Abstract
Strip steel serves as a crucial raw material in numerous industries, including aircraft and automobile manufacturing. Surface defects in strip steel can degrade the performance, quality, and appearance of industrial steel products. Detecting surface defects in steel strip products is challenging due to the low contrast between defects and background, small defect targets, as well as significant variations in defect sizes. To address these challenges, a two-stage attention-based feature-enhancement network (TAFENet) is proposed, wherein the first-stage feature-enhancement procedure utilizes an attentional convolutional fusion module with convolution to combine all four-level features and then strengthens the features of different levels via a residual spatial-channel attention connection module (RSC). The second-stage feature-enhancement procedure combines three-level features using an attentional self-attention fusion module and then strengthens the features using a RSC attention module. Experiments on the NEU-DET and GC10-DET datasets demonstrated that the proposed method significantly improved detection accuracy, thereby confirming the effectiveness and generalization capability of the proposed method.
1. Introduction
Strip steel, as an indispensable foundational material in modern industry, plays a crucial role in various fields such as construction, automotive, and machinery. It is essential not only for the external appearance of products but also for their inherent strength and durability. Therefore, strict control over surface quality is paramount in the production process of strip steel to ensure its performance.
Existing strip steel surface defect detectors rely on the accurate extraction of feature maps with high semantic information for their success. Attention-based approaches, including those dependent on spatial- and channel-based attention, are commonly used to extract important information from strip steel images by focusing on the most relevant information while suppressing irrelevant details [1]. Spatial-based attention, an adaptive mechanism for selecting regions of interest, highlights defect areas in images with complex backgrounds and varying defect sizes. In addition, channel-based attention recalibrates the weights of each channel to emphasize the most relevant feature channels in images with complex backgrounds and low contrast. Self attention [2], spatial-based attention, is crucial in obtaining global information by calculating the relationships among elements within a feature map. Self attention can enhance the ability of the detection model to handle variations in feature patterns caused by differences in intraclass defect sizes, and increase robustness to complex texture backgrounds. Based on the aforementioned analysis, this study proposes an effective integration of various attention mechanisms. This strategy aims to adaptively focus on the most important information while suppressing irrelevant details, thereby enhancing the feature representation and generalization capabilities of the model.
Furthermore, the model should exhibit strong robustness across images with varying defect sizes, ensuring reliable detection and analysis under varying conditions. While the feature pyramid network (FPN) [3] and its variants [4] are commonly used in feature fusion networks, they only fuse features across adjacent layers, leading to interlayer information transmission that depends on the selection of the intermediate layer information. This indirect interaction method limits cross-level information propagation, resulting in information loss.
To address this issue, our study utilizes a two-stage feature enhancement structure that combines local features from various levels to obtain global information. The global information is then fused with local features at each level to obtain feature representation with both global characteristics and local details, thus improving the overall detection accuracy. In particular, in the first stage of feature enhancement, an attentional convolutional (AC) fusion module is applied to integrate features from all levels of the backbone network, capturing global information at the resolution of third-level features, thereby preserving the characteristics of small defects. In the second stage, an attentional self-attention (AS) module is used to fuse the features obtained in the first stage, under the guidance of the highest-resolution output from the fourth layer of the backbone network, to capture comprehensive global contextual information. In addition, this study introduces a residual spatial-channel attention connection module (RSC) that integrates global information from the AC or AS modules with the backbone network’s original features, enabling it to focus on important defect areas while suppressing background noise interference. In this paper, we take full advantage of the advantages of various attention mechanisms, to uncover the predictive potential of the model for steel surface defects. In the backbone network, a mixed block of convolution and self-attention blocks is used, and in the neck network, a lightweight self-attention block is used, which effectively balances performance and latency. In addition, a novel feature fusion network that is more conducive to retaining global information is used, breaking the inherent method of using FPN and its variants. The experimental results demonstrate that our proposed method excels in mean average precision (mAP) with the efficacy of each module further confirmed through ablation experiments. By using TAFENet-loaded detectors in production, it is expected that product quality will be significantly improved by accurately identifying and classifying defects on the surface of strip steel during foundry and metallurgical processes.
The rest of this paper is organized as follows. Section 2 reviews the related literature in the fields of defect detection methods, attention mechanisms, and multiscale object detection. Section 3 presents our novel architecture for surface defect detection and details our proposed approach. Section 4 presents the experimental evaluations and provides a comprehensive analysis of the results. Finally, Section 5 concludes the paper.
