Abstract
Digital watermarking technology is an effective method for copyright protection of digital information, such as images, documents, etc. In this paper, we propose a high capacity text image watermarking technique against printing and scanning processes. Firstly, this method obtains the invariant in the process of printing and scanning under the mathematical hypothesis model of print-scan transformation. Then based on the print-scan invariant, the Fourier descriptor is used to flip the trivial pixel points with high frequency information on the character boundary. Next, considering the resolution of the print-scan equipment and its influence on the print-scan invariant, a quadratic quantization function is proposed to embed watermark information of multiple bits for a single character. Finally, the QR code (Quick Response code) is researched, which has large information capacity, robust error correction ability and high decoding reliability. By using the QR code as the watermark information, we can reduce the impact of bit error rate during watermark extraction, and the robustness of the watermark information can be improved. The experimental results show that the proposed text watermarking algorithm has the advantages of anti-print scanning, anti-scaling, large capacity and good visual effects.
1. Introduction
With the development of the Internet, data and information are ubiquitous in our daily life, and information exchange is becoming more frequent. However, digital information is easy to copy and transcribe, the copyright protection of digital information is becoming ever more prominent. Digital watermarking technology provides a way to solve the appeal problem. At present, the digital watermarking technology is relatively mature for images because they have a lot of redundant information to embed watermark, and these algorithms usually use the information in frequency domain of image for watermark embedding. For example, literature [1,2,3,4] embeds watermark information in the discrete wavelet transform (DWT) domain of image and achieve good results. But the text document has relatively little redundant information, so how to effectively add digital watermark to the document is relatively difficult [5]. In addition, a text file not only appears in the form of digital information, but also in paper status by printing, copying, etc. Therefore, it is essential to study the anti-print scan text watermark for copyright protection [6].
The digital watermark is embedded with the redundant carrier of the text, and it is supposed to have better robustness, good visual effects and huge watermark capacity. Therefore, we need to make a tradeoff amongst the three to achieve better results. In general, the current text watermarking algorithms can be divided into three categories [7,8]: One is based on the text structure, another is based on the natural language processing, and the third is based on the image processing.
The text structure-based methods embed the watermark information by adjusting some features of text, such as line spacing, word spacing, and punctuation position. Brassil et al. proposed a method of line-shift coding [9] and word-shift coding [10]. Line spacing is used to embed watermark information in line-shift coding. Word-shift coding uses the word spacing to embed watermark information. They are both anti-print scan algorithms. However, these methods cannot resist the influence of text format changes, and the watermark capacity is relatively small. Many scholars are likewise constantly researching the algorithm of this type. For example, Alattar et al. [11] use line-shift coding and word-shift coding to embed watermark information together, and add error correction technology to resist attacks.
Linguistic-based approaches use the semantic features of the text to embed a watermark. For example, by replacing certain words or sentences in the text to embed the watermark without touching the semantics of the text content. Liu et al. [12,13] studied the text watermarking algorithm based on semantic features. This type of method will change the text content, so it does not applicable to the cases where the text content cannot be changed. The following research [14] is a good review article which presents a comparative analysis of structural and linguistic method, and some guidelines and directions are proposed in this paper.
Image-based methods need to convert the text documents into images, and embed the watermark by processing the features in the image. According to the different features used, the current image-based methods can be roughly divided into several types: based on shape features, gray-based features, boundary-based features, pixel-based features, and shading-based features. Table 1 shows the analysis and comparison of several algorithms.

Table 1.
Comparison of text watermarking algorithms based on image processing.
In summary, existing text watermarking algorithms have different spaces for improvement in watermark capacity, visual effects, robustness, and blind extraction. Therefore, this paper proposes a text watermarking algorithm that is resistant to print-scan and can embed information at large capacities. The algorithm combines the print-scan invariant, Fourier boundary descriptors, quadratic quantization function, and the QR code, etc. The algorithm increases the watermark capacity by more than 200%, and the performance is improved in terms of robustness, visuality and bit error rate.
2. Related Theory
This section introduces some theories in watermarking algorithm. They are as follows: print-scan invariant, Fourier boundary descriptor, quadratic quantization function and the QR code.
2.1. Print-Scan Invariant
In [25], the print-scan process is studied, and the transformation process of the print-scan is obtained as shown in Equation (1), where is the character image before the print-scan process, is the character image after the print-scan process. is a kernel function, which is only related to the print-scan process. represents the image pixel; represents the convolution operation.
