Abstract
We propose an econometric procedure based mainly on the generalized random forests method. Not only does this process estimate the quantile treatment effect nonparametrically, but our procedure yields a measure of variable importance in terms of heterogeneity among control variables. We also apply the proposed procedure to reinvestigate the distributional effect of 401(k) participation on net financial assets, and the quantile earnings effect of participating in a job training program.
1. Introduction
Causal machine learning, which is based on two approaches: the double machine learning (DML), cf. Chernozhukov et al. (2018), and the generalized random forests method (GRF), cf. Athey et al. (2019), has been actively studied in economics in recent years. With the identification strategy of selection on observables, empirical applications have been investigated by using the aforementioned two approaches, including the works by Gilchrist and Sands (2016) and Davis and Heller (2017). When it comes to the identification strategy of selection on unobservables, few empirical papers using causal machine learning can be found in the existing literature. Those empirical applications very often lack important observed control variables or involve reverse causality, and thus researchers resort to the instrumental variable approach. Additionally, it remains unclear how the quantile treatment effect is to be estimated under the DML and GRF methods. In this paper, with the use of instrumental variables, we propose an econometric procedure for estimating quantile treatment effects based primarily on the generalized random forests of Athey et al. (2019).
Chernozhukov and Hansen (2005) propose an estimator that addresses endogeneity in quantile regressions via rank similarity, a crucial feature absent in the prior approaches. Using rank similarity, this estimator studies the heterogeneous quantile effects of an endogenous variable over the entire population (rather than for the compliers). Rank similarity thus identifies population-based quantile treatment effects, cf. Frandsen and Lefgren (2018). This approach does not require the monotonicity assumption used in Abadie et al. (2002) and allows for binary or continuous endogenous and instrumental variables. Chernozhukov and Hansen (2008) create a bridge between two-stage least squares (2SLS) estimator and their 2005 estimator, and propose an estimator robust to weak instruments. However, it is noteworthy that these estimator are unable to estimate unconditional quantiles, which are, as discussed in Guilhem et al. (2019), quantities that should be of utmost interest to empirical researchers. In this paper, we use the instrumental variable quantile regression of Chernozhukov and Hansen (2008) as a vehicle for identifying the quantile treatment effect.
Athey and Imbens (2016) is the first paper that develops the regression tree model to estimate heterogeneous treatment effects using the honest splitting algorithm. Wager and Athey (2018) extend the regression tree model to causal forests. Recently, Athey et al. (2019) have developed the generalized random forests model, which is a unified framework in the sense that it is built on local moment conditions capable of encompassing many models. Therefore, we bring the first order condition of the instrumental variable quantile regression into the local moment conditions and then modify the GRF algorithm. Accordingly, the quantile treatment effect can be estimated under the framework of causal random forests. Thus, our proposed estimator and the generalized random forests model both share the advantage of estimating the conditional quantile treatment effect nonparametrically.
Chen and Tien (2019) investigate the instrumental variable quantile regression in the context of double machine learning. Although related to their paper, our procedure is not considering the same high-dimensional setting. Further, in contrast to the DML for instrumental variable quantile regressions, the proposed econometric procedure yields a measure of variable importance in terms of heterogeneity among control variables. The pattern of variable importance across quantiles can be revealed as well. We highlight the usage of exploring variable importance by reinvestigating two empirical studies - the distributional effect of 401(k) participation on net financial assets, and the quantile effect of participating in a job training program on earnings.
The rest of the paper is organized as follows. The model specification and practical algorithm are introduced in Section 2. Section 3 presents the measure of variable importance. Section 4 presents two empirical applications. Section 5 concludes the paper. The Appendix A discusses the usage of a doubly robust method along with the causal random forests structure for achieving more efficient estimation. The Appendix A also discusses the identifying restrictions and regularity conditions for the instrumental variable quantile regression and the generalized random forests, and further verifies conditions for establishing consistency and asymptotic normality of the proposed estimator.
2. The Model and Algorithm
We propose the causal random forests with the instrumental variable quantile regression (GRF-IVQR, hereafter). Estimation procedure of the GRF-IVQR is constructed as below, essentially based on the method developed in Athey et al. (2019).
