Abstract
The usual t test, the t test based on heteroskedasticity and autocorrelation consistent (HAC) covariance matrix estimators, and the heteroskedasticity and autocorrelation robust (HAR) test are three statistics that are widely used in applied econometric work. The use of these significance tests in trend regression is of particular interest given the potential for spurious relationships in trend formulations. Following a longstanding tradition in the spurious regression literature, this paper investigates the asymptotic and finite sample properties of these test statistics in several spurious regression contexts, including regression of stochastic trends on time polynomials and regressions among independent random walks. Concordant with existing theory (Phillips 1986, 1998; Sun 2004, 2014b) the usual t test and HAC standardized test fail to control size as the sample size in these spurious formulations, whereas HAR tests converge to well-defined limit distributions in each case and therefore have the capacity to be consistent and control size. However, it is shown that when the number of trend regressors all three statistics, including the HAR test, diverge and fail to control size as . These findings are relevant to high-dimensional nonstationary time series regressions where machine learning methods may be employed.
JEL Classification:
C12; C14; C23
It is meaningless to talk about ‘confirming’ theories when spurious results are so easily obtained.(Hendry 1980)
1. Introduction
In a well-cited contribution that emphasized the importance of diagnostic testing in econometrics, (Hendry 1980) highlighted how easy it is to mistake spurious relationships as genuine when using trending data of the type that are so commonly encountered in econometric work, especially in macroeconomics. Spurious regressions occur when conventional significance tests are so seriously biased towards rejection of the null hypothesis of no relationship that the alternative of a genuine relationship is accepted when the variables have no meaningful relationship and may even be statistically independent. Hendry’s article showcased the potential for nonsense regressions with the illustration of a regression between UK consumer prices and cumulative rainfall that displayed a high level of ‘significance’ and passed many—but not all—diagnostic tests.
Spurious regressions continue to attract considerable attention in econometric work, long after the exploratory study by (Yule 1926), the simulation experiments of (Granger and Newbold 1974), and the cautionary warnings made by David Hendry and many other writers since then. The limit theory of (Durlauf and Phillips 1988; Phillips 1986) provided the first analytic steps forward on this subject by explaining the phenomena of persistent null hypothesis rejections in spurious regressions. These two studies helped applied researchers understand the failure of conventional significance tests by showing that in regressions with independent or even correlated trending I(1) data the usual regression t- and F-ratio test statistics do not possess limiting distributions but actually diverge as the sample size leading inevitably to rejections of the null of no association. Closely related work by (Phillips and Durlauf 1986; Durlauf and Phillips 1988; Park and Phillips 1988, 1989; Phillips and Hansen 1990; Phillips and Loretan 1991; Phillips 1991) extended the analytics to cover models of cointegrated and reduced rank error correction systems. Much of this work was reviewed in a useful form for practitioners by (Banerjee et al. 1993).
The original study by (Phillips 1986) on spurious regression asymptotics formed the basis of a large subsequent literature that has analyzed spurious regressions among various classes of trend stationary, long memory, nonstationary, and near-nonstationary time series. A recent article by (Ernst et al. 2017) provided further analysis by deriving an expression for the standard deviation of the sample correlation coefficient between two independent standard Brownian motions. While this expression does not explain the phenomenon of spurious regression between two independent random walks, it does reveal that the limiting correlation is not centered on the origin and is highly dispersed. This result complements the original findings in (Phillips 1986) and many subsequent papers that the coefficient of determination in a spurious regression has a well-defined limit distribution and does not converge in probability to zero.
In later work, (Phillips 1998) pointed out that spurious regressions typically reflect the fact that trending data may always be ‘explained’ by a coordinate system of other trending variables—which includes the example of UK price series being well-explained by cumulative rainfall that was used by David Hendry (Hendry 1980). In this broad sense of interpretation, there are no spurious regressions for trending time series, just alternative ‘valid’ representations of the time series trajectories (and those of its limiting stochastic process, given a suitable normalization) in terms of other stochastic processes and deterministic functions of time.
The asymptotic theory in (Phillips 1998) utilized the general representation of a stochastic process in terms of an orthonormal system and provided an extension of the Weierstrass theorem to include the approximation of continuous functions and stochastic processes by Wiener processes. That theory was applied to two classic examples of spurious regressions: regression of stochastic trends on time polynomials, and regressions among independent random walks. Such regressions were shown to reproduce asymptotically in part (and in whole as the regressor space expanded with sample size) the underlying valid representations of one trending process in terms of others, a coordinate system that is entirely analogous to orthonormal or Fourier series representations of a continuous function in terms of polynomials or other simple classes of functions over some interval. An important feature of these ‘valid’ trend relationships is that the coefficients in the representations, like those in the Karhunen–Loève representation of a general stochastic process, are themselves random variables. Randomness in the representation of time-series trajectories is embodied in these coefficients. Much subsequent work has utilized these ideas and analytic methods, either in justifying certain regression representations or in using partial versions of these regression representations to focus on certain features—such as long run features—of the data (notably: Phillips 2005, 2014; Müller 2007; Sun 2004, 2014a, 2014b, 2014c; Hwang and Sun 2018; Müller and Watson 2016, 2018).
An important element in the Hendry (Hendry 1980) discussion of econometric practice was its emphasis on the value of diagnostic testing to ascertain limitations of regressions used in applications. In any empirical regression equation, the properties of the residuals depend inevitably on the properties of the data. To build upon a saying of the famous statistician John Tukey, in the regression equation the empirical investigator chooses the variables y and X (possibly with the aid of an autometric regression or a machine learning algorithm) and god gives back Any misspecification in the relationship between y and X must therefore be manifest in the properties of This is precisely what occurs in a spurious regression—the residual embodies the consequences of a model’s fundamental error of specification—as is revealed by the fact that tests for residual serial correlation such as the Durbin Watson statistic converge in probability to zero in such regressions (Phillips 1986).
