Abstract
Aiming at the problems of misdetection, leakage, and low recognition accuracy caused by numerous surface defects and complex backgrounds of laser nozzles, this paper proposes DEC-YOLO, a novel detection model centered on the DEC Module (DenseNet-explicit visual center composite module). The DEC Module, as the core innovation, combines the dense connectivity of DenseNet with the local–global feature integration capability of the explicit visual center (EVC) to enhance gradient propagation stability during the training process and enhance fundamental defect feature extraction. To further optimize detection performance, three auxiliary strategies are introduced: (1) a head decoupling strategy to separate classification and regression tasks, (2) cross-layer connections for multi-scale feature fusion, and (3) coordinate attention to suppress background interference. The experimental results on a custom dataset demonstrate that DEC-YOLO achieves a mean average precision (mAP@0.5) of 87.5%, surpassing that of YOLOv7 by 10.5%, and meets the accuracy and speed requirements needed in the laser cutting production environment.
1. Introduction
Laser cutting technology forms a core component of the laser industry, and its processing accuracy and operating efficiency have a decisive influence on the quality of workpieces and production efficiency. The role of auxiliary gases is crucial in laser cutting operations. These gases are discharged through a nozzle at the front of the cutting head and form a high-speed stream within the nozzles [1]. This airflow not only helps to quickly remove molten material, ensuring a smoother cutting surface, but also effectively cools the cutting area, limiting the expansion of the heat-affected zone. The shape of the nozzles and the characteristics of the resulting flow field are, therefore, decisive for the efficiency of laser cutting. Small defects in the nozzles may lead to the uneven distribution of airflow, which, in turn, affects the quality of the cut, or even causes scattering of the laser beam, thus reducing the cutting efficiency. Therefore, it is vital that the quality and integrity of the nozzles be strictly monitored and tested during the production process. Defect detection on the nozzle surface is a critical part of ensuring the quality of the final product, and this includes the identification of minor defects such as surface cracks, dents, scratches and other defects that occur on the surface of the nozzles during the manufacturing process.
In the current industrial production system, the surface defect detection of the laser nozzles is still based on manual visual inspection. As the modern manufacturing production rhythm continues to improve, the limitations of the traditional manual inspection mode are increasingly prominent, with the low detection efficiency and high misjudgment rate, detection rate, and production line speed leading to a significant mismatch. At the same time, the detection results are easily affected by the operator’s subjective experience differences and physiological fatigue, resulting in the unreliability of the inspection system and the fact that it is difficult to meet the needs of intelligent manufacturing in real-time. With the synergistic development of artificial intelligence technology and computer hardware performance, deep learning-based defect detection techniques offer new solutions. By designing a deep neural network architecture and implementing iterative training and parameter optimization, these algorithms can autonomously complete multi-level feature extraction and characterization, learning to achieve high-precision defect recognition. Analyzed at the algorithmic architectural level, these algorithms can be classified into two-stage detection algorithms and single-stage detection algorithms depending on whether they have explicit region suggestions or not. The two-stage detection algorithm adopts the cascade processing mechanism of ‘candidate box generation + classification regression’, typically represented by Faster R-CNN [2], which first generates a proposal of the potential target region, and then carries out fine classification and bounding box regression. Single-stage detection algorithms, such as the YOLO series [3,4,5,6,7,8,9] and SSD [10], on the other hand, adopt an end-to-end processing paradigm to implement multi-scale classification and localization regression directly on the feature map, which effectively improves the detection efficiency. The YOLO series achieved remarkable success in industrial applications due to its balance between computational efficiency and detection accuracy. Derived from YOLOv5 [5], which introduced modular architecture design and PyTorch-based deployment optimization, subsequent iterations have systematically enhanced model performance for industrial scenarios. YOLOv8 [7] expanded its applicability by integrating multi-task capabilities, including instance segmentation and pose estimation, while maintaining real-time inference speeds critical for assembly-line quality inspection and robotic vision systems. The latest iterations, YOLOv11 [8] and YOLOv12 [9], further optimize industrial adaptability through lightweight network architectures and advanced training strategies. These innovations reduce computational overhead by 18–25% compared to earlier versions, enabling seamless deployment on edge devices such as drones and embedded controllers. In addition, DETR (DEtection TRansformer) [11] excels in long-range dependency modeling through end-to-end design.
In order to adapt to the fast pace of production, designing a defect detection method applicable to surface defects of the laser nozzles is an important research topic. Defect detection on the surface of the laser nozzles has the following main difficulties: (1) the lack of defect detection datasets, based on this scene, only a small number of samples, and the number of samples of various defects not being balanced, which increases the difficulty of training; (2) the defects of the complex form of the defects, the defects of a large scale span, the existence of many small targets (micro-defects), and the feature extraction network making it easy to lose the localization information of the small targets after downsampling, resulting in unsatisfactory detection results; and (3) the complexity of the background of the nozzles in this application scenario having a great interference with the detection, which leads to unsatisfactory detection results.
In this paper, a new model for detecting surface defects on the laser nozzles is proposed by introducing DEC module, cross-layer connection, head decoupling strategy, and coordinate attention with YOLOv7 as the main network. The new model, named DEC-YOLO, can accurately and quickly identify the surface defects of the nozzles, which helps to realize the intelligence of the defect detection of the nozzles. The main contributions of this study are as follows.
- (1)
- The DEC module was constructed based on the ideas of DenseNet and the explicit vision center (EVC) to enhance the extraction of basic information.
- (2)
- Two effective measures are proposed to improve the performance of YOLOv7. Cross-layer connection is used to achieve the fusion of feature information between shallow and deep networks, and coordinate attention is used to reduce the interference of background information.
- (3)
- The head decoupling strategy is devised to process the classification and regression tasks separately, which further improves the effectiveness of feature extraction.
- (4)
- By acquiring and processing images of different laser cutting heads in different scenarios, a dataset of surface defects on the laser nozzles containing three kinds of defects, namely, scratch, uneven surface, and contour damage, has been constructed to make up for the gap of commercially available data. This dataset is used to train and evaluate the DEC-YOLO algorithm.
2. Related Work
2.1. Defect Detection
The laser nozzle surface defect detection field has not yet formed a systematic research system, but in the field of industrial appearance inspection and defective product detection have emerged a number of relocatable technological breakthroughs. For example, laser nozzle surface defect detection shows good generalization ability in scenarios such as steel surface defects detection, tile surface defects detection, bridge surface defects detection, etc., and its technology paradigm can be migrated to nozzle surface defects detection tasks. In the application of two-stage detection algorithms, Akhyar et al. [12] developed a flexible detection framework for metal surface defects (FDD), which significantly enhances the model’s characterization capability for geometrically deformed defects through the integration of deformable convolutional networks (DCN) and deformable region of interest (RoI) pooling modules. This technical improvement effectively addresses the challenges posed by irregular defect morphologies in industrial inspection scenarios. The guided anchoring method proposed in this study significantly enhances detection accuracy on benchmark datasets including NEU-DET through probability density modeling-optimized region proposal generation. Zhao et al. [13] designed a multi-scale feature fusion strategy by reconfiguring the feature extraction network architecture of faster R-CNN, and the mean average precision of small target detection on steel surface defects dataset is 74.2%, which is 12.8% higher than that of the baseline model. Chen et al. [14] developed an improved faster R-CNN algorithm for aluminum alloy surface micro-defects, which successfully improves the recognition accuracy of micro-cracks by integrating global semantic information through context-aware RoI pooling.
