1. Introduction
Current mainstream linguistic theory has been built upon language data obtained from native speakers of a large sample of the world’s diverse languages. What is often overlooked, however, is that most people in the world speak more than one language, and that such speakers often combine elements from both of their languages within a single utterance, and sometimes even within a single word. This type of language mixing is spontaneous in that it is not possible to predict when a switch or insertion will occur; however, it is also highly constrained (
Lipski 1978;
Pfaff 1979;
Poplack 1980;
Woolford 1983).
1 Considerable research has consequently been dedicated to understanding the formal linguistic principles that underlie such language mixing (e.g.,
Poplack 1980,
1981;
Sankoff and Poplack 1981;
Joshi 1985;
Di Sciullo et al. 1986;
Mahootian 1993;
Belazi et al. 1994;
MacSwan 2000;
Liceras et al. 2008).
Within the framework of the minimalist program (
Chomsky 1993,
1995,
2005), a productive line of research has assumed that the principles that govern bilingual language mixing are the same as those that govern monolingual unmixed language; that there should be no specific constraints that apply only to language mixing (
MacSwan 2000). For example, if linguistic competence involves choosing and combining lexical items via operations such as select and merge to form convergent syntactic derivations, then the simple difference between unilingual unmixed language and bilingual mixed language is that the latter operates over lexical items from two languages rather than one. Consequently, mixed-language data can provide a unique testing ground for linguistic theory and, in turn, it can offer important insights into the nature of the underlying linguistic system(s) a bilingual has acquired.
While investigations within this line of research have often taken a lexicalist view of morphosyntax (e.g.,
Cantone and Müller 2008;
van Gelderen and MacSwan 2008;
Van Dulm 2009;
Moro Quintanilla 2014), other researchers (e.g.,
González-Vilbazo and López 2011;
Grimstad et al. 2014;
Alexiadou et al. 2015;
Riksem 2017) have also been exploring the predictions and explanatory power of non-lexicalist frameworks such as Distributed Morphology (DM;
Halle and Marantz 1993;
Marantz 1997;
Embick and Noyer 2007). As such, the first goal of this paper is to focus on a particular language mixing pattern that has been reported in the literature, and to re-examine it within the theoretical framework of DM. Specifically, the object of investigation is a fairly robust asymmetry whereby switches between a Spanish determiner (D) and an English noun (N), such as (1a), are considered to be grammatical, but those between an English D and a Spanish N, as in (1b), are not (
Jake et al. 2005;
MacSwan 2005;
Liceras et al. 2008,
2016).
2| 1. | a. | la | house |
| | | the.DF.SG.F | house |
| | | | |
| | b. | * the | casa |
| | | the.DF | house |
In previous minimalist accounts of this asymmetry, some have argued that it is a consequence of an underlying asymmetry in the morphosyntactic features of the two languages; specifically, that Spanish has grammatical gender features whereas English does not (e.g.,
MacSwan 2005;
Liceras et al. 2008;
Moro Quintanilla 2014). While the account that will be proposed here also attributes a central role to the gender feature asymmetry, it will be argued that it is the relationship between gender and nominal declension classes in Spanish that is the true source. Interestingly, the proposed theoretical account makes the prediction that not all language pairs with a gender feature asymmetry will exhibit a mixed determiner phrase (DP) asymmetry. It will be argued that this is the case for French–English.
It is important to note that this account will assume that the bilinguals in question have the same underlying linguistic system in their two languages as do monolingual native speakers of each of their respective languages. Indeed, this may be the case for individuals who acquired both of their languages from birth, and who are perfectly balanced with respect to proficiency and frequency of use.
3 An important issue with this assumption, however, is that most bilinguals do not fit these “ideal” characteristics. As such, the theoretical proposal will also be discussed with respect to the different predictions it makes for bilinguals who have acquired their two languages under different learning conditions (e.g., simultaneous versus late sequential bilinguals). The second goal of this paper is then to present an experiment investigating some of these predictions for French–English mixed DPs. Experimental data, however, are not directly reflective of a bilingual’s underlying linguistic competence, but may also reflect performance factors related to language processing. For bilinguals, the relative ease with which they process and access words from their two languages can depend on external factors such as language proficiency and dominance (i.e., whether they use one language preferentially). As such, the impact of these factors will also be taken into consideration when forming hypotheses.
The remainder of this paper will be organized as follows.
Section 2 will provide the necessary background, including a more detailed look at the mixed DP asymmetry in Spanish–English (2.1), a brief overview of the DM framework (2.2), and the particular view on gender that will adopted (2.3). This view will be demonstrated in the context of unmixed Spanish DPs. In
Section 3, this framework will be extended to account for Spanish–English mixed DPs (3.1), and to make predictions for French–English mixed DPs (3.2). This proposal will then be discussed with respect to the predictions that such a model makes for bilinguals with a late age of acquisition (3.3), and with respect to how language proficiency and language dominance might influence the patterns observed in actual mixed-language data (3.4).
Section 4 will then present the details of an experimental study designed to test the predictions made for different types of French–English bilinguals. Results will be presented in
Section 5 and discussed in
Section 6.
Section 7 will conclude.
3. Proposed Distributed Morphology Account of Mixed Determiner Phrases
Extending the DM model to language mixing in general, we can make the following two assumptions. First, it will be assumed that bilinguals have functionally separate distributed lexicons, such that in unilingual language mode they can access the set of lists associated to one language with limited interference from the other.
10 Second, during language mixing, neither language is inhibited. As such, List 1 elements from either language can be selected into the numeration, and List 2 VIs from both languages can compete for insertion after spell-out.
By applying these assumptions to the above account for unmixed Spanish DPs, an analysis for Spanish–English mixed DPs can now be proposed. This will then be extended to make predictions for French–English. As mentioned in the introduction, this proposal will assume that the bilinguals in question have “perfect” competence in each of their two languages. It will also assume that their innate knowledge is reflected in mixed language data. As such, the discussion of the theoretical proposal will focus on the impact that age of acquisition (AoA) and factors related to language processing may have on the expected patterns.
3.1. Analysis for Spanish–English
With respect to the specific structure involved in DPs, it will be assumed that English differs from Spanish in two relevant ways. First, because English has no grammatical gender system, it has only a plain n, and the definite determiner, the, has only a [DF] feature. Second, like established loanwords in Spanish, it will be assumed that English nominal roots are free, not bound.
3.1.1. The Mixed Determiner Phrase Asymmetry
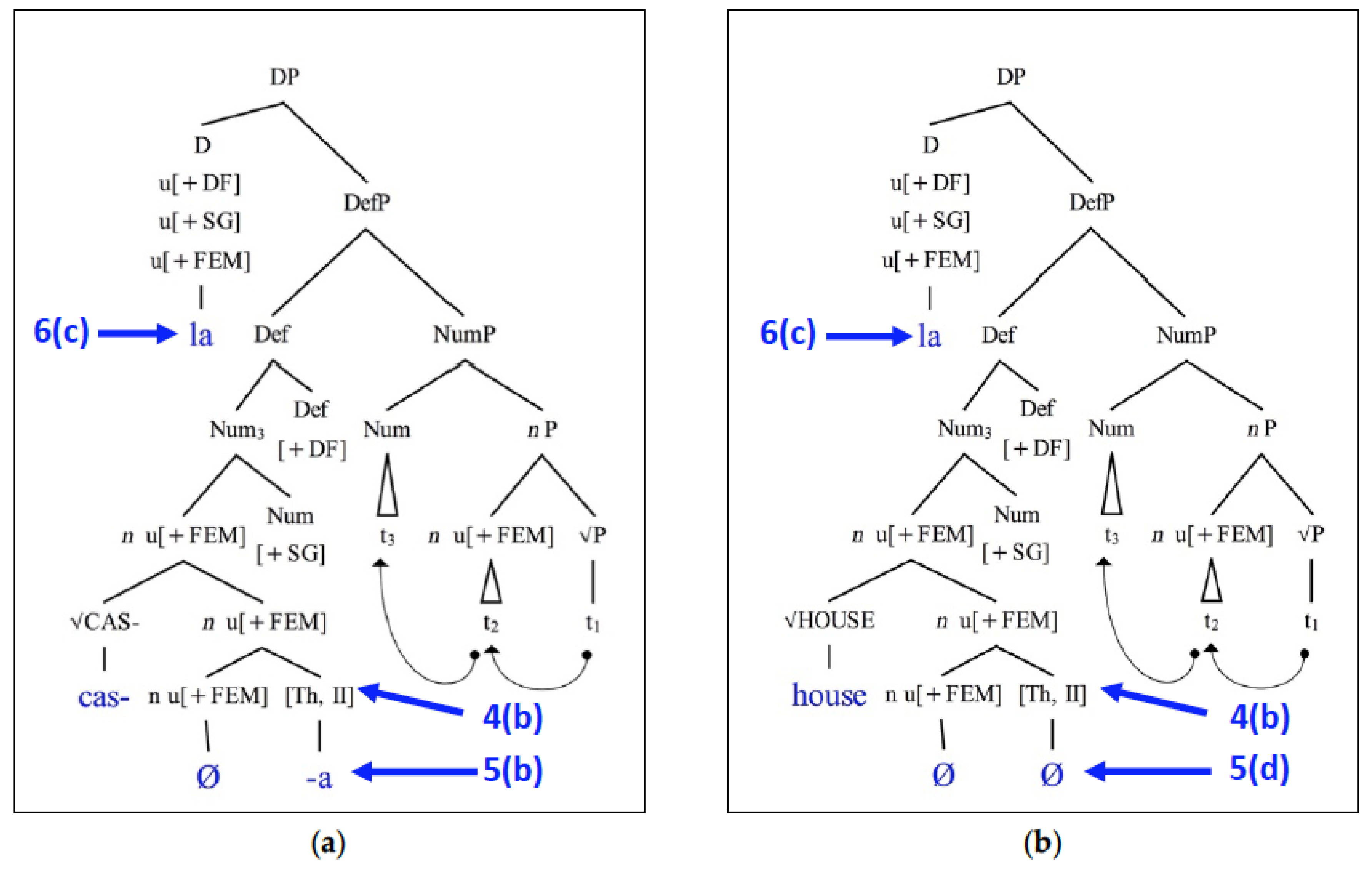
Looking first at how mixed DPs such as
la house are derived,
Figure 1b shows that when an English root merges with a Spanish
n, this operates in exactly the same way as with unmixed Spanish DPs. The crucial difference occurs during vocabulary insertion. Because the theme node is not right adjacent to a bound root in this case, rule (5d) applies, and no theme vowel is inserted. Because D values its uninterpretable ϕ-features (PERSON, NUMBER and GENDER) against a feature bundle containing a feminine gender feature, the Spanish determiner
la (6c) wins the competition for insertion, resulting in
la house. Note that an important question in this case is whether an English root will merge an
n with the
u[+FEM] feature or that with the
u[-FEM] feature. This will be addressed below in
Section 3.1.2.
