

Predictive Processing and Inhibitory Control Drive Semantic Enhancements for Non-Dominant Language Word Recognition in Noise


Abstract
:1. Introduction
1.1. Bilingual Speech Perception in Noise
1.2. Predictability versus Prediction
- The team was trained by their coach.
- Eve was made from Adam’s rib.
- The good boy is helping his mother and father.
- 4.
- Mom talked about the pie.
- 5.
- He is considering the throat.
- 6.
- The party next door lasted into the night and I couldn’t sleep because of all the noise.
1.3. The Current Study
Exploring the Role of Inhibitory Processes in Managing Acoustic and Linguistic Interference
2. Materials and Methods
2.1. Overview of Experimental Session
2.2. Participants
2.3. Main Experimental Task
2.3.1. Trial Procedure
2.3.2. Design and Materials
2.3.3. Auditory Stimuli
2.4. AX-Continuous Performance Task
3. Results
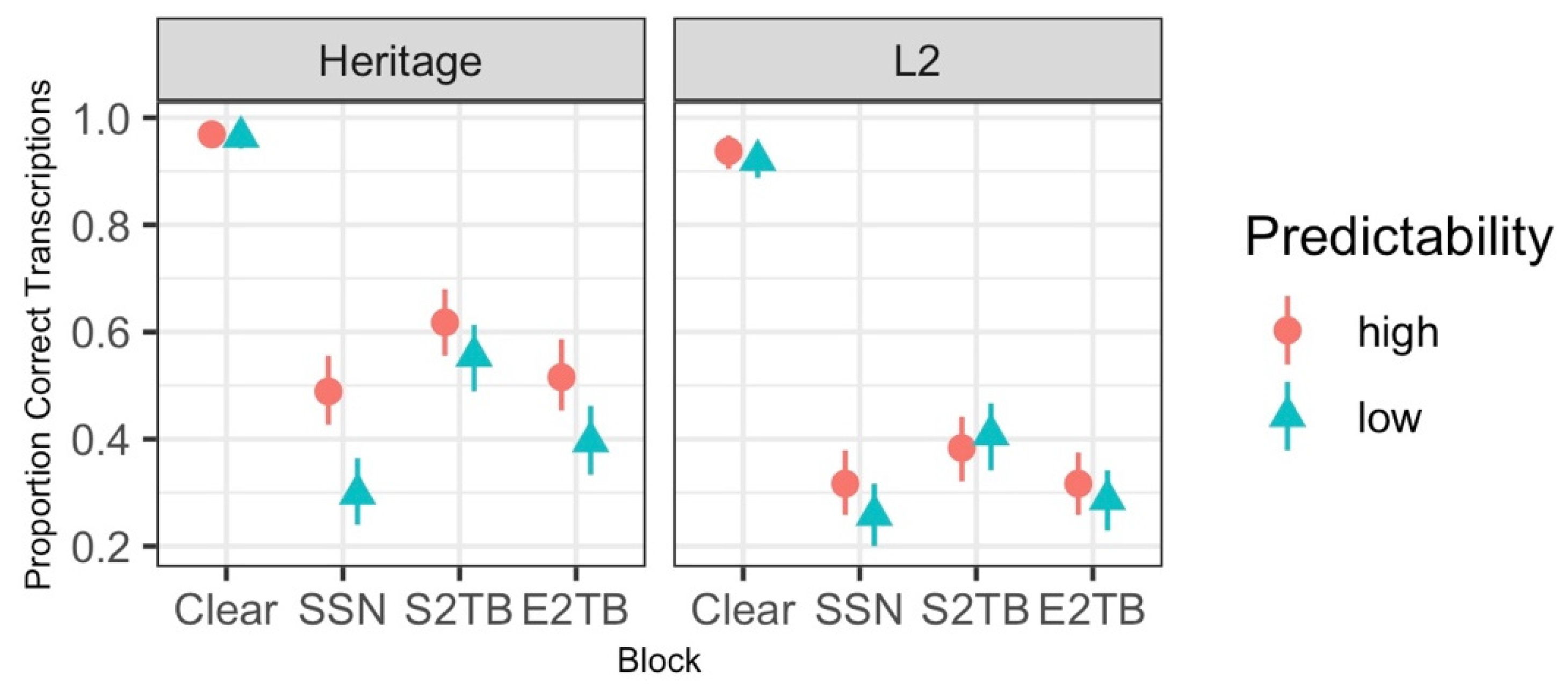
3.1. Accuracy Analysis
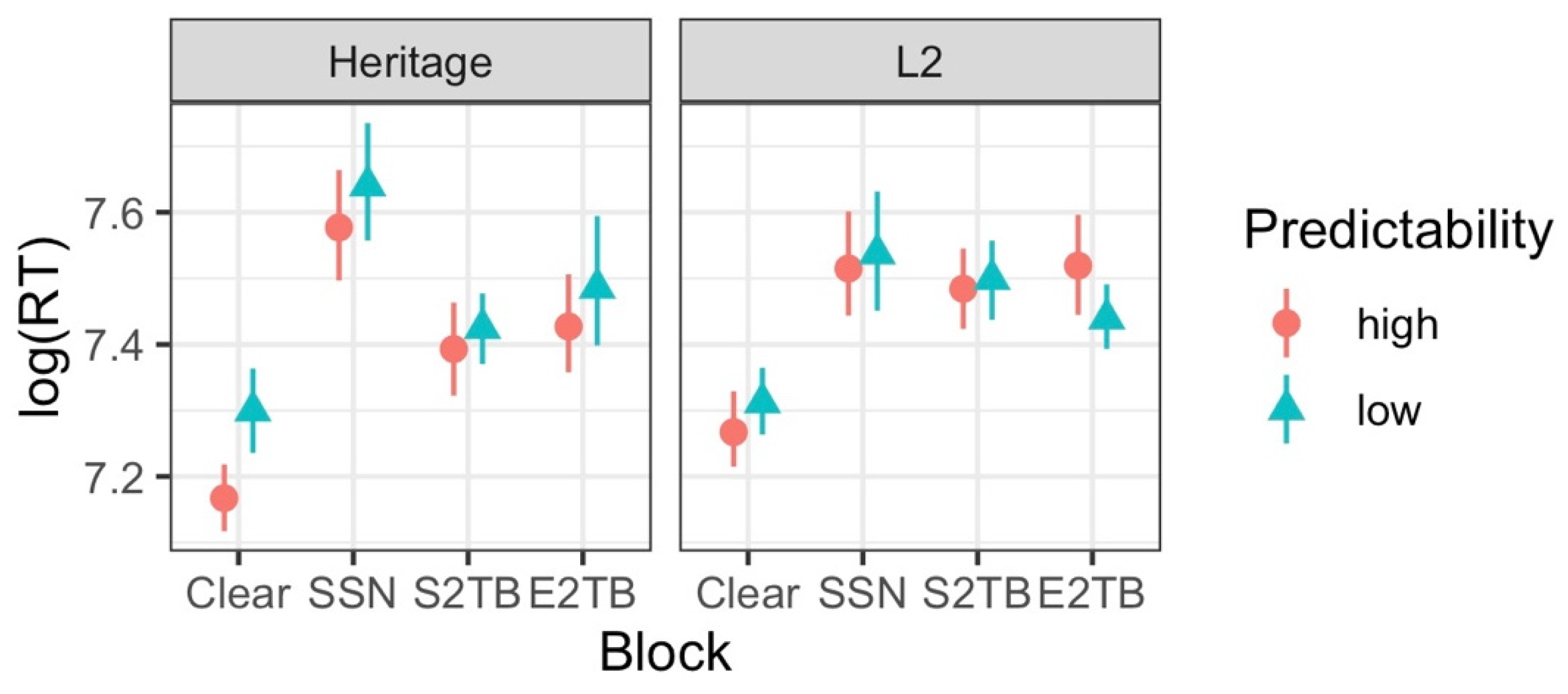
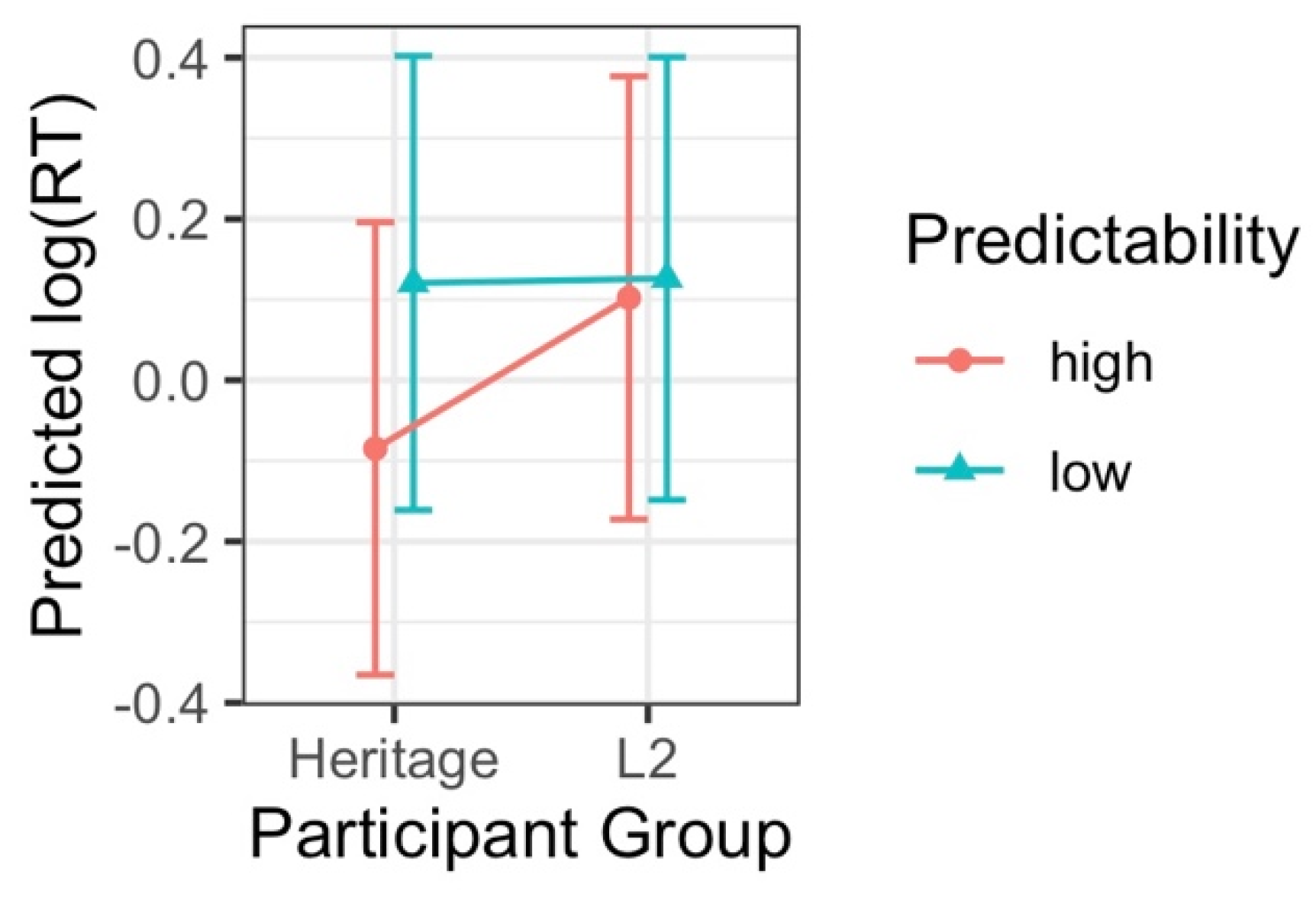
3.2. Reaction Time (RT) Analysis
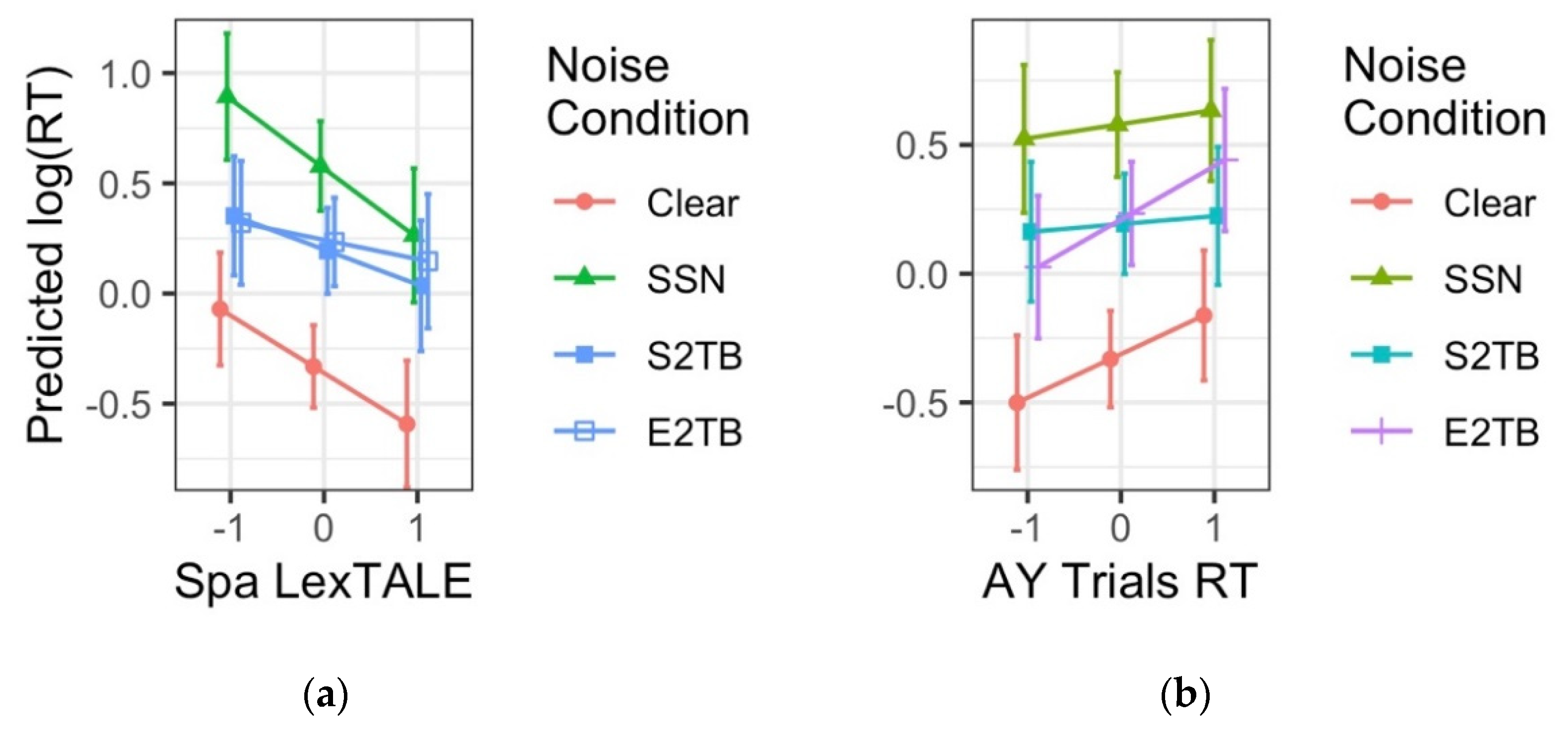
3.3. Individual Differences Analysis
3.3.1. AX-CPT Results
3.3.2. Individual Differences Results
4. Discussion
4.1. Summary of Findings
4.2. Listeners Can Benefit from Constraining Sentence Contexts under Some Conditions
4.3. Separating the Effects of Energetic versus Informational Masking
4.4. Inhibitory Control Ability Modulates Interference from the Dominant Language