2. Related Works
2.1. Defect Detection Methods
Currently, two defect detection methods are commonly used: traditional machine learning-based and deep learning-based methods. Traditional machine learning-based methods generally perform feature extraction and classification to complete detection. For example, Song et al. [5] extracted strip steel surface defect features using local binary patterns and classified them using a support vector machine. Yue et al. [6] employed a relief algorithm for feature selection and the AdaBoost multiclassifier combination algorithm to classify rail surface defects. However, these methods rely heavily on manual feature selection and may not be suitable for complex recognition tasks.
With advances in hardware and progress in deep learning technology, deep learning-based methods have gained popularity. Detection models based on convolutional neural networks (CNNs) have demonstrated remarkable performance in steel surface defect detection owing to their ability to automatically learn discriminative features. These deep-learning-based approaches have addressed the limitations of traditional machine learning methods and have achieved significant improvements in complex scene detection. For example, Huang et al. [7] used depth-wise separable convolution layers and an atrous spatial pyramid pooling algorithm to create a small CNN-based model. Cheng et al. [8] designed a model using the RetinaNet framework to integrate attention mechanisms and feature fusion techniques to enhance the accuracy of defect detection.
These studies demonstrate ongoing efforts to improve defect detection in various domains by leveraging different deep learning architectures and incorporating innovative techniques, such as feature fusion and attention mechanisms.
2.2. Attention Mechanisms
(1) Spatial attention: Various methods have been developed to achieve spatial attention. For example, the recurrent attention model [9] uses a recurrent neural network to implement the attention mechanism. Another method is the spatial transformer network (STN) [10], which explicitly predicts relevant regions through a subnetwork. The STN model includes a learnable transformation module that can spatially transform input data to enable flexible feature extraction.
(2) Channel attention: By adaptively recalibrating the weight of each channel, channel attention helps to determine the focus of the model. Hu et al. [11] first introduced channel attention in their novel squeeze-and-excitation network (SENet), which was designed to capture global information and channel relationships. GSoP-Net [12] was proposed to address the issue in squeeze modules, wherein global average pooling fails to effectively gather complex global information. Furthermore, ECANet [13] was proposed to improve the excitation module by reducing the complexity of the fully connected layers.
2.3. Self-Attention Mechanism and CNN
As a spatial attention mechanism, the self-attention mechanism introduced by the transformer model [2] for natural language processing (NLP) tasks has been applied to computer-vision tasks. This approach has led to significant advancements in the field. To reduce computational complexity, Liu et al. [14] proposed a Swin transformer architecture that employs sliding windows and utilizes shift windows in spatial dimensions to effectively capture global and boundary features. The method based on the self-attention mechanism has excellent performance and has brought great challenges to CNN. However, the work represented by ConvNeXt [15], ConvNeXt v2 [16] and Pelk [17] has caused researchers to examine CNN again through the study of large-kernel convolutional networks. In addition, the method of combining the self-attention mechanism with CNN has become an important research direction. For example, Peng et al. [18] proposed a hybrid network structure conformer for object detection, which uses an interactive method to fuse multiscale local features from CNN and global representations from the transformer.
2.4. Multiscale Object Detection
In multiscale object detection, large-scale features contain low-dimensional texture details and the location information of small objects, whereas small-scale features contain high-dimensional semantic information and the location information of large objects.
The FPN [3] was proposed to perform cross-scale connection and information exchange as well as improve detection accuracy through mutual assistance among information. The asymptotic feature pyramid network (AFPN) [4] exchanges information across non-adjacent layers to better fuse feature information. Ref. [19] proposed an FPN structure with parallel residual bidirectional fusion for accurate object detection. The centralized feature pyramid (CFP) [20] was proposed to learn individual feature information. Ref. [21] proposed a new FPN structure to deal with limitations in detecting large objects.
However, an excessive number of paths and indirect interaction methods may cause information loss during feature transmission. Additionally, cross-level information exchange can result in several pieces of feature information having minimal impact on the final prediction.
3. Method
The attention mechanism imitates human behavior—it emphasizes the most relevant information while suppressing other information. In addition, although previous models have modified the feature fusion architecture with various improved FPNs, the neck network still has problems in terms of the efficiency of information exchange.
