
RFCT: Multimodal Sensing Enhances Grasping State Detection for Weak-Stiffness Targets
 , ,
, , 
 and
and
Abstract
:1. Introduction
- (1)
- We propose a new visual–tactile fusion method for a target grasping state detection network to achieve more accurate detection of the grasping state of targets.
- (2)
- In grasping state detection of weak-stiffness targets, we introduce multiple grasping states based on adding deformation degree detection to the slip detection of the target to make the robot more dexterous and intelligent.
- (3)
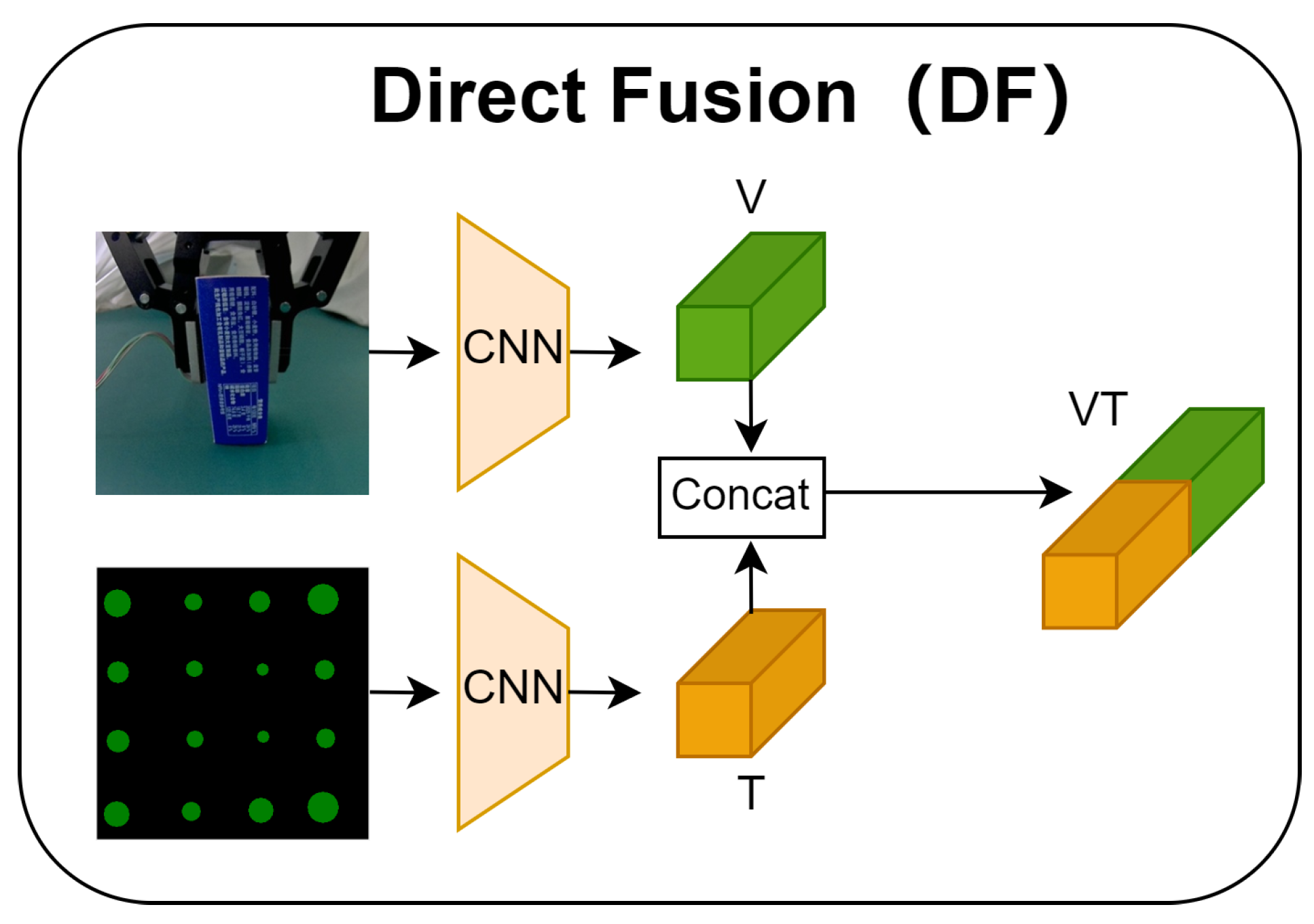
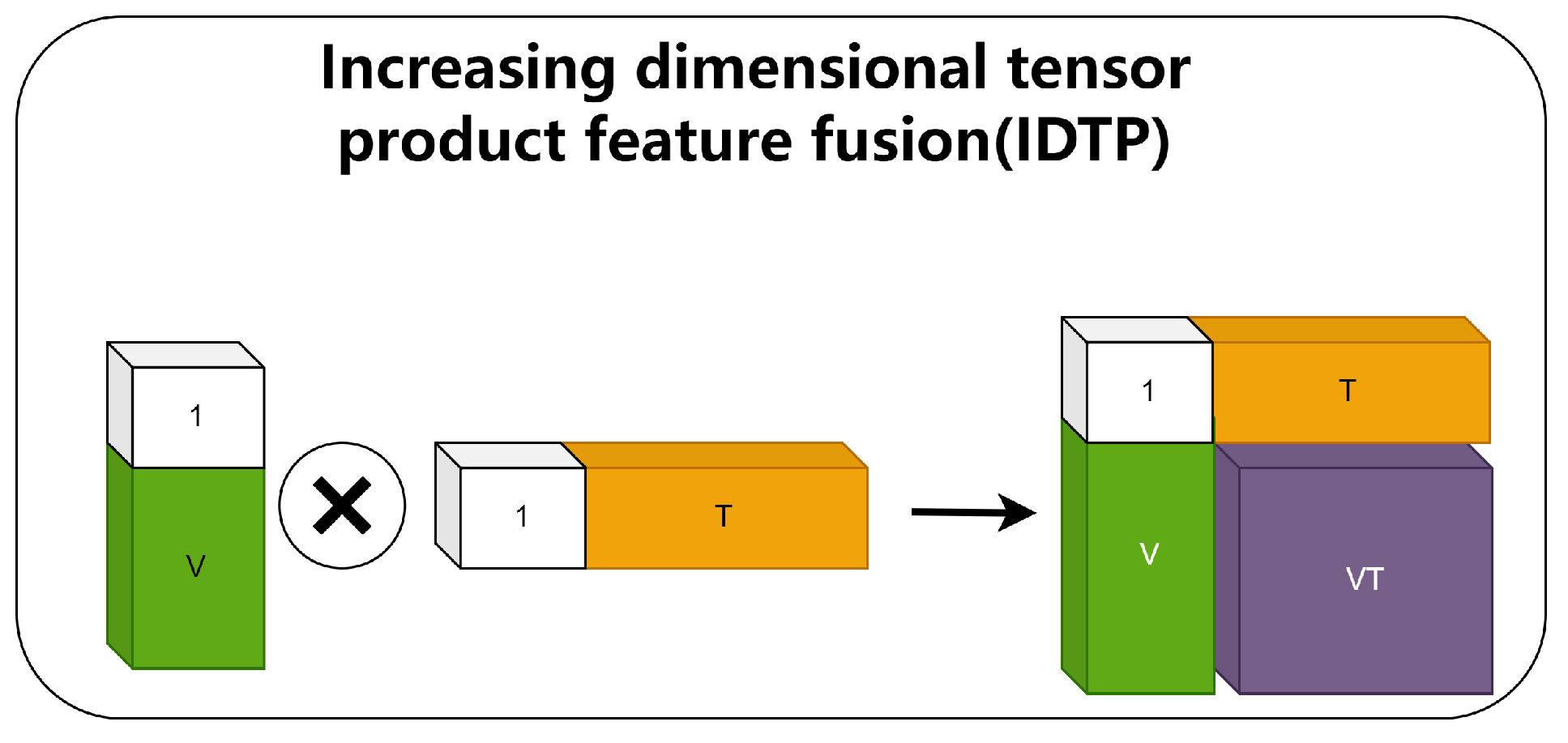
- The IDTP method is proposed to obtain IVTF using the CBAM attention mechanism for the automatic capture of sensitive weights on channels and spaces to extract more important information on visual–tactile features, which has advantages over the DF method.
2. Related Works
2.1. Target Grasping Status Detection
2.2. Visual–Tactile Fusion Learning
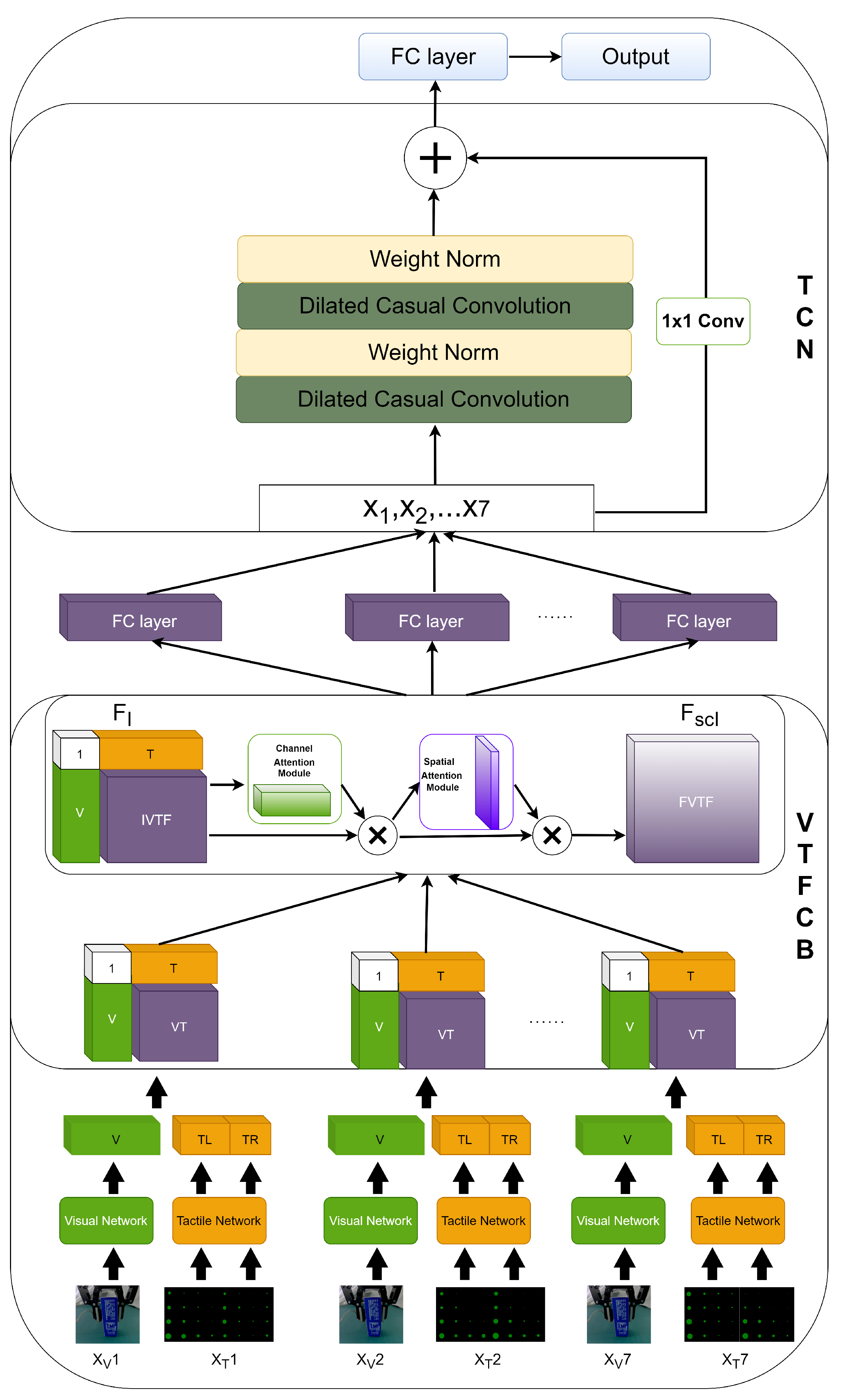
3. Methods
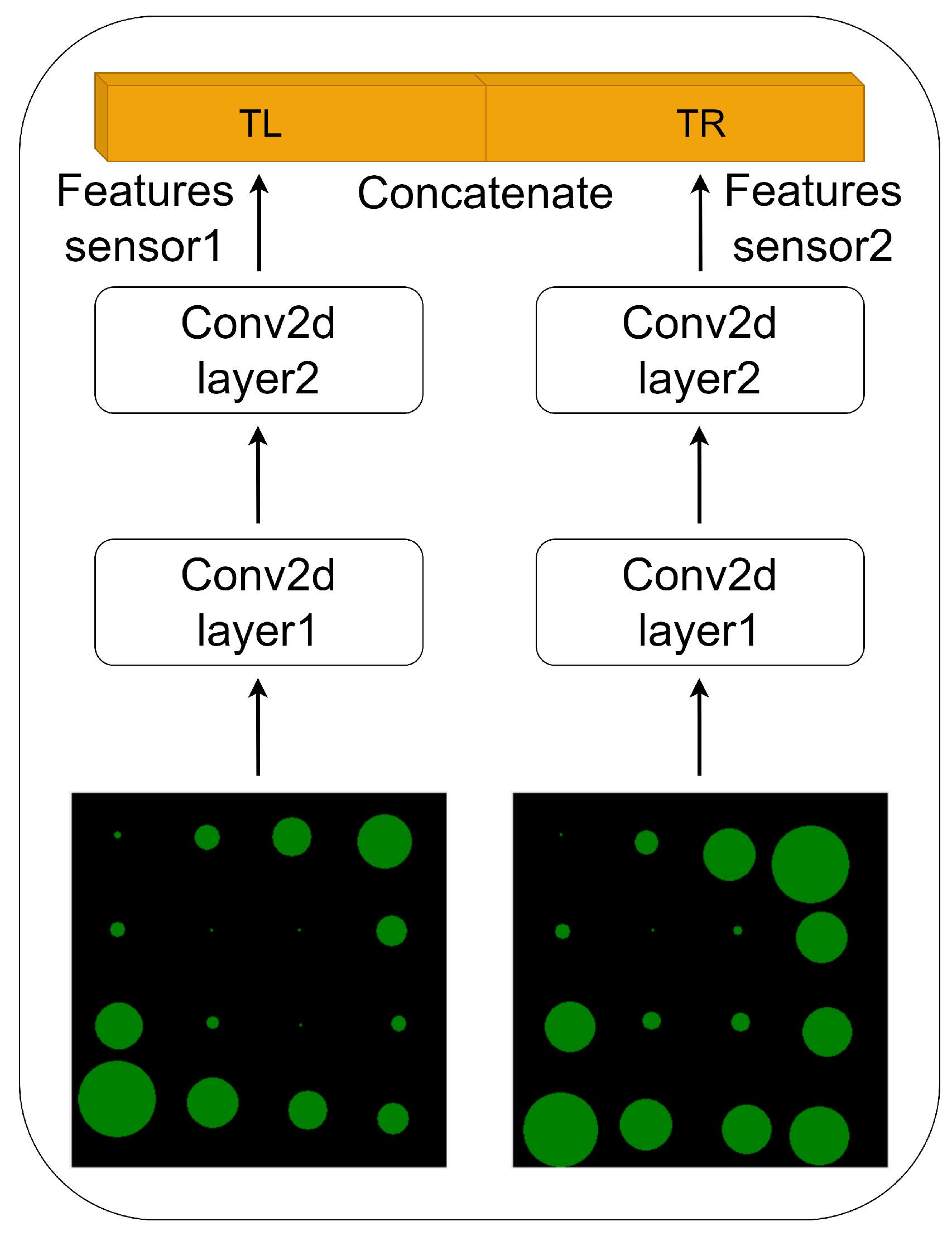
3.1. Visual and Tactile Feature Extraction Networks
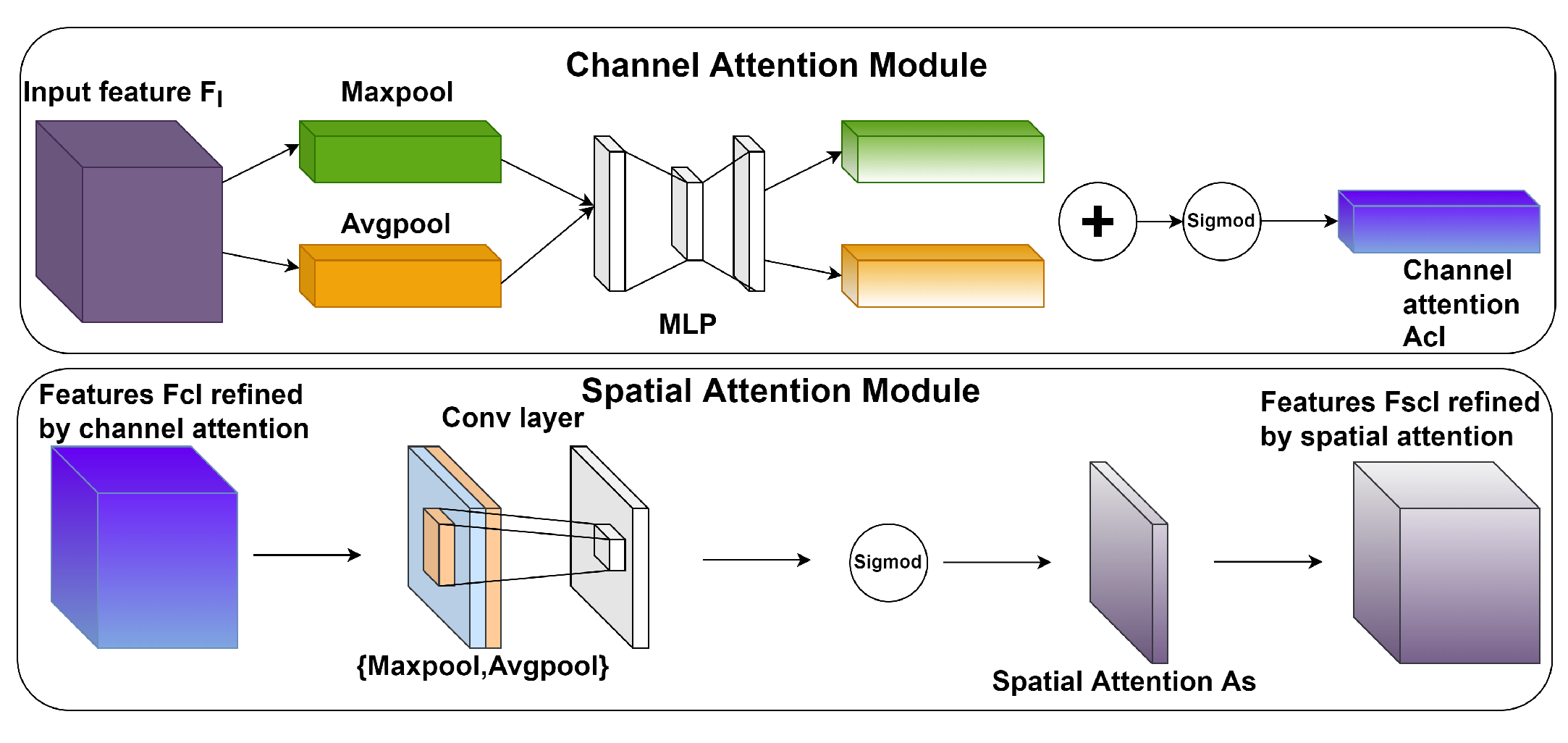
3.2. VTFCB Module
3.3. TCN Module
4. Data Collection and Experimental Setup
4.1. Data Collection
4.2. Experimental Setup
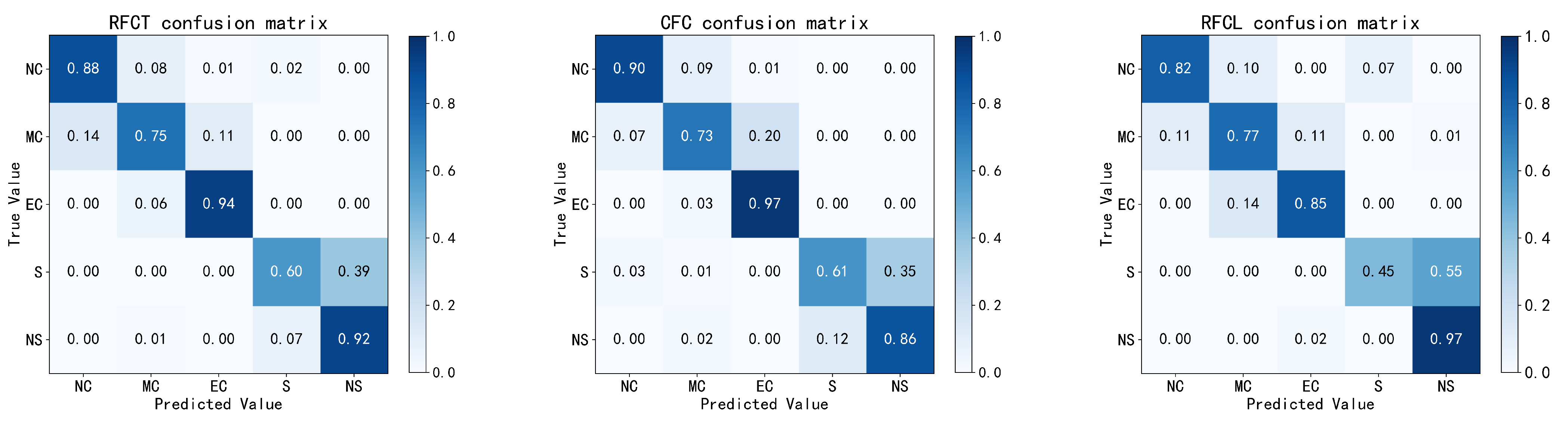
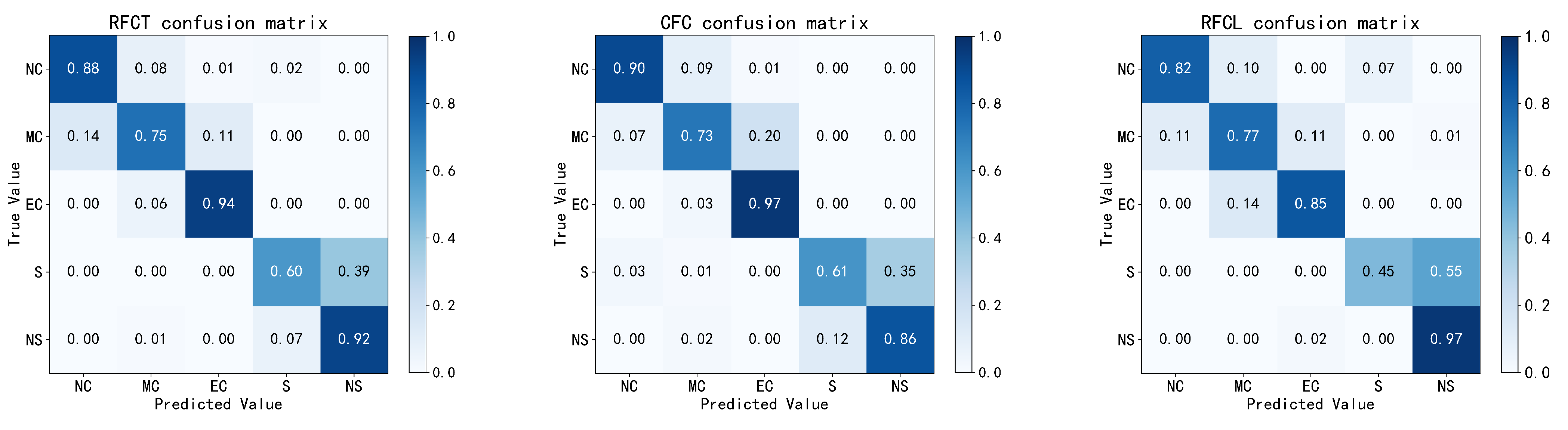