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | Poorer performance on the BX condition (in contrast with the BY condition, which serves as a general control comparison) is more likely to occur for individuals who experience difficulty with proactive goal maintenance, such as the elderly (Braver et al. 2001) and those diagnosed with schizophrenia (Cohen et al. 1999), and is less likely in neurotypical, young adult populations. |
References
- Anwyl-Irvine, Alexander L., Jessica Massonnié, Adam Flitton, Natasha Kirkham, and Jo K. Evershed. 2020. Gorilla in our midst: An online behavioral experiment builder. Behavioral Research Methods 52: 388–407. [Google Scholar] [CrossRef] [PubMed]
- Bates, Douglas, Martin Maechler, Ben Bolker, and Steven Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Beatty-Martínez, Anne L., Christian A. Navarro-Torres, Paola E. Dussias, María T. Bajo, Rosa E. Guzzardo Tamargo, and Judith F. Kroll. 2020. Internactional context mediates the consequences of bilingualism for language and cognition. Journal of Experimental Psychology: Learning, Memory, and Cognition 46: 1022–47. [Google Scholar] [CrossRef] [PubMed]
- Beatty-Martínez, Anne L., Rose E. Guzzardo Tamargo, and Paola E. Dussias. 2021. Phasic pupillary responses reveal differential engagement of attentional control in bilingual spoken language processing. Scientific Reports 11: 23474. [Google Scholar] [CrossRef] [PubMed]
- Bilger, Robert C., J. M. Nuetzel, William M. Rabinowitz, and C. Rzeczkowski. 1984. Standardization of a test of speech perception in noise. Journal of Speech, Language, and Hearing Research 27: 32–48. [Google Scholar] [CrossRef]