The two-stage target detection algorithm achieves high detection accuracy through a cascaded network architecture, but its complex region suggestion mechanism leads to computational redundancy, which makes it difficult to meet the actual demand for real-time performance in industrial inspection. In contrast, the single-stage detector, with its end-to-end optimization strategy, offers significant advantages in terms of detection efficiency and is more suitable for high-speed production line scenarios. In 2015, Redmon et al. [15] proposed the first deep learning-based single-stage target detector YOLO (you only look once), the one-shot forward inference mechanism of which enables the detection speed to break the real-time threshold, but suffers from the defects of small target leakage and insufficient localization accuracy. In recent years, scholars have made multi-dimensional improvements to the YOLO series for industrial defect detection characteristics. Zhang et al. [16] introduced a transfer learning strategy in bridge defect detection, which, combined with the focal loss function, effectively mitigated the sample imbalance problem. For the morphological diversity of aluminum profile surface defects, the AM-YOLOv3 network developed by Sun et al. [17] innovatively integrates the channel attention module to achieve the multi-scale feature extraction of aluminum profile surface defects, and optimizes the distribution of the anchor frame parameters by using the k-medians algorithm, which improves the convergence speed of the network, and the mean value of the detection accuracy is also improved. Jiangyun Li et al. [18] constructed a deep network architecture containing 27 convolutional layers to achieve the precise location and size quantitative analysis of steel defects, which provides an important technical support for the quality control of the continuous casting and rolling process. Wan et al. [19] added a dedicated small target detection layer in YOLOv5s to effectively alleviate the problem of missing feature information for micro-defects on tile surfaces through a feature pyramid expansion strategy. The YOLOv5s-keb model proposed by Li et al. [20] integrates the ECA attention module with the BiFPN feature pyramid, combined with the k-means++ anchor frame optimization algorithm, to achieve a balance between detection accuracy and model efficiency.
With the iterative upgrading of algorithms, the new generation of YOLO framework shows stronger industrial adaptability. Wang et al. [21] innovatively fused the YOLOv6 detector with Canny–Devernay sub-pixel analysis technology to achieve a dimensional measurement accuracy of 0.12 mm in the inspection of lock parts. For the characteristics of steel surface defects, Wang et al. [22] introduced a decoupled weighted BiFPN structure in YOLOv7, which makes full use of the feature information to improve the detection accuracy through a dynamic feature re-weighting mechanism, and optimizes the loss function to achieve faster and better performance. The EFC-YOLO network designed by Li et al. [20] enhances the feature extraction capability by adding an improved fusion-faster module. At the same time, the SCA attention mechanism is introduced to better capture the positional information dependence, and the de-weighted bidirectional feature pyramid network structure is adopted to increase the branching of the fusion step and reduce the computation to achieve better positional information capture and feature fusion, which achieves better detection accuracy with less computation. Qi et al. [23] optimized the activation function combination of YOLOv7-tiny by the neural architecture search technique to improve the model feature extraction capability by introducing an attention mechanism and optimizing the activation function in the steel micro-defect detection task, and optimized the model lightweight performance using lightweight operators. The CSW-YOLOv7 model proposed by Xu et al. [24] fuses the global modeling capability of the CotNet transformer with the SimAM attention mechanism, together with the WIoUv3 loss function, to improve the accuracy of the model faster. The TI-YOLOv7 algorithm proposed by Xie et al. [25] employs the transformer inception module to enhance local feature extraction capability, combined with MPDIoU metric function makes the model performance has been improved to provide a new solution for complex industrial scenarios. The MSG-YOLO proposed by Li et al. [26] achieves multi-scale contextual feature capture and key region response enhancement by designing a multi-scale dynamic grouping channel-enhanced convolutional module, which combines joint channel–space attention and a dynamic grouping strategy to optimize feature reorganization, and improves mAP by 2.2% over YOLOv9 on a customized dataset under a lightweight design. Wang et al. [27] proposed the YOLO-WAD model, which expands the receptive field by introducing C2f-WTConv to enhance small-target defect feature extraction, combines the ASF structure with C2f-EMA to optimize the multi-scale feature fusion and weight assignment, and employs the DyHead detection head to enhance the classification and localization capability, achieving an overall detection accuracy of 95.6% on the self-constructed dataset. The FMV-YOLO proposed by He et al. [28] addresses the difficulty of achieving fine-grained feature recognition and small defect localization in industrial environments by integrating an adaptive fine-grained channel attention (FCA) module for efficient defect recognition, a multi-scale attention fusion (MSAF) with normalized Wasserstein distance loss for accurate small defect localization, and a lightweight VoV-GSCSP neck.
The above methods are of great significance for the study of the surface defect detection of laser nozzles, but applied to this scenario, most algorithms have low detection accuracy due to insufficient feature extraction and poor feature fusion capability, as well as slow detection speed due to increased model complexity or the introduction of complex computation. Since YOLOv7 [29] has shown high accuracy and fast detection speed in many defect detection tasks, and has some stability in real production applications, in order to meet the real-time and accuracy requirements of laser nozzle detection and to achieve a good balance between detection speed and accuracy, we choose YOLOv7 as the improved baseline model.
2.2. YOLOv7 Algorithm
As a representative of the third generation of single-stage detectors, YOLOv7 [29] achieves the optimization of detection accuracy and inference speed through a modular architecture. The network architecture adopts a four-stage cascaded design: The input preprocessing module optimizes zero-padding ratios through adaptive image scaling technology to enhance computational efficiency. The backbone integrates composite convolution blocks (CBS), efficient layer aggregation networks (ELAN), and max-pooling convolutional layers (MPConv) to construct a multi-scale feature pyramid with enhanced representational capacity. The neck implements an enhanced path aggregation network (PANet) for hierarchical feature fusion. The detection head employs re-parameterization techniques to achieve task-decoupled prediction while maintaining parameter efficiency. This systematic architecture ensures coordinated optimization across preprocessing, feature extraction, multi-scale fusion, and prediction subsystems, particularly effective for detecting micro-defects in high-resolution industrial images.
In the backbone network design, the CBS module achieves nonlinear feature enhancement through the convolution (Conv)-batch normalization (BN)-shaped linear unit (SiLU) tertiary cascade structure, which improves the feature representation capability over the traditional ReLU activation function. The ELAN module enhances the learning capability of the network by constructing cross-layer constant connections to form a multi-branch gradient propagation path. The MPConv layer fuses maximum pooling with depth-separable convolution to reduce computational complexity while maintaining the sensory field. The spatial pyramid pooling cross-stage partial connectivity module (SPPCSP) integrated at the end of the network optimizes the feature extraction process, reduces computation, and expands the receptive field by fusing global context information through multi-scale residual connections. The feature fusion layer adopts a two-stream pyramid architecture to achieve cross-scale interaction between deep semantic information and shallow texture features through top-down and bottom-up bidirectional feature fusion mechanisms. The detection head part introduces a structural reparameterization technique to transform the multi-branch convolution in the training phase into a single convolutional kernel in the inference phase to achieve a balance between speed and accuracy in the training process. The design performs confidence prediction, category determination, and bounding box regression on the {20 × 20, 40 × 40, and 80 × 80} three-scale feature maps output from PANet, respectively, and finally decouples the detection parameters by convolution.