Accommodating departures in fitted relationships from conventional assumptions on the properties of regression errors and thereby some of the effects of misspecification has been a longstanding goal of econometrics. One of the great advances in econometric research over the last half-century in response to this goal has been the development of methods of inference that are robust to some of the properties of the data and, particularly, those of the regression error. Such robustness can offer protection against specification error in validating inference. This research has led to the progressive development of heteroskedastic and autocorrelation consistent (HAC) procedures1 and subsequently to heteroskedastic and autocorrelation robust (HAR) methods2 These methods control for the effects of serial dependence and heterogeneity in regression errors and they play a key role in achieving robustness in inference. One area where methods of achieving valid statistical inference via HAC procedures has proved especially important in practice are regressions that involve trending variables and cointegration. This goal motivated the early research on optimal semiparametric approaches to the estimation of cointegrating relationships (Phillips and Hansen 1990) and continues to play a role in subsequent developments in this field (Phillips 2014; Hwang and Sun 2018).
HAC methods generally have good asymptotic properties but they are susceptible to large size distortions in practical work. Several alternative methods have been proposed in the recent literature to improve finite sample performance. Among these, the ‘fixed-b’ lag truncation rule (Kiefer and Vogelsang 2002a, 2002b, 2005) has attracted considerable interest. The method uses a truncation lag M for including sample serial covariances that is proportional to the sample size n (i.e., for some fixed )) and sacrifices consistent variance matrix (and hence standard error) estimation in the interest of achieving improved performance in statistical testing by mirroring finite sample characteristics of test statistics in the new asymptotic theory of these tests. The formation of t ratio and Wald statistics based on HAC estimators without truncation belongs to the more general class of HAR test statistics. There are known analytic advantages to the fixed b approach, primarily related to controlling size distortion. In particular, research by (Jansson 2004; Sun et al. 2011; Sun 2014b) has shown evidence from Edgeworth expansions of enhanced higher-order asymptotic size control in the use of these tests. Recently, (Lazarus et al. 2018; Müller 2014; Sun 2018) have surveyed work in this literature and given recommendations for practical implementation.
In studying spurious regression on trend phenomena, (Phillips 1996, 1998) showed that the use of HAC methods attenuated the misleading divergence rate (under the null hypothesis of no association) by the extent to which the truncation lag In particular, the divergence rate of the t statistic in a spurious regression involving independent variables is rather than . Pursuing this philosophy further, (Sun 2004) offered a new solution to deal with inference in spurious regressions. He argued that the divergence of the usual t-statistic arises from the use of a standard error estimator that underestimates the true variation of the ordinary least squares (OLS) estimator. He proposed the use of a fixed-b HAR standard error estimator with a bandwidth proportional to the sample size (where M∼ at the same rate as n). The resulting t-statistic converges to a non-degenerate limiting distribution which depends on nuisance parameters. These discoveries revealed that prudent use of HAR techniques in regression testing might widen the range of inference to include spurious regression.
In the same spirit as (Sun 2004, 2014b), the present contribution analyzes possible advantages in using HAR test statistics in the context of simple trend regressions such as
where is For trend assessment in models of this type it is of interest to test the null hypothesis of the absence of a deterministic trend in (1). This framework is a prototypical example of much more complex models where deterministic trend, stochastic trends, and trend break components may all be present, hence methods of asymptotically valid estimation and testing are needed. A recent general approach to the consistent estimation of such complex models by machine learning filtering methods is given in (Phillips and Shi 2019).
The present paper considers three types of t test widely used in econometrics: the usual t test, the t test based on HAC covariance matrix estimators, and the fixed-b HAR test. We apply these t-statistics to three classic examples of spurious regressions: regression of stochastic trends on time polynomials, regression of stochastic trends on deterministic time trend and regression among independent random walks. The asymptotic behavior of these three different t-statistics are investigated. In the regression of stochastic trends on time polynomials and the regression among independent random walks, it is shown that the usual t test and HAC based t test are likely to indicate a significant relation with probability that goes to one as the sample size n goes to infinity. However, provided the number of regressors (K) is fixed, the HAR t-statistics converge to well-defined distributions free from nuisance parameters. As a result, when appropriate critical values are drawn from these limiting distributions, the HAR t-statistics would not diverge and valid inference on the regression coefficients would be possible, concordant with (Sun 2004).
In contrast to these results and those of (Sun 2004), we find that HAR t-statistics diverge at rate as . Hence, the characteristics of spurious regression return even with the use of HAR test statistics in models with an increasing number of regressors. These findings seem relevant for machine learning and autometric model building methods which accommodate large numbers of regressors, including those of the variety where model searching often begins with more regressors than sample observations and penalized methods of estimation are needed to obtain even preliminary results.
Our results also reveal that the other two t-statistics (the usual t and HAC-based t) diverge at greater rates when than when K is fixed. In the regression of stochastic trends on deterministic time trends, we derive the limiting distributions of the statistics under both the null and alternative hypotheses. The HAR test turns out to be the only test which is consistent and has controllable size. All the limit theory for these tests receives strong support in simulations. As will become evident, the appealing asymptotic properties of the HAR test in the fixed number of regressors case are manifest even in situations where some commonly-used regularity conditions in the construction of HAR tests are violated.
The rest of the paper is organized as follows. Section 2 examines regressions of stochastic trends on a complete orthonormal basis in and establishes the limiting distributions of the three different t-statistics with explicit application to the prototypical case of a spurious linear trend regression. Section 3 examines the limit behavior of the t-statistics in regressions among independent random walks. Simulations are reported in Section 4. Section 5 concludes. All proofs are given in the Appendix A, Appendix B and Appendix C.