In [21], the invariant of the print-scan process is obtained by mathematically inferring Equation (1). That is, the ratio of black pixels contained in each character to the average of the black pixels of all characters is an invariant before and after the print-scan process. Then the invariant can be used to embed the watermark. The invariant is defined as shown in Equation (2), where the denominators and are the average black pixels of all the characters after print-scan and before print-scan. The numerator is the integral operation for the pixel points of each character on the entire text image.
It is worth mentioning that literature [21] also has shortcomings. When watermark embedding is conducted based on the invariant, it is necessary to keep the average value of the pixels of the entire document unchanged, so the text is divided into the embedding part and the adjusting part, and the ratio is 3:1. Therefore the maximum watermark capacity is 75% of the number of characters. In this paper, we find that and can be the average of a certain reference line in the text, so that the adjustment part of the literature [21] is not needed to ensure that the average black pixels of the whole document is unchanged. Figure 1 shows the original text image and the scanned text image, and Figure 2 shows the improved print-scan invariant obtained with the first line as a benchmark. As can be observed in Figure 2, the improved print-scan invariant is consistent before and after the print-scan process, and the error here does not exceed 0.015.

Figure 1.
The print-scan process; (a) the original binary image; (b) the scanned text image.
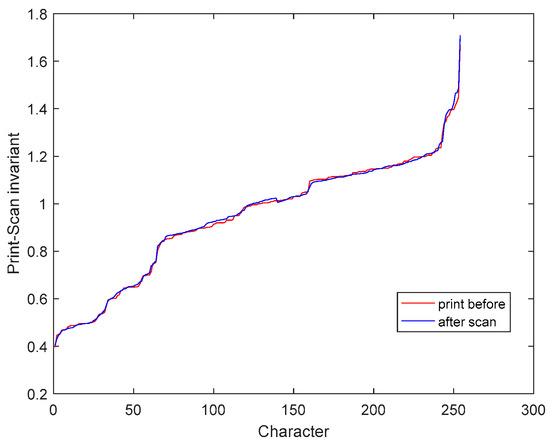
Figure 2.
The improved print-scan invariant.
2.2. Fourier Boundary Descriptors
The Fourier descriptor is the frequency domain coefficient obtained after the Fourier transform of the graph boundary points. Its idea is that for a closed boundary in a plane, a limited number of scattering coordinates , ,… can be found to represent it. These coordinate points can then be treated as plural. And it is shown in Equation (3):
Thus, the closed curve boundary can be represented in one-dimensional space. For the one-dimensional sequence , its discrete Fourier transform is shown in Equation (4). Where is the Fourier descriptor coefficient of the boundary. can be regenerated by through the inverse Fourier transform, and the inverse Fourier transform function is shown in Equation (5).
When in Equation (5), then we can conclude that . It is a known fact that the high-frequency component of the Fourier coefficient indicates the fineness of the detail, and the low-frequency component determines the overall shape. Therefore, the boundary point can be adjusted by the parameter , and the purpose of increasing or decreasing the pixel point can be achieved without affecting the overall shape.
The research in [26] studies the Fourier descriptor and shows its good feature in anti-RST(Rotation-Scale-Translation) attacks and its wide applications. Previous literature [19,22,27] used the Fourier descriptor to practice on digital watermarking. Among them, the research in [19] uses the Fourier descriptor to embed watermark on the high frequency coefficient, but the method is less robust and unblind. Reference [22] uses the Fourier descriptor to flip the boundary pixels, but the scheme can still be enhanced and optimized. Literature [27] uses Fourier descriptors to preprocess watermark information, and then applies Sudoku to embed watermarks.
2.3. Quadratic Quantization Function
Currently there exist some schemes based on character as a carrier to embed watermarks. In [21], each Chinese character or English letter can be embedded with a one bit watermark information. In [22], each English letter can be embedded with a one bit watermark. According to the complexity of its partial structure, some Chinese characters can be divided into multiple character components to embed information of multi-bits. The quantization process of these two methods is relatively simple and not suitable for large-capacity watermark embedding. Furthermore, according to the resolution step size they selected, the maximum number of pixels flipped by a single character is ( is the average of the pixel points). In this paper, based on the error rate before and after the print-scan, a quadratic quantization function is proposed to embed bits watermark information into a single character by flipping the pixels.
