Visual information serves as the foundation of VSLAM, providing rich data that, in the context of a local world coordinate system, allows for real-time output of the camera’s absolute pose. However, visual data have a lower sampling frequency and are susceptible to factors such as field of view and environmental conditions. In contrast, IMU sensors have a higher sampling frequency and are less affected by environmental factors. However, IMU sensors only provide the carrier’s acceleration and angular velocity information, requiring continuous integration to output the carrier’s absolute pose. Nevertheless, prolonged operation inevitably leads to accumulated errors, resulting in the divergence of the localization result. To address these challenges, VIO algorithms integrate visual and IMU information to compensate for their respective limitations, thereby achieving high-precision localization.
3.2.1. IMU Preintegration Model
The IMU measures a moving vehicle’s inertial forces to obtain its own three-axis acceleration and three-axis angular velocity. By continuously integrating these measurements, the IMU can provide the vehicle’s velocity, position, and Euler angles. Typically, an IMU consists of two main components: an accelerometer for measuring three-axis acceleration and a gyroscope for measuring three-axis angular velocity. The IMU used in this paper is a low-cost MEMS IMU, known for its relatively lower measurement accuracy and higher noise levels, which can lead to error accumulation and drift.
Due to the relatively low speeds of the motion carriers in this paper, effects such as centripetal acceleration and Coriolis acceleration caused by the Earth’s rotation can be neglected. Therefore, the output of the IMU is mainly affected by measurement noise and bias. Assuming that the measurement noises of the accelerometer and gyroscope are
and
, respectively, and their biases are
and
, the IMU measurement model can be established as Equation (
4):
In the equation,
represent the measured values of the accelerometer and gyroscope at time
t, respectively, while
and
represent the true acceleration and true angular velocity of the IMU at time
t. The IMU’s bias can be considered a Wiener process, also known as a random walk or Brownian motion, with its derivative following a Gaussian distribution [
25].
According to the above measurement model, the continuous-time form of the IMU motion can be described as Equation (
5):
In the equation,
,
,
,
,,
, respectively, represent the position, velocity, acceleration, quaternion attitude, and angular velocity of the IMU relative to a given world coordinate system at time. Define the time interval