2.1. Generalized Random Forests
The classification tree and regression tree (CART) and its extension, random forests Breiman (2001), are effective methods for flexibly estimating regression functions in terms of out-of-sample predictive power. Random forests have become particularly popular methods. A key attraction is that they require relatively little tuning and have superior performance to more complex methods such as deep learning neural networks, cf. Section 3.2 of Athey and Imbens (2019). Recently, random forests have garnered interest and have been extended to causal effects; that is, the generalized random forests estimator.
In what follows, we describe how we incorporate the instrumental variable quantile regression into the framework of GRF and modify the resulting estimator accordingly.
Given data , we estimate the parameter of interest via the following moment conditions
where stands for the score function and are optional nuisance parameters. The above moment conditions, similar to the generalized method of moments (GMM), can be used to identify many objects of interest from an economic perspective. We seek forest-based estimates, , which are the conditional quantile treatment effects, in the context of instrumental variable quantile regressions.
Chernozhukov and Hansen (2005) laid the theoretical foundations for the instrumental variable quantile regression (IVQR). With outcome , endogenous treatment variable , instrumental variable , and control variables , the IVQR can be represented as the following moment conditions
where is the conditional quantile treatment effect, are the nuisance parameters, is the indicator function, and is a quantile index.
The sample counterpart of the local moment conditions and the estimator of are introduced by Athey et al. (2019) and defined as below.
where are tree-based weights averaged by the forest, which measure how often each training example falls in the same leaf as x. In other words, these weights represent the relevance of each sample when we estimate . Specifically, the weights are obtained by a forest-based algorithm. For the point of interest x, let represent the set of samples which fall in the same terminal leaf and contain x in bth tree, where . That is to say, the weight of each sample for the point of interest x will be the frequency with which the ith sample is in the same terminal leaf among all trees . That is,
With such forest-based weights and a pre-specified quantile index , we minimize the criterion function constructed using sample moment conditions, and then an estimate of the conditional quantile treatment effect is obtained. In the subsequent section, we discuss how to grow the trees and the forests with the instrumental variable quantile regression.
2.2. Tree Splitting Rules
Growing a tree is a recursive binary splitting process. The spirit of the tree-based algorithm is to split the data in the parent node P in half by maximizing the heterogeneity of the associated two children nodes .
Specifically, for node j with data , we define the node parameters as follows.
where . In each node, we minimize the following criterion
which is based on the GRF method. However, the minimization is infeasible due to the unknown value of . Athey et al. (2019) turn this minimization problem of into an accessible model-free maximization problem of
where are numbers of observations in children and parent nodes. Along the way of maximizing , the is estimated by the IVQR with respect to all possible splittings which correspond to the set . Consequently, the estimation is computationally infeasible. To circumvent this difficulty, Athey et al. (2019) suggest a gradient tree algorithm which maximizes an approximate criterion . In what follows, with two new ingredients and defined below, we construct step by step.
We first define as the gradient of the expectation of the moment condition.
where is a cumulative distribution function, and m is the dimension of X. For simplicity of derivation, we fix the following notations. , , ⋯, , and we suppress which means the estimation is conditional on the parent node. Accordingly, can be written as the gradient of with respect to the parent node parameters.
where is the probability density function of . Therefore, the inverse of ,
We then construct the pseudo-outcomes,
where is a vector that picks out the -coordinate from the vector. In the case with one treatment variable D, the vector is . Thus, the corresponding pseudo-outcomes are
where the denotes the number of observations in the children node C. The splitting rule is to maximize the following approximate criterion
Notice that since some terms in , such as , do not affect the optimization of , the can be further simplified as follows.
Using the modified above, is our splitting rule for the instrumental variable quantile regression within the framework of generalized random forests. Based on the splitting rule, the tree is grown by recursively partitioning the data until a stopping criterion is met, cf. Section 2.4.
2.3. The Algorithm and an Example Illustrating Weights Calculation
With the splitting rule established, we can now grow the entire forests. In Athey and Imbens (2016) and Wager and Athey (2018), the concept of honest estimation is introduced, which is also included in the generalized random forests model. A model is honest if the information for the model construction and estimation is not the same. In the tree-forming case, the honesty here is consider as a sub-sample splitting between tree forming and weight calculation.
Here is an example of the implementation of honest estimation. Suppose we have eight samples in our data J, where . We split the sample in half honestly, and we have two sub-samples for tree forming and weight calculation. By the splitting rule, we can construct the following tree with ,

Next, we identify where the data of is located in the tree.