2. Regression of Stochastic Trend on Time Polynomials
2.1. Model Details and Background
The development in this section concentrates on a simple unit root time series
whose increments form a stationary time series with zero mean, finite absolute moments to order , and continuous spectral density function . We assume that satisfies the functional central limit theorem (FCLT)
for which primitive conditions are well known (e.g., Phillips and Solo 1992). The results that follow are illustrative and apply with suitable modification to more general nonstationary time series, such as near integrated or long memory series, which upon standardization converge to limiting stochastic processes with sample paths that are continuous almost surely.
By the Karhunen–Loève (KL) expansion theorem (e.g., Loève 1963, p. 478) into a countable linear combination of orthogonal functions, the KL representation for the Brownian motion is
where
are eigenvalues and corresponding eigenfunctions of the Brownian motion covariance kernel , and
are independently and identically distributed (iid) as . This series representation of is convergent almost surely and uniformly in . Denoting as the stochastic coefficients, the KL representation (4) could be rewritten as
Starting from the KL representation of , (Phillips 1998) studied the asymptotic properties of regressions of on deterministic regressors of the type
or, equivalently (with ),
Least squares estimation gives
where with , and . Let be any vector with . When K is fixed and , (Phillips 1998) proved that
where diag and . In the expanding regressors case where and , it was also shown in (Phillips 1998) that
where satisfies , diag, , and are the random coefficients in the KL representation (5). Therefore, the fitted coefficients in regression (7) tend to random variables in the limit as that match those in the KL representation of the limit process . In other words, least squares regressions reproduce in part (when K is finite) and in whole (when ) the underlying orthonormal representations.
2.2. Three t-Statistics
Suppose interest centers on testing whether the regression coefficients are significant or more generally whether some linear combination of the underlying coefficients in the estimated regression (6) is equal to 0, that is
Three types of t-statistics are considered. The first is the usual t-ratio defined as
with the usual error variance estimate. The second t-statistic is constructed by using a HAC variance estimator and has the following representation
where
with
Here, is a kernel estimate of the long run variance of its argument, is a lag kernel, M is a bandwidth parameter satisfying as and the argument in (10).
If we choose a fixed and set , the condition as is violated. In that case, the long run variance estimate is a fixed-b estimate and leads to the HAR t-statistic
where
with
, and is a lag kernel function as before.
With minor changes of the proof given in (Phillips 1998), it is easy to deduce that for fixed K, and as as discussed earlier. Therefore, such tests indicate statistically significant regression coefficients with probability that goes to one as . These results match what is now standard spurious regression limit theory for inference.
In addition, as we show in Theorem 2 below, the large regressor case where leads to different results. In this case, both t-statistics and have greater rates of divergence that depend on the expansion rate of given by and . Thus, with the addition of more regressors the combined effect of the regression coefficients—as well as that of the individual coefficients—appears more significant and diverges when as In consequence, large numbers of regressors effectively worsen the spurious regression problem.
Is there a test which does not always indicate that coefficients are significant in the ‘spurious’ regression (6)? As the results of (Sun 2004) show, the answer is positive for the case where K is fixed. In this event, the HAR test is appealing in the sense that when and K is fixed, so that test size is controlled in the limit. Therefore, when appropriate critical values obtained from the limit distribution of are employed, the coefficients do not inevitably signal significance as and the usual misleading test implications of spurious regression do not manifest. However, in the important case where the regressor space expands and , the test statistic diverges to infinity at rate and the coefficients become significant again even under HAR testing.
These results are collected in the following two theorems.
Theorem 1.
For fixed K, as and , we have
(i)
(ii)
Remark 1.
The fixed-b HAR based t-statistic asymptotically follows a well-defined limit distribution when the number of regressors K is fixed. The limit distribution is free from nuisance parameters and is easily computable but depends on the lag kernel as well as the form of the trend regressors, which influence the detrended standard Brownian motion process The asymptotic critical values, therefore, differ from those of the usual standard normal limit distribution of a t-statistic. But the specific features of the limit distribution of which retain randomness in the denominator of the limiting statistic, help to control size in finite sample testing.
Theorem 2.
As , and , the following results hold:
(i)
where .
(ii)
(iii)
Remark 2.
Theorem 2 shows that all three t-statistics diverge as but at different rates, each of which depends on K. The divergence rate of the fixed-b test statistic is the slowest and depends only on These results strengthen the findings in (Phillips 1998) that attempts to deal with serial dependence in controlling size in significance testing generally fail when enough effort is put into the regression design to fit the trajectory. This failure now includes HAR testing when . All the tests are therefore ultimately confirmatory of the existence of a ‘relationship’—in the present case a coordinate representation relationship among different types of trends, at least when a complete representation is attempted by allowing the number of regressors K to diverge with The results of the theorem may be interpreted to mean that when a serious attempt is made to model a stochastic trend using deterministic functions (either a large number of such regressors or regressors that are carefully chosen to provide a successful representation and trajectory fit) it will end up being successful even when a spurious regression robust method such as fixed-b HAR test is used.
An additional matter concerning the form of these tests may usefully be highlighted. To construct the HAC and HAR t-statistics, the following condition
with is usually imposed (e.g., Kiefer et al. 2000; Kiefer and Vogelsang 2002a, 2002b) as in standard approaches to robust covariance matrix estimation. In other words, the process is typically assumed to be unconditionally stationary or weakly dependent with uniformly bounded second moments so that series such as (15) converge. However, this condition is violated in both regressions (6) and (7) as
depends on t. For example, when the components are with partial sums satisfying (3) then
depends on t. Regardless of this violation, HAC and HAR t-statistics may still be constructed in the traditional way; and the HAR statistic, has nuisance parameter-free asymptotic properties even though the above unconditional stationarity condition is not satisfied.
