1. Introduction
The IWD is a versatile tool that can be easily applied to model various processes across different fields. These include reliability, ecology, medicine, biological studies, public health, and economics. The distribution has been extensively explored in the literature, where its properties and wide-ranging applications have been discussed. Notable contributions can be found in the works of [
1,
2,
3,
4].
The CDF and PDF of the IWD with parameters
is given, respectively, by
and
where
is the scale parameter and
is the shape parameter.
The GIWD was first introduced by [
5] and has proven to be an effective model for a wide range of applications. It is particularly useful in fields such as medicine and biological studies, where it can accurately represent various processes. Its flexibility makes it a valuable tool in these disciplines, providing a reliable framework for modeling complex phenomena.
The CDF and PDF of the GIWD with parameters
are given, respectively, by
and
where
and
are the scale parameters and
is the shape parameter.
The authors of [
6] successfully defined the three-parameter modified Weibull distribution by extending the traditional Weibull distribution. This extension involved the inclusion of an additional term,
. Similarly, the authors of [
7] developed a new extended Weibull distribution by modifying the Weibull distribution through the addition of the term
. Following a comparable approach, it is possible to derive the MGIWD by adding the term
. Then, the CDF and PDF of the MGIWD with parameters
can be given, respectively, as
and
where
and
are the scale parameters and
and
are the shape parameters.
The DD, which was first proposed by [
8], has found several important applications across a variety of fields. In finance, actuarial sciences, and economics, it plays a key role in modeling the distribution of personal income, where it is highly valued for its ability to represent income size distribution. The DD, which is the most well-known model in economics, is essentially a BIIID with an added scale parameter and a sub-model of the GB2, as highlighted by [
9].
The CDF and PDF of DD with parameters
are given, respectively, as
and
where
is a scale parameter and
and
are the shape parameters.
A generalization for DD has been proposed by a number of authors in order to produce more adaptable models. The authors of [
10] presented a new model named gamma Dagum distribution, and the Weibull Dagum distribution was proposed by [
11]. By explicitly interpreting the Dagum family’s parameters in terms of the income median, inequality, and poverty measures, ref. [
12] proposed novel formulations of the Dagum family, which are widely appreciated for modeling the income distribution. In [
13], the exponentiated generalized exponential Dagum distribution was proposed and investigated. One of the generalizations that is the subject of this study is the MDD, which was studied by [
14]. It is also considered a generalization of both MBIIID [
15] and the modified Fr´echet distribution [
16]. The CDF and PDF of MDD with parameters
can be written, respectively, as
and
where
is a scale parameter and
,
, and
are the shape parameters.
A range of CDF forms that can be useful for fitting data was outlined by [
17]. These forms provide different approaches for modeling and analyzing data in various contexts. Among the various CDFs discussed, one notable example is the BIIID, which is often employed due to its versatility and ability to fit different types of data effectively. The BIIID has a wide range of applications in statistical modeling. It is particularly useful in various fields where statistical analysis is essential, including reliability, forestry, and engineering; see, for example, [
18,
19,
20]. The CDF and PDF of BIIID with parameters
, which are a special case of the CDF and PDF for DD when
in Equations (
7) and (
8), can be written, respectively, as
and
There are various techniques available for introducing multivariate distributions. One of the earliest approaches was proposed by [
21], who introduced the multivariate Pareto distribution. This particular distribution is characterized by having Pareto marginals, which are individual Pareto distributions for each variable in the multivariate context. Another technique for obtaining multivariate distributions is introduced by [
22]. In his paper, a method to derive the multivariate Burr Type-XII distribution is presented. This distribution is notable for deriving Burr Type-XII marginals, meaning that each individual marginal follows a Burr Type-XII distribution. Additionally, ref. [
23] proposed a new class of multivariate distributions conducted by compounding the likelihood function of a specific distribution with a gamma distribution. Also, by applying a suitable transformation to Takahashi’s multivariate Burr distribution [
22], ref. [
24] introduce a new type of distribution known as the MVGED. Ref. [
25] introduces two distinct techniques for creating multivariate versions of the GB2 distribution. The first technique emphasizes stochastic dependency through gamma random variables, while the second relies on generalizing the distribution of the order statistics.
