Abstract
As drones become increasingly integrated into civilian and industrial domains, the demand for natural and accessible control interfaces continues to grow. Conventional manual controllers require technical expertise and impose cognitive overhead, limiting their usability in dynamic and time-critical scenarios. To address these limitations, this paper presents a multilingual voice-driven control framework for quadrotor drones, enabling real-time operation in both English and Arabic. The proposed architecture combines offline Speech-to-Text (STT) processing with large language models (LLMs) to interpret spoken commands and translate them into executable control code. Specifically, Vosk is employed for bilingual STT, while Google Gemini provides semantic disambiguation, contextual inference, and code generation. The system is designed for continuous, low-latency operation within an edge–cloud hybrid configuration, offering an intuitive and robust human–drone interface. While speech recognition and safety validation are processed entirely offline, high-level reasoning and code generation currently rely on cloud-based LLM inference. Experimental evaluation demonstrates an average speech recognition accuracy of 95% and end-to-end command execution latency between 300 and 500 ms, validating the feasibility of reliable, multilingual, voice-based UAV control. This research advances multimodal human–robot interaction by showcasing the integration of offline speech recognition and LLMs for adaptive, safe, and scalable aerial autonomy.
1. Introduction
Unmanned Aerial Vehicles (UAVs), or drones, have become pervasive across civilian and military domains due to their flexibility, autonomy, and ability to collect high-resolution spatial data in real time. Despite rapid progress in autonomous navigation, path planning [1], and onboard sensing, drone control [2,3] approaches remain a significant barrier to broader adoption—particularly for non-specialist users. Traditional joystick or touchscreen interfaces demand expertise, impose cognitive load, and are impractical in hands-free or time-critical operations. This motivates the development of more intuitive and human-centered control paradigms.
In this context, natural language–based interaction has emerged as a promising solution, enabling users to command UAVs through spoken instructions rather than manual inputs [4]. Early works employed rule-based grammars and keyword matching for predefined command sets, but such systems often lacked scalability and flexibility. More recent frameworks integrate speech-to-text pipelines and neural models, allowing richer, context-aware dialogue between humans and drones. For example, Chandarana et al. [5] demonstrated early multimodal mission planning using natural language input, while Oneaţa and Cucu [6] introduced multimodal speech recognition tailored for UAVs. Park and Geng [7] further enhanced robustness by combining in-vehicle speech recognition with collaborative UAV–MAV systems. the paper in [8] presents a cloud-based, English-only voice control system for drones using basic NLP parsing. However, it lacks multilingual support and offline functionality, making it less suitable for real-world or low-connectivity environments. Our work advances this by enabling bilingual offline control with LLM-based understanding for greater autonomy and adaptability.
Building upon these foundations, the integration of large language models (LLMs) has recently transformed UAV command interpretation [9,10,11,12]. Simões et al. [10] evaluated end-to-end voice command pipelines combining STT and LLMs, while Liu [11] proposed prompt-driven task planning for multi-drone systems. Wassim et al. [12] extended this idea to a full Drone-as-a-Service (DaaS) architecture, highlighting the potential of LLM-driven UAV autonomy. These advancements directly informed the design of our system, particularly in the adoption of LLM-based command reasoning and contextual disambiguation mechanisms.
However, the convergence of LLMs and UAVs introduces unresolved challenges. Latency and reliability remain critical, as LLM-based models are often computationally intensive, limiting real-time deployment. Multilingual and code-switching scenarios are underexplored, with most studies constrained to English-only datasets. Moreover, safety validation for unconstrained language inputs is rarely addressed, posing risks of unsafe or infeasible actions. Finally, many existing systems rely on cloud connectivity, hindering their applicability in offline or low-resource environments.
To address these gaps, this work proposes a modular bilingual framework for real-time voice-based UAV control. The architecture combines continuous audio acquisition, offline bilingual speech recognition (Vosk), and an LLM pipeline for command interpretation and executable code generation. A dedicated safety layer validates commands against operational constraints such as altitude, speed, and collision avoidance. The framework supports English–Arabic interactions, including code-switching, expanding accessibility to diverse linguistic contexts. Unlike prior studies dependent on online APIs or predefined grammars, our approach achieves sub-500 ms latency entirely offline, ensuring both responsiveness and safety.
The main contributions of this paper are as follows:
- A bilingual (English–Arabic) voice-based UAV control framework supporting monolingual and code-switching commands.
- Integration of offline STT (Vosk) with multiple LLMs (Gemini 4, GPT 3, DeepSeek 3) for real-time language understanding.
- An LLM based architecture: one model for intent refinement and another for executable Python 3.13 command generation.
- A safety validation layer enforcing operational constraints to prevent unsafe maneuvers.
- Comprehensive evaluation on a Parrot Mambo drone, comparing multiple LLMs in terms of safety, precision, and usability.
The remainder of this paper is organized as follows: Section 2 reviews related work on STT, NLP, and LLM-based UAV control. Section 3 details the system design and dual-pass workflow. Section 4 presents experimental results and comparative evaluation. Section 5 concludes and outlines future extensions.