. Based on the above equation, the motion equation from time
to time
can be determined as Equation (
6).
In order to avoid repeated integration during each optimization process, the IMU preintegration theory was proposed in reference [
26]. Based on Equation (
6), the inter-frame IMU pre-integration result can be obtained as Equation (
7):
Based on the IMU preintegration result, the pose transformation matrix between adjacent frames can be obtained as Equation (
8):
In the equation, can be obtained by transforming the quaternion and the translation vector .
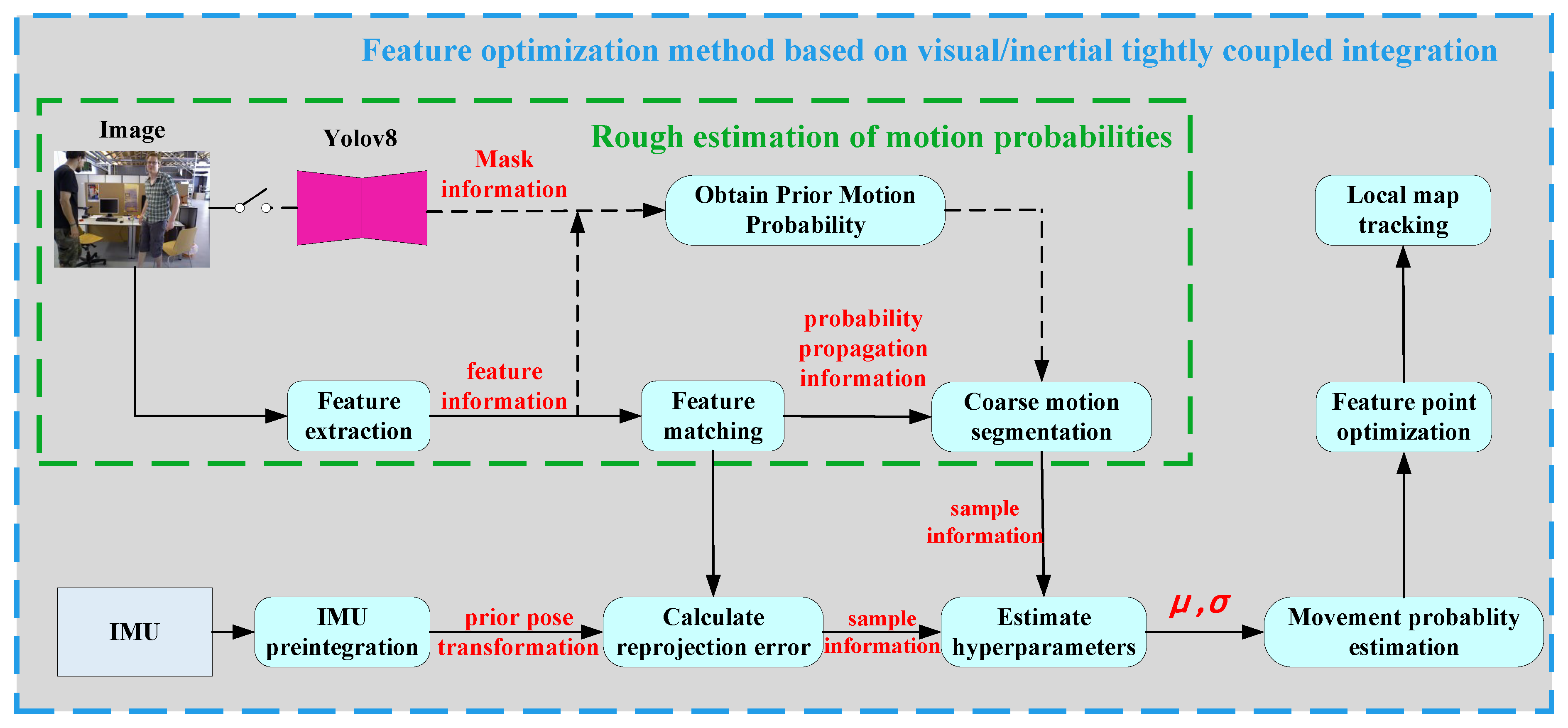
3.2.2. The Motion-Consistency-Detection Algorithm Based on Visual–Inertial Measurement Unit
Generally speaking, when a feature point is static, its reprojection error should be close to zero due to satisfying the epipolar geometric constraint. However, when the feature point moves, the epipolar geometric constraint is no longer satisfied, and thus, the reprojection error is no longer zero, increasing with the magnitude of the movement. Assuming the coordinates of a 3D point in the local world coordinate system are
, and this point is observed by both adjacent frames
and
, the following constraint exists for the landmark point:
In the equation,
and
, respectively, represent the coordinate transformation matrices from the world coordinate system to the image frame
and
the corresponding camera coordinate system.
and
, respectively, represent the 3D coordinates of the landmark point
k in the corresponding camera coordinate system to the images
and
. Based on the above equation, the constraint relationship between them can be obtained as Equation (
10):
and
, respectively, represent the camera–IMU coordinate transformation matrix at different times, which is usually considered to remain unchanged with the motion of the carrier. As shown in
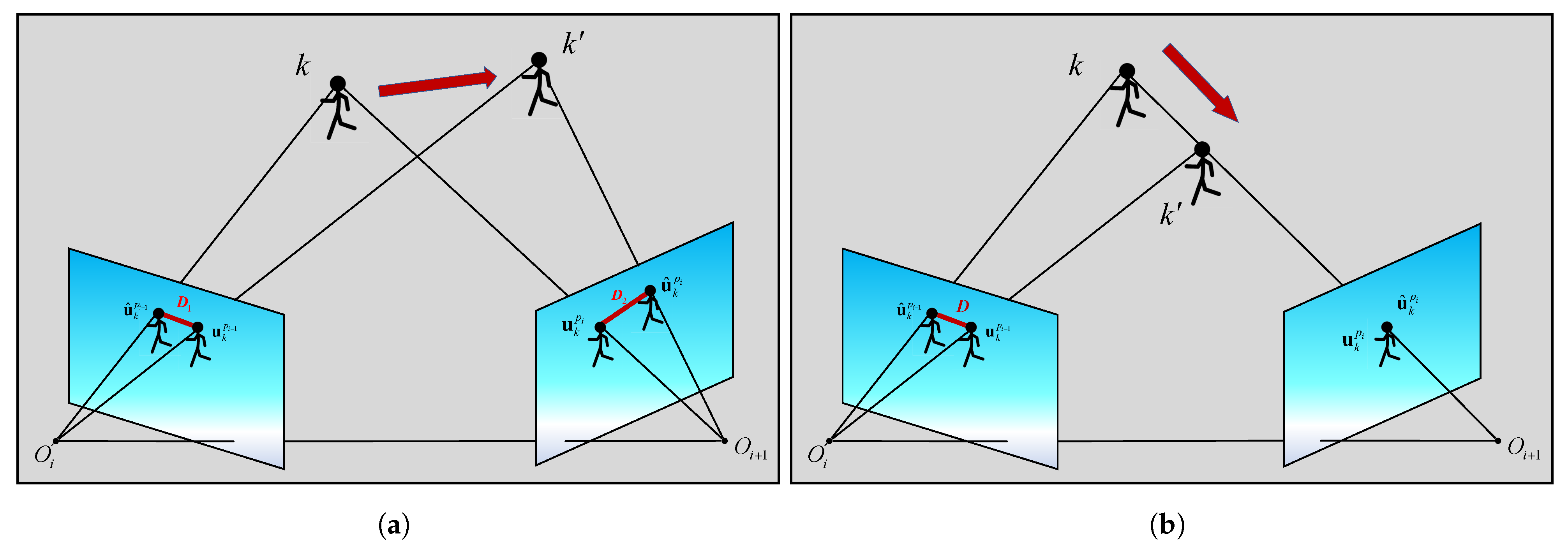
Figure 4a, for a 3D point in the world coordinate system, due to its displacement, it no longer satisfies the epipolar geometric constraint with the projected points in images
and
leading to the appearance of reprojection errors (highlighted in red).
Constructing the reprojection error of the co-visible feature points in the image frame
, we can obtain Equation (
11):
In the equation,
represents the observed coordinates of a feature point in the pixel coordinate system of the image frame
,
represents the theoretical coordinates of the feature point in the pixel coordinate system of the image frame