The above results apply straightforwardly to the simple case of a spurious linear regression on trend where the time series is a unit root process generated by
with and is the partial sum of a zero mean stationary process with continuous spectral density The standardized process satisfies the functional law
The fitted regression model is
where is the LS estimate of which satisfies (Durlauf and Phillips 1988)
so that is consistent, including the case where However, as is well known, the usual t-statistic has order and diverges as indicating a significant relationship between and t in spite of the fact that This outcome follows directly from Theorem 1 and the (alternate) representation for the standard Brownian motion as
which implies that
Thus, when , the scaled LS estimator has a random limit from (18) that approximates but does not exactly reproduce the leading random coefficient term in the representation (19). Importantly in this case, the deterministic functions in (19) are not orthonormal and there is dependence in between the functions r and This dependence induces an asymptotic inefficiency in the trend coefficient estimate , since Var .
Next, in testing versus the following statistics are considered:
where
is a kernel function, and for . The asymptotic properties of these test statistics follow in the same way as before when with giving the following results.
(i) Under ,
(ii) Under ,
where and . Thus, under the null hypothesis both and diverge but and has a well defined nuisance parameter free limit distribution that may be used in statistical testing. Under the alternative hypothesis, all the listed statistics are divergent but at different rates. Only has effective discriminatory power, being consistent and having controllable size. These results match those in (Sun 2004, 2014a) showing that for simple trend misspecifications like that of a finite degree polynomial trend function in place of a stochastic trend, use of fixed-b HAR testing controls size and leads to a consistent test.
3. Regressions Among Independent Random Walks
This section extends these ideas to regressions among independent random walks. Let be a Brownian motion on the interval . (Phillips 1998) proved that there exist a sequence of independent standard Brownian motions that are independent of , and a sequence of variables defined on an augmented probability space such that, as ,
The random coefficients are statistically dependent on . Replacing the Wiener processes by orthogonal functions in using the Gram-Schmidt process
gives the representation
In the following, we consider the unit root process with mean zero stationary components with continuous spectral density and satisfying the functional law
Let be K independent standard Gaussian random walks, all of which are independent of . Consider the linear regression , based on observations of these series. The large n asymptotic behavior of is (Phillips 1986) where is the vector standard Brownian motion weak limit of the standardized partial sum processes .
Suppose we orthogonalize the regressors using the Gram-Schmidt process
By standard weak convergence arguments we have
Now let , and consider the regression
The LS estimator has the limit
where is a vector. Thus, the empirical regression of on reproduces the first K terms in the representation of the limit Brownian motion B in terms of an orthogonalized coordinate system formed from K independent standard Brownian motions.
Suppose now that we are interested in testing whether a linear combination of equals zero, viz.,
with satisfying . Again, three types of t-statistics are considered:
where
is a kernel function, and for .
The following theorem establishes the limiting distributions of these three t-statistics.
Theorem 3.
For fixed K, as ,
(i)
(ii) When
(iii)
where and
Remark 3.
As it is shown in Theorem 3, and diverge at rate and , respectively. Hence, such tests indicate inevitable significance of the regressors when and . However, the HAR based t-statistic is convergent in distribution, which leads to valid statistical testing when appropriate critical values from the limit distribution of are used. Note that , with
where is a standard Brownian motion. Hence, the nuisance parameter ω appearing in the numerator and dominator of the limiting distribution of cancels. The limit distribution of is therefore free of nuisance parameters.
Remark 4.
Even when , we have
Thus depends on t in a similar way. Therefore, as we discussed earlier, the usual regularity conditions employed in constructing HAC and HAR t-statistics cannot apply here.
Remark 5.
In view of (30) and Theorem 4.3 in (Phillips 1998), almost surely and uniformly as . We can expect that the rates of divergence of and are greater in the case where than they are when K is fixed. Moreover, similar to the earlier finding in Theorem 2, the HAR statistic will diverge at rate . Details are omitted to save space. Hence, fitted coefficients of the spurious random walk regressors would eventually be deemed significant when fixed critical values are employed in testing under all three t-statistics including when both K, .
4. Simulations
This section reports simulations to investigate the performance in finite samples of the different t-statistics in spurious trend regressions, simple time trend regression, and spurious regression among stochastic trends.
We first examined spurious regression of a stochastic trend on time polynomials. Consider the standard Gaussian random walk , where 3. Orthogonal basis functions where , were used as regressors and fitted time trend regressions of the form were run with ,…,. We focus on the prototypical null hypothesis in what follows. In the construction of the HAC and HAR t-statistics, a uniform kernel function was employed.
Figure 1 reports the kernel estimates of the probability densities for these t-statistics under different model scenarios based on 10,000 simulations. The first row of graphs in Figure 1 gives the results for the different t-statistics as the sample size n increases with fixed . It is evident that both the usual t-statistic and HAC t-statistic (with and ) diverge as n increases and the HAC statistic diverges at a slower rate. In contrast, the HAR t-statistic () is evidently convergent to a well-defined probability distribution as the sample size expands. These results clearly corroborate Theorem 1.
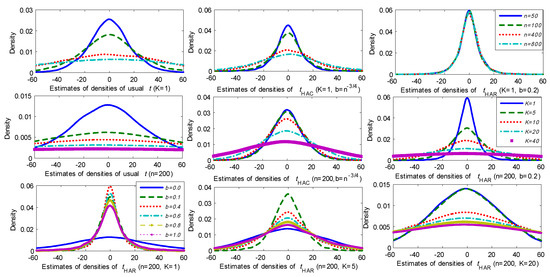
Figure 1.
Densities of different t-statistics in spurious trend regression of a random walk.
