
The Importance of Being Onset: Tuscan Lenition and Stops in Coda Position


Abstract
1. Introduction
2. A Phonological Description of What GT Is
“The phonetic results of intervocalic weakening given here are necessarily abstractions from the multitude of realizations which occur in actual speech, determined sociolinguistically and geographically, by speed of speech, etc. Their status is that of the usual realization in relaxed, but not necessarily fast, speech”.
3. When Does GT Occur?
- Do obstruents in the coda position undergo spirantization of the same kind experienced by post-vocalic onsets?
- Are their outputs similar to those of non-postvocalic onset stops, i.e., in post-coda context?
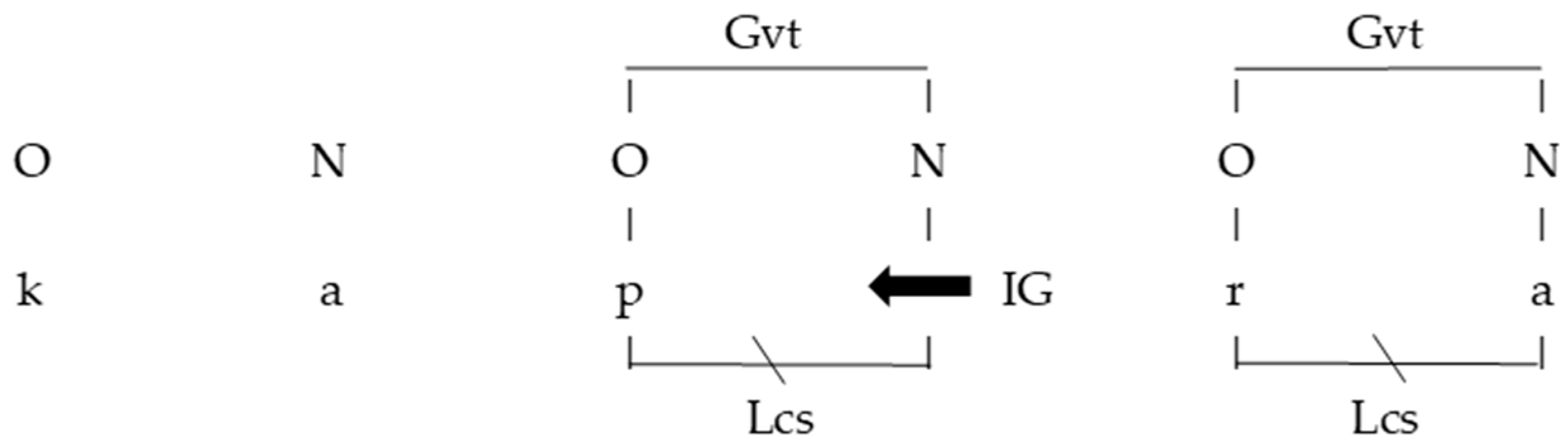
4. The Analytic Tools: Strict CV, Coda Mirror, and Element Theory
5. Diatopic and Sociolinguistic Variation Concerning GT
6. Materials and Methods
6.1. Participants and Data Collection
6.2. Analytic Procedures
6.2.1. Allophonic Classification
6.2.2. Quantitative Analysis
7. Results
7.1. Allophonic Classification of Intervocalic and Coda Stops
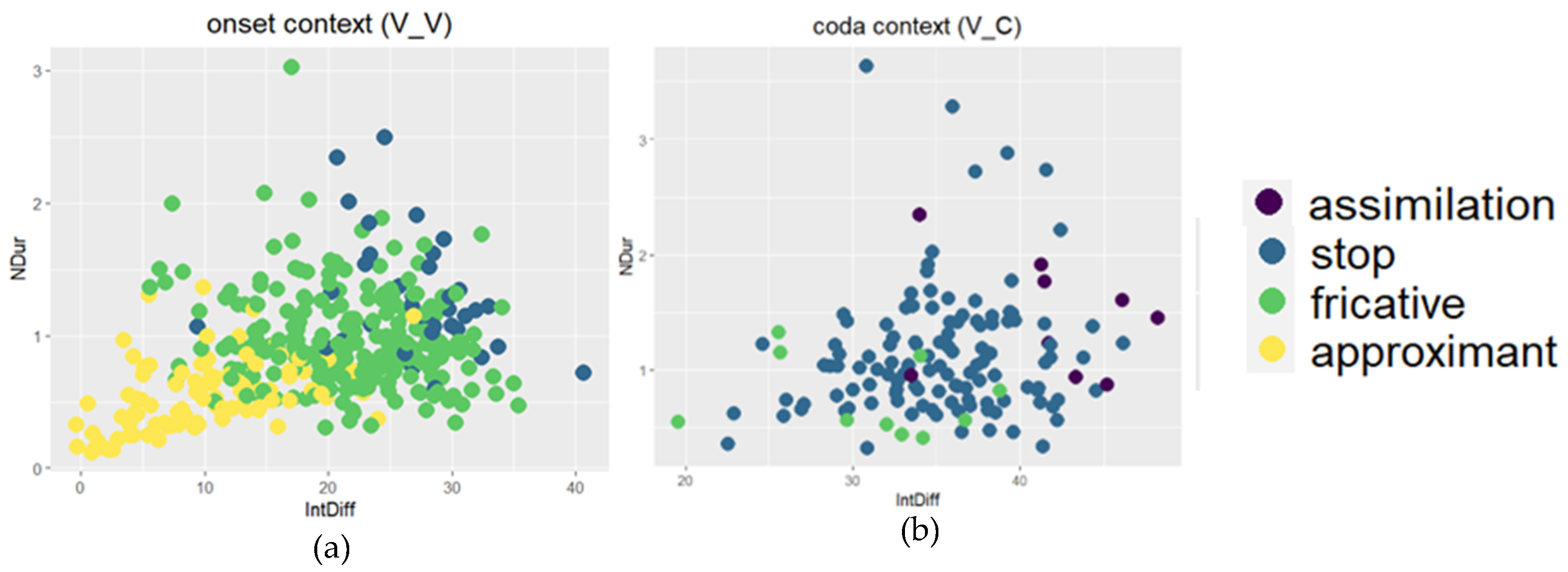
7.2. Quantitative Analysis of Intervocalic and Coda Stops
8. Discussion
8.1. The Importance of Being Onset
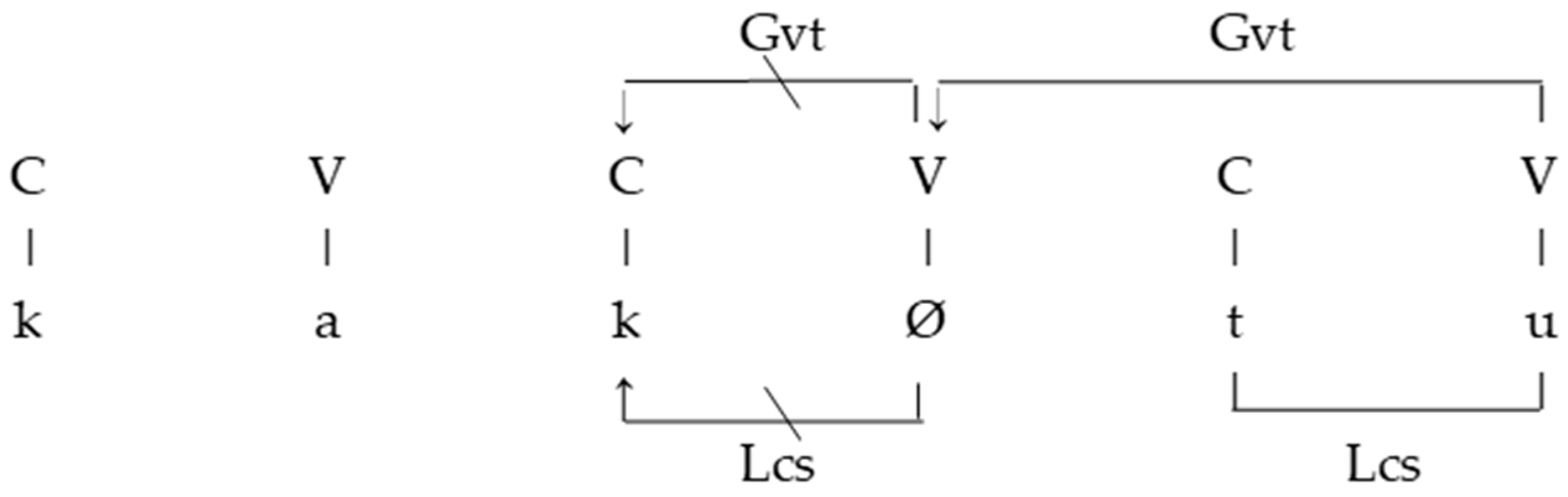
8.2. Phonological Analysis in Strict CV and Coda Mirror Frameworks
8.3. Lenition as Stopness Loss
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | Strong voiceless fricatives show a narrower closure than the prototypical ones, cfr. Sorianello (2003, p. 3082). |
| 2 | |
| 3 | Indeed, Tuscan speakers usually refer to GT as “ci aspirata”, literally “aspirated C”, in reference to the orthographic representation of /k/, i.e., ⟨c⟩. |
| 4 | The choice of setting the classification boundary between stops and fricatives when friction takes more than (the second) half of the phone duration follows Marotta (2001) and Villafaña Dalcher (2008). They consider the occurrence of an occlusion phase followed by frication noise for more than half of phone duration as an instance of weakening, instantiated as a sort of affricate (termed “semifricative” in Marotta, 2008). As we found these allophones in very low percentages (3%) in our corpora, instead of creating an underrepresented category, we grouped them together with fricatives, considering both affricates and fricatives as spirantized voiceless outputs. For the affrication of stops as an instance of lenition in other languages see, among others, Honeybone (2001) for Liverpool English, Pfiffner and Martinez-Garcia (2023) for Dutch, Yaqoub et al. (2023) for the Alma Arabic variety. |
| 5 | Distinguishing the 118 post-tonic coda stop realizations according to the finer classification, acoustic measures means and standard deviations are the following:
Interestingly, but obviously more data would be needed as it is just one case, the post-stressed stop with ephentesis is the longest and most constricted one, with a normalized duration closer to the assimilated geminate outputs. |
| 6 | Glides /w j/ may follow too. Their syllabic affiliation is, however, problematic (see the discussions in e.g., Marotta, 1988; Canalis, 2018). |
| 7 | In rhotics and laterals, stopness may be present as the apical contact, since in Tuscan they are prototypically produced as alveolar trills [r] and apical laterals [l] (Bertinetto & Loporcaro, 2005). |
References
- Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19(6), 716–723. [Google Scholar] [CrossRef]
- Baayen, R. H. (2008). Analyzing linguistic data: A practical introduction to statistics using R (1st ed.). Cambridge University Press. [Google Scholar] [CrossRef]
- Backley, P. (2011). An introduction to element theory. Edinburgh University Press. [Google Scholar]
- Bafile, L. (1997). La spirantizzazione toscana nell’ambito della teoria degli elementi. In Studi linguistici offerti a G. Giacomelli dagli amici e dagli allievi (pp. 27–38). Unipress. [Google Scholar]
- Bafile, L. (2003). Il trattamento delle consonanti finali nel fiorentino: Aspetti fonetici. In G. Marotta, & N. Nocchi (Eds.), Atti delle XIIIe Giornate di studio del GFS (A.I.A.) (pp. 205–212). Pisa 28-30 Novembre 2002. ETS. [Google Scholar]
- Barton, K. (2023). MuMIn: Multi-model inference. Available online: https://CRAN.R-project.org/package=MuMIn (accessed on 8 July 2024).
- Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using Lme4. Journal of Statistical Software, 67(1), 1–48. [Google Scholar] [CrossRef]
- Bertinetto, P. M. (1981). Strutture prosodiche dell’italiano. accento, quantità, sillaba, giuntura, fondamenti metrici. Accademia della Crusca. [Google Scholar]
- Bertinetto, P. M., & Loporcaro, M. (2005). The sound pattern of standard Italian, as compared with the varieties spoken in Florence, Milan and Rome. Journal of the International Phonetic Association, 35(2), 131–151. [Google Scholar] [CrossRef]
- Bertinetto, P. M., Sorianello, P., & Ricci, I. (2007). Sulla gerarchia dei fattori che governano la gorgia. un’applicazione dell’algoritmo di decisione c&rt. In V. Giordani, V. Bruseghini, & P. Cosi (Eds.), Atti del III Convegno Nazionale AISV ‘Scienze Vocali e del linguaggio’ metodologie di valutazione e risorse linguistiche, Trento (pp. 167–180). EDK Editore. [Google Scholar]
- Boersma, P., & Weenink, D. (2023). Praat: Doing phonetics by computer [computer program]. Available online: http://www.praat.org/ (accessed on 8 July 2024).