, which is the inter-frame projection result, and
represents the forward projection function from the camera coordinate system to the pixel coordinate system. However, in certain motion scenarios, using the reprojection error of feature points to determine their static or dynamic nature may not be effective. As shown in
Figure 4b, when a dynamic object moves toward or away from the optical center of the camera, the reprojection error remains zero regardless of the direction of motion. To address this issue, this paper proposes a bidirectional projection method: for the same feature point, it is necessary not only to compute its reprojection error in the current frame, but also to obtain its reprojection error in the previous frame through IMU preintegration. The calculation formula in this case is as Equation (
12):
In the equation, represents the observed coordinates of a feature point in the pixel coordinate system of the image frame , and represents the theoretical coordinates of the feature point k n the pixel coordinate system of the image frame , which corresponds to the inter-frame projection result.
In computer vision and 3D reconstruction, it is commonly assumed that the reprojection error follows a Gaussian distribution [
27,
28]. Based on this assumption, the probability of a feature point’s movement can be calculated using the reprojection error. Assuming the Gaussian distribution has a mean of
, the movement probability of the feature point can be described as Equation (
13):
In the equation,
r represents the bidirectional reprojection error of the feature point. It can be observed that, as the reprojection error increases, the probability of the feature point’s movement also increases. To avoid the influence of IMU preintegration errors on the reprojection error, this paper proposes a dynamic adaptive method for determining the threshold, which includes methods for determining the mean and standard deviation. In theory, the reprojection error of a completely static feature point should be zero. However, due to noise in IMU measurements and distortion in the camera, the reprojection error is not zero. Therefore, this paper designs a dynamic adaptive loss function to determine the mean and standard deviation of the Gaussian distribution; the calculation method is given by Equation (
14):
In the equation, represents the label value, where 0 indicates a static feature point and 1 indicates a dynamic feature point, and represents the predicted probability of the motion state of the feature point, denoted as .