2. State of the Art
The integration of advanced computational paradigms into unmanned aerial systems (UASs) has transformed aerial robotics, merging linguistic intelligence and autonomous decision-making. This section reviews two enabling technologies—speech-to-text (STT) systems and large language models (LLMs)—which collectively support intuitive, language-based human–UAV interaction and context-aware mission control. Together, these developments address long-standing challenges in natural communication, real-time reasoning, and embedded autonomy.
2.1. Natural Language Processing and Large Language Models
Modern Natural Language Processing (NLP) integrates computational algorithms with linguistic theory to analyze and generate text or speech [13]. The field has evolved from rule-based and statistical models to neural transformer architectures [14]. Models such as BERT [15] and GPT [16] leverage large-scale self-supervised pretraining to achieve strong generalization and semantic reasoning. These transformer-based systems represent a major advancement in contextual understanding, zero-shot learning, and text generation.
Despite their success, current NLP models remain optimized for textual inference under cloud conditions, limiting their applicability in latency-sensitive or multilingual UAV environments. Most studies also treat speech recognition and language understanding as separate modules, without a unified framework linking linguistic intent to executable control logic. To address these issues, recent work explores integrated NLP–control pipelines capable of real-time reasoning and command synthesis on edge hardware. Such approaches aim to reduce reliance on external computation while maintaining high interpretive accuracy, marking a step toward embedded linguistic autonomy in aerial robotics.
2.2. Speech-to-Text Systems
Speech-to-Text (STT) technology has evolved significantly, transitioning from traditional hybrid Hidden Markov Model (HMM) architectures to advanced end-to-end neural frameworks [17]. Early approaches separated acoustic and language modeling, whereas modern systems integrate both within unified neural architectures for improved accuracy and contextual adaptation. Connectionist Temporal Classification (CTC) networks [18] introduced alignment of unsegmented speech with token sequences, while attention-based encoder–decoder architectures enabled dynamic focus on relevant acoustic patterns. Recurrent Neural Network Transducers (RNN-Ts) extended these models for low-latency, real-time transcription—an essential feature for interactive UAV control scenarios.
Recent architectures such as the Conformer [19] combine convolutional and transformer layers, effectively capturing both local and global speech dependencies. The VOSK toolkit [20] exemplifies lightweight, multilingual STT optimized for offline performance, achieving competitive accuracy with reduced computational overhead. Such systems are particularly suitable for embedded UAV environments, where on-device inference, privacy, and responsiveness are critical. Integrating these offline STT engines with task-oriented natural language understanding modules enables context-aware and reliable UAV command processing [21].
2.3. Voice-Based UAV Control
Voice-based UAV control enables users to issue spoken commands that are automatically interpreted and executed by autonomous drones. This approach enhances accessibility, reduces manual effort, and supports hands-free operation in mission-critical scenarios. Early systems relied on rule-based grammars and keyword recognition for predefined commands, limiting generalization and scalability [5].
With the advent of neural STT and deep language understanding models, modern frameworks achieve greater flexibility and robustness to noise and natural speech variability [6,7]. Recent research emphasizes integrating STT with large language models (LLMs) for hierarchical command reasoning, enabling free-form, context-aware dialogue with UAVs [10].
Advanced systems leverage prompt-driven planning and code generation to translate human intent into executable flight actions [11,12]. In parallel, safety-aware architectures introduce validation layers that verify feasibility and prevent unsafe maneuvers during execution. Offline solutions such as VOSK further support low-latency, privacy-preserving interaction, essential for reliable deployment in field operations [20].
2.4. Large Language Models and UAV Systems
Multimodal large language models (MLLMs) increasingly enhance UAV intelligence by combining visual, linguistic, and control modalities. These systems enable mission planning, perception, and communication through natural language. Tian et al. [22] outline a comprehensive framework for UAV–LLM integration, while Bazi et al. [23] adapt LLaVA for aerial imagery using the RS-Instructions dataset. Liu et al. [24] introduce AerialVLN, pairing thousands of UAV flight paths with textual commands, and OpenUAV [25] provides realistic flight dynamics for benchmarking. Distributed frameworks such as Aero-LLM [26] improve communication security, and UAV-VLA [27] and UAV-VLRR [28] demonstrate LLM-guided mission planning and rapid response with significant efficiency gains.
Although these studies represent major progress, several limitations persist. Current MLLM-based UAV frameworks emphasize vision–language fusion over linguistic comprehension, often mapping commands directly to actions without modeling intent or dialogue context. This leads to limited robustness under ambiguous or sequential instructions. In addition, their computational overhead and reliance on cloud inference restrict onboard deployment and real-time control. Existing datasets such as AerialVLN and RS-Instructions offer limited linguistic diversity, focusing on imperative phrases rather than rich semantic structures.