We turn now to the case of the casa, where a Spanish root merges with an English n. Because n has no gender feature, theme node insertion rule (4d) applies and so nothing is inserted. As such, the bound root cannot get a theme vowel to complete its phonological form. In order to get a theme node inserted and thus a theme vowel, the Spanish root has to merge with a Spanish n with a gender feature; however, if that is the case, then the D terminal node will also have a feminine feature by virtue of agree, and so the feminine Spanish determiner la (6c) is the VI that wins the competition for insertion, not the (6f). As such, the casa is blocked via the subset principle.
| 6. | List 2 VIs for Spanish (a–e) and English (f) competing for D[DF.SG.F] |
| | a. | F.PL.DF | → | las |
| | b. | PL.DF | → | los |
| | c. | F.DF | → | la |
| | d. | M.DF | → | el |
| | e. | DF | → | lo |
| | f. | DF | → | the |
It is therefore not so much the case that mixed DPs consisting of an English D and a Spanish N violate any morphosyntactic requirements of the computational system. Rather, they are blocked by the availability of a more highly specified Spanish VI. Interestingly, such an account is not incompatible with the grammatical features spell-out hypothesis of
Liceras et al. (
2008), which also assigns a preference to the more grammaticalized functional element, but leaves room for the acceptability of the less grammaticalized option (the English D) in situations where it is more efficient with respect to processing resources.
3.1.2. The Analogical Criterion
As it is assumed that Spanish has two possible ns, (nu[-FEM]/nu[+FEM]), there is an option with respect to which Spanish n an English root will be licensed under in mixed DPs. Indeed, there are three possible outcomes for root licensing. First, it could be entirely arbitrary; because such English roots are combined spontaneously with Spanish elements and not repeatedly, it is unlikely that licensing conditions exist for these roots in the same way that they do for Spanish roots, whose licensing conditions would have been established during lexical acquisition via cues in the input. This would predict that all the options presented in (7) would be equally acceptable. Second, there could be a preference for licensing all English roots under the nu[-FEM] by default, leading to preferences for (7b) and (7d). Finally, there could be a preference for licensing English roots under the n of their translation equivalent, leading to preferences for (7a) and (7d).
| 7. | a. | la | house |
| | | the.DF.F | house (c.f. house = casa.F) |
| | | | |
| | b. | el | house |
| | | the.DF.M | house |
| | | | |
| | c. | la | book |
| | | the.DF.F | book (c.f. book = libro.M) |
| | | | |
| | d. | el | book |
| | | the.DF.M | book |
This third option is known as the “analogical criterion”, and
Liceras et al. (
2008) found strong evidence for this with the L1-Spanish L2-English sequential bilinguals that they tested using an acceptability judgment task. Data from the corpora, however, suggest that the analogical criterion may be more of a tendency than a rule. For example, in the Spanish–English corpus-based studies presented in
Table 1, it is clear that an English N with a masculine translation equivalent almost categorically appeared with a masculine Spanish D; whereas an English N with a feminine translation equivalent had considerably more optionality in terms of the gender of the Spanish D with which it appeared. This suggests that, in production, analogical gender is applied to all English Ns if it can be easily retrieved from memory. If it is not retrieved, then masculine gender is applied as default.
11Experimental results from a study employing eye-tracking with the visual world paradigm support this pattern.
Kroff et al. (
2016) found that lexical access to English Ns with a feminine Spanish translation was facilitated by the presence of a feminine D, indicating that this was a useful cue during comprehension. This could be because feminine Ds rarely co-occur in the input with English Ns that have a masculine translation (i.e., only about 3–4%). On the other hand, they found that lexical access to English Ns that have a masculine translation was not facilitated by the presence of a masculine D, suggesting that the masculine D is not a useful cue. Again, this is perhaps because masculine Ds co-occur in the input with English Ns that have either a masculine translation (96–97%) or a feminine translation (22–81%), which appears to be due to the default masculine status.
3.2. Predictions for French–English
French and Spanish have very similar gender systems, with two grammatical genders, masculine and feminine, that are assigned arbitrarily to inanimate nouns. It will therefore be assumed that inanimate roots in French are also licensed under either nu[+FEM] or nu[-FEM]. Unlike Spanish, however, French has no declension class suffixes. As such, roots in French are typically free as opposed to bound. While French has both feminine and masculine singular definite determiners, as does Spanish, there are some differences with respect to the VIs that French–English bilinguals have available for insertion into D, as shown in (8). Importantly, the feature specification of le (8c) is the same as that of the (8d), because unlike in Spanish, there is no other gender-unspecified determiner (i.e., Spanish lo). These properties of French sometimes lead to different predictions with respect to the mixed DP asymmetry and the analogical criterion.
| 8. | List 2 VIs for French (a–c) and English (d) competing for D[DF.SG.F] |
| | a. | PL.DF | → | les |
| | b. | F.DF | → | la |
| | c. | DF | → | le |
| | d. | DF | → | the |
3.2.1. The Mixed Determiner Phrase Asymmetry
Since French nouns do not have obligatory affixes that are dependent on a gender feature (c.f. declension class suffixes in Spanish), this means that there is nothing prohibiting French roots from combining with a genderless English n. As such, one of the main predicted differences between French–English and Spanish–English mixed DPs is that combinations of an English D and a French N, as in (9a), are expected to be grammatical, as well as those involving a French D and an English N, as in (9b). In other words, no mixed DP asymmetry is expected.
In support of this prediction is data from a Norwegian–English mixed language corpus (
Alexiadou et al. 2015;
Riksem 2017), which suggest that the mixed DP asymmetry is not present in this language pair despite their having a similar underlying gender feature asymmetry; both DPs in (10) are attested (see (
Burkholder et al. 2017) for more details). Importantly, Norwegian roots, like French roots and unlike Spanish roots, are free.
12| 9. | a. | the | maison |
| | | the.DF | house |
| | | | |
| | b. | la | house |
| | | the.DF.F | house |
| 10. | a. | det | andre | crew-et |
| | | the.DF.N | other | crew-DF.SG.N |
| | | | | |
| | b. | the | by | |
| | | the.DF | city | |
3.2.2. The Analogical Criterion
Because it is assumed that French and Spanish have
ns with the same gender features (
nu[-FEM]/nu[+FEM]), this leads to the prediction that French–English, like Spanish–English, has an option with respect to which French
n an English root will be licensed under in mixed DPs. There is indeed evidence of this from French–English corpus data (
Poplack et al. 1982). After controlling for biological gender, it was determined that 78% of English Ns with masculine translation equivalents took analogical gender (e.g., 11d), compared to only 42% of those with feminine translation equivalents (e.g., 11a). While this pattern is very similar to what they found in the Spanish–English corpora (see
Table 1), it is notable that the application of analogical gender for masculine Ns was not as categorical in this French–English corpus. The authors note that this increased variability could be due to a higher number of cases where it was unclear to them which analogical gender should be assigned, which may have been partly related to their own lesser familiarity with French compared to Spanish.
| 11. | a. | la | house |
| | | the.DF.F | house (c.f. house = maison.F) |
| | | | |
| | b. | le | house |
| | | the.DF.M | house |
| | | | |
| | c. | la | sun |
| | | the.DF.F | sun (c.f. sun = soleil.M) |
| | | | |
| | d. | le | sun |
| | | the.DF.M | sun |
There is also evidence that L1-French speakers may apply different strategies than L1-Spanish speakers with respect to the analogical criterion. While
Liceras et al. (
2008) found strong evidence for the analogical criterion with their L1-Spanish L2-English sequential bilinguals, they found that L1-French L2-Spanish bilinguals (with English as a second L1) tended to prefer applying masculine as default, at least in Spanish–English mixed DPs.
3.3. Impact of Age of Acquisition
The DM-based analysis suggests that there may be different mixed DP patterns for simultaneous versus late sequential bilingual acquisition. For bilinguals acquiring two L1s simultaneously, it could be expected that new Spanish/French roots encountered in nominal contexts would become licensed under the appropriate gender-bearing
n (either
nu[+FEM] or
nu[-FEM]), whereas new English roots would become licensed under the plain
n. As such, in language mixing contexts, both gender-bearing
ns and the plain
n would be available to these bilinguals when selecting the numeration. This is what has been assumed in the above theoretical analyses. In contrast, if it is assumed that after a particular age, functional features not present in the L1 are no longer available to L2 learners (e.g.,
Hawkins and Chan 1997), then it is possible that late L2 learners may not have all three
ns in their repertoire.
