Abstract
Current approaches to dynamic sign language recognition commonly rely on dense landmark representations, which impose high computational cost and hinder real-time deployment on resource-constrained devices. To address this limitation, this work proposes a computationally efficient framework for real-time dynamic Mexican Sign Language (MSL) recognition based on a multimodal minimal angular-geometry representation. Instead of processing complete landmark sets (e.g., MediaPipe Holistic with up to 468 keypoints), the proposed method encodes the relational geometry of the hands, face, and upper body into a compact set of 28 invariant internal angular descriptors. This representation substantially reduces feature dimensionality and computational complexity while preserving linguistically relevant manual and non-manual information required for grammatical and semantic discrimination in MSL. A real-time end-to-end pipeline is developed, comprising multimodal landmark extraction, angular feature computation, and temporal modeling using a Bidirectional Long Short-Term Memory (BiLSTM) network. The system is evaluated on a custom dataset of dynamic MSL gestures acquired under controlled real-time conditions. Experimental results demonstrate that the proposed approach achieves 99% accuracy and 99% macro F1-score, matching state-of-the-art performance while using fewer features dramatically. The compactness, interpretability, and efficiency of the minimal angular descriptor make the proposed system suitable for real-time deployment on low-cost devices, contributing toward more accessible and inclusive sign language recognition technologies.
1. Introduction
Sign languages constitute complex communicative systems that integrate both manual and non-manual components. Among the latter, facial expressions and body postures play a fundamental role in encoding grammatical functions—such as interrogation, negation, and emphasis—as well as conveying semantic and emotional nuances [1,2]. Consequently, the omission of non-manual modalities in automatic recognition systems significantly limits their ability to accurately and comprehensively interpret signed messages [3,4].
The representation of dynamic elements in MSL, including letters such as J, K, Ll, Rr, Ñ, X, and Z, as well as numbers, days of the week, expressions, and emotions, poses an additional challenge for automatic recognition systems. Although recent advances in multimodal sensing and deep learning have led to substantial progress, many existing approaches still focus primarily on manual gestures or rely on dense representations derived from full landmark maps. For instance, frameworks such as MediaPipe Holistic extract up to 468 keypoints per frame. While these dense representations are information-rich, they also introduce high latency and considerable computational overhead, which complicates real-time processing and restricts deployment on resource-constrained devices such as mobile phones or embedded platforms [5,6]. Furthermore, numerous studies explore the use of deep learning—particularly Convolutional Neural Networks (CNNs)—for emotion recognition [7,8,9,10,11,12,13,14,15].
Zhi et al. (2019) discuss the FAP (Face Animation Parameters) standard, which consists of 66 facial displacement and rotation parameters [16]. Mukhiddinov et al. (2023) examine the use of the standard 68-point facial landmark model as a basis for contemporary algorithms. However, their method focuses specifically on upper-face features obtained through MediaPipe Face Mesh [17]. Similarly, Li et al. (2025) report that their DTAGN method uses IntraFace to detect 49 facial landmarks, emphasizing refined extraction of key facial components [18].
In this study, we propose an efficient approach for dynamic sign-language gesture recognition based on internal angular descriptors derived from a reduced, strategically selected subset of 28 keypoints distributed across the face, hands, and upper body. This compact geometric representation robustly captures the multimodal dynamics of gestures and offers invariance to translation, rotation, and scaling. Although validated in the context of MSL, the proposed design is generalizable to other natural sign languages [19,20,21,22]. In this work, we evaluate seven dynamic one-handed signs (letters) (see Figure 1), six two-handed signs (Figure 2), and five signs that incorporate facial components typical of MSL (Figure 3).

Figure 1.
The seven dynamic signs (with movement) performed with one hand are: (a) letter J; (b) letter K; (c) letter Ll; (d) letter Rr; (e) letter Z; (f) letter X; (g) letter Ñ.
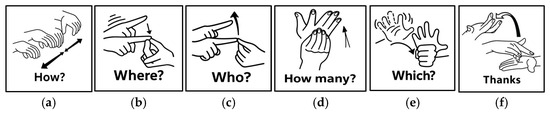
Figure 2.
The six two-handed signs in MSL are: (a) How?; (b) Where?; (c) Who?; (d) How many?; (e) Which?; and (f) Thanks.
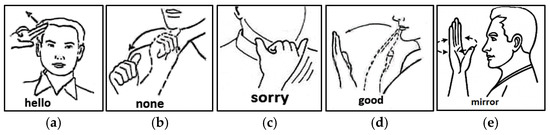
Figure 3.
The five signs that incorporate facial components typical of MSL are: (a) Hello; (b) None; (c) Sorry; (d) Good; (e) Mirror.
The main contributions of this work are as follows:
- i.
- The proposal of a minimal and multimodal angular geometric representation
- ii.
- Its integration with an efficient BiLSTM-based temporal modeling framework for dynamic sign.
- iii.
- The experimental validation of the proposed system under real-time conditions with high accuracy and low computational cost.
2. Related Works
Automatic sign language recognition has advanced significantly thanks to AI, especially deep learning. However, most approaches have focused on manual gestures, leaving aside non-manual components such as facial expressions and body posture, which are crucial to the specific meaning of some. This review analyses the most recent work on manual and multimodal sign recognition, highlighting efficient approaches that inspire the proposal presented in this study.
2.1. Classic and Foundational Models
Koller et al. (2020) introduced a linguistic-feature-based approach to visual sign language recognition using HMM models and visual classifiers in British Sign Language (BSL), emphasizing the importance of incorporating linguistic structure rather than relying solely on generic visual features [23]. They presented a hybrid architecture combining CNNs and BLSTMs to model sign sequences with high precision. García-Gil et al. (2024) present an innovative method of real-time recognition of the MLS based on the analysis of six angles formed between the distal phalanges and the palm, eliminating the need for complex image processing [24]. Using machine learning (ML) algorithms, the system achieves 99% accuracy and an F1-score of 99% and serves as the basis for this study.
2.2. Models Based on LSTM
Shamitha & Badarinath (2023) developed a real-time system for the recognition of 24 dynamic signs in Indian Sign Language (ISL), using MediaPipe Holistic for keypoint extraction and a pure LSTM architecture for gesture classification [25]. The system achieves 97% accuracy in tests on its own dataset. Bhadouria et al. (2024) present a sign language recognition system based on MediaPipe and LSTM networks, where manually extracted real-time landmarks are used as input for a sequential network capable of capturing temporal dependencies [26]. Caraka et al. (2025) propose an innovative LSTM-based model for the recognition of the Indonesian Sign Language (BISINDO), using an optimized architecture to capture body movements and manual gestures extracted by MediaPipe [27]. The model achieves a validation accuracy of 92.86%, surpassing previous approaches in both accuracy and computational efficiency.
2.3. Models Based on BiLSTM
Renjith and Manazhy (2024) developed a sign language recognition system based exclusively on a Bidirectional LSTM network, trained on sequences of keypoints extracted from video [28]. Their study demonstrates that a BiLSTM model, without convolutional layers, can effectively capture the temporal and directional structure of dynamic gestures with high accuracy. Zhang et al. (2024) propose an innovative approach in which a BiLSTM is applied to radio-frequency (RF) signals rather than video [29]. Their work shows that bidirectional networks can identify characteristic movement patterns of sign language even in non-visual domains. Similarly, Rautela Singh et al. (2025) present a purely BiLSTM-based model applied to video sequences of dynamic signs [30]. The system focuses on capturing the temporal evolution of joint movements without prior convolutional stages, demonstrating robustness to inter-user variability and differences in gestural speed.
2.4. LSTM Hybrid
Mejía Pérez et al. (2022) developed an automatic MLS recognition system that integrates hand, face, and body gestures in 3D using an OAK-D camera and LSTM/GRU networks [31]. With a dataset of 3000 samples, their best model achieves 97% accuracy on clean data and 90% on noisy data, highlighting the importance of non-manual gestures for robust recognition. Baihan et al. (2024) propose the CNNSa-LSTM model, which combines CNN, self-attention, and LSTM, together with a hybrid optimization algorithm (HOA + PFA) [32]. They obtain 98.7% accuracy, 0.131 WER, and 0.114 SER, demonstrating high effectiveness in continuous recognition of complex signs. Huang and Chouvatut (2024) present a video-based sign language recognition methodology that integrates a ResNet backbone with an LSTM to capture spatial and temporal features jointly [33]. Their approach employs ResNet-18 to avoid granularity explosion, followed by an LSTM to model temporal dynamics. Evaluated on the Argentine Sign Language (LSA64) dataset, the system achieves 86.25% accuracy, an F1-score of 84.98%, and a precision of 87.77%.
Lara-Cázares et al. (2025) developed a hybrid neural network for accurate recognition of the extended alphabet and dynamic signs of MLS [34]. Their model integrates hand, face, and body signals captured with MediaPipe and processed by a deep, efficient architecture that distinguishes between static and dynamic signs. They report an accuracy of 91.23% and an F1-score of 90.91%. Kamble (2025) proposes SLRNet, a real-time system for recognizing letters of the ASL alphabet and functional words using a webcam [35]. The system employs MediaPipe Holistic to extract 543 landmarks per frame and a stacked LSTM model to classify sequences of 30 frames. Their approach achieves a validation accuracy of 86.7%, demonstrating that a fully LSTM-based framework is viable for live sign detection. Meanwhile, Chiradeja et al. (2025) employ Hybrid Graph Embedding and Adaptive Convolutional Networks [36]. Given the hybrid nature of their method and the use of CNNs for spatial processing, these approaches are often combined with recurrent models to handle the temporal dynamics of sign sequences.