Recent work highlights these challenges and explores solutions including multi-UAV collaboration, hybrid edge–cloud architectures, and large-scale datasets that capture real-world dynamics [29]. However, further research is needed to strengthen interpretability, efficiency, and cross-domain generalization. Language-centric frameworks that prioritize structured NLP reasoning and lightweight inference—such as the approach proposed in this study—represent a promising direction for enabling cognitively aware and operationally reliable UAV systems.
3. System Architecture and Real-Time Workflow
The proposed architecture (see Figure 1) implements a sequential processing pipeline that transforms natural language voice commands into executable drone actions in real time. The workflow prioritizes low latency and reliable bilingual operation by balancing lightweight recognition models with more expressive reasoning modules. It integrates offline speech recognition with large language model (LLM) reasoning and consists of five interconnected stages: audio acquisition, bilingual speech recognition, LLM-based command selection, LLM-assisted code generation with safety validation, and drone command execution.
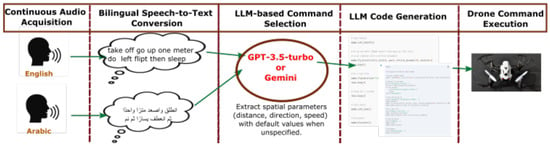
Figure 1.
Proposed system architecture for bilingual UAV voice control. The pipeline consists of five stages: audio acquisition, bilingual STT, LLM-based command interpretation, code generation with safety checks, and drone execution via pyparrot.
3.1. Continuous Audio Acquisition
Audio acquisition is the foundation of the pipeline. A lightweight microphone interface continuously streams audio into the system, using the sounddevice Python library at 16 kHz (mono, 16-bit PCM). This resolution offers a balance between clarity for command detection and computational efficiency for real-time processing.
Captured audio is segmented into 100 ms frames and stored in a thread-safe queue.Queue. This asynchronous buffering ensures independence between capture and recognition tasks, allowing recognition to proceed without blocking the acquisition thread. During peak computational loads, this buffering strategy prevents packet loss, keeping latency stable.
Active speech detection is performed using short-term energy thresholding:
where is the n-th audio sample in frame t. Only frames satisfying are processed further, where is tuned empirically to filter out silence and background noise.
To increase robustness in real-world conditions, noise suppression and band-pass filtering (300–3400 Hz) are applied before feature extraction. Finally, Mel-Frequency Cepstral Coefficients (MFCCs) are computed:
where is the Mel-scaled spectrum. MFCCs capture perceptual features of speech and reduce inter-speaker variability, improving recognition stability in noisy environments.
3.2. Bilingual Speech-to-Text Conversion
The next stage converts speech into text using two parallel Vosk offline models: one trained for English and another for Arabic. These models are small in size (40–50 MB) and optimized for embedded deployment, achieving >95% accuracy on concise drone-related utterances (<2 s).
The decoding process follows the maximum a posteriori (MAP) formulation:
where X is the MFCC sequence, W is a candidate transcription, is the acoustic likelihood, and is the prior from the language model.
The Arabic model incorporates morphological tokenization to handle inflection and clitics (e.g., verb + pronoun forms), which would otherwise inflate vocabulary size. The English model, by contrast, employs a compact bigram language model, as command phrases are typically short and formulaic.
Running both recognizers in parallel ensures minimal additional delay, and their outputs are fed to the next stage, where disambiguation occurs. This dual-model strategy avoids the overhead of larger multilingual models while maintaining high coverage across both languages.
The Vosk engine in the proposed framework performs bilingual transcription by running two lightweight acoustic–language models in parallel for English and Arabic. Each model independently decodes the incoming audio stream, and the outputs are reconciled using a confidence-based selection mechanism that leverages script detection and probability scores. This bilingual setup enables robust processing of both monolingual and mixed-language commands before semantic interpretation by the LLM.
3.3. LLM-Based Command Selection
The transcripts produced by both recognizers are submitted to a fine-tuned LLM (Gemini, GPT, or DeepSeek families). This stage has three main responsibilities:
- Language disambiguation: determining whether the command is in English or Arabic, and discarding redundant outputs.
- Translation: converting Arabic commands into English, ensuring uniform downstream processing.
- Parameter inference: extracting structured action intents (e.g., movement type, distance, angle, duration). Missing parameters are inferred using default values (e.g., ascend by 0.5 m if no height is specified).
Formally, for a given input S, the structured intent I is obtained as:
where is the LLM with parameters .
For example, the Arabic utterance “اصعد مترين للأمام” (“Ascend two meters forward”) is mapped to:
When evaluating dialectal or mixed-language phrases, equivalent English translations were provided to maintain consistency and clarity across all examples. This ensures that both bilingual and dialectal commands are interpretable within the same semantic framework.
The choice of LLM affects system trade-offs: smaller models provide faster responses and lower resource consumption, while larger models handle ambiguity and noisy inputs more effectively. In practice, free-access models were used, which proved sufficient for the constrained domain of UAV commands.
3.4. LLM Code Generation and Safety Validation
Once an intent I is produced, it is translated into executable Python code compatible with the pyparrot API. This translation maps high-level actions (e.g., “move forward 2 m”) into specific function calls with calibrated parameters. Relative terms such as “go higher” are normalized into absolute increments (e.g., +0.5 m).