For late L1-Spanish/L1-French L2-English bilinguals, this may mean that they do not have a plain n. If so, this predicts that both English and French/Spanish roots can only merge with a gender-bearing n. This has several possible consequences.
First, in Spanish–English mixed DPs, when Spanish roots merge with a plain English
n, this already creates issues due to declension classes. As such, not having an English
n in the repertoire of abstract morphemes does not change anything for Spanish roots. On the other hand, this possibility would mean that English roots (e.g., √HOUSE) appearing in Spanish–English mixed language contexts would always have to merge with either
nu[+FEM] or
nu[-FEM]. This predicts that such English Ns should only appear with Spanish Ds. This is because
el and
la are both more specified than
the, meaning that they would be preferentially chosen at vocabulary insertion if available, as per the subset principle.
13 There is actually good evidence for this prediction. In the Spanish–English corpora presented in
Table 1, full English DPs (e.g.,
the book) are extremely rare compared to those consisting of a Spanish D and an English N (e.g.,
el book).
Second, for DPs with French roots appearing in mixed language contexts, not having a plain English n could mean that D will always have a gender feature obtained from agreeing with a gender-bearing French n. As such, mixed DPs with a feminine noun, such as the maison, should be blocked in favour of unmixed DPs, such as la maison, because the more specified French VI la (8b) will always win over the English the (8d). However, because le (8c) has the same specification as the (8d), optionality is expected for mixed DPs such as the soleil and unmixed DPs such as le soleil (11a). In other words, a partial mixed DP asymmetry would actually be expected for a group of late L1-French L2-English bilinguals, whereby only feminine French Ns cannot appear with English Ds.
Finally, for English roots appearing in French–English mixed language contexts, no preference would be expected for a French D to be inserted. Consequently, full English DPs would be considered acceptable, unlike in Spanish–English. This is because the is assumed to have the same feature specification as le, and because English roots can be merged with nu[-FEM] by default regardless of the gender of its translation.
With respect to late L1-English L2-French/L2-Spanish bilinguals, they may not have gendered
ns in their repertoire of functional features. These bilinguals would also not likely have any gender features specified on the VIs for determiners, and therefore Spanish
la and
el, as well as French
la and
le, would all have the same feature specifications as English
the.
14 This would predict that, in mixed language contexts, English roots would be acceptable with all three of the available determiners, and as such, there would be considerable optionality. This prediction is consistent with the acceptability judgment data for L1-English L2-Spanish bilinguals presented by
Liceras et al. (
2008), which indicated that English nouns were found to be equally acceptable with either Spanish determiner, regardless of the gender of the noun’s Spanish translation equivalent.
For such late L1-English bilinguals, it would also be expected that they would not represent Spanish declension classes in the same way as L1-Spanish speakers, because they would not have the gendered
ns on which declension class suffixes are dependent. As such, this also predicts that such bilinguals would not display mixed DP asymmetry. Indeed, the L1-English bilinguals in the
Liceras et al. (
2008) study show a strong preference for mixed DPs consisting of an English D and a Spanish N (e.g.,
the casa) over those consisting of a Spanish D and an English N (e.g.,
la house), and rated them considerably higher than the L1-Spanish group.
3.4. Effects of Language Dominance and Proficiency on Processing
Experimental data collected using methods other than acceptability judgment tasks have actually found that there may be greater language switch costs associated with mixed DPs such as
la house, for example using a picture naming task (
Fairchild and Van Hell 2017), self-paced reading (
Litcofsky and Van Hell 2017), as well as event-related potentials combined with rapid serial visual presentation (idem.). In Fairchild and Van Hell’s picture naming task, it was proposed that this cost was associated with difficulty retrieving the appropriate gender-marked Spanish D rather from difficulty retrieving the English N, as even though participants were L1-Spanish, they were currently dominant in English. They hypothesize that balanced or Spanish-dominant bilinguals might not exhibit the same processing asymmetry. However, in the experiments conducted by
Litcofsky and Van Hell (
2017), also with L1-Spanish L2-English bilinguals, they found that that switch costs were related to language dominance such that they were greater in the dominant-to-weak direction, regardless of the L1. In other words, it was Spanish-dominant bilinguals who had greater processing costs when reading mixed DPs such as
la house. This is what was found in the Fairchild and Van Hell study for English-dominant bilinguals. These different results could reflect the fact that the former study tested production, while the latter tested reading.
Relative language proficiency may also impact the extent to which the analogical criterion is applied in language use. In order for an English noun to surface with the gender of its translation equivalent, the mental representation of that translation must be accessed from memory. The ease with which this is done may depend on the way in which translations are stored, which may in turn depend on the bilingual’s language proficiency. For example, one of the most prominent models of the bilingual mental lexicon,
Kroll and Stewart’s (
1994) revised hierarchical model (RHM), suggests that L1 words are learned in direct association with their concepts, whereas L2 words (i.e., in sequential L2 acquisition) tend to be learned by directly associating them to their L1 translation. As such, L2 links to concepts are only indirect, mediated through the L1. As learners become more proficient in their L2, the direct links between L2 words and concepts become stronger. Assuming this type of psycholinguistic model, it is possible that unbalanced sequential bilinguals who have these strong lexical links between L2 and L1 words might have a stronger tendency to transfer the licensing conditions of the L1 (French or Spanish) root to that of the L2 (English) root than would balanced simultaneous bilinguals who do not have such strong associations between L2 and L1 lexical representations.
The following section presents a study designed to test some of the predictions and issues presented in the previous sections. Two primary research questions are addressed: first, whether there is evidence of a French–English mixed DP asymmetry; and second, how the analogical criterion is applied in mixed DPs with an English lexical root. In particular, the impact of language background factors such as AoA and language dominance will be investigated by comparing the results of simultaneous bilinguals to those of late sequential L1-French L2-English bilinguals. The specific hypotheses will be presented in
Section 4.4.
4. Methods and Materials
The experiment combines two methodologies: an acceptability judgment task (AJT) and self-paced reading (SPR). The SPR paradigm was chosen as it was expected to elicit more implicit grammaticality assessments of targeted structures. This paradigm is typically used to measure the processing load of words during reading comprehension, where reading times (RTs) are correlated with lexical properties such as frequency and word length (
Haberlandt 1994). Importantly, the processing load can also be increased due to the presence of a morphosyntactic violation (e.g., subject–verb agreement error). Indeed, previous studies using this methodology have demonstrated that morphosyntactic violations lead to increased RTs at the point of the anomaly (e.g.,
De Vincenzi et al. 2003). This effect has also been correlated with the P600 event-related potential (ERP) component, which indexes morphosyntactic violations (
Ditman et al. 2007). In the context of language mixing, it is expected that RTs in an SPR will be longer at points of illicit or less preferred switches between languages. Increased RTs, however, may also reflect increased processing effort due to factors other than the implicit detection of grammatical anomalies. For example, it could be more costly to switch to a less activated language (
Litcofsky and Van Hell 2017). Having participants also judge the acceptability of each sentence allows for the results of two dependent measures to be directly compared, and for the results of this study to be more easily related to those of previous studies that employed an AJT.
4.1. Participants
A total of 49 French–English bilinguals participated in this study. Of these, 10 were excluded for the following reasons: (1) not being a native speaker of just French, or French and English; (2) having early exposure to a language other than French or English; (3) having a high level of proficiency in a language other than French or English; and (4) not being a self-described language mixer.
15 This was determined by their responses to a detailed language background questionnaire (
Sabourin et al. 2016) and a language-mixing questionnaire (adapted from (
Byers-Heinlein 2013)). One additional participant was later excluded for rating sentences significantly lower than all other participants (see
Section 5). The remaining 38 participants (30 female) were all between the ages of 18 and 35 (mean = 20.5, SD = 4.1). They were divided into groups based on their age of immersion (AoI) in English, which was operationalized at the age at which their daily exposure to English reached 20%.
Table 2 shows the linguistic profiles of each of the three resulting groups: simultaneous bilinguals (AoI = 0), early L2 learners (AoI < 7), and late L2 learners (AoI > 7).
4.2. Stimuli
4.2.1. Critical Stimuli
Forty-eight nouns were selected to form part of the critical DPs. All were mono-morphemic and commonly known non-cognates, and approximately half had feminine gender in French (23/48). Nouns beginning with vowels were generally excluded in order to avoid élision between the definite determiner and the noun, which neutralizes the overtly marked gender of the determiner. No established loan words (such as the English words
job, fun, which are commonly used in French) were included. The properties of these critical nouns in both languages are compared in
Table 3.
A two-way repeated measures analysis of variance (ANOVA) was conducted for both word frequency and word length, using Language (English vs. French) as the within-item independent variable, and Gender (masculine vs. feminine) as the between-item independent variable. For word frequency, there were no significant main effects or interaction, indicating that word frequency was matched across language and gender. In terms of word length, neither Gender nor the interaction between Language and Gender were determined to be significant; however, the main effect of Language was determined to be significant (F(1,46) = 10.497, MSE = 10.109, p = 0.002), indicating that French nouns were significantly longer on average than English nouns overall. Little impact, however, is expected, as the magnitude of the difference is quite small (0.7 graphemes), and the words in French and English are all relatively short (both have a maximum of seven graphemes).
