Abstract
Recent advancements in large language models (LLMs) have significantly improved text-to-image (T2I) generation, enabling systems to produce visually compelling and semantically meaningful images. However, preserving fine-grained semantic consistency in generated images, particularly in response to complex and region-specific textual prompts, remains a key challenge. In this work, we propose a context-aware hierarchical agent mechanism that integrates a semantic condensation strategy to enhance attention efficiency and maintain critical visual-textual alignment. By dynamically fusing contextual information, the method effectively balances computational efficiency and ensures semantic alignment with textual descriptions. Experimental results demonstrate improved visual coherence and semantic consistency across diverse prompts, validated through quantitative metrics and qualitative analysis. Our contributions include: (i) introducing a novel semantic condensation strategy that enhances attention efficiency while preserving critical feature information; (ii) developing a new hierarchical agent attention mechanism to enhance computation efficiency; (iii) designing an iterative feedback method based on CLIP Score to improve image diversity and overall quality.
1. Introduction
Recent advancements in diffusion models have markedly improved both visual fidelity and semantic alignment in text-to-image generation. Transformer-based models such as PixArt-α [1], Stable Diffusion 3/3.5 [2], and Flux.1 Kontext [3], trained on large-scale multimodal datasets, has further pushed image quality beyond its UNet-based predecessors, including Stable Diffusion 1.5 [4] and SDXL [5]. In parallel, increasingly powerful text encoders and large language models (LLMs), such as GLM [6], GPT-4 [7], Llama3 [8], have enriched textual representations and expanded the diversity of expressible concepts. Despite these strides, achieving fine-grained spatial control over object relationships and attributes remains a key challenge. Semantic misalignment—specifically, the failure to correctly bind objects with their intended attributes or associated subcomponents—continues to be a persistent limitation in modern text-to-image systems.
As illustrated in Figure 1, RPG [9] exhibits missing objects, such as the Starbucks coffee cup, and misplaces the cat, leading to inconsistent spatial layouts; SDXL [5] introduces an incorrect Starbucks logo on the vase, renders the cat with overly smooth details, and positions the flower vase and coffee cup inaccurately; SD3 [2] generates two coffee cups instead of one and exaggerates the cat’s facial expression; Playground v3 [10] maintains a generally plausible scene but suffers from minor spatial inconsistencies, missing logos, and unexplained light spots. In contrast, our proposed method preserves accurate object placement, consistent object-attribute alignment, and detailed textures, producing a coherent and visually realistic scene closely matching the textual prompt.

Figure 1.
Outputs from different T2I models (RPG, SDXL, SD3, Playgroundv3) generated using the same prompt: “From left to right, bathed in soft morning light, a cozy nook features a steaming Starbucks latte on a rustic table beside an elegant vase of blooming roses, while a plush ragdoll cat purrs contentedly nearby, its eyes half-closed inblissful serenity.”.
Existing techniques—such as attention optimization, layout priors, and latent-space refinement—offer only partial mitigation of semantic misalignment. They often struggle to simultaneously achieve precise object–attribute binding, computational efficiency, and scalability in multi-object scenarios. Regional prompting methods like RAG [11] enable localized control through explicit region-text binding and subsequent refinement; however, their fixed architectural design limits flexibility when handling complex, multi-region prompts or highly structured scenes, and they generalize poorly across domains. Tuning-free approaches such as RPG [9] and Multidiffusion [12] face complementary challenges: they typically operate on denoised latents or attention maps using split-and-merge strategies. As the number of regions grows, these methods suffer from rapidly degrading control coherence, making it difficult to preserve inter-region consistency. Similarly, Omost [13] processes regions independently in latent space before merging, which suppresses cross-region interaction and consequently compromises both attribute precision and global visual harmony—often manifesting as spatial discontinuities or conflicting attributes across region boundaries.
To address these challenges, we propose PathSelect, a novel tuning-free framework that introduces Dynamic Token Condensation and Hierarchical Attention for accelerated text-to-image diffusion. By adaptively condensing semantically redundant tokens and guiding cross-region interactions through a multi-level attention hierarchy, our method substantially improves regional controllability, object–attribute alignment, and cross-region consistency—while maintaining computational efficiency and supporting visually diverse outputs. Our main contributions are summarized as follows:
(1) Dynamic Token Condensation: We introduce a semantic condensation strategy that compresses redundant or weakly informative tokens into composite representations, thereby strengthening the alignment between objects and their descriptive attributes.
(2) Hierarchical Agent Attention Mechanism: We design a hierarchical agent attention mechanism to refine interactions between regional prompts and image latents, enabling precise object–attribute and subobject binding across regions while reducing computational overhead.
(3) CLIP Score–Based Iterative Feedback: We develop an iterative CLIP-based feedback mechanism that evaluates and adjusts the generation target at each iteration. This process improves semantic alignment and preserves diversity, particularly in complex multi-object scenarios.
While our approach demonstrates improved semantic alignment and visual coherence, it has several limitations. Performance may vary with prompt phrasing, particularly for unconventional or highly abstract descriptions, where alignment stability can degrade. The model also struggles with linguistically complex inputs—such as those involving nested modifiers, implicit references, or fine-grained relational semantics—which can lead to attribute misassignment or object omission. Moreover, our evaluation focuses primarily on general-domain benchmarks; robustness across specialized domains remains to be thoroughly assessed. We plan to address these challenges in future work through more adaptive language grounding and domain-aware training strategies.
2. Related
Current text-to-image models face significant challenges in accurately capturing fine-grained semantics and spatial arrangements described in complex prompts. This issue, known as semantic alignment, becomes especially evident when handling prompts with multiple objects, attributes, and spatial relationships. To address this, existing methods can be broadly categorized into four primary approaches.
Optimization-based methods refine attention scores or text embeddings to improve object representation and attribute binding. Attend-and-Excite [14] enhances object-specific attention to ensure inclusion, Divide-and-Bind [15] separates entities spatially by varying attention maps, SynGen [16] enforces alignment between linguistic and cross attention maps, and Composable Diffusion [17] decomposes complex prompts into simpler components. While these methods improve object inclusion in moderately complex prompts, they often struggle with dense prompts involving intricate spatial and attribute requirements, leading to incomplete objects, misaligned attributes, or semantic errors. Recently, ReNO [18] proposed Reward-based Noise Optimization, which iteratively refines the initial latent noise using reward models to enhance image quality and prompt alignment without training. However, it incurs additional inference cost and may be less effective for complex multi-object spatial arrangements. CoMat [19] introduces an image-to-text concept matching mechanism and an attribute concentration module to guide the diffusion model in revisiting overlooked concepts and improving attribute binding. This enhances prompt fidelity for complex multi-object and multi-attribute scenarios. However, it still relies on effective concept extraction and may struggle with very fine-grained spatial arrangements.