- Birdsong, David. 2018. Plasticity, variability and age in second language acquisition and bilingualism. Frontiers in Psychology 9: 81. [Google Scholar] [CrossRef]
- Blumenfeld, Henrike K., and Viorica Marian. 2013. Parallel language activation and cognitive control during spoken word recognition in bilinguals. Journal of Cognitive Psychology 25: 547–67. [Google Scholar] [CrossRef]
- Bradlow, Ann R., and Jennifer A. Alexander. 2007. Semantic and phonetic enhancements for speech-in-noise recognition by native and non-native listeners. Journal of the Acoustic Society of America 121: 2339–49. [Google Scholar] [CrossRef]
- Braver, Todd S., Deanna M. Barch, Beth A. Keys, Cameron S. Carter, Jonathan D. Cohen, Jeffrey A. Kaye, Jeri S. Janowsky, Stephan F. Taylor, Jerome A. Yesavage, Martin S. Mumenthaler, and et al. 2001. Context processing in older adults: Evidence for a theory relating cognitive control to neurobiology in healthy aging. Journal of Experimental Psychology: Genderal 130: 746–63. [Google Scholar] [CrossRef]
- Braver, Todd S., Jessica L. Paxton, Hannah S. Locke, and Deanna M. Barch. 2009. Flexible neural mechanisms of cognitive control within human prefrontal cortex. Proceedings of the National Academy of Sciences 106: 7351–56. [Google Scholar] [CrossRef] [Green Version]
- Calandruccio, Lauren, Emily Buss, Penelope Bencheck, and Brandi Jett. 2018. Does the semantic content or syntactic regularity of masker speech affect speech-on-speech recognition? The Journal of the Acoustical Society of America 144: 3289–302. [Google Scholar] [CrossRef]