- Bourdieu, P. (1979). La distinction. critique sociale du jugement. Minuit. [Google Scholar]
- Broniś, O. (2016). Italian vowel paragoge in loanword adaptation. Phonological analysis of the roman variety of standard Italian. Italian Journal of Linguistics, 28(2), 25–68. [Google Scholar]
- Calamai, S. (2011). Per una storia della pronuncia degli italiani: Opinioni e atteggiamenti intorno alla pronuncia fiorentina. In A. Nesi, M. S. Scotti, & N. Maraschio (Eds.), Storia della lingua italiana e Storia dell’Italia Unita. L’italiano e lo stato nazionale (pp. 175–184). Cesati. [Google Scholar]
- Calamai, S. (2017). Tuscan between standard and vernacular: A sociophonetic perspective. In M. Cerruti, C. Crocco, & S. Marzo (Eds.), Towards a new standard (pp. 213–241). De Gruyter. [Google Scholar] [CrossRef]
- Callender, C. (2010). Trubetzkoy, autosegmental phonology and the segmental status of geminates. In M. Procházka, M. Malá, & P. Šaldová (Eds.), The prague school and theories of structure (pp. 45–60). V&R Unipress GmbH. [Google Scholar]
- Canalis, S. (2018). The status of Italian glides in the syllable. In R. Petrosino, P. Cerrone, & H. Van Der Hulst (Eds.), From sounds to structures (pp. 3–29). De Gruyter. [Google Scholar] [CrossRef]
- Celata, C., & Kaeppeli, B. (2003). Affricazione e rafforzamento in italiano. Alcuni dati sperimentali. Quaderni del laboratorio di linguistica della Scuola Normale Superiore, 4, 43–59. [Google Scholar]
- Celata, C., Meluzzi, C., & Bertini, C. (2022). Acoustic and kinematic correlates of heterosyllabicity in different phonological contexts. Language and Speech, 65(3), 755–780. [Google Scholar] [CrossRef]
- Chandrasekaran, C., Trubanova, A., Stillittano, S., Caplier, A., & Ghazanfar, A. A. (2009). The natural statistics of audiovisual speech. Edited by Karl J. Friston. PLoS Computational Biology, 5(7), e1000436. [Google Scholar] [CrossRef]
- Chierchia, G. (1986). Length, syllabification, and the phonological cycle in Italian. Journal of Italian Linguistics, 8, 5–34. [Google Scholar]
- Clements, N. (1985). The geometry of phonological features. Phonology Yearbook, 2, 225–252. [Google Scholar] [CrossRef]
- Contini, G. (1960). Per un’interpretazione strutturale della cosiddetta ‘gorgia toscana’. Boletim de Filologia, 19, 269–281. [Google Scholar]
- Cravens, T. D. (1984). Iintervocalic consonant weakening in a phonetic-based strength phonology: Foleyan hierarchies and the Gorgia Toscana. Theoretical Linguistics, 11(3), 269–310. [Google Scholar] [CrossRef]
- Cravens, T. D. (2000). Sociolinguistic subversion of a phonological hierarchy. WORD, 51(1), 1–19. [Google Scholar] [CrossRef]
- Cravens, T. D., & Giannelli, L. (1995). Relative salience of gender and class in a situation of multiple competing norms. Language Variation and Change, 7(2), 261–285. [Google Scholar] [CrossRef]
- Crocco, C. (2017). Everyone has an accent. Standard Italian and regional pronunciation. In M. Cerruti, C. Crocco, & S. Marzo (Eds.), Towards a new standard: Theoretical and empirical studies on the restandardization of Italian (pp. 89–117). De Gruyter Mouton. [Google Scholar]
- D’Agostino, M., & Paternostro, G. (2018). Speaker variables and their relation to language change. In W. Ayres-Bennett, & J. Carruthers (Eds.), Manual of romance sociolinguistics (pp. 197–216). De Gruyter. [Google Scholar] [CrossRef]
- De Pascale, S., & Marzo, S. (2016). Gli italiani regionali. Atteggiamenti linguistici verso le varietà geografiche dell’italiano. Incontri. Rivista Europea Di Studi Italiani, 31(1), 61–76. [Google Scholar] [CrossRef]
- De Pascale, S., Marzo, S., & Speelman, D. (2017). Evaluating regional variation in Italian: Towards a change in standard language ideology? In M. Cerruti, C. Crocco, & S. Marzo (Eds.), Towards a new standard (pp. 118–142). De Gruyter. [Google Scholar] [CrossRef]
- D’Imperio, M., & Rosenthall, S. (1999). Phonetics and phonology of main stress in Italian. Phonology, 16(1), 1–28. [Google Scholar] [CrossRef]
- Ennever, T., Meakins, F., & Round, E. R. (2017). A replicable acoustic measure of lenition and the nature of variability in Gurindji Stops. Laboratory Phonology: Journal of the Association for Laboratory Phonology, 8(1), 20. [Google Scholar] [CrossRef]
- Farnetani, E., & Kori, S. (1986). Effects of syllable and word structure on segmental durations in spoken Italian. Speech Communication, 5(1), 17–34. [Google Scholar] [CrossRef]
- Fava, E., & Magno Caldognetto, E. (1976). Studio sperimentale delle caratteristiche elettroacustiche delle vocali toniche e atone in bisillabi italiani. In R. Simone, U. Vignuzzi, & G. Ruggiero (Eds.), Studi di fonetica e fonologia, Atti del IX convegno della S.L.I. (pp. 35–79) Bulzoni. [Google Scholar]
- Galli de’ Paratesi, N. (1984). Lingua Toscana in bocca ambrosiana: Tendenze verso l’italiano standard: Un’inchiesta sociolinguistica. Il Mulino. [Google Scholar]
- Giacomelli, R. (1934). Controllo fonetico per diciassette punti dell’AIS nell’Emilia, nelle Marche, in Toscana, nell’Umbria e nel Lazio. Archivum Romanicum, 18, 153–211. [Google Scholar]
- Giannelli, L. (2000). Toscana (2nd ed.). Pacini. [Google Scholar]
- Giannelli, L., & Cravens, T. D. (1997). Consonantal weakening. In M. Maiden, & M. Parry (Eds.), The dialects of Italy (pp. 32–40). Routledge. [Google Scholar]
- Giannelli, L., & Savoia, L. M. (1978). L’indebolimento consonantico in Toscana I. Rivista Italiana di Dialettologia, 2, 25–58. [Google Scholar]
- Giannelli, L., & Savoia, L. M. (1980). L’indebolimento consonantico in Toscana II. Rivista Italiana di Dialettologia, 4, 39–101. [Google Scholar]
- Goldsmith, J. A. (1976). Autosegmental phonology. Massachusetts Institute of Technology. [Google Scholar]
- Goldsmith, J. A. (1990). Autosegmental and metrical phonology. Basil Blackwell. [Google Scholar]
- Goldstein, L. (2003). Emergence of discrete gestures. In M.-J. Solé, D. Recasens, & J. Romero (Eds.), Proceedings of the 15th international congress of phonetic sciences, Barcelona, Spain (pp. 85–88). Casual Productions. [Google Scholar]
- Harris, J. (1994). English sound structure. Basil Blackwell. [Google Scholar]
- Harris, J., & Lindsey, G. (1995). The elements of phonological representation. In J. Durand, & F. Katamba (Eds.), Frontiers of phonology (pp. 34–79). Longman. [Google Scholar]
- Hay, J., & Foulkes, P. (2016). The evolution of medial/t/over real and remembered time. Language, 92(2), 298–330. [Google Scholar] [CrossRef]
- Honeybone, P. (2001). Lenition inhibition in Liverpool English. English Language and Linguistics, 5(2), 213–249. [Google Scholar] [CrossRef]
- Hualde, J. I., & Nadeu, M. (2012). Lenition and phonemic overlap in Rome Italian. Phonetica, 68(4), 215–242. [Google Scholar] [CrossRef]
- Hudson, R. A. (1996). Sociolinguistics. Cambridge University Press. [Google Scholar]
- Jakobson, R., Gunnar M. Fant, C., & Halle, M. (1952). Preliminaries to speech analysis: The distinctive features and their correlates. MIT Press. [Google Scholar]
