the mathematical foundation on which the
DVACE model optimizes the estimation of the original image
X by minimizing the exponential term that represents the squared error between the observed noisy image
Y and the restored image
X. By adjusting the variance, the density of noise present in the image can be increased or decreased. Additionally, by modifying the mean, the image can appear underexposed (
Figure 2a) or overexposed (
Figure 2b). This demonstrates how the illumination of the image changes, either darkening or brightening. Finally, the histogram corresponding to the simulated image is presented.
Figure 3 presents the flowchart of the proposed model architecture for
RGB images, while
Figure 4 shows the flowchart of the proposed model architecture for
GS images.
Each architecture calculates the
Signal-to-Noise Ratio (SNR) of the input image. The
SNR metric [
21] is used to enhance the network’s ability to determine the most suitable model—whether to apply a model that brightens dark images or one that darkens bright images—during the actual processing stage. The
SNR is defined for an image
, where
and
c represent the spatial and channel dimensions. The
SNR quantifies the mean intensity relative to the variance in the image:
where the mean and the variance are computed as follows:
This formulation provides a robust measure of the image intensity relative to its noise distribution. It is evident that the design of Algorithms 1 and 2 was based on the proposed architectures.
The
SNR thresholds used in both the
RGB and
GS algorithms were determined experimentally by calculating the average
SNR of the corrupted images used to train the network. Equations (
23)–(
31) illustrate the
DVACE procedure.
Given a set of images in different modalities (
for
GS images and
for
RGB images), the classification process based on the
SNR can be rigorously expressed as a decision function, which is defined as follows:
where
X represents the input image;
is the processed image by the
DVACE model;
represents the
