Abstract
The exponential growth and complexity of legal agreements pose significant Big Data challenges and strategic risks for modern organizations, often overwhelming traditional, manual contract management workflows. While AI has enhanced legal research, most current applications require extensive domain-specific fine-tuning or substantial annotated data, and Large Language Models (LLMs) remain susceptible to hallucination risk. This paper presents an AI-based Agreement Management System that addresses this methodological gap and scale. The system integrates a Python 3.1.2/MySQL 9.4.0-backed centralized repository for multi-format document ingestion, a role-based Collaboration and Access Control module, and a core AI Functions module. The core contribution lies in the AI module, which leverages zero-shot learning with OpenAI’s GPT-4o and structured prompt chaining to perform advanced contractual analysis without domain-specific fine-tuning. Key functions include automated metadata extraction, executive summarization, red-flag clause detection, and a novel feature for natural-language contract modification. This approach overcomes the cost and complexity of training proprietary models, democratizing legal insight and significantly reducing operational overhead. The system was validated through real-world testing at a leading industry partner, demonstrating its effectiveness as a scalable and secure foundation for managing the high volume of legal data. This work establishes a robust proof-of-concept for future enterprise-grade enhancements, including workflow automation and predictive analytics.
1. Introduction
The exponential growth and complexity of legal agreements pose significant Big Data challenges and strategic risks for modern organizations. Organizations face a “data-to-data” revolution where contracts are no longer static documents but dynamic information that undergoes revision and amendment across numerous business relationships [1]. This shift is part of the broader digital transformation impacting contract law, requiring a comprehensive regulatory approach [2]. Manually managing a high volume of these lengthy, complex documents is not only a clerical burden but also a significant strategic risk, leading to overlooked clauses, compliance violations, and financial penalties [3]. Research shows that businesses lose an average of 9% in annual revenue due to inefficient contract management [4]. The traditional reliance on legal professionals is often a time-consuming and costly solution, creating a barrier for small businesses and individuals with limited resources. This escalating complexity and the inherent limitations of manual processes [5] underscore the need for a technological solution that can scale.
While AI has enhanced the speed and accuracy of legal research [6], current automated approaches face significant methodological and practical constraints. Traditional techniques often depend on domain-specific model fine-tuning or require substantial annotated data for training, which is rarely feasible in practice. Early approaches, such as rule-based NLP models, lacked adaptability across diverse document types and were time-consuming to implement [7]. Furthermore, even newer neural models remain challenging to adapt to new legal domain [8], and are susceptible to AI hallucinations (generating fabricated content), a critical risk in legal contexts where precision is paramount [9]. This issue, underscored by incidents where lawyers submitted court briefs with non-existent case citations produced by ChatGPT, necessitates robust human oversight. Recent work in applied text analysis [10] shows that descriptive evaluation can be complemented by structured semantic validation techniques to improve transparency. While our system focuses on practical validation in an enterprise setting rather than topic-model benchmarking, these methods represent a promising direction for future analytical extensions.
To address these shortcomings, this paper presents an AI-based Agreement Management System designed to simplify contract analysis and mitigate these risks. The core research contribution of this work is the development and validation of an AI Functions module that performs executive summarization, clause extraction, and natural-language contract modification. Unlike the conventional tools that require extensive training, this assistant operates in a zero-shot setting by leveraging advanced prompt engineering and logic chaining with a pre-trained Large Language Model (LLM). Beyond the core AI functions, the platform incorporates foundational modules for multi-format document ingestion and centralized storage, along with a role-based access control framework. This architecture positions the system as a scalable solution for managing large volumes of legal data. The effectiveness of these components has been validated through practical implementation and testing in a real-world business environment at AlFaris International Group, demonstrating the system’s tangible utility and commercial relevance. This paper details the system’s architecture and its core functionality, positioning it as a foundational step toward a comprehensive AI-based Agreement Management platform that addresses the strategic risks of managing legal data at scale. The primary objective of this framework is to design and validate an AI-assisted agreement management framework that improves contract traceability, legal clause interpretation, and lifecycle oversight in enterprise environments.