This study proposes a novel strip steel surface defect detection method. Particularly, well-designed attention-based modules are proposed to utilize the advantageous features of various attention mechanisms, and a two-stage feature-enhancement structure is proposed to achieve efficient information interaction and fusion as well as to retain local feature information during feature fusion (Figure 1).
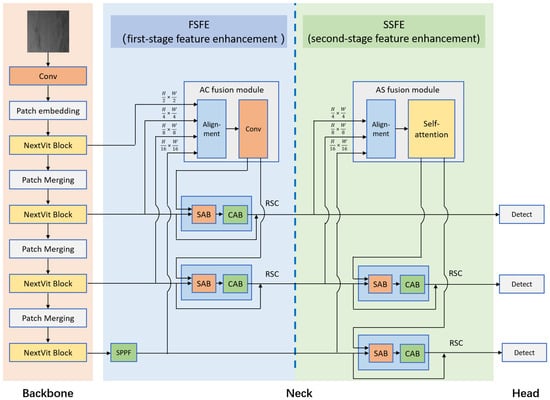
Figure 1.
Architecture of the proposed TAFENet with three main parts: feature extraction backbone, feature-enhancement neck, and detection heads. The feature fusion neck network has two feature-enhancement stages. First, the four-level features output by the backbone network are input into the neck network, then all of them are input into the FSFE (first-stage feature enhancement), where the outputs are fused with the features of the second and third layers through the RSC module. Subsequently, the features of the second, third, and fourth layers are input into the SSFE (second-stage feature enhancement), and the outputs are fused with the features of the third and fourth layers through the RSC module.
3.1. Backbone Network
Although approaches based on CNNs have been proposed to extract rich local detailed feature information, these methods are inefficient at extracting long-distance pixel relevance. Networks based on self-attention, such as the vision transformer (VIT) [22] and Swin transformer [14], have been proposed to learn the spatial relationship between each pixel/token and the others to obtain long-distance pixel relevance in an image. However, because of the lack of balance between speed and accuracy in networks based on self-attention, a backbone network that uses self-attention is not an ideal solution for applications in object detection.
Therefore, we propose the NextVit [23] backbone network structure as the backbone, as it was designed to be effectively deployed in real industrial scenarios. NextVit obtains short- and long-distance dependencies by mixing the convolution and self-attention blocks in each NextVit block. Particularly, for each NextVit block, a hybrid strategy that combines convolutional and self-attention blocks in a hybrid paradigm of (N + 1) * L is proposed. N convolutional blocks and one self-attention block are sequentially stacked at each stage, enhancing the ability of shallow networks to obtain global information and exploit a trade-off between performance and latency.
3.2. Neck Network
To improve the effectiveness of multiscale feature fusion and enhance the detection ability of strip steel surface defects, this study proposes the design of a neck network based on two-stage attention-based feature-enhancement procedures.
(1) Attention-based modules: The attention-based modules proposed in this study include the self-attention block, SAB, and CAB.
Figure 2 illustrates the self-attention block structure. After each convolution layer, batch normalization can achieve a faster inference than layer normalization. Furthermore, adding an attention bias to the attention map can save representation capacity and reduce the pressure on keys to encode position information. Therefore, relative to the size of the V matrix, the key matrix is reduced, and the head dimensions of key K and query Q are allocated to D channels and V = 2D channels, respectively, reducing the calculation time. Moreover, the lightweight activation function Hardswish was adopted.
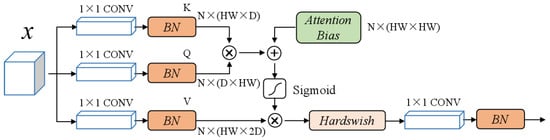
Figure 2.
Structure of a self-attention block. The input activation map size is . N is the number of heads.
Figure 3 shows the structure of the SAB. SAB fuses global and local features through spatial attention. The global information uses a convolution layer to adjust channel dimensions. A Sigmoid layer and the average pooling/bilinear interpolation operation are used to align the resolution with local features and generate semantic weights . Subsequently, the semantic weights are multiplied elementwise with local feature information to emphasize important areas in local feature maps through global information, and the result is added to the global feature information. Therefore, SAB can fuse global and local features and extract spatial attention information. Finally, reparameterized convolutional blocks (RepBlocks) [24] are used to further fuse the information. The final output of the SAB is shown in Equations (1) and (2).