5. Experimental Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiong, P.; Tong, X.; Song, A.; Liu, P.X. Robotic Multifinger Grasping State Recognition Based on Adaptive Multikernel Dictionary Learning. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Billard, A.; Kragic, D. Trends and Challenges in Robot Manipulation. Science 2019, 364, eaat8414. [Google Scholar] [CrossRef]
- Yan, G.; Schmitz, A.; Funabashi, S.; Somlor, S.; Tomo, T.P.; Sugano, S. SCT-CNN: A Spatio-Channel-Temporal Attention CNN for Grasp Stability Prediction. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 2627–2634. [Google Scholar]
- Veiga, F.; Peters, J.; Hermans, T. Grip Stabilization of Novel Objects Using Slip Prediction. IEEE Trans. Haptics 2018, 11, 531–542. [Google Scholar] [CrossRef]
- Li, J.; Dong, S.; Adelson, E. Slip Detection with Combined Tactile and Visual Information. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7772–7777. [Google Scholar]
- Yan, G.; Schmitz, A.; Tomo, T.P.; Somlor, S.; Funabashi, S.; Sugano, S. Detection of Slip from Vision and Touch. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 3537–3543. [Google Scholar]
- Cui, S.; Wang, R.; Wei, J.; Li, F.; Wang, S. Grasp State Assessment of Deformable Objects Using Visual-Tactile Fusion Perception. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 538–544. [Google Scholar]