Layout-to-Image methods use structured inputs such as bounding boxes or segmentation masks for explicit spatial guidance. BoxDiff [20] enforces regional placement through cross attention constraints, and InstanceDiffusion [21] adds instance-level control.
IFAdapter [22] further enhances instance-level feature control by leveraging appearance tokens and semantic maps to better align generated content with textual prompts. Although these approaches achieve precise spatial control, they face challenges with abstract descriptions or prompts lacking explicit spatial details, and instance-level methods like IFAdapter may introduce additional computation and are sensitive to inaccuracies in semantic maps, limiting their flexibility and robustness in complex multi-object scenes.
Large language model-augmented approaches use LLMs to improve text representations and generate intermediate layouts through a text-to-layout-to-image pipeline. RPG [9], MuLan [23], and RAG [11] enhance compositional alignment across regions. While these methods improve region-level consistency and multi-object alignment, they introduce computational overhead and often require fine-tuning or additional layout generation steps, reducing scalability and limiting applicability to real-time or large-scale scenarios.
Tuning-free methods manipulate latent features or attention maps without additional training. DenseDiffusion [24] adjusts cross attention activations in masked regions, and MultiDiffusion [12] combines denoised regional latents using spatial masks, Ctrl-X [25] injects structural and appearance features to control layout and semantics, but it requires reference images, limiting its applicability. VMix [26] improves control through cross attention mixing, yet it relies on predefined mixing strategies, which can reduce flexibility in complex multi-region scenarios.
Unified multimodal models, such as FLUX.1 Kontext [3], aim to integrate text and reference images within a shared latent space to improve multi-turn consistency, object stability, and editability. Nevertheless, FLUX.1 Kontext still exhibits limitations when handling complex multi-region prompts: iterative or dense editing can degrade quality and blur details; combining reference layouts with prompts may compromise layout preservation or style and attribute changes; fine-grained semantic understanding remains limited for multiple objects, attributes, and spatial relationships; and generating high-resolution or complex compositions can cause detail loss or deformation. These challenges highlight that even state-of-the-art unified models do not fully solve multi-region semantic alignment with robust spatial and attribute control.
To address these limitations, we propose a training-free framework integrating three complementary components: Dynamic Token Condensation, Hierarchical Agent Attention Mechanism, and Iterative Feedback with CLIP score. Dynamic Token Condensation condenses redundant or less informative tokens in the text embedding space, preserving essential semantic information and preventing attribute misbinding. Hierarchical Agent Attention Mechanism introduces intermediary agent tokens for structured local-to-global attention, ensuring coherent interactions among regions and consistent spatial layouts. Iterative Feedback with CLIP score applies semantic feedback using CLIP to detect and correct misalignments between generated images and prompts, enabling fine-grained semantic refinement without fine-tuning. Together, these components form a principled, modular, and training-free pipeline that addresses the shortcomings of prior approaches, preserving semantic fidelity, spatial control, and attribute coherence even under dense and complex prompts.
3. Methods
We formulate text-to-image generation as an optimization problem that balances semantic alignment and computational efficiency under a constrained token budget. Given a textual prompt and a diffusion-based generator, the objective is to generate an image that maximizes semantic consistency with the prompt while minimizing redundant textual representations. Based on this formulation, we propose a unified multi-stage framework that decomposes the problem into complementary sub-processes. Figure 2 presents the overall architecture and illustrates the end-to-end generation pipeline from the input prompt to the final output image.
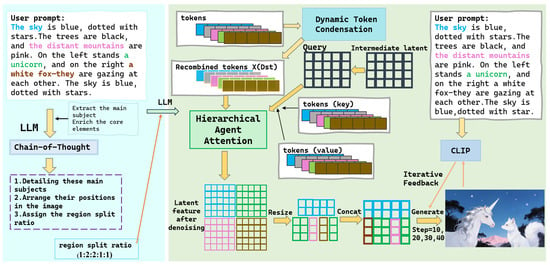
Figure 2.
Overview of the Model Architecture Integrating Hierarchical Agent Attention Mechanism, Dynamic Token Condensation, and Iterative Feedback with CLIP Score. The input prompt is processed by a large language model to generate regional sub-prompts, which are encoded into tokens. Dynamic Token Condensation reduces redundant tokens while preserving key information, and the Hierarchical Agent Attention Mechanism aggregates features across regions for local and global coherence. The model is refined through iterative feedback with the CLIP score to improve semantic alignment and visual fidelity.
3.1. Overall Overview
Generation begins with structured sub-prompts produced by a large language model, highlighting key semantic elements for downstream operations. Tokens are first compressed using token condensation under budget constraints, merging redundant or semantically similar tokens to reduce computational load while preserving critical information. The condensed tokens are then processed by a hierarchical semantic aggregation mechanism, dynamically combining local and global features to maintain compositional coherence. During generation, external semantic evaluators (CLIP) provide advisory feedback at intermediate diffusion steps to guide adjustments of token features and attention maps. This feedback improves semantic alignment and visual fidelity without directly modifying the model’s optimization objective or learned parameters. Finally, the refined token features are decoded through a latent-space denoising pipeline, producing a final image that accurately reflects the prompt while maintaining high visual quality. Importantly, while CLIP-based feedback is employed to enhance semantic alignment during inference, the core components of our framework—Dynamic Token Condensation and Hierarchical Agent Attention—are designed to operate independently of any external evaluator. These modules address fundamental challenges in token efficiency and cross-region coherence that persist even in the absence of CLIP guidance. As demonstrated in our ablation studies (Section 4.3), the proposed architecture yields consistent improvements over standard attention and static token reduction baselines under identical CLIP feedback conditions, confirming that the performance gains stem primarily from our adaptive token management and hierarchical feature aggregation—not merely from the use of CLIP.
3.2. Dynamic Token Condensation
3.2.1. Motivation
The quadratic complexity of attention mechanisms with respect to token count poses a significant bottleneck for real-time text-to-image diffusion models. Traditional token reduction techniques, such as pruning or static merging, attempt to alleviate this by uniformly reducing token numbers. However, these methods often suffer from significant information loss or fail to adapt to the varying semantic density across different image regions and generation timesteps, leading to suboptimal preservation of critical visual details.
