Abstract
Bias and hallucinations in low-resource cultural artefacts significantly impede text-to-image generation models from understanding and disseminating. Focusing on Tibetan as a Chinese minority culture, we produced a children’s picture book through two methods: AI generation and human illustrator. Eye-tracking experiments were employed to investigate participants’ implicit attitudes, aesthetic biases, and cultural perceptions towards these two sources. The results revealed that (1) the hand-drawn group demonstrated higher fidelity to Tibetan culture, exhibiting a positive aesthetic calibration effect in terms of cultural adaptability owing to viewers’ attention duration to the cultural symbols details. (2) The AI-generated group elicited greater viewer interest and emotional engagement through its asymmetric color palettes, especially in color richness and stylistic rendering, and achieved professional-level compositional maturity in multi-character scene generation. This study provides empirical evidence to inform the division of labor between humans and AI in children’s book illustration and explores potential models for future human-AI collaboration.
1. Introduction
As large models demonstrate significant capabilities across fields in medicine [1], education [2], gaming [3], and management [4], the issue of cultural consistency is increasingly surfacing as a critical impediment to their effective application. Within the diverse domain of cultural heritage, general-purpose models inherently exhibit a robust understanding of general universal culture. However, their knowledge remains markedly insufficient in relation to ethnic minorities, marginalized communities, and subcultural groups. In the current landscape, a pressing question remains unresolved: does AI possess a genuine perceptual capacity for low-resource cultures, correctly generate contextually appropriate cultural symbols, and, within multimodal generation, accurately translate these symbols into faithful visual representations? This is particularly critical for subcultural groups, where erosion, misrepresentation, or even discriminatory portrayal of their cultural symbols by AI systems can severely compromise their deeply valued cultural frameworks. Although existing model fine-tuning approaches based on cultural symbols have made progress, their limitations remain notable: these methods are often tailored to specific cultures, lack the capacity for a universal understanding of low-resource cultures, and struggle to ensure the precise visual representation of cultural symbols in cross-modal generation (e.g., text-to-image). It is particularly noteworthy that detailed evaluation and generation studies focusing on Chinese ethnic minority cultures, such as Tibetan culture, are still absent from the existing literature. To address this gap, this study aims to thoroughly investigate the perception and generation quality of large models regarding Tibetan culture. We seek not only to identify the specific issues of cultural inaccuracy in current models but also to provide empirical evidence for developing more culturally sensitive generative models in the future by comparing human-crafted and AI-generated content. Consequently, this study proposes the following research questions:
- RQ1: In the context of Tibetan culture, what quantifiable differences exist in the representation of cultural symbols between images generated by large models (AIGI) and those drawn by humans (HMGI)?
- RQ2: How do participants with AI experience perceive and evaluate the distinctions between AIGI and HMGI in terms of cultural authenticity and esthetic dimensions?
Furthermore, it is important to note that AI-generated content has achieved a high degree of alignment with human preferences in universal aesthetics [5], and its ability to accurately represent specific cultural symbols requires further investigation. Although not the primary focus of this study, we will explore supplementary questions regarding the dimensions viewers prioritize when comparing hand-drawn and AI-generated illustrations—including the accuracy of cultural details, symbolic appropriateness, and emotional depth—as valuable supplementary aspects to enhance our understanding.
In summary, this study makes three primary contributions:
- Through rigorous user experiments, it reveals the ’cultural perception gap’ in current text-to-image models when representing low-resource cultures and delineates their strengths (visual impact) and weaknesses (cultural accuracy).
- It constructs a mixed-method framework integrating eye-tracking, subjective ratings, and in-depth interviews, offering a new paradigm for quantitatively evaluating the cultural alignment of generative models.
- The findings provide critical design implications and ethical caveats for generative AI applications in cultural heritage and point toward optimized pathways for future human-AI collaborative creation.
2. Literature Review
This chapter systematically reviews existing research relevant to culturally-aware generative models. It begins by exploring the potential of AIGC for cultural elicitation and dissemination. The focus then shifts to established benchmarks and methods for the cultural evaluation of LLMs and text-to-image models. Subsequently, the chapter details three key technical pathways for enhancing cultural faithfulness: dataset construction, controllable image generation, and cultural alignment methods. Finally, it outlines persistent challenges and limitations in the field, primarily limited generalization and narrow evaluation dimensions, thereby clearly identifying current research gaps.
2.1. Cultural Elicitation with AIGC
The introduction of artificial intelligence technology has made significant advances in the preservation of cultural heritage, particularly in the restoration of physical artifacts and structures. Firstly, integrated with traditional computer vision techniques, AI enables precise identification and capture of surface details on cultural relics, effectively assisting archeologists in restoration efforts. Using its visual acuity that surpasses human capabilities, AI can accurately detect subtle alterations imperceptible to the naked eye, including weathering, corrosion, cracks, leakage, and discoloration [6,7]. Secondly, through the application of advanced technologies such as deep learning and Neural Radiance Fields (NeRF) [8], AI has further achieved three-dimensional digital reconstruction, fragment completion, and high-fidelity virtual replication of cultural artifacts, paving new avenues for the permanent preservation and innovative transmission of cultural heritage.
However, although the aforementioned studies primarily focus on utilizing AI’s “eyes” for the identification and restoration of physical cultural relics—tasks that are grounded in tangible objects with physical existence—research concerning the direct use of AI to generate works representing cultural symbols and art remains at the center of ongoing risk and ethical debates.
2.2. Cultural Evaluation of LLMs
Culture is deeply woven into daily life. Although interactions between individuals of different cultural backgrounds may not always have clear boundaries, researchers have begun to train predominantly on English data, embedding a Western-centric bias [9,10,11,12], which leads to the neglect or misrepresentation of culturally scarce resources in their training datasets [13]. Consequently, participants from non-English-speaking regions are more likely to encounter outputs they find offensive or disrespectful. In fact, LLMs are biased, and these issues of hallucination and prejudice become particularly pronounced when they process low-resource data, raising critical concerns about social and cultural alignment [14]. In response, a significant body of work has emerged to evaluate these models. These studies mainly focus on identifying biases, stereotypes, and characteristic behaviors manifested in the reasoning processes of LLMs and the proposed solutions. The dominant evaluation paradigms include the following.
- Direct Assessment: This approach leverages established social science scales to evaluate LLMs for cultural biases and misunderstandings. The benchmarks used, both original and adapted, include cross-linguistic measurements incorporating multicultural common sense from countries such as China and Saudi Arabia [15,16,17,18,19];
- Comparative Assessment: Here, elements from diverse cultural backgrounds are introduced as alignment targets to assess an LLM’s ability to perceive and adapt to participants from different cultures [20,21]. Studies have shown that simply changing the language of the prompt [22] or perceived nationality [23,24] can trigger culturally biased responses.
- Task-Specific Performance: This line of research examines performance deficits arising from a lack of cultural knowledge, such as understanding and applying proverbs [25].
2.3. Key Implementation Techniques
2.3.1. Dataset Construction
At its core, cultural biases in large language models (LLMs) stem from the scarcity or inefficient use of relevant training data [26]. To address the issue of data scarcity, several strategies have been proposed. Enhancing the quality of low-resource cultural data and introducing fine-grained cultural classifications can effectively delineate cultural boundaries and affiliations, thereby improving the utilization of these cultures within training datasets [27]. Other approaches include constructing rich and diverse “culture banks” through user self-narratives [28], and creating “silicon samples” by conditioning models on thousands of socio-demographic background stories from real human participants in large-scale surveys; this latter method has validated the potential of high-fidelity LLMs to act as proxies for subcultural groups [29]. Furthermore, researchers have attempted to simulate real-world cross-cultural interaction scenarios by building “culture parks” [30], incorporating reward models with fine-grained classifications [31], and developing frameworks [32] that leverage multicultural perspectives [33] or facilitate debates among multiple LLMs [34]. Collectively, these diverse efforts represent significant attempts to resolve the challenge of cultural consistency.
2.3.2. Controllable Image Generation
As a vital medium for cultural transmission, images facilitate rapid information exchange in multiple dimensions. However, the generation of images containing specific cultural symbols—even the creation of their corresponding prompts—is prone to misalignment, leading to cultural erosion, stereotyping, and misinformation. In the realm of multimodal cultural alignment, visual components demonstrate a cultural sensitivity comparable to that of text, with their quality highly dependent on the accompanying textual content [35]. Consequently, achieving precise cultural value alignment remains a central challenge in current research on AIGC picture books based on large cross-modal models. Controllable image generation technology aims to achieve precise control over the visual output of AI-generated content (AIGC) through the integration of specific algorithms and external plugins. This approach enables creators to maintain creative freedom while effectively ensuring that the generated results meet expected quality standards. To acquire high-quality experimental samples, this study systematically reviews the well-established optimization tools currently recognized in academia, categorizing them according to their operational mechanisms and human-computer interaction modes (Table 1).

Table 1.
Overview of Controllable Image Generation Tools.
2.3.3. Cultural Alignment Methods
Regarding cultural alignment, the research focus has shifted from basic text-image semantic matching to the precise visualization of complex, fine-grained cultural symbols. Efforts are underway to improve the quality of training data for large models by constructing datasets tailored for knowledge-intensive scenarios [53], allowing for stable representations of cultural characteristics [54], and incorporating multimodal information [55]. On the technical front, several methods are being used to improve cultural accuracy. These include leveraging cross-modal attention mechanisms to enhance the comprehension of complex textual instructions [56,57,58]; utilizing human feedback (RLHF) [59] to refine text-image alignment [60,61,62,63,64]; and applying AI feedback (RLAIF) from reward models [65,66]. Parameter-Efficient Fine-Tuning (PEFT) techniques are widely adopted to enable rapid model adaptation with limited culture-specific data [67,68,69,70]. Currently, layout planning and compositional prompting techniques, which explicitly define spatial relationships and attribute bindings of visual elements [70,71,72], have proven effective in mitigating the risks of mismatch, confusion, and “hallucination” during the generation of cultural symbols.
2.4. Persistent Challenges and Limitations
2.4.1. Limited Generalization
A common thread among these studies is their use of various cultural dimensions to measure the quality of LLM-generated content. However, some scholars argue that research on LLMs’ “cultural awareness” lacks a clear and consensual definition of the complex, multifaceted concept of “culture” itself [22,73,74]. Furthermore, this research often overlaps with inquiries into morality [75] and etiquette [76], which lack distinctly defined boundaries.
2.4.2. Narrow Evaluation Dimensions
While existing benchmarks have advanced the evaluation of technical performance, their assessment dimensions are often too narrow to adequately capture the complexity and richness of cultural representation [77]. Mainstream research typically over-relies on automated metrics, such as FID for assessing overall image quality and realism and CLIP Score for measuring text-image alignment. However, these generic metrics are essentially statistical measures of pixel distribution or shallow semantics and are incapable of quantifying a model’s performance on deeper dimensions like cultural detail accuracy, symbolic appropriateness, and emotional resonance [78]. For instance, an AI-generated image of Tibetan culture might achieve a high FID score, yet the patterns on the attire could be fictional, or the depicted religious rituals might be erroneous. Such critical failures in cultural accuracy cannot be effectively captured by prevailing automated metrics. This over-reliance on automated metrics has led to a superficial evaluation of models’ “cultural intelligence,” neglecting the nuances and contextual dependencies that are vital to cultural understanding [10]. Consequently, there is a pressing need to establish a multidimensional evaluation framework that integrates objective measurements with subjective judgments, balancing technical performance with cultural depth, to more comprehensively assess the true capabilities of generative models in the cultural domain.
3. Methodology
Accurately measuring large language models’ understanding of Tibetan culture presents significant challenges. The initial step involves selecting appropriate generative models. Through a systematic evaluation process, we identified top-performing cross-modal large models from currently mainstream generative models. Building on this, we established a comprehensive workflow for creating Tibetan children’s picture books, encompassing the complete process from story script generation through image selection to manual illustration. Finally, we detailed the characteristics of the participant cohort and the equipment and laboratory environment required for the experiments.