2. Related Work
2.1. AI Applications in Legal Tech Analysis
AI has been increasingly applied to automate as well as support various legal text analysis tasks. Choi [6] has highlighted how AI, particularly in the form of LLMs, have enhanced both accuracy and speed of legal research to unprecedented levels, allowing lawyers to devote more of their time to more strategic aspects of their work. Beyond research, AI-powered tools assist in contract review by flagging potential inconsistencies or issues and suggesting revisions, thereby improving the quality and reliability of legal analysis. Furthermore, the digital transformation brought by AI is restructuring the legal service market, pushing services toward greater efficiency and accessibility [11]. Despite the undeniable benefits gained by the usage of AI-powered tools, ethical concerns remain paramount given the legal setting. Davenport [9] points out that while LLMs such as GPT-4o [12] can summarize and analyze legal documents sufficiently, that does not guarantee their outputs to be accurate. Issues such as hallucinations, where AI generates fabricated or incorrect information, can mislead stakeholders and could result in disastrous consequences if unverified. For example, an incident where lawyers submitted court briefs containing non-existent case citations produced by ChatGPT underscores the need for human oversight [9]. Therefore, ensuring accuracy and incorporating human oversight remain critical considerations. These strengths and weaknesses of AI applications in legal text analysis highlight the importance of our system, which aims to build an agreement assistant that leverages LLM capabilities while ensuring reliability for non-expert users.
2.2. Summarization Techniques for Documents
Summarization of legal documents is done to condense lengthy and complex documents into shorter forms that retain the essential information, enabling faster understanding and decision-making. Jain et al. [13] reviewed various summarization methods for legal documents, categorizing them into extractive and abstractive approaches. Extractive methods select important sentences directly from the text (e.g., TextRank algorithm [14]), whereas abstractive methods generate new sentences to convey the core meaning (e.g., BERTSUM [15] for legal summarization). Recent studies have explored the use of BERT [16] for extractive summarization of complex, formal documents. For example, Barros et al. [17] used BERT to summarize federal police documents, yielding improved accuracy in identifying key sentences in comparison to traditional extractive methods. Although their work focused on police reports, the use of BERT for summarizing lengthy, structured, and formal domain-specific documents demonstrates an approach that is applicable to legal documents as well. However, most existing summarization techniques require fine-tuning on specialized legal datasets, which may not be feasible in practical scenarios. In our system, a pre-trained LLM (GPT-4o [12]) is used with prompt engineering to generate meaningful summaries without the need for additional model training.
2.3. Clause Extraction Methods
Clause extraction is the task of identifying and categorizing specific provisions within legal documents, such as payment terms, confidentiality clauses, or termination conditions. Early approaches relied on rule-based methods, using predefined keywords or patterns to detect clause headings and content, but such methods usually lacked adaptability to diverse drafting styles. Furthermore, they are time-consuming to implement. For instance, Lee et al. [7] developed a rule-based NLP model to extract risk clauses from construction contracts, taking advantage of domain knowledge to define the extraction rules with high accuracy. To address the limitations of purely rule-based systems, Shah et al. [18] proposed a hybrid approach, combining machine learning with heuristic rules to extract clauses from contracts, showing improved accuracy over purely rule-based techniques. However, this hybrid approach required domain-specific feature engineering and substantial annotated data for training, limiting generalizability. In our system, clause extraction is performed using GPT-4o [12] with prompt engineering, allowing flexible identification of different clause types without additional model training or extensive data preparation.
2.4. LLMs for Document Q&A
Question answering (QA) systems aim to provide direct answers to users’ queries based on document content, with recent approaches using LLMs to improve accuracy and contextual understanding in this task. In the legal domain specifically, Legal Question Answering (LQA) involves answering queries about laws, statutes, and contracts, tasks traditionally performed by legal professionals through research and interpretation [19]. LQA is a subset of Legal Intelligence (LI), which is composed of AI technologies supporting legal decision-making and data analysis tasks. Martinez-Gil [11] describes LQA as a key component of LI, which broadly encompasses AI technologies supporting legal decision-making, contract analysis, and legal research. Deep learning-based LQA systems train neural network models on large datasets of legal questions and answers to identify relevant legal concepts and generate accurate responses, aiding in tasks such as legal research, contract review, and legal writing [19]. Recent studies underscore that the deployment of LLMs, when coupled with structured information retrieval—a technique known as Retrieval-Augmented Generation (RAG)—offers the potential to significantly enhance accuracy and reduce hallucinations in the QA task [20]. Recent research highlights a shift from traditional information retrieval approaches to neural network-based models, as the latter process unstructured legal data efficiently and provide direct, context-aware answers rather than long lists of documents [8]. However, Martinez-Gil [8] also indicates that neural models require significant training resources, have low interpretability, and remain challenging to adapt to new legal domains. This system addresses these constraints by utilizing GPT-4o’s [12] question answering capabilities with carefully designed prompts to enable users to query uploaded contracts about specific terms or clauses, providing meaningful answers without requiring task-specific model fine-tuning.