- Funabashi, S.; Kage, Y.; Oka, H.; Sakamoto, Y.; Sugano, S. Object Picking Using a Two-Fingered Gripper Measuring the Deformation and Slip Detection Based on a 3-Axis Tactile Sensing. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3888–3895. [Google Scholar]
- Yan, G.; Schmitz, A.; Funabashi, S.; Somlor, S.; Tomo, T.P.; Sugano, S. A Robotic Grasping State Perception Framework With Multi-Phase Tactile Information and Ensemble Learning. IEEE Robot. Autom. Lett. 2022, 7, 6822–6829. [Google Scholar] [CrossRef]
- Calandra, R.; Owens, A.; Jayaraman, D.; Lin, J.; Yuan, W.; Malik, J.; Adelson, E.H.; Levine, S. More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch. IEEE Robot. Autom. Lett. 2018, 3, 3300–3307. [Google Scholar] [CrossRef]
- Cui, S.; Wang, R.; Wei, J.; Hu, J.; Wang, S. Self-Attention Based Visual-Tactile Fusion Learning for Predicting Grasp Outcomes. IEEE Robot. Autom. Lett. 2020, 5, 5827–5834. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Tomo, T.P.; Regoli, M.; Schmitz, A.; Natale, L.; Kristanto, H.; Somlor, S.; Jamone, L.; Metta, G.; Sugano, S. A New Silicone Structure for uSkin—A Soft, Distributed, Digital 3-Axis Skin Sensor and Its Integration on the Humanoid Robot iCub. IEEE Robot. Autom. Lett. 2018, 3, 2584–2591. [Google Scholar] [CrossRef]
- Yousef, H.; Boukallel, M.; Althoefer, K. Tactile Sensing for Dexterous In-Hand Manipulation in Robotics—A Review. Sensors Actuators A Phys. 2011, 167, 171–187. [Google Scholar] [CrossRef]