To create the critical DPs, nearly all of these nouns were paired with a singular definite determiner (43/48). The remaining five appeared with a singular indefinite determiner, either due to a better fit with the sentence context, or to avoid élision, as mentioned above. No differences were expected between the results for definite and indefinite determiners, as their features are comparable in both languages. One sentence was created for each of the 48 critical DPs, and three dependent variables were manipulated in order to produce six conditions for each sentence (see
Table 4 for an example and the
Supplementary Materials for a complete list). First, the language of the determiner in the critical DP was either French or English. Second, the language of the noun was either the same as the determiner (unmixed DP), or the opposite (mixed DP). Finally, for conditions with French determiners, the gender of the determiner either matched or mismatched the gender of the noun or its translation equivalent. Sentences were also coded for the gender of the noun or its translation equivalent.
The critical DP was always the third DP of the sentence, where the first was a language neutral proper name, and the second was a fully switched DP. This was done to establish the language mixing of the sentence before the critical DP was encountered, potentially reducing the processing cost of the critical language switch by priming it with a previous language switch. Also, the words preceding the critical determiner were always in the same language as that determiner, and the words following the critical noun were always in the same language as that noun. This was done in order to ensure that the language switch between the determiner and the noun was more along the lines of a multi-word “code-switch” as opposed to a single word “nonce borrowing” or insertion. Finally, the critical noun was never the last constituent in the sentence in order to avoid any sentence wrap-up effects.
4.2.2. Filler Items
Three types of filler sentences were included as stimuli (see
Table S1). First, 15 sentences were created such that they contained a morphosyntactic mismatch between constituents belonging to the same language, such as number and verb tense violations. A control condition was created for these sentences by repairing the mismatch. This type of filler was included in order to determine whether both measures of the experimental task, ratings and RTs, were able to elicit the expected distinctions between grammatical and ungrammatical sentences. Similarly, another 15 sentences were created such that they contained a type of language switch that is commonly considered in the literature to be ungrammatical, such as between an auxiliary and a main verb, between a pronoun and a verb, or between a noun and a post-posed adjective (which produces a word-order conflict). Again, a control condition was created for these sentences by repairing the mismatch. This type of filler was included in order to determine whether language switch violations were treated in the same way as the within-language morphosyntactic violations with respect to both dependent measures. Finally, 10 mixed-language sentences were created that were completely grammatical, with language switches occurring at uncontroversial sites, such as between a noun and a verb, or between a noun and a prepositional phrase.
4.3. Procedure
All participants were recruited through the University of Ottawa’s Integrated System of Participation in Research (ISPR), and were awarded one point towards their course grade. All subjects gave their informed consent for inclusion before they participated in the study. The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Social Sciences and Humanities Research Ethics Board of the University of Ottawa (REB# 02-16-26). The entire testing session lasted approximately 60 min for each participant. Participants were first asked to complete the consent form, language background questionnaire and language-mixing questionnaire. They were then seated in a sound-attenuated room in front of a computer screen for the experimental task.
Participants were instructed that they would be reading mixed-language sentences one word at a time on the computer screen. They were told that the words of each sentence would be first covered in dashes, and to see each successive word, they were to press the space bar (as per the “moving window paradigm” of SPR). After each sentence, they would be asked to rate how acceptable it was to them on a scale from 1 to 4 by pressing the corresponding number key on the keyboard. They were instructed that a rating of “1” meant that the sentence “sounded terrible, it was not acceptable”; a rating of “2” meant that it “sounded pretty bad”; a rating of “3” meant that it “sounded ok, but not very natural; and a rating of “4” meant that is “sounded good, it was perfectly acceptable”. This 4-point scale was visible on the computer screen each time they were asked to make a rating, with the “1” marked as “Terrible” and the “4” marked as “Fine”.
Each participant saw a total of 88 experimental sentences, presented using the Linger software program (version 2.94,
http://tedlab.mit.edu/~dr/Linger), plus eight practice sentences. All words were displayed in black 20-point font on a light grey background. Spaces between words were not covered in dashes, and a period marked the end of each sentence. They saw each critical (
n = 48) and filler (
n = 40) sentence once, counterbalanced across conditions such that they saw an equal number of sentences in each condition. Sentences were presented in a semi-randomized order, and separated into six blocks such that each block began with a filler sentence and no more than two sentences of the same condition appeared consecutively. Participants were given a self-regulated break between each block. One third of both critical and filler sentences were followed by a yes/no question that was entirely in English.
4.4. Hypotheses
The first set of hypotheses that were tested pertained to the mixed DP asymmetry. Based on the arguments presented in
Section 3.2.1, it was expected that there should be no directional asymmetry for language switches between English and French determiners and nouns. This was expected to be the case at least for the simultaneous bilinguals. In contrast, and as discussed in
Section 3.3, late L1-French L2-English bilinguals were expected to possibly show a partially-mixed DP asymmetry; DPs such as
the soleil.M should be acceptable, but not those such as
the maison.F. Finally, this group of late bilinguals may also show reduced processing costs for mixed DPs consisting of an English D and a French N, because this language switch goes in the direction of the weak to the dominant language (see
Section 3.4).
The second set of hypotheses tested predictions regarding gender assignment for English roots in mixed DPs, and the extent to which the analogical criterion applied. Based on the arguments presented in
Section 3.2.2, it was expected that there would be considerable variability for English roots whose translation equivalents are licensed under
nu[+FEM] (i.e., sentences containing
le house and
la house should have similar acceptability ratings and similar RTs for the critical nouns), but no variability for roots whose translation equivalents are licensed under
nu[-FEM] (i.e., only
le soleil should be acceptable, not
la soleil).
It was further expected that the late bilinguals would have a greater tendency to apply analogical gender to English nouns whereas the simultaneous bilinguals were expected to possibly show a greater tendency to apply the masculine gender as default. This is because the direct lexical connections between translations in the L2-to-L1 direction translation equivalents were expected to be stronger for the late bilinguals, as per the RHM, and thus easier to activate (see
Section 3.4).
5. Results
The accuracy of participants’ responses to the comprehension questions was first calculated in order to determine whether they were paying sufficient attention to the reading task. It was determined that all participants responded with high accuracy to the comprehension questions, with a mean of 95.9% (SD = 4.8%), and a range of 77.4–100%.
Acceptability ratings were collected for each sentence, and the mean and standard deviation were calculated for each participant across all conditions in order to identify any outliers. One participant’s mean rating was indeed more than 2.5 standard deviations from the group’s overall mean, and so was excluded from the data analysis.
19 For the 38 remaining participants, mean ratings were calculated for each participant by condition, and this was used as the first dependent variable.
RTs were time-locked to participants’ button press on the critical word in each sentence, that is, the word where the language switch or morphosyntactic violation became apparent (or not, for their respective control conditions). Mean RTs were calculated for each participant, and data points that were 2.5 standard deviations above (4.9% of the data) or below (none) each participant’s mean were replaced by their mean value. Mean RTs were then re-calculated based on this trimmed data for each participant across conditions in order to identify outliers; one participant’s mean was greater than 2.5 standard deviations from the group mean (a simultaneous bilingual), and so this participant’s RT data was excluded from the statistical analyses; however, their acceptability judgment data were still analyzed. For each of the remaining 37 participants, mean RTs were calculated by condition, and this was used as the second dependent variable.
5.1. Grammaticality Violations in Filler Items
The two types of filler items involving within-language morphosyntactic violations and uncontroversial language switch violations were analyzed using a three-way repeated measures ANOVA for each dependent variable (ratings and RTs). Filler Type (language switch violation vs. morphosyntactic violation), Grammaticality (violation vs. control), and Group (simultaneous vs. early vs. late) were the independent variables.
Results for the ratings revealed a significant main effect of Grammaticality (F(1,35) = 188.437, MSE = 32.352, p < 0.001), indicating that both types of violations received significantly lower ratings than their grammatical counterparts. There was also a significant main effect of Filler Type (F(1,35) = 6.548, MSE = 1.480, p = 0.015), which was likely driven by the significant interaction between Filler Type and Grammaticality (F(1,35) = 7.772, MSE = 1.585, p = 0.009). This interaction indicates that, while both types of violations were rated significantly lower than their grammatical counterparts, as confirmed by planned paired-sample t-tests (t(37) = 11.963, p < 0.001; and t(37) = 7.969, p < 0.001, respectively), the magnitude of this difference was significantly larger for the within-language morphosyntactic violations (mean difference = 1.25 compared to 0.73). This likely reflects the fact that the participants have more metalinguistic knowledge of grammatical errors than they do of language switch violations. The main effect of Group did not reach significance (p = 0.897), nor was its three-way interaction with Filler Type and Grammaticality, suggesting that all groups showed similar effects.
Results for RTs mirrored those of the ratings. There was a significant main effect of Grammaticality (F(1,34) = 22.750, MSE = 527,233.974,
p < 0.001), indicating that both language switch violations and morphosyntactic violations were read significantly more slowly than their grammatical counterparts. The main effect of
filler type was only marginally significant (
p = 0.067), as was the interaction between Filler Type and Grammaticality (
p = 0.093). This interaction suggests that, while both within-language morphosyntactic violations and language switching violations were read significantly more slowly than their grammatical counterparts, as confirmed by planned paired-sample t-tests (t(36) = 5.590,
p < 0.001; and t(36) = 3.685,
p = 0.001, respectively), the magnitude of this difference was marginally larger for the within-language morphosyntactic violations. There was also a significant main effect of Group (F(2,34) = 5.550, MSE = 787,180.376,
p = 0.008), indicating that the simultaneous bilinguals were overall slower than the early and late groups (
p = 0.027 and
p = 0.032, respectively).
20 There was, however, no three-way interaction between Group, Filler Type, and Grammaticality (
p = 0.596), suggesting again that all groups showed similar effects of grammaticality on both types of filler sentence.
