Abstract
Surrealism applies metaphors to create a vocabulary of contexts and scenes. Can AI interpret surrealism? What occurs if a negative prompt is input for 3D reconstruction? This study aims to generate surreal images in AI and to assess the subsequent 3D reconstructed models as an exemplification of context. This AI interpretation study uses 87 sets of conflicting prompts to generate images with novel 3D structural and visual details. Eight characteristic 3D models were selected with geometric features modified by functions, such as the reduction in noise, to identify the changes made to the original shape, with upper and lower bounds of between 92.11% and 47.89% for area and between 20.51% and 1.46% for volume, which indicates structural details. This study creates a unique numeric identity of surreal images upon 3D reconstruction in terms of the relative % of the changes made to the original shape. AI can create a connection between 2D surreal imagination and the 3D physical world, in which the images and models are also appropriate for video morphing, situated elaboration in AR scenes, and verified 3D RP prints.
1. Introduction
AI can create visual outputs that represent a collection of humanity’s unconsciousness (Figure 1). Surrealism in AI is a more creative and enlightened morphological exemplification of reversed reconstruction approaches. Surrealism should be revised and recursively reconstructed in accordance with the prompts that exemplify differing symbolic vocabularies and contexts. The results consist of a series of contexts obtained through the contemporary exploration of AI reality.

Figure 1.
AI-generated surreal images: (a) the prompt: “I am a fool, but it’s not my fault. Surreal theme. 240391”; (b) the prompt: “I_am_a_fool_but_it_is_not_my_fault_surreal_20250809144319_03”; (c) 3D model of (b).
This study aims to interpret surrealism in AI by assessing the performance through 3D reconstruction. Surrealism applies metaphors to create a vocabulary of contexts and scenes. This AI interpretation applies conflict prompts to create surreal images and to reconstruct 3D structural and visual details of the images. The details should verify the relationship between prompts and outputs. Both the conflict and post-generation prompts were compared for consistency before and after the output was created. The AI-assisted 3D structural and visual details represent computer unconsciousness and group consciousness, the former of which should be assessed to obtain surreal identity variations with different types of quantitative values.
This study also aims to assess the surreal images created by AI by evaluating the outcomes after being converted to 3D models.
Related Studies
Artificial intelligence (AI) imaging technologies produce excitement and anxiety [1]. AI represents a fundamental shift in the creation process, moving to the use of datasets to compile and generate art compared to the use of personal experiences and emotional depth by human artists [2]. AI art can be connected to reality by only a limited amount, with some AI models generating surprising results [3]. The relationship between AI-generated art and human creativity can be complementary [2]. Many works of art can reflect how people and computational systems are intertwined [4]. Machines may suggest new ways for us to see ourselves, as they can be taught to see like humans [4].
AI-generated art has emerged in digital surrealism. Questions have been raised regarding the surrealist attitude or approach in the age of artificial intelligence [5]. Surrealists have sought to channel the unconscious through their work [6]. AI should be embraced as an extension of our collective consciousness [7].
AI-assisted image analyses have been implemented in medical practice using volume data reconstruction [8] or aggregate shape characteristics in asphalt mixtures [9]. Three-dimensional reconstruction can be achieved using a single image of the human body [10] or face [11], indoor scenes [12], and high-quality textured 3D models [13] or using three images of faces [14] and four images with Gaussian splatting [15].
AI surrealist characters are a specific form of content that can be reconstructed on a virtual platform and then assessed afterward. Few attempts have been made to examine AI simulation in this field. Three-dimensional reconstruction usually requires sufficiently high-quality imagery to improve modeling quality. Surveys have shown that 3D Gaussian splatting (3DGS), which represents a paradigm shift in neural rendering, has the potential to become a mainstream method for the 3D representations of characters. It effectively transforms multi-view images into 3D Gaussian images in real-time [16]. 3DGS produces highly detailed 3D reconstructions. Software can estimate camera poses for arbitrarily long video sequences [17]. In surface reconstructions of large-scale scenes captured by unmanned aerial vehicles (UAVs), the quality of surface reconstruction can be ensured only through heavy computational cost [18]. High-precision, real-time rendered reconstruction can also be applied to cultural relics and buildings in large scenes [19], such as peach orchards [20] or historic architecture, using 360° capture [21]. For example, this process was part of the large-scale 3D digitization of the architectural remains of the Notre-Dame de Paris after the destructive fire [22], and neural rendering has been applied to leaf structure analysis [23], the analysis and promotion of dance heritage [24], or as an ethical framework for cultural heritage and creative industries [25]. Special renderers have been developed for the effective visualization of point clouds or meshes [26].
However, a single 2D image does not usually allow effective 3D reconstruction. Rodin® (Jawset Visual Computing, Munich, Germany, v1.0.0) utilizes a generative model to sculpt 3D digital avatars using diffusion [27], with the 3D NeRF (neural radiance field) model presenting computational efficiency. Three-dimensional content generation has benefited from advanced neural representations and generative models [28]. For instance, generative AI has been used to create virtual costume accessories [29], paint characters [30], and historical temple art [31].
Reconstructed two-dimensional character-related images can be represented as three-dimensional digital humans and virtual costumes and accessories. This reconstruction should reactivate the tangible features of surreal paintings by adapting characters and interacting with details and composition; this can create a more situated connection to AI art and modern consciousness.
2. Materials and Methods
This study aims to create and assess 3D models of surreal images as part of an elaborated interpretation (Figure 2). Prompts with conflicting intentions are tested to enable more potential for generating surreal scenes. Subsequent assessment is required and is conducted to quantitatively characterize surreal identities. Three-dimensional graphics and models are used to support the assessment of manipulatable 3D data as the substantiation of a concept or as an extension of texts and metaphors.
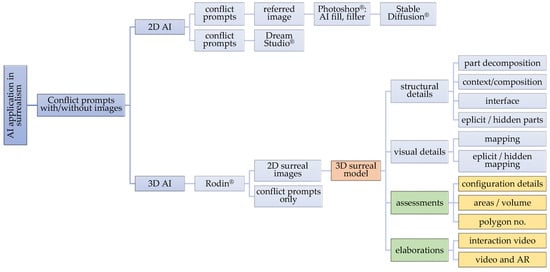
Figure 2.
AI application flowchart in surrealism interpretation.
This interpretive AI used for surrealism comprises three aspects: (1) creating genuine surreal images using programs, such as Dream Studio® (Stability AI Ltd., London, UK, 2023) or Stable Diffusion® (Stability AI Ltd., London, UK, v3.0); (2) creating 3D models of the images using Rodin as a more elaborate interpretation of the structural details; and (3) assessing the 3D representation of surreal images using Geomagic Studio® (Geomagic, Inc., Morrisville, NC, USA, v2014.1.0.1706) functions. A two-way interpretation is also conducted: (1) from prompts to images, i.e., the generation of 2D context through parts and meanings; (2) from images to 3D, i.e., the segmentation and measurement of 3D details. Chained AI layers should cover the scope of text prompts, 2D image generative fill, 3D, 3D parts, and videos. Multiple variations should continuously be requested from the AI, while the compromise between the visual and structural details should be continuously considered.
Three-dimensional surrealism can be studied in four main ways:
- Generation by prompt/image-to-3D: This is related to paradigm transfer, symbolic representation, and metaphors.
- Inspection of 3D-to-parts: The definition (allocation, deployment, main support) of the individual parts enables the classification of context, hierarchy, composition, and interfaces.
- Assessment of the details of the 3D surreal models regenerated by Rodin®.
- Propagation by video, AR, and RP: This is related to 2D image video morphing (differentiation-to-specific animation), augmented reality (AR), and 3D rapid prototyping (RP) prints.
In image-to-3D generation, the number of allowed views or images is between 1 and 4. Since each surreal image was unique, only one image was used to create a 3D mesh. The higher the image resolution, the better the details within the maximum polygon count of 1,000,000 in the applied program of Rodin®. Image resolution in this study was 512 × 512 at 96 dpi (lady’s head) and above. The 3D reconstruction did not generate models at a 100% resemblance level, since the missing information on the back of a subject had to be created by using the configuration and texture of the front. Each model was repeatedly adjusted for a maximum of 20 trials. Each trial will generate a 3D model to simulate the provided image, with slight differences in outline, allocation of parts, or the size of the body. It was the author who determined and selected the one with the best resemblance.
2.1. Conflict Prompts for AI-Generated Images and 3D Models
Conflicting prompts comprised contrary statements, subjects, and behaviors in the following form: “[x] is [y] and it is not [x]’s fault, surreal” (Table 1). The latter always denies the former or provides a formal status with explanations. “Surreal” was part of the prompt.

