




MetaGAN: Metamorphic GAN-Based Augmentation for Improving Deep Learning-Based Multiple-Fault Localization Without Test Oracles

Abstract
1. Introduction
2. Background and Related Works
2.1. Clustering-Based Multiple-Fault Localization
- Test Execution Stage: Execute the complete test suite on the program P to generate the passed test cases set and the failed test cases set , while recording execution traces (e.g., branch coverage or method call graphs).
- Intelligent Clustering Stage: Based on the execution characteristics of failed test cases, apply a specific clustering algorithm to generate fault-centric clusters .
- Test Suite Construction Stage: Combine each cluster with the passed test cases to construct a targeted diagnostic suite .
- Parallel Repair Stage: Developers perform concurrent debugging using the tailored suite , generating the corresponding patches .
2.2. Metamorphic Testing
2.3. Generative Adversarial Network
2.4. Related Works
3. Materials and Methods
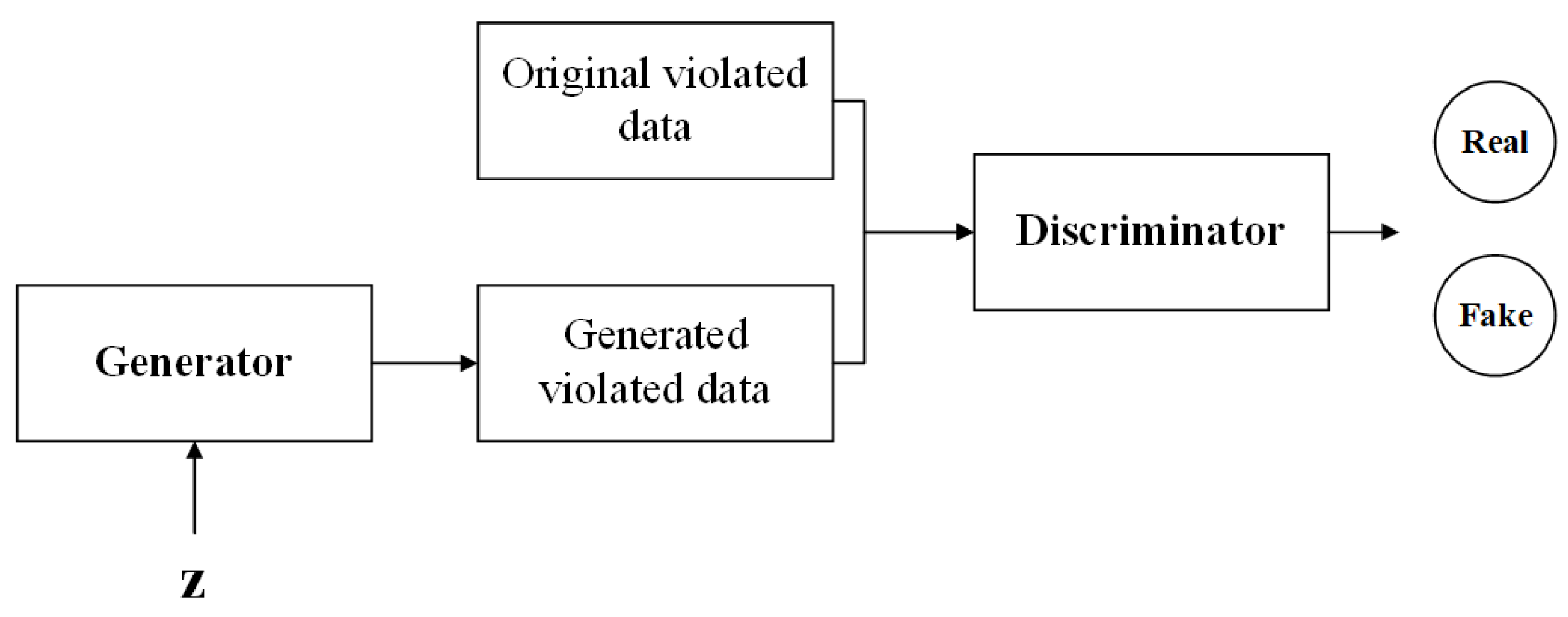
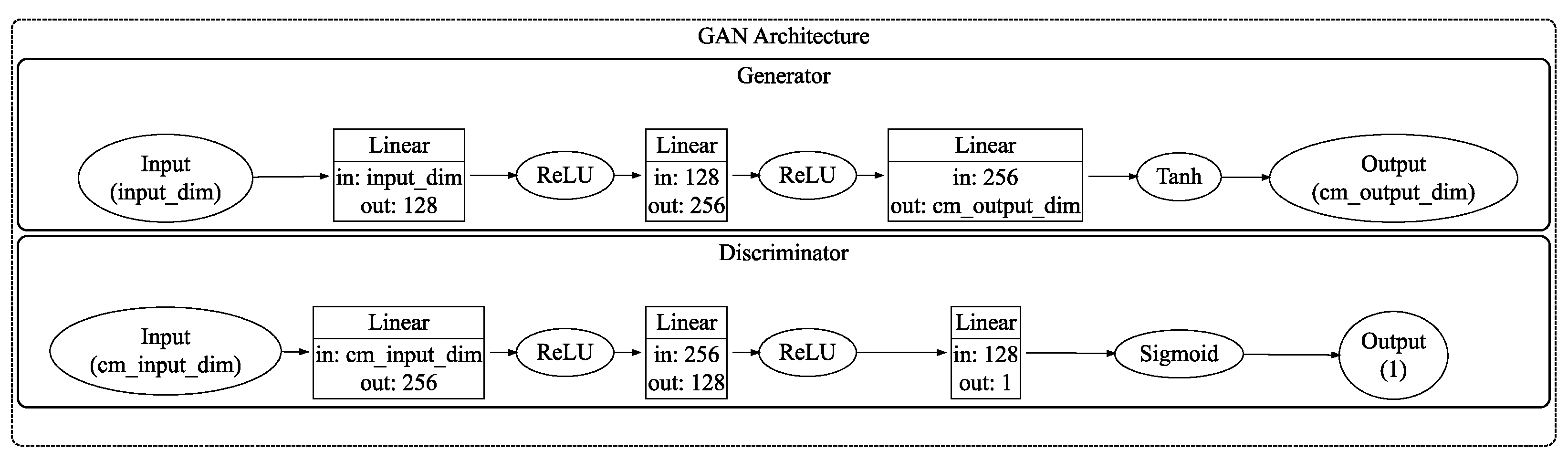
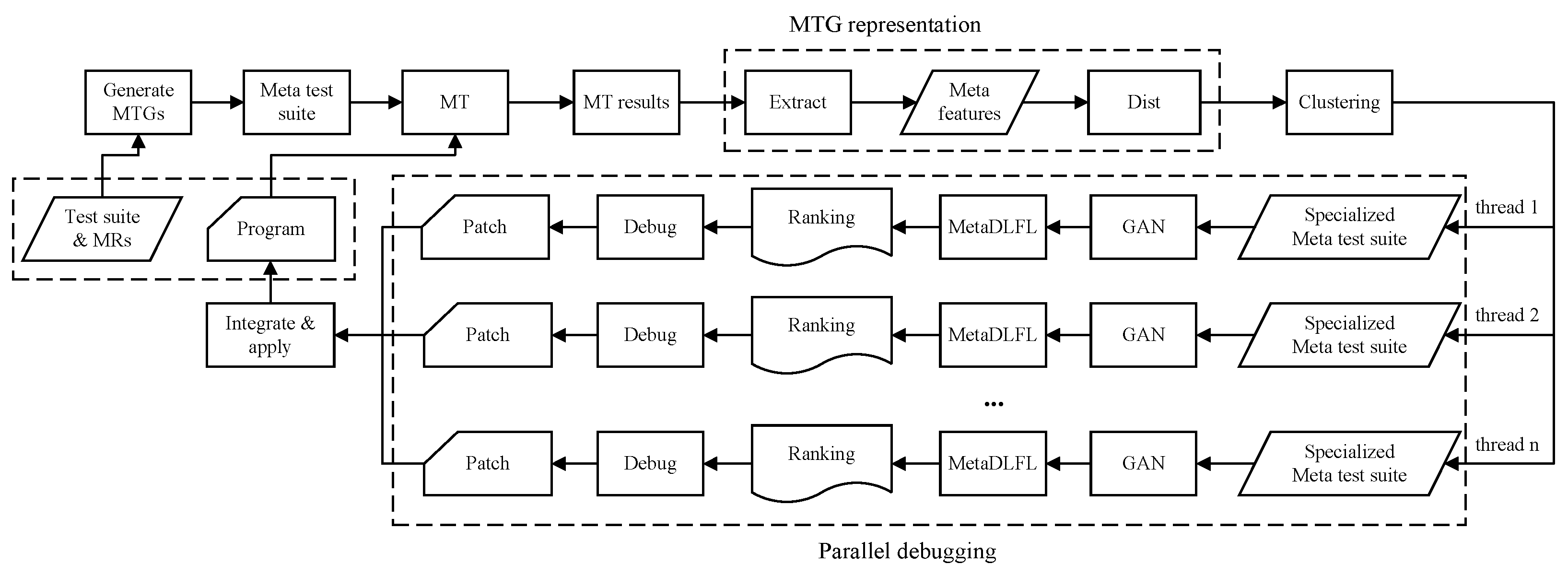
3.1. Components
3.2. Workflow