- Cohen, Jonathan D., Deanna M. Barch, Cameron Carter, and David Servan-Schreiber. 1999. Context-processing deficits in schizophrenia: Converging evidence from three theoretically motivated cognitive tasks. Journal of Abnormal Psychology 108: 120–33. [Google Scholar] [CrossRef] [PubMed]
- Cooke, Martin. 2006. A glimpsing model of speech perception in noise. The Journal of the Acoustical Society of America 119: 1562–73. [Google Scholar] [CrossRef] [PubMed]
- Cooke, Martin, Maria Luisa Garcia Lecumberri, and Jon Barker. 2008. The foreign language cocktail party problem: Energetic and informational masking effects in non-native speech perception. Journal of the Acoustic Society of America 123: 414–27. [Google Scholar] [CrossRef]
- Coulter, Kristina, Annie C. Gilbert, Shanna Kousaie, Shari Baum, Vincent L. Gracco, Denise Klein, Debra Titone, and Natalie A. Phillips. 2021. Bilinguals benefit from semantic context while perceiving speech in noise in both of their languages: Electrophysiological evidence from the N400 ERP. Bilingualism: Language and Cognition 24: 344–57. [Google Scholar] [CrossRef]
- Cutler, Anne, Andrea Weber, Roel Smits, and Nicole Cooper. 2004. Patterns of English phoneme confusions by native and non-native listeners. Journal of the Acoustic Society of America 116: 3668–78. [Google Scholar] [CrossRef]
- Diez, Emiliano, María Angeles Alonso, Natividad Rodríguez, and Angel Fernandez. 2018. Free-Association Norms for a Large Set of Words in Spanish. [Database]. Available online: https://iblues-inico.usal.es/iblues/nalc_about.php (accessed on 20 April 2022).
