
ARGUS: Retrieval-Augmented QA System for Government Services

 ,
,  , , , , , , , and
, , , , , , , and
Abstract
1. Introduction
- A Domain-Specific Large Language Model Framework for Government Services: We propose a novel paradigm for constructing large language models (LLMs) tailored to government service tasks. We design a hybrid retrieval-augmented generation (RAG) strategy that combines graph-path guidance with relevant text retrieval to enhance knowledge controllability and generation accuracy. This is achieved by embedding human-like chain-of-thought reasoning into domain-specific fine-tuning and developing an automated knowledge graph construction pipeline based on prompt engineering within the LlamaIndex framework.
- Response Quality Control via RAGAS Evaluation: We develop a structured response evaluation mechanism integrating the RAGAS framework. To address the challenge of verifying LLM-generated content, we design a methodology that combines structured prompt templates with multidimensional evaluation metrics. This ensures contextual consistency, factual accuracy, and the practical value of model outputs while providing a quality assurance mechanism for high-risk application scenarios.
- Practical Deployment and Validation in Real-World Government Services: We implement the proposed system in actual government service scenarios, demonstrating significant improvements in response accuracy and processing efficiency. The system offers a practical and scalable solution for enhancing government consultation services, providing a feasible technical path and methodological reference for constructing intelligent government service platforms.
2. Related Works
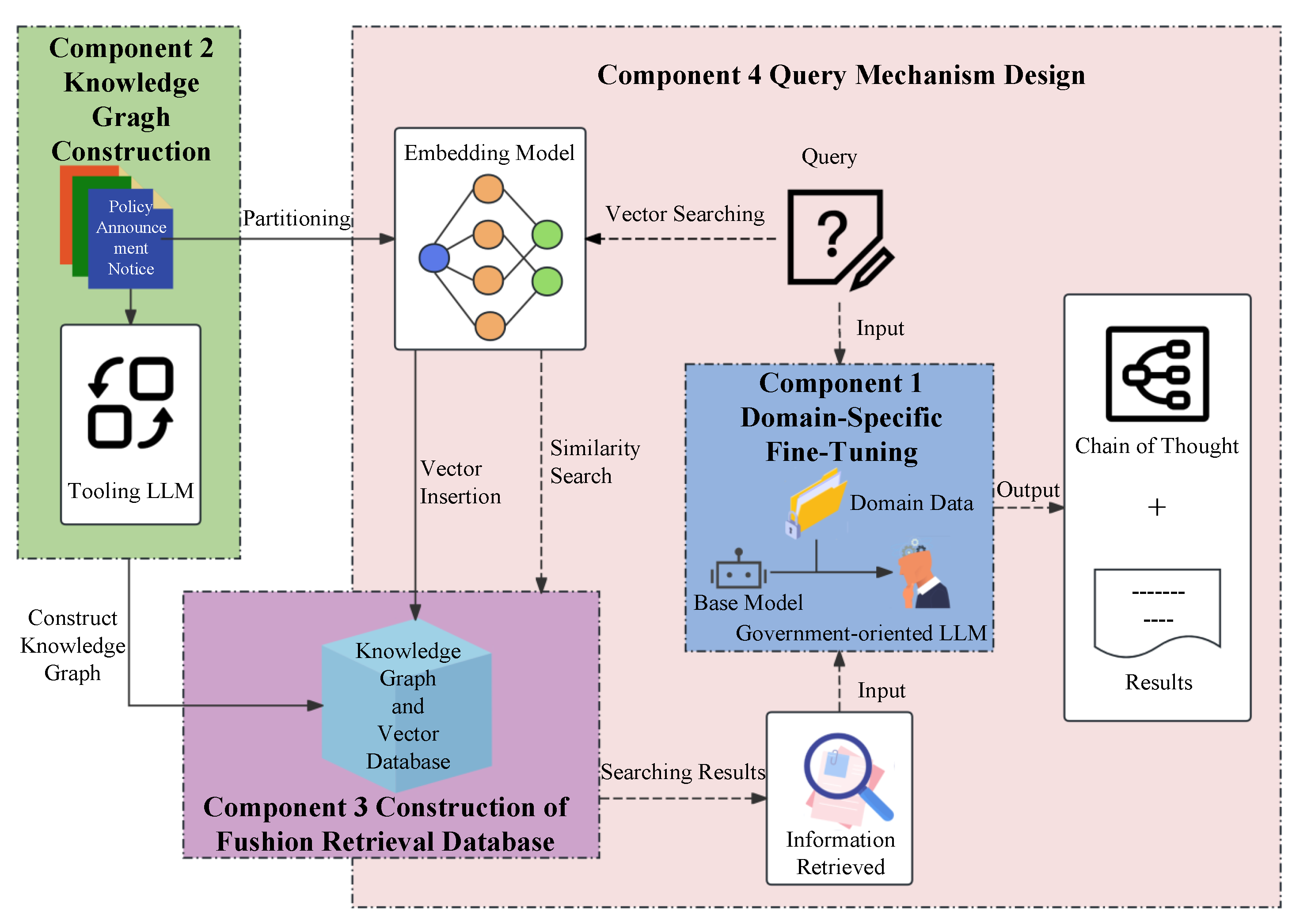
3. Construction of a Government-Oriented Large Language Model QA System
3.1. Domain-Specific Fine-Tuning
- Removal of invalid cases: Entries not requiring telephone follow-up, such as feedback-only entries, were excluded.
- Normalization check: HTML formatting symbols and redundant or duplicate information were removed.
- Error Correction: Grammatical and typographical errors were corrected.
- Bias and Conflict Mitigation: To reduce policy misalignment and regional inconsistencies, only authoritative and up-to-date regulations were retained. Cases showing conflicting interpretations or outdated references were excluded based on cross-checking with official databases.
- Structural alignment: The dataset entries were transformed into a standardized format, ‘Materials–Steps–Notes’, to improve procedural clarity and minimize ambiguity during generation.
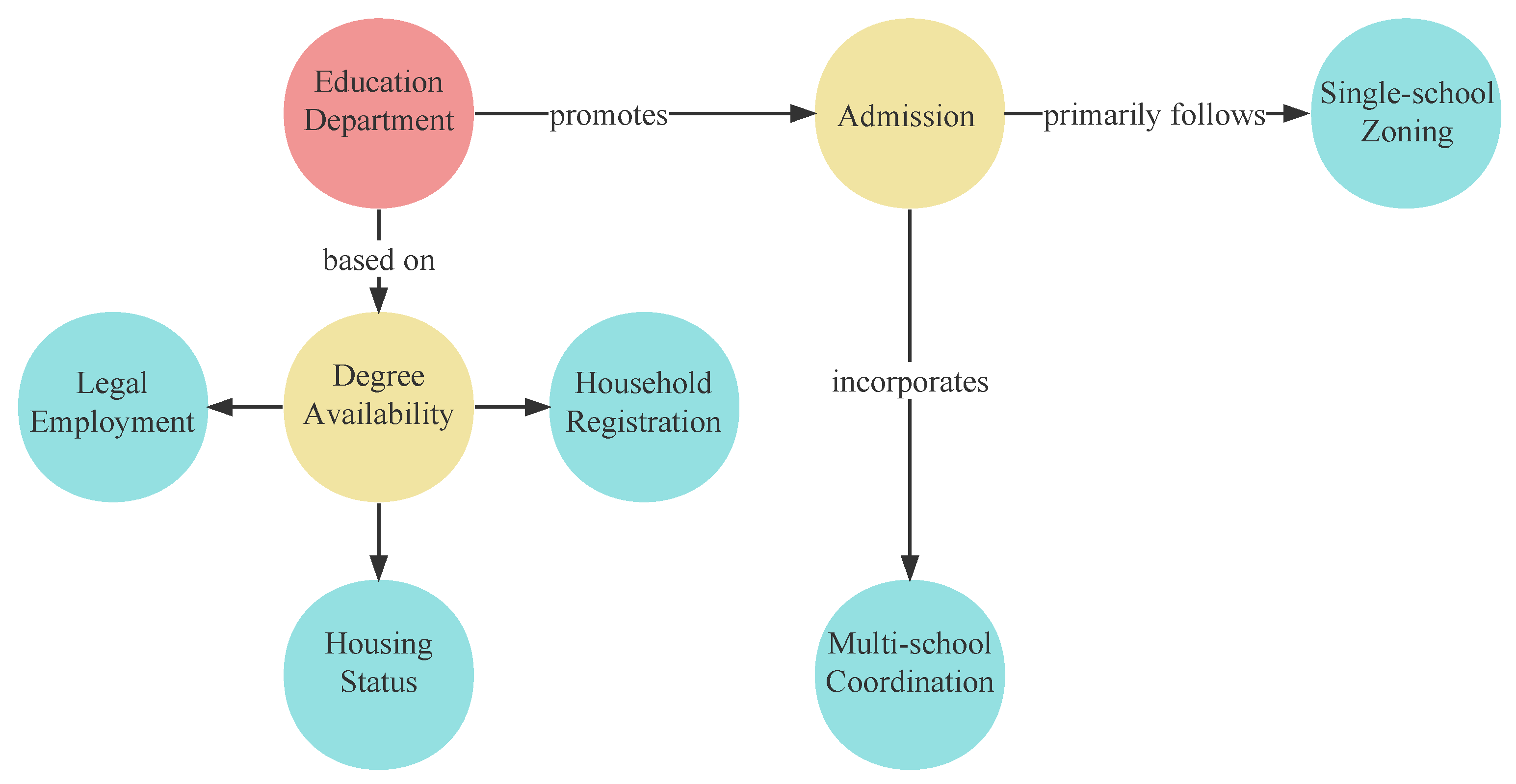
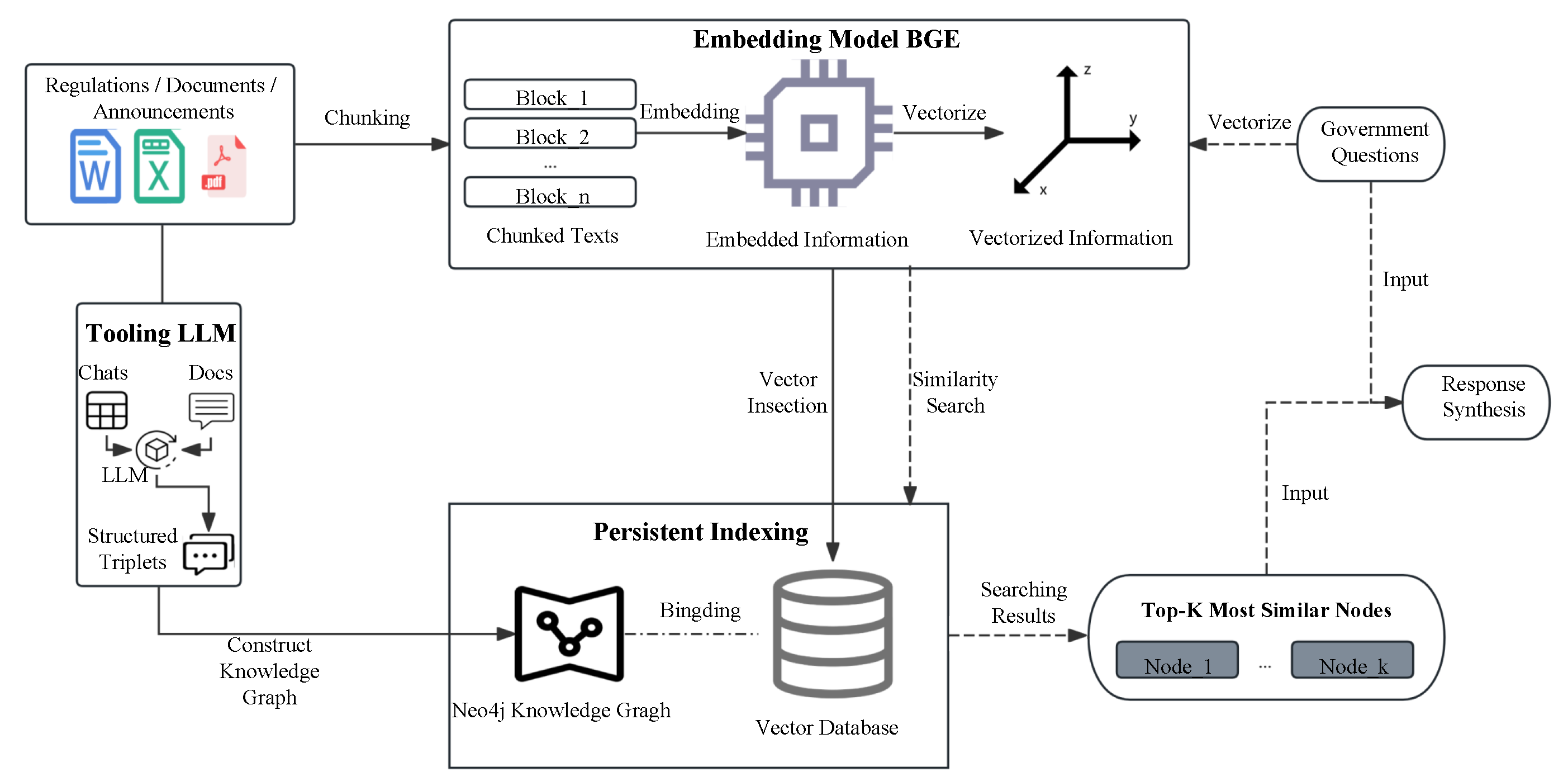
3.2. Knowledge Graph Construction
- Demand Analysis: Identify core needs from the query.
- Key-Point Extraction: Extract constraint conditions from user input.
- Policy Matching: Match relevant clauses from retrieved knowledge.
- Policy Mapping: Transform legal clauses into executable steps.
- Conclusion Generation: Generate draft responses based on the processed information.
3.2.1. Sources of the Knowledge Graph Dataset
3.2.2. Knowledge Graph Construction Using Large Language Models
| Algorithm 1 Prompt template for triplet extraction |
|
3.3. Construction of Vector Embeddings and Storage
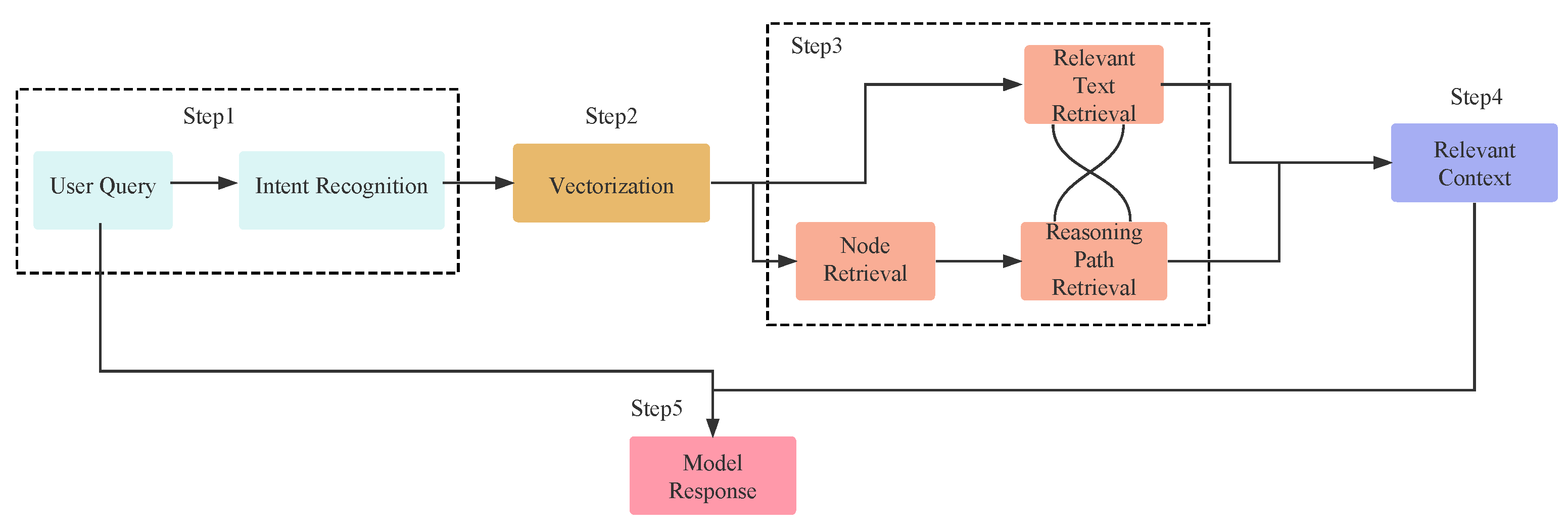
3.4. Hybrid Retrieval
4. Validation Experiments
4.1. Experimental Setup
4.1.1. Experimental Device
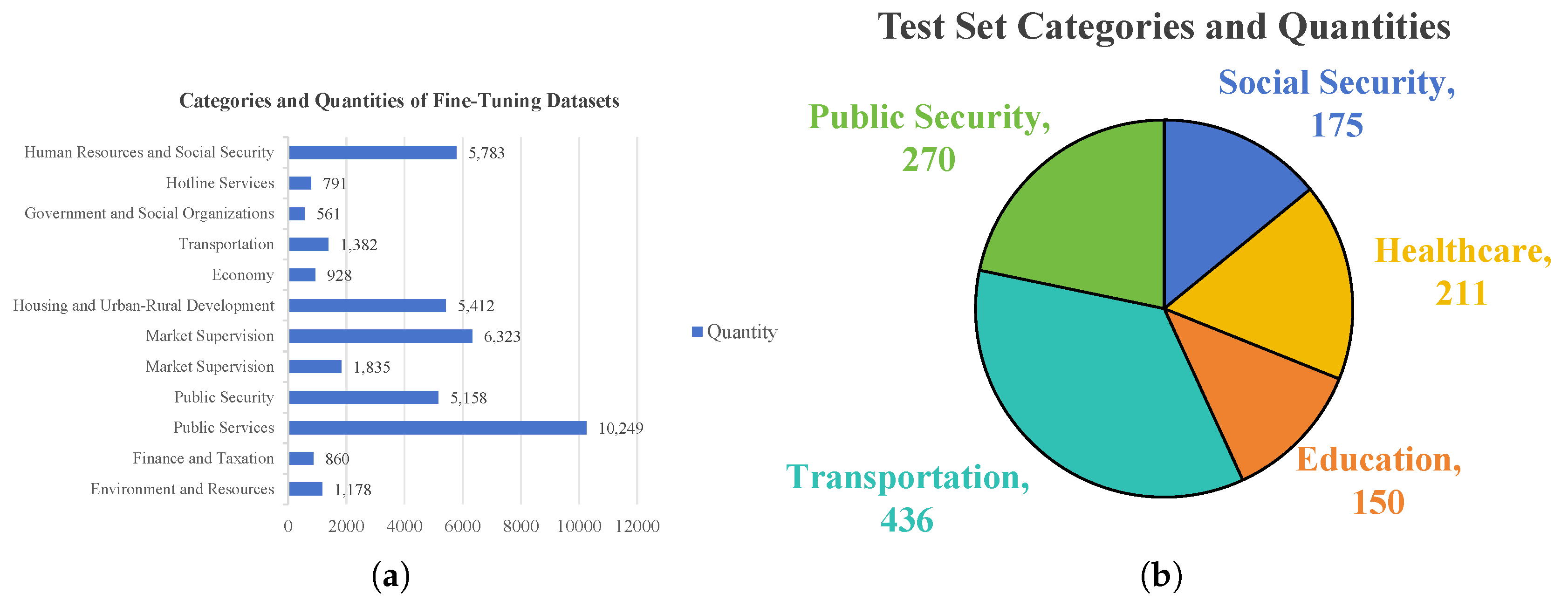
4.1.2. Test Set Design
4.1.3. Baseline Models
4.2. Evaluation Metrics
4.2.1. Objective Metrics
4.2.2. RAGAS Metrics for Ablation Study
4.2.3. RAGAS Metrics for Subtask Evaluation
4.2.4. Summary of Metrics
4.3. Subtask Experiments
4.4. System Effectiveness Validation
4.4.1. Validation of Human-like Chain of Thought
4.4.2. Ablation Study on the Knowledge Graph
4.4.3. Retrieval-Augmented Classification Experiment
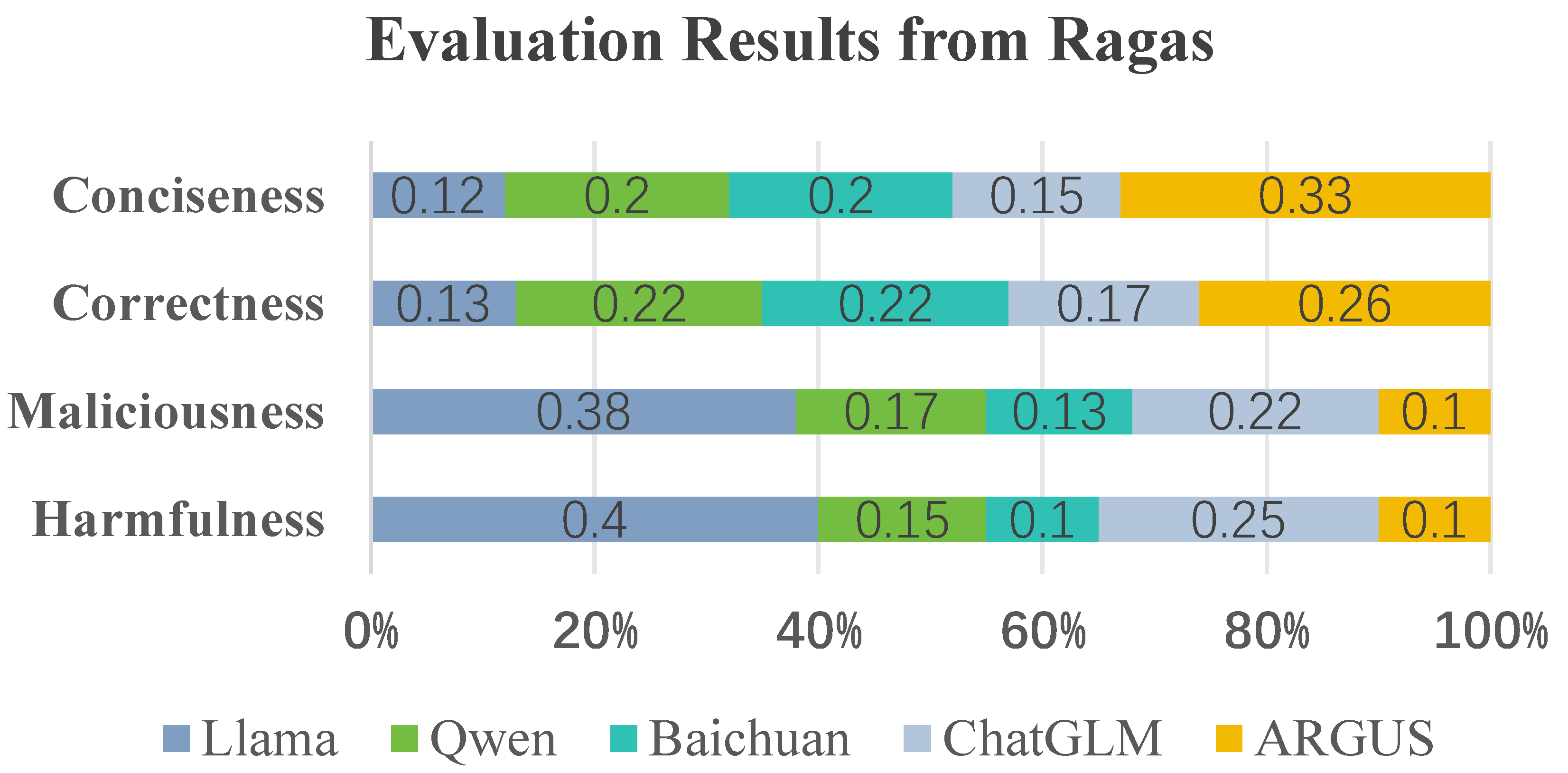
4.5. Human-like Evaluation Based on RAGAS
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GQA | Government Question-Answering |
| ARGUS | Answer Retrieval and Governance Understanding System |
Appendix A. Response Comparison in Five Government Service Subdomains

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Social Security | How is the deductible threshold applied when Hainan-insured residents seek medical treatment in other provinces? |
| LlaMa | The deductible threshold is 1,000 yuan. If the medical expenses exceed this amount, the deductible is waived. Hainan residents who have purchased basic medical insurance can receive a 20% discount on the deductible. |
| Qwen | 1. **Insurance Coverage Out-of-Province**: Many health insurance plans cover medical expenses incurred outside the resident’s home province. However, this coverage can often come with different terms and conditions than local care. ... 6. **Reimbursement Process**: If there are any discrepancies or if you need assistance with claims for out-of-province treatments, understanding the reimbursement process is crucial. This might involve submitting detailed documentation to your insurer for a refund based on the terms of your policy. If you have specific questions about your insurance plan and how it applies when seeking medical care outside Hainan, I would recommend contacting your health insurance provider directly or reviewing your policy documents for precise details. |
| Baichuan | When Hainan insured residents seek medical treatment outside their home province, they need to apply for “cross provincial registration and settlement”. After being approved by the relevant authority of the place where you are treated or through insurance companies designated by your insurer (insurer), you can receive medical services at the local medical institution in compliance with regulations and settle them according to regulations. The deductible threshold is calculated based on the actual amount paid for medical expenses, including registration fees, treatment fees, medicine costs, etc. After deducting personal accounts, reimbursement standards are implemented according to the prescribed range of medical service items and payment ratios by insurance companies or medical institutions in accordance with relevant regulations |
| ChatGLM | To reapply for a lost residence permit as a non-local resident, the following documents would typically be required: 1. A completed application form for the reapplication of a lost/stolen residence permit. 2. Evidence of identity, such as a passport or national ID card. 3. Proof of address, such as utility bills or rental agreements. 4. A copy of the old residence permit (if available). 5. Any other documents required by the immigration authority in your case. 6. The applicable fee for reapplying for a lost/stolen residence permit. |
| ARGUS | <think>
Alright, now I need to answer the user’s question: “How is the deductible threshold applied when Hainan-insured residents seek medical treatment in other provinces?” Step 1: Identify user intent—Understand how the deductible threshold applies when Hainan-insured residents receive treatment outside the province. Step 2: Break down key elements—(1) Subject: Hainan-insured residents; (2) Question: How is the deductible applied; (3) Scenario: Out-of-province treatment; (4) Policies: Hainan’s deductible rules vs. local reimbursement catalog. Step 3: Retrieve relevant info—Deductible follows Hainan policy, but reimbursement adheres to the local province’s catalog. Step 4: Formulate clear answer—Hainan sets the deductible; reimbursement is based on where treatment occurs. Step 5: Final summary—“How is the deductible threshold applied for Hainan-insured residents receiving out-of-province treatment?” </think> Although the deductible amount is determined in accordance with Hainan Province’s medical insurance policies, the reimbursement must adhere to the medical insurance catalog used in the province where the medical treatment is actually received. |
| Reference Answer | The deductible threshold is applied according to Hainan’s regulations, but the medical insurance catalog of the treatment location in the other province must be used. |
| Healthcare | Can family members use the insured person’s medical insurance card to purchase medications at a pharmacy? |