2.5. Prompt Engineering and Logic Chaining
Prompt engineering involves designing and structuring input prompts to guide LLM outputs towards accurate, contextually relevant, and task-specific responses. It has become increasingly important as NLP has shifted from the “pre-train and fine-tune” paradigm to “pre-train and prompt”, enabling models to perform specialized tasks without additional fine-tuning [21]. However, designing effective prompts requires significant manual human effort, and hand-crafted prompts usually fail to capture the full semantic complexity of domain-specific tasks. Recent research has focused on the theoretical depth of prompt methods, exploring advanced learning frameworks for adaptability [22]. Logic chaining, or multi-step prompting, extends prompt engineering by structuring sequences of prompts to break down complex tasks into simpler reasoning steps, which improves accuracy as well as interpretability. For instance, chain-of-thought prompting has demonstrated improved performance on reasoning tasks by encouraging models to generate intermediate explanations before producing final answers. Despite these advances, prompt engineering approaches still require careful design and evaluation, as poorly constructed prompts or lack of domain adaptation can result in inaccurate or incomplete outputs. This system uses prompt engineering and logic chaining to structure queries to GPT-4o [12] for clause extraction, summarization, and user question answering, enabling effective legal document analysis without the need for task-specific fine-tuning.
In summary, the existing literature identifies two critical limitations in automated legal analysis: the high barrier to entry posed by the need for extensive, domain-specific model training and the persistent risk of AI hallucination associated with large language models. Our proposed AI-based Agreement Management System directly overcomes these gaps through its core methodological approach. By exclusively utilizing zero-shot learning with a pre-trained LLM and advanced structured prompt chaining, our system successfully performs complex legal tasks like advanced summarization, clause extraction, and Q&A without requiring any task-specific fine-tuning or large proprietary datasets. This makes the technology immediately accessible and adaptable, providing a highly scalable alternative to data-hungry neural and hybrid models. Furthermore, by incorporating human oversight through the user interface and focusing on context-aware responses (similar to Retrieval-Augmented Generation principles), the system aims to enhance reliability and mitigate the critical ethical risks associated with AI-generated legal content.
3. Materials and Methods
3.1. System Overview
The AI-based Agreement Management System is an advanced, modular platform designed to transform the cumbersome process of legal contract review into a scalable, secure digital workflow [23,24]. The system is built around three integrated modules: Contract Ingestion and Storage, the Core AI Functions, and Collaboration and Access Control. At a high level, the system enables users to upload multi-format contracts and instantly receive zero-shot analytical insights powered by the GPT-4o [12] API. All documents and metadata are managed in a central MySQL [25] repository, with security enforced by dynamic role-based access controls [26,27]. These controls define specific user access levels, including admin (full read/write), a normal user (read/write access to contracts), and a restricted mode (read-only access).
The core analytical power resides in the AI Functions module, which utilizes structured prompt chaining for actionable insights. This includes a novel User-Driven Contract Modification feature, allowing users to apply edits using plain English (e.g., “Please change the expiration date to 31 March 2026”). Furthermore, a set of Quick Action Tools instantly addresses common legal interpretation tasks: Generate Executive Summary provides a plain-language synopsis; Extract Clauses identifies key provisions like Payment or Termination terms; Simplify Legal Jargon explains complex terms such as “indemnification”; Red Flag Clauses highlights potentially risky provisions; and a Glossary of Terms extracts and defines key contractual vocabulary. The following sections detail the architecture and implementation of this integrated system, highlighting how its modular design facilitates scalability for future enterprise enhancements.
3.2. System Architecture
The proposed AI-based Agreement Management System (as seen in Figure 1) is designed as a modular system to ensure scalability, maintainability, and secure contract analysis [28,29]. The modular approach enables independent development of subsystems while supporting future extensions such as automated breach detection and finance integration. A description of the distinct layers is provided below:
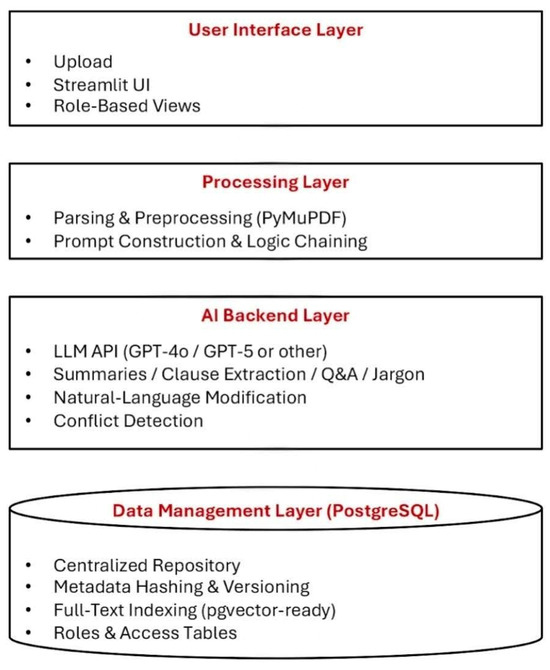
Figure 1.