- Katz, J., & Pitzanti, G. (2019). The phonetics and phonology of lenition: A campidanese sardinian case study. Laboratory Phonology: Journal of the Association for Laboratory Phonology, 10(1), 1–40. [Google Scholar] [CrossRef]
- Kaye, J., Lowenstamm, J., & Vergnaud, J.-R. (1985). The internal structure of phonological segments: A theory of charm and government. Phonology Yearbook, 2, 305–328. [Google Scholar] [CrossRef]
- Kaye, J., Lowenstamm, J., & Vergnaud, J.-R. (1990). Constituent structure and government in phonology. Phonology, 7(1), 193–231. [Google Scholar] [CrossRef]
- Kingston, J. (2008). Lenition. In L. Colantoni, & J. Steele (Eds.), Proceedings of the 3rd conference on laboratory approaches to spanish phonology (pp. 1–31). Cascadilla Proceedings Project. [Google Scholar]
- Kirchner, R. (2004). Consonant lenition. In B. Hayes, R. Kirchner, & D. Steriade (Eds.), Phonetically based phonology (1st ed., pp. 313–345). Cambridge University Press. [Google Scholar] [CrossRef]
- Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2017). lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software, 82(13), 1–26. [Google Scholar] [CrossRef]
- Labov, W. (2001). Principles of linguistic change. Vol. 2: Social factors. Blackwell. [Google Scholar]
- Loporcaro, M. (2005). La sillabazione di muta cum liquida dal latino al romanzo. In S. Kiss, L. Mondin, & G. Salvi (Eds.), Latin et langues romanes (pp. 419–430). De Gruyter. [Google Scholar] [CrossRef]
- Lowenstamm, J. (1996). CV as the only syllable type. In J. Durand, & B. Laks (Eds.), Current trends in phonology, models and methods (pp. 419–443). European Studies Research Institute. [Google Scholar]
- Lowenstamm, J. (1999). The beginning of the word. In J. Rennison, & K. Kühnhammer (Eds.), Phonologica 1996 (pp. 153–166). Syllables!? Holland Academic Graphics. [Google Scholar]
- Mairano, P., Nodari, R., Ardolino, F., De Iacovo, V., & Mereu, D. (2025). Inherently Long Consonants in Contemporary Italian Varieties: Regional Variation and Orthographic Effects. Languages, 10(6), 118. [Google Scholar] [CrossRef]
- Marotta, G. (1985). Modelli e misure ritmiche. La durata vocalica in italiano. Zanichelli. [Google Scholar]
- Marotta, G. (1988). The Italian diphthongs and the autosegmental framework. In P. M. Bertinetto, & M. Loporcaro (Eds.), Certamen phonologicum: Papers from the 1987 cortona phonology meeting (pp. 399–430). Rosenberg and Sellier. [Google Scholar]
- Marotta, G. (1995). Apocope nel parlato di Toscana. Studi italiani di linguistica teorica e applicata, XXIV/2, 297–322. [Google Scholar]
- Marotta, G. (2001). Non solo spiranti. la ‘gorgia toscana’ nel parlato di Pisa. L’Italia Dialettale, 62, 27–60. [Google Scholar]
- Marotta, G. (2003). Una rivisitazione acustica della ‘gorgia’ toscana. In F. A. Leoni, F. Cutugno, M. Pettorino, & R. Savy (Eds.), Atti del convegno nazionale Il parlato italiano. Napoli (13–15 Febbraio 2003). D’Auria. [Google Scholar]
- Marotta, G. (2008). Lenition in tuscan Italian (gorgia toscana). In J. B. De Carvalho, T. Scheer, & P. Ségéral (Eds.), Lenition and fortition (pp. 235–272). Mouton de Gruyter. [Google Scholar] [CrossRef]
- Marotta, G. (2014). New parameters for the sociophonetic indexes: Evidence from the Tuscan varieties of Italian. In C. Celata, & S. Calamai (Eds.), Studies in language variation (pp. 137–168). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Marotta, G., Cossu, P., & Avano, G. (2023). Voiceless stops in Syllable coda in tuscan Italian. In R. Skarnitzl, & J. Volín (Eds.), Proceedings of the 20th international congress of phonetic sciences (pp. 1995–1999). Guarant International. [Google Scholar]
- Marotta, G., & Vanelli, L. (2021). Fonologia e prosodia dell’italiano. Carocci editore. [Google Scholar]
- Martinez-Gil, F. (2019). Spirantization and the phonology of spanish voiced obstruents. In S. Colina, & F. Martinez-Gil (Eds.), The routledge handbook of spanish phonology (pp. 34–83). Routledge. [Google Scholar]
- McCrary, K. (2004). Reassessing the role of the syllable in Italian phonology: An experimental study of consonant cluster syllabification, definite article allomorphy and segment duration [Doctoral dissertation, University of California]. [Google Scholar]
- Morandini, D. (2007). The phonology of loanwords into Italian [Master’s thesis, University College London]. [Google Scholar]
- Pacini, B. (1998). Il processo di cambiamento dell’indebolimento consonantico a Cortona: Studio sociolinguistico. RID: Rivista Italiana di Dialettologia, 22, 15–57. [Google Scholar] [CrossRef]
- Pacini, B. (2010, December 14–15). Spirantizzazione fiorentina: Da ‘covert prestige’ a ‘overt prestige? Poster Presented at the Workshop Sociophonetics, at the Crossroads of Speech Variation, Processing and Communication, Pisa, Italy. [Google Scholar]
- Parrell, B. (2010). Articulation from acoustics: Estimating constriction degree from the acoustic signal. The Journal of the Acoustical Society of America, 128(4), 2289. [Google Scholar] [CrossRef]
- Petrova, O., Plapp, R., Ringen, C., & Szenyörgyi, S. (2006). Voice and Aspiration: Evidence from Russian, Hungarian, German, Swedish, and Turkish. The Linguistic Review, 23, 1–35. [Google Scholar] [CrossRef]
- Pfiffner, A., & Martinez-Garcia, J. (2023). Spirantization of word final plosives in Standard Dutch. In R. Skarnitzl, & J. Volín (Eds.), Proceedings of the 20th international congress of phonetic sciences (pp. 877–881). Guarant International. [Google Scholar]
- Phillips, B. S. (1984). Word frequency and the actuation of sound change. Language, 60(2), 320. [Google Scholar] [CrossRef]
- Piccardi, D. (2017). Sociophonetic factors of speakers’ sex differences in Voice Onset Time: A Florentine case study. In C. Bertini, C. Celata, G. Lenoci, C. Meluzzi, & I. Ricci (Eds.), Fattori sociali e biologici nella variazione fonetica (pp. 83–106). Officinaventuno. [Google Scholar] [CrossRef]
- Piccardi, D., & Ardolino, F. (2021). Gaming variables in linguistic research. Italian scale validation and a Minecraft pilot study. In C. Bernardasci, D. Dipino, D. Garassino, S. Negrinelli, E. Pellegrino, & S. Schmid (Eds.), L’individualità del parlante nelle scienze fonetiche: Applicazioni tecnologiche e forensi (pp. 299–324). Studi AISV 8. Officinaventuno. [Google Scholar] [CrossRef]
- Pierrehumbert, J. B. (2001). Exemplar dynamics: Word frequency, lenition and contrast. In J. L. Bybee, & P. J. Hopper (Eds.), Typological studies in language (pp. 137–157). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Podesva, R. J., & Kajino, S. (2014). Sociophonetics, gender, and sexuality. In S. Ehrlich, M. Meyerhoff, & J. Holmes (Eds.), The Handbook of language, gender, and sexuality (pp. 103–122). Wiley. [Google Scholar] [CrossRef]
- Pömp, J., & Draxler, C. (2017, September 28–29). OCTRA—A configurable browser-based editor for orthographic transcription (2017). Phonetik und Phonologie im deutschsprachigen Raum (pp. 145–148), Berlin, Germany. [Google Scholar]
- R Core Team. (2022). R: A language and environment for statistical computing. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 8 July 2024).