4. Experimental Design
4.1. Research Questions
4.2. Benchmark
4.3. Independent Variables
4.4. Measurements
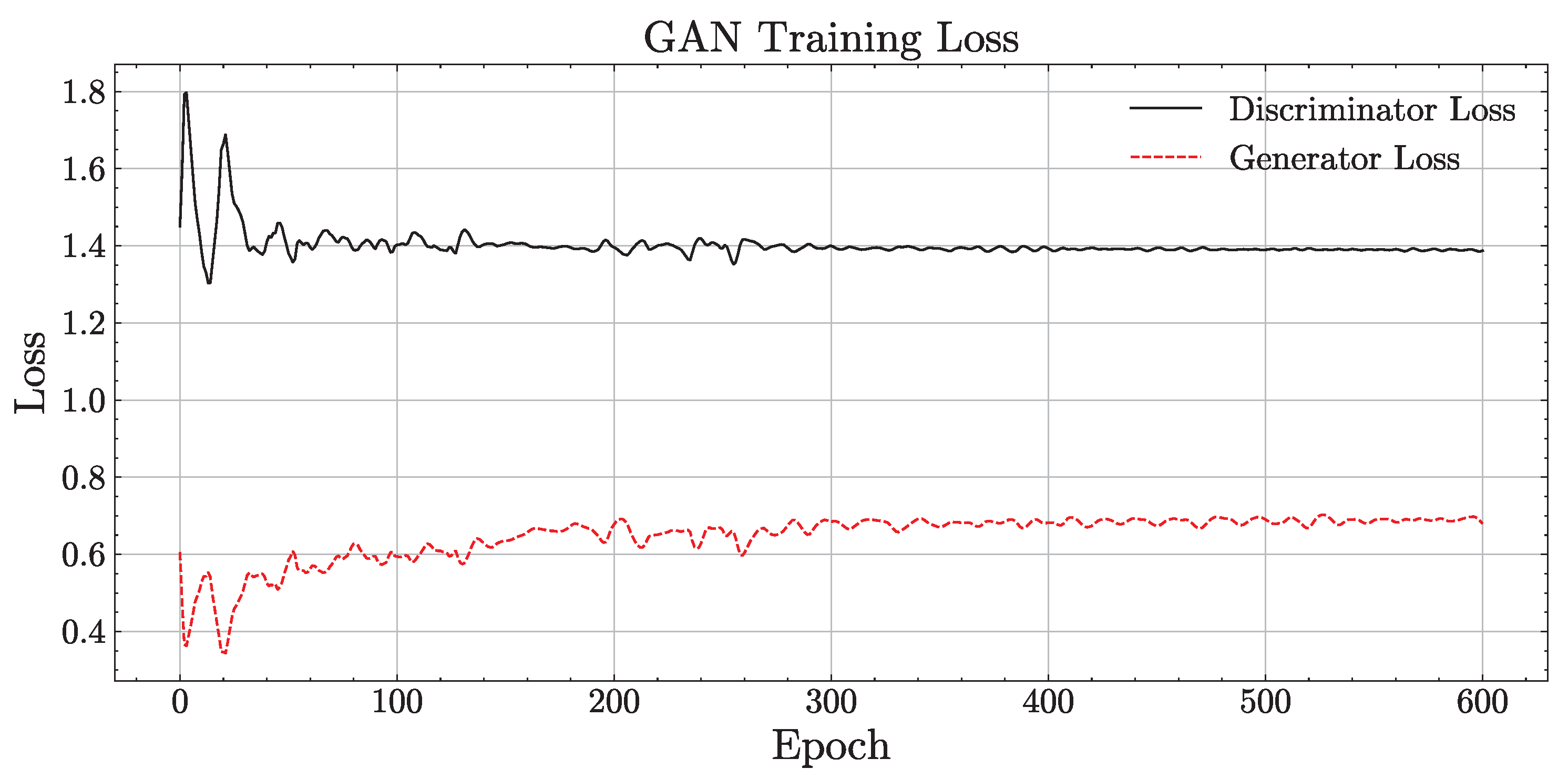
4.5. Implementation
5. Results
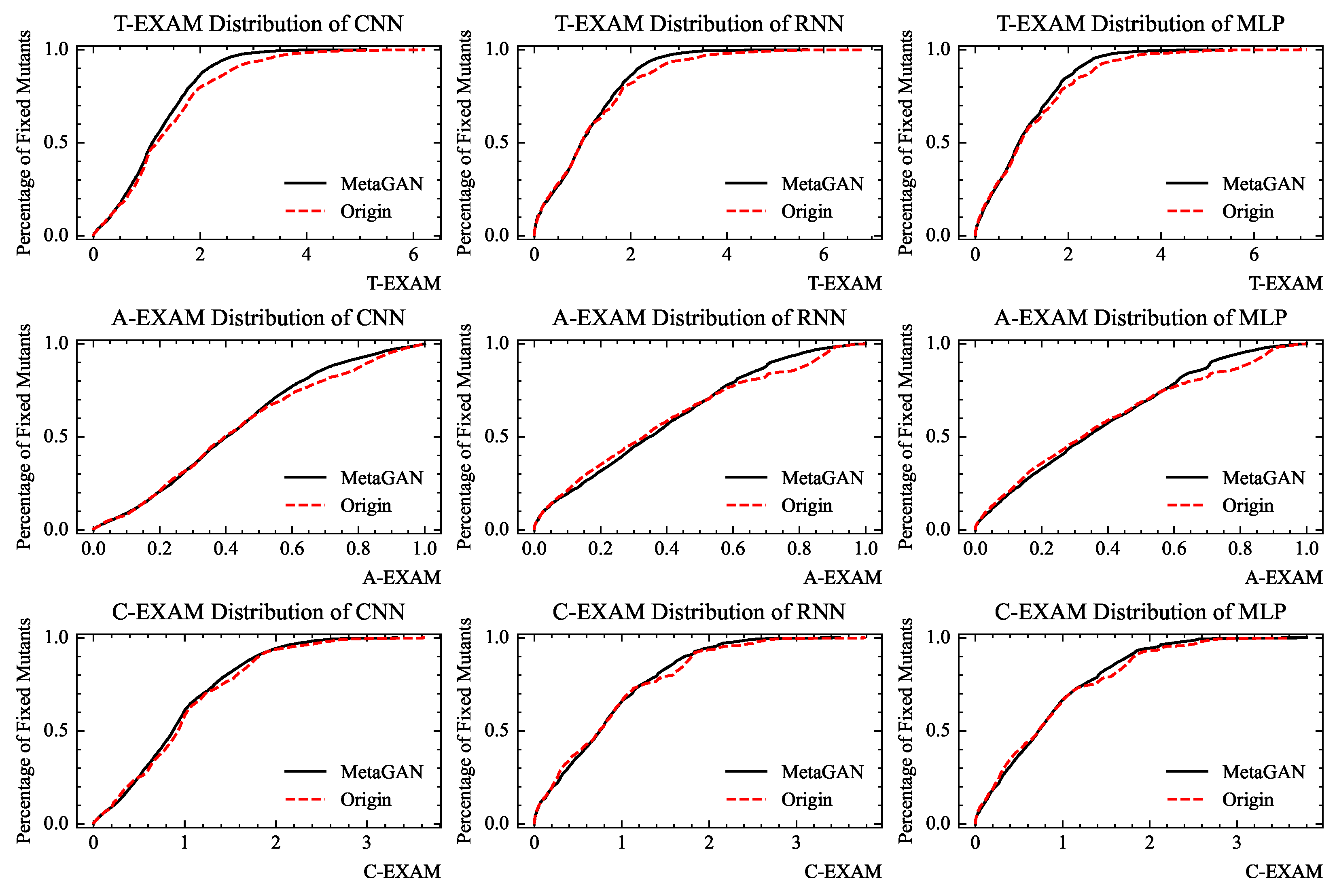
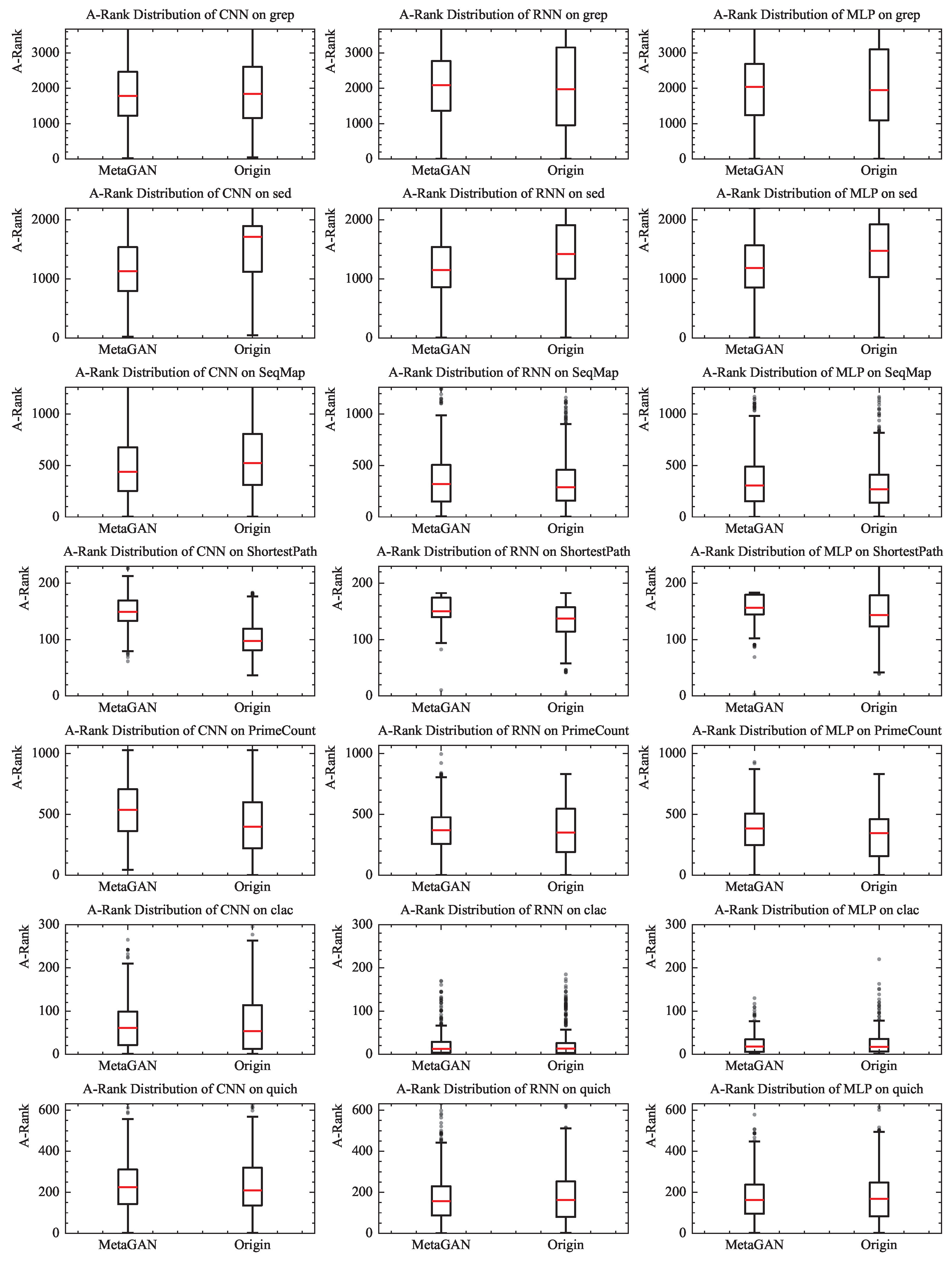
5.1. RQ1 More Effective Mitigation of Oracle Problem
5.2. RQ2 Using Different DLFL Methods
5.3. RQ3 the Effectiveness of Different Fault Programs
5.4. Ablation Experiments
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SFL | Single-Fault Localization |
| MFL | Multiple-Fault Localization |
| DLFL | Deep Learning-based Fault Localization |
| SBFL | Spectrum-Based Fault Localization |
| MT | Metamorphic Testing |
| MR | Metamorphic Relations |
| MTG | Metamorphic Test Group |
| CBMFL | Cluster-Based Multiple-Fault Localization |
| GAN | Generative Adversarial Networks |
| MDFL | Multiple Deep learning-based Fault Localization |
| MetaDLFL | Metamorphic Deep Learning-based Fault Localization |
| MetaMDFL | Metamorphic Multiple Deep learning-based Fault Localization |
| MetaGAN | Metamorphic GAN-based Augmentation for Improving Multiple Deep |
| Learning-based Fault Localization Without Test Oracles |