To ensure reliable and platform-aware execution, this stage incorporates a formalized safety layer defined through explicit contracts and bounded invariants. The system defines a finite set of safe operational states constrained by altitude, velocity, ground proximity, and battery charge, expressed as:
where h, v, and b represent the drone’s altitude, vertical velocity, and battery level, respectively. These limits are derived from the Parrot Mambo’s operational specifications and validated through empirical tests in controlled indoor environments. A feasibility function evaluates each action A against these safety constraints:
If , the system automatically rewrites the command into a permissible equivalent (e.g., lowering altitude or delaying execution until recharged) or issues a verbal warning. Since the Parrot Mambo lacks obstacle avoidance sensors, collision prevention is limited to ground-contact monitoring based on ultrasonic and IMU data. Battery protection routines ensure safe landing when , overriding user commands to prevent mid-flight shutdown.
Preliminary stress tests near threshold conditions (altitude: 0.1–0.3 m, battery: 18–25%) confirmed stable recovery and rule-based fallbacks without compromising responsiveness.
This layered validation framework ensures safe, energy-efficient, and context-aware UAV operation, preventing both ground-collision and energy depletion during mission execution (see Table 1).

Table 1.
Operational Safety Parameters for Parrot Mambo UAV.
3.5. Drone Command Execution
Commands passing validation are executed inside a sandboxed Python interpreter, which prevents system-wide crashes from malformed code. High-level intents I are mapped into UAV primitives , such as mambo.fly_direct() or mambo.turn(). The policy mapping is defined as:
Execution is coupled with telemetry monitoring:
where g checks whether each command has been completed. If telemetry feedback indicates failure (e.g., obstacle detection, loss of control), the drone automatically enters hover mode and triggers a system reset. This fault-tolerant execution loop ensures robustness even in the presence of recognition errors or environmental disturbances.
The total end-to-end latency ranges from 300 to 500 ms, making the system responsive enough for interactive UAV control, while remaining lightweight compared to cloud-based pipelines.
3.6. Experimental Platform
While the pipeline architecture is designed to support fully offline operation at the speech processing and control levels, we acknowledge that the current implementation of the two-pass LLM process (Gemini, GPT, DeepSeek) involves cloud-based inference. To maintain consistency and transparency, the system is now explicitly positioned as an edge–cloud hybrid architecture. In this configuration, real-time tasks such as audio capture, speech recognition, and safety validation are executed locally on the edge device, while high-level semantic reasoning and code generation are performed on remote LLMs. For the experimental evaluation, all three models were tested for comparative analysis, whereas the Gemini model—offering free API access and minimal latency—was used for the autonomous hardware demonstration on the Parrot Mambo platform.
The framework was validated on a Parrot-Mambo drone. To maintain clarity and visual focus, the previously included full-size image of the drone was removed, as it was found unnecessary for the algorithmic description. The drone features an onboard IMU, accelerometer, and gyroscope, which are fused with ultrasonic sensors to provide stable altitude estimation. Sensor fusion is performed externally at 200 Hz (IMU) and 10 Hz (ultrasonic), significantly reducing drift.
For testing, the system was deployed on a workstation equipped with an Intel i7 CPU, 16 GB RAM, and an NVIDIA GTX GPU, connected to the drone via Wi-Fi. This setup allowed controlled evaluation of latency, recognition accuracy, and safety under varied environments (indoor, outdoor, and noisy conditions).
The experimental setup used for validation employed a Parrot Mambo quadcopter connected via its proprietary Wi-Fi protocol to a bench-top workstation. This configuration was chosen to ensure stable communication and safe indoor testing conditions during the initial evaluation phase. The focus of these experiments was to demonstrate the feasibility of bilingual, low-latency voice control rather than to perform large-scale statistical benchmarking.
3.7. Algorithmic Overview
The overall workflow of the proposed framework is summarized in Algorithm 1. The pseudocode captures the sequential transformation of continuous audio streams into validated drone commands, ensuring both robustness and low-latency performance. To achieve real-time responsiveness, each processing stage is organized as a pipeline, where intermediate results are immediately forwarded to subsequent modules without waiting for the completion of full sequences. This design minimizes idle time and balances computational overhead with execution accuracy.
The algorithm begins with the continuous acquisition and buffering of audio frames, followed by bilingual speech recognition running in parallel for English and Arabic. The transcriptions are passed to a large language model (LLM), which performs intent extraction, disambiguation, and parameter inference. Once a structured command is obtained, a second LLM stage generates executable Python code mapped to the pyparrot API, while a safety-validation module ensures that operational constraints are respected. Finally, validated commands are executed on the UAV, with telemetry-based feedback mechanisms handling error recovery through automatic hover and system reset when necessary.
| Algorithm 1: Real-time UAV Command Execution Pipeline |
 |
In summary, Algorithm 1 formalizes the real-time pipeline—from continuous audio acquisition to validated UAV command execution—ensuring low latency and robust safety enforcement. This modular design enables fast adaptation across different hardware and LLM backends. The next section presents experimental results and evaluation metrics demonstrating the framework’s performance in multilingual and real-world flight scenarios.