3.1. Evaluating the Understanding of Tibetan Culture
The evaluation of Large Language Models (LLMs) has evolved from assessing singular natural language processing capabilities towards a systematic taxonomy based on task difficulty. This framework primarily encompasses the following dimensions:
- Natural Language Understanding and Generation: As core competencies, understanding tasks include text classification, information extraction, sentiment analysis, and semantic matching. The HELM benchmark further constructs 59 metrics in 42 scenarios to holistically evaluate models [79]. Generation tasks encompass machine translation, text summarization, and text creation. Among these, BLEU [80] is commonly used to assess machine translation quality, while the ROUGE metric [81] is standard to evaluate text summarization.
- Knowledge Question Answering and ReLLMs’ing: This dimension examines a model’s knowledge storage and logical reasoning abilities. Knowledge question answering typically involves reading comprehension and open-domain question answering, with benchmarks such as AGIEval utilizing large-scale standardized exams (e.g., Gaokao, SAT) to assess general capabilities [82]. Logical reasoning includes solving mathematical problems, textual interpretation, and code generation, as explored in [83,84,85].
- Safety and Ethics: In response to LLMs’ safety concerns, evaluations focus on compliance in typical safety scenarios and robustness against instruction-based attacks. Relevant datasets and studies include [86,87,88]. Although evaluation efforts in this field are extensive, a noticeable gap remains in the assessment of subcultural knowledge systems. Given this context, we have adopted an automated evaluation method to ensure the precision of the assessment and the reliability of the findings.
3.1.1. Datasets, Samples, and Measurement Metrics
The NCIFD dataset (https://github.com/letsgoLakers/NCIFD (accessed on 15 May 2025)) is a large-model instruction-tuning dataset specialized for ethnic cultures, comprising NCSI constructed by Self-Instruct and NCQA built by Self-QA. The dataset is structured around seven core cultural domains—architecture, attire, craft, cuisine, etiquette, language, and rituals—with approximately equal representation across these categories (Table 2). This balanced distribution ensures comprehensive coverage of Tibetan cultural elements and provides a reliable baseline for subsequent evaluation tasks, enabling systematic assessment of model performance across diverse cultural aspects.
Table 2.
NCIFD Dataset Composition.
For the initial prompt generation phase, we conducted a comparative evaluation of six prominent LLMs commonly used in both China and the United States (Table 3).
Table 3.
Comparative Overview of Selected Large Language Models.
Specifically, we selected six representative large models from both domestic and international sources for evaluation to ensure comprehensiveness and diversity. The selection includes: Baidu’s ERNIE 4.5 Turbo, serving as an outstanding open-source model renowned for its Chinese language and multimodal comprehension capabilities [89]; DeepSeek’s DeepSeek-V3.2-Exp-Thinking, chosen for its remarkable reasoning abilities and highly competitive cost-effectiveness [90]; and Alibaba’s Qwen3-VL-Thinking, whose visual reasoning functionality is crucial for analyzing cultural symbols [91]. Concurrently, the evaluation incorporates top-tier international models to establish performance benchmarks: Google’s Gemini 2.5, recognized for its leading comprehensive capabilities [92]; OpenAI’s ChatGPT-4o, serving as an industry-standard benchmark [93]; and Anthropic’s Claude, selected for its unique strengths in safety and logical coherence [94]. This combination aims to comprehensively assess the performance of large models in low-resource cultural scenarios from diverse perspectives including different technical approaches, regional backgrounds, and capability emphases.
For classification tasks, metrics such as precision, recall, accuracy and the precision-recall (PR) curve are typically used [95]. These metrics are calculated by comparing the model’s predictions against the ground truth labels to quantify the overall performance of the algorithm. The prevailing methodology for evaluating large language models involves a systematic framework combining multiple metrics and benchmarks. This multi-faceted approach integrates assessments across different dimensions: it employs Perplexity to capture the model’s intrinsic predictive uncertainty; utilizes a suite of metrics, including ROUGE [81], BLEU [80], METEOR [96], and BERTScore [97] to evaluate the coverage, fluency, and semantic similarity of generated text; and finally, reports task-specific performance metrics, such as Accuracy and F1-score [98], across a range of diverse tasks on established benchmarks like GLUE [99], SuperGLUE [100], MMLU [101], and BIG-bench [102], thereby providing a comprehensive measure of general model capability.
Grounded in the characteristics of Tibetan culture as a low-resource domain, we focus on evaluating the aforementioned models on two key aspects when generating Tibetan cultural stories: precision and semantic entropy, supplemented by generalization analysis.
For low-resource domains that are underrepresented in large model training data, ROUGE has demonstrated reliable effectiveness in accuracy measurement. This metric has been successfully applied across numerous specialized and niche fields, including medical subdomains such as renal biopsy interpretation [103], medical dialogue [104], traditional Chinese medicine [105], and MRI radiology data [106]. Furthermore, recent studies have also employed it to assess the accuracy of Uighur translation tasks [107]. These applications validate ROUGE’s prominent capability in directly and effectively measuring the completeness and accuracy of key information units.
Therefore, we selected ROUGE-N as the core metric for evaluating the cultural accuracy of model-generated content (1).
- : The set of reference texts against which the generated content is compared.
- : An n-gram sequence of length n appearing in the reference texts.
- : The number of n-grams co-occurring in both the candidate text and reference set.
- : The total number of n-grams present in the reference set.
Although ROUGE cannot capture deeper cultural emotions or contextual nuances, it provides a training-free, stable, and reproducible quantitative basis for assessing cultural fact accuracy. Given that Tibetan culture possesses a wealth of unique core symbols, artifacts, and narrative paradigms (e.g., the production process of “Bangdian” and the dining etiquette of “Tsampa”), the accurate transmission of these cultural facts is paramount. By quantifying the alignment between generated texts and authoritative reference texts regarding these key cultural entities and facts, ROUGE effectively ensures accuracy in core cultural factual content.
Beyond ensuring the accuracy of generated content, it is equally critical to evaluate the likelihood of model hallucinations—that is, the reliability of the outputs. To this end, we introduce semantic entropy as a core metric (2). Its principal advantage lies in not requiring prior task-specific knowledge or data, enabling it to directly assess the reliability of generated content from a semantic perspective and intuitively reflect the model’s confidence in its own outputs [108,109].
- : Semantic entropy of the semantic variable .
- : The total number of semantic symbols (sets of synonymous expressions).
- : The set of indices of syntactic symbols corresponding to the semantic symbol .
- : The probability of this semantic symbol, which is the sum of the probabilities of all its corresponding syntactic symbols.
- log: Typically denotes the natural logarithm (base e) or the base-2 logarithm (commonly in information theory); the specific base should be clarified by the context.
Unlike accuracy metrics based on exact matches, the assessment via semantic entropy does not rely on strict verbatim alignment with a reference dataset. Instead, it permits the model a reasonable degree of freedom within semantically consistent boundaries. This characteristic allows it to effectively measure the model’s healthy generalization capability while adhering to core semantic constraints. Consequently, accuracy metrics and semantic entropy form a powerful cross-complementary pair.
To visually compare the comprehensive performance of different models across both accuracy (measured by ROUGE) and reliability (measured by semantic entropy) dimensions, we further introduce an Accuracy-Reliability Cross Plot. This plot holistically illustrates the overall performance distribution of the six models within this two-dimensional evaluation space.
This selection directly addresses the core challenges in cultural generation: ROUGE ensures the accuracy of cultural facts, semantic entropy guarantees the fluency of cultural narratives, and generation testing across sub-themes directly reveals the breadth and adaptability of the model’s cultural knowledge.
3.1.2. Methods and Results
To evaluate the genuine capabilities of different models in a zero-shot scenario, we selected six representative large language models for comparison. A fixed prompt was used in the experiment: “Please create a children’s popular science story with a Tibetan cultural theme. The story should encompass seven complete plot points to ensure a rich narrative structure and have a total length of more than 500 words. Ensure that the content is engaging and accurate in conveying Tibetan cultural elements, using language that is easy for children to understand.” Using this prompt, we performed 20 repeated generations for each model to collect sufficient samples for subsequent quantitative analysis and comparison. In a zero-shot generation setting, we first examine whether model-generated content accurately reflects distinctive Tibetan cultural characteristics. We employ the ROUGE-semantic entropy metric to quantitatively compare the model outputs against expert-curated reference texts. The result is as follows (Figure 1).
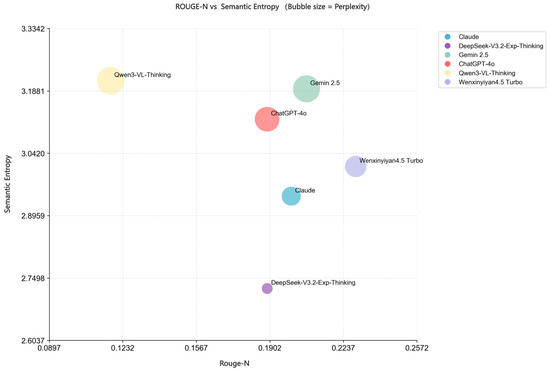
Figure 1.
Accuracy-Reliability Cross Plot.
This figure plots the semantic entropy on the y-axis against the ROUGE score on the x-axis, with the bubble size directly representing the magnitude of the semantic entropy. A higher semantic entropy indicates a lower confidence in the model for the text generation task in this experiment [110]. Consequently, the large bubbles in the upper section (representing Qwen, Gemini, and GPT-4) suggest that these models were the most “hesitant” when generating Tibetan cultural stories. In contrast, DeepSeek exhibits the lowest semantic entropy, indicating higher internal consistency or predictive certainty when generating children’s stories utilizing Tibetan cultural knowledge. However, its ROUGE score, which reflects the semantic similarity between generated content and reference texts, is not the highest. This implies that while the model generates text fluently, its coverage and reproduction of key cultural facts are not the most accurate. In general, ERNIE (WenxinYiyan) achieves the best balance between semantic entropy and ROUGE scores, demonstrating strong performance in both fluent generation and cultural accuracy, thereby showing the most robust comprehensive capability among the evaluated models.
To systematically evaluate the generalization and transfer learning capabilities of large language models in generating Tibetan cultural content, this study designed a step-by-step assessment pipeline.
First, we adopted the Tibetan cultural taxonomy from the NCIFD dataset as our benchmark, establishing seven core themes: Dialogue, Custom, Etiquette, Craftsmanship, Diet, Apparel, and Landmark. Through a systematic review of the dataset, we further delineated the subcategories within each theme, thereby constructing a structured cultural knowledge framework and a comprehensive tagging system. This process laid a solid foundation for subsequent analysis.
Subsequently, we performed LDA topic modeling on all stories generated by the six large language models. The themes extracted through LDA were systematically mapped and compared against the benchmark taxonomy. Tokens that could be unambiguously assigned to an existing benchmark category were labeled as a “Reference Cluster,” indicating the model’s accurate replication of established cultural knowledge.
For clustering results that exhibited a low match with any benchmark category, ambiguous thematic assignments, or recurrence across multiple categories, we defined them as “Vague Cluster” and “Overlap Cluster,” respectively. The content within these clusters primarily consisted of model-generated specific terms and cultural elements not explicitly covered by the benchmark system.
To accurately determine the cultural validity and appropriate classification of this subset of data, three experts in Tibetan cultural studies were invited to conduct independent manual annotation. To ensure inter-annotator consistency, we quantified the inter-rater reliability using Cohen’s Kappa coefficient [111]. Cases with initial disagreements were adjudicated by a senior researcher according to the pre-defined classification guidelines, a process that further reinforced the reliability of the classification criteria.
Representative terms from the Vague (Table 4) and Overlap (Table 5) Clusters, along with the experts’ final evaluation results, are presented in the table below.