Layered architecture of the AI-based Agreement Management System.
3.2.1. User Interface Layer
The UI layer provides the primary point of interaction for end users. It enables:
- Multi-format document uploads (PDF, Word, multi-page JPEG) into the Contract Ingestion and Storage module.
- Role-based access control, supporting differentiated views and permissions for legal, finance, and administrative staff.
For implementation, the interface was developed using Streamlit [30], chosen for its low development overhead and ability to deliver browser-based access without client installation. This design ensures usability for non-technical stakeholders [31]. Features are dynamically presented according to user roles to maintain confidentiality and appropriate access. The UI layer is designed to support long-term deployment, with its current structure and functionality providing a robust and accessible user experience.
3.2.2. Processing Layer
This layer coordinates document preprocessing and dynamic prompt construction, which form the basis of the Core AI Functions module. The system employs the PyMuPDF [32] library to extract text from PDF documents [33], ensuring accurate parsing of contracts. A prompt construction module then generates context-aware prompts tailored to user-selected tasks, including executive summarization, clause extraction, and legal Q&A.
3.2.3. AI Backend Layer
At the system’s core lies the Large Language Model (LLM) integration, which currently leverages the OpenAI GPT-4o [12] API. This layer performs all AI-driven tasks:
- Zero-shot executive summarization of agreements [34].
- Clause extraction and terminology simplification.
- Natural-language Q&A with retrieval-augmented grounding.
To ensure logical consistency and reliability, the system applies structured prompt chaining [35], where complex contract queries are decomposed into sequential reasoning steps such as clause extraction, interpretation, transformation, and validation against the source agreement. The entire logic for formatting prompts, handling API requests, and processing the LLM’s structured output is managed by Python 3.1.2 [36].
3.2.4. Data Management Layer
The data management (persistence) layer is built on MySQL [25], which manages agreements, metadata, and user activity logs. Key design features include:
- Normalized schema for agreements, extracted clauses, and role assignments.
- Full-text indexing for efficient retrieval during legal Q&A tasks [37].
- Metadata hashing to track versions and ensure contract traceability [38].
- Extensibility for vector storage (such as an external embeddings database) to support retrieval-augmented generation.
The system is deployed using a dual strategy to ensure both developmental agility and enterprise readiness. The platform was validated for rapid prototyping using Streamlit [30] Cloud. For long-term scalability and modular upgrades, a containerized deployment using Docker [39] on AWS [40] was successfully tested, confirming alignment with standard enterprise deployment practices [41].
Regarding security, Role-based Access Control is currently enforced to govern system usage and visibility. User roles (admin, normal, restricted) are managed and persisted within the MySQL [25] data management layer. The system enforces these permissions using Streamlit [30] session-level controls to dynamically adjust the UI features and content visible to each user, thereby maintaining data confidentiality. Future enhancements will include stronger encryption for stored data, detailed audit logging, and full compliance with Saudi data residency regulations. Future development will further address emerging risks in AI-assisted legal systems, including prompt injection, adversarial manipulation, and unauthorized inference attacks, through model-level safeguards and role-based access defenses.
3.3. Implementation
The current implementation focuses on realizing the functionalities of the Contract Ingestion and Storage, Core AI Functions, and Collaboration & Access Control modules, detailed below:
3.3.1. Contract Ingestion and Storage
This module implements the foundational steps necessary for contract analysis, linking the User Interface Layer to the Data Management Layer.
The data ingestion process begins when a user uploads a multi-format contract (e.g., PDF) via the User Interface (UI). The system immediately initiates the document parsing routine, where the PyMuPDF [32] library is used to automatically extract the raw text content from the file, a critical step for preparing the contract for LLM analysis. Following this successful text extraction, the full document and its raw content are stored in the MySQL [25] Data Management Layer. This storage includes using metadata hashing to track document versions and ensure the contract is correctly indexed and stored within the centralized repository.
3.3.2. Implementation of Core AI Functions
The core contribution is housed within this module, executed by the Processing and AI Backend Layers, which rely on advanced Prompt Engineering and the GPT-4o [12] LLM.