GS image space;
represents the
RGB image space with
C channels;
is the function computing the
SNR of the image; and
and
are predefined
SNR thresholds for
GS and
RGB images, respectively.
and are the unimodal enhancement functions for GS images, and the following apply:
and are the multimodal enhancement functions for RGB images, and the following apply:
The convolutional operation ∗ between an input tensor
and a kernel
is defined as follows:
where
accounts for padding in the kernel size, and
is the bias term for channel
k.
A non-linear transformation is applied to the convolutional result:
where the activation function
is defined as follows:
this introduces non-linearity, enabling feature extraction from high-dimensional spaces.
Dimensional reduction is performed through max-pooling:
where
define the pooling window size. This operation selects the most dominant feature per region.
A secondary convolutional pass refines the extracted features:
where
represents a new set of learned weights.
To restore spatial resolution, we applied weighted bilinear interpolation:
where
are interpolation weights satisfying the following:
A final convolutional step reconstructs the enhanced image as follows:
where
represents a final learned weight set for output feature mapping.
Following the
Denoising Vanilla Autoencoder (DVA) training structure and methodology [
22], two databases were created using images from the “1 Million Faces” dataset [
23], from which only 7000 images were selected.
The first database contains images with a mean intensity
of {0.01 to 0.5} and
of 0.01 for bright images, while the second database contains images with a mean intensity
ranging from {−0.01 to −0.05} and a variance
of 0.01 for dark images. Each database includes images in both
RGB and
GS. The implementation details to ensure reproducibility are provided in
Table 1.
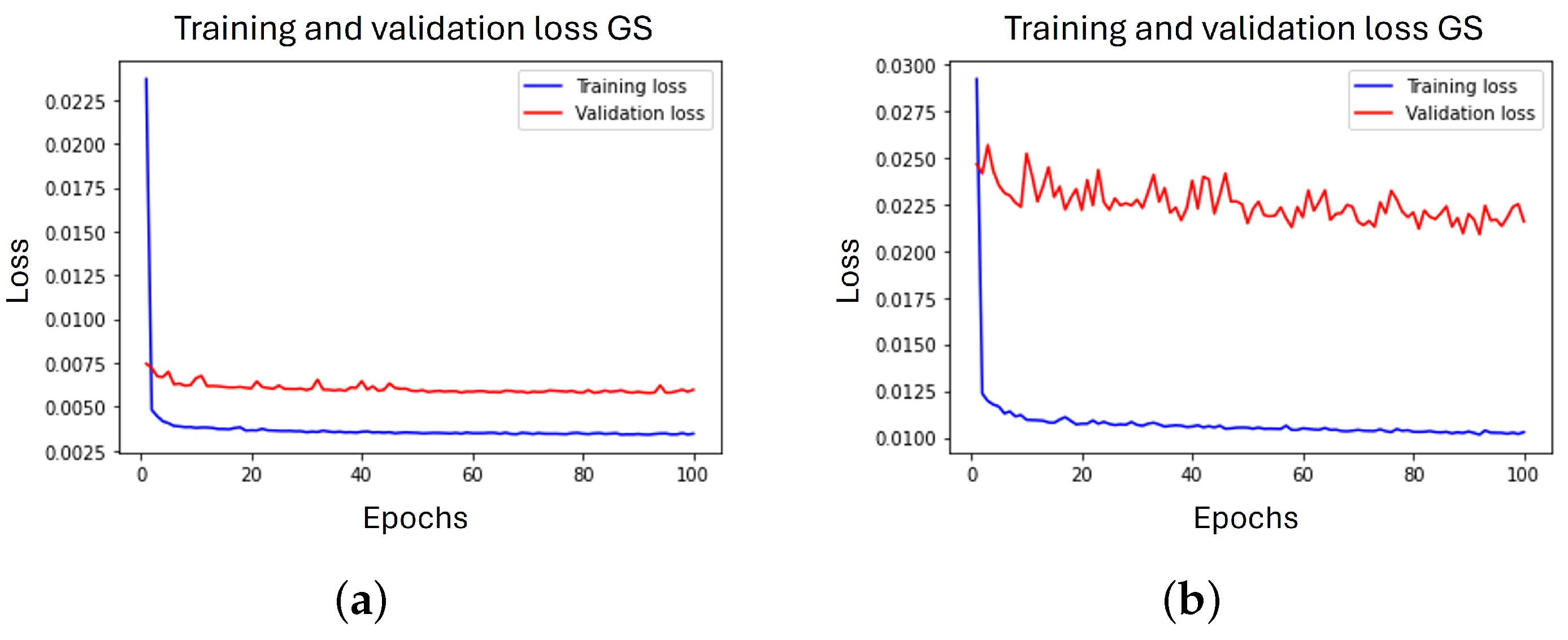
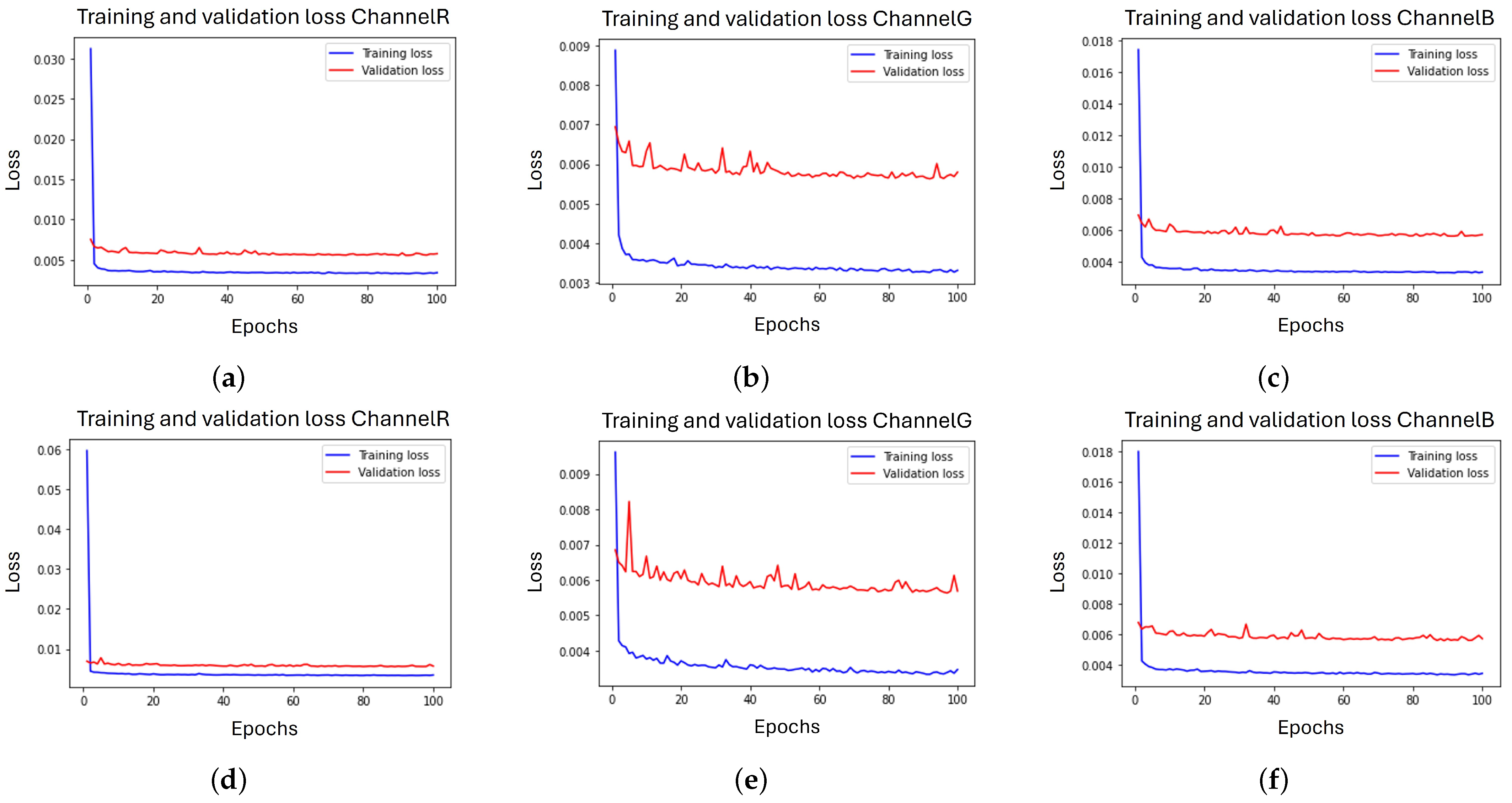
The learning curves obtained during the training process are illustrated in
Figure 5 and
Figure 6.