Table 1.
Prompts, AI-generated surreal images, and 3D models.
Conflicting prompts apply contrasting or conflicting values and judgments to the same model repetitively, instead of using explicit statements. Prompts that include conflicting content and exemplification include “void and solid”, “X and not X”, or “surreal” specifically. Prompts were made with or without reference images during the AI modeling of 3D parts. The implied style in AI emerges or extends beyond the consistency usually delivered by an ordinary, straightforward prompt (the prompts after “vs.” in Table 1 and subsequent tables). The number is part of the image file name automatically created by the AI program, probably as a numeric ID. It was kept as proof. The “4K” means a corresponding image resolution of 3840 × 2160 is requested. The conflicts include metaphors, under different levels of conflict, as inclusion or exclusion filters, to inspire novel concepts or to display contrasting entities.
2.2. Chained AI Generations from Image to 3D Model
Surrealism is a style with design factors that can be generated, interpreted, and elaborated by AI. Surrealism should be revised and recursively reconstructed in order to purposely alternate vocabularies and compositions. The AI images were reconstructed into 3D models by AI programs. The prompts with conflicting intentions were compared with those automatically generated by AI programs, and then the images were regenerated using Dream Studio®, Stable Diffusion®, Rodin®, or DeeVid.ai® (Deevid AI, Singapore, v1.7.1) in a reversed process (Table 1). The afterward-generated prompts are usually straightforward, feature-based, and an oversimplified description of the final generated feature made from conflicting prompts. This represents a significant difference between a metaphor and an explicit object.
A series of chained AI layers is applied, ranging from 2D image editing, 3D modeling, and differentiation into 3D parts to videos (Table 2). First, the 2D image should be reconstructed as a 3D model using AI in the following ways: (1) method 1—input prompts, prompts with 2D images, or 2D images; (2) method 2—use 2D images to generate 3D models; (3) method 3—use prompts to generate 3D models directly. Second, AI-generated images should be able to be manipulated into new stories, like directing a video of purposely problem-solving operations.
Table 2.
Chained AI applications.
The export pipeline for AR/VR is fairly straightforward. First, a surreal image is converted to a 3D model in Rodin® in the OBJ format. Then, the mesh is (1) compressed, (2) uploaded to the Sketchfab® cloud platform, and (3) published as an AR model after the proper adjustments of size and orientation. Each AR model is paired with a QR code, which can be scanned by a smartphone to download the model from the cloud. After facing toward a surface and moving the camera around to confirm the working plane, the AR model will be loaded and appear as though in the real world, which can be rotated and enlarged in front of the background.
The export pipeline to create a video is also straightforward. Instead of 3D models, only two images were needed, and a video was created between the two frames. In this study, images with similar contexts, i.e., human heads and bodies, were preferred.
2.3. Structural Details and Visual Details
In preliminary tests and observations, it was important to emphasize the missing part of the boundary box. This was achieved by using linear members as the most influential indicators of changes, since the ability to create thin, curved, linear members is one of the most important indicators of reconstruction functions in AI. Types of assessed categories included configurations (main subject, not background) and the composition context in terms of the structural and visual details of the surreal 3D polyhedron.
In the structural configuration details, each model consists of various numbers of surface and volumetric attributes in one polyhedron, which differ between the initial and ending states. The attributes, as convex and concave parts, include linear members, spikes, ends, thin planes, wrinkles, folding faces, and recessed gaps. The initial state was 3D-reconstructed using Rodin®. The ending state was achieved using 3D filtering to modify the model through a series of 3D functions. The initial configuration was smoothed out, resulting in the following: (1) missing parts of members (i.e., shortened linear members); (2) smoothed parts of members (i.e., spikes); and (3) shrunken parts of members (i.e., radius). The composition context represents the combination of the above-mentioned parts. The consistency of the configurations represents the smooth transfer of geometries from front to back, as the latter was not displayed in the original image.
In terms of the visual details, the surface appearance varied between initial and ending mapping statuses. The former usually has an original mapping image that corresponds to the geometry, with consistent texture in the front and the back. The latter may require the modification of the mapping location or the reduction in the mapping area with regard to simplified geometries.
2.4. Assessment of the 3D Surreal Models
Eight types of configurations (Figure 3) were selected from nearly 100 AI-generated surreal images and assessed in terms of structural details, from modified values of area and volume. The reconstructed 3D models exhibited the detailed and explicit 3D spatial structure, such as the basic configurations, referencing shapes, and composition context. Three types of 3D models were classified by the long and thin linear (1—hair in Figure 3), convex (8—apple in Figure 3), and concave (7—mask above head in Figure 3) shapes. Each surreal 3D model reveals the number and the distribution of linear and volumetric elements. The level of detail and the complexity are significantly contributed to by the general perception of the diameter, curvature, and length of a linear element. The context varied from the evenly or partially distributed pattern to the differentiated allocation of linear and convex–concave elements.

Figure 3.
The eight surrealist case studies and the unique complexity and composition of the structural details.
2.4.1. Eight Test Cases
Based on nearly 100 generations of surreal images, eight cases were selected for the unique complexity and composition of structural details (Figure 3). Each surreal image is associated with an original prompt, and a unique 3D model is created with rich structural and visual details. These words in parentheses are prompts generated by the AI programs with their own versions of prompts prior to or after generating 3D models. A significant difference exists between the conflicting metaphor and the explicit subject.
- 1—hair: 3418588830_1000_solid_and_void_Billy__surreal_art__8k-hairs (vs. abstract mask with 360-degree branching antlers and ribbon.)
- 2—wire head: 021-2565578021_He_is_fool_but_it_is_not_her_fault__surreal__4k (vs. man with heart-shaped object and 10000 branches in 146 m on head.)
- 3—flower head: I am a fool and it is not my fault, surreal, 6K-3 (vs. decorative animal-themed mask with colorful accents.)
- 4—banana head-2: 3751076485_A_banana_is_happy_but_it_is_not_its_fault__surreal__4k (vs. person with banana and egg head.)
- 5—lady’s head: 555970878_He_is_fool_but_it_is_not_her_fault__surreal__4k (vs. surreal split-faced woman with flowers and a child.)
- 6—eye: 703629898_do_not_yell_at_me__surreal__8k (vs. surreal green cat eye with abstract elements.)
- 7—mask above head: I am a fool and it is not my fault, surreal, 6K-1 (vs. man in a suit standing upright.)
- 8—apple: 1000 solid and void apple, surreal art, 8k (vs. abstract sculpture with spiral form.)
2.4.2. Assessing Functions and Measures
The types of assessment included referencing function and values, which were subject to absolute and relative measures obtained from structural details between 3D model versions (Figure 4). This was achieved by comparing the original and various modified configurations numerically. The details were usually reduced either in size or appearance upon modification. Since all the parts were merged, the surface areas were assessed as they are indicators of the level of detail. Even if the values of the volume and surface area were elevated, this does not necessarily represent a significant change for the number of polygons, except in Quicksmooth and Decimate.
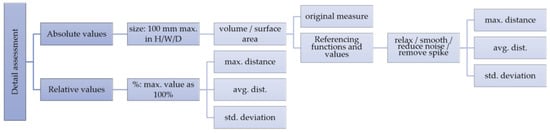
Figure 4.
Process of assessment of surreal 3D-reconstructed models.
- Polyhedron check: Each model initially went through the verification process in Mesh Doctor and Geomagic Studio® in order to ensure that each 3D model was correct.
- Referred dimensions: Each model was rescaled to the referred dimension of 100 mm and was set to a maximum length, width, or depth, depending on box volume, before comparison. The dimension was retrieved through the following steps: analysis, followed by distance, and then the box for the maximum dimension of the original model.
- Referencing shapes: Any change made to reduce the details should be carried out with reference to the original surface area or volume. Although the linear elements may become too small in diameter to be inspected visually, compared to the large alternation of volume, the long, thin, and curly elements like hairs are considered to be among the most important shape detail references.
- De-featuring functions and values: During the operations applied to each model, details are usually modified or reduced either in size or appearance. In general, the absolute values of volume and area could be changed or reduced compared to the original shape or the maximum deviation as the referencing values.Each rescaled model has to go through several operations to inspect new versions with different volumes and areas, in addition to modified structural details. Auxiliary assessment de-features 3D models and examines the difference between configuration details before and after a series of de-featuring functions. Polyhedron modification used common Geomagic Studio® 3D functions, such as Quicksmooth@10 (i.e., applied 10 times), Reduce noise@5, Relax@1, Remove spike (max) (i.e., using the “max” option), and Decimate (50%, i.e., only half of the total polygons are maintained) to simplify or smooth out details into a relatively small size. The details would usually be reduced either in size or appearance. In general, the absolute values would be reduced.
- Comparisons: The slightly modified new versions of the boundaries are visually distinct from the original shape through differing details. Geometric factors like points and polygons are first registered, and then they calculate the feature deviations in volume, surface area, standard deviation, average distance, and maximum distance.
- Absolute values: The values and meta-values of each configuration or between versions.
- ○
- Absolute values—1: The absolute values comprised the volume, surface area, and polygon numbers of each model.
- ○
- Absolute values—2: Standard deviation, maximum distance, and average distance were calculated from the original model and each de-featured version.
- Relative values:
- ○
- Relative values—1: The % was calculated based on the changes made to the original shape, in terms of values of area and volume, upon the application of each de-featuring function. The smaller the % (the more area or volume has been reduced), the larger the change. The process is also used to define the upper and lower bounds and the fluctuation pattern of the area and volume.The equation is (A/B) × 100, in which (1) “A” represents the area or volume modified by a specific function, such as Quicksmooth@10; (2) “B” represents the area or volume of the original model; and (3) the value is 100%.
- ○
- Relative values—2: In general, the “reduce noise” de-featuring function resulted in the largest difference made to the original shape, in terms of standard deviation, maximum distance, and average distance. By assigning the highest one to 100% as the maximum reference value, all the defeatured versions of each test model were transferred into charts. In general, the closer the relative value to is 100%, the larger the deviation. This was usually the case when most details were smoothed out or disappeared.The equation is (C/D) × 100, in which (1) “C” represents the standard deviation, maximum distance, and average distance modified by a specific function, such as Quicksmooth@10; (2) “D” represents the highest standard deviation, maximum distance, and average distance to the original model among all modified results; and (3) is the value of 100%.
3. Results
3.1. Conflicting Prompts
A total of eighty-seven prompts were utilized in Dream Studio®, eight in Stable Diffusion®, and six in Rodin® (Figure 5). A few images were selected from among the quadra-based outputs of Dream Studio®. About 100 outputs were generated in Stable Diffusion® txt2img-images, and 24 were generated in txt2img-grids. This is to test if the conflicting prompts will generate surreal images even using different AI software platforms, such as Dream Studio®, Stable Diffusion®, and Rodin®. The results were positive.