- Yamaguchi, A.; Atkeson, C.G. Combining Finger Vision and Optical Tactile Sensing: Reducing and Handling Errors While Cutting Vegetables. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 1045–1051. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Lee, H.; Sun, H.; Park, H.; Serhat, G.; Javot, B.; Martius, G.; Kuchenbecker, K.J. Predicting the Force Map of an ERT-Based Tactile Sensor Using Simulation and Deep Networks. IEEE Trans. Autom. Sci. Eng. 2023, 20, 425–439. [Google Scholar] [CrossRef]
- Yi, Z.; Xu, T.; Shang, W.; Wu, X. Touch Modality Identification With Tensorial Tactile Signals: A Kernel-Based Approach. IEEE Trans. Autom. Sci. Eng. 2022, 19, 959–968. [Google Scholar] [CrossRef]
- Yuan, W.; Srinivasan, M.A.; Adelson, E.H. Estimating Object Hardness with a GelSight Touch Sensor. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 208–215. [Google Scholar]
- Kwiatkowski, J.; Cockburn, D.; Duchaine, V. Grasp Stability Assessment through the Fusion of Proprioception and Tactile Signals Using Convolutional Neural Networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 286–292. [Google Scholar]
- Kwiatkowski, J.; Jolaei, M.; Bernier, A.; Duchaine, V. The Good Grasp, the Bad Grasp, and the Plateau in Tactile-Based Grasp Stability Prediction. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 4653–4659. [Google Scholar]
