Abstract
Pre-trained visual language models have become excellent basic models for many downstream tasks in transfer learning. However, due to the serious gap between the data scale of downstream tasks and the large-scale data used by pre-trained models, migration to downstream tasks will face the dilemma of discriminability and generalization. Therefore, it is necessary to learn task-specific knowledge while retaining general knowledge. How to accurately identify and distinguish these two types of representations remains a challenge. This paper proposes a dual-subspace driven cross-modal semantic interaction and dynamic feature fusion framework, which uses a decentralized covariance dual-subspace decomposition method to decouple visual and text features by constructing task subspaces and general knowledge subspaces, and performs refined modal interactions on the decoupled general features and task features through a cross-modal semantic interaction adapter module. Finally, a cross-level semantic fusion module based on a gating mechanism is used to achieve dynamic fusion of different semantics from shallow to deep. We verify the effectiveness of this method on three tasks: generalization to novel classes, novel target datasets, and domain generalization. Compared with a variety of advanced methods, the proposed method has achieved excellent performance in all evaluation tasks.
1. Introduction
In recent years, vision-language models (VLMs) [1], trained on large-scale image–text pairs through contrastive learning [2,3], have achieved cross-modal alignment between images and texts. These models have demonstrated strong generalization and cross-task adaptability across a wide range of practical applications. For instance, in medical image classification [4,5], VLMs can leverage textual descriptions of disease types to assist in distinguishing image features of different conditions (e.g., differentiating pneumonia from normal lung images), thereby improving classification accuracy. In medical image segmentation [6,7], VLMs enhance segmentation precision by exploiting knowledge acquired during pretraining. In the biological domain [8,9], they facilitate more accurate semantic matching of biological signals. In robotic control [10,11], their outstanding zero-shot capabilities strengthen the understanding of complex environments. Despite these advantages, VLMs still face several challenges in downstream applications. The large number of parameters makes direct fine-tuning computationally expensive and prone to catastrophic forgetting of pre-trained knowledge, while the reliance on manually crafted prompts requires domain expertise, which is particularly difficult to obtain in specialized fields such as rare disease identification.
Two mainstream transfer schemes have recently emerged in this field. The first is prompt learning, which introduces learnable prompt vectors, such as CoOp [12] and MaPLe [13]. By freezing the pre-trained parameters and optimizing only a small number of prompts, this approach achieves a balance between training efficiency and few-shot adaptability. The second is the use of lightweight modules, such as CLIP-Adapter [14], which improves cross-modal alignment through residual lightweight components, and Tip-Adapter [15], which enables efficient adaptation via a non-trainable key–value cache mechanism. Both approaches aim to enhance task adaptability at low computational cost. However, they still face notable limitations. On the one hand, most methods emphasize single-modality modeling while overlooking the intrinsic semantic dependencies between image and text in decision-making. On the other hand, in few-shot scenarios, they are susceptible to interference and even catastrophic forgetting of pre-trained general knowledge, which undermines the effectiveness of representations. As a result, models struggle to fully exploit pre-trained semantic information, thereby constraining their adaptability and robustness.
Moreover, although existing studies primarily focus on improving the accuracy and adaptability of vision-language models (VLMs), relatively little attention has been paid to their portability and practical usability in real-world applications. A practical vision-language framework should not only perform well on benchmark datasets but also exhibit the capability to flexibly transfer across diverse tasks and computational environments. To this end, the framework proposed in this paper is designed with particular emphasis on a modular dual-subspace decoupling strategy and a lightweight feature interaction mechanism, enabling “plug-and-play” integration with various visual backbones and text encoders. This design allows the framework to adapt to multiple downstream tasks without extensive retraining, thereby ensuring high scalability and resource efficiency.
To address these challenges, this paper presents a dual-subspace-driven cross-modal semantic interaction and dynamic feature fusion framework, with three main contributions:
- A decentralized covariance dual-subspace decomposition method is developed to map visual and textual features into a shared subspace and a task-specific subspace. This design enables knowledge separation and collaborative modeling, effectively mitigating catastrophic forgetting of pre-trained knowledge and excessive feature coupling during task adaptation.
- Based on the dual-subspace architecture, a cross-modal semantic interaction adapter module and a gated cross-level semantic fusion module are introduced. The former performs independent interactions between shared and task-specific subspace features to avoid interference between general and task knowledge, while the latter employs a gating mechanism to dynamically adjust feature weights across levels, ensuring consistent semantic alignment.
- The proposed framework is evaluated on multiple benchmark datasets. Experimental results indicate that the method consistently achieves state-of-the-art performance compared with existing approaches, confirming its effectiveness and robustness.
2. Related Work
2.1. Vision-Language Models
Visual Language Models (VLMs) have made significant progress in multiple tasks with their powerful multimodal modeling capabilities, exhibiting clear advantages over traditional models that rely solely on visual or textual supervision. In recent years, representative models such as CLIP [16], ALIGN [17], and FILIP [18] have achieved breakthroughs in joint image-text modeling. These models are typically based on self-supervised strategies, utilizing large-scale architectures and vast amounts of image-text pairs for training, thereby learning unified representations across modalities. Many modal tasks [19,20] have achieved promising results relying on the powerful cross-modal data alignment capabilities of VLMs. CLIP is an excellent work in visual language modeling, which aligns images and textual descriptions through contrastive learning, demonstrating strong zero-shot capabilities in a series of downstream tasks. Tasks such as real-time big data processing [21], camera AR tracking [22], intelligent IoT multi-target monitoring [23,24], texture classification [25], and process monitoring [26] also leverage VLMs to enhance scene adaptation and generalization performance. Despite the remarkable effectiveness of visual language models, they still face the problem of severe degradation in generalization ability when applied to downstream tasks.
