High Efficiency Ring-LWE Cryptoprocessor Using Shared Arithmetic Components



Abstract
1. Introduction
- We propose a ring-LWE cryptoprocessor architecture in which the same arithmetic components, including one polynomial multiplier and one polynomial adder, are used in both encryption and decryption operations to reduce hardware complexity. As a result, the proposed ring-LWE cryptoprocessor requires less hardware resource than existing architectures to perform encryption and decryption operation.
- We deploy the polynomial multiplier using NTT multiplier with parallel based MDF architecture to enhance the polynomial multiplication. Furthermore, the pipeline technique is applied in the proposed design to reduce the system latency.
- We implement the proposed ring-LWE cryptoprocessor architecture on Xilinx Virtex-7 FPGA board and compare the obtained results with its predecessors. Performance evaluation results show that the proposed architecture offers a higher throughput and a better efficiency than others.
2. Background
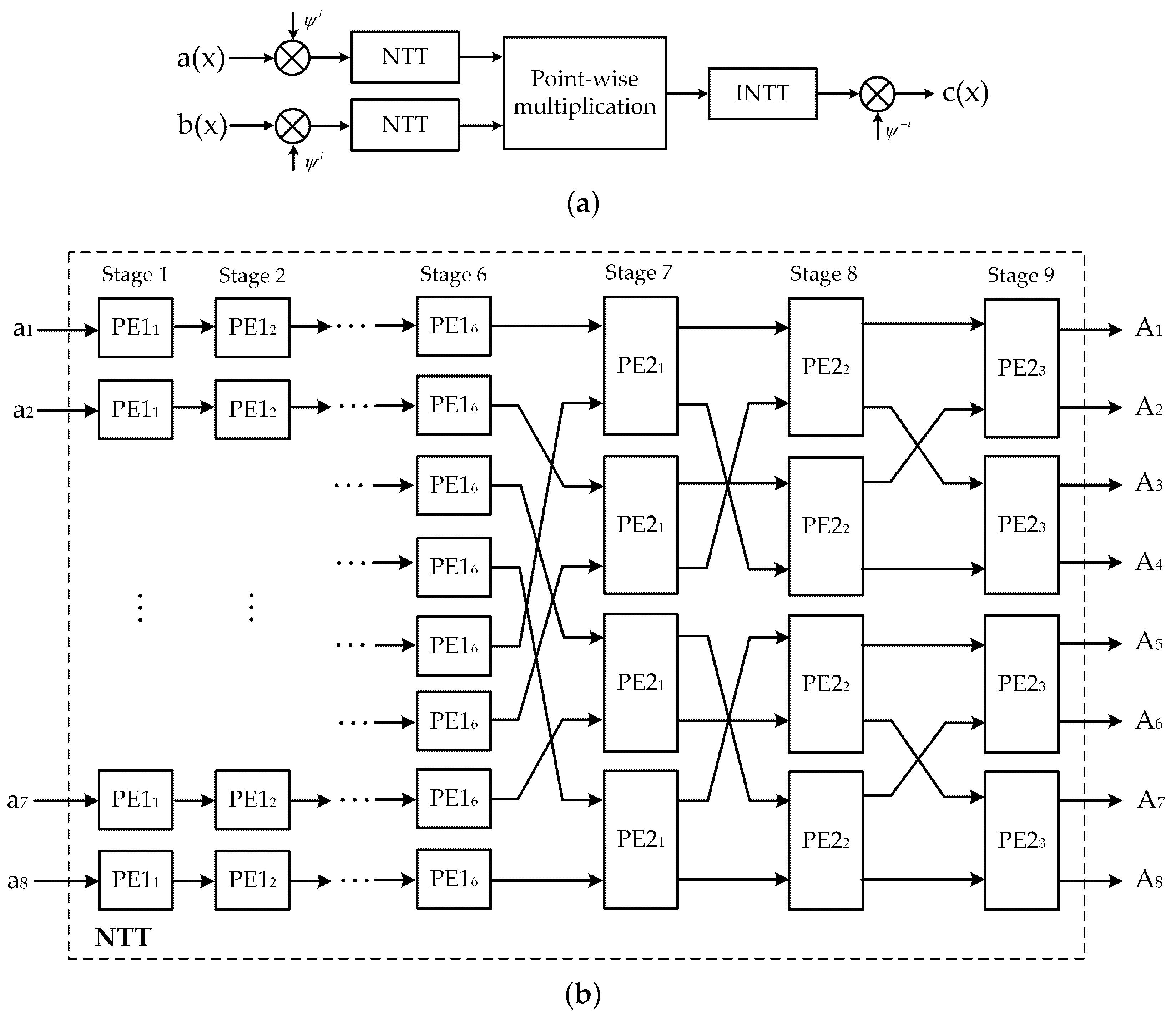
2.1. Ring-LWE Cryptosystem
2.2. Arithmetic Operations over Ring
2.3. Discrete Gaussian Sampler
3. Proposed Ring-LWE Cryptoprocessor Architecture Using Shared Arithmetic Components
3.1. Proposed Algorithm for the Ring-LWE Cryptoprocessor
| Algorithm 1: Proposed ring-LWE cryptography algorithm using shared arithmetic components |
| Input: Output: Ciphertext , or original messsage m while do for to do if then else end if; end for end while Return while do for to do if ( then else end if; end for; end while; Return |
3.2. Ring-LWE Cryptoprocessor Architecture Using Shared Arithmetic Components
3.3. Proposed NTT Polynomial Multiplier Using MDF Architecture
4. Implementation Results and Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ochoa-Jiménez, E.; Rivera-Zamarripa, L.; Cruz-Cortés, N.; Rodríguez-Henríquez, F. Implementation of RSA Signatures on GPU and CPU Architectures. IEEE Access 2020, 8, 9928–9941. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Lee, H. Efficient Algorithm and Architecture for Elliptic Curve Cryptographic Processor. J. Semicond. Technol. Sci. 2016, 16, 118–125. [Google Scholar] [CrossRef]
- Basu Roy, D.; Mukhopadhyay, D. High-Speed Implementation of ECC Scalar Multiplication in GF(p) for Generic Montgomery Curves. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1587–1600. [Google Scholar] [CrossRef]