4. Experimental Results
It is essential to recognize that all algorithms require a validation process to assess their effectiveness in comparison to existing methods. To gain a comprehensive understanding of their performance, it is crucial to employ techniques that quantitatively and/or qualitatively evaluate their outcomes.
Therefore, the following quantitative and qualitative quality criteria were used to assess and validate the results obtained by
DVACE in comparison to the other specialized techniques discussed in
Section 2.
Quantitative metrics provide a means of evaluating the quality of digital images after processing. These metrics can be categorized into reference-based metrics, which compare the processed image against a ground truth, and non-reference metrics, which assess image quality without requiring a reference. The metrics used in this study are as follows:
Erreur Relative Globale Adimensionnelle de Synthèse (ERGAS) [
22,
24].
Mean Square Error (MSE) [
22].
Normalized Color Difference (NCD) estimates the perceptual error between two color vectors by converting from the
space to the CIELuv space. This conversion is necessary because human color perception cannot be accurately represented using the RGB model as it is a non-linear space [
25]. The perceptual color error between the two color vectors is defined as the Euclidean distance between them, as given by Equation (
32).
where
is the error, and
,
, and y
are the difference between the components
,
, and
, respectively, between the two color vectors under consideration.
Once
was found for each one of the pixels of the images under consideration, the
NCD was estimated according to Equation (
33).
where
is the norm of magnitude of the vector of the pixel of the original image not corrupted in space
, and
M and
N are the dimensions of the image.
Perception-based Image Quality Evaluator (PIQE) is a no-reference image quality assessment method that evaluates perceived image quality based on visible distortion levels [
26]. Despite being a numerical metric, it is particularly useful for identifying regions of high activity, artifacts, and noise, as it generates masks that indicate the areas where these distortions occur. Consequently,
PIQE is also classified as a qualitative metric as it is based on human perception and assesses visual quality from a non-mathematical perspective [
26].
The activity mask of an image is a tool that quantifies the level of detail or complexity in a specific region based on intensity variations. Its computation is derived from Equations (
34) and (
35).
where
is the gradient of the image, and
y
are the derivatives of the image in the position
.
where
is the variance in each of the blocks, and the
of size
y
is the average of the gradient in the block.
The artifact mask in an image indicates distortions, such as irregular edges that degrade visual quality. These distortions are detected by analyzing non-natural patterns in regions with high activity levels, where inconsistent blocks are identified and classified as artifacts.
The noise mask is evaluated based on variations in undesired activity within low-activity regions, measuring the dispersion of intensity values within a block, as shown in Equation (
36). If the dispersion significantly exceeds the expected level, the region is classified as noise.
Peak Signal-to-Noise Ratio (PSNR) [
22,
27].
Relative Average Spectral Error (RASE) [
22,
28].
Root Mean Squared Error (RMSE) [
22,
29].
Spectral Angle Mapper (SAM) [
22,
30].
Structural Similarity Index (SSIM) [
22,
31].
Universal Quality Image Index (UQI) [
22,
32].
The
DVACE evaluation was performed using classic benchmark images commonly used for algorithm assessment, including Airplane, Baboon, Barbara, Cablecar, Goldhill, Lenna, Mondrian, and Peppers, in both
RGB and
GS formats. Each evaluation image was corrupted with Gaussian noise, with a variance
of
and a mean intensity
ranging from
to
, in increments of
.
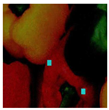
Figure 7 presents a close-up of the original peppers in both
RGB and
GS formats.
As shown in
Table 2 and
Table 3, the quantitative results for the peppers
RGB image are presented for
and
, respectively, with
. It is evident that, in most cases where the mean was nonzero,
DVACE achieved superior image restoration.
Similarly,
Table 4 and
Table 5 present the quantitative results for the peppers
GS image for different mean values and
. It was observed that, in most cases where
,
DVACE achieved superior image restoration compared to all the other algorithms used for comparison.
As shown in
Table 4 and
Table 5, the
peppers image was evaluated under different noise conditions.