| LlaMa | In China, it seems that family members can use the insured person’s medical insurance card to receive treatment from hospitals and clinics. However, regarding medication purchases at pharmacies, I couldn’t find specific information on whether family members can directly use the insured person’s medical insurance card. It’s likely that there are regulations in place for how medical insurance cards can be used in different settings. To get a clear answer, you may want to contact the relevant authorities or check with your local health insurance provider for more information. |
| Qwen | In China, there are strict regulations and restrictions on the use of medical insurance cards (also known as social security cards or medical insurance cards) to ensure the rational allocation of medical resources and the protection of personal privacy. Usual situation
In this case, only cardholders can use their medical insurance cards for medical services and drug purchases at medical institutions. However, in certain specific situations, such as when family members require emergency treatment or long-term care due to illness and the insured is unable to personally go to the hospital or pharmacy, direct relatives can be arranged Parents, spouses, children, etc. will handle it on their behalf. However, this situation usually requires the provision of relevant proof materials and confirmation through review by medical institutions. The specific regulations in Hainan or other regions may vary. Please consult the local medical insurance bureau for the latest policy details and operational guidelines. In general, it is recommended to directly communicate with you Contact social insurance institutions or hospital service windows in the region to obtain the most accurate information and follow specific local regulations when using medical insurance cards. |
| Baichuan | No, it is not allowed for any non-insurance personnel (including family members) to use an insured person’s medical insurance card to buy drugs unless otherwise prescribed by laws and regulations or agreed upon in contracts between insurers.This regulation is aimed at protecting the legitimate rights and interests of insurance beneficiaries and avoiding insurance fraud. |
| ChatGLM | Other members of the family can use the insured’s medical insurance card to purchase medication at the pharmacy, subject to the terms and conditions specified by the insurance company. If the insurance contract specifies a home The members of the court share the right to use the medical insurance card, so they can jointly use this card to purchase the necessary drugs. However, if your company or insurance company has special regulations You may need to understand these regulations to ensure proper use of your medical insurance card. |
| ARGUS | <think>
Alright, now I need to answer the user’s question: “Can a family member use the insured person’s medical insurance card to purchase medicine at a pharmacy?” Step 1: I need to identify the user’s main intent. The user wants to know whether a family member can use the insured person’s medical insurance benefits, specifically in the context of buying medication at a pharmacy. Step 2: I should break down the key components of the question (1) the relationship between the family member and the insured person; (2) whether such proxy usage is allowed; (3) if allowed, what preconditions or setup steps are required; (4) how the process works at the pharmacy. Step 3: I will search the reference materials for relevant information. The policy states that, to enable such usage, family members must first complete a binding process via a “family relationship account” and activate a shared fund mechanism. Once this is set up, the family member can present their own electronic medical insurance certificate at the pharmacy, and the cost will be deducted from the insured person’s individual medical insurance account. Step 4: I will convert this information into a clear, actionable explanation for the user first, complete the family binding and shared fund setup; then, the family member may use their own certificate to make purchases. Step 5: I summarize the answer as “How can a family member use the insured person’s medical insurance account to purchase medicine at a pharmacy?” </think> To enable usage, family members must first complete the binding process with the insured individual by linking their profiles through a family relationship account and establishing a shared fund mechanism. After these steps are successfully set up, the family member can present their own electronic medical insurance certificate at the pharmacy, allowing them to use the insured person’s individual medical insurance account for medication purchases. |
| Reference Answer | Family members must first be linked to the insured person through a family account binding process and establish a shared medical insurance account. Once both steps are completed, family members can present their own electronic medical insurance certificate at the pharmacy to use the insured person’s individual medical insurance account for payment. |
| Public Security | What documents are required for non-local residents to reapply for a lost residence permit? |
| LlaMa | The specific documents required may vary depending on the country’s laws and regulations. It is always best to consult with a local government affairs expert or a qualified immigration attorney for more information. |
| Qwen | For non-local residents in China, the process to reapply for a lost Residence Permit typically involves several steps and requires specific documentation. Here’s what you generally need: 1. **Personal Identification Documents**: -Original ID card (Resident Identity Card) -Passport 2. **Lost Report**: -A written report stating that your Residence Permit has been lost, stolen, or damaged. This should include details such as when and where it was last seen. ... 10. **Police Clearance Certificate**: -In some cases, you may need to provide a police clearance certificate stating that there are no criminal records against your name in China. |
| Baichuan | following documents are required for re-application: (1) Application form; (2) A photo ID such as a passport, residence permit, or driver’s license; (3) Proof that you have paid the registration fee prescribed by laws and regulations (if applicable); (4) If your identity card is lost or damaged during its validity period due to theft, fire, etc., it shall provide proof of loss or damage in accordance with relevant regulations; |
| ChatGLM | If the resident identity certificate of non local residents has been lost, they should report the loss of the certificate to the exit and entry management department of the public security organ in their place of residence and apply for a temporary certificate. Specific documents that need to be prepared and
The materials may vary depending on policies in different countries and regions, but typically the following documents may be required: 1. Passport or other valid travel documents; 2. The applicant’s household registration book or other identification documents (such as a resident ID card); ... Please note that policies may vary in different countries and regions, so be sure to check the local immigration or consulate website for detailed information when submitting your application. |
| ARGUS | <think>
OK, I now want to answer the user’s question: “How can I get a residence permit for non registered residence residents after losing it? What materials need to be prepared?” The first step is to clarify the core intention of the user. What the user wants to know is how the “non local registered residence” people should get a new certificate when their “residence permit is lost”. The second step, I need to disassemble the elements of the problem (1) The subject of the transaction is a non registered residence resident of the city; (2) The procedure involves reissuing a lost residence permit; (3) The core requirement is the materials that should be prepared when reissuing. The third step is to search for information related to “replacement of lost residence permit” from the materials. The information clearly states that the applicant should provide either a “Resident Household Registration Book” or a “Resident Identity Card”. Step four, I will organize these policy contents into clear and executable suggestions the main materials are ID cards or household registration books, and other materials may only be involved in the event of a change of address or other special circumstances. Last, summarize What are the required documents for non local residents to apply for a replacement residence permit after losing it </think> If the residence permit of non registered residence residents needs to be reissued after being lost, the required materials include: 1. The applicant’s “Resident Registration Book” or “Resident Identity Card”. These materials need to be brought to the local police station for reissuance procedures. If there are special circumstances such as changes in residential address, relevant supporting documents may need to be provided (such as proof of property ownership, lease agreement, etc.), but for simple loss and replacement, the above two types of documents are the main materials. |