References
- Wong, W.E.; Li, X.; Laplante, P.A. Be more familiar with our enemies and pave the way forward: A review of the roles bugs played in software failures. J. Syst. Softw. 2017, 133, 68–94. [Google Scholar] [CrossRef]
- Wang, H.; Li, Z.; Liu, Y.; Chen, X.; Paul, D.; Cai, Y.; Fan, L. Can higher-order mutants improve the performance of mutation-based fault localization. IEEE Trans. Reliab. 2022, 71, 1157–1173. [Google Scholar] [CrossRef]
- Dutta, A.; Manral, R.; Mitra, P.; Mall, R. Hierarchically Localizing Software Faults Using DNN. IEEE Trans. Reliab. 2020, 69, 1267–1292. [Google Scholar] [CrossRef]
- Gou, X.; Zhang, A.; Wang, C.; Liu, Y.; Zhao, X.; Yang, S. Software Fault Localization Based on Network Spectrum and Graph Neural Network. IEEE Trans. Reliab. 2024, 73, 1819–1833. [Google Scholar] [CrossRef]
- Wong, W.E.; Gao, R.; Li, Y.; Abreu, R.; Wotawa, F. A Survey on Software Fault Localization. IEEE Trans. Softw. Eng. 2016, 42, 707–740. [Google Scholar] [CrossRef]