2.2. Efficient Transfer Learning
In recent years, research on the efficient adaptation of visual–language models (VLMs) has mainly focused on prompt learning and adapter-based methods. Compared with traditional manually designed prompt templates, prompt learning methods substantially reduce the dependence on human expertise, making them particularly suitable for domains with high professional barriers such as finance, medicine, and biology. Represented by CoOp, this approach replaces fixed prompt templates with learnable continuous context vectors, enabling adaptive modeling of downstream tasks and significantly improving the recognition accuracy of base classes. However, CoOp exhibits weak generalization ability to novel categories and struggles to transfer effectively to unseen classes.
To address this issue, CoCoOp [27] introduced a lightweight meta-network to dynamically generate prompt initialization based on image features, which improved generalization but incurred high training cost and introduced noise. KgCoOp [28] regularized learnable prompts by constraining them toward fixed templates such as “a photo of a [class],” thereby improving generalization while maintaining fitting ability. CoPL [29] enhanced the proportion of task-relevant visual information in prompts by weighting the similarity between image local features and prompts. Although these methods improved prompt design, they rely on a single prompt and remain insufficient to capture the complexity and diversity of image information. ProDA [30] introduced multiple learnable cues for each category to construct diverse descriptions, adapting to richer visual representations, but the improvement in generalization remained limited. MaPLe proposed a multi-modal prompt learning strategy that leverages both visual and textual cues simultaneously, allowing the model to adaptively balance information from different modalities and further enhance generalization to unseen classes.
In parallel, adapter-based lightweight parameter tuning methods have shown promising progress in VLMs. CLIP-Adapter enhanced the matching accuracy of downstream tasks by inserting lightweight adapter modules into visual and text encoders, leveraging residual connections to adjust feature distributions, and outperforming simple prompt tuning methods. For resource-constrained scenarios, Tip-Adapter designed a training-free adapter structure. By combining a key–value caching mechanism with pre-trained knowledge, it achieved efficient adaptation with zero training overhead.
Overall, these studies demonstrate that partial module learning has gradually replaced traditional full-model fine-tuning and become a prevailing trend. However, they also reveal a core challenge: different layers of VLMs exhibit heterogeneous performance in transfer learning. Effectively leveraging pre-trained knowledge in few-sample scenarios to adapt to diverse and complex downstream tasks remains an open problem requiring further investigation.
3. Model
3.1. Problem Definition
Vision–Language Models (VLMs) face several challenges when adapted to downstream classification tasks. In few-shot scenarios, models are prone to overfitting, which can lead to catastrophic forgetting of the general knowledge acquired during pretraining, thereby limiting cross-task transferability. To address this issue, this paper proposes a dual-subspace-driven cross-modal semantic interaction and dynamic feature fusion framework. In each Transformer layer, three core modules, Multi-Modal Feature Disentanglement (MMFD), Cross-Modal Semantic Interaction Adaper (CMSIA), and Gated Cross-Layer Semantic Fusion (GCSF),are introduced to separate universal and task-specific features, enable cross-modal interactions, and integrate multi-level semantic information. This design aims to enhance task discriminability while preserving generalization capability. The detailed implementation process is as follows.
The training dataset comprises RGB images of size , denoted as , with corresponding class labels . Textual descriptions are generated using CLIP’s generic prompt template, A photo of a , where represents the -th class. This process produces a textual set . Each image and its corresponding text are processed through independent -layer encoders. At the -th layer, the visual and textual features and , are decomposed into two distinct components via a Multi-Modal Feature Disentanglement (MMFD) module. The universal subspace encodes generalizable knowledge acquired during pretraining, providing a robust foundation applicable across multiple tasks, while the task-specific subspace captures information that is specialized for the current downstream classification task, enabling the model to adapt effectively to task-specific nuances. The decomposed features are further processed by a Cross-Modal Semantic Interaction (CMSIA) Adaper module, which models interactions within both universal and task-specific subspaces. This disentangled interaction yields four sets of cross-modal features, denoted as and respectively. These representations allow the model to capture complementary information between modalities while preserving the separation between general and task-specific knowledge.
To exploit hierarchical information across layers, a Gated Cross-Layer Fusion (GCSF) module aggregates the interacted features and produces fused hierarchical visual and textual representations and .
The fused features are integrated with the original layer features through residual connections:
After Transformer layers, the final visual and textual representations, and , are extracted. Cross-modal similarity is computed using cosine similarity:
where denotes the norm.
The similarity scores are scaled by a temperature parameter τ and converted into class probabilities via the SoftMax function:
The predicted class is corresponding to the label with the highest probability as follows:
This framework enables effective disentanglement of universal and task-specific knowledge, facilitates fine-grained cross-modal interaction, and leverages hierarchical fusion to enhance both generalization and task-specific performance on downstream classification tasks.
3.2. Overall Framework
As illustrated in Figure 1, this study builds upon CLIP by sequentially integrating a Multi-Modal Feature Disentanglement module (MMFD), a Cross-Modal Semantic Interaction Adaper module (CMSIA), and a Gated Cross-Layer Semantic Fusion module (GCSF) after each Transformer layer. The MMFD module decomposes the output of each layer into features in a universal subspace and a task-specific subspace. The universal subspace preserves general semantic knowledge accumulated during pretraining, while the task-specific subspace captures information relevant to the downstream task, providing a foundation for subsequent fine-grained cross-modal interaction.