| Reference Answer | The documents required for non-local residents to reapply for a lost residence permit include the applicant’s household registration booklet (hukou) or resident identity card. |
| Transportation | What is the processing time for the registration of newly purchased electric vehicles? |
| LlaMa | In the United States, electric vehicles are becoming increasingly popular as a means of transportation. As such, many states have implemented policies and procedures to facilitate the registration of these vehicles. One of the most common questions people have when it comes to registering an electric vehicle is how long it takes. This question is particularly important for those who are new to the process and may not be familiar with the necessary paperwork or procedures. By answering this question accurately and providing the necessary information, you can help ensure that people are able to register their electric vehicles quickly and easily. |
| Qwen | General Steps to Register a New Electric Vehicle 1. **Purchase Documentation**: - Obtain a valid invoice or purchase contract for the EV. 2. **Vehicle Inspection**: - The vehicle needs to pass a mandatory inspection at a designated testing station authorized by local traffic police. 3. **Insurance**: - Purchase third-party liability insurance (compulsory motor vehicle insurance) and any additional voluntary insurances you want 4. **Application Form**: - Fill out the registration application form, which can usually be obtained from the local public security bureau or traffic management office. 5. **Submit Documentation**: - Present all necessary documents to a designated service center at the local traffic police department. Commonly required documents include: 6. **Processing Time**: - Once you submit all necessary documents, the processing time can vary from a few days to several weeks depending on local traffic management regulations and the current volume of applications. |
| Baichuan | The registration processing time for newly purchased electric vehicles varies by region, usually within 1–3 weeks after purchase. The specific processing time may be affected by the work efficiency of the local vehicle management office and the vehicle inspection time The impact of factors such as processing procedures. It is recommended to consult with the dealer or local vehicle management office after purchasing the car to confirm the specific registration processing time. |
| ChatGLM | The following is the general process: 1. Obtain a copy of the “Unified Invoice for Motor Vehicle Sales” and materials such as the purchase contract from the local public security bureau and traffic police department; 2. Apply for vehicle purchase tax at the tax department; 3. Purchase vehicle insurance from an insurance company; 4. Go to the bank to handle the vehicle loan procedures (if any); 5. Submit the above materials to the traffic management department of the public security organ. The specific time for the traffic police department of the public security bureau in your area to handle registration may be affected by factors such as the workload and number of staff at the local vehicle management office. Therefore, it is not possible to Provide an accurate time. We suggest that you consult the local vehicle management office for detailed information and procedures before purchasing a car. |
| Argus | <think>
Okay, I’m going to answer the user’s question now: “What are the online registration channels for new students in Haikou
The first step is to analyze the user’s intention. The user wants to know the specific channels for “online registration”, including keywords such as “Haikou City”, “New Student Enrollment”, and “Online Registration Channel”. The second step is to break down the key elements in the problem “New student enrollment” refers to enrollment in primary and junior high schools, and “online registration channels” refer to the ways or platforms that can complete registration online. The third step is to search and match relevant policy information. According to the information, new students in Haikou can apply online through the official website of the Education Bureau, WeChat official account, relevant apps, etc. Step 4, I need to translate these policy information into user executable answers such as clearly listing the platform name and use method (such as whether it is an APP, website or official account). The fifth step is to summarize and output a clear and concise answer “What are the online registration channels for new students in Haikou </think> The online registration channels for new students in Haikou City include: 1. Official website of Haikou Education Bureau; 2. WeChat official account of Haikou Education Bureau; 3. YeChengban app; 4. Haiyiban APP. |
| Reference Answer | The processing hours for the registration of newly purchased electric vehicles are from 8:30 a.m. to 12:30 p.m. and 2:00 p.m. to 5:30 p.m. on weekdays (Monday to Friday), and from 8:30 a.m. to 12:30 p.m. on weekends (Saturday). |
| Education | How are school admission zones for compulsory education delineated in Haikou City? |
| LlaMa | A very specific question! I’m unable to provide information on how school admission zones for compulsory education are delineated in Haikou City. If you need the most accurate and up-to-date information, I recommend contacting the relevant authorities or checking their official website for more details. Would you like some general information about compulsory education in China instead? |
| Qwen | The division of compulsory education enrollment areas (usually referred to as school districts) in Haikou City is determined by the local education administrative department based on the layout of schools, school size, and the number of eligible children within the jurisdiction It is formulated based on the distribution situation. The specific scope of the school district may be adjusted annually to ensure that educational resources are utilized reasonably and to meet the needs of students for nearby schooling as much as possible. |
| Baichuan | Hello! The division of compulsory education school districts in Haikou City is reasonably planned by the Municipal Education Bureau based on the surrounding communities and population distribution of each school. Specific division of school districts, construction Please follow the official website of the Education Bureau or consult the education department for the latest information and detailed data. |
| ChatGLM | Generally speaking, the compulsory education enrollment areas in Haikou City are divided into the following types: 1. Urban center area: including the city center, Haidian Island, Longhua District and other areas 2. Suburban and rural areas: The competition for enrollment in these areas is relatively small 3. New development areas: With the advancement of urbanization, newly developed real estate and residential areas are gradually included in the scope of compulsory education school districts It should be noted that the Haikou Education Bureau adjusts the division of enrollment areas based on actual conditions every year. Therefore, it is recommended that you consult local schools or teachers before enrolling your child. |
| Argus | <think>