Table 4.
Representative Examples of Vague Cluster and Expert Classification.
Table 5.
Expert Classification of Overlapping Content Clusters.
As shown in Table 4, the large language models generated a wide range of vocabulary pertaining to Tibetan natural landscapes, which were not sufficiently covered by the classification system of the benchmark dataset (NCIFD). This discrepancy primarily stems from the inherent logic of the dataset’s construction: the “Landmark” category in the reference dataset is distinctly biased towards architectural entities (e.g., monasteries, palaces). Such structures are typically laden with more dense and multi-layered historical, cultural, and religious knowledge, thus being regarded as more salient carriers of cultural connotations. In contrast, descriptions of natural landscapes often focus on geographical location and environmental features, and they were not included in the reference dataset as core elements intended to highlight the essence of Tibetan culture. Consequently, during automatic topic clustering, a multitude of natural landscape terms lacked pre-defined categorical anchors, resulting in ambiguous assignments and necessitating manual intervention based on expert knowledge.
It is noteworthy that although these natural landscape terms were ultimately classified by experts under the “Landmark” category, most also received low association scores with the “Custom” category. This phenomenon stems from their dual cultural significance. For instance, the lakes mentioned are often regarded as “Holy Lakes” in Tibetan culture, embodying both a physical geographical entity and a religious-cultural symbol. This duality led to deliberation among some experts, weighing the universal perception of a landmark against its specific role in religious customs. However, as one expert noted during the evaluation, “Not every individual universally acknowledges the practice of attributing religious significance to natural landscapes.” Ultimately, a high level of consensus was reached on the “Landmark” classification, based on their most prominent characteristic as natural entities. Furthermore, the emergence of the term “Digital Guardian Spirit” was consistently identified by experts as a case of “cultural hallucination” generated by the LLMs. The expert review concluded that this term lacks any credible foundation in Tibetan culture or religion and should be regarded as a fabricated concept. This specific case clearly demonstrates the potential for LLMs to produce entirely factually inaccurate outputs within specific cultural domains. Moreover, the experts’ acute and unanimous identification of such inaccuracies underscores their high level of professional sensitivity and discernment in evaluating the cultural content generated by LLMs.
The analysis (Table 5) indicates that the terms causing classification overlaps were predominantly personal names and kinship terms, which were initially ambiguously clustered among “Dialogue,” “Custom,” and “Etiquette.” However, the experts’ final evaluations revealed a clear cultural logic underlying this phenomenon.
First, ordinary personal names (e.g., Drolma, Zhaxi) were consistently classified under “Dialogue.” This aligns with common social practices in Tibetan society, where peers typically address each other directly by their given names (rather than using surnames) to convey familiarity and an egalitarian relationship. Second, kinship terms for elders (e.g., Ama, Aba) were unanimously assigned to the “Etiquette” category by the experts. This reflects the cultural tradition of respecting hierarchical order based on age, where the use of specific address forms is itself a fundamental aspect of polite conduct.
Regarding the initial association of these terms with the “Custom” category, a plausible explanation lies in the inherent cultural symbolism embedded in Tibetan names (for instance, “Nyima” symbolizes the sun, “Dawa” the moon). However, the experts reasoned that this symbolism is more cultural than functional; it does not constitute a prescriptive customary rule governing daily social interactions. Consequently, it was not assigned a high weight in the “Custom” category.
A particularly insightful finding is that the boundaries between “Dialogue” (familiarity) and “Etiquette” (politeness) are not rigidly distinct in the Tibetan cultural context. As one expert astutely observed, “Sometimes, an overemphasis on polite forms of address can actually create distance and undermine intimacy in a relationship.” This subtle negotiation exemplifies the dynamic interplay between intimacy and formality in social relations, and it also explains why automated classification algorithms struggle here, underscoring the indispensability of expert cultural intuition.
The treemap (Figure 2) clearly illustrates the distribution of cultural knowledge applications across seven Tibetan cultural categories for the six large language models. As shown, ERNIE (WenxinYiyan) covers all seven cultural domains, with the most balanced distribution of vocabulary across them, demonstrating a higher semantic diversity and conceptual density in its knowledge of Tibetan culture. In stark contrast, the cultural vocabulary generated by the DeepSeek model is the most limited in scope. Its outputs are heavily concentrated in the “Common Tibetan Names” category, with minimal generation in areas requiring deeper cultural understanding, such as “Cultural Customs” and “Daily Habits,” indicating a significant imbalance in its knowledge structure. Based on the comprehensive findings outlined above, this study selects ERNIE (WenxinYiyan) as the primary generative model. We will employ this model to produce the complete script for the Tibetan cultural children’s picture book, along with the corresponding prompts and final illustrations, thereby constructing the experimental dataset for subsequent eye-tracking studies and human evaluations.
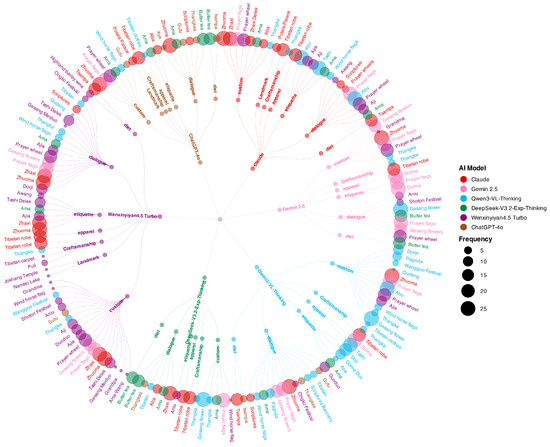
Figure 2.
Treemap of 7 Aspects in Tibetan Culture.
3.2. Story Selection and Image Generation
The creation of the experimental set involved two key steps: story selection and image generation. We first utilized ERNIE to generate and select an appropriate Tibetan cultural story script. The key scenes of the script were then transformed into visual prompts, which were finally used by its text-to-image function mode to generate the corresponding illustrations.
3.2.1. Story Script: The Making of a Rainbow-Colored Tibetan Knot
The Bangdian (Tibetan apron), a vibrant multi-colored accessory traditionally worn by women around the waist, represents an important element of intangible cultural heritage. Its craftsmanship involves multiple steps, including fabric selection, dyeing, and weaving. This study focuses specifically on the dyeing process—the most visually rich phase—as the narrative core, developing the storyline around Drolma, a Tibetan girl, helping her mother prepare the Bangdian for the Wangkor Festival.
We utilized the ERNIE text-to-text generation function (WenxinYiyan) to generate the story script and the corresponding text-to-image prompts as described. The specific story scripts, along with their corresponding ERNIE prompts and the resulting generated images, have been compiled and stored in the table within the Supplementary Materials for clarity and reproducibility.
3.2.2. Illustration Generation: AIGI and HMGI
The illustrations for the study were created in two distinct sets: one generated by the AI model (hereinafter referred to as AIGI (AI-Generated Image)) and the other manually generated by a human artist (hereinafter referred to as HMGI). We used the ERNIE (WenxinYiyan) model to produce the images utilized in the experiment. We consistently used descriptive terms such as “children’s picture book,” “Tibetan girl,” and “Bangdian production” for image generation prompts.
Given the absence of a defined and standardized outcome for AI-generated images, we selected images exhibiting greater consistency as the control group and preserved them. We selected seven pivotal story moments and portraits of three main characters as target stimuli. We used the ERNIE (WenxinYiyan) model to produce the images utilized in the experiment. For each of the seven story moments and three character portraits (10 stimuli in total), we generated 20 initial candidate images using consistent descriptive prompts (e.g., “children’s picture book style,” “Tibetan girl,” and “Bangdian production”). From this pool of 200 total candidates, a final set of images was selected as the AIGI group. The selection process was conducted by a panel of three researchers and was based on the following predefined, multi-dimensional criteria:
Narrative Consistency: The image must accurately depict the key action, setting, and elements described in the specific story moment or character prompt.
Cultural & Character Fidelity: For characters, consistency in appearance (e.g., facial features, attire) across different scenes was prioritized. For scenes, elements like traditional clothing (“Bangdian”) and environment were checked for basic cultural recognizability against the textual description.
Aesthetic & Technical Quality: Images with obvious anatomical distortions, blurred features, logical inconsistencies in the scene, or poor compositional balance were excluded. Style Uniformity: A “children’s picture book style” was interpreted as having clear lines, vibrant colors, and a somewhat simplified but expressive form, avoiding overtly photorealistic or overly abstract outputs.
Images were independently evaluated by each researcher. A candidate was included in the final stimuli set only if it met all four criteria and achieved unanimous agreement among the three researchers. This rigorous process resulted in the rejection of approximately 65–70% of the initially generated images per prompt. The final selected AIGI stimuli are therefore those deemed most consistent, culturally recognizable, and technically sound by consensus.
For the human-drawn control group, a professional illustrator was commissioned to create hand-drawn illustrations. The artist was provided with the identical text-to-image prompts and the full story script used for AI generation but was instructed to exercise full artistic interpretation within the constraints of the narrative and descriptive terms. This approach allows for a direct comparison between AI-generated images (filtered by the above criteria) and human artistic creation originating from the same textual source. The objective is to analyze the distinctions between AI-generated photographs and those produced by human artist collaboration. For each trial, corresponding to one story scene, the narrative text was displayed in the center of the screen, flanked by the AI-generated illustration above it and the human-drawn version below. Critically, during the actual experiment, the presentation order of all trials (encompassing all 7 story scenes and both illustration types) was fully randomized. This randomization was implemented to eliminate potential biases arising from fixed positional or sequential patterns, thereby ensuring the independence of participant judgments. The following illustrations, generated by the text-to-image model of ERNIE (WenxinYiyan), constitute the experimental group in this study and are hereafter referred to as the “AIGI” group.The following illustrations (Figure 3) were manually drawn by human artists and constitute the control group in this study. To ensure comparability with the AI-generated group in terms of composition, character portrayal, and narrative representation, artists were required to strictly adhere to the story scripts and prompts generated by ERNIE. All participating artists are second-year graduate students from the School of Art and Design, Huazhong University of Science and Technology.

Figure 3.
Experimental Materials.
3.3. Subjects
The study participants were chosen among graduate students and educators in art design and computer science. A total of 38 students and professors were identified via questionnaires, all of whom utilized AI technologies (including ChatGPT, MidJourney, Copilot, etc.) for more than 10 h weekly and had defined usage objectives in at least two application contexts (such as text generation, image creation, and code debugging). The results of the screening questionnaire indicated that the mean usage time among all participants was 17 h per week, with 60 percent reporting that they mainly utilized it for professional purposes. The particular data obtained from surveys and interviews is presented in Table 6.
Table 6.
Fundamental details of participants.
3.4. Equipment and Environment
To enhance experimental immersion and ecological validity, we presented the story text alongside the corresponding illustrations to the participants during testing. This approach was designed to encourage participants to base their aesthetic judgments within a framework of Tibetan cultural awareness, implicitly treating the activity as a knowledge acquisition task. This design served a dual purpose: first, by establishing a natural learning context, it alleviated potential psychological pressure during eye-tracking, allowing participants to provide more authentic aesthetic responses in a relaxed state; second, it effectively measured participants’ sensitivity to text-image coherence and compatibility—a key metric in our evaluation of content quality.
- Pre-test Questionnaire:The experiment began with participants completing a digital questionnaire collecting demographic background and AI experience. Building on existing research linking self-efficacy to technology acceptance, this baseline assessment aimed to establish participants’ prior familiarity with AI tools, which could potentially influence their subsequent evaluation of AIGI.
- Eye-tracking Experiment:The core eye-tracking experiment was conducted in a laboratory with controlled lighting using a Tobii Pro eye tracker. The session comprised three sequential tasks, each with specified timing parameters to standardize data collection:
- –
- Free Viewing: Participants observed a series of 10 images presented in random order, with each image displayed for 1 s. The purpose was to establish baseline visual attention patterns in the absence of specific task instructions.