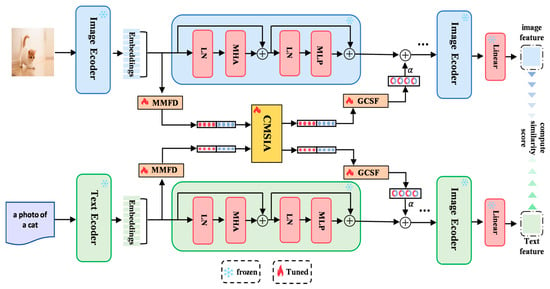
Figure 1.
The overall architecture of our proposed method.
To mitigate interference between universal and task-specific knowledge during interaction, the CMSIA module enforces independent subspace interactions. Specifically, cross-modal semantic interactions are performed exclusively between the visual and textual universal subspace features, and separately between the visual and textual task-specific subspace features. This design ensures that each type of knowledge is aligned within its respective modality while preventing contamination of the universal knowledge by task-specific information. As a result, the model maintains pre-trained knowledge integrity and strengthens cross-modal consistency for task-relevant features, thereby improving adaptability to downstream tasks.
Recognizing that different encoder layers exhibit distinct patterns of knowledge retention—where lower layers primarily encode fundamental visual and linguistic patterns and higher layers capture abstract, task-oriented semantic representations—this study introduces the GCSF module to adaptively compute layer-dependent fusion weights. The module assigns greater weights to foundational universal knowledge at lower layers and emphasizes task-specific knowledge at higher layers. The fused features are then integrated with the original Transformer outputs via residual connections, preserving essential information from the original features while incorporating enhanced representations optimized through cross-modal interaction.
Collectively, these innovations enable the model to effectively balance universal and task-specific knowledge, retain the advantages of CLIP pretraining, and achieve substantial improvements in both accuracy and robustness on downstream tasks.
3.3. Implement
3.3.1. Covariance-Guided Dual-Subspace Feature Decoupling Mechanism
Inspired by the work of Wang [31], who demonstrated that constraining model updates along the directions corresponding to the smallest singular values during incremental learning can effectively preserve the generalization knowledge in pre-trained models, we propose a non-centralized covariance-based dual-subspace decomposition method. We extend this principle to the multimodal scenario, achieving a statistical separation of multimodal features by jointly decoupling textual and visual representations. It should be noted that the “universal subspace” and the “task-specific subspace” do not correspond to strict semantic partitions; rather, they represent a statistical approximation based on the covariance structure of the features. The universal subspace corresponds to the principal directions with higher variance, which typically capture stable and transferable features learned during large-scale pre-training, thereby helping to retain generalization ability and mitigate catastrophic forgetting when adapting to downstream tasks. In contrast, the task-specific subspace is spanned by low-variance or residual directions, which exhibit higher plasticity, allowing the model to flexibly adapt to the distribution of downstream tasks without disrupting the pre-trained representations. A schematic illustration is shown in Figure 2.
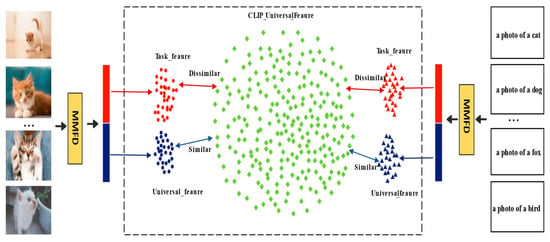
Figure 2.
The feature disentanglement process.
To implement this feature decoupling, we design the Multi-Modal Feature Disentanglement (MMFD) module, which is integrated after each layer of the text and visual encoders in the CLIP model. The specific process is as follows: First, we obtain the initial representations of the universal and task-specific subspaces by applying two independent linear transformations to map the original visual features and text features to their respective candidate subspaces:
Here, and are the transformation matrices for the text and visual features, respectively, and are the dimensions of the transformed subspaces, and and are the corresponding bias terms, denotes the number of tokens, and denotes the batch size
Next, we reshape the transformed features into two-dimensional matrices and , and compute the non-centralized covariance matrices:
We then perform eigenvalue decomposition on these covariance matrices:
here, and are the unitary matrices of eigenvectors for the text and visual features, respectively, and and are the diagonal matrices of eigenvalues, sorted in descending order.
The eigenvectors are sorted in descending order according to their corresponding eigenvalues and then divided by a proportion . Let and denote the number of feature vectors in the text and visual matrices, respectively. The first and eigenvectors form the universal subspace, while the remaining eigenvectors form the task-specific subspace. The universal subspace captures directions with larger variance, preserving pre-trained knowledge, whereas the task-specific subspace is more flexible, allowing adaptation to downstream tasks.
Here, denotes the floor operation
The remaining eigenvectors form the null space, which represents the part of the feature space with minimal influence from pre-trained knowledge. This space can be used to guide the model to focus on task-specific features:
Finally, we project the transformed features and onto their respective subspace bases:
After projecting, the decoupled text and visual feature matrices are reshaped back to their original dimensions to obtain , , and .