Okay, now I have to answer the user’s question: ”How is the enrollment area designated for compulsory education enrollment in Haikou City in 2022 The first step is to understand the core intention of the user which is to inquire about the basis and execution method of the enrollment area delineation. The keywords are “compulsory education enrollment”, “designated enrollment areas”, and “Haikou City 2022”. The second step is to break down the elements of the problem including: (1) identifying the main influencing factors of the enrollment area; (2) Clear delineation methods in policies (such as single school zoning, multi school coordination, random allocation, etc.); (3) Is there any special arrangement. The third step is to extract key information from the data. Firstly, the policy states that zoning is determined comprehensively based on factors such as the number of eligible children, school distribution, administrative divisions, and transportation conditions. Secondly, it is mentioned in the admission policy that if the number of eligible students is less than the enrollment plan, single school zoning will be implemented; If the number of people exceeds, a combination of multi school coordination and random allocation will be used. Step four, I will transform these policy contents into an information structure that users can understand and execute, ensuring clear logic and accurate expression. The fifth step is to summarize and output the answer: “How are the districts designated for compulsory education enrollment in Haikou City in 2022 </think> The delineation of compulsory education enrollment areas in Haikou City in 2022 is based on multiple comprehensive factors and implemented in accordance with scientific and reasonable principles. Specifically, the education department will set the enrollment scope for schools based on the actual situation such as the number of eligible children and adolescents, the distribution and scale of schools, administrative divisions, and transportation conditions. In terms of implementation, if the number of eligible children does not exceed the school’s enrollment plan, single school zoning is usually implemented; If it exceeds the plan, the admission list will be determined through multi school coordination and random allocation. |
| Reference Answer | Based on factors such as the number of school-age children, the distribution and size of schools, administrative divisions, and transportation conditions, the education authorities delineate school admission zones in a scientifically informed manner. A predominantly single-school zoning approach is adopted, supplemented by coordinated multi-school planning when necessary. When the number of eligible applicants is less than the enrollment quota, students are admitted directly through the single-school zoning scheme. In cases of oversubscription, admission is determined by random allocation, and students not selected through this process are assigned by the education authorities to nearby schools with available capacity. |
Appendix B. Chain-of-Thought Generalization Across Multiple Domains
| Social Security | How to search for the participation records of urban and rural residents’ medical insurance? |
| Original Model Response | <think> Well, I need to figure out how to check my participation records in the Urban and Rural Resident Basic Medical Insurance (URRBMI) system. I’m not very familiar with the process, so I’ll need to think it through step by step. First, I recall that there are two main channels: online and offline. Let me consider the online options first. Online channels may include official websites or mobile applications. Does the National Healthcare Security Administration (NHSA) have an official website? I believe it does, and I remember that it provides some inquiry services on the website. Would I need to visit that site? And would I need to register an account or log in directly? If I don’t already have an account, I might have to create one first.
...
Overall, I should probably start with the online channel as it’s more convenient and efficient. If I encounter any issues, I’ll then consider visiting an office in person or calling the hotline for support.
</think> 1. Online Inquiry: (1) Via the National Healthcare Security Administration (NHSA) Website: Open your browser and visit the official NHSA website: https://www.nhsa.gov.cn. Navigate to the “Online Services” or “Personal Service Portal.” Register and log into your personal account. If you don’t have one, you’ll need to register using a valid mobile number and email address. (2) Inquire About Participation Information: After logging in, locate options like “Healthcare Services” or “Participation Certificate.” Choose “URRBMI Participation Record Inquiry,” enter required personal information (such as name and ID number), and submit. Upon system verification, your participation and payment records will be displayed. (3) Via Mobile App: Download and install the “National Healthcare Service Platform” app. Register or log into your account. Navigate to “Services” or “Inquiries” and select “Participation Record Inquiry.” Input the relevant personal information to proceed. 2. Offline Inquiry: (1) Visit the Local Medical Insurance Service Center: Look up the address of your district/county healthcare security bureau (branches usually exist at the local level) Bring your ID card and social security card. At the service desk, ask how to access your participation records. You may be asked to fill out a form and verify your identity. (2) Call the Hotline: Find the customer service number of your local healthcare security bureau (typically 12345 or a local number, e.g., 010-82516758 in Beijing). Call and follow the voice prompts to select healthcare services. Provide your personal details to complete the inquiry. 3. Other Methods: Bank Inquiry: If your insurance contributions were paid through a bank, you may access participation records at a bank counter or through online banking. Procedures may differ by institution, so it’s advisable to contact your bank’s customer service for guidance. Hospital System: If you have visited a hospital before, your participation information might be available in the hospital’s insurance system. However, this method is not as straightforward as the official online channels and is best used in conjunction with them. |
| Fine-Tuned Model Response | <think>Main user inquiry analysis: Understand how to access participation records of the Urban and Rural Resident Basic Medical Insurance (URRBMI); Key issue clarification: Access channels and inquiry methods for URRBMI participation records; Policy information matching: Participation records can be obtained through both online and offline channels; Transforming policy information into user-oriented responses: Inform users of the specific access channels and methods; Conclusion: Participation records for URRBMI can be retrieved via online or offline means. </think> Participation records for the Urban and Rural Resident Basic Medical Insurance can be accessed through both online and offline channels. Online platforms include: the “Hainan Medical Insurance” mobile application (APP), the official WeChat accounts of the Hainan Provincial Healthcare Security Bureau, the National Healthcare Service Platform APP, the official WeChat account of the National Healthcare Security Administration, the Hainan Government Service Network, the Hainan Provincial Government Service Hotline, the Haikou Municipal Government Service Center official WeChat account, the “Haikou Citizens” APP, the official WeChat account of the Haikou Healthcare Security Bureau, the official website of the Haikou Municipal Government, and the official WeChat account of the Haikou Healthcare Security Bureau. Offline channels include medical insurance counters at district-level hospitals and service windows at district-level government service centers. |
| Healthcare | Can I entrust someone else to purchase medicine on my behalf due to special reasons? |