The second row of graphs in Figure 1 presents the estimated densities of the three t-statistics as K increases for a fixed sample size . As K increases, all three t-statistics are clearly divergent but at different rates. For each statistic the increase in dispersion as K increases is evident. The last row reports the results for the HAR t-statistic with and bandwidth coefficient . As K increases while maintaining the same bandwidth setting, the densities become more progressively dispersed. For fixed K, it is clear that the quantile is not a monotonic function of b. For , when b is close to zero, the limiting distributions become more dispersed. When b is close to one, the limiting distributions also get dispersed for all three choices of K. As explained in (Sun 2004), for small or moderate K, when b is close to zero, the behavior of the t-statistic may be better captured by conventional limit theory without taking into account the persistence of the regression residuals. But when b is close to unity, we can not expect the standard variance estimate to capture the strong autocorrelation. If we choose the kernel and use the full sample (i.e., setting ), the long run variance estimate equals zero by construction. We conjecture that for fixed K it may be possible to find an optimal bandwidth by following an approach similar to the method used in (Sun et al. 2011) that controls for size and power. From the shape of the densities in the last row of graphs in Figure 1, we would expect that any such optimal bandwidth will get closer to zero as K gets larger. Extension of robust testing techniques to machine learning regressions where K may be very large will likely require very careful bandwidth selection in significance testing that takes the magnitude of K into account.
Figure 2 and Figure 3 present rejection frequencies of the three t-statistics in spurious trending regression when conventional critical values from the standard normal distribution at the 5% significance level are used. These frequencies are calculated based on 10,000 simulations with the sample size . A manifest feature in Figure 2 and Figure 3 is that the rejection frequencies increase faster towards one as the number of regressors K increases. This feature corroborates Theorem 2 and the simulation results in Figure 1, which reveal the progressive dispersion of the densities of the three t-statistics as K increases, suggesting that the rejection frequencies are increasing functions of K for each test.
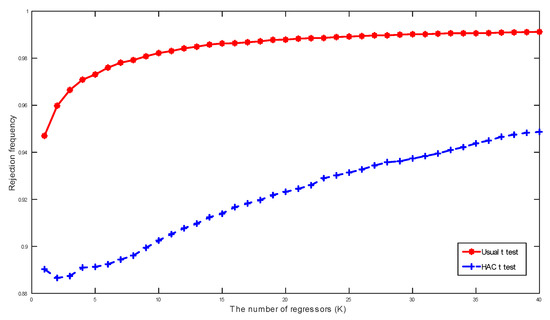
Figure 2.
Rejection frequencies of the usual t and heteroskedasticity and autocorrelation consistent (HAC) t-statistics in spurious trend regression of a random walk calculated based on 10,000 simulations with sample size and the critical values from the standard Normal distribution at significance level.
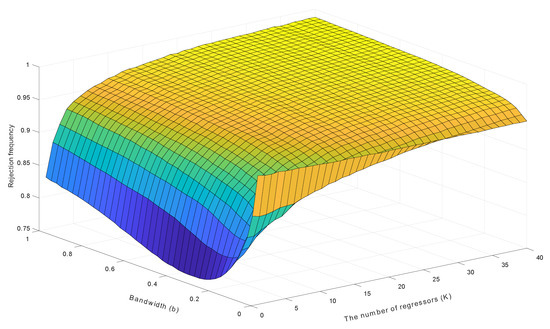
Figure 3.
Rejection frequencies of the heteroskedasticity and autocorrelation robust (HAR) t-statistic in spurious trending regressions.
The surface displayed in Figure 3 also reveals the effect of the bandwidth choice on the rejection frequencies of the HAR test, in which the bandwidth b varies from 0 to 1 at step length 0.025. It is evident that the rejection frequency of the HAR test is a nonlinear function of b, especially when K is small. Optimal selection of a bandwidth that controls size and power of the HAR test is therefore possible. The value of should moderately deviate from zero when K is small and move towards zero faster as K increases. The findings in Figure 3 support the conjecture about the optimal bandwidth choice, which was discussed above based on the results in Figure 1.
Next, we consider a simple spurious linear trend regression of on a linear time trend where and . Figure 4 reports the sampling densities for different t-statistics based on 10,000 simulations. The first row of graphs presents kernel estimates of densities of the t-statistics for sample sizes . Again, the usual t-statistic and HAC statistic are divergent but at different rates. The HAR statistic is evidently convergent. The second row in Figure 4 provides results for the HAR statistic with different bandwidth choices. It is clear that the distributions become more dispersed as b moves close to zero or close to one. In this respect the findings are similar to those of Figure 1 when . In Figure 5, the rejection frequencies of the HAR statistic with various bandwidth values are reported, which are calculated based on 10,000 simulations with sample size n = 200 and critical values from the standard Normal distribution at 5% significance level. Rejection frequency again follows a U-shaped function of b. This curve suggests that, for simple spurious linear trend regression, the value of the optimal bandwidth should be around 0.3.
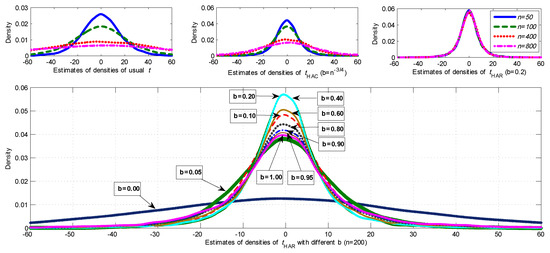
Figure 4.
Densities of different t-statistics in simple spurious linear trend regression.
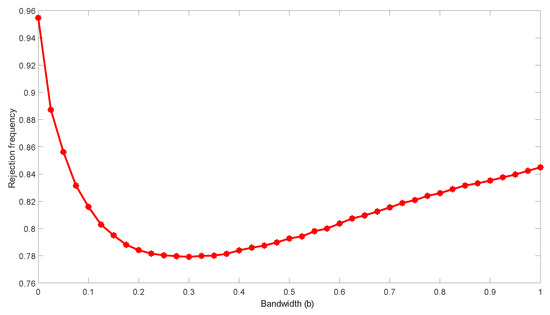
Figure 5.