Then we use this information to calculate the frequency and obtain the weights. Suppose we do not have any out of sample points of interest, we use each of the eight samples as point of interest, one at a time. If the point of interest is , since a is in the same leaf with , samples each gets of weight, get 0 of weight. If the point of interest is , since b is in the same leaf with , sample gets 1 of weight, get 0 of weight. By utilizing this method, we can get the weight for all data points. The following is the weight matrix for the above 1-tree model,
| Point of interest | a | b | c | d | e | f | g | h |
| Weight for sample a | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Weight for sample b | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Weight for sample c | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Weight for sample d | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Weight for sample e | 0 | 0 | 0 | |||||
| Weight for sample f | 0 | 0 | 0 | |||||
| Weight for sample g | 0 | 0 | 0 | |||||
| Weight for sample h | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
Athey et al. (2019) prove that with proper honest sub-sampling rate and regularity conditions, the generalized random forests estimator is consistent and asymptotic normal to .
To build the random forests with honest tree, we first randomly select of sample for each tree. Then in each tree, we use subsampling rate for honest splitting. For the average quantile treatment effect, we adopt each point in the data as the point of interest using their own weights one by one and get the average of all results.
2.4. Practical Implementation
When implementing the generalized random forests algorithm, we first obtain baseline grids through the conventional IVQR estimator, and then utilize those grids to grow the tree. With the IVQR estimator and its standard error , we construct the interval . We divide this interval into 100 equal parts, and then obtain the baseline grid
For tree in the random forest estimation, half of the data is randomly selected. Consequently, we should reconstruct the grid for each tree. Similarly, we build the grid for the tree b
which is obtained via the randomly selected half of data in the tree b.
Following the concept of honest estimation, we further split the data into two parts denoted as data and . Data is used to grow the tree, and data is used to form the weight . As to grow the tree with data , in what follows, we outline the splitting process in each node. We first estimate the parent node parameters and by optimizing
with the grid for the tree b. We then implement the splitting criterion
for every split.
The tree keeps splitting recursively until they reach the minimum-node-size constraint or a situation that the data in the parent node has little variation, therefore further splitting is infeasible. These two practical stopping criteria on splitting suffice for reasonable estimates.
Regarding estimation of the weight, we first identify where the observations in will be located in the tree constructed by the data . Using the algorithm discussed in the Section 2.3, we compute the weight for every data point. Accordingly, we have determined the estimation of growing a tree b.
By growing a total of B trees and averaging the weight in each tree, we obtain the weight of each observation. With the weight , we estimate the conditional local quantile treatment effect
To yield the local quantile treatment effect, we could average all x-pointwise conditional local quantile treatment effects. However, the averaging procedure can be further modified to get more efficient estimates, which is discussed in the Appendix A. Nevertheless, our empirical studies in Section 4 suggest that with a proper sampled data, the aforementioned practical procedure performs substantially well.
3. Variable Importance
Athey et al. (2019) and the associated grf R package develop a measurement for sorting variable importance which is a unique advantage of tree-based models. To explore the variable importance across quantiles, we adopt their measure of importance reproduced as follows.
where the number of maximum depth is pre-specified by empirical researchers. Specifically, this measure of variable importance only considers the splitting frequency for variable in trees .
This version of importance measurement shares similarity with the Gini importance widely used in random forests. Therefore, both algorithms prefer continuous variables since they have more potential splitting chances compared to binary variables. We thus shall be cautious when interpreting variable importance between a continuous variable and a categorical variable. Another important remark is that we should not conclude a particular covariate is unrelated to treatment effects simply because the tree did not split on it. There can be many different ways to pick out a subgroup of units with high or low treatment effects. Thus by comparing the average characteristics of units with high treatment effects to those with low treatment effects, researchers could obtain a fuller picture of the differences between these groups across all covariates.
Similar to the R-squared, variable importance signifies whether a variable yields enough explanatory power to the outcome variable in light of variation. Variable importance can also be used for model selection. In recent literature, e.g., O’Neill and Weeks (2018), researchers adopt variable importance measurement for policy making. Given hundreds of variables, the forest-based algorithm picks out important variables, which suffices for policy makers to identify their benchmark models.