3. Methods
The ELAN module improves the learning ability of the network without destroying the original gradient path, but it is based only on the traditional convolution operation, which can only capture local information and is susceptible to redundant features. Therefore, we developed the DEC module based on the DenseNet block [30] and the explicit vision center (EVC) module [31] and applied it after the ELAN module connected to the detection head. The DEC module complements the extracted feature information, enhances the extraction of basic information, and achieves the effective use of computational resources and high accuracy. Meanwhile, in order to enhance YOLOv7’s understanding of global and local information, we performed a cross-layer connection based on the idea of BiFPN [32] by tensor splicing the shallow feature maps in the backbone part with the deep feature maps in the PAN structure. Through the decoupling strategy [33] of the head design, the classification and regression tasks are processed separately, further enhancing the effect of feature extraction. Finally, the coordinate attention [34] is embedded into the YOLOv7 backbone network to suppress the background information interference and strengthen the defective features. Figure 1 illustrates the structure of DEC-YOLO.
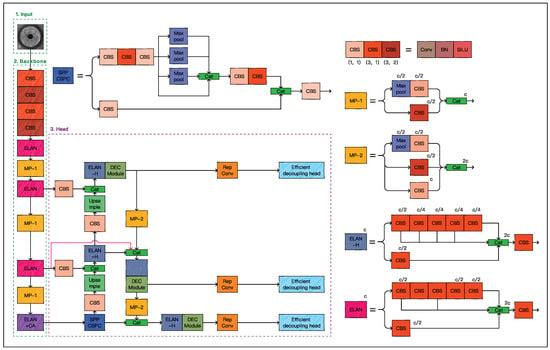
Figure 1.
Structure of DEC-YOLO.
3.1. DEC Module
Based on the ideas of DenseNet and the explicit visual center module, we developed the DEC module. The DEC module consists of three parallel connected DenseNet module, lightweight multilayer perceptron (MLP) and learning visual center (LVC) components, which significantly enhances the utilization of local and global information, enabling the model to capture and utilize key details and the overall layout of the image more effectively. It also effectively enhances gradient propagation stability during the training process, promotes the efficient transfer of features in the network, and further improves the feature extraction capability of the model. The channel scaling mechanism in the DEC module enhances feature discriminability through a dynamic attention-based strategy. It operates in three stages. (1) Global context aggregation: Spatial information is compressed via global average pooling (GAP) to generate channel-wise statistics. (2) Attention weight generation: A lightweight two-layer MLP with a bottleneck structure (compression ratio ) produces channel-specific attention weights, activated by ReLU and Sigmoid functions. (3) Feature recalibration: Original features are adaptively scaled by these weights through channel-wise multiplication, emphasizing critical channels while suppressing noise. Figure 2 shows the specific structure of the DEC module in detail. With this design, we expect YOLOv7 to achieve more accurate target detection in complex scenes.
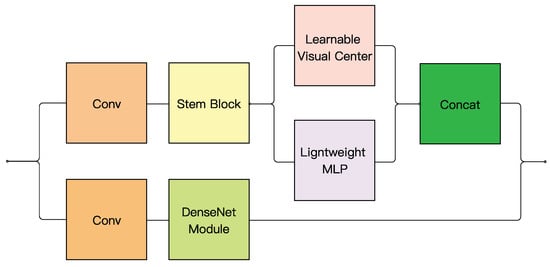
Figure 2.
Structure of DEC module.
Specifically speaking, the DenseNet module in the DEC block is introduced to enhance gradient propagation stability during the training process and enhance feature propagation through dense cross-layer connections. Unlike the ELAN module, which focuses on constructing multi-branch gradient paths for local feature learning, the DenseNet module explicitly promotes hierarchical feature reuse by concatenating outputs from all preceding layers. This design ensures that both low-level texture details (critical for small defect localization) and high-level semantic information are preserved and fused adaptively. Additionally, the dense connectivity mitigates information loss during downsampling operations, which is particularly vital for detecting micro-defects in complex nozzle backgrounds. The parallel integration of the DenseNet module, lightweight MLP, and LVC components allows the DEC module to synergize local feature reinforcement (via DenseNet block) and global dependency modeling (via lightweight MLP and LVC), thereby addressing the limitations of ELAN in capturing long-range contextual relationships.
The DenseNet module is improved based on the idea of a dense block, and the structure is shown in Figure 3. The network consists of a dense block and a branch that has been processed by the underlying convolutional module. Each of the layers in the dense block takes additional input from all previous layers and passes its own feature mapping to all subsequent layers.
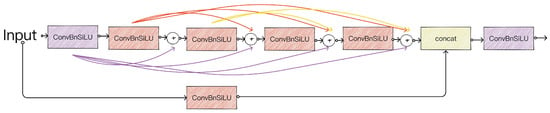
Figure 3.
Structure of DenseNet module.
This transfer is based on a concatenation strategy, meaning that each layer receives and integrates the ‘collective knowledge’ from the previous layers. For a DenseNet network with N-th layers, the total number of connections increases significantly, and if a dense block contains N convolutional layers, the output of the N-th layer can be expressed as follows:
In the formula, denotes the nonlinear operation of the N-th layer, and denotes the operation of splicing all the outputs before the N-th layer by feature channel dimension. Finally, the outputs of the main branch and the added branches are concatenated by the concat operation to achieve the deep fusion of features, which further enhances the generalization ability and feature transfer efficiency of the model.
The lightweight MLP is responsible for capturing the global long-range dependencies of the image, while LVC focuses on processing and enhancing the local edge region information of the image. Before both, a stem module performs feature smoothing. The stem module contains a convolution with the number of output channels set to 256, followed by a batch normalization layer and an activation function layer. The specific structure is shown in Figure 4.
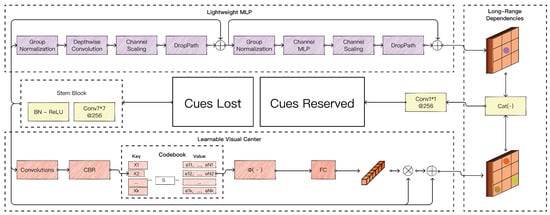
Figure 4.
Structure of explicit visual center.
The lightweight MLP architecture contains two residual modules, a depthwise convolution layer and a channel MLP module, as illustrated in Figure 5. The depthwise convolution module groups the input features along the channel dimension and extracts spatial features using a 1 × 1 depthwise convolution layer (DConv). This design reduces computational overhead while maintaining feature representation capabilities. Subsequently, the features undergo channel scaling and DropPath regularization, followed by residual concatenation. The channel MLP module further processes the features by applying group normalization (GN) and channel-wise MLP (CMLP) operations. The above process can be summarized as:

Figure 5.
Structure of lightweight MLP.
In the formula, is the output of the depthwise convolution layer, is the group normalization, and is a depthwise convolution with the kernel size of .
For the channel MLP module, the output of the previous steps is first group normalized and subsequently fed into the channel MLP for further processing. After channel MLP processing, the features are sequentially processed through channel scaling and DropPath regularization, and finally, the output is obtained through residual concatenation. This process can be summarized as follows:
where is the channel MLP.