Rejection frequencies of the HAR t-statistic in spurious linear trend regressions.
Last, we consider spurious regressions of a standard Gaussian random walk process on independent Gaussian random walks , where with and with Figure 6 shows kernel estimates of the probability densities for these t-statistics under different scenarios based on 10,000 simulations. Figure 7 and Figure 8 report the simulated rejection frequencies of these t-statistics for various values of K and b. The patterns exhibited are evidently similar to those in Figure 1, Figure 2 and Figure 3. The same qualitative observations made for Figure 1, Figure 2 and Figure 3 therefore apply to these regressions.
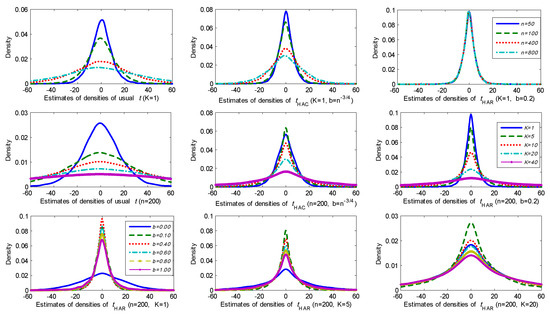
Figure 6.
Densities of different t-statistics in spurious regression among random walks.
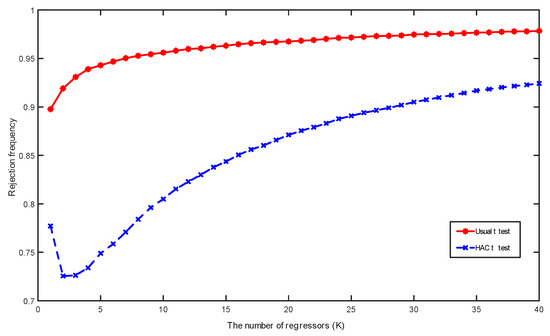
Figure 7.
Rejection frequencies of the usual t and HAC t-statistics in spurious regressions among random walks calculated based on 10,000 simulations with sample size and critical values from the standard Normal distribution at significance level.
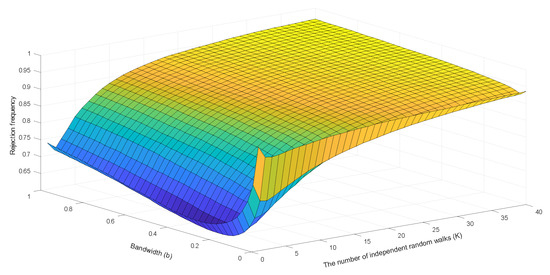
Figure 8.
Rejection frequencies of the HAR t-statistic in spurious regressions among random walks.
5. Conclusions
Robust inference in trend regression poses many challenges. Not least of these is the critical difficulty that a trending time series trajectory can be represented in a coordinate system by many different functions, be they relevant or irrelevant, stochastic or non-stochastic. Valid significance testing in this context needs to allow for the fact that trend regression formulations inevitably fail to capture all the subtleties of reality and to a greater or lesser extent, therefore, involve some spurious components. The practical implications of this message are powerfully stated in the header by David Hendry that opens this article.
The present work has studied the asymptotic and finite sample performance of simple t statistics that seek to achieve some degree of robustness to misspecification in such settings. The analysis is based on three classic examples of spurious regressions, including regression of stochastic trends on time polynomials, regression of stochastic trends on a simple linear trend, and regression among independent random walks. Concordant with existing theory, the usual t-statistic and HAC standardized t-statistic both diverge and imply ‘nonsense relationships’ with probability going to one as the sample size tends to infinity. Also concordant with existing theory, when the number of regressors K is fixed, the HAR standardized t-statistics converge to non-degenerate distributions free from nuisance parameters, thereby controlling size and leading to valid significance tests in these spurious regressions. These findings reinforce the optimism expressed in earlier work that fixed-b methods of correction may fix inference problems in spurious regressions.
But when the number of trend regressors , the results are different. First, rates of divergence of the usual t-statistic and HAC t-test are greater by the factor than when K is fixed. Second, the fixed-b HAR t-statistic is no longer convergent and instead diverges at the rate leading to spurious inference of significance when . Thus, in the case of models with expanding regressor sets, none of these standard statistics produce valid consistent tests with controllable size. The failure of the HAR test in this setting is particularly important, given the growing use of machine learning algorithms in econometric work where large numbers of regressors are a normal feature in initial specifications. Future research might usefully focus on methods of controlling size and achieving consistent significant tests in such settings. A further area of research that is relevant in practical work involves extension of the present results to regressions that involve more general forms of stochastic trend processes, including higher-order integrated and fractionally integrated processes, as well as unbalanced regressions. The methods of the present paper should be useful in developing asymptotic analyses of such potentially spurious regressions.
Author Contributions
Conceptualization: P.C.B.P. 80%, X.W. 10%, and Y.Z. 10%; Methodology: P.C.B.P. 60%, X.W. 20%, and Y.Z. 20%; Programming: P.C.B.P. 0%, X.W. 50%, and Y.Z. 50%; Writing: P.C.B.P. 60%, X.W. 20%, and Y.Z. 20%; Editing: P.C.B.P. 60%; X.W. 20%, and Y.Z. 20%.
Funding
Phillips acknowledges research support from the NSF under Grant No. SES 18-50860 and a Kelly Fellowship at the University of Auckland. Wang acknowledges the support from the Hong Kong Research Grants Council General Research Fund under No. 14503718. Zhang acknowledges financial support from the National Natural Science Foundation of China under Projects No.71401166, 71973141, and 7187303.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| space of square integrable functions on . | |
| ⟹ | weak convergence. |
| integer part of. | |
| definitional equality. | |
| tends to zero in probability. | |
| tends to zero almost surely. | |
| bounded in probability. | |
| converge in probability. | |
| min. | |
| ∼ | asymptotic equivalence. |
| ≡ | distributional equivalence. |
| distributed as |
Appendix A. Proofs of Theorems in Section 2
Lemma A1.
