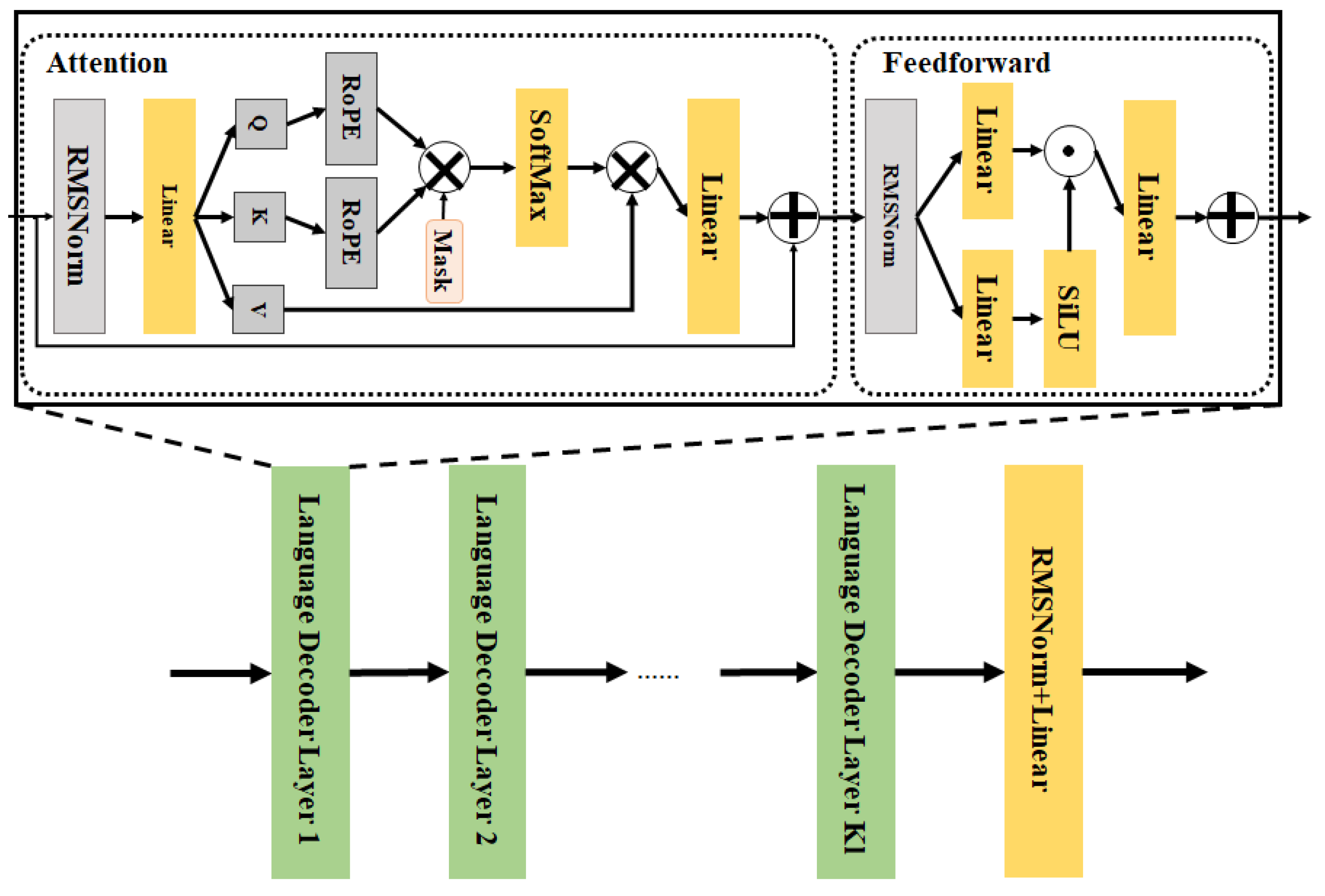
To better demonstrate the improved adaptability of the enhanced model to workover scenes, we conducted comparative experiments between the enhanced model and the basic Qwen-VL model. We evaluated the performance of the models in terms of both the accuracy of scene interpretation and the reliability of text generation.