- Repetti, L. (1993). L’accento dei prestiti recenti in italiano. Quaderni Patavini di Linguistica, 12, 79–87. [Google Scholar]
- Repetti, L. (2012). Consonant-final loanwords and epenthetic vowels in italian. Catalan Journal of Linguistics, 11, 167–188. [Google Scholar] [CrossRef]
- Russo, M. (2022). Locality domains on lenition. spirantization (Gorgia) and voicing in Tuscan Dialects. Linx, 84, 1–91. [Google Scholar] [CrossRef]
- Scheer, T. (2004). A lateral theory of phonology. Mouton de Gruyter. [Google Scholar]
- Scheer, T., & Ziková, M. (2010). The coda mirror V2. Acta Linguistica Hungarica, 57(4), 411–431. [Google Scholar] [CrossRef]
- Schiel, F. (1999, August 1–7). Automatic phonetic transcription of non-prompted speech. ICPhS 1999 (pp. 607–610), San Francisco, CA, USA. [Google Scholar]
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. [Google Scholar] [CrossRef]
- Ségéral, P., & Scheer, T. (2001). La coda-miroir. Bulletin de La Société de Linguistique de Paris, 96, 107–152. [Google Scholar]
- Sérégal, P., & Scheer, T. (2008). The coda mirror, stress and positional parameters. In J. B. De Carvalho, T. Scheer, & P. Ségéral (Eds.), Lenition and fortition (pp. 483–518). Mouton de Gruyter. [Google Scholar] [CrossRef]
- Sorianello, P. (2001). Un’analisi acustica della’gorgia’fiorentina. L’Italia Dialettale, 62, 61–94. [Google Scholar]
- Sorianello, P. (2003). Spectral characteristics of voiceless fricative consonants in Florentine Italian. In M.-J. Solé, D. Recasens, & J. Romero (Eds.), Proceedings of the 15th international congress of phonetic sciences, Barcelona, Spain (pp. 3081–3084). Casual Productions. [Google Scholar]
- Sorianello, P. (2004). Proprietà spettrali del rumore di frizione nel consonantismo fiorentino. In F. Albano Leoni, F. Cutugno, M. Pettorino, & R. Savy (Eds.), Il parlato italiano (CD-ROM). D’Auria. [Google Scholar]
- Sorianello, P. (2010). Gorgia toscana. In Enciclopedia dell’Italiano. Treccani. [Google Scholar]
- Sorianello, P., Bertinetto, P. M., & Agonigi, M. (2005). Alle sorgenti della variabilità della ‘gorgia fiorentina: Un approccio analogico. In P. Cosi (Ed.), Convegno nazionale Dell’AISV—Associazione Italiana di scienze della voce, misura dei parametri. aspetti tecnologici ed implicazioni nei modelli linguistici (pp. 327–362). EDK Editore. [Google Scholar]
- Ulfsbjorninn, S. (2017). Bogus clusters and lenition in Tuscan Italian: Implications for the theory of sonority. In G. Lindsey, & A. Nevins (Eds.), Language faculty and beyond (pp. 278–296). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Urban, G. (1986). Linguistic consciousness and allophonic variation: A semiotic perspective. Semiotica, 61(1–2), 33–59. [Google Scholar] [CrossRef]