The preprocessed data from the Data Management Layer is used to execute a specialized, structured GPT-4o [12] prompt. This prompt automatically extracts key information—including the Contract Type, Parties Involved, and Effective/Expiration Dates. This information is then dynamically displayed in dedicated UI components, providing the user with an immediate overview of the contract (see Figure 2). Once this initial data is presented, the user can then choose from the following actions:
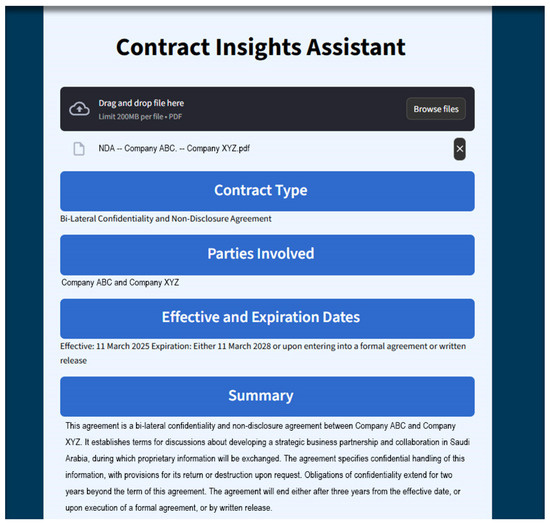
Figure 2.
Main interface displaying uploaded contract and extracted metadata. All information shown in the image is correct, with the exception of the company names, which have been replaced due to confidentiality.
- Quick Action Tools: Five targeted quick-action buttons are implemented on the UI (see Figure 3) to perform specific interpretation tasks, thereby reducing cognitive load for non-experts. Each tool (Generate Executive Summary, Extract Clauses, Simplify Legal Jargon, Red Flag Clauses, Glossary of Terms) utilizes a specialized prompt, contextualized by the extracted metadata, to query the GPT-4o [12] API.
 Figure 3. Quick action buttons and natural language question interface.
Figure 3. Quick action buttons and natural language question interface. - User Query Handling: Open-ended user questions are managed by a logic-chaining mechanism. This constructs layered prompts that combine the user’s query with the document’s full content and extracted metadata, ensuring the LLM delivers accurate, context-aware responses. For instance, a user can input: “What happens if the project is terminated before the effective date?” and the system will provide a direct answer based on the contract content.
- User-Driven Contract Modification: A novel, interactive feature allows users to apply textual edits using simple natural language instructions (e.g., “Please change the expiration date…”) (see Figure 4). The system processes this by constructing a specialized modification prompt, which directs GPT-4o [12] to generate a revised version of the full contract, accelerating the drafting process.
 Figure 4. Contract modification interface for applying edits using plain language.
Figure 4. Contract modification interface for applying edits using plain language.
3.3.3. Collaboration and Access Control
This module leverages the Data Management Layer and User Interface Layer to enforce security and manage document traceability.
- Role-Based Access Control: Role assignment for users (e.g., administrator, legal, finance) is managed within the MySQL [25] database. This is enforced by Streamlit [30] session-level controls in the UI, dynamically adjusting displayed features and access to maintain data confidentiality.
- Version Comparison and Change Tracking: The module utilizes the full-text indexing and versioning features of the persistence layer to manage document traceability. This foundation is built to support the future implementation of automated version comparison and change tracking.
3.3.4. Deployment and UI Design
The implemented system utilized the Streamlit [30] Cloud Deployment Layer for fast validation and remote access. The UI itself was designed for clarity and accessibility: metadata fields were styled for emphasis, action buttons were horizontally aligned for visual balance, and the interface was tested for responsiveness across desktop and tablet devices. Figure 2, Figure 3 and Figure 4 illustrate the deployed system’s simplicity and clarity.
4. Results
The AI-Powered Agreement Management System, specifically the Core AI Functions module, was evaluated using an industrial validation strategy rather than experimental benchmarking, as no comparable end-to-end AI-based contract management systems are currently available. Evaluation was conducted with legal and contract administration teams across multiple subsidiaries of AlFaris International Group, a corporate holding organization operating under complex agreement portfolios.
Testing was performed using real enterprise contracts under a non-disclosure agreement (NDA), which prevents public dataset release but ensures realistic assessment under authentic legal and business constraints. The evaluation successfully confirmed that the system was highly effective in core analytical tasks such as clause extraction, summarization, and natural-language editing. Ultimately, the system received a formal Letter of Endorsement from AlFaris International Group, definitively validating the tool’s effectiveness in streamlining the review of common legal documents and confirming its relevance to critical business needs.
The system’s analytical outputs were consistently relevant and context-aware, confirming the efficacy of the zero-shot, prompt-chained methodology.
- Performance Across Document Types: Outputs from the GPT-4o [12] model were reliable across various contracts, including MOUs and NDAs, completing each task as instructed without requiring task-specific training or fine-tuning.