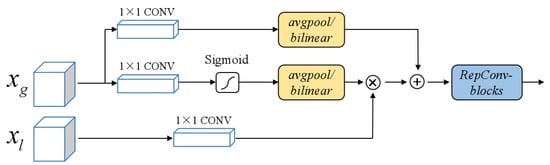
Figure 3.
Structure of SAB. donates global feature information from the AC or AS module, and donates local feature information from the backbone network.
Figure 4 shows the structure of the CAB. The CAB is introduced to gain further attention from the perspective of channels for fused features. The CAB model can automatically learn the weights of each channel to enhance focus on important information and reduce attention to noise or irrelevant information. First, the input feature map x with C channels captures the channel-wise global information through global average pooling and global maximum pooling . Then, to capture the correlation between multiple channels, two multilayer perceptrons with shared parameter information are used in global average pooling (GAP) and global maximum pooling (GMP) branches. Each multilayer perceptron contains two fully connected layers and an ReLU layer. In order to reduce the number of parameters, the channel size output from the first fully connected layer is set to C/2, and due to the ability of two multilayer perceptrons to share parameters from two parallel global pool branches, parameter overhead can be reduced. Finally, the results of the two branches are combined, and the channel attention coefficient is obtained through sigmoid and convolution layers, which serve to weigh the input feature channels. Equation (3) shows the final output of the CAB.
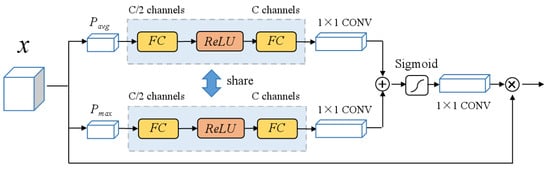
Figure 4.
Structure of the CAB. The CAB calculates the attention coefficient through global average pooling and global maximum pooling branches, respectively. The multilayer perceptrons in the two branches share parameters.
The RSC attention module is constructed using the aforementioned SAB and CAB. First, the SAB is used to fuse global information from the AC or AS module with local information from the backbone network and extract spatial attention information. Subsequently, the CAB is used to extract channel attention information. Finally, the output of the RSC has a residual connection with the input of RSC from the backbone network. In the process of combining global information with the corresponding levels, the spatial and channel attention coefficients at multiple scales are calculated to highlight objects and areas.
(2) Two-stage feature-enhancement structure: Depending on the scale of the features (from large to small), the features of different levels extracted from the backbone network are represented as , , , and .
In the AC fusion module of the FSFE, third-layer features are used to uniformly align the sizes of the input features. By applying convolution operations, this module integrates information from various levels to enable a comprehensive representation of the input data and thereby obtain global information. This fusion process helps to retain important multiscale features while reducing the loss of small details. Specifically , , , and are input and aligned to the size of through average pooling/bilinear operation, as shown in Equation (4). Subsequently, the obtained feature is input into RepBlocks to obtain , as shown in Equation (5). Finally, is divided into two parts in the channel dimension, denoted by and , as shown in Equation (6). In the subsequent network structure, and are fused with and , respectively, through RSC attention modules to obtain and , respectively. The FSFE retains high-resolution feature information with fine details to enhance detection accuracy.
In the AS fusion module of the SSFE, self-attention mechanisms enable the model to obtain long-distance pixel relevance within feature maps, thereby capturing global information from the input data and reducing the influence of noise or irrelevant details. The features are aligned with the minimum input size before the extraction of global context information through the self-attention module to reduce computational complexity. Particularly, , , and are input and aligned to the size of through the avgpool operation to obtain feature , as shown in Equation (7). Then, is input into the self-attention blocks to obtain the contextual information , as shown in Equation (8). Finally, is divided into two parts in the channel dimension, denoted by and , as shown in Equation (9). In the subsequent network structure, and are fused with and , respectively, through the RSC attention modules to obtain and , respectively. SSFE extracts global context information to improve the robustness of intraclass defect size differences and complex backgrounds.
Following the AC or AS module fuses multiscale features and splits the obtained features with global information in the channel dimension, the corresponding features are retransmitted to local features through the RSC attention modules.
3.3. Loss Function
For a traditional IoU, when the two bounding boxes do not intersect, the value of IoU is zero, which causes the gradient to disappear. Furthermore, IoU is not sensitive to objects of different sizes, particularly when the sizes of the predicted and ground truth boxes are extremely different.