- Edwards, Bethany G., Deanna M. Barch, and Todd S. Braver. 2010. Improving prefrontal cortex function in schizophrenia through focused training of cognitive control. Frontiers in Human Neuroscience 4: 32. [Google Scholar] [CrossRef]
- Federmeier, Kara D., Devon B. McLennan, Eesmerelda De Ochoa, and Marta Kutas. 2002. The impact of semantic memory organization and sentence context information on spoken language processing by younger and older adults: An ERP study. Psychophysiology 39: 133–46. [Google Scholar] [CrossRef]
- Federmeier, Kara D., Marta Kutas, and Rina Schul. 2010. Age-related and individual differences in the use of prediction during language comprehension. Brain and Language 115: 149–61. [Google Scholar] [CrossRef]
- Fernandez, Angel, Emiliano Diez, María Angeles Alonso, and María Soledad Beato. 2004. Free-association norms for the Spanish names of the Snodgrass and Vanderwart pictures. Behavior Research Methods, Instruments, & Computers 36: 577–84. [Google Scholar] [CrossRef] [Green Version]
- Festen, Joost M., and Reinier Plomp. 1990. Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. Journal of the Acoustic Society of America 88: 1725–36. [Google Scholar] [CrossRef] [PubMed]
- Fricke, Melinda. 2022. Modulation of cross-language activation during bilingual auditory word recognition: Effects of language experience but not competing background noise. Frontiers in Psychology 13: 674157. [Google Scholar] [CrossRef] [PubMed]
- Fricke, Melinda, Megan Zirnstein, Christian Navarro-Torres, and Judith F. Kroll. 2019. Bilingualism reveals fundamental variation in language processing. Bilingualism, Language and Cognition 22: 200–7. [Google Scholar] [CrossRef] [PubMed]
- Garcia Lecumberri, Maria Luisa, Martin Cooke, and Anne Cutler. 2010. Non-native speech perception in adverse conditions: A review. Speech Communication 52: 864–86. [Google Scholar] [CrossRef]
- Golestani, Narly, Stuart Rosen, and Sophie K. Scott. 2009. Native-language benefit for understanding speech-in-noise: The contribution of semantics. Bilingualism: Language and Cognition 12: 385–92. [Google Scholar] [CrossRef]
- Gonthier, Corentin, Brooke N. Macnamara, Michael Chow, Andrew R. A. Conway, and Todd S. Braver. 2016. Inducing proactive control shifts in the AX-CPT. Frontiers in Psychology 7: 1822. [Google Scholar] [CrossRef]
- Gor, Kira. 2014. Raspberry, not a car: Context predictability and a phonological advantage in early and late learners’ processing of speech in noise. Frontiers in Psychology 5: 1449. [Google Scholar] [CrossRef]
- Hazan, Valerie, and Andrew Simpson. 2000. The effect of cue-enhancement on consonant intelligibility in noise: Speaker and listener effects. Language & Speech 43: 273–94. [Google Scholar] [CrossRef]
- Hervais-Adelman, Alexis, Maria Pefkou, and Narly Golestani. 2014. Bilingual speech-in-noise: Neural bases of semantic context use in the native language. Brain & Language 132: 1–6. [Google Scholar] [CrossRef]
- Ito, Aine, Martin Corley, and Martin J. Pickering. 2018. A cognitive load delays predictive eye movements similarly during L1 and L2 comprehension. Bilingualism: Language and Cognition 21: 251–64. [Google Scholar] [CrossRef] [Green Version]
- Izura, Cristina, Fernando Cuetos, and Marc Brysbaert. 2014. Lextale-Esp: A test to rapidly and efficiently assess the Spanish vocabulary size. Psicológica 35: 49–66. [Google Scholar] [CrossRef]
- Jacobs, April, Melinda Fricke, and Judith F. Kroll. 2016. Cross-language activation begins during speech planning and extends into second language speech. Language Learning 66: 324–53. [Google Scholar] [CrossRef] [PubMed]
- Kalikow, Daniel N., Kenneth N. Stevens, and Lois L. Elliott. 1977. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. The Journal of the Acoustical Society of America 61: 1337–51. [Google Scholar] [CrossRef] [PubMed]
- Kilman, Lisa, Adriana Zekveld, Mathias Hällgren, and Jerker Rönnberg. 2014. The influence of non-native language proficiency on speech perception performance. Frontiers in Psychology 5: 651. [Google Scholar] [CrossRef]
- Kousaie, Shanna, Shari Baum, Natalie A. Phillips, Vincent Grocco, Debra Titone, Jen-Kai Chen, Xiaoqian J. Chai, and Denise Klein. 2019. Language learning experience and mastering the challenges of perceiving speech in noise. Brain and Language 196: 104645. [Google Scholar] [CrossRef]
- Krizman, Jennifer, Ann R. Bradlow, Silvia Siu-Yin Lam, and Nina Kraus. 2017. How bilinguals listen in noise: Linguistic and non-linguistic factors. Bilingualism, Language and Cognition 20: 834–43. [Google Scholar] [CrossRef]
- Kroll, Judith F., and Paola E. Dussias. 2013. The comprehension of words and sentences in two languages. In The Handbook of Bilingualism and Multilingualism, 2nd ed. Edited by Tej K. Bhatia and William C. Ritchie. Malden: Wiley-Blackwell Publishers, pp. 216–43. [Google Scholar] [CrossRef]
- Kroll, Judith F., Kinsey Bice, Mona Roxana Botezatu, and Megan Zirnstein. 2022. On the dynamics of lexical access in two or more languages. In The Oxford Handbook of the Mental Lexicon. Edited by Anna Papafragou, John C. Trueswell and Lila R. Gleitman. New York: Oxford University Press, pp. 583–97. [Google Scholar] [CrossRef]
- Kutas, Marta, Kara D. Federmeier, and Thomas P. Urbach. 2014. The “negatives” and “positives” of prediction in language. In The Cognitive Neurosciences. Edited by Michael S. Gazzaniga and George R. Mangun. Cambridge: MIT Press, pp. 649–56. [Google Scholar]
- Lemhöfer, Kristin, and Mirjam Broersma. 2012. Introducing LexTALE: A quick and valid lexical test for advanced learners of English. Behavioral Research Methods 44: 325–43. [Google Scholar] [CrossRef]
- Lenth, Russell V. 2021. Emmeans: Estimated Marginal Means, Aka Least-Squares Means. R Package Version 1.6.3. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 20 April 2022).