- –
- Image Quality Assessment: Participants compared paired images (original and processed versions, presented in randomized order). This task consisted of two sub-phases:
- *
- Overall Aesthetic Appeal Judgment: Participants were given 5 s per pair to select the more visually appealing image and rate its aesthetic appeal.
- *
- Cultural Detail Quality Judgment: Participants were given 7 s per pair to rate the quality of cultural details in the same image pair.
- –
- AIGI Identification: Participants were required to identify the AI-generated image within each pair within a 5 s time limit per trial. The system recorded their selection accuracy and response time.
Upon the expiration of the allotted time for each trial, a visual prompt appeared at the center of the screen; however, the display did not auto-advance to the next trial. This design provided a consistent time frame for focused observation while preventing rushed viewing due to a strict cutoff, allowing participants to proceed at their own pace once ready. This approach aimed to elicit more deliberate and natural gaze data. - Post-test Procedure:When completed the eye-tracking tasks, participants received immediate feedback on their performance on the AIGI identification task. They then completed a final questionnaire that evaluated their satisfaction with and attitudes toward AIGI, specifically focusing on perceptions of AIGI maturity and distinctiveness. This design allowed for examination of potential discrepancies between participants’ actual performance and their self-efficacy beliefs regarding AI technology [112]. The detailed flowchart is presented below (Figure 4).
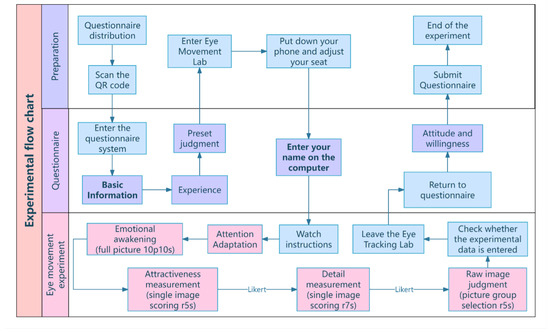 Figure 4. Experimental flow chart.
Figure 4. Experimental flow chart.
4. Results
This chapter aims to analyze and discuss the experimental findings, focusing on three core dimensions: cultural detail accuracy, narrative and emotional depth, and artistic intentionality. By examining user behavior data from eye-tracking experiments (including fixations and gaze duration) along with pre- and post-test questionnaire responses, we highlight the distinct strengths and weaknesses of AIGI and HMGI across these dimensions.
4.1. Accuracy of Cultural Details
In the image of the appearance of the protagonist, the HMGI image received more concentrated attention to the details of the face, confirming the participants’ perception of the characters in a specific style. Analysis reveals that the AI model generated an image of a Tibetan girl with eye features rendered in a highly stereotypical “narrow-eyed” manner. This representation does not stem from the observation of real facial features among Tibetans but is more likely a reflection of a stylized prejudice against East and Southeast Asian populations present in training data, often shaped from a Western-centric perspective [113,114,115,116]. This output highlights a systemic risk in current text-to-image models: the tendency to simplify, or even perpetuate, harmful stereotypes when representing ethnic minority figures. The AI-generated character lacks the facial traits of ethnic minorities, and the HMGI adjusted image compensates for this esthetic flaw, which is also the main reason for the higher HMGI match rate in this collection of photographs (Figure 5).
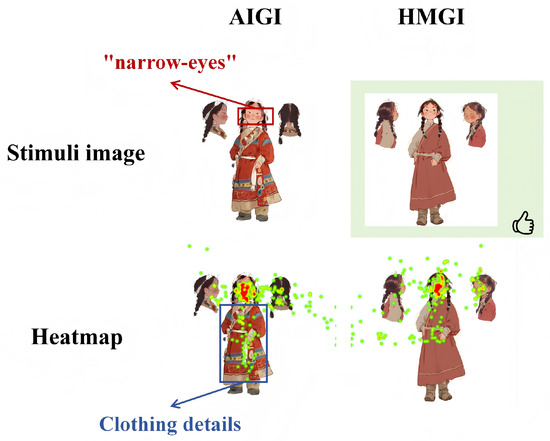
Figure 5.
Culture Details Alignment of HMGI. The green background represents participants’ cumulative aesthetic preference; red text highlights details inconsistent with Tibetan culture; blue text indicates areas where participants’ visual attention was prominently concentrated.
4.2. Narrative and Emotional Depth
In the final group portrait description of the story of the picture book, HMGI and AIGI are evenly separated for the first time. In addition to the focus on the protagonist, “Drolma,” the obvious heat value in the AIGI image is also concentrated on the supporting characters, and the text part of the discussion has also received slightly higher attention than other content, with significantly more time spent on words such as “animal friends.” The HMGI modified the image with the animal body, which was corrected to the supporting character that appeared in the previous image, with the results indicating that such optimization and modification were redundant (Figure 6a). This means that AIGI has a greater creative advantage and can work on images and content that human painters cannot always complete. It is represented in picture book stories that can engage children’s imaginations while also stimulating the development of their cognitive and graphic understanding skills.
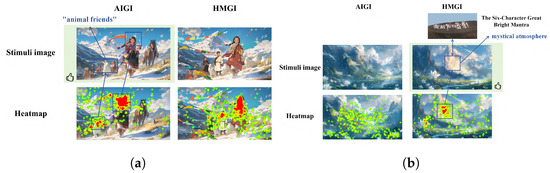
Figure 6.
Narrative and Emotional Depth. (a) Fantasy Elements Convey of AIGI; (b) Mystical Atmosphere of HMGI. The green background represents participants’ cumulative aesthetic preference; blue text indicates areas where participants’ visual attention was prominently concentrated.
It is worth mentioning the experimental results of the final set of photos. As shown in the results below (Figure 6b), the AI-generated content for landscape scenes appeared conventional and failed to capture the distinctive geographical characteristics of Tibet or convey the mystical atmosphere central to the context of the story. In contrast, the human illustrator incorporated representative fantasy icons (such as mountain-top symbols) into the landscape, thereby enhancing both cultural recognition and narrative depth. This discernible difference allowed study participants to consistently distinguish between AI-generated and human-drawn illustrations.
AI-generated visuals must be picture book drawings with the illusory features of cartoons, animation, and characteristic ethnic cultures. Therefore, this research modifies the judgment criteria for images, incorporating character consistency, prop coordination, and color rendering for participants to sort and select based on their value following judgment. Color is the most intuitive visual aspect in an image and influences the first impression of the audience. Among AI deep participants, particularly those with non-professional backgrounds, the attractiveness of color essentially conveys the attractiveness of a picture.
This is also why picture rendering has a negative correlation with judgment, but a strong positive correlation with attractiveness rating in sorting selection (Table 7). Most consumers notice a difference between the colors of picture book graphics and real-world photographs. Picture book images allow for more color creation, and color rendering can make them more vivid and infectious. The degree of color rendering has a substantial negative connection in the table, indicating that the more participants pay attention to the color rendering of the image, the more they lose their ability to make correct judgments. Color rendering has the potential to confuse and mislead participants into making correct judgments, demonstrating that generative artificial intelligence is superior at using color for rendering, particularly in the processing of surreal colors such as picture book images, where generative artificial intelligence has a significant advantage and talent.
Table 7.
Pearson Test Results for Judgment Criteria.
4.3. Intentionality in Artistic Composition
The eye movement experiment has four tasks in total. The eye tracker monitors the duration of the gaze of the participants, the scanning range, and the clicks during the completion of the task. This study initially examines the ’gaze length’ of the participants in each set of photos using eye tracking. It is important to recognize that the source judgment constitutes the final task. In the first three trials, the images vary solely in sequence, requiring participants to rapidly assess the origin of the visuals based on intuition. Consequently, their gaze length (Figure 7) is extremely brief and lacks research significance; therefore, it is excluded from the analysis. The distribution of gaze duration across several image groups in different tasks reveals early disparities, with image-text matching requiring the longest period and beauty evaluation necessitating the shortest. The distinct disparities among various tasks and image groups must be examined in conjunction with the questionnaire content.
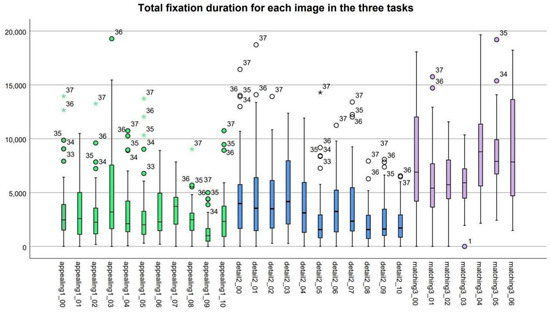
Figure 7.
Total Annotation Time of Distribution. (Circles (∘) indicate mild outliers; asterisks (★) denote extreme outliers. Colors correspond to experimental tasks: green (Aesthetic Preference), blue (Detail Scrutiny), and purple (Image-Text Matching)).
The accuracy of AI-generated images has always been a major concern of the academic community. Common quality assessment standards for AI-generated photos include alignment, security, and explainability. These metrics are used to compare the fit and likeness of AI-generated photos with images captured and made by real humans. The most sensitive discrimination indicator is objective consistency. Although the stimuli images in the experiment were randomly shown, the individuals had already formed mental associations with distinct protagonists, supporting roles, and story content [117,118,119]. Character inconsistency remains a fundamental obstacle for current AI-generated imagery in sequential storytelling. In picture books requiring narrative continuity, the same character generated by AI models often exhibits substantial variations in appearance across different illustrations. When the characters taught by the participants differed from the characters given in the photographs (changes in clothes, styling, look, and facial traits), the images with the greatest variances were frequently mistaken for AI-generated images. This breach of continuity directly undermines narrative immersion and coherence, making it difficult for readers to follow the storyline. This study selected the most divergent AI-generated output from a multi-character scene as a representative case (shown in the following Figure 8). Experimental data confirm that when confronted with such pronounced character inconsistencies, participants could rapidly identify the non-human origin of the work and demonstrated a marked preference for human-drawn illustrations that maintained character consistency. This may be the main reason why the consistency of character in this study shows sensitivity to judgment.
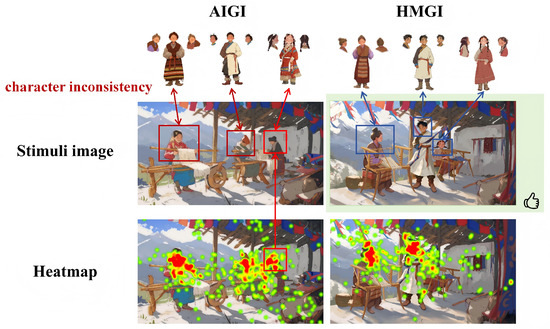
Figure 8.
Character consistency of HMGI. The green background represents participants’ cumulative aesthetic preference; red text highlights details inconsistent with Tibetan culture.
5. Discussion
This chapter provides an in-depth discussion of the research findings. It first examines cultural identification, analyzing differences in audience cultural identification with images from different sources and their underlying causes. It then discusses aesthetic preferences, identifying key visual elements that influence audience evaluation. Finally, it explores the relationship between participant backgrounds and their attitudes toward AI technology from a technology acceptance perspective.