2.5. Models Not Based on LSTM
González-Rodríguez et al. (2024) developed a bidirectional translation system between MLS and Spanish, using MediaPipe to extract manual keypoints and comparing multiple neural models [37]. Their BRNN model achieved the highest accuracy (98.8%), highlighting the effectiveness of manual features for gesture recognition and the feasibility of accessible interfaces for individuals with hearing disabilities.
Kakizaki et al. (2024) proposed a system for recognizing the dynamic alphabet of Japanese Sign Language (JSL), based on manual pose estimation with MediaPipe, effective feature extraction, and attribute selection using Random Forest [38]. The selected features were classified using a kernel-based Support Vector Machine (SVM) model, achieving 97.2% and 98.4% accuracy on their own dynamic sign datasets for JSL and LSA64, respectively.
Kim and Kim (2025) introduced a dynamic clip segmentation method to improve video-based sign language recognition, adapting the number of segments to the video duration using models such as the Video Swin Transformer [39,40]. Their approach reaches 98.67% accuracy and reduces inference time by 28.57%, enhancing both temporal fidelity and system efficiency. In addition, they present a technique for dynamically detecting start and end points in sign language streams to improve accuracy in mobile environments. They propose adjusting the sampling frequency in real time to account for variability in frame capture across devices with different performance levels. Compared with fixed sampling methods, their approach improves Top-1 accuracy to 66.54% and Top-5 accuracy to 83.64%, demonstrating greater robustness and adaptability for sign recognition under mobile conditions.
Walsh et al. (2025) organized the SLRTP2025 challenge to evaluate sign language production models from text [41]. The winning system, based on retrieval and pretrained models, achieved 31.40 BLEU-1 and 0.0574 DTW-MJE. They also introduced a standardized skeleton-based metric to enable consistent comparison across future evaluations. Hilario-Acuapan et al. (2025) developed an MLS recognition system based on sign decomposition and analysis of arm joint trajectories, achieving promising results with YOLOv8 and CNN architectures [42]. Niu (2025) presented an improved MobileNet-based model incorporating multiscale convolution and the ELU activation function, achieving up to 98.26% accuracy in gesture recognition and outperforming other lightweight models across multiple datasets [43].
Hafeez, K.A. et al. (2024) proposed a scalable proof-of-concept deep learning framework for American Sign Language (ASL) recognition, addressing communication barriers faced by the North American Deaf community [44]. Their Multimodal Transformer Network (MTN) processes visual data from camera streams by integrating skeletal landmarks extracted via MediaPipe Holistic with convolutional features derived from a ResNet50 model pretrained on ImageNet. This multimodal architecture operates across five distinct modalities and achieves 94% accuracy on a set of 22 ASL classes, demonstrating strong performance despite using a limited dataset.
Hashi et al. (2025) further advanced sign language recognition research by introducing a hybrid CNN-Transformer framework optimized using a Grey Wolf Algorithm for accurate American Sign Language (ASL) recognition [45]. Their model integrates convolutional neural networks for spatial feature extraction with Transformer-based modules for temporal sequence modeling, demonstrating strong performance in both static and dynamic sign classification tasks.
Šajina et al. (2025) proposed a GCN-Transformer model as a novel deep learning solution based on sensor-derived motion data [46]. Their architecture combines Graph Convolutional Networks (GCNs) to capture spatial dependencies with Transformer modules to model temporal interactions, achieving state-of-the-art performance across multiple datasets. In addition, they introduced the FJPTE evaluation metric and specialized loss functions (MPJD and VL) designed to enhance the realism and temporal coherence of predicted movements. These contributions have broader implications for modeling complex human interactions, including the nuanced facial and body dynamics that are critical to sign language communication. Collectively, these recent studies underscore the importance of advanced hybrid architectures and multimodal inputs for achieving accurate, robust, and real-time sign language recognition and pose forecasting in assistive communication technologies.
Feigang Tan et al. (2024) proposed a video-based deep-segmentation approach for foreign-object detection in urban rail transit, addressing key limitations of laser-based systems, such as blind spots and limited visual interpretability [47,48]. By formulating the task as a foreground–background segmentation problem and integrating convolutional neural networks, morphological post-processing, and channel–spatial attention mechanisms, their method achieved robust performance under real subway operating conditions. In a related direction, recent studies have explored hybrid CNN-Transformer architectures for facial micro-expression recognition, reporting high accuracy and low latency through hierarchical feature extraction and region-based segmentation strategies.
3. Materials and Methods
A real-time module was implemented using OpenCV (version 4.13.0; Palo Alto, CA, USA) and MediaPipe (version 0.10.31; Google LLC, Mountain View, CA, USA), operating at 18 FPS within 2.5-s windows [49,50,51]. For each frame, 28 internal angles were computed: 12 corresponding to both hands, obtained from triplets formed by the wrist and fingertip landmarks; 4 in the upper torso, including the wrist–elbow–shoulder articulations; and 12 in the face, associated with eyebrow, eye, and mouth movements.
3.1. Calculation and Capture of Angular Descriptors (Stage 1)
The angles were computed using the arccosine of the normalized dot product, clipped to the [−1, 1] interval to ensure numerical stability against potential rounding errors. This process generates a temporal sequence of angular vectors for each video clip. The angular descriptor associated with each of the 28 proposed points is defined by Equation (1).
where are the coordinates of the three points that form the angle of interest . The frames were manually annotated via keyboard and stored in CSV files together with sequence metadata (sequence_id, frame_index, timestamp). This angular representation provides translation invariance and constitutes the foundation for subsequent temporal modeling. Each sequence was represented as a tensor of dimensions . Missing values were imputed using the median, and afterwards, all variables were standardized using the statistics of the training set.
For the ML stage, we evaluated both static models based on sequence-level aggregated features—including Random Forest (RF), SVM, and Multi-Layer Perceptron (MLP) [52,53,54]—as well as temporal models such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks [55,56]. The latter were trained using the Adam optimizer, class-weighted cross-entropy loss, regularization techniques such as dropout and early stopping, and stratified 5-fold cross-validation, applying subject-wise grouping whenever possible.
Model selection was based on the macro-F1 score obtained from cross-validation. The best configuration was retrained using the combined training and validation sets and evaluated once on the independent test set. We report accuracy, macro F1-score, per-class metrics, and confusion matrices to ensure a comprehensive evaluation.
Finally, the inference pipeline standardizes the features and enables prediction either through a static classifier operating on aggregated descriptors or directly from the sequence using temporal networks. This integrated strategy not only ensures robustness to data variability but also enables a systematic comparison between static and dynamic approaches for automatic sign-language recognition.
3.2. Software and Hardware Features
Our system achieves a throughput of 18.2 ± 0.4 frames per second under the specified operating conditions (Table 1). To evaluate performance, we implemented an exhaustive benchmarking protocol that included latency and resource utilization metrics, following established best practices for real-time systems.

Table 1.
Real-Time System Performance Metrics.
The experiments were conducted on a workstation equipped with an AMD Ryzen 5 5600G processor (AMD Inc., Santa Clara, CA, USA), an NVIDIA GeForce RTX 3060 Ti GPU (NVIDIA Corporation, Santa Clara, CA, USA), 8 GB DDR4 RAM, and a Logitech C920 HD Pro camera (Logitech International S.A., Lausanne, Switzerland). Video capture was configured at 18 FPS, a sampling rate selected to provide sufficient temporal resolution for preserving the kinematic continuity of the signs without introducing excessive redundancy. Each sequence was recorded in 2.5-s windows, corresponding to approximately 30 frames, an interval suitable for capturing the full cycle of dynamic gestures without forcing artificial modifications in signing speed. Recordings were performed at 1080p resolution. Protocol: 1000-frame warm-up, 5000-frame measurement window, 10 independent trials.
The software pipeline was implemented on Windows 10 (64-bit) using Python 3.1.2, OpenCV for video processing, NumPy for vectorized numerical operations, and MediaPipe—specifically the FaceMesh, Hands, and Pose modules—for keypoint extraction [57]. This configuration enabled efficient real-time processing and the extraction of multimodal descriptors with low latency.
3.3. Data Acquisition and Pre-Processing
The data acquisition process was implemented through a sequential pipeline encompassing keypoint extraction, geometric descriptor computation, and signal conditioning for temporal modeling. Using the MLS recordings, MediaPipe Holistic extracted 2D keypoints for each frame, enabling the construction of a custom dataset comprising static, dynamic, and compound signs. The dataset is appropriately sized, containing more than 1200 labeled sequences: 371 letters, 385 functional words, and 450 interrogative signs.