5.2. The Mixed Determiner Phrase Asymmetry
A three-way repeated measures ANOVA was conducted for each dependent variable (ratings and RTs) with Determiner Language (French
21 vs. English), DP Type (unmixed vs. mixed) and Group (simultaneous vs. early vs. late) as independent variables. Results for ratings (
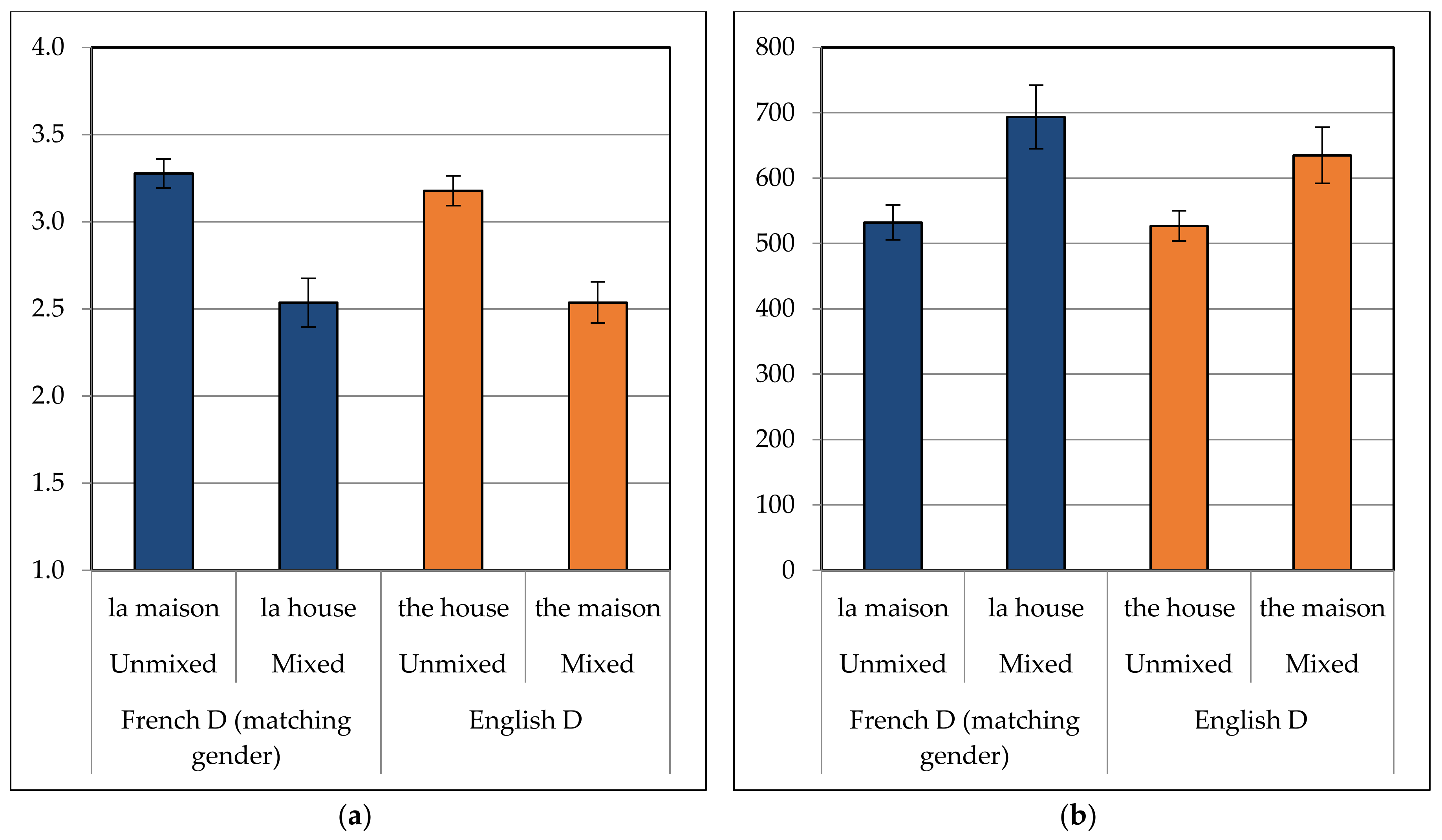
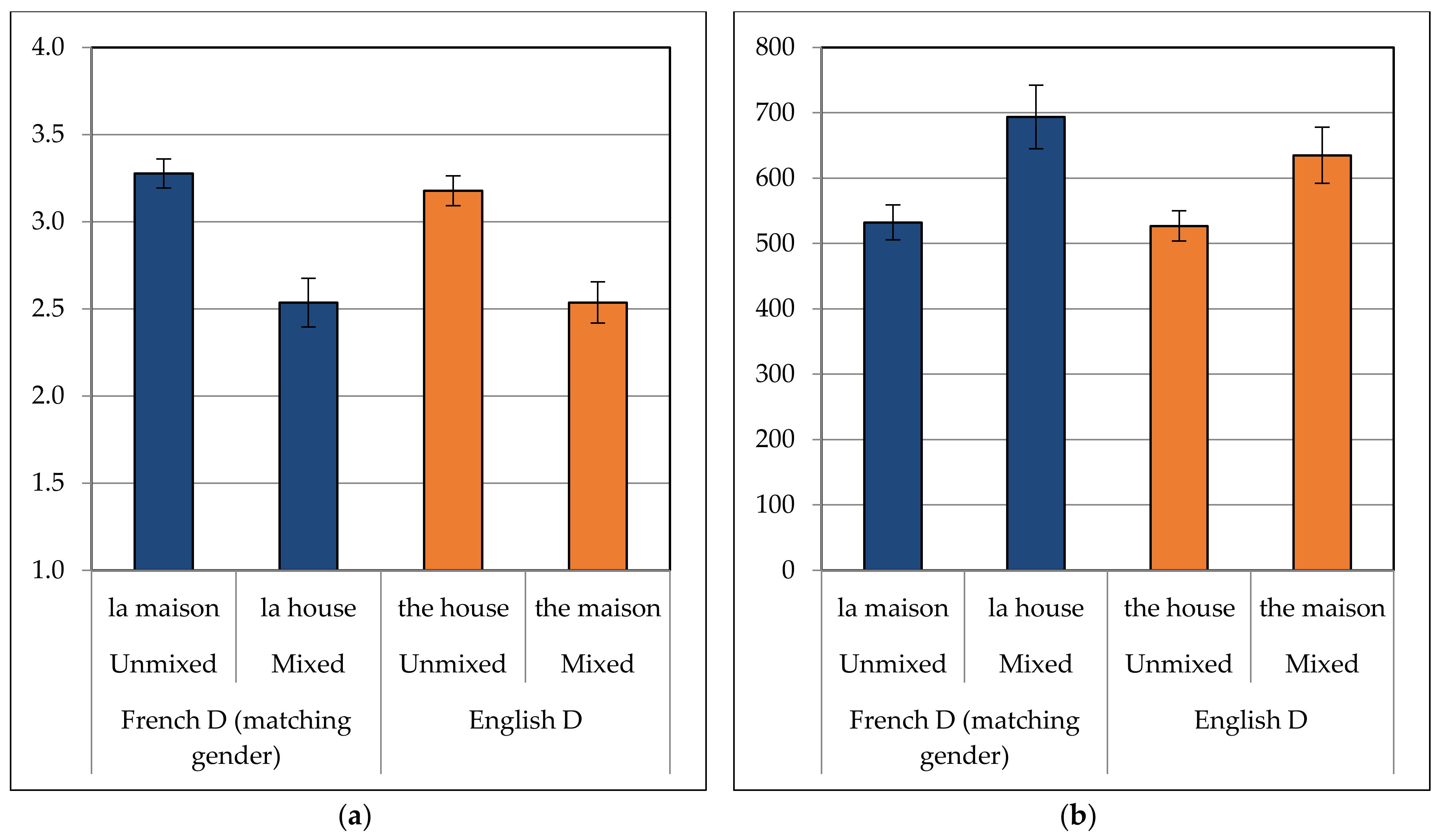
Figure 2a) revealed a significant main effect of DP Type (F(1,35) = 62.703, MSE = 17.851,
p < 0.001), indicating that participants preferred unmixed over mixed DPs overall (mean difference = 0.69).
22 The main effect of Determiner Language was not significant (
p = 0.343), and crucially, neither was the interaction between Determiner Language and DP Type (
p = 0.457), indicating that there was indeed no preference for mixed DPs with French determiners over English determiners. The main effect of Group was not determined to be significant (
p = 0.897), nor did it significantly interact with any other variable, suggesting that all groups shared the same pattern.
The patterns for ratings are mirrored in
Figure 2b, which shows the mean RTs for critical nouns in the same four conditions. Indeed, statistical analyses confirm these patterns. There was a significant main effect of DP Type (F(1,34) = 22.799, MSE = 486,233.390,
p < 0.001), indicating that participants preferred unmixed over mixed DPs (mean difference = 135 ms). The main effect of Determiner Language was not significant (
p = 0.519), and again, neither was the interaction between Determiner Language and DP Type (
p = 0.318). Interestingly, the numerical trend was in the opposite direction than would be expected for the Spanish–English mixed DP asymmetry, with the English nouns following French determiners (e.g.,
la house) being read more slowly than French nouns following English determiners (e.g.,
the maison; mean difference = 59 ms). There was a significant main effect of Group (F(2,34) = 3.694, MSE = 422,112.890,
p = 0.035) suggesting that the simultaneous bilinguals were again the slowest overall. The factor Group did not interact with any other factor, again suggesting that the patterns were similar across all three participant groups. Because, however, the hypotheses were made a priori regarding differences between the simultaneous and late bilingual groups, these were further investigated in order to identify any potential patterns or tendencies.