3.3.2. Cross-Modal Semantic Interaction Adapter Module
To mitigate potential interference between universal and task-specific features in cross-modal learning, we propose a Cross-Modal Semantic Interaction Adapter (CMSIA), as illustrated in Figure 3. This module extends the conventional adapter by introducing two shared low-dimensional interaction matrices between the down-projection and up-projection stages. These matrices enable independent interactions for universal and task-specific features, effectively preserving pretrained knowledge while enhancing downstream task adaptation and preventing interference between general and task-specific features. Specifically, for the universal and task-specific features obtained from the MMFD module, denoted as , and , we construct independent interaction pathways for both visual and textual modalities. During the interaction stage, two parallel low-rank matrices and , are introduced. The universal features of both modalities interact through , while the task-specific features interact through . The computation process is defined as follows:
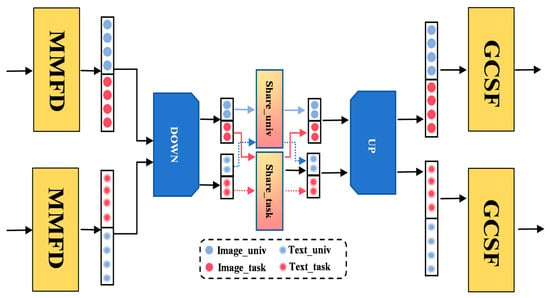
Figure 3.
The modality interaction process.
Here, and are the downsampling matrices for the visual and text modalities, respectively, while and are the upsampling matrices. and are the interaction matrices for different subspace features, and (.) represents the activation function, implemented as Relu. After cross-modal interaction and capture the universal and task-specific subspace features of the visual modality, while and encode the corresponding representations for the textual modality.
3.3.3. Gated Cross-Level Semantic Fusion Module
After effectively disentangling the pre-trained universal features and downstream task-specific features using the MMFD module and performing cross-modal interactions via the CMSIA module, the challenge of integrating these features across layers remains. In practice, the model’s dependence on universal and task-specific features varies considerably across layers, rendering single-layer fusion insufficient to capture the full semantic representation. To address this, we introduce the Gated Cross-Level Semantic Fusion (GCSF) module, which dynamically balances the contributions of universal and task-specific features across layers, enabling optimal semantic fusion.
For any modality , the task-specific and universal features are first concatenated:
Next, the fusion weights are generated using a two-layer neural network:
Here, and are the weight matrices of the gating network, and are the bias terms, and is the Sigmoid activation function.
Finally, the contributions of task-specific and universal features are dynamically balanced using the generated weights to produce the fused output:
here, denotes element-wise multiplication.
Algorithm 1 provides the pseudocode of our proposed method.
| Algorithm 1 # Pseudocode for Dual-Subspace Cross-Modal Decoupling & Fusion |
| for each image I_i and text T_k: Xv, Xt = VisualEncoder(I_i), TextEncoder(T_k) for layer = 1 to L: # 1. Multi-Modal Feature Disentanglement Xv_univ, Xv_task = MMFD(Xv) Xt_univ, Xt_task = MMFD(Xt) # 2. Cross-Modal Semantic Interaction Adapter Xv_univ_mut, Xt_univ_mut = CMSIA(Xv_univ, Xt_univ) Xv_task_mut, Xt_task_mut = CMSIA(Xv_task, Xt_task) # 3. Gated Cross-Level Semantic Fusion beta_v = GatingNetwork(concat(Xv_task_mut, Xv_univ_mut)) beta_t = GatingNetwork(concat(Xt_task_mut, Xt_univ_mut)) Xv_fused = beta_v Xv_task_mut + (1-beta_v) Xv_univ_mut Xt_fused = beta_t Xt_task_mut + (1-beta_t) Xt_univ_mut # Residual connection Xv, Xt = Xv + alpha_res Xv_fused, Xt + alpha_res Xt_fused |
4. Experiments
Based on previous work, we systematically evaluate the performance of the proposed method, covering the generalization ability from base classes to new classes, cross-dataset transfer effect, and domain generalization performance.
4.1. Experimental Setup
4.1.1. Datasets
The proposed method is evaluated on 11 image classification datasets, covering a wide range of tasks: general object recognition (ImageNet [32], Caltech101 [33]), fine-grained recognition (OxfordPets [34], StanfordCars [35], Flowers102 [36], Food101 [37], FGVCAircraft [38]), scene understanding (SUN397 [39]), texture recognition (DTD [40]), satellite imagery (EuroSAT [41]), and action recognition (UCF101 [42]). Detailed information of the datasets is shown in Table 1.

Table 1.
Summary of the 11 datasets.
4.1.2. Baselines
We compare the proposed method with several state-of-the-art methods, including CLIP, CoOp, CoCoOp, KgCoOp, ProGrad [43], and AAPL [44]. ProGrad has different settings in cross-dataset experiments and domain generalization experiments from existing experiments, so we compare it with them in this experiment.
4.1.3. Implementation Details
All experiments were conducted on an NVIDIA V100 GPU with 32 GB of memory. The software environment consisted of Python 3.8.2 and PyTorch 2.4.0. For data construction, each experiment utilized a training set comprising 16 images per category, and all images were resized to 224 × 224 RGB. The visual encoder was configured as ViT-B/16, and text prompts followed the default CLIP template, “a photo of a [class]”. Model parameters were optimized using the AdamW optimizer with an initial learning rate of 0.0019. Mixed-precision training was employed to enhance computational efficiency. For the large-scale ImageNet dataset, which contains numerous categories, a batch size of 8 and a training schedule of 3 epochs were adopted to accelerate training. For all other datasets, a batch size of 4 and 10 training epochs was used to ensure sufficient convergence.
4.2. Base-to-Novel Generalization
In this experiment, we evaluate the recognition performance on 11 widely used datasets by reporting the accuracy for base classes (Base), novel classes (Novel), and the harmonic mean (HM), which quantifies the trade-off between the two. The results are summarized in Table 2.
Table 2.
Comparison with state-of-the-art methods on different datasets in the Base-to-Novel Generalization setting. Bold values indicate the best performance.