4. Empirical Studies
In this section, we reinvestigate two empirical studies on quantile treatment effects: the effect of 401(k) participation on wealth, cf. Chernozhukov and Hansen (2004), and the effect of job training program participation on earnings, cf. Abadie et al. (2002). Not only does this conduct data-driven robustness checks on the econometric results, but the GRF-IVQR yields a measure of variable importance in terms of heterogeneity among control variables. This complements the existing empirical findings. In addition, we compare our empirical results with those from Chen and Tien (2019), the IVQR estimation based on the double machine learning approach, which is an alternative in causal machine learning literature.
As a critical note, we do not estimate and report the conditional quantile treatment effect (CQTE) in the applications. When the outcome level has an impact on the effect size and the conditional outcome variable are heterogeneous, then the CQTE could report spurious heterogeneity; see comprehensive summary of the problem in Strittmatter (2019). The same problem carries through to the importance measure. Therefore, the variable importance has to be interpreted with caution across different quantiles.
4.1. The 401(k) Retirement Savings Plan
Examining the effects of 401(k) plans on accumulated wealth is an issue of long-standing empirical interest. For example, based on the identification of selection on observables, Chiou et al. (2018) and Chernozhukov and Hansen (2013) suggest that the income nonlinear effect exists in the 401(k) study. Nonlinear effects from other control variables are identified as well. Few papers, however, investigate variable importance among control variables, cf. Chen and Tien (2019). In addition to estimating the quantile treatment effect of 401(k) participation, we fully explore variable importance across the conditional quantiles of accumulated wealth in light of the generalized random forests. The corresponding findings shed some light on the existing literature.
The data with 9915 observations are from the 1991 Survey of Income and Program Participation. The outcome variable is the net financial asset. The treatment variable is a binary variable standing for participation in the 401(k) plan. The instrument is an indicator for being eligible to enroll in the 401(k) plan. Control variables consist of age, income, family size, education, marital status, two-earner status, defined benefit pension status, individual retirement account (IRA) participation status, and homeownership status, which follow the model specification used in Chernozhukov and Hansen (2004).
Table 1 signifies that the quantile treatment effects estimated by the GRF-IVQR are similar to those calculated in Chernozhukov and Hansen (2004). The 401(k) participation has larger positive effects on net financial assets for people with higher savings propensity which corresponds to the upper conditional quantiles. The estimated treatment effects show a monotonically increasing pattern across the conditional distribution of net financial assets. Thus, the pattern identified by Chernozhukov and Hansen (2004) is assured through our data-driven robustness checks.

Table 1.
Quantile treatment effects of the 401(k) participation on wealth.
Based on the measure of variable importance introduced in Section 3, Table 2 and Figure 1 depict that income, age, education, and family size are the first four important variables in the analysis1. On average, income and age are the most important variables accounting for heterogeneity, which lead to values of the variable importance 64.4% and 15.6%, respectively. We should interpret the variable importance measure with caution, because researchers could reduce the importance measure of one variable by adding a highly correlated additional variable to the model. Accordingly, in this case, the two highly correlated variables have to share the sample splits. However, even with the caution mentioned above, we now have an additional dimension, , which suffices to compare variable importance across quantiles. Particularly, the importance of age variable increases as the savings propensity (quantile index) goes up. The importance of income variable, however, decreases across conditional distribution of net financial assets. In addition, these four variables are also identified as important in the context of double machine learning, cf. Chen and Tien (2019).
Table 2.
Variable importance.
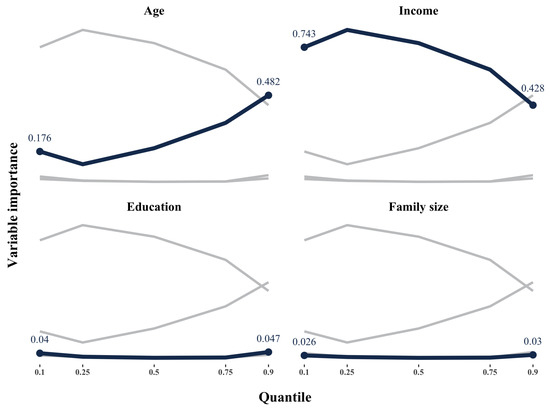
Figure 1.
Variable importance across quantiles.