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM J. Comput. 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Rentería-Mejía, C.P.; Velasco-Medina, J. High-Throughput Ring-LWE Cryptoprocessors. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2332–2345. [Google Scholar] [CrossRef]
- Nguyen Tan, T.; Lee, H. Efficient-Scheduling Parallel Multiplier-Based Ring-LWE Cryptoprocessors. Electronics 2019, 8, 413. [Google Scholar] [CrossRef]
- Nguyen Tan, T.; Lee, H. High-Secure Fingerprint Authentication System Using Ring-LWE Cryptography. IEEE Access 2019, 7, 23379–23387. [Google Scholar] [CrossRef]
- Nguyen Tan, T.; Lee, H. High-Performance Ring-LWE Cryptography Scheme for Biometric Data Security. IEIE Trans. Smart Process. Comput. 2018, 7, 97–106. [Google Scholar] [CrossRef]
- Liu, Z.; Azarderakhsh, R.; Kim, H.; Seo, H. Efficient Software Implementation of Ring-LWE Encryption on IoT Processors. IEEE Trans. Comput. 2017. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, C.; Lin, H.; Chen, Y.; Zhang, M. Resource-Efficient and Side-Channel Secure Hardware Implementation of Ring-LWE Cryptographic Processor. IEEE Trans. Circuits Syst. I Reg. Pap. 2019, 66, 1474–1483. [Google Scholar] [CrossRef]
- Rentería-Mejía, C.P.; Velasco-Medina, J. Hardware Design of an NTT-Based Polynomial Multiplier. In Proceedings of the 2014 Southern Conference on Programmable Logic (SPL), Buenos Aires, Argentina, 5–7 November 2014; pp. 1–5. [Google Scholar]
- Regev, O. On Lattices, Learning with Errors, Random Linear Codes, and Cryptography. In Proceedings of the ACM symposium on Theory of Computing, Baltimore, MD, USA, 22–24 May 2005; pp. 84–93. [Google Scholar]
- Cao, Z.; Wu, X. An Improvement of the Barrett Modular Reduction Algorithm. Int. J. Computer Mathematics 2014, 91, 1874–1879. [Google Scholar] [CrossRef]
- Roy, S.S.; Vercauteren, F.; Verbauwhede, I. High Precision Discrete Gaussian Sampling on FPGAs. In Proceedings of the Selected Areas in Cryptography, Burnaby, BC, Canada, 14–16 August 2013; pp. 383–401. [Google Scholar]
- Du, C.; Bai, G. Towards Efficient Discrete Gaussian Sampling for Lattice-Based Cryptography. In Proceedings of the 2015 International Conference on Field Programmable Logic and Applications (FPL), London, UK, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Condo, C.; Gross, W.J. Pseudo-Random Gaussian Distribution Through Optimised LFSR Permutations. Electron. Lett. 2015, 51, 2098–2100. [Google Scholar] [CrossRef]