- Yi, Z.; Xu, T.; Shang, W.; Li, W.; Wu, X. Genetic Algorithm-Based Ensemble Hybrid Sparse ELM for Grasp Stability Recognition With Multimodal Tactile Signals. IEEE Trans. Ind. Electron. 2023, 70, 2790–2799. [Google Scholar] [CrossRef]
- Han, Y.; Yu, K.; Batra, R.; Boyd, N.; Mehta, C.; Zhao, T.; She, Y.; Hutchinson, S.; Zhao, Y. Learning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer. arXiv 2021, arXiv:2112.06374. [Google Scholar]
- Funabashi, S.; Ogasa, S.; Isobe, T.; Ogata, T.; Schmitz, A.; Tomo, T.P.; Sugano, S. Variable In-Hand Manipulations for Tactile-Driven Robot Hand via CNN-LSTM. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020; pp. 9472–9479. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Seminara, L.; Gastaldo, P.; Watt, S.J.; Valyear, K.F.; Zuher, F.; Mastrogiovanni, F. Active Haptic Perception in Robots: A Review. Front. Neurorobot. 2019, 13, 53. [Google Scholar] [CrossRef]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, Fully Connected Deep Neural Networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Kalchbrenner, N.; Espeholt, L.; Simonyan, K.; van den Oord, A.; Graves, A.; Kavukcuoglu, K. Neural Machine Translation in Linear Time. arXiv 2017, arXiv:1610.10099. [Google Scholar]