4.2. The Job Training Program
Abadie et al. (2002) use the Job Training Partnership Act (JTPA) data to estimate the quantile treatment effect of job training on the earning distribution2. The data is from Title II of the JTPA in the early 1990’s, which consists of 11,204 samples, 5102 of which are male, and 6102 of which are female. In the estimation, they take 30-month earnings as the outcome variable, enrollment for JTPA service as the treatment variable, and a randomized offer of JTPA enrollment as the instrumental variable. Control variables include education, race, marital status, previous year work status, job training service strategies, age, and whether earnings data is from the second follow-up survey. In the female group, an additional control, aid to families with dependent children (AFDC), is added. We follow the same model specifications when estimating the GRF-IVQR.
Table 3 and Table 4 show that for females, job training program generates a significantly positive treatment effect on earnings at 0.5 and 0.75 quantiles. GRF-IVQR signifies similar results.
Table 3.
Effects of JTPA enrollment on earning (male).
Table 4.
Effects of JTPA enrollment on earning (female).
For the male group, Table 5 and Figure 2 depicts that work less than 13 weeks (wlkess13) and on-the-job training and/or job search assistance (ojt_jsa) are the most important variables. However, there is no apparent pattern suggesting that variable importance differs across quantiles. The pattern of variable importance resulting from the GRF-IV and the GRF-IVQR are different as well.
Table 5.
Variable importance (male).
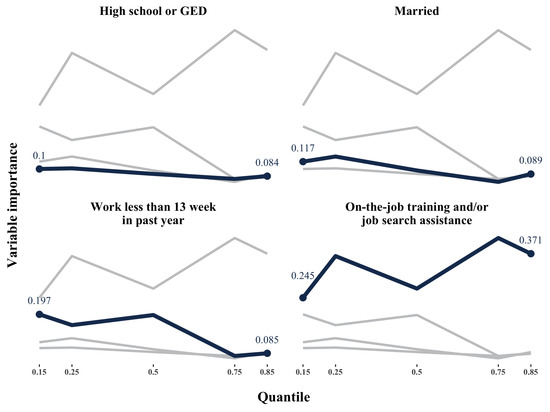
Figure 2.
Top 4 variable importance (male).
As to the GRF-IVQR, in Table 5, the variance importance for Hispanics and the age group 45 to 54 are 0 across all quantiles, while the GRF-IV suggests these two variables are of some importance. Possible explanations are as follows. Compared to the GRF-IVQR’s moment condition, the GRF-IV still performs well in nodes with a relatively small amount of data. Consequently, the GRF-IVQR is more restrictive for growing a shallower tree than the GRF-IV. Therefore, some variables used to make a split in deeper nodes will not be chosen by the GRF-IVQR algorithm. Besides, at deeper nodes, the data is very similar in each node. Specifically, this situation occurs frequently with a large number of binary variables, and thus leads to no variation in a certain variable. Therefore, in practical estimation, the GRF-IVQR grows a relatively small tree.
For the female group, Table 6 and Figure 3 depicts that classroom training (class_tr) and on-the-job training and/or job search assistance (ojt_jsa) are the most important variables. The importance of on-the-job training and/or job search assistance decreases across quantiles, which is different from the pattern in the male group. The issue concerning no variation of a binary variable in deeper nodes becomes severe in the female group.
Table 6.
Variable importance (female).
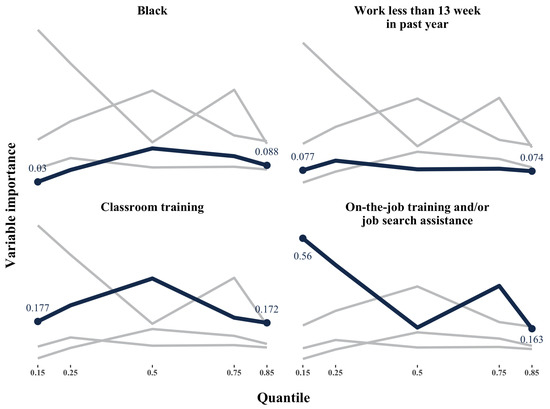
Figure 3.
Top 4 variable importance (female).
The variance importance for Hispanics and several age binary variables are 0 across all quantiles, which indicates that in the female group, the aforementioned characteristics variables are more homogeneous over the conditional distribution of earnings.
5. Conclusions
Based on the generalized random forests of Athey et al. (2019), we propose an econometric procedure to estimate the quantile treatment effect. Not only does this method estimate the treatment effect nonparametrically, but our procedure yields a measure of variable importance, in terms of heterogeneity among control variables. We provide the practical algorithm and the associated R codes. We also apply the proposed procedure to reinvestigate the distributional effect of 401(k) participation on net financial assets, and the quantile effect of participating a job training program on earnings. Income, age, education, and family size are identified as the first-four important variables in the 401(k) analysis. In the job training program example, our procedure suggests that the previous year work status and the job training service strategies are important control variables.