5.1. Cultural Identification
Cultural identification emerged as a central finding in this study. Although distinctions between AI-generated and human-made illustrations were previously drawn based on aesthetic preference and visual rendering, the deeper mechanism driving user evaluation is ultimately the alignment between their internal cultural schema and the visual representation. The theory of cultural genes provides a robust framework for understanding AI’s differential performance in generating cultural content. Dawkins, in The Selfish Gene, introduced the concept of the “meme,” suggesting that certain highly condensed forms within a culture can represent its essential characteristics, possessing strong propagability and representativeness [120]. In this study, we further categorize them into three types:
First, at the level of “Core Genes,” AI demonstrates the ability to capture and reproduce stereotypical, widely recognized cultural symbols. For instance, in terms of color rendering, the palettes generated by AI align well with the mystical and fantastical atmosphere emphasized in Tibetan cultural narratives. This indicates that its learning of certain well-known visual styles (“Core Genes”) is effective. However, this capability is superficial and unstable. When it comes to “Attached Genes” that require deep cultural knowledge for discernment, the model’s limitations are fully exposed. Its outputs included characters with discriminatory stereotypical features such as “slanted eyes,” and, in depicting the Bangdian crafting process, it erroneously presented chemical dyes instead of accurately representing the key cultural practice of using natural plant dyes. The root cause of these omissions and errors lies in the fact that “Attached Genes”—such as the spiritual connotations behind specific crafts or the cultural appropriateness of facial features—rely on dense, non-textual networks of contextual knowledge, creating a comprehension gap for current models regarding such deep semantics. However, when it comes to “Attached Genes” that require deep cultural knowledge for discernment, the model’s limitations are more thoroughly exposed. Its outputs included characters with discriminatory stereotypical features such as “slanted eyes,” and, in depicting the Bangdian crafting process, it erroneously presented chemical dyes instead of accurately representing the key cultural practice of using natural plant dyes. The root cause of these omissions and errors lies in the fact that “attached genes”—such as the spiritual connotations behind specific crafts or the cultural appropriateness of facial features—rely on dense, non-textual networks of contextual knowledge, creating a comprehension gap for current models regarding such deep semantics. Our experiments (Figure 9) reveal that attached genes often intertwine with core genes, which also explains why AI tends to become confused when processing landmarks, personal names, and dialogues—it can sense cultural connections but cannot accurately attribute or express them without deeper contextual understanding.
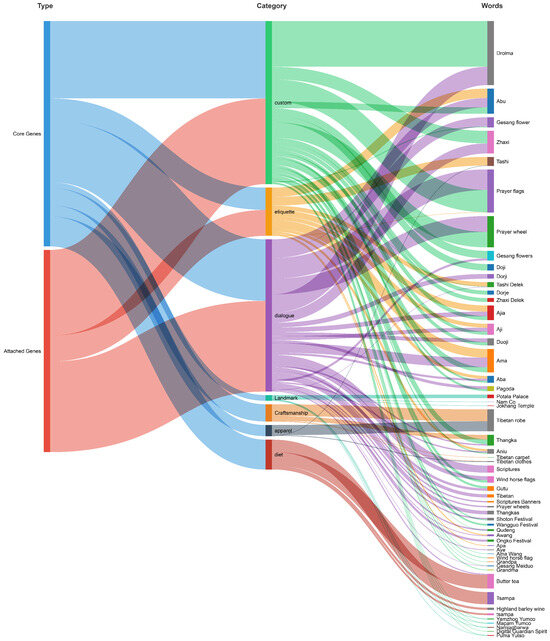
Figure 9.
Branching Structure of Cultural Genes.
Furthermore, AI’s outputs often present a “half-baked” state of “Hybrid Genes,” where its innovative attempts become distorted due to incomplete understanding. A representative case is an AIGI image featuring anthropomorphic animal figures, likely inspired by the Tibetan allegorical painting “The Four Harmonious Animals,” a classic Tibetan Buddhist allegorical painting depicting an elephant, a monkey, a hare, and a bird (often a partridge) standing on each other’s backs to reach fruit on a tree. The image symbolizes harmony, interdependence, and respect for elders, as each animal represents a different age and ability, yet cooperates to achieve a common goal. It is widely used in Tibetan art, murals, and thangkas to convey values of communal peace and ethical collaboration. However, the depiction included only the elephant and the rabbit, missing the partridge and the monkey (Figure 10). This precisely exemplifies the failed representation of cultural “hybrid genes”: the model captures the clue for cultural innovation but exhibits “hallucinations” and confusion in complete representation and coherent organization. It is “aware” of certain underlying narrative or symbolic needs within the culture but does not know “how” to execute them correctly.

Figure 10.
A Truncated Version of “The Four Harmonious Animals”. Red for inconsistency with Tibetan culture; orange for correct adherence to Tibetan cultural elements.
In conclusion, current AI technology has achieved preliminary success in imitating “Core Genes” and shows initial, albeit often erroneous, innovative potential at the level of “Hybrid Genes.” However, it still faces fundamental limitations in deeply understanding and accurately expressing “Attached Genes.” In contrast, human illustrators, leveraging their cultural insight, adeptly avoid these issues and intentionally emphasize cultural details through nuanced brushwork—a depth of understanding and creative capability that current AI technology has not yet achieved. The cultural gene framework clearly illustrates that AI’s cultural cognition is imbalanced between “breadth” (recognizing a wide range of symbols) and “depth” (understanding spiritual connotations). Future research must focus on bridging this cognitive gap.
5.2. Aesthetic Preference
Although the primary focus of this study is on the identification and representation of Tibetan cultural elements, the observed differences in participants’ aesthetic preferences offer an equally compelling dimension for consideration. AI-generated works were sometimes praised for their vibrancy in color and visual impact, while human-drawn illustrations were strongly preferred in terms of overall artistic appreciation and aesthetic endurance. This heat map (Figure 11) uses a multidimensional aesthetic evaluation framework, where the left group measures immediate visual impact (initial attraction) and the right group assesses sustained aesthetic value after prolonged viewing (aesthetic endurance). Both dimensions are computed through the synthesized metrics of participants’ selection preferences, rating scores, and decision time. The distribution pattern reveals significant differences in overall aesthetic performance in images depicting different narrative themes.
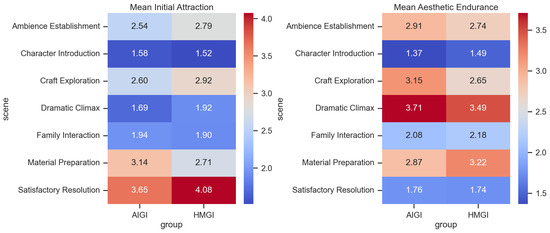
Figure 11.
Aesthetic heatmap.
This study provides statistical evidence that AI-generated content and human creation possess complementary strengths across different aspects of cultural storytelling. Human advantages lie in the deep expression of emotion and cultural resonance, while AI shows significant potential in creating specific atmospheres and visual impact. Future content creation strategies should consider this divergence to achieve optimal human-AI collaboration.
- Initial AttractionHMGI Dominates Emotional and Resolution Scenes: HMGI received significantly higher initial attraction scores in scenes requiring emotional resonance and cultural depth, such as the Satisfactory Resolution (4.08) and Craft Exploration (2.92).AIGI Excels in Specific Narrative Segments: In contrast, AIGI performed better, even surpassing HMGI, in scenes demanding objective detail depiction, like Ambience Establishment (2.79) and Material Preparation (3.14).Largest Gap and Consensus: The largest score difference was observed in the Satisfactory Resolution scene (0.43), while scores were closest in the Family Interaction scene (0.04), indicating convergent initial impressions in the latter.
- Aesthetic EnduranceAdvantage Reversal and Scenario Specificity: The distribution of advantages in Aesthetic Endurance changed significantly compared to Initial Attraction. AIGI demonstrated stronger enduring appeal in the Dramatic Climax (3.71) and Craft Exploration (3.15) scenes, whereas HMGI’s advantages were evident in Material Preparation (3.22) and Family Interaction (2.18).Key Finding: In the Material Preparation scene, HMGI achieved a dual lead in both Initial Attraction (2.71) and Aesthetic Endurance (3.22), suggesting it successfully balanced “instant appeal” with “lasting value” in this context.Common Weakness: Notably, both groups scored lowest on Aesthetic Endurance in the Character Introduction scene (AIGI: 1.37, HMGI: 1.49), hinting at potential inherent challenges in the scene’s composition or narrative design.
In summary, the aesthetic preferences for HMGIs and AIGIs primarily fall within an overlapping interval. We cannot conclusively determine the superiority of either approach based solely on quantitative metrics, but we can clearly identify their respective strengths: HMGIs excel in cultural depth and detailed authenticity, whereas AIGIs demonstrate potential in visual innovation and fantasy expression. This finding suggests that in cross-cultural visual communication, technical accuracy alone does not solely determine audience reception, revealing a complex interplay between aesthetic experience and cultural perception that warrants further exploration.
5.3. Technology Acceptance
A significant correlation emerged between participant characteristics and their performance in distinguishing AIGI from HMGI. We examine AIGC in terms of innovation, originality, and maturity. The most noticeable negative association of the figure is the downward gradient distribution of maturity, which reflects the considerable negative relationship between the judgment ability of the participants and the appraisal of maturity. The evaluation of innovation and originality does not appear to have the same value (Figure 12).
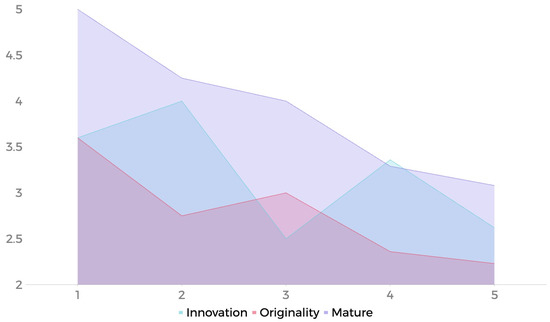
Figure 12.
Participants’ evaluation of AIGI’s discernment ability (x-axis) and maturity (y-axis).
Specifically, participants with higher accuracy were typically frequent users of AI tools, capable of keenly identifying the stylistic hallmarks of AI-generated art. Ironically, these proficient users expressed greater caution and concern regarding the application of AI in text-to-image generation. They widely believed that in the current state lacking effective oversight, AI technology is not yet suitable for generating content about ethnic minority cultures, as it easily leads to cultural misrepresentation and cognitive misinformation.
In contrast, participants who seldom used AI maintained a more optimistic outlook on the future development of AIGI. They tended to believe that accurately rendering cultural elements was merely a technical challenge that would be solved with time.
Fundamentally, this cognitive divergence reveals two distinct modes of technology acceptance. Proficient users, grounded in extensive practice, possess a more sober awareness of the technology’s limitations and potential risks. Conversely, the optimism observed among less-experienced users may stem from curiosity and initial excitement towards emerging technology, leading them to temporarily overlook the objective gap between current technical capabilities and real-world requirements [121].
Participants who cannot identify the source of the image have unwittingly demonstrated a crucial characteristic of generative AI: producing works comparable to human invention. This has a direct impact on how people perceive the maturity of AI technology. The fundamental reason is that participants who cannot recognize the source are more likely to objectively evaluate the quality of the image, rather than being influenced by the creation technique. This impartiality allows participants to objectively judge the attractiveness and detail of the image, attributing the evaluation results to the maturity of AI technology rather than a mere human input.
The concept of “visual literacy,” further developed by Fransecky, posits that it is a capability most people possess in the early stages of cognitive development [122]. As Stokes indicates, this trained visual skill is not an art-school mode of seeing, but rather an everyday competence acquired through social conditioning [123]. However, while AI has the technical capacity to create visual “beauty,” it lacks the intrinsic perception to discover and feel it. This fundamental limitation is particularly evident in the representation of Tibetan culture: AI systems cannot genuinely comprehend which specific local features should be emphasized as culturally significant [124]. Their outputs often remain at the level of superficial formal imitation, failing to capture the deeper meanings embedded within cultural symbols.
Participants’ good attitudes toward generative AI implicitly reflect the fact that it works well in the specific application scenario of “visual performance.” As a result, participants will assume that AI-generated photos are reliable and useful in real applications. For the high-acceptance segment of deep AI participants, when the generative AI performance exceeds expectations, it will quickly translate into positive feedback on technological progress. This attitude shows their tolerance and expectations for technology: as long as the result is satisfactory, the specifics of the creation process (such as whether it is humanly made) are unimportant.