As shown in Table 2, our method demonstrates consistent advantages across all evaluation metrics. For the Base category, it achieves an average accuracy of 84.02%, outperforming CoOp (82.69%), KgCoOp (80.73%), and AAPL (80.27%), indicating strong fitting ability on known classes. In the Novel category, our method reaches 75.65%, substantially higher than CoOp (63.22%) and AAPL (72.17%), demonstrating superior generalization to unseen classes. Considering the balance between Base and Novel performance, our approach attains the highest Harmonic Mean (HM) of 79.65%, surpassing CoOp (71.66%), ProGrad (76.16%), and KgCoOp (77.00%), thereby exhibiting strong overall generalization.
On individual datasets such as DTD and EuroSAT, our method achieves the best results across all three metrics, with EuroSAT reaching an HM of 84.29%. Even on strong baselines like UCF101 and Caltech101, it maintains either leading or comparable performance, verifying its robustness across diverse tasks. Notably, on a few datasets including Caltech (Novel), Cars (Novel), and Food101 (Novel), the improvements are relatively limited. This can be attributed to dataset characteristics and category complexity: the Caltech Novel classes exhibit high visual similarity and a limited number of samples, which constrains the model’s ability to fully capture intra-class diversity; Cars is a fine-grained dataset with subtle inter-class differences, limiting few-shot generalization; and the Novel classes in Food101 encompass a wide range of visually distinct food items, where individual images cannot cover the full diversity, thereby restricting model performance under few-shot conditions. Overall, these observations indicate that, although our method exhibits robust generalization overall, few-shot performance remains challenging on datasets that are extremely small, highly fine-grained, or internally diverse.
4.3. Few-Shot Learning Evaluation
To evaluate the adaptability of our model in data-scarce scenarios, we conducted experiments under low-sample training conditions of 1, 2, 4, and 8 shots, examining performance fluctuations across different sample sizes. The results are presented in Figure 4. As the number of samples decreases from 16 to 1, overall performance declines, although the reduction remains relatively moderate. Notably, the model maintains high accuracy under 8-shot and 4-shot conditions, demonstrating strong robustness and generalization. Certain datasets, such as Pets and Caltech101, exhibit minimal sensitivity to sample size, with negligible performance fluctuations, indicating effective adaptation to low-sample conditions. In contrast, datasets including EuroSAT, FGVC, and DTD are more sensitive, showing substantial performance degradation as the number of shots decreases. Even at extremely low sample sizes (1 or 2 shots), the model retains reasonable performance overall, highlighting its stability and practical utility in few-shot learning tasks. These results demonstrate that the proposed model consistently achieves strong performance under constrained data conditions, supporting its applicability in real-world few-shot scenarios.
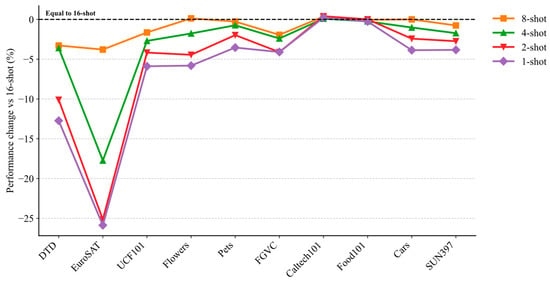
Figure 4.
Performance fluctuations under the few-shot setting.
4.4. Cross-Dataset Evaluation
Table 3 presents the performance of the proposed method compared to other models in cross-dataset transfer scenarios. Overall, the proposed approach demonstrates superior performance across multiple key tasks, particularly on ImageNet, Flowers, Aircraft, SUN397, and UCF101. On ImageNet, our method achieves an accuracy of 71.70%, highlighting its capability to handle large-scale general image recognition tasks. For the Flowers dataset, it attains 71.96%, surpassing CoOp by 3.25 percentage points and KgCoOp by 0.71 percentage points, indicating enhanced expressiveness in fine-grained classification. Notably, on the Aircraft dataset, accuracy reaches 24.30%, which is 5.83% higher than CoOp and 1.36% higher than CoCoOp, further demonstrating the method’s adaptability in fine-grained and complex scenes. In the UCF101 action recognition task, our approach achieves 69.50%, exceeding CoOp by 2.95 percentage points and AAPL by 0.20 percentage points, illustrating strong cross-modal transfer capability. While performance is slightly lower than the best results on certain datasets such as Caltech101 and EuroSAT, this can be attributed to specific characteristics of these datasets. Caltech101 contains relatively few samples per category and imbalanced class distributions, which can limit the effectiveness of methods that rely on preserving generalizable subspace knowledge, whereas CoCoOp’s class-adaptive prompts may better capture the features of small-sample categories. EuroSAT, as a remote sensing dataset, exhibits visual patterns that differ significantly from everyday object images; although our method employs multi-modal feature disentanglement and cross-layer semantic fusion, it may not fully adapt to the fine-grained textures and color distributions unique to remote sensing images. In general, the slightly lower performance on these datasets reflects the intrinsic differences in data distribution and cross-domain adaptation challenges, while the proposed method maintains stable and robust performance across the majority of diverse downstream tasks, confirming its overall effectiveness and generalization capability.
Table 3.
Comparison of the Proposed Method with State-of-the-Art Methods in the Cross-Dataset Evaluation Setting. Bold values indicate the best performance.