- Wong, W.E.; Debroy, V.; Gao, R.; Li, Y. The DStar Method for Effective Software Fault Localization. IEEE Trans. Reliab. 2014, 63, 290–308. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Z.; Feng, Y.; Zhang, Z.; Chan, W.K.; Zhang, J.; Zhou, Y. Improving Fault-Localization Accuracy by Referencing Debugging History to Alleviate Structure Bias in Code Suspiciousness. IEEE Trans. Reliab. 2020, 69, 1021–1049. [Google Scholar] [CrossRef]
- Tang, C.M.; Chan, W.K.; Yu, Y.T.; Zhang, Z. Accuracy Graphs of Spectrum-Based Fault Localization Formulas. IEEE Trans. Reliab. 2017, 66, 403–424. [Google Scholar] [CrossRef]
- Zhang, Z.; Lei, Y.; Mao, X.; Yan, M.; Xu, L.; Zhang, X. A study of effectiveness of deep learning in locating real faults. Inf. Softw. Technol. 2021, 131, 106486. [Google Scholar] [CrossRef]
- Fu, L.; Lei, Y.; Yan, M.; Xu, L.; Xu, Z.; Zhang, X. MetaFL: Metamorphic fault localization using weakly supervised deep learning. IET Softw. 2023, 17, 137–153. [Google Scholar] [CrossRef]
- Fu, L.; Wu, Z.; Lei, Y.; Yan, M. MetaMFL: Metamorphic Multiple Fault Localization without Test Oracles. IEEE Trans. Reliab. 2024, 1–15. [Google Scholar] [CrossRef]
- Zakari, A.; Lee, S.P.; Abreu, R.; Ahmed, B.H.; Rasheed, R.A. Multiple fault localization of software programs: A systematic literature review. Inf. Softw. Technol. 2020, 124, 106312. [Google Scholar] [CrossRef]