- Expert Review: An independent legal expert confirmed the system was well-designed and effectively executed its intended functions. The modular structure, intuitive interface, and targeted features (e.g., summarization and modification) were praised as practical for the intended non-expert user base.
- System Stability and Usability: The application remained stable throughout testing, with no observed crashes, functioning reliably when the underlying prompt logic was valid. The interface, featuring quick-action buttons, was deemed intuitive and helped reduce cognitive load for users without a legal or technical background.
Preliminary testing revealed a limitation in response time latency, where a delay in receiving responses from the GPT-4o [12] API was observed and attributed to external factors, such as internet connection and server response time, rather than the application itself.
Furthermore, subsequent testing highlighted the critical constraint of AI Hallucination Risk. Large language models are susceptible to generating plausible but inaccurate or fabricated content. Therefore, it is essential that the assistant be viewed as a powerful support tool rather than a final authority: the outputs should not be relied upon for high-stakes decision-making without expert human review. This caution is particularly important in legal contexts where precision and correctness are paramount. Accordingly, legal professionals must validate the outputs before acting on them, especially for unfamiliar or complex contracts. To minimize unsupported or fabricated outputs (hallucinations), the system contains all AI responses to grounded evidence by requiring clause-level references directly from the uploaded agreement, preventing reliance on external assumptions.
5. Discussion
The developed components of the AI-based Agreement Management System, specifically the Core AI Functions, Contract Ingestion and Storage, and Collaboration & Access Control modules (as outlined in the system roadmap in Figure 5), collectively establish a robust, enterprise-ready foundation for managing legal assets. The successful real-world testing at AlFaris International Group definitively validated the platform’s utility, confirming its effectiveness in core tasks like clause extraction, summarization, and natural-language editing, as noted in the results.
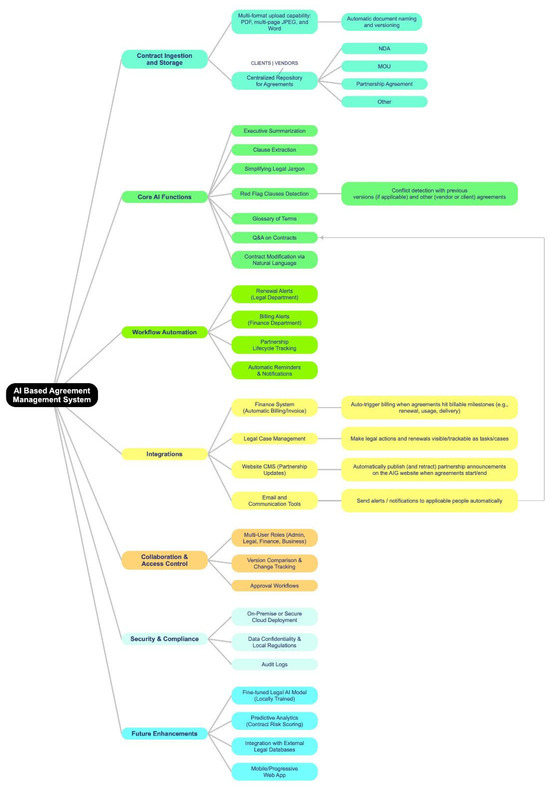
Figure 5.
A roadmap of the whole system.
The primary research novelty lies in the Core AI Functions module’s methodological approach. It validates the efficacy of a zero-shot LLM approach for complex, high-value legal analysis—including metadata extraction, clause identification, and legal jargon simplification—through the innovative use of structured prompt chaining. This methodology demonstrates a highly scalable and accessible alternative to traditional Legal AI, which typically requires extensive, costly domain-specific model fine-tuning and annotated data. Furthermore, the successful implementation of a natural-language contract modification feature transforms the platform from a passive analytical tool into an interactive, proactive support system for non-expert users.
The integration of the Contract Ingestion and Storage and Collaboration & Access Control modules is critical for supporting the “Big Data” challenges inherent in legal ecosystems. The Ingestion module’s centralized, multi-format repository provides the necessary data infrastructure to manage the exponential growth of document versions and amendments. Concurrently, the Collaboration module enforces essential security and compliance requirements by employing role-based access control and managing version comparison and change tracking.
While the practical validation was strong, preliminary testing identified a constraint regarding Response Time Latency, attributed to external API factors. More significantly, subsequent testing highlighted the critical constraint of AI Hallucination Risk. Therefore, the system is viewed as a powerful support tool, but the necessity of expert human review for high-stakes decision-making remains a vital operational constraint.