4.5. Domain Generalization
To evaluate the model’s ability to handle domain shifts and generalize to out-of-distribution data, we trained it on ImageNet and tested it on four variants that introduce different types of domain shifts: ImageNetV2 [45], ImageNet-Sketch [46], ImageNet-A [47], and ImageNet-R [48]. The results are summarized in Table 4. On ImageNetV2, our method achieves an accuracy of 64.64%, surpassing approaches such as CoCoOp, indicating strong adaptability to distribution shifts similar to the training domain. On the more challenging ImageNet-Sketch dataset, it attains 49.27%, highlighting its robust cross-modal feature transfer capability. For ImageNet-R, which contains a variety of rendering styles, the model achieves the highest accuracy of 77.17%, demonstrating strong structural invariance and high-level semantic transferability.
Table 4.
Comparison of the Proposed Method with state-of-the-art methods in the Domain Generalization setting. Bold values indicate the best performance.
Although the performance on ImageNet-A, which consists of adversarially selected examples, is slightly lower than some existing methods, an accuracy of 48.27% remains reasonable and reflects the model’s stability when handling extreme samples. This slight performance drop may be attributed to the adversarial characteristics and extreme noise in ImageNet-A, which limit the model’s ability to fully rely on general subspace knowledge for prediction, while its strong cross-modal knowledge transfer remains effective on regular and structured images. Overall, these results indicate that the proposed method exhibits strong generalization in cross-domain scenarios, effective cross-modal transfer, and robust structural and semantic invariance.
4.6. Ablation Analysis
To systematically evaluate the contributions of each module in the proposed method, we conducted a series of ablation experiments. The method comprises a feature decoupling module, a cross-modal interaction module, and a gated fusion module. The first two modules are interdependent and operate as a cooperative unit, responsible for disentangling multi-modal features and aligning semantics across modalities. The gated fusion module adaptively integrates universal and task-specific features, balancing generalization and discriminability. It is worth noting that traditional adapter usage typically falls into two categories: single-side adapters, added only after each layer of either the visual (V) or textual (T) modality, and dual-side adapters, added after layers of both visual and textual modalities. Our ablation experiments are designed to examine both single- and dual-side scenarios, assessing the effects of cross-modal collaboration and the contributions of each proposed module.
The ablation settings are defined as follows:
w/o L. removes the visual encoder adapter while retaining the text encoder adapter, to analyze the effect of cross-modal feature collaboration under a single-sided condition and assess the necessity of dual-sided modeling.
w/o V. removes the text encoder adapter while retaining the visual encoder adapter, similarly evaluating cross-modal collaboration under a single-sided condition
w/o GF (Direct Sum). removes the gated fusion module and fuses universal and task-specific features via simple element-wise summation, to verify the role of gating in feature fusion and adaptive weighting.
w/o All Proposed Modules. removes the feature decoupling, cross-modal interaction, and gated fusion modules, retaining only the text and visual encoder adapters, to evaluate the overall contribution of the proposed method compared with the baseline adapters.
The experimental results, as illustrated in Figure 5, show that the full model consistently outperforms all ablation conditions, validating the effectiveness and synergistic benefits of the proposed modules.
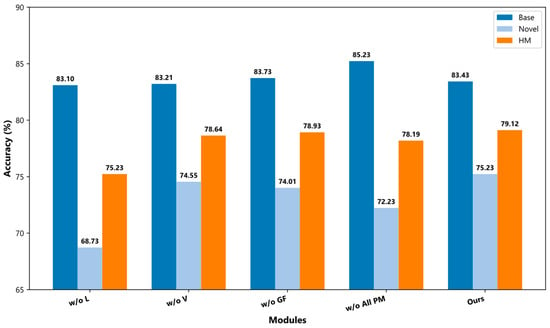
Figure 5.
Ablation experiment comparison.
4.7. Parameter Sensitivity Experiments
We conducted a sensitivity experiment on the shared layer dimension in the cross-modal semantic interaction module to analyze its impact on model performance. As shown in Figure 6 (left),the accuracy of the Base class gradually increases with the increase in the dimension, from 82.27 at a smaller dimension to 84.18 at a larger dimension, indicating that a larger dimension helps improve the model’s ability to fit the seven categories, but the accuracy of the Novel class begins to decline after the dimension reaches 32, indicating that too large a dimension may introduce more trainable parameters, resulting in overfitting on new classes with less data. Considering the performance of both Base and Novel classes, the harmonic mean reaches the best when the dimension is 16. Therefore, choosing a moderate shared layer dimension helps to improve the model’s expressiveness while taking into account the generalization performance of new classes.
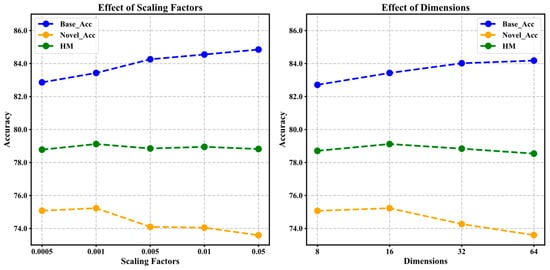
Figure 6.
Effect of shared layer dimension (left) and scaling factor (right).
In this experiment, we analyzed the impact of the scaling factor on the model, and the results are shown in Figure 6 (right). Overall, the model performs best when the scaling factor is 0.001, and the model reaches 83.43, 75.23, and 79.12 in Base, Novel, and HM, respectively. As the scaling factor increases, the accuracy of the model on Base gradually improves, but the accuracy on Novel decreases significantly, and overfitting to the base class occurs. When the scaling factor of the model is small, the model’s insufficient ability to interact with modal features leads to poor performance in the Base class; when the scaling factor is moderate, the model achieves good feature alignment between different modalities, while improving the performance of the Base class, it also maintains the generalization ability of the Novel class, thus achieving the best balance; and when the scaling factor continues to increase, the model overfits the Base class features, resulting in a decrease in the generalization ability of the Novel class, and the overall HM no longer improves. The above results show that when the scaling factor is 0.001, the optimal performance balance between the seen category and the new category can be achieved.