According to the analysis of the print-scan invariant in Section 2.1, the error rate of the print-scan equipment used in this paper is less than 0.015. The experimental results also show that the value of the print-scan invariant ranges from 0.4 to 2.0. Therefore, in the case where the resolution and the flipping ratio are appropriate, it is conceivable to divide gradients within a certain pixel inversion range , and then select an appropriate quantization function for watermark coding.
In this paper, the quantization function is proposed under the principle of resolution, invariant, coding scheme and simplicity, and it is shown in Equation (6), where indicates the print-scan invariant of the character; is a constant indicating the quantization step size, where is available; can be obtained according to the selected pixel flipping range , here assume .
Taking the error rate of the print-scan process and the precision of the pixel flipping into account, the quantization function can be combined with the Gray code for watermarking coding, then the error-rate will be reduced during watermark extraction. Therefore, Equation (7) is used to quantize bits watermark information, and different quantized values represent different watermark codes. Then the inverse function of the Equation (7) can be used to obtain the print-scan invariant according to the watermark information. Thus, the number of black pixels that need to be flipped by different watermark information is shown in Equation (8).
2.4. QR Code
The QR code has the characteristics of large information capacity, strong error correction capability, high decoding reliability and low production cost. What’s more, it has wide application in the field of information security [28]. In recent years, the QR code has also begun to be utilized in the field of digital watermarking. Literature [29] uses the QR code as a carrier and it is combined with two-level wavelet decomposition coefficients to embed watermark information, but its practicability is not strong. Literature [30] uses the three-level discrete wavelet transform coefficients of an image as the carrier, and embeds the QR code as watermark information in the carrier. Literature [24] uses the method similar to the literature [30] to embed the QR code as watermark information into the text image. However, since the text image is binary, this method will produce a layer of shading in the text image, and its robustness is not good enough to resist printing and scanning.
In general, the QR code can reduce the incidence of bit error rate during watermark extraction because of its ability to correct errors. Furthermore, due to its large information capacity, it is a good choice to use the QR code as a watermark. But the QR code is composed of a dot matrix, and its minimum size is . Therefore, there must be enough carriers to embed the QR code information. This paper utilizes the online open source tool [31] to generate a QR code that can be scanned using WeChat.
3. Proposed Model
This section will introduce the proposed watermark embedding and extraction method, as well as the flipping scheme of boundary pixels.
3.1. Watermark Embedding Process
Based on the previous introduction, the following is an example of embedding two bits of watermark information for each character. The watermark embedding process is as follows:
- The watermark information is obtained and arranged into a sequence , where is the watermark length.
- Converting the text image into a binary image, denoising, removing characters whose pixels are less than a certain threshold , for example, punctuation, etc. This paper takes greater than half of the average pixels of all characters.
- The processed binary image is divided into character row units, and then the effective characters of each row are segmented to obtain a character set , where is the row index and is the column index. The corresponding black pixels set is .
- Calculating the average value of black pixels of all characters in the first row, then calculating the ratio set of the remaining character black pixels to . And they are shown in Equations (9) and (10), respectively.
- Solving the quantization function Equation (6) according to the watermark information. If , then solving ; else if , then solving ; else if , then solving ; else if , then solving ; finding the appropriate solution . Then we can get the print-scan invariant set of all characters after embedding the watermark information and the set is .
- Calculating the pixel flipping ratio set for watermarked characters.
- According to the pixel flipping ratio set , the pixel points of the corresponding characters are flipped with the pixel flipping strategy in Section 3.3.
3.2. Watermark Extraction Process
According to the watermark embedding process, the corresponding extraction process is as follows:
- Converting the watermarked image into a binary image, removing noise, and removing characters whose pixel points are less than a certain threshold , such as punctuation. It should be stressed that this paper takes greater than half of the average pixels of all characters.
- The processed binary image is divided into character line units, and then the effective characters of each line are segmented to obtain a valid character set , where is the row index and is the column index. The corresponding black pixels set is .
- Calculating the average value of black pixels of all characters in the first row. Then calculating the ratio set of the remaining character black pixels to , as shown in Equations (11) and (12), respectively.
- Finding the watermark information carried by the character according to and the quantization function Equation (6). If , then getting ; else if ; then getting ; else if ; then getting ; else if ; then getting ;
- Generating a corresponding QR code based on the watermark information.