- Linck, Jared A., Judith F. Kroll, and Gretchen Sunderman. 2009. Losing access to the native language while immersed in a second language: Evidence for the role of inhibition in second-language learning. Psychological Science 20: 1507–15. [Google Scholar] [CrossRef] [Green Version]
- MacKay, Ian R., Diane Meador, and James E. Flege. 2001. The identification of English consonants by native speakers of Italian. Phonetica 58: 103–25. [Google Scholar] [CrossRef] [PubMed]
- Marian, Viorica, Henrike K. Blumenfeld, and Margarita Kaushanskaya. 2007. The Language Experience and Proficiency Questionnaire (LEAP-Q): Assessing language profiles in bilinguals and multilinguals. Journal of Speech, Language, and Hearing Research 50: 940–67. [Google Scholar] [CrossRef]
- Marian, Viorica, James Bartolotti, Sarah Chabal, and Anthony Shook. 2012. CLEARPOND: Cross-Linguistic Easy-Access Resource for Phonological and Orthographic Neighborhood Densities. PLoS ONE 7: e43230. [Google Scholar] [CrossRef] [PubMed]
- Martin, Clara D., Guillaume Thierry, Jan-Rouke Kuipers, Bastien Boutonnet, Alice Foucart, and Albert Costa. 2013. Bilinguals reading in their second language do not predict upcoming words as native readers do. Journal of Memory and Language 55: 381–401. [Google Scholar] [CrossRef]
- Matuschek, Hannes, Reinhold Kliegl, Shravan Vasishth, Harald Baayen, and Douglas Bates. 2017. Balancing type I error and power in linear mixed models. Journal of Memory and Language 94: 305–15. [Google Scholar] [CrossRef]
- Mayo, Lynn H., Mary Florentine, and Søren Buus. 1997. Age of second-language acquisition and perception of speech in noise. Journal of Speech, Language, and Hearing Research 40: 686–93. [Google Scholar] [CrossRef] [PubMed]
- Meador, Diane, James E. Flege, and Ian R. A. MacKay. 2000. Factors affecting the recognition of words in a second language. Bilingualism, Language and Cognition 3: 55–67. [Google Scholar] [CrossRef]
- Meuter, Renate F. I., and Alan Allport. 1999. Bilingual language switching in naming: Asymmetrical costs of language selection. Journal of Memory and Language 40: 25–40. [Google Scholar] [CrossRef]
- Misra, Maya, Taomei Guo, Susan Bobb, and Judith F. Kroll. 2012. When bilinguals choose a single word to speak: Electrophysiological evidence for inhibition of the native language. Journal of Memory & Language 67: 224–37. [Google Scholar] [CrossRef]
- Morales, Julia, Carlos J. Gómez-Ariza, and Maria Teresa Bajo. 2013. Dual mechanisms of cognitive control in bilinguals and monolinguals. Journal of Cognitive Psychology 25: 531–46. [Google Scholar] [CrossRef]
- Morales, Julia, Carlos J. Gómez-Ariza, and Maria Teresa Bajo. 2015. Bilingualism modulates dual mechanisms of cognitive control: Evidence from ERPs. Neuropsychologia 66: 157–69. [Google Scholar] [CrossRef]
- Nuechterlein, Keith H. 1991. Vigilance in schizophrenia and related disorders. In Neuropsychology, Psychophysiology, and Information Processing. Edited by Stuart R. Steinhauer, John H. Gruzelier and Joseph Zubin. Amsterdam: Elsevier, vol. 5, pp. 397–433. [Google Scholar]
- Paxton, Jessica L., Deanna M. Barch, Martha Storandt, and Todd S. Braver. 2006. Effects of environmental support and strategy training in older adults’ use of context. Psychology and Aging 21: 499–509. [Google Scholar] [CrossRef]
- Pierce, Lara J., Denise Klein, Jen-Kai Chen, Audrey Delcenserie, and Fred Genesee. 2014. Mapping the unconscious maintenance of a lost first language. Proceedings of the National Academy of Sciences 111: 17314–19. [Google Scholar] [CrossRef] [PubMed]
- Rosvold, H. Enger, Allan F. Mirsky, Irwin Sarason, Edwin D. Bransome, and Lloyd H. Beck. 1956. A continuous performance test of brain damage. Journal of Consulting Psychology 20: 343–50. [Google Scholar] [CrossRef] [PubMed]
- Scharenborg, Odette, and Marjolein van Os. 2019. Why listening in background noise is harder in a non-native language than in a native language: A review. Speech Communication 108: 53–64. [Google Scholar] [CrossRef]
- Scharenborg, Odette, Juul M. J. Coumans, and Roeland van Hout. 2018. The effect of background noise on the word activation process in nonnative spoken-word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition 44: 233–49. [Google Scholar] [CrossRef]