- Vennemann, T. (1988). Preference laws for syllable structure and the explanation of sound change. Mouton de Gruyter. [Google Scholar]
- Vennemann, T. (2012). Structural complexity of consonant clusters: A phonologist’s view. In P. Hoole, L. Bombien, M. Pouplier, C. Mooshammer, & B. Kühnert (Eds.), Consonant clusters and structural complexity (pp. 11–32). De Gruyter. [Google Scholar] [CrossRef]
- Villafaña Dalcher, C. (2008). Consonant weakening in florentine italian: A cross-disciplinary approach to gradient and variable sound change. Language Variation and Change, 20(2), 275–316. [Google Scholar] [CrossRef]
- Vogel, I. (1982). La sillaba come unità fonologica. Zanichelli. [Google Scholar]
- Wickham, H. (2016). Ggplot2: Elegant graphics for data analysis (2nd ed.). Springer. [Google Scholar] [CrossRef]
- Yaqoub, L., Hellmuth, S., & Bailey, G. (2023). The voiceless velar stop/k/in rijal alma arabic: Revisited. In R. Skarnitzl, & J. Volín (Eds.), Proceedings of the 20th international congress of phonetic sciences (pp. 3686–3690). Guarant International. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age | Sex | Level of Education |
|---|---|---|
| Young adults (22–32 y.o.) N = 20 | Males N = 10 | Graduated N = 5 |
| Non-graduated N = 5 | ||
| Females N = 10 | Graduated N = 5 | |
| Non-graduated N = 5 | ||
| Older adults (45–65 y.o.) N = 22 | Males N = 10 | Graduated N = 5 |
| Non-graduated N = 5 | ||
| Females N = 12 | Graduated N = 5 | |
| Non-graduated N = 7 |
| Token | Sentence | |
|---|---|---|
| Coda (V_C) | ||
| /p/ | /ˈkapsule/ “capsules” | Ho comprato nuove capsule biodegradabili |
| “I bought new biodegradable capsules” | ||
| /kapˈtato/, “intercepted” | L’antenna ha captato un segnale radio | |
| “The aerial intercepted a radio signal” | ||
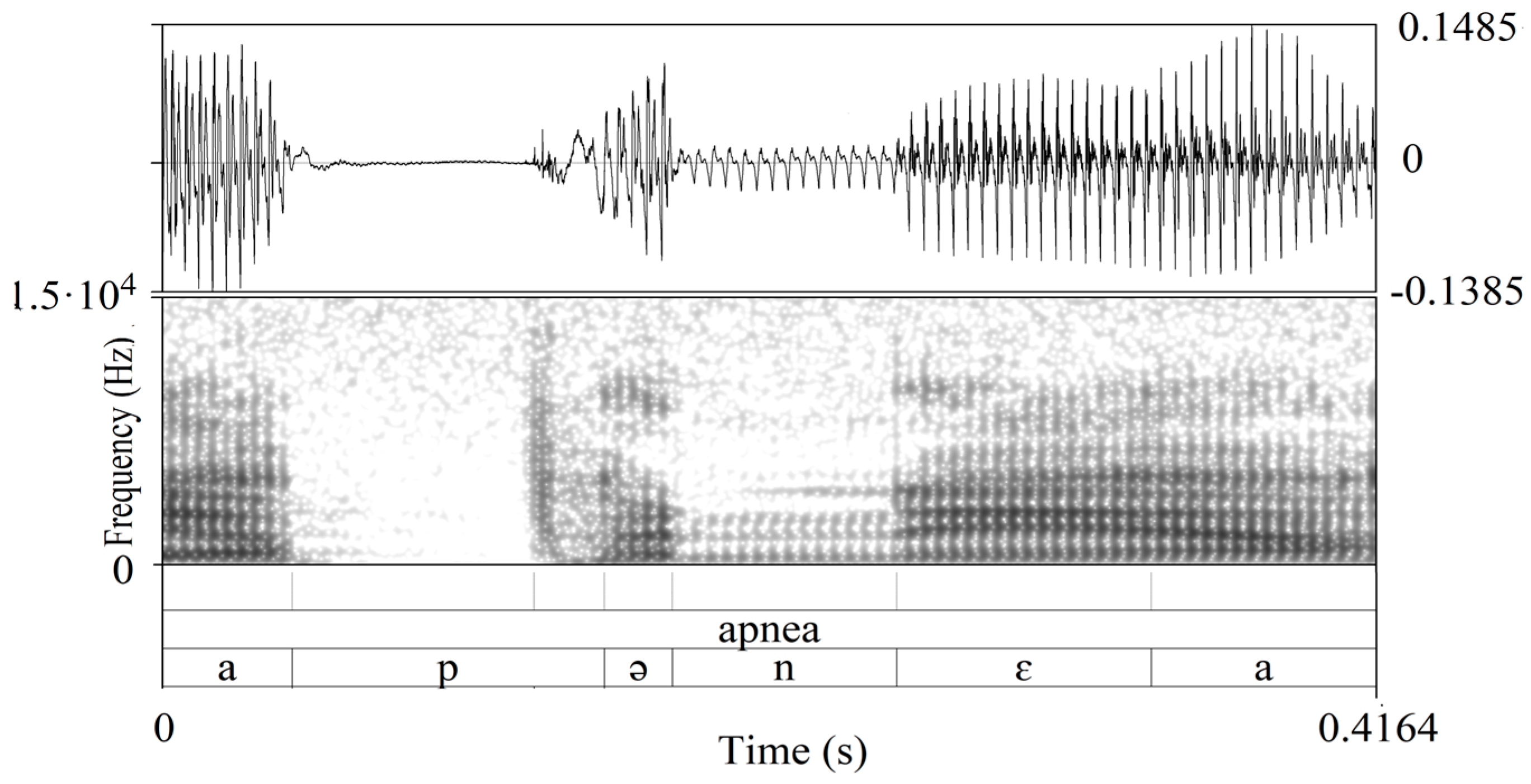
| /apˈnɛa/, “freediving” | Segue un corso di apnea subacquea | |
| “He/she is taking a freediving course” | ||
| /ipˈnɔsi/ “hypnosis” | Segue una tecnica di ipnosi terapeutica | |
| “He/she is following a therapeutic hypnosis technique” | ||
| /t/ | /ˈritmo/ “rhythm” | Ballavano a ritmo di musica |
| “They were dancing to the rhythm of music” | ||
| /atmosˈfɛra/ “atmosphere” | C’è un’atmosfera strana | |
| “There is a strange atmosphere” | ||
| /k/ | /ˈtɛknika/ “technique” | Segue una tecnica di ipnosi terapeutica |
| “He/She follows a therapeutic hypnosis technique” | ||
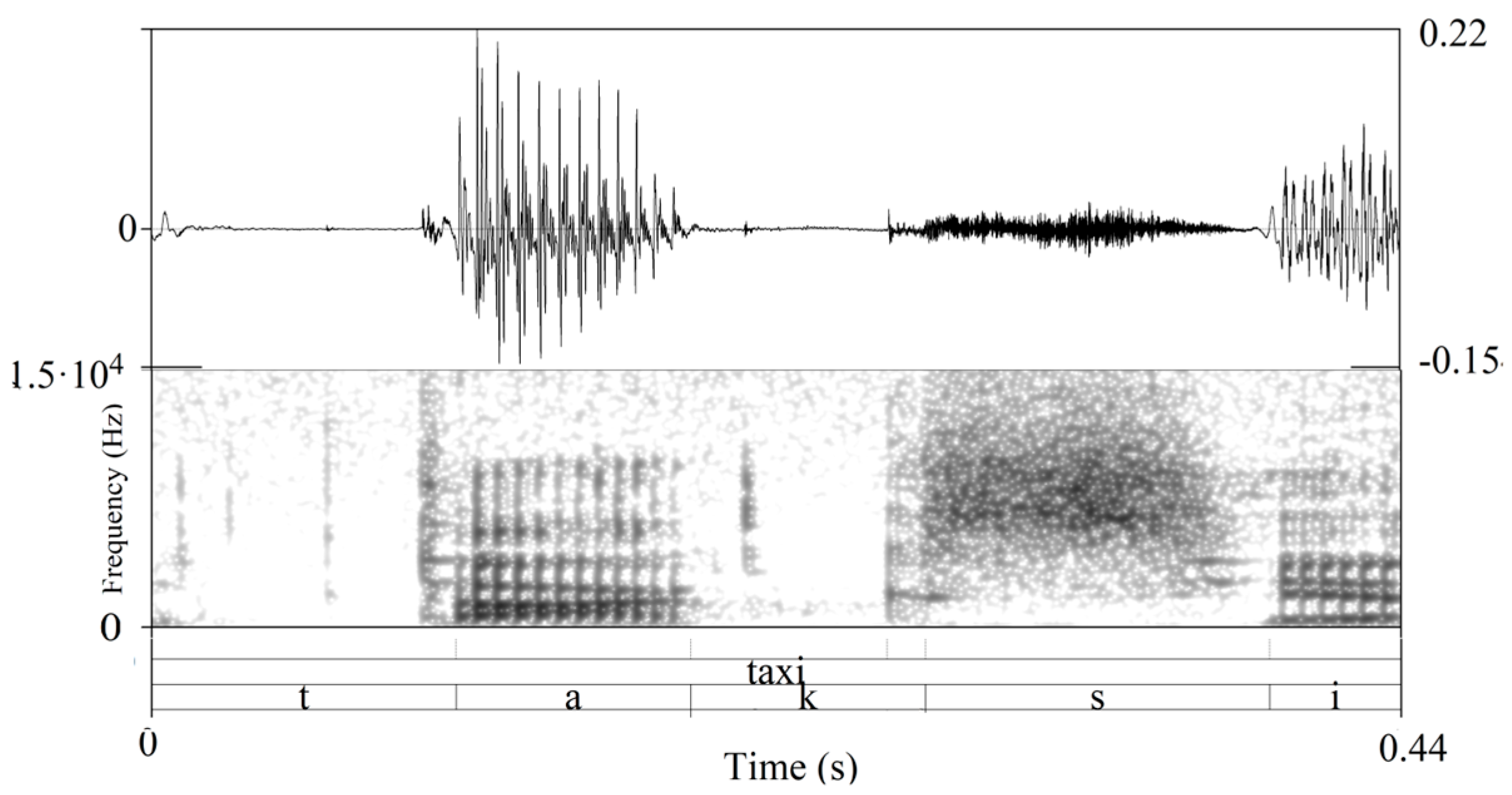
| /ˈtaksi/ “taxi” | Ho preso un taxi alla stazione | |