To address these limitations, we introduce Dynamic Token Condensation (DTC), a novel compression paradigm that enables content-aware and adaptive token reduction, as illustrated in Figure 3. Unlike static approaches that apply uniform compression, DTC dynamically determines where, when, and how to merge tokens based on the semantic richness of each region and the requirements of the current generation stage. This dynamic mechanism leverages randomized spatial partitioning, similarity-based greedy matching, and scatter-reduce aggregation, allowing the model to preserve crucial information while reducing redundancy. By doing so, DTC achieves a more favorable trade-off between computational efficiency and generation quality. To formalize this objective, DTC can be viewed as a constrained optimization problem that seeks to maximize semantic retention while reducing the number of tokens, ensuring that critical information in semantically dense regions is preserved under a computational budget constraint. In contrast to methods like Token Merging [27], which merge tokens based solely on feature similarity without spatial awareness, DTC explicitly enforces local representativeness through spatial partitioning, guaranteeing that even semantically sparse regions retain at least one representative token—critical for preserving the compositional structure of complex prompts.
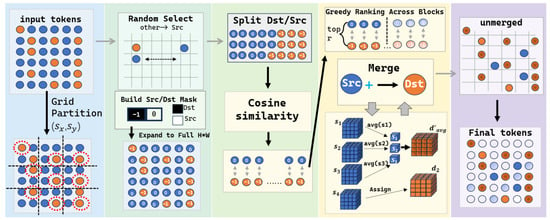
Figure 3.
Diagram of the Semantic Condensation Process from Region Tokens to Agent Tokens After Text Encoding.
3.2.2. Dynamic Spatial Partitioning of Tokens
DTC begins by reshaping the input token sequence into a pseudo-spatial grid , where . This spatial layout enables region-aware condensation aligned with the compositional structure of the prompt. The goal is to reduce the total number of tokens from to while preserving semantically important information.
- Random Spatial Partitioning:
Tokens are divided into regions using vertical and horizontal strides and :
where H and W denote the height and width of the token grid, respectively, and are the vertical and horizontal strides, and ⌊·⌋ denotes the floor operation, so that only complete regions are considered.
This partitioning enforces a local budget constraint, ensuring that each spatial region contributes at most one representative token. Within each region, one token is randomly selected as a Destination (Dst) token, and the remaining tokens are designated as Source (Src) tokens. Formally, for the region at :
The random selection of Dst tokens serves as a stochastic approximation to region-wise representative sampling, which avoids introducing deterministic bias toward specific spatial positions and ensures unbiased coverage of semantic content across regions.
The corresponding region-wise mask is defined as:
When randomness is disabled (no_rand = True), the first token in each region is chosen deterministically.
- Mapping to Global Indices:
Local Dst/Src assignments are then mapped to global indices in the original token tensor. This ensures that the partitioning preserves spatial coverage across the entire feature map. Let and denote the global indices of Dst and Src tokens, respectively:
This global mapping ensures that representative tokens maintain consistent spatial coverage across the feature map, which preserves critical information while reducing redundancy. The selected Dst tokens serve as the foundation for the subsequent aggregation step, enabling a content-aware compression that balances semantic retention with computational efficiency.
3.2.3. Greedy Dynamic Token Aggregation
After partitioning the token tensor into Src and Dst subsets, DTC performs content-aware aggregation to condense the token representation while preserving semantically important information. Let and denote the sets of Src and Dst tokens, with cardinalities and , respectively.
Each token feature is first normalized along the channel dimension. The pairwise cosine similarity between Src and Dst tokens is computed as:
Cosine similarity is adopted to measure semantic affinity in the normalized feature space, allowing the aggregation process to favor Src tokens that contribute redundant semantic information to their most related Dst tokens.
For each Src token, the Dst token with maximum similarity is identified. Src tokens are then sorted in descending order of their maximum similarity scores, and the top r tokens are selected for merging according to a predefined semantic condensation ratio. This greedy selection can be interpreted as a tractable approximation to a constrained assignment problem, where Src tokens with the highest semantic redundancy are preferentially merged under a fixed token budget.
Formally, let denote the selected tokens, and let denote the set of Src tokens mapped to the Dst token k. The aggregation is performed as:
Tokens not selected for merging remain unchanged, ensuring that less significant but potentially informative Src tokens are preserved. After aggregation, the merged Dst tokens and unmerged Src tokens are restored to their original spatial positions, yielding a condensed token tensor:
This greedy aggregation process effectively reduces the total number of tokens from to while maintaining semantic integrity. By merging Src tokens into the most similar Dst tokens, the method prioritizes the preservation of high-semantic-density regions. Combined with the spatial partitioning stage, DTC achieves adaptive, content-aware token reduction that balances computational efficiency with semantic retention. The procedure is fully differentiable and maintains the spatial structure of the token map, making it suitable for real-time text-to-image diffusion models. The greedy selection strategy is justified by the near-submodularity of semantic redundancy: merging the most similar source tokens first yields diminishing returns in information loss, approximating an optimal assignment under a cardinality constraint.
3.3. Hierarchical Agent Attention Mechanism
Compared with standard cross attention, where each query token attends to the entire key–value set in a single flat interaction, Hierarchical Agent Attention introduces an intermediate agent layer to decouple global semantic aggregation from token-wise refinement. This design is particularly suitable under DTC, where token distributions become uneven and conventional full-resolution attention becomes both inefficient and less stable.
In the first stage, a small set of agent tokens aggregates information from the condensed token set, forming compact representations that summarize global and region-level semantics while filtering redundancy introduced by token merging. In the second stage, the main query tokens attend to these agent representations instead of the raw token context, enabling efficient access to globally coherent information. A lightweight residual connection from the original value features preserves fine-grained local details.
By restructuring attention into two hierarchical stages, the proposed mechanism reduces computational complexity while improving robustness to token reduction, yielding more stable semantic representations than standard cross attention with minimal architectural modification. the Hierarchical Agent Attention can be expressed as:
where is the mapping function that generates the global semantic representation at the agent layer.
3.3.1. Stage 1: Agent Global Compression
These agent tokens are initialized from the condensed token sequence generated by DTC, ensuring semantic alignment with the compressed context. Stage 1 of Hierarchical Agent Attention compresses the global information of the input token sequence using a small set of agent tokens. This design addresses the inefficiency of attending to long sequences, enabling computationally efficient aggregation while preserving essential global context.
Let the input token set be , and let denote the number of agent tokens. Each agent token aggregates information from all input tokens via a weighted sum:
Each agent token aggregates information from the full context through attention. Specifically, let the agent tokens be denoted as and the context tokens as . The agent features are computed as:
where is the value embedding of the token, and the attention weight is given by:
with and being the query and key embeddings, respectively. This formulation exactly follows the computation in Figure 4: the agent tokens generate queries (), which attend to the keys () and values () derived from the context, producing compressed agent features.
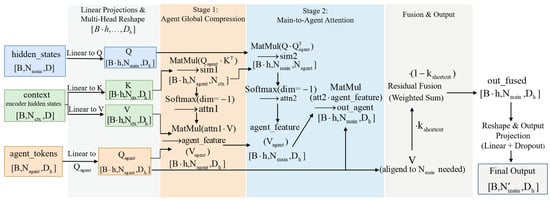
Figure 4.