DVACE consistently achieves the highest SSIM and PSNR, with the lowest MSE, RMSE, and NCD, ensuring optimal noise reduction and contrast enhancement. It also minimized ERGAS, RASE, and SAM, confirming its superior spectral fidelity. Histogram Equalization and Gamma Correction improved contrast but introduced spectral distortions. The deep learning-based methods (DnCNN, NafNet, and Restormer) showed variability, while the MSR-based techniques and SSR exhibited higher error rates.
DVACE maintained the best trade-off between denoising and structural fidelity.
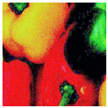
Table 6 presents a visual comparison of the results obtained by
DVACE and the aforementioned algorithms for both noise reduction and contrast enhancement on the baboon image in
RGB with
. This table illustrates that, while the proposed algorithm introduces some distortions, it achieves the best noise reduction results alongside the
NAFNet network. Additionally, in terms of contrast enhancement,
DVACE demonstrated superior restoration (comparable to Histogram Equalization).
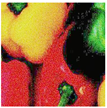
Table 7 presents a visual comparison for the peppers image in
RGB with
. Visually,
DVACE and the median filter exhibited less noise reduction. However, the contrast enhancement achieved by
DVACE was comparable to that of the dedicated algorithms designed for this task.
Table 8 presents a comparison for the peppers image in
GS with
. The results indicate that
DVACE achieved the best performance in both noise reduction and contrast enhancement.
Table 9 presents a comparison for the peppers
GS image with
, confirming the trend observed with
DVACE, which achieved the best results in both noise reduction and contrast enhancement.