Author Contributions
Both authors contributed equally to the paper.
Funding
This research was partly funded by the personal research fund from Tokyo International University, and financially supported by the Center for Research in Econometric Theory and Applications (Grant no. 107L900203) from The Featured Areas Research Center Program within the framework of the Higher Education Sprout Project by the Ministry of Education (MOE) in Taiwan.
Acknowledgments
We are grateful to the two anonymous referees for their constructive comments that have greatly improved this paper. We thank Patrick DeJarnette, Masaru Inaba, Min-Jeng Lin and Shinya Tanaka for discussions and comments. This paper has benefited from presentation at the Aoyama Gakuin University, Kansai University, and 2019 Annual Conference of Taiwan Economic Association. The usual disclaimer applies.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DML | Double machine learning |
| GRF | Generalized random forests |
| IVQR | Instrumental variable quantile regression |
Appendix A
Appendix A.1. Improving Efficiency by Doubly Robust Estimators
Chernozhukov et al. (2018) and Athey and Wager (2018) pioneered the use of the doubly robust estimator embedded in a framework of causal machine learning. The resulting estimator becomes more accurate and gains efficiency. In light of their idea, it might be beneficial to incorporate the doubly robust estimation in our methodology.
A doubly robust augmented inverse propensity weighted (AIPW) estimator was introduced by Robins et al. (1994). The AIPW estimator for average treatment effect is constructed by two components as follows.
Appendix A.2. The Doubly Robust Estimation for Causal Forests
Athey and Wager (2019) and their grf R package implement a variant of doubly robust AIPW estimators for causal forests. Specifically, for estimating average treatment effect, their doubly robust estimator is shown as follows.
Glynn and Quinn (2009) provide some evidence that the doubly robust estimator performs better in terms of efficiency than inverse probability weighting estimators, matching estimators, and regression estimators. To explore how adapting the doubly robust method in the causal forest estimator affects the efficiency and accuracy, we follow their DGP designs and conduct Monte Carlo experiments with different degree of confoundedness. In the simulation, , and are covariates following , D is the treatment variable, Y is the outcome variable, and is the disturbance which follows . Two data generating processes are considered. Degree of confoundedness are modeled in three levels: low, moderate, and severe.
Table A1.
Simulation setting.
Table A1.
Simulation setting.
| Outcome (control) | Outcome (treatment) | ||
| Simple DGP | |||
| Complicate DGP | |||
| Degree of confoundedness | True treatment assignment probabilities | ||
| Low | |||
| Moderate | |||
| Severe | |||
With three different sample sizes, , and 1000, three degrees of confoundedness, and two DGP settings, the Monte Carlo results are tabulated in Table A2. The results confirm that the causal forest with doubly robust estimation indeed has efficiency gains over the conventional causal forest.
Table A2.
Finite-sample performance: causal forests with doubly robust estimation.
Table A2.
Finite-sample performance: causal forests with doubly robust estimation.
| Linear DGP | Nonlinear DGP | ||||
|---|---|---|---|---|---|
| Causal forest | Causal forest with doubly robust | Causal forest | Causal forest with doubly robust | ||
| Sample size | Confoundedness degree | RMSE | RMSE | RMSE | RMSE |
| 250 | low | 0.3730 | 0.1693 | 0.7542 | 0.3147 |
| 250 | moderate | 0.4200 | 0.2099 | 0.9295 | 0.3914 |
| 250 | severe | 0.4562 | 0.2218 | 1.0205 | 0.3997 |
| 500 | low | 0.3206 | 0.1081 | 0.6911 | 0.1855 |
| 500 | moderate | 0.3634 | 0.1417 | 0.8711 | 0.2320 |
| 500 | severe | 0.4107 | 0.1497 | 0.9529 | 0.2505 |
| 1000 | low | 0.2745 | 0.0717 | 0.6041 | 0.1124 |
| 1000 | moderate | 0.3244 | 0.1008 | 0.7755 | 0.1540 |
| 1000 | severe | 0.3742 | 0.1098 | 0.8919 | 0.1709 |
Appendix A.3. The Doubly Robust Estimation for Instrumental Causal Forests
With instrumental variables, Athey and Wager (2018) provide a doubly robust estimator for local average treatment effect; namely
Appendix A.4. An Unsolved Task: The Doubly-Robust GRF-IVQR
Researchers would like to incorporate the doubly robust estimation in the GRF-IVQR model, following similar ideas introduced above. However, it remains unclear how to do it. We leave this unsolved task as future work.