To ensure semantic consistency and experimental validity, recordings were obtained from five participants: one 45-year-old woman, two men aged 49 and 22, and two male adolescents aged 17 and 16. This diversity supports both intra- and inter-signer variability while preserving controlled acquisition conditions. To avoid undue extrapolation, the scope of the dataset and the conclusions derived from this study have been explicitly delimited. In particular, it is clarified that the reported results correspond to the evaluated dynamic vocabulary and to the controlled acquisition conditions employed (environment, illumination, and participants). Although the proposed approach is designed to be generalizable to other sign languages and datasets, such generalization is presented as a methodological hypothesis supported by the geometric and invariant nature of the angular descriptors, rather than as an empirical claim beyond the analyzed corpus.
For a detailed description of the complete acquisition workflow and access to the dataset repository, the reader may refer to the following link: https://github.com/gggvamp/MSL/blob/main/angulos_movimiento2.csv (accessed on 3 January 2026); code: https://github.com/gggvamp/MSL/blob/main/LstmPredicccion2%20(1).py (accessed on 3 January 2026); video: https://github.com/gggvamp/MSL/blob/main/Video.mp4 (accessed on 3 January 2026).
To reduce dimensionality while preserving essential linguistic information, each frame was transformed into a vector of 28 internal angles describing the relative geometry of the hands, torso, and face. These angular descriptors, derived from anatomically meaningful triplets, offer translation invariance, robustness to inter-individual variation, and a more stable representation against noise inherent to keypoint estimation. The resulting vectors were stored in a structured format to facilitate downstream processing.
Before being used for modeling, the angular data underwent an exhaustive pre-processing procedure. Missing values were imputed using the median of each feature, an appropriate strategy for episodic noise produced by occlusions or momentary detector failures. All features were standardized using subject-wise Z-score normalization to compensate for physiological differences—such as hand size, gestural amplitude, or facial expressiveness—and to encourage models to learn linguistic patterns rather than rely on biometric features. A temporal smoothing step was then applied using a moving median filter, which reduced keypoint jitter without distorting the gesture’s true temporal evolution.
The dataset was partitioned using a stratified scheme by subject and sign, applied at the complete-sequence level, ensuring that all sequences from the same individual remained fully isolated between the training and evaluation phases. This strategy prevents temporal overlap and partial data reuse across splits, thereby eliminating potential information leakage. In addition, stratification by sign maintains a balanced class distribution across subsets, enabling a rigorous, controlled assessment of the model’s ability to generalize to unseen users. Finally, Figure 4 illustrates the locations of the 28 keypoints used to compute internal angles.
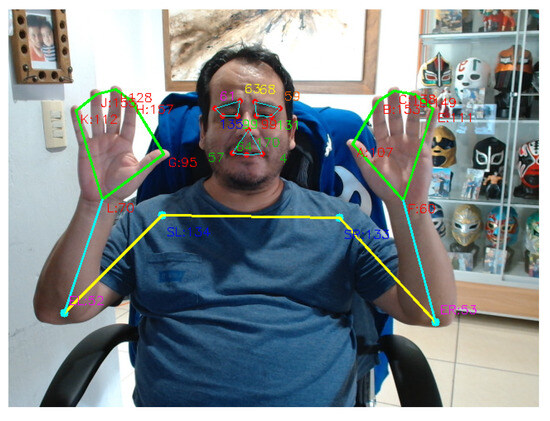
Figure 4.
Spatial distribution of the 28 keypoints used for internal angle computation.
In face detection, the face mesh from mediapipe returns 468 specific points of the face. Still, we only take 12 per Ekman studio, resulting in a reduction to 28 angular descriptors, not only decreasing the problem’s dimensionality but also providing a more efficient and linguistically grounded representation, consistent with previous studies [58]. This approach is particularly appealing given that, in the recent works reviewed in this article, most methods employ at least 42 landmarks, apart from the study by Hilario-Acuapan et al. (2025), which does not include finger-related keypoints [42]. A detailed comparison of these approaches is presented in Table 2.
Table 2.
Comparison of components, landmarks, and characteristics in human and gestural recognition studies.
Table 2.
Comparison of components, landmarks, and characteristics in human and gestural recognition studies.
| Reference | Hand Component | Torso Component | Face Component | Landmarks | Features |
|---|---|---|---|---|---|
| Mejía-Pérez [31] | 21 points per hand | 5 keypoints (chest, shoulders, elbows) | 20 reduced mesh points | 67 keypoints (42 hands + 5 body + 20 face) | 3D coordinates + models in LSTM/GRU |
| Lara-Cazares [34] | 21 landmarks per hand | N/A | N/A | 21 landmarks | Angles and lines (slopes between points) |
| Walsh [41] | 21 landmarks per hand | 54 pose landmarks | 5 landmarks on the head | 101 landmarks (42 hands + 54 torso + 5 head) | 108-dimensional pose vector |
| Biswas [59] | 21 per hand | 33 pose landmarks | 468 face landmarks | 543 landmarks (21 + 21 + 33 + 468) | 1662 coordinates (X, Y, Z, visibility) |
| Kakizaki [38] | 21 per hand (X, Y, Z) | Not used | Not used | 21 landmarks | 3529 features (760 distances + 2520 angles) |
| Shamitha S [25] | 21 per hand | Not used | Not used | 21 landmarks | Normalized coordNorm vector (x, y) |
| García-Gil [24] | 21 per hand | Minimal reliance | Minimal reliance | 21 landmarks | 6 internal angles (αA–αF) |
| Kim [14] | 21 per hand | 17 pose | Implicit pose | 59 keypoints (42 hands + 17 pose) | Frame-to-frame position changes (Ci) |
| González [37] | 21 per hand | 5 torso | 11 reduced face features | 58 keypoints | 174 features (X, Y, Z) |
| Sharvari [35] | Distances between hand keypoints | Shoulders and elbows | 20 facial + head rotation features | N/A (distances extracted) | 44 characteristics, 22 via PCA |
| Hilario-Acuapan [42] | Dolls 5 signs | Shoulders and elbows | YOLOv8 pose keypoints | 17 keypoints (pose YOLOv8) | Movement shape features |
It indicates the comparison of components, landmarks, and feature representations across human and gestural recognition studies. The number of landmarks reported corresponds to the original configurations used in each survey and may include hand, body, and face keypoints depending on the methodology. Feature types are described as reported by the authors, with no reprocessing or normalization applied for this comparison.
3.4. Mathematical Foundations of the BiLSTM Model for Sign Recognition
To predict sign movements using an LSTM (Long Short-Term Memory) network, the input consists of a sequence , where each vector represents the 28 angular descriptors per frame and corresponds to the temporal duration of each gesture. The output label is defined as . The mathematical foundation relies on the formulation of recurrent neural networks (RNNs) and the internal structure of LSTM cells, which capture long-term temporal dependencies within the sequence. Since the Bidirectional LSTM (BiLSTM) used in this work is a direct extension of the standard LSTM architecture, the mathematical formulation of the LSTM cell is first presented before introducing its bidirectional variant. Model training is performed by minimizing the class-weighted cross-entropy loss, shown in Equation (2).
The class weights are optional and allow for class balancing, while denotes the softmax distribution produced by the network. To contextualize the operation of LSTM cells, it is helpful to recall that a “simple” RNN defines the hidden state at time based on the current input vector and the previous state, as expressed in Equation (3).
where denotes the new hidden state at time . The function represents the nonlinear activation (typically tanh or ReLU); when tanh is used, the hidden state remains bounded within the interval . The matrices correspond to the input-to-hidden weights, is the input vector at step , denotes the recurrent (hidden-to-hidden) weights, and is the bias term associated with the hidden state. It is important to note that training with Backpropagation Through Time (BPTT) is susceptible to gradient vanishing or exploding due to repeated products of Jacobians, expressed as . To address this issue, the LSTM architecture introduces an explicit memory with gating mechanisms that regulate long-term gradient flow, leading to the cell Equations (4)–(9) presented below.
where denotes the logistic sigmoid function and represents the element-wise product. The term allows gradients to be preserved over time when , thereby mitigating the vanishing-gradient problem. To convert the sequence into a discrete prediction, the recurrent block composed of one or two layers (LSTM/BiLSTM) compresses the temporal dynamics into a representation vector , either by taking the final hidden state or by applying a temporal pooling operation over . A linear projection to classes is then applied on top of this representation, followed by a softmax normalization to obtain posterior probabilities, as shown in Equation (10).
Here, denotes the vector of pre-softmax activations (logits), ,where corresponds to the hidden-state size in a standard LSTM, or in a BiLSTMand is the output-layer bias. This formulation enables end-to-end training using cross-entropy loss and is compatible with regularization techniques such as dropout and weight decay. In the BiLSTM variant, the forward and backward hidden states are concatenated to capture both past and “future” context within the temporal window, as shown in Equation (11).
The resulting vector simultaneously encapsulates both past and future context at time . Given that the sequence contains time steps, the BiLSTM produces a set of vectors . The pooling operation is a function that aggregates these vectors into a single fixed-size representation. Common strategies include mean pooling, max pooling, and last pooling—the latter uses the final hidden state, a choice often adopted in unidirectional LSTMs. In this way, becomes a representative vector of the entire sequence, suitable for processing by a fully connected layer followed by a softmax normalization for classification. The model is trained by minimizing the loss function using Backpropagation Through Time (BPTT) over windows of length (in this case, ), with the Adam optimizer. Equation (12), describes how the derivative of with respect to the parameters accumulates gradients over time:
Optimization is performed via backpropagation through time (BPTT) across the gates . To ensure numerical stability, gradient clipping is applied as For sequence normalization with near-fixed length, padding up to is allowed, and a mask is used to remove contributions outside the valid window. Feature-wise standardization (z-score) is performed using training-set statistics, as formalized in Equation (13).