Copulas are powerful multivariate statistical modeling tools that depict the dependence structure between random variables independently of their marginal distributions. According to Sklar’s Theorem (see [
26]), each multivariate distribution can be decomposed into its marginal distributions and an associated copula function. Also, the concept of a copula is derived from the separation of the joint CDF into two parts: one that explains the dependent structure and the other that describes the marginal behavior. Among the various families of copulas, the Clayton copula is widely used for modeling asymmetric lower tail dependence. Let the k-variate random vector
; then, the k-variate Clayton copula can be given as
where
are uniformly distributed marginal variables, and
is the copula parameter controlling the strength of dependence. As
, the Clayton copula approaches independence.
This paper uses two methods suggested in [
21,
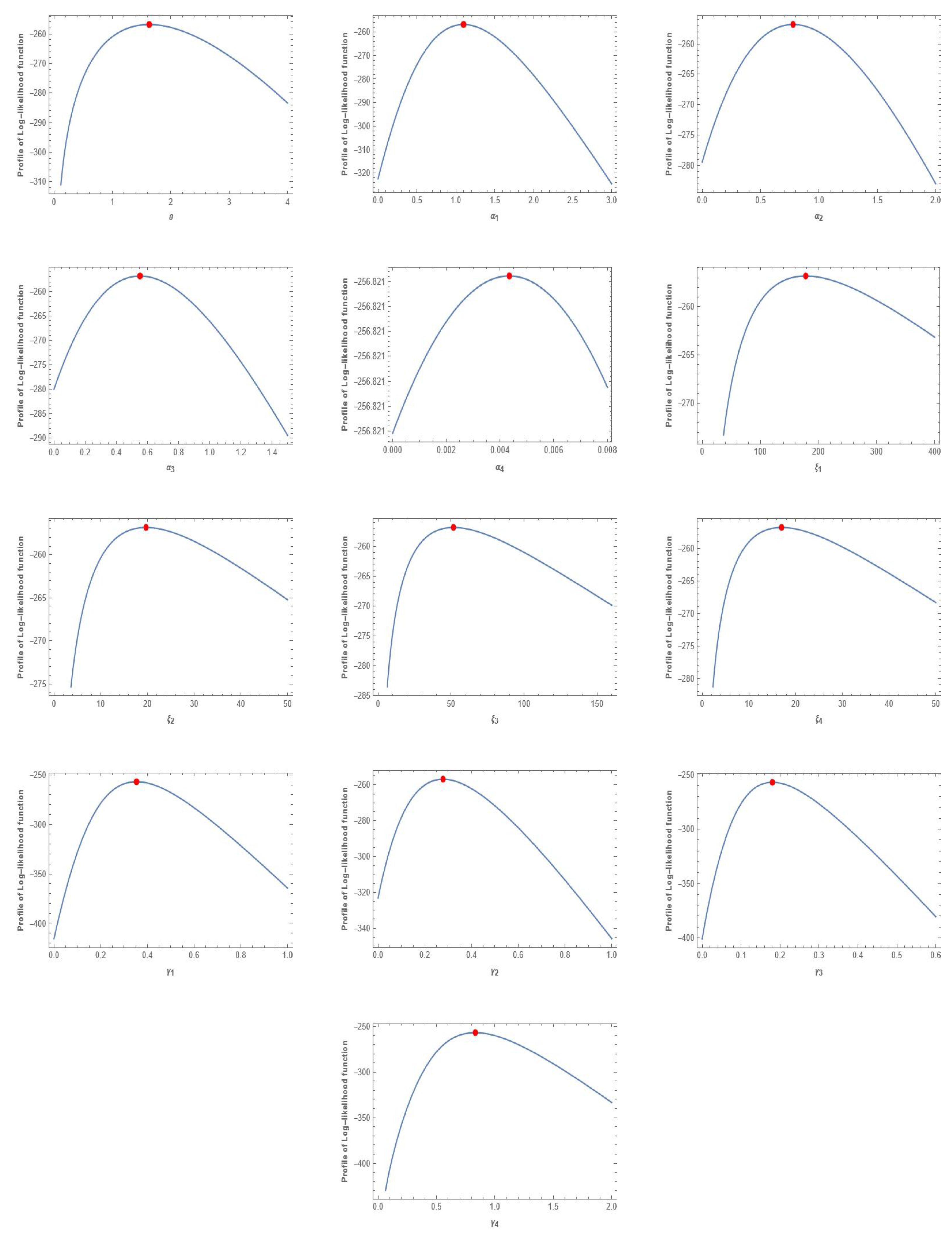
22] to obtain the joint PDF for the MVMDD and its sub-models. Furthermore, it is possible to demonstrate that the joint CDF for MVMDD can be achieved for the first approach by using the conventional approach, and the second approach can be obtained by using the Clayton copula. Several properties are discussed for MVMDD. The maximum likelihood estimation