4.4.1. Comparative Analysis of the Accuracy of Scene Interpretation
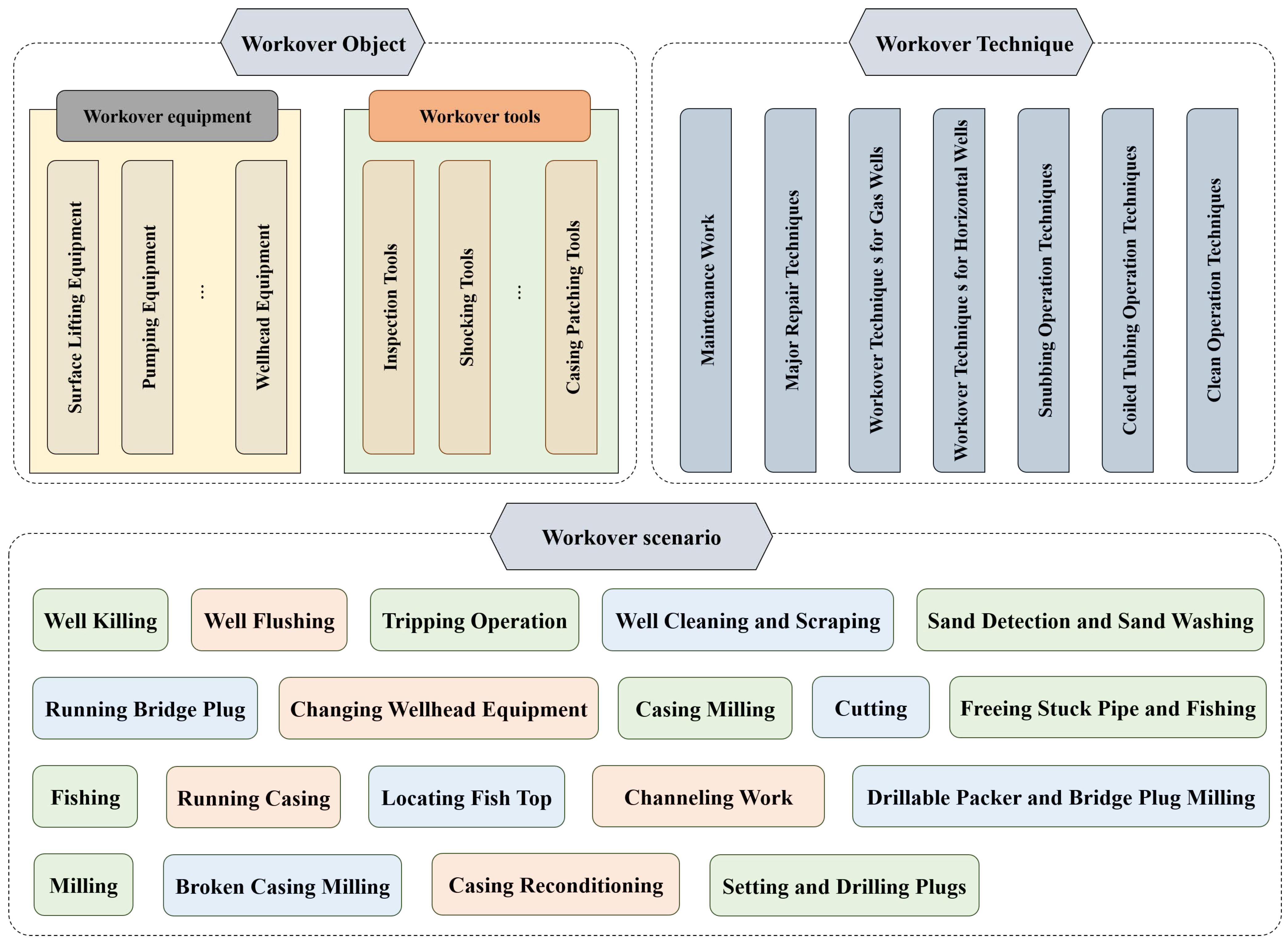
The focus of this experiment is on accurately identifying various types of equipment and workers at workover sites to ensure the outstanding performance of the recognition system. The system should not only quickly and accurately distinguish key operational equipment, such as drilling rigs, pump trucks, and cranes, but also be sensitive enough to differentiate the identities and activity statuses of operators, safety supervisors, and other on-site workers. Achieving high-precision capture of dynamic elements in complex workover scenes is crucial for enhancing safety management, optimizing workflows, and early detection and prevention of accident risks at construction sites. This lays a solid foundation for the digital transformation and intelligent management of the oil and gas extraction industry. During our research process on the validation set, which included 1243 images with corresponding annotations, we selectively focused on key workover equipment and on-site workers, as shown in
Table 5, as the main research subjects, and quantified the performance differences of the vision language model before and after the implementation of prompt enhancement technology. It is worth mentioning that the table lists different names for the same target, and the content mentioned here has been processed for plural vocabulary. The study covered the evaluation of the precise identification and classification capabilities of workover equipment and personnel, revealing how prompt enhancement technology effectively enhances the practicality and robustness of vision language models in complex industrial environments, especially in oil extraction workover scenes. This provides a solid theoretical and practical basis for further advancing the intelligent management technology of oil fields.