As such, in general,
Table 6,
Table 7,
Table 8 and
Table 9 provide a visual assessment of
DVACE against alternative methods.
DVACE, DnCNN, and NAFNet produced cleaner images with well-preserved details, while Histogram Equalization and Gamma Correction enhanced contrast but amplified artifacts. Activity masks show
DVACE retained details with minimal distortions. Artifact masks reveal that
DVACE introduced fewer distortions than Median and MSRCP, while noise masks confirmed superior noise suppression compared to MSR-based methods and SSR. Overall,
DVACE provided the most balanced restoration.
To comprehensively present the results of the metrics calculated from the images in the validation dataset, which were processed by each of the aforementioned methods, box plots are provided below.
Figure 8 presents the
ERGAS metric distribution across different methods. The noisy image showed the highest values, with
DVACE achieving a low median and minimal variance, confirming its stable performance. Histogram Equalization and Gamma Correction also performed well, whereas MSR and MSRCR exhibited higher ERGAS values, indicating weaker global reconstruction.
DVACE maintained a consistent advantage with fewer outliers.
Figure 9 illustrates the
MSE distribution. The noisy image exhibits high error and dispersion, while
DVACE achieved a lower median
MSE with reduced variance, ensuring effective reconstruction. The deep learning models (DnCNN and NafNet) showed greater variability, and the MSR-based methods performed inconsistently.
DVACE remained one of the most reliable techniques.
Notably, Gamma Correction and Histogram Equalization, despite not being deep learning techniques or having noise reduction capabilities, achieved the next best results. In contrast, SSR demonstrated the poorest performance as both its dispersion and average error were significantly higher than those of the other methods.