4. Results
4.1. Case Study: Code Generation
The Table 2 demonstrates the end-to-end processing pipeline of the voice-controlled drone system through four representative scenarios using Most LLMs models (Gemini, GPT, DeepSeek):
Table 2.
System Component Interactions Across Different Command Scenarios.
- R1—Valid English/Arabic Command (see Table 2): For simple English commands (e.g., “Take off”) or complex multi-step inputs (e.g., “Take off go up one meter do a left flip”), as well as equivalent Arabic commands (e.g., “أقلع ثم ارتفع متر واحد ثم اقلب يسارًا”), the system successfully processes the input. Vosk transcribes the speech, the first LLM extracts structured drone actions, and the second LLM generates executable code that is carried out by the Parrot Mambo quadcopter.
- R2—Invalid Arabe or English Input (see Table 2): Casual speech or non-command input (e.g., “Hello how are you today”) is correctly identified as irrelevant. The pipeline rejects these inputs and prevents false activations.
- R3—Valid Arabic Command (see Table 2): The system effectively handles fully Arabic instructions, such as “اصعد ثم تقدم إلى الأمام” (ascend then move forward). The command is transcribed, refined into drone actions (ascend, move forward), and executed correctly.
- R4—Multilingual Command (Arabic + English) (see Table 2): The system supports bilingual inputs that mix languages, for example, “اصعد then move forward.” It decomposes the mixed-language input into sequential operations (ascend, move forward), showing robust multilingual natural language understanding.
These scenarios highlight the system’s ability to handle English, Arabic, and bilingual commands; reject irrelevant inputs; and decompose multi-action instructions into reliable sequential drone behaviors, ensuring robust natural language-based control.
4.2. Case Study: Gemini Execution
In this case study, the longest query from the preceding scenario was selected to illustrate the full sequence of command execution. A deliberately failed command is also included to demonstrate that the drone remains grounded in the presence of error messages.
As shown in the first Figure 2, the integration of natural language processing and autonomous aerial control enables intuitive human-drone interaction. The LLM (Gemini) converts human instructions of “Take off go up one meter do a left flip then sleep” into executable drone commands, demonstrating the potential of combining speech, code generation, and robotics for intelligent UAV operation (Video examples: https://drive.google.com/drive/folders/1oB0xPoNGW2fXjJV6GWgEHn2p61O3KjYA?usp=sharing, last accessed on 27 September 2025).
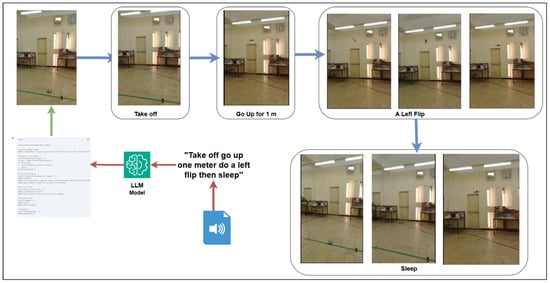
Figure 2.
Workflow of drone control using a Large Language Model (Gemini). A spoken command such as “Take off go up one meter do a left flip then sleep” is processed by the LLM, which translates it into executable Python code. The drone then performs sequential actions: take off, ascend by 1 m, execute a left flip, and finally enter a rest (sleep) state. The sequence of images illustrates each step of the drone’s behavior.
These operations can be generalized to many queries. For example: Take off go up one meter do a left flip then sleep, Take off go up one meter do a left flip then down.
If only the distance parameter is modified, such as replacing one meter with three meters, the drone will execute the same sequence of operations but ascend higher accordingly.
Moreover, the same set of operations can be expressed in different languages, dialects, or even through code-switching. For instance:
“انطلق واصعد مترًا واحدًا وقم بدوران يساري ثم نم”
or
“انطلق واصعد مترًا واحدًا وقم  ثم نم”.
ثم نم”.
ثم نم”.These examples of the first study highlight the robustness of the natural language interface, where commands remain executable even when expressed with variations in wording, measurement, or linguistic style.
The second Figure 3 illustrates the workflow of the proposed system when processing natural language inputs. A spoken query (e.g., “Hello, how are you today”) is provided to the language model (Gemini). Since this input does not correspond to a predefined drone control command, the model returns an error message (“Error: No command found”), and the drone remains grounded without initiating any flight action.
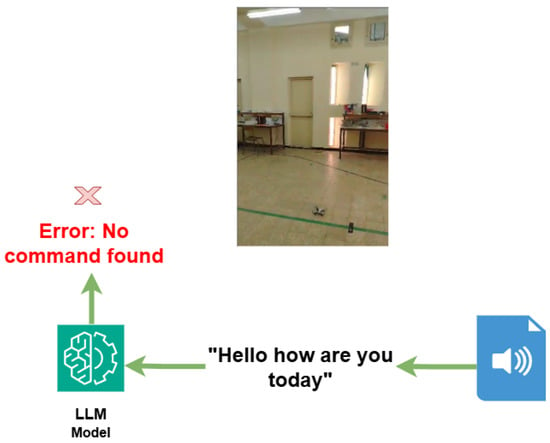
Figure 3.