- Cooley, J.W.; Tukey, J.W. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Roy, S.S.; Vercauteren, F.; Mentens, N.; Chen, D.D.; Verbauwhede, I. Compact Ring-LWE Cryptoprocessor. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems (CHES), Busan, South Korea, 23–26 September 2014; pp. 371–391. [Google Scholar]
- Pöppelmann, T.; Güneysu, T. Towards Practical Lattice-Based Public-Key Encryption on Reconfigurable Hardware. In Proceedings of the International Conference on Selected Areas in Cryptography, Burnaby, BC, Canada, 14–16 August 2013; pp. 68–85. [Google Scholar]
- Mahdizadeh, H.; Masoumi, M. Novel Architecture for Efficient FPGA Implementation of Elliptic Curve Cryptographic Processor over GF(2163). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 21, 2330–2333. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed | R8M [5] | [6] | [18] | [19] | |
|---|---|---|---|---|---|
| Devices | Virtex-7 | Stratix IV | Virtex-7 | Virtex-6 | Virtex-6 |
| LUTs (enc./dec.) | 61,258/– | 62,994/27,313 | 61,514/25160 | 5595/5595 | 1536/1536 |
| Slices (enc./dec.) | 23,707/– | 56,435/32,019 | 42,374/23,495 | 4760/4760 | 953/953 |
| Frequency (enc./dec.) (MHz) | 284/330 | 226/216 | 269/315 | 250/251 | 277/276 |
| Clock cycles (enc./dec.) | 242/235 | 391/225 | 240/224 | 13,769/8883 | 13,300/5800 |
| Time (enc./dec.) (s) | 0.85/0.71 | 1.73/1.04 | 0.89/0.71 | 54.86/35.39 | 47.90/21.00 |
| Throughput (enc./dec.) (Mbps) | 8432/721 | 4465/492 | 8054/720 | 130/14 | 150/24 |
| Efficiency (Kbps/LUT) | 137 | 66 | 130 | 23 | 95 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen Tan, T.; Thi Bao Nguyen, T.; Lee, H. High Efficiency Ring-LWE Cryptoprocessor Using Shared Arithmetic Components. Electronics 2020, 9, 1075. https://doi.org/10.3390/electronics9071075
Nguyen Tan T, Thi Bao Nguyen T, Lee H. High Efficiency Ring-LWE Cryptoprocessor Using Shared Arithmetic Components. Electronics. 2020; 9(7):1075. https://doi.org/10.3390/electronics9071075
Chicago/Turabian StyleNguyen Tan, Tuy, Tram Thi Bao Nguyen, and Hanho Lee. 2020. "High Efficiency Ring-LWE Cryptoprocessor Using Shared Arithmetic Components" Electronics 9, no. 7: 1075. https://doi.org/10.3390/electronics9071075
APA StyleNguyen Tan, T., Thi Bao Nguyen, T., & Lee, H. (2020). High Efficiency Ring-LWE Cryptoprocessor Using Shared Arithmetic Components. Electronics, 9(7), 1075. https://doi.org/10.3390/electronics9071075