| Original Model Response | <think> Okay, so the user is asking if they can have someone else buy medicine for them because of special reasons. I need to figure out the answer based on government regulations. Let me think through this step by step. First, I should consider the legal framework. In China, there are specific laws and regulations about medication procurement. I remember that the “Drug Administration Law” is relevant here. It probably covers who can buy and dispense drugs. Next, I should think about the administrative regulations. There might be rules about whether a proxy is allowed, especially if the person has a legitimate reason, like being unable to purchase themselves due to health or other issues. Also, I need to consider practical aspects. Pharmacies might require certain documents, like a written authorization or an ID, to allow someone else to make the purchase. The user should check with their local pharmacy to confirm what’s needed. I should also think about the user’s possible situation. They might be elderly, have a disability, or another valid reason. The government likely supports such convenience, so there should be a procedure in place. I should structure the response to first state that it’s generally allowed under the law, then mention the specific regulation (Drug Administration Law), and suggest checking with local authorities for any additional requirements. Also, including practical steps like providing a letter of authorization would be helpful. I need to make sure the answer is clear and policy-relevant, aligning with administrative norms. So, the response should affirm the possibility, cite the relevant law, and offer practical advice. </think> Yes, you can entrust someone else to purchase medicine on your behalf due to special reasons. According to the “Drug Administration Law” and relevant regulations, individuals may authorize another person to purchase medicine for them. This is permissible as long as the transaction complies with legal and administrative requirements. When arranging for someone else to purchase medicine, it is advisable to provide a written authorization or necessary identification to facilitate the process. For specific requirements, you may consult the local pharmaceutical authorities or the pharmacy where you intend to make the purchase. |
| Fine-Tuned Model Response | <think> - **Analysis of the user’s main inquiry**: Whether it is permissible to entrust another person to purchase medication on one’s behalf. - **Deconstruction of key elements**: Involves special circumstances, third-party authorization, and drug purchasing. - **Policy information retrieval**: Refer to relevant regulatory provisions such as the *Regulations on the Supervision and Administration of the Use of Medical Security Funds*, which stipulate conditions for authorized drug purchases. - **Conversion of policy into executable response**: For instance, explain the specific requirements and procedures for delegated drug purchasing. - **Conclusion**: It is permissible to delegate others to purchase medication on one’s behalf, but the relevant procedures must be followed in accordance with the stipulated regulations. </think> According to the Regulations on the Supervision and Administration of the Use of Medical Security Funds, it is permitted to entrust another person to purchase medication; however, the relevant procedures must be completed in accordance with the prescribed requirements. |
| Public Security | How to apply for a senior citizen preferential certificate? |
| Original Model Response | <think>
Okay, so I need to figure out how to apply for a senior citizen preferential certificate. I’m not exactly sure where to start, but I think the first step is to check the requirements. I remember that usually, government services require some form of identification, so maybe a valid ID is needed. I should also consider the age requirement—typically, it’s 60 and above, right? So, the person needs to be at least 60 years old to apply. Next, I think about where to apply. Is it done online or in person? I’m not sure, but maybe some places allow online applications. If not, they might have to visit a local government office. I should also consider the documents needed. Probably, they’ll need proof of age, like a birth certificate or passport, and maybe a recent passport-sized photo. I’m not certain about the photo size, though—maybe 2 × 2 inches? I also wonder if there’s a specific application form. Maybe the government provides a form that needs to be filled out. If it’s online, they might download it from a website, but if it’s in person, they might get it at the office. Then, after submitting the application, there’s probably a processing time. I’m not sure how long that takes, but it’s good to mention that they’ll receive a response within a certain period. I should also think about whether there’s a fee involved. Some services are free, while others have a small charge. I’m not sure about this one, so I’ll include that it’s advisable to check for any fees and possible exemptions. Additionally, it’s important to know where to collect the certificate once approved. Is it via mail or in person? Maybe the local government office will notify them once it’s ready. I should structure this information in a clear, step-by-step manner. Maybe start with checking eligibility, then gathering documents, then deciding on the application method (online or in person), submitting the application, waiting for processing, and finally collecting the certificate. I also need to make sure the information is accurate and up-to-date. Since policies can change, it’s best to direct them to the official government website or contact the local office for the most current details. That way, they get reliable information without any confusion. Wait, I’m not sure about the exact documents required. It might vary by location, so it’s safer to mention that they should check with their local government or the official website for specific requirements. That way, they don’t miss any necessary documents. Also, I should consider any potential issues they might face, like if they can’t go in person. Maybe there’s a way to apply by mail or have someone else submit on their behalf. Including that could be helpful. In summary, the steps would be: check eligibility, gather required documents, choose application method, submit application, wait for processing, and collect the certificate. I should present this in a clear, numbered list, and advise them to contact the local government for any specific details or assistance. </think> To apply for a senior citizen preferential certificate, follow these organized steps: ... 7. **Collect Certificate**: Once approved, the certificate can be collected in person or via mail, depending on the local government’s procedure. For the most accurate and current information, visit the official government website or contact your local government office. They can provide specific details and assistance if needed. |
| Fine-Tuned Model Response | <think> - **Analysis of the user’s primary inquiry**: Application for a senior citizen preferential certificate. - **Decomposition of key elements**: Age, identification documents, application location, and processing time. - **Policy information matching**: The processing procedure for senior citizen preferential certificates. - **Transformation into executable user response**: Provide specific processing steps and required materials. - **Conclusion**: The senior citizen preferential certificate must be applied for in accordance with the prescribed procedures and requirements. </think> According to relevant policy regulations, individuals aged 60 and above are eligible to apply for a senior citizen preferential certificate. The procedure is as follows: Bring valid documents such as an ID card, household registration book, and retirement certificate to the community service center at the place of household registration; Fill out the application form and submit the required materials; Wait for review, and upon approval, collect the senior citizen preferential certificate. |
| Education | What does the “Three Exemptions” policy in vocational schools specifically include? |
| Original Model Response | <think>
Okay, so I need to figure out what the Three Exemptions policy in vocational schools specifically includes. I’m not entirely sure about this, but I think it’s related to exemptions from certain fees or requirements. Let me start by breaking down the question. First, I know that vocational schools, also known as trade schools or technical colleges, focus on practical skills for specific careers. The term “Three Exemptions” suggests there are three specific areas where students are exempt from certain obligations or fees. I remember hearing that in some countries, vocational students might have different regulations compared to traditional universities. Maybe the Three Exemptions refer to exemptions from military service, public exams, or some form of taxation? Or perhaps they’re exempt from certain course requirements, fees, or other administrative tasks. I should consider the context of the country. Since the question doesn’t specify, I’ll assume it’s about China because I’ve heard about such policies there. In China, vocational education is a key part of the education system, and there have been policies to encourage students to pursue vocational training. Looking into China’s policies, I recall that vocational students might be exempt from certain fees, maybe the miscellaneous