Figure 5.
AI-generated surreal images, prompts, and 3D models.
At least 29 variations were conducted with different subjects and conflicting approaches. The conflicting prompts were tested in slightly different arrangements in terms of the subject or the conflicting entity. There were 29 variations made.
- 1077007943_me_and_not_me__surreal_art__8k.
- 531961084_1000_me_and_1000_not_me__surreal_art__8k.
- 23033414_do_not_yell_at_me__surreal__8k.
- 3418588830_1000_solid_and_void_Billy__surreal_art__8k.
- 1524467197_1000_solid_and_void_apple__surreal_art__8k.
- 4007284743_1000_solid_and_void_Jennifer__surreal_art__8k.
- 266410813_100_fools_and_not__surreal__6K.
- 596229310_100_Jennifer_and_not__surreal__6K-2.
- 3516006625_Mike_is_a_fool_but_not_complicated__surreal__4k.
- 2336015536_She_is_fool_but_it_is_not_her_fault__surreal__4k-2.
- frigid-2991933948_I_am_a_fool_and_it_is_not_my_fault__surreal__8k.
- 38912012_He_is_a_fool_and_it_is_not_my_fault__surreal__8k.
- 3751076485_A_banana_is_happy_but_it_is_not_its_fault__surreal__4k.
- 257115976_A_fish_is_happy_but_it_is_not_its_fault__surreal__4k.
- 492401790_It_is_a_tree_but_it_is_not_its_fault__surreal__6K.
- 1784076920_It_is_a_mirror_but_it_is_not_her_fault__3D__surreal__6K.
- 2893672328_It_is_an_apple_but_it_is_not_her_fault__3D__surreal__6K.
- 1406038605_Love_is_crazy_and_it_is_not_my_fault__surreal__8k.
- 2937607763_transient_manifolds__surreal__6K.
- 4186875177_100_transience_Mary_and_it_is_not_her_fault__surreal__6K.
- 462063062_10_transient_wind__morning__eyelash__Mary__surreal__6K.
- 1409120371_10_transient_wind_and_not__Jennifer__surreal__6K.
- 1512025954__transient_tree__not_fool__surreal__6K.
- 3396700402_12_voids_of_solids__surreal__4k.
- 430935147_12_Jennifer_of_voids__surreal__4k.
- 2496967679_12_strips__of_mirrors__surreal__4k-33.
- 1913567941_my_life_as_a_fish__surreal__8k.
- 4230474486_Love_is_a_thousand_fish__surreal__8k.
3.2. AI Generation from Image to 3D Model
A chained process was used to select preferred styles using options and intensities as controls. From the image to the 3D model, the process consisted of chained AI tools with fulfilled responses (Table 3). The text prompts, images, and 3D models were used to substantiate the content and context of the surreal visualization. Although different AI tools may create similar surreal outputs, the tool-generated prompts presented a feature-based description that was dramatically different from the original prompts, as can be seen below.
Table 3.
Three-dimensional model generation using prompts or surreal 2D images.
- Outcome 1—image-to-image: Photoshop® (Adobe Inc., Mountain View, CA, USA, v27.0.0) (generative fill, define main subject) to complete the subject.
- Outcome 2—prompt/image-to-image: Stable Diffusion®, Dream Studio®.
- Outcome 4—image-to-3D model: Stable Diffusion®, Dream Studio®, Rodin®.
- Outcome 3—prompt-to-3D model: Rodin® (3D direct reconstruction).
There were differences between the 3D-like image and the real 3D model. There were favorable and unfavorable connections between the prompt, the 2D image, and the 3D model, as AI could become an enlightened tool to discover other unconscious possibilities. Most of the 3D models were created with a feature-enhanced form. This challenges the complex details with a reasonable layout of depth, mapping texture, and polygon numbers. The entangled sub-parts were difficult to model in perfect proportion and detail without the repetitive selections of options and strength.
The surreal definition of 3D representation consists of an integrated and entangled subject, a peripheral background, and a morphological interpretation. The subject has to be read closely with prompts to understand the elaborated meaning. The background becomes a perfect, easy, and instant supporting interpretation in either a contrasting or subject-enhancing way. In the case of the apple prompt, a limited number of the generated images presented scenes made of very fine linear or wire-like elements, and the void definition was seamlessly integrated as part of the main subject. The outcome was robust and generally needed no additional interpretation of the background to enhance or support the morphological content. As a result, this made it very easy to reconstruct the 3D model, as no additional effort was needed to delete the background.
A frame-like output was usually assumed. Most of the outputs present a certain level of stage-like display or gravity supported by Stable Diffusion®, rather than Dream Studio®. It seems that the latter had a richer subject interpretation than the former. The differences between a scene and a subject presented the various emphases of the interfaces with peripheral backgrounds (Table 4).
Table 4.
Three-dimensional subjects with less connection to the peripheral background.
3.3. Three-Dimensional Feature Modifications
The following images present the structural details defeatured after the application of Quicksmooth@10, Reduce noise@5, Relax@1, Remove spike (max), and Decimate (50%) (Table 5). The different features were displayed more clearly after the original shape, and the detail-filtered shape in blue color was aligned and registered together (Table 6). The latter actions were conducted by Quicksmooth@10, Reduce noise@5, Relax, Remove spike, and Decimate 50. As implied by the individual name, the functions are used to smooth out the details on an object’s surface.
Table 5.
The modified structural details of eight typical models.
Table 6.
The original and modified models aligned.
3.4. Comparing Charts by Assessment
Charts for the eight case studies were compared and summarized by area and volume in values (Figure 6, Table 7, Appendix A, and Appendix B), %, fluctuation (Figure 7), and upper–lower bound. This includes a volume–area decrease scale and the differences between each model. The unique patterns were classified by either the largest, smallest, or most increased level of standard deviation. The patterns were identified using numeric identities (IDs) in terms of ranges and geometries. The IDs refer to styles defined by specific characteristics of the % of relative difference in shape and size (fine hair, coarse hair, lumpy body in convex body, concave hole), proportion between details (lumpy and hair-like parts), and distribution of similar elements (partial area, full body) as a whole. As indicated by the area decrease in %, the model “1—hair” has the maximum % difference between area and volume, in contrast to the model “8—apple”. This changed for a volume decrease by %. The comparison of the fluctuations of the chart also determines the unique range of the upper–lower bounds. This is a shape guide, which pairs configuration with the corresponding % in terms of area, volume, and difference.