Future work (refer to the roadmap in Figure 5) will focus on transitioning the platform into a secure, enterprise-grade solution by pursuing three strategic Future Enhancements: AI specialization and scale will be achieved through the implementation of a fine-tuned legal AI model (locally trained) to ensure data security and enhance domain-specific accuracy, while leveraging the centralized data repository to develop Predictive Analytics (contract risk scoring). To achieve ecosystem expansion and broader contextual knowledge, the platform will integrate with external legal databases. Furthermore, user accessibility will be optimized through the deployment of a Mobile/PWA interface to enhance user experience and adoption. Finally, future work will also extend cross-domain validation by collaborating with additional organizations to evaluate performance across differing contractual standards and regulatory environments.
This research successfully establishes a robust, functional framework that not only democratizes access to legal data but also defines a scalable, secure pathway for integrating advanced AI into the strategic management of legal contracts at an enterprise level. While the system demonstrates strong practical potential, its current validation is scoped to a single enterprise group, and broader multi-industry evaluation remains an important direction for generalizability. The system is designed to augment, rather than replace, human legal review, and operates under mandatory human verification to ensure accountability and prevent unintended legal consequences.
Author Contributions
Conceptualization: S.A.A.; methodology: S.A.A. and S.O.A.; software: S.O.A.; data curation: S.O.A.; validation: S.O.A., S.A.A. and R.J.; formal analysis and investigation: S.O.A.; visualization: S.O.A.; resources: S.A.A.; supervision: S.A.A. and R.J.; writing, original draft preparation: S.O.A.; writing, review and editing: R.J. and S.A.A.; project administration: S.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data supporting the findings of this study were provided by AlFaris International Group (Riyadh, Saudi Arabia). Due to the confidential and proprietary nature of these agreements, the data are not publicly available. Access to the sample agreements used for system development was granted internally through S.A.A.
Acknowledgments
The authors acknowledge the support of AlFaris International Group (Riyadh, Saudi Arabia) in providing technical evaluation and feedback during the system’s development. During the preparation of this manuscript, the authors used ChatGPT (GPT-5, OpenAI) for language refinement and structural suggestions. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
Authors Syed Omar Ali and Syed Abid Ali were employed by the company AlFaris International Group. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Ashley, K.D. Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Allied Business Academies. The Impact of Digital Transformation on Contract Law. J. Leg. Ethical Regul. Issues 2023, 28, 1–9. [Google Scholar]
- LegalSifter. The True Cost of Contract Reviews: Hidden Expenses Beyond Legal Fees. 2023. Available online: https://www.legalsifter.com/blog/contract-review-cost (accessed on 1 September 2025).
- ConvergePoint. The Risks of Poor Contract Management Practices. 2023. Available online: https://www.convergepoint.com/contract-management-software/the-cost-of-poor-contract-management-practices (accessed on 1 September 2025).
- Agiloft. 7 Common Challenges for Contract Management Professionals. 2024. Available online: https://www.agiloft.com/blog/7-common-challenges-for-contract-management-professionals/ (accessed on 1 September 2025).
- Choi, J.H.; Schwarcz, D. AI Assistance in Legal Analysis: An Empirical Study. J. Leg. Educ. 2025, 73, 384. Available online: https://ssrn.com/abstract=4539836 (accessed on 1 January 2026). [CrossRef]
- Lee, J.; Yi, J.S.; Son, J. Development of automatic-extraction model of poisonous clauses in international construction contracts using rule-based NLP. J. Comput. Civ. Eng. 2019, 33, 04019003. [Google Scholar] [CrossRef]
- Martinez-Gil, J. A survey on legal question-answering systems. Comput. Sci. Rev. 2023, 48, 100552. [Google Scholar] [CrossRef]
- Davenport, M.J. Enhancing Legal Document Analysis with Large Language Models: A Structured Approach to Accuracy, Context Preservation, and Risk Mitigation. Open J. Mod. Linguist. 2025, 15, 232–280. [Google Scholar] [CrossRef]
- Pazhouhan, M.; Karimi Mazraeshahi, A.; Jahanbakht, M.; Rezanejad, K.; Rohban, M.H. Wave and Tidal Energy: A Patent Landscape Study. J. Mar. Sci. Eng. 2024, 12, 1967. [Google Scholar] [CrossRef]
- Mania, K. The Digital Transformation of Legal Industry: Management Challenges and Technological Opportunities. Danube 2022, 13, 209–225. [Google Scholar] [CrossRef]
- OpenAI. GPT-4o [Large Multimodal Model]; OpenAI: San Francisco, CA, USA, 2024; Available online: https://openai.com/index/hello-gpt-4o (accessed on 1 September 2025).