fees that regular high school students have to pay. That could be one exemption. Another could be exemption from the Gaokao, the college entrance exam, since vocational students might have their own entrance exams or alternative pathways. The third exemption might relate to military service, where vocational students could have a different process or exemption. Wait, I’m not entirely sure about military service. Maybe it’s something else, like exemption from certain work requirements or labor taxes. Alternatively, it could be exemptions from public service duties after graduation, allowing them to enter the job market more freely. I should verify each point. Let me think: in China, vocational schools often have policies that reduce the financial burden on students. So, exemptions from miscellaneous fees makes sense as one exemption. The second could be exemption from the Gaokao, allowing vocational students to enter higher vocational colleges without taking the main exam. The third might be exemption from the college entrance exam for university admission, but I’m not sure if that’s the case. Alternatively, maybe the three exemptions are related to fees, textbooks, and transportation. Or perhaps it’s about exemptions from certain courses, allowing students to focus on their vocational training. I think the most accurate points are exemptions from miscellaneous fees, public exams, and possibly public service duties or military service. I should structure the answer with these three points, explaining each clearly and concisely. </think> The Three Exemptions policy in vocational schools, particularly in the context of China, is designed to support students by reducing their financial and regulatory burdens. Here’s a structured explanation of the policy: 1. **Exemption from Miscellaneous Fees**: Vocational students are often exempt from paying certain additional fees that are typically required of students in general secondary education. This includes costs for extracurricular activities, clubs, or other non-academic expenses, making vocational education more affordable. ... 3. **Exemption from Military Service Obligations**: Vocational students may have specific exemptions or alternative pathways regarding military service. This can provide them with flexibility in their career choices and personal plans after graduation. These exemptions collectively aim to streamline the educational journey for vocational students, focusing on practical skills and reducing unnecessary financial and regulatory hurdles. |
| Fine-Tuned Model Response | <think> [“The user’s primary inquiry is to understand the content of the `Three Exemptions’ policy in vocational schools. The key components of this policy include tuition exemption, accommodation exemption, and textbook fee exemption.”; “By retrieving relevant policy information, it was found that students in vocational schools are entitled to enjoy these three exemptions.”; “The policy information was then converted into an executable answer for the user, specifying the exact monetary amounts for tuition, accommodation, and textbook fees.”; “The final conclusion is that the `Three Exemptions’ policy in vocational schools includes tuition exemption, accommodation exemption, and textbook fee exemption, with the specific amounts being 1980 yuan, 800 yuan, and 1000 yuan respectively.”] </think> The “Three Exemptions” policy in vocational schools includes exemption of tuition fees, accommodation fees, and textbook fees. Specifically, the amounts are: Tuition fee—1980 yuan, Accommodation fee—800 yuan, Textbook fee—1000 yuan. |
| Transportation | Which categories of motor vehicle driving licenses are applicable for individuals with monocular visual impairment, provided their corrected vision or uncorrected vision in the better eye reaches 5.0 or above on the standard visual acuity chart, and their horizontal field of vision reaches 150 degrees? |
| Original Model Response | <think>
Okay, so I need to figure out which categories of motor vehicle driving licenses are applicable for individuals with monocular visual impairment, given their corrected or uncorrected vision in the better eye is 5.0 or above and their horizontal field of vision is at least 150 degrees. First, I should understand what monocular visual impairment means. Monocular means only one eye is impaired, so the other eye is typically normal or has better vision. The user’s better eye has a vision of 5.0 or above, which is 20/20 vision in the Snellen chart, so that’s good. Also, the horizontal field of vision is 150 degrees, which is pretty wide, almost normal. Next, I should recall the different categories of driving licenses. In many jurisdictions, licenses are categorized based on the type of vehicles you can drive, such as cars, motorcycles, buses, etc. But in some places, especially in China, the categories are labeled from A1 to D. I think A1 is for large passenger buses, A2 for heavy trucks, A3 for medium-sized buses, B1 for medium trucks, B2 for regular trucks, and C1 for small cars, C2 for small automatic cars, D for low-speed vehicles. Now, considering visual requirements. Typically, for a regular car license, the vision requirement is at least 5.0 in the better eye, which the user meets. The field of vision is also important for safe driving, especially for maneuvering and avoiding obstacles. 150 degrees is quite wide, so that should be sufficient. I should check if monocular vision is allowed. In many places, as long as the better eye meets the criteria, monocular vision is acceptable. Some jurisdictions might have stricter rules, but in general, if the user’s vision is good and the field is adequate, they should qualify for standard licenses. So, the user can apply for C1, C2, or D categories. C1 is for small cars, C2 for automatic cars, and D for low-speed vehicles. These are the most common categories for individuals without special vehicle needs. I should also consider if there are any restrictions or additional requirements. Sometimes, they might need a medical certificate or special testing, but the user already meets the vision criteria, so that shouldn’t be an issue. In conclusion, the applicable categories are C1, C2, and D. These are suitable for individuals with monocular impairment who meet the specified vision standards. </think> The applicable categories of motor vehicle driving licenses for individuals with monocular visual impairment, who meet the specified vision standards, are: - **C1**: Applicable for small cars. - **C2**: Applicable for small automatic cars. - **D**: Applicable for low-speed vehicles. These categories are suitable given the individual’s corrected or uncorrected vision of 5.0 or above in the better eye and a horizontal field of vision of 150 degrees. |
| Fine-Tuned Model Response | <think> - **Transformation of policy information into executable user guidance**: Individuals with monocular visual impairment whose better eye meets or exceeds 5.0 on the standard visual acuity chart and whose horizontal visual field reaches 150 degrees are eligible to apply for driving licenses for the following vehicle categories: small passenger cars, small automatic transmission cars, low-speed freight vehicles, three-wheeled vehicles, and motor vehicles adapted for individuals with disabilities (small automatic passenger vehicles). - **Conclusion**: Individuals with monocular visual impairment whose corrected or uncorrected vision in the better eye reaches 5.0 or above and who possess a horizontal visual field of 150 degrees or more may apply for licenses for small passenger vehicles, small automatic transmission vehicles, low-speed freight vehicles, three-wheeled vehicles, and specially adapted small automatic passenger vehicles for persons with disabilities. </think> According to the relevant regulations, individuals with monocular visual impairment who have corrected or uncorrected vision in the better eye reaching 5.0 or above, and whose horizontal visual field reaches 150 degrees, are eligible to apply for driving licenses for the following vehicle categories: small passenger vehicles, small automatic transmission vehicles, low-speed freight vehicles, three-wheeled vehicles, and small automatic passenger vehicles specifically adapted for individuals with disabilities. |
Appendix C. Human-like Evaluation Details
Appendix C.1. Evaluation Criteria
- -
- Conciseness: Measured the brevity and clarity of a response while preserving its informativeness.