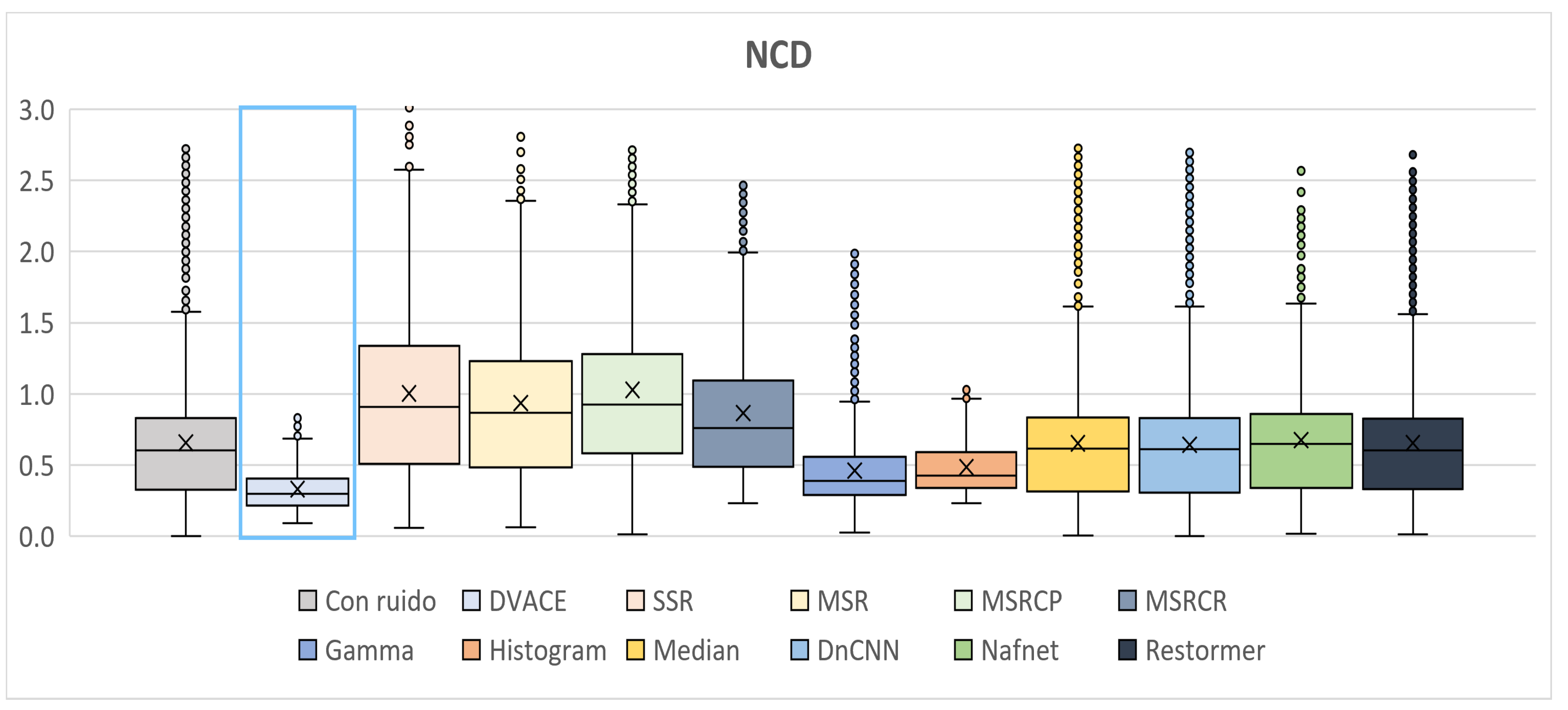
As shown in
Figure 10, the
NCD metric, which reflects color fidelity, was evaluated.
DVACE achieved one of the lowest median
NCD values with minimal dispersion, confirming its effectiveness in preserving perceptual color accuracy. While Histogram Equalization and Gamma Correction yielded competitive results, it introduce variability. The deep learning methods performed well but with slightly higher dispersion.
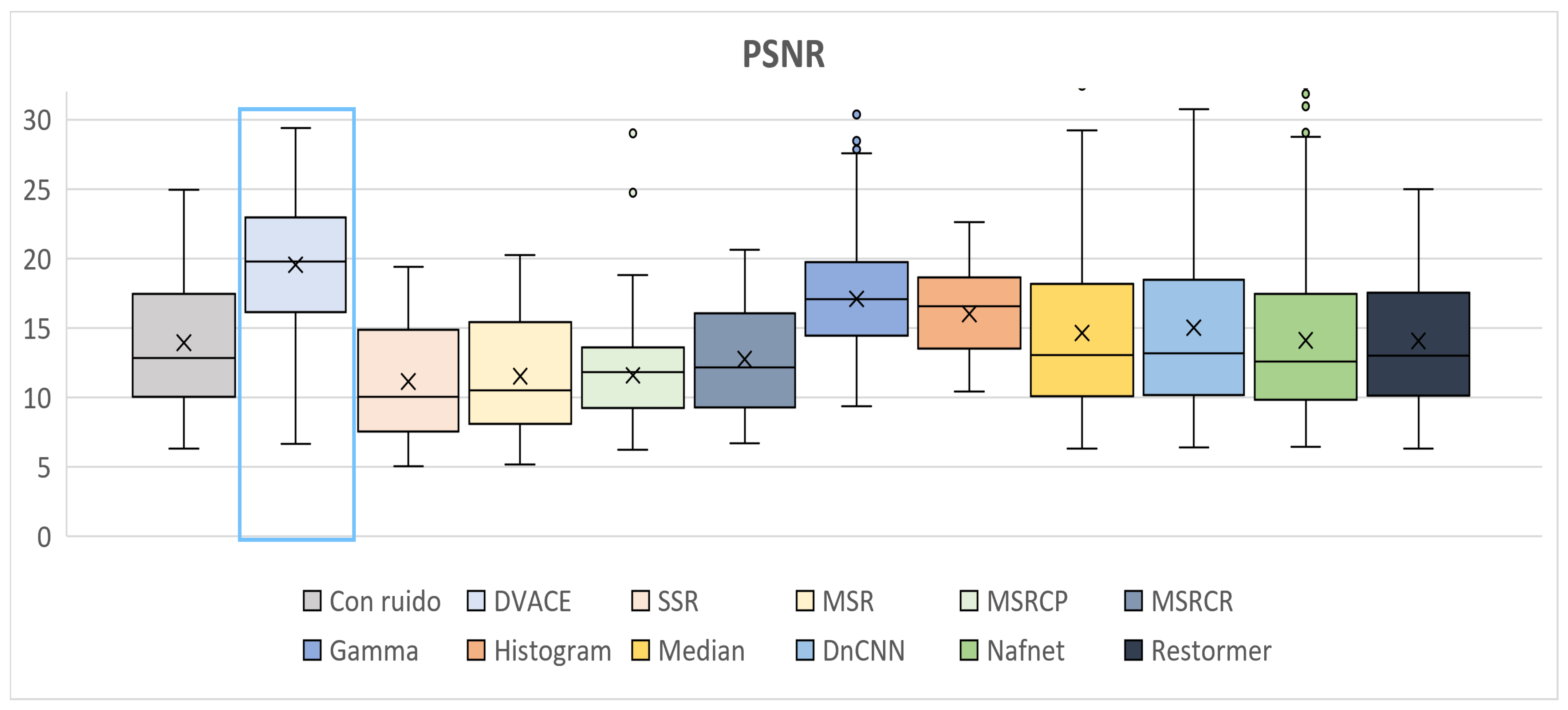
Figure 11 presents the
PSNR distribution. The noisy image exhibited the lowest values, while
DVACE achieved a high median
PSNR with low variance, ensuring effective noise reduction and image fidelity. The deep learning models maintained competitive values but showed dataset-dependent behavior. The MSR-based methods performed worse in key metrics.
As shown in
Figure 12, the
RASE values, which indicate spectral reconstruction accuracy, were captured. The noisy image had the highest values, whereas
DVACE maintained a lower median with reduced variance. Histogram Equalization and Gamma Correction achieved good results but exhibited more variability. The deep learning models and MSR-based methods showed inconsistent performance.
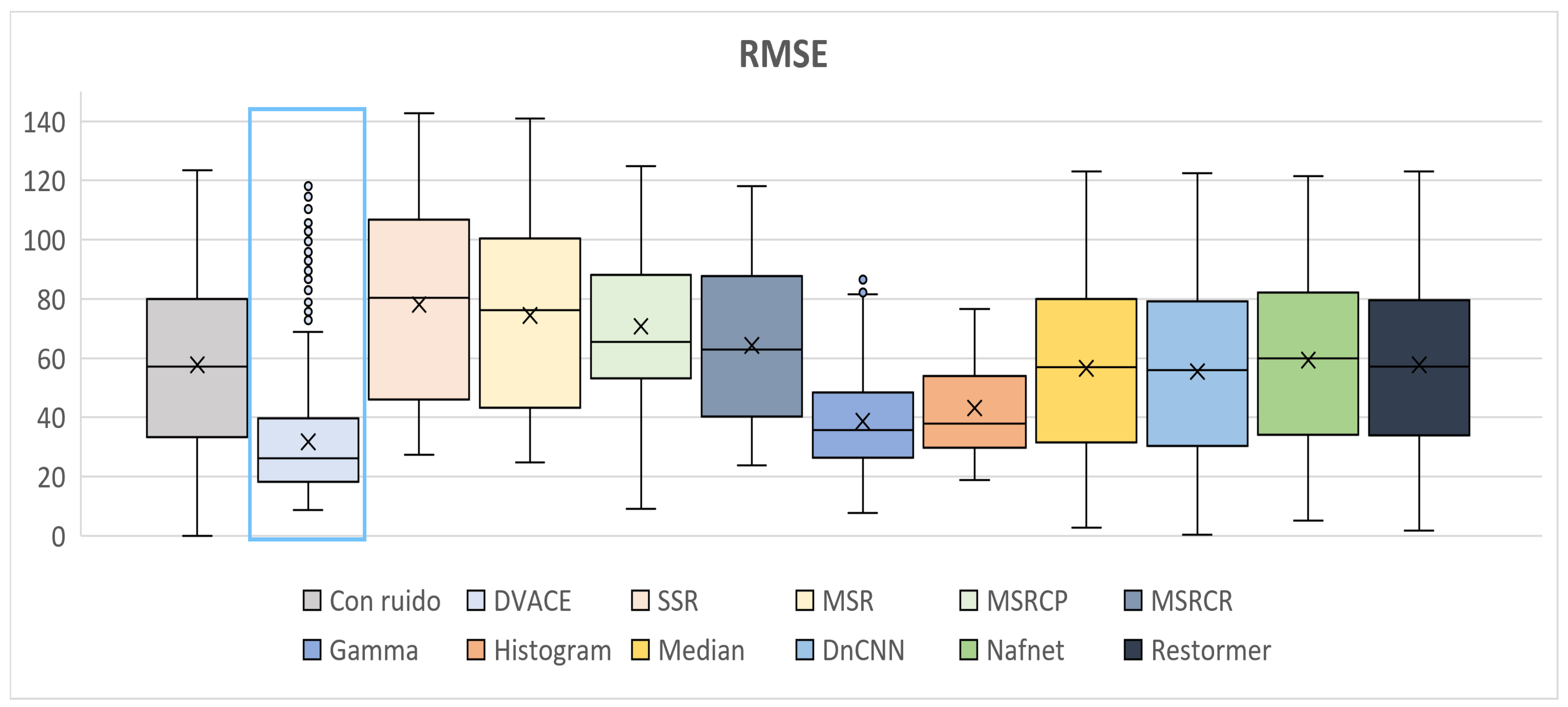
Figure 13 illustrates the
RMSE values, reflecting the reconstruction accuracy. The noisy image exhibited the highest
RMSE, while
DVACE achieved a low median with reduced dispersion, confirming its stability. The deep learning models remained competitive but more variable. The MSR-based methods and SSR showed weaker performance.