3.3. Pixel Flipping Strategy
This paper flips the character boundary pixels by adjusting the high frequency component of the Fourier descriptor. The high-frequency component only affects the fineness of the boundary, and has little effect on the overall shape of the character, so we use it for pixel flipping. The flipping strategy is as follows:
- According to the result of Section 3.1, inputting character and its corresponding pixel flipping rate .
- If , it is considered that the character does not need to be flipped, and it can be left as it is; otherwise, it will enter step 3.
- Extracting the boundary of the character and calculating the Fourier descriptor of the character according to Equation (4), where and is the number of boundary points of the character . Let , , .
- Reconstructing the boundary with Equation (5), then filling the boundary to get the character .
- If , then let ; otherwise . Then calculating the print scan invariant of the character and getting the difference between and the target . Let .
- If , then let , .
- If or , Then the flipping process ends, replacing the original character with ; Otherwise, let , jump to step 4 and continue the flipping process.
4. Experimental Results and Discussion
The watermarking algorithm proposed in this paper does not target specific character types and font sizes, and has strong generality. In the experiment, we embed watermark to the English and Chinese documents, then analyze the visual effect, capacity and robustness of the watermark. At last, we compare the experiment results with those of the existing schemes.
4.1. Visual Effect
Depending on the definition of the quantization function, the pixel flipping range of the character will affect the visual effect. Here we select an English letter picture for watermark embedding test, as shown in Figure 3a, where the letters are Arial four-font. Figure 3b shows the case where a 42-bit watermark is embedded in the original picture at . Figure 3c shows the case where a 42-bit watermark is embedded in the original picture at . Figure 3d shows the case where a 42-bit watermark is embedded in the original picture at . It can be seen that the larger is, the worse the visual effect is after embedding the same watermark information. Figure 4 shows the enlarged view of the letter k in each case. Contrary to the visual effect, a larger results in better robustness and greater correct rates of watermark information extraction after printing and scanning. Therefore, it is necessary to balance the visual effect and the robustness, which in turn depends on the error range of the printing scanning equipment. According to the analysis of Figure 2, the error range of the printing scanning equipment (Pantum M7300FDW, resolution 600DPI) used in this experiment was less than 0.015, so needs to be no less than 0.15. With the improvement of the precision of the printing and scanning equipment, for example, the error range of the printing scanning equipment used in the literature [22] was less than 0.005, thus, a smaller value can be selected for that case.

Figure 3.
The comparation of the visual effect with different .

Figure 4.
Letter k enlarged view.
This paper uses peak signal to noise ratio (PSNR) and similarity (SIM) percentage to judge the visual effect of the image after embedding watermark. Their calculation methods are shown in Equations (13)–(15). In Equation (13), is the image to be evaluated, is the reference image, is the size of the image, and is the mean square error of the two images. In Equation (14), represents the pixel bit width, and the unit of is dB. The larger indicates the better visual effect. in Equation (15) represents the similar percentage of the two images.
According to the calculation method of and , Table 2 shows the results of calculating and separately for the subgraphs obtained by embedding the same watermark information under different in Figure 3. It can be seen that the smaller indicates the better visual effect and the higher similarity.
Table 2.
The peak signal to noise ratio (PSNR) and similarity (SIM) with different δ.
4.2. Capacity and Robustness
According to the algorithm proposed in this paper, it is possible to embed bits () watermark information for a single character by adjusting the quantization function. Figure 5 shows the image before and after embedding 80-bit watermark information in a Chinese–English mixed document. Figure 6 shows an enlarged view of the characters after embedding the watermark information. In the figure, some punctuation and small characters are processed, leaving only the characters used for embedding the watermark. For English characters, a single letter symbol can be embedded with two bits of watermark information. For complex Chinese characters, a single character can be split into multiple parts for watermark embedding. For example, the Chinese character “印” can be split into two character components, and the Chinese character “数” can be split into three character components, thereby it further increases the watermark capacity.

Figure 5.
Test in a Chinese–English mixed document.

Figure 6.
Character used for watermark embedding.