Hierarchical Agent Attention Mechanism. The attention mechanism consists of two stages: Stage 1 (Agent Global Compression) compresses the context information through attention from agent tokens to the encoder hidden states, producing agent features. Stage 2 (Main-to-Agent Attention) allows the main tokens to attend to these agent features, integrating the compressed contextual information. Finally, a residual fusion combines a weighted sum of the original values with the attended output, followed by linear projection and dropout to produce the final output. Dimensions of the tensors at each step are indicated in brackets.
From a theoretical perspective, this aggregation can be interpreted as a low-rank approximation of the full token set, aiming to maximize global semantic coverage under a strict token budget M:
where denotes a semantic similarity measure and reconstructs the original token features from the agent feature set . This highlights that agent tokens are not merely a computational shortcut—they provide a principled representation of global context, filtering redundancy while retaining high-level semantic and structural information.
The theoretical advantages of Stage 1 include:
Computational efficiency: By compressing tokens into agent tokens , Stage 1 avoids the quadratic complexity of full-sequence attention, significantly reducing memory and computation.
Global context representation: Agent tokens capture high-level semantic and structural information from the entire sequence.
Redundancy reduction: The weighted aggregation filters out repetitive or less informative local details, producing cleaner representations.
Scalability: The number of agent tokens can be adjusted independently of the input length, supporting longer sequences or higher-resolution inputs.
Compatibility with dynamic token operations: Agent tokens maintain critical global information even when tokens are merged or split, ensuring robustness under adaptive sequence modifications.
In summary, Stage 1 establishes a compact, globally aware representation of the input sequence, balancing computational efficiency with semantic retention. This stage forms a theoretically interpretable foundation for the subsequent hierarchical refinement in Stage 2.
3.3.2. Stage 2: Agent-to-Main Sequence Feature Propagation
Stage 2 enables the main input tokens to interact with the agent features generated in Stage 1, allowing each token to access globally compressed semantic information while retaining fine-grained local details. Unlike standard cross attention, where each query attends to the full token set, this stage leverages agent features as an intermediate representation, effectively decoupling global semantic aggregation from token-wise refinement.
Let the main input token set be , and let the agent features from Stage 1 be , where . Each main token is first projected into a query embedding . Crucially, the key embeddings used in this stage are not re-projected from , but are directly inherited from the query projections of the agent tokens in Stage 1, denoted as . The value embeddings are the agent features themselves .
The interaction between main tokens and agent features is then computed as:
where is the aggregated output for token , and the attention weight is given by:
Here, explicitly represents the distilled global semantic information from Stage 1. To preserve local details, a residual shortcut is applied:
where is the original value embedding of the token , and controls the balance between global and local information. In our implementation, is fixed to 0.5 without additional tuning. Where controls the contribution of the original token features.
Stage 2 allows each input token to incorporate globally compressed information from the agent tokens while preserving its own local details. By restricting the interaction to a compact set of agent features instead of the full token sequence, this design reduces the attention interaction space and is therefore more computationally efficient than standard token-to-token attention. This efficiency advantage is empirically validated in the experimental results presented later, which reports reduced interaction size and lower inference time compared to the full attention baseline.
By summarizing the input through agent features, Stage 2 maintains a balance between global and local information, efficiently capturing long-range dependencies, filtering noise and redundancy, and remaining robust to irrelevant variations. This formalization highlights that each token’s cross-attention update is mediated by compressed agent features rather than the full sequence, making the computational cost linear with respect to the number of agent tokens instead of the total input length. Stage 2 thus provides a flexible and resilient means to integrate global context, complementing the compressed representations generated in Stage 1.
3.4. Iterative Feedback with CLIP Score
To further enhance semantic alignment in challenging cases, we optionally integrate an iterative feedback loop based on the CLIP similarity score. At each sampling step, the intermediate image is evaluated against the input text prompt using the pretrained CLIP model:
This score serves as a post hoc diagnostic signal, not as a training objective or network component. In our implementation, can be used to modulate sampling behavior—for instance, by adjusting guidance strength or reweighting denoising steps—via a user-defined function :
where denotes tunable sampling parameters at step t.
Importantly, all core results in Section 4.1, Section 4.2 and Section 4.3 are reported excluding this feedback mechanism, to ensure a fair evaluation of the proposed DTC and Hierarchical Agent Attention modules in isolation. The CLIP-based feedback is introduced only as an optional refinement strategy that can be combined with any base generator. It demonstrates compatibility with external guidance signals but is not required for the main method to outperform baselines.
Thus, CLIP acts solely as a zero-shot evaluator—enabling dynamic, gradient-free refinement without altering the generative model or its latent dynamics.
All figures generated using AI-assisted tools are clearly disclosed; no AI tool was used for manuscript writing or data interpretation.
4. Experiment
4.1. Experimental Setting
We implement our approach on top of RPG [9] as the baseline framework, since RPG provides a representative, training-free, graph-based reasoning pipeline that is compatible with various text encoders and diffusion backbones. For the text encoder, we employ LLaMA2-7B, GPT-4, and DeepSeek-R1. These models are selected to cover a diverse spectrum of language modeling paradigms and capabilities: LLaMA2-7B serves as a strong open-weight baseline widely adopted in reproducible research; GPT-4 represents a widely used class of high-performance closed-source language models that demonstrate consistent capabilities in semantic understanding and compositional reasoning; DeepSeek-R1, by contrast, exhibits competitive performance on complex instruction-following tasks. This combination enables us to evaluate the robustness of our method across text encoders with different scales, training strategies, and accessibility profiles. For image synthesis, we adopt SDXL-Lightning [28] as the diffusion model. SDXL-Lightning is designed to achieve high-quality image generation with reduced inference cost through distillation from SDXL, making it well-suited for efficiency-oriented evaluation. We use 20 inference steps with a guidance scale of 3.5 to balance generation fidelity and inference time while maintaining consistency with the RPG framework. To comprehensively evaluate generation quality, we compare our approach with several state-of-the-art text-to-image generation methods, including Pixart-α-ft [1], Flux.1-dev [3], Stable v2 [4], Stable XL [5], RPG [9], RAG [11], Attn-Exct v2 [14], Composable v2 [17], Structured v2 [29] and GORS. To ensure reproducibility and generalizability, all experiments are conducted using multiple random seeds, and all reported metrics are averaged across these seeds.