This study used the WIoU as the loss function because WIoU considers the contributions of bounding boxes of different sizes to the loss. For strip steel surface defects with large differences in the size of intraclass defects, WIoU can reduce the negative influence caused by geometric factors and the size changes in the object. The calculations are presented in Equations (10) and (11).
where and denote the width and height of the smallest enclosing box that can cover the prediction and ground truth boxes, respectively. The superscript “*” indicates an operation that removes the computational graph to avoid the effect of the calculated gradient of on the convergence of the model.
4. Experiments and Results Analysis
4.1. Datasets
The NEU-DET dataset [25], created by Northeastern University, comprises strip steel surface defect images. The dataset included 6 different types of defects, with 300 gray images for each type, totaling 1800 images (Figure 5). All images were 200 × 200 pixels in size.

Figure 5.
Six types of defects in the NEU-DET dataset. (a) Crazing, (b) inclusion, (c) patches, (d) pitted surface, (e) rolled-in scale, and (f) scratches.
The industrial metal surface defect dataset, the GC10-DET [26], contains 3570 gray images of 10 types of defects, all of which were collected from real industrial scenes (Figure 6).

Figure 6.
Ten types of defects in the GC10-DET dataset. (a) Punching (Pu), (b) weld line (Wl), (c) crescent gap (Cg), (d) water spot (Ws), (e) oil spot (Os), (f) silk spot (Ss), (g) inclusion (In), (h) rolled pit (Rp), (i) crease (Cr), and (j) waist folding (Wf).
The above datasets are collected from plenty of strip steel surface defect samples in real industrial scenarios and classified by category. In NEU-DET, 300 samples are selected for each category, while in GC10-DET, the number of samples is not completely uniform due to the small number of some defect category samples.
4.2. Evaluation Metrics
The evaluation metric used in this study is the mAP calculated from the average precision (AP), which is determined based on the precision (P) and recall (R) values. Specifically, AP indicates the detection accuracy of one category, while mAP is the average precision of multiple categories, which is used to measure the overall accuracy performance of the algorithm in all categories. It is one of the most important evaluation metrics of the object detection algorithm, which is obtained by averaging the AP values of all categories. The calculation method for mAP is described in Equations (12)–(15).
where TP denotes the number of correctly detected boxes, FP denotes the number of incorrectly detected boxes, and FN denotes the number of missed detection boxes. Furthermore, and N represents the total category number.
4.3. Implementation Details
The proposed method was implemented using the Ubuntu operating system with an Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20 GHz processor and four TITAN Xp GPUs. The deep learning framework PyTorch 1.12.1 was utilized for the implementation. During the training of the NEU-DET dataset, the image sizes were adjusted to 224 × 224 pixels, and for the GC10-DET dataset, the image sizes were adjusted to 512 × 512 pixels. In both cases, the datasets were randomly divided in a 7:1:2 ratio to generate the training, validation, and test sets. The NextVit backbone was initialized with a pretrained weight trained on the ImageNet dataset. The stochastic gradient descent with an initial learning rate of 0.01 and a weight decay of 0.0005 was used as the optimizer. During the training process, various data augmentation techniques were applied to enhance the performance of the model. These techniques include horizontal flipping, affine transformation, mosaicism, hue changes, brightness changes, and saturation changes. The model was trained for 300 epochs using the augmented datasets.
4.4. Experimental Results
After the experiments, the resulting performance metrics were compared with those of existing state-of-the-art detection methods. For the NEU-DET dataset, Table 1 lists the comparison results, and Figure 7 shows the visualization results wherein the box in the figure represents the predicted defect area, defect category, and confidence. TAFENet can accurately locate defects and achieve high confidence in each category. TAFENet achieved the highest AP for crazing, inclusion, patches, and scratches, obtaining values of 55.3%, 87.5%, 93.8%, and 95.8%, respectively. Notably, crazing and inclusion pose challenges because of their low contrast with the background, rendering them difficult to distinguish. The attention mechanism addresses this issue by highlighting defect objects. Moreover, inclusions, patches, and scratches exhibited significant variations in defect size within their respective categories. The self-attention mechanism effectively captures global long-distance dependencies, contributing to performance improvements in these categories and enhancing the robustness to categories with complex backgrounds, such as crazing. Moreover, the feature-enhancement structure in TAFENet successfully integrates local features, minimizes feature loss, and preserves important details, particularly fine details. Consequently, TAFENet achieves good results for crazing with an average precision of 55.3%. TAFENet achieved the highest mAP of 79.6%, validating its effectiveness.