For any , let be the -projection residual of B on , with , and iid . When
- (i)
- uniformly in ,
- (ii)
- with ,
- (iii)
- ,
- (iv)
Lemma A2.
When , , , and ,
Proof of Lemma A1.
(i) It is easy to see that , and
uniformly in r. So by the Chebyshev’s inequality, uniformly in r.
(ii) See (Phillips 2002), Lemma 3.1.
(iii)–(iv) The proofs of (iii) and (iv) are similar. Hence, only the proof of (iv) is given below. By noticing that and for each the functions are bounded uniformly in r, we have
Therefore,
since is uniformly bounded and
Further
Therefore,
Finally, we get
□
Proof of Lemma A2.
(i) See (Phillips 2002), Lemma 2.2.
(ii) Using the Hungarian strong approximation (e.g., Csörgö and Horváth 1993), we can construct an expanded probability space with a Brownian motion for which
or
Applying the matrix norm , (Phillips 2002) proved that
and
where and are the random coefficients in the orthonormal representation (5). Therefore, we have
as . The second inequality comes from Hölder’s inequality. Hence, when , we have
It is straightforward to see that when
Therefore, when
(iii), (iv) The proofs of (iii) and (iv) are similar, so only (iv) is proved here. When
Therefore, when
□
Proof of Theorem 1.
(i) and (ii) The proofs are similar to those in (Phillips 1998) and are omitted.
(iii) From (Phillips 1998), when and K is fixed, . Let , we have
The scaled long run variance estimator can be written as
Noticing that
it follows that
Therefore,
Let , , , and It then follows immediately that
□
Appendix B. Derivations Leading to (23)–(28)
Lemma A3.
For the regression model (17) let with . Irrespective of whether a is zero or not, when and , the following results hold:
- (i)
- for ,
- (ii)
- (iii)
- (iv)
- where , , are defined as in (20)–(22), respectively, for , is a kernel function and .
Proof of Lemma A3.
(i) Using the functional law and continuous mapping it is straightforward to obtain
Therefore, for any ,
(ii) From the expression of given in (20), the following is immediate
(iii) As when , we have for any and
Therefore, from the continuous mapping theorem, it follows that
Hence,
(iv) For the HAR based test given in (22), we have
By continuous mapping
Then,
□
Proof of (23)–(28).
The stated results now follow directly from the above and the fact that under and under □
Appendix C. Proof of the Theorem in Section 3
Proof of Theorem 3.
(i): In the regression (31), we already have that , , for , and . Let Based on continuous mapping, we have
Noticing that
we obtain
Therefore
and
(ii) As when , for any and , we have
Hence, for any ,
and
Therefore,
and
(iii) Note that
Therefore,
and
□
References
- Banerjee, Anindya, Juan J. Dolado, John W. Galbraith, and David Hendry. 1993. Co-Integration, Error Correction, and the Econometric Analysis of Non-Stationary Data. Oxford: Oxford University Press. [Google Scholar]
- Csörgö, Miklós, and Lajos Horváth. 1993. Weighted Approximations in Probability and Statistics. New York: Wiley. [Google Scholar]
- Durlauf, Steven N., and Peter C. B. Phillips. 1988. Trends versus random walks in time series analysis. Econometrica 56: 1333–54. [Google Scholar] [CrossRef]
- Eicker, Friedhelm. 1967. Limit theorems for regression with unequal and dependent errors. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. Beijing: Statistics, vol. 1, pp. 59–82. [Google Scholar]
- Ernst, Philip A., Larry A. Shepp, and Abraham J. Wyner. 2017. Yule’s “nonsense correlation” solved! Annals of Statistics 45: 1789–809. [Google Scholar] [CrossRef]
- Granger, Clive W. J., and Paul Newbold. 1974. Spurious regressions in econometrics. Journal of Econometrics 74: 111–20. [Google Scholar] [CrossRef]
- Hendry, David F. 1980. Econometrics—Alchemy or science. Economica 47: 387–406. [Google Scholar] [CrossRef]
- Huber, Peter J. 1967. The behavior of maximum likelihood estimates under nonstandard conditions. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. Beijing: Statistics, vol. 1, pp. 221–33. [Google Scholar]
- Hwang, Jungbin, and Yixiao Sun. 2018. Simple, robust, and accurate F and t tests in cointegrated systems. Econometric Theory 34: 949–84. [Google Scholar] [CrossRef]
- Jansson, Michael. 2004. The error in rejection probability of simple autocorrelation robust tests. Econometrica 72: 937–46. [Google Scholar] [CrossRef]
- Kiefer, Nicholas M., and Timothy J. Vogelsang. 2002a. Heteroskedasticity-autocorrelation robust testing using bandwidth equal to sample size. Econometric Theory 18: 1350–66. [Google Scholar] [CrossRef]
- Kiefer, Nicholas M., and Timothy J. Vogelsang. 2002b. Heteroskedasticity-autocorrelation robust standard errors using the bartlett kernel without truncation. Econometrica 70: 2093–95. [Google Scholar] [CrossRef]
- Kiefer, Nicholas M., and Timothy J. Vogelsang. 2005. A new asymptotic theory for heteroskedasticity-autocorrelation robust tests. Econometric Theory 21: 1130–64. [Google Scholar] [CrossRef]
- Kiefer, Nicholas M., Timothy J. Vogelsang, and Helle Bunzel. 2000. Simple robust testing of regression hypotheses. Econometrica 68: 695–714. [Google Scholar] [CrossRef]
- Lazarus, Eben, Daniel J. Lewis, James H. Stock, and Mark W. Watson. 2018. HAR inference: Recommendations for practice. Journal of Business & Economic Statistics 36: 541–59. [Google Scholar]
- Loève, Michel. 1963. Probability Theory, 3rd ed. New York: Van Nostrand. [Google Scholar]
- Müller, Ulrich K. 2007. A theory of robust long-run variance estimation. Journal of Econometrics 141: 1331–52. [Google Scholar] [CrossRef]