With this, we obtain both the computational complexity and the adequacy of the angular descriptor. With 28 inputs per time step and a hidden size , the per-step computational cost of an LSTM is , corresponding to the four projections for the gates. The 28 internal angles provide a compact, translation-invariant, and linguistically informed representation (hand–torso–face), reducing noise and helping the BiLSTM capture relevant temporal dynamics while minimizing overfitting.
3.5. Data Acquisition and Angle-Based Feature Extraction (Algorithm 1)
This algorithm implements a real-time pipeline for acquiring Mexican Sign Language (MSL) data through angular feature extraction. The system processes video streams at 18 FPS, detects multimodal landmarks (face, hands, and body), and computes 28 translation-invariant angular descriptors. Sequences of 2.5 s (≈30 frames) are stored in CSV format for subsequent temporal modeling with LSTM networks. The interactive interface enables real-time labeling and complete control of the data acquisition process, as summarized in Algorithm 1.
| Algorithm 1: Real-time MLS Data Acquisition and Angular Feature Extraction |
| 1: // Initialization Phase 2: Initialize MediaPipe models: FaceMesh, Hands, Pose 3: Configure camera: FPS_TARGET ← 18, RESOLUTION ← 1080p 4: SEQUENCE_DURATION ← 2.5 s, FRAMES_PER_SEQUENCE ← 30 5: Create CSV file with headers for 28 angular features + metadata 6: // Main Processing Loop 7: while camera is active do 8: frame ← capture_frame() 9: frame ← flip_frame_horizontally(frame) 10: image_rgb ← convert_to_RGB(frame) 11: // Multi-modal Landmark Detection 12: if face_detected then 13: Extract 12 facial landmarks → Calculate 28 angles (eyebrows, eyes, mouth) 14: end if 15: if hands_detected then 16: Extract wrist + 5 fingertips per hand → Calculate 12 hand angles 17: end if 18: if body_detected then 19: Extract shoulders/elbows → Calculate 4 torso angles 20: end if 21: feature_vector ← combine(12_hand + 4_torso + 12_facial_angles) 22: // Recording Control Logic 23: if recording_active = true then 24: if elapsed_time < SEQUENCE_DURATION then 25: Store frame_data in buffer 26: frame_count ← frame_count + 1 27: else 28: Save buffer to CSV → Increment sequence_id 29: Reset buffers and counters 30: recording_active ← false 31: end if 32: end if 33: // User Interface Handling 34: if key_pressed = ESC then 35: break // Exit program 36: else if key_pressed = SPACE then 37: Toggle recording state 38: else if key_pressed in [Label] then 39: Assign corresponding label 40: end if 41: Display processed frame with annotations 42: end while 43: // Cleanup Phase 44: Release camera resources |
| Algorithm for real-time data acquisition and angular feature extraction, detailing the initialization of MediaPipe models, camera configuration, frame processing for landmark detection, and data recording. User controls manage the recording state and labeling, with cleanup performed at exit. |
3.6. Architecture and Training of the BiLSTM Prediction Model (Algorithm 2)
MediaPipe Holistic was used for joint detection of facial mesh, hands, and full-body pose in video sequences captured at 18 FPS over 2.5-s windows (~30 frames). Each frame is horizontally flipped, and from the 2D landmarks, 28 translation-invariant angular descriptors are derived: 12 from the hands (wrist and fingertip segments), four from the torso (shoulders, elbows, and wrists), and 12 from the face (eyes, eyebrows, and mouth). Angles are computed using the dot product and the arccos function, with numerical clipping to the interval [−1, 1], providing robustness to scale variations, illumination changes, and partial occlusions, while reducing dimensionality relative to the complete landmark set.
Each sequence corresponds to a dynamic MSL letter. The system serializes sequences into a CSV file containing a sequence identifier, frame index, label, timestamp, and the 28 computed angles. This structure explicitly distinguishes between frame-level and sequence-level information, preventing temporal leakage. Sequences are sorted and undergo intra-sequence imputation (forward fill) to address missing landmarks; remaining gaps are filled using the global median.
Each sequence is standardized to a fixed length using padding or trimming, with masking applied during training. Z-score normalization is computed exclusively on the training partition to preserve independence across data splits.
Recurrent Neural Networks (RNNs) have been widely used for processing sequential data; however, their ability to model long-range temporal dependencies is limited by the well-known vanishing gradient problem. To address this limitation, Long Short-Term Memory (LSTM) units were developed—architectures that incorporate a gating system to stably regulate the cell state across extended temporal intervals. An LSTM cell integrates input, forget, and output gates that autonomously control the flow of information, enabling robust modeling of nonlinear and non-stationary sequential patterns [60,61].
In the context of dynamic sign language recognition, LSTMs are particularly well-suited for capturing the temporal evolution of angular descriptors, which exhibit both local short-term variations—such as digital articulation—and long-term dependencies associated with the execution of complete signs. Bidirectional LSTM networks (BiLSTM) extend this paradigm by processing sequences in both temporal directions. This dual propagation generates enriched representations by simultaneously integrating retrospective and prospective context, yielding superior capability to infer complex dependencies in multimodal settings [62,63].
For sign recognition, this characteristic enhances the disambiguation of gestures whose semantic interpretation depends on both early motion trajectory elements and later components, such as facial expressions and final posture. The ability of BiLSTMs to integrate bidirectional information naturally aligns with linguistic properties of sign languages, where co-articulation across sequential components is essential for semantic interpretation. This process is detailed in Algorithm 2.
| Algorithm 2: Real-time MSL Inference with BiLSTM using Angular Features |
| 1: // Initialization Phase 2: Load artifacts: best_model.keras, scaler_stats.json (mean,std) 3: Parse config → FEATURE_COLS; SEQLEN_TARGET ← 30; SMOOTH_WINDOW ← 5 4: Initialize MediaPipe models: FaceMesh, Hands, Pose 5: Configure camera: FPS_TARGET ← 18, RESOLUTION ← 1080p 6: Initialize buffers: buffer_frames ← ∅, pred_history ← Deque (SMOOTH_WINDOW) 7: // Main Processing Loop 8: while camera is active do 9: frame ← capture_frame() 10: frame ← flip_frame_horizontally(frame) 11: image_rgb ← convert_to_RGB(frame) 12: // Multi-modal Landmark Detection 13: face_lms ← FaceMesh.process(image_rgb) 14: hands_lms ← Hands.process(image_rgb) 15: pose_lms ← Pose.process(image_rgb) 16: // Angle Extraction (per frame) 17: if face_lms detected then 18: Compute 12 facial angles (eyebrows, eyes, mouth) 19: end if 20: if hands_lms detected then 21: Extract wrist + 5 fingertips per hand → Compute 12 hand angles 22: end if 23: if pose_lms detected then 24: Extract shoulders/elbows (+ wrists) → Compute 4 torso angles 25: end if 26: feature_vector ← combine(12_hand + 4_torso + 12_facial) → replace None 27: append(feature_vector, buffer_frames) 28: // Inference Trigger 29: if length(buffer_frames) ≥ SEQLEN_TARGET then 30: seq_Tx28 ← take last SEQLEN_TARGET from buffer_frames 31: seq_Tx28 ← pad_or_trim(seq_Tx28, SEQLEN_TARGET) 32: seq_Tx28 ← standardize(seq_Tx28; mean,std from scaler_stats.json) 33: probs ← BiLSTM.predict(seq_Tx28) 34: pred_label ← argmax(probs) 35: push(pred_label, pred_history) 36: smoothed_label ← mode(pred_history) 37: top3 ← take_top3(probs) 38: end if 39: // On-Screen Overlay 40: display(smoothed_label, top3, len(buffer_frames) mod SEQLEN_TARGET, SEQLEN_TARGET) 41: // User Interface Handling 42: key_pressed ← read_key() 43: if key_pressed = ESC then 44: break // Exit program 45: else if key_pressed = SPACE then 46: // Forced inference with current buffer 47: seq_Tx28 ← take last SEQLEN_TARGET (or all if fewer) 48: seq_Tx28 ← pad_or_trim → standardize → predict → update pred_history 49: smoothed_label ← mode(pred_history); top3 ← take_top3(probs) 50: end if 51: end while 52: // Cleanup Phase 53: Release camera resources 54: Close display windows |
| BiLSTM prediction model for real-time inference using angular features. The algorithm outlines the initialization of models and camera settings, followed by a loop that captures frames, detects landmarks, computes angles, and performs inference, all validated in real time to ensure practical usability. |
3.7. LSTM and BiLSTM Network Architecture
The temporal modeling stage was implemented using LSTM and Bidirectional LSTM (BiLSTM) networks, designed to capture both short- and long-range dependencies present in the angular sequences. As mentioned above, each dynamic gesture was represented as a sequence of T 30-time steps, where each step corresponded to a 28-dimensional vector of internal angular descriptors. These sequences were standardized and included masking to ignore padding values during training. This compact multimodal representation integrates manual and non-manual components from the hands, torso, and face, providing a stable and linguistically meaningful descriptor for sequential learning.