| “I took a taxi from the station” | ||
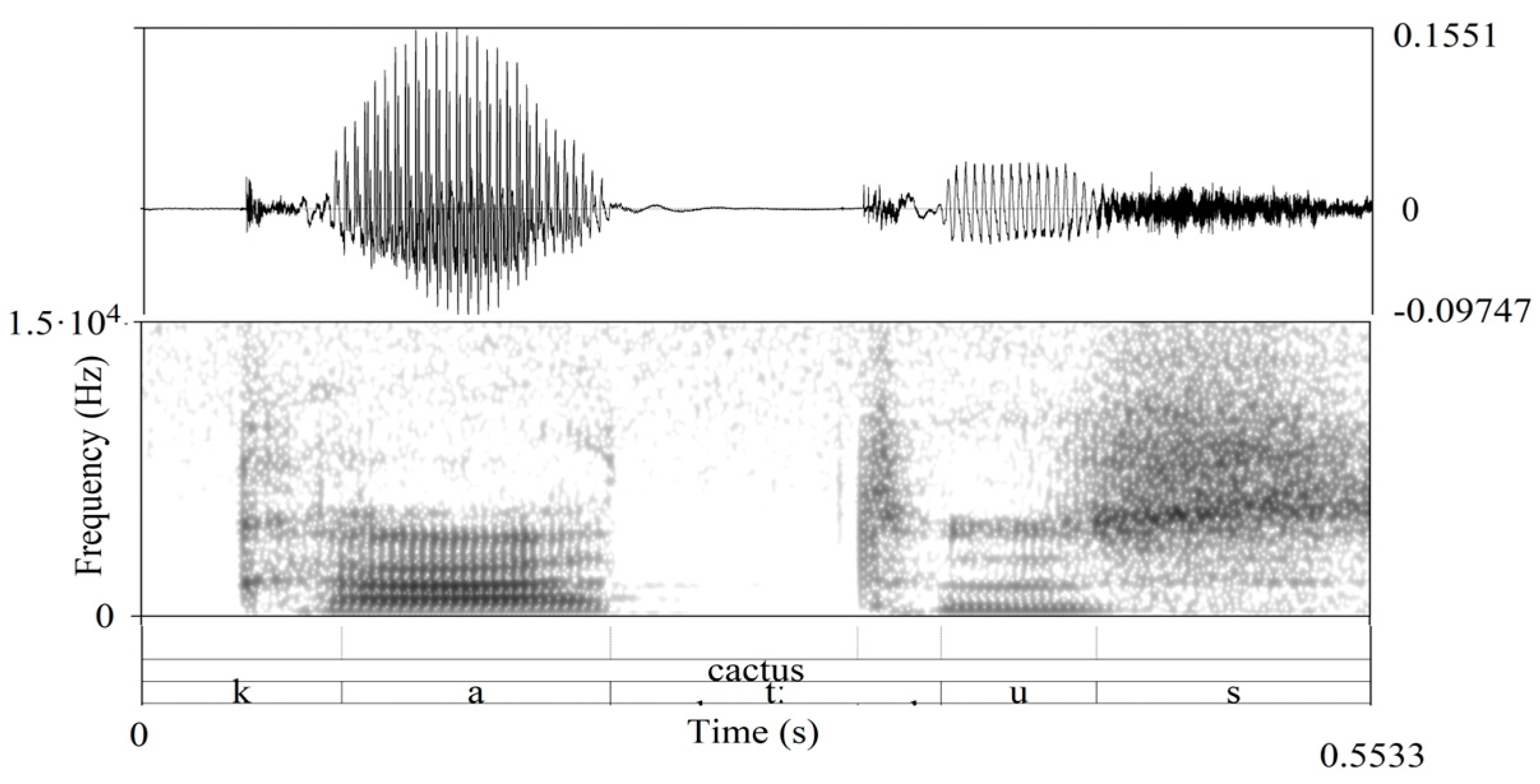
| /ˈkaktus/ “cactus” | È caduto su un cactus spinoso | |
| “He fell onto a thorny cactus” | ||
| Onset (V_V) | ||
| /p/ | /ˈkrɛpa/ “crack” | Ho ricoperto la crepa grossa |
| “I covered the large crack” | ||
| /ˈrapa/ “turnip” | Oggi c’è solo rapa bollita | |
| “Today there is only boiled turnip” | ||
| /ˈtipo/ “guy” | Luca è un tipo a posto | |
| “Luca is an upright guy” | ||
| /t/ | /ˈʧɛto/ “class” | Fa parte del ceto medio |
| “He belongs to the middle class” | ||
| /ˈdito/ “finger” | Ho picchiato il dito mignolo | |
| “I hit my pinky finger” | ||
| /ˈfɔto/ “picture” | Ho ancora quella foto ricordo | |
| “I still have that photo as a souvenir” | ||
| /k/ | /ˈbuka/ “hole” | Hanno scavato una buca profonda |
| “They dug a deep hole” | ||
| /ˈkwɔko/ “cook” | Giuseppe è un cuoco notevole | |
| “Giuseppe is a remarkable cook” | ||
| /ˈfiki/ “figs” | Fanno le nozze coi fichi secchi | |
| “They are celebrating their wedding with dried figs” (idiom) | ||
| Stop | Fricative | Approximant | Deletion | Assimilated | Total | |
|---|---|---|---|---|---|---|
| Coda (V_C) | 207 (88.8%) | 15 (6.4%) | 0 | 0 | 11 (4.7%) | 233 (100.0%) |
| /p/ | 57 (95.0%) | 1 (1.7%) | 2 (3.3%) | 60 (100.0%) | ||
| /t/ | 75 (90.4%) | 8 (9.6%) | 83 (100.0%) | |||
| /k/ | 75 (83.3%) | 6 (6.7%) | 9 (10.0%) | 90 (100.0%) | ||
| Onset (V_V) | 36 (9.5%) | 232 (61.4%) | 101 (26.7%) | 9 (2.4%) | n/a | 378 (100.0%) |
| /p/ | 19 (15.1%) | 94 (74.6%) | 13 (10.3%) | 0 | 126 (100.0%) | |
| /t/ | 12 (9.5%) | 99 (78.6%) | 15 (11.9%) | 0 | 126 (100.0%) | |
| /k/ | 5 (4.0%) | 39 (31.0%) | 73 (57.9%) | 9 (7.1%) | 126 (100.0%) |
| Coda (V_C) | GT application | Non-continuant 218 (93.6%) | Continuant 15 (6.4%) | |||
| Allophones | Stop 207 (88.8%) | Assimilation 11 (4.7%) | Fricative 15 (6.4%) | Approximant 0 | Deletion 0 | |
| Onset (V_V) | GT application | Non-continuant 41 (9.5%) | Continuant 453 (90.5%) | |||
| Allophones | Stop 36 (9%) | Assimilation n/a | Fricative 232 (61.4%) | Approximant 140 (26.7%) | Deletion 9 (2.4%) | |
| Onset | Coda | |||||
|---|---|---|---|---|---|---|
| Variable Level | Non-Continuant | Continuant | Total | Non-Continuant | Continuant | Total |
| Education | ||||||
| graduated | 32 (17.8%) | 148 (82.2%) | 180 (100.0%) | 103 (96.3%) | 4 (3.7%) | 107 (100.0%) |
| non-graduated | 4 (2.0%) | 194 (98.0%) | 198 (100.0%) | 115 (91.3%) | 11 (8.7%) | 126 (100.0%) |
| Sex | ||||||
| female | 23 (11.6%) | 175 (88.4%) | 198 (100.0%) | 118 (96.7%) | 4 (3.3%) | 122 (100.0%) |
| male | 13 (7.2%) | 167 (92.8%) | 180 (100.0%) | 100 (90.1%) | 11 (9.9%) | 111 (100.0%) |