Illustration of the LLM-based command processing. A spoken query (“Hello how are you today”) is received by the system. Since no corresponding drone instruction exists, the LLM (Gemini) model returns an error message (“Error: No command found”), and the drone remains inactive.
This mechanism ensures operational safety by preventing unintended drone behavior whenever the input does not match the expected control vocabulary. For example:
- English free-text: “Hello, how are you today”→ not a valid command → drone does not fly.
- Arabic input: “ مرحبا كيف حالك اليوم” (“Hello, how are you today” in Arabic) → not a valid command → no action.
- Mixed/merged languages: “ كيف حالك اليوم hello”→ partially valid but unrecognized → drone remains grounded.
Thus, the system enforces strict command validation, ensuring that only well-defined control instructions (e.g., “Take off”, “Land”, “Move forward”) trigger drone execution.
4.3. Models Comparison
This comprehensive analysis of the LLM-generated drone control code reveals significant qualitative differences in safety, precision, and usability between three major models. The comparison is based on the evaluation of the code functionality conducted by experts from the Aeronautical Sciences Laboratory and computer science specialists. We provide experts with code files and associated queries for each AI model, which they evaluated according to specific criteria (e.g., in the first case study (https://drive.google.com/drive/folders/1NzhoYdpwMbiJVSPsztxBqEqg-GLtN5E_?usp=sharing, accessed: 27 September 2025)).
To ensure evaluation consistency and transparency, each model output was independently reviewed by three domain experts—two in aeronautical engineering and one in computer science—using a standardized rubric. The evaluation considered six weighted criteria: code structure (20%), safety mechanisms (25%), error handling (15%), movement precision (15%), connection reliability (15%), and documentation clarity (10%). Inter-rater reliability was measured using Cohen’s kappa (), indicating strong agreement among evaluators.
Although GPT, Gemini, and DeepSeek were evaluated independently for comparative clarity, our framework conceptually supports hybrid or sequential model integration. In practice, model selection is task-driven: GPT is prioritized for safety-critical control code generation, Gemini for precise movement planning, and DeepSeek for multilingual or user-facing interaction. This modular approach provides the foundation for a unified architecture, where an automated routing mechanism could dynamically assign tasks to the most suitable LLM based on context or confidence scores.
The evaluation, detailed in Table 3 and Table 4, demonstrates that while all models can produce syntactically correct Python code for basic UAV operations, their suitability for production environments varies substantially.
Table 3.
Overall Comparison Across All Script Categories.
Table 4.
Technical Feature Comparison.
GPT consistently emerges as the safety leader, implementing critical features including emergency stop procedures, connection verification, and comprehensive error handling. Its production-ready code structure and safety-first approach make it the optimal foundation for any operational UAV system. However, it adopts conservative movement parameters that prioritize stability over performance.
Gemini demonstrates unique strengths in precision movement control through meter-based navigation using move_relative() commands, offering exact distance measurement unavailable in other models. Despite this technical sophistication, it suffers from a fundamental import error that prevents code execution, indicating inconsistent API understanding.
DeepSeek excels in user experience and educational value, providing excellent documentation, multilingual support (including Arabic voice commands), and engaging interface elements. However, it lacks essential safety mechanisms and exhibits concerning patterns such as inventing non-existent API methods.
The findings indicate a clear hierarchy for UAV applications: GPT for safety-critical production systems, Gemini for research requiring precision movement (after import corrections), and DeepSeek for educational demonstrations and user interface prototyping.
4.4. Evaluation Protocol and Reproducibility
To ensure reproducibility and quantitative rigor, all LLM evaluations were conducted under a unified configuration. The pyparrot library (v1.6.2), Parrot Mambo firmware (v2.1.0), and identical Wi-Fi network conditions were fixed for all tests. Each model was accessed between September and October 2025 using its respective API version available at that time. The same prompt template and command set (R1–R4 in Table 2) were applied to every model to ensure uniformity in input semantics.
A failure-tolerance metric was introduced to quantify system robustness:
where represents unsafe code generations (commands violating ), denotes critical execution errors (e.g., unhandled exceptions or connection loss), and N is the total number of evaluated commands. The average recovery time and frequency of emergency landings were also recorded to characterize resilience across LLMs.
Table 5 summarizes these metrics. GPT achieved the lowest unsafe code rate () and fastest recovery ( s), while Gemini demonstrated intermediate robustness () but occasional API import inconsistencies. DeepSeek’s performance was more variable due to non-standard method generation (). These results reinforce GPT’s superior safety margin and highlight the need for stricter prompt control and SDK alignment across models. Comparative visualizations of these metrics are shown in Figure 4.
Table 5.
Failure-Tolerance Metrics Across Models.