5.2.1. Between-Group Differences: The Maison vs. The Soleil
It was hypothesized that there might be a partial mixed DP asymmetry for the late bilinguals, whereby they might have only a dispreference for mixed DPs consisting of an English D paired with a feminine French N (e.g.,
the maison.F) and not one for those paired with a masculine French N (e.g.,
the soleil.M). In order to further investigate this possibility, a closer look was taken at the conditions including an English D. The ratings data are shown in
Table 5.
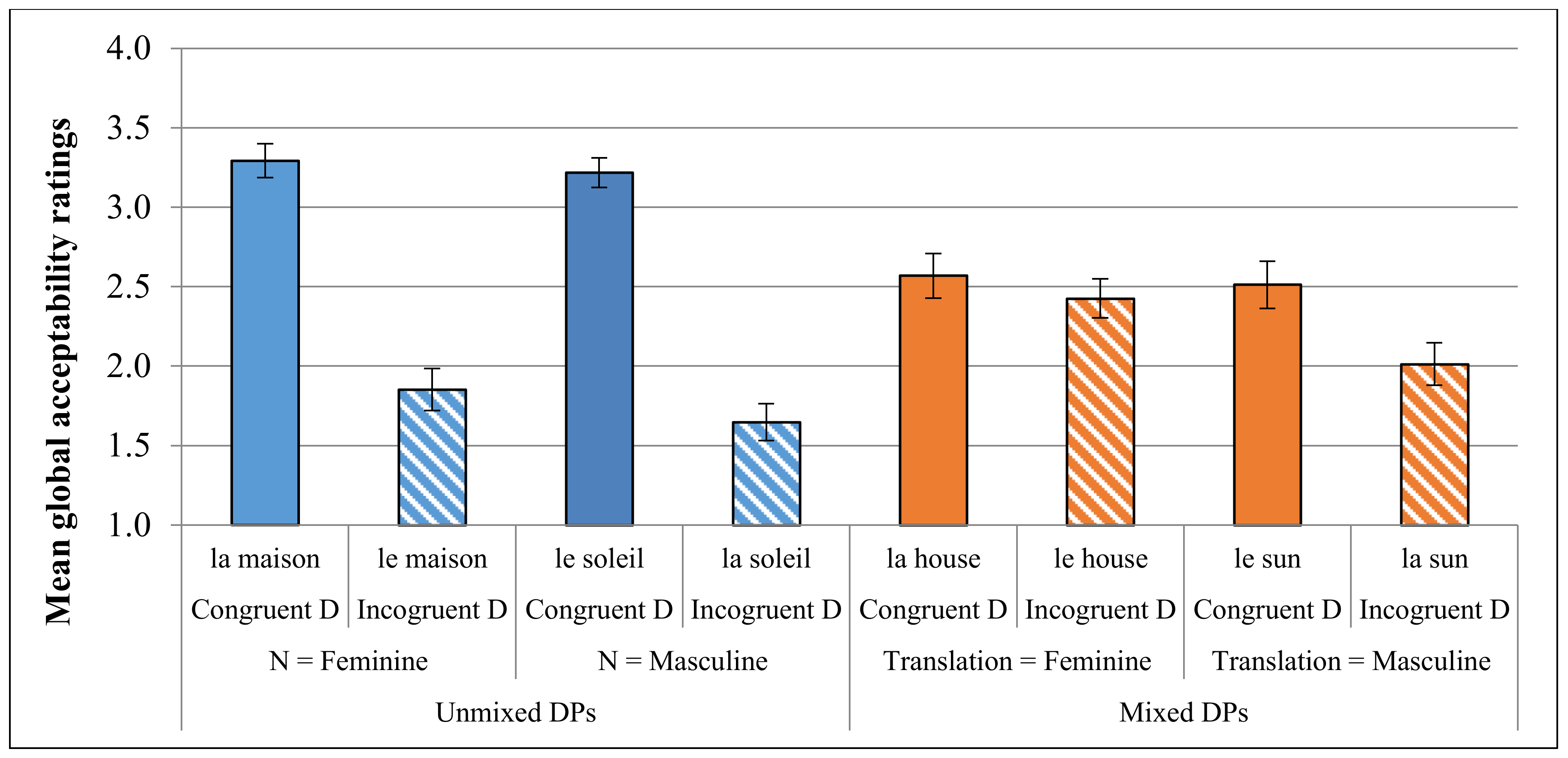
23 The raw means alone suggest that both groups seem to have a slight preference for mixed DPs with a masculine N over those with a feminine N, and that the preference is greater for the late bilinguals (0.19 compared to 0.07). This pattern is consistent with the hypothesis, but of course the magnitudes of the differences are very small (though not nearly as small as for their unmixed counterparts, where the differences are very near null).
An exploratory two-way ANOVA was conducted just for the late bilinguals, with DP Type (unmixed vs. mixed) and Noun Gender as the independent variables. While there was a marginally significant effect of DP Type (F(1,12) = 4.437, MSE = 165,983.554,
p = 0.057), neither the effect of Noun Gender nor the interaction were significant (
p = 0.674 and
p = 0.645, respectively). Exploratory planned pair-wise comparisons confirmed that the difference in ratings between mixed DPs with English D did not differ significantly depending on the gender of the French N (
p = 0.840). As such, there is no evidence here that late bilinguals demonstrate any type of mixed DP asymmetry, despite the faint indication of the expected pattern in
Table 5.
5.2.2. Between-Group Differences: Processing Costs
It was also hypothesized that the group of late bilinguals (but not the simultaneous bilinguals) would show a greater processing cost for mixed DPs where the switch direction was from the stronger (French) to the weaker (English) language (e.g.,
la house) compared to the opposite direction (e.g.,
the maison).
Table 6 presents the relevant data.
Looking at the patterns alone, it appears that both groups have a greater language switch cost in the French-to-English direction compared to the English-to-French direction. An exploratory two-way ANOVA was conducted for each of the two participant groups, with DP Type (unmixed vs. mixed) and Determiner Language as the independent variables. While there was a significant effect of DP Type for both the late and simultaneous groups (F(1,12) = 10.073, MSE = 268,640.337, p = 0.008; and F(1,16) = 19.891, MSE = 406,207.887, p < 0.001, respectively), this factor did not significantly interact with Determiner Language for either group (p = 0.439 and p = 0.227, respectively). As such, there is no robust evidence of greater processing costs for either group, and contrary to the hypothesis, both groups shared the same pattern. The reason for this similar, but a non-significant pattern will become clearer in the analysis investigating the analogical criterion, presented in the next section.
5.3. The Analogical Criterion in Mixed Determiner Phrases with English Nouns
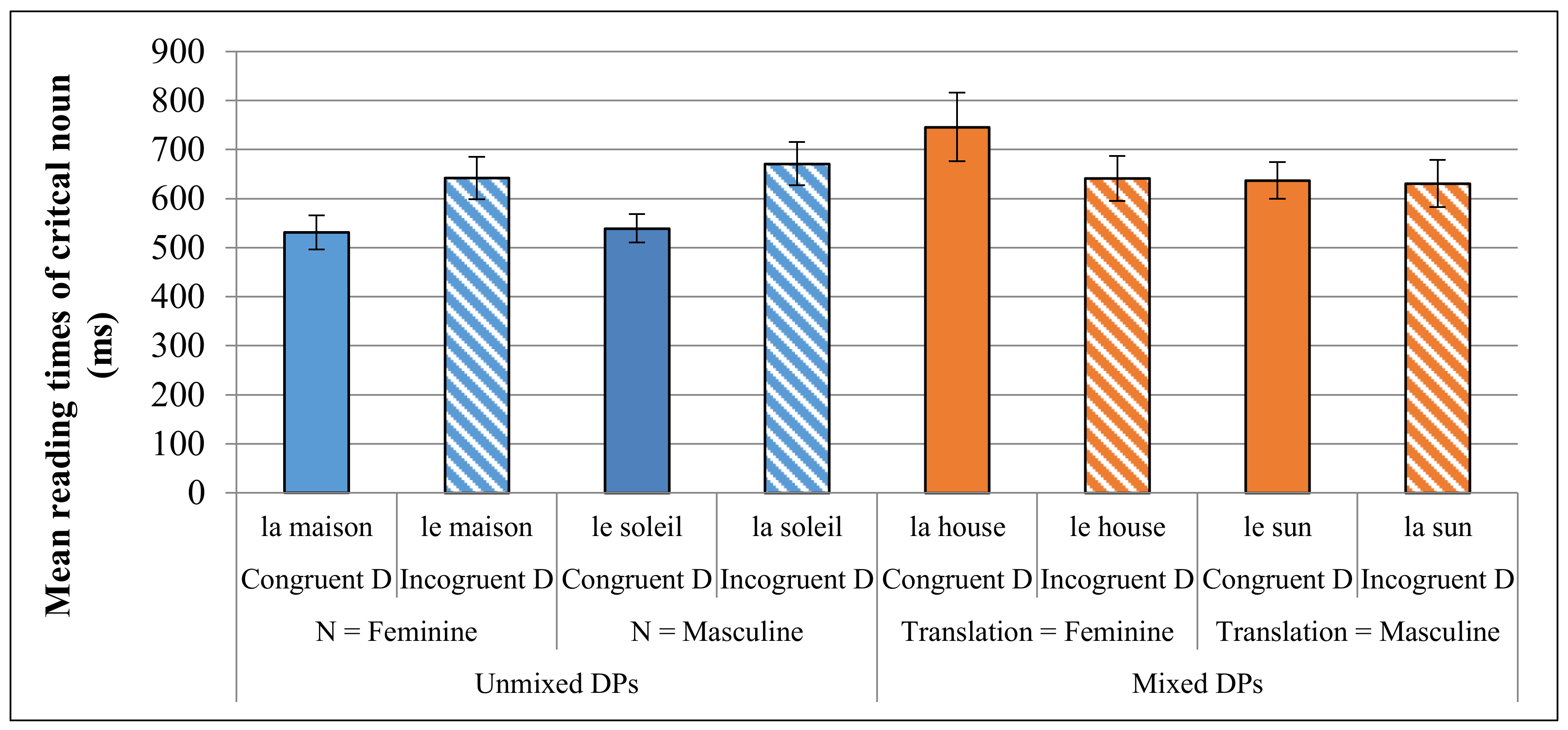
Looking only at experimental conditions with critical DPs containing a French D, a four-way repeated measures ANOVA was conducted for each dependent variable, with DP Type (unmixed vs. mixed), Gender Congruence (congruent vs. incongruent), Noun Gender (feminine vs. masculine), and Group (simultaneous vs. early vs. late) as independent variables.