Table 1.
Comparison results of the NEU-DET dataset. The bold value indicates the highest AP value or mAP value in the corresponding column of the table.

Figure 7.
Visualized detection results on the NEU-DET dataset. The detection category and confidence are shown above the detection box.
For the GC10-DET dataset, the comparison results are listed in Table 2.
Table 2.
Comparison results of the GC10-DET dataset. The bold value indicates the highest AP value or mAP value in the corresponding column.
As listed in Table 2, TAFENet achieved the highest AP for weld line (Wl) at 93.5%; inclusion (In), 29.4%; and creases (Cr), 88.4%. Moreover, TAFENet’s AP values for categories such as punching (Pu), crescent gap (Cg), water spot (Ws), and waist folding (Wf) were close to the best results, at 97.2% versus 99.5%, 94.6% versus 95.8%, 74.8% versus 76.9%, and 89.7% versus 91.9%, respectively, demonstrating the effectiveness of TAFENet. Specifically, the significant differences in the sizes of intraclass defects for weld lines, crescent gaps, and creases, including their higher aspect ratios and wide distribution range, validate the efficacy of the spatial attention mechanism. TAFENet also achieved good results (89.7%) for waist folding despite its low contrast with the background. This validated the effectiveness of the proposed attention mechanism. TAFENet achieved the highest mAP of 70.9%, demonstrating the generalizability of TAFENet for strip steel surface defect detection. When inputting a steel strip surface defect image in the test, the average running speed of TAFENet is about 30 fps. This meets the needs of real-time detection, because in the backbone network we use the NextVit feature extraction network designed specifically for real industrial scenarios, which can extract feature information containing short- and long-distance dependencies while achieving the best trade-off between performance and latency through a new hybrid strategy. In the neck network, we use a lightweight self-attention block to avoid complex calculations.
4.5. Ablation Study
To verify the effectiveness of the attention-based modules and two-stage feature-enhancement structure in TAFENet, we conducted ablation experiments using various settings on the NEU-DET dataset.
In the baseline setting, the RSC attention module includes only the SAB, which is necessary for information fusion. The SSFE does not include a self-attention block. However, as listed in Table 3, when we added the self-attention block to the SSFE, the overall accuracy improved by 1.6%. Significant improvements were observed for the inclusions and scratches, indicating that the self-attention mechanism is beneficial for handling variations in the sizes of intraclass defects. Moreover, by adding the CAB to the RSC attention module, the overall accuracy is improved by 2.6%. This enhancement is notable for crazing, patches, and pitted surfaces because the corresponding feature channels are effectively highlighted. These results demonstrate the usefulness of both self-attention and the CAB for improving the performance of TAFENet.
Table 3.
Attention-based modules ablation experiment results on the NEU-DET dataset.
As listed in Table 4, compared with the FPN structure, after replacing the two-stage feature-enhancement structure, the overall accuracy increased by 3.1%. Categories with small details, such as crazing and pitted surfaces, demonstrate noteworthy improvements of 11.9% and 3.0%, respectively, indicating that the two-stage feature-enhancement structure helps reduce feature loss. Moreover, inclusions and scratches were also improved by 1.4% and 3.6%, respectively, owing to the ability of the two-stage feature-enhancement structure to capture and integrate global information. These results indicate that the two-stage feature-enhancement structure is effective in improving the performance of TAFENet.
Table 4.
Neck network ablation experiments on the NEU-DET dataset.
4.6. Discussion
In the design of the model, we fully considered the computational complexity of the model while improving the performance, so we chose some simple and proven effective structures. In the future, we will focus on the latest methods to further improve the model’s tradeoff between performance and latency. Compared with the traditional FPN structure, the two-stage feature enhancement structure proposed in this paper has explored the model’s learning potential for the position information of objects of various sizes. In the future, we will conduct more research on this basis to make the structure of the entire model simpler and more efficient. Defects on the surface of strip steel will reduce its corrosion and wear resistance, and its aesthetics will also be greatly reduced. In this paper, the proposed method has accurate precision and real-time detection capabilities. By implementing the proposed method, it can help timely detection of the problematic products in strip steel surface defect detection, optimize production processes, reduce scrap rates, and improve material strength and durability, ultimately making strip steel products more competitive in the market. In addition, the proposed method can help manufacturers comply with stricter industry standards and ensure product consistency and reliability.