- He, B.; Miao, Q.; Zhou, Y.; Wang, Z.; Li, G.; Xu, S. Review of Bioinspired Vision-Tactile Fusion Perception (VTFP): From Humans to Humanoids. IEEE Trans. Med. Robot. Bionics 2022, 4, 875–888. [Google Scholar] [CrossRef]
- Johansson, R.; Flanagan, J. Coding and Use of Tactile Signals from the Fingertips in Object Manipulation Tasks. Nat. Rev. Neurosci. 2009, 10, 345–359. [Google Scholar] [CrossRef] [PubMed]
- McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef]
- Gao, S.; Dai, Y.; Nathan, A. Tactile and Vision Perception for Intelligent Humanoids. Adv. Intell. Syst. 2022, 4, 2100074. [Google Scholar] [CrossRef]
- Ribeiro, E.G.; de Queiroz Mendes, R.; Grassi, V. Real-Time Deep Learning Approach to Visual Servo Control and Grasp Detection for Autonomous Robotic Manipulation. Robot. Auton. Syst. 2021, 139, 103757. [Google Scholar] [CrossRef]
- Yuan, W.; Zhu, C.; Owens, A.; Srinivasan, M.A.; Adelson, E.H. Shape-Independent Hardness Estimation Using Deep Learning and a GelSight Tactile Sensor. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 951–958. [Google Scholar]
- Yan, Y.; Hu, Z.; Shen, Y.; Pan, J. Surface Texture Recognition by Deep Learning-Enhanced Tactile Sensing. Adv. Intell. Syst. 2022, 4, 2100076. [Google Scholar] [CrossRef]
- Funabashi, S.; Isobe, T.; Hongyi, F.; Hiramoto, A.; Schmitz, A.; Sugano, S.; Ogata, T. Multi-Fingered In-Hand Manipulation With Various Object Properties Using Graph Convolutional Networks and Distributed Tactile Sensors. IEEE Robot. Autom. Lett. 2022, 7, 2102–2109. [Google Scholar] [CrossRef]