As shown in the line charts on the left side of Figure 7, the model exhibits a similar trend on the EuroSAT and UCF101 datasets: as the proportion of universal feature subspaces increases, the performance on base classes gradually declines, while the generalization ability does not show a corresponding improvement. This indicates that increasing the proportion of universal features does not necessarily enhance generalization performance. A possible reason is that the decoupling between universal and task-specific features is not yet fully achieved, leading to mutual interference between the two types of representations. Since complete feature independence has not been realized in the current framework, we adopt the partition ratio that yields the optimal overall HM performance across all datasets. Future work will further explore more effective and robust feature disentanglement mechanisms to improve the generalization and stability of the model in multi-task scenarios.
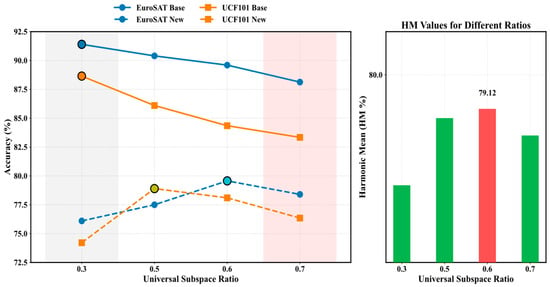
Figure 7.
Effect of the proportion of universal feature subspaces on model performance. In the right-side bar chart, the red color represents the best performance.
As shown in Table 5, although our method introduces more trainable parameters compared with previous prompt-learning approaches, the overall parameter scale remains small relative to the CLIP backbone, accounting for only about 5.48% of its total parameters. This moderate increase in parameters leads to a significant performance improvement, with our method achieving the highest HM value (79.12%) among all compared methods. In future work, we will further explore lightweight optimization strategies to reduce the number of trainable parameters and inference latency while maintaining performance improvements.
Table 5.
Comparison of model parameters and performance among different prompt-learning methods.
4.8. Feature Visualization
As shown in Figure 8, to verify the spatial distinguishability between general and task-specific features of images and text in the pre-trained model, this study conducts an analysis using a multi-class cat image dataset. First, the image features extracted by CLIP are L2-normalized and then separated according to their eigenvalues. For each patch (excluding the CLS token), the activation intensities of both general and task-specific features are computed, and the activations of task-specific features are superimposed onto the original image for visualization. The results show that, even among different cat breeds, the general features are mainly concentrated in key regions such as the nose, back, and ears, while the task-specific features focus on fine-grained details such as paws, fur, and spots. This indicates a clear spatial distinction between general and task-specific features. However, some overlapping activations between the two types of features are observed in certain regions (e.g., paws or body parts), especially in images with complex backgrounds. These irrelevant activations should be removed from the general features to reduce noise interference. Based on these observations, future work will focus on optimizing the processing of general features within the current decomposition module and exploring more effective decomposition strategies to enhance the separation of task-specific features, thereby further improving the transferability and robustness of the model in downstream tasks.

Figure 8.
Visualization of General and Task-Specific Features.
5. Conclusions
In this study, we proposed a dual-subspace driven cross-modal semantic decoupling and fusion framework to enhance the generalization of visual–language models across diverse downstream tasks. By separating task-specific and general knowledge subspaces and leveraging cross-modal interaction and dynamic semantic fusion, the framework effectively balances task adaptability and generalization in few-sample scenarios. Nevertheless, limitations remain: manual separation of general and task-specific features may be inflexible, and overlaps between these features, especially in complex backgrounds, can introduce noise. Future work will focus on optimizing general feature processing and exploring alternative decomposition strategies to improve task-specific feature separation, further enhancing transfer performance, robustness, and adaptability of visual–language models in diverse downstream applications.
Author Contributions
Conceptualization, W.L. (Wei Long) and J.L.; Methodology, W.L. (Wei Liang) and J.L.; Software, Z.G., Z.P. and X.L.; Validation, J.Y., C.L. and W.L. (Wei Long); Formal Analysis, W.L. (Wei Liang), J.L. and Z.P.; Resources, J.L.; Data Curation, Z.G. and X.L.; Supervision, Z.P. and J.L.; Funding Acquisition, J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Major Program of Xiangjiang Laboratory under Grant 25XJ01001, 24XJJCYJ01002.
Data Availability Statement
The original contributions of this study are fully included in this article. For further inquiries, please contact the corresponding authors.