- -
- Correctness: Assessed the factual alignment between the response and the ground-truth reference or supporting documents.
- -
- Maliciousness: Detected whether the response contained hostile or offensive content.
- -
- Harmfulness: Evaluated the potential of the response to mislead users or cause administrative misinterpretation.
Appendix C.2. Scoring Instructions
Appendix C.3. Evaluation Scope
Appendix C.4. Reliability Measures
References
- Ion, R.; Avram, A.M.; Păiş, V.; Mitrofan, M.; Mititelu, V.B.; Irimia, E.; Badea, V. An open-domain QA system for e-governance. arXiv 2022, arXiv:2206.08046. [Google Scholar] [CrossRef]
- Pham, L.; Limbu, Y.B.; Le, M.T.T.; Nguyen, N.L. E-government service quality, perceived value, satisfaction, and loyalty: Evidence from a newly emerging country. J. Public Policy 2023, 43, 812–833. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef]
- Sundberg, L.; Holmström, J. Fusing domain knowledge with machine learning: A public sector perspective. J. Strateg. Inf. Syst. 2024, 33, 101848. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, M.; Ta, N.; Sun, H.; Guo, Y.; Zhou, W.; Guo, Y.; Zhang, W.; Feng, J. Large language models and their application in government affairs. J. Tsinghua Univ. Sci. Technol. 2024, 64, 649–658. [Google Scholar] [CrossRef]
- Yang, S.; Chen, F.; Yang, Y.; Zhu, Z. A Study on Semantic Understanding of Large Language Models from the Perspective of Ambiguity Resolution. In Proceedings of the 2023 International Joint Conference on Robotics and Artificial Intelligence, Shanghai, China, 21–23 July 2023; pp. 165–170. [Google Scholar] [CrossRef]
- Tang, X.; Zheng, Z.; Li, J.; Meng, F.; Zhu, S.C.; Liang, Y.; Zhang, M. Large language models are in-context semantic reasoners rather than symbolic reasoners. arXiv 2023, arXiv:2305.14825. [Google Scholar] [CrossRef]
- Matarazzo, A.; Torlone, R. A Survey on Large Language Models with some Insights on their Capabilities and Limitations. arXiv 2025, arXiv:2501.04040. [Google Scholar] [CrossRef]
- Gao, S.; Gao, L.; Li, Q.; Xu, J. Application of large language model in intelligent Q&A of digital government. In Proceedings of the 2023 2nd International Conference on Networks, Communications and Information Technology, Qinghai, China, 16–18 June 2023; pp. 24–27. [Google Scholar] [CrossRef]
- Lin, H. Designing Domain-Specific Large Language Models: The Critical Role of Fine-Tuning in Public Opinion Simulation. arXiv 2024, arXiv:2409.19308. [Google Scholar] [CrossRef]
- Lu, W.; Luu, R.K.; Buehler, M.J. Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities. npj Comput. Mater. 2025, 11, 84. [Google Scholar] [CrossRef]
- Wang, X.; Tan, Y.; Yang, T.; Yuan, M.; Wang, S.; Chen, M.; Ren, F.; Zhang, Z.; Shao, Y. Efficient Large Language Model Application Development: A Case Study of Knowledge Base, API, and Deep Web Search Integration. J. Comput. Commun. 2024, 12, 171–200. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Y.; Wang, K. Optimizing reasoning abilities in large language models: A step-by-step approach. TechRxiv 2024. [Google Scholar] [CrossRef]
- Vaillancourt, E.; Thompson, C. Instruction tuning on large language models to improve reasoning performance. TechRxiv 2024. [Google Scholar] [CrossRef]
- Fang, F.; Bai, Y.; Ni, S.; Yang, M.; Chen, X.; Xu, R. Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training. arXiv 2024, arXiv:2405.20978. [Google Scholar] [CrossRef]
- Sun, C.; Lin, K.; Wang, S.; Wu, H.; Fu, C.; Wang, Z. LalaEval: A Holistic Human Evaluation Framework for Domain-Specific Large Language Models. arXiv 2024, arXiv:2408.13338. [Google Scholar] [CrossRef]
- Pasquarelli, L.; Koutcheme, C.; Hellas, A. Comparing the Utility, Preference, and Performance of Course Material Search Functionality and Retrieval-Augmented Generation Large Language Model (RAG-LLM) AI Chatbots in Information-Seeking Tasks. arXiv 2024, arXiv:2410.13326. [Google Scholar]
- Sung, C.W.; Lee, Y.K.; Tsai, Y.T. A new pipeline for generating instruction dataset via RAG and self fine-tuning. In Proceedings of the 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), Osaka, Japan, 2–4 July 2024; pp. 2308–2312. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. Available online: https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf (accessed on 15 May 2025).
- Trajanoska, M.; Stojanov, R.; Trajanov, D. Enhancing knowledge graph construction using large language models. arXiv 2023, arXiv:2305.04676. [Google Scholar] [CrossRef]
- Es, S.; James, J.; Anke, L.E.; Schockaert, S. Ragas: Automated evaluation of retrieval augmented generation. In Proceedings of the the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, St. Julian’s, Malta, 17–22 March 2024; pp. 150–158. Available online: https://aclanthology.org/2024.eacl-demo.16/ (accessed on 13 June 2025).