5. Conclusions
The surface defects of strip steel have a serious impact on the appearance and performance of strip steel. In order to detect these defects, it is of great significance to study the strip steel surface defect detection system.
In recent years, the strip steel surface defect detection methods based on deep learning have offered excellent performance. However, these methods have room for improvement in the use of multiple attention mechanisms and the loss of features at certain levels caused by feature fusion networks. Therefore, this paper proposes TAFENet for strip surface defect detection.
First, a hybrid block based on convolution and self-attention blocks is used in the backbone network, and then a two-stage feature-enhancement structure is used in the feature fusion network, in which the RSC attention module is based on the spatial and channel attention mechanisms. In experiments, TAFENet achieved excellent results, demonstrating mAP values of 79.6 and 70.9 on the NEU-DET and GC10-DET datasets, respectively. These results demonstrate the high detection accuracy and robust generalizability of TAFENet, leading to the following conclusions.
- Use of the hybrid block of convolution and self-attention blocks, and reasonable use of the lightweight self-attention blocks, can achieve a balance between performance and latency in detection of strip steel surface defect.
- The two-stage feature-enhancement structure enhances the prediction capability for subtle details in strip steel surface defects by minimizing the loss of feature information.
- The targeted use of multiple attention mechanisms can mitigate the impacts of interfering factors and enhance the ability to detect defects with varying aspect ratios and irregular shapes.
In the future, our goal is to continue to improve and expand this method for wider application in various fields of detection.
Author Contributions
Conceptualization, L.Z., H.G., Y.F. and Z.W.; Methodology, L.Z., H.G. and Y.F.; Validation, L.Z. and Z.F.; Formal analysis, Y.S.; Data curation, Z.F.; Writing—original draft, L.Z.; Writing—review & editing, L.Z.; Visualization, Z.F.; Supervision, H.G. and Z.W.; Project administration, L.Z.; Funding acquisition, L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded in part by the National Natural Science Foundation of China under Grant 62403405, in part by the Science and Technology Plan Project of Henan Province under Grant 242102210092, in part by Henan Province Key Research and Development Project under Grant 241111212200, and in part by the Postgraduate Education Quality Course Project of Henan Province under Grant YJS2022KC34.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
Zuofei Wang is employed by the company Henan Dinghua Information Technology Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Guo, M.; Xu, T.; Liu, J.; Liu, Z.; Jiang, P.; Mu, T.; Zhang, S.; Martin, R.R.; Cheng, M.; Hu, S. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic feature pyramid network for object detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; pp. 2184–2189. [Google Scholar]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Yue, B.; Wang, Y.; Min, Y.; Zhang, Z.; Wang, W.; Yong, J. Rail surface defect recognition method based on AdaBoost multi-classifier combination. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 391–396. [Google Scholar]
- Huang, Y.; Qiu, C.; Wang, X.; Wang, S.; Yuan, K. A compact convolutional neural network for surface defect inspection. Sensors 2020, 20, 1974. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Yu, J. RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. IEEE Trans. Instrum. Meas. 2020, 70, 2503911. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3024–3033. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Chen, H.; Chu, X.; Ren, Y.; Zhao, X.; Huang, K. Pelk: Parameter-efficient large kernel convnets with peripheral convolution. arXiv 2024, arXiv:2403.07589. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 367–376. [Google Scholar]
- Chen, P.Y.; Chang, M.C.; Hsieh, J.W.; Chen, Y.S. Parallel residual bi-fusion feature pyramid network for accurate single-shot object detection. IEEE Trans. Image Process. 2021, 30, 9099–9111. [Google Scholar] [CrossRef] [PubMed]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. arXiv 2022, arXiv:2210.02093. [Google Scholar] [CrossRef] [PubMed]
- Jin, Z.; Yu, D.; Song, L.; Yuan, Z.; Yu, L. You should look at all objects. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 332–349. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, J.; Xia, X.; Li, W.; Li, H.; Wang, X.; Xiao, X.; Wang, R.; Zheng, M.; Pan, X. Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. arXiv 2022, arXiv:2207.05501. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Ind. Inform. 2019, 69, 1493–1504. [Google Scholar] [CrossRef]
- Lv, X.; Duan, F.; Jiang, J.J.; Fu, X.; Gan, L. Deep metallic surface defect detection: The new benchmark and detection network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [PubMed]
- Lin, T. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Jocher Glenn. Ultralytics yolov8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 5 September 2024).
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).