The lightweight MLP is designed to model global dependencies through channel-wise operations. As illustrated in Figure 5, the architecture comprises two cascaded fully connected (FC) layers applied along the channel dimension. For an input feature map (), the first FC layer compresses the channel dimension to (compression ratio ) followed by a ReLU activation to introduce nonlinearity. The second FC layer restores the channel dimension to C without activation to preserve linearity for residual learning. This design ensures parameter efficiency (32,768 trainable units: ) while effectively capturing cross-channel interactions. Mathematically, the channel MLP is formulated as
where and denote learnable weights, and are bias terms.
For the LVC module, its structural design includes a built-in codebook, structured as in Figure 6, which consists of a series of code words, each representing a feature prototype. In addition, the LVC module is equipped with a set of scaling factors, S, for adjusting the strength of the association between features and code words. The codebook in the LVC module consists of learnable feature prototypes, initialized randomly and optimized end-to-end during training. Each codeword is a trainable vector with the same dimension as the encoded features, evolving through backpropagation to represent distinct semantic patterns in the feature space. The scaling factors are also learnable parameters initialized via Xavier initialization, which adaptively adjust the association strength between encoded features and codewords. The codebook and scaling factors are integrated into the end-to-end training framework, updated via gradient descent along with other network parameters. This design allows the model to dynamically discover and emphasize critical local regions (e.g., corners or edges) without relying on pre-defined priors. For features originating from the stem module, they are first processed through a series of convolutional layers, a batch normalization layer, and a ReLU activation module for feature encoding. Subsequently, these encoded features are mapped into the inbuilt codebook. This process involves comparing and correlating the encoded features with each code word in the codebook, aiming to identify the code words in the codebook to which each local feature is most similar. In order to achieve an adjustment in the degree of association between the feature and the codebook code words, appropriate scaling factors are applied. These factors enhance or diminish the intensity of the features corresponding to a particular code word, thus allowing the model to focus more on key local areas in the image. Depending on the degree of match with the codebook and the adjustment of the scaling factors, the features are reintegrated and output. Ultimately, these features are combined with the lightweight MLP through the concat operation and channel adjustments to obtain the final output.

Figure 6.
Structure of learning visual center.
The output feature maps of lightweight MLP and LVC fused by channel splicing can be represented as
In the formula, X is the output of the EVC and denotes the feature map splicing along the channel dimension. and denote the output features of the lightweight MLP and LVC used respectively. is the output of the stem block, which is obtained from the following formula:
In the formula, is the top feature of the feature pyramid, denotes the convolution with step size 1, denotes the batch normalization layer, and denotes the ReLU activation function.
3.2. Cross-Layer Connection
Given the tiny size of some of the defects present on the surface of the laser nozzles, there is a relative scarcity of their corresponding number of pixels. As the number of layers in the convolutional neural network increases, the convolution operation extracts and processes feature information more and more deeply. As a result, the features of defects with small sizes are easily ignored or lost, which makes it difficult to accurately capture such defects during the detection process, resulting in low detection accuracy. YOLOv7 fuses the structure of the FPN (feature pyramid network) and the PAN (path aggregation network) by constructing top-down and bottom-up paths combined with three different sizes of detection heads for output. This design enables the deep feature map to fuse both high-level and low-level semantic information, which, in turn, improves the detection accuracy of multi-scale targets. However, significant loss of low-level semantic information may occur during the up-sampling process, which adversely affects the recognition and localization of defects. In order to retain the critical low-level semantic information and achieve accurate localization of small-size defect locations, we borrowed the idea of BiFPN and introduced cross-layer connection. The exact structure is shown in Figure 1, and we denote this process with a thick red line. Specifically, we tensor splice the shallow feature maps in the backbone part with the deep feature maps in the PAN structure according to the size of the feature maps, so that the deep feature maps can fully incorporate the information of the shallow features. This improvement effectively incorporates low-level semantic information such as edges and contours into the PAN structure without significantly increasing the number of parameters, which not only enhances the model’s ability to recognize small-sized targets, but also improves the accuracy and stability of detection. By introducing a cross-layer connection strategy, our model significantly enhances the detection of small-size defects while preserving low-level semantic information. This provides an effective solution for the detection of surface defects on laser nozzles.
3.3. Efficient Decoupling Head
In the field of defect detection, classification and regression tasks are typically implemented through feature-sharing strategies for joint prediction. However, the divergence in optimization objectives between these tasks often leads to task conflicts, adversely affecting detection performance. To solve this problem, GE et al. [27] proposed a decoupled detection head mechanism, which constructs independent branches for the classification and localization tasks, and effectively mitigates inter-task interference. The specific structure is shown in Figure 7.
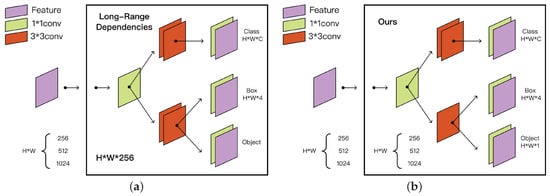
Figure 7.
Structure of decoupling head and efficient decoupling head. (a) Structure of decoupling head. (b) Structure of efficient decoupling head.
While task separation in decoupled heads improves prediction accuracy, their multi-branch design significantly increases model complexity: (1) Independent network modules double parameter counts, exacerbating training resource consumption; and (2) parallel computation paths prolong inference latency. To balance model performance and computational efficiency, this study proposes a lightweight decoupled head structure based on a hybrid channel strategy. As shown in Figure 7, the structure combines a single convolutional layer with dual convolutional layers in parallel. The output channels of the REP module are also compressed to reduce the computational overhead without affecting the characterization capability. Furthermore, an anchor-free mechanism is introduced to simplify the prediction decoding process: Dynamic candidate box generation replaces predefined anchor parameters, reducing the design complexity and optimizing post-processing steps, thereby accelerating the inference speed.
3.4. Coordinate Attention
Experimental studies have shown that the detection model based on the YOLOv7 architecture suffers from the limitation of insufficient feature extraction capability in the task of detecting surface defects on the laser nozzles. The traditional network structure is difficult to effectively capture the key defect features in the target area, and this deficiency leads to a significant decrease in the detection accuracy of the model in complex industrial scenarios, resulting in leakage detection phenomena. Therefore, we introduce a coordinate attention (CA) after the fourth ELAN module of the YOLOv7 backbone to enhance the feature characterization capability of the network. This attention mechanism can accurately locate the spatial position information of the target object by simultaneously modeling inter-channel dependencies and spatial orientation perception. The structure of the CA attention mechanism is shown in Figure 8. The CA attention mechanism first encodes the coordinate information of the input feature maps along the horizontal and vertical directions to establish long-range spatial dependencies. Then, it realizes cross-channel interaction through nonlinear transformation and, finally, generates feature maps with spatial-channel synergistic attention. This bi-directional attention mechanism effectively solves the shortcomings of traditional convolutional operations in global context modeling, and enables the network to more accurately focus on the morphological features of the defects on the surface of the laser nozzles.
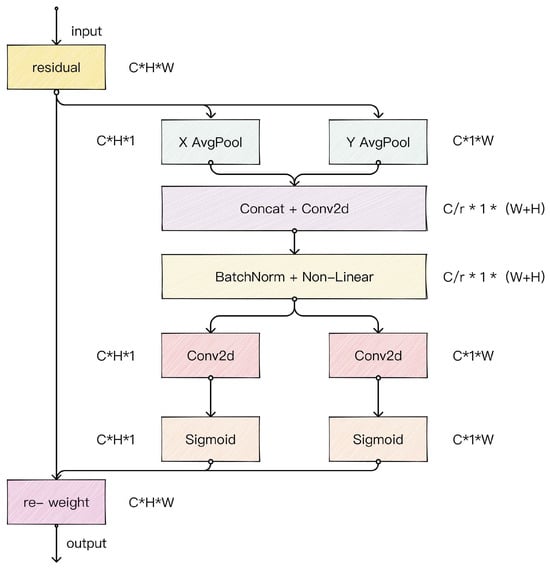
Figure 8.