- Jones, J.A.; Bowring, J.F.; Harrold, M.J. Debugging in Parallel. In Proceedings of the 2007 International Symposium on Software Testing and Analysis, New York, NY, USA, 9–12 July 2007; ISSTA ’07. pp. 16–26. [Google Scholar]
- Wu, Y.; Liu, Y.; Wang, W.; Li, Z.; Chen, X.; Doyle, P. Theoretical Analysis and Empirical Study on the Impact of Coincidental Correct Test Cases in Multiple Fault Localization. IEEE Trans. Reliab. 2022, 71, 830–849. [Google Scholar] [CrossRef]
- Barr, E.T.; Harman, M.; McMinn, P.; Shahbaz, M.; Yoo, S. The Oracle Problem in Software Testing: A Survey. IEEE Trans. Softw. Eng. 2015, 41, 507–525. [Google Scholar] [CrossRef]
- Xie, X.; Ho, J.; Murphy, C.; Kaiser, G.; Xu, B.; Chen, T.Y. Application of Metamorphic Testing to Supervised Classifiers. In Proceedings of the 2009 Ninth International Conference on Quality Software, Jeju, Republic of Korea, 24–25 August 2009; pp. 135–144. [Google Scholar]
- Xie, X.; Ho, J.W.; Murphy, C.; Kaiser, G.; Xu, B.; Chen, T.Y. Testing and validating machine learning classifiers by metamorphic testing. J. Syst. Softw. 2011, 84, 544–558. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.Y.; Cheung, S.C.; Yiu, S.M. Metamorphic Testing: A New Approach for Generating Next Test Cases. arXiv 2020, arXiv:2002.12543. [Google Scholar]
- Xie, H.; Lei, Y.; Yan, M.; Yu, Y.; Xia, X.; Mao, X. A universal data augmentation approach for fault localization. In Proceedings of the 44th International Conference on Software Engineering, New York, NY, USA, 21–29 May 2022; ICSE ’22. pp. 48–60. [Google Scholar]
- Lei, Y.; Liu, C.; Xie, H.; Huang, S.; Yan, M.; Xu, Z. BCL-FL: A Data Augmentation Approach with Between-Class Learning for Fault Localization. In Proceedings of the 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 15–18 March 2022; pp. 289–300. [Google Scholar]
- Zhuo, Z.; Donghui, L.; Lei, X.; Ya, L.; Xiankai, M. A Data Augmentation Method for Fault Localization with Fault Propagation Context and VAE. IEICE Trans. Inf. 2024, E107-D, 234–238. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Lei, F. Metafl Dataset. 2024. Available online: https://github.com/YanLei-Team/MetaFL_dataset (accessed on 1 December 2024).