The increase of the watermark capacity will also lead to an increase in the bit error rate during the watermark extraction process. Since the QR code has strong error correction capability and has a large information capacity, it is a good choice to embed the QR code as watermark information in the text picture. On the one hand, the watermark capacity is increased, on the other hand, the robustness of the watermark information is also improved. In addition, the algorithm proposed in this paper also performs denoising processing before watermark extraction, thus reducing the impact of small noise. Figure 7 shows the comparison between the embedded QR code and the final extracted QR code in the text of Figure 1. It can be seen that although Figure 7b has a bit error, it can still scan the information carried in the QR code. In Section 4.3 we compare the robustness of our algorithm with the existing algorithms from the perspective of the bit error rate.

Figure 7.
Embedded and extracted QR code.
4.3. Comparison with the State-of-the-Arts
This section compares the literature of [21,22] and the method of this paper. In the watermark capacity, the literature [21] can embed the least watermark information, about 75% of the total number of characters. The watermark information that can be embedded in [22] is about 100% of the total number of characters. The watermark information that can be embedded with the method of this paper is greater than 200% of the total number of characters. When combined with the QR code, more watermark information can be embedded with the proposed method. The watermark capacity comparison of different schemes is shown in Table 3.
Table 3.
The comparison of watermark capacity.
In terms of visual effects, this paper uses three schemes to embed the same watermark information for multiple document images of different fonts, and compares their respective PSNR and SIM scores. In [21], all characters in the scheme have to be flipped, so the text image after embedding the watermark has the largest change compared with the original text image. In the literature [22], there is no adjustment part, so the number of characters that need to flip the pixels is less than the literature [21] scheme. Therefore, the overall visual effect of the literature [22] is better. Compared with the literature [22], our algorithm requires fewer characters to flip the pixels, and because of the introduction of the quantization function, the pixel flipping range has a gradient effect, so that the character only needs to flip fewer pixels to embed the watermark. Table 4 and Table 5 compare the PSNR and SIM scores of existing schemes in different fonts.
Table 4.
The PSNR value of different models.
Table 5.
The SIM value of different models.
In terms of robustness, the literature [21,22] are almost the same. The algorithm proposed in this paper is affected by the quantization function. When the is larger, the robustness is better, and the bit error rate of single character is lower during watermark extraction. However, since the method of this paper has a larger watermark capacity, it is possible to reduce the impact of the bit error rate by increasing the error correction and verification schemes, thereby improving the robustness of the watermark. Furthermore, this paper also proposes to use the QR code as the watermark information, and use the error correction and verification functions of the QR code to improve the robustness of the watermark. Figure 7 shows the case of using a QR code as watermark information. In addition, our algorithm also has a good effect in anti-scaling and anti-noise. Table 6 shows the bit error rate under various attack conditions. This paper selects a text image to embed 100 bits watermark information with three methods. ERR-n represents the number of the error bits.
Table 6.
Bit error rate of different models under various attack conditions.
5. Conclusions
This paper proposes a high capacity watermarking algorithm for the printed document. Our algorithm is designed by studying the print-scan process, Fourier descriptor, quantization function and the QR code. Furthermore, the performance of the proposed algorithm is compared with the previous methods to demonstrate the advantages in capacity, visual effect and robustness. Compared with the existing methods, our algorithm has the following advantages:
- Larger watermark capacity. This paper analyzes the accuracy of the print-scan equipment to design a suitable quantization function, and makes a reasonable balance between the visual effect and the watermark capacity, so that the watermark capacity is greatly improved. In addition, by using the quantization function, a single character can carry bits watermark information, making it possible to embed QR code or other patterns in the document. The QR code itself has a larger information capacity, so this paper implements a large-capacity text watermarking algorithm.
- Better visual effect. Compared with the existing methods, this algorithm has a better visual effect and the visual effect can be adjusted according to the actual situation. This visual effect has strong generality, both English and Chinese fonts have good results.
- Better robustness. This algorithm can resist the attack of print-scan process, the attack of image scaling, the attack of noise and many more, and this algorithm can realize the blind extraction. Moreover, in order to further reduce the influence of the extraction error rate, this paper proposes to use the QR code as the watermark information. Since the QR code itself has an error correction function, the information carried by the QR code can still be scanned within a certain error range, thereby making the robustness better.