Structure of coordinate attention.
The input X is decomposed into a one-dimensional feature code in horizontal and vertical coordinates by global pooling through a pooling layer of dimensions and with the following process expression:
In the formula, and denote the two components of the input feature map channel c with coordinates and , respectively. and denote the component of the c-th channel with length h and width w, respectively. In this way, feature fusion along two spatial directions results in a pair of feature maps with directional information. The network module can not only satisfy the long-range dependency in one spatial direction, but it can also retain the position information along the other spatial direction. The intermediate feature maps of the spatial information in the horizontal and vertical directions are obtained by dimensionality reduction of the channel through the shared convolution, which is expressed as follows:
In the formula, represents the convolution operation, represents the ReLU activation function, and f denotes the intermediate feature mapping that encodes the spatial information in the horizontal and vertical directions. Afterwards, it is divided into two separate tensors along the spatial dimension to obtain two attention weight values by convolution and Sigmoid activation function. Finally, the weights are combined with the inputs to obtain an attention-enhanced feature map. The above process can be expressed as
In the formula, and denote the attentional weight values in both directions. denotes the Sigmoid activation function. and denote the convolution. denotes the input feature map. and denote the attentional weight values in both directions.
4. Results and Discussion
4.1. Dataset
4.1.1. Data Collection
In this paper, the laser nozzles of the laser cutting machine in the production workshop of Han’s Smart Control Technology Co. are used as an experimental research object. We took 250 images of different damaged nozzles with an industrial camera at the production site as a data source for nozzle defect detection. We collected RGB images of surface defects of three types of laser nozzles, as shown in Table 1, and constructed a dataset of surface defects of laser nozzles.

Table 1.
Information on the dataset of surface defects on the laser nozzles.
The dataset covers three types of defects containing uneven surfaces, scratches, and contour damage taken at different shooting angles and distances. The images in the dataset have the following characteristics: (1) The image resolution is , and (2) there are some complex background factors in the images, such as occlusion, overlap, and blurring. The dataset has 250 images of laser nozzles, which are divided into a training set, validation set, and test set in the ratio of 7:1.5:1.5. The training set is used to train the models, the validation set is used to determine if the training results are optimal, and the test set is used to test and compare the detection performance of each model. All datasets are stored in JPG format.
4.1.2. Data Augmentation
In order to improve the generalization performance and robustness of the model, we implement a comprehensive data enhancement strategy for the dataset, aiming at adapting to diversified training needs, so as to extract image features more effectively, avoid the risk of overfitting, and effectively cope with complex and changing scenarios in real-world environments. Specifically, eight different data enhancement techniques were used to augment the original dataset: random rotation over a range of (−45° to +45°, random contrast adjustment, panning transformation, image flipping, miscut transformation, HSV color space enhancement, addition of Gaussian noise, and brightness adjustment. Among them, random contrast adjustment and HSV color space enhancement are designed to mitigate brightness inconsistencies caused by changing ambient lighting conditions or sensor differences. The translation and miscut transformations simulate the phenomenon of object occlusion by randomly selecting a number of fixed-size square regions and filling them with zero pixel values, which enhances the model’s ability to adapt to such situations. Random rotation and image flipping techniques are used to increase the orientation diversity of the image, allowing the model to recognize targets at different angles. Adding Gaussian noise and brightness adjustments simulates image degradation processes such as background blurring or differences in photo quality, which improves the model’s ability to optimize for such image degradation. With these combined data enhancements, we expect to significantly improve the performance of the model in real-world applications.
The final training set contains 2250 images for defect detection, including 2000 enhanced images and 250 original images, with no overlap between the training and test sets. A portion of the enhanced images is shown in Figure 9. We use Labelling (V version 1.8.6) as the labelling software. The label box is rectangular, and the label name is in English. In accordance with the targeted detection dataset YOLO format, we first set up the working directory and the defect categories, named scratch, uneven surface, and contour damage, respectively. Then, we select the rectangular box to select the defect range with its corresponding defect category in turn. After confirming, the YOLO format file is generated automatically. Information on the dataset of surface defects on the laser nozzles after data enhancement is provided in Table 2.
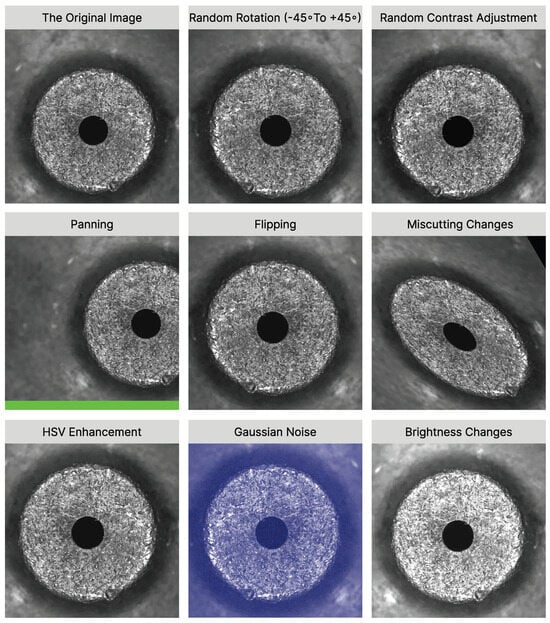
Figure 9.
The original image and the image after random rotation (−45° to +45°), random contrast adjustment, panning, flipping, miscutting changes, HSV enhancement, Gaussian noise, and brightness changes, respectively.
Table 2.
Information on the data set of surface defects on the laser nozzles after data enhancement.
In the process of optimizing the model training, we introduce the mosaic data enhancement strategy in the YOLO network, aiming to expand the image dataset in a specific way, and then enrich the learning content of the network, as shown in Figure 10.
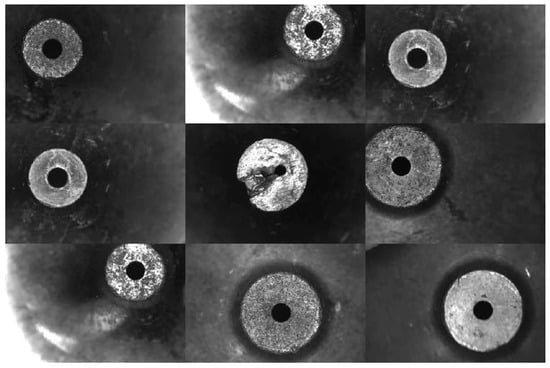
Figure 10.
Nine images stitched together after mosaic data are enhanced.