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, Berkeley, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; University of California Press: Berkeley, CA, USA, 1967; Volume 5, pp. 281–298. Available online: https://www.cs.cmu.edu/~bhiksha/courses/mlsp.fall2010/class14/macqueen.pdf (accessed on 1 December 2024).
- Chen, T.; Tse, T.; Zhou, Z.Q. Semi-Proving: An Integrated Method for Program Proving, Testing, and Debugging. IEEE Trans. Softw. Eng. 2011, 37, 109–125. [Google Scholar] [CrossRef]
- Jiang, M.; Chen, T.Y.; Kuo, F.C.; Towey, D.; Ding, Z. A metamorphic testing approach for supporting program repair without the need for a test oracle. J. Syst. Softw. 2017, 126, 127–140. [Google Scholar] [CrossRef]
- Gong, C.; Zheng, Z.; Li, W.; Hao, P. Effects of Class Imbalance in Test Suites: An Empirical Study of Spectrum-Based Fault Localization. In Proceedings of the 2012 IEEE 36th Annual Computer Software and Applications Conference Workshops, Izmir, Turkey, 16–20 July 2012; pp. 470–475. [Google Scholar]
- Zhang, L.; Yan, L.; Zhang, Z.; Zhang, J.; Chan, W.; Zheng, Z. A theoretical analysis on cloning the failed test cases to improve spectrum-based fault localization. J. Syst. Softw. 2017, 129, 35–57. [Google Scholar] [CrossRef]
- Zhang, Z.; Lei, Y.; Mao, X.; Yan, M.; Xu, L.; Wen, J. Improving deep-learning-based fault localization with resampling. J. Softw. Evol. Process 2021, 33, e2312. [Google Scholar] [CrossRef]
- Wu, Y.H.; Li, Z.; Liu, Y.; Chen, X. Fatoc: Bug isolation based multi-fault localization by using optics clustering. J. Comput. Sci. Technol. 2020, 35, 979–998. [Google Scholar] [CrossRef]
- Gao, R.; Wong, W.E. MSeer: An advanced technique for locating multiple bugs in parallel. In Proceedings of the 40th International Conference on Software Engineering, New York, NY, USA, 27 May–3 June 2018; ICSE ’18. p. 1064. [Google Scholar]
- Do, H.; Elbaum, S.; Rothermel, G. Supporting controlled experimentation with testing techniques: An infrastructure and its potential impact. Empir. Softw. Eng. 2005, 10, 405–435. [Google Scholar] [CrossRef]
- Parnin, C.; Orso, A. Are automated debugging techniques actually helping programmers? In Proceedings of the 2011 International Symposium on Software Testing and Analysis, New York, NY, USA, 17–21 July 2011; ISSTA ’11. pp. 199–209. [Google Scholar]
- Debroy, V.; Wong, W.E.; Xu, X.; Choi, B. A Grouping-Based Strategy to Improve the Effectiveness of Fault Localization Techniques. In Proceedings of the 2010 10th International Conference on Quality Software, Zhangjiajie, China, 14–15 July 2010; pp. 13–22. [Google Scholar]
- Richardson, A. Nonparametric statistics for non-statisticians: A step-by-step approach by Gregory W. Corder, dale I. foreman. Int. Stat. Rev. 2010, 78, 451–452. [Google Scholar] [CrossRef]
- Wong, W.E.; Debroy, V.; Golden, R.; Xu, X.; Thuraisingham, B. Effective Software Fault Localization Using an RBF Neural Network. IEEE Trans. Reliab. 2012, 61, 149–169. [Google Scholar] [CrossRef]
- Li, Y.; Liu, P. A preliminary investigation on the performance of SBFL techniques and distance metrics in parallel fault localization. IEEE Trans. Reliab. 2022, 71, 803–817. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Program | eLOC | #Versions with #Faults | #MRs | #Testcases | |||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||||
| clac | 300 | 23 | 185 | 217 | 60 | 3 | 1000 |
| grep | 3673 | 148 | 358 | 240 | 60 | 3 | 1000 |
| PrimeCount | 1065 | 16 | 82 | 154 | 60 | 3 | 1000 |
| quich | 632 | 16 | 82 | 154 | 60 | 3 | 1000 |
| sed | 2196 | 83 | 343 | 239 | 60 | 3 | 1000 |
| SeqMap | 1261 | 189 | 360 | 240 | 60 | 3 | 100 |
| ShortestPath | 230 | 18 | 113 | 186 | 60 | 3 | 1000 |
| Programs | MRs | Basis |
|---|---|---|
| grep | MR1: Deconstruct range expressions MR2: Split bracket structures MR3: Replace range operators with predefined classes | Regular expressions |