LSTM networks employ input, forget, and output gates to regulate information flow and mitigate the vanishing gradient problem, thereby maintaining a cell state that can preserve relevant temporal context. The BiLSTM architecture extends this mechanism by processing the sequence in both forward and backward temporal directions. As a result, each hidden state incorporates both retrospective and prospective information, a property particularly valuable for dynamic sign recognition, where semantic interpretation depends on the interaction between early and late components of the gesture, as well as on facial cues that may occur at different stages of the movement.
Figure 5 illustrates the adopted BiLSTM architecture and the LSTM cell’s internal structure. In bidirectional configurations, the outputs of the forward and backward passes are concatenated to create an enriched contextual representation. A temporal pooling operation—either mean pooling or the final hidden state—is then applied to obtain a fixed-length vector, which is subsequently projected onto the output classes through a fully connected layer followed by softmax normalization.
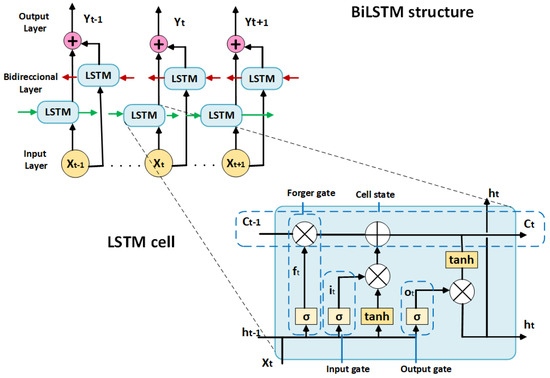
Figure 5.
BiLSTM network architecture and LSTM cell detail. The model consists of two bidirectional LSTM layers (hidden size = 128 per direction), followed by Dropout regularization (rate = 0.3) and a fully connected softmax output layer.
The networks were trained using weighted cross-entropy loss, the Adam optimizer, and regularization techniques such as dropout and early stopping to prevent overfitting. This architecture demonstrated strong capability in modeling the multimodal temporal dynamics characteristic of MSL gestures.
3.7.1. Stage 1: Data Acquisition and Preparation
The process begins with the recording of complete gesture sequences using a webcam. Each temporal window (~2.5 s) is processed with MediaPipe Holistic, which simultaneously detects facial, hand, and torso landmarks. From these two-dimensional keypoints, a compact vector of 28 internal angles is computed, summarizing the essential geometric configuration of each sign and substantially reducing dimensionality compared to using raw coordinates.
The resulting vectors are stored in a structured database and manually annotated by the authors. To enhance sequence quality, the dataset undergoes a robust preprocessing pipeline comprising:
- median-based imputation of missing values,
- per-subject Z-score normalization to mitigate inter-subject variability, and
- a temporal median filter to suppress frame-level noise.
Subsequently, the dataset is partitioned using a stratified scheme across subjects and signs, ensuring that individuals assigned to training, validation, and testing remain completely disjoint. This strategy prevents identity leakage and provides a reliable assessment of the model’s generalization capability.
3.7.2. Stage 2: Temporal Modelling and Prediction
The preprocessed sequences are fed into a two-layer sequential BiLSTM model designed to capture bidirectional temporal dependencies. Unlike a unidirectional LSTM, the BiLSTM simultaneously exploits past and future context, which is crucial for disambiguating gestures whose initial trajectories appear similar but diverge in their final phase (e.g., the letters “Rr” and “Ll”).
The architecture incorporates intermediate Dropout layers, followed by a softmax output layer that produces probability distributions over the target classes. Training is performed using class-weighted categorical cross-entropy to address dataset imbalance, together with the Adam optimizer (LR = 10−3). The BiLSTM architecture comprises two stacked bidirectional LSTM layers, each with a hidden size of 128 units per direction. A Dropout layer with a rate of 0.3 is applied between recurrent layers to reduce overfitting. The final sequence representation is projected onto the output classes through a fully connected layer with softmax activation.
Additional regularization strategies include early stopping to prevent overfitting and ReduceLROnPlateau to adaptively adjust the learning rate when performance plateaus [64]. Finally, data partitioning is conducted at the level of complete sequences, preventing temporal leakage across training, validation, and testing, and ensuring consistent system evaluation. See Figure 6.
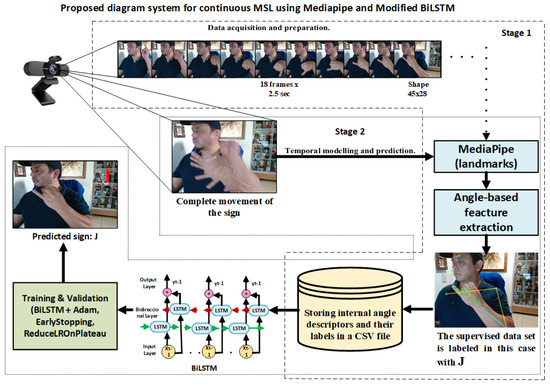
Figure 6.
Proposed system diagram for continuous dynamic sign recognition in MSL.
In Stage 1, the camera captures the entire gesture sequence, and MediaPipe extracts the corresponding angular descriptors, which are then stored alongside their supervised label. In Stage 2, the resulting sequences are processed by the trained BiLSTM model, which, during inference, predicts the corresponding sign, illustrated here as the letter “J”.
The methodological discussion has been expanded to justify the selection of internal angular descriptors and the BiLSTM model as the core components of the proposed system. Internal angles provide invariance to translation, rotation, and scale, while significantly reducing problem dimensionality without discarding linguistically relevant information. Moreover, the use of a BiLSTM enables effective modeling of the complete temporal evolution of each gesture by integrating both initial and final contextual details. Additionally, ablation studies—such as removing individual modalities (face, torso, or hands) or reducing the number of angular features—as well as cross-dataset evaluations, are explicitly identified as future work to further strengthen the empirical validation of the proposed approach.
4. Results
4.1. General Description
The BiLSTM model trained with angular descriptors demonstrated strong performance across the three evaluated subsets: dynamic MSL letters, functional words, and interrogative signs. The following summarizes the main findings and their interpretation.
The system was trained and evaluated using real-time recordings of dynamic sign sequences, each represented by 28 internal angular features computed per frame. Dataset partitioning was performed at the full-sequence level to prevent temporal leakage across training, validation, and testing, ensuring a consistent and reliable assessment of the model’s generalization capability.
4.2. Global Performance Metrics (Confusion Matrix)
A confusion matrix summarizes a classifier’s performance by comparing true and predicted labels. Each row corresponds to the actual class and each column to the predicted class (or vice versa). The main diagonal reflects correct classifications for each category, whereas the off-diagonal values represent misclassifications—instances where samples from one class were predicted as another. To interpret the matrix effectively, the first criterion is diagonal dominance, which indicates consistent and reliable class discrimination. Conversely, off-diagonal bands or clusters reveal systematic error patterns, often arising from gesture similarity, dataset imbalance, or potential labeling inaccuracies. For this reason, the confusion matrix should be evaluated together with the class support (number of samples per category), which provides essential context for assessing the magnitude and relevance of these confusions [65].
The overall performance of the system was quantified using Accuracy, Precision, Recall, and macro-averaged F1-score, metrics that offer a balanced evaluation even in the presence of class imbalance. Additionally, validation loss and training accuracy were monitored to assess the stability of the optimization process and detect potential overfitting. As depicted in Figure 7a–c.
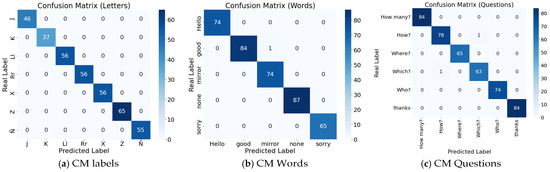
Figure 7.
(a) The confusion matrix for dynamic letters is strictly diagonal, with all 371 instances correctly classified. All seven classes achieved perfect metrics (Precision/Recall/F1 = 1.00), indicating excellent separability of kinematic trajectories, even for potentially ambiguous pairs; (b) For functional words, only one isolated confusion is observed (good → mirror), while all other cases are classified correctly (global accuracy = 100%, N = 385). Class-wise metrics remain near 1.00, and the single error corresponds to a minor gestural overlap; (c) Interrogatives show only one minor misclassification (How? → Where?), with all remaining combinations correct (N = 450). Most classes achieve perfect scores, while How? and Which? maintain very high values (0.99 and 0.98). These results confirm that facial and torso angles provide helpful non-manual cues for disambiguation.
For visualization purposes, confusion matrices are presented using a hybrid format that combines absolute counts with row-normalized percentages. While normalization facilitates rapid assessment of class-wise recall, including raw counts preserves critical information on the actual numbers of correct and incorrect predictions, which is essential for interpreting error patterns in multiclass dynamic sign recognition (see Table 3) for a detailed classification report on dynamic MSL signs. The table summarizes class-wise Precision, Recall, and F1-score, together with class support, corresponding to the confusion matrices shown in Figure 5. While confusion matrices provide a visual, count-based representation of classification outcomes, this table quantitatively reports the derived performance metrics, enabling precise comparison across dynamic letters, functional words, and interrogative signs.
Table 3.
Detailed MSL dynamic signs classification report.