It should be noted that this algorithm needs to design the quantization function according to the error range produced by the print-scan equipment. For different printing and scanning equipment, the quantization function may be different and the visual effects will be different. In addition, the boundary flipping strategy can also be optimized when there are many character boundary points. Moreover, for the improvement of robustness, other better error correction and verification schemes can be designed to reduce the impact of bit error rate during the extraction process. For example, the two-layer cellular neural network (CNN) architectures proposed in literature [32] are very suitable for generating highly robust watermarking patterns. In general, the research of text watermarking algorithm is still essential, and the research space is still very broad. In addition, for further work, we will focus on optimizing this algorithm with neural network, enhancing the security of watermark information and implementing this algorithm in a consumable SoC of printer.
Author Contributions
Conceptualization, K.H. and X.T.; methodology, K.H. and X.T.; software, X.T. and H.Y.; validation, H.Y. and X.T.; formal analysis, K.H. and X.T.; investigation, K.H., X.T. and H.Y.; resources, K.H., M.Y. and A.Y.; data curation, X.T. and H.Y.; writing—original draft preparation, X.T. and H.Y.; writing—review and editing, K.H. and M.Y.; project administration, K.H., A.Y. and X.T.; funding acquisition, K.H., A.Y. and M.Y.
Funding
This research was funded by National Science and Technology Major Project grant number 2017ZX01030-102-002.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Vaidya, S.P.; Mouli, P.C.; Santosh, K.C. Imperceptible watermark for a game-theoretic watermarking system. Int. J. Mach. Learn. Cybern. 2018, 10, 1323–1339. [Google Scholar] [CrossRef]
- Lee, Y.; Seo, Y.; Kim, D. Digital blind watermarking based on depth variation prediction map and DWT for DIBR free-viewpoint image. Signal Process. Image Commun. 2019, 70, 104–113. [Google Scholar] [CrossRef]
- Leopardi, A.; Soresina, D.; Marcantonio, D.; Malacarne, A.; Conci, N.; Boato, G. Blind image watermarking in Wavelet-domain robust to printing and smart-phone acquisition. Electron. Imaging 2018, 13, 1–9. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Duong, D.A. Robust and high capacity watermarking for image based on DWT-SVD. In Proceedings of the 11th IEEE-RIVF International Conference on Computing and Communication Technologies, Can Tho, Vietnam, 25–28 January 2015. [Google Scholar]
- Sang, J.; Fang, Q.; Xu, C. Exploiting Social-Mobile Information for Location Visualization. ACM Trans. Intell. Syst. Technol. 2017, 8, 1–19. [Google Scholar] [CrossRef]
- Zeeshan, M.; Ullah, S.; Anayat, S.; Hussain, R.G.; Nasir, N. A Review Study on Unique Way of Information Hiding: Steganography. Int. J. Data Sci. Technol. 2017, 3, 45–51. [Google Scholar] [CrossRef][Green Version]
- Xie, G.; Liu, Y.; Xin, G.; Yang, P. Review on Text Watermarking Resistant to Print-Scan, Screen-Shooting; Springer Science and Business Media LLC: Cham, Switzerland, 2019; pp. 140–149. [Google Scholar]
- Khadam, U.; Iqbal, M.M.; Azam, M.A.; Khalid, S.; Rho, S.; Chilamkurti, N. Digital Watermarking Technique for Text Document Protection Using Data Mining Analysis. IEEE Access 2019, 7, 64955–64965. [Google Scholar] [CrossRef]
- Brassil, J.T.; Low, S.; Maxemchuk, N.F. Copyright protection for the electronic distribution of text documents. Proc. IEEE 1999, 87, 1181–1196. [Google Scholar] [CrossRef]
- Brassil, J.T.; Low, S.; Maxemchuk, N.F. Electronic marking and identification techniques to discourage document copying. IEEE J. Sel. Areas Commun. 1995, 13, 1495–1504. [Google Scholar] [CrossRef]
- Alattar, A.M.; Alattar, O.M. Watermarking Electronic Text Documents Containing Justified Paragraphs and Irregular Line Spacing. In Proceedings of the SPIE—The International Society for Optical Engineering, San Jose, CA, USA, 22 June 2004; pp. 685–695. [Google Scholar]