During the testing phase, the scene assessment of the vision-language model encompasses 8 targets. By inputting “List the workover targets in the image” into the language branch, the model is prompted to meet the task requirements, facilitating the statistical evaluation of the model’s recognition performance. The study selects accuracy, precision, and recall as three metrics to objectively assess the model’s scene recognition capability. Accuracy indicates the overall correctness of the model’s classification for all samples, providing an intuitive reflection of the model’s discrimination and classification ability. High precision implies that the classifier should tend to classify samples as positive when facing “highly confident” instances, effectively mapping the model’s ability to distinguish non-target categories. Thus, an increase in precision directly corresponds to the enhancement of the model’s ability to discern negative samples. Conversely, an improvement in recall highlights the classifier’s determination and efficiency in capturing all positive samples, demonstrating the model’s acumen in differentiating positive instances. A higher recall indicates the model’s positivity and superior differentiation in recognizing positive classes. The calculation formulas are as follows:
where
TP represents True Positives,
FP represents False Positives,
FN represents False Negatives, and
TN represents True Negatives. During the experimental process, due to the presence of multiple target classes in a large number of images, the multi-class confusion matrix results are illustrated in
Figure 10. In the figure, category 8 represents the set of samples where none of the classes 0 to 7 exist.
From the images, it can be visually observed that the model, after prompt enhancement, exhibits significant improvements in the recognition accuracy and precision for various target categories, with a slight increase in recall, as summarized in
Table 6. Regarding the results, the categories of Modular building and Pumping equipment showed relatively low precision in the original vision language model’s recognition. The former might be attributed to the conventional understanding that the equipment on the wellsite does not include this category. However, we introduced this category in our study because a Modular building serves as the rest area for construction personnel, which is instructive for the delineation of wellsite areas. On the other hand, pumping equipment might be overlooked by the model due to scale issues, which is also a problem inherent in the current Vision Transformer-based vision encoder. Overall, compared to the previous version, the model’s accuracy has improved by 13.21%, precision by 14.94%, and recall by 0.32%. The enhanced prompt model demonstrates a significant enhancement in scene judgment capability, enabling the identification of workover scene targets.
Furthermore, we also calculated the precision and recall rates for each category both before and after prompt enhancement. The results, presented in
Table 7, show that most categories have experienced improvements in both precision and recall rates. These results further verify the significant improvement of the suggested enhancement model in recognizing targets of different categories.
4.4.2. Comparative Analysis of the Reliability of Text Generation
The core of this experiment lies in the in-depth analysis of the specific impact of prompt enhancement strategies on the performance of the vision language model, focusing on evaluating its effectiveness in improving the accuracy, naturalness, and contextual coherence of text generation. By providing clear guiding information to the vision language model through prompt enhancement, it significantly reduces the ambiguity and inaccuracy of the output while maintaining the diversity of predictions. The experiment employs standardized evaluation metrics, using the change in perplexity (
PPL) of the model’s generated text after prompt enhancement as an indirect reflection of language fluency and logical coherence [
48]; the calculation formula is as follows:
where
PPL(
W) stands for generated text
W; exp represents exponential function with natural logarithm e;
N represents the number of samples;
C represents the length of the generated text tokens;
pt denotes the vocabulary distribution of the true labels; and
qt represents the predicted vocabulary distribution. Perplexity serves as a reliability metric for language generation models, primarily because it reflects the quality and internal logical consistency of generated text from multiple dimensions. Perplexity indicates the uncertainty of the model’s predictions given the data, with lower values indicating more accurate predictions and a deeper understanding of language patterns by the model. In vision language generation tasks, low perplexity not only indicates that the model can better understand vision inputs and generate natural and coherent text but also reflects the model’s progress in learning and capturing the relationship between vision features and language descriptions.
Recall-Oriented Understudy for Gisting Evaluation (ROUGE) is an evaluation metric for assessing the quality of generated text by comparing it with reference text [
49]. It focuses on evaluating the recall of the generated text concerning the reference text, which measures the extent to which the generated content covers the information present in the reference text. This is achieved by calculating metrics, such as the longest common subsequence, including the consideration of out-of-vocabulary terms. The formula for calculating ROUGE is as follows:
where
X and
Y represent the reference text and the generated text, respectively;
lX and lY represent the lengths of the reference text and the generated text, respectively;
LCS(
X,
Y) denotes the longest common subsequence of
X and
Y;
Rlcs and
Plcs represent recall and precision, respectively;
Flcs represents the ROUGE score;
is a hyperparameter representing the balance between recall and precision, which was set to 8 during the experimental process to ensure no key information was overlooked.
Consensus-based Image Description Evaluation (CIDEr) is a crucial evaluation metric for image description tasks, focusing on measuring the similarity and semantic consistency between machine-generated image descriptions and reference descriptions. CIDEr [
50] aggregates the co-occurrence of n-grams, weighted by Term Frequency-Inverse Document Frequency (TF-IDF), between model-generated descriptions and multiple reference descriptions into a single score, emphasizing the importance of reaching consensus with multiple reference descriptions. TF-IDF plays a key role in mining keywords in the text and assigning weights to each word to reflect its importance to the document’s topic. TF-IDF consists of two parts: Term Frequency (TF), representing the frequency of a word appearing in a document, usually normalized to prevent bias towards longer documents, and Inverse Document Frequency (IDF), representing the reciprocal of a word’s frequency across the entire corpus, typically logarithmically scaled to prevent bias towards rare words. This approach helps capture the overall quality of descriptions and favors generated content that closely aligns with human consensus, providing a comprehensive indicator of description quality under multiple reference standards. The calculation method for CIDEr is as follows:
where
gk represents the TF-IDF vector;
Ii represents the evaluated image;
represents the vocabulary of n-grams;
I represents the set of image datasets;
Si = [s
i1,…,s
im] represents the image description for
Ii, where
sij is one of its words;
hk(sij) denotes the frequency of occurrence of phrase
wl in the reference sentence
sij; min() denotes the minimum value; CI represents the CIDEr metric result; c
i represents the candidate sentence;
N denotes the highest order of n-grams used;
represents the weight of n-grams, typically set to 1/N; m represents the number of reference sentences; and ||
gn|| denotes the size of vector
gn.
Comparative analysis of model reliability using perplexity as a metric not only allows for the evaluation of prediction efficiency from a statistical perspective but also provides insights into the model’s generalization ability, internal mechanisms, and adaptability to complex tasks. ROUGE evaluates the quality by comparing the overlap between generated content and reference text, providing a multidimensional, practical, and interpretable assessment that effectively reflects the content overlap between generated and reference texts. CIDEr, stemming from statistical consensus, emphasizes the contextual consistency and consensus information between generated content and multiple reference descriptions, capturing contextual relevance in descriptions. However, this metric exhibits poorer adaptability for evaluating longer sentences. Therefore, we utilized the image’s overall description sentence, as mentioned earlier, as the reference text for CIDEr. Additionally, we guided text generation with the prompt “Describe the image in one sentence” for the vision language model’s textual input. These three metrics were employed to assess the generated text of the vision language model before and after prompt enhancement, as shown in
Table 8.
The results from the table indicate that the perplexity of the vision-language model decreased from 3414.88 to 74.96 after prompt enhancement, suggesting a reduction in uncertainty when handling workover scene description tasks. The model’s predictive capability improved, leading to more precise text generation. Moreover, the ROUGE metric increased from 0.217 to 0.379, indicating that the generated scene descriptions are closer to the original information content, enhancing information coverage. Additionally, the generated text exhibits closer adherence to the sentence structure and grammatical features of the reference text, demonstrating improved quality or information recall capability. Lastly, the model’s CIDEr score increased from 0.038 to 3.324. The original model’s performance in scene description was disappointing, as it failed to meet application requirements due to a lack of domain-specific language expression capabilities. However, the improvement indicates a significant enhancement in performance in tasks such as image description or related text generation, achieving a high degree of consistency with human evaluation standards in image description tasks. In summary, the prompt-enhanced vision-language model demonstrates the capability to provide language descriptions for workover scenes.
To better demonstrate the impact of hint enhancement on model performance, we present text generation results for a test scenario, as shown in
Figure 11. This image illustrates the process of Well Overhaul scene during workover operations. In the lower left corner of the image is the workover rig, and the derrick equipment with a platform for workover is in the middle, along with lifting equipment and vertical tubing. A large workover rig and equipment stand in an outdoor setting. The result of Qwen-VL is as follows: The picture depicts a bustling scene at a large workover platform against a backdrop of a clear blue sky. The platform, composed of red and yellow structures, features a prominent crane arm, numerous cables and pipelines, indicating its industrial nature. On the platform, workers dressed in safety gear are engaged in workover operations, while several trucks are parked nearby, likely used for transporting equipment or materials. A large red and yellow oil rig is being used to extract crude from a well. Prompt_VL indicates the result as follows: In a clear sky, a large workover rig stands prominently in an open area, surrounded by several trees. The rig features a tall tower with a red and white platform near the top, and below it, multiple pieces of machinery and equipment are arranged, including a derrick equipment and pipelines. The scene portrays a hectic yet organized atmosphere at the workover platform. The baseline model provides a somewhat referenceable recognition of the image, focusing on the workover platform and successfully identifying the pipes. However, it also hallucinates the presence of “workers” and “several trucks”. In contrast, the prompt-enhanced model eliminates these hallucinations and successfully identifies the large-scale workover rig, derrick, and pipes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}