Appendix A.5. Identifying Restrictions and Regularity Conditions for the GRF-IVQR
Following Chernozhukov and Hansen (2008), we consider the instrumental variable quantile regression characterizing the structural relationship:
where
- Y is the scalar outcome variable of interest.
- U is a scalar random variable (rank variable) that aggregates all of the unobserved factors affecting the structural outcome equation.
- D is a vector of endogenous variables determined by .
- V is a vector of unobserved disturbances determining D and correlated with U.
- Z is a vector of instrumental variables.
- X is a vector of included control variables.
The one-dimensional rank variable and the rank similarity (rank preservation) condition imposed on the outcome equation play an important role in identifying the quantile treatment effect. To derive the standard error of the IVQR estimator, the following assumptions are needed as well.
Assumption CH1.
are iid defined on the probability space and have compact support.
Assumption CH2.
For the given τ, is in the interior of the parameter space.
Assumption CH3.
Density is bounded by a constant a.s.
Assumption CH4.
at has full rank for each θ in Θ, for .
Assumption CH5.
has full rank at .
Assumption CH6.
The function is one-to-one over parameter space.
Assumptions CH1–CH6 are compatible with those imposed in Athey et al. (2019); for example, both sets of assumptions do not apply to time-series data.
Assumption ATW1
(Lipschitz x-signal). For fixed values of , we assume that is Lipschitz continuous in x.
Assumption ATW2
(Smooth identification). When x is fixed, we assume that the M-function is twice continuously differentiable in with a uniformly bounded second derivative, and that is invertible for all , with .
Assumption ATW3
(Lipschitz -variogram). The score functions have a continuous covariance structure. Writing γ for the worst-case variogram and for the Frobenius norm, then for some ,
Assumption ATW4
(Regularity of ). The ψ-functions can be written as , such that λ is Lipschitz-continuous in , is a univariate summary of , and is any family of monotone and bounded functions.
Assumption ATW5
(Existence of solutions). We assume that, for any weights with , the estimating equation returns a minimizer taht at least approximately solves the estimating equation , for some constant .
Assumption ATW6
(Convexity). The score function is a negative sub- gradient of a convex function, and the expected score is the negative gradient of a strongly convex function.
Given Assumptions ATW1-ATW6, the Theorems 3 and 5 of Athey et al. (2019) guarantee that the GRF estimator achieves consistency and asymptotic normality. In what follows, we check each assumptions for the proposed GRF-IVQR estimator.
Observe that the score function of the IVQR
In Chernozhukov and Hansen (2008), the moment functions are conditional on . For simplicity, we write conditional functions as when considering splitting in within the framework of generalized random forests.
Checking Assumption ATW1.
Thus the expected score function
We want the conditional cumulative distribution function is Lipschitz continuous. Since every function with bounded first derivatives is Lipschitz, we need the conditional density is bounded. Assumption CH3 states that the conditional density is bounded by a constant a.s.. In particular, is a density of a convolution of a continuous random variable and a discrete random variable, we also need the continuous variable not to be degenerate.
Checking Assumption ATW2.
We want V is invertible and therefore needs to be invertible. In addition, the conditional density is required to have continuous uniformly bounded first derivative. If is continuously differentiable, then its first derivative is uniformly bounded. Those conditions are implied by Assumptions CH4 and CH5. Thus is invertible as well.
Checking Assumption ATW3.
Taylor expansion implies the following approximation of .
Since the conditional probability density function is bounded, there exists a , such that
Checking Assumption ATW4. The score function can be written as
where
Checking Assumption ATW5. Since Assumption ATW5 is used to ensure the existence of solutions, it is required.
Checking Assumption ATW6. With a V-shaped check function of the instrumental variable quantile regression, the corresponding score function is a negative subgradient of a convex function, and the expected score function is a negative gradient of a strongly convex function. Therefore, Assumption ATW6 holds.