- Liu, Y.; Zhu, Y.; Xin, G. A zero-watermarking algorithm based on merging features of sentences for Chinese text. J. Chin. Inst. Eng. 2015, 38, 391–398. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, X.; Gan, C.; Wang, H. An Efficient Linguistic Steganography for Chinese Text. In Proceedings of the IEEE International Conference on Multimedia & Expo, Beijing, China, 2–5 July 2007. [Google Scholar]
- Taleby Ahvanooey, M.; Li, Q.; Shim, H.J.; Huang, Y. A Comparative Analysis of Information Hiding Techniques for Copyright Protection of Text Documents. Secur. Commun. Netw. 2018, 2018, 5325040. [Google Scholar] [CrossRef]
- Tan, L.; Sun, X.; Sun, G. Print-Scan Resilient Text Image Watermarking Based on Stroke Direction Modulation for Chinese Document Authentication. Radioengineering 2012, 21, 170–181. [Google Scholar]
- Borges, P.V.K.; Mayer, J. Text luminance modulation for hardcopy watermarking. Signal Process. 2007, 87, 1754–1771. [Google Scholar] [CrossRef]
- Villán, R.; Voloshynovskiy, S.; Koval, O.; Vila, J.; Topak, E.; Deguillaume, F. Text data-hiding for digital and printed documents: Theoretical and practical considerations. In Proceedings of the Security, Steganography, and Watermarking of Multimedia Contents VIII, San Jose, CA, USA, 17 February 2006. [Google Scholar]
- Thongkor, K.; Amornraksa, T. Digital image watermarking for printed and scanned documents. In Proceedings of the Ninth International Conference on Digital Image Processing (ICDIP 2017), Hong Kong, China, 21 July 2017. [Google Scholar]
- Solachidis, V.; Pitas, I. Watermarking Polygonal Lines Using Fourier Descriptors. IEEE Comput. Graph. Appl. 2004, 24, 44. [Google Scholar] [CrossRef]
- Wu, M.; Liu, B. Data hiding in binary image for authentication and annotation. IEEE Trans. Multimed. 2004, 6, 538. [Google Scholar] [CrossRef]
- Qi, W.F.; Li, X.L.; Yang, B.; Cheng, D. Document watermarking scheme for information tracking. J. Commun. 2008, 29, 183–190. [Google Scholar]
- Tan, L.; Hu, K.; Zhou, X.; Chen, R.; Jiang, W. Print-scan invariant text image watermarking for hardcopy document authentication. Multimed. Tools Appl. 2019, 78, 13189–13211. [Google Scholar] [CrossRef]
- Kim, H.Y.; Mayer, J. Data Hiding for Printed Binary Documents Robust to Print-Scan, Photocopy and Geometric Attacks. J. Commun. Inf. Syst. 2008, 23. [Google Scholar] [CrossRef]
- Cardamone, N.; d’Amore, F. DWT and QR Code Based Watermarking for Document DRM. In International Workshop on Digital Watermarking; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Smith, E.B.; Qiu, X. Statistical image differences, degradation features, and character distance metrics. Int. J. Doc. Anal. Recognit. 2003, 6, 146–153. [Google Scholar] [CrossRef]
- Dong, L.; Wang, J.; Li, Y.; Tang, Y.Y. Sector Projection Fourier Descriptor for Chinese character recognition. In Proceedings of the IEEE International Conference on Cybernetics (CYBCO), Lausanne, Switzerland, 13–15 June 2013. [Google Scholar]
- Zhang, L.; Zheng, H. A high capacity multiple watermarking scheme based on Fourier descriptor and Sudoku. In Proceedings of the Eighth International Conference on Machine Vision (ICMV 2015), Barcelona, Spain, 8 December 2015. [Google Scholar]
- Labeljoy. Available online: https://www.labeljoy.com/qr-code/qr-code-specification/ (accessed on 10 October 2019).
- Panyavaraporn, J.; Horkaew, P.; Wongtrairat, W. QR code watermarking algorithm based on wavelet transform. In Proceedings of the Communications and Information Technologies (ISCIT), Surat Thani, Thailand, 4–6 September 2013. [Google Scholar]
- Nishane, S.; Umale, V.M. Digital image watermarking based on DWT using QR code. Int. J. Curr. Eng. Technol. 2015, 5, 1530–1532. [Google Scholar]
- OSCHINA.NET. Available online: http://tool.oschina.net/qr (accessed on 10 October 2019).
- Arena, P.; Baglio, S.; Fortuna, L.; Manganaro, G. Self-organization in a two-layer CNN. IEEE Trans. Circuits Syst. 1998, 45, 157–162. [Google Scholar] [CrossRef]







© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).