cannot be obtained in closed form, so a numerical method can be used. The effectiveness of the suggested model and the approach in a practical setting has been demonstrated using two real data sets.
The structure of the paper is organized as follows.
Section 2 presents the derivation of some necessary prerequisites. In
Section 3, the MVMDD and its sub-models are introduced.
Section 4 explores various statistical properties of these distributions.
Section 5 investigates the multivariate dependence properties for MVMDD. The maximum likelihood estimation method is discussed in
Section 6. Two applications within the public health field and warranty policies are illustrated in
Section 7. Finally,
Section 8 provides concluding remarks and future work.
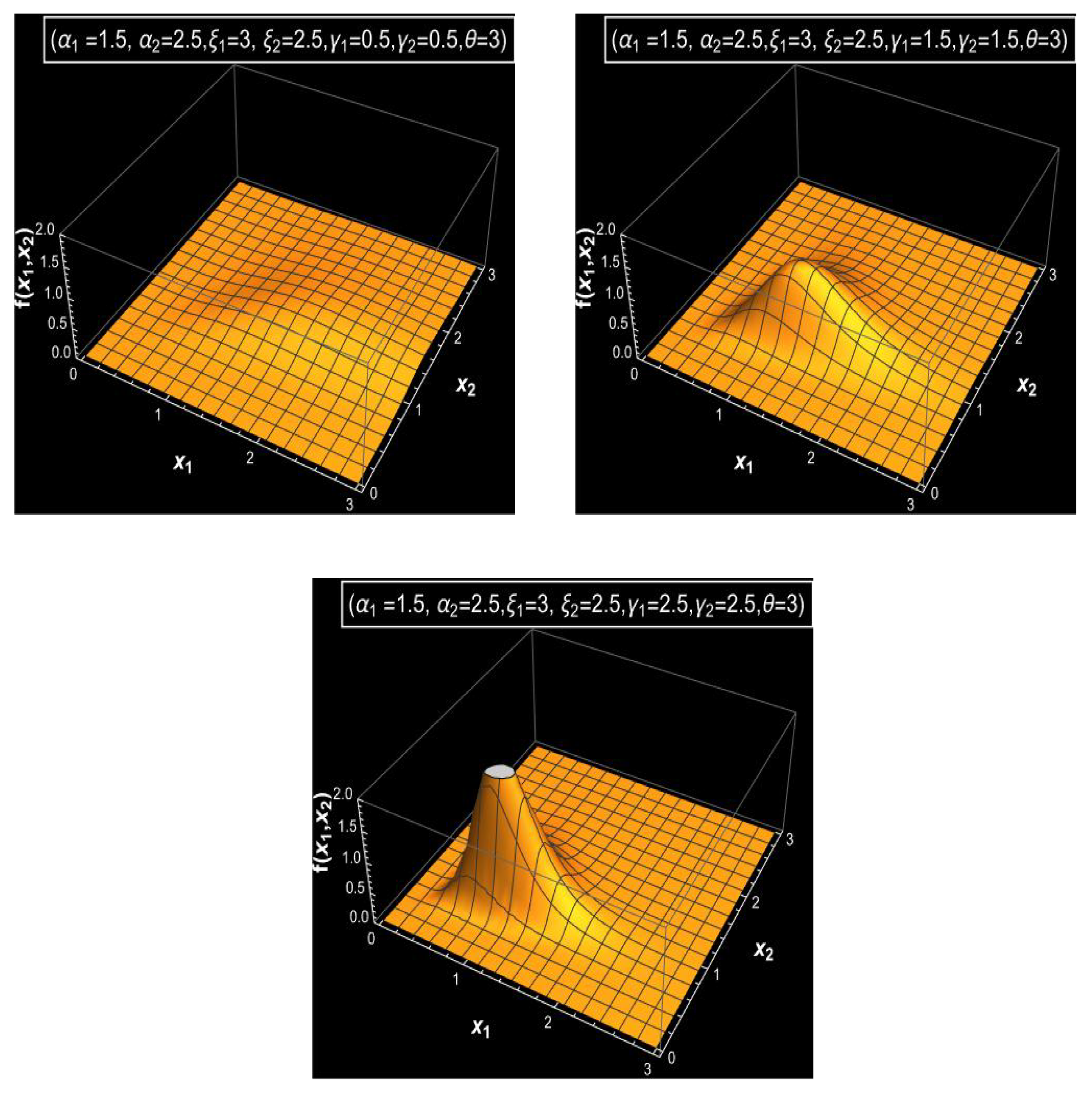
4. Properties of the Proposed Distribution
In this section, some properties of MVMDD are discussed. The marginals of PDF and CDF for MVMDDs can be obtained in closed form and also classified as the PDF and CDF of MVMDDs. Additionally, the conditional distribution can be obtained for MVMDD, and the random samples can be generated from MVMDD.
Lemma 5. For any MVMDD, the following properties are satisfied.
- (i)
Every marginal CDF obtained from MVMDD is also classified as the CDF of MVMDD.
- (ii)