| Age | ||||||
| young | 20 (11.1%) | 160 (88.9%) | 180 (100.0%) | 103 (96.3%) | 4 (3.7%) | 107 (100.0%) |
| adult | 16 (8.1%) | 182 (91.9%) | 198 (100.0%) | 115 (91.3%) | 11 (8.7%) | 126 (100.0%) |
| Predictors | Estimate | Odds Ratios | SE | z Value | p |
|---|---|---|---|---|---|
| (Intercept) | −4.51 | 0.01 | 0.73 | −6.17 | <0.001 |
| position [onset] | 7.98 | 2924.63 | 0.82 | 9.75 | <0.001 |
| level of education [non-graduated] | 2.04 | 7.67 | 0.69 | 2.93 | 0.003 |
| phoneme [p] | −1.78 | 0.17 | 0.58 | −3.06 | 0.002 |
| phoneme [t] | −0.45 | 0.64 | 0.52 | −0.88 | 0.380 |
| Stop | Assimilated | Fricative | Total | |||
|---|---|---|---|---|---|---|
| Released Stop | Unreleased Stop | Stop + Epenthesis | ||||
| V_stop e.g., /kaktus/ | 60 (71.4%) | 12 (14.3%) | 1 (1.2%) | 11 (13.1%) | 0.0% | 84 (100.0%) |
| V_s e.g., /taksi/ | 28 (58.3%) | 13 (27.1%) | 0 | 0 | 7 (14.6%) | 48 (100.0%) |
| V_N e.g., /ritmo/ | 75 (74.3%) | 11 (10.9%) | 7 (6.9%) | 0 | 8 (7.9%) | 101 (100.0%) |
| Total | 163 (70.0%) | 36 (15.5%) | 8 (3.4%) | 11 (4.7%) | 15 (6.4%) | 233 (100.0%) |
| Phone Duration (ms) | NDur | IntDiff (dB) | |
|---|---|---|---|
| Coda (V_C) (n = 137) | 100 (36) | 1.13 (0.55) | 35 (5) |
| Assimilated (n = 9) | 156(37) | 1.46 (0.50) | 42 (5) |
| Stop5 (n = 118) | 98 (32) | 1.14 (0.55) | 35 (5) |
| Fricative (n = 10) | 74 (30) | 0.75 (0.33) | 31 (6) |
| Onset (V_V) (n = 378) | 63 (22) | 0.90 (0.44) | 19 (8) |
| Stop (n = 36) | 77 (10) | 1.29 (0.42) | 27 (6) |
| Fricative (n = 232) | 73 (14) | 0.97 (0.36) | 22 (6) |
| Approximant (n = 101) | 42 (17) | 0.55 (0.26) | 12 (6) |
| Deletion (n = 9) | 0 | 0 | 0 |
| Predictors | Estimates | Std. Error | df | t Value | p |
|---|---|---|---|---|---|
| (Intercept) | 35.57 | 2.24 | 15.21 | 15.88 | <0.001 |
| Syllabic position [onset] | −17.01 | 2.68 | 13.06 | −6.34 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avano, G.; Cossu, P. The Importance of Being Onset: Tuscan Lenition and Stops in Coda Position. Languages 2025, 10, 129. https://doi.org/10.3390/languages10060129
Avano G, Cossu P. The Importance of Being Onset: Tuscan Lenition and Stops in Coda Position. Languages. 2025; 10(6):129. https://doi.org/10.3390/languages10060129
Chicago/Turabian StyleAvano, Giuditta, and Piero Cossu. 2025. "The Importance of Being Onset: Tuscan Lenition and Stops in Coda Position" Languages 10, no. 6: 129. https://doi.org/10.3390/languages10060129
APA StyleAvano, G., & Cossu, P. (2025). The Importance of Being Onset: Tuscan Lenition and Stops in Coda Position. Languages, 10(6), 129. https://doi.org/10.3390/languages10060129