4.2. Experimental Results
We evaluate our approach on the T2IcompBench [30] benchmark in Table 1, which assesses text–image alignment in terms of attribute binding (Color, Shape, Texture), object understanding (Spatial), relationships (Non-Spatial), and an aggregated Complex score, and compares our method with Composable v2, Stable v2, SDXL, PixArt-α-ft, RPG, GORS, Flux.1-dev, RAG, DALL·E 3, SD3, Playground v3, and PixArt-Σ [31]. Our model achieves the best performance on most attribute-related metrics, including Color (0.8743), Shape (0.6548), Texture (0.6902), as well as the highest Complex score (0.4741), demonstrating strong fine-grained attribute binding and compositional understanding. At the same time, Table 1 shows that our method attains slightly lower scores on Spatial reasoning (0.4826) compared to RAG (0.5193), and on Non-Spatial relations (0.3553) compared to DALL·E 3 (0.3721). This can be attributed to the design focus of our approach, which prioritizes region-level semantic consistency and attribute correctness under dense multi-object prompts, rather than explicitly enforcing global spatial layouts or abstract inter-object relations via auxiliary supervision or large-scale relational priors. In contrast, RAG employs region-aware hard bindings that directly constrain spatial structure, while DALL·E 3 benefits from strong implicit relational priors learned from large-scale proprietary data. Consequently, our method trades a small amount of performance on isolated spatial or relational metrics for improved overall compositional coherence and reduced cross-region semantic conflicts, a balance that is reflected in its superior Complex score and robustness on complex, multi-attribute prompts.

Table 1.
Quantitative Comparison on T2ICompBench, we compare the parameters based on the data from the papers of these models, and there is some improvement in each attribute.
The Table 2 reports FID scores of various text-to-image models on MS-COCO, where lower values indicate better alignment with the real image distribution. X&Fuse (6.65) and our method (7.08) achieve the strongest performance, followed closely by Parti (7.23) and Imagen (7.27). In contrast, DALL·E 2 (10.39) and Show-o (9.24) exhibit higher FID scores, reflecting a larger discrepancy from the ground-truth distribution. Notably, our approach attains competitive fidelity without any model training or fine-tuning, demonstrating that careful design of inference-time mechanisms can rival or approach the performance of heavily trained generative systems.
Table 2.
Text-to-Image Generation Quality Metrics on MS-COCO.
The Table 3 summarizes the attribute alignment performance of different text-to-image models based on Color, Texture, and Shape. Among the models listed, “Ours” achieves the highest scores across all three attributes, indicating slightly better fidelity in capturing fine-grained visual details. SD3 performs competitively, particularly on Texture, while RAG shows a balanced performance across Color and Shape. DALLE-3 scores lower on Shape, suggesting comparatively weaker accuracy in encoding structural object properties. Overall, the results highlight that the proposed model maintains a modest advantage in attribute consistency over existing baselines.
Table 3.
BLIP-VQA Evaluation of Attribute Consistency: Color, Texture, and Shape.
We further evaluate the performance of our approach through qualitative analysis by comparing the generated images from our method with those of SD3, SDXL, RPG, and PlayGround v3. As shown in Figure 5, our method consistently produces images that are more visually coherent and semantically aligned with the input prompts across a variety of scenarios.

Figure 5.
Comparison of Results from Different Generation Models.
As shown in Table 4, PathSelect achieves competitive latency and memory consumption compared to existing text-to-image models, and significantly outperforms RPG—the closest plug-in baseline—in both speed and memory efficiency. Our method introduces only a minimal computational overhead (+2.7% FLOPs) attributable to the hierarchical agent attention module. This demonstrates that PathSelect not only enhances semantic alignment and image generation quality but also offers practical efficiency advantages, making it well-suited for real-world deployment.
Table 4.
Computational Efficiency Comparison.
For a broad spectrum of prompts, our approach consistently demonstrates superior visual coherence, semantic fidelity, and structural stability compared to existing diffusion-based models. Across complex multi-object scenes, open landscapes, architectural environments, and fine-grained single-subject prompts, our method maintains correct spatial placement, geometric proportions, and physically consistent lighting, resulting in images with stable global layouts and accurate depth cues. Unlike SDXL and RPG, which frequently exhibit perspective distortions, inconsistent object scaling, or background mismatches, our approach produces scenes in which all elements integrate naturally and retain clear semantic relationships. Furthermore, while PlayGround v3 tends toward exaggerated stylization, oversaturated colors, and texture simplification, our method achieves a balanced visual appearance with realistic shading, smooth color transitions, and well-preserved material details. The robustness of our approach is particularly evident in challenging cases involving reflective surfaces, fine textures, or anthropomorphic characters, where competing models often introduce attribute drift, structural artifacts, or inconsistent rendering of secondary elements. Overall, the results in Figure 5 illustrate that our method delivers more realistic, semantically accurate, and compositionally coherent images across diverse and demanding prompts, consistently outperforming state-of-the-art alternatives in both scene-level and object-level generation tasks.
4.3. Ablation Study
To systematically evaluate the independent contributions of each component, the ablation study is divided into two levels. Section 4.3.1 focuses on the influence of key hyperparameters and essential computational units. By adjusting parameters or removing local operations, this section examines the model’s sensitivity to different factors. Section 4.3.2 further assesses the contribution of each functional module from a structural perspective. By individually removing or replacing entire submodules, it quantitatively analyzes their roles in maintaining semantic consistency, generation quality, and robustness. Together, these two analyses provide a comprehensive understanding of the performance impact of each model component.
4.3.1. Parameter Sensitivity and Component Effectiveness Analysis
The relationship between the number of inference steps and generation time is illustrated in Figure 6. Compared to the original model, our method significantly reduces computational overhead, particularly as the number of inference steps increases. While the original approach exhibits a steep rise in generation time (from ~12 s to ~22.5 s), the current method maintains stable performance at lower step counts and shows much slower growth, achieving ~17 s at 50 steps—demonstrating improved efficiency and scalability.
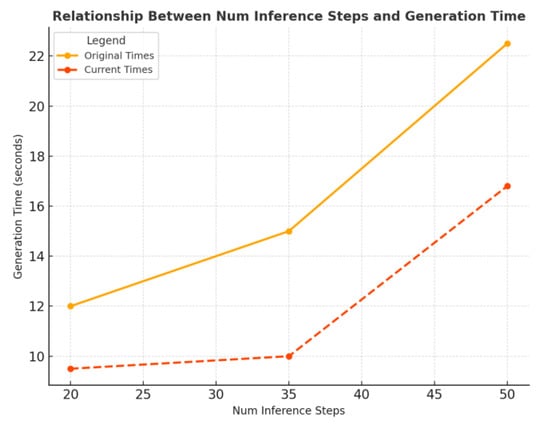
Figure 6.
Relationship Between Num Inference Steps and Generation Time.