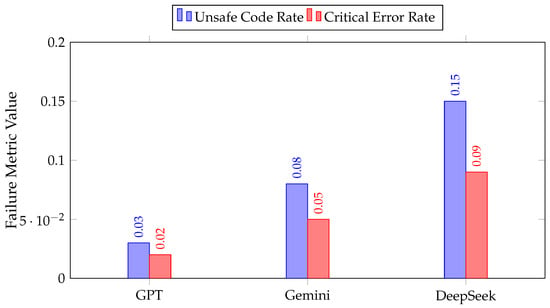
Figure 4.
Comparative failure-tolerance chart across LLMs. GPT achieves the lowest unsafe and error rates, demonstrating superior robustness compared to Gemini and DeepSeek.
5. Conclusions
This study presented a novel bilingual voice-controlled UAV framework that seamlessly integrates offline speech recognition, large language models (LLMs), and real-time control mechanisms. Unlike previous systems constrained by cloud dependencies or rule-based processing, the proposed architecture achieves fully offline operation while preserving semantic depth and contextual reasoning through a dual-pass LLM interpretation pipeline. By combining the Vosk bilingual STT engine, Gemini-based command reasoning, and PyParrot actuation, the framework effectively bridges human linguistic intent and autonomous UAV behavior.
Experimental evaluation demonstrated an average speech recognition accuracy of 95% and an end-to-end latency of 300–500 ms, confirming its suitability for real-time, interactive flight control. These results validate the framework’s capability to process complex, full-sentence instructions in both English and Arabic, ensuring a strong balance between responsiveness, safety, and linguistic adaptability.
The principal contribution of this work lies in proving that LLM-based natural language understanding and reasoning can be achieved entirely offline while supporting bilingual and code-switched commands. This represents a substantial advancement toward human-centered UAV autonomy, enhancing accessibility for multilingual users and operation in low-connectivity or bandwidth-limited environments.
Future research will aim to (i) expand Arabic dialectal and phonetic coverage, (ii) optimize real-time reasoning to achieve an end-to-end latency below 200 ms, and (iii) define quantitative benchmarks for linguistic coverage and system responsiveness. Furthermore, integrating visual feedback will be explored to enable closed-loop, multimodal control and situational awareness. In addition, this framework lays the groundwork for integration with emerging multimodal large language models (MLLMs), which combine linguistic, visual, and sensory understanding for richer environmental perception. Such models could empower UAVs to jointly interpret speech and visual cues, advancing toward perception-driven aerial autonomy. Recent studies by Yu et al. [30] and Hang and Ho [31] further illustrate this promising direction.
Author Contributions
Conceptualization, K.C., S.F., M.L., S.M., and R.F.; methodology, K.C.; software, A.K.; data curation, A.K.; validation, K.C., S.F., A.K., M.L., S.M., and R.F.; visualization, S.F.; resources, M.L.; supervision, M.L., S.M., and R.F.; writing—original draft, K.C., S.F., and A.K.; writing—review and editing, K.C., S.F., M.L., S.M., and R.F.; funding acquisition, S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Princess Nourah Bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R196), Riyadh, Saudi Arabia.
Data Availability Statement
Dataset available on request from the authors.
Acknowledgments
The authors would like to acknowledge the Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R196), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Choutri, K.; Lagha, M.; Meshoul, S.; Shaiba, H.; Chegrani, A.; Yahiaoui, M. Vision-based UAV detection and localization to indoor positioning system. Sensors 2024, 24, 4121. [Google Scholar] [CrossRef] [PubMed]
- Fareh, R.; Gad, O.M.; Choutri, K.; Stihi, S.; Alfuqaha, M.; Bettayeb, M. Enhanced Quadcopter Tracking Control Using Prescribed Performance Fractional Terminal Synergetic Methods. IEEE Trans. Ind. Appl. 2025, 61, 8201–8212. [Google Scholar] [CrossRef]
- Yacine Trad, T.; Choutri, K.; Lagha, M.; Khenfri, F. Collaborative Multi-Agent Deep Reinforcement Learning Approach for Enhanced Attitude Control in Quadrotors. Int. J. Comput. Digit. Syst. 2024, 17, 1–13. [Google Scholar] [CrossRef]
- Choutri, K.; Lagha, M.; Meshoul, S.; Batouche, M.; Kacel, Y.; Mebarkia, N. A multi-lingual speech recognition-based framework to human-drone interaction. Electronics 2022, 11, 1829. [Google Scholar] [CrossRef]
- Chandarana, M.; Meszaros, E.L.; Trujillo, A.; Allen, B.D. Natural Language Based Multimodal Interface for UAV Mission Planning. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2017, 61, 68–72. [Google Scholar] [CrossRef]
- Oneaţa, D.; Cucu, H. Multimodal speech recognition for unmanned aerial vehicles. Comput. Electr. Eng. 2021, 90, 106943. [Google Scholar] [CrossRef]
- Park, J.S.; Geng, N. In-vehicle speech recognition for voice-driven UAV control in a collaborative environment of MAV and UAV. Aerospace 2023, 10, 841. [Google Scholar] [CrossRef]