6. Conclusions
This study used a systematic experimental design that integrates eye-tracking, questionnaire surveys, and in-depth interviews to thoroughly investigate the capabilities and limitations of large generative models in visually representing Tibetan culture. We addressed the two core research questions and provided a comprehensive discussion of the findings: clarifying the systematic differences in cultural symbol representation between AIGI and HMGI, and revealing how participant evaluation is moderated by both AI experience and cultural cognition. The theoretical contributions and practical implications are then elaborated, including the proposed cross-cultural evaluation framework and its significance for technological development. Finally, we honestly discuss research limitations and suggest viable directions for future work.
6.1. RQ1: Systematic Differences in Cultural Symbol Representation Between AIGI and HMGI
In response to the first research question—“In the context of Tibetan culture, what quantifiable differences exist in the representation of cultural symbols between images generated by large models (AIGI) and those drawn by humans (HMGI)?”—our analysis reveals three primary layers of systematic differences:
- Regarding the accuracy of cultural details:
Human illustrators demonstrated significant superiority. Specific manifestations include: (1) In clothing patterns, the HMGI accurately depicted the crossed structure of Tibetan robes and the colored stripes of the Bangdian (apron), whereas AIGI frequently exhibited structural errors, such as incorrect front placket directions and chaotic accessory combinations. (2) In architectural features, human artists precisely rendered the trapezoidal outlines and black window frames characteristic of Tibetan architecture, while AIGI often incorporated elements from other ethnic architectural styles, resulting in cultural hybridity. (3) In object depiction, the HMGI handled details of religious and daily utensils (e.g., prayer wheels, butter teapots) accurately, whereas AIGI showed issues with proportional and structural distortion. These differences are corroborated by eye-tracking data—participants’ fixation durations on cultural detail areas in the HMGI were significantly longer than in AIGI (by an average of 1.2 s), indicating that the former provided richer and more credible cultural information.
- Concerning the appropriateness of symbol usage:
AIGI exhibited notable problems with stereotyping. The most typical case is character generation: AIGI repeatedly produced character faces with “slanted eye” features, a stereotypical representation from a Western perspective that deviates significantly from the actual appearance of Tibetan people. Furthermore, when depicting the “Bangdian crafting” process, AIGI erroneously presented the use of chemical dyes instead of the natural plant dyes used in traditional Tibetan practice. These errors not only reflect cultural biases within the training data but also reveal a fundamental flaw in the current models: the lack of a cultural fact-checking mechanism.
- Pertaining to the depth of emotional expression:
The HMGI achieved richer emotional conveyance through subtle artistic treatment. Human illustrators carefully designed the direction of characters’ gazes, subtle curves of the mouth, and body postures to convey emotional states consistent with the narrative atmosphere. In contrast, expressions generated by AIGI were often superficial and lacked narrative coherence. In the “Family Interaction” scenario, the HMGI scored significantly higher on emotional depth (4.2/5) than AIGI (2.9/5), a gap that widened further in the aesthetic endurance tests.
6.2. RQ2: Participant Evaluation Is Moderated by Both AI Experience and Cultural Cognition
Addressing the second research question—“How do participants with AI experience perceive and evaluate the distinctions between AIGI and HMGI in terms of cultural authenticity and aesthetic dimensions?”—our study uncovered a fascinating cognitive divergence:
AI proficiency significantly influenced identification ability and evaluation criteria. Cross-analysis between participants’ frequency of AI use and their performance in the AIGI identification task revealed a significant positive correlation (r = 0.68, p < 0.01). “Proficient users” who used AI tools for more than 10 h per week achieved an identification accuracy of 87%, whereas “novices” with little AI exposure had an accuracy of only 42%. More importantly, the evaluation logic of the two groups differed fundamentally: proficient users judged primarily based on the accuracy of cultural details and the appropriateness of symbols; non-proficient users relied more on surface features like overall color and composition.
Attitudes towards the technology exhibited an “experience paradox.” Contrary to intuition, proficient users expressed greater caution regarding the application of AIGI in cultural dissemination. While they acknowledged AIGI’s technical capabilities in color rendering and atmosphere creation, they expressed deep concern about its cultural accuracy. One participant with three years of AI drawing experience stated: “I understand the potential of these technologies, but I also know their limitations deeply. In a serious field like cultural heritage, even a tiny error can cause profound misunderstandings.” In contrast, non-proficient users showed more optimism about the future development of AIGI, believing that “technical problems will eventually be solved over time.”
Cultural cognition emerged as the ultimate criterion. Regardless of category, participants ultimately returned to the same core standard: whether the work matched their internal impression of Tibetan culture. Works that successfully translated core Tibetan cultural qualities—such as “mystery,” “sanctity,” “warmth,” and “healing”—received higher ratings, regardless of their origin (AI or human). This consistency suggests that the advancement of the technology itself is not the decisive factor; rather, cultural fidelity is the key predictor of acceptance.
6.3. Theoretical Contribution and Practical Implications
The theoretical contributions of this study are threefold: First, we established a theoretical framework for cross-modal cultural assessment, extending the evaluation of cultural symbols from the textual to the visual domain. Second, we uncovered the complex relationship between AI experience and cultural evaluation, enriching the application of technology acceptance theory in the field of cultural computing. Finally, we proposed the concept of the “Cultural Perception Gap” to describe the disparity between a model’s cultural understanding capability and human cultural expectations.
On a practical level, this study provides clear directions for future technological development: (1) There is an urgent need to construct multimodal datasets encompassing low-resource cultures to provide a more comprehensive foundation for model cultural cognition. (2) Specialized evaluation metrics for cultural accuracy should be developed, moving beyond generic image quality assessment systems. (3) We recommend establishing human-AI collaborative workflows for cultural content creation, organically integrating human cultural wisdom with AI’s technical efficiency.
6.4. Limitations and Future Work
This study has several limitations: the participant pool was primarily drawn from a university population, necessitating an expansion in future research; the focus was solely on Tibetan culture; so, generalizing conclusions to other ethnic minority cultures should be carried out cautiously; and short-term experiments cannot capture the long-term effects of cultural understanding.
Future work will proceed in three directions: developing fine-grained evaluation benchmarks specifically for cultural symbols, exploring controllable generation methods that integrate cultural knowledge, and investigating evaluation frameworks for generative models from cross-cultural perspectives. We believe that through sustained effort, generative technology can play a more positive and responsible role in cultural preservation and innovation.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/electronics15010015/s1, Table S1: AIGI-Generated Images, Scripts, and Prompts.
Author Contributions
Conceptualization, Y.L. (Yongjian Liu); Methodology, Y.Q. and A.H.; Software, Y.Q.; Validation, Y.L. (Yongjian Liu); Formal Analysis, Y.Q.; Investigation, A.H. and Y.L. (Yuhan Liu); Resources, Y.L. (Yongjian Liu); Data Curation, A.H. and Y.Q.; Writing—Original Draft Preparation, Y.L. (Yuhan Liu), Y.Q. and A.H.; Writing—Review and Editing, Y.L. (Yongjian Liu) and L.B.; Visualization, Y.L. (Yuhan Liu) and Y.Q.; Supervision, Y.L. (Yongjian Liu) and L.B.; Project Administration, Y.L. (Yongjian Liu); Funding Acquisition, Y.L. (Yongjian Liu). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China (Grant Number SQ2024YFF0900127) under project “Key Technology Research, Development, and Application of Generative Artificial Intelligence-Based Professional Knowledge Services”; the National Natural Science Foundation of China (Grant No. 62271360) under project “Thangka target recognition”; the Lhasa Key Science and Technology Program “Digital Platform for Tibetan Plateau Culture and Art” (Grant No. LSKJ202404); the Hubei Yangtze River Culture Conservation and Promotion Research Project “Application and Dissemination of Digital Technology in Hubei Cultural Tourism Scenarios” (Grant No. HCYK2025Z08).
Institutional Review Board Statement
This study was conducted in accordance with the Declaration of Helsinki, and approved by the Review Board of Medical Ethics Committee of Tongji Medical College, Huazhong University of Science and TechnologyInstitutional (protocol code S094 and date of approval 25 June 2025).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.Written informed consent has been obtained from the patients to publish this paper.
Data Availability Statement
The eye-tracking experimental data supporting the findings of this study have been deposited in the figshare repository and are publicly available via the DOI link provided (https://doi.org/10.6084/m9.figshare.30885491).
Acknowledgments
The authors express sincere gratitude to the members of the National Key Research and Development Program of China for their support and encouragement throughout the research project. Special thanks are given to colleagues at the School of Architecture and Urban Planning at Huazhong University of Science and Technology and the School of Computer Science and Artificial Intelligence at Wuhan University of Technology for their valuable discussions and insights, which significantly contributed to the development of the study. The authors are also grateful to all participants in the review for their invaluable cooperation and contributions to the success of the project. During the preparation of this study, the authors utilized AI image generation tools to create the experimental stimuli (AIGI group images). The authors have critically reviewed, selected, and edited all AI-generated outputs, and take full responsibility for the content and interpretation presented in this publication.
Conflicts of Interest
The authors declare no conflicts of interest, and the funders had no role in the design of the study, in the collection, analyses, or interpretation of data, in the writing of the manuscript, or in the decision to publish the results.