Results for ratings (
Figure 3) showed a significant main effect of Gender Congruence (F(1,35) = 95.228, MSE = 51.487,
p < 0.001) as well as of Gender (F(1,35) = 14.794, MSE = 2.230,
p < 0.001), but not of DP Type (
p = 0.150). The interaction between DP Type and Gender Congruence was significant (F(1,35) = 65.262, MSE = 23.218,
p < 0.001), indicating that the difference between DPs with congruent vs. incongruent gender was much larger in unmixed French DPs compared to mixed DPs. Crucially, there was also a very strong trend towards significance for the three-way interaction between DP Type, Gender Congruence and Noun Gender (F(1,35) = 4.065, MSE = 0.510,
p = 0.051). Planned pairwise comparisons indicated that for unmixed DPs there was a significant gender congruence effect for nouns with both masculine and feminine gender (t(37) = 9.520,
p < 0.001; t(37) = 12.166,
p < 0.001); however, for mixed DPs the congruence effect was significant only when the gender of the translation equivalent was masculine (t(37) = 4.545,
p < 0.001), and not when it was feminine (t(37) = 1.357,
p = 0.183). There was no significant main effect of Group (
p = 0.601), nor did it participate in a significant interaction with the other three variables (
p = 0.138).
Even though the factor Group did not interact with any of the other independent variables, separate two-way repeated measures ANOVA were conducted for the simultaneous and late bilinguals. This was done because it was hypothesized a priori that these two groups might have different preferences with respect to gender assignment for English nouns. Specifically, it was expected that Late L2-English bilinguals would have a greater tendency to apply analogical gender to English nouns in mixed DPs. As such, these two ANOVAs looked only at mixed DPs with French Ds, and the independent variables were Gender and Congruence. For the late bilinguals, the main effect of Congruence was significant (F(1,12) = 12.600, MSE = 1.942, p = 0.004), but the interaction between Gender and Gongruence was not (p = 0.496), suggesting that the effect of congruence was the same regardless of the translation’s gender. Indeed, planned pair-wise comparisons indicated that nouns with both feminine and masculine translations were significantly preferred with analogical gender (t(12) = 2.758, p = 0.017 and t(12) = 2.485, p = 0.029, respectively). For the simultaneous bilinguals, the main effect of Congruence was significant (F(1,17) = 5.316, MSE = 2.067, p = 0.034) and the interaction between Gender and Congruence was marginally significant (F(1,27) = 4.048, MSE = 0.467, p = 0.060). Planned pair-wise comparisons indicated that the effect of congruence was only significant when the noun’s translation equivalent had masculine gender (t(17) = 2.990, p = 0.008), but not when it had feminine gender (t(17) = 1.061, p = 0.303). This supports the hypothesis that the late bilinguals have a stronger preference for assigning analogical gender to English nouns in mixed DPs than do simultaneous bilinguals.
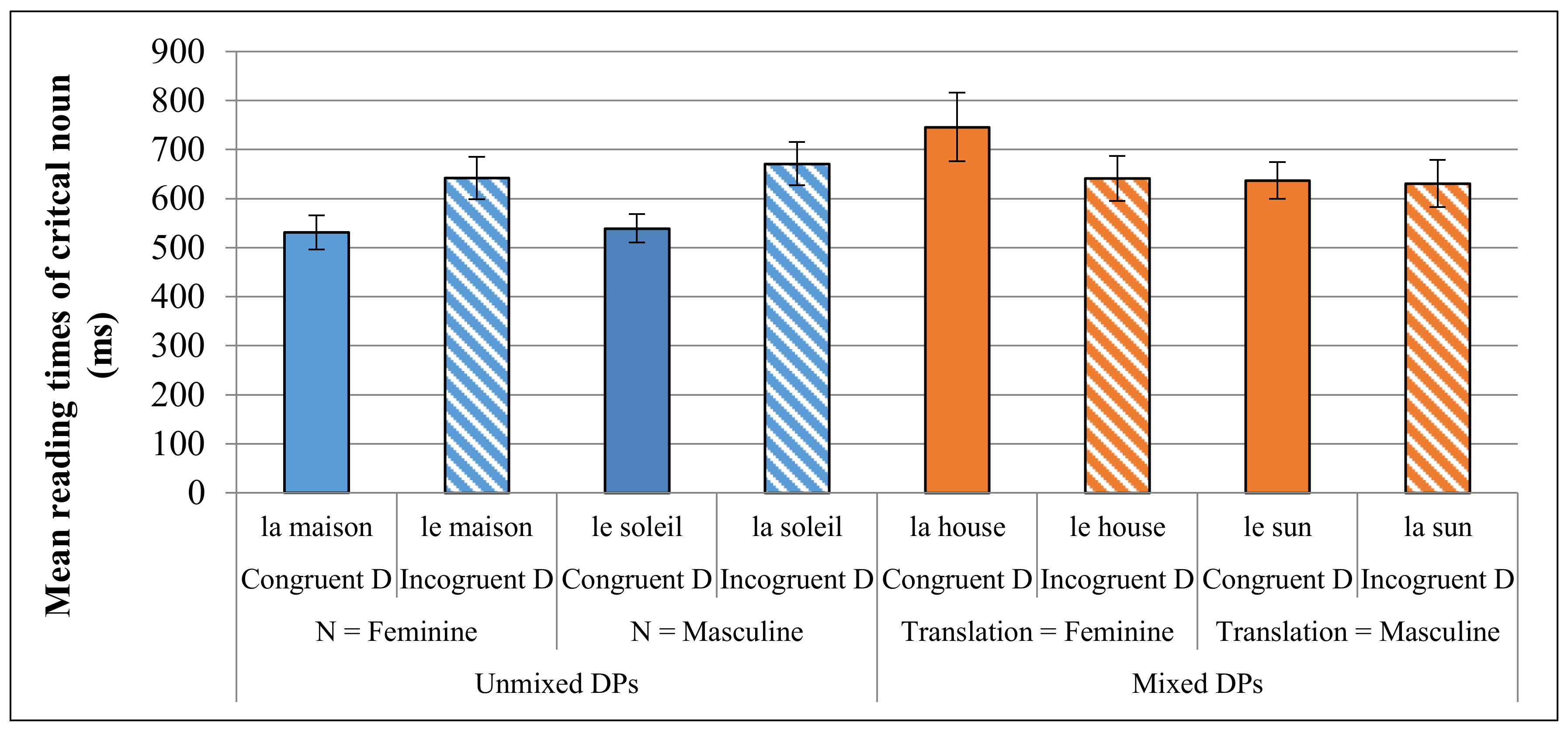
In terms of the four-way ANOVA using RT as the dependent variable (
Figure 4), there was a significant main effect of DP Type (F(1,34) = 5.783, MSE = 247,550.451,
p = 0.022), but no significant effect of Gender (
p = 0.386) or of Gender Congruence (
p = 0.181). There was, however, a significant interaction between DP Type and Gender Congruence (F(1,34) = 13.904, MSE = 386,115.394,
p = 0.001). Planned pairwise comparisons suggested that this was again the result of a different pattern for unmixed compared to mixed DPs. For unmixed DPs, gender incongruence between a French N and a French D resulted in significantly slower RTs (t(36) = −4.729,
p < 0.001), as expected; however, for mixed DPs, the RTs were significantly slower when the French determiner was congruent in gender with the English noun’s translation equivalent (t(36) = 2.690,
p = 0.011). This is the opposite of the expected result. While the three-way interaction between DP Type, Gender Congruence and Noun Gender was not significant (
p = 0.536), planned pair-wise comparisons were conducted in order to further investigate the surprising pattern. The results of these comparisons suggest that it was only in cases where the English N’s translation equivalent was feminine that the RTs were significantly slower in the congruent (e.g.,
la house) compared to the incongruent (e.g.,
le house) condition (t(36) = 2.661,
p = 0.012). When the English noun’s translation equivalent was masculine (e.g.,
sun), there was no significant gender congruency effect (t(36) = 0.147,
p = 0.884). Further, this effect for English Ns with a feminine translation was statistically significant for the late bilinguals (t(12) = 2.478,
p = 0.029), but only marginally significant for the simultaneous bilinguals (t(16) = 1.944,
p = 0.070), despite the greater statistical power of the latter group due to the larger group size. These results will be interpreted and further discussed in the next section.