Corollary.(Consistency and asymptotic normality of the GRF-IVQR estimator) Given Assumptions ATW1-6, Assumptions CH1-6, and Theorems 3 and 5 of Athey et al. (2019), the GRF-IVQR is consistent and asymptotically normal:
The variance estimator
where and are consistent estimators for the and respectively.
References
- Abadie, Alberto, Joshua Angrist, and Guido Imbens. 2002. Instrumental variables estimates of the effect of subsidized training on the quantiles of trainee earnings. Econometrica 70: 91–117. [Google Scholar] [CrossRef]
- Athey, Susan, and Guido Imbens. 2016. Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences 113: 7353–60. [Google Scholar] [CrossRef] [PubMed]
- Athey, Susan, and Guido Imbens. 2019. Machine learning method that economists should know about. Annual Review of Economics 11: 685–725. [Google Scholar] [CrossRef]
- Athey, Susan, Julie Tibshirani, and Stefan Wager. 2019. Generalized random forests. The Annals of Statistics 47: 1148–78. [Google Scholar] [CrossRef]
- Athey, Susan, and Stefan Wager. 2018. Efficient policy learning. arXiv arXiv:1702.02896v4. [Google Scholar]
- Athey, Susan, and Stefan Wager. 2019. Estimating treatment effects with causal forests: An application. arXiv arXiv:1902.07409. [Google Scholar]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Chen, Jau-er, and Jia-Jyun Tien. 2019. Debiased/Double Machine Learning for Instrumental Variable Quantile Regressions. Working Paper. Taipei, Taiwan: Center for Research in Econometric Theory and Applications, National Taiwan University. [Google Scholar]
- Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal 21: C1–C68. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2004. The effects of 401(k) participation on the wealth distribution: An Instrumental quantile regression analysis. Review of Economics and Statistics 86: 735–51. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2005. An IV model of quantile treatment effects. Econometrica 73: 245–61. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2008. Instrumental variable quantile regression: A robust inference approach. Journal of Econometrics 142: 379–98. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2013. NBER 2013 Summer Institute: Econometric Methods for High-Dimensional Data. Available online: http://www.nber.org/econometrics_minicourse_2013/ (accessed on 15 July 2013).
- Chiou, Yan-Yu, Mei-Yuan Chen, and Jau-er Chen. 2018. Nonparametric regression with multiple thresholds: Estimation and inference. Journal of Econometrics 206: 472–514. [Google Scholar] [CrossRef]
- Davis, Jonathan M. V., and Sara B. Heller. 2017. Using causal forests to predict treatment heterogeneity: An application to summer jobs. American Economic Review 107: 546–50. [Google Scholar] [CrossRef]
- Frandsen, Brigham R., and Lars J. Lefgren. 2018. Testing rank similarity. Review of Economics and Statistics 100: 86–91. [Google Scholar] [CrossRef]
- Gilchrist, Duncan Sheppard, and Emily Glassberg Sands. 2016. Something to talk about: Social spillovers in movie consumption. Journal of Political Economy 124: 1339–82. [Google Scholar] [CrossRef]
- Glynn, Adam N., and Kevin M. Quinn. 2009. An introduction to the augmented inverse propensity weighted estimator. Political Analysis 18: 36–56. [Google Scholar] [CrossRef]
- Guilhem, Bascle, Louis Mulotte, and Jau-er Chen. 2019. Addressing Strategy endogeneity and performance heterogeneity: Evidence from firm multinationality. Academy of Management Proceedings 2019: 12733. [Google Scholar]
- O’Neill, Eoghan, and Melvyn Weeks. 2018. Causal tree estimation of heterogeneous household response to time-of-use electricity pricing schemes. arXiv arXiv:1810.09179. [Google Scholar]
- Robins, James M., Andrea Rotnitzky, and Lue Ping Zhao. 1994. Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association 89: 846–66. [Google Scholar] [CrossRef]
- Strittmatter, Anthony. 2019. Heterogeneous earnings effects of the job corps by gender: A translated quantile apporach. Labour Economics 61: 101760. [Google Scholar] [CrossRef]
- Wager, Stephan, and Susan Athey. 2018. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association 113: 1228–42. [Google Scholar] [CrossRef]
| 1. | Following the default setting of the grf package, we set the max.depth equal to 4. |
| 2. | Since Abadie, Angrist and Imbens (2002) and Chernozhukov and Hansen (2005) impose different identification strategies, the corresponding estimated quantile treatment effect are, in general, for distinct sub-populations. |



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).