References
- Chen, Z.; Liu, R.; Huang, S.; Guo, Y.; Ren, Y. A Survey of Large-Scale Deep Learning Models in Medicine and Healthcare. Comput. Model. Eng. Sci. 2025, 144, 37. [Google Scholar] [CrossRef]
- Wang, S.; Xu, T.; Li, H.; Zhang, C.; Liang, J.; Tang, J.; Yu, P.S.; Wen, Q. Large Language Models for Education: A Survey and Outlook. arXiv 2024, arXiv:2403.18105. [Google Scholar] [CrossRef]
- Gallotta, R.; Todd, G.; Zammit, M.; Earle, S.; Liapis, A.; Togelius, J.; Yannakakis, G.N. Large Language Models and Games: A Survey and Roadmap. IEEE Trans. Games 2024, 1–18. [Google Scholar] [CrossRef]
- Strelau, R. Challenges of applying generative ai in knowledge management: Insights from a systematic literature review. Organ. Kier. 2025, 2, 57–75. [Google Scholar]
- Grassini, S. Computational power and subjective quality of AI-generated outputs: The case of aesthetic judgement and positive emotions in AI-generated art. Int. J. Hum. Comput. Interact. 2025, 41, 9056–9065. [Google Scholar] [CrossRef]
- Mishra, M.; Lourenço, P.B. Artificial intelligence-assisted visual inspection for cultural heritage: State-of-the-art review. J. Cult. Herit. 2024, 66, 536–550. [Google Scholar] [CrossRef]
- Colace, F.; Gaeta, R.; Lorusso, A.; Pellegrino, M.; Santaniello, D. New ai challenges for cultural heritage protection: A general overview. J. Cult. Herit. 2025, 75, 168–193. [Google Scholar] [CrossRef]
- Cardarelli, L. From fragments to digital wholeness: An AI generative approach to reconstructing archaeological vessels. J. Cult. Herit. 2024, 70, 250–258. [Google Scholar] [CrossRef]
- Tao, Y.; Viberg, O.; Baker, R.S.; Kizilcec, R.F. Cultural bias and cultural alignment of large language models. PNAS Nexus 2024, 3, 346. [Google Scholar] [CrossRef]
- Cao, Y.; Zhou, L.; Lee, S.; Cabello, L.; Chen, M.; Hershcovich, D. Assessing cross-cultural alignment between ChatGPT and human societies: An empirical study. arXiv 2023, arXiv:2303.17466. [Google Scholar]
- Agarwal, D.; Shukla, A.; Sitaram, S.; Vashistha, A. Fluent but Culturally Distant: Can Regional Training Teach Cultural Understanding? arXiv 2025, arXiv:2505.21548. [Google Scholar] [CrossRef]
- Palta, S.; Rudinger, R. FORK: A bite-sized test set for probing culinary cultural biases in commonsense reasoning models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 9952–9962. [Google Scholar]
- Yao, J.; Yi, X.; Wang, J.; Dou, Z.; Xie, X. Caredio: Cultural alignment of llm via representativeness and distinctiveness guided data optimization. arXiv 2025, arXiv:2504.08820. [Google Scholar]
- Warmsley, D.; Xu, J.; Johnson, S.D. Assessing the sociocultural alignment of large language models: An empirical study of chinese-speaking populations. In Social, Cultural, and Behavioral Modeling, Proceedings of the 17th International Conference, SBP-BRiMS 2024, Pittsburgh, PA, USA, 18–20 September 2024; Springer: Cham, Switzerland, 2024; pp. 246–256. [Google Scholar]
- Ayash, L.; Alhuzali, H.; Alasmari, A.; Aloufi, S. SaudiCulture: A benchmark for evaluating large language models’ cultural competence within Saudi Arabia. J. King Saud Univ. Comput. Inf. Sci. 2025, 37, 123. [Google Scholar] [CrossRef]
- Myung, J.; Lee, N.; Zhou, Y.; Jin, J.; Putri, R.A.; Antypas, D.; Borkakoty, H.; Kim, E.; Perez-Almendros, C.; Ayele, A.A.; et al. BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages. arXiv 2025, arXiv:2406.09948. [Google Scholar]
- Naous, T.; Ryan, M.J.; Ritter, A.; Xu, W. Having Beer after Prayer? Measuring Cultural Bias in Large Language Models. arXiv 2024, arXiv:2305.14456. [Google Scholar] [CrossRef]
- Masoud, R.I.; Liu, Z.; Ferianc, M.; Treleaven, P.; Rodrigues, M. Cultural alignment in large language models: An explanatory analysis based on hofstede’s cultural dimensions. arXiv 2023, arXiv:2309.12342. [Google Scholar]
- Arora, S.; Karpinska, M.; Chen, H.T.; Bhattacharjee, I.; Iyyer, M.; Choi, E. CaLMQA: Exploring culturally specific long-form question answering across 23 languages. arXiv 2025, arXiv:2406.17761. [Google Scholar]
- Koto, F.; Mahendra, R.; Aisyah, N.; Baldwin, T. IndoCulture: Exploring Geographically-Influenced Cultural Commonsense Reasoning Across Eleven Indonesian Provinces. arXiv 2024, arXiv:2404.01854. [Google Scholar] [CrossRef]
- Santurkar, S.; Durmus, E.; Ladhak, F.; Lee, C.; Liang, P.; Hashimoto, T. Whose Opinions Do Language Models Reflect? arXiv 2023, arXiv:2303.17548. [Google Scholar] [CrossRef]
- Adilazuarda, M.F.; Mukherjee, S.; Lavania, P.; Singh, S.; Aji, A.F.; O’Neill, J.; Modi, A.; Choudhury, M. Towards Measuring and Modeling “Culture” in LLMs: A Survey. arXiv 2024, arXiv:2403.15412. [Google Scholar] [CrossRef]
- Bhatt, S.; Diaz, F. Extrinsic Evaluation of Cultural Competence in Large Language Models. arXiv 2024, arXiv:2406.11565. [Google Scholar] [CrossRef]
- Martínez-Rolán, X.; Cabezuelo-Lorenzo, F.; Oliveira, L. Los nuevos escenarios de la sociedad digital ante el desafío de la inteligencia artificial (IA) generativa. Encontros Bibli 2025, 30, e105080. [Google Scholar] [CrossRef]
- Liu, C.C.; Koto, F.; Baldwin, T.; Gurevych, I. Are Multilingual LLMs Culturally-Diverse Reasoners? An Investigation into Multicultural Proverbs and Sayings. arXiv 2024, arXiv:2309.08591. [Google Scholar] [CrossRef]
- Zhou, N.; Bamman, D.; Bleaman, I.L. Culture is Not Trivia: Sociocultural Theory for Cultural NLP. arXiv 2025, arXiv:2502.12057. [Google Scholar] [CrossRef]
- Liu, C.C.; Gurevych, I.; Korhonen, A. Culturally Aware and Adapted NLP: A Taxonomy and a Survey of the State of the Art. arXiv 2025, arXiv:2406.03930. [Google Scholar] [CrossRef]
- Shi, W.; Li, R.; Zhang, Y.; Ziems, C.; Yu, C.; Horesh, R.; de Paula, R.A.; Yang, D. CultureBank: An Online Community-Driven Knowledge Base Towards Culturally Aware Language Technologies. arXiv 2024, arXiv:2404.15238. [Google Scholar]
- Argyle, L.P.; Busby, E.C.; Fulda, N.; Gubler, J.R.; Rytting, C.; Wingate, D. Out of one, many: Using language models to simulate human samples. Polit. Anal. 2023, 31, 337–351. [Google Scholar] [CrossRef]
- Li, C.; Teney, D.; Yang, L.; Wen, Q.; Xie, X.; Wang, J. CulturePark: Boosting Cross-cultural Understanding in Large Language Models. arXiv 2024, arXiv:2405.15145. [Google Scholar]
- Feng, R.; Gao, S.; Chen, X.; Chen, L.; Shang, S. CulFiT: A Fine-grained Cultural-aware LLM Training Paradigm via Multilingual Critique Data Synthesis. arXiv 2025, arXiv:2505.19484. [Google Scholar]
- Hershcovich, D.; Frank, S.; Lent, H.; de Lhoneux, M.; Abdou, M.; Brandl, S.; Bugliarello, E.; Piqueras, L.C.; Chalkidis, I.; Cui, R.; et al. Challenges and Strategies in Cross-Cultural NLP. arXiv 2022, arXiv:2203.10020. [Google Scholar] [CrossRef]
- Sorensen, T.; Moore, J.; Fisher, J.; Gordon, M.; Mireshghallah, N.; Rytting, C.M.; Ye, A.; Jiang, L.; Lu, X.; Dziri, N.; et al. A Roadmap to Pluralistic Alignment. arXiv 2024, arXiv:2402.05070. [Google Scholar] [CrossRef]
- Ki, D.; Rudinger, R.; Zhou, T.; Carpuat, M. Multiple LLM Agents Debate for Equitable Cultural Alignment. arXiv 2025, arXiv:2505.24671. [Google Scholar] [CrossRef]
- Yadav, S.; Zhang, Z.; Hershcovich, D.; Shutova, E. Beyond Words: Exploring Cultural Value Sensitivity in Multimodal Models. arXiv 2025, arXiv:2502.14906. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22500–22510. [Google Scholar]
- Kawar, B.; Zada, S.; Lang, O.; Tov, O.; Chang, H.; Dekel, T.; Mosseri, I.; Irani, M. Imagic: Text-based real image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6007–6017. [Google Scholar]
- Avrahami, O.; Hayes, T.; Gafni, O.; Gupta, S.; Taigman, Y.; Parikh, D.; Lischinski, D.; Fried, O.; Yin, X. Spatext: Spatio-textual representation for controllable image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18370–18380. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Chefer, H.; Alaluf, Y.; Vinker, Y.; Wolf, L.; Cohen-Or, D. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Trans. Graph. (TOG) 2023, 42, 1–10. [Google Scholar] [CrossRef]
- Li, Y.; Liu, H.; Wu, Q.; Mu, F.; Yang, J.; Gao, J.; Li, C.; Lee, Y.J. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22511–22521. [Google Scholar]
- Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.Y.; Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv 2021, arXiv:2108.01073. [Google Scholar]
- Brooks, T.; Holynski, A.; Efros, A.A. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18392–18402. [Google Scholar]
- Souček, T.; Gatti, P.; Wray, M.; Laptev, I.; Damen, D.; Sivic, J. Showhowto: Generating scene-conditioned step-by-step visual instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2025; pp. 27435–27445. [Google Scholar]
- Zavadski, D.; Feiden, J.F.; Rother, C. Controlnet-xs: Designing an efficient and effective architecture for controlling text-to-image diffusion models. arXiv 2023, arXiv:2312.06573. [Google Scholar]
- Qin, C.; Zhang, S.; Yu, N.; Feng, Y.; Yang, X.; Zhou, Y.; Wang, H.; Niebles, J.C.; Xiong, C.; Savarese, S.; et al. Unicontrol: A unified diffusion model for controllable visual generation in the wild. arXiv 2023, arXiv:2305.11147. [Google Scholar] [CrossRef]
- Mou, C.; Wang, X.; Xie, L.; Wu, Y.; Zhang, J.; Qi, Z.; Shan, Y. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 4296–4304. [Google Scholar]
- Tan, Z.; Liu, S.; Yang, X.; Xue, Q.; Wang, X. Ominicontrol: Minimal and universal control for diffusion transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Honolulu, HI, USA, 19–23 October 2025; pp. 14940–14950. [Google Scholar]
- Huang, L.; Chen, D.; Liu, Y.; Shen, Y.; Zhao, D.; Zhou, J. Composer: Creative and controllable image synthesis with composable conditions. arXiv 2023, arXiv:2302.09778. [Google Scholar] [CrossRef]
- Guo, Y.; Yang, C.; Rao, A.; Liang, Z.; Wang, Y.; Qiao, Y.; Agrawala, M.; Lin, D.; Dai, B. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv 2023, arXiv:2307.04725. [Google Scholar]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar] [CrossRef]
- Qu, L.; Li, H.; Wang, T.; Wang, W.; Li, Y.; Nie, L.; Chua, T.S. TIGeR: Unifying Text-to-Image Generation and Retrieval with Large Multimodal Models. arXiv 2025, arXiv:2406.05814. [Google Scholar]
- Chen, W.; Li, L.; Yang, Y.; Wen, B.; Yang, F.; Gao, T.; Wu, Y.; Chen, L. CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 8073–8082. [Google Scholar]
- Feng, Y.; Sun, J.; Li, C.; Li, Z.; Ai, J.; Zhang, F.; Chang, Y.; Zhou, S.; Zhang, S.; Dai, Y.; et al. A High-Quality Dataset and Reliable Evaluation for Interleaved Image-Text Generation. arXiv 2025, arXiv:2506.09427. [Google Scholar]
- Lian, L.; Li, B.; Yala, A.; Darrell, T. LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models. arXiv 2024, arXiv:2305.13655. [Google Scholar]
- You, Z.; Nie, S.; Zhang, X.; Hu, J.; Zhou, J.; Lu, Z.; Wen, J.R.; Li, C. LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning. arXiv 2025, arXiv:2505.16933. [Google Scholar]
- Yu, R.; Ma, X.; Wang, X. Dimple: Discrete Diffusion Multimodal Large Language Model with Parallel Decoding. arXiv 2025, arXiv:2505.16990. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; pp. 27730–27744. [Google Scholar]