6. Discussion
The two primary research questions that the experimental study sought to address were first, whether there was evidence of a French–English mixed DP asymmetry, and second, how the analogical criterion is applied in mixed DPs with an English lexical root. Secondary goals were to investigate the impact of language background factors such as AoA, and to take into account factors that affect processing, such as L2 proficiency and dominance.
With respect to the mixed DP asymmetry, the results for both dependent measures indicated that, overall, there was no preference for switching between a French D and an English N (e.g., la house) compared to the reverse (e.g., the maison). These results thus support the theoretically motivated hypothesis that there should be no mixed DP asymmetry for French–English.
It must, of course, be conceded that even in Spanish–English language mixing, where the mixed DP asymmetry is expected based on corpora data, AJTs have not provided corroborative evidence of its existence (
Liceras et al. 2008,
2016). The experimental task used in the present study, however, differs from those of previous studies in several ways. First, several things were done in order to decrease the saliency of the mixed DPs being investigated—critical DPs were embedded in sentences that had other language-switch points; no unilingual sentences were included, in either critical or filler conditions; and several other types of within- and between-language morphosyntactic anomalies were included in filler items. Second, combining the AJT with SPR might also have had the benefit of reducing the participants’ tendency to be prescriptive or to apply metalinguistic knowledge when making these judgments for two reasons—having comprehension questions after one third of the sentences encouraged participants to focus a significant part of their attention on meaning as opposed to just grammatical structure; and, because the sentences were presented only one word at a time and never in their entirety, participants could not go back and reread sentences. As such, they might not have the same opportunity to deconstruct and consciously analyze their grammatical structure, thus relying more on their intuition as opposed to their metalinguistic knowledge. It is perhaps the application of metalinguistic knowledge that allowed Spanish–English bilinguals to accept DPs such as
the casa in previous studies; the DM-based analysis in
Section 3.1 predicts that such DPs are not ungrammatical per se, but are blocked by the availability of those with a more highly specified determiner (i.e.,
la casa). Intuitively, bilinguals might not like such a DP, but if given time to consider it, they might not know why. Mixed DPs such as
the casa might even be in their input if there are L1-English L2-Spanish speakers in their environment, for whom the mixed DP asymmetry is not expected. Of course, the only way to determine whether the more implicit methodology used here is capable of detecting a mixed DP asymmetry would be to use it to test a language pair where it is expected, i.e., Spanish–English. One indication that it might be able to do so is that there was robust evidence from the filler items that other uncontroversial language switch violations were indeed rated significantly lower and read significantly more slowly.
It was also hypothesized that late L1-French L2-English bilinguals may show a partial mixed DP asymmetry, specifically a dispreference for mixed DPs consisting of an English D and a feminine French N (e.g.,
the maison.F). This was hypothesized because such bilinguals may not have a plain
n in their repertoire of abstract morphemes due to their late AoA, and because the English D
the is expected to have the same feature specification as the French D
le. No evidence, however, was found of any asymmetry. This suggests that late bilinguals may have a plain
n, which could be because plain
n is a subset of an
n with a gender feature. Consequently, no “new” morphosyntactic feature actually needs to be acquired by the late learners. It is also possible that such a partial asymmetry could still be found using this methodology with participants having an even later age of L2 immersion, as others assume a later end to the sensitive period for morphosyntax, such as around puberty (e.g.,
Johnson and Newport 1989;
DeKeyser 2000).
The group of late bilinguals was also hypothesized to show increased processing costs for mixed DPs consisting of a French D and an English N because this language switch goes from the dominant to the weak language, following the results of
Litcofsky and Van Hell (
2017). Unexpectedly, both the late and simultaneous groups demonstrated this pattern despite the latter group being very balanced. It was later determined that this was because mixed DPs such as
la house were read significantly more slowly than any other mixed DP with a French D, even those which violated both the analogical criterion and default licensing under the masculine
n (e.g.,
la sun). This result was also unexpected. It suggests, however, that participants might not have too much difficulty reading/assessing English nouns that appear following the masculine determiner (e.g.,
le house,
le sun) because any English noun can appear with the default masculine determiner. Likewise, they seem to have little difficulty reading/assessing (and later rejecting) English nouns with masculine translations following a feminine determiner (e.g.,
la sun), suggesting that the issue is not in accessing the licensing conditions of the corresponding French translation equivalent. Rather, it seems that this may be a result of variability in the input for English nouns with feminine translations (
le/
la house), which is shown to be a robust pattern in Spanish–English corpora (
Poplack et al. 1982;
Jake et al. 2002;
Clegg and Waltermire 2009), and likely also for French (
Poplack et al. 1982). Because participants do not have a strong intuition regarding such mixed DPs, this may result in a slower reading time when they encounter one due to the uncertainty. This appears to be particularly so with the late bilinguals, for whom the effect was the most statistically robust. Interestingly, this was also the group who tended to more strongly prefer the analogical criterion, as indicated by their results for acceptability ratings. While this preference was expected for this group, the RT results suggest that its cause is not related to the predictions of the RHM, whereby translations were expected to be more easily accessed by unbalanced sequential bilinguals due to their stronger direct lexical connections. If this were the case, they would have also shown extra processing effort when attempting to access the translation equivalent of masculine nouns following feminine determiners (e.g.,
la sun). Rather, the late bilinguals’ preference for analogical gender might reflect a difference in their attitude compared to simultaneous bilinguals, such that the former group attributes greater importance to preserving “French” properties when mixing their languages, thus spending more time deciding what their preference is, and then applying analogical gender preferentially.
These results also suggest that the self-paced reading times of mixed DPs do reflect conscious, strategic preferences to a certain extent. This contrasts with the RTs for unmixed DPs, which really did seem to reflect modulations in processing time related to the grammaticality of particular constructions. Having participants rate the sentences with respect to their acceptability might reduce the benefits of the more implicit RT measure. As such, while it was argued that adding the SPR element to an AJT may decrease the strategic nature of the latter task, this might also increase the strategic nature of the former methodology. It would be interesting to see if the same patterns would persist when the acceptability judgment aspect is removed from the self-paced reading task, rendering it a simple reading task with comprehension questions focusing on meaning.
In a similar vein, the inclusion of within-language morphosyntactic violations may also have affected participants’ acceptability ratings of sentences containing mixed DPs. First of all, gender agreement violations in unmixed French DPs are very salient errors to native speakers. As such, drawing participants’ conscious attention to such errors may have increased their likelihood of applying the same “rules” to mixed DPs. This could have resulted in an increased tendency to assign analogical gender to English nouns in mixed DPs, particularly for the late bilinguals, who might be more prescriptive. Second, asking participants to use the same acceptability scale to assess within-language violations and potential language switch violations might have also reduced the effectiveness of the task. Bilinguals likely have significant metalinguistic knowledge of within-language morphosyntactic violations as a result of the explicit teaching and correction of grammatical errors, particularly in formal, written (unmixed) language. Language mixing, however, is typically used in informal oral contexts, and bilinguals rarely pay conscious attention to issues of grammaticality. Indeed, the results for the control conditions indicated that participants did have significantly stronger judgments for within-language violations than for language switch violations. This suggests that the scale was more sensitive to the former type of violation, and thus perhaps less able to detect subtle differences in the latter.
7. Conclusions
The mixed DP asymmetry of Spanish–English has been investigated from various perspectives over the years, yet there are still many conflicting views with respect to what it means for the underlying linguistic system acquired by bilinguals. The DM-based theoretical account presented in
Section 3 assumes a somewhat different underlying system than do previous accounts.
Generally speaking, there are two important theoretical advantages to a DM approach to language mixing. First, because morphology is taken out of the lexicon, this means that the same syntactic processes apply both above and below the word-level (
Grimstad et al. 2014;
Alexiadou et al. 2015); “words” are therefore derived from their morphological sub-components in the same way that sentences are derived from their lexical sub-components. As such, word-internal and word-external language mixing, which are often treated separately (e.g.,
Poplack and Dion 2012; see also
Grimstad et al. 2014), can be accounted for, at least formally, using the same mechanisms. Secondly, because VIs from both languages compete for insertion into fully specified syntactic terminal nodes, this allows for optionality when VIs from the two languages have the same feature specifications. This leads to theoretically motivated predictions with respect to where optionality can be expected in mixed language utterances, and where there should be a categorical language preference. This optionality is one of the reasons why it is challenging to model language mixing, yet it is an aspect that DM is particularly well suited to handle.
Demonstrating that the DM framework can account for mixed language data also provides empirical support for the underlying assumptions of this model. In particular, the assumption that gender is not a root property, but a feature on
n, is supported by the argument that bilinguals have options as to which
n a translation can become licenced under. Further, the theoretical analysis of Spanish gender and declension class argued for by
Kramer (
2015) generated specific predictions regarding how this phenomenon was expected to manifest itself in French–English, and also predictions regarding how different paths of dual-language acquisition may affect the patterns. The study presented addressed some of the resulting hypotheses and provided positive evidence for this account, thus lending empirical support to Kramer’s analysis. The two main findings were that there was no evidence for a mixed DP asymmetry for French–English bilinguals, as expected, and that late sequential bilinguals are more likely than simultaneous bilinguals to apply analogical gender to English roots in mixed DPs. The strength of conclusions based on the first result rests on the assumption that such an asymmetry could be found for Spanish–English using this particular experimental methodology. As such, testing this is an important direction for future work. While the second result was predicted based on a model of the bilingual mental lexicon, the reading time data suggest that this pattern might not actually reflect differing types of lexical access across languages for the two groups, but different attitudes and preferences. Conducting experimental studies using even more covert measures, such as event-related potentials and eye-tracking, could help to investigate these questions further.



{kind=link}
{kind=link}
{kind=link}
{kind=link}