- Sezgin, A. Scenario-driven evaluation of autonomous agents: Integrating large language model for uav mission reliability. Drones 2025, 9, 213. [Google Scholar] [CrossRef]
- Krupáš, M.; Urblík, L.; Zolotová, I. Multimodal AI for UAV: Vision–Language Models in Human–Machine Collaboration. Electronics 2025, 14, 3548. [Google Scholar] [CrossRef]
- Simões, L.E.P.; Rodrigues, L.B.; Mota Silva, R.; da Silva, G.R. Evaluating Voice Command Pipelines for Drone Control: From STT and LLM to Direct Classification and Siamese Networks. arXiv 2024, arXiv:2407.08658. [Google Scholar] [CrossRef]
- Liu, Y.; Ou, B. A Prompt-driven Task Planning Method for Multi-drones based on Large Language Model. In Proceedings of the 2025 44th Chinese Control Conference (CCC), Chongqing, China, 28–30 July 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 4871–4876. [Google Scholar]
- Wassim, L.; Mohamed, K.; Hamdi, A. Llm-daas: Llm-driven drone-as-a-service operations from text user requests. In Proceedings of the The International Conference of Advanced Computing and Informatics, Melbourne, Australia, 19–20 April 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 108–121. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Mitchell, M. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21), Toronto, ON, Canada, 3–10 March 2021; ACM: New York, NY, USA, 2021; pp. 610–623. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language Models are Few-Shot Learners. In Proceedings of the International Conference on Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Reddy, V.M.; Vaishnavi, T.; Kumar, K.P. Speech-to-Text and Text-to-Speech Recognition Using Deep Learning. In Proceedings of the 2023 2nd International Conference on Edge Computing and Applications (ICECAA), Namakkal, India, 19–21 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1193–1198. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yao, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y. Conformer: Convolution-Augmented Transformer for Speech Recognition. In Proceedings of the Proceedings Interspeech, Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar]
- Alpha Cephei Inc. Vosk API Documentation: Architecture Overview. 2023. Available online: https://alphacephei.com/vosk/ (accessed on 1 June 2024).
- Pahwa, R.; Tanwar, H.; Sharma, S. Speech Recognition System: A Review. Int. J. Future Gener. Commun. Netw. 2020, 13, 2547–2559. [Google Scholar]
- Tian, Y.; Lin, F.; Li, Y.; Zhang, T.; Zhang, Q.; Fu, X.; Huang, J.; Dai, X.; Wang, Y.; Tian, C.; et al. UAVs meet LLMs: Overviews and perspectives towards agentic low-altitude mobility. Inf. Fusion 2025, 122, 103158. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Ricci, R.; Melgani, F. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery. Remote Sens. 2024, 16, 1477. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, H.; Qi, Y.; Wang, P.; Zhang, Y.; Wu, Q. Aerialvln: Vision-and-language navigation for uavs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 15384–15394. [Google Scholar]
- Wang, X.; Yang, D.; Wang, Z.; Kwan, H.; Chen, J.; Wu, W.; Li, H.; Liao, Y.; Liu, S. Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology. arXiv 2024, arXiv:2410.07087. [Google Scholar] [CrossRef]
- Wang, L.; Xu, M. Aero-LLM: A Distributed Framework for Secure UAV Communication and Intelligent Decision-Making. arXiv 2025, arXiv:2502.05220. [Google Scholar]
- Sautenkov, O.; Yaqoot, Y.; Lykov, A.; Mustafa, M.A.; Tadevosyan, G.; Akhmetkazy, A.; Cabrera, M.A.; Martynov, M.; Karaf, S.; Tsetserukou, D. UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation. In Proceedings of the 2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Melbourne, Australia, 4–6 March 2025; pp. 1588–1592. [Google Scholar]
- Yaqoot, Y.; Mustafa, M.A.; Sautenkov, O.; Lykov, A.; Serpiva, V.; Tsetserukou, D. UAV-VLRR: Vision-Language Informed NMPC for Rapid Response in UAV Search and Rescue. arXiv 2025, arXiv:2503.02465. [Google Scholar]
- El Khoury, K.; Zanella, M.; Gérin, B.; Godelaine, T.; Macq, B.; Mahmoudi, S.; De Vleeschouwer, C.; Ayed, I.B. Enhancing remote sensing vision-language models for zero-shot scene classification. In Proceedings of the ICASSP 2025–2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–5. [Google Scholar]
- Yu, S.; Androsov, A.; Yan, H. Exploring the prospects of multimodal large language models for Automated Emotion Recognition in education: Insights from Gemini. Comput. Educ. 2025, 232, 105307. [Google Scholar] [CrossRef]
- Hang, C.N.; Ho, S.M. Personalized Vocabulary Learning through Images: Harnessing Multimodal Large Language Models for Early Childhood Education. In Proceedings of the 2025 IEEE Integrated STEM Education Conference (ISEC), Princeton, NJ USA, 15 March 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–7. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).