- Müller, Ulrich K. 2014. HAC corrections for strongly autocorrelated time series. Journal of Business & Economic Statistics 32: 311–22. [Google Scholar]
- Müller, Ulrich K., and Mark W. Watson. 2016. Low-frequency econometrics. In Advances in Economics: Eleventh World Congress of the Econometric Society. Edited by Bo Honoré and Larry Samuelson. Cambridge: Cambridge University Press, vol. 2, pp. 53–94. [Google Scholar]
- Müller, Ulrich K., and Mark W. Watson. 2018. Long-run covariability. Econometrica 86: 775–804. [Google Scholar] [CrossRef]
- Park, Joon Y., and Peter C. B. Phillips. 1988. Statistical inference in regressions with integrated processes: Part 1. Econometric Theory 4: 468–97. [Google Scholar] [CrossRef]
- Park, Joon Y., and Peter C. B. Phillips. 1989. Statistical inference in regressions with integrated processes: Part 2. Econometric Theory 5: 95–131. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 1986. Understanding spurious regression in econometrics. Journal of Econometrics 33: 311–40. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 1991. Optimal inference in cointegrated systems. Econometrica 59: 283–306. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 1996. Spurious regression unmasked. In Cowles Foundation Discussion Paper. No. 1135. New Haven: Yale University. [Google Scholar]
- Phillips, Peter C. B. 1998. New tools for understanding spurious regressions. Econometrica 66: 1299–325. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 2002. New unit root asymptotics in the presence of deterministic trends. Journal of Econometrics 111: 323–53. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 2005. HAC estimation by automated regression. Econometric Theory 21: 116–42. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 2014. Optimal estimation of cointegrated systems with irrelevant instruments. Journal of Econometrics 178: 210–24. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Steven N. Durlauf. 1986. Multiple time series regression with integrated processes. Review of Economic Studies 55: 473–96. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Bruce E. Hansen. 1990. Statistical inference in instrumental variables regression with I(1) processes. Review of Economic Studies 57: 99–125. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Mico Loretan. 1991. Estimating long-run economic equilibria. Review of Economic Studies 59: 407–36. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Zhentao Shi. 2019. Boosting the Hodrick-Prescott filter. In Cowles Foundation Discussion Paper. No. 2192. New Haven: Yale University. [Google Scholar]
- Phillips, Peter C. B., and Victor Solo. 1992. Asymptotics for linear processes. The Annals of Statistics 20: 971–1001. [Google Scholar] [CrossRef]
- Robinson, Peter M. 1998. Inference-without-smoothing in the presence of nonparametric autocorrelation. Econometrica 66: 1163–82. [Google Scholar] [CrossRef]
- Sun, Yixiao. 2004. A convergent t-statistic in spurious regression. Econometric Theory 20: 943–62. [Google Scholar] [CrossRef]
- Sun, Yixiao. 2014a. Let’s fix it: Fixed-b asymptotics versus small-b asymptotics in heteroscedasticity and autocorrelation robust inference. Journal of Econometrics 178: 659–77. [Google Scholar] [CrossRef]
- Sun, Yixiao. 2014b. Fixed-smoothing asymptotics in a two-step GMM framework. Econometrica 82: 2327–70. [Google Scholar] [CrossRef]
- Sun, Yixiao. 2014c. Fixed-smoothing asymptotics and asymptotic F and t tests in the presence of strong autocorrelation. In Essays in Honor of Peter C. B. Phillips (Advances in Econometrics, Volume 33). Bingley: Emerald Group Publishing Limited, pp. 23–63. [Google Scholar]
- Sun, Yixiao. 2018. Comments on “HAR inference: Recommendations for practice”. Journal of Business & Economic Statistics 36: 565–68. [Google Scholar]
- Sun, Yixiao, Peter C. B. Phillips, and Sainan Jin. 2011. Power maximization and size control in heteroskedasticity and autocorrelation robust tests with exponentiated kernels. Econometric Theory 27: 1320–68. [Google Scholar] [CrossRef][Green Version]
- White, Halbert. 1980. A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica 48: 817–38. [Google Scholar] [CrossRef]
- White, Halbert. 1982. Asymptotic Theory for Econometricians, 1st ed. Cambridge: Academic Press. [Google Scholar]
- Yule, G. Udny. 1926. Why do we sometimes get nonsense correlations between time series? A study in sampling and the nature of time series. Journal of the Royal Statistical Society 89: 1–63. [Google Scholar] [CrossRef]
| 1. | Heteroskedastic robust standard errors were introduced by (Eicker 1967; Huber 1967; White 1980). HAC estimators were introduced by (White 1982) and have a long subsequent history of enhancement. |
| 2. | Heteroskedastic and autocorrelation robust standard errors were introduced in (Kiefer and Vogelsang 2002a, 2002b) and, following this lead, (Phillips 2005) used the HAR terminology to characterize a class of robust inferential procedures in an article concerned with the development of automated mechanisms of valid inference in econometrics. Other important early contributions concerning HAC covariance matrix estimators without truncation were given by (Kiefer and Vogelsang 2005; Kiefer et al. 2000; Robinson 1998). |
| 3. | Weakly dependent innovations in the form of an AR(1) error process, viz., , with were also considered. The results were similar and so only the case is reported here. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).