- Fan, Y.; Watkins, O.; Du, Y.; Liu, H.; Ryu, M.; Boutilier, C.; Abbeel, P.; Ghavamzadeh, M.; Lee, K.; Lee, K. DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; pp. 79858–79885. [Google Scholar]
- Kirstain, Y.; Polyak, A.; Singer, U.; Matiana, S.; Penna, J.; Levy, O. Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; pp. 36652–36663. [Google Scholar]
- Lee, K.; Liu, H.; Ryu, M.; Watkins, O.; Du, Y.; Boutilier, C.; Abbeel, P.; Ghavamzadeh, M.; Gu, S.S. Aligning Text-to-Image Models using Human Feedback. arXiv 2023, arXiv:2302.12192. [Google Scholar]
- Wallace, B.; Dang, M.; Rafailov, R.; Zhou, L.; Lou, A.; Purushwalkam, S.; Ermon, S.; Xiong, C.; Joty, S.; Naik, N. Diffusion Model Alignment Using Direct Preference Optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8228–8238. [Google Scholar]
- Wu, X.; Sun, K.; Zhu, F.; Zhao, R.; Li, H. Human Preference Score: Better Aligning Text-to-Image Models with Human Preference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 2096–2105. [Google Scholar]
- Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. Constitutional AI: Harmlessness from AI Feedback. arXiv 2022, arXiv:2212.08073. [Google Scholar] [CrossRef]
- Yu, T.; Zhang, H.; Li, Q.; Xu, Q.; Yao, Y.; Chen, D.; Lu, X.; Cui, G.; Dang, Y.; He, T.; et al. RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 19985–19995. [Google Scholar]
- Zhong, S.; Huang, Z.; Wen, W.; Qin, J.; Lin, L. SUR-adapter: Enhancing Text-to-Image Pre-trained Diffusion Models with Large Language Models. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 567–578. [Google Scholar]
- Zhang, X. AI-Assisted Restoration of Yangshao Painted Pottery Using LoRA and Stable Diffusion. Heritage 2024, 7, 6282–6309. [Google Scholar] [CrossRef]
- Qu, L.; Li, H.; Wang, W.; Liu, X.; Li, J.; Nie, L.; Chua, T.S. SILMM: Self-Improving Large Multimodal Models for Compositional Text-to-Image Generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 18497–18508. [Google Scholar]
- Kannen, N.; Ahmad, A.; Andreetto, M.; Prabhakaran, V.; Prabhu, U.; Dieng, A.B.; Bhattacharyya, P.; Dave, S. Beyond Aesthetics: Cultural Competence in Text-to-Image Models. arXiv 2025, arXiv:2407.06863. [Google Scholar]
- Lim, Y.; Shim, H. Addressing Image Hallucination in Text-to-Image Generation through Factual Image Retrieval. arXiv 2024, arXiv:2407.10683. [Google Scholar]
- Lim, Y.; Choi, H.; Shim, H. Evaluating Image Hallucination in Text-to-Image Generation with Question-Answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 26290–26298. [Google Scholar]
- Cao, Y.; Li, S.; Liu, Y.; Yan, Z.; Dai, Y.; Yu, P.S.; Sun, L. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT. arXiv 2023, arXiv:2303.04226. [Google Scholar] [CrossRef]
- Liu, J. Empowering New Cultural Program Explorations with AIGC in the Intelligent Media Era. Front. Soc. Sci. Technol. 2024, 6, 60–65. [Google Scholar] [CrossRef]
- Ramezani, A.; Xu, Y. Knowledge of cultural moral norms in large language models. arXiv 2023, arXiv:2306.01857. [Google Scholar] [CrossRef]
- Dwivedi, A.; Lavania, P.; Modi, A. EtiCor: Corpus for Analyzing LLMs for Etiquettes. arXiv 2023, arXiv:2310.18974. [Google Scholar]
- Wang, Y.; Zhu, Y.; Kong, C.; Wei, S.; Yi, X.; Xie, X.; Sang, J. CDEval: A Benchmark for Measuring the Cultural Dimensions of Large Language Models. In Proceedings of the 2nd Workshop on Cross-Cultural Considerations in NLP, Bangkok, Thailand, 16 August 2024; pp. 1–16. [Google Scholar]
- Chiu, Y.Y.; Jiang, L.; Lin, B.Y.; Park, C.Y.; Li, S.S.; Ravi, S.; Bhatia, M.; Antoniak, M.; Tsvetkov, Y.; Shwartz, V.; et al. CulturalBench: A Robust, Diverse and Challenging Benchmark for Measuring LMs’ Cultural Knowledge Through Human-AI Red-Teaming. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; pp. 25663–25701. [Google Scholar] [CrossRef]
- Liang, P.; Bommasani, R.; Lee, T.; Tsipras, D.; Soylu, D.; Yasunaga, M.; Zhang, Y.; Narayanan, D.; Wu, Y.; Kumar, A.; et al. Holistic evaluation of language models. arXiv 2022, arXiv:2211.09110. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; Duan, N. Agieval: A human-centric benchmark for evaluating foundation models. arXiv 2023, arXiv:2304.06364. [Google Scholar] [CrossRef]
- Huang, J.; Chang, K.C.C. Towards reasoning in large language models: A survey. arXiv 2022, arXiv:2212.10403. [Google Scholar]
- Saikh, T.; Ghosal, T.; Mittal, A.; Ekbal, A.; Bhattacharyya, P. Scienceqa: A novel resource for question answering on scholarly articles. Int. J. Digit. Libr. 2022, 23, 289–301. [Google Scholar] [CrossRef]
- Talmor, A.; Herzig, J.; Lourie, N.; Berant, J. Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv 2018, arXiv:1811.00937. [Google Scholar]
- Puig, X.; Ra, K.; Boben, M.; Li, J.; Wang, T.; Fidler, S.; Torralba, A. Virtualhome: Simulating household activities via programs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8494–8502. [Google Scholar]
- Srivastava, S.; Li, C.; Lingelbach, M.; Martín-Martín, R.; Xia, F.; Vainio, K.E.; Lian, Z.; Gokmen, C.; Buch, S.; Liu, K.; et al. Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 477–490. [Google Scholar]
- Zhu, X.; Chen, Y.; Tian, H.; Tao, C.; Su, W.; Yang, C.; Huang, G.; Li, B.; Lu, L.; Wang, X.; et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv 2023, arXiv:2305.17144. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar]
- Deng, Z.; Ma, W.; Han, Q.-L.; Zhou, W.; Zhu, X.; Wen, S.; Xiang, Y. Exploring DeepSeek: A Survey on Advances, Applications, Challenges and Future Directions. IEEE/CAA J. Autom. Sin. 2025, 12, 872–893. [Google Scholar] [CrossRef]
- Yang, A.; Li, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Gao, C.; Huang, C.; Lv, C.; et al. Qwen3 technical report. arXiv 2025, arXiv:2505.09388. [Google Scholar] [CrossRef]
- Comanici, G.; Bieber, E.; Schaekermann, M.; Pasupat, I.; Sachdeva, N.; Dhillon, I.; Blistein, M.; Ram, O.; Zhang, D.; Rosen, E.; et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv 2025, arXiv:2507.06261. [Google Scholar] [CrossRef]
- Hurst, A.; Lerer, A.; Goucher, A.P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.; Welihinda, A.; Hayes, A.; Radford, A.; et al. Gpt-4o system card. arXiv 2024, arXiv:2410.21276. [Google Scholar] [CrossRef]
- Anthropic. The Claude 3 Model Family: Opus, Sonnet, Haiku. Available online: https://www.google.com.hk/url?sa=t&source=web&rct=j&opi=89978449&url=https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf&ved=2ahUKEwj6jKWfnbyRAxXWyTgGHXfLFmsQFnoECA0QAQ&usg=AOvVaw3IPcOaw3w4_mjNiyMCY4x6 (accessed on 15 May 2025).
- Hart, P.E.; Stork, D.G.; Duda, R. Pattern Classification; Wiley Hoboken: Hoboken, NJ, USA, 2001. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Wang, Y.; Ma, X.; Zhang, G.; Ni, Y.; Chandra, A.; Guo, S.; Ren, W.; Arulraj, A.; He, X.; Jiang, Z.; et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024; pp. 95266–95290. [Google Scholar]
- Ghazal, A.; Rabl, T.; Hu, M.; Raab, F.; Poess, M.; Crolotte, A.; Jacobsen, H.A. Bigbench: Towards an industry standard benchmark for big data analytics. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1197–1208. [Google Scholar]
- Lin, S.Y.; Jiang, C.C.; Law, K.M.; Yeh, P.C.; Tsai, M.K.; Chou, C.L.; Wang, I.K.; Ting, I.W.; Chen, Y.W.; Chou, C.Y.; et al. Evaluation of generative AI assistance in clinical nephrology: Assessing GPT-4, GPT-4o, Gemini 1.0 Ultra, and PaLM 2 in patient interaction and renal biopsy interpretation. Digit. Health 2025, 11, 20552076251342067. [Google Scholar] [CrossRef]
- Liu, Y.; Ju, S.; Wang, J. Exploring the potential of ChatGPT in medical dialogue summarization: A study on consistency with human preferences. BMC Med. Inform. Decis. Mak. 2024, 24, 75. [Google Scholar] [CrossRef]
- Luo, J.; Yu, H.; Tan, C.; Yu, H. Enhanced Qwen-VL 7B model via instruction finetuning on Chinese medical dataset. In Proceedings of the 2024 5th International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 12–14 April 2024; pp. 526–530. [Google Scholar]
- Tel, A.; Bolognesi, F.; Michelutti, L.; Biglioli, F.; Robiony, M. Assessment of ChatGPT performance in orbital MRI reporting with multimetric evaluation of transformer based language models. Sci. Rep. 2025, 15, 35654. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q. Evaluating Uighur literary translation: A comparative study of ChatGPT, Google Translate, and Bing Translator. PLoS ONE 2025, 20, e0335261. [Google Scholar]
- Kuhn, L.; Gal, Y.; Farquhar, S. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. arXiv 2023, arXiv:2302.09664. [Google Scholar] [CrossRef]
- Farquhar, S.; Kossen, J.; Kuhn, L.; Gal, Y. Detecting hallucinations in large language models using semantic entropy. Nature 2024, 630, 625–630. [Google Scholar] [CrossRef]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Zhao, Z.; An, Q.; Liu, J. Exploring AI tool adoption in higher education: Evidence from a PLS-SEM model integrating multimodal literacy, self-efficacy, and university support. Front. Psychol. 2025, 16, 1619391. [Google Scholar] [CrossRef]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, PMLR, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Lan, X.; An, J.; Guo, Y.; Chiyou, T.; Cai, X.; Zhang, J. Imagining the Far East: Exploring Perceived Biases in AI-Generated Images of East Asian Women. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025; pp. 1–7. [Google Scholar]
- Phillips, P.J.; Jiang, F.; Narvekar, A.; Ayyad, J.; O’Toole, A.J. An other-race effect for face recognition algorithms. ACM Trans. Appl. Percept. (TAP) 2011, 8, 1–11. [Google Scholar] [CrossRef]
- Xu, Y.; Fang, X.; Li, X.; Yang, J.; You, J.; Liu, H.; Teng, S. Data uncertainty in face recognition. IEEE Trans. Cybern. 2014, 44, 1950–1961. [Google Scholar] [CrossRef]
- Graesser, A.C.; Singer, M.; Trabasso, T. Constructing inferences during narrative text comprehension. Psychol. Rev. 1994, 101, 371. [Google Scholar] [CrossRef]
- Zwaan, R.A.; Radvansky, G.A. Situation models in language comprehension and memory. Psychol. Bull. 1998, 123, 162. [Google Scholar] [CrossRef]
- Horton, W.S.; Rapp, D.N. Out of sight, out of mind: Occlusion and the accessibility of information in narrative comprehension. Psychon. Bull. Rev. 2003, 10, 104–110. [Google Scholar] [CrossRef]
- Dawkins, R. The Extended Selfish Gene; Oxford University Press: Oxford, UK, 2016. [Google Scholar]
- Wei, X.; Chu, X.; Geng, J.; Wang, Y.; Wang, P.; Wang, H.; Wang, C.; Lei, L. Societal impacts of chatbot and mitigation strategies for negative impacts: A large-scale qualitative survey of ChatGPT users. Technol. Soc. 2024, 77, 102566. [Google Scholar] [CrossRef]
- Fransecky, R.B.; Debes, J.L. Visual Literacy: A Way to Learn—A Way to Teach; Association for Educational Communications and Technology: Washington, DC, USA, 1972. [Google Scholar]
- Stokes, S. Visual literacy in teaching and learning: A literature perspective. Electron. J. Integr. Technol. Educ. 2002, 1, 10–19. [Google Scholar]
- Rettberg, J.W. Machine Vision: How Algorithms Are Changing the Way We See the World; John Wiley & Sons: Hoboken, NJ, USA, 2023. [Google Scholar]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.