4.3. Global Performance Metrics (ROC and AUC)
ROC curves (Receiver Operating Characteristic) are graphical representations that describe the behavior of a classifier as the decision threshold varies. They plot the True Positive Rate (TPR or Recall) against the False Positive Rate (FPR) across all possible thresholds. A ROC curve that approaches the upper-left corner indicates a model with high discriminative capability. In contrast, the Area Under the Curve (AUC) quantifies this performance in a single value: an AUC of 1.0 corresponds to perfect class separation, whereas an AUC of 0.5 reflects performance equivalent to random guessing [66]. The following are the graphs of the multiclass ROC and AUC curves. The combination of geometric invariance of internal angles and bidirectional temporal aggregation of BiLSTM produces wide and stable decision margins. As illustrated in Figure 8.
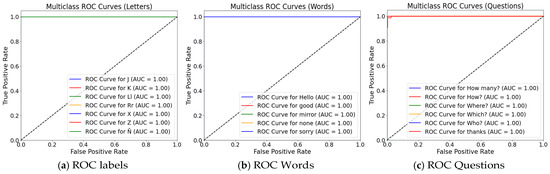
Figure 8.
ROC and AUC curve (a) for the seven dynamic MLS letters; (b) for the five words analyzed in this study; (c) for the six basic questions.
A rapid decrease in loss is observed during the first epoch, followed by a low and stable plateau for both training and validation. The absence of a late separation between the two curves indicates a stable optimization process without overfitting. Likewise, the smooth changes in slope are consistent with the automatic learning-rate adjustments applied by the ReduceLROnPlateau algorithm. As shown in Figure 9.
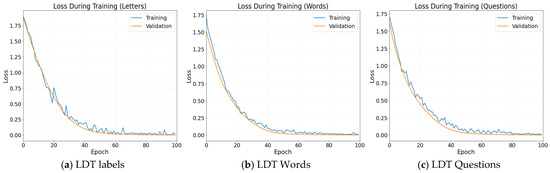
Figure 9.
Loss during training curves: (a) for the seven dynamic MLS letters; (b) for the five functional words; (c) for the six basic questions.
The accuracy curves increase monotonically over the training epochs, eventually stabilizing near 1.0. The validation curve closely tracks the training curve, indicating no overfitting and confirming the model’s ability to generalize effectively. This behavior is consistent with the regularization of mechanisms applied, including dropout and early stopping. See Figure 10.
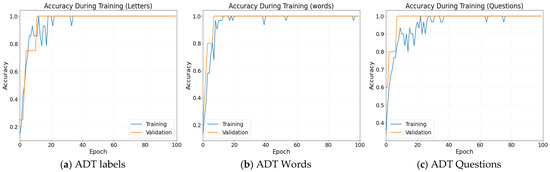
Figure 10.
Accuracy During Training curves: (a) for the seven dynamic MLS letters; (b) for the five functional words; (c) for the six basic questions.
4.4. Visual Demonstration of Model Performance
The model’s predictions for real captured sequences are shown. Each sequence corresponds to the complete execution of the gesture (~30 frames), and the model output is displayed as Predicted sign: [class] together with the associated probabilities for the evaluated classes (J, Z, Who?, Thanks, How?). These samples were randomly selected from the 18 signs considered in this study, which were themselves randomly drawn from the MLS vocabulary. The images directly reflect the core content of the research, as they illustrate the model’s performance, demonstrate consistency with the training metrics (loss and accuracy), and provide practical examples of the sign recognition process under real conditions, as shown in Figure 11a–o.

Figure 11.
Prediction examples under different acquisition conditions: (a–c) nighttime recordings with LED lamps performing the dynamic sign J; (d–f) midday recordings performing the dynamic sign Z; (g–i) sequences captured from a 15-year-old participant executing the question Who?; (j–l) sequences performed by a 45-year-old woman producing the dynamic sign Thanks; and (m–o) sequences captured from a 17-year-old participant executing the dynamic sign How?
The previous figures illustrate the dynamic multimodal recognition process implemented using the minimal angular geometry approach and BiLSTM-based temporal modeling. In each case, the system captures sequences of approximately 2.5 s (≈30 frames) at 18 FPS, during which MediaPipe Holistic detects keypoints on the face, hands, and torso. From these keypoints, 28 invariant angular descriptors are computed to describe the articulatory configuration of the sign. These angles, obtained through the normalized dot product between anatomical coordinate triplets, preserve the geometric relationships of the gesture regardless of body position, scale, or rotation.
The BiLSTM model analyzes the temporal series of these angular vectors in both directions (past and future), enabling the extraction of the complete evolution of each gesture: the descending curved trajectory of “J”, the characteristic zigzag pattern of “Z”, the manual and facial variations typical of the question “Who?”, and the articulatory movements of “Thanks” and “How?”, which integrate both manual and non-manual components. During inference, the model applies a softmax layer to estimate class probabilities and employs temporal smoothing to stabilize real-time predictions.
Overall, these examples demonstrate the system’s ability to accurately recognize the multimodal kinematics of dynamic signs by combining angular information from the hands, face, and torso with robust temporal processing that captures the linguistic and grammatical behavior of MLS.
The rigor of the evaluation process is reinforced through a more detailed description of the data partitioning strategy, which was performed in a subject-wise and sign-wise stratified manner, ensuring complete separation between the training, validation, and test sets. This strategy eliminates the possibility of temporal or identity leakage between sequences, thus guaranteeing a realistic assessment of the model’s generalization capability to unseen users. In addition, macro-averaged metrics (macro-F1, precision, and recall) are emphasized, mitigating the impact of class imbalance and providing a more balanced evaluation of system performance.
5. Discussion
The results demonstrate that a compact set of 28 minimal angular descriptors, combined with bidirectional BiLSTM temporal modeling, enables highly accurate dynamic sign recognition while substantially reducing computational complexity. This finding is particularly relevant when contrasted with approaches such as Mejía-Pérez et al. [31], which rely on more than 60 keypoints to represent hands, torso, and facial regions. Although such dense representations provide detailed spatial information, they incur higher dimensionality and increased computational cost. In contrast, the proposed approach preserves linguistically relevant multimodal cues through a compact angular representation, improving stability and processing efficiency.
While effective for purely manual gestures, these methods do not incorporate non-manual components, which play a fundamental grammatical and semantic role in MSL. By integrating angular information from hands, face, and torso within a reduced descriptor, the proposed system overcomes this limitation while maintaining robustness under controlled capture conditions.
High-resolution approaches, such as those of Biswas et al. [59], extract more than 500 keypoints per frame and generate over 1600 features. Although such representations can be beneficial in constrained laboratory settings, they typically require GPU acceleration and are sensitive to occlusions and sensor noise. By contrast, the proposed system operates using only 28 angular features and achieves comparable recognition performance on standard CPUs, highlighting an effective trade-off between representational richness and computational efficiency. Similar observations apply to methods based on derived vectors or 3D coordinates, such as those reported by Kakizaki et al. [38], which rely on hundreds or thousands of features per frame, thereby increasing both computational load and the risk of overfitting.
Regarding temporal modeling, previous studies have shown that unidirectional LSTMs can perform adequately for short or well-aligned gesture sequences but may struggle when discriminative information appears near the end of the movement. The BiLSTM architecture employed in this work addresses this limitation by jointly modeling past and future temporal context within each sequence window. This capability is particularly advantageous for distinguishing gestures with similar initial trajectories but different terminal patterns, such as J and Z. Under controlled acquisition conditions, this behavior is reflected in highly concentrated confusion matrices and ROC/AUC values close to unity.
Hybrid architectures combining CNNs with LSTMs have also demonstrated strong performance in dynamic sign recognition tasks. However, these approaches typically require intensive visual feature extraction and larger datasets. In the present study, the angular geometry representation already encodes the essential spatial structure, allowing the model to focus exclusively on temporal dynamics and eliminating the need for convolutional processing. This design choice reduces training costs and enables stable real-time operation at 18 FPS on CPU-based platforms. The proposed angular representation is compact and linguistically structured, and the bidirectional nature of the BiLSTM already enables implicit temporal focusing by integrating both past and future context.
Finally, classical classifiers such as SVM and RF remain effective for static gesture recognition but exhibit limitations when modeling continuous temporal dynamics. In contrast, BiLSTM-based modeling preserves temporal coherence and provides more consistent decision boundaries for gestures whose semantic interpretation depends on motion evolution rather than static posture.
Despite its strong performance, the proposed approach is subject to limitations, including sensitivity to prolonged occlusions and restriction to the evaluated vocabulary. Attention-based mechanisms, while effective in many sequence modeling tasks, were intentionally excluded to isolate and assess the contribution of the minimal angular representation. The compact and linguistically structured nature of the descriptor, combined with bidirectional temporal modeling, already enables implicit temporal focusing. Nevertheless, attention-based extensions remain a promising direction for future work, particularly for larger vocabularies and continuous sign language recognition scenarios.
6. Conclusions
The present work validates a compact, multimodal geometric strategy for dynamic recognition of MSL, based on a reduced set of 28 invariant internal angular descriptors and bidirectional BiLSTM temporal modeling. Unlike traditional approaches that rely on hundreds of landmarks per frame, the proposed representation preserves both manual and non-manual linguistic information while achieving substantial dimensionality reduction and maintaining competitive performance under the evaluated conditions.