| sed | MR1: Deconstruct range expressions MR2: Split bracket structures MR3: Replace range operators with predefined classes | Regular expressions |
| SeqMap | MR1: Concatenate elements from p to the end of MR2: Shorten MR3: Modify | String transformation |
| ShortestPath | MR1: Swap and MR2: Subpath of the shortest path is also the shortest MR3: Shortest path is the optimal combination of shorter subpaths | Algorithm properties |
| PrimeCount | MR1: is a monotonically increasing function MR2: is a counting function MR3: Second Hardy–Littlewood conjecture | Algorithm properties |
| clac | MR1: Subtract itself MR2: Symmetry of the sine function MR3: Two equivalent doubling methods | Mathematical expressions |
| quich | MR1: Subtract itself MR2: Symmetry of the sine function MR3: Two equivalent doubling methods | Mathematical expressions |
| Mutation Operation | |
|---|---|
| 1 | Replace logical operators |
| 2 | Replace comparison operators |
| 3 | Swap increment and decrement operators |
| 4 | Replace assignment operators |
| 5 | Replace boolean assignment operators |
| 6 | Replace arithmetic operators |
| 7 | Replace boolean arithmetic operators |
| 8 | Swap the boolean literals true and false |
| 9 | Change the position where elements are inserted |
| 10 | Change the semantics of an STL range predicate |
| 11 | Swap STL minimum by maximum calls |
| Metric | Better Freq. | Worse Freq. | Overall RImp Score | Conclusion |
|---|---|---|---|---|
| T-EXAM | 14 | 7 | 0.892960659 | Better |
| A-EXAM | 13 | 8 | 0.974837410 | Better |
| C-EXAM | 11 | 10 | 0.967180769 | Better |
| A-Rank | 13 | 8 | 0.946765588 | Better |
| Top-10% | 8 | 13 | 1.000105119 | Better |
| Top-50% | 10 | 11 | 1.010203019 | Better |
| SFL Tool | A-Rank | T-EXAM | A-EXAM | C-EXAM | Top-2% | Top-5% | Top-25% |
|---|---|---|---|---|---|---|---|
| CNN | 0.8729 | 0.9641 | 0.9568 | 0.9219 | 0.9197 | 0.9808 | 0.9400 |
| RNN | 0.9084 | 0.9843 | 0.9748 | 0.9713 | 0.9809 | 0.9741 | 0.9038 |
| MLP | 0.9003 | 0.9777 | 0.9714 | 0.9490 | 0.9528 | 0.9249 | 0.9120 |
| Metric | Better Freq. | Similar Freq. | Worse Freq. | Overall WSR Score | Conclusion |
|---|---|---|---|---|---|
| T-EXAM | 19 | 2 | 0 | Better | |
| A-EXAM | 13 | 0 | 8 | 0.000190739 | Better |
| C-EXAM | 17 | 1 | 3 | Better | |
| A-Rank | 13 | 0 | 8 | Better | |
| Top-50% | 15 | 0 | 6 | 0.030766804 | Better |
| Metric | Better Freq. | Similar Freq. | Worse Freq. | Overall WSR Score | Conclusion |
|---|---|---|---|---|---|
| T-EXAM | 16 | 4 | 1 | Better | |
| A-EXAM | 12 | 3 | 6 | Better | |
| C-EXAM | 15 | 5 | 1 | Better | |
| A-Rank | 11 | 2 | 8 | Better | |
| Top-50% | 14 | 4 | 3 | Better |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, A.; Feng, W.; Zhu, X.; Wang, J.; Ao, Y.; Feng, H. MetaGAN: Metamorphic GAN-Based Augmentation for Improving Deep Learning-Based Multiple-Fault Localization Without Test Oracles. Electronics 2025, 14, 2596. https://doi.org/10.3390/electronics14132596
Hu A, Feng W, Zhu X, Wang J, Ao Y, Feng H. MetaGAN: Metamorphic GAN-Based Augmentation for Improving Deep Learning-Based Multiple-Fault Localization Without Test Oracles. Electronics. 2025; 14(13):2596. https://doi.org/10.3390/electronics14132596
Chicago/Turabian StyleHu, Anlin, Wenjiang Feng, Xudong Zhu, Junjie Wang, Yiping Ao, and Hao Feng. 2025. "MetaGAN: Metamorphic GAN-Based Augmentation for Improving Deep Learning-Based Multiple-Fault Localization Without Test Oracles" Electronics 14, no. 13: 2596. https://doi.org/10.3390/electronics14132596
APA StyleHu, A., Feng, W., Zhu, X., Wang, J., Ao, Y., & Feng, H. (2025). MetaGAN: Metamorphic GAN-Based Augmentation for Improving Deep Learning-Based Multiple-Fault Localization Without Test Oracles. Electronics, 14(13), 2596. https://doi.org/10.3390/electronics14132596