- Guo, D.; Liu, H.; Fang, B.; Sun, F.; Yang, W. Visual Affordance Guided Tactile Material Recognition for Waste Recycling. IEEE Trans. Autom. Sci. Eng. 2022, 19, 2656–2664. [Google Scholar] [CrossRef]
- Macaluso, E. Modulation of Human Visual Cortex by Crossmodal Spatial Attention. Science 2000, 289, 1206–1208. [Google Scholar] [CrossRef]
- Allen, P. Surface Descriptions from Vision and Touch. In Proceedings of the 1984 IEEE International Conference on Robotics and Automation Proceedings, Atlanta, GA, USA, 13–15 March 1984; Volume 1, pp. 394–397. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]

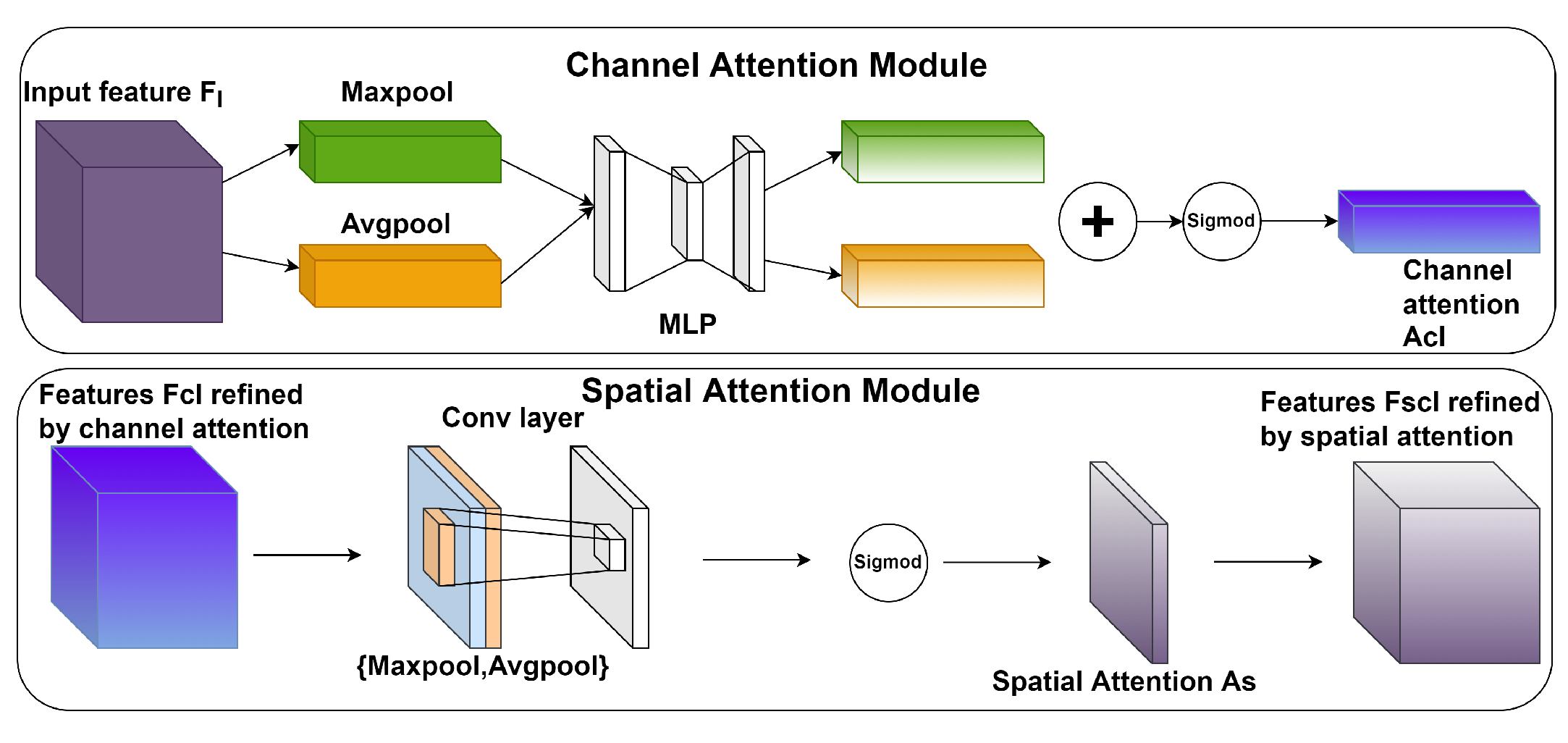




{kind=link}
{kind=link}
{kind=link}
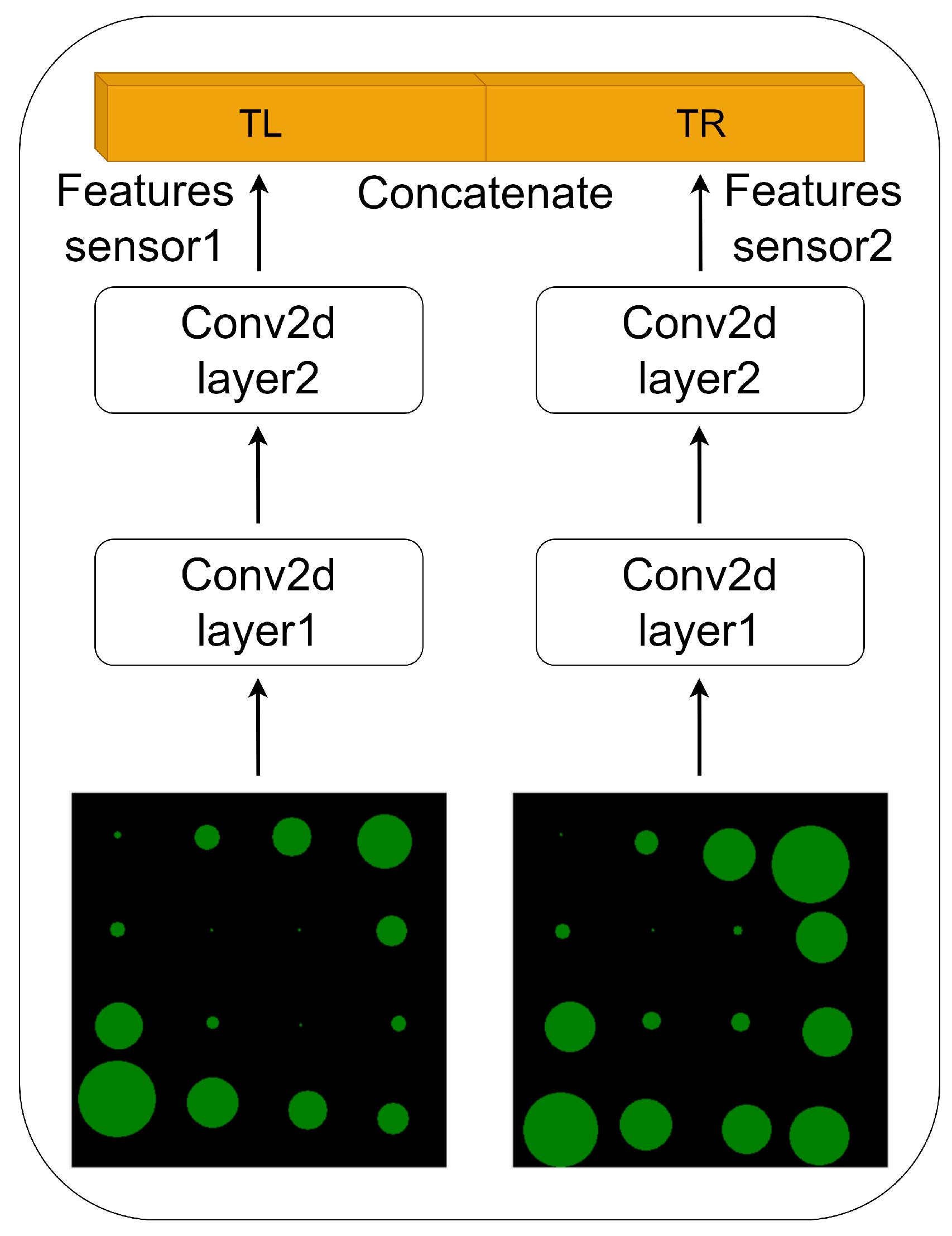{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Sequence Length | Precision | Recall | F1 Score |
|---|---|---|---|---|
| RT | 7 | 74.06 | 72.19 | 72.62 |
| C3D | 7 | 75.49 | 74.54 | 74.75 |
| RL | 7 | 76.17 | 72.03 | 72.18 |
| Single Tactile | 7 | 69.50 | 66.09 | 66.06 |
| Single Visual | 7 | 41.90 | 41.60 | 41.07 |
| Model | Sequence Length | Precision | Recall | F1 Score |
|---|---|---|---|---|
| RL | 6 | 74.77 | 70.55 | 70.30 |
| 7 | 76.17 | 74.54 | 72.18 | |
| 8 | 75.74 | 72.03 | 71.42 | |
| 9 | 75.81 | 66.09 | 70.60 |