Figure 6.
Surreal identity assessment process.
Table 7.
The assessed values of the eight model types.
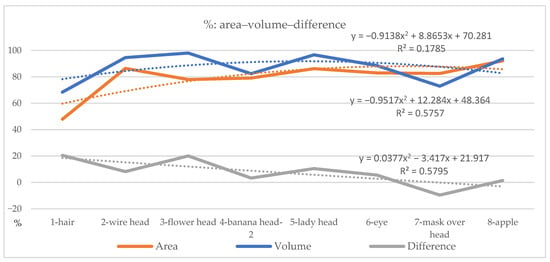
Figure 7.
Maximum reduction in filtered values in the area and volume of the eight types.
3.4.1. First Comparisons
The first comparisons are made to the values of area and volume. The deep V shape (see Appendix A), which indicates the large alternation of the surface area or volume over defeatured functions, is one of the most important indicators for judging details. The area is reduced and alternates in a way that is similar to the volume, except in case 3, which is dominated by a center-accumulated shape with relatively small or short branches. Although area and volume are given in different units, any case with the “volume > area” status becomes a unique configuration.
3.4.2. Second Comparisons
The second comparisons are made to the % of modified area and volume. Compared to 100% as the maximum (see Appendix B), the lower the % of an assessed value, the more diversity exists in the original configuration. The deep V in “1—hair”, which exhibits a large alternation in %, is one of the most important indicators for judging details. As a result, any case with the “volume > area” (i.e., “7—mask above head”) status is also a unique configuration.
The % in area–volume comparisons include the following: (1) % area > volume: the large differences result in a unique hairy shape in “1—hair” and a lumpy shape with short details on the periphery in “3—flower head”, while others are lumpy with short and fat linear elements (6—eye) or lumpy with thin details (2—wire head; 5—lady’s head); (2) % area ≈ volume: lumpy with short and fat linear elements (4—flower head) and lumpy details (8—apple); (3) % area < volume: lumpy with shelled elements (mask) (7—mask above head).
The upper and lower bounds are defined by “1—hair” (47.89%) and “8—apple” (92.10%) for area values and 20.51% and 1.46% for volume values. A sequence of 1 > 3 > 4 > 7 > 6 > 5 > 2 > 8 is presented as a % decrease in area, and 1 > 7 > 4 > 6 > 8 > 2 > 5 > 3 as a % decrease in volume. The “1—hair” and “4—banana head” models retain the same sequence. The “5—lady’s head” has the largest difference in terms of the five rankings.
3.4.3. Fluctuation
The fluctuation, which presents the alternations between area and volume in % (see Appendix B), is used to indicate the intersection that occurs between the two lines in the chart. The more intersection occurs (i.e., “1—hair”), the more unique the shape is, since defeaturing functions have made obvious changes. The fluctuation also presents contrasting or coherent configurations, where the former was used as an indicator not just for uniqueness but also for hidden similarities under the diversified configurations. The “1—hair” model fluctuated with two intersections.
3.5. Analytic Meta-Assessment
Comparing the original shape with the defeatured version of the same 3D model can highlight the unique identity of structural details according to numeric values within a group of models. The original shape was registered and assessed with different defeatured versions of the 3D models to find out the number of changes made to the surface configuration in terms of standard deviation, average distance, and maximum distance. Since the Reduce noise@5 generates the highest deviation or distance in general, it is converted into 100% referred to by the defeaturing function later, alternating structural details. The larger the value is, the more details from the original configuration are modified. As a result, “Reduce noise” is an indicator and a useful defeaturing function after being applied five times repetitively. In general, it has value as an important indicator of details.
3.5.1. Standard Deviation
Standard deviation refers to the measures described in “Section 2.4.2”, especially in the listed “5. Comparisons.” The upper and lower bounds are found in 1—hair and 8—apple (Figure 8) in terms of detail type or appearance. The highest R2 occurred in the 1—hair model for the std. devi. %, specifically for thin and linear details. The lowest R2 occurred in the 5—apple in std. devi. %, specifically for the more convex part of the shape. Others are present in both the lumpy and linear details. A body with fat hair is different from a head with thin hair, as, for example, in the 2—wire head model. In terms of the distribution and amount, the uniformly distributed hairs are highly detailed, such as in the 1—hair model, and this is the same in the 2—wire head model, but only in a specific section.