Every marginal PDF obtained from MVMDD is also classified as PDF of MVMDD.
- (iii)
Every conditional distribution obtained from MVMDD is also classified as MVMDD and is given by
which follows the MVMDD with joint PDF
.
Proof. To prove the preceding lemma, the following steps are required:
- (i)
The proof for Lemma (5) (i) can be obtained directly from (
19) as follows:
which is the joint CDF for MVMDD
, and
,
,
, and
.
- (ii)
The proof for Lemma (5) (ii) can be obtained directly by integrating (
17) from 0 to
∞ with respect to
as follows:
which is the joint PDF for MVMDD
.
- (iii)
The proof for Lemma (5) (iii) can be obtained directly from (
17), and the proof of Lemma (5) (ii) is as follows:
where
is given by (
17) and
can be directly obtained from the proof of Lemma (5) (ii) as follows:
□
The following lemma can be used to generate random samples from MVMDD.
Lemma 6. Let be the joint PDF of MVMDD, which is given by (17). - (i)
The marginal PDF of and the conditional PDFs of , , …, are, respectively, given by - (ii)
The corresponding CDFs for the marginal PDF of and the conditional PDFs of , , …, are, respectively, given by
Proof. From Lemma 5 (ii and iii), Lemma 6 (i) can be easily proved. Additionally, Lemma 6 (ii) can be proved from Lemma 6 (i) by the traditional method. □











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}