1. Introduction
In the literature of operations research (OR) and machine learning (ML), stochastic optimization problems of the following form have been widely studied:
where
is a random vector with distribution
,
is the decision variable restricted to the set
,
represents a cost/loss function and
is a measure of risk under the constraint that the distribution of the random variable is
. In ML applications, the function
typically takes the form
. In OR,
always typifies the disutility function, and
is used as a tool to quantify risks.
In practice, the true distribution
of
is often unknown. To overcome the lack of knowledge on this distribution, distributionally robust optimization (DRO) was proposed as an alternative modeling paradigm. It seeks to find a decision variable
that minimizes the worst-case expected loss
, where
is referred to as the ambiguity set characterized through some known properties of the true distribution
. The choice of
is of great significance and there are typically two ways to construct it. The first is moment-based ambiguity which contains distributions whose moments satisfy certain conditions [
1]. The other, more popular approach is the discrepancy-based ambiguity set which is generally taken as a ball that contains distributions close to a nominal distribution with respect to a statistical distance. Popular choices of the statistical distance include Kullback–Leibler (KL) divergence [
2,
3], the Wasserstein metric [
4], etc. Since the Wasserstein metric can be defined between a discrete distribution and a continuous distribution, the ambiguity set based on the Wasserstein metric includes richer distributions than that based on divergence [
5]. This makes the Wasserstein metric more popular in modeling the ambiguity set. However, the authors of [
5] point out that the ball
is desirable as it contains various forms of distributions; however, the flip side is that it may be considered overly-conservative as distributions differing greatly from the empirical distribution may also be included.
Motivated by this, we extend classic Wasserstein metrics to shortfall–Wasserstein metrics by applying the utility-based shortfall risk measures to summarize the distribution of a transportation cost random variable. The formal definition will be given in
Section 2. It is worth noting that the properties of the utility-based shortfall risk measure are widely researched in the literature of risk measures [
6,
7] and that it naturally includes the expectation as special cases. Based on the shortfall–Wasserstein metrics, we define an ambiguity set and formulate a new DRO problem. The utility based shortfall risk measure has been applied well in DRO; see, e.g., [
8,
9]. However, in the literature, the shortfall risk measure serves as an objective risk measure. In this paper, we employ a utility-based shortfall risk measure to construct the ambiguity set instead of the objective function, which is novel. Moreover, in this paper, we study the tractability of the new problem. In particular, we study the reformulation of the problem and reduce the problem to a convex problem with tractability. For the new metric, the property of the finite sample guarantee is also studied. In particular, to obtain those results, a key result is the projection result of the ambiguity set based on the shortfall–Wasserstein metric. Such projection result for different ambiguity sets have been studied by [
10,
11]. In this paper, a necessary and sufficient condition for the projection result of the new ambiguity set is given.
The main contribution of the paper can be summarized as follows.
A new family of Wasserstein metrics based on utility-based shortfall risk measures is introduced and is called the shortfall–Wasserstein metric. We propose a data-driven DRO problem based on the shortfall–Wasserstein metric. It is shown that the new DRO model has the benefits of desirable properties of finite sample guarantee and computational tractability.
For the new shortfall–Wasserstein metric, we define the corresponding uncertainty set, which is called the shortfall–Wasserstein ball, and give an equivalent characterization of the projection result to a one-dimensional ball. Based on the projection result, we show that the multi-dimensional constraint of our distributionally robust optimization model can be reformulated as a one-dimensional one. Based on this reformulation, we established the finite sample guarantee of the DRO problem which is free from the curse of dimensionality.
We obtain a dual formulation for the robust optimization problem and verify the strong duality. In addition, the dual form admits a reformulation that can be completely characterized when taking the discrete empirical distribution as the center of ambiguity sets.