The specific data processing and enhancement process is described as follows. In the initial phase of model training, we randomly crop and merge nine images into one image. This approach not only significantly increases the size of the dataset, but also provides the model with more diverse learning material. To further enhance the quality of the input image, we adjusted the values of the HSV color space, specifically, setting the hue, saturation, and luminance to 0.015, 0.7, and 0.4, respectively. This adjustment aims to optimize the visual features of the image while effectively mitigating the adverse effects of occlusions, light variations, and shadows on target detection. To further increase the diversity of the data, we used a stochastic scaling technique to resize the images with a scale factor of 0.8 and applied an image flipping strategy where each image was flipped horizontally or vertically with a 50% probability. We perform a stitching operation on the nine images that have been pre-processed as described above, extracting fixed regions from each image and organizing these regions into a matrix form that combines them into a completely new image. In this process, special care is taken to ensure effective fusion of the image with the target frame to keep the labelling information of the data intact. Through the above method, we successfully achieve the diversified processing of the background of the detected objects, which not only enhances the model’s ability to adapt to complex scenes but also significantly improves its generalization ability.
4.2. Experiments
The training environment for all models in this study was an RTX 4090 graphics card. During model training, the batch size, learning rate, and epoch were set to 8, 0.001, and 200, respectively. The backbone network of DEC-YOLO is based on the original architecture of YOLOv7, with weights initialized using a pre-trained model on the ImageNet dataset. We retained the low-level features learned by the pre-trained model for general object detection tasks and performed end-to-end fine-tuning for the laser nozzle surface defect detection task. Specifically, all parameters of the pre-trained layers were optimized through backpropagation, with no layers frozen. The parameters of newly added modules were initialized using the He normal distribution.
In this section, we focus on the details of the evaluation metrics and experiments. By making a series of improvements to the baseline model, we performed the surface defect detection of the laser nozzles based on DEC-YOLO. Table 3, Table 4, Table 5 and Table 6 summarizes the detection results of the different experiments, culminating in a mAP@0.5 of 87.5% for DEC-YOLO.
Table 3.
Results of ablation experiments with different strategies.
Table 4.
Experimental results of models using efficient decoupling head, decoupling head, and original coupling head.
Table 5.
Comparison experiment of different attention mechanism. (YOLO * represents the model after the introduction of DEC module, Cross-Layer Connection and Efficient Decoupling Head).
Table 6.
Comparative experimental results of different models.
4.2.1. Evaluation Index
In this paper, in order to evaluate the detection accuracy of the model, the three main parameters P (precision), R (recall), and (mean average precision) are used.
The calculation of precision and recall is as follows:
In the formula, represents the number of accurately detected targets, represents the number of incorrectly identified targets, and represents the number of undetected targets. In addition, P represents the proportion of correctly predicted positive samples out of all predicted positive instances, while R represents the proportion of accurately predicted positive samples out of all actual positive instances. The F1-score is the reconciled average of precision and recall. A larger F1-score indicates a higher-quality model.
The calculation of mAP (mean average precision) is summarized below:
In the above formula, N denotes the total number of categories to be categorized. (average precision) denotes the average precision for a particular target category, calculated by averaging the precision scores obtained at different recall levels. Conversely, denotes the average of all values across all categories, allowing a comprehensive assessment of the algorithm’s performance across multiple categories. IOU is the intersection ratio of the original label’s bbox and the model’s predicted bbox, and mAP@0.5 is the accuracy of the model’s localization when 0.5 is used as the threshold for localization, and IOU exceeding 0.5 is considered to be correctly localized and vice versa. mAP@0.5:0.95 is defined as the IoU threshold from 0.5 to 0.95 in 0.05 steps and taking the mean of all maps.
4.2.2. Ablation Experiments
In order to verify the effectiveness of optimization methods such as the DEC module, cross-layer connection, and efficient decoupling head on the surface defect detection of laser nozzles and their contribution to the model optimization process, this paper conducts ablation experiments on a customized dataset of surface defect detection of laser nozzles. Different optimization methods are introduced through these experiments to observe their impact on improving the detection results of the YOLOv7 algorithm. We designed eight experiments, each set of which was tested with the same parameters and network environment, in which different optimization methods were added to the baseline step by step to demonstrate the contribution of improving the model performance. The specific experimental results of the ablation experiments are shown in Table 3 below, where the baseline is the YOLOv7 network without any improvement strategy added, and A–D denote the introduction of the DEC module, the introduction of cross-layer connection, the introduction of an efficient decoupling head, and the CA attention mechanism, respectively.
From Table 3, it can be observed that the introduction of the DEC module to the original YOLOv7 network resulted in an 8.3% improvement in mAP@0.5. The AP values for the three defect categories—scratch, uneven surface, and contour damage—significantly surpassed those of the original YOLOv7 network, with increases of 11.2%, 2.7%, and 11.0%, respectively. The incorporation of cross-layer connections further enhanced the mAP@0.5 by 2.4%, demonstrating that this design strengthens the network’s ability to extract features from surface defects of laser nozzle tips. The adoption of an efficient decoupled head improved mAP accuracy by 3.1%, achieving an optimal balance between performance and inference time while minimizing additional computational costs. With the integration of the coordinate attention (CA), the mAP@0.5 reached 77.5%, representing a 0.5% improvement over the original YOLOv7 network. This enhancement primarily stems from the CA attention mechanism’s ability to suppress interference from complex background information and amplify critical defect features during the detection of surface imperfections on laser nozzle tips.
Furthermore, to validate the effectiveness and compatibility of the proposed improvement modules, we incrementally integrated the DEC module, cross-layer connections, efficient decoupled head, and coordinate attention into the baseline model. As shown in Table 3, the combined modules achieved superior performance across all metrics compared to individual module implementations. The final integrated DEC-YOLO model demonstrated a 10.5% improvement in mAP@0.5 over the baseline, representing the optimal outcome. Figure 11 compares the precision–recall (P-R) curves of DCE-YOLO and YOLOv7, further validating the synergistic enhancement from multi-module optimization.
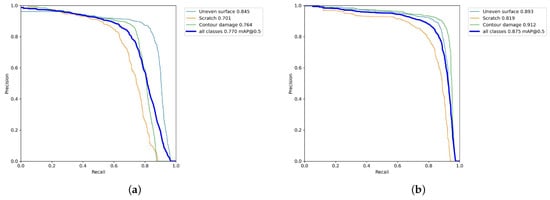
Figure 11.
P-R curve chart of the YOLOv7 model and the DEC-YOLO model. (a) P-R results of the YOLOv7 model. (b) P-R results of the DEC-YOLO model.
The AP value of contour damage class defects is improved from 76.4% to 91.2%, with an increase of 19.4%. It shows that the DEC module solves the problem of gradient disappearance that may occur in the training process, refines the extracted feature information, and effectively enhances the feature characterization ability of these kinds of defects. The AP values of the scratch class defects and the uneven surface class defects are increased from 70.1% to 81.9% and 84.5% to 89.3%, respectively, which are increases of 16.8% and 5.7% respectively. It is verified that the CA attention mechanism significantly improves the localization accuracy of complex contour defects by suppressing the background noise, and the cross-layer connection strategy by fusing multi-scale features. In summary, it can be proved that the four improvement strategies to the DEC-YOLO network design are reasonable, with the laser nozzles surface defect detection showing the best effect, with better detection accuracy and detection speed.