Effectiveness of Agent Ratio (a_r). The experiments on varying a_r demonstrate its significant impact on the quality of generated images. As shown in Figure 7, with the prompt “A golden retriever wearing a red Santa hat and a green scarf, sitting in the snow next to a snowman with a carrot nose and coal eyes”, the following trends were observed: At a low a_r of 0.2–0.4, images lack sufficient detail, and features such as the Santa hat and snowman are either incomplete or poorly rendered, resulting in weak semantic consistency and attribute binding. At the optimal a_r range of 0.6–0.8, images achieve the best balance between detail and coherence, with accurately rendered features like the red Santa hat, green scarf, and snowman’s facial details, while maximizing semantic consistency, attribute binding, and object interaction. However, with a high a_r of 1.0, overfitting begins to occur, causing slight misalignments or unnecessary details, although the overall quality remains acceptable.

Figure 7.
Detail Differences in Generated Images Under Different Agent Ratios.
Effectiveness of the condensation ratio. As shown in Figure 8, with the agent ratio (a_r) fixed at 0.8, adjusting the condensation ratio (ratio) demonstrates clear trends. At low ratios (e.g., 0.3), the generated images lack sufficient detail, with incomplete rendering of features. As the ratio increases to 0.5–0.7, the image quality improves significantly, with better detail and semantic consistency. However, when the ratio becomes too high (e.g., 0.9), the features are not simplified, but semantic consistency starts to break down, resulting in outputs that deviate from the prompt. This indicates that moderate ratio values (0.5–0.7) achieve the best balance between detail and semantic consistency.

Figure 8.
Detail Differences in Generated Images Under Different Merging Ratios.
In Figure 9, the original model generates only one image at a time and is influenced by parameters such as num_inference_steps, seed, and guidance_scale, making parameter tuning a challenging task. To address this, we used CLIP Score as a reference and implemented a dynamic feedback-based parameter tuning mechanism, as illustrated in Figure 10. During each iteration, the model generates an image, which is evaluated against the prompt using CLIP to obtain a score. Based on the score, adjustments are made to increase or decrease specific parameters, ensuring that the generated images maintain maximum semantic consistency with the prompt. The image with the highest final score is selected as the final output. Figure 1 shows multiple experimental runs of CLIP Score and their average trend, demonstrating that scores increase rapidly in the first few iterations and gradually saturate around iteration 5, while the corresponding percentage improvement over the baseline highlights the rapid improvement, fine-tuning, and eventual saturation phases, confirming that five iterations effectively balance performance and efficiency.

Figure 9.
Iterative Image Generation Process Based on CLIP Score.
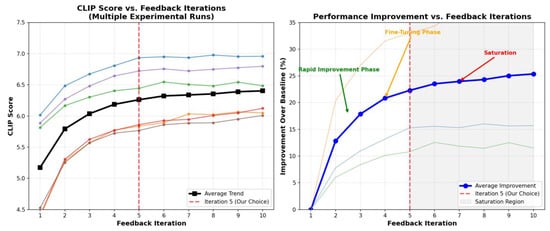
Figure 10.
CLIP Score Improvement Over Feedback Iterations.
4.3.2. Module-Wise Ablation Study
To quantify each module’s contribution, we conduct a module-wise ablation by progressively removing one component at a time. All experiments are performed under the same prompt sets and inference settings.
The full model delivers the best overall results, achieving the highest CLIP Score (6.82), Fidelity (0.85), and Coherence (0.88), demonstrating that the three modules work synergistically. All experiments are conducted under the same configuration: image resolution 1024 × 1024, 20 sampling steps, batch size = 1, and CLIP Feedback with 2 iterations.
Removing Semantic Condensation results in the most significant performance drop—particularly in CLIP Score and Fidelity, while inference time increases. This is because Semantic Condensation merges semantically similar tokens, retaining core concepts and discarding redundant information, which allows the attention mechanism to focus on essential elements. Consequently, text–image alignment improves and object attributes remain coherent. Without this module, noisy and redundant tokens distract attention, reduce cross-region feature propagation, and slow convergence, which explains why its removal has the largest impact. The pronounced impact on CLIP Score and Fidelity can be further understood through the lens of CLIP’s contrastive pretraining objective. CLIP encoders are optimized to map images and texts with shared semantics into proximate regions of a shared embedding space. However, when the generator produces features contaminated by low-level noise or irrelevant spatial details, the resulting image embedding drifts away from the text embedding, lowering the CLIP Score. Semantic Condensation mitigates this by acting as a semantic bottleneck: it clusters tokens based on high-level semantic similarity before cross attention, thereby producing cleaner, more conceptually coherent feature maps. As shown in Figure 11, early-stage outputs without condensation exhibit fragmented color regions and inconsistent object boundaries, which directly degrade both perceptual fidelity and semantic alignment. In contrast, our condensed representations yield smoother, globally consistent structures that better match CLIP’s expectation of “canonical” object appearances—explaining the simultaneous gains in CLIP Score and Fidelity. Omitting Agent Attention mainly weakens Coherence and increases runtime, since the hierarchical, multi-level design guides attention across regions to maintain consistent object-attribute binding and spatial relationships. Without this structure, inter-region communication becomes noisier, layouts are less coherent, and attention computation grows, leading to longer inference time. Removing CLIP Feedback causes a moderate drop in CLIP Score and Coherence but reduces runtime. This iterative mechanism progressively refines image generation to better align with textual prompts, correcting residual semantic misalignments; without it, inference is faster, but semantic precision and coherence decrease. These observations, supported by Table 5 and Table 6 demonstrate that each module contributes through a distinct intrinsic mechanism, confirming that the gains stem from semantic-aware architecture rather than increased computation.

Figure 11.
Progressive visualization of generated images and corresponding Color Abstraction Maps.
Table 5.
Quantitative Ablation of Key Modules (√ indicates usage, × indicates non-usage).
Table 6.
Fair Comparison with Simple Alternatives and CLIP Re-Ranking (No CLIP Feedback Used in Core Evaluation).
All inference times are measured on an NVIDIA 4090 GPU with a batch size of 1, image resolution 1024 × 1024, and 20 denoising steps, ensuring fair comparison across all methods. To address concerns about the source of performance gains, we conduct a controlled comparison against a broad spectrum of token reduction strategies—including deterministic (uniform stride), stochastic (random merging), attention-based (Top-K), and recent dynamic methods (DynamicViT, DiffMoE)—as well as CLIP-based re-ranking, all evaluated without iterative feedback during core generation (Table 6). Our method consistently outperforms these baselines, demonstrating that semantic condensation guided by hierarchical agents genuinely improves generation quality beyond generic token pruning or post hoc selection. Notably, our single-pass model (DTC + Agent Attention) achieves a FID of 27.6—approaching the quality of CLIP re-ranking (26.8 FID)—while requiring only ~13.5 s versus 17.2 s for re-ranking. This confirms that the gains stem from our architecture-aware token compression, not from computational artifacts or brute-force sampling.