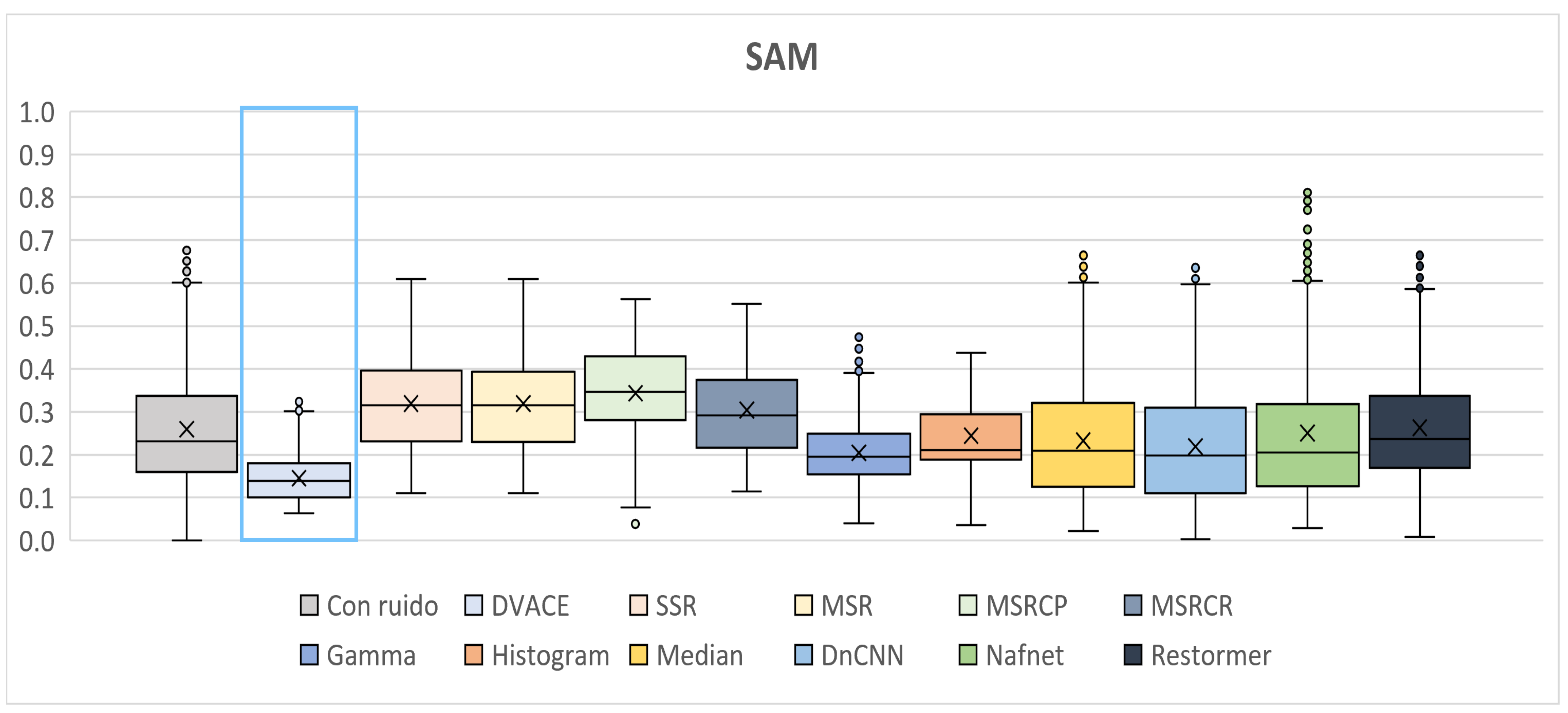
Figure 14 presents the
SAM values, which measure the spectral fidelity. The noisy image showed significant spectral distortions, while
DVACE achieved one of the lowest median
SAM values, ensuring improved spectral consistency. Histogram Equalization and Gamma Correction performed well but introduced more variability.