In order to deeply verify the effectiveness and advantages of the efficient decoupling head, we design three comparison experiments to comprehensively compare the above models with those using the original coupling head and the decoupling head. We evaluate the performance of the three models in terms of detection accuracy and inference speed, as shown in Table 4. The experimental results show that the efficient decoupled head significantly improves the detection accuracy while maintaining a small inference speed loss. Compared with the original coupled head model, our efficient decoupled head significantly improves the mAP@0.5 value by 2.9%, although it loses 31.65 FPS. And in terms of inference speed, the model combined with the efficient decoupled head outperforms the model combined with the decoupled head. Comparative experimental data show that while the mAP@0.5 value is improved by 0.3%, the speed of the model incorporating the efficient decoupled head reaches 143.79 FPS, which is 7.21 FPS higher than that of the model incorporating the decoupled head. Therefore, the use of a highly efficient decoupled head structure allows for a more efficient detection accuracy and speed, providing better performance for real-time applications. Although the speed of our method is slightly reduced compared to the original coupling head, this reduction is within acceptable limits as we achieve a reasonable improvement in the model inference speed while maintaining high accuracy.
Regarding the use of the attention mechanism, several alternatives to the CA attention mechanism were investigated in order to further validate the effectiveness of CA attention mechanisms and their compatibility with improved models. These include CBAM, squeeze-and-excitation attention (SE), normalization-based attention (NAM), and efficient channel attention (ECA). These mechanisms have been widely studied and applied in different tasks and domains. We integrate and experiment with the CA attention mechanism and the above comparative mechanisms separately. We give the comparison results of the CA attention mechanism with the above four alternatives on the cutter surface defect dataset by comparing the mAP@0.5 values of the different experimental results to assess the compatibility of the different attention mechanisms with the improved model. The data of the comparison experiments are shown in Table 5, and the experiments are based on the model after the introduction of the DEC module, cross-level connection, and efficient decoupling header, denoted by YOLO*. The experimental results show that the introduction of the CA attention mechanism helps to improve the detection performance of the model, and effectively reduces the interference of the complexity of the production environment and the inconspicuous features of the target on the model. Compared with other attention mechanisms, the CA attention mechanism shows better results.
4.2.3. Comparison Experiment of Different Models
To comprehensively evaluate the detection performance of the DEC-YOLO algorithm for surface defects on laser nozzles, we conducted comparative experiments with mainstream detection algorithms, including faster R-CNN, SSD, YOLOv5s, YOLOv6s, YOLOv7-tiny, YOLOv8l, YOLOv9t, YOLOv10n, and YOLOv11n, under identical training configurations. As shown in Table 6, DEC-YOLO achieves a remarkable mAP@0.5 of 87.5%, surpassing all compared methods by significant margins. Specifically, DEC-YOLO outperforms SSD by 31.7% and faster R-CNN by 17.5%. Among the YOLO variants, DEC-YOLO demonstrates superior accuracy improvements over YOLOv5s (14.3%), YOLOv6s (14.4%), YOLOv7-tiny (11.8%), YOLOv8l (8.3%), YOLOv9t (7.3%), YOLOv10n (8.8%), and YOLOv11n (8.2%). Notably, DEC-YOLO exhibits exceptional performance in detecting contour damage, achieving an AP@0.5 of 91.2%, which is 14.8% higher than that of YOLOv7 (76.4%) and 8.6% higher than that of YOLOv8l (82.6%). While DEC-YOLO employs a larger parameter size compared to lightweight models like YOLOv10n and YOLOv11n, it maintains a competitive inference speed of 103.4 FPS, meeting real-time requirements in industrial settings. Additionally, DEC-YOLO achieves the highest F1-score of 0.86, indicating balanced precision–recall performance. These results validate that the proposed DEC module, cross-layer connections, and coordinate attention synergistically enhance feature extraction capability, enabling robust detection even under complex backgrounds and small-scale defects.
4.3. Visualization and Analysis of Test Results
In order to visualize the superiority of this paper’s algorithm in the detection of defects on the surface of the laser nozzles, we visualize and analyze the detection effect of this paper’s algorithm on the surface of the nozzle. As can be seen from Figure 12, compared with the YOLOv8l, YOLOv7, and YOLOv5s algorithms, the improved DEC-YOLO algorithm is able to identify more defects, which significantly improves the confidence of the target identification, and especially detects more defects efficiently under the condition of low light, which proves its ability to adapt to the low-light environment. Although DEC-YOLO shows high accuracy in laser nozzle surface defect detection, some limitations still exist in practical applications. To gain a deeper understanding of the model’s performance boundaries, we systematically analyzed the error cases in the test set, which mainly include the following two types of problems. (1) Missed Detection of Small Defects: The model occasionally misses detection in images with low resolution or in scenes with very small defect sizes. For example, the blue box labels in Figure 12 demonstrate that multiple tiny defects are not detected. After analyzing, this kind of problem mainly stems from the insufficient resolution of the deep feature maps, resulting in the loss of spatial information of small targets. In addition, complex backgrounds (e.g., metallic reflections) may interfere with the focusing of the attention mechanism on tiny defects. (2) False Positives: Some of the false positives cases are caused by the similarity between the background texture and the defect morphology. Meanwhile, although coordinate attention suppresses some of the noise, the local attention weight allocation is still insufficient in highly reflective or complex texture regions. In Figure 12, we mark the misreported defects with red boxes, where multiple contour damages are misclassified as uneven surface. Another class of misreporting stems from the limitations of the data enhancement strategy, e.g., over-enhanced noise simulation may result in a model that is sensitive to high-frequency noise.

Figure 12.
(a–d) Detection results of different models.
Compared with other algorithms, DEC-YOLO is able to detect more defects of the contour damage category. This indicates that the improved algorithm has a lower sensitivity, stronger anti-interference ability and higher network robustness when the lighting conditions change. Meanwhile, in the defect-intensive scenario, the presence of a large number of small defects and their mutual occlusion significantly increases the complexity of detection. However, the optimized DEC-YOLO algorithm successfully improves the detection of defects with a significant increase in the defect recognition confidence for the scratch and uneven surface classes, showing its effectiveness in a high-density defect environment. Overall, compared with other algorithms, the model has obvious advantages in reducing the false positive rate (FPR) and missed detection rate (FNR). To quantify the detection performance of DEC-YOLO in complex scenes, 100 images containing complex backgrounds were randomly selected from the test set for frame-by-frame analysis in this study. As shown in Table 7, DEC-YOLO outperforms the comparison algorithms in two key metrics, namely, false positive rate (FPR) and missed detection rate (FNR). The four algorithms generally have fewer cases of false positives (FP), while the other comparison algorithms have more serious cases of missed detections. In Figure 12a,b, YOLOv5 and YOLOv7 miss multiple uneven surfaces and contour damages due to feature loss, whereas in Figure 12c, YOLOv5, YOLOv7, and YOLOv8 miss multiple scratches. In contrast, DEC-YOLO has a significantly lower false positive rate than the other compared algorithms, and it is worth noting that the confidence level of DEC-YOLO detection is also significantly higher than that of the other algorithms in Figure 12. The experimental results fully validate the improvement of the YOLOv7 algorithm, which effectively enhances its ability to detect defects on the surface of the laser nozzles in complex environments.
Table 7.
Comparison of false positive rate (FPR) and false negative rate (FNR) for different methods (FPR = false positives/total detections, FNR = false negatives/true defects).