Overall, the additional computational cost introduced by each module remains relatively small. Semantic Condensation adds only 1.7% FLOPs while improving semantic compactness, making it nearly cost-free. Agent Attention introduces a moderate increase (6.4%) due to its hierarchical fusion design, but the gain in coherence and attribute binding justifies the overhead. CLIP Feedback contributes the largest increase (9.8%) because of extra forward passes used for iterative scoring. Nevertheless, it remains optional at inference time and substantially improves semantic accuracy. Together, these results indicate that the proposed modules enhance image quality with minimal computational burden. Table 7 reports the computational efficiency comparison of different Stage 2 attention mechanisms, showing that the proposed agent-token interaction significantly reduces attention computation compared to full token-to-token attention.
Table 7.
Additional FLOPs Introduced by Each Module.
Table 8 compares the computational efficiency of different Stage 2 attention mechanisms under a fixed resolution of 1024 × 1024, a random seed of 2468, and 20 sampling steps. In the baseline configuration, each token attends to all other tokens in the sequence, resulting in a quadratic interaction size of and the highest inference time. In the Stage2-Direct variant, agent tokens are not used, but attention is still applied to the full token sequence, leading to only a modest reduction in inference time. In contrast, the proposed Stage2-Agent mechanism restricts each token’s attention to a compact set of agent tokens (, where ), substantially reducing redundant token-to-token computations. As a result, Stage2-Agent achieves the lowest inference time, validating the efficiency advantage of the agent-token interaction design under consistent experimental settings.
Table 8.
Ablation Study on Hierarchical Agent Attention Mechanism.
Table 9 shows that the peak GPU memory usage tends to increase with the number of input prompt tokens, as cross-attention computation generally scales with the number of text tokens. Longer prompts can lead to higher memory usage in the baseline model, where every token participates in full token-to-token attention. By contrast, the Stage2-Agent mechanism, which interacts with a compact set of agent tokens, appears to show a relatively smaller increase in memory with longer prompts, suggesting improved memory efficiency for longer textual inputs.
Table 9.
Effect of Prompt Length on Peak GPU Memory.
The Color Abstraction Maps illustrate the progression of visual quality across the ten stages. Early stages exhibit scattered and inconsistent color regions, indicating less stable spatial structure and tonal distribution. As the stages advance, color regions become increasingly coherent, with smoother gradients and well-defined object areas, demonstrating improved global color stability and semantic consistency. These visual trends align with the quantitative metrics, confirming that the model’s outputs gradually converge toward more stable and perceptually consistent images.
5. Conclusions
In this work, we introduce PathSelect, a training-free framework for efficient and semantically faithful text-to-image generation. Without any model retraining, PathSelect achieves state-of-the-art results on T2ICompBench (Color: 0.8743, Complex: 0.4741) and a competitive FID of 7.08 on MS-COCO, outperforming several recent baselines. The proposed Dynamic Token Condensation and Hierarchical Agent Attention mechanisms jointly improve inference efficiency while preserving fine-grained object–attribute binding and spatial coherence. An optional CLIP-guided feedback loop can be applied to further enhance semantic alignment when required.
Limitation and Future work. PathSelect may be sensitive to variations in prompt phrasing and can struggle with highly abstract or linguistically complex inputs. Moreover, its cross-domain generalization remains underexplored. Future work will focus on adaptive prompt parsing, better modeling of nuanced language, and automated attention configuration to improve robustness across diverse application scenarios.
Author Contributions
Y.F. designed the study and G.Y. wrote the main manuscript text. O.Y. supervised the project and acquired funding. T.H. collated the references. R.D. assisted in data organization. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China—General Program, grant number 62476216, titled “Mechanism and Prediction Method of Gas Concentration Spatiotemporal Evolution in Coal Mining Face Driven by Particle Size Data”; and the University Engineering Research Center Project, grant number 24JR110, titled “Cross-modal Video Language for Underground Unsafe Behaviors.”.
Data Availability Statement
The data supporting the findings of this study are available from the corresponding author upon reasonable request. The datasets generated and analyzed during the current study are not publicly available due to privacy concerns related to the participants, but anonymized versions of the data can be made available upon request. The code used for the experiments is available at https://github.com/ygl123ygl/tm-aattenT2I (accessed on 31 December 2025).
Acknowledgments
The authors would like to thank the colleagues and technical staff who provided valuable administrative and technical support during the preparation of this study. The authors also acknowledge the assistance received in data organization and reference management, which contributed to the smooth completion of the manuscript. In addition, the authors acknowledge the use of OpenAI’s ChatGPT (version 5.2) and other AI-based image generation tools for producing several schematic figures included in this work.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| T2I | Text to Image |
| CLIP | Contrastive Language–Image Pre-training |
| SD | Stable Diffusion |
References
- Chen, J.; Yu, J.; Ge, C.; Yao, L.; Xie, E.; Wu, Y.; Wang, Z.; Kwok, J.; Luo, P.; Lu, H.; et al. Pixart-α: Fast Generative optimization via transformer for photorealistic text-to-image synthesis. arXiv 2023, arXiv:2310.00426. [Google Scholar]
- Esser, P.; Kulal, S.; Blattmann, A.; Entezari, R.; Müller, J.; Saini, H.; Levi, Y.; Lorenz, D.; Sauer, A.; Boesel, F.; et al. Scaling rectified flow transformers for high-resolution image synthesis. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Labs, B.F.; Batifol, S.; Blattmann, A.; Boesel, F.; Consul, S.; Diagne, C.; Dockhorn, T.; English, J.; English, Z.; Esser, P.; et al. FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space. arXiv 2025, arXiv:2506.15742. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar] [CrossRef]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 320–335. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Yang, L.; Yu, Z.; Meng, C.; Xu, M.; Ermon, S.; Cui, B. Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms. In Proceedings of the Forty-first International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Liu, B.; Akhgari, E.; Visheratin, A.; Kamko, A.; Xu, L.; Shrirao, S.; Lambert, C.; Souza, J.; Doshi, S.; Li, D. Playground v3: Improving text-to-image alignment with deep-fusion large language models. arXiv 2024, arXiv:2409.10695. [Google Scholar]
- Chen, Z.; Li, Y.; Wang, H.; Chen, Z.; Jiang, Z.; Li, J.; Wang, Q.; Yang, J.; Tai, Y. Region-aware text-to-image generation via hard binding and soft refinement. arXiv 2024, arXiv:2411.06558. [Google Scholar]
- Bar-Tal, O.; Yariv, L.; Lipman, Y.; Dekel, T. Multidiffusion: Fusing Diffusion Paths for Controlled Image Generation. 2023. Available online: https://openreview.net/forum?id=D4ajVWmgLB (accessed on 31 December 2025).