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Rajabi, E.; Midha, R.; de Souza, J.F. Constructing a knowledge graph for open government data: The case of Nova Scotia disease datasets. J. Biomed. Semant. 2023, 14, 4. [Google Scholar] [CrossRef]
- Pellegrino, M.A.; Rula, A.; Tuozzo, G. KGHeartBeat: An Open Source Tool for Periodically Evaluating the Quality of Knowledge Graphs. In Proceedings of the International Semantic Web Conference. Springer, Hanover, MD, USA, 11–15 November 2024; pp. 40–58. [Google Scholar] [CrossRef]
- Dong, K.; Sun, A.; Kim, J.J.; Li, X. Syntactic multi-view learning for open information extraction. arXiv 2022, arXiv:2212.02068. [Google Scholar] [CrossRef]
- Su, P.; Vijay-Shanker, K. Investigation of improving the pre-training and fine-tuning of BERT model for biomedical relation extraction. BMC Bioinform. 2022, 23, 120. [Google Scholar] [CrossRef] [PubMed]
- Robertson, S.; Zaragoza, H. The probabilistic relevance framework: BM25 and beyond. Found. Trends® Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Alhabashneh, O.; Iqbal, R.; Doctor, F.; James, A. Fuzzy rule based profiling approach for enterprise information seeking and retrieval. Inf. Sci. 2017, 394, 18–37. [Google Scholar] [CrossRef]
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv 2025, arXiv:2501.12948. [Google Scholar] [CrossRef]
- Gharagozlou, H.; Mohammadzadeh, J.; Bastanfard, A.; Ghidary, S.S. Semantic relation extraction: A review of approaches, datasets, and evaluation methods with looking at the methods and datasets in the Persian language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–29. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Hang, C.N.; Yu, P.D.; Tan, C.W. TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking. IEEE Trans. Artif. Intell. 2025. [Google Scholar] [CrossRef]
- Cao, H. Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark. arXiv 2024, arXiv:2406.01607. [Google Scholar] [CrossRef]
- Pelofske, E.; Liebrock, L.M.; Urias, V. Cybersecurity threat hunting and vulnerability analysis using a Neo4j graph database of open source intelligence. arXiv 2023, arXiv:2301.12013. [Google Scholar] [CrossRef]
- Wang, B.; Deng, X.; Sun, H. Iteratively prompt pre-trained language models for chain of thought. arXiv 2022, arXiv:2203.08383. [Google Scholar] [CrossRef]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609. [Google Scholar] [CrossRef]
- Wang, B.; Zhao, H.; Zhou, H.; Song, L.; Xu, M.; Cheng, W.; Zeng, X.; Zhang, Y.; Huo, Y.; Wang, Z.; et al. Baichuan-m1: Pushing the medical capability of large language models. arXiv 2025, arXiv:2502.12671. [Google Scholar] [CrossRef]
- GLM, T.; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv 2024, arXiv:2406.12793. [Google Scholar] [CrossRef]
- Ibtasham, M.S.; Bashir, S.; Abbas, M.; Haider, Z.; Saadatmand, M.; Cicchetti, A. ReqRAG: Enhancing Software Release Management through Retrieval-Augmented LLMs: An Industrial Study. In Proceedings of the International Working Conference on Requirements Engineering: Foundation for Software Quality; Springer: Cham, Switzerland, 2025; pp. 277–292. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar] [CrossRef]
- Rei, R.; Stewart, C.; Farinha, A.C.; Lavie, A. COMET: A neural framework for MT evaluation. arXiv 2020, arXiv:2009.09025. [Google Scholar] [CrossRef]
- Sarmah, B.; Li, M.; Lyu, J.; Frank, S.; Castellanos, N.; Pasquali, S.; Mehta, D. How to Choose a Threshold for an Evaluation Metric for Large Language Models. arXiv 2024, arXiv:2412.12148. [Google Scholar] [CrossRef]
| Case | Cleaned but Unstructured | Structured with 178 Materials–Steps–Notes |
|---|---|---|
| Example 1 | “According to the XX Regulation, … (a long paragraph of regulatory background and historical context), in special circumstances, … the service window addresses are … contact information…” | Materials: Quotation of the relevant clauses from the XX Regulation; Steps: 1. Prepare documents, 2. Submit the application, 3. Wait for review; Notes: See TableX for addresses and contact numbers. |
| Example 2 | “Users must bring their original ID card and household register along with copies, and fill out the application form; the detailed process is … (a lengthy description including subsidy policies, notes, hotline number)” | Materials: ID card, household register; Steps: Fill out the form → Submit → Receive receipt; Notes: Reissue within 7 days using the receipt. |
| Metric | Type | Role and Purpose |
|---|---|---|
| ROUGE-1 | Lexical overlap | Measures content completeness using n-gram overlap between the output and reference. |
| S-BERT | Semantic similarity | Assesses sentence-level embedding similarity using cosine similarity. |
| COMET | Generation quality | Predicts generation quality using a learned scoring model based on references. |
| Context Precision | Retrieval quality | Assesses the relevance of retrieved context chunks to the reference. |
| Context Recall | Retrieval coverage | Measures how much of the reference content is captured by the retrieved context. |
| Faithfulness | Factual consistency | Assesses factual consistency between the responses and retrieved evidence. |
| Response Relevancy | Query alignment | Evaluates how well the response addresses the user’s original intent. |
| Domain | ROUGE-1 (%) | Response Relevancy-5 (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA | Qwen | Baichuan | ChatGLM | ARGUS | LLaMA | Qwen | Baichuan | ChatGLM | ARGUS | |
| Social Security | 27 ± 9 | 46 ± 11 | 43 ± 9 | 42 ± 14 | 71 ± 5 | 42 ± 17 | 57 ± 12 | 55 ± 10 | 56 ± 13 | 89 ± 7 |
| Healthcare | 31 ± 15 | 53 ± 10 | 56 ± 8 | 50 ± 13 | 65 ± 6 | 41 ± 18 | 46 ± 13 | 50 ± 11 | 45 ± 14 | 82 ± 5 |
| Public Security | 56 ± 5 | 51 ± 12 | 54 ± 9 | 48 ± 13 | 64 ± 5 | 70 ± 5 | 76 ± 6 | 79 ± 4 | 73 ± 7 | 81 ± 6 |
| Transportation | 35 ± 18 | 41 ± 13 | 40 ± 10 | 39 ± 12 | 73 ± 10 | 44 ± 17 | 49 ± 11 | 51 ± 8 | 46 ± 12 | 74 ± 5 |
| Education | 40 ± 16 | 61 ± 10 | 62 ± 8 | 55 ± 12 | 70 ± 5 | 45 ± 15 | 70 ± 11 | 72 ± 9 | 65 ± 13 | 86 ± 10 |
| Q1 (Education) | What are the online application channels for new student enrollment in primary and secondary schools in Haikou? |
| Original Model Response | <think>
Okay, so I need to figure out the online application channels for new student enrollment in primary and secondary schools in Haikou. Let me start by breaking this down. First, I know that Haikou is the capital city of Hainan Province in China. The question is about enrolling new students, so we’re talking about primary (elementary) and secondary (middle school) levels. I should consider the government’s approach to online services. In China, many government services are being digitized, so there’s likely an official portal or app for this purpose. I remember hearing about the “Ganjiu” platform, which is used for various government services. Maybe that’s one channel. Also, the Haikou (Bureau of Education) probably has an official website. They would likely have an online application section there. I should check if that’s the case. Another possibility is the Hainan Province’s government service platform. Since Haikou is part of Hainan, the provincial platform might handle school enrollments. It’s possible that applications can be submitted there as well. I should also think about the Haikou Municipal Government’s portal. They often have sections for education and enrollment, so that’s another potential channel. Wait, there’s also the “iHaikou” app. I think many cities in China have their own apps for municipal services. It’s likely that Haikou has one, and enrollment might be handled through that app. So, to summarize, the channels would include: 1. Haikou’s official website. 2. The Hainan Province Government Service Platform. 3. The Haikou Municipal Government’s official website. 4. The “Ganjiu” platform. 5. The “iHaikou” app. I should make sure these are accurate. Maybe I can think about each one: ... 5. **iHaikou App**: Download the “iHaikou” app, a mobile-friendly application that offers various municipal services, including school enrollment. These channels provide convenient and accessible ways to apply online for school enrollment in Haikou. |
| Fine-Tuned Model Response | <think> Analyze the user’s main intent, which is to inquire about online application channels; Decompose the key elements of the question, including “new student enrollment in primary and secondary schools” and “online application channels”; Match relevant policy information to identify the procedures for online application in Haikou; Convert the policy information into user-executable answers, such as providing specific website links or contact methods; Conclude with the question: “What are the online application channels for new student enrollment in Haikou?” </think> The online application channels for new student enrollment in Haikou are: 1. Haikou Education Bureau official website; 2. Haikou Education Bureau WeChat public account; 3. Yechengban APP; 4. Haiyiban APP. |
| Retention Ratio (%) | ROUGE-1 (%) | S-BERT (%) | COMET (%) | Context Precision (k = 5) (%) | Context Recall (%) | Faithfulness (%) |
|---|---|---|---|---|---|---|
| 0 | 34.0 | 68.3 | 70.5 | – | 43.8 | 49.6 |
| 25 | 63.7 | 71.5 | 76.3 | 45.2 | 52.2 | 66.6 |
| 50 | 68.8 | 74.7 | 78.1 | 43.1 | 46.5 | 65.6 |
| 75 | 68.7 | 74.7 | 78.1 | 34.3 | 68.3 | 60.0 |
| 100 | 68.5 | 74.9 | 78.2 | 51.3 | 53.7 | 70.6 |
| 125 | 66.6 | 74.9 | 78.7 | 43.3 | 45.4 | 65.7 |
| Retrieval Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Knowledge Graph | 0.74 | 0.68 | 0.71 |
| Vector Retrieval | 0.75 | 0.72 | 0.73 |
| Fusion | 0.75 | 0.76 | 0.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, S.; Xie, X.; Tang, R.; Wang, X.; Sun, K.; Li, G.; Xu, Z.; Xue, P.; Li, Z.; Fu, X. ARGUS: Retrieval-Augmented QA System for Government Services. Electronics 2025, 14, 2445. https://doi.org/10.3390/electronics14122445
Jiang S, Xie X, Tang R, Wang X, Sun K, Li G, Xu Z, Xue P, Li Z, Fu X. ARGUS: Retrieval-Augmented QA System for Government Services. Electronics. 2025; 14(12):2445. https://doi.org/10.3390/electronics14122445
Chicago/Turabian StyleJiang, Song, Xiaofeng Xie, Rongnian Tang, Xuanqi Wang, Kaihao Sun, Guanghan Li, Zhenkai Xu, Peng Xue, Ziling Li, and Xuedong Fu. 2025. "ARGUS: Retrieval-Augmented QA System for Government Services" Electronics 14, no. 12: 2445. https://doi.org/10.3390/electronics14122445
APA StyleJiang, S., Xie, X., Tang, R., Wang, X., Sun, K., Li, G., Xu, Z., Xue, P., Li, Z., & Fu, X. (2025). ARGUS: Retrieval-Augmented QA System for Government Services. Electronics, 14(12), 2445. https://doi.org/10.3390/electronics14122445