Assuming the extracted set of absolutely static points in the image
I is denoted by
, the set of features with absolute motion is denoted by
, and the set of temporarily static features is denoted by
. Since both the absolutely static and absolutely moving features can obtain accurate probability values using semantic labels, for each frame of the image, the semantic information can be used to determine the estimated samples, and the expression is given by Equation (
15):
After computing the reprojection error for each feature point, it is necessary to first utilize the semantic information to provide estimated samples for the aforementioned binary classification problem. Subsequently, using the sample information, the objective is to minimize the dynamic adaptive loss function in order to obtain the estimated mean and standard deviation values. The optimization objective can be described by Equation (
16).
By solving the above optimization problem, we can obtain the mean and standard deviation that minimize the cross-entropy loss [
29]. Combining Equation (
13), we can obtain the probability of movement for temporary stationary feature points. In some special cases, such as when the carrier motion environment is stationary or there are no feature points in absolute motion, the prior semantic information can only provide single-class sample information. In such cases, it is not possible to obtain a reasonable mean and standard deviation by minimizing the loss function. In this case, it is only necessary to estimate the mean and standard deviation using the absolute static features in the environment. The reprojection error of absolute static features in the environment can be used as samples, and the maximum likelihood estimation method can be used to estimate the mean and variance of the Gaussian distribution. Then, using Equation (
13), the movement probability of other feature points can be calculated. The algorithm framework is shown in Algorithm 1.
| Algorithm 1 Motion consistency detection algorithm based on visual–inertial coupling |
Input: current frame , previous adjacent frame , set of absolute static points in the current frame , set of absolute motion feature points in the current frame , set of temporarily static feature points in the current frame , IMU pre-integration results between consecutive frames . Output: probability of feature point set movement in the current frame ;
- 1:
for
do - 2:
; - 3:
end for - 4:
if
then - 5:
; - 6:
for do - 7:
- 8:
end for - 9:
else - 10:
for do - 11:
; - 12:
end for - 13:
- 14:
for do - 15:
- 16:
end for - 17:
end if
|
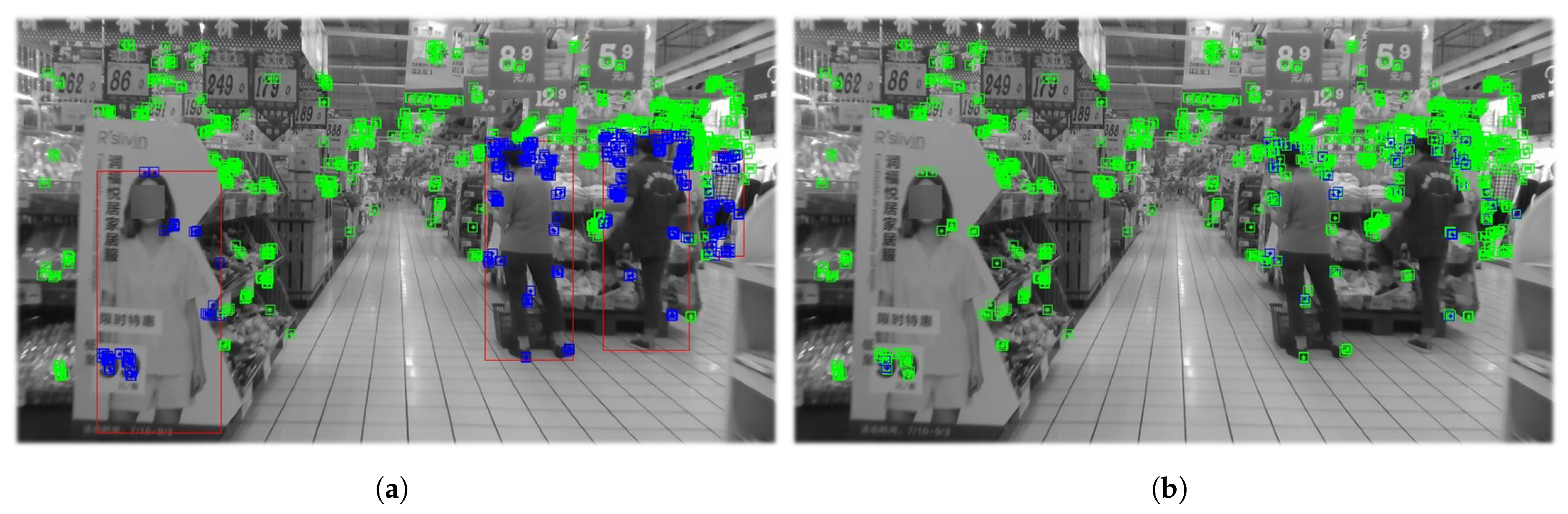
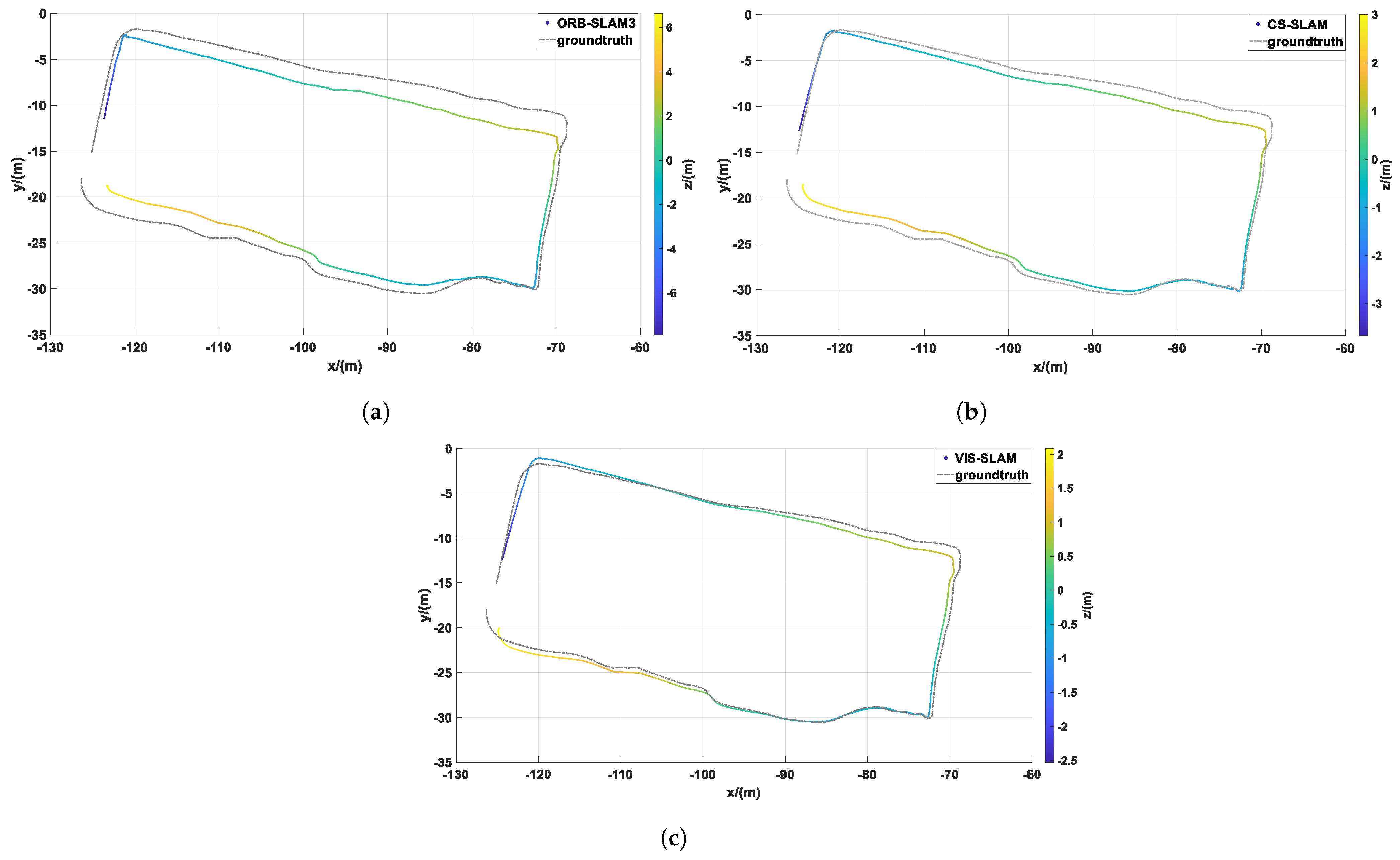
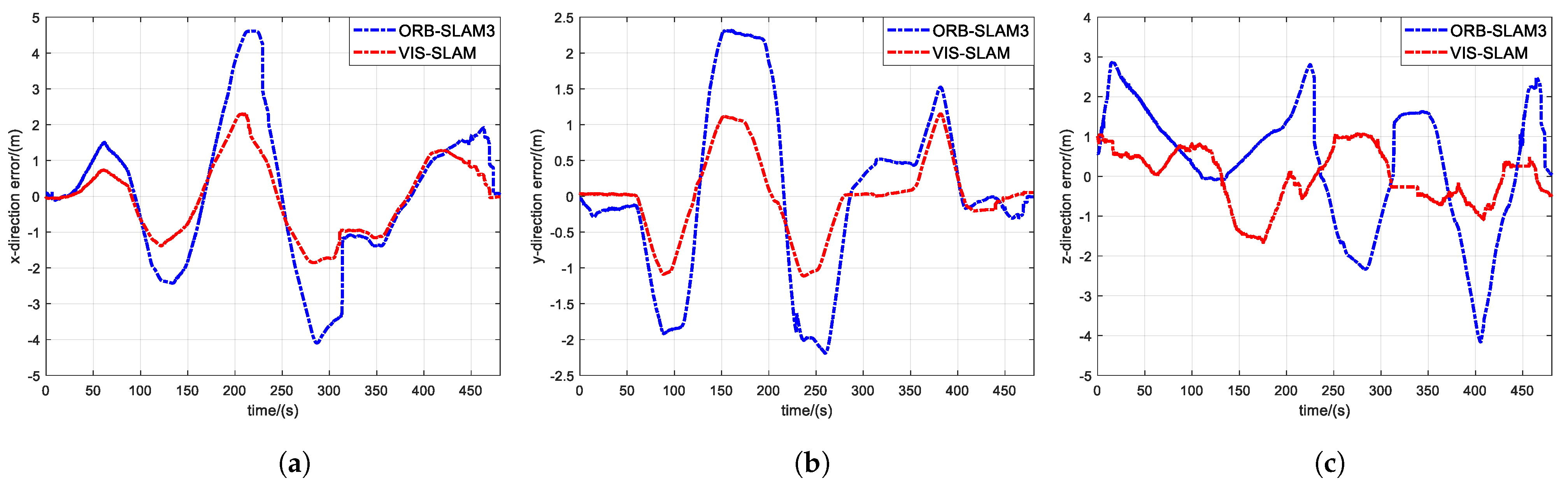
Figure 5 and
Figure 6 compare the results of the coarse segmentation algorithm with the feature-extraction results after IMU correction.
In test image 1, there are three individuals, with only one customer in motion, while the other two individuals are in a stationary position with minimal movement. However, in the motion coarse segmentation algorithm based on deep learning, the prior probability of motion assigned to the “person” feature attribute is high, resulting in misclassification of feature points falling on stationary individuals as dynamic points (see
Figure 5a). In contrast, due to the introduced IMU-assisted correction method in the motion-consistency-detection algorithm, some of the misclassifications caused by coarse segmentation are corrected. As shown in
Figure 5b, the number of dynamic features on the stationary customer is significantly reduced. As shown in
Figure 6a, the YOLOv8 network detects four human objects, but the leftmost individual is not a real human, but a billboard, and the rightmost individual is just a mannequin. However, in the motion-coarse-segmentation algorithm, the feature points falling on these two objects are labeled as dynamic features. In comparison, the proposed algorithm in this section has fewer misclassifications. The number of dynamic features mentioned on the billboard and mannequin is significantly reduced, almost zero. As shown in
Figure 6b, two customers in the middle, who did not undergo significant movement, should also have a corresponding reduction in the number of dynamic features on them.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}