- Team, O. Omost Github Page. 2024. Available online: https://github.com/lllyasviel/Omost (accessed on 31 December 2025).
- Chefer, H.; Alaluf, Y.; Vinker, Y.; Wolf, L.; Cohen-Or, D. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Trans. Graph. (TOG) 2023, 42, 1–10. [Google Scholar] [CrossRef]
- Li, Y.; Keuper, M.; Zhang, D.; Khoreva, A. Divide & bind your attention for improved generative semantic nursing. arXiv 2023, arXiv:2307.10864. [Google Scholar] [CrossRef]
- Yu, C.; Wu, T.; Li, J.; Bai, X.; Yang, Y. Syngen: A syntactic plug-and-play module for generative aspect-based sentiment analysis. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, N.; Li, S.; Du, Y.; Torralba, A.; Tenenbaum, J.B. Compositional visual generation with composable diffusion models. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 423–439. [Google Scholar]
- Eyring, L.; Karthik, S.; Roth, K.; Dosovitskiy, A.; Akata, Z. Reno: Enhancing one-step text-to-image models through reward-based noise optimization. Adv. Neural Inf. Process. Syst. 2024, 37, 125487–125519. [Google Scholar]
- Jiang, D.; Song, G.; Wu, X.; Zhang, R.; Shen, D.; Zong, Z.; Liu, Y.; Li, H. Comat: Aligning text-to-image diffusion model with image-to-text concept matching. Adv. Neural Inf. Process. Syst. 2024, 37, 76177–76209. [Google Scholar]
- Xie, J.; Li, Y.; Huang, Y.; Liu, H.; Zhang, W.; Zheng, Y.; Shou, M.Z. Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 7452–7461. [Google Scholar]
- Wang, X.; Darrell, T.; Rambhatla, S.S.; Girdhar, R.; Misra, I. Instancediffusion: Instance-level control for image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6232–6242. [Google Scholar]
- Wu, Y.; Zhou, X.; Ma, B.; Su, X.; Ma, K.; Wang, X. Ifadapter: Instance feature control for grounded text-to-image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Honolulu, Hawai’i, 19–23 October 2025; pp. 15949–15959. [Google Scholar]
- Li, S.; Wang, R.; Hsieh, C.J.; Cheng, M.; Zhou, T. Mulan: Multimodal-llm agent for progressive and interactive multi-object diffusion. arXiv 2024, arXiv:2402.12741. [Google Scholar]
- Kim, Y.; Lee, J.; Kim, J.H.; Ha, J.W.; Zhu, J.Y. Dense text-to-image generation with attention modulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 7701–7711. [Google Scholar]
- Lin, K.H.; Mo, S.; Klingher, B.; Mu, F.; Zhou, B. Ctrl-x: Controlling structure and appearance for text-to-image generation without guidance. Adv. Neural Inf. Process. Syst. 2024, 37, 128911–128939. [Google Scholar]
- Wu, S.; Ding, F.; Huang, M.; Liu, W.; He, Q. VMix: Improving Text-to-Image Diffusion Model with Cross-Attention Mixing Control. arXiv 2024, arXiv:2412.20800. [Google Scholar]
- Hu, T.; Li, L.; van de Weijer, J.; Gao, H.; Shahbaz Khan, F.; Yang, J.; Cheng, M.M.; Wang, K.; Wang, Y. Token merging for training-free semantic binding in text-to-image synthesis. Adv. Neural Inf. Process. Syst. 2024, 37, 137646–137672. [Google Scholar]
- Lin, S.; Wang, A.; Yang, X. Sdxl-lightning: Progressive adversarial diffusion distillation. arXiv 2024, arXiv:2402.13929. [Google Scholar] [CrossRef]
- Feng, W.; He, X.; Fu, T.J.; Jampani, V.; Akula, A.; Narayana, P.; Basu, S.; Wang, X.E.; Wang, W.Y. Training-free structured diffusion guidance for compositional text-to-image synthesis. arXiv 2022, arXiv:2212.05032. [Google Scholar]
- Huang, K.; Sun, K.; Xie, E.; Li, Z.; Liu, X. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Adv. Neural Inf. Process. Syst. 2023, 36, 78723–78747. [Google Scholar]
- Chen, J.; Ge, C.; Xie, E.; Wu, Y.; Yao, L.; Ren, X.; Wang, Z.; Luo, P.; Lu, H.; Li, Z. Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 74–91. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.; Ghasemipour, S.K.S.; Ayan, B.K.; Mahdavi, S.S.; Lopes, R.G.; et al. Imagen: Photorealistic text-to-image diffusion models. arXiv 2022, arXiv:2205.11487. [Google Scholar]
- Chang, H.; Zhang, H.; Barber, J.; Maschinot, A.J.; Lezama, J.; Jiang, L.; Yang, M.H.; Murphy, K.; Freeman, W.T.; Rubinstein, M.; et al. Muse: Text-to-image generation via masked generative transformers. arXiv 2023, arXiv:2301.00704. [Google Scholar]
- Kirstain, Y.; Levy, O.; Polyak, A. X&fuse: Fusing visual information in text-to-image generation. arXiv 2023, arXiv:2303.01000. [Google Scholar]
- Razzhigaev, A.; Shakhmatov, A.; Maltseva, A.; Arkhipkin, V.; Pavlov, I.; Ryabov, I.; Kuts, A.; Panchenko, A.; Kuznetsov, A.; Dimitrov, D. Kandinsky: An improved text-to-image synthesis with image prior and latent diffusion. arXiv 2023, arXiv:2310.03502. [Google Scholar]
- Zhou, M.; Wang, Z.; Zheng, H.; Huang, H. Guided Score identity Distillation for Data-Free One-Step Text-to-Image Generation. arXiv 2024, arXiv:2406.01561. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv 2022, arXiv:2206.10789. [Google Scholar]
- Xie, J.; Mao, W.; Bai, Z.; Zhang, D.J.; Wang, W.; Lin, K.Q.; Gu, Y.; Chen, Z.; Yang, Z.; Shou, M.Z. Show-o: One single transformer to unify multimodal understanding and generation. arXiv 2024, arXiv:2408.12528. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Liu, B.; Lu, J.; Zhou, J.; Hsieh, C.J. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Adv. Neural Inf. Process. Syst. 2021, 34, 13937–13949. [Google Scholar]
- Shi, M.; Yuan, Z.; Yang, H.; Wang, X.; Zheng, M.; Tao, X.; Zhao, W.; Zheng, W.; Zhou, J.; Lu, J.; et al. DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers. arXiv 2025, arXiv:2503.14487. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.