- Jain, D.; Borah, M.D.; Biswas, A. Summarization of legal documents: Where are we now and the way forward. Comput. Sci. Rev. 2021, 40, 100388. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 404–411. [Google Scholar]
- Liu, Y.; Lapata, M. Fine-tune BERT for Extractive Summarization. arXiv. 2019. Available online: https://arxiv.org/abs/1903.10318 (accessed on 1 September 2025).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Barros, T.S.; Pires, C.E.S.; Nascimento, D.C. Leveraging BERT for extractive text summarization on federal police documents. Knowl. Inf. Syst. 2023, 65, 4873–4903. [Google Scholar] [CrossRef]
- Shah, P.; Joshi, S.; Pandey, A.K. Legal clause extraction from contract using machine learning with heuristics improvement. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–3. [Google Scholar]
- Abdallah, A.; Piryani, B.; Jatowt, A. Exploring the state of the art in legal QA systems. J. Big Data 2023, 10, 127. [Google Scholar] [CrossRef]
- Ramakrishnan, A.; Chhabria, T.; Sarawagi, S. RAG-Legal: Retrieval Augmented Generation for Legal Question Answering. In Proceedings of the 2024 International Conference on Legal Knowledge and Information Systems (JURIX), Brno, Czechia, 11–13 December 2024; IOS Press: Amsterdam, The Netherlands, 2024; pp. 1–10. [Google Scholar]
- Wang, Y.; Wang, W.; Chen, Q.; Huang, K.; Nguyen, A.; De, S. Prompt-based zero-shot text classification with conceptual knowledge. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; Volume 4, pp. 30–38. [Google Scholar]
- Feng, K.; Huang, L.; Wang, K.; Wei, W.; Zhang, R. Prompt-based learning framework for zero-shot cross-lingual text classification. Eng. Appl. Artif. Intell. 2024, 133, 108481. [Google Scholar] [CrossRef]
- Parnas, D.L. On the criteria to be used in decomposing systems into modules. Commun. ACM 1972, 15, 1053–1058. [Google Scholar] [CrossRef]
- Bass, L.; Clements, P.; Kazman, R. Software Architecture in Practice, 3rd ed.; Addison-Wesley: Boston, MA, USA, 2013. [Google Scholar]
- Oracle Corporation. MySQL Reference Manual; Oracle Corporation: Redwood Shores, CA, USA, 2024; Available online: https://www.mysql.com (accessed on 1 September 2025).
- Ferraiolo, D.F.; Barkley, J.F.; Kuhn, D.R. A role-based access control model and reference implementation. ACM Trans. Inf. Syst. Secur. 1999, 2, 34–64. [Google Scholar] [CrossRef]
- Mayer-Schönberger, V.; Cukier, K. Big Data: A Revolution That Will Transform How We Live, Work, and Think; Houghton Mifflin Harcourt: Boston, MA, USA, 2013. [Google Scholar]
- Buschmann, F.; Henney, K. Pattern-Oriented Software Architecture: A System of Patterns; Wiley: Hoboken, NJ, USA, 1996. [Google Scholar]
- Sommerville, I. Software Engineering, 10th ed.; Pearson Education: Boston, MA, USA, 2016. [Google Scholar]
- Streamlit, Inc. Streamlit: The Fastest Way to Build Data Apps [Software]; Streamlit, Inc.: San Francisco, CA, USA, 2019; Available online: https://streamlit.io (accessed on 1 September 2025).
- Nielsen, J. Usability Engineering; Academic Press: Cambridge, MA, USA, 1993. [Google Scholar]
- PyMuPDF Developers. PyMuPDF [Software]; PyMuPDF: San Francisco, CA, USA, 2024; Available online: https://github.com/pymupdf/PyMuPDF (accessed on 1 September 2025).
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 1877–1901. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Fei, X.; Chi, E.; Le, Q.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Python Software Foundation. The Python Language Reference, Version 3.1.2, [Software]; Python Software Foundation: Wilmington, DE, USA, 2010; Available online: https://www.python.org (accessed on 1 September 2025).
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; Addison-Wesley: Boston, MA, USA, 2011. [Google Scholar]
- Merkle, R.C. Protocols for public key cryptosystems. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 14–16 April 1980. [Google Scholar]
- Docker, Inc. Docker Engine Documentation [Software]; Docker, Inc.: San Francisco, CA, USA, 2024; Available online: https://www.docker.com (accessed on 1 December 2025).
- Amazon Web Services. Amazon Elastic Compute Cloud (EC2) Documentation [Cloud Platform]; Amazon Web Services, Inc.: Seattle, WA, USA, 2024; Available online: https://aws.amazon.com/ec2/ (accessed on 1 December 2025).
- Newman, S. Building Microservices: Designing Fine-Grained Systems, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2021. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.