The system demonstrates highly accurate recognition of dynamic letters, functional words, and interrogative expressions, indicating that angular relationships between anatomical segments effectively encode the kinematic and grammatical cues required for complete gesture interpretation, including interrogative structures such as Who? and How? This capability is reinforced by integrating facial and torso information and by bidirectional temporal modeling that captures the onset, evolution, and closure of each gesture trajectory.
The observed performance can be attributed to four complementary factors: (i) the use of invariant angular features that are robust to moderate translation, scale, and rotation while integrating manual and non-manual modalities; (ii) bidirectional temporal modeling that captures the complete temporal evolution of gestures and disambiguates visually similar trajectories; (iii) a rigorous experimental protocol, including subject-wise sequence partitioning and appropriate normalization, which prevents data leakage and enhances class separability; and (iv) effective regularization strategies that preserve model stability even for classes with limited support.
Despite these encouraging results, the reported performance was obtained under controlled acquisition conditions and for a predefined vocabulary. Accordingly, this study should be interpreted as a proof-of-concept demonstrating the effectiveness of minimal angular representations combined with BiLSTM modeling for dynamic sign recognition. The variability observed during data acquisition, although visually documented, does not constitute a systematic evaluation of generalization to unconstrained environments or heterogeneous signer populations.
The main limitations of the proposed approach include sensitivity to prolonged occlusions, dependence on the trained vocabulary, the use of fixed-length temporal windows (approximately 30 frames), and reliance on the underlying landmark detection framework, whose failures directly propagate to the angular representation. Future work will address these limitations by extending the evaluation to less constrained environments, broader vocabularies, and more diverse signer populations.
Finally, future research will explore integrating temporal attention mechanisms to highlight discriminative frames and improve robustness to occlusions, as well as evaluating lightweight Transformer architectures operating directly on angular sequences to capture long-range temporal dependencies without excessive computational complexity. Expanding the dataset to uncontrolled environments and multilingual sign language contexts also represents a promising direction for further validation and scalability.
Supplementary Materials
The following supporting information can be downloaded at: https://github.com/gggvamp/MSL/blob/main/BiLstmPredicccion2%20(1).py (accessed on 3 January 2026). Video S1: https://drive.google.com/file/d/1M5CUPtOeGfxK-V7tZjgSL1kEGSY4Zhys/view (accessed on 3 January 2026).
Author Contributions
G.G.-G. conceptualized the work, edited the manuscript, and prepared the dataset. G.d.C.L.-A. conceptualized the work, wrote parts of the manuscript, provided additional analysis, and revised the manuscript. Y.E.R.-P. Supervised, wrote parts of the manuscript, provided additional analysis, and revised the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
Technical Industrial Teaching Center supported this research. The action program was under academic direction (research work PI-09-2025).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This information has been detailed in the Supplementary Materials.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Elliott, E.A.; Jacobs, A.M. Facial Expressions, Emotions, and Sign Languages. Front. Psychol. 2013, 4, 115. [Google Scholar] [CrossRef]
- Kimmelman, V.; Imashev, A.; Mukushev, M.; Sandygulova, A. Eyebrow position in grammatical and emotional expressions in Kazakh-Russian Sign Language: A quantitative study. PLoS ONE 2020, 15, e0233731. [Google Scholar] [CrossRef]
- Morgan, G. The linguistics of British sign language: An introduction. R Sutton-Spence and B Woll, Cambridge University Press: London, 1999, 299pp ISBN: 0 5216 3142 4; ISBN: 0 5216 3718X. (A 90-minute video accompanying the books is available from CACDP). In Deafness & Education International; Wiley: Hoboken, NJ, USA, 2001; Volume 3, pp. 137–138. [Google Scholar] [CrossRef]
- Rosen, R.S. American Sign Language Curricula: A Review. Sign Lang. Stud. 2010, 10, 348–381. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Gu, H.; Cheng, G. Feature Points Extraction from Faces. 2003. Available online: https://www.semanticscholar.org/paper/Feature-Points-Extraction-from-Faces-Gu-Cheng/5bbdb6832da5c29e533a94e4c5114aedff5ffcaa (accessed on 23 November 2025).
- Fasel, I.R.; Bartlett, M.S.; Movellan, J.R. A comparison of Gabor filter methods for automatic detection of facial landmarks. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21 May 2002; pp. 242–246. [Google Scholar] [CrossRef]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active Shape Models-Their Training and Application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Lv, X.S. Facial Expression Recognition Based on a Hybrid Model Combining Deep and Shallow Features|Cognitive Computation. Available online: https://link.springer.com/article/10.1007/s12559-019-09654-y (accessed on 23 November 2025).
- Abdulsattar, N.S.; Hussain, M.N. Facial expression recognition using HOG and LBP features with convolutional neural network. Bull. Electr. Eng. Inform. 2022, 11, 1350–1357. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 23 November 2025).
- Khorrami, P.; Paine, T.L.; Huang, T.S. Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition? arXiv 2015, arXiv:1510.02969. [Google Scholar]
- Kim, M.; Pavlovic, V. Structured Output Ordinal Regression for Dynamic Facial Emotion Intensity Prediction. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 649–662. [Google Scholar] [CrossRef]
- Koelstra, S.; Pantic, M.; Patras, I. A dynamic texture-based approach to recognition of facial actions and their temporal models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1940–1954. [Google Scholar] [CrossRef]
- Zhi, R.; Liu, M.; Zhang, D. A comprehensive survey on automatic facial action unit analysis. Vis. Comput. 2020, 36, 1067–1093. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Djuraev, O.; Akhmedov, F.; Mukhamadiyev, A.; Cho, J. Masked Face Emotion Recognition Based on Facial Landmarks and Deep Learning Approaches for Visually Impaired People. Sensors 2023, 23, 1080. [Google Scholar] [CrossRef]
- Li, S.; Wang, J.; Tian, L.; Wang, J.; Huang, Y. A fine-grained human facial key feature extraction and fusion method for emotion recognition. Sci. Rep. 2025, 15, 6153. [Google Scholar] [CrossRef] [PubMed]
- Samaan, G.H.; Wadie, A.R.; Attia, A.K.; Asaad, A.M.; Kamel, A.E.; Slim, S.O.; Abdallah, M.S.; Cho, Y.-I. MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition. Electronics 2022, 11, 3228. [Google Scholar] [CrossRef]
- Amit, M.L.; Fajardo, A.C.; Medina, R.P. Recognition of Real-Time Hand Gestures using Mediapipe Holistic Model and LSTM with MLP Architecture. In Proceedings of the 2022 IEEE 10th Conference on Systems, Process & Control (ICSPC), Malacca, Malaysia, 17 December 2022; pp. 292–295. [Google Scholar] [CrossRef]
- Grande, A. Diccionario de Señas Mexicanas. Available online: https://www.academia.edu/8911310/Diccionario_de_se%C3%B1as_mexicanas (accessed on 23 November 2025).