| Model | Sequence Length | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 7 | 82.89 | 82.07 | 81.65 | |
| RFT | 7 | 81.76 | 80.92 | 80.43 |
| RT | 7 | 74.06 | 72.19 | 72.62 |
| 7 | 81.36 | 81.21 | 80.58 | |
| CF | 7 | 80.79 | 79.32 | 78.70 |
| C3D | 7 | 75.49 | 74.54 | 74.75 |
| 7 | 80.01 | 77.31 | 76.77 | |
| RFL | 7 | 79.84 | 76.90 | 76.56 |
| RL | 7 | 76.17 | 72.03 | 72.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, W.; Zhu, W.; Zhao, Z.; Wang, K.; Lu, Q.; Luo, L.; Yeh, W.-C. RFCT: Multimodal Sensing Enhances Grasping State Detection for Weak-Stiffness Targets. Mathematics 2023, 11, 3969. https://doi.org/10.3390/math11183969
Ruan W, Zhu W, Zhao Z, Wang K, Lu Q, Luo L, Yeh W-C. RFCT: Multimodal Sensing Enhances Grasping State Detection for Weak-Stiffness Targets. Mathematics. 2023; 11(18):3969. https://doi.org/10.3390/math11183969
Chicago/Turabian StyleRuan, Wenjun, Wenbo Zhu, Zhijia Zhao, Kai Wang, Qinghua Lu, Lufeng Luo, and Wei-Chang Yeh. 2023. "RFCT: Multimodal Sensing Enhances Grasping State Detection for Weak-Stiffness Targets" Mathematics 11, no. 18: 3969. https://doi.org/10.3390/math11183969
APA StyleRuan, W., Zhu, W., Zhao, Z., Wang, K., Lu, Q., Luo, L., & Yeh, W.-C. (2023). RFCT: Multimodal Sensing Enhances Grasping State Detection for Weak-Stiffness Targets. Mathematics, 11(18), 3969. https://doi.org/10.3390/math11183969