- Silva-Corvalán, Carmen, and Jeanine Treffers-Daller. 2016. Digging into dominance: A closer look at language dominance in bilinguals. In Language Dominance in Bilinguals. Issues of Measurement and Operationalization. Edited by Carmen Silva-Corvalán and Jeanine Treffers-Daller. Cambridge: Cambridge University Press, pp. 1–14. [Google Scholar] [CrossRef]
- Van Engen, Kristin J. 2010. Similarity and familiarity: Second language sentence recognition in first- and second-language multi-talker babble. Speech Communication 52: 943–53. [Google Scholar] [CrossRef]
- Van Engen, Kristin J., and Ann R. Bradlow. 2007. Sentence recognition in native- and foreign-language multi-talker background noise. Journal of the Acoustic Society of America 121: 519–26. [Google Scholar] [CrossRef]
- Wlotko, Edward W., and Kara D. Federmeier. 2015. Time for prediction? The effect of presentation rate on predictive sentence comprehension during word-by-word reading. Cortex 68: 20–32. [Google Scholar] [CrossRef] [Green Version]
- Woods, Kevin J. P., Max H. Siegel, James Traer, and Josh H. McDermott. 2017. Headphone screening to facilitate web-based auditory experiments. Attention, Perception, & Psychophysics 79: 2064–72. [Google Scholar] [CrossRef]
- Zirnstein, Megan, Janet G. van Hell, and Judith F. Kroll. 2018. Cognitive control ability mediates prediction costs in monolinguals and bilinguals. Cognition 176: 87–106. [Google Scholar] [CrossRef] [PubMed]
- Zirnstein, Megan, Janet G. van Hell, and Judith F. Kroll. 2019. Cognitive control and language ability contribute to online reading comprehension: Implications for older adult bilinguals. International Journal of Bilingualism 23: 971–85. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Heritage Spa | L2 Spa | |||
|---|---|---|---|---|
| N (n female) | 15 (6 F) | 16 (13 F) | ||
| Age (SD) | 25.2 (4.3) | 28.6 (4.7) | ||
| Eng | Spa | Eng | Spa | |
| Oral comprehension, self-rating (SD) | 10.0 (0.0) | 9.1 (1.0) | 10.0 (0.0) | 7.6 (2.1) |
| Speaking ability, self-rating (SD) | 9.9 (0.5) | 7.4 (1.5) | 10.0 (0.0) | 6.6 (2.0) |
| Reading ability, self-rating (SD) | 9.9 (0.3) | 6.7 (2.7) | 10.0 (0.0) | 7.8 (2.1) |
| % daily exposure (SD) | 71% (15%) | 23% (13%) | 84% (15%) | 15% (15%) |
| Age began acquiring (SD) | 2.2 (2.2) | 0.5 (1.0) | 0.2 (0.5) | 14.2 (4.9) |
| Age became fluent (SD) | 5.5 (3.3) | 10.8 (7.1) | 4.8 (3.8) | 22.2 (4.3) |
| LexTALE (SD) | 0.90 (7%) | 0.71 (15%) | 0.95 (7%) | 0.61 (7%) |
| AY Trials Accuracy, % (SD) | 86% (15%) | 86% (15%) | ||
| AY Trials RT, ms (SD) | 574 (178) | 571 (173) | ||
| Fixed Effect Estimates | ||||
|---|---|---|---|---|
| Coefficient | Odds Ratio | SE | CI (95%) | p |
| Intercept (=low Predictability) | 1.85 | 0.24 | 1.44–2.39 | <0.001 |
| Group | 0.64 | 0.16 | 0.38–1.05 | 0.079 |
| Predictability [high] | 0.71 | 0.06 | 0.60–0.83 | <0.001 |
| Block c1 (S2TB vs. E2TB) | 0.72 | 0.05 | 0.63–0.83 | <0.001 |
| Block c2 (SSN vs. 2TB avg) | 1.24 | 0.05 | 1.14–1.35 | <0.001 |
| Group * Predictability [high] | 0.63 | 0.10 | 0.46–0.87 | 0.005 |
| Group * Block c1 | 0.93 | 0.13 | 0.70–1.23 | 0.601 |
| Group * Block c2 | 1.14 | 0.10 | 0.96–1.35 | 0.123 |
| Predictability [high] * Block c1 (S2TB vs. E2TB) | 1.14 | 0.11 | 0.93–1.38 | 0.200 |
| Predictability [high] * Block c2 (SSN vs. 2TB avg) | 0.88 | 0.05 | 0.78–0.99 | 0.030 |
| Group * Predictability [high] * Block c1 | 1.00 | 0.20 | 0.67–1.48 | 0.994 |
| Group * Predictability [high] * Block c2 | 0.93 | 0.11 | 0.74–1.18 | 0.567 |
| Random Effects | ||||
| σ2 | 3.29 | |||
| τ00 Participant | 0.41 | |||
| N Participant | 31 | |||
| Observations | 2790 | |||
| Marginal R2/Conditional R2 | 0.066/0.169 | |||
| Fixed Effect Estimates | ||||
|---|---|---|---|---|
| Coefficient | Estimate | SE | CI (95%) | p |
| Intercept (=low Predictability) | 0.24 | 0.10 | 0.05–0.44 | 0.015 |
| Target Duration | 0.02 | 0.03 | −0.04–0.08 | 0.555 |
| Group | −0.03 | 0.19 | −0.42–0.35 | 0.858 |
| Predictability [high] | −0.08 | 0.04 | −0.16–−0.01 | 0.031 |
| Target Duration * Predictability [high] | 0.11 | 0.04 | 0.04–0.18 | 0.002 |
| Block c1 (Clear vs. All Noise) | −0.57 | 0.07 | −0.69–−0.44 | <0.001 |
| Block c2 (SSN vs. 2TB avg) | 0.39 | 0.11 | 0.17–0.61 | 0.001 |
| Block c3 (S2TB vs. E2TB) | 0.01 | 0.08 | −0.15–0.17 | 0.898 |
| Predictability [high] * Group | 0.19 | 0.08 | 0.03–0.34 | 0.016 |
| Group * Block c1 | 0.12 | 0.12 | −0.11–0.36 | 0.302 |
| Group * Block c2 | −0.34 | 0.21 | −0.76–0.08 | 0.111 |