As shown in
Figure 15, the
SSIM, which reflects the image quality, was evaluated. The noisy image had the lowest values, while
DVACE achieved a high median with minimal variance, confirming its structural preservation. The deep learning models showed competitive performance, while the MSR-based methods underperformed.
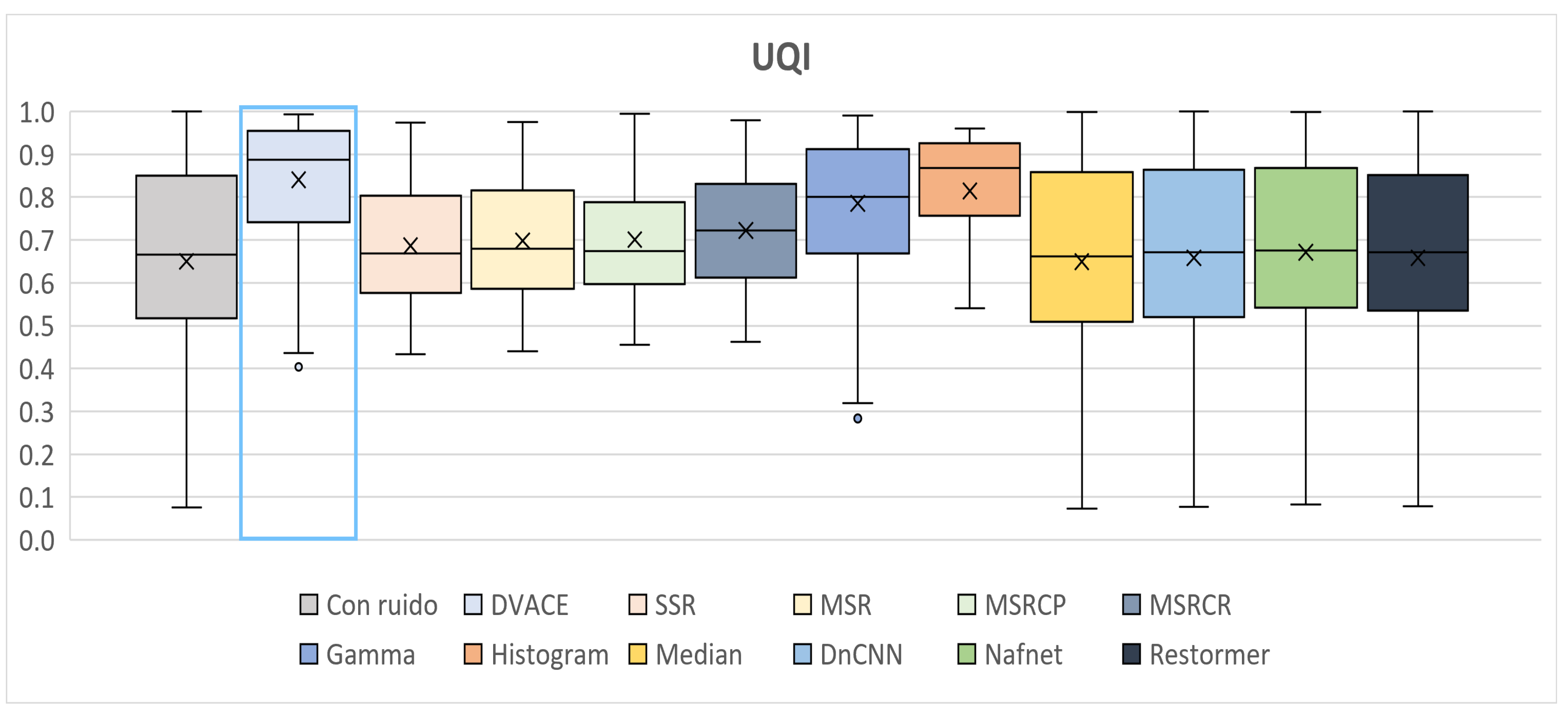
Finally, as shown in
Figure 16, the
UQI values, which assess the perceptual quality, were recorded. The noisy image exhibited the lowest UQI, while
DVACE achieved one of the highest medians with low dispersion, ensuring strong consistency. The deep learning models performed well but exhibited slightly higher variability.
Another critical factor to consider when evaluating the effectiveness of an image restoration method is its execution speed.
Table 10 presents the execution times of
DVACE for images with dimensions
,
,
,
,
, and
, all of which were corrupted via Gaussian noise with
and
.
Table 11 compares
DVACE with two versions of
DnCNN, showing that
DVACE maintained competitive execution times, especially for larger image resolutions. For
512 × 512 and
1024 × 1024,
DVACE outperformed
DnCNN in efficiency, with processing times of
0.049 s and
0.075 s, respectively, demonstrating its advantage in speed without compromising restoration quality.



 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}