5. Conclusions
Aiming at the key problems of poor stability and insufficient accuracy in the detection of surface defects on the laser nozzles, this paper proposes the DEC-YOLO algorithm based on the YOLOv7 architecture to be applied to the detection of surface defects on the laser nozzles, which achieves the accurate identification of defects on the surface of the laser nozzles. Specifically, our proposed DEC module enhances gradient propagation stability during the training process, complements the extracted feature information, enhances the extraction of basic information, and contributes more to the improvement of detection accuracy. Meanwhile, we adopt cross-layer connection to achieve the fusion of feature information between shallow and deep networks. Through the decoupling strategy designed by the head, the classification and regression tasks are processed separately, which further enhances the effect of feature extraction. Embedding coordinate attention into the YOLOv7 backbone network enhances the feature information extraction ability by establishing spatial dimensional long-range dependencies, which enables the network to pay more attention to valuable regions and further improves the detection accuracy of the network. In addition, this paper provides data support for this area by constructing a dataset containing 2250 sample images of the three main defect categories in the cutting head miter surface. After several comparative tests and ablation experiments, we have successfully obtained an improved YOLOv7 algorithm model with better detection effect. Compared with the traditional manual detection methods, our deep learning-based method has stronger generalization ability and is less affected by environmental factors and image quality. It can identify common defects in laser nozzles surface defect detection, achieve high-speed real-time detection, and is more suitable for deployment in complex industrial production environments. However, there is still room for improvement in the model’s ability to identify small target defects. In future work, we will also design targeted experiments (such as monitoring gradient norms and ablating the impact of different modules on gradient propagation) to quantitatively analyze the specific contribution of the DEC module to gradient stability. Also, our dataset does not yet cover all types of defects on the surface of laser nozzles. The dataset constructed in this study contains three categories of defects, namely scratch, uneven surface and contour damage, which are selected based on the statistical reports of actual production failures provided by the partner company Han’s Smart Control Technology Co., Daqo Laser Global Production Base, No.128 Chongqing Road, Fuyong Street, Bao’an District, Shenzhen, China. Among them, scratch directly affects the nozzle airflow uniformity; uneven surface is strongly related to material processing and is prone to laser scattering; and contour damage causes serious distortion of the airflow distribution, which is the most hazardous, covering more than 80% of the common defects in this scenario. However, other defects (e.g., microcracks, oxidation spots, etc.) that may exist in real production environments have not yet been included in this dataset, which may impose some limitations on the generalization ability of the model. In future work, we will further extend the dataset to include new defect categories such as microcrack and oxidation, and enhance the generalization capability of the model through collaborative multi-plant data collection. Meanwhile, we plan to introduce synthetic data generation techniques (e.g., GAN-based defect simulation) to solve the problem of labelling defects with small samples. Although DEC-YOLO has made significant progress in the detection of surface defects on laser nozzles, further optimization is needed in terms of tiny defect leakage and complex background false alarms. Future work will focus on the lightweight design of multi-scale feature fusion and the development of dynamic data enhancement strategies to improve the robustness of the model in industrial scenarios.
Author Contributions
Writing—original draft, software, S.L.; conceptualization and methodology, S.L. and F.Z.; visualization, S.L., F.Z. and Y.Z.; writing—review and editing, S.L, Y.Z. and H.D.; resources, H.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
We are grateful to the High-Performance Computing Center of Central South University for the assistance with the computations. In addition, we are grateful for the data support provided by Han’s Smart Control Technology Co.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Petring, D. Basic description of laser cutting. In LIA Handbook of Laser Materials Processing; Ready, J.F., Farson, D.F., Eds.; Laser Institute of America, Magnolia Publishing: Orlando, FL, USA, 2001; pp. 425–428. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv5: Ultralytics. GitHub Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 June 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 4 August 2024).
- Wang, D.; Tan, J.; Wang, H.; Kong, L.; Zhang, C.; Pan, D.; Li, T.; Liu, J. SDS-YOLO: An Improved Vibratory Position Detection Algorithm Based on YOLOv11. Measurement 2025, 244, 116518. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations 2021, Vienna, Austria, 4 May 2021. [Google Scholar]
- Akhyar, F.; Liu, Y.; Hsu, C.-Y.; Shih, T.K.; Lin, C.-Y. FDD: A deep learning-based steel defect detectors. Int. J. Adv. Manuf. Technol. 2023, 126, 1093–1107. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 1–13. [Google Scholar] [CrossRef]
- Chen, K.; Zeng, Z.; Yang, J. A deep region-based pyramid neural network for automatic detection and multi-classification of various surface defects of aluminum alloys. J. Build. Eng. 2021, 43, 102523. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, C.; Chang, C.C.; Jamshidi, M. Concrete bridge surface damage detection using a single-stage detector. Comput. Civ. Infrastruct. Eng. 2020, 35, 389–409. [Google Scholar] [CrossRef]
- Sun, L.; Wei, J.; Zhu, D.; Shi, M. Surface Defect Detection Algorithm of Aluminum Profile Based on AM-YOLOv3 Model. Laser Optoelectron. Prog. 2021, 58, 2415007. [Google Scholar]
- Li, J.; Su, Z.; Geng, J.; Yin, Y. Real-time Detection of Steel Strip Surface Defects Based on Improved YOLO Detection Network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar] [CrossRef]
- Wan, G.; Fang, H.; Wang, D.; Yan, J.; Xie, B. Ceramic tile surface defect detection based on deep learning. Ceram. Int. 2022, 48, 11085–11093. [Google Scholar] [CrossRef]
- Li, Y.; Xu, S.; Zhu, Z.; Wang, P.; Li, K.; He, Q.; Zheng, Q. EFC-YOLO: An Efficient Surface-Defect-Detection Algorithm for Steel Strips. Sensors 2023, 23, 7619. [Google Scholar] [CrossRef]
- Wang, H.; Xu, X.; Liu, Y.; Lu, D.; Liang, B.; Tang, Y. Real-Time Defect Detection for Metal Components: A Fusion of Enhanced Canny–Devernay and YOLOv6 Algorithms. Appl. Sci. 2023, 13, 6898. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient Detection Model of Steel Strip Surface Defects Based on YOLO-v7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]
- Xiangming, Q.; Xu, D. Improved Yolov7-tiny Algorithm for Steel Surface Defect Detection. Comput. Eng. Appl. 2023, 59, 176–183. [Google Scholar]
- Xu, X.; Zhang, G.; Zheng, W.; Zhao, A.; Zhong, Y.; Wang, H. High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning. Machines 2023, 11, 834. [Google Scholar] [CrossRef]
- Xie, Y.; Yin, B.; Han, X.; Hao, Y. Improved YOLOv7-based steel surface defect detection algorithm. Math. Biosci. Eng. 2024, 21, 346–368. [Google Scholar] [CrossRef]
- Li, Z.; Jia, D.; He, Z.; Wu, N. MSG-YOLO: A Multi-Scale Dynamically Enhanced Network for the Real-Time Detection of Small Impurities in Large-Volume Parenterals. Electronics 2025, 14, 1149. [Google Scholar] [CrossRef]
- Wang, Y.; Yun, W.; Xie, G.; Zhao, Z. YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules. Sensors 2025, 25, 1755. [Google Scholar] [CrossRef]
- He, L.; Zheng, L.; Xiong, J. FMV-YOLO: A Steel Surface Defect Detection Algorithm for Real-World Scenarios. Electronics 2025, 14, 1143. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [PubMed]
- Ai, S.; Liu, F.; Zhang, D. Pill Defect Detection Based on Improved YOLOv5s Network. Instrumentation 2022, 9, 27–36. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).