Conflicts of Interest
Author Wei Long was employed by the company Changsha Duxact Biotech Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Li, Z.; Wang, J.; Hua, L.; Liu, H.; Song, W. Automatic tracking method for 3D human motion pose using contrastive learning. Int. J. Image Graph. 2024, 24, 2550037. [Google Scholar] [CrossRef]
- Mao, X.; Shan, Y.; Li, F.; Chen, X.; Zhang, S. CLSpell: Contrastive learning with phonological and visual knowledge for chinese spelling check. Neurocomputing 2023, 554, 126468. [Google Scholar] [CrossRef]
- Hajare, N.; Rajawat, A.S. Black gram disease classification via deep ensemble model with optimal training. Int. J. Image Graph. 2025, 25, 2550033. [Google Scholar] [CrossRef]
- Bhat, P.; Anoop, B.K. Improved invasive weed social ski-driver optimization-based deep convolution neural network for diabetic retinopathy classification. Int. J. Image Graph. 2025, 25, 2550012. [Google Scholar] [CrossRef]
- Shi, C.; Cheng, Y.; Wang, J.; Wang, Y.; Mori, K.; Tamura, S. Low-rank and sparse decomposition based shape model and probabilistic atlas for automatic pathological organ segmentation. Med. Image Anal. 2017, 38, 30–49. [Google Scholar] [CrossRef]
- Wang, J.; Lv, P.; Wang, H.; Shi, C. SAR-U-Net: Squeeze-and-excitation block and atrous spatial pyramid pooling based residual U-Net for automatic liver segmentation in Computed Tomography. Comput. Methods Programs Biomed. 2021, 208, 106268. [Google Scholar] [CrossRef] [PubMed]
- Tan, P.; Wang, X.; Wang, Y. Dimensionality reduction in evolutionary algorithms-based feature selection for motor imagery brain-computer interface. Swarm Evol. Comput. 2020, 52, 100597. [Google Scholar] [CrossRef]
- Yao, L. Global exponential convergence of neutral type shunting inhibitory cellular neural networks with D operator. Neural Process. Lett. 2017, 45, 401–409. [Google Scholar] [CrossRef]
- Yu, L.; Zhou, K. A dynamic local path planning method for outdoor robot based on characteristics extraction of laser rangefinder and extended support vector machine. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1659004. [Google Scholar] [CrossRef]
- Sun, Y.; Jiang, W. Human Behavior Recognition Method Based on Edge Intelligence. Discret. Dyn. Nat. Soc. 2022, 2022, 3955218. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Khattak, M.U.; Rasheed, H.; Maaz, M.; Khan, S.; Khan, F.S. Maple: Multi-modal prompt learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19113–19122. [Google Scholar]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. Clip-adapter: Better vision-language models with feature adapters. Int. J. Comput. Vis. 2023, 132, 581–595. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, W.; Fang, R.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; Li, H. Tipadapter: Training-free adaption of clip for few-shot classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 493–510. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PmLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Yao, L.; Huang, R.; Hou, L.; Lu, G.; Niu, M.; Xu, H.; Liang, X.; Li, Z.; Jiang, X.; Xu, C. Filip: Fine-grained interactive language-image pre-training. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Zhou, X.; Liang, W.; Wang, K.I.-K.; Shimizu, S. Multi-modality behavioral influence analysis for personalized recommendations in health social media environment. IEEE Trans. Comput. Soc. Syst. 2019, 6, 888–897. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Wang, K.I.-K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-learning-enhanced human activity recognition for internet of healthcare things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Tong, Y.; Sun, W. The role of film and television big data in real-time image detection and processing in the Internet of Things era. J. Real-Time Image Process. 2021, 18, 1115–1127. [Google Scholar] [CrossRef]
- Sun, W.; Mo, C. High-speed real-time augmented reality tracking algorithm model of camera based on mixed feature points. J. Real-Time Image Process. 2021, 18, 249–259. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Liang, W.; Zeng, Z.; Yan, Z. Deep-learning-enhanced multitarget detection for end–edge–cloud surveillance in smart IoT. IEEE Internet Things J. 2021, 8, 12588–12596. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Li, W.; Yan, K.; Shimizu, S.; Wang, K.I.-K. Hierarchical adversarial attacks against graph-neural-network-based IoT network intrusion detection system. IEEE Internet Things J. 2021, 9, 9310–9319. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, Y.; Yang, J. ELGONBP: A grouped neighboring intensity difference encoding for texture classification. Multimed. Tools Appl. 2023, 82, 10311–10336. [Google Scholar] [CrossRef]
- Wu, M.; Wu, Y.; Liu, X.; Ma, M.; Liu, A.; Zhao, M. Learning-based synchronous approach from forwarding nodes to reduce the delay for Industrial Internet of Things. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 10. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Yao, H.; Zhang, R.; Xu, C. Visual language prompt tuning with knowledge-guided context optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6757–6767. [Google Scholar]
- Goswami, K.; Karanam, S.; Udhayanan, P.; Joseph, K.J.; Srinivasan, B.V. Copl: Contextual prompt learning for vision-language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 18090–18098. [Google Scholar]
- Lu, Y.; Liu, J.; Zhang, Y.; Liu, Y.; Tian, X. Prompt distribution learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 3, pp. 5206–5215. [Google Scholar]
- Wang, S.; Li, X.; Sun, J.; Xu, Z. Training Networks in Null Space of Feature Covariance with Self-Supervision for Incremental Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2563–2580. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA; pp. 248–255. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–1 July 2004; IEEE: Piscataway, NJ, USA; p. 178. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C.V. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA; pp. 3498–3505. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Nilsback, M.-E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; IEEE: Piscataway, NJ, USA; pp. 722–729. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101–mining discriminative components with random forests. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VI 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 446–461. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE International Conference on Computer Vision, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar] [CrossRef]
- Zhu, B.; Niu, Y.; Han, Y.; Wu, Y.; Zhang, H. Prompt-aligned gradient for prompt tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 15659–15669. [Google Scholar]
- Kim, G.; Kim, S.; Lee, S. Aapl: Adding attributes to prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 1572–1582. [Google Scholar]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V. Do imagenet classifiers generalize to imagenet? In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5389–5400. [Google Scholar]
- Wang, H.; Ge, S.; Lipton, Z.; Xing, E.P. Learning robust global representations by penalizing local predictive power. Adv. Neural Inf. Process. Syst. 2019, 32, 10506–10518. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15262–15271. [Google Scholar]
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8340–8349. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).