- Bowden, R.; Windridge, D.; Kadir, T.; Zisserman, A.; Brady, M. A Linguistic Feature Vector for the Visual Interpretation of Sign Language. In Computer Vision—ECCV 2004; Pajdla, T., Matas, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 390–401. [Google Scholar] [CrossRef]
- Koller, O.; Camgoz, N.C.; Ney, H.; Bowden, R. Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2306–2320. [Google Scholar] [CrossRef]
- García-Gil, G.; López-Armas, G.d.C.; Sánchez-Escobar, J.J.; Salazar-Torres, B.A.; Rodríguez-Vázquez, A.N. Real-Time Machine Learning for Accurate Mexican Sign Language Identification: A Distal Phalanges Approach. Technologies 2024, 12, 152. [Google Scholar] [CrossRef]
- Shamitha, S.H.; Badarinath, K. Sign Language Recognition utilizing LSTM and Mediapipe for Dynamic Gestures of ISL. IJFMR-Int. J. For. Multidiscip. Res. 2023, 5. [Google Scholar] [CrossRef]
- Bhadouria, A.; Bindal, P.; Khare, N.; Singh, D.; Verma, A. LSTM-Based Recognition of Sign Language. In Proceedings of the 2024 Sixteenth International Conference on Contemporary Computing, Noida, India, 8–10 August 2024; en IC3-2024. Association for Computing Machinery: New York, NY, USA, 2024; pp. 508–514. [Google Scholar] [CrossRef]
- Caraka, R.E.; Supardi, K.; Kurniawan, R.; Kim, Y.; Gio, P.U.; Yuniarto, B.; Mubarok, F.Z.; Pardamean, B. Empowering deaf communication: A novel LSTM model for recognizing Indonesian sign language. Univers. Access Inf. Soc. 2025, 24, 771–783. [Google Scholar] [CrossRef]
- Renjith, S.; Manazhy, R.; Sumi Suresh, M.S. Sign Language Recognition using BiLSTM model. In Proceedings of the 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), Pune, India, 5–7 April 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Li, F.; Yu, W.; Wang, C.; Jiang, Y. Sign Language Recognition Based on CNN-BiLSTM Using RF Signals. IEEE Access 2024, 12, 190487–190504. [Google Scholar] [CrossRef]
- Rautela, A.S.; Ashfaq, E.; Chetia, B.P.; Bhadrike, I.; Chauhan, P.; Theng, D.; Hiwale, M. Dynamic Gesture Recognition Using LSTM for Real-Time Indian Sign Language Prediction. In Advancements in Machine Learning; Saini, J.R., Mapari, S.A., Vibhute, A.D., Urooj, S., Kacprzyk, J., Ghinea, G., Eds.; Springer Nature: Cham, Switzerland, 2026; pp. 38–53. [Google Scholar] [CrossRef]
- Mejía-Peréz, K.; Córdova-Esparza, D.-M.; Terven, J.; Herrera-Navarro, A.-M.; García-Ramírez, T.; Ramírez-Pedraza, A. Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks. Appl. Sci. 2022, 12, 5523. [Google Scholar] [CrossRef]
- Baihan, A.; Alutaibi, A.I.; Alshehri, M.; Sharma, S.K. Sign language recognition using modified deep learning network and hybrid optimization: A hybrid optimizer (HO) based optimized CNNSa-LSTM approach. Sci. Rep. 2024, 14, 26111. [Google Scholar] [CrossRef]
- Huang, J.; Chouvatut, V. Video-Based Sign Language Recognition via ResNet and LSTM Network. J. Imaging 2024, 10, 149. [Google Scholar] [CrossRef] [PubMed]
- Lara-Cázares, A.; Moreno-Armendáriz, M.A.; Calvo, H. Advanced Hybrid Neural Networks for Accurate Recognition of the Extended Alphabet and Dynamic Signs in Mexican Sign Language (MSL). Appl. Sci. 2024, 14, 10186. Available online: https://agris.fao.org/search/en/providers/122436/records/67644e4d6a5a95f3405a7f19 (accessed on 24 November 2025). [CrossRef]
- Kamble, S. SLRNet: A Real-Time LSTM-Based Sign Language Recognition System. arXiv 2025, arXiv:2506.11154. [Google Scholar]
- Chiradeja, P.; Liang, Y.; Jettanasen, C. Sign Language Sentence Recognition Using Hybrid Graph Embedding and Adaptive Convolutional Networks. Appl. Sci. 2025, 15, 2957. [Google Scholar] [CrossRef]
- González-Rodríguez, J.-R.; Córdova-Esparza, D.-M.; Terven, J.; Romero-González, J.-A. Towards a Bidirectional Mexican Sign Language–Spanish Translation System: A Deep Learning Approach. Technologies 2024, 12, 7. [Google Scholar] [CrossRef]
- Kakizaki, M.; Miah, A.S.M.; Hirooka, K.; Shin, J. Dynamic Japanese Sign Language Recognition Throw Hand Pose Estimation Using Effective Feature Extraction and Classification Approach. Sensors 2024, 24, 826. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.; Kim, B. Techniques for Detecting the Start and End Points of Sign Language Utterances to Enhance Recognition Performance in Mobile Environments. Appl. Sci. 2024, 14, 9199. [Google Scholar] [CrossRef]
- Kim, T.; Kim, B. Enhancing Sign Language Recognition Performance Through Coverage-Based Dynamic Clip Generation. Appl. Sci. 2025, 15, 6372. [Google Scholar] [CrossRef]
- Walsh, H.; Fish, E.; Sincan, O.M.; Lakhal, M.I.; Bowden, R.; Fox, N.; Woll, B.; Wu, K.; Li, Z.; Zhao, W.; et al. SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work. arXiv 2025, arXiv:2508.06951. [Google Scholar] [CrossRef]
- Hilario-Acuapan, G.; Ordaz-Hernández, K.; Castelán, M.; Lopez-Juarez, I. Toward a Recognition System for Mexican Sign Language: Arm Movement Detection. Sensors 2025, 25, 3636. [Google Scholar] [CrossRef]
- Niu, P. Convolutional neural network for gesture recognition human-computer interaction system design. PLoS ONE 2025, 20, e0311941. [Google Scholar] [CrossRef]
- Hafeez, K.A.; Massoud, M.; Menegotti, T.; Tannous, J.; Wedge, S. American Sign Language Recognition Using a Multimodal Transformer Network. In Proceedings of the 2024 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Kingston, ON, Canada, 6–9 August 2024; pp. 654–659. [Google Scholar] [CrossRef]
- Hashi, A.O.; Mohd Hashim, S.Z.; Mirjalili, S.; Kebande, V.R.; Al-Dhaqm, A.; Nasser, M.; A Samah, A.B. A hybrid CNN-transformer framework optimized by Grey Wolf Algorithm for accurate sign language recognition. Sci. Rep. 2025, 15, 43550. [Google Scholar] [CrossRef] [PubMed]
- Šajina, R.; Oreški, G.; Ivašić-Kos, M. GCN-Transformer: Graph Convolutional Network and Transformer for Multi-Person Pose Forecasting Using Sensor-Based Motion Data. Sensors 2025, 25, 3136. [Google Scholar] [CrossRef] [PubMed]
- Tan, F.; Zhai, M.; Zhai, C. Foreign object detection in urban rail transit based on deep differentiation segmentation neural network. Heliyon 2024, 10, e37072. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Yi, J.; Tan, F. Facial micro-expression recognition method based on CNN and transformer mixed model. Int. J. Biom. 2024, 16, 463–477. [Google Scholar] [CrossRef]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.-L.; Grundmann, M. MediaPipe Hands: On-device Real-time Hand Tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Bharat. A Comprehensive Guide to Computer Vision Research in 2025. OpenCV 2024. Available online: https://opencv.org/blog/computer-vision-research/ (accessed on 18 December 2025).
- Zelinsky, A. Learning OpenCV—Computer Vision with the OpenCV Library (Bradski, G.R. et al.; 2008) [On the Shelf]. In IEEE Robotics & Automation Magazine; IEEE: New York, NY, USA, 2009; Volume 16, p. 100. [Google Scholar] [CrossRef]
- Louppe, G. Understanding Random Forests: From Theory to Practice. arXiv 2015, arXiv:1407.7502. [Google Scholar] [CrossRef]
- Katoch, S.; Singh, V.; Tiwary, U.S. Indian Sign Language recognition system using SURF with SVM and CNN. Array 2022, 14, 100141. [Google Scholar] [CrossRef]
- Abdel-aziem, A.H.; Soliman, T.H.M. A Multi-Layer Perceptron (MLP) Neural Networks for Stellar Classification: A Review of Methods and Results. Int. J. Adv. Appl. Comput. Intell. 2023, 3, 29–37. [Google Scholar] [CrossRef]
- Ławryńczuk, M.; Zarzycki, K. LSTM and GRU type recurrent neural networks in model predictive control: A Review. Neurocomputing 2025, 632, 129712. [Google Scholar] [CrossRef]
- Subramanian, B.; Olimov, B.; Naik, S.M.; Kim, S.; Park, K.-H.; Kim, J. An integrated mediapipe-optimized GRU model for Indian sign language recognition. Sci. Rep. 2022, 12, 11964. [Google Scholar] [CrossRef]
- Walt, S.V.D.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef]
- Ekman, P. Are there basic emotions? Psychol. Rev. 1992, 99, 550–553. [Google Scholar] [CrossRef]
- Biswas, S.; Biswas, M.; Mandal, A.; Liza, F.T.; Sarker, J. Efficient Extractive Text Summarization for Online News Articles Using Machine Learning. arXiv 2025, arXiv:2509.15614. [Google Scholar] [CrossRef]
- Lindemann, B.; Müller, T.; Vietz, H.; Jazdi, N.; Weyrich, M. A survey on long short-term memory networks for time series prediction. Procedia CIRP 2021, 99, 650–655. [Google Scholar] [CrossRef]
- Ghosh, S. A Review on the Long Short-Term Memory Model|Artificial Intelligence Review. Available online: https://link.springer.com/article/10.1007/s10462-020-09838-1 (accessed on 26 November 2025).
- Ghosh, S. Natural language processing and sentiment analysis: Perspectives from computational intelligence. In Computational Intelligence Applications for Text and Sentiment Data Analysis; Academic Press: Cambridge, MA, USA, 2023; pp. 17–47. [Google Scholar] [CrossRef]
- Duy, H.A.; Srisongkram, T. Bidirectional Long Short-Term Memory (BiLSTM) Neural Networks with Conjoint Fingerprints: Application in Predicting Skin-Sensitizing Agents in Natural Compounds. J. Chem. Inf. Model. 2025, 65, 3035–3047. [Google Scholar] [CrossRef] [PubMed]
- Al-Kababji, A.; Bensaali, F.; Dakua, S.P. Scheduling Techniques for Liver Segmentation: ReduceLRonPlateau Vs OneCycleLR. arXiv 2022, arXiv:2202.06373. [Google Scholar]
- Sathyanarayanan, S.; Tantri, B.R. Confusion Matrix-Based Performance Evaluation Metrics. Afr. J. Biomed. Res. 2024, 27, 4023–4031. [Google Scholar] [CrossRef]
- Dasari, N. ROC AUC Explained: A Beginner’s Guide to Evaluating Classification Models. Towards Data Science. Available online: https://towardsdatascience.com/roc-auc-explained-a-beginners-guide-to-evaluating-classification-models/ (accessed on 26 November 2025).











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.