| Group * Block c3 | 0.24 | 0.16 | −0.08–0.56 | 0.134 |
| Predictability [high] * Block c1 | −0.17 | 0.07 | −0.31–−0.03 | 0.021 |
| Predictability [high] * Block c2 | −0.08 | 0.11 | −0.29–0.13 | 0.450 |
| Predictability [high] * Block c3 | −0.06 | 0.11 | −0.29–0.16 | 0.581 |
| Predictability [high] * Group * Block c1 | 0.03 | 0.14 | −0.24–0.31 | 0.812 |
| Predictability [high] * Group * Block c2 | 0.05 | 0.21 | −0.37–0.47 | 0.826 |
| Predictability [high] * Group * Block c3 | −0.31 | 0.22 | −0.75–0.13 | 0.167 |
| Random Effects | ||||
| σ2 | 0.57 | |||
| τ00 TargetWord | 0.04 | |||
| τ00 Participant | 0.27 | |||
| τ11 Participant.Blockc1 | 0.03 | |||
| τ11 Participant.Blockc2 | 0.14 | |||
| τ11 Participant.Blockc3 | 0.01 | |||
| ρ01 Participant.Blockc1 | 0.59 | |||
| ρ01 Participant.Blockc2 | 0.30 | |||
| ρ01 Participant.Blockc3 | 0.11 | |||
| N Participant | 31 | |||
| N TargetWord | 120 | |||
| Observations | 1927 | |||
| Marginal R2/Conditional R2 | 0.128/0.461 | |||
| Errors | Reaction Times (ms) | |||||
|---|---|---|---|---|---|---|
| Total | Heritage | L2 | Total | Heritage | L2 | |
| AX-CPT Condition | ||||||
| AX | 0.049 (0.004) | 0.049 (0.003) | 0.049 (0.005) | 439 (155) | 477 (197) | 405 (101) |
| AY | 0.054 (0.008) | 0.053 (0.008) | 0.055 (0.008) | 572 (172) | 573 (178) | 571 (173) |
| BX | 0.050 (0.007) | 0.051 (0.008) | 0.049 (0.002) | 380 (170) | 419 (207) | 343 (121) |
| BY | 0.047 (0.001) | 0.046 (0.000) | 0.048 (0.001) | 396 (187) | 430 (241) | 364 (119) |
| Fixed Effect Estimates | ||||
|---|---|---|---|---|
| Coefficient | Estimate | SE | CI (95%) | p |
| Intercept (=low Predictability) | 0.22 | 0.09 | 0.03–0.40 | 0.023 |
| Target Duration | 0.02 | 0.03 | −0.04–0.08 | 0.522 |
| Group | −0.18 | 0.20 | −0.56–0.21 | 0.369 |
| Predictability [high] | −0.09 | 0.04 | −0.17–−0.02 | 0.018 |
| AY Trials RT | 0.12 | 0.09 | −0.06–0.29 | 0.189 |
| Spa LexTALE | −0.21 | 0.10 | −0.40–−0.01 | 0.038 |
| Target Duration * Predictability [high] | 0.11 | 0.04 | 0.04–0.19 | 0.002 |
| Block c1 (Clear vs. All Noise) | −0.59 | 0.06 | −0.70–−0.47 | <0.001 |
| Block c2 (SSN vs. 2TB avg) | 0.42 | 0.09 | 0.24–0.60 | <0.001 |
| Block c3 (S2TB vs. E2TB) | −0.03 | 0.08 | −0.20–0.13 | 0.695 |
| Predictability [high] * Group | 0.20 | 0.07 | 0.06–0.34 | 0.005 |
| Group * Block c1 | 0.08 | 0.08 | −0.08–0.24 | 0.333 |
| Group * Block c2 (SSN vs. 2TB avg) | −0.50 | 0.12 | −0.74–−0.25 | <0.001 |
| Group * Block c3 | −0.01 | 0.13 | −0.27–0.25 | 0.958 |
| Predictability [high] * Block c1 (Clear vs. All Noise) | −0.15 | 0.07 | −0.30–−0.01 | 0.040 |
| Predictability [high] * Block c2 | −0.13 | 0.11 | −0.35–0.09 | 0.244 |
| Predictability [high] * Block c3 | −0.01 | 0.12 | −0.24–0.21 | 0.910 |
| Block c1 * AY Trials RT | 0.07 | 0.04 | −0.00–0.15 | 0.060 |
| Block c2 * AY Trials RT | −0.06 | 0.06 | −0.18–0.05 | 0.256 |
| Block c3 * AY Trials RT (S2TB vs. E2TB) | −0.18 | 0.06 | −0.29–−0.06 | 0.003 |
| Block c1 * Spa LexTALE | −0.07 | 0.04 | −0.15–0.01 | 0.071 |
| Block c2 * Spa LexTALE (SSN vs. 2TB avg) | −0.19 | 0.06 | −0.31–−0.07 | 0.002 |
| Block c3 * Spa LexTALE | −0.07 | 0.06 | −0.20–0.05 | 0.268 |
| Random Effects | ||||
| σ2 | 0.58 | |||
| τ00 TargetWord | 0.04 | |||
| τ00 Participant | 0.23 | |||
| N Participant | 30 | |||
| N TargetWord | 120 | |||
| Observations | 1841 | |||
| Marginal R2/Conditional R2 | 0.185/0.441 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fricke, M.; Zirnstein, M. Predictive Processing and Inhibitory Control Drive Semantic Enhancements for Non-Dominant Language Word Recognition in Noise. Languages 2022, 7, 239. https://doi.org/10.3390/languages7030239
Fricke M, Zirnstein M. Predictive Processing and Inhibitory Control Drive Semantic Enhancements for Non-Dominant Language Word Recognition in Noise. Languages. 2022; 7(3):239. https://doi.org/10.3390/languages7030239
Chicago/Turabian StyleFricke, Melinda, and Megan Zirnstein. 2022. "Predictive Processing and Inhibitory Control Drive Semantic Enhancements for Non-Dominant Language Word Recognition in Noise" Languages 7, no. 3: 239. https://doi.org/10.3390/languages7030239
APA StyleFricke, M., & Zirnstein, M. (2022). Predictive Processing and Inhibitory Control Drive Semantic Enhancements for Non-Dominant Language Word Recognition in Noise. Languages, 7(3), 239. https://doi.org/10.3390/languages7030239