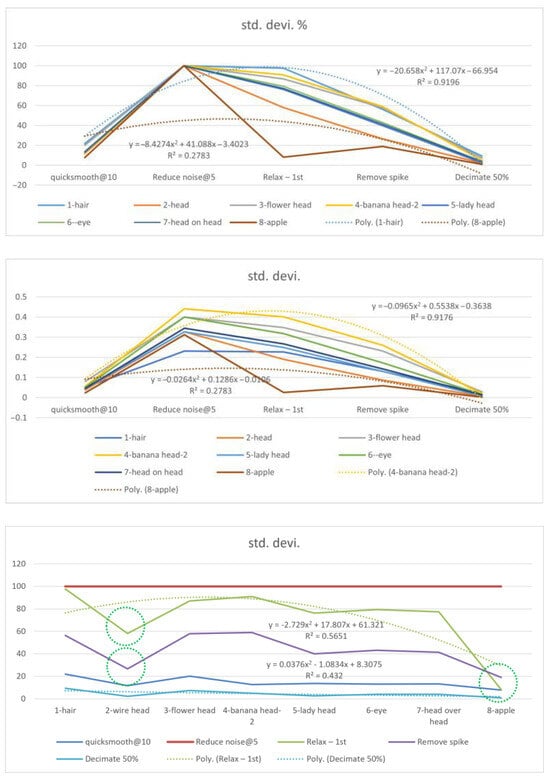
Figure 8.
Standard deviation (%) of the eight types of details.
The fluctuation varies from high (Relax—light green), middle (Remove spikes—purple), low (lowest % in Quicksmooth, Decimate—bottom two, in blues), to none (highest % in reduce noise—red), particular at the locations circled by green lines.
The standard deviation in % is a relatively preferred measure. The unique patterns were found in the 1—hair and 8—apple models, specifically regarding hairless and feature-lacking lumpy bodies. In the combined levels of linear and convex components of the eight models, the former may have less weight to dominate the final measure.
3.5.2. Avg. Distance
The upper and lower bounds were present in the 1 hair and 8 apple models (Figure 9). The highest R2 occurred in the 1—hair model with avg. dist. %, for thin and linear details. The lowest R2 occurred in the 5—apple model with avg. dist. %, for the convex part of the shape. The former exhibited a higher measurement, and the latter exhibited the opposite result. The fluctuation varied from high (Relax—light green), middle (Remove spikes—purple), low (lowest % in Quicksmooth, Decimate—bottom two, in blues), to none (highest % in reduce noise—red), particular at the locations circled by green line. The average distance in % is a preferred relative measure. The unique patterns were found in 1—hair and 8—apple.
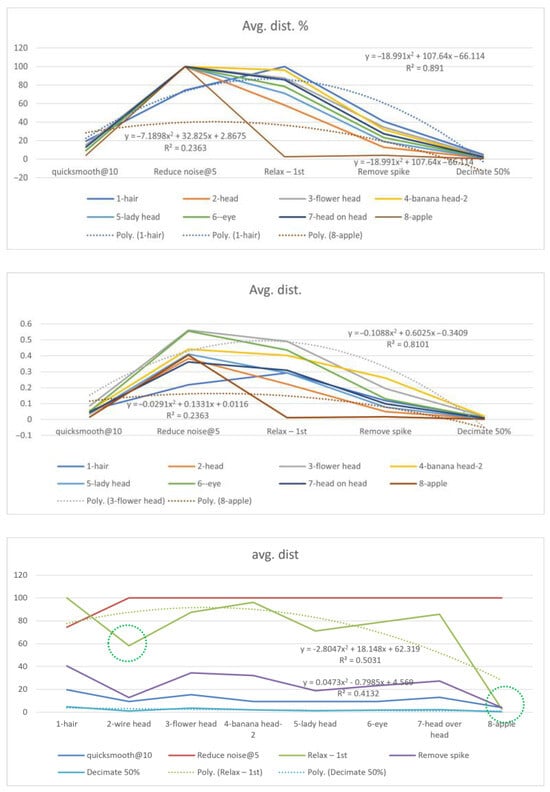
Figure 9.
Average distance (%) of the eight types of details.
3.5.3. Maximum Distance
The maximum distance became a useful measure for identity, since significant changes presented an easily identified pattern of certain unique configurations. The upper and lower bounds were present in the 3—flower head and 8—apple models (Figure 10). The highest R2 occurred in the 3—flower head model with a maximum. dist. %. The lowest R2 occurred in the 5—apple model with max. dist. % for the more convex part of the shape. However, the former presented an increased measurement with a narrower range, and the latter presented the opposite result with a larger range.
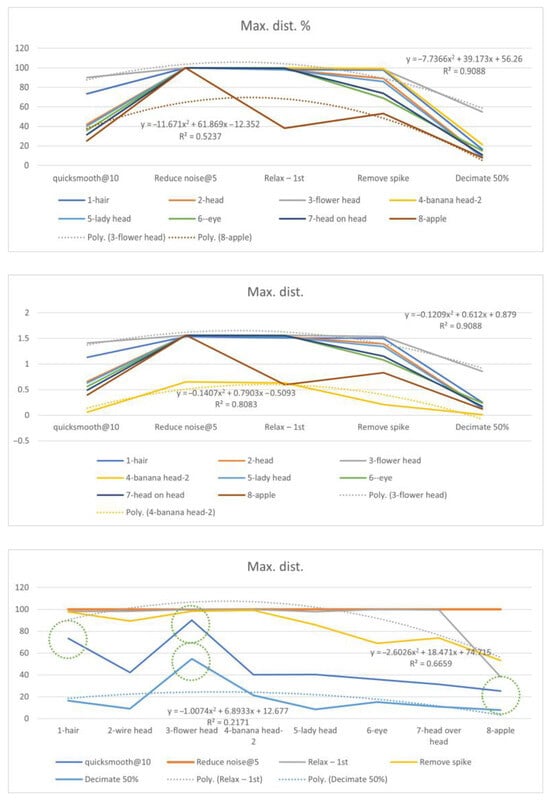
Figure 10.
Maximum distances (%) of the eight types.
The fluctuation varies from high (Relax) to middle (Remove spikes, Quicksmooth, Decimate—purple) to none (reduce noise), particular at the locations circled by green lines. Fluctuation usually indicates identity in a unique configuration. The Quicksmooth, Decimate, and Relax functions are three of the most fluctuating indicators. Quicksmooth is an important indicator for the 1—hair and 3—flower head models, with the near-highest values. Quicksmooth and Decimate are important indicators for the 3—flower head model as the near-highest values. Relax is one of the most important indicators for the 8—apple model, with the lowest value. The 3—head flower model has the largest maximum distance overall through most of the modification functions, since it has short hair-like elements distributed close to the lump. The 6—apple model has the lowest distance, i.e., it maintains most of its configuration.
The maximum distance in % is a preferred relative measure. The unique patterns were found in the 3—flower head and 8—apple models. The 1—hair model was next to the 3—flower head model.
3.6. Three-Dimensional AI Propagation
Surrealism should be revised and recursively reconstructed in order to enrich novel interpretations using the original vocabularies for new compositions. Compatibility enables the study of morphological input–output translation and substantiation, since the 3D format enables further collaborative software editing or export to AR and RP as an issue in adjusting or designing the next interpretation. In addition to 3D reconstruction, recursive propagation in video and AR was achieved by combining DeeVid.ai® and Sketchfab® and changing the 2D image to video or to 3D smartphone-based field interactions. The present surrealism enables the image segmentation of the subject from a metaphor to an actor of video. The “fish”, as a metaphor, was segmented from a surreal frame and merged into a banana in another frame, just like a director’s choice in a surreal movie (Figure 11a). Moreover, surreal subjects can be merged into the real world in different contexts and scenarios to re-elevate the “unconscious” to a new level of surrealism (Figure 11b) by scanning the model’s QR code and downloading a 3D model. Three-dimensional models can be printed using an FDM machine as an alternative to verify surreal models (Figure 11c).

Figure 11.
(a) Video was created from two individual surreal images at each end, using the image segmentation of the metaphorical “fish”; (b) surreal AR subjects in the real world; (c) 3D PLA models printed using an FDM machine.
4. Discussion
Does AI have better background knowledge than people? This knowledge may or may not be included as part of the prompts, in terms of an explicit description capable of mapping specific subjects. Feature-oriented generation is different from implied generation made of metaphors. This is one of the reasons why the prompts originally used to generate images in Dream Studio® are different from the ones displayed in Rodin® after 3D reconstruction. Moreover, the reversed process of using prompts displayed in Rodin® for 3D reconstruction cannot generate similar diffused results in Stable Diffusion®.
Based on the assessed values, AI becomes an efficient approach for studying consciousness-related surreal 3D graphics, using 3D datasets for manipulations in metaphor delivery, entity identity, and content propagation in videos and AR. The study of surrealism creates an open AI environment that supports enriched tools to generate or explore suggested contents or contexts beyond verbal prompts. Both the prompts and the interpreted results or outcomes are made of tangible or intangible metaphors in a subtle or explicit manner. The metaphors correspond to prompts through collective unconscious background knowledge. The prompts, results, and outcomes eventually create a style or identity made of structural and visual details, which are sufficient for subsequent elaboration. The three-dimensional models facilitate the reconstruction of the spatial structures of prompts and results and make the terms of prompts more comprehensive.
4.1. Conflicting Prompts and Visual Entities
General generation is different from criteria-oriented solutions and specific problem-solving approaches. Conflicting prompts lead to the solving of the following two concerns: horizontal effect and ambiguity engineering, the former of which excludes the creation of something beyond predefined prompt setups or boundaries, and the latter, which produces, assesses, or reacts to the ambiguous characteristics of model appearances.
Conflict resolution comes from conflicting prompts, which included both positive and negative prompts, instead of beyond or in the middle of the two prompt types. Anything is appropriate initially, since the conflict resolution comes from an ill-defined prompt with positive and negative intentions. In order to present the conflicts, AI has to reason out an output with a certain level of resemblance to the prompts without violating the meanings at the two ends.
No matching prompts and non-reversible reconstructions were obtained from the default prompts from other AI generations. No matching prompts were recognized from the default prompts for output from other AI generations. This is non-reversible reconstruction, since the default prompts from other AI generations are “explicit”.
Using 3D modeling can be an appropriate way to inspect original prompts or 2D image-based outputs in order to clarify intentions. A 3D configuration, which presents the results of conflict resolution and ambiguity engineering, is necessary, since it substantiates a complicated image in a more assessable way. Additionally, defining or initiating a style in a 2D image and then creating corresponding models in 3D represents a two-way novel solution with identity emerging from the black box.
Style and sense, which are hard to describe but easy to identify in an example image, become the only terms to describe the situation. “Seeing is believing” is still an enjoyable way to examine the prompt’s original intention, to evaluate LLMs, and to act as proof of options by creating polyhedral 3D scenes out of predefined polygon numbers (for example, 1,000,000 in Rodin®). As a result, conflicting prompts enable a novel solution for interpreting surrealism.
Prompts ≠ Visual Entities
Conflicting prompts imply tangible yet intangible contexts. Since the outputs are displayed by explicit or symbolic graphic representations of the conscious, subconscious, or unconscious, initial prompts or graphics should usually be made as clear and specific as possible. Prompts do not equal visual parts, as they are subject to surrealist interpretation. Once the delivery or control of the explicit interface or interactions between entities has been reverted, the demand for AI in delivering the exact will of creators is no longer rigid. The output context was not even necessarily related to prompts but represented an exclusive resolution of conflicts.
The hierarchy of AI options implies AI style in terms of consistency (emerging, extension) or conflict as an inclusive or exclusive filter to deliver concepts or display entities. Unexpected context or interfaces in the initial state of creation is also where the creation of AI emerged, instead of parsing for a human’s exact command in the following steps. Thus, context is made of structured 3D/2D entities in terms of depth or overlaid hierarchical composition and segmentation. The former interprets and arranges parts by depth. The latter formulates subject, foreground, and background in terms of bottom-up (from element to whole) and top-down (from whole to part) arrangements.
4.2. Ambiguity Engineering
AI-based surrealist interpretation eventually creates a unique model identity. The AI-based interpretation of surrealism consists of explicit and hidden entities. Explicit details are structural, and visual details are used to generate a 2D image or a 3D model. The hidden entities are logic, touches, identity, or interfaces. AI can learn to adopt vocabularies and interfaces from existing styles to create novel surreal scenes. While explicit surrealism accumulates subjects into a familiar scene with interpretable objects, morphological surrealism accumulates unfamiliar structures into a scene or object of novelty. The reasoning process between the input and output is a different approach to the engineering of ambiguity.
Conflicting prompts are followed by an AI-based adjustment to substantiate possible ambiguity. Part of the logic of surrealism may come from the typology of elements, using systematic classification to organize aspects according to similar or dissimilar characteristics. Similarly, this logic exists in terms of context. For example, abnormal accumulation may appear as vertically stacked houses on a car or a horizontally entangled apple and wires. A character may be given an exaggerated form (for example, head vs. body or hair vs. body) or replaced form (for example, banana head). The elaborated “touches” of style contribute to a unique identity of sense using parts, interfaces, or visual details through checkpoints or seed gain.
This is a difference between the first original surreal prompt and the second subsequent prompt, which was regenerated from a newly reconstructed 3D model in Rodin® or ComfyUI® (comfyanonymous, San Francisco, CA, USA, 2023).
4.3. Balanced Details in a 3D Model
Balanced reality should be achieved between structural and visual details without losing quality and composition. A single image from one angle may not be enough to define the correct visual depth or to create a full model from front to back. As a result, an image may create parts with missing compositions in depth, for example, when linear narrow wood pieces collide inside the human body. Eventually, the level of both details may be restricted by the allowed polygon numbers, upon which the proper allocation of numbers in different parts is used to shape fine curvatures and edges.
Mapping the unseen parts is important for ensuring the shape is complete and the texture is correct and to transition smoothly to unseen regions without missing sections or blurred details. The three-dimensional models were inspected in 360 degrees prior to being finalized. Any unseen or undefined 3D sections in a 2D image were selected from generated alternatives with differing consistencies and smooth transitions of shapes and textures between front and back.
There are always small sections missing from images for 3D reconstruction. The conversion from the morphological to the physical configuration level frequently consists of merging, balancing, and mapping structural and visual details in one single model. Merged reality places structural and visual details in one single 3D model. It is interesting that an image set will map all the textures onto a single 3D model. Misaligned mapping may occur for fine details. The same situation may also occur with a convex or concave polyhedron for deeply recessed or concave sections.
4.4. Surreal Definition in 3D Representation
Three-dimensional reconstruction is a differentiating and restructuring process, which enables the study of parts and subjects, and the interpretation of how the trained morphology was not only visually or symbolically represented but also differentiated in relative proportion and size will be reconsidered and adjusted. The differentiation of the physical sections was carried out in terms of the application-oriented interpretation of the geometries, which is not necessarily consciousness-based segmentation; for example, a head surrounded by fish and red berries.
The restructuring process results in the morphological grouping of unconscious minds. The segmented parts, which open up to more personal choices, are regrouped into new emphases or focuses to form a concept prior to delivery. For example, an out-of-scale head behind a person represents the hidden mind of the subject. This is one of the most interesting issues relevant to architectural visual experience, since (1) the perception of details and proportion of a subject varies by distance; (2) people’s perception may emphasize different sections or may merge images of the subject (a button, hairstyle, hand gesture, etc.).
4.5. AI Identity
The old tangible and intangible identity of a person or cultural entity has evolved into AI identity (resemblance to the AI model) in terms of collective unconsciousness. The new AI identity (resemblance to the AI model) is subject to the user, applied software, or LLMs. This result is an AI identity derived from conflicting prompts that is unexpected and inspired and merges within the AI context.
The novel level of identity is concerned with the context that contributes to the identity of each outcome. In addition to structural and visual details, a meta-relationship has emerged with a unique integrated entity able to undergo physical inspection.
Symbolic identities are useful for post-propagation in videos and AR. A symbolic composite identity may consist of borrowed entities for implied meanings, ironic criticism, or social reflection. Related general generation is different from criteria-oriented solutions with specific problem-solving approaches.
4.5.1. The “Building” Metaphor
An architecture-oriented analysis of surrealism was able to display AI identity. This is not a question of 2D or 3D, or vice versa; it is a question of reality or metaphor. For AI, this is a new prompt approach instead of using conflicting prompt syntax.
A surreal image provides a general perception either of a simple subject or a group of entities. A united identity delivers a story, which may consist of many sub-identities. How the sub-identities are composed and transformed into a different identity deserves to be studied. It is like asking how many elements are available to create a scene, just like how many building components are required to create a unique style.
An identity is similar to the style of a building, which can be analyzed by how it is reconstructed. A surreal image is similar to a building in reconstructing a style or delivering a concept. Like architectural design, a surreal image has to be reconstructed into a 3D model to extend or learn the reconstructed experience of space. Both of these are working with certain types of spatial structure to fulfill a requisite or conceptual requirement of meaning. An identity or entity is contributed to by a collection of sub-entities with a separate identity. The group diffusion is different from the composition of sub-diffusions. This is also true in a painting or a sculpture in different sections of a wall panel, which is an integrated entity.
A surreal image is similar to a house of imagination. If a building can be represented and analyzed in 3D, a surreal image can be conducted the same way as a space made of 3D entities from transferred identities. Since 3D building spaces are represented by the drawings of plans, elevations, and sections, the orthogonal and authentic representations are also useful to display the details in a clearer way.
Redefined identity sets are very similar to redefined unconsciousness. The surreal model presents an evolved composition of identities like a scene created by 3D artists. Identity is manipulated by layers of depth. Some identities are only revealed through sectional views, through the internal structure. If a building or sculpture can be analyzed in this way, a surreal entity can be too, based on configuration and subject background.
4.5.2. AI Details
Identities, or details, are defined by % area–volume, modified functions, fluctuation with intersections (volume–area difference vs. decreasing scale of each), arrangement of distribution, and upper and lower bounds. Fluctuations compare a deep V-shape vs. almost flat for a detailed vs. a less detailed shape.
The arrangement of the distribution can be classified into the following: (1) a center-accumulated shape of an object that was initiated instead of relatively long distributed branches: 2, 3, 5; flat volume < V-area. (2) The arrangement of distributed fat branches: 4, 6; shallow V-volume ≈ V-area (8: more consistent, smaller %; 4, 6: less consistent, medium %). (3) The arrangement of distributed long and narrow branches: 1, deep V-volume << V-area. (4) The arrangement of distributed shell-like shapes: 7 shallow V-volume > V-area.
The distribution of details (value + %) can be classified as (1) long, thick hair on a small body: 1 (body made by almost all hair, % by many intersections); (2) long, thick hair on part of the body: 2 (body made by almost all hair, % by many intersections); (3) short, thin hair on a lumpy body: 3, 5, 6; (4) short, fat element on lumpy body: 4 (from many bananas to the one of human body); (5) shell: 7; (6) repetitive linear arranged lumpy sections: 8 (linked by small linear rod).
General trends enable the illustration of terms as follows: (1) The proportion between highly and less detailed parts: a lumpy object may still have a small number of highly detailed parts. The relative proportion may lead to subjective judgments. (2) Highly detailed parts: hair with long and separated branches/twigs. Depending on the proportion of details, the smaller reduction in volume is caused by a larger reduction in surface area. (3) Densely detailed parts: head with accumulated and centered parts within fat branches/twigs, where volume ≈ area. Depending on the proportion of details, the reduction in volume is caused by the lumpy body, similar to the reduction in surface area within the fat details. (4) Lowly detailed parts: the head in shell form is accumulated and centered by minor branches/twigs. Depending on the proportion of details, the larger reduction in volume is caused by the lumpy body instead of by the reduction in surface area in lesser details.
The differences between original volume/area and modified volume/area are determined by the following. (1) Ratios: when volume is less than surface area (Relax), it is highly detailed; (2) reduction speed: volume vs. surface area vs. dist./deviation; (3) feature types with relax/Quicksmooth/reduce noise/remove spike; (4) std. deviation % involves max. distance and avg. distance in terms of the 1—hair and 8—apple models.
The advantage consists of the enabled assessment, the more successful reconstruction that delivers the 3D metaphor, and the novel numeric evaluation that is superior to visual judgment. The shortage aims to alter the original shape, character, or style through the five functions, which may change the preferred 3D interpretation in an alternative manner before assessment.
4.5.3. Identity and Assessment
Surrealism creates styles and identities that are generated, interpreted, and elaborated by AI. Surrealists sought to channel the unconscious through their work; theirs was an art of ids [6]. Chained AI processes and tools have evolved to discover preferred styles with various structural and visual details as controls. Conflicting prompts create unexpected and satisfactory AI identities (seed gains, for example). The unexpected but inspired outcomes merge geometries and AI identities. Since all the sections are merged, the surface areas can be easily assessed as an indicator of the level of detail. As a result, AI identity (the resemblance to the AI model) is derived from a series of prompts, applied software, LLMs, gains, trial and error, outcomes, 3D details, and assessment.
Details generated by AI present a relative measure of scales. Eight types of assessed categories were achieved through configurations, composition, referencing function, values, and %. An object may be full of very small connected linear elements that can be described as a pattern or could be part of relatively different shapes with the aim of drawing attention by projected area. As a result, the details of an object can be assessed using specific dimensions.
4.6. Convergent or Divergent Conscious Maps
I found an easy way to create a surreal image by applying inconsistencies in a divergent way. A surreal image embodies implications or metaphors with spatial structures underlined by hierarchically designated visual weight, depth, and conversations between entities. It is an open, divergent creation. All the resources used to create a surreal image are not necessarily derived from the same LLM. The more diversified the resources, the more enlightened the image.
AI can forge output with a sense of humanity. Surreal AI covers the conscious, subconscious, and unconscious. An identity, which is created using everyday subjects and unique scenes, is created with the elaboration of surreal touches, such as “she”, “I”, “he”, “fish”, and “solid–void”. AI tools vary between straightforward prompts and conflicting prompts.
Surrealism is real. Surrealism has details and identity, since the conscious, subconscious, or unconscious are real and are formulated using details and identity. The conscious map, in terms of 2D or 3D approaches, consists of a series of AI layers and corresponding tools for decomposing or propagating previously generated outcomes. Does Rodin® help surreal study? Dream Studio®, Stable Diffusion®, and Rodin® with proper prompts did. While the differences are not considered perfectly consistent, should the diversity of all Rodin®-generated alternatives contribute anything? In fact, Rodin® examines a surreal subject during the analysis of context and vocabulary. What would happen if a reality-based trained model were used to interpret an artistic, symbolic, or abstract form of sculpture image, using one to four images? The consciousness map is concerned with regard to creating subjective surreal 3D models from surreal 2D images.
Imagination can be either a convergent or divergent process. Does imagination take place before, after, or during the activity? The virtual text-based description occurs before and is verified by 2D AI-generated diffusive outputs, based on grouped human consciousness. Convergence, the controlled imagination, uses multiple layers of diffusive AI outputs obtained from Photoshop® neural filters, Dream Studio®, Diffusion®, and Rodin® to test the same prompts. Divergence, the diffusive imagination, is not only present in 2D images but also when using 3D tools to substantiate sufficient details.
The subjective part of the analysis does not require balance, and the status is purposely applied to possible creations. Convergence and divergence represent an alternative and interlaced wave-like process with different amplitudes, frequencies, and orientations as a back-and-forth conversation between the human consciousness and the AI unconsciousness. It is convergent for selecting and arranging control options but diverges from the LLM after initial prompts.
4.6.1. Horizontal Effect and Recursive Reconstruction
In AI, surrealism is not an end, but a means to explore without horizontal effect. AI is a mirror of the collective unconscious, and humanity is the collective unconscious of AI [7]. A good simulation communicates the corresponding reality in various ways; in the meantime, a good reconstruction regenerates the corresponding reality with sufficient options using explicit and implicit metaphors. The reversed reconstruction of metaphors applies implicit prompts to generate explicit 3D models. Attempted surreal outcomes were revised and recursively reconstructed for the satisfied refinement of vocabularies and compositions.
4.6.2. Evolved Inconsistency
The AI images represent a surreal arena in AI and an architectural style of a construction. Is creating a surreal image the same as building design? AI is an evolved process that reconstructs surreal images out of a collection of explicit resources as metaphors to substantiate an implicated statement of prompt. It is possible to explore the inconsistency of the 3D model and the extended representation of the subject in terms of geometries, texture, composition, assessment, or even as AR. It is the inconsistency that makes the difference, or even uniqueness.
4.6.3. Limitations
There is also a technical limitation to creating 100% resemblance at the first trial. Different generation platforms feature various levels of efficiency in terms of polygon counts or texture mapping. However, the limitations should be solved in the future. The most important issue discussed in this study is a novel approach using conflicting prompts to avoid horizontal effect, which is beyond the original setting of applying additive description of prompts to refine expected outcomes. The advantage should be significant, depending on how we redefine our pattern of behavior for a new perspective of answers.
5. Conclusions
Surrealism is a process that can be repetitively revised and recursively reconstructed in order to purposely re-visualize unconscious metaphors and contexts. An image is everything. The realistic 3D as-built model can be reconstructed from surreal images with details that enrich or help the comprehension or creation of surrealism.
Surreal 3D images emerge from conflicting prompts, and AI-assisted 3D reconstruction is used for assessment. Positive prompts, such as building elements, are straightforward, refined statements embodying the specific design process. From the construction process to the verification of style, the merged AI generations meet the authentic construction requirements in terms of consistency. It is negative for conflicting prompts. The difference enables a more creative design or a generation possibility. The merged 3D model, which was used to redefine the statements of design in a reversed manner, still maintains the representative elements in a 3D-assessable spatial structure in terms of numeric identity.
Surrealism is a style with design factors that are generated, interpreted, and elaborated, possibly by AI. Surrealism applies metaphors to create surreal contexts and scenes and can change them into new metaphors. Chained applications should then be used for a series of operations (as indicated in Table 2). I found that the novel approach of prompt context can create results to meet the needs of creation.
Future studies should include the decomposition of the parts of the surreal images for the unconscious interpretation or segmentation of entities or vocabularies beyond merged geometries.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable for studies not involving humans or animals.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A

Figure A1.
First comparison in value of 1—Hair.

Figure A2.
First comparison in value of 2—Wire Head.

Figure A3.
First comparison in value of 3—Flower Head.

Figure A4.
First comparison in value of 4—Banana Head-2.

Figure A5.
First comparison in value of 5—Lady Head.

Figure A6.
First comparison in value of 6—Eye.

Figure A7.
First comparison in value of 7—Mask above Head.

Figure A8.
First comparison in value of 8—Apple.
Appendix B

Figure A9.
Second comparison in % of 1—Hair.

Figure A10.
Second comparison in % of 2—Wire Head.

Figure A11.
Second comparison in % of 3—Flower Head.

Figure A12.
Second comparison in % of 4—Banana Head-2.

Figure A13.
Second comparison in % of 5—Lady Head.

Figure A14.
Second comparison in % of 6—Eye.

Figure A15.
Second comparison in % of 7—Mask Above Head.

Figure A16.
Second comparison in % of 8—Apple.
References
- O’Meara, J.; Murphy, C. Aberrant AI creations: Co-Creating surrealist body horror using the DALL-E Mini text-to-image generator. Convergence 2023, 29, 1070–1096. [Google Scholar] [CrossRef]
- TOMAAS. Surrealism Turns 100: How AI Positions It at the Forefront of Art. Available online: https://medium.com/@Tomaas.eth/surrealism-turns-100-how-ai-positions-it-at-the-forefront-of-art-fa2c0d80fd81 (accessed on 29 June 2025).
- Kratky, A. Poetic Automatisms: A comparison of surrealist automatisms and artificial intelligence for creative expression. In ArtsIT, Interactivity and Game Creation; Wölfel, M., Bernhardt, J., Thiel, S., Eds.; ArtsIT 2021, Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2022; Volume 422, pp. 359–378. [Google Scholar] [CrossRef]
- Willis, H. Blurry, Morphing and Surreal—A New AI Aesthetic Is Emerging in Film. The Conversation. Available online: https://theconversation.com/blurry-morphing-and-surreal-a-new-ai-aesthetic-is-emerging-in-film-242098 (accessed on 19 September 2025).
- Falconer, R. What Happens to the Surrealist Mindset in the Age of Artificial Intelligence? Reviews, Frieze, 18 January 2019. Available online: https://www.frieze.com/article/what-happens-surrealist-mindset-age-artificial-intelligence (accessed on 29 June 2025).
- Dafoe, T. Surrealism in the Age of AI, ARTnews. Available online: https://www.artnews.com/list/art-news/artists/surrealism-and-artificial-intelligence-art-1234704046/ (accessed on 29 June 2025).
- Surrealism Today. AI Surrealism: Exploring Digital Dreamscapes and the Collective Unconscious. Available online: https://surrealismtoday.com/ai-surrealism-collective-unconscious/ (accessed on 29 June 2025).
- Wang, D.; Huai, B.; Ma, X.; Jin, B.; Wang, Y.; Chen, M.; Sang, J.; Liu, R. Application of Artificial Intelligence-Assisted Image Diagnosis Software Based on Volume Data Reconstruction Technique in Medical Imaging Practice Teaching. BMC Med. Educ. 2024, 24, 405. [Google Scholar] [CrossRef]
- Peng, C.; Wang, Z.C.; Zhu, C.Z.; Kuang, D.M. 3D reconstruction of asphalt mixture based on 2D images. Constr. Build. Mater. 2025, 462, 139938. [Google Scholar] [CrossRef]
- Kim, M.; Kim, T.; Lee, K.-T. 3D Digital Human Generation from a Single Image Using Generative AI with Real-Time Motion Synchronization. Electronics 2025, 14, 777. [Google Scholar] [CrossRef]
- Fathallah, M.; Eletriby, S.; Alsabaan, M.; Ibrahem, M.I.; Farok, G. Advanced 3D Face Reconstruction from Single 2D Images Using Enhanced Adversarial Neural Networks and Graph Neural Networks. Sensors 2024, 24, 6280. [Google Scholar] [CrossRef]
- Wen, M.; Cho, K. Object-Aware 3D Scene Reconstruction from Single 2D Images of Indoor Scenes. Mathematics 2023, 11, 403. [Google Scholar] [CrossRef]
- Dundar, A.; Gao, J.; Tao, A.; Catanzaro, B. Progressive Learning of 3D Reconstruction Network from 2D GAN Data. arXiv 2025, arXiv:2305.11102v1. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Wang, B.; Jiang, H. Artificial Intelligence Technology in 3D Facial Reconstruction: An Approach to Reutilize 2D Standardized Images in Plastic Surgery. Aesth. Plast. Surg. 2025. [Google Scholar] [CrossRef]
- Yang, C.; Li, S.; Fang, J.; Liang, R.; Xie, L.; Zhang, X.; Tian, Q. GaussianObject: High-Quality 3D Object Reconstruction from Four Views with Gaussian Splatting. ACM Trans. Graph. 2024, 43, 1–13. [Google Scholar] [CrossRef]
- Bao, Y.; Ding, T.; Huo, J.; Liu, Y.; Li, Y.; Li, W.; Gao, Y.; Luo, J. 3d gaussian splatting: Survey, technologies, challenges, and opportunities. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 6832–6852. [Google Scholar] [CrossRef]
- Dong, Z.H.; Ye, S.; Wen, Y.H.; Li, N.; Liu, Y.J. Towards Better Robustness: Progressively Joint Pose-3DGS Learning for Arbitrarily Long Videos. arXiv 2025, arXiv:2501.15096. [Google Scholar] [CrossRef]
- Qian, J.; Yan, Y.; Gao, F.; Ge, B.; Wei, M.; Shangguan, B.; He, G. C3DGS: Compressing 3D Gaussian Model for Surface Reconstruction of Large-Scale Scenes Based on Multi-View UAV Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 4396–4409. [Google Scholar] [CrossRef]
- Wang, W. Real-Time Fast 3D Reconstruction of Heritage Buildings Based on 3D Gaussian Splashing. In Proceedings of the 2024 IEEE 2nd International Conference on Sensors, Electronics and Computer Engineering (ICSECE), Jinzhou, China, 29–31 August 2024; pp. 1014–1018. [Google Scholar] [CrossRef]
- Chen, Y.; Xiao, K.; Gao, G.; Zhang, F. High-Fidelity 3d Reconstruction of Peach Orchard using a 3DGS-Ag model. Comput. Electron. Agric. 2025, 234, 110225. [Google Scholar] [CrossRef]
- Rahimi, F.B.; Demers, C.M.; Dastjerdi, M.R.K.; Lalonde, J.F. Agile digitization for historic architecture using 360° capture, deep learning, and virtual reality. Autom. Constr. 2025, 171, 105986. [Google Scholar] [CrossRef]
- Comte, F.; Pamart, A.; Ruby, K.; De Luca, L. Strategies and Experiments for Massive 3D Digitalization of the Remains After the Notre-Dame de Paris’ Fire. In Proceedings of the 10th International Workshop 3D-ARCH “3D Virtual Reconstruction and Visualization of Complex Architectures”, Siena, Italy, 21–23 February 2024; Volume XLVIII-2/W4-2024, pp. 127–134. [Google Scholar] [CrossRef]
- Wang, L.; Yang, L.; Xu, H.; Zhu, X.; Cabrel, W.; Mumanikidzwa, G.T.; Liu, X.; Jiang, W.; Chen, H.; Jiang, W. Single-view-based high-fidelity three-dimensional reconstruction of leaves. Comput. Electron. Agric. 2024, 227, 109682. [Google Scholar] [CrossRef]
- Stacchio, L.; Garzarella, S.; Cascarano, P.; De Filippo, A.; Cervellati, E.; Marfia, G. DanXe: An extended artificial intelligence framework to analyze and promote dance heritage. Digit. Appl. Archaeol. Cult. Herit. 2024, 33, e00343. [Google Scholar] [CrossRef]
- Stacchio, L.; Balloni, E.; Gorgoglione, L.; Mancini, A.; Giovanola, B.; Tiribelli, S.; Zingaretti, P. An ethical framework for trustworthy Neural Rendering applied in cultural heritage and creative industries. Front. Comput. Sci. 2024, 6, 1459807. [Google Scholar] [CrossRef]
- Stuart, L.A.; Pound, M.P. 3DGS-to-PC: Convert a 3D Gaussian Splatting Scene into a Dense Point Cloud or Mesh. arXiv 2025, arXiv:2501.07478. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, B.; Zhang, T.; Gu, S.; Bao, J.; Baltrusaitis, T.; Shen, J.; Chen, D.; Wen, F.; Chen, Q.; et al. Rodin: A generative model for sculpting 3d digital avatars using diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4563–4573. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Q.; Kang, D.; Cheng, W.; Gao, Y.; Zhang, J.; Liang, Z.; Liao, J.; Cao, Y.P.; Shan, Y. Advances in 3d generation: A survey. arXiv 2024, arXiv:2401.17807. [Google Scholar] [CrossRef]
- Belkevičiūtė, G. Skaitmeninių Technologijų Inovacijos Mados Produktų Virtualizavimui. Doctoral Dissertation, Kauno Technologijos Universitetas, Kaunas, Lithuania, 2025. Available online: https://stud.lt/skaitmeniniu-technologiju-inovacijos-mados-produktu-virtualizavimui/ (accessed on 13 February 2025).
- Shih, N.-J. AI- and AR-Assisted 3D Reactivation of Characters in Paintings. Heritage 2025, 8, 207. [Google Scholar] [CrossRef]
- Shih, N.-J. Using AI to Reconstruct and Preserve 3D Temple Art with Old Images. Technologies 2025, 13, 229. [Google Scholar] [CrossRef]





































































































Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).