2. Shortfall–Wasserstein Metric
Motivated by data-drivenness, the choice of
is usually chosen as the empirical distribution. Let us denote the training dataset by
and the empirical distribution by
, with
denoting the Dirac distribution at
. In the DRO models introduced above, the choice of the probability metric
d plays a significant role in constructing the ambiguity set
. One of the most widely used probability metrics is the (type-1) Wasserstein metric [
16]
which is applicable to any distributions
with finite first moments. In this paper, we take
norm
with
. The ambiguity set based on the Wasserstein metric is naturally defined as
which is called the Wasserstein ball centered at
with radius
. In the literature, the distributional robust problem with the ambiguity set being the above Wasserstein ball has been widely studied [
4,
12,
13] and is known as the Wasserstein data-driven distributionally robust optimization model (W-DD-DRO),
As argued by [
5], the ball
is desirable as it contains various forms of distributions; however, the flip side is that it may be considered overly-conservative as distributions differing greatly from the empirical distribution may also be included. Motivated by this, they proposed the CVaR–Wasserstein and expectile–Wasserstein balls and studied the reformulation and tractability of the corresponding DRO problems. In this paper, we extend the expectile–Wasserstein metrics to Shortfall–Wasserstein metrics by applying normalized utility-based shortfall risk measures to evaluate the transportation cost.
2.1. Risk Measures
We first introduce some notions of risk measures. Let be the probability space, and is the -algebra on . Following the convention in mathematical finance, we describe a risk by a random variable . A risk measure is a functional mapping from a set of risks to . We list some desired properties as follows:
- (P1)
(Translation invariance) for ;
- (P2)
(Positive homogeneity) for any ;
- (P3)
(Monotonicity) for any ;
- (P4)
(Subadditivity) ;
- (P5)
(Convexity) ;
- (P6)
(Law invariance) for any .
A risk measure satisfying the above properties (P1) and (P2) is called a monetary risk measure and a risk measure satisfying the above properties (P1)–(P4) is called a coherent risk measure, which has been viewed as one of the most important risk measures since the seminal work [
17]. A risk measure
is called a convex risk measure if it satisfies properties (P1), (P2) and (P5). We then introduce the definition of utility-based shortfall risk measures.
Definition 1 (Utility-based shortfall risk measures)
. Let be non-decreasing and continuous, satisfying . For a random variable X, the utility-based shortfall risk measure is defined as It is well known that any utility-based shortfall risk measure satisfies the monotonicity and translation invariance, and thus is a monetary risk measure. Based on the utility-based shortfall risk measure, we now formally give the definition of shortfall–Wasserstein metric as follows.
Definition 2 (Shortfall–Wasserstein metric)
. A metric is called the Shortfall–Wasserstein metric if it has the form ofwhere and is the norm on . We first study the basic properties of the shortfall–Wasserstein metric.
Proposition 1. Let be a convex, non-decreasing and continuous function satisfying . We have the following statements:
- (i)
satisfies the identity of indiscernibles, i.e., if and only if ;
- (ii)
satisfies the symmetry, that is, for any ;
- (iii)
satisfies the non-negativity, i.e., for any ;
- (iv)
If u is positively homogeneous, then satisfies the triangle inequality: for any , , .
Proof. (i) Denote by
the set of all distributions on
with margins
and
. To see the sufficiency, note that when
and
, the set
contains the joint distribution of
. Therefore,
as
. To see the necessity, note that under the condition,
satisfies convexity. By Theorem 4.2 of [
18], we have
. By that, the Wasserstein metric satisfies the identity of indiscernibles, then we have
.
(ii) The symmetry follows immediately.
(iii) Note that and u is non-decreasing, we have for every . As the norm is non-negative and u is non-decreasing, we have , which means that satisifes the non-negativity.
(iv) From the definition,
is convex and homogeneous as
u is convex and homogeneous. It follows that for any
,
exists such that
From Theorem 6.10 of [
19], we know that
exists such that
has the joint distribution
and
has the joint distribution
. As a result,
where the second equality is the result of the homogeneity of
and the last inequality holds due to the convexity of
and the subadditivity of the norm. □
Proposition 1 tells us that when u is increasing, convex and positively homogeneous with , then the metric satisfies all the desired properties of a distance metric.
2.2. Formula of DRO Problems Based on Shortfall-Wasserstein Metric
Based on the shortfall–Wasserstein metric, we define the following ambiguity set
which is called the shortfall–Wasserstein ball centered at the empirical distribution
. We consider the following problem
where
is the decision vector,
is the feasible set of decision vector, and
l is the loss function. The above problem (
2) is called the shortfall–Wasserstein data-driven distributionally robust optimization model (SW-DD-DRO).
To end the section, we present two applications of stochastic optimization (
1): regression and risk minimization.
2.2.1. Regression
Considering a linear regression problem, our purpose is to find a linear predictor function
with
the regression coefficient vector. Our attention here is to find an accurate estimator of
that is robust to adversarial perturbations of the data. Thus, distributionally robust regression models are constructed in the following form:
In the literature, the loss function always takes the form
with
, and the regression model is known as least-squares regression when
. For convenience, we denote
and
, then the problem can be reformulated as the form of (
2).
2.2.2. Portfolio Optimization
If we denote by
a random vector of returns from
n different financial assets and by
the allocation vector, then the random variable
means the total return of the portfolio. Thus, the problem (
1) is considered a portfolio optimization problem. As an example, the risk measure
is a well-known class of downside risk measure as the loss function takies the form of
.
4. Worst-Case Expectation under the Shortfall–Wasserstein Metric
This section studies the tractability of solving (
4). For notational convenience, denote
, and
X has a known probability distribution
. We define the primal problem in the following form:
where
. Let
,
[
15]. For every such
, define
For any
,
,
as
is finite. As a result, for every measurable
,
. Thus we have
According to the tradition in optimization theory, we refer to the following problem as the dual to the primal problem:
Consequently, the weak duality holds:
To further identify the equivalence between
and
, for every
, we define
as follows:
To simplify the notation, we write whenever and ; thus, we have . In Theorem 2, we show that, for performance measures l satisfying Assumption 4, equals .
Assumption 4. The function is upper semicontinuous with .
Theorem 2. Under Assumption 4 and , we can conclude
- (a)
;
- (b)
A dual optimizer of the form exists for some and defined as in (20). Moreover, any feasible solutions and are optimizers of the primal and dual problem, satisfying , if and only if
Additionally, if the primal optimizer exists and there is solely one y in that attains the supremum in for μ, almost every , then is unique.
Remark 1. From (21), if the optimal measure exists, , which means the worst-case joint probability is identified by a transport plan that transports mass from x to the optimizer of the local optimization problem . Furthermore, when , we obtain . Remark 2. If a subset exists, for any , the rate the loss function grows to is faster than the rate of growth, then . The reason is that for every and , ; thus, . Therefore, sometimes, it may be necessary to require the loss function l not to grow faster than c.
Corollary 2. Under the Assumption 4 and , we can conclude Proof. From the proof of Theorem 2, we can see that there always exist
, then we conclude
The proof is complete. □
Remark 3. This conclusion that the optimal value of the multi-dimensional primal problem can be obtained by paying attention to the univariate reformulation in the right-hand side of (23) is of great significance. Moreover, the right-hand side of (23) is completely characterized given and the training dataset . Looking back on the problem (
11), with
X taking values in
with equal probability and
, we obtain
Indeed, this result implies that this multi-dimensional optimization problem in (
5) can also be solved by putting effort into the completely characterized reformulation of (
24). Considering the problem with the ambiguity set constructed by the classic Wasserstein metric (the norm defined in the metric is also
with
),
Denote the inner maximum problem
, we can obtain a similar result by applying Theorem 7 of [
10] and Theorem 1 of [
15], that is
Observing the formulas above, we can find that
when
. The result (
24) is much more flexible than the result (
25) as the form of the
is optional.
To elaborate on the way our results help to solve practical problems, several simulations are introduced in the following.
5. Simulation
In this section, we show the application of Corollary 2 in solving the regression problem and the portfolio optimization problem. Moreover, several simulations are operated to investigate the performance of our model.
5.1. Regression Model
As mentioned in
Section 2, our result can help to find an accurate estimator of the regression coefficient vector in linear regression problems
with
and
. In the literature, loss functions with the form
are widely studied, especially when
and
. To elaborate on how this result helps to solve the tractability of regression programs, an example is presented below.
Example 1. The Least Absolute Deviation (LAD) regression model seeks the regression coefficient estimator that minimizes the sum of absolute residuals . Take , and more specifically, we take , . Then we have Let , then can be further broken down into the following form: Considering the case , then To make the supremum bounded, it is necessary to have , such that . Similarly, when , we can also derive . We next consider the following three cases.
- Case A.
Considering when , we can see that is non-increasing whether is non-negative or non-positive; thus, attains its supremum at , with
- Case B.
Considering when , we are supposed to further consider the form of under the cases and .
(Case B.1) If , The supremum in this case is .
(Case B.2) If and , The supremum in this case is .
(Case B.3) If and and , The supremum in this case is .
(Case B.4) If and and , The supremum in this case is .
Combining the above four subcases, we conclude that the supremum is in Case B. Moreover, in all different situations, keeps the property of first monotonically increasing and then monotonically decreasing.
- Case C.
Considering when , similar to Case A, is non-decreasing and attains its supremum at , with
Combining the above three cases, we have that is monotonically increasing and then monotonically decreasing under all situations. The supremum is . As a result, we have the optimum value We can also consider this problem under the Wasserstein metric. A similar discussion yields that
Although the two results share similar formulas, the result under the shortfall–Wasserstein metric is more flexible as it is possible to adjust the parameters to achieve better performance.
The model that we simulated here is as follows:
Applying the above result under the shortfall–Wasserstein metric to this practical problem, we are supposed to find an estimator
that minimizes
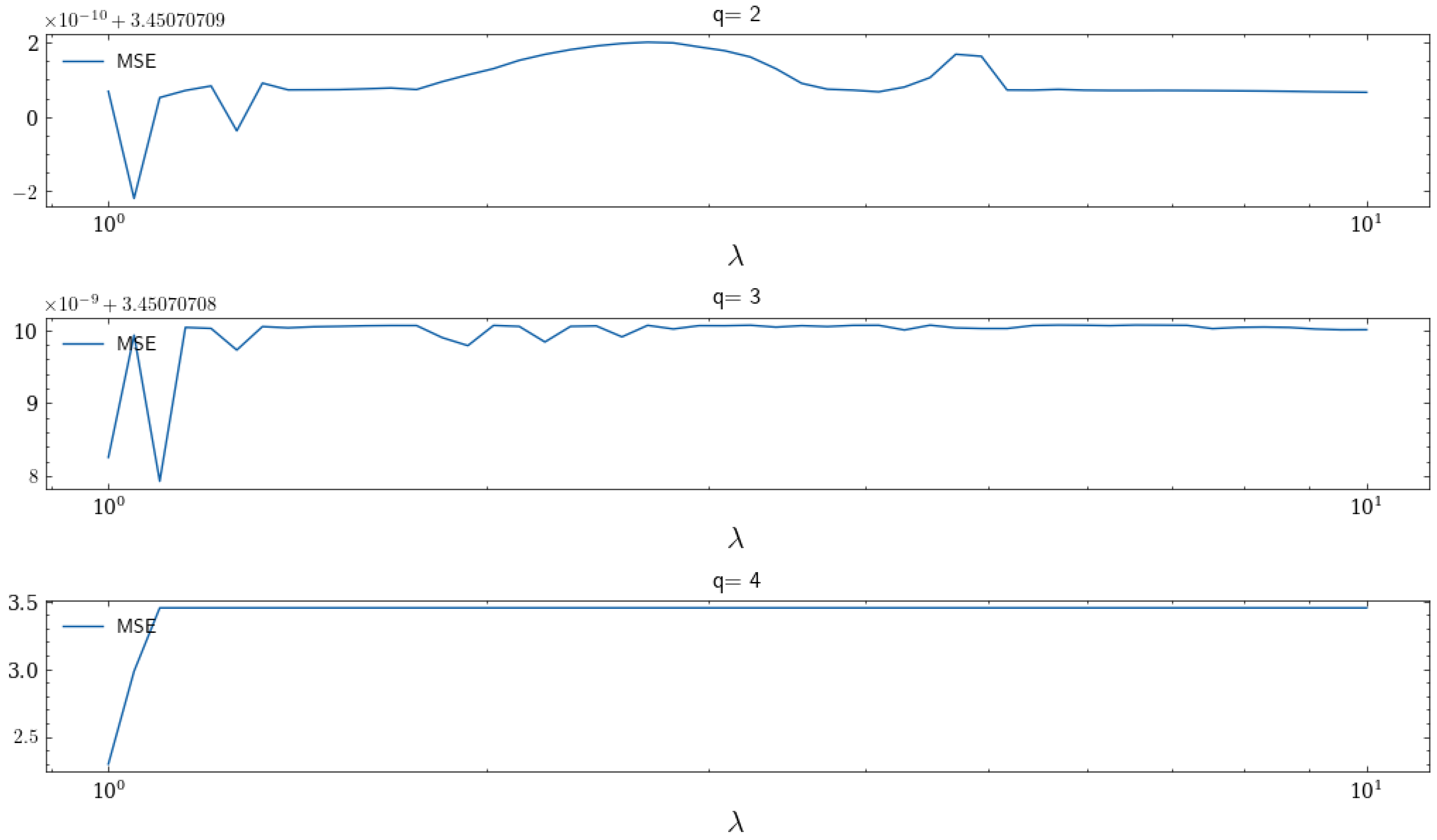
When , it reduces to the case of the classic Wasserstein metric. To illustrate their performance, we generate six hundred sets of samples with generated from the distribution and generated from the distribution independently and identically. The trend of MSE as ranges from one to ten is presented below.
In
Figure 1, we find that it is possible to achieve smaller MSE by adjusting the value of
. Moreover, when
and
, the value of
that minimizes MSE is larger than 1, which means that the shortfall–Wasserstein robust regression can achieve a better prediction effect than the Wasserstein robust regression.
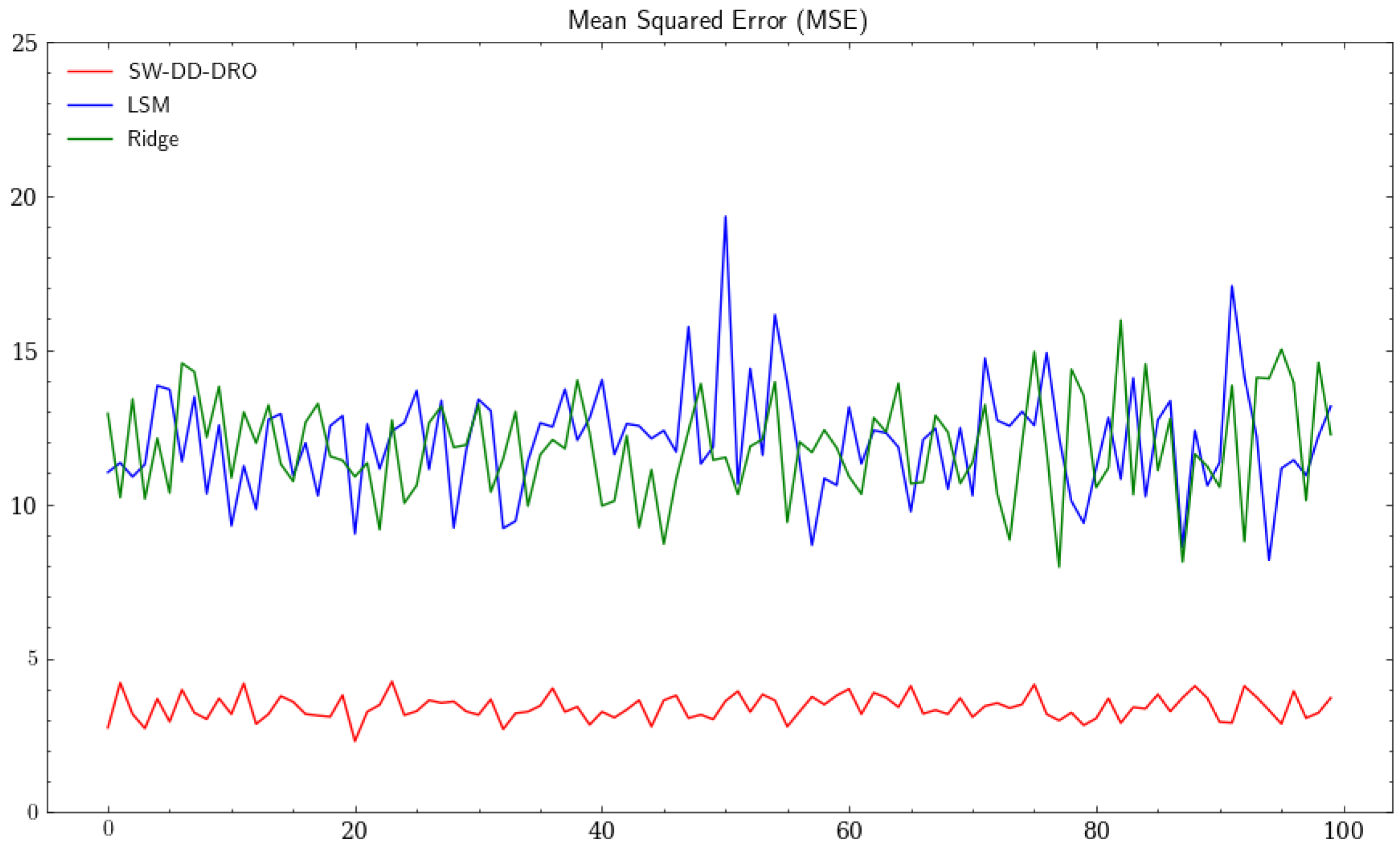
To test the robustness of our model, we further introduce some outliers and compare the performance with the least-squares regression (LSR) model and the ridge regression model. We set for the shortfall–Wasserstein robust regression model and the regularization coefficient 1 for the ridge regression. We conduct one hundred times iterations, producing one hundred sets of samples each time, half of which served as the training set while the rest served as the testing set. Moreover, ten sets of outlier samples are added to the training set at each iteration. The result is presented below.
In
Figure 2, the MSE under the shortfall–Wasserstein robust regression model is much smaller and less volatile than the MSE under the other two models, which means the shortfall–Wasserstein robust regression model is better in resisting the large deviations in the predictors. As a result, the result based on the shortfall–Wasserstein metric is reliable, stable, and superior to the one based on the Wasserstein metric.
5.2. Portfolio Optimization
With
being a random vector of returns from
n different financial assets and
being the allocation vector, the problem becomes a portfolio optimization problem. In this subsection, we take
to characterize the downside risk, and the problem we are interested in is of the following form:
where
c is a constant. By Corollary 2, with
, the inner maximum problem can be reformulated to the following form:
With the ambiguity set constructed by the classic Wasserstein metric, the result is the same as the form of the above formula with
. For simulation, we choose four MSCI index assets, which are the MSCI Denmark index, the MSCI Turkey index, the MSCI Greece index, and the MSCI Norway index. We collect the daily closing prices of those indexes ranging from 1 January 2020 to 31 December 2022 from
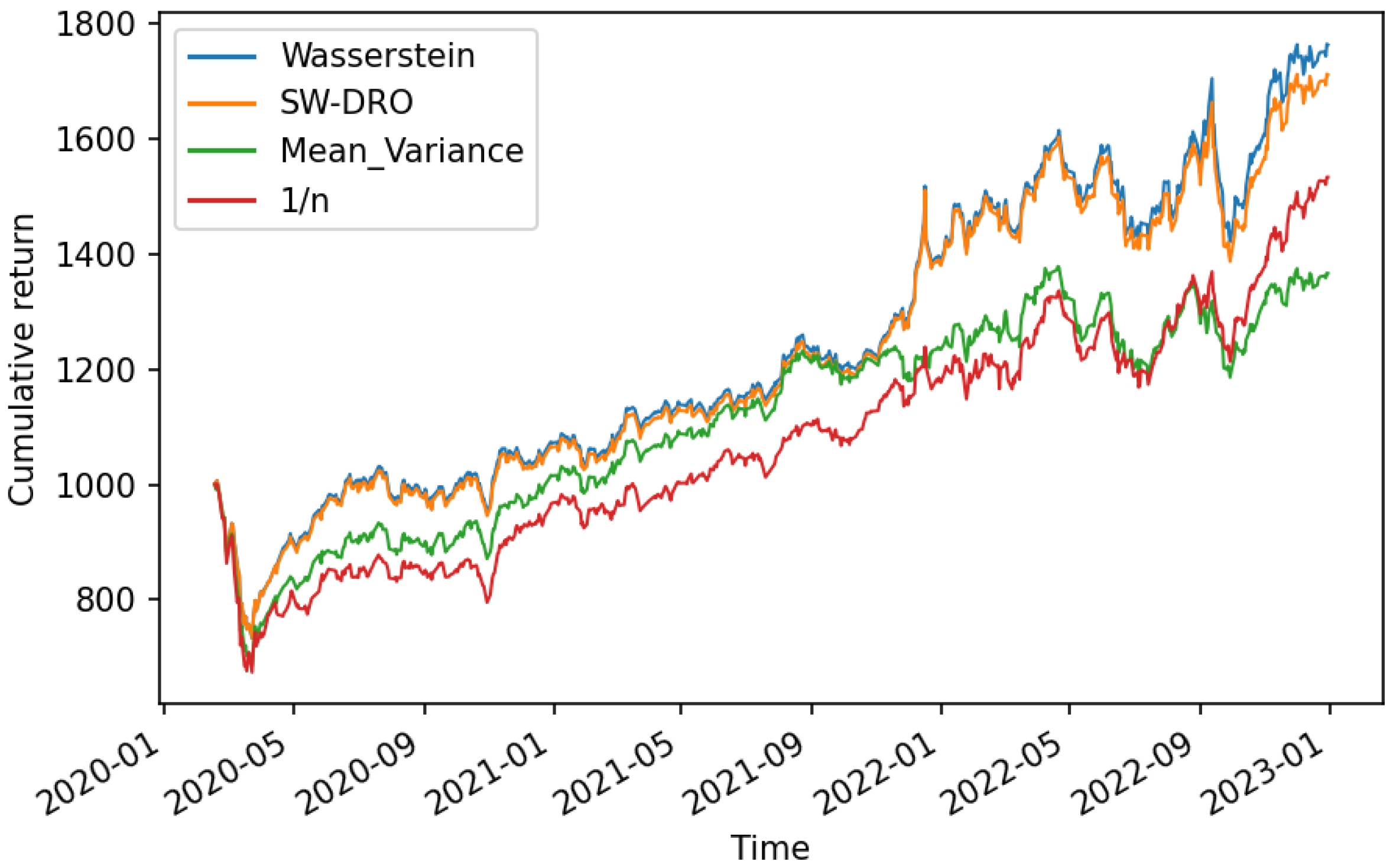
cn.investing.com. It is noteworthy that the COVID-19 outbreak began in 2020, and the distribution of assets is highly uncertain during this period. Based on those data, assume the initial asset is USD 1000 and there is no short sale. We set a 30-day time sliding window, the optimal weight is calculated based on the previous 30 days of historical data, and this result is taken as the investment decision of the next day. As the time window rolls, the cumulative return curves under different strategies are presented below.
The four curves represent the cumulative returns under the model constructed by the shortfall–Wasserstein metric with
, the model constructed by the classic Wasserstein metric, the mean-variance model and the
portfolio model, respectively. The mean-variance model, a model that aims to minimize investment variance under certain expected returns, was proposed by [
24]. The
portfolio model divides the money equally among each asset, and [
25] found that the
portfolio performs well when the overall distribution of assets is highly uncertain.
In
Figure 3, we can see that the first two cumulative return curves under the robust optimization models outperform the curves under the mean-variance model and the
portfolio model. Because of the similarity of the result of models under the shortfall–Wasserstein metric and the classic Wasserstein metric, the first two curves essentially behave the same. Since 2020, the global economy has been in recession due to the pandemic. In 2022, the epidemic was relatively stable and the economy slowly began to recover. During this period, the distribution of the four assets is highly uncertain. All four of these models perform well as the curves climb steadily, but the robust models take the variability into account and make better decisions, especially during the recovery period.
In general, in regression problems, our results are more reliable and robust when the sample is contaminated; in portfolio optimization problems, when the distribution of assets is highly uncertain, our results perform significantly better. Moreover, our result can be more widely used than the result under the Wasserstein model as it is applicable for many complex forms of the function l. Even when the loss function is relatively simple, our model can achieve the same or even better performance than the classic Wasserstein model by adjusting the form of the function .
6. Conclusions
In this paper, we propose a new DRO framework by extending the classic Wasserstein metrics to the shortfall–Wasserstein metrics. We study the tractability and reformulations of the shortfall–Wasserstein DRO problems for the loss function which is linear in the decision vector. This case of objective function includes many applications, such as regression and portfolio selection. One interesting result in the paper is that we give an equivalent characterization of the projection result to a one-dimensional ball. Based on the projection result, we show that the multi-dimensional constraint of our distributionally robust models can be reformulated as a one-dimensional one. Based on this reformulation, we established the finite sample guarantee of the DRO problem which is free from the curse of dimensionality. We present the application of our model in regression and provide simulation results to illustrate the performance of our results. In addition, we also present the real-data analysis on a portfolio selection to illustrate the performance of our new DRO model. Since this paper focuses on the linear cost function , a possible future study is to consider the general loss function and study the reformulations and tractability of the general DRO